Table of Contents |
guest 2024-04-25 |
Getting Started with LabKey Server
Data Grid Tutorial
System Integration: Instruments and Software
LabKey Server Solutions
Academic Research Solutions
Pharma & Biotech Solutions
Clinical & Provider Solutions
Install LabKey Server (Quick Install)
What's New in 17.1
Release Notes 17.1
Upcoming Features in 17.2
Tutorials
Videos
Demos
Demos and Videos
FAQ - Frequently Asked Questions
How to Cite LabKey Server
LabKey Terminology/Glossary
Archive: Documentation
What's New in 16.3
Release Notes 16.3
What's New in 16.2
Release Notes 16.2
What's New in 16.1
Release Notes 16.1
What's New in 15.3
Release Notes 15.3
What's New in 15.2?
Release Notes 15.2
What's New in 15.1?
Release Notes 15.1
LabKey Argos
What's New in 14.3?
Release Notes 14.3
What's New in 14.2?
Release Notes 14.2
What's New in 14.1?
Release Notes 14.1
What's New in 13.3?
Release Notes 13.3
What's New in 13.2?
Release Notes 13.2
Learn What's New in 13.1
Release Notes 13.1
Video Demonstrations 13.1
New Feature "Sprint" Demos
Learn What's New in 12.3
Release Notes 12.3
12.3 Video Demonstrations
Learn What's New in 12.2
Release Notes 12.2
12.2 Video Demonstrations
Learn What's New in 12.1
12.1 Release Notes
12.1 Video Demonstrations
Learn What's New in 11.3
11.3 Release Notes
11.3 Video Demonstrations
Learn What's New in 11.2
11.2 Release Notes
11.2 Video Demonstrations
Learn What's New in 11.1
11.1 Release Notes
11.1 Release Webinar
Learn What's New in 10.3
10.3 Release Notes
Learn What's New in 10.2
10.2 Release Notes
Learn What's New in 10.1
10.1 Release Notes
Learn What's New in 9.3
9.3 Upgrade Tips
Learn What's New in 9.2
9.2 Upgrade Tips
Learn What's New in 9.1
9.1 Upgrade Tips
Learn What's New in 8.3
Learn What's New in 8.2
8.2 Upgrade Tips
Learn What's New in 8.1
8.1 Upgrade Tips
Learn What's New in 2.3
Learn What's New in 2.2
Learn What's New in 2.1
Learn What's New in 2.0
What's New 17.2
Release Notes 17.2
Data Basics
Build User Interface
Add Web Parts
Manage Web Parts
Web Part Inventory
Use Tabs
Add Custom Menus
Web Parts: Permissions Required to View
Data Grids
Data Grids: Basics
Import Data
Sort Data
Filter Data
Filtering Expressions
Column Summary Statistics
Select Rows
Customize Grid Views
Saved Filters and Sorts
Join Columns from Multiple Tables
Lookup Columns
Export Data
Participant Details View
Query Scope: Filter by Folder
Field Properties Reference
URL Field Property
String Expression Format Functions
Conditional Formats
Date & Number Display Formats
Date and Number Formats Reference
Reports and Visualizations
Report Web Part: Display a Report or Chart
Data Views Browser
Bar Charts
Box Plots
Pie Charts
Scatter Plots
Time Charts
Column Visualizations
Quick Charts
Query Snapshot
R Reports
RStudio and LabKey Server
R Report Builder
Saved R Reports
Datasets in R
Multi-Panel R Plots
Lattice Plots
Participant Charts in R
R Reports with knitr
Input/Output Substitutions Reference
FAQs for LabKey R Reports
R Tutorial Video
JavaScript Reports
Attachment Reports
Link Reports
Participant Reports
Query Report
Manage Reports and Charts
Manage Categories
Manage Thumbnail Images
Measure and Dimension Columns
Legacy Reports
Advanced Reports / External Reports
Chart Views
Crosstab Reports
SQL Queries
LabKey SQL Tutorial
SQL Query Browser
LabKey SQL Reference
Lookups: SQL Syntax
Create a SQL Query
Edit SQL Query Source
Query Metadata
Query Metadata: Examples
Edit Query Properties
Query Web Part: Display a Query
Add a Calculated Column to a Query
Create a Pivot Query
Parameterized SQL Queries
SQL Examples: JOIN, Calculated Columns, GROUP BY
Cross-Folder Queries
SQL Synonyms
External Schemas and Data Sources
External MySQL Data Sources
External Oracle Data Sources
External Microsoft SQL Server Data Sources
External PostgreSQL Data Sources
External SAS Data Sources
Linked Schemas and Tables
Manage Remote Connections
LabKey Data Structures
Preparing Data for Import
Data Quality Control
Lists
List Tutorial
List Tutorial: Setup
Create a Joined Grid
Add a URL Property
Create and Populate Lists
Create a List by Defining Fields
Populate a List
Import a List Archive
Manage Lists
Connect Lists
Edit a List Design
Choose a Primary Key
Search
Search Administration
Laboratory Data
Tutorial: Design a General Purpose Assay Type (GPAT)
Step 1: Assay Tutorial Setup
Step 2: Infer an Assay Design from Spreadsheet Data
Step 3: Import Assay Data
Step 4: Work with Assay Data
Step 5: Data Validation
Step 6: Integrate Assay Data into a Study
ELISA Assay Tutorial
ELISpot Assay
ELISpot Assay Tutorial
Import ELISpot Data
Review ELISpot Data
ELISpot Properties
Flow Cytometry
LabKey Flow Module
Supported FlowJo Versions
Flow Cytometry Overview
Tutorial: Import a Flow Workspace
Step 1: Set Up a Flow Folder
Step 2: Upload Files to Server
Step 3: Import a Flow Workspace and Analysis
FCS File Resolution
Step 4: Customize Your Grid View
Step 5: Examine Graphs
Step 6: Examine Well Details
Step 7: Export Flow Data
Tutorial: Perform a LabKey Flow Analysis
Step 1: Define a Compensation Calculation
Step 2: Define an Analysis
Step 3: Apply a Script
Step 4: View Results
Add Sample Descriptions
Custom Flow Queries
Add Statistics to FCS Queries
Calculate Suites of Statistics for Every Well
Flow Module Schema
Analysis Archive Format
FCS Express
Tutorial: Import Flow Data from FCS Express
FCS keyword utility
Flow Team Members
FluoroSpot Assay
Genomics Workflows
Set Up a Genotyping Dashboard
Example Workflow: LabKey and Galaxy
Example Workflow: LabKey and Illumina
Example Workflow: LabKey and PacBio
Example Workflow: O'Connor Module
Import Haplotype Assignment Data
Work with Haplotype Assay Data
HPLC - High-Performance Liquid Chromatography
Luminex
Luminex Assay Tutorial Level I
Setup Luminex Tutorial Project
Step 1: Create a New Luminex Assay Design
Step 2: Import Luminex Run Data
Step 3: Exclude Analytes for QC
Step 4: Import Multi-File Runs
Step 5: Copy Luminex Data to Study
Luminex Assay Tutorial Level II
Step 1: Import Lists and Assay Archives
Step 2: Configure R, Packages and Script
Step 3: Import Luminex Runs
Step 4: View 4pl and 5pl Curve Fits
Step 5: Track Analyte Quality Over Time
Step 7: Use Guide Sets for QC
Step 8: Compare Standard Curves Across Runs
Track Single-Point Controls in Levey-Jennings Plots
Import Luminex Runs
Luminex Calculations
Luminex QC Reports and Flags
Luminex Reference
Review Luminex Assay Design
Luminex Properties
Luminex File Formats
Review Well Roles
Luminex Conversions
Customize Luminex Assay for Script
Review Fields for Script
Troubleshoot Luminex Transform Scripts and Curve Fit Results
Microarray
Microarray Assay Tutorial
Expression Matrix Assay Tutorial
Microarray Properties
NAb (Neutralizing Antibody) Assays
NAb Assay Tutorial
Step 1: Create a NAb Assay Design
Step 2: Import NAb Assay Data
Step 3: View High-Throughput NAb Data
Step 4: Explore NAb Graph Options
Work with Low-Throughput NAb Data
Use NAb Data Identifiers
NAb Assay QC
Work with Multiple Viruses per Plate
NAb Plate File Formats
Customize NAb Plate Template
NAb Properties
Proteomics
Proteomics Tutorial
Step 1: Set Up for Proteomics Analysis
Step 2: Search mzXML Files
Step 3: View PeptideProphet Results
Step 4: View ProteinProphet Results
Step 5: Compare Runs
Step 6: Search for a Specific Protein
Proteomics Video
Work with MS2 Data
Search MS2 Data Via the Pipeline
Set Up MS2 Search Engines
Set Up Mascot
Set Up Sequest
Set Up Comet
Working with mzML files
Search and Process MS2 Data
Configure Common Parameters
Configure X! Tandem Parameters
Configure Mascot Parameters
Configure Sequest Parameters
Sequest Parameters
MzXML2Search Parameters
Examples of Commonly Modified Parameters
Configure Comet Parameters
Import Existing Analysis Results
Trigger MS2 Processing Automatically
Set Proteomics Search Tools Version
Explore the MS2 Dashboard
View an MS2 Run
Customize Display Columns
Peptide Columns
Protein Columns
View Peptide Spectra
View Protein Details
View Gene Ontology Information
Experimental Annotations for MS2 Runs
Protein Search
Peptide Search
Compare MS2 Runs
Compare ProteinProphet
Export MS2 Runs
Working with Small Molecule Targets
Export Spectra Libraries
View, Filter and Export All MS2 Runs
Work with Mascot Runs
Loading Public Protein Annotation Files
Using Custom Protein Annotations
Using ProteinProphet
Using Quantitation Tools
Protein Expression Matrix Assay
Link Protein Expression Data with Annotations
Spectra Counts
Label-Free Quantitation
Combine XTandem Results
MS1
MS1 Pipelines
Panorama - Targeted Proteomics
Configure Panorama Folder
Panorama QC Dashboard
Panorama QC Plots
Panorama Plot Types
Panorama QC Annotations
Panorama QC Guide Sets
Pareto Plots
Panorama: Clustergrammer Heat Maps
Panorama Document Revision Tracking
Proteomics Team
Signal Data Assay
Assay Administrator Guide
Assay Feature Matrix
Set Up Folder For Assays
Assay Designs and Types
Import Assay Design
Design a New Assay
General Properties
Design a Plate-Based Assay
Edit Plate Templates
Participant/Visit Resolver
Manage an Assay Design
Improve Data Entry Consistency & Accuracy
Set up a Data Transformation Script
Copy Assay Data into a Study
Copy-To-Study History
Experiment Descriptions & Archives (XARs)
Experiment Terminology
XAR Files
Uses of XAR.xml Files
Import a XAR.xml
Troubleshoot XAR Import
Import XAR Files Using the Data Pipeline
Example 1: Review a Basic XAR.xml
Examples 2 & 3: Describe Protocols
Examples 4, 5 & 6: Describe LCMS2 Experiments
Design Goals and Directions
Life Science Identifiers (LSIDs)
LSID Substitution Templates
Assay User Guide
Import Assay Runs
Reimport Assay Runs
Sample Sets
Import Sample Sets
Samples: Unique IDs
View SampleSets and Samples
Link Assay Data to Sample Sets
Parent Samples: Derivation and Lineage
Sample Sets: Examples
'Active' Sample Set
Run Groups
DataClasses
Electronic Laboratory Notebooks (ELN)
Tutorial: Electronic Lab Notebook
Step 1: Create the User Interface
Step 2: Import Lab Data
Step 3: Link Assays to Samples
Step 4: Using and Extending the ELN
Assay Request Tracker
Assay Request Tracker: User Documentation
Assay Request Tracker: Administrator Documentation
Reagent Inventory
Research Studies
Study Tour
Tutorial: Cohort Studies
Step 1: Install the Sample Study
Step 2: Study Data Dashboards
Step 3: Integrate Data from Different Sources
Step 4: Compare Participant Performance
Tutorial: Set Up a New Study
Step 1: Define Study Properties
Step 2: Import Datasets
Step 3: Assign Cohorts
Step 4: Import Specimens
Step 5: Visualizations and Reports
Study User Guide
Study Navigation
The Study Navigator
Study Data Browser
Cohorts
Participant Groups
Comments
Dataset Quality Control States
Study Administrator Guide
Create a Study
Create and Populate Datasets
Create a Dataset from a File
Create a Dataset by Defining Fields
Create Multiple Dataset Definitions from a TSV File
Import Data to a Dataset
Import via Copy/Paste
Import From a Dataset Archive
Create Pipeline Configuration File
Import Study Data From REDCap Projects
Dataset Properties
Edit Dataset Properties
Dataset System Fields
Use Visits or Timepoints/Dates
Create Visits
Edit Visits or Timepoints
Import Visit Map
Import Visit Names / Aliases
Manage a Study
Custom Study Properties
Manage Datasets
Manage Visits or Timepoints
Study Schedule
Manage Locations
Manage Cohorts
Manage Participant IDs
Alternate Participant IDs
Alias Participant IDs
Manage Comments
Manage Study Security (Dataset-Level Security)
Configure Permissions for Reports & Views
Matrix of Permissions
Securing Portions of a Dataset (Row and Column Level Security)
Manage Dataset QC States
Manage Study Products
Manage Treatments
Manage Assay Schedule
Demonstration Mode
Create a Vaccine Study Design
Continuous Studies
Import, Export, and Reload a Study
Export Study Objects
Study Import/Export Files and Formats
Serialized Elements and Attributes of Lists and Datasets
Publish a Study
Publish a Study: Protected Health Information
Publish a Study: Refresh Snapshots
Ancillary Studies
Shared Datasets and Timepoints
Data Aliasing
Study Data Model
Linking Data Records with External Files
Specimen Tracking
Specimen Request Tutorial
Step 1: Repository Setup (Admin)
Step 2: Request System (Specimen Coordinator)
Step 3: Request Specimens (User)
Step 4: Track Requests (Specimen Coordinator)
Specimens: Administrator Guide
Import Specimen Spreadsheet Data
Import a Specimen Archive
Specimen Archive File Reference
Specimen Archive Data Destinations
Troubleshoot Specimen Import
Import FreezerPro Data
Delete Specimens
Specimen Properties and Rollup Rules
Customize Specimens Web Part
Flag Specimens for Quality Control
Edit Specimen Data
Customize the Specimen Request Email Template
Export a Specimen Archive
Specimen Coordinator Guide
Email Specimen Lists
View Specimen Data
Generate Specimen Reports
Laboratory Information Management System (LIMS)
Electronic Health Records (EHR)
EHR: Animal History
EHR: Animal Search
EHR: Data Entry
EHR: Administration
EHR Team
Collaboration
Collaboration Tutorial
Step 1: Use the Message Board
Step 2: Collaborate Using a Wiki
Step 3: Track Issues
File Repository Tutorial
Step 1: Set Up a File Repository
Step 2: File Repository Administration
Step 3: Search the Repository
Step 4: Import Data from the Repository
Files
Using the Files Repository
Share and View Files
File Sharing and URLs
Import Data from Files
File Administrator Guide
Files Web Part Administration
Upload Files: WebDAV
Set File Roots
Troubleshoot File Roots and Pipeline Overrides
File Terminology
Integrating S3 Cloud Data Storage
Data Processing Pipeline
Set a Pipeline Override
Pipeline Protocols
Enterprise Pipeline
Install Prerequisites for the Enterprise Pipeline
JMS Queue
RAW to mzXML Converters
Configure LabKey Server to use the Enterprise Pipeline
Configure the Conversion Service
Configure Remote Pipeline Server
Configure Pipeline Path Mapping
Use the Enterprise Pipeline
Troubleshoot the Enterprise Pipeline
Messages
Use Message Boards
Administer Message Boards
Object-Level Discussions
Wikis
Wiki Admin Guide
Copy Wiki Pages
Wiki User Guide
Wiki Syntax
Wiki Syntax: Macros
Special Wiki Pages
Embed Live Content in HTML Pages or Messages
Examples: Embedded Web Parts
Web Part Configuration Properties
Add Screenshots to a Wiki
Manage Wiki Attachment List
Issue/Bug Tracking
Using the Issue Tracker
Administering the Issue Tracker
Workflow Module
Workflow Tutorial
Step 1: Set Up Workflow Tutorial
Step 2: Run Sample Workflow Process
Step 3: Workflow Process Definition
Step 4: Customize Workflow Process Definition
Workflow Process Definition
Electronic Data Capture (EDC)
Survey Designer: Basics
Survey Designer: Customization
Survey Designer: Reference
Survey Designer: Example Questions
REDCap Survey Data Integration
Adjudication Module
Set Up an Adjudication Folder
Initiate an Adjudication Case
Make an Adjudication Determination
Monitor Adjudication
Infection Monitor
Role Guide: Adjudicator
Role Guide: Adjudication Lab Personnel
Tours for New Users
Contacts
Development
LabKey Client APIs
JavaScript API
Tutorial: Create Applications with the JavaScript API
Step 1: Create Request Form
Step 2: Confirmation Page
Step 3: R Histogram (Optional)
Step 4: Summary Report For Managers
Repackaging the App as a Module
Tutorial: Use URLs to Pass Data and Filter Grids
Choose Parameters
Show Filtered Grid
Tutorial Video: Building Reports and Custom User Interfaces
JavaScript API - Samples
Adding Report to a Data Grid with JavaScript
Export Data Grid as a Script
Export Chart as JavaScript
Custom HTML/JavaScript Participant Details View
Custom Button Bars
Insert into Audit Table via API
Declare Dependencies
Loading ExtJS On Each Page
Licensing for the ExtJS API
Search API Documentation
Naming & Documenting JavaScript APIs
Naming Conventions for JavaScript APIs
How to Generate JSDoc
JsDoc Annotation Guidelines
Java API
Prototype LabKey JDBC Driver
Remote Login API
Security Bulk Update via API
Perl API
Python API
Rlabkey Package
Troubleshooting Rlabkey Connections
SAS Macros
SAS Setup
SAS Macros
SAS Security
SAS Demos
HTTP Interface
Examples: Controller Actions
Example: Access APIs from Perl
Compliant Access via Session Key
Set up a Development Machine
Enlisting in the Version Control Project
Enlisting Proteomics Binaries
Customizing the Build
Machine Security
Notes on Setting up a Mac for LabKey Development
Creating Production Builds
Encoding in Tomcat 7
Gradle Build
Develop Modules
Tutorial: Hello World Module
Map of Module Files
Example Modules
Modules: Queries, Views and Reports
Module Directories Setup
Module Query Views
Module SQL Queries
Module R Reports
Module HTML and Web Parts
Modules: JavaScript Libraries
Modules: Assay Types
Tutorial: Define an Assay Type in a Module
Assay Custom Domains
Assay Custom Views
Example Assay JavaScript Objects
Assay Query Metadata
Customize Batch Save Behavior
SQL Scripts for Module-Based Assays
Transformation Scripts
Example Workflow: Develop a Transformation Script (perl)
Example Transformation Scripts (perl)
Transformation Scripts in R
Transformation Scripts in Java
Transformation Scripts for Module-based Assays
Run Properties Reference
Transformation Script Substitution Syntax
Warnings in Tranformation Scripts
Modules: ETLs
Tutorial: Extract-Transform-Load (ETL)
ETL Tutorial: Set Up
ETL Tutorial: Run an ETL Process
ETL Tutorial: Create a New ETL Process
ETL: User Interface
ETL: Configuration and Schedules
ETL: Column Mapping
ETL: Queuing ETL Processes
ETL: Stored Procedures
ETL: Stored Procedures in MS SQL Server
ETL: Functions in PostgreSQL
ETL: Check For Work From a Stored Procedure
ETL: SQL Scripts
ETL: Remote Connections
ETL: Logs and Error Handling
ETL: All Jobs History
ETL: Examples
ETL: Reference
Modules: Java
Module Architecture
Getting Started with the Demo Module
Creating a New Java Module
The LabKey Server Container
Implementing Actions and Views
Implementing API Actions
Integrating with the Pipeline Module
Integrating with the Experiment Module
Using SQL in Java Modules
GWT Integration
GWT Remote Services
Java Testing Tips
HotSwapping Java classes
Deprecated Components
Modules: Folder Types
Modules: Query Metadata
Modules: Report Metadata
Modules: Custom Footer
Modules: SQL Scripts
Modules: Database Transition Scripts
Modules: Domain Templates
Deploy Modules to a Production Server
Upgrade Modules
Main Credits Page
Module Properties Reference
Common Development Tasks
Trigger Scripts
Availability of Server-side Trigger Scripts
Script Pipeline: Running R and Other Scripts in Sequence
LabKey URLs
URL Actions
How To Find schemaName, queryName & viewName
LabKey/Rserve Setup Guide
Web Application Security
HTML Encoding
Cross-Site Request Forgery (CSRF) Protection
MiniProfiler
LabKey Open Source Project
Source Code
Release Schedule
Issue Tracker
LabKey Scrum FAQ
Developer Email List
Branch Policy
Test Procedures
Running Automated Tests
Hotfix Policy
Previous Releases
Previous Releases -- Details
Submit Contributions
Confidential Data
CSS Design Guidelines
UI Design Patterns
Design Guidelines Supplemental
Documentation Style Guide
Check in to the Source Project
Renaming files in Subversion
Developer Reference
Administration
Tutorial: Security
Step 1: Configure Permissions
Step 2: Test Security with Impersonation
Step 3: Audit User Activity
Step 4: Handle Protected Health Information (PHI)
Projects and Folders
Navigate Site
Project and Folder Basics
Site Structure: Best Practices
Manage Projects and Folders
Create a Project or Folder
Move, Delete, Rename Projects and Folders
Enable a Module in a Folder
Export / Import a Folder
Export and Import Permission Settings
Manage Email Notifications
Define Hidden Folders
Folder Types
Community Modules
Workbooks
Establish Terms of Use
Security
Configure Permissions
Security Groups
Global Groups
Site Groups
Project Groups
Guests / Anonymous Users
Security Roles Reference
Site Administrator
Matrix of Report, Chart, and Grid Permissions
Role / Permissions Table
User Accounts
Add Users
Manage Users
My Account
Manage Project Users
Authentication
Configure LDAP
Configure Database Authentication
Passwords
Password Reset & Security
Configure SAML Authentication
Configure CAS Single Sign On Authentication
Configure Duo Two-Factor Authentication
Create a .netrc or _netrc file
HTTP Basic Authentication
Test Security Settings by Impersonation
Compliance
Compliance: Protected Health Information
Compliance Settings
Compliance Terms of Use
Compliance Module Logging
Admin Console
Site Settings
Usage/Exception Reporting - Details
Look and Feel Settings
Branding
Web Site Theme
Email Template Customization
Experimental Features
Manage Missing Value Indicators / Out of Range Values
Short URLs
Configure System Maintenance
Configure Scripting Engines
Audit Site Activity
SQL Query Logging
Actions Diagnostics
Cache Statistics
Dump Heap
Memory Usage
Running Threads
Query Performance
Site/Container Validation
Install LabKey
Installation Basics
Install LabKey Server (Windows Graphical Installer)
Install LabKey Manually
Install Required Components
Configure the LabKey Web Application
labkey.xml Configuration File
Third-Party Components and Licenses
Install a Remote Pipeline Server via the Windows Installer
PremiumStats Install
Supported Technologies
Troubleshoot Installation
Installation Error Messages
Dump Memory and Thread Usage Debugging Information
Common Install Tasks
Install Microsoft SQL Server
Install PostgreSQL (Windows)
Install PostgreSQL (Linux, Unix or Macintosh)
Install LabKey Server on Solaris
Notes on Installing PostgreSQL on All Platforms
Install and Set Up R
Determine Available Graphing Functions
Install SAS/SHARE for Integration with LabKey Server
Configure Webapp Memory
Set Up Robots.txt and Sitemaps
GROUP_CONCAT Install
Example Setups and Configurations
Example Hardware/Software Configuration
Set up a JMS-Controlled Remote Pipeline Server
Example Installation of Flow Cytometry on Mac OSX
Configure R on Linux
Configure the Virtual Frame Buffer on Linux
Example Linux Installation
Upgrade LabKey
Manual Upgrade Checklist
Manual Upgrade Script for Linux, MacOSX, and Solaris
Upgrade Support Policy
Backup and Maintenance
Backup Checklist
A Sample Backup Plan
Sample Scripts for Backup Scenarios
PostgreSQL Maintenance
Administer the Site Down Servlet
Staging, Test and Production Servers
Example of a Large-Scale Installation
Tips for Configuring a Staging Server
Products and Services
LabKey Server Editions
Training
Custom Community Modules
LabKey Argos
Argos Tour
LabKey Natural Language Pipeline (NLP)
Configure LabKey NLP
Process Files Using Natural Language Pipeline (NLP)
Document Abstraction Workflow
Automatic Assignment for Abstraction
Manual Assignment for Abstraction
Document Abstraction
Review Document Abstraction
LabKey Biologics
LabKey Biologics: Preview
Panorama Partners Program
LabKey User Conference Resources
LabKey User Conference 2016
LabKey User Conference 2015
LabKey User Conference 2014
LabKey User Conference 2013
LabKey User Conference 2012
LabKey User Conference 2011
Documentation Home
Getting Started
- Tutorials - Tutorials for new users.
- Videos - Video resources for beginners and experts.
- Install LabKey Server (Quick Install) - Install LabKey Server with a graphical installer.
- LabKey Terminology/Glossary - Definitions for common terms in LabKey Server.
Documentation Contents
- Data Basics - Build applications from user interface panels and views on underlying data.
- Laboratory Data - Work with instrument-derived data.
- Research Studies - Integrate heterogeneous data in longitudinal/cohort studies.
- Collaboration - Set up file repositories, message boards, and issue trackers.
- Development - Developer resources.
- Administration - Create projects, configure security, advanced installation.
- Products and Services - LabKey Server products and services.
Documentation Highlights
- What's New in 17.1 - Highlighted features in the 17.1 release.
- Release Notes 17.1 - Detailed feature list.
- Upcoming Features in 17.2 - Features in development for the 17.2 release.
Getting Started with LabKey Server
 This topic is for absolute beginners to LabKey Server. It explains what LabKey Server is for, how it works, and how to build solutions using its many features.
This topic is for absolute beginners to LabKey Server. It explains what LabKey Server is for, how it works, and how to build solutions using its many features.
What is LabKey Server?
LabKey Server's features can be grouped into three main areas:1. Data Repository
LabKey Server lets you bring data together from multiple sources into one repository. These sources can be physically separated in different systems, such as data in Excel spreadsheets, different databases, FreezerPro, REDCap, etc. Or the data sources can be separated "morphologically", having different shapes. For example, patient questionnaires, instrument-derived assay data, medical histories, and specimen inventories all have different data shapes, with different columns names and different data types. LabKey Server can bring all of this data together to form one integrated whole that you can browse and analyze together.2. Data Showcase
LabKey Server lets you securely present and highlight data over the web. You can present different profiles of your data to to different audiences. One profile can be shown to the general public with no restrictions, while another profile can be privately shared with selected individual colleagues. LabKey Server lets you collaborate with geographically separated teams, or with your own internal team members. In short, LabKey Server lets you create different relationships between data and audiences, where some data is for general viewing, other data is for peer review, and yet other data is for group editing and development.3. Electronic Laboratory
LabKey Server provides many options for analyzing and inquiring into data. Like a physical lab that inquires into materials and natural systems, LabKey Server makes data itself the object of inquiry. This side of LabKey Server helps you craft reports and visualizations, confirm hypotheses, and generally provide new insights into your data, insights that wouldn't be possible when the data is separated in different systems and invisible to other collaborators.The LabKey Server Platform
LabKey Server is a software platform, as opposed to an application. Applications have fixed use cases targeted on a relatively narrow set of problems. As a platform, LabKey Server is different: it has no fixed use cases, instead it provides a broad range of tools that you configure to build your own solutions. In this respect, LabKey Server is more like a car parts warehouse and not like any particular car. Building solutions with LabKey Server is like building new cars using the car parts provided. To build new solutions you assemble and connect different panels and analytic tools to create data dashboards and workflows.The following illustration shows how LabKey Server takes in different varieties of data, transforms into reports and insights, and presents them to different audiences.
How Does LabKey Server Work?
LabKey Server is a web server, and all web servers are request-response machines: they take in requests over the web (typically as URLs through a web browser) and then craft responses which are displayed to the user.Modules
Modules are the main functionaries in the server. Modules interpret requests, craft responses, contain all of the web parts, and application logic. The responses can take many different forms:- a web page in a browser
- an interactive grid of data
- a report or visualization of underlying data
- a file download
- a long-running calculation or algorithm
- PostgreSQL
- MS SQL Server
- Oracle
- My SQL
- SAS

User Interface
You configure your own user interface by adding panels, aka "web parts", each with a specific purpose in mind. Some example web parts:- The Wiki web part displays text and images to explain your research goals and provide context for your audience. (The topic you are reading right now is displayed in a Wiki web part.)
- The Files web part provides an area to upload, download, and share files will colleagues.
- The Query web part displays interactive grids of data.
- The Report web part displays the results of an R or JS based visualization.

Folders and Projects
Folders are the "blank canvases" of LabKey Server, the workspaces where you organize dashboards and web parts. Folders are also important in terms of securing your data, since you grant access to audience members on a folder-by-folder basis. Projects are top level folders: they function like folders, but have a wider scope. Projects also form the center of configuration inside the server, since any setting made inside a project cascades into the sub-folders by default.Security
LabKey uses "role-based" security to control who has access to data. You assign roles, or "powers", to each user who visits your server. Their role determines how much they can see and do with the data. The available roles include: Administrator (they can see and do everything), Editors, Readers, Submitters, and others. Security is very flexible in LabKey Server. Any security configuration you can imagine can be realized: whether you want only a few select individual to see your data, or if you want the whole world to see your data.The server also has extensive audit logs built. The audit logs record:- Who has logged in and when
- Changes to a data record
- Queries performed against the database
- Server configuration changes
- File upload and dowload events
- And many other activities
The Basic Workflow: From Data Import to Reports
To build solutions with LabKey Server, follow this basic workflow: import or synchronize your data, apply analysis tools and build reports on top of the data, and finally share your results with different audiences. Along the way you will add different web parts and modules as needed. To learn the basic steps, start with the tutorials, which provide step-by-step instructions for mastering the basic building blocks available in the server.Ready to See More?
- You don't need to download or install anything to try a few basic features right now: Data Grid Tutorial.
- To further explore LabKey Server, install the server on your local machine, and try a step-by-step tutorial.
Data Grid Tutorial
- Securely share your data with colleagues through interactive grid views
- Collaboratively build and explore interactive visualizations
- Drill down into de-identified data for study participants
- Combine related datasets using data integration tools
System Integration: Instruments and Software
Assay Instruments and File Types
| Assay Typeoooooooo | Description | File Typesooooooooooooooooooo | Documentationooooooooooooo |
|---|---|---|---|
| ELISA | LabKey Server features graphical plate configuration for your experiments. | Excel | ELISA Assay Tutorial |
| ELISpot | LabKey Server features graphical plate configuration for your experiments. | Excel, TXT | ELISpot Assay |
| Fluorospot | LabKey Server features graphical plate configuration for your experiments. The current implementation uses the AID MultiSpot reader. | Excel | FluoroSpot Assay |
| Flow Cytometry - FlowJo | Analyze FCS files using a FlowJo workspace. | FCS, JO, WSP | Flow Cytometry |
| Flow Cytometry - FCSExpress | LabKey Server can be used as the data store for an FCS Express installation. | FCS | FCS Express |
| HPLC | View multiple, overlayed curves and calculate the areas under curves. A file listener automatically loads new results directly from the instrument. | TXT, Excel | HPLC - High-Performance Liquid Chromatography |
| Luminex® | Import multiplexed bead arrays based on xMap technology. | Bio-Plex Excel | Luminex File Formats |
| Microarray - Agilent | LabKey Server automates running the Feature Extractor software on the instrument generated TIFF file, and then associates the resulting MAGE-ML data file, along with a PDF QC report, a JPEG thumbnail, and other outputs with sample information and customizable, user-entered run-level metadata. | CSV, JPEG, TIFF, MAGE-ML | Microarray |
| Microarray - Affymetrix | The current implementation has been successfully integrated with GeneTitan. | Excel, CEL | Microarray |
| Mass Spectrometry | Perform searches against FASTA sequence databases using tools such as XTandem, Sequest, Mascot, or Comet. Perform validations with PeptideProphet and ProteinProphet and quantitation scores using XPRESS or Q3. | mzXML | Proteomics |
| NAb | Low- and high-throughput, cross plate, and multi-virus plates are supported | Excel, CSV, TSV | NAb (Neutralizing Antibody) Assays |
Research and Lab Software
| Software | Description | Documentationooooooooooooooooooo |
|---|---|---|
| FCSExpress | Use LabKey as the data store for FCSExpress. | FCS Express |
| FreezerPro | Synchronize to data in a FreezerPro server. | Import FreezerPro Data |
| Galaxy | Use LabKey Server in conjunction with Galaxy to create a sequencing workflow. | Example Workflow: LabKey and Galaxy |
| Illumina | Build a workflow for managing samples and sequencing results generated from Illumina instruments, such as the MiSeq Benchtop Sequencer. | Example Workflow: LabKey and Illumina |
| ImmPort | Automatically synchronize with data in the NIH Immport database. | About ImmuneSpace |
| Libra | Work with iTRAQ quantitation data. | Using Quantitation Tools |
| Mascot | Work with Mascot server data. | Set Up Mascot |
| PeptideProphet | View and analyze PeptideProphet results. | Step 3: View PeptideProphet Results |
| ProteinProphet | View and analyze ProteinProphet results. | Using ProteinProphet |
| Protein Annotation Databases | UniProtKB Species Suffix Map, SwissProt, TrEMBL, Gene Ontology Database, FASTA. Data in these publicly available databases can be synced to LabKey Server and combined with your Mass Spec data. | Loading Public Protein Annotation Files |
| Q3 | Load and analyze Q3 quantitation results. | Using Quantitation Tools |
| R | LabKey and R have a two-way relationship: you can make LabKey a client of your R installation, or you make R a client of the data in LabKey Server. You can also display the results of an R script inside your LabKey Server applications; the results update as the underlying data changes. | R Reports |
| REDCap | Synchronize with data in a REDCap server. | REDCap Survey Data Integration |
| Scripting Languages | LabKey Server supports all major scripting languages, including R, JavaScript, PERL, and Python. | Configure Scripting Engines |
| Skyline | Integrate with the Skyline proteomics tool. | Panorama - Targeted Proteomics |
| XPRESS | Load and analyze XPRESS quantitation data. | Using Quantitation Tools |
| XTandem | Load and analyze XTandem results. | Step 1: Set Up for Proteomics Analysis |
Databases
| Database | Description | Documentation |
|---|---|---|
| PostgreSQL | PostgreSQL can be installed as a primary or external data source. | Install PostgreSQL (Windows) |
| MS SQL Server | MS SQL Server can be installed as a primary or external data source. | Install Microsoft SQL Server |
| SAS | SAS can be installed as an external data source. | External SAS Data Sources |
| Oracle | Oracle can be installed as an external data source. | External Oracle Data Sources |
| MySQL | MySQL can be installed as an external data source. | External MySQL Data Sources |
Authentication Software
| Authentication Provider | Description | Documentation |
|---|---|---|
| CAS | Use CAS single sign on. | Configure CAS Single Sign On Authentication |
| Duo | Use Duo Two-Factor sign on. | Configure Duo Two-Factor Authentication |
| LDAP | Authenticate with an existing LDAP server. | Configure LDAP |
| SAML | Configure a SAML authentication provider. | Configure SAML Authentication |
LabKey Server Solutions
- Academic Research: Adaptable solutions that enable academic researchers to focus on discovery, not data management.
- Pharma & Biotech: Seamlessly integrate data into a secure, central repository for cross-project analysis and optimize processes with flexible, automated workflows.
- Clinical & Provider: Researchers and physicians can access integrated data in a compliant environment with a full suite of tools to expose disease trends and make data-driven treatment decisions.
Academic Research Solutions
Getting Started
- 10 Minute Tour - Try the basics of working with tabular data in LabKey Server.
- System Integration: Instruments and Software - Explore a directory of instruments and systems our users are already using with LabKey.
- Reports and Visualizations - Built in visualizations and charts unlock insights for sharing.
Documentation
- Collaboration - Work together effectively with colleagues.
- Data Basics - LabKey offers a scalable way to bring 'spreadsheets' to life in research science.
- R Reports - Integrate statistical analysis using R.
- More Documentation
Tutorials
- Tutorial: Security - Learn how to organize projects and ensure only appropriate access to your private data.
- Tutorial: Cohort Studies - Integrate and analyze observational study data.
- More Tutorials
Additional Resources
- Products and Services - LabKey Server Products and Services.
- LabKey Terminology/Glossary - Definitions for common terms in LabKey Server.
- FAQ - Frequently Asked Questions
Pharma & Biotech Solutions
Centralize Data Securely
Integrate high volumes of data from diverse systems into a secure centralized repository.Achieve Faster, More Reliable Processes
Automate workflows and standardize processes, review and refine to achieve maximum efficiency.Enable Aggregated Data Analysis
Analyze your complete data landscape, conducting queries and visualizations using LabKey tools or external analysis packages.Facilitate Cross-Project Collaboration
Extend the use of data by making it available to collaborators in a secure, web-based environment.Clinical & Provider Solutions
Achieve Maximum Visibility Through Integration
Bring together high volumes of data from multiple locations and instruments to create an integrated data picture.- Electronic Data Capture (EDC) - Replace a paper process with a reliable electronic format.
- System Integration: Instruments and Software - LabKey supports many different instruments out of the box and can be customized to support more.
Have Confidence in Compliance
Create a security and audit framework to ensure consistent compliance with regulatory standards.Distill Data into Personalized Treatments
Explore broad trends in disease and highly specific similarities in patients to craft effective, patient-specific treatment plans.Enable Collaborative Treatment
Easily share data across networks, bringing the finest minds and broadest experiences together for the best treatment of every patient.Install LabKey Server (Quick Install)
Register with LabKey
- Go to http://labkey.com/forms/register-to-download-labkey-server
- Fill out the required fields and press Submit.
Download LabKey Server
- Select the Windows (.exe) version, aka the Graphical Windows Installer.
Install LabKey Server
- When the download is complete, run the installer file.
- Complete the installer wizard, accepting all of the default values.
- If for any reason the installer does not complete, see Install LabKey Server (Windows Graphical Installer) for more complete step-by-step information and troubleshooting help.
- On the final page of the wizard, select Open browser to LabKey Server and click Close.
- A browser window will open.
- If this is the initial install, create a user account based on an email address (a fictional email is ok), choose a password and click Next.
- Wait for the modules to install.
- Set any Defaults you wish. These properties can be changed later through the Admin Console. Click Next.
- Installation is now complete!
Begin Using LabKey Server
Here are some ways to get started using LabKey Server:- Learn about setting up LabKey projects and workspaces.
- Explore LabKey tools for collaboration in teams.
- Install and explore the sample study.
- Choose a LabKey tutorial.
Other Installation Options
For additional information, troubleshooting help, and other installation options, see Install LabKey.What's New in 17.1
Feature Highlights of Version 17.1
Community News
Release Notes 17.1
Visualizations
- Time Charts - Time charts have been incorporated into common chart designer. (docs)
- Plotting Numeric Values in Text Columns - The server can now create plots for text columns that contain numbers. Non-numeric values such as '<1' representing values below or above the limits of quantitation will be ignored, allowing users to create visualizations from columns that contain a mix of numeric and text values. (docs)
- Bar Chart Enhancements - Incorporate data from more columns using bar groupings. (docs)
- Column Statistics -- New statistics include Median, Median Absolute Deviation, Quartiles, and Interquartile Range. Simplified UI for all column summary statistics. Available in LabKey Server Premium Editions. (docs)
- Grid Export - Specify how column headers are exported with data grids. (docs)
Instrument Data
- Assay Request Module - An extension of the Issues module designed especially for the assaying of samples/specimens. Available in LabKey Server Premium Editions. (docs)
- (NAb) Quality Control - Exclusion and comments for NAb assay data. (docs)
- (NAb) Statistics - Display %CV (percent coefficient of variation) on NAb assay result graphs. (docs)
- (Luminex) Quality Control - Exclude analytes from singlepoint unknown samples. (docs)
- (Genotyping) MiSeq - Support for new FASTQ header formatting. (docs)
- (Proteomics) Panorama Statistics and Quality Control
- Moving Range, Mean Cumulative Sum (CUSUMm), and Variability CUSUM plots to Levey-Jennings plots in Panorama QC folders. (docs)
- Summary hover tooltips show statistics for all methods. (docs)
- Pareto plots include data from mR and CUSUM for all guide sets. (docs)
- QC Plot interface enhanced with size/layout flexibility, legend options, etc. (docs)
- QC folders automatically delete previously uploaded Skyline documents that are redundant with new imports. (docs)
Sample Sets
- Sample Ids - New flexible options for naming samples in sample sets. Build a unique id for each sample using fields from the current row, random numbers, iterating integers, etc. (docs)
Study
- Delete Multiple Visits - Improved study management by deleting multiple visits or timepoints in a study. (docs)
- Cancel Import - Elect to stop import of a study if it would create new visits for imported data. (docs)
- Disallow Visit Overlap - Import of a visit map will fail if there are visits with overlapping time periods. (docs)
- Thumbnail Image Deletion - The user interface now provides for a way to delete custom icons and thumbnail images. (docs)
Administration
- FISMA Compliance Enhancements - Available in LabKey Server Premium Editions.
- Configure user accounts to expire after a set date. (docs)
- Disable user accounts after periods of non-use. (docs)
- Notify administrators if audit logging fails. (docs)
- Limit the allowable number of login attempts. (docs)
- Restrict identity service providers to only FICAM approved providers. (docs)
- On Server Folder Copy - Populate a new folder from an existing folder on the server without first exporting to an archive. (docs)
- New Role - Message Board Contributor This new roll allows participation in message board conversations. (docs)
- Disable Discussion Link - Ability to disable object-level discussions at the site or project level. (docs)
- Pipeline enhancements - Manage multiple pipeline protocols in a new web part. (docs)
NLP and Document Abstraction
- Improved Document Queuing - An improved task list allows the user to control the sequence of documents they process and makes it easier to reopen processing if they mistakenly approve a document. (docs)
- Case Status API - Obtain the calculated case status value via API. (docs)
- Document Batching - Abstractors can manage their task list by 'batching' related documents.
Adjudication
- Improved Upload Interface - Clearer upload interface clarifying what will happen and which steps are optional. (docs)
- Case Data Updates - New case data can be added even after a determination has been reached. New data can replace or be merged with existing case data. (docs)
- Infection Monitor Interface. Infection monitors are no longer notified unless an infection is confirmed. (docs)
Documentation
- Workflow Tutorial - Shows how to set up a new business process workflow on LabKey Server.
- Tutorial: Electronic Lab Notebook - Shows how to set up a simple sample and experiment tracking application using basic LabKey Server user interface components.
- Sample Sets: Examples - Improved sample set examples show how to provide unique sample ids, track parentage/lineage, and more.
- LabKey User Conference Resources - User presentations and slide decks from previous LabKey User Conferences.
- Query Metadata: Examples - Improved examples show how to use query metadata to modify data grids.
- Assay Feature Matrix: Reference page for features included with assay types.
- Electronic Health Records (EHR): Expanded documentation of electronic health record (EHR) features and extensibility.
Development
- Gradle Build Framework - LabKey Server developers can now build the server from source using the Gradle build framework. Ant build targets will be removed in release 17.2. (docs)
Operations
Upcoming Features in 17.2
Upcoming Features
Some features we are currently working on for the 16.3 release of LabKey Server:
Recent Documentation Updates
Click the links below to see the most recent changes to the LabKey Server documentation.
Tutorials

These tutorials provide an "hands on" introduction to the core features of LabKey Server, giving step-by-step instructions for building solutions to common problems.
They are listed roughly from simple to more complex. You can start with the New User tutorials, or you can start with a tutorial further down the list that interests you.
New User Tutorials | ||
| Data Grid Tour Take a quick tour through LabKey Server. |
• Data grids and visualizations | • tutorial |
| Security Learn how to organize and secure your data using LabKey Server. |
• Project and folder
organization • Customize look and feel • Security and user groups |
• tutorial |
|
File
Sharing Manage, search, and share file resources. |
• Import and manage data
files • Search data • Share data files |
• tutorial |
| Collaboration Tools Learn how to use LabKey Server's secure, web-based collaboration tools. |
• Set up message boards
and announcements • Provide contextual content using a wiki • Manage team tasks with a shared issue tracker |
• tutorial |
| List Explore list data structures. |
• Use and connect lists • Add lookups and URL properties |
• tutorial |
| Electronic Lab Notebook Learn how set up a basic ELN. |
• Capture sample and assay data • Connect data in different tables • Refine user interface and link navigation |
• tutorial |
Study Tutorials | ||
| Study Features Integrate and analyze observational study data and assay/mechanistic data. |
• Discover data trends; compare cohorts • Integrate heterogeneous data • Visualize data in time charts |
• tutorial |
|
Set Up a New
Study |
• Create and configure a
new Study • Integrate heterogeneous datasets • Set up specimen management • Use your own data or provided sample data |
• tutorial |
| Specimen Repository Management (for Admins) |
• Set up a specimen repository and request system | • tutorial |
| Use the Specimen Repository (for Specimen Requesters) |
• Browse and request specimen vials with an online shopping cart | • tutorial |
Assay Tutorials | ||
|
Introduction to Assay
Tools |
• Design
instrument-specific tables for your assay data • Import run data to an assay design • Perform quality control tests on data • Add data to a pre-existing study |
• tutorial |
|
NAb (Neutralizing Antibody) Assay |
• Create a design/model for the NAb
plate • Examine results and curve fit options |
• tutorial • interactive example |
|
ELISA Assay |
• Set up ELISA plate
templates • Import ELISA assay data • Visualize and analyze the data |
• tutorial |
|
ELISpot Assay |
• Configure an ELISpot
plate template • Create designs based on the configured template • Import and analyze data |
• tutorial • interactive example |
| Proteomics (CPAS) Storage and analysis for high-throughput proteomics and tandem mass spec experiments. |
• Import and annotate MS2
data • Analyze data with X! Tandem, Peptide/ProteinProphet • Build custom data grids and reports |
• tutorial |
| Flow Cytometry: Basics Set up a repository for management, analysis, and high-throughput processing of flow data. |
• Set up a flow
dashboard • Import data from FCS files and FlowJo • Build custom grids of imported data |
• tutorial • interactive example |
|
Flow Cytometry: Flow
Analysis |
• Define a Compensation
Calculation • Calculate statistics using the LabKey Flow engine |
• tutorial • interactive example |
|
Luminex: Level I |
• Import Luminex assay
data • Collect pre-defined analyte, run and batch properties • Exclude an analyte's results from assay results • Import several files of results together |
• tutorial • interactive example |
|
Luminex: Level II |
• View curve fits and
calculated values for each titration |
• tutorial • interactive example |
|
Microarray |
• Upload data from MAGE-ML data files |
• tutorial • interactive example |
|
Expression Matrix |
• Tie expression data to sample and feature/probe information |
• tutorial |
Developer Tutorials | ||
| JavaScript Client API: Build a Reagent Request System |
• Create a reagent request
tracking system • Visualize reagent request history • Optimize reagent fulfillment system |
• tutorial
• interactive example |
| JavaScript Client API: URLs, Filters, Passing Data Between Pages |
• Pass parameters between
pages via a URL • Filter a grid using a received URL parameter |
• tutorial |
| Export Chart as JavaScript | • Work with JavaScript directly to customize a visualization | • tutorial |
| JavaScript Charts | • Create custom visualizations in JavaScript | • tutorial |
| Modules: Queries, Views and Reports | • Develop file-based
queries, views, and reports in a module • Encapsulate functionality in a module |
• tutorial |
| Hello World Module | • Develop file-based
views. • Encapsulate functionality in a module |
• tutorial |
| Workflow Module Incorporate business process management workflows. |
• Install and use a sample workflow • Customize workflow process definitions |
• tutorial |
| Assay Module | • Create custom assay
design and user interface • Encapsulate functionality in a module |
• tutorial |
| Extract-Transform-Load Module Create and use a simple ETL. |
• Extract data into LabKey programattically • Clean or reshape data with transform scripts |
• tutorial |
Videos
Start Here
| Title | Description | Version | Video Link | Length |
| LabKey Server Overview | An introduction to LabKey Server. | Video | 4 min | |
| Site Navigation | Navigate projects and folders with popover menus. | Video | 1 min | |
| New Chart Designer | Use drag-and-drop column selection and a more intuitive layout of configuration options to create a visualizations. | 16.3 | Video | 6 mins |
| Pie and Bar Charts | New options for creating bar charts and pie charts as column visualizations and in the chart designer. | 16.3 | Video | 7 mins |
Webinars and Feature Demonstrations
| Title | Description | Version | Video Link | Length |
| Additional Column Summary Statistics | New column summary statistics options including standard deviation and standard error. | 16.3 | Video | 4 mins |
| Apply Template to Multiple Folders | Apply a folder archive template to multiple folders simultaneously. | 16.3 | Video | 8 mins |
| Resolve Samples in Other Locations | Samples in different containers can now be resolved in a single sample set. | 16.3 | Video | 6 mins |
| Retain Luminex Exclusions on Reimport | Users can now opt to retain the exclusion of wells, analytes, or titrations when reimporting Luminex assay runs. | 16.3 | Video | 3 mins |
| Expanded Data Views Customization | Reorder subcategories and alphabetize Items in Data Views Browser. | 16.2 | Video | 5 mins |
| MS2 Reporting Tweaks | Propagate the FDR filter applied to the decoy results to the target peptide results. | 16.2 | Video | 4 mins |
| Panorama QC Improvements | The Quality Control Dashboard shows a summary of the most recent file uploads, along with color-coded QC reports. | 16.2 | Video | 6 mins |
| Notifications for Issues | An experimental feature displays a notification inbox in the upper right corner of the LabKey Server interface. | 16.2 | Video | 6 mins |
| Multiple FASTAs for a Single Search | XTandem and Mascot searches can be performed against multiple FASTAs simultaneously. | 16.2 | Video | 3 mins |
| Small Molecule Support | Panorama QC folders now support both proteomics (peptide/protein) and small molecule data. | 16.2 | Video | 3 mins |
| Self-Service Email Changes | Users can update their own email address. | 16.2 | Video | 3 mins |
| Views/Reports Terminology Updates | The “Views” menu has been renamed to “Grid Views”, and focuses exclusively on modifying grids. The new “Reports” menu consolidates the available report types. | 16.2 | Video | 4 mins |
| Aggregates and Quick Visualizations on Data Grids | Create small charts for one column of data, including Histograms, Box Plots, and Pie Charts. Display aggregate values at the bottom of a data column, including Average, Count, etc. | 16.2 | Video | 7 mins |
| Specimen Repository – FreezerPro Configuration | Add custom fields via the field mapping user interface. To ensure appropriate field mapping, the user interface now filters by data type. Refine data loaded from the FreezerPro server with expanded filter comparators. | 16.2 | Video | 9 mins |
| Improved Issues List Customization | The Issues administration page has been re-organized for clarity and enhanced for ease of use. | 16.2 | Video | 15 mins |
| API Access via Session Key | Compliant API Access to Sensitive Information via Session Key | 16.2 | Video | 7 mins |
| SAML Integration | SAML authentication is now supported in LabKey Server Professional, Professional Plus, and Enterprise Editions. | 16.2 | Video | 7 mins |
| Argos Project | Leverage clinical/patient data for research. Jan 2015 | 15.1 | Video | 6 min |
| Collaborative Dataspace - Overview | Gain new insights from completed studies by pooling data and expertise. July 2014 | 14.2 | Video | 7 min |
| Import Excel Spreadsheets | Consolidate spreadsheets with the data processing pipeline. March 2014 | 14.1 | Video | 3 min |
| ETL Overview | Extract-Transform-Load (ETL) Using LabKey Server. Nov 2013 | 13.3 | Video | 2 min |
| Specimen Management | Specimen Management Using LabKey Server. Nov 2013 | 13.3 | Video | 2 min |
| Visualization Seminar |
Part I - Developer Alan Vezina explains in depth how to create box and scatter plots. |
13.1 |
Part 1 Part 2 Part 3 |
21 min 22 min 9 min |
| REDCap Integration with LabKey Server | Import REDCap data into LabKey Server. | 13.2 | Video | 9 min |
| R Views with knitr | Create views that combine HTML with R script. | 13.2 | Video | 1 min |
| Site Navigation | Navigate projects and folders with popover menus. | 13.2 | Video | 2 min |
| Survey Designer - Quick Tour | Key features of the survey designer | 13.1 | Video | 5 min |
| Panorama Proteomics Webinar |
Targeted proteomics assays. Feb 2013 |
13.1 |
Video | 62 min |
| FCS Express Data Exports | How to use LabKey Server with FCS Express. | 12.3 | Video | 36 min |
| Managing Protected Health Information (PHI) | Review of features for randomizing protected health information. Dec 2012 | 12.3 | Video | 3 min |
| Assessing Data with Quick Charts | Quickly review and assess data with Quick Charts. Aug 2012 | 12.2 | Video | 4 min |
| Study Admin: Organizing Data | Organize your datasets, setting status and category for each item. Aug 2012 | 12.2 | Video | 2 min |
| Security | Sharing Data with Another Lab: configure permissions for outside users. May 2012 | 12.1 | Video | 4 min |
| Participant Lists | Browse participant lists with faceted filtering. May 2012 | 12.1 | Video | 2 min |
| Participant Reports | Create and customize participant data reports. May 2012 | 12.1 | Video | 2 min |
| Visualize Group Data Trends | Visualize group/cohort performance. Jan 2012 | 11.3 | Video | 3 min |
| Ancillary Studies | Create ancillary studies based on a subset of study subjects. Jan 2012 | 11.3 | Video | 2 min |
| Data Browser | Browse visual summaries of study data. Jan 2012 | 11.3 | Video | 2 min |
User Conference Videos
Our annual User Conference offers an opportunity for all our users to connect with us and with each other to learn more about how LabKey Server can be a part of collaborative, reproducible, and globally distributed research. Some selected videos are included below. More are available on the conference presentation page.
Hope to see you there next time!
| Organization | Title | Conference Year | Presentation | Length |
| Oxford | Integrating Clinical and Laboratory Data from NHS Hospitals for Viral Hepatitis Research - David Smith | 2016 | View | 30 min |
| Fred Hutch | Optide-Hunter: Informatics Solutions for Optimized Peptide Drug Development Through the Integration of Heterogeneous Data and Protein Engineering Hierarchy - Mi-Youn Brusniak | 2016 | View | |
| Genentech | Skyline and Panorama: Key Tools for Establishing a Targeted LC/MS Workflow - Kristin Wildsmith | 2016 | View | 22 min |
| O'Connor Lab | Real-Time Open Data Sharing of Zika Virus Research using LabKey - Michael Graham | 2016 | View | 21 min |
| Just Bio | Therapeutic Antibody Designs for Efficacy and Manufacturability - Randal Ketchem | 2016 | View | 32min |
| HICOR | Using Data Transparency to Improve Cancer Care - Karma Kreizenbeck | 2015 | Video | 17 min |
| IPCR | Providing Access to Aggregated Data without Compromising PHI - Nola Klemfuss | 2015 | Video | 24 min |
| ESBATech | Data Management at ESBATech - Stefan Moese | 2015 | Video | 25 min |
| MHRP | Evolving Lab Workflows to Meet New Demands in the U.S. Military HIV Research Program (MHRP) - Stephen Goodwin | 2015 | Video | 50 min |
| Genomics England | The UK 100,000 Genomes Project - Jim Davies | 2015 | Video | 48 min |
| USF | Maximizing the Research Value of Completed Studies - Steven Fiske | 2015 | Video | 40 min |
| Argos | Unlocking Medical Records with Natural Language Processing - Sarah Ramsay, Emily Silgard, Adam Rauch | 2015 | Video | 48 min |
| WISC | Developing a Mobile UI for Electronic Health Records - Jon Richardson | 2015 | Video | 11 min |
| Artefact | When to Customize: Design of Unique Visual Tools in CDS - Dave McColgin | 2015 | Video | 11 min |
| Panorama | Panorama Public: Publishing Supplementary Targeted Proteomics Data Process with Skyline - Vagisha Sharma | 2015 | Video | 10 min |
| HIPC | Creating Interactive and Reproducible R Reports using LabKey, Rserve, and knitr - Leo Dashevskiy | 2015 | Video | 9 min |
| JPL | Realtime, Synchronous Data Integration across LabKey Application Server Data using High-throughput Distributed Messaging Systems - Lewis McGibbney | 2015 | Video | 13 min |
| HICOR / LabKey | Data Visualization Studio - Catherine Richards and Cory Nathe | 2015 | Video | 52 min |
| LabKey | Schema Studio - Matt Bellew | 2015 | Video | 44 min |
| HIDRA | Progress Report on the Hutch Integrated Data Repository and Archive. Oct 2014 | 2014 | Video | 60 min |
| SCRI | Using Existing LabKey Modules to Build a Platform for Immunotherapy Clinical Trials. Oct 2014 | 2014 | Video | 40 min |
| HIPC | Enabling Integrative Modeling of Human Immunological Data with ImmuneSpace. Oct 2014 | 2014 | Video | 54 min |
| Rho | Using Web-technologies to Improve Data Quality. Oct 2014 | 2014 | Video | 16 min |
| Novo Nordisk | Management and Integration of Diverse Data Types in Type 1 Diabetes Research. Oct 2014 | 2014 | Video | 35 min |
| CDS | The Collaborative Dataspace Program: an Integrated Approach to HIV Vaccine Data Exploration. Oct 2014 | 2014 | Video | 40 min |
| LabKey | Protecting Data, Sharing Data. Oct 2014 | 2014 | Video | 43 min |
| LabKey | Evolution of Connectivity in LabKey Server. Oct 2014 | 2014 | Video | 28 min |
| HIDRA | User Application: The Hutch Integrated Data Repository Archive (HIDRA). Sept 2013 | 2013 | Video | 58 min |
| ITN TrialShare | User Application: ITN TrialShare: Advancing clinical trial transparency through data sharing. Sept 2013 | 2013 | Video | 38 min |
| HIPC | User Application: Using LabKey and the R statistical language to facilitate data integration and reproducible results within the Human Immunology Project Consortium. Sept 2013 | 2013 | Video | 54 min |
| JDRF nPOD | User Application: DataShare: Accelerating Type 1 Diabetes Basic Science Research. Sept 2013 | 2013 | Video | 42 min |
| ICEMR | User Application: The use of LabKey Server in a globally distributed research project. South Asia International Center of Excellence for Malaria Research (ICEMR). Sept 2013 | 2013 | Video | 35 min |
| Overview | Introduction and Overview of LabKey Server. Britt Piehler. Sept 2012 | 2012 | Video | 56 min |
| IDRI | User Application: Adapting LabKey for novel applications: Infectious Disease Research Institute. Sept 2012 | 2012 | Video | 48 min |
| ATLAS | User Application: ATLAS: Data Sharing in HIV Research. Sept 2012 | 2012 | Video | 46 min |
| Dataspace | User Application: The Collaborative Data Space (CDS) as a case study. Sept 2012 | 2012 | Video | 30 min |
| ITN | ITN TrialShare: From Concept to Deployment. Sept 2012 | 2012 | Video | 30 min |
| LabKey | History of LabKey Server. Mark Igra. Sept 2012 | 2012 | Video | 31 min |
| LabKey | LabKey Security. Mark Igra. Sept 2012 | 2012 | Video | 42 min |
| LabKey | LabKey Server Assays: usage and development. Josh Eckels. Sept 2012 | 2012 | Video | 50 min |
| LabKey | LabKey Server Automation: Pipelines. Josh Eckels. Sept 2012 | 2012 | Video | 24 min |
| LabKey APIs | LabKey Server Automation: API Architecture. Karl Lum. Sept 2012 | 2012 | Video | 20 min |
| LabKey | Beyond the grid: using the LabKey reporting system to visualize, analyze, and present data in meaningful ways. Adam Rauch. Sept 2012 | 2012 | Video | 54 min |
Development Demonstration Videos
As part of the development process, we put together video demonstrations of a few key features which have been through the full develop/test cycle and are planned for the next major release. These videos are often at a more nuts and bolts development level and less polished than if they had been produced for a general audience. Here are a few selected offerings:
| Title | Description | Version | Video Link | Length |
| Workflow | Abstraction Workflow. Susan. March 2016 | 16.1 | Video | 8 mins |
| Workflow | Export Request Workflow. Susan. March 2016 | 16.1 | Video | 4 mins |
| Adjudication | Adjucation Tool. Cory. March 2016 | 16.1 | Video | 13 mins |
| Grid | Support Inline Thumbnails in a Grid. Xing. March 2016 | 16.1 | Video | 3 mins |
| Specimen | FreezerPro Configuration Improvements. Bernie. March 2016 | 16.1 | Video | 5 mins |
| Folder | Study/folder Templates. Susan. March 2016 | 16.1 | Video | 4 mins |
| MS2 | Mascot Related Improvements. Tony. March 2016 | 16.1 | Video | 4 mins |
| HLPC | Chromatogram Enhancements. Ian. March 2016 | 16.1 | Video | 5 mins |
| Dataspace | Dataspace Features: Study Axis, Aggregation. Jessi, Xing, Cory. March 2016 | 16.1 | Video | 13 mins |
| Panorama | Panorama QC Overview Dashboard. Cory. March 2016 | 16.1 | Video | 6 mins |
| Assay | Support for Warnings in Assay Transform Scripts. Marty. March 2016 | 16.1 | Video | 5 mins |
| Genomics | Data Portals, PHI Handling. Dave. March 2016 | 16.1 | Video | 8 mins |
| Compliance | Compliance Module - Activity/IRB/PHI/TOU per Container. Xing. March 2016 | 16.1 | Video | 5 mins |
| MS2 | Post-search Fraction Rollup. Josh. March 2016 | 16.1 | Video | 5 mins |
| Admin | Headless Upgrade Process. Adam. March 2016 | 16.1 | Video | 6 mins |
| Assay | FluoroSpot Assay. Karl. July 2015 | 15.2 | Video | 8 mins |
| Proteomics | Panorama QC Features. Binal. July 2015 | 15.2 | Video | 5 mins |
| Samples | Sample Set Features. Kevin. July 2015 | 15.2 | Video | 7 mins |
| Plot | Categorical Plot Selection. Marty. July 2015 | 15.2 | Video | 3 mins |
| Study | Republish Studies from Manage Page. Cory. July 2015 | 15.2 | Video | 5 mins |
| Export | Permissions Export and Import. Susan. July 2015 | 15.2 | Video | 5 mins |
| Workflow | Test Request Workflow. Susan. July 2015 | 15.2 | Video | 6 mins |
| TOU | Site-wide Terms of Use. Susan. July 2015 | 15.2 | Video | 5 mins |
| Modules | Module Properties. Kevin. July 2015 | 15.2 | Video | 4 mins |
| ETL | ETL Features. Marty. July 2015 | 15.2 | Video | 37 mins |
| Argos | Dashboard, timeline, filtering, security, SQL synonyms. Cory & Adam. March 2015 | 15.1 | Video | 37 mins |
| Panorama | Panorama QC features. Josh. March 2015 | 15.1 | Video | 8 mins |
| ETL | Extract-transform-load enhancements. Tony. March 2015 | 15.1 | Video | 9 mins |
| Study | Thumbnail extraction and dataset tagging. Adam. March 2015 | 15.1 | Video | 7 mins |
| Study | Republishing studies. Aaron. March 2015 | 15.1 | Video | 3 mins |
| Specimens | Specimen import performance improvements. Dave. March 2015 | 15.1 | Video | 7 mins |
| CDS | Plotting large datasets in CDS. Nick. March 2015 | 15.1 | Video | 3 mins |
| O'Connor | Bulk edit for experiments. Nick. March 2015 | 15.1 | Video | 6 mins |
| Luminex | Luminex QC features. Aaron. March 2015 | 15.1 | Video | 7 mins |
| Argos | Accrual estimation report. Cory. December 2014 | 14.3 | Video | 5 mins |
| Argos | Multiple data portals; logging PHI data access. Adam. December 2014 | 14.3 | Video | 11 mins |
| Specimens | Improve specimen rollup rules. Adam. December 2014 | 14.3 | Video | 7 mins |
| Study | Delete sites from study; list management changes. Adam. December 2014 | 14.3 | Video | 10 mins |
| Luminex | Allow use of alternate negative control bead on per-analyte basis. Cory. December 2014 | 14.3 | Video | 8 mins |
| Luminex | Allow calculation of EC-50/AUC controls without adding to L-J plots. Aaron. December 2014 | 14.3 | Video | 4 mins |
| Luminex | Use Uploaded Positivity Cutoff File. Aaron. December 2014 | 14.3 | Video | 4 mins |
| Genotyping | Haplotype Import Behavior. Aaron. December 2014 | 14.3 | Video | 3 mins |
| Genotyping | Report discrepancies between STR and other haplotype assignments. Aaron. December 2014 | 14.3 | Video | 2 mins |
| NAb | NAb: Multi-virus support. Karl. December 2014 | 14.3 | Video | 15 mins |
| Profiler | Mini-profiler. Kevin. December 2014 | 14.3 | Video | 8 mins |
| CDS | Prototype: Large Plots. Nick. December 2014 | 14.3 | Video | 6 mins |
| Sample Indices | Set Default Values for Thaw List. Tony. July 2014 | 14.2 | Video | 6 min |
| FreezerPro API | FreezerPro API Automation. Karl. July 2014 | 14.2 | Video | 12 min |
| Guide Sets | Luminex Metric Tracking Improvements. Cory. July 2014 | 14.2 | Video | 6 min |
| Specimen Admin | Specimen Administration Enhancements. Adam Rauch. July 2014 | 14.2 | Video | 10 min |
| Specimen Reports | Blinded Specimen Progress Report. Cory. July 2014 | 14.2 | Video | 5 min |
| Report Changes | Report and Dataset Editing Changes and Email Notifications. Dave. July 2014 | 14.2 | Video | 8 min |
| Impersonation | Impersonation UI Changes. Adam. July 2014 | 14.2 | Video | 6 min |
| Upload | Drag-and-drop File Uploader. Kevin. July 2014 | 14.2 | Video | 6 min |
| Argos | Argos Application Overview (HIDRA). Cory. July 2014 | 14.2 | Video | 15 min |
| Study Designer | New tools for defining study treatments, immunization, and assay schedules. Cory. March 2014 | 14.1 | Video | 7 min |
| FreezerPro | Import data from FreezerPro archives into a LabKey Study. Karl. March 2014 | 14.1 | Video | 7 min |
| Date Formats | Date Parsing and Formatting. Adam. March 2014 | 14.1 | Video | 11 min |
| Specimen Management | Specimen Management System Enhancements. Adam & Dave. March 2014 | 14.1 | Video | 25 min |
| Draw Timestamp | Specimen Draw Timestamp Change. Dave. March 2014 | 14.1 | Video | 4 min |
| Pipeline Scripts | File-based R Pipeline Scripts. Kevin. March 2014 | 14.1 | Video | 8 min |
| File Uploader | Experimental Feature: Multi-file Uploader. Kevin. March 2014 | 14.1 | Video | 8 min |
| Short URLs | Create memorable, sharable, short URLs. Josh. March 2014 | 14.1 | Video | 5 min |
| Manage Views | The manage views interface is now closely integrated with the data views web part. Karl. Oct 2013 | 13.3 | Video | 8 min |
| Export Charts as JavaScript | Alan demonstrates how to export a chart to JavaScript, edit it, and include it in an HTML page. Sept 2013 | 13.3 | Video | 9 min |
| Survey | Create surveys and long form questionnaires with the survey designer. Cory. Jan 2013 | 13.1 | Video | 33 min |
| Security: Linked Schemas | Securely show selected data in a folder. Mark. April 2013 | 13.1 | Video | 16 min |
| Pathology Viewer | View participants linked to multiple studies and publications. Adam. Jan 2013 | 13.1 | Video | 4 min |
Presentations (Slides only)
| Title | Description |
| Panorama | Targeted mass spec experiments. Integration with Skyline. June 2013 |
| From the Lab to the Network | LabKey for Labs: managing lab data, data sharing with multiple clients. May 2013 |
| Data Management for Global Health | Research with globally distributed sites, participants, and data. Feb 2013 |
| LabKey Server: Scientific Data Integration, Analysis, Collaboration | LabKey Fundamentals - PDF format. Feb 2013 |
| LabKey Server: An Open Source Platform for Scientific Data Integration | A presentation of LabKey fundamentals. PowerPoint Presentation. Dec 2010 |
| LabKey Training Presentations |
Learn LabKey fundamentals with these training presentations. A series of 10 presentations, including: data analysis, studies, assays, specimens, and server operations. PowerPoint Presentations. Feb 2011 |
| Observational Studies: Manage Data and Specimens | Manage data and specimens in your observational study. PDF file. May 2011 |
| Assays | Move your experimental data our of spreadsheets to an integrated data environment. PDF file. April 2011 |
| Data Management and Integration | A presentation to the 4th International Conference on Primate Genomics. PDF file. April 2010 |
| Managing Next Generation Sequencing and Multiplexed Genotyping Data | Learn the key features of LabKey Server's genotyping tools. PowerPoint Presentation. Dec 2010 |
| Webinar: LabKey Server Release 10.3 | Learn the key features of the 10.3 release. PowerPoint Presentation. Dec 2010 |
| Proteomics 8.3 Webinar | Learn about Proteomics features for the 8.3 release. PDF file. Dec 2008 |
| Reagent Database | Automate high-volume flow cytometry analysis using the Reagent Database Module. PDF file. March 2011 |
Demos
Feature Demonstrations and Hands-On Experiences |
||
Overview of LabKey Server: |
Try a few features now in our hands-on grid demo: |
|
|
||
Visualizations made easy with the Plot Editor: |
Learn to navigate LabKey projects and folders: |
|
Take a click-through tour of a LabKey Study: |
Introducing LabKey Biologics: |
|
|

|
|
Related Topics
Demos and Videos
Feature Demonstrations and Hands-On Experiences |
||
Overview of LabKey Server: |
Try a few features now in our hands-on grid demo: |
|
|
|
||
Visualizations made easy with the Plot Editor: |
Learn to navigate LabKey projects and folders: |
|
Take a click-through tour of a LabKey Study: |
Introducing LabKey Biologics: |
|
|
|
|
|
Related Topics
FAQ - Frequently Asked Questions
What is LabKey Server?
LabKey Server provides data-related solutions for clinical, laboratory, and biotech researchers. Feature highlights include: research collaboration for geographically separated teams, open data publishing, data security and compliance, as well as solutions for complex data integration, workflow, and analysis problems. LabKey Server is a software platform: a toolkit for crafting your own data and workflow solutions. It is highly flexible and can be adapted to many different research and laboratory environments. You can keep your existing workflows and systems using LabKey Server to augment them, or you can use LabKey Server as an end-to-end workflow solution.Who uses LabKey Server?
Academic researchers, clinicians, and biotechnical professionals all use LabKey Server to support their work. LabKey Server provides a broad range of solutions for data collaboration and security, clinical trial management, data integration and analysis, and more. Please visit LabKey.com to learn more.Which assay instruments and file types does LabKey Server support?
LabKey Server supports all common tabular file types: Excel formats (XLS, XLSX), Comma Separated Values (CSV), Tab Separated Values (TSV). LabKey Server also recognizes many instrument-specific data files and metadata files, such as Flow Cytometry FCS files, ELISpot formatted XLS files, and many more. In general, if your instrument provides tabular data, then the data can be imported using a "general purpose" assay type. You may also be able to take advantage of other specific assay types, which are designed to make the most of your data. For details, see the documentation for your instrument class. Both general and instrument-specific assay types are highly-flexible and configurable by the user, so you can extend the reach of any available type to fit your needs. Contact LabKey if you have problems importing your data or have specific questions about which file types and instruments are supported.When will the next version be released?
New features are released three times a year. Release dates can be found in our release schedule.Who builds LabKey Server?
LabKey Server is designed by the researchers who use it, working in collaboration with LabKey's professional software developers.How much does it cost?
All source code distributed with the Community Edition is free. Third-parties can provide binary distributions with or without modifications under any terms that are consistent with the Apache License. LabKey provides Community Edition binary distributions for free. Premium Editions of LabKey Server are paid subscriptions that provide additional functionality to help teams optimize workflows, securely manage complex projects and explore multi-dimensional data. These Premium Editions also include LabKey’s professional support services and allow our experts to engage with your team as long-term partners committed to the success of your informatics solutions.What equipment do I need to run LabKey Server?
LabKey acts as a web server and relies on a relational database server. It can be installed and run on a stand-alone PC, or it can be deployed in a networked server environment. You can deploy the server within your organization's network, or we can deploy and manage a hosted solution for you. Single laboratory installations can be run on a single dedicated computer, but groups with more computationally demanding workflows routinely integrate with a variety of external computing resources.Who owns the software?
LabKey Server Community Edition is licensed under Apache License 2.0, with premium features licensed under a separate LabKey license. Developers who contribute source code to the project make a choice to either maintain ownership of their code (signified via copyright notice in the source code files) or assign copyright to LabKey Corporation. Source code contributors grant a perpetual transferable license to their work to the community under terms of the Apache License. The Apache License is a broadly used, commerce-friendly open source license that provides maximum flexibility to consumers and contributors alike. In particular, anyone may modify Apache-licensed code and redistribute or resell the resulting work without being required to release your modifications as open source.Do I need to cite LabKey Server?
If you use LabKey Server for your work, we request that you cite LabKey Server in relevant papers.How can I get involved?
There are many ways to get involved with the project. Researchers can download and evaluate the software. You can join community forums for Proteomics, Flow Cytometry, and Study. Java Developers can enlist in the project, set up the build environment, and join the Developers Center. Research networks, laboratories, foundations, and government funding agencies can sponsor future development. Software vendors can develop proprietary modules. Developers interested in building from source or creating new modules should visit the Developer Center.How can I find documentation for older versions of LabKey Server?
See the links below for release notes from previous versions and archived documentation:Do you have a press contact?
For media and conference inquiries about LabKey Server, please contact:Kelsey Gibsonkelseyg@labkey.com
How to Cite LabKey Server
How to Cite LabKey Server
If you use LabKey Server for your research, please reference the platform using one of the following:General Use: Nelson EK, Piehler B, Eckels J, Rauch A, Bellew M, Hussey P, Ramsay S, Nathe C, Lum K, Krouse K, Stearns D, Connolly B, Skillman T, Igra M. LabKey Server: An open source platform for scientific data integration, analysis and collaboration. BMC Bioinformatics 2011 Mar 9; 12(1): 71.Proteomics: Rauch A, Bellew M, Eng J, Fitzgibbon M, Holzman T, Hussey P, Igra M, Maclean B, Lin CW, Detter A, Fang R, Faca V, Gafken P, Zhang H, Whitaker J, States D, Hanash S, Paulovich A, McIntosh MW: Computational Proteomics Analysis System (CPAS): An Extensible, Open-Source Analytic System for Evaluating and Publishing Proteomic Data and High Throughput Biological Experiments. Journal of Proteome Research 2006, 5:112-121.Flow: Shulman N, Bellew M, Snelling G, Carter D, Huang Y, Li H, Self SG, McElrath MJ, De Rosa SC: Development of an automated analysis system for data from flow cytometric intracellular cytokine staining assays from clinical vaccine trials. Cytometry 2008, 73A:847-856.Additional Publications
A full list of LabKey publications is available here.LabKey Terminology/Glossary
User Interface Terms
- Web Part - A user interface panel designed for specific functionality. Examples: file management panel, wiki editor, data grid.
- Dashboard/Tab - A collection of web parts assembled together for expanded functionality.
- Folder - Folders are the "blank canvases" of LabKey Server: the workspaces where you organize web parts and dashboards. Folders are also important in security: they form the main units around which security is applied and administered.
- Project - Projects are top level folders. They function like folders, but have a larger scope. Projects form the centers of configuration, because the settings made at the project level cascade down into their sub-folders by default. (You can reverse this default behavior if you wish.)
- Assay/Assay Design - A container for instrument-derived data, customizable to capture information about the nature of the experiment and instrument.
- List - A general data table - a grid of columns and rows.
- Dataset - A table like a list, but associated with and integrated into a wider research study. Data placed into a dataset is automatically aligned by subject ids and timepoints.
- Data Grid - A web-based interactive table that displays the data in a Dataset, List, Query.
- Report - A transformational view on the underlying data, produced by applying a statistical, aggregating, or visualizing algorithm. For example, an R script that produces a scatter plot from the underlying data.
Database Terms
- Table - The primary data container in the database - a grid of rows and columns.
- Query - A selection of data from tables (Lists and Datasets). Queries form the mediating layer between LabKey Server and the database(s). Queries are useful for staging data when making reports: use a query to select data from the database, then base a report on the query. Each table presents a "default query", which simply repeats the underlying table. Users can also create an unlimited number of custom queries which manipulate the underlying tables either by filtering, sorting, or joining columns from separate tables.
- View - Formatting and display on top of a query, created through the data grid web user interface.
- Schema/Database Schema - A collection of tables and their relationships. Includes the columns, and any relationships between the columns. LabKey uses schemas to solve many data integration problems. For example, the structure of the 'study'schema anticipates (and solves) many challenges inherent in an observational/cohort study.
- Lookups - Lookups link two table together, such that a column in the source table "looks up" its values in the target table. Use lookups to consolidate data values, constrain user data entry to a fixed set of values, and to create hybrid tables that join together columns from the source and target tables. Lookups form the basis of data integration in LabKey Server. LabKey Server sees foreign key/primary key column relationships as "lookup" relationships.
Assay Terms
- Assay design - A container for capturing assay data. Assay designs can be generic, for capturing any sort of assay data (see GPAT below), or specific, for capturing data from a targeted instrument or experiment.
- Assay type - Assay designs are based on assay types. Assay types are "templates", often defined to support a specific technology or instrument such as Luminex, Elispot, ELISA, NAb, Microarray, Mass Spectrometry, etc.
- Assay results (also referred to as assay data) - The individual rows of assay data, such as a measured intensity level of a well or spot.
- Assay run - A grouping of assay results, typically corresponding to a single Excel file or cycle of a lab instrument on a specific date and time, recorded by a researcher or lab technician who will specify any necessary properties.
- Assay batch - A grouping of runs that are imported into LabKey Server in a single session.
- GPAT - General Purpose Assay Type. The most generic assay type/"template", used to import a single tabular data block from a spreadsheet or text file. At assay design time, the GPAT type can infer the field names and types from an example instance of the data it is designed to store. GPAT assays don't perform any analysis of the data, other than collecting and storing. Like any data capture device in LabKey Server, you can layer queries, reports, visualizations on top of GPAT designs, such as SQL queries, R reports, and others. There are many other assay types that are specialized for a specific instrument or experiment type, such as Luminex, Elispot, ELISA, mass spectrometry etc. These specialized assay types typically provide built-in reports and visualizations specifically tailored to the given instrument or experiment type.
ETL (Extract, Transform, Load) Terms
- Transform - An operation that copies data from the result of a source query into adestinationdataset or other tabular data object.
- ETL XML File - A file that contains the definition of one or more transforms.
- Filter strategy - A setting that determines which rows are considered before the source query is applied.
- Target option - A setting that determines what the transfer does when the source query returns keys that already exist in the destination.
Study Terms
- Study - A container for integrating heterogeneous data. Studies bring together data of different types and shapes, such as medical histories, patient questionnaires, assay/instrument derived data, specimen inventories, etc. Data inside of 'study datasets' is automatically aligned by subject id and time point.
- Subject - The entity being tracked in a study, typically an organism such as a participant, mouse, mosquito, etc.
- Visit/Timepoint - Identifier or date indicating when the data was collected.
- Dataset - The main tables in a LabKey Server Study, where the heterogeneous data resides. There are three sub-groups: demographic datasets, clinical datasets (the default), and assay/specimen datasets.
Archive: Documentation
Documentation Archive
This section contains an archive of the "What's New" and "Release Notes" for specific versions of LabKey Server.- Documentation Archive.
- Previous Releases - list of all previous releases along with release date, download links, and source control revision number.
Release Notes Archive
What's New in 16.3
Feature Highlights of v16.3
Community News
Release Notes 16.3
Visualization
- Bar and Pie Charts - Two new built-in visualization types are now available: Bar Charts and Pie Charts. (video)
- Chart Designer: A new chart designer is available for a wide range of built-in visualization types, featuring drag-and-drop column selection and a more intuitive layout of configuration options. (docs) (video)
- Improved Data Views: A new setting lets you control the display height for the Data Views web part. (docs)
- Binning for Large Data Sets: Data point binning improves the readability of scatter plots over large data sets. (docs)
- (Premium Editions) Additional Column Summary Statistics: New statistics options have been added, including standard deviation and standard error. (docs) (video)
System Integration
- R Studio Integration: Design R reports in RStudio using data selected in LabKey Server. Contact LabKey for set up and support options.
- New SQL Methods: The SQL methods GREATEST and LEAST are now supported for PostgreSQL, MS SQL Server, Oracle, and MySQL. (docs)
- ETL Engine Improvements
- Improved PostgreSQL Scalability: A limitation has been removed that imposed a limit of 100 columns on PostgreSQL tables that are targets of an ETL process.
- Alternate Key: Use an alternate key, instead of the target table's primary key, when merging data with an ETL process. (docs)
- Set Range: Developers can use ranges to aid development of ETL scripts. (docs)
- Transformation Improvements: ETL transformation using a Java class is now supported. (docs) ETL processes may now output constant values into a target column. (docs)
Security
- Improved Duo Configuration: A new option lets you indicate how LabKey Server user accounts are matched to Duo accounts, either by user id, user name, or email address. (docs)
Administration
- Date and DateTime Data Types: Date and DateTime data types are more intuitive to use. Admins can set default formats for each type at various scopes in the server. (docs)
- Apply a Template to Multiple Folders: When importing a folder archive, you have the option to select a subset of objects to import, and can also choose to apply that template to multiple folders simultaneously. (docs) (video)
Study Data Management
- New UI for Assay Schedule: The process for scheduling assays has been simplified. (docs)
- New UI for Vaccine Study Products and Treatments: Simplify study registration and making immunization products consistent and manageable across multiple studies. (docs and docs)
- Study Performance Improvements: The underlying database schema for studies has been redesigned, providing greater performance and using less storage space in the database.
NLP and Document Abstraction
- Natural Language Processing: Use the LabKey NLP engine or integrate another to extract data from free text documents and reports. (docs)
- Document Abstraction Workflow: Improved document abstraction workflow, including options for manual abstraction, automatic abstraction, and document review. (docs)
- Disease-based Document Assignment: Specialize abstraction workflow and assignments based on the disease group represented in the document. (docs)
- Document Abstraction UI: More intuitive interface streamlines the process of abstracting information from documents. (docs)
Assays / Instrument Data
- Signal Data Module: Capture data and metadata for HPLC experiments. (docs)
- Sample Sets: Samples in different containers can be resolved in a single sample set. (docs) (video)
- (Luminex) Retain Exclusions when Reimporting Runs: If you have excluded wells, analytes, or titrations, you can opt to continue excluding them on reimport. (docs) (video)
- (Luminex) Ignore Bead Numbers on Analytes: Bead numbers are no longer included as part of the analyte name. (docs)
- (Panorama) Performance Improvements: The internal queries used by Panorama have been optimized to improve page load times.
Development
- Improved Study Export/Import: The dataset_metadata.xml file in a study archive now provides: (1) an <index> tag to indicate index fields, (2) a <sharedConfig> tag to indicate columns that should be added to all the datasets, and (3) on import of a study archive, the <scale> tag (which holds column size information) is applied to existing columns in the target study. (docs)
- API Session Key: Run client API code in the context of a user account without storing your credentials on the client machine. (docs)
Operations
- New supported versions:
Potential Backwards Compatibility Issues
- Support for PostgreSQL 9.1 has been removed.
Upgrade to 16.3
- Upgrading the Issues Module. If the server is restarted prematurely during upgrade, the issues tracker migration code will not be re-run automatically (because it is implemented as a deferred upgrade script). To run the upgrade code manually go to this URL: ./labkey/issues/home/upgradeIssues.view It will trigger the same upgrade code that the automatic upgrade should have run. For more details see Support Ticket #27963.
Documentation
- LabKey User Conference 2016 Resources: (docs)
What's New in 16.2
Feature Highlights of v16.2
LabKey User Conference 2016 Speakers Announced
Join us for the 2016 LabKey User Conference & Workshop! At this two day event, attendees will have the opportunity to:- Hear how leading users are improving efficiency, transparency, and data quality with LabKey Server
- Enhance their technical knowledge of the LabKey Server platform
- Receive hands-on technical guidance from LabKey developers
- Learn the fundamentals of LabKey Server administration and core capabilities of the platform
- Connect and collaborate with other LabKey Server users
Location: Seattle, WA
Venue: Pan Pacific Hotel, 2125 Terry Avenue, Seattle, WA 98121Learn More and Register: http://www.labkey.com/about/events/2016-user-conference/
LabKey Biologics Preview
Release Notes 16.2
Collaboration
- Improved Issue Administration: The Issues administration page has been re-organized for clarity. The custom field editor has been updated to use the standard field editor. The number of custom fields that can be added is now unlimited. Multiple issue lists in the same container are supported. Individual issues can be moved between containers. Inheriting configuration from another issues list is no longer supported, but custom fields can be set as lookups to shared lists via the standard field editor. (docs) (demo)
Study Data Management
- FreezerPro Enhancements: Add custom fields via the field mapping user interface. To ensure appropriate field mapping, the user interface now filters by data type. Refine data loaded from the FreezerPro server with expanded filter comparators. (docs) (demo)
Administration
- User Account Improvements: Users can update their own email address. (docs) (demo)
- Data Views Performance Improvements: The Data Views Browser loads faster, making it easier for users to explore the queries and reports in a study.
- Improved Query Browser Performance: The Query Browser loads faster, making it easier for administrators to browse the core database tables and the queries built on top of them.
Visualization
- Column Visualizations: Small charts for one column of data, including Histograms, Box Plots, and Pie Charts. (docs) (demo)
- Column Aggregates: Display aggregate values at the bottom of a data column, including Average, Count, etc. (docs) (demo)
- Quickly Remove Column: Quickly remove a column from a data grid through the column header menu. (docs) (demo)
- Improved Menu Layout for Data Grids: The "Views" menu has been renamed to "Grid Views", and focuses exclusively on modifying grids. The new "Reports" menu consolidates the available report types. (docs) (demo)
- R Markdown v2: Markdown v2 is now supported when creating knitr R reports. (docs)
User Interface
- User Interface Tours: Shows users how your application works by providing a step by step path through the UI, each step provides a pointer, explanatory text, and links to the next step and further documentation. (docs)
- New Icons: Most of the user interface has been updated from bitmap icons to use font-based icons. Views (docs)
- Reorder Reports and Charts: Administrators can reorganize reports within categories. (docs) (demo)
- Reorder Subcategories in Data Views Browser: Administrators can reorder subcategory groupings using a drag-and-drop interface.(docs) (demo)
- Alphabetize Items in Data Views Browser: Administrators can order items alphabetically or according to the order they are returned from the database. (docs) (demo)
- Notifications Inbox: An experimental feature displays a notification inbox in the upper right corner. (docs) (demo)
Sample Sets and Specimens
- New Data Structure: DataClass: Use DataClasses to capture properties and parentage for samples, such as those produced from complex bio-engineering processes. (Also available in release 16.1.) (docs)
- Sample Parentage/Lineage: A new way to indicate parentage in Sample Sets has been added. The previous way to indicate lineage, the "Parents" column, is still present, but should be considered deprecated. (docs)
Security
- SAML Authentication: SAML authentication is now supported. Available in LabKey Server Professional, Professional Plus, and Enterprise Editions. (docs) (demo)
Assays and Instrument Data
- (Panorama) QC Dashboard Improvements: The Quality Control Dashboard shows a summary of the most recent file uploads, along with color-coded QC reports. (docs) (demo)
- (Panorama) Small Molecule QC: Panorama QC folders now support both proteomics (peptide/protein) and small molecule data. (docs) (demo)
- (Panorama) Heat Maps with Clustergrammer: Visualize expression matrix data using the Clustergrammer web service. (docs)
- (MS2) Multiple FASTAs for Single Search: XTandem and Mascot searches can be performed against multiple FASTAs simultaneously. (docs) (demo)
- (MS2/Mascot) Improvements in Mascot Search Results: Propagate the FDR filter applied to the decoy results to the target peptide results. (docs) (demo)
Documentation
- Improved List Tutorial: Learn about using lists. (docs)
- Tours for New Users: Create tours of tools and interfaces for your users. (docs)
- Improved Examples for Surveys: Additional example code for online surveys is provided, including populating default values from database values, conditional/branching questions, and Likert scales. (docs)
Development
- Rlabkey Source Repository: The Rlabkey API has been moved from SVN to GitHub.
What's New in 16.1
Feature Highlights of v16.1
- FreezerPro - A new user interface makes it easy to connect to and import data from your FreezerPro installation.
- Panorama Enhancements - Analyze small molecule data, and track performance metrics on an improved quality control dashboard.
- User Interface Features - Preview file contents and images; customize message board notifications; upgrade without administrator login.
Community News
LabKey User Conference 2016: Save-the-Date
Mark your calendar for the LabKey User Conference 2016! This year’s LKUC will take place October 6-7 in Seattle, WA. Stay tuned for additional details and registration information.Zika Real-Time Data Sharing
LabKey partners at the O’Connor Lab at University of Wisconsin Madison have been making headlines with their real-time sharing of Zika research data via LabKey Server. Dave O’Connor and his colleagues are sharing raw-data, study commentary, and results with the public, updating available information daily. To see the live Zika data, visit the O’Connor Lab LabKey ServerRelease Notes 16.1
Study Data Management
- FreezerPro: Improved setup and configuration, including a graphical user interface for selecting specimen types and mapping columns. Improved performance when importing data. Available in LabKey Server Professional, Professional Plus, and Enterprise Editions. (docs)
- Adjudication Module: Facilitate independent assessments of a given case, where two or more assessors have access to the same data, but none can see any other's decision before they have made their own determination. Used for gaining confidence that a given diagnosis or decision is correct. (docs)
Assays / Instrument Data
- (Panorama) Quality Control Dashboard: Quality control summary is based on data in subfolders. New metric added: Mass Accuracy. Graph both precursor and fragment values on the same plot. (docs)
- (Panorama) Small Molecule Support: Support for storing and viewing small molecule data via Skyline documents. (docs)
- (Panorama) Automatically Link Skyline Document Versions: When importing Skyline documents, different versions of the same document are automatically linked together. (docs)
- (Mass Spec) Configure Mascot at the Project or Folder-level: Use the site-wide Mascot configuration as the default; use the project and folder-level configuration to override the site-wide configuration. (docs)
- (Mass Spec) Mascot-specific Details: Additional details are now imported from Mascot search results, including metadata, decoy, and alternative peptide information. (docs)
- (HPLC) HPLC Assay Design: A new HPLC module includes an HPLC assay design, supports automatic or manual upload of result files, and contains overlayed chromatogram visualizations for multiple runs. (docs)
User Interface
- Hover for File Preview: Hover over a file icon in the repository to see a preview of the file contents. (docs)
- Display Image Thumbnails in a Grid: Display inline thumbnails for file and attachment fields in lists, sample sets, or assay result grids. (docs)
- Customizable Email Templates for Announcements: Customize the email sent for message board activity. (docs)
Security
- Security Bulk Update API: Supports programmatic update of security groups and role assignments. Improved import of groups from external systems. (docs)
Development
- Trigger Scripts: Trigger scripts can now be applied when importing data to Lists. (docs) | (docs)
- Transform Scripts: Assay import using transformation scripts now can include warning reporting, offering the user the option to proceed or cancel the import. (docs)
- Long Text Strings: For administrator defined tables such as lists, datasets, and assay results, text columns can now hold the maximum number of characters allowed by the underlying database implementation. Previously, LabKey Server limited string columns in these tables to a maximum of 4000 characters, regardless of the maximum length allowed by the database implementation. (docs)
Operations
- Improved Server Upgrade Process: Starting in 16.1, the server initiates upgrade and startup of all modules at server startup time. Administrators can still log in to view upgrade/startup progress, but the server will no longer wait for a login. Previously, the server would upgrade the core module at server startup, but would wait for an administrator login before upgrading other modules or initiating module startup. This change streamlines the startup process, simplifies upgrade code, and facilitates scripted upgrades of LabKey Server.
- Support PostgreSQL 9.5: For details, see Supported Technologies.
- New Full-Text Search Administration Option: A new option lets you specify the directory type used by the underlying full-text search library. In most cases, we recommend using the default setting. If you encounter problems with full-text search, contact LabKey for recommended changes to this setting. (docs)
Potential Backwards Compatibility Issues
- Default Request URL Pattern Change: New default URL pattern, for details see LabKey URLs.
What's New in 15.3
Feature Highlights of v15.3
- Custom Footers and Login Pages - Tailor your site with custom footers and login pages.
- SQL Query Logging - Query logger tracks who has queried the database, when, and what SQL query was used.
- Document Revision Tracking - Refine mass spectrometry method development with document version tracking.
- ETL Column Mapping - Copy data between tables with different column names with ETL column name mapping.
Community News
- User Conference Videos and Slide Decks - Presentations from the 2015 user conference are now available as videos and slide decks.
- Genomics England - Genomics England is partnering with LabKey to design and develop a solution that will integrate and securely share complex clinical and genomic data for the 100,000 Genomes Project.
- Just Biotherapeutics - Just Biotherapeutics, Inc. and LabKey are teaming up to develop a new software product that help will biotechnology R&D teams produce more effective and affordable biotherapeutics by optimizing the development process.
- Premium Editions - LabKey Software has introduced Premium Editions of LabKey Server. For feature details of each edition, see LabKey Server Editions.
Release Notes 15.3
Extract-Transform-Load (ETLs)
- Undo ETL job: Roll back changed records in the target table. (docs)
- Column name mapping: Copy data between tables, even when their columns names do not match. (docs)
- Call an ETL job from another ETL job: ETLs can queue up other ETLs, even ones that exist in a different module. (docs)
- Stored procedures as gates for ETLs: Let a stored procedure determine if there is work for an ETL. (docs)
- ETL job history table: View a history of all ETLs that have run on the site. (docs)
Look and Feel
- Turn off default LabKey footer: Remove the default LabKey Server footer. Available in LabKey Server Professional, Professional Plus, and Enterprise Editions. (docs)
- Custom footers: Add a custom footer to replace the default LabKey Server footer. (docs)
- Custom login page: Provide a custom login page that replaces the default login page. (docs)
Security
- User self-registration: Administrators can let users create their own accounts on the server. (docs)
- Automatic user registration: Administrators can enable or disable auto-creation of new accounts in LDAP and SSO authentication systems. (docs)
- SQL query logging: Log each query request against an external data source including the user, impersonation information, date and time, and the SQL statement used to query the data source. Useful in applications that require review of data retrievals. Available in LabKey Server Professional Plus and Enterprise Editions. (docs)
Assays / Instrument Data
- (MS2) Merge XTandem search results: Combine existing XTandem search results into a merged analysis. (docs)
- (Panorama Mass Spec) Document revision tracking: Keep track of refinements to mass spec methods by linking different versions of a document into a series. (docs)
- (Panorama Mass Spec) Pareto plots: Pareto plots provide a summary of outlier values, identifying the most likely causes of quality control problems. (docs)
- (NAb) Improved handling of NAb data: On import, NAb dilution and well data is now stored in the database in two new tables, DilutionData and WellData, instead of being stored as a file on the server. Users can write queries against, and export from, these new tables. Also, the run details view is rendered from the new tables, instead of being parsed from the original data file. Note that on upgrade to LabKey Server 15.3, existing NAb data files on the server will be parsed and imported to the new database tables. (docs)
- (Genomics) PacBio support: Manage samples and sequencing results generated from a PacBio Sequencer. (docs)
Data Integration
- Improved schema export: The schema export dialog now lets you provide a target schema and a target directory for the exported files. (docs)
Operations
- Support for Tomcat 8: (docs)
- Performance: Improved caching performance for queries and custom views.
Development
- (Python) Export data as a python client script: Support Python clients of LabKey Server by generating a Python script that retrieves data from the database. (docs)
- (Python) Assay data support: New methods in the Python Client API support assay data (loadBatch and saveBatch). (docs)
- (Python) Support for Python 3: The updated Python Client API supports Python 3. (docs)
- Site validation enhancements: New site validation checks show (1) folders where Guests have read permissions and (2) pipeline roots that don't exist in the file system. (docs)
Potential Backwards Compatibility Issues
- Microsoft SQL Server: Starting in LabKey Server 15.3, Microsoft SQL Server 2008 R2 is no longer supported.
- Java 7: Starting in LabKey Server 15.3, Java 7 is no longer supported.
What's New in 15.2?
Highlights of v15.2
- Analyze - Explore plate results for FluoroSpot, a multi-cytokine variant of ELISPOT
- Integrate - Join Gene Ontology annotations with expression data
- Share - Support compliant data sharing with site-wide terms of use
- Monitor - Visualize quality control ranges using guide sets in Panorama
- Migrate - Transfer schemas and security groups, users and roles
LabKey User Conference
Registration is open for the LabKey User Conference and Workshop 2015, October 1 and 2 in Seattle. Seats sold out early last year, so register soon. Hope to see you there!Community News
LabKey Server-based projects continue to make an impact:- HICOR: The Hutch Institute for Cancer Outcomes Research (HICOR) debuted the HICOR IQ portal, enabling HICOR partners to visualize cancer incidence, survival and insurance claims data to help them improve care. Covered in the Hutch News.
- O'Connor Lab: A new case study describes how Professor David O’Connor’s lab at the University of Wisconsin uses LabKey Server as its “operating system,” speeding its efforts to understand how genetics affects immunity.
- Natural Language Processing (NLP): The Fred Hutch and LabKey are collaborating to develop tools for NLP-assisted clinical data abstraction and annotation workflows, as covered in the Hutch News.
- Argos: Also as reported in the Hutch News, the Argos data exploration technology is now in pilot use at the Fred Hutch, helping teams perform hypothesis generation, trial accrual estimation and cohort discovery in a HIPAA-compliant manner.
Release Notes 15.2
Assays / Instrument Data
- FluoroSpot Assay: New assay type to support FluoroSpot experimental results. Results can be viewed in a graphical representation of the experimental plate, with selectable highlights for given samples and antigens. (docs)
- Protein Expression Matrix Assay: New assay type to support protein expression matrix results. (docs)
=== Sponsored by HIRN - Human Islet Research Network
- GO (Gene Ontology) Annotation Improvements: Imported GO annotations are now queriable, making it possible to include them in custom SQL queries, reports, and charts, and to join them with related data, such as protein expression and mass spectrometry data. (docs)
=== Sponsored by HIRN - Human Islet Research Network
- (Mass Spec) Guide Set for Panorama Quality Control Plots: Visualize the expected range of values in the quality control dashboard. (docs)
=== Sponsored by Panorama Partners Program members
Data Integration / Studies
- Auto Generation of Schema Export Scripts: Auto-generate a migration script for moving tables and data to a different environment/schema. (docs)
- (Experimental Feature) Shared Demographic Datasets and Timepoints: Use a common set of participant and visit data in multiple studies simultaneously. (docs)
=== Sponsored by HIPC - Human Immunology Project Consortium
Collaboration
- Site-wide Terms of Use: Require users to agree to a 'terms of use' when logging into the site. The terms of use is scoped to the entire site as a whole, instead of scoped to an individual project. (docs)
=== Sponsored by ITN - Immune Tolerance Network
- Folder Display Title: Display titles can be specified for folders that can be different from the underlying folder name. (docs)
- File Upload for Sample Sets: Upload new sample sets from a file. Supported formats include: tab-separated value files (TSV) or Excel files (XLS and XLSX). (docs)
Security
- Export/Import Permission Settings: Propagate security configurations from one environment to another. (docs)
=== Sponsored by Fred Hutchinson Cancer Research Center
- Single Sign On Authentication: Allow users to sign on to multiple applications while providing their credentials only once to a Central Authentication Service (CAS) Server. (docs)
=== Sponsored by University of South Florida Health Informatics Institute
Extract-Transform-Load (ETLs)
- ETL Auto Restart: ETL jobs requeue and restart if the server shuts down during the job.
===Sponsored by SNPRC - Southwest National Primate Research Center
Development
- Module Properties: New properties for modules, including author, label, and description. (docs)
=== Sponsored by HIPC - Human Immunology Project Consortium
- Generate Java Data Access Code: Export the definition of any data grid as Java code. Use this code to load the data into a Java application. (docs)
Operations
- 3rd Party Software Included in the Windows Graphical Installer:
- PostgreSQL 9.4.4
- Java Runtime Environment (JRE) 8u45
- Apache Tomcat 7.0.62
- Site Validation Service: A new site validation service has been introduced, to help diagnose issues with schema integrity, etc. (docs)
Potential Backwards Compatibility Issues
- Java 7 no longer supported. Starting with version 15.2, LabKey Server no longer supports Java 7. Please upgrade to Java 8. (docs)
- PostgreSQL 9.0.x no longer supported. We recommend upgrading to the latest point release of PostgreSQL 9.4.x. (docs)
- Email Notification for Specimen Requests. After upgrading to 15.2, existing studies may need to have their specimen email notifications reconfigured. To do this, go the study in question, click the Manage tab and click Manage Notifications (near the bottom of the page). Inside the text boxes Notify of New Requests and Always CC, hit the Enter key in between each email entry. Failing to reconfigure the notifications in this way may result in notifications being sent to only the first email address in each list.
- Email Unregistered Addresses: In LABKEY.Message, the parameter 'allowUnregisteredUser' (which allowed logged-in users to send emails to unregistered addresses) has been deprecated. In version 15.2, an administrator must enable email to unregistered addresses by assigning the role "Email Non-Users" to some user or group. (docs)
What's New in 15.1?
Highlights of v15.1
- Polish. Usability improvements, including thumbnail extraction, expanded notifications and module reload
- Quality. Nearly 500 bugs fixed, plus new QC tools for targeted mass spec and Luminex
- Performance. Speedier extract-transform-load and specimen import pipeline
Argos Debut
Argos is a LabKey-based application that helps ordinary users filter and explore clinical data and specimen resources to generate hypotheses, investigate study feasibility, and evaluate courses of treatment. Developed in partnership with the Fred Hutchinson Cancer Research Center, the first version of Argos relies upon the Caisis data model, so early adoption is easiest for those with existing Caisis installations. To explore Argos, see the 6-minute video and Fred Hutch overview. For further details, please contact LabKey.Community News
LabKey Server-based projects continue to make an impact:- ITN TrialShare: As reported in the New England Journal of Medicine, participant-level results from the Immune Tolerance Network's groundbreaking study on prevention of peanut allergies are now publicly available on the ITN's award-winning TrialShare clinical research portal.
- Panorama: New tools for reviewing assay performance trends for targeted mass spec data will be covered at the American Society for Mass Spectrometry (ASMS) Conference this spring. Look for the June 2 poster and March 31 user group meeting.
- Primate EHRs: A new case study explores the electronic health record (EHR) system developed in partnership with the Oregon and Wisconsin National Primate Research Centers (ONPRC & WNPRC), which will soon be used by the Southwest National Primate Research Center (SNPRC).
- Adair/Kiem Labs: Another new case study explores how the labs of Jennifer Adair and Hans-Peter Kiem at the Fred Hutch use LabKey Server to speed efforts in development of stem cell gene therapy for wide range of diseases, from HIV/AIDS to cancers.
Release Notes 15.1
Studies
- Dataset tagging: A new tag property added to datasets lets you group datasets by keyword. (docs)
=== Sponsored by ITN - Immune Tolerance Network
- Republish study: Republish a previously published study using the same settings. (docs)
=== Sponsored by ITN - Immune Tolerance Network
- Expanded notification options: Receive notifications for all changes to reports and datasets, or changes in particular categories. (docs)
=== Sponsored by ITN - Immune Tolerance Network
- Extraction of thumbnail images: Thumbnail images embedded in Word, Excel, and PowerPoint documents can be automatically integrated into data views. (docs)
=== Sponsored by ITN - Immune Tolerance Network
- Improved time charts: Time charts now handle large numbers of participants. User interface for time charts offers pagination for large numbers of participants.
=== Sponsored by University of South Florida Health Informatics Institute
Specimens
- Specimen importer: Performance for the specimen importer pipeline has been improved. (video)
=== Sponsored by HVTN - HIV Vaccine Trials Network and ITN - Immune Tolerance Network
Collaboration
- Data pipeline: When you process and upload data, the data pipeline remembers and returns to the last directory you visited. (docs)
- Auto-completion: Username and email fields have improved auto-completion in the following areas: specimen requests, issues, messages, and user/permissions management.
- Issues management: Issue lists can inherit admin settings from another folder, simplifying and consolidating administration tasks when managing multiple issues lists. (docs)
- Full-text search: Improved performance for full-text search.
=== Sponsored by O'Connor Labs, University of Wisconsin
- ETL (Extract-Transform-Load) improvements - (video)
- Performance has been improved for large jobs.
- Support for cancellation of running jobs. (docs)
- Support ETLs into target tables which have JavaScript Triggers Scripts.
- A bulkLoad option minimizes logging and processing overhead. (docs)
- Allow finer granularity of transaction size when writing into the target table, including no transaction option. (docs)
===Sponsored by SNPRC - Southwest National Primate Research Center - ETL export to files, such as TSV and CSV files. (docs)
- Support for pipeline command tasks in ETLs. (docs)
- Support for stored procedures which return result sets; use the result set as source query. (docs)
- Support for stored procedures that pass parameter values to further stored procedure steps in the same ETL. (docs)
=== Sponsored by Fred Hutchinson Cancer Research Center
Assays / Instrumental Data
- (ELISpot) Handle "too numerous to count" values: Instrument codes for "too numerous to count" are recognized and excluded from calculations. (docs)
- (Luminex) Improved quality control reports: Quickly view the Levey-Jennings plots directly from the QC report page. (docs)
=== Sponsored by Vaccine Immunology Statistical Center (VISC)
- (Luminex) Guide sets: New user interface lets you manage and delete guides sets. (docs)
=== Sponsored by Vaccine Immunology Statistical Center (VISC)
- (Luminex) Disable flagging: When a metric has too few runs to be useful as a quality control guide set, you can selectively disable flagging for that metric. (docs)
=== Sponsored by Vaccine Immunology Statistical Center (VISC)
- (Luminex) Run re-calculations as a pipeline job: After inspecting and choosing to exclude certain data values, the curve fit recalculation can be processed in the background using the pipeline. (docs)
=== Sponsored by HVTN - HIV Vaccine Trials Network
- (Luminex) Levey-Jennings plots: Improved performance for calculation of Levey-Jennings plots.
=== Sponsored by Vaccine Immunology Statistical Center (VISC)
- (NAb) Reverse dilution direction: The default direction of dilution on a plate can be reversed. (docs)
=== Sponsored by MHRP - U.S. Military HIV Research Program
- (Genotyping) Bulk update/Data cleanup: Bulk edit simplifies experiment management. (docs)
=== Sponsored by O'Connor Labs, University of Wisconsin
- (Genotyping) Feature annotations: Import feature annotation data via the script pipeline.
=== Sponsored by HIPC - Human Immunology Project Consortium
- (Panorama/Targeted Mass Spec) Quality control: Quality control folder type helps you evaluate instruments and analytes over time. (docs) (video)
=== Sponsored by Panorama Partners Program members
Development and Operations
- Recommended Java Upgrade: As part of the 15.1 release, we recommend that all users upgrade to use Java 1.8u40 or later. The end of life date for Java 1.7 is scheduled for April 2015, after which, public updates will no longer be available. (installation docs), (configuration docs)
- Module resources reload: To make development easier on a production server, many file-based module resources are dynamically reloaded (from the /deploy directory) when the server detects changes to those files.
- SQL Server synonyms: Synonyms on tables and views are supported. (docs)
- Rlabkey security: Rlabkey now defaults to TLSv1, instead of SSL3. (docs)
Potential Backwards Compatibility Issues
- Java Client API changes - HttpClient library: The underlying HTTP library used by the Java Client API has been migrated from Apache Commons HttpClient 3.1 to Apache HttpComponents HttpClient 4.3.5. We have made every effort to hide the substantial changes in the underlying library from users of our Java client API. However, some Java API methods exposed Apache classes that have been removed (e.g., HttpMethod, HttpConnectionManager, and the old HttpClient), making 100% compatibility impossible. Please test your code thoroughly against the new library. (API docs)
- Java Client API changes - Self-signed Certificates: For security reasons, the Java client API no longer connects by default with servers having self-signed certificates. Users of the API can override this behavior by calling Connection.setAcceptSelfSignedCerts(true).
- Character Encoding Changes: Study, list, and folder archives are now all written using the UTF-8 character encoding for text files, and imported archives are parsed as UTF-8. In addition, text exports from grids consistently use UTF-8 character encoding. Formerly, these operations used the server's default character encoding.
LabKey Argos
What's New in 14.3?
Highlights of LabKey Server v14.3
- Visualize inputs, outputs and histories for extract-transform-load (ETL) jobs.
- Explore projects and folders together through a unified interface.
- Compare categories with the bar plot API.
- Stay Informed with improved email notifications.
- Speed customization using the performance profiler and module development checklist.
- Safeguard protected health information (PHI) by logging access and intended use, as seen in HIDRA.
Resources
User News
- Collaborative DataSpace: A new, 7-minute video shows the DataSpace vision for cross-study data exploration and cohort discovery.
- Katze Lab: The Katze team used LabKey Server for its new Science paper on Ebola susceptibility, a study featured in the New York Times.
- Hutch Integrated Data Repository Archive (HIDRA): The Fred Hutch news explored HIDRA's plans for natural language processing (NLP) of Cancer Consortium data.
- Panorama: The NCI's newly launched proteomics portal uses Panorama, the LabKey Server-based repository for targeted proteomics. A Panorama overview just went to press.
Release Notes 14.3
Collaboration
- Consolidated project/folder navigation menu
This experimental feature lets you view and navigate all projects and folders on one consolidated menu. (docs)
=== Sponsored by HIPC - Human Immunology Project Consortium
- PHI activity auditing
We've added infrastructure to support auditing of user activity with PHI data. The new infrastructure provides the ability to log activity based on flexible, module-defined criteria. For example, log all SQL queries executed against a particular schema, the patient IDs involved whenever PHI data is accessed, and/or the user's stated purpose in querying the data. For more information contact us.
- Improved administration for email notifications
The user interface for administrators has been improved, making it easier to set message and file notification behavior. (docs)
=== Sponsored by ITN - Immune Tolerance Network
- Enhanced information on report changes
When reports are updated, we provide greater detail on the nature of the change, distinguishing between changes to a report's content (for example, the filter settings or measures displayed) and its metadata properties (for example, the report title or author). (docs)
=== Sponsored by ITN - Immune Tolerance Network
- Improved list management
The Manage Lists page now uses a standard grid that supports sorting, filtering, export, viewing of lists in multiple folders, and multiple select for deleting lists and exporting list archives. (docs)
Data Integration
- Extract-Transform-Load (ETL) history
A new user interface provides detailed histories and visualizations of ETL jobs. (docs)
===
Visualization
- Bar plots
A new JavaScript-based visualization type represents values as vertical bars. (docs), (examples)
===
Observational/Cohort Studies
- Published studies details
A new query lets administrators view details about published and ancillary studies for a given parent study. (docs)
=== Sponsored by ITN - Immune Tolerance Network
- Study location management
Locations associated with a study can be deleted, provided they are unused inside the study. All unused locations can also be deleted in bulk. (docs)
=== Sponsored by ITN - Immune Tolerance Network
Specimen Management
- Improved specimen views
The fields available for rollup aggregation have been expanded to included user-added fields and vial-to-specimen rollups. (docs)
=== Sponsored by ITN - Immune Tolerance Network
Data Processing Pipeline
- Cancel running jobs
Improved behavior for cancelling running pipeline jobs, such as specimen import/refresh jobs and published study refresh jobs. (docs)
=== Sponsored by ITN - Immune Tolerance Network
Assays/Experimental Data
- (Luminex) Negative control beads
An improved user interface lets you select a preferred negative control bead for a given analyte. (docs)
=== Sponsored by HVTN - HIV Vaccine Trials Network
- (Luminex) EC50/AUC controls
You can calculate EC50/AUC for titrations without adding them to the quality control report or to Levey-Jennings plots. (docs)
=== Sponsored by Vaccine Immunology Statistical Center (VISC)
- (Luminex) Positivity threshold importing
LabKey Server now supports file-based import of positivity thresholds for antigens, instead of manual entry. (docs)
=== Sponsored by HVTN - HIV Vaccine Trials Network
- (NAb) Multi-virus plate support
The plate designer has been enhanced to support multiple viruses, controls, and specimens on a single plate. (docs)
=== Sponsored by MHRP - U.S. Military HIV Research Program
- (NAb) FileMaker metadata import
LabKey Server now supports file-based import of metadata from FileMaker files, instead of manual data entry. (docs)
=== Sponsored by MHRP - U.S. Military HIV Research Program
- (Genotyping) Haplotype assay improvements
The haplotype assay now supports species names and haplotype renaming. A new report shows discrepancies between STR and other haplotype assignments. (docs)
=== Sponsored by O'Connor Labs, University of Wisconsin
- (Panorama/Targeted Mass Spec) general improvements
Support for importing Skyline file format. Improved plotting and additional plotting types. New workflow for sharing data with journals. (docs)
=== Sponsored by MacCoss Lab, University of Washington
Documentation
- Development environment setup: New checklist makes it easy to set up a development environment for simple modules. (docs)
- JavaScript Client APIs: Revised tutorial has an easier set up and code explanations. (docs)
- Module development: Revised documentation provides guidance on which sort of module to develop. (docs)
- Server API actions: New documentation explains how to develop server-based Java views, actions, and forms. (docs) | (docs)
- Luminex calculations: New documentation provides reference information on Luminex calculations. (docs)
Development
- Schema Browser: Improved performance for the Schema Browser.
- Datasets and schema: Improved performance when loading table and schema information.
- Specimen foreign keys: Improved performance for tables that have foreign keys into the specimen repository.
- Mini-Profiler: A new mini-profiler helps developers analyze code performance, such as which queries were run on a page and how much time the queries required to complete. (docs)
Potential Backwards Compatibility Issues
- Dataset import behavior change: For consistency with other data types, imported data rows are now treated as an insert (disallowing duplicates), instead of a merge. Note that this change was introduced in version 14.2.
- SQL order of precedence change: Prior to 14.3, bitwise operator precedence varied based on the underlying SQL database. We suggest always using parentheses when using bitwise operators.
- .deleted directory: After files or folders are deleted via the Files web part, they are no longer moved to the .deleted directory, instead they are directly deleted from the server. After renaming a folder, when an existing folder already has the same name, the already existing folder is moved to the .deleted directory.
- Pipeline configuration: When configuring a pipeline, LabKey Server looks for configuration files, by default, in the following directory: LABKEY_HOME/config. To reset the config directory see Configure LabKey Server to use the Enterprise Pipeline.
What's New in 14.2?
Highlights of LabKey Server v14.2
- Organize and share files using a new drag-and-drop file uploader (docs)
- Analyze high-volume results using Rserve to execute scripts remotely (docs)
- Integrate specimen information with automated FreezerPro® import (docs)
User News
- ITN TrialShare wins prestigious award: The National Academy of Sciences has recognized the Immune Tolerance Network's TrialShare Clinical Trial Research Portal as a model of innovation by naming it the winner of the Research Data and Information Challenge.
- HIDRA Argos pilot launches: The Fred Hutchinson Cancer Research Center recently profiled the Argos data exploration and visualization portal for the Hutch Integrated Data Repository Archive (HIDRA) - see: It's personal: New database aims to change how cancer is treated.
- Panorama webinar slots available: Register now for the free webinar on Tuesday, August 19, 9am PST. The webinar will explore projects that use Panorama, recent enhancements, and how to create custom reports. Panorama is a repository for targeted proteomics.
Resources
Release Notes 14.2
Collaboration
- Native, browser-based drag-and-drop file uploader. New uploader works out of the box, requiring no Java applets to install or configure. (docs)
- Improved pipeline processing for scripts and external commands. Supported scripts include R, Python, Perl, and others. Set output directories and file names. Job deletion can delete associated experiment runs. (docs)
=== Sponsored by HIPC - Human Immunology Project Consortium
- Rserve integration. Generate R reports on a remote Rserve server. (docs)
=== Sponsored by Fred Hutchinson Cancer Research Center and HIPC - Human Immunology Project Consortium
- Export selected records. Export individual or multiple records that have been selected in a data grid. (docs)
=== Sponsored by HVTN - HIV Vaccine Trials Network
- Between/not between filters. Filter by value range. (docs)
=== Sponsored by HIPC - Human Immunology Project Consortium
- Improved Data Views web part. Authors and editors can edit/delete reports in the Data Views panel/web part. (docs)
=== Sponsored by HIPC - Human Immunology Project Consortium
- Email notifications. Receive notification when the content of a report or dataset changes. (docs)
=== Sponsored by ITN - Immune Tolerance Network
- Improved user interface and documentation for impersonating users, groups, and roles. (docs)
Observational Studies
- Improved import/export of shared study data and metadata. (docs)
=== Sponsored by CAVD - The Collaboration for AIDS Vaccine Discovery via the Bill and Melinda Gates Foundation
- Faster performance for study archive export & import.
=== Sponsored by ITN - Immune Tolerance Network
- Import and export custom study properties in study archives. (docs)
=== Sponsored by ITN - Immune Tolerance Network
- Manage study products. Define and share vaccine treatment protocols and schedules across studies. (docs)
=== Sponsored by CAVD - The Collaboration for AIDS Vaccine Discovery via the Bill and Melinda Gates Foundation
Specimen Management
- Customizable specimen report webpart, allowing display of reports by participant, cohort type, requested by location, and others. (docs)
=== Sponsored by ITN - Immune Tolerance Network
- Improved FreezerPro integration. Import data directly into the specimen management system on demand or on a regular schedule. (docs)
=== Sponsored by a major pharmaceutical corporation.
- Improved export and import of specimen repository settings. (docs)
=== Sponsored by ITN - Immune Tolerance Network
- Improved specimen refresh. In published studies, update the user that performs the specimen refresh. (docs)
=== Sponsored by HVTN - HIV Vaccine Trials Network
- New specimen rollup rules for Combine and LatestNonBlank. (docs)
=== Sponsored by HVTN - HIV Vaccine Trials Network
- Faster performance for specimen archive import.
=== Sponsored by HVTN - HIV Vaccine Trials Network
Assays
- (Luminex) Use historical means for Levey-Jennings plots. (docs)
=== Sponsored by CAVD - The Collaboration for AIDS Vaccine Discovery via the Bill and Melinda Gates Foundation
- (Luminex) Skip Ruminex calculations. (docs)
=== Sponsored by CAVD - The Collaboration for AIDS Vaccine Discovery via the Bill and Melinda Gates Foundation
- (Haplotype) Improved Haplotype assay. New report types, add data for additional species. (docs)
=== Sponsored by University of Wisconsin - O'Connor Lab
- Participant/visit resolvers. Use an existing list from another source. Set default values. Simplify upload and improve consistency. (docs)
=== Sponsored by CAVD - The Collaboration for AIDS Vaccine Discovery via the Bill and Melinda Gates Foundation
- Reduce assay user input error. Guidance for using defaults and validation. (docs)
Documentation
- Context sensitive help. New context-sensitive help links navigate directly to the relevant documentation topic. (docs)
- Project/Folders Best Practices. New documentation provides dos and don'ts for setting up projects and folders. (docs)
- Guidance for preparing data for import into LabKey Server. (docs)
- Updated documentation for using saved filters and sorts. (docs)
- Updated File Repository Tutorial. New step provides an advanced keyword and search application.
- Updated Collaboration Tutorial. (docs)
- Updated Security Tutorial. (docs)
- Updated General Assay and NAb Assay Tutorials. (docs) | (docs)
Operations
- knitr designer view. Set JavaScript dependencies to support the knitr designer view. (docs)
=== Sponsored by HIPC - Human Immunology Project Consortium - Support for SQL Server 2014.
- Support for MySQL 5.6 external data sources.
- Support for building and running on Java 8.
- Removed support for PostgreSQL 8.4
Potential Backwards Compatibility Issues
- Dataset import behavior change: For consistency with other data types, imported data rows are now treated as an insert (disallowing duplicates), instead of a merge.
What's New in 14.1?
Highlights of LabKey Server v14.1
- Automate data processing with configurable pipeline tasks (docs)
- Untangle name and date inconsistencies across datasets and continents (docs | docs | docs)
- Collaborate in planning vaccine protocols using the study designer (docs)
- Share results conveniently with memorable, short URLs (docs)
- Intrigue new users with a visual overview and 10-minute, interactive tour (video | tour)
Release Notes 14.1
Data Integration
- Pipeline processing for scripts and script sequences - Simplified configuration for pipeline tasks. [docs]
=== Sponsored by Human Immunology Project Consortium (HIPC) - Alias ParticipantIDs - Consolidate data that uses different names for the same participant/subject using alias ids. [docs]
=== Sponsored by University of Wisconsin - O'Connor Labs - Vaccine study designer - Design vaccine-related studies for registration and data aggregation from multiple groups. [docs]
=== Sponsored by Collaboration for AIDS Vaccine Discovery (CAVD) - Lists available in workbooks - Lists defined in a folder are visible in child workbooks. [docs]
=== Sponsored by Oregon National Primate Research Center (ONPRC) - PostgreSQL functions in ETLs - Use PostgreSQL functions as the transform step in ETLs. [docs]
Specimen Management
- Provisioning of Specimen Tables - Improved performance for specimen archive imports.
=== Sponsored by HIV Vaccine Trials Network (HVTN) - Admin Customizable Specimen Fields - Add and modify non-required fields in the specimen tables. [docs]
=== Sponsored by Immune Tolerance Network (ITN) - Rollup Fields in Specimen Tables - Options for storing aggregate and latest values within the specimen tables. [docs]
=== Sponsored by Immune Tolerance Network (ITN) - Customizable Specimen Email Template - Generate the most useful specimen archive notifications. [docs]
=== Sponsored by Immune Tolerance Network (ITN) - Specimen draw timestamps - Store the DrawDate and DrawTime separately to avoid erroneous conflicts when times are blank. [docs]
=== Sponsored by HIV Vaccine Trials Network (HVTN) - FreezerPro integration support. [docs]
=== Sponsored by a major pharmaceutical corporation.
Assays
- Pipeline Assay Import - New task imports assay data using the data processing pipeline. [docs]
=== Sponsored by Human Immunology Project Consortium (HIPC) - (Affymetrix) Import Affymetrix microarray runs from GeneTitan Excel files.
=== Sponsored by Human Immunology Project Consortium (HIPC) - (Expression Matrix) Support for GEO series matrix TSV files. [docs]
=== Sponsored by Human Immunology Project Consortium (HIPC) - (Flow) FlowJo 10.0.6 support. [docs]
=== Sponsored by LabKey Software - (Luminex) Support for script to calculate positivity.
=== Sponsored by Vaccine Immunology Statistical Center (VISC) - (NAb) Select data identifiers - When viewing NAb runs, select how you will identify the data by selecting a Participant/Visit identifier. [docs]
=== Sponsored by Vaccine Immunology Statistical Center (VISC)
Collaboration
- Updated File Browser UI - The file browser has an improved interface. [docs]
=== Sponsored by LabKey Software - Set Date and Number Formats - Set consistent display of dates and numbers at the project- or folder-level. [docs]
=== Sponsored by LabKey Software - Non-US Date Parsing - Set formats for parsing internationally ambiguous dates, such as 03/10/2014. [docs]
=== Sponsored by LabKey Software - Additional security roles - Added "See Audit Log Events" and "See Email Addresses" roles. [docs]
=== Sponsored by Immune Tolerance Network (ITN) - Short URLs - Create convenient, memorable links to specific content on your server. [docs]
=== Sponsored by MacCoss Lab of Biological Mass Spectrometry
Documentation
- 10 Minute Tour - See how you can share data with researchers and colleagues. [try it]
=== Sponsored by LabKey Software - (Video) LabKey Server Overview – A 4-minute introduction to LabKey Server. [watch]
=== Sponsored by LabKey Software - (Video) Locate and Import Spreadsheets - Consolidate scattered spreadsheets and begin working with them in LabKey Server. [watch]
=== Sponsored by LabKey Software - Java File Uploader - Troubleshooting documentation for the multi-file uploader. [docs]
=== Sponsored by LabKey Software - Custom Menus - Add easy access to tools and studies in a projects. [docs]
New APIs
- saveBatches - As part of enabling multi-experiment uploads, a saveBatches() method has been added to Experiment.js, analagous to saveBatch(). [docs]
=== Sponsored by International Centers of Excellence for Malaria Research (ICEMR) - AssayImportRunTaskType - Pipeline importer looks for output from the previous task. Imports to a selected assay database tables. [docs]
=== Sponsored by Human Immunology Project Consortium (HIPC)
Study
- Extended Study Data Model - Study products, treatments, and other support for cross study consistency. [docs]
=== Sponsored by Collaboration for AIDS Vaccine Discovery (CAVD) and the Gates Foundation - Visit Description Hover Text - Add an optional short description to appear as hover text on visits or timepoints. [docs]
=== Sponsored by Immune Tolerance Network (ITN) - Thumbnails/mini-icons preserved on folder export/import. [docs]
=== Sponsored by Immune Tolerance Network (ITN) - Protocol Day and Participant Visit Day - Align data across multiple studies. [docs]
Experimental Features
- New Multi-file Uploader - Upload multiple files using a drag-and-drop interface (Web-DAV based). [docs]
=== Sponsored by LabKey Software
What's New in 13.3?
Highlights of LabKey Server v13.3
ResourcesRelease Notes 13.3
Data Integration
- ETL modules - Automate and streamline the assembly of data repositories from multiple sources with Extract-Transform-Load modules. ( video | docs )
- Export Charts as JavaScript - Export timecharts, scatterplots, and box charts as JavaScript for further customization. ( docs )
- Cloud Storage Integration - Manage large data files in the cloud using S3 Cloud Storage. ( docs )
Assays and 'Omics
- (Luminex) Improved quality control with single point controls in Levey-Jennings plots. ( docs )
- (NAb) New graphing layout options. ( docs )
- (MS2) Spectra library export - Export Bibliospec libraries of the spectra data associated with peptide identifications. ( docs )
- (MS2) Comet peptide search - Support for the open source Comet peptide identification search engine. ( docs )
- GEOMicroarray - Support for importing microarray data, as downloaded from GEO. ( docs )
- Flow - FlowJo 9.7.2 support
Observational Studies
- Improved Study Designer - Improved flexibility when populating values in dropdowns and creating cohorts.
Specimen Repository Management
- Introductory Video and Tutorial - Watch the video for an overview; read the tutorial for more details. ( video | docs )
- Custom Aliquots - Manage non-vial specimen types such as tissue blocks. ( docs )
- Request System Improvements - Limit which types of sites can request specimens. Customize QC flagging, comments, and groupings to easily display the sets of specimens your team needs most. ( docs )
- Export specimen settings - Export more metadata about the specimen repository and request system settings. ( docs )
UI Improvements
- Improved Views Management - Improved user interface for views and queries management. ( docs )
- Data Views Browser - The Data Views web part is available for displaying queries, reports, and views outside of a study-type folder. ( docs )
- Editable Tabs - Add, rename, move, and delete tabs for better custom project design. ( docs )
- Faceted Filters - Improved selection and filtering behavior: faceted filters respect prior filters. ( docs )
Documentation
- Improved New User Tutorials - Explore more features and get up to speed faster with updated introductory tutorials: ( docs )
- Report Permissions - New guidelines matrix for setting permissions levels on individual reports and views. ( docs )
Server Administration and Operations
- Tomcat 7 - Support for Tomcat 7. ( docs )
- PostgreSQL 9.3 - Support for PostgreSQL 9.3. ( docs )
- Audit log - Improved performance of audit log querying.
- Full-text search - Improved performance of full-text searches.
- Encrypted property store - Support for encrypted property sets. ( docs )
Installation and Upgrade
- Distribution file changes - The file structure for distribution downloads has changed in version 13.3. ( docs )
- Upgrade processing time - Note that the upgrade process for 13.3 may take longer than usual, due to audit log provisioning.
- Full-text search reindexing - The full-text search index will be regenerated after upgrading to 13.3, which can result in higher than usual indexer activity.
- GROUP_CONCAT installation - New instructions for installing/upgrading group_concat functions for SQL Server installations. ( docs )
- Proteomics Enlistment - For developers who build LabKey Server from source, the mass spectrometry binaries are now provided as a separate enlistment. ( docs )
- Module build process - For module developers, there are new options available in the module build process. ( docs )
New APIs
What's New in 13.2?
Highlights of LabKey Server version 13.2
- See more of what matters with improved project and folder navigation. video | documentation
- Leverage more of your existing observational study data with REDCap integration. video | documentation
- Create elegant, dynamic R reports with the knitr visualization package. video | documentation
Resources
Release Notes 13.2
Observational Studies
- Study publication enhancements. Refresh data in published studies. Publish hidden datasets. Mask participant ids in lists when publishing.
- Protected health information management. Import alternate ids and date offsets.
- Data management. Improved delete behavior when browsing datasets.
Collaboration
- REDCap integration. Integrate REDCap clinical data with other data in LabKey Server.
- Improved navigation. Popup navigation menu for projects and folders.
Specimens
- Specimen aliquots. Support for vial aliquoting.
- Improved specimen workflow: Improved request customization. Faceted filtering panel. Support for tissues. Improved specimen import/export.
- Editable specimen records. User interface for editing specimen records.
Visualization
- Knitr. Create dynamic R reports by interweaving R code in HTML or Markdown pages.
- Time Charts. Improved scaling and trellising.
- Thumbnails. Autogenerate thumbnails for charts.
Assays
- (Affymetrix) Support for Affymetrix assay. Track file, sample, and other metadata for Affymetrix GeneTitan data. The data is available for downstream analysis in R or other tools.
- (Luminex) Reruns and titration exclusion. Exclude a full titration's data at once, and easily re-import corrected data.
- (NAb) Improved metadata upload. Single file upload for data and metadata in high throughput NAb assays.
- (Targeted Mass Spec) Search. Improved search by modification.
- (Targeted Mass Spec) Chromatogram Library folder type. Build collections of reference chromatograms for proteins and peptides for designing future targeted assays.
- Improved assay file import. Improved rename behavior when importing multiple files of the same name.
- Assay data archiving. Automatic archiving of files for deleted assay runs.
New APIs
- Dataset and query rename. Renamed queries and datasets are updated in custom views, reports, and query snapshots.
- Reporting API. New GetData client API lets developers chain grouping, aggregation, filtering, and more to extract data.
- Attachment field. Attachments are supported in file-based module assays.
Learn What's New in 13.1
Highlights of the 13.1 Release
- Survey Designer - Collect detailed information from collaborators, participants, and clients.
- Secure Views. Securely share client-specific views by linking data schemas across folders.
- High-throughput Assay. Support for high-throughput 384 well NAb assay.
Release Notes 13.1
Observational Studies
- Participant ID aliases. Manage alternate participant IDs from multiple sources; display and search for subjects using any of their aliases.
- Mask clinic names. Obscure clinic and draw site names when exporting or publishing.
- Date shift exclusion. Exclude selected dates from shifting on study export.
- Expanded data types for study publication. Option to include wikis, reports, webparts, properties, and other data on study publication.
- Subcategories for data views. Organize datasets and views in a hierarchy of categories.
Security
- Linked Schemas. Securely show data from one folder in another folder.
- Filtered/parameterized schemas. Refine data views by applying metadata filters and overrides to schemas templates.
- Web Part Permissions. Apply security role requirements to individual web parts.
Assays and 'Omics
- (NAb) High-throughput NAb assay. Support for high-throughput 384 well NAb assay.
- (Genotyping) Improved support for Illumina. Validate sample sheet based on Illumina indexes. Add custom fields to data exports.
- Culture adaptation assay. Create culture adaptation experiments.
Collaboration
- Survey Designer. Design web-based surveys and long form questionaires.
- Faceted filtering panel. Slide out faceted filtering panel on datasets.
- Rename and move tabs. Rename, move and delete folder tabs.
Specimen Tracking
- Request notifications configuration. Configure vial list to appear in either email body or email attachment.
- Clinic name protection. Mask clinic and draw site names with a generic label.
- Vial grouping configuration. Configure grouping hierarchy in vial browser.
- Active/inactive users highlighting. Easily identify inactive users in the specimen tracking system.
New APIs
- Updated PERL library Labkey::Query 1.03. Added ability to specify timeouts and user agent.
- Updated Query API. Added support for ExtJS 4.x store. Similar to the Ext 3.x store, in order to help with client-side component migration.
Video Demonstrations 13.1
| Title | Description | Video Link |
| Survey Designer - Quick Tour |
Steve Hanson shows key features of the survey designer. April 2013 |
Play Video |
More Videos: New Feature "Sprint" Demos
New Feature "Sprint" Demos
Below are video excerpts from our monthly, new feature meetings. In each excerpt, a developer demonstrates the feature and takes questions from the audience. If you would like an invitation to our next "sprint" demo meeting please email sprintdemo@labkey.com.
| Title | Description | Sprint Number | Video Link |
| Secure Collaboration: Linked/Filtered Schemas |
Mark Igra shows how to securely show data in a folder (without granting access to the entire folder). April 2013 |
13.1.4 | Play Video |
| Alternate Participant IDs | Adam Rauch explains how to set up alternate participant ids. March 2013 | 13.1.3 | Play Video |
| Web Part Permissions | Alan Vezina explains how to set security requirements for individual web parts/page parts. March 2013 | 13.1.3 | Play Video |
| Culture Adaptation Assay | Avital Sadot describes new assay types to support culture adaptation experiments. March 2013 | 13.1.3 | Play Video |
| Pathology Viewer |
Adam Rauch demonstrates recent custom application work. Jan 2013 |
13.1.2 | Play Video |
| Survey Designer | Corey Nathe shows how to create surveys and long form questionnaires with the survey designer. Jan 2013 | 13.1.2 | Play_Video |
Learn What's New in 12.3
Highlights of the 12.3 Release
- Safe Data Publication. Publish an anonymized snapshot of your data.
- Rich Assay Workflows. Data versioning provides rich data curation and precise quality control. Replace mistaken data, but retain the original data in the version history. Track assay progress and quality control, with assay progress reports.
- Targeted MS Experiments. New "Panorama" MS module supports targeted mass specrometry experiments, including integration with Skyline.
Release Notes 12.3
Study
- Study publication. Publish a secure, anonymized snapshot of your data.
- Unenrolled participant handling. Track unenrolled/pre-enrolled participants.
- Unscheduled visit handling. Allow data from unscheduled visits.
- Category hierarchy for participant groups. Organize participant groups into categories, such as "Treatment Groups" or "Treatment Regimes".
Quality Control
- Improved audit configuration. Configure auditing for any table.
- Auditing performance improvements.
Visualization and Reports
- Charting Query-based Columns. Query-based columns are available in time charts.
- Charting. Color-coded data points in scatter and box plots.
Assay
- Assay data versioning and replacement. Replace mistaken data with corrected versions. Retain previous data for auditing and data transparency.
- QC flagged progress reports. Track assay completion and quality control status on the same report. Data from unscheduled visits is also tracked.
- Support for folder move and rename.
- (ELIspot) Improved graphical calibration view.
- (Flow Cytometry) Integration with FCSExpress.
- (Mass Spec) Targeted MS Experiments. New "Panorama" MS module supports targeted mass specrometry experiments, including integration with Skyline.
- (Mass Spec) Peptide Map Export. Export combined peptide map for all runs in a comparison set.
- (Genotyping) Haplotype assignment. - Support for haplotype assignment and reporting.
Specimens
- Improved options for specimen request email notifications.
- Publish anonymized specimen snapshots.
- Ancillary study. Create an ancillary study based on a specimen request.
Administration
- Study Publishing. A suite of tools for protecting and randomizing PHI (protected health information).
- User properties. User table is now customizable.
- Custom Tabs. Support for tabbed layouts in XML-defined custom folder types.
- Graphical interface for file repository. Graphical user interface for moving and renaming files/directories in file management tool.
- Configurable tabs. Add and rename tabbed layout. Migrate child folders to child tabs.
Documentation and Samples
- New sample data. We have increased the scope of our fictional sample data set to match our growing feature set. 200+ new, imaginary human participants. New measurements (for example, viral count), new participant groups, richer visualizations.
New APIs
- Ext features. Setting for Ext 3 library delivery.
- LABKEY.MultiRequest. Note that LABKEY.MultiRequest no longer extends Ext.Observable so any Observable methods such as .addListener() will no longer work on LABKEY.MultiRequest.
12.3 Video Demonstrations
Featured Videos
| Title | Description | Video Link |
| Managing Protected Health Information | Steve Hanson reviews tools to randomize PHI data. | Play Video |
Developer New Feature Demonstrations
During each software development "sprint", the development team provides live demonstrations of newly minted features that have passed a full cycle of development, testing, and stabilization. These features are ready for your inspection and use on your test servers. We're hoping to hear your feedback as we finalize our work. If you would like an invitation to our next sprint demo meeting please email sprintdemo@labkey.com
| Title | Description | Video Link |
| Specimen Snapshots | Developer Cory Nathe reviews recent work on study publication features, especially options for handling specimen data. | Play_Video |
| Workflows for Assays - Upload Dashboard | Cory Nathe reviews new assay workflow tools, featuring the data upload dashboard. | Play Video |
| Workflows for Assays - Assay Progress Reports | Cory Nathe explains how to track assay completion, featuring data tracking for unscheduled visits. | Play Video |
| Unscheduled Visit Handling | Developer and LabKey Partner Matt Bellew explains how to track data collected on unscheduled visits. | Play Video |
| Charting Query-Based Columns | Developer Cory Nathe shows that columns defined in SQL queries are now available in the charting wizards and in the view customizer. | Play Video |
Learn What's New in 12.2
Highlights from LabKey Server version 12.2
- Quick Charts. Create a chart from a column in two clicks. Create a "best guess" chart of your data. Charts are automatically redrawn when the underlying data is filtered. Toggle between box plot/scatter plot renderings.
- Remote pipeline server installer. Easily configure a remote pipeline server with a wizard-style installer.
- Illumina support. Upload, manage, and analyze your Illumina samples.
- Folder Export/Import. Improved folder archiving includes: (1) exporting folder settings such as folder type, enabled modules, etc., (2) exporting external schema definitions, (3) allowing study archives inside of folder archives, (4) creation of folder templates.
Release Notes 12.2
Studies
- Participant reports. Improved user interface and data formatting.
- Dataset status. Track your study's progress by setting the status of each dataset as draft, locked, unlocked, etc. Summary table shows status of each dataset in a study.
- Faceted filtering. Filter dialog now includes data facets. Faceted filtering can be turned on or off for individual columns.
- Timepoint auto-creation. Improved behavior when automatically creating timepoint upon data import. Now set a default timepoint duration. (For date-based studies only.)
- Folder Export/Import. Improved folder archiving includes: (1) exporting folder settings such as folder type, enabled modules, etc., (2) exporting external schema definitions, (3) allowing study archives inside of folder archives, (4) support for folder templates.
- Custom thumbnail previews. Add custom preview thumbnails to the data browser.
- Participant group categories. Organize your participant groups into categories, such as Gender, Infection Status, etc.
- New "link" report type. Add a report that links to an external document or web page.
- List fields. Records in a list now include these automatically updated fields: Created, CreatedBy, Modified, ModifiedBy.
Assays
- Transform scripts. Associate multiple transform/QC scripts with an assay design. Scripts will run in series upon data upload.
- Background/unstimulated wells. (ELISpot). Subtract background noise from data using unstimulated wells as a control.
- Improved spectra count support (Proteomics). Additional options for performing the spectra count comparison, and exporting it for use in other tools.
- NAb migration tool (NAb). Migrate your NAb data from LabKey's legacy implementation to LabKey's current NAb implementation.
- Luminex curve fits (Luminex). Improved curve fit behavior makes assay quality control more efficient.
- Illumina support (Genotyping). Upload, manage, and analyze your Illumina results.
- Copy flow data to a study. (Flow Cytometry). Copy-to-study now applies to flow data.
Visualization
- Quick charts. Create a chart from a column in two clicks. Create a "best guess" chart of your data. Charts are automatically redrawn when the underlying data is filtered. Toggle between box plot/scatter plot renderings.
- Box plots. Chart the quartile distributions. Outliers are shown as data points. Cohorts and participant groups are included as options for the X axis.
- Scatter plots. Chart correlations in your data. Edit the radius, color, and opacity of data points.
- Time charts. New look and feel for the chart editing environment: (1) popup dialog boxes, (2) edit axis properties directly from chart, (3) updated filter panel, (4) "View Mode" hides the editing buttons. Refactored to use the new charting API -- see the API section below for details.
- Links from data points. Developers can add a function to be called when a data point is clicked.
- New Charting API / JavaScript Libraries. See the API section below for details.
Pipeline
- Remote pipeline server installer. Easily configure a remote pipeline server with a wizard-style installer.
Security
- Impersonate roles. Impersonate security roles in addition to impersonating security groups and individual users.
- Auditing. Dataset export events (including filter information) can be viewed in the audit log.
Specimens
- sampleminded support. Import specimen data in the sampleminded format.
- Specimen search/requests. Users can now select multiple items simultaneously from dropdown menus.
- Specimen request notification. Set default notification behavior when specimens are requested from the repository.
- Specimen import. Build a specimen request by uploading a file containing specimen ids.
Search
- Full-text search for lists. Customizable indexing of list data and metadata.
New APIs
- Charting API. New graphics API combines the D3 and Raphael javascript libraries.
- Ext 4.1.0. LabKey Server now uses Ext 4.1.0.
- Declaring dependencies. New mechanism for declaring script dependencies.
- LabKey SQL improvements. GROUP_CONCAT aggregate function support on Microsoft SQL Server and ability to specify custom delimiters.
- Tighter security on some core queries. Previously, all authenticated users (non-guests) were able to see data in the core.members and core.principal queries. These are now restricted to users with Admin permissions.
Related Links
12.2 Video Demonstrations
These videos demonstrate key features from the 12.2 release of LabKey Server.
To view these videos in full screen, click the icon in the lower right as the video plays.
Assessing Data with Quick Charts
Shows how to quickly assess the meaning of new data using Quick Charts.
Study Administration: Organizing Data
Shows how to organize your study data, such as setting the status and category for documents.
Learn What's New in 12.1
Highlights of the 12.1 Release
- Customizable Participant Reports. Create exportable reports focusing on selected participants and data. (See a video demonstration.)
- Participant Lists. Get to your participant data quickly with faceted filtering. (See a video demonstration.)
- Permissions Reports. See who has access with detailed permissions reports. (See a video demonstration.)
12.1 Release Notes
Study
- Participant lists. Quickly find study participants using a new faceted filtering interface. (See a video demonstration.)
- Project settings import and export. LabKey Server now support export/import of project and folder settings, enabling rapid configuration of multiple containers with similar settings.
- Customizable participant report. Create exportable reports focusing on particular participants and data. (See a video demonstration.)
- External/attachment reports. Specify report type, description, author, and other metadata when adding supplementary documents.
- Study Schedule view. View and edit which datasets are required for a given timepoint in your study.
- Placeholder datasets. Create a placeholder dataset in expectation of incoming data.
- Data Browser. Improved data browser shows locked/unlocked status, optional data cut date column.
- Full text search for protocol documents. Full text search is now applied to your study's protocol document and summary description.
Collaboration
- Message board notifications. Message boards now support forum- and thread-level message board notifications.
- Discussion links. Start an email-based or message-based discussion when viewing datasets and reports.
Visualization
- Error bars. Time charts now support error bars.
- Faceted filtering. New faceted filter interface for lookup fields. (See a video demonstration.)
Assay
- Quality control flags (Luminex). Improved quality control flags for Luminex assay types.
- Script background processing (Luminex and GPAT). Long-running transform scripts for Luminex and "general purpose" (GPAT) assays can be run as a background pipeline job.
- Normalized spot counts (ELISpot). Normalized spot counts are now included in the ELISpot assay design.
- Beckman Coulter CXP LMD files (Flow Cytometry). Beckman Coulter CXP files are now supported.
- FlowJo GatingML workspaces (Flow Cytometry). Import FlowJo PC workspaces containing GatingML gate definitions.
- GEO Excel file generation. (Microarray). Automatically generate GEO Excel spreadsheets.
- Improved search protocol editor (Proteomics). Easily configure additional search settings, like quantitation and PeptideProphet/ProteinProphet probability cutoffs. Easily assign jobs to specific Globus clusters and queues.
- Data Export: Excel 2007. Export datasets and lists to Excel 2007 file format.
Pipeline
- Job cancellation. Cancel jobs currently in the queue or running.
- Support for multiple Globus clusters. Submit jobs to multiple Globus GRAM enabled clusters.
Security
- Permissions report. Detailed permissions report are provided for each folder, clearly listing who as access at what level, making it easier to understand complex security settings. (See a video demonstration.)
New APIs
- Message board API improvements.
- Google Web Toolkit update. The Google Web Toolkit (GWT) has been upgraded to the following versions: GWT 2.4.0, GXT 2.2.5, and GWT DND 3.1.2. If you use the GWT development tools to debug, you can get the latest SDK here: http://code.google.com/webtoolkit/download.html
12.1 Video Demonstrations
These videos demonstrate key features from the 12.1 release of LabKey Server.
To view these videos in full screen, click the icon in the lower right as the video plays.
Security: Sharing Data with Another Lab
Shows new security features: (1) security visualizer, (2) permissions reports, and (3) adding security groups to other groups.
Participant Lists
Shows how to browse participant lists with faceted filtering.
Participant Reports
Shows how to create, customize and export a participant report.
Learn What's New in 11.3
Highlights of the 11.3 Release
Data Management- Create an ancillary study to focus on interesting subsets of your data. (watch video)
- Easily organize your data with a new tabbed user interface. (watch video)
- Quickly create participant groups and cohorts. (watch video)
- Browse visual summaries of all your data in the new data browser. (watch video)
- See aggregate data trends with an improved time chart designer. (watch video)
- Effortlessly scroll through large data grids with an improved data viewer. (watch video)
- Ensure high-quality Luminex data with new graphical quality control tools.
- Easily create sophisticated security policies with nested security groups.
- Manage complex security group relationships with a graphical security visualizer.
- Test security settings by impersonating groups in addition to individual users.
11.3 Release Notes
Study Features
- Study Home Page
- Improved user interface and graphics, provide a cleaner, more intuitive design. (watch video)
- Tabs provide easy navigation through your study. (watch video)
- Protocol documents, investigators, and grant institutions can be specified to provide context for your study.
- Ancillary Studies
- Select a subset of your study data to create an ancillary study. (watch video)
- Participant Groups
- Easily create a new group from a filtered grid of participants. (watch video)
Visualization
- Time charts
- Create graphs for both visit- and date-based data.
- Specify date settings separately for measures from different datasets.
- Overlay or replace participant graph lines with group aggregated lines. (watch video)
- Generate charts for each participant group/cohort. (watch video)
- Customize y-axes labels on multi-measure timecharts, including multiple ranges and units.
- Data Browser
- See a visual summary of available reports and datasets. (watch video)
- Hover over popups provide a summary and a dynamically generated thumbnail image. (watch video)
- Column Header Locking
- Column headers do not scroll off the top of the page as you scroll through a large set of data records. (watch video)
- Reports
- Improved rendering performance for reports.
Assays
- ELIspot
- Customize the run details page like any other grid view in LabKey Server.
- Luminex
- Create guide sets to establish the acceptable range of values for a given analyte and to establish whether new runs are out of range as they are uploaded.
- See trends in EC50 values to evaluate the assay's performance over time.
- Graphically track EC50/AUC/MFI values for quality control.
- Luminex assays now include %CV (coefficient of variation) to help identify problematic data.
- Exclude problematic data points and re-run the curve fit.
- Flow Cytometry
- Import only selected groups from a FlowJo workspace.
- Integrate flow normalization using R flowWorkspace package.
- Import and export flow analysis zip archives.
- Proteomics
- Import and display Libra results, including iTraq quantitation results.
- Integrated Lorikeet spectra view on peptide details page for improved zooming, viewing additional ion types, and more.
- Retain merged search-specific and default settings to more easily evaluate configuration that produced the results.
- Genotyping
- Dramatically improved performance for genotyping analyses and allele combining.
- Delete matches from results.
Security
- We now support impersonation of a group as well as individual users.
- Users can reset their passwords when authenticated against an LDAP database.
- Nested security groups are now supported.
- Visualize your project security settings with a graphical representation of group/user relationships.
Other Features
- Run validation scripts on spreadsheets upon import.
- Support for multiple LabKey Server instances using a single SQL Server database.
- Improved installation and upgrade wizard.
- Improved project and folder creation wizard.
- New Linux installer.
- LabKey Server is now available as an Amazon Machine Image.
Extensibility and New APIs
- PowerPoint Presentation: Summary of API Changes
- JavaScript API
- fieldName is included in metadata used by LABKEY.ext.Store & getQueryDetails.
- Other Changes
- Support for ExtJS 4.
- Support for PostgreSQL 9.1.x.
Upgrade Notes
- Customers with large installations of LabKey Server may experience longer than normal upgrade times to due to changes in LabKey's auditing module.
11.3 Video Demonstrations
These videos demonstrate key features from the 11.3 release of LabKey Server.
To view these videos in full screen, click the icon in the lower right as the video plays.
New User Interface Features
Shows how to (1) navigate with the tab-based user interface, (2) search for data with the data browser, (3) scroll through large datasets.
Visualizing Group Data Trends
Shows how to (1) create a new participant group and (2) chart mean group/cohort performance over time.
Ancillary Studies
Shows how to create a new ancillary study based on a subset of study subjects.
Learn What's New in 11.2
Highlights of the 11.2 Release
New Analysis and Visualization Tools- Create advanced time charts with multiple data plots on a single axis.
- Mark out interesting data by quickly creating participant groups.
- Specify different curves for different analytes within a single Luminex assay run
- Organize your folders with a drag-and-drop graphical user interface.
- Import visit names in dataset and specimen data.
- Give live presentations without exposing confidential information using demonstration mode.
- Use advanced SQL queries with greatly improved performance when connecting to large external data sources.
- Integrate with your existing data with new support for Oracle DB external data sources.
- Import Excel 2007/2010 files (XLSX files).
11.2 Release Notes
Study
- Participant Groups. Easily create participant groups to organize and filter datasets without the overhead of configuring new cohorts.
- Visit Names. You can now import visit names in dataset and specimen data.
- Demonstration mode. Demonstration mode hides participant id's so that you can safely give live demonstrations of your study data without exposing confidential information.
- Study Navigator improvements. The Study Navigator now shows a count of distinct participants rather then a count of rows/measures.
Assay
- Data import: Excel 2007/2010. We now support importing Excel 2007/2010 files (XLSX files).
- Data editing improvements. You can now directly edit run properties for all assay types and assay results for some assay types (most notably GPAT), without the need to delete and re-import the run. Changes are fully audited.
- Luminex curve plots. You can now specify different curves for different analytes within a single run
- Luminex import improvements. We now support samples split across multiple plates and importing multiple files as a single assay run.
- Luminex well and analyte exclusion. You can now flag particular wells and analytes for exclusion from downstream analysis.
Visualization
- Time chart with multiple plots. You can now chart multiple measures on a single axis.
Specimens
- Specimen tube type. You can now specify a specimen's "tube type".
- New view: Specimens per participant. New view shows detailed specimen information for a particular study participant.
Flow Cytometry
- FlowJo import. We now support boolean gates containing relative and absolute gate paths and sub-populations of boolean gates in FlowJo workspaces.
- FlowJo gate names. Parentheses are now supported in gate names.
- Positivity reports. We now support flow cytometry positivity reports: contact LabKey for more information.
Proteomics
- Libra support. We've added support for running Libra to perform iTRAQ quantitation.
- Protein details roll-up view. We've improved the protein details page with the inclusion of a roll-up view.
User Interface Features
- Drag-and-drop folder management. Organize your folders with a new drag-and-drop graphical interface.
- SQL query editor improvements. Improved performance for query editing and error highlighting.
- Filter dialog. We've re-implemented the filter dialog with improved look-and-feel, better error handling, and easier date entry.
Other Features
- Performance improvements. Greatly improved performance when connecting to large external data sources.
- Data Import to module-defined tables. You can now import data into module-define tables either by copy-and-paste or file upload of spreadsheets or TSVs.
- Wiki page anchors. Wiki pages now support bookmarks/anchors.
- Conditional Formatting. Tool tips now display an explanation for the conditional formatting.
- Site level query validation. You can now test all of the queries on a site at one time.
- List title fields. Custom title fields in lists now export/import as part of a list archive.
Extensibility and New APIs
JavaScript API
- New method: LABKEY.Specimen.getVialTypeSummary()
- New method: LABKEY.Security.hasEffectivePermission()
- New method: LABKEY.Security.moveContainer()
- New LABKEY.QueryWebPart properties:
- LABKEY.Chart: support for multiple measures on a time chart: config.columnYName
Other Changes
- New Python API for querying LabKey Server
- Scatter Plot API
- Support for Oracle DB external data sources
- Ext 4 Integration
Upgrade Notes
- If your LabKey Server installation contains a large number of flow runs, you may experience long upgrade times when upgrading to version 11.2. Please contact LabKey Support for more information.
11.2 Video Demonstrations
These videos demonstrate key features from the 11.2 release of LabKey Server.
- Time Charts: Comparing Multiple Measures on One Chart
- Specimens: Tracking Participant Consent
- Security: Demonstration Mode
- Summary of API Changes
Time Charts: Comparing Multiple Measures on One Chart
Specimens: Tracking Participant Consent
Security: Demonstration Mode
Summary of API Changes
Learn What's New in 11.1
Highlights of the Latest Release
Enhanced Assay Data Management- Automatically integrate assay results into your clinical records upon upload.
- Quickly import assay results and create new assay designs.
- Improved performance for general purpose assay processing.
- Create professional-quality graphs with the new time chart wizard.
- Improve your web presence with new web themes and a new theme designer.
- Analyze MS2 data with new visualization views.
- Improve performance with server-side validation and transformation scripts.
- Author advanced SQL queries with parameterized queries, pivot tables, and expanded support for SQL Server and PostgreSQL functions.
- Create interactive reports in JavaScript and build R reports more easily via an improved designer.
11.1 Release Notes
Assays
- Performance improvements for general purpose assays.
- Copy-to-study improvements. To reduce data duplication, assay data is now linked as a lookup instead of being copied into a study dataset.
- Automated copy-to-study. Assay data can be copied to a study as part of upload.
- Improved microarray feature extractor pipeline. The microarray feature extractor is now integrated into the Enterprise pipeline.
- Improved assay import. Improved assay import and design inference. See the Assay Tutorial for details.
- ELISpot assay improvements. Automated statistical calculations of spot counts now appear as a column in grid view.
Visualization
- Improved time chart wizard. We've added a new user interface for creating time charts. Time charts can be easily exported to a PDF file.
- New MS2 visualizations. We've added new visualizations to the run comparison and run details views. See the Proteomics section below for details.
User Interface
- New web themes. We've added three new built-in themes and a custom theme designer.
- Look and feel improvements We've improved the look and feel of the buttons and dropdowns on web parts.
- New user interface design guidelines documentation.
Development
- Server-side validation/transformation scripts.
- SQL Enhancements. New support for parameterized queries, pivot tables, and expanded support for SQL Server and PostgreSQL functions
Proteomics
- Improved support for Sequest. The Enterprise pipeline has been re-implemented to utilize FASTA database indexing for much greater performance and efficiency.
- New peptide comparison visualizations. The peptide comparison view now uses the full featured customizable grid view and we've added a new Venn diagram visualization.
- New protein details visualization. The protein and protein group details pages now include a peptide coverage map. The coverage map can also be exported to an Excel-readable HTML file.
Genotyping and Sequencing
- Support for reads designated with 3' multiplex identifiers (MID) and amplicons. Reads are now linked directly to the appropriate sample based on 5' MID, 3' MID, and amplicon properties.
- Support for manual combination and modification of genotyping matches.
- Support for filtering out low quality bases at export time.
Other Enhancements
- Date filter improvements. The date filter dialog now includes a graphical date picker user interface.
- Reporting improvements. A new AJAX implementation provides a better user experience.
- File management improvements. We've improved the user interface for the file management tool.
- Improved email notification settings. Administrators can edit email notification schedules for multiple users at one time.
- Daily digest notifications. New scheduling options are available for email notifications: you can choose notification summaries every 15 minutes or once daily.
- Specimen tracking improvements. Specimen tracking in studies supports vial merging.
- Column Aggregates. You can now add an aggregating function to a column, including: sum, average, count, minimum, or maximum.
Extensibility and New APIs
JavaScript
- Server-side validation script enhancements
- Executed on the server, as the user who submitted the request.
- Use require(“dir/dependencyName") to include other file-based module script files.
- Supports a subset of the JavaScript client APIs: LABKEY.ActionURL, LABKEY.Filter, LABKEY.Message, LABKEY.Query, LABKEY.Security, LABKEY.Utils.
- Client-side JavaScript reports
- Alternate view of data grids, analogous to R reports.
- Available through Views menu: Views -> Create -> JavaScript View.
- Enhanced editor for javascript source code.
- LABKEY.Specimen - Now you can pass a config object, instead of separate parameters. (Backwards compatible with older behavior.)
- LABKEY.Message - Now you can specify a principal id (= a group or individual user) instead of email addresses. Only works on server-side scripts.
LabKey SQL Syntax Additions
- Support for PostgreSQL specific functions: ascii, btrim, char_length, etc.
- Support for SQL Server specific functions: ascii, char, charindex, etc.
- Support for comma syntax instead of join syntax.
- Support for nested joins.
- Auto-generation of expression aliases.
- AS is optional for expression aliases
- SELECT column alias now supported in ORDER BY clauses.
- SQL Query Parameters, with default values
- User/Group functions: USERID(), ISMEMBEROF(groupId)
- ISEQUAL(a,b) equivalent to: (a=b OR (a IS NULL AND b IS NULL))
- Support for PIVOT
Assays
- TargetStudy column now supported for GPAT assays on the result domain.
- Assay query metadata can now be placed in a file-based module.
MS2
- Two new server APIs that support automatic processing of MS spectra files as they are produced by the instrument, without operator intervention:
- The StartSearchCommand initiates MS2 searching on specified data files using a named, pre-configured search protocol. If a data file is not found in the specified location at the time this command is called, the search job will still be initiated and will enter a "File Waiting" status.
- The FileNotificationCommand tells LabKey Server to check for any jobs in a given folder that are in the File Waiting status.
- Two wrapper classes make these APIs easier to call from a batch file:
- The MS2SearchClient class takes data file and protocol information from a CSV file and uses it to call StartSearchCommand one or more times. MS2SearchClient is designed to be called in a batch file.
- The PipelineFileAvailableClient is a simple wrapper over FileNotificationCommand to enable calling from a batch file.
Filter Syntax
- New filter operators (~dateeq and ~dateneq) provide more intuitive semantics.
- visitdate~dateeq=2001-01-01 is equivalent to: visitdate >= 2001-01-01:00:00:00 and visitdate < 2001-01-02:00:00:00.
Data Persistence
- Improved general purpose assay data persistence
- Before 11.1, there were three forms of persistence:
- Metadata stored in OntologyManager
- Data stored in OntologyManager (aka "The Blender")
- Data also stored in materialized temp tables
- In 11.1, there are only two forms of persistence
- Metadata stored in OntologyManager
- Data stored only in OntologyManager maintained hard tables
11.1 Release Webinar
Learn What's New in 10.3
Highlights of the 10.3 Release
Scalable Performance and Reliability- Improved performance for large datasets
- Support for high-throughput, 384-well plate, and multi-plate NAb assay runs
- Read-only file repository ensures integrity of original data
- New tools help you manage sequences, samples, and metadata
- Integration with Galaxy for leveraging your existing workflows
- Metadata tracking for the Illumina platform
- Improved tools for creating intuitive data visualizations
- Conditional formatting helps you see data patterns
- Improved user interface for easier view customization
10.3 Release Notes
Scalable Performance and Reliability
- Improved performance for large datasets.
- Support for high-thoughput NAb assays. Added support for 384-well plate assay runs, multiple plate upload and processing (up to 8 plates at a time), and cross-plate analysis.
- Read-only pipeline directories. The pipeline now supports a read-only file system and writing analysis results to a parallel writable file system.
- Reagent database enhancements. The reagent database can now be customized, including bulk editing. (Available as an add-on module)
Data Management and Integration
- Conditional formatting. Data formatting can now be changed depending on the value of the data.
- Customize view enhancements. Custom views are easier to design and create with a new user interface.
- Improved SQL/XML editor. A more sophisticated SQL and XML editor now supports syntax highlighting, line numbers, and search.
- Support for MySQL External Data Sources. Access any data you have stored in MySQL databases and use it with all the standard LabKey analysis, query, and visualization tools.
- Multivalued columns. Single columns can now display multiple values. (Availability is currently limited to the genotyping and reagent modules.)
Next Generation Sequencing and Genotyping
- Roche 454 GS FLX and Junior instruments. LabKey Server now supports Roche 454 GS FLX and Junior long-read sequencing instruments.
- Data management. Data management for dictionaries of reference sequences, sample information, metrics, and metadata about each run.
- Data analysis. Sequences, quality scores, and multiplex identifiers can be analyzed directly or exported to FASTQ files for use in other tools.
- Galaxy genotyping workflows. LabKey sends reads, sample information, and reference sequences of interest to Galaxy. After the Galaxy workflow runs, LabKey automatically imports the resulting matches and makes them available for single- and multi-run analysis.
- Metadata management for Illumina sequencing assays. LabKey introduces initial support for the Solexa/Illumina platform.
- Genotyping and Illumina features are available as add-on modules.
Visualization
- New visualization tools. LabKey has begun a new effort to expand our visualization tools. The expanded tool set allows for intuitive creation of visualizations, offering users a wide pallet of visualization options. The beta version is available as an add-on module.
Other Enhancements
- New CSS theme. Provides improved look and feel.
- Permission settings for custom buttons. Permissions sensitive rendering of custom buttons.
- User-defined fields in issue tracker. The issue tracker now supports user defined fields and editable email templates.
- Search. Indexing for custom file properties/metadata; indexing for metadata of MAGE-ML, mzXML, mzML files.
- Recalculable SILAC ratios. Users can now exclude individual peptide-level quantitation results and recalculate the protein ratio results for runs analyzed with XPRESS or Q3.
- Enhanced MS2 views and UI. Improved grid views and run comparisons.
- mspicture support. For MS2 runs, related mspicture files are automatically linked to the run.
- File based metadata (NAb). Sample metadata can now be uploaded as files, instead of entered manually.
- New details URL on study.StudyData table.
- PostgreSQL 9.0. LabKey server now supports PostgreSQL 9.0.
- New wiki {div} macro allows for the injection of inline CSS styles or CSS classes.
Extensibility and New APIs
Powerpoint summary of 10.3 API and XML Schema Changes.Perl APIs- New Perl API allows you to query, insert and update data.
- JavaScript APIs now use Ext 3.2.2
- New container management APIs: LABKEY.Security.createContainer(), LABKEY.Security.deleteContainer(), and LABKEY.Security.getFolderTypes(). Manage projects, folders and workbooks.
- New LABKEY.Utils.textLink. Returns a string containing a well-formed html anchor that will apply theme specific styling.
- New LABKEY.Query.saveQueryViews(). Creates or updates a custom view for a given query.
- Modified LABKEY.QueryWebPart(). 'config.buttonBar' now includes 'permission', 'permissionClass', and 'requiresSelection' to control the visibility of custom buttons.
- Modified LABKEY.Query.selectRows(). 'showRows' and 'selectionKey' configuration options have been added.
- Standardized naming convention for AJAX functions. 'success' and 'failure' properties on the 'config' object replace, but are backwards compatible with, the old names: 'successCallback', 'errorCallback', and 'failureCallback'.
- tableInfo.xsd
- New elements <fkMultiValued> and <fkJunctionLookup> to support multivalued columns.
- New <dimension> and <measure> elements on <ColumnType> to provide metadata for visualizations.
- New attributes on <ButtonBarItem>:
- insertPosition, insertBefore, insertAfter to control the placement of buttons added to the button bar.
- permission and permissionClass to control button visibility.
- Support for conditional formats with <ConditionalFormatsType>.
- New <onRender> element on <ButtonBarOptions> to invoke a JavaScript function when the grid is rendered.
- New 'GROUP_CONCAT' aggregate function.
- New support for 'SELECT *'. It is not longer necessary to use 'SELECT Table.*'.
- No longer necessary to prefix unambiguous columns with table names or table aliases.
- Before 10.3, three forms of persistence were used:
- Metadata was stored in OntologyManager.
- Data was stored in OntologyManager.
- Data was also stored in materialized "hard" temp tables.
- In 10.3, two forms of persistence are used:
- Metadata is stored in OntologyManager.
- Data is stored only in OntologyManager maintained "hard" database tables.
Bug Fixes
New Documentation
- Quick Tutorial series for new users:
- Data Analysis Tutorial
- File Management Tutorial
- Security Tutorial
- Collaboration Tutorial
- Manage Views
Upgrade Tips
- New look and feel. A new CSS theme is available with version 10.3.
- To upgrade the entire site to the new theme, navigate to Admin -> Manage Site -> Admin Console -> Look and Feel Settings. In the drop down "Web Themes", select 10.3.
- To upgrade an individual project to the new theme, navigate to Admin -> Manage Project -> Project Settings. In the drop down "Web Themes", select 10.3.
- Database backup. When upgrading to 10.3, we highly recommend that you perform a database backup.
- PostgreSQL customers should run a "vacuum" and an "analyze" after the upgrade is complete.
Learn What's New in 10.2
Highlights of the Latest Release
Search:- Find more content, including folder and list metadata
- Refine search results with an improved advanced search UI
- Integrate content from your intranet and external sites
- Monitor activity with improved auditing, progress feedback and email notifications
- Define required file metadata and collect it with each upload
- Streamline the user interface with customizable toolbars and actions
- Define custom folder types and button bars with XML
- Validate and transform field values with server-side JavaScript handlers
- Save R analyzes back to the server with an enhanced Rlabkey library
10.2 Release Notes
Search
- Searches can now span the contents of both a LabKey Server and external sites
- Once an administrator configures search for external sites, users can execute searches across an organization's resources, even when those resources live on different systems.
- Administrators can customize permission levels for search results from external sites.
- Additional data types are now included in search results:
- List metadata
- External schema metadata
- Container path elements (for example, "NIHM/Studies/2010/Study Data")
- Study labels
- Dataset names, labels and descriptions
- Lab/site labels
- Administrators can optionally exclude entities from search results, including:
- The contents of a LabKey project or folder (via the Folder Settings -> Full-Text Search tab)
- List metadata
- External schemas
- Administrative enhancements
- A new administration interface makes it easier to relocate and clear the primary search index
- Administrators no longer need to install BouncyCastle to support the search of encrypted PDFs
- Updated search technology
- Lucene search engine has been upgraded to v3.0.1
File Upload
- Enhanced customization tools for admins
- File web part's toolbar and column headers can be customized using a simple, drag/drop UI.
- Admins can specify additional metadata that must be entered during the upload of each file. Metadata settings can be inherited by child folders.
- Improved interface for specifying which file actions are enabled through the Import menu item and shown individually in the toolbar.
- Enhanced feedback for users and admins
- Email notifications can be configured to be sent automatically when files are uploaded or deleted.
- A progress bar is now shown during upload of files.
- More types of information available
- New audit history view shows file events.
- New "File Extension" column shown in the file browser displays the file type.
- New "Usage" column indicates when a file is used by an assay.
- The "Created By" field is now tracked for folders, not just files.
- Area-specific enhancements
- Flow import wizard now uses file browser
- File interface replaces pipeline interface for must study users.
- The "Data Pipeline" link in the "Study Overview" section now reads "Manage Files".
- This link now leads to the File Management UI, unless a pipeline has been configured. If a pipeline override has been set up, the link leads to the pipeline management UI.
External Data Sources and Schemas
- Enhancements for managing external data sources.
- New data schema administration page provides current connection status for all data sources
- New mechanism for automatically reloading external schema metadata as part of nightly maintenance
- New ability to reconnect to data sources that go offline and return
- Bulk reloading now available for all external schemas
- Enhancements for defining external schemas
- When defining or updating an external schema, an administrator can now mark a schema such that it is filtered out of the list of schemas shown in the schema browser.
- Administrators can selectively include/exclude external schema metadata from full-text search.
- Security enhancements.
- Tighter security now enforced for external schema definitions. Folder admins can no longer update external schema definitions; only site admins can define and update external schemas
Assays
- Proteomics (MS2)
- Enhanced MS2 Runs Overview UI page.
- New webpart for MS2 Runs Overview.
- Sample sets for all assay data types.
- Sample sets now have an HTML interface that allows insert, update and delete. Like all LabKey grids, sample sets also support insert/update/delete through the client API.
- Sample sets use the new validation framework described in the "Validation" section of this page.
- Neutralizing Antibodies (NAb)
- Sort and page size are now remembered when NAb results are accessed via ‘view results.'
Custom Data Types
- New list designer interface
- List properties (e.g., name, description, title field, etc.) can be edited from the same page as list fields.
- A graphical marker is now shown for the key field.
- Fewer clicks are needed to delete lists.
- The list design view now shows which fields are lookups to other tables. Previously, you could only see the field name and the datatype.
- Improved algorithm for auto-picking the list title field:
- LabKey picks the first non-lookup string column (this could be the key). If there are no string fields, LabKey uses the key.
- LabKey does not exclude nullable fields from consideration.
- You can still explicitly set the title column according to your preferences.
- List archive time-stamping. List archive titles now include a time stamp that indicates when the archive was created, just like study archive titles. This helps to distinguish archives.
- List drop-downs are now sorted. Drop-down lists are now sorted in ascending alphabetical order by the display column. This makes it easier to find desired values, particularly for long lists.
- Improvements to the design tool for lists, assays and datasets
- Cleaner definition of field data types and lookups. A new popup for the "Type" property of fields allows you to select a built-in type for the field, or set the field to be a lookup to another table, which itself defines the type.
- A new, built-in "user" data type can represent users of the LabKey Server system.
Specimens
- Configurable rules for specimen availability. During specimen import, LabKey Server can now run an administrator-defined query (or queries) to determine which vials should have requestability set to a specific value and update vial requestability when necessary.
- Each vial with requestability set via these queries is annotated so that users and administrators can determine why the vial is or is not requestable.
- Administrators can specify the order in which the queries are run in order to resolve conflicts if two queries attempt to mark a single vial as both requestable and unrequestable.
- Checks run exclusively during specimen load. This means that changes to the queries will not affect the requestability of vials currently stored in the system until the next specimen import.
User Interface
- Web parts can now be reordered and deleted without a page refresh from the server
- This makes it much quicker and easier to rearrange portal pages.
- Administrators can still rearranges webparts on a portal page by clicking on the up and down arrows in the web part headers, but the process is swifter.
- Deletion occurs without a server refresh.
- Adding a web part still requires a server refresh because customization of the web part is sometimes required.
- Scrolling menus for views
- You can now scroll to items in long "Views" menus that previously would have been inaccessible.
- More accessible menus
- Admin, Help, My Account and SignIn/SignOut menus now float on the top right side of the page.
- This means that you never need to scroll right to read them on wide pages.
- Previously, they were fixed on the top right, so scrolling was sometimes necessary to reach them.
- Improved file naming
- Query export (tsv, xls, and iqy) filenames now use query/table name (instead of "tsv_" or "data_") followed by standard timestamp (one-second granularity, but guaranteed unique).
- List archive file names now include a timestamp, just like study archives.
Extensibility
Resource: Powerpoint summary of 10.2 API Schema Changes. Includes schema changes in v10.2.- Button bars for any query or table can be customized through XML or the JavaScript client API
- Can add, replace, or delete buttons or drop-down menus.
- Custom button bars can leverage the functionality supplied by default buttons.
- Folder types can now be defined in XML files. Custom folder type definitions, including active modules and web parts (with configuration) can now be defined in XML files in the "folderTypes" directory of any file-based module.
- Useful when many folders need the same basic configuration.
- An administrator can further customize the folder after setting the folder type.
- A file-based module can use an XML template exported from an existing folder. A folder's template can be downloaded from its "Admin->Manage Project->Folder Settings" page.
- Customize view option now available for module-defined query views. This allows users to create customized views for module-based queries, with the caveat that the views need to be saved under new names.
- "Views" folder for default modules. Java modules can now have an associated "<module>/resources/views" folder, just like other modules. Simple .html views can be placed in this folder for use by the module. These views can be easily modified and changes are rendered immediately.
- Query metadata override via module file.
- A module-based query can be renamed by specifying the name attribute in meta-data XML, not just the UI.
- Can specify format, label, etc for built-in tables in a /queries/<schema>/<query>.query.xml file
- Schema Browser enhancements
- Schemas can be displayed by data source.
- "System" schemas can now be filtered out.
- New "define multiple schemas" page
- Improved schema administration page.
- JDBC driver prototype
- Potential alternative Java API
- Uses existing, well understood JDBC API
- Fairly direct mapping for SELECT and metadata queries
- Allows use of existing tools and libraries, like DbVisualizer
Data Validation
- Overview. Server-side JavaScript APIs are now available for transforming and/or validating data on a per-field or per-row basis when insert/update/delete occurs. A validation script can modify data or throw an error before insert/update/delete in most situations.
- The script is run for changes that occur through HTML-based forms, client APIs and list batch insert.
- In the future, the script will also run for list archive, dataset archive import and dataset batch insert.
- Script location. The script used for transformation/validation for a particular table is placed in a module's "queries" folder. The script name needs to be in the form SCHEMA/QUERY.js, where SCHEMA and QUERY are the names of the query and schema associated with the table.
- Sample. A sample script is available in the source code under server/test/modules/simpletest/queries/vehicle/colors.js
- Comparison with pre-existing tools
- This new type of script does its work in-process, whereas existing transformation/validation tools worked out-of-process and communicated via files with the server.
- Existing methods for performing transformations only worked during data import, not at the point of every insert/update/delete.
JavaScript Client API
- LABKEY.QueryWebPart now supports button customization, including the specification of new buttons and the use of multi-select on any query, not just updateable queries. Paging, sorting and filtering are now performed in-place using AJAX.
- LABKEY.Query.saveRows() is now officially a public API. Allows you to do multiple insert/update/deletes across different tables in a single transaction.
- LABKEY.DataRegion is now a public API for interacting with data grids. It supports paging, filtering, sorting, etc. Methods include getChecked(), showMessage(), clearAllFilters() and setOffset().
- LABKEY.Experiment.saveMaterials() is deprecated. This API was redundant with the improved QueryUpdateService API for samples/materials, plus the new ability to create materials as part of inserting a new assay run. Use LABKEY.Query instead.
- LABKEY.Experiment.saveBatch(). This API for programatically creating assay runs now supports adding materials as inputs and outputs. It also now supports referring to files by path. The path can either be the absolute path on the web server or the path relative to the root for that folder.
- LABKEY.Assay.getStudyNabGraphURL Retrieves the URL of an image that contains a graph of dilution curves for NAb results that have been copied to a study. This can be used from study folders containing NAb summary data
- LABKEY.Utils.onTrue() for web parts fetched dynamically that require common script files.
- LABKEY.Utils.generateUUID() for generating UUIDs/GUIDs like “92329D39-6F5C-4520-ABFC-AAB64544E172” from JavaScript code.
- LABKEY.Message.sendMessage no longer requires a logon. This allows guest users to submit a form that triggers an email notification via this API.
- General Enhancements
- JavaScript APIs now use Ext 3.2.1
- Ext menus resize in a smoother manner.
- A link to the server's JavaScript console is now available from the "Admin->Developer Links" menu.
- Updated Documentation
Other Client APIs
- Java client API
- Now requires JDK 1.6+
- Existing tools are encouraged to update their older JARs
- Adds equivalents of the following JavaScript APIs:
- LABKEY.Query.getQueryDetails()
- LABKEY.Assay.saveBatch()
- Rlabkey
- saveResults.
- Allows saving the results of R analyses back to the server as assay runs
- XML/JSON
- requiresSelection option added to button configuration.
- LabKey SQL
- AGE(date1, date2, interval). New, three-parameter version of the function for calculating ages.
- CAST ( AS ). This function lets you cast an expression as a type. CAST(R.d AS SQL_VARCHAR) is the same as CONVERT(R.d,SQL_VARCHAR).
- Custom SQL queries now support the container filter parameter.
- This lets you run a custom query over data from multiple folders at once.
- For example, you can now write a single aggregate report across all folders that shows the count of NAb runs in each lab’s subfolder.
- A container filter is settable through the "Views" menu or through the client API.
Performance
- Areas of enhancement include:
- Flow interface
- Assay copy-to-study verification page, particularly on sites with large numbers of specimens.
Collaboration Tools
- Issue Trackers
- Improved UI for handling duplicate issues
- The number of any duplicate bug is now rendered as a link. This provides ready access to duplicates.
- A duplicate issue identifier is now required when an issue is resolved as a duplicate
- Users can now edit the "Duplicate" field when reopening a bug.
- Each issue now lists all related issues that have been marked as its duplicates.
- Resolving a bug as a duplicate now automatically enters a descriptive comment in both the source and target bugs.
- The existing "Issues" web part now includes a "New Issue" button. Previously this button was only available from the "Issues List" page
- The new "Issues List" web part now can be added to any portal page. This web part displays the contents of an issue list.
- Wikis
- Author names now visible when you use the wiki "Compare With" menu available through the wiki's "History" page.
- Messages
- The number of users who will receive an "Admin Broadcast" message is now listed next to the checkbox that allows you to broadcast a mail. This helps you avoid accidental broadcasts.
Admin
- Maximum size setting for files stored in the database.
- By default, the maximum size is 50MB. This can be customized through the "Customize Site" page (accessed through Admin -> Site Settings).
- Security improvements.
- Enhanced security management interface. The folder tree interface on the permissions management page is now easier to use.
- User passwords are now salted to increase system security.
- Improved audit logging for failed logins.
- Admin menu enhancements
- For folders that have a study, "Manage Study" is now included in the Admin drop-down.
- The "Developer Links" menu item now includes a link to the "Server JavaScript Console."
- The Admin menu now floats at the right side of the page, so it does not get bumped beyond the browser's field of view on wide pages.
- Version information for LabKey Server v10.2
- Java 5 is no longer supported.
- The installer now includes Tomcat 5.5.29
- LabKey Server is now compatible with Tomcat 6.0.
Documentation
New:- Tutorial: Use URLs to Filter and Pass Data
- Modules: Folder Types
- Security administration
- Message boards
- Search
- External Schemas
- File Administration Guide
- R API
- Developer documentation structure simplified
Bug Fixes
For an exhaustive list of all issues resolved in 10.2, see Items Completed in 10.2Learn What's New in 10.1
Highlights of the Latest Release
Search: securely and quickly find the information you need- Instantly find subjects, datasets, columns, folders, and studies
- Easily search all text in Excel, PowerPoint, Word, PDF, and other files
- View only the content your permission settings allow you to read
- Efficiently upload files and directories with an intuitive, drag-and-drop interface
- Maintain flexibility with options to search, download, annotate, or analyze uploaded files
- Reduce setup and administration time with automatic file system synchronization
- Quickly find common operations with a more streamlined data grid interface
- View all data for each subject 10 times faster than in 9.3
- Import complex specimen and assay data more quickly than ever before
10.1 Release Notes
Search
LabKey v10.1 introduces a new search engine that provides full-text search across your server using Lucene search syntax. Search is secure, so you only see results that you have sufficient permissions to view. Results are ordered by relevance. For details, please see LabKey's search documentation.Participant Searches. Study managers are often particularly interested in seeing all of the data available for a particular individual across all studies. It is now easy to search for a particular participant ID. The appropriate participant page will be the top hit, followed by attachments and other documents that mention this participant.Example. Searching labkey.org for participant 249318596 shows these results. The participant page for this individual tops the list, followed by files that include this participant and several pages of documentation. Security rules ensure that only public studies are included in results.Data types. Most data types on your server are searched:- Metadata for datasets and assays.
- Includes column names for datasets
- Includes descriptions, types, etc for assays.
- Participant IDs
- Wikis, including attachments
- Messages, including attachments
- Issues
- Files
- Automatically includes the contents of all file directories.
- Does not include the contents of a pipeline override unless this location allows search.
- Does not include the contents of .zip archives.
File Upload
File management has become more powerful, centralized and streamlined in LabKey v10.1. Please see the file documentation for full coverage of 10.1 improvements, which include:- Easy upload of groups of files. You can now upload entire directories of files or multiple individual files without installing a separate WebDav client for multi-file management.
- No pipeline management required. Default settings for file storage now allow most admins to skip setting up a pipeline (now called a pipeline override).
- Assay file upload can be centralized. The "Files" web part now provides a central location for file processing for all different types of assays.
- Support for a two-step, upload-then-import assay workflow. It is now easy to separate the task of uploading many assay files to your server from the process of importing these files into assay data structures. See details on your options in the picture below.
 Upgrade Tips. The enhancements mentioned above required major changes to the locations where files are stored on the file system. Tips:
Upgrade Tips. The enhancements mentioned above required major changes to the locations where files are stored on the file system. Tips:
- Selection of a site-level file root occurs during upgrade. During upgrade, if you have not previously specified a site-level file root, you will be prompted to enter one. You can either accept the default or override with a new one.
- Files are migrated during upgrade.
- During upgrade, the system looks in all existing file roots and moves the files it finds into new @files directories in a new directory structure that mirrors the project/folder structure of your LabKey Server. The location of the @files directories (and thus the destination of each set of files) is determined by the site-level file root you set at upgrade time. Note that file roots were called web roots in 9.3.
- Of the three different types of directory roots that LabKey supports (file sets, pipeline, and named file sets), this change only affects file sets. Pipeline and named file sets are considered 'external files' and are not managed by the server. If you don't know what a named file set is, you most likely do not have any, so you can ignore this tip.
- You can check to see which files may be affected by looking at the files summary view (linked on the admin console). This page shows all three types of roots. Only those under the @files node are affected. Logging (to the console) is in place to display movement of files and any errors.
- If you have a pipeline root and a web root set to the same location and you plan to upgrade to 10.1, it is recommended that you make changes such that only one of these roots points to a given location. Typically, you will delete the web root before you upgrade. This eliminates redundancy and ensures that that your pipeline will display the expected files after upgrade. If you do not make a change, your files may be visible at the web root, but not at the pipeline root.
- File roots may need adjustment to make the file "Import" button appear. If you have set a pipeline root for a folder that differs from the file directory, you will not see an "Import" button in the Files web part. If possible, change project settings to use the default site-level file root instead of a pipeline root (which is set in 10.1 via a pipeline override). As a workaround, if you can't use the default root (usually because nonuniform inheritance of roots is desired), you can import files via the pipeline files web part.
- Deleted files are no longer retained. Previously, the Files web part moved deleted files into a hidden folder. As of 10.1, these files are no longer retained, so you should not rely on the hidden folder as a backup.
Lists
New list archives. You can now export all lists in a folder to an archive, then import this archive into a different folder on the same LabKey Server or a new one. This allows you to move lists efficiently.Enhanced import process for individual lists. This includes:- Better behavior when a user cancels an import or navigates away during import, plus a new progress bar.
- Faster canceling during import.
Assays
Assay search scope includes a shared project. You can now place an assay design in a central location such that all users in different projects can make use of it. Before 10.1, you could only place an assay design in a single project or folder and it could only be used to import assays into that particular folder. The "/Shared" project is now included in the assay search scope. It is the third namespace searched.NAb assays. NAb now provide support for:- Viewing graphs of different curve types. The Run Details page now allows you to choose any of of three curve fit options. See the NAb assay tutorial for an example.
- "Positive Area Under the Curve" (PAUC) calculations. The are addition to the "Area Under the Curve" (AUC) calculation added in v9.3. They appear on the Run Details page.
- Working with a broader variety of plate templates. You can now work with plates where concentration increases, not just those where it decreases. To reverse the dilution direction on the plate template, see the plate template documentation.
- You can now download all of a run’s files as a .ZIP file.
- A link to lets you jump directly to the file browser UI for a run’s directory.
Core Components
Improved grid view UI- The enhanced Export drop-down makes it easier to export data grids to Excel (.xls and .iqy), text (.tsv) and scripts (JavaScript, R and SAS).
- Export XAR now apprears under the Export drop-down when this option is appropriate.
- Multi-line and tab text are now supported during import/export of studies and lists. Special characters (tab, newline) are escaped using when exporting and unescaped on import.
- This is particularly helpful for a large wiki that has a large table of contents. Save duration dropped by more than half for the labkey.org documentation tree.
Administration
Upgrades- LabKey Server will no longer upgrade from versions of LabKey older than v2.3.
- Postgres 8.4 is now recommended, but both 8.3 and 8.4 are supported.
- Admin options are now available for setting strong password rules and password expiration
- The "My Account" page now provides a "Change Password" button.
- Clicking on "Log In" when already logged in will result in an immediate redirect back, which should then display the logged in status.
- Troubleshooters can view site admin information but can't change it.
- Troubleshooters get an abbreviated admin menu (both in the navbar and the drop-down menu) to access the admin console.
- Most of the Diagnostics links are available.
- Troubleshooter role (and no other roles) can be assigned at the root.
- New admin option allows you to set the group of users who can be assigned an issue, along with the default assignment. You can set the "Assigned To" dropdown to show either all members of all project groups, or the members of a particular project group.
- The "Notify" field now auto-completes from the "Site Users" list.
- Workbooks do not show up in the folder tree.
- Workbooks cannot contain child folders or child workbooks (they appear more like documents than folders).
- Admins cannot set some per-folder admin options, such as set modules, missing value indicators or security. All of these things are inherited from the parent.
- The dataset details view now includes a "Manage dataset" button, which allows swift admin of a dataset.
RLabKey Client API
Enhancements support the advanced R user working within a native R environment. Enhancements include:- Improved accessibility and selection of input datasets, plus saving analysis results in a structured fashion. This includes R functions to:
- Connect to a LabKey server and set folder context
- Enumerate query objects and their fields (including lookup fields)
- Improve the flexibility of filters used in the SelectRows command
- Save data frames representing statistical results as assay data sets in LabKey
- Better control over column names. The new colNameOpt setting on selectRows and on ExecuteSql allows you to choose the way column names are determined. Previously the R client API used the caption for column names and the R report used a modified version of the field key.
JavaScript Client API
New APIs- LABKEY.Pipeline. New class that allows programmatic manipulation of the data pipeline. Allows you to kick off certain types of pipeline jobs. Currently supports only jobs that are configured in XML, so does not support study import, export, etc.
- LABKEY.Query.getQueryDetails. Returns details about a given query including detailed information about result columns.
- LABKEY.Utils.endsWith. Determines whether one string ends with another string.
- LABKEY.ActionURL.getContainerName. Gets the current container's name instead of the container's entire path. For example, if you are in the /Project/SubFolder/MyFolder container, this method would return 'MyFolder' while getContainer() would return the entire path.
- A new "File Manager" component will be exposed in JavaScript as a beta. Changes to its APIs are expected in future releases. Developers will be able to customize the buttons displayed by this component.
- Ext grid panel. This grid now provides an export button that exports the grid on screen.
- Event change for LABKEY.ext.Store. This API now fires the commit complete event after deletion finishes.
- LABKEY.Experiment.saveBatch now supports data output files. These are files tracked by the dataOutputs property on LABKEY.Exp.Run.
- LABKEY.ActionURL.getParameter, LABKEY.ActionURL.getParameter. Now includes POST parameters in addition to GET parameters that have previously been available.
Java APIs
Upgrade Tip: Please recompile Java client code. The 10.1 Java API is source-compatible but not binary-compatible with 9.3. This means you will need to recompile your Java client applications using 10.1.New Java APIs- GetUsers. This Java Client API returns a list of users given selection criteria.
Other API Changes
New APIs available in both Java and JavaScript client libraries- LABKEY.Security.getContainers. Returns information about the specified container, including the user's current permissions within that container. If the includeSubfolders config option is set to true, it will also return information about all descendants the user is allowed to see.
- age(date1,date2). Supplies the difference in age between the two dates, calculated in years. Postgres does not support using timestampdiff on intervals larger than day. This function allows you to determine larger time differences.
- Cross-project queries. LabKey now supports cross-project queries by allowing the first item in the path to be a container path. To indicate that a query is going across projects, use a path that starts with a slash: “/Home/subfolder”.schema.query. In other words, the syntax is “/<FULL FOLDER PATH>”.<SCHEMA>.<QUERY> - for example: “/My Project/My Folder/Subfolder”.study.Participants
Schema, Table and Column Changes
Experiment (exp) Schema- New tables for this schema. These provide details about which files and samples are used in various steps in a run.
- exp.MaterialInputs. Contains one row per material input in a protocol application for a run in this folder.
- exp.DataInputs. Contains one row per data input in a protocol application for a run in this folder.
- New columns on many Experiment (exp) tables.
- Created. Contains the date and time that this data was added to the system
- CreatedBy. Contains the user that created this data
- Modified. Contains the date and time that this data last modified
- ModifiedBy. Contains the user that last modified this data
- New pipeline.jobs table for this schema.
- Includes data about all scheduled, running, and completed pipeline jobs.
- New column for study.SpecimenDetail
- ProcessingTechInitial. Identified the technician who processed the vial.
- Certain study nouns can now be customized during study creation.
- Choosing non-default nouns affects the entire study schema -- all table names and column names.
- No effect on existing tables or schemas. Only affects newly created studies.
- New StudyData table for this schema.
- Shows columns shared by datasets.
- Formerly internal-only; now exposed.
- New columns in the core.Containers table
- Description
- Workbook. Boolean that is set to true when the the container is a workbook.
- Title. Functions like the "Name" column, but does not need to be unique.
XML Schemas
Changes to schemas:- study.xsd.
- timepointtype. This new attribute identifies the time measurement system used for a study. Just as before, you can use absolute visit dates or timepoints relative to a fixed start time. Additionally, as of 10.1, you can choose a timeline that supports a continuous schedule of monitoring. Terminology is still being refined as the feature is being finished. This attribute is not exposed in the UI, so it can only be used in imported studies.
- tableInfo.xsd
- propertyURI. You can now identify properties that live in a separate, shared container using either the propertyURI element or the column name of the attribute.
Module Development
Modules can now contribute to the main credits page. To make this happen for your module, create a jars.txt file documenting all jars and drop it in the following directory: <YOUR MODULE DIRECTORY>srcMETA-INF<YOUR MODULE NAME>. The jars.txt file must be written in wiki language and contain a table with appropriate columns. See this sample file for an example.Modules without any Java code can now contribute pipeline configurations. Previously, modules had to include Java code to indicate that they had Spring-based pipeline configuration files available.File-based assays can now be designed to jump to a "begin" page instead of a "runs" page. If an assay has a begin.html in the assay/<name>/views/ directory, users are directed to this page instead of the runs page when they click on the name of the assay in the assay list.Documentation
New or enhanced sections of documentation:- files
- fileUpload
- fileImport
- fileSharing
- adminFiles
- fileTerminology
- luceneSearch
- configDbLogin
- Comments
- Admin guide: manageComments
- User guide: comments
- Tutorial: assignComments
- Documentation for the module.properties file.
- A "Help" link to the documentation now appears at the top right side of all pages of your site, next to the "My Account" link. Previously, this link appeared in the left navigation bar, which is often hidden from users.
Bug Fixes
For an exhaustive list of all issues resolved in 10.1, see Items Completed in 10.1.Learn What's New in 9.3
Overview
The latest version of LabKey Server brings you next-generation technologies on top of an ever-more stable, more flexible and speedier platform. Significant performance enhancements in v9.3 mean that you’ll see faster page loads and swifter data processing across the product.New capabilities introduced in this release are summarized below. For an exhaustive list of all improvements made in 9.3, see Items Completed in 9.3. Refer to the 9.3 Upgrade Tips to quickly identify behavioral changes associated with upgrading from v9.2 to v9.3.Download LabKey Server v 9.3.Performance
The speed of loading pages and processing data across diverse areas of LabKey Server has improved significantly. You will see speed improvements for:- Importing lists on PostgreSQL. This now takes one third as much time on v9.3 as it took on v9.2.
- Copying assay results to studies or deleting runs
- Specimen, security and user administration pages
- Certain queries over lists and assays
- Servers with large folder trees
- Large wikis
External Schemas and Data Sources
External Data Sources. You can now define a database other than the LabKey database as a source of external schemas and tables. LabKey currently supports SQLServer, PostgreSQL and SAS data sources. You can define an arbitrary number of data sources in your labkey.xml file.SAS Data Sources. SAS external schemas and data sources are now supported. Publishing SAS datasets to your LabKey Server provides secure, dynamic access to datasets residing in a SAS repository. Published SAS data sets are dynamic, meaning that LabKey treats the SAS repository as a live database; any modifications to the underlying data set in SAS are immediately viewable on LabKey. The data sets are visible only to those who are authorized to see them. Authorized users can view published data sets using the familiar, easy-to-use grid user interface used throughout LabKey. They can customize their views with filters, sorts, and column lists. They can use the datasets in custom queries and reports. They can export the data in Excel, web query, or TSV formats. They can access the data sets from JavaScript, SAS, R, and Java client libraries.Study
Time-varying cohort assignments. LabKey Server now provides a sophisticated cohort tracking system that allows cohort assignments to change over time. A given participant may move through more than one of a study's designated cohorts (e.g., Negative, Acute, and/or Established) across their study visits. Documentation: User Guide for Cohorts and Admin Guide for Cohorts. Features:- Queries and reports can now be time-aware; in other words, they can show results that reflect each participant’s cohort at the time the data was collected.
- The "Cohorts" dropdown above grid views provides options for filtering the view based on the times participants when were assigned to particular cohorts.
- Administrators still have the option to set up a study's cohorts as time-invariant, simplifying UI options for users.
- Additional data types included in import/export/reload:
- Lists. All lists in the study folder are now exported if the lists option is checked in the study exporter. Study import will create new lists or replace existing lists with list schema, properties, and data in the study archive.
- QCStateLabel columns in datasets. This allows you to export labels for quality control states.
- Specimen repository settings when you do not have an existing specimen archive. Previously an archive was required.
- Enhanced error checking and logging during import/reload, including:
- Checking of all queries and custom views for errors during import/reload.
- Logging of status and errors to a single pipeline log that can be browsed from the UI. The log also provides counts for imported queries, views, reports, and lists.
- Enhanced pipeline processing, including the following options:
- Browse to a study archive or select a pipeline zip file whose name ends with .study.zip.
- Store multiple study.xml files (e.g., study.xml, foo.study.xml, or study001.study.xml) in the same directory.
- Reload (in addition to import) via pipeline browsing to local .zip file. If the study exists, the “Reload Study” button appears on the manage study page, linking to the Import/Reload Study page.
- Enhanced documentation for the study load file format for programmers generating file-based studies. See:
- XML Schema Reference, which provides documentation for LabKey XML schemas
- Serialized Elements and Attributes of Lists and Datasets.
- Improved UI text on import study page
Data Grids
Field/column designer enhancements. The columns of LabKey datasets, assays and lists are described as lists of fields, each of which has associated properties (e.g., Name, Description, etc). Improvements to the field designer allow you to set additional properties, reorder fields, add import aliases and adjust the visibility of columns. features added:- Custom URLs for gridview columns. The "URL" property of any list/dataset/assay field can now be customized using substitution parameters that reflect live data in the grid. This allows you to produce URLs that are determined by the data stored in a particular row of a dataset. You might use a custom URL to link to custom details page for a particular participant or subject. Or you might set up an "Image" column that automatically provides links to files named with participant or subject IDs.
- Ability to change the order of fields in list, assay and dataset designs. The order of fields determines the order of columns in default grid views, as well as the insert, update, and detail views.
- Column aliases. You can now specify an arbitrary number of alternative column aliases for fields in the list/dataset/assay design editors. When LabKey Server imports data from files (TSV, Excel, etc) it uses these aliases to match file column headers to field names.
- Visibility/editability in insert, update, and details views. Users can now determine whether columns are hidden from the update and default views, plus whether they are read-only in the update view. Hidden fields are not part of the default grid views and will only be shown in "Customize View" when the user clicks on the checkbox to show hidden columns.
- Ability to export a list of dataset fields and field properties. The new "Export Fields" button on the dataset definition page allows an admin to export a TSV file that contains the header line and meta data in a format matching TSV dataset schema import.
Assays
Transform scripts for run properties. Transformation scripts can now modify run- and batch-level properties during data import. As with transformation of uploaded data, a script can only transform run or batch properties that already exist in the assay definition. A script cannot create a new run or batch property.New versions of TPP and X!Tandem. The newest version of LabKey Server includes the most recent versions of these tools for MS2 proteomics.New NAb-curve fit algorithm. A third curve fit algorithm, "polynomial," is now available in the list of NAb curve-fit options displayed during NAb data import. This algorithm allows you to quantifying a sample’s neutralization behavior based on the area under a calculated neutralization curve, commonly abbreviated as “AUC”. The assay's run report (accessed through the details link) generates all graph, IC50, IC80 and AUC information using the selected curve fit method.Viability assay. This new, built-in assay type can collect and organize results for all types of Guava runs, including AQC, EQC, and proficiency testing. The new assay tool enables the submission of cell viability and recovery data directly to a data portal, where lab and program staff can have easy access to all submitted data. This approach provides complete and efficient data uploads while simplifying a lab’s post-Guava assay workflows. The LABKEY.Query.selectRows API can be used to query uploaded assay results a Viability Assay.Assay folder type. This new folder type makes it easier to set up and organize assays. It displays the "Assay List" web part and provides a list of available assays. It also provide links for setting up the pipeline, creating additional assays and managing existing assays.JavaScript Client API
Auto-generation of Ext forms. LABKEY.ext.FormPanel can generate simple forms using query or assay metadata. It extends Ext.form.FormPanel and understands various LabKey metadata formats. When a LABKEY.ext.FormPanel is created with additional metadata, it will try to intelligently construct fields of the appropriate type.Email notifications. LABKEY.Message.sendMessage sends an email notification message through your LabKey Server.Group renaming. You can now rename groups either through the UI or the API. See: LABKEY.Security#renameGroup.Effective permissions. Effective permissions are now provided for both users and/or groups as part of the following APIs: LABKEY.Security.getUserPermissions, LABKEY.Security.getGroupPermissions, and LABKEY.Security.getContainers.Fine-grained control over the display of buttons and links in grid views and the LABKEY.QueryWebPart. For example, you can now hide the Edit and Details columns and the "Insert New" button in the button bar as well. LABKEY.QueryWebPart:- showUpdateColumn
- showDetailsColumn
- showInsertNewButton
- showDeleteButton
- showExportButtons
- showBorders
- showRecordSelectors
- showPagination
- shadeAlternateRows
- printView
- Events documented
- Static fields, methods and events now marked static
- Additional examples provided.
- Cross-linking to related documentation topics improved
Developer Toolkit
Schema browser. This interactive schema exploration tool allows developers to easily determine the columns and data types that compose LabKey tables. It replaces the existing Query module exploration/management UI, so it provides links to validate queries, create new user-defined queries in each schema, edit the source or design of user-defined queries and access the "Schema Administration" page. New features:- Users can view all schemas they have permissions to read in a container and get descriptions about what kind of data are stored in each schema.
- Users can view all tables and queries they have permissions to read in each schema and get descriptions about what kind of data are exposed from each.
- User-defined queries are differentiated from built-in tables/queries.
- Users can view all columns they are allowed to read in each query and get information about those columns, especially the following:
- Programmatic name (the name used in queries and the API).
- Data type.
- Description of the kind of data exposed in that column.
- For foreign keys, information about what table/column it joins to.
- Users can quickly view data in any of the tables/queries by clicking through to a standard grid view.
Site Management
Group renaming. You can now rename groups either through the security UI or the API. See: LABKEY.Security#renameGroup.Folder for adding robots.txt and sitemap files. You can now place site-specific, static content (such as robots.txt and sitemaps) into the new extraWebapp directory, a peer to modules and labkeyWebapp. These files won't be deleted when the site is upgraded.Easier setup for perl scripting engines. The scripting engine setup dialog now automatically offers the perl path if perl is already on the system path.New Documentation, Tutorials and Demos
- Advanced List Tutorial and Demo
- LabKey XML Schema Reference
- SAS Integration
- User Guide: Dataset Quality Control
- Admin Guide: Dataset Quality Control Management
- Specimen Quality Control
- Add Screenshots to a Wiki
9.3 Upgrade Tips
Table Schemas
Cohorts. Advanced cohort support allows participants to change cohorts over time. Changes to the study schema are minor:- Cohort (a foreign key to study.Cohort) has been added to ParticipantVisit.
- InitialCohort (a foreign key to study.Cohort) has been added to Participant.
- Unchanged data columns:
- Point IC<CUTOFF>. Point-based titer. <CUTOFF> represents the cutoff percentage specified for the run. Since the user can choose multiple cutoffs, a column will be produced for each cutoff chosen.
- Curve IC<CUTOFF>. Curve-based titer, using selected Curve Fit Method
- Enhanced run column:
- CurveFitMethod. In addition to 4PL and 5PL, this can now be Polynomial
- New data columns:
- Curve IC<CUTOFF> 4PL. 4PL curve-based titer
- Curve IC<CUTOFF> 5PL. 5PL curve-based titer
- Curve IC<CUTOFF> Poly. Polynomial curve-based titer
- AUC_4PL. Area under the 4PL curve fit
- AUC_5PL. Area under the 5PL curve fit
- AUC_Poly. Area under the Polynomial curve fit
XML Schemas
Study import/export. The new “isMvEnabled” boolean element in tableInfo.xsd is now used by datasets_metadata.xml. The “mvColumnName” attribute has been deprecated because “isMvEnabled” better matches the schema.tsv property.R Column Names
Some column names for labkey.data have changed, so you may need to update your scripts. Some names have gotten longer because additional characters were necessary to guarantee that names were unique. You can see the new names by calling names(labkey.data) at the start of your script. To avoid the potential need to update column names in the future, it may be helpful to simply set the names of labkey.data's columns to predictable values at the start of each script.Java Remote API
Please use the newest version of the Java API jar (v9.3). This jar will work against both new and older servers. It fixes a problem with parsing dates that do not include at time zone.Deprecated Components
The following components have been deprecated for some time and are no longer available in LabKey Server 9.3:- Postgres 8.1. Please upgrade to Postgres 8.3. It is now required.
- Perl Cluster Pipeline. Please move to the Enterprise Pipeline.
Automatic Upgrades for External Components
Tomcat v5.5.27. Tomcat v5.5.27 is installed automatically with the LabKey v9.3 installer for new installations of LabKey Server. Upgrading an existing LabKey installation to v9.3 will not upgrade the Tomcat version automatically. If you wish to upgrade Tomcat from v5.5.20 to v5.5.27 for an existing LabKey installation, you will need to do it manually.JRE v1.6.0-10. Upgrading an existing LabKey Server to v9.3 will upgrade the JRE from 1.5 to 1.6 automatically if and only if the JRE 1.5 was installed by the LabKey installer. In other words, if you are running a JRE 1.5 that you installed yourself, external to the LabKey installer, you will be on your own to upgrade it if you wish to do so. An upgrade to the 1.6 JRE isn't required for LabKey v9.3, but likely will be for LabKey v10.1 or v10.2.Learn What's New in 9.2
Overview
Version 9.2 represents a important step forward in the ongoing evolution of the open source LabKey Server. Enhancements in this release are designed to:- Support leading medical research institutions using the system as a data integration platform to reduce the time it takes for laboratory discoveries to become treatments for patients
- Provide quick-to-deploy software infrastructure for communities pursing collaborative clinical research efforts
- Deliver a secure data repository for managing and sharing laboratory data with colleagues, such as for proteomics, microarray, flow cytometry or other assay-based data.
User administration and security
Finer-grained permissions settings for administrators- Tighter security. Admins can now receive permissions tightly tailored to the subset of admin functions that they will perform. This allows site admins to strengthen security by reducing the number of people who possess broad admin rights. For example, "Specimen Requesters" can receive sufficient permissions to request specimens without being granted folder administration privileges.
- New roles. LabKey Server v9.2 includes four entirely new roles: "Site Admin," "Assay Designer," "Specimen Coordinator" and "Specimen Requester." This spreadsheet shows a full list of the new admin roles and the permissions they hold. It also shows roles that may be added in future releases of LabKey Server.
- Brief list of roles instead of long list of groups. Previously, the permissions management interface displayed a list of groups and allowed each group to be assigned a role. This list became hard to manage when the list of groups grew long. Now security roles are listed instead of groups, so the list is brief. Groups can be assigned to these listed roles or moved between roles.
- Rapid access to users, groups and permission settings. Clicking on a group or user brings up a floating window that shows the assigned roles of that group or user across all folders. You can also view the members of multiple groups by switching to the groups tab.
- Now individual users, not just groups, can be assigned to security roles. This allows admins to avoid creating groups with single members in order to customize permissions.
- This allows customization and export of the view.
- Administrators can create custom lists to store metadata about groups by joining a list with groups data. Any number of fields can be added to information about a each user or group. These lists can be joined to:
- Built in information about the user (name, email etc)
- Built in information about the group (group, group members)
- The results can also be combined with built-in information about roles assigned to each user & group in each container. From this information a variety of reports can be created, including group membership for every user and permissions for every group in every container.
- These reports can be generated on the client and exported as Excel Spreadsheets
- Deactivate/Re-Activate buttons are now on the user details page as well as the user list. When clicked on the user list, a confirmation page is shown listing all the selected users (users that are already activate/inactive are filtered out if action is deactivate/re-activate).
- Clicking Delete on the user list now takes you to a confirmation page much like the deactivate/re-activate users command. If at least one of the selected users is active, it will also include a note and button that encourages the admin to deactivate the user(s) rather than permanently delete them.
Study
Study export, import and reload- Studies can be reloaded onto the same server or onto a different LabKey Server. This makes it easy to transfer a study from a staging environment to a live LabKey platform.
- You can populate a brand new study with the exported contents of an existing study. For similar groups of studies, this helps you leverage your study setup efforts.
- Studies can be set up to reloaded data from a data depot nightly. This allows regular transfer of updates from a remote, master database to a local LabKey Server. It keeps the local server up-to-date with the master database automatically.
- Field-Level Missing Value (MV) Indicators allow individual data fields to be flagged. Previously, only two MV values were allowed (N and Q). Administrators can now customize which MV values are available. A site administrator can customize the MV values at the site level and project administrators can customize the MV values at the folder level. If no custom MV values are set for a folder, they will be inherited from their parent folder. If no custom values are set in any parent folders, then the MV values will be read from the server configuration.
- MV value customization consists of creating or deleting MV values, plus editing their descriptions.
- A new API allows programmatic configuration of MV values for a folder. This allows study import/export to include MV values in its data and metadata.
- MV values are now displayed with a pop-up and a MV indicator on an item’s detail page.
- When inserting or updating an item with a MV-enabled field, possible MV values are now offered in a drop-down, along with the ability to set a raw value for the field. Currently a user is only able to specify one or the other on the update page.
Specimens
Import of specimen data allowed before completion of quality control (QC)- Specimen import is now more lenient in the conflicts it allows in imported specimen data. Previously, import of the entire specimen archive was disallowed if conflicts were detected between transaction records for any individual vial. In 9.2, all fields with conflicts between vials are marked "NULL" and the upload is allowed to complete.
- Use a saved, custom view that filters for vials with the "Quality Control Flag" marked "True" in order to identify and manage vials that imported with conflicts.
- Vial events with conflicting information are flagged. Conflicts are differentiated by the presence of an "unknown" value for the conflicting columns, plus color highlighting. For example, you would see a flag when an imported specimen's globalUniqueID is associated with more than one primary type, as could occur if a clinic and repository entered different vial information pre- and post-shipment.
- Vial events that indicate a single vial is simultaneously at multiple locations are flagged. This can occur in normal operations when an information feed from a single location is delayed, but in other cases may indicate an erroneous or reused globalUniqueID on a vial.
- Vials or primary specimens that meet user-specified protocol-specific criteria are flagged. Examples of QC problems that could be detected with this method include:
- A saliva specimen present in a protocol that only collects blood (indicating a possibly incorrect protocol or primary type).
- Primary specimen aliquoted into an unexpectedly large number of vials, based on protocol expectations for specimen volume (indicating a possibly incorrect participantID, visit, or type for one or more subset of vials).
- The new "specimencheck" module identifies mismatched specimens and displays them in a grid view. It identifies specimens whose participantID, sequenceNum and/or visit dates fail to match, then produces a report that can be used to perform quality control on these specimens. For developers, the "specimencheck" module also provides an example of a simple file-based module.
- This allows specimen managers to indicate that a particular quality control problem has been investigated and resolved without modification of the underlying specimen data.
- A specimen manager can also manually flag vials as questionable even if they do not meet any of the previously defined criteria.
- Records of manual flagging/unflagging are preserved over specimen imports, in the same manner as specimen comments.
- When exported to Excel, individual worksheets of specimen reports may include blank columns. This is due to the fact that columns are included for all visits that have specimens of any kind, rather than for just those visits with specimens matching the current worksheet’s filter. Exported Excel files now display a minimal set of visit columns per report worksheet.
- Additional columns can be optionally presented in vial view and exported via Excel. These include the number of sibling vials currently available, locked in requests, currently at a repository and expected to become available, plus the total number of sibling vials.
- These columns are available via the ‘customize view’ user interface, so different named/saved views can be created. The built-in ability to save views per user enables specimen coordinators to see in-depth detail on available counts, while optionally presenting other users with a more minimal set of information.
- Faster loading of specimen queries. Please review the 9.2 Upgrade Tips to determine whether any of your queries will need to be updated to work with the refactored specimen tables.
- New filter options are available for specimen reports. You can now filter on the presence or absence of a completed request.
Assays
Validation and Transform Scripts- Both transformation and validation scripts (written in Perl, R or Java) can now be run at the time of data upload. A validation script can reject data before acceptance into the database if the data do not meet initial quality control criteria. A data transformation script can to inspect an uploaded data file and modify the data or populate empty columns that were not provided in the uploaded data. For example, you can populate a column calculated from other columns or flag out-of-range values.
- Validation support has been extended to NAb, Luminex, Microarray, ELISpot and file-based assay types. Validation is not supported for MS2 and Flow assays.
- A few notes on usage:
- Columns populated by transform scripts must already exist in the assay definition.
- Executed scripts show up in the experimental graph, providing a record that transformations and/or quality control scripts were run.
- Transform scripts are run before field-level quality control. Sequence: Transform, field-level quality control, programmatic quality control
- A sample script and details on how to write a script are currently available in the specification.
- For an assay, a specimenID that doesn't appear in a study is displayed with a red highlight to show the mismatch in specimenID and participantID. GlobalUniqueIDs are matched within a study, not between studies.
- The columns included in the "Run Summary" section of the NAb "Details" page can be customized. If there is a custom run view named "CustomDetailsView", the column set and order from this view will apply to NAb run details view.
- Significant performance enhancements. For example, switching from a run to a print view is much faster.
- Users with read permissions on a dataset that has been copied into the study from a NAb assay now see an [assay] link that leads to the "Details" view of a NAb assay.
Proteomics
Proteomics metadata collection- The way that users enter proteomics run-level metadata has been improved and bulk-import capabilities have been added. The same approach used for specifying expected properties for other LabKey assays is now used for proteomics.
- It is now possible to copy proteomics run-level data to a study dataset, allowing the proteomics data to be integrated with other study datasets. Note that the study dataset links back to the run that contains the metadata, not the search results.
- A new utility on the protein administration page allows you to test parsing a FASTA header line
Views
Filter improvements- A filter notification bar now appears above grid views and notes which filters that have been applied to the view.
- The links above an assay remember your last filter. This helps you avoid reapplying the filter. For example, if you have applied a filter to the view, the filter is remembered when you switch between batches, runs and results. The filter notification bar above the view shows the filters that remain with the view as you switch between batches, runs and results.
File management
WebDAV UI enhancements provide a user-friendly experience- Users can browse the repository in a familiar fashion similar to the Windows Explorer, upload files, rename files, and delete files. All these actions are subject to permission checking and auditing. Drag and drop from desktop and multi-file upload with progress indicator are supported. Additional information about the files is displayed, such as the date of file creation or records of file import into experiments.
Flow
Flow Dashboard UI enhancements- These changes provide a cleaner set of entry points for the most common usages of Flow. The advanced features of the current Flow Dashboard remain easily accessible. Changes include:
- More efficient access to flow runs
- Ability to upload FCS files and import FlowJo workspaces from a single page.
Custom SQL Queries
New SQL functions supported- COUNT(*)
- SELECT Table.*
- HAVING
- UNION in subqueries
- Parentheses in UNION and FROM clauses
Client API
New Tutorial and Demo for LabKey JavaScript APIs New JavaScript APIs- LABKEY.Query.exportSql. Accepts a SQL statement and export format and returns an exported Excel or TSV file to the client. The result set and the export file are generated on the server. This allows export of result sets over over 15,000 rows, which is too much for JavaScript to parse into objects on the client.
- LABKEY.QueryWebPart. Supports filters, sort, and aggregates (e.g., totals and averages). Makes it easier to place a Query Web Part on a page.
- LABKEY.Form. Utility class for tracking the dirty state of an HTML class
- LABKEY.Security Expanded. LABKEY.Security provides a range of methods for manipulating and querying security settings. A few of the new APIs:
- LABKEY.Security.getGroupsForCurrentUser. Reports the set of groups in the current project that includes the current user as a member.
- LABKEY.Security.ensureLogin. A client-side function that makes sure that the user is logged in. For example, you might be calling an action that returns different results based on the user's permissions, like what folders are available or setting a container filter.
- Enhanced LABKEY.Security.getUsers. Now includes users' email addresses as the "email" property in the response.
- The Java library now includes programmatic access to NAb data.
- A new menu option under the "Export" button above a grid view will generate a valid script that can recreate the grid view. For example, you can copy-and-paste generated JavaScript into a wiki page source or an HTML file to recreate the grid view. Filters that have been applied to the grid view that are shown in the filter bar above the view are included in the script.
Collaboration
Customization of the “Issues” label- The issues module provides a convenient tracking service, but some of the things one might want to track with this service are best described by titles other than “issues.” For example, one might use the issues module to track “requests,” “action items,” or “tickets.”
- Administrator can now modify the label displayed in the issue module’s views. The admin can specify a singular and plural form of the new label on a per-container basis. In most places in the UI where either term "Issue" or "Issues" is used, these configured values are used instead. The only exceptions to this are the name of the issues module when displayed in the admin console and folder customization, and the name of the controller in URLs.
- Attachments
- A new option to hide the list of page attachments is available. Files attached to wiki pages are currently displayed below the page content, even if those attachments. This is undesirable in cases where the attachments are simply images used within the page content itself.
- When wiki attachments are displayed, a file attachment divider is shown by default. CSS allows the text associated with the divider to be hidden.
- HTML Editor
- The wiki HTML editor has been updated to a newer version.
- The button for manipulating images is now enabled in the Visual Editor.
- Spellcheck is enabled on Firefox (but not IE).
- Print. You can now print a subtree of a wiki page tree.
- Forms where you enter code and want to format it nicely. This includes the Wiki and query SQL editors.
- Forms where you enter TSV. This includes sample set, list, dataset, and custom protein annotation uploads.
- Support for simple tab entry, as well as multi-line indent and outdent with shift-tab.
- Expiration of messages is now "Off" by default for newly created message boards. Existing message boards remain as they are.
Administration
PostgreSQL- Support for PostgreSQL 8.4 Beta 1.
9.2 Upgrade Tips
Specimen Queries
The "Specimens" table has been split into two new tables, "Vials" and "Specimens," to enhance query speed. This means that you will need to reference one additional table when you use the raw specimen tables perform a lookup.Queries that use the raw specimen tables will need to be updated. However, queries that use the special, summary tables (Specimen Detail and Specimen Summary) are unaffected and do not need to be modified.Example: A 9.1 query would have referenced the PrimaryType of a vial as follows:SpecimenEvent.SpecimenId.PrimaryType
SpecimenEvent.VialId.SpecimenId.PrimaryType
Specimen Import
Specimen import is now more lenient in the conflicts it allows in imported specimen data. Previously, import of the entire specimen archive was disallowed if conflicts were detected between transaction records for any individual vial. In 9.2, all fields with conflicts between vials are marked "NULL" and the upload is allowed to complete.Use a saved, custom view that filters for vials with the "Quality Control Flag" marked "True" in order to identify and manage vials that imported with conflicts.Example: In 9.1, a vial with a single globalUniqueSpecimenID was required to have the same type (blood, saliva, etc.) for all transactions. Vials that listed different types in different reaction records prevented upload of the entire archive. In 9.2, the conflicting type fields would be marked "NULL" such that these vials and their problematic fields can be reviewed and corrected after upload.PostgreSQL 8.3
PostgreSQL 8.2 and 8.1 are unsupported on LabKey Server 9.2 and beyond, so you will need to upgrade.Security Model
Extensive changes have been made to the security model in LabKey Server 9.2. Please see the Permissions and Roles spreadsheet for a detailed mapping of permissions under the old model to permissions under the new.View Management
For 9.2, the "Manage Views" page is accessible to admins only. This means that nonadmins cannot delete or rename views of their own creation, as they could previously. Delete/rename ability will be restored for nonadmins in a future milestone.MS2 Metadata Collection
The metadata collection process for mass spec files has been replaced. It is now based on the assay framework.Wiki Attachments
Authors of wiki pages now have the option to show or hide the list of attachments that is displayed at the end of a wiki page. If displayed, the list of attachments will now appear under a bar that reads "File Attachments." This bar helps distinguish the attachment list from the page list. For portal pages where display of this bar is undesirable, you can use CSS to hide the bar.Quality Control (QC)
The "QC Indicator" field is now called the "Missing Value" field.Folder/Project Administration UI
The "Manage Project" menu under the "Admin" dropdown on the upper right (and on the left navigation bar) has changed. The new menu options available under "Manage Project" are:- Permissions (For the folder or project-- you can navigate around the project/folder tree after you get there)
- Project Users (Equivalent to the old "Project Members" option)
- Folders (Same as the current "Manage Folders," focused on current folder)
- Project Settings (Same as existing option of the same name, always available for the project)
- Folder Settings (Available if the container of interest is a folder. Equivalent to the old "Customize Folder." Allows you to set the folder type and choose missing value indicators)
Learn What's New in 9.1
- Support leading medical research institutions using the system as a data integration platform to reduce the time it takes for laboratory discoveries to become treatments for patients
- Provide fast-to-deploy software infrastructure for communities pursing collaborative clinical research efforts
- Deliver a secure data repository for managing and sharing laboratory data with colleagues, such as for proteomics, microarray, flow cytometry or other assay-based data.
Quality Control
- Field-level quality control. Data managers can now set and display the quality control (QC) status of individual data fields. Data coming in via text files can contain the special symbols Q and N in any column that has been set to allow quality control markers. “Q” indicates a QC has been applied to the field, “N” indicates the data will not be provided (even if it was officially required).
- Programmatic quality control for uploaded data. Programmatic quality control scripts (written in R, Perl, or another language of the developer's choice) can now be run at data upload time. This allows a lab to perform arbitrary quality validation prior bringing data into the database, ensuring that all uploaded data meets certain initial quality criteria. Note that non-programmatic quality control remains available -- assay designs can be configured to perform basic checks for data types, required values, regular expressions, and ranges in uploaded data.
- Default values for fields in assays, lists and datasets. Dataset schemas can now be set up to automatically supply default values when imported data tables have missing values. Each default value can be the last value entered, a fixed value or an editable default.
Assay/Study Data Integration
- Display of assay status. Assay working folders now clearly display how many samples/runs have been processed for each study.
- Improved study integration. Study folders provide links to view source assay data and designs, as well as links to directly upload data via appropriate assay pipelines.
- Hiding of unnecessary "General Purpose" assay details. Previously, data for this type of assay had a [details] link displayed in the copied dataset. This link is now suppressed because no additional information is available in this case.
- Easier data upload. Previously, in order to add data to an assay, a user needed to know the destination folder. Now users are presented with a list of appropriate folders directly from the upload button either in the assay runs list or from the dataset.
- Improved copy to study process. It is now easier to find and fix incorrect run data when copying data to a study. Improvements:
- Bad runs can now be skipped.
- The run details page now provides a link so that run data can be examined.
- There is now an option to re-run an assay run, pre-populating all fields, including the data file, with the previous run. On successful import, the previous run will be deleted.
Proteomics and Microarrays
- Protein Search Allows Peptide Filtering. When performing a protein search, you can now filter to show only proteins groups that have a peptide that meets a PeptideProphet probability cutoff, or specify an arbitrarily complex peptide filter.
- Auto-derivation of samples during sample set import. Automated creation of derivation history for newly imported samples eases tracking of sample associations and history. Sample sets now support an optional column that provides parent sample information. At import time, the parent samples listed in that column are identified within LabKey Server and associations between samples are created automatically.
- Microarray bulk upload.
- When importing MageML files into LabKey Server, users can now include a TSV file that supplies run-level metadata about the runs that produced the files. This allows users to reuse the TSV metadata instead of manually re-entering it.
- The upload process leverages the Data Pipeline to operate on a single directory at a time, which may contain many different MageML files. LabKey Server automatically matches MageML files to the correct metadata based on barcode value.
- An Excel template is provided for each assay design to make it easier to fill out the necessary information.
- Microarray copy-to-study. Microarray assay data can now be copied to studies, where it will appear up as an assay-backed dataset.
Assays
- Support for saving state within an assay batch/run upload. Previously, once you started upload of assay data, you had to finish at one point in time. Now you can start by uploading an assay batch, then upload the run data later.
- NAb improvements:
- Auto-complete during NAb upload. This is available for specimen, visit, and participant IDs.
- Re-run of NAb runs. After you have uploaded a NAb run and you wish to make an edit, you can redo the upload process with all the information already pre-filled, ready for editing.
Specimen Tracking
- Specimen shopping cart. When compiling a specimen request, you can now perform a specimen search once, then build a specimen request from items listed in that search. You can add individual vials one-at-a-time using the "shopping cart" icon next to each vial. Alternatively, you can add several vials at once using the checkboxes next to each vial and the actions provided by the "Request Options" drop-down menu. After adding vials to a request of your choice, you return to your specimen search so that you can add more.
- Auditing for specimen comments. Specimen comments are now logged, so they can be audited.
- Specimen reports can now be based on filtered vial views. This increases the power of reporting features.
Views
- Enhanced interface for managing views. The same interface is now used to manage views within a study and outside of a study.
- Container filters for grid views. You can now choose whether the list of "Views" for a data grid includes views created within the current folder or both the current folder and subfolders.
- Ability to clear individual columns from sorts and filters for grid views. The "Clear Sort" and "Clear Filter" menu items area available in the sort/filter drop-down menu available when you click on a grid view column header. For example, the "Clear Sort" menu item is enabled when the given column is included in the current sort. Selecting that item will remove just that column from the list of sorted columns, leaving the others intact.
- More detailed information for the "Remember current filter" choice on the Customize View page. When you customize a grid view that already contains sorts and filters, these sorts and filters can be retained with that custom view, along with any sorts and filters added during customization. The UI now explicitly lists the pre-existing sorts and filters that can be retained.
- Stand-alone R views. You do not need to associate every R view with a particular grid view. R views can be created independently of a particular dataset through the "Manage Views" page.
- Improved identification of views displayed in the Reports web part. The Reports web part now can accept string-based form of report ID (in addition to normal integer report ID) so that you can refer to a report defined within a module.
Flow Cytometry
- Ability to download a single FCS file. A download link is now available on the FCS File Details page.
- New Documentation: Demo, Tutorial and additional Documentation
- Richer filter UI for "background column and value." Available in the ICS Metadata editor. This provides support for "IN" and multiple clauses. Example: Stim IN ('Neg Cont', 'negctrl') AND CD4_Count > 10000 AND CD8_Count > 10000
- Performance improvements. Allow loading larger FlowJo workspaces than previously possible.
- UI improvements for FlowJo import. Simplify repeated uploading of FlowJo workspaces.
Development: Client API
- New SAS Client API. The LabKey Client API Library for SAS makes it easy for SAS users to load live data from a LabKey Server into a native SAS dataset for analysis, provided they have permissions to read those data. It also enables SAS users to insert, update, and delete records stored on a LabKey Server, provided they have appropriate permissions to do so. All requests to the LabKey Server are performed under the user's account profile, with all proper security enforced on the server. User credentials are obtained from a separate location than the running SAS program so that SAS programs can be shared without compromising security.
- Additions to the Java, JavaScript, R and SAS Client Libraries:
- Quality Control support. Clients can request quality control values when selecting rows or executing SQL. For further documentation, see the Java or JavaScript libraries. For example, in the JavaScript library, see: config.requiredVersion in LABKEY.Query#selectRows and LABKEY.Query.ExtendedSelectRowsResults#rows in LABKEY.Query.ExtendedSelectRowsResults#constructor
- Container (folder) filtering. Allows you to filter the views displayed for an assay based on the containing folder. For further details, see config.containerFilter in LABKEY.Query#selectRows in the Javascript Library.
- Additions to the Javascript API:
- Callback to indicate that a web part has loaded. Provides a callback after a LABKEY.WebPart has finished rendering.
- Information on the current user (LABKEY.user). The LABKEY.Security.currentUser API exposes limited information on the current user.
- API/Ext-based management of specimen requests. See: LABKEY.Specimen.
- Sorting and filtering for NAb run data retrieved via the LabKey Client APIs. For further information, see: LABKEY.Assay#getNAbRuns
- Ability to export tables generated through the client API to Excel. This API takes a JavaScript object in the same format as that returned from the Excel->JSON call and pops up a download dialog on the client. See LABKEY.Utils#convertToExcel.
- Improvements to the Ext grid.
- Quality control information available.
- Performance improvements for lookup columns.
- Documentation for R Client API. Available here on CRAN.
Development: Modules
- File-based modules. File-based modules provide a simplified way to include R reports, custom queries, custom query views, HTML views, and web parts in your modules. You can now specify a custom query view definition in a file in a module and it will appear alongside the other grid views for the given schema/query. These resources can be included either in a simple module with no Java code whatsoever, or in Java-based modules. They can be delivered as a unit that can be easily added to an existing LabKey Server installation. Documentation: Overview of Simplified Modules and Queries, Views and Reports in Modules.
- File-based assays. A developer can now create a new assay type with a custom schema and custom views without having to be a Java developer. A file-based assay consists of an assay config file, a set of domain descriptions, and view html files. The assay is added to a module by placing it in an assay directory at the top-level of the module. For information on the applicable API, see: LABKEY.Experiment#saveBatch.
Development: Custom SQL Queries
- Support for additional SQL functions:
- UNION and UNION ALL
- BETWEEN
- TIMESTAMPDIFF
- Cross-container queries. You can identify the folder containing the data of interest during specification of the schema. Example: Project."studies/001/".study.demographics.
- Query renaming. You can now change the name of a query from the schema listing page via the “Edit Properties” link.
- Comments. Comments that use the standard SQL syntax ("--") can be included in queries.
- Metadata editor for built-in tables. This editor allows customization of the pre-defined tables and queries provided by LabKey Server. Users can change number or date formats, add lookups to join to other data (or query results), and change the names and description of columns. The metadata editor shows the metadata associated with a table of interest and allows users to override default values. Edits are saved in the same XML format used to describe custom queries.
Collaboration
- Version comparison tool for wiki pages. Differences between older and newer versions of wiki pages can now be easily visualized through the "History"->"Compare Versioned Content"->"Compare With" pathway.
- Attachments can now be downloaded from the "Edit" page. Also, if an attachment is an image, clicking on it displays it in a new browser tab.
Administration
- Tomcat 5.5.27 is now supported.
- Upgrade to PostgreSQL 8.3 is now strongly encouraged. For anyone running PostgreSQL 8.2.x or earlier, you will now see a yellow warning message in the header when logged in as a system admin. Upgrade to PostgreSQL 8.3 to eliminate the message. The message can also be hidden. Upgrade documentation.
9.1 Upgrade Tips
PostgreSQL 8.3 Upgrade Tip for Custom SQL Queries
Problem. After upgrading to PostgreSQL 8.3, some custom SQL queries may generate errors instead of running. An example of an error message you might observe:Query 'Physical Exam Query' has errors
java.sql.SQLException: ERROR: operator does not exist: character varying = integer
- View your query in the Query Designer.
- Save your query. The Query Designer will make the adjustments necessary for compatibility with PostgreSQL 8.3 automatically.
- Your query will now run instead of generating an error message.
- Open it in the Source Editor.
- In the query editor, add single quotes around numbers so that they will be saved appropriately. For example, change
WHERE "Physical Exam".ParticipantId.ParticipantId=249318596WHERE "Physical Exam".ParticipantId.ParticipantId='249318596'- Your query will now run instead of generating an error message.
Learn What's New in 8.3
Study
Quality Control for Study DataLabKey’s quality control enhancements facilitate formal review procedures for new data acquired by your team. Team members can clearly mark and track the progress of data through a series quality control stages that are custom-tailored to your team's workflows.- Quality Control via Automated Validation Checks
- Validation allows your team to check data for reasonableness and catch a broad range of field-level data-entry errors during the upload process.
- When an assay administrator adds or edits a schema field property, she can define range checks and/or regular expression checks on the property that are applied during data upload and row insertion.
- Uploaded assay data must satisfy any range or regular expression validations before it will be accepted into the database.
- Validation is available for all areas except Flow and MS1/MS2.
- Quality Control States to Facilitate Human Approval of Study Data
- The quality control process allows study administrators to define a series of approval and review states for data. These states can be associated with "public" or "nonpublic" settings that define the default visibility of the data.
- Different data approval states (and thus approval pathways) can be defined for data added to a study through different pathways (e.g., assay data copied to a study, CRF data imported via the Pipeline or TSV data inserted directly into a study dataset).
- Reviewers can the filter overview data grid by Quality Control State and thus find all data requiring review from a single screen.
- All quality control actions are audited.
- Specimen report Participant ID (PTID) formatting. Specimen reports containing PTID lists are now output with one PTID per cell, rather than a delimited string in a single cell.
- Specimen notification configuration. Specimen notifications can now be configured to originate from either a fixed email address (previously the only option) or from the user who generates the notification.
- Repository selection. Requests by specimen (rather than by vial) now auto-select the best repository, or prompt the user to select if more than one is available.
- Specimen annotations. Specimen coordinators can now add comments at the vial or specimen level. These comments are visible at in both specimen and vial views by default. Comments should be maintained over specimen imports.
- Changing vial volumes. Specimen import now allows volumes for a single vial to change over time.
- Email notifications. If a specimen vial view with name "SpecimenEmail" is created, this view will be used for the vial list in all specimen request notification emails. This provides simpler and more readable email messages for the labs and repositories.
- Studies and the datasets they contain can be set to be editable by user groups.
- Users with edit permissions can edit existing rows of data, insert entire new rows or import a table that contains many new rows of data.
- Editing a dataset requires "write" permissions to both the folder and the dataset.
- R View Caching.
- Scripts that are slow to render (due to large datasets or the complexity of the script) are now retained. This allows you to see the R View produced by this script without waiting for it to re-run.
- Currently available only for LabKey Study.
- Performed automatically.
- Dataset Snapshots
- Helps you quickly load datasets and views by minimizing data-reprocessing, which can slow data rendering.
- Allows you to create a snapshot of a dataset in time from a custom query, then build swift-loading views on top of this snapshot.
- Snapshots can be configured such that they will update regularly if the underlying data has been updated during a given time interval. This allows you to coalesce changes and re-process data only when necessary, in a way that does not slow your work.
- You can now define extra properties (metadata) that you wish to associate with your study or cohorts. This allows you to associate arbitrary buckets of data with your study.
- A search inside a study folder now finds matches for participant IDs, cohort names, dataset names, column names, dataset data itself, etc.
- Add the “Search” web part to search.
- Admins can now add a “Visit” web part that introduces a Visit section to any study portal page.
Pipeline Data Processing
Configurable Workflows- Add new analysis tools to preconfigured workflows
- Create your own workflows from scratch
- Add, remove, or edit command-line arguments to analysis tools
- Assign specific tasks to different computing resources
- XML file-based configuration, using the Spring Framework
- Start with a single machine that runs the web server and all analysis tools
- Add remote work machines that run specific analysis tools
- Interface with clusters through the Globus Toolkit
- Monitor job status from a single location
- Capture the inputs and outputs from each task as it runs
- Generate detailed experimental descriptions in XAR format to show exactly what analysis was performed
- Automatically load all recognized file types into the database when job is complete
Flow
ICS Metadata -- Beta Version- ICS metadata supply the information necessary to distinguish background (control) wells from experimental wells and calculate average background values.
- Improved “Import FlowJo Workspace” wizard.
- Ability to examine FCS files in directory separate from the workspace.
- Ability to render graphs from FlowJo-calculated statistics
- Improved comment editing
- Addition of discussion lists
- Achieved through database optimization.
Site and Project Administration
User-Extensible Style Sheets- Admins can upload and edit customized stylesheets that define themes on a project- and/or site-wide basis.
- All of the "Look and Feel" UI elements that are currently configurable at the site level can now be superseded at the project level. This allows each project to have a custom web UI and custom string replacements in emails generated from the site.
- If a setting exists at the project level, it overrides the corresponding setting at the site level. Settings include all the UI elements currently set through the site administration pages, including logos, site name, support links, etc.
- With the new, expanded abilities for project-level administrators, site admins can delegate project-specific admin work without granting site-wide privileges to project admins.
- Project admins can view project member details and logs, plus impersonate any project member within the project.
- Site admins can now define and edit Site Groups. These provide a handy way for admins to manage individuals who have the same role across many projects.
- Project admins can assign permissions within projects to Site Groups.
- User accounts can be deactivated, preventing undesired access while still retaining user information (e.g., authorship of issues, message board posts, specimen requests, etc.) for display in the audit log and author fields throughout the product.
- When deactivated user attempts to login, the event is logged.
- All admin session attributes (e.g., terms-of-use containers, lastFilter, previous page and container expansion state) are restored after impersonation is done.
- All actions of impersonators are now logged, so the audit trail for the actions of impersonators is more complete.
- You can now use generic link checking tools to check your site for missing links. Missing wiki pages return a 404 error.
- All areas of LabKey Server now allow you to fully display a single list on a portal page via the "Single List" web part. You can select which view of the list to display.
Expanded LabKey API
The 8.3 release of LabKey Server expands the set of Server APIs available while adding two new Client API libraries along side the existing Javascript library, one library for R and one for Java. Client APIs make calling the Server API easier. The LabKey API enables developers for any LabKey installation to:- Write scripts or programs in several languages to perform routine, automated tasks.
- Provide customized data visualizations or user interface for specific tasks that appears alongside the existing LabKey web server user interface.
- Develop entirely new user interfaces (web-based or otherwise) that run apart from the LabKey web server, but interact with its data and services.
- The Server API provides a set of URLs (or "links") exposed from the LabKey Server that return raw data instead of nicely-formatted HTML (or "web") pages. These may be called from any program capable of making an HTTP request and decoding the JSON format used for the response (Perl, JavaScript, Java, R, C++, C#, etc.). The new Server APIs are exposed by the new Client APIs covered below.
- Allows selecting, inserting, updating and deleting data, plus executing arbitrary LabKey SQL.
- Provides javadoc documentation.
- Makes it easy to query LabKey Server and retrieve results in the native data structure for the language.
- Available for download via CRAN (the central repository of R packages) as the “Rlabkey” package.
- New "Export to R Script" option on the web site generates an R script stub that uses the Rlabkey package to retrieve the data you are currently viewing.
- Exposes user information via security reporting APIs.
- Allows updating metadata on extensible objects (e.g., study properties, cohorts and schemas).
- Supplies lists of users in a project, folder or group, optionally filtered by name.
- Allows a developer to retrieve the container hierarchy visible to the current user.
- New EditorGridPanel and Store widgets, which are data-bound extensions of the Ext grid and store user interface widgets. The grid now exposes all of the properties, methods, and events from the Ext grid, and can participate in complex Ext layouts.
- Allow modification of data (insert, update and delete) in study datasets, not just lists or custom schemas.
- Improve filtering, including support for “Equals One Of.”
- Expand the choice of SQL functions that can be used within LabKey Server, including:
- SELECT DISTINCT
- FULL JOIN
- COALESCE
Learn What's New in 8.2
Study
Dataset Editing- Users with editor rights now have the ability to edit the content of a dataset in a study. Admins can edit existing rows or insert new ones on any dataset grid view. This feature is off-by-default and must be turned on by an admin.
- Edits can be made either through the LabKey Server UI or via the LabKey APIs.
- Participant views can now be customized through script editing. The new "customize view" option on any participant view lets you edit the default script to create multiple custom views.
- Participant views can be displayed in their own sections on portal pages (via a new Participant View web part).
- The search web part now searches study content in addition to wiki, issue and message content.
- Almost all aspects of a study that can be configured through the UI can now be configured through the a study schema import file. This change includes additional key fields and dataset visibility.
- You can now insert data into a dataset without having to generate keys. This lets you enter more than one row per participant visit.
- Dataset toolbars and buttons have been condensed and simplified to help you find dataset options more easily.
Flow
Graph Generation from FlowJo Workspaces- LabKey server now generates graphs from FlowJo-calculated statistics when a user loads a FlowJo workspace from the pipeline.
Collaboration
Improvements to Wiki Editing Interface- The field of view for editing wiki pages can now be widened by hiding the table of contents in edit mode.
- Wiki text can be automatically converted to HTML using the new "Convert" button in the editor.
- Keyboard shortcuts are now available for "Save" (Ctrl+S) and "Save & Close" (Ctrl+Shift_S).
- Editing is more efficient because the page is not reloaded each time you save.
- You can now "Collapse All" items in a wiki table of contents.
- WebDAV can be used in place as FTP as a transfer protocol. WebDav uses port 80, so it does not require an additional entry point through your firewall.
- You can now add attachments (such as screen captures and documents) to issues.
Assays & Lists
Customizable Ordering of List Item Properties- Fields can be displayed in a logical sequence that makes sense for end users. This allows the designer of an assay to determine the order of columns in an upload form.
- When importing list data, users now have access to an auto-generated Excel template that displays the fields included in the list design.
Proteomics (CPAS)
Phase 1 of New MS2 Search Protocol Definition UI- LabKey Server now offers a GUI for defining the most commonly changed search parameters. This lets you avoid editing XML directly. Future releases will add additional parameters to the GUI.
- The Venn diagrams made available for MS2 comparisons in 8.1 are now available for MS1.
- Several bug fixes and improved performance when exporting or comparing large MS2 runs.
Views and Reports
Display of Individual Sections of R Views- The Report web part can now be configured to display an individual section (or sections) of a R View instead of the entire R View. This helps you display only the information that is most helpful to your audience.
- The URL parameters now provided by the labkey.url.params list allow greater customization of your R scripts, including creation of parameterized charts.
Development Tools
APIs Function Cross-Container- The new, optional "container" parameter allows data to live in one folder, while display occurs in another folder.
- For example, by specifying the container of a schema, you can build a chart in one folder from a query that lives in a different folder.
- The addition of the "maxRows" and "offset" parameters to LABKEY.Query.selectRows() makes it easier to work with large tables. These parameters allow control of paging through the display of only a chosen number of rows, starting at a certain row number.
- Non-admins can now be granted sufficient privileges to write scripts
- Admins can now add members to the "Developers" global group.
- This includes the ability to control the frame type and body class for the getWebPart.api via the frameType and bodyClass parameters.
- Enable better caching of .js files
- Provide code compression of .js files before transmission
- The URL for this is: /labkey/project/<project>/search.api?terms=page
- Provides better control of server-side error handling
- Coalesce and Convert are now available for queries
Administrative Tools
New Level of Permissions- Members of the "Developers" permissions group are non-admins who can write/save/upload scripts. This provides developers with the freedom they need to develop tools, without providing potentially-excessive levels of permissions.
- Hidden folders can help you hide admin-only materials (such as raw data) to avoid overwhelming end-users with material that they do not need to see.
- Folders whose names begin with "." or "_" are automatically hidden from non-admins.
- You can use the "Show Admin" / "Hide Admin" toggle to show the effect of hiding folders from the perspective of a non-admin.
- Auditing now logs changes to site and module settings.
- You can now leverage Google Analytics to measure usage patterns of your site.
8.2 Upgrade Tips
- OpenSSO support and LDAP authentication have been moved to the new Authentication module. This module is not included in our standard distribution, but is included in the proteomics, labkey, and chavi distributions.
- SQL Server dialects have been moved to a new module, BigIron. BigIron is not included in our standard build; only the proteomics build has it at the moment.
Learn What's New in 8.1
CPAS
MS2 Enhancements- Use spectra counting to compare runs via label-free quantitation.
- Produce Venn diagrams to visualize overlap between run groups.
- Gain deeper insights into your data through improved protein annotation.
- Access more FASTA file formats thanks to improved parsing of FASTA files.
- Choose from a wider range of display names for proteins.
- Enjoy better access to R tools from MS2.
- Compare run groups more easily.
- Automate MS1 searches via the pipeline.
- Compare MS1 runs based on shared peptide identifications.
- Mine data you have already uploaded and searched:
- Search for features by peptide sequence
- Find similar features by mz and retention time
Assays
New Data Types. LabKey Server’s fully customizable assay designer helps you sidestep data management bottlenecks. Version 8.1 expands the number of data types you can bring into the system:- ELISpot Assays
- Customize run metadata and plate templates, upload raw data files from CTL and AID instruments and store data in standard LabKey data tables with sortable/filterable data grids.
- Microarray Assays
- Assay types have been expanded to include Microarrays. Leverage Labkey's data pipeline to use Agilent's feature extraction software on TIFF files and upload MageML files into the LabKey Server database.
- File columns for Lists. You can now define columns of type 'File' for lists, just like you can for assay run and upload set domains.
- Multiline text fields in Lists. UI now supports multiline text fields in insert/update/details views. It also allows embedded carriage returns.
Study
New Study Demo & Tutorial. LabKey.org now provides a suite of sample datasets and views to help you get you up and running in using the Study Application.- Use these samples to explore the power of Study for organizing and visualizing your datasets.
- The Study Demo Tutorial guides you through setting up the Study Demo on your own server, including custom datagrid views, charts and R views.
Flow
Initial Implementation of File Repository. Provides reliable, checksummed delivery of flow data to the server via drag and drop directly onto a web browser.- You can now perform FTP uploads from the browser.
- MD5 checksums to ensure accuracy of the upload
- Support for importing FlowJo templates.
- Support for importing auto-compensation scripts.
- Run a flow script against a subset of all wells; e.g., filter for all wells that are "8 color".
Developer Tools
New API Framework for Creating Reports and Views. The new set of APIs for reports and views provides a flexible framework for users to quickly develop and deploy grids and charts without help from LabKey’s core development team. The first release of this growing suite of APIs provides:- Javascript client-side APIs, which allow you to retrieve and modify data queries, plus design and render live chart and grid views. The chart APIs provide image map support for existing JFreeCharts generated by the reporting system.
- Server-side APIs, which provide basic query functionality
- Complete, javadoc-style API Reference documentation
Reports and Views
These enhancements to Labkey's 8.1 core UI and infrastrucure will speed your data processing and discovery efforts.R View Enhancements- Source scripts for R views can be made available to non-admins, allowing easier sharing.
- All users can now easily flip between an R View, the R script for the View, the source datagrid for the View and the handy page of “Help” text. Each of these items appears on its own tab in the R View Builder.
- Inherited R views. R views in a parent folder can be made available to data grids in child folders, helping you leverage your efforts.
- The custom view used to create an R view is now listed inside the view and you can edit the view as well.
- Saved R Views respect the filters added to the URL for a custom view so that the user can run these saved views on a subset of the full dataset.
- R views can now be run against grid views different than the original source grid view. This lets you write a script once and run it against different datasets.
- LabKey now keeps track of selections on multiple pages of large datasets, so you can work with large amounts of data more efficiently. Selections on multiple pages of data are remembered, so you can perform operations on these rows as a group, no matter where the rows appear in your dataset.
- Choose the number of rows to display in any grid view: 40, 100, 250, 1000, selected rows or all rows
- Scoping options for queries and custom views. Custom views can be inherited from parent folders.
- New "Is One Of" Filter. Use the new "Is One of" criterion to filter data while designing custom data grid views.
- Simple yet flexible, the designer lets you plot multiple y-values simultaneously using one or many y-axes. Produce one or many subplots, covering each or every participant.
- Reports and Views appear in the "View" drop down menu above any data grid view.
- Data visualizations can now be featured more prominently on portal pages via the new "Reports" webpart.
Admin
Seamless Authentication for Single-Sign-On- When single sign-on is configured, links from a partner site to LabKey automatically redirect to the single sign-on authority if LabKey considers the browser unauthorized. LabKey uses the referrer to determine whether to redirect unauthorized user to the single-sign-on link. This makes the authentication process seamless.
- "Manage Folders" now allows you to delete a folder/project even when it has subfolders. Previously it was necessary to delete subfolders individually before deleting a top-level folder.
- LabKey now supports PostgreSQL 8.3
- File Repository (Beta): This handy tool provides reliable, checksummed delivery of data to the server via drag and drop directly onto a web browser.
- This new tool allows you to verify that all the links in your wiki pages lead to valid pages of content.
8.1 Upgrade Tips
Learn What's New in 2.3
CPAS
Enhancements to LabKey's application for mass-spec proteomics strengthens the position of CPAS as the best platform for processing, storing, searching and comparing thousands of runs of MS2 data.- Run Comparisons. Improvements to peptide-based MS2 run comparisons, including the ability to compare runs from different search engines and view XPRESS quantitation data.
- Data Import. Faster and more complete import of data from UniProt and FASTA protein files.
- MS1. New MS1 module for importing and viewing MS1 features from files generated by the open-source msInspect tool.
Research Studies
LabKey now makes it easier to manage large studies tracking partipants over time. It provides new facilities for integrating data from participant-completed forms with assay results derived from each participant's biological specimens.- More Flexible Data Integration. Specimen identity can be mapped to assay results after the assays have been run by means of a user-defined cross-reference list. Data rows can now contain participant/visit IDs, a specimen ID, or a mapping ID that allows lookup of participant/visit information via list or file.
- Time-based Studies. Support for analyzing time-based trends in studies where participants don't necessarily check in on a fixed visit schedule.
- Dataset "Snapshots". Better support for viewing dataset "snapshots" and direct read-only database access to the underlying study tables, for users of SQL-based query and reporting tools.
Assay and Experiment Services
With every release, LabKey Server broadens and deepens its support for describing, importing and annotating datasets from the instruments and assays requested by our customers. In Release 2.3, general assay and experiment improvements include:- Integration. Improved integration of specimens, assay plan and assay designs
- Usability. Enhanced usability of sample sets, plus the added capability to derive samples from other samples and to describe their properties.
- Sample Views. Views that display all derived samples from a given sample, and indicate what runs use it.
- TZM-bl Neutralization Assay (NAB) Improvements. Improvements include better data upload options, customization of assay parameters and new support for four- and five- parameter curve-fitting graphs.
Administration and Collaboration
Refinements to search and wiki features make it even easier to find and share information with colleagues:- Search. Support for exact phrase searching and the use of logical operators in searches.
- Wiki. Simplified UI for attachment of multiple files to Wiki Pages.
Learn What's New in 2.2
Highlights
Version 2.2 represents a important step forward in the ongoing evolution of LabKey Server and its applications. In this release, LabKey introduces the following new capabilities:Assays
Assays are experimental data sets that have well-defined structures and sets of associated properties. When a set of experimental runs is ready for upload, LabKey uses assay definitions to automatically generate appropriate data entry pages. These forms use intelligent defaults and pre-defined picklist choices (termed Lists) to reduce the burden of data entry and improve accuracy. Assays are a powerful solution to a common problem faced by lab researchers: ensuring that sufficient information is collected for each run such that variations can be explained by replicating and comparing runs. LabKey Server makes it possible for researchers to define their own criteria for "sufficient" information without requiring software or database expertise to do so.R Integration
LabKey users can now take advantage of a powerful and widely-used scripting language to analyze and chart Study and Assay data. A single menu command pushes the data into R and executes a script that a user has created himself or run from a library of saved scripts. Script results in the form of reports and charts can be incorporated back into LabKey portal and wiki pages. Module developers can take advantage of R integration to enhance the flexibility of any data view.caBIG(TM) Support
With version 2.2, the CPAS proteomics application on LabKey Server is now certified as caBIG(TM) Silver-level compliant. Compliance enables researchers to publish MS2 experiment data such that it is accessible to remote application programs written to the standard caBIG(TM) interface, as defined by the US National Cancer Institute. Support for caBIG enables LabKey Server to participate in data search and exchange applications across the cancer research community. With caBIG(TM) support, LabKey Server becomes the fastest and easiest way to achieve caBIG(TM)-compliance for datasets, including samples and MS2 protein identifications.New Feature Details by Module
Study
Assays- Assay results can be entered via forms or uploaded from spreadsheets after an assay schema has been defined.
- Results can be reviewed for correctness, then "published" into a study, where they can be rolled-up by participant or by visit.
- LabKey now supports the definition of Luminex assay schemas and the upload and publication of Luminex datasets.
- The R environment can be configured from the site administration page.
- LabKey provides a built-in editor for authoring R scripts
- Live R Views can be displayed and managed securely
- Long-running R scripts can execute as Pipeline jobs.
- LabKey now supports customization of display formats on both a field-by-field and a study-wide basis.
- Example: Studies can now display dates as “04MAY07” rather than the internationally ambiguous “04/05/07”. (Note: not all display formats are supported for data input).
- Customized formats apply to dataset views and specimen views.
- LabKey has added five additional storage location fields and a flag for determining specimen availability
Flow Cytometry
Upload, Store, and Display FlowJo-Calculated Statistics- Users can now upload and display FlowJo-calculated statistics on a LabKey Server, for quality control checks or for shared access.
- Upload process will optionally read graphs from the FlowJo workspace or generate graphs at the server from the uploaded statistics.
- New gate editor enables users to edit the existing gate template of an analysis script for a given sample using an interactive web page on the LabKey Server.
- New gate templates must still be uploaded from Flo Jo.
ms2
Enhancements to Protein and Peptide Views- GO charts are now available for protein views
- Proteins can be exported from ProteinProphet views (in addition to peptides)
- XpressProteinRatioParser and Q3ProteinRatioParser performance have improved.
- LabKey now supports multi-instrument PeptideProphet.
- Terminal modifications are now handled correctly.
- Sequest cluster pipeline performance has improved.
Administration
Enhanced Integration with External Tables- Rows can be inserted and edited in external, user-defined tables that are identified by a Query. These can be accessed via a checkbox on the Schema Administration page on the Query tab. A defined Primary Key is required.
- Formatting or "lookup" relationships in an external schema can be specified via an XML file
- Administrators can determine whether searches include subdirectories
- Administrators can control the search path order
- Users can access other servers securely based on their LabKey login, via a redirection exchange with the LabKey login page.
Collaboration
File Management Enhancements- Uploaded files on message boards and wiki pages can now be saved in accessible directories.
- The Files web part enables project administrators to configure and manage uploaded files, including:
- Configure save directories by uploading user, assay, study, or other field value
- View files for all readers
- Upload files for all uploaders
- Shows all files in directory
- Shows user for files uploaded through UI
- Site administrators can configure system defaults
- Improved reliability in tracking files across move and undelete actions and an upload log file
- Available to developers of other modules asa an attachment service
- Data views can be embedded in wiki pages
- Static and dynamic content can be embedded with complex layout in a single page, without custom modules
- The content of one wiki page can be embedded in other wiki pages.
- Duplication of content is no longer necessary.
- Editing an Issue now adds a user to future notification emails.
- Users can now access their email preferences from the "Discuss This" section.
Learn What's New in 2.1
CPAS
caBIG silver-compliant experimental information - CPAS now exposes all of its experimental information through a caBIG silver-compliant interface.Custom protein annotations - Upload your own annotations for proteins, specified by IPI number, gene name, or SwissProt identifier. You can then add these annotations to various MS2 pages and use them to quickly identify proteins of interest.Protein search enhancements - Export the protein and protein group results to Excel and TSV formats.Improved query views for MS2 runs - Additional columns are now available in the query-based MS2 run views, including protein annotations. Performance improvements as well.Improved protein information on export - Protein descriptions, sequence masses, and other protein values are now available when exporting an MS2 run.Protein-based MS2 Protein Group View - Instead of having a nested list of peptides that support each protein group, you can now have a nested list of the proteins within the group. You can select the protein annotations to show for each of the proteins.Study
Lists integration - The list feature allows users to upload their own relational data. Each list can have arbitrary columns. Data can be entered by hand or uploaded via spreadsheets. Study dataset columns can be defined as lookups (foreign keys) to list data.Specimen "shopping carts" Allow users to build up specimen requests over time before submitting for approval.Create study folder from protocol design The vaccine study protocol designer allows users to create a study folder with information about the cohorts described in the protocol.Flow
New Flow Dashboard - Manage entire Flow Cytometry analysis workflow from a single dashboard.More Statistics - LabKey Flow now supports the full set of statics calculated by FlowJo.Improved Performance - Up to 40% faster calculation on multi-processor servers.Server
Improved look and feel - Updated user interface and improved navigation.Support for Java 6 - Server now builds with JDK 6 and runs under JRE 6. Java 5 is still supported.Improvements to multi-word searches - Each word is searched individually instead of searching for an exact phrase.LDAP SASL support - Allows secure communication with an LDAP authentication server.Learn What's New in 2.0
- Documentation for version 2.0: Documentation Home
- Release date for version 2.0: April 2, 2007.
What's New 17.2
Release Notes 17.2
Data Basics
 A scatter plot of the same data:
A scatter plot of the same data:
Topics
Build User Interface
- Add Web Parts - Web parts are user interface panels that you can add to a folder/project page. Each web part provides some way for users to interact with your application and data. For example, the Files web part provides access to any files in your repository.
- Manage Web Parts - Set properties and permissions for a web part.
- Web Part Inventory - Available web parts.
- Use Tabs - Bring together related functionality on a single tab to create data dashboards.
- Add Custom Menus - Provide quick pulldown access to commonly used tools and pages in your application.
- UI Design Patterns - Guidelines for user interface design.

Related Topics
- Projects and Folders - A project or folder provides the container for your application. You typically develop an application by adding web parts and other functionality to an empty folder or project.
- JavaScript API - Use the JavaScript API for more flexibility and functionality.
- Module-based apps - Modules let you build applications using JavaScript, Java, and more.
Add Web Parts
Add a Web Part
- Navigate to a page or tab in a folder or project.
- Scroll down to the bottom of the page.
- Choose the web part from the <Select Web Part> drop down box and click Add

Related Topics
See Web Part Inventory for a catalog of web parts. See Manage Web Parts to learn how to customize web part settings and move or remove web parts.Manage Web Parts

Web Part Controls
The particular control options available vary by type of web part. Most web parts have this basic set:
- Customize: Options for customization; for instance, search may be configured to include subfolders or not. Other web parts have small/medium/large display options.
- Permissions: Configure web parts to be displayed only when the user has some required role or permission. For details see Web Parts: Permissions Required to View.
- Move Up/Down: Adjust the location of the web part on the page.
- Remove From Page: This option removes the web part UI but not the associated module or any underlying data or other content.
Web Part Specific Control Options
The list of actions provided in the dropdown is specific to the web part. For example, the actions on the dropdown for the Messages web part include new message creation, list view, email preferences and administration, and an admin option for controlling the naming, sorting, and other behavior of the messages feature.
Web Part Inventory
| Web Part Name | Description | Documentation |
|---|---|---|
| Assay Batches | Displays a list of batches for a specific assay | Step 4: Work with Assay Data |
| Assay List | Provides a list of available assay designs and options for managing assays | Assay List |
| Assay Results | Displays a list of results for a specific assay | Step 4: Work with Assay Data |
| Assay Runs | Displays a list of runs for a specific assay | Step 4: Work with Assay Data |
| Assay Schedule | Define and track expectations of when and where particular assays will be run | Manage Assay Schedule |
| CDS Management | Management area for the Dataspace folder type | Collaborative DataSpace Case Study |
| Contacts | List of users on this server | Contacts |
| Custom Protein Lists | Shows protein lists that have been added to the current folder | Using Custom Protein Annotations |
| Data Classes | Capture capture complex lineage and derivation information, especially when those derivations include bio-engineering systems such as gene-transfected cells and expression systems. | DataClasses |
| Data Pipeline | Configure the data pipeline for access to data files and set up long running processes | Data Processing Pipeline |
| Data Transform Jobs | Provides a history of all executed ETL runs | ETL: User Interface |
| Data Transforms | Lists the available ETL jobs, and buttons for running them | ETL: User Interface |
| Data Views | Data browser for reports, charts, views | Data Views Browser |
| Datasets | Datasets included in the study | Manage Datasets |
| Enrollment Report | Simple graph of enrollment over time in a visit based study | Enrollment Report |
| Experiment Runs | List of runs within an experiment | Experiment Terminology |
| Feature Annotation Sets | Sets of feature/probe information used in microarray assays | Expression Matrix Assay Tutorial |
| Files | The file repository panel. Upload files for sharing and import into the database | Files |
| Flow Analyses | List of flow analyses that have been performed in the current folder | Step 4: View Results |
| Flow Experiment Management | Tracks setting up an experiment and analyzing FCS files | Step 1: Set Up a Flow Folder |
| Flow Reports | Create and view positivity and QC reports for Flow analyses | Flow Reports |
| Flow Scripts | Analysis scripts each holding the gating template, rules for the compensation matrix, and which statistics and graphs to generate for an analysis | Step 1: Define a Compensation Calculation |
| Genotyping Analyses | Genotyping analyses run in the current project | Example Workflow: LabKey and Galaxy |
| Genotyping Overview | Options for configuring and managing a genotyping project | Set Up a Genotyping Dashboard |
| Immunization Schedule | Show the schedule for treatments within a study | Manage Study Products |
| Issues List | Track issues for collaborative problem solving | Step 3: Track Issues |
| Issues Summary | Summary of issues in the current folder's issue tracker | Using the Issue Tracker |
| List - Single | Displays the data in an individual list | Manage Lists |
| Lists | Displays directory of all lists in the current folder | Manage Lists |
| Manage Peptide Inventory | Search and pool peptides via this management interface | Peptide Search |
| Mass Spec Search (Tabbed) | Combines "Protein Search" and "Peptide Search" for convenience | Protein Search |
| Messages | Show messages in this folder | Messages |
| Messages List | Short list of messages without any details | Messages |
| Microarray Runs | List of microarray runs | Microarray Assay Tutorial |
| MS1 Feature Search | Search by mass-to-charge ratio or retention time | MS1 |
| MS1 Runs | List of MS1 runs | MS1 |
| MS2 Runs | List of MS2 runs | Explore the MS2 Dashboard |
| MS2 Runs Browser | Folder browser for MS2 runs | View, Filter and Export All MS2 Runs |
| MS2 Runs with Peptide Counts | An MS2Extensions web part adding peptide counts with comparison and export filters | Peptide Search |
| MS2 Sample Preparation Runs | List of sample preparation runs | Explore the MS2 Dashboard |
| Pending MAGE-ML Files | List of pending microarray data files | Microarray Assay Tutorial |
| Peptide Freezer Diagram | Diagram of peptides and their freezer locations | Peptide Search |
| Peptide Search | Search for specific peptide identifications | Peptide Search |
| Pipeline Files | A management interface for files uploaded through the pipeline | Data Processing Pipeline |
| Projects | Provides a list of projects on your site | Projects Web Part |
| Protein Search | Dashboard for protein searches by name and minimum probability | Step 6: Search for a Specific Protein |
| Query | Shows results of a query as a grid | Query Web Part: Display a Query |
| Report | Display the contents of a report or view | Report Web Part: Display a Report or Chart |
| Run Groups | List of run groups within an analysis. | Run Groups |
| Run Types | Links to a list of experiment runs filtered by type | Experiment Terminology |
| Sample Sets | Sets of samples that have been uploaded for inclusion in assays/experiments | Sample Sets |
| Search | Text box to search wiki & other modules for a search string | Search |
| Sequence Runs | List of genotyping sequencing runs | Example Workflow: LabKey and Galaxy |
| Specimen Report | Summary report on the specimen repository | Generate Specimen Reports |
| Specimen Search | Search the specimen repository | View Specimen Data |
| Specimen Tools | Buttons for common specimen repository tasks | Step 3: Request Specimens (User) |
| Specimens | List of specimens by type | View Specimen Data |
| Study Data Tools | Button bar for common study analysis tasks. Buttons include, Create A New Graph, New Participant Report, etc. | Step 2: Study Data Dashboards |
| Study List | Displays basic study information (title, protocol, etc.) in top-down document fashion. | Study Tour |
| Study Overview | Management links for a study folder. | Study Tour |
| Study Protocol Summary | Overview of a Study Protocol (number of participants, etc). | Study |
| Study Schedule | Tracks data collection over the span of the study. | Study Schedule |
| Participant Details | Dashboard view for a particular study participant. | Study Tour |
| Participant List | Interactive list of participants. Filter participants by group and cohort. | Study Tour |
| Survey Designs | A list of available survey designs/templates to base surveys on. | Survey Designer: Basics |
| Surveys | A list of survey results, completed by users. | Survey Designer: Basics |
| Vaccine Design | Define immunogens, adjuvants, and antigens you will study | Create a Vaccine Study Design |
| Vaccine Study Protocols | List of current vaccine protocols (deprecated interface) | Create a Vaccine Study Design |
| Views | List of the data views in the study, including R views, charts, SQL queries, etc. | Customize Grid Views |
| Wiki | Displays a wiki page. | Wikis |
| Workbooksmakecolumnwider | Provides a light-weight container for managing smaller data files. | Workbooks |
| Web Part Name | Brief Description | Documentation |
|---|---|---|
| Files | Lists a set of files | Files |
| Flow Summary | Common flow actions and configurations | Step 1: Set Up a Flow Folder |
| Lists | Directory of the lists in a folder | Lists |
| Microarray Summary | Summary of Microarray information | Microarray |
| MS2 Statistics | Statistics on how many runs have been done on this server, etc | Proteomics |
| Protein Search | Form for finding protein information | Proteomics |
| Protocols | Displays a list of protocols | Experiment Descriptions & Archives (XARs) |
| Run Groups | List of run groups | Run Groups |
| Run Types | List of runs by type | Run Groups |
| Sample Sets | Sets of samples that have been uploaded for inclusion in assays/experiments | Experiment Descriptions & Archives (XARs) |
| Search | Text box to search wiki & other modules for a search string | Search |
| Specimen Tools | Buttons for common specimen repository tasks | Step 3: Request Specimens (User) |
| Specimens | Vertical list of specimens by type | Customize Specimens Web Part |
| Study Data Tools | Button bar for common study analysis tasks. Buttons include, Create A New Graph, New Participant Report, etc. | Step 2: Study Data Dashboards |
| Participant List | List of study participants | Study Tour |
| Views | List of views available in the folder | Customize Grid Views |
| Wiki | Displays a narrow wiki page | Wikis |
| Wiki Table of Contents | Table of Contents for wiki pages | Wikis |
Use Tabs
 Some folder types, such as study, come with specific tabs already defined, but with administrative permissions, you can also add and modify tabs to suit your needs.
Some folder types, such as study, come with specific tabs already defined, but with administrative permissions, you can also add and modify tabs to suit your needs.
Default Display Tab
As a rule of thumb, when multiple tabs are present, the leftmost tab is displayed by default when a user first navigates to the folder. Exceptions to rule are the "Overview" tab in a study folder and the single pre-configured tab created by default in most folder types, such as the "Start Tab" in a collaboration folder. To override these behaviors, see below:- "Overview" - When present, the Overview tab is always displayed first, regardless of its position in the tab series. To override this default behavior, hide the "Overview" tab and place whichever tab you want to display by default in the leftmost position. Any web parts lost when
- "Start Tab"/"Assay Dashboard" - Similar behavior is followed for the single, pre-configured tab that is created with each new folder, for example, "Start Tab" for Collaboration folders and "Assay Dashboard" for Assay folders. This single pre-configured tab, when present, will always take display precedence over other tabs regardless of its position on the tab series. To override this default behavior, hide the pre-configured tab and place whichever tab you want to be displayed by default in the leftmost position.
Tab Edit Mode
By clicking the pencil icon next to the rightmost tab, you can toggle Tab Edit Mode which will enable a triangle pulldown menu on each tab for editing, as well as a + tab for adding new tabs.
Add a New Custom Tab
When edit mode is active, create a new custom tab by clicking the + tab between the pencil and rightmost current tab. Provide a name and click OK. Add new webparts to the new tab as desired.Hide Tabs
You can hide tabs from view by non-admin users by using the Hide link on any tab menu, including custom tabs you have added. When you hide a tab, the contents of that tab are not deleted. Only admins can see the hidden tab, and could later change it back to no longer be hidden. The intent of hiding tabs is to simplify user display, not to provide secure storage of private data.Delete Tabs
Tabs you have added may be deleted. You cannot delete tabs built in to the folder type (such as the default Start Page tab in a project or the tabs in a default study), but they can be hidden from non-admin view.Rearrange Tabs
In tab edit mode, pull down the triangle menu and choose Move > Left or Move > Right to change the order tabs appear.Rename Tabs
In tab edit mode, pull down the triangle menu and choose Rename to change tab's text.Custom Tabbed Folders
Developers can create custom folder types, including tabbed folders. For more information, see Modules: Folder Types.Add Custom Menus
 Included in this topic:
Included in this topic:
Add a Custom Menu
This walkthrough uses a collaboration project named "Andromeda" on an evaluation server installed locally, into which we have installed the demo study in order to have some sample content to make into custom menus. The contents of your project will of course determine what can be placed on menus. When you first create a project, you have the option to click Menu Bar from the project settings page to directly access this UI, but you can also return at any time with project admin permissions.- From the project home page, select Admin > Folder > Project Settings.
- Click the Menu Bar tab.

- For each custom menu you would like, add a web part on this page.
- Populate and customize the menu bar web parts (see below for instructions for each type).

- Optionally limit visibility of the menu based on user's permission.
- Reorder web parts using the up and down arrows - the top web part will become the left-most custom menu.
- Click the X in the upper left on the web part if you want to delete a menu.
- Click Refresh Menu Bar to see your changes reflected.
- Be sure to refresh the menu bar before leaving the page to ensure your menus are properly saved.
Wiki Menu
The Wiki Menu adds a wiki page to the menu. By creating a wiki page that is a series of links to other pages or folders, you can customize a basic menu for linking to common locations and tools from anywhere in the project. Different teams might have different menus, or multiple menus could organize content however you require.To construct an example, we created two basic wikis "Project Overview" and "Staff Directory" in the home folder for the Andromeda project. The project also has a "Charleston" study in a subfolder. Now we can make a menu wiki:- Navigate to a page where you want to add a menu wiki. In this example we use the Andromeda project home page.
- Create a new Wiki web part.
- Click Create a new wiki page in the new web part.
- Give your new page a unique title (such as "menu1").
- Name your wiki as you want the menu title to appear "Team Links" in this example.
- Add links to folders and documents you have created, in the order you want them to appear on the menu.
[overview]
[Charleston Project|http://localhost:8080/labkey/project/Andromeda/Charleston/begin.view?]
[directory]
- In this example, we include three menu links: the overview document, the Charleston project home page, and the staff directory document in that order.
- Note that the URL shown here is an example of a possible local path. In practice, you would paste the URL of your own desired folder. For details see, Wiki Syntax.
- Save and Close the wiki, which will look something like this:

- Return to the Project Settings > Menu Bar tab.
- Select Wiki Menu from the Add Web Part pulldown and click Add.
- In the new web part, select Customize from the arrow pulldown.
- Select the location of your menu wiki from the pulldown for Folder containing the page to display: In this example, we used the /Andromeda project root.
- Select the menu wiki we just created, "menu1 (Documents)" from the pulldown for Name and title of the page to display:
- Click Submit to save.
- If your menu does not immediately appear in the menu bar, click Refresh Menu Bar.
- You can now hover over your new menu anywhere in the Andromeda project and click to directly open the included wiki pages.

Study List
If your project contains one or more studies, you can add a quick access menu for reaching the home page for any given study from the top bar.- Return to the Project Settings > Menu Bar tab.
- Add a Study List web part. Available studies will be listed in the new web part as well as in the menu named "Studies".

AssayList2
If your project contains Assays, you can add a menu for them using the AssayList2 web part. Available assays are listed, along with a manage button, for easy access from anywhere in your project.Custom Menu
A Custom Menu lets you create a menu to display either:- a list or query
- folders
- Go to the Project Settings > Menu Bar tab, add a Custom Menu web part.
- The web part and menu are named "My Menu" by default.
- Select Customize from the arrow pulldown.

- To create a list or query menu (the default):
- Change the Title and pull down lists to select the Folder, Schema, Query, View, Title Column, and URL for the menu.
- Click Submit.
- Click Refresh Menu Bar.
 Note that the built in project and folder menus cannot be edited or relocated through the UI; this alternate way to create a folder menu could be used to provide a selected subset of folders.
Note that the built in project and folder menus cannot be edited or relocated through the UI; this alternate way to create a folder menu could be used to provide a selected subset of folders.
Custom Menu Permissions
By selecting the Permissions link from the pulldown on any item on the Menu Bar tab, you can choose to show or hide the given menu based on the user's permission. The Required Permission field is a pulldown of all the possible permission levels. Check Permission On: allows you to specify where to check for that permission.
Web Parts: Permissions Required to View
- Role / Permissions Details Matrix - Details on the set of permissions provided by each role.
- Security Roles Reference - Provides the intent and function of each role.
 Set the required permission and click Save:
Set the required permission and click Save: By default, the system checks whether the user has the required permission in the current folder. To check the user's permissions against another folder, click Choose Folder and browse to the desired folder.These settings apply to individual web parts, so you could configure two web parts of the same type with different permission settings.Note that these settings do not change the security settings already present in the current folder and cannot be used to grant access on the resource displayed in the web part that the user does not already have.
By default, the system checks whether the user has the required permission in the current folder. To check the user's permissions against another folder, click Choose Folder and browse to the desired folder.These settings apply to individual web parts, so you could configure two web parts of the same type with different permission settings.Note that these settings do not change the security settings already present in the current folder and cannot be used to grant access on the resource displayed in the web part that the user does not already have.Data Grids

Data Grid Topics
The following topics explain how to work with data grids:- Data Grids: Basics - Learn the basic anatomy of a data grid.
- Import Data
- Sort Data
- Filter Data
- Select Rows - Select individual data records and groups of records.
- Customize Grid Views - Create custom grid views for your data.
- Saved Filters and Sorts - Save filters and sorts with as named or default grid views.
- Join Columns from Multiple Tables - Join columns from multiple tables together in a single grid view.
- Field Properties Reference - Use the field properties editor to customize column display and behavior.
- Export Data - Export your grid data to Excel files, text files, and scripts.
- Export Data Grid as a Script - Export your data to an R, SAS or JavaScript script.
- Customize Participant Views - Use a specialized form of data grid found in LabKey Studies.
- Query Scope: Filter by Folder - Control which data folders are included in a grid view.
Data Grids: Basics
Anatomy of a Data Grid View
The following image shows a typical data grid view.
- grid view title: Shows the kind of data structure (in this case a "Dataset") and the title ("Physical Exam, All Visits").
- QC state filter: Shows whether the data shown is filtered by quality control state.
- button bar: Shows the different tools that can be applied to your data.
- grid view indicator: Shows the current view/perspective on the data. Views are created to show or highlight a particular aspect of the data. Each data grid has a default view that displays all of its rows and columns.
- column headers: Click a column header for a list of actions:

- data records: Displays the data as a 2-dimensional table of rows and columns.
Button Bar
The button bar tools available may vary with different types of data grid. Study datasets can provide additional functionality, such as filtering by cohort, that are not available to lists. Assays and proteomics data grids provide many additional features.Common buttons and menus include:- Grid Views - pull-down menu for creating, selecting, and managing various grid views of this data.
- Reports - pull-down menu for creating and selecting saved reports.
- Charts - pull-down menu for creating and selecting charts based on the data grid.
- Insert - insert a new single row, or bulk import data.
- Delete - delete one or more rows selected by checkbox.
- Export - export the data grid as a spreadsheet, text, or in various scripting formats.
- Paging - change how many rows are shown per page, or choose options to show selected or unselected rows across pages.
- Design/Manage - with appropriate permissions, change the structure and behavior of the given list or dataset.
Customize Grid Views
- You can create grid views that show a subset of the columns or that combine columns from multiple data grids.
- You can also create customized reports that present the data as a chart or graph.
Other Display Tools
Examples
The following links show different views of a single data grid:- Grid View: Physical Exam: default grid
- Joined Grid: Physical Exam: Physical + Demographics grid
- Chart: Diastolic vs. Systolic Pressures: All Visits
- Participant Details: Physical Exam: Participant details view
Import Data
Sort Data
- Sort data by a given column
- Clear sorts
- Advanced: Understand Sorting URLs
Sort Data in a Column
To sort data displayed in a grid view, click on the column name. If the column is sortable (and most columns you will encounter in grids are sortable), the sort/filter popup menu will appear. The following screen shot shows the Physical Exam data grid. The Temperature column has been clicked to bring up sort options: Choose Sort Ascending or Sort Descending to sort the dataset based on the contents of the chosen column.Once you have sorted your dataset using a particular column, a triangle icon (
Choose Sort Ascending or Sort Descending to sort the dataset based on the contents of the chosen column.Once you have sorted your dataset using a particular column, a triangle icon ( ) will appear in the column header. If the column's sort is ascending, the triangle points up. If the column's sort is descending, the triangle points down.
) will appear in the column header. If the column's sort is ascending, the triangle points up. If the column's sort is descending, the triangle points down.
Clear Sorts
To remove a sort on an individual column, click the column caption and select Clear Sort.Advanced: Understand Sorting URLs
You can sort a grid view using multiple columns at a time, which follows these rules:- The grid view is sorted by the most recently clicked column first.
Related Topics
Filter Data
- Filter Column Values
- Faceted Filtering
- Clear One or All Filters
- Understand Filter URLs
- Filter By Group
Filter Column Values
- Click on a column name and select Filter.

Filter by Value
In some cases, the filter popup will have two tabs. If there is a Choose Values tab, you can directly select one or more individual values using checkboxes. Click on a label to select only a single value, add or remove additional values by clicking on checkboxes.
Filtering Expressions
Filtering expressions available in dropdowns vary by datatype and context. Possible filters include, but are not limited to:- Presence or absence of a value for that row
- Equality or inequality
- Comparison operators
- Membership or lack of membership in a named semicolon separated set
- Starts with and contains operators for strings
- Between (inclusive) or Not Between (exclusive) two comma separated values
- Switch to the Choose Filters tab, if available.
- Specify a filtering expression (such as "Is Greater Than"), and value (such as "37") and click OK.

 ) appears next to the columns title. Current filters are listed above the view; hover to reveal action buttons.
) appears next to the columns title. Current filters are listed above the view; hover to reveal action buttons.
- Leading spaces on strings are not stripped. For example, consider a list filter like Between (inclusive) which takes two comma-separated terms. If you enter range values as "first, second", rows with the value "second" (without the leading space) will be excluded. Enter "first,second" to include such rows.
- By default, LabKey filtering is case-sensitive. However, if your LabKey installation is running against Microsoft SQL Server, filtering is case-insensitive.
Persistent Filters
Some filters on some types of data are persistent (or "sticky") and will remain applied on subsequent views of the same data. For example, some types of assays have persistent filters for convenience; these are listed in the active filter bar above the grid.Use Faceted Filtering
If a column contains 100 or fewer distinct values, then a pick list of faceted filters is provided in the filter dialog on the Choose Values tab (Provided that the column type is one of the following: Lookup, Boolean, Integer, Text, DateTime, or if the column is marked as a dimension). In the image below, the Language column has eight options; French is shown selected. When applying multiple faceted filters to a data grid, the options shown as available in the panel will respect prior filters. For example, if you first filter the Demo Study demographics dataset by "Country" and select only "Uganda", then if you open a second filter on "Primary Language" you will see only "French" and "English" as options - our sample data includes no patients from Uganda who speak German or Spanish. The purpose is to simplify the process of filtering by presenting only valid filter choices. This also helps you unintentionally empty results.
When applying multiple faceted filters to a data grid, the options shown as available in the panel will respect prior filters. For example, if you first filter the Demo Study demographics dataset by "Country" and select only "Uganda", then if you open a second filter on "Primary Language" you will see only "French" and "English" as options - our sample data includes no patients from Uganda who speak German or Spanish. The purpose is to simplify the process of filtering by presenting only valid filter choices. This also helps you unintentionally empty results.
Clear One or All Filters
To clear a filter from a single column, click on the column heading and select Remove Filter.To clear all filters (and all sorts), click on the Clear All link that appears when you hover over the filter bar. Alternatively, click on any column heading and select Filter. In the filter dialog click the Clear All Filters button.Advanced: Understand Filter URLs
Filtering specifications are included on the page URL. The following URL filters the demo study "Physical Exam" dataset to show only rows where temperature is greater than 37. The column name, the filter operator, and the criterion value are all specified as URL parameters.https://www.labkey.org/study/home/Study/demo/dataset.view?datasetId=5004&Dataset.sort=ParticipantId&Dataset.Temp_C~gt=37In general there is no need to edit the filter directly on the URL; using the filter box is easier and less error-prone.The most recent filter on a grid is remembered, so that the user's last filter can be displayed. To specify that a grid should be displayed using the user's last filter settings, set the .lastFilter URL parameter to true, as shown:https://www.labkey.org/Issues/home/Developer/issues/list.view?.lastFilter=trueFilter by Group
Within a study dataset, you may also filter a data grid by participant group. Click the Filter button on the left above the grid to open the filter panel. Select checkboxes in this panel to further filter your data. Note that filters are cumulatively applied and listed in the active filter bar above the data grid.
Related Topics
Filtering Expressions
| Expression | Arguments | Description | |
|---|---|---|---|
| Has Any Value | Returns all values, including null | ||
| Is Blank | Returns blank values | ||
| Is Not Blank | Returns non-blank values | ||
| Equals | 1 | Returns values matching the value provided | |
| Does Not Equal | 1 | Returns non-matching values | |
| Is Greater Than | 1 | Returns values greater than the provided value | |
| Is Less Than | 1 | Returns values less than the provided value | |
| Is Greater Than or Equal To | 1 | Returns values greater than or equal to the provided value | |
| Is Less Than or Equal To | 1 | Returns values less than or equal to the provided value | |
| Contains | 1 | Returns values containing a provided value | |
| Does Not Contain | 1 | Returns values not containing the provided value | |
| Starts With | 1 | Returns values which start with the provided value | |
| Does Not Start With | 1 | Returns values which do not start with the provided value | |
| Between, Inclusive | 2, comma separated | Example usage: -4,4 | Returns values between or matching two comma separated values provided |
| Not Between, Exclusive | 2, comma separated | Example usage: -4,4 | Returns values which are not between and do not match two comma separated values provided |
| Equals One Of | 1 or more, semi-colon separated | Example usage: a;b;c | Returns values matching any one of a semi-colon separated list |
| Does Not Equal Any Of | 1 or more, semi-colon separated | Example usage: a;b;c | Returns values not matching a semi-colon separated list |
| Contains One Of | 1 or more, semi-colon separated | Example usage: a;b;c | Returns values which contain any one of a semi-colon separated list |
| Does Not Contain Any Of | 1 or more, semi-colon separated | Example usage: a;b;c | Returns values which do not contain any of a semi-colon separated list |
Boolean Filtering Expressions
Expressions available for data of type boolean (true/false values):- Has Any Value
- Is Blank
- Is Not Blank
- Equals
- Does Not Equal
Date Filtering Expressions
Date and DateTime data can be filtered with the following expressions:- Has Any Value
- Is Blank
- Is Not Blank
- Equals
- Does Not Equal
- Is Greater Than
- Is Less Than
- Is Greater Than or Equal To
- Is Less Than or Equal To
Numeric Filtering Expressions
Expressions available for data of any numeric type, including integers and double-precision numbers:- Has Any Value
- Is Blank
- Is Not Blank
- Equals
- Does Not Equal
- Is Greater Than
- Is Less Than
- Is Greater Than or Equal To
- Is Less Than or Equal To
- Between, Inclusive
- Not Between, Exclusive
- Equals One Of
- Does Not Equal Any Of
String Filtering Expressions
String type data, including text and multi-line text data, can be filtered using the following expressions:- Has Any Value
- Is Blank
- Is Not Blank
- Equals
- Does Not Equal
- Is Greater Than
- Is Less Than
- Is Greater Than or Equal To
- Is Less Than or Equal To
- Contains
- Does Not Contain
- Starts With
- Does Not Start With
- Between, Inclusive
- Not Between, Exclusive
- Equals One Of
- Does Not Equal Any Of
- Contains One Of
- Does Not Contain Any Of
Column Summary Statistics
 Premium Feature — An enhanced set of summary statistics is available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
Premium Feature — An enhanced set of summary statistics is available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
Add Summary Statistics to a Column
- Click a column header, then select Summary Statistics.

- The popup will list all available statistics for the given column, including their values for the selected column.
- Check the box for all statistics you would like to display.

- Click Apply. The statistics will be shown at the bottom of the column.

- Count (non-blank): The number of values in the column that are not blank, i.e. the total number of rows for which there is data available.
- Sum: The sum of the values in the column.
- Mean: The mean, or average, value of the column.
- Minimum: The lowest value.
- Maximum: The highest value.
- Count (blank): The number of blank values.
- Count (distinct): The number of distinct values.
- Median: Orders the values in the column, then finds the midpoint. When there are an even number of values, the two values at the midpoint are averaged to obtain a single value.
- Median Absolute Deviation (MAD): The median of the set of absolute deviations of each value from the median.
- Standard Deviation (of mean): For each value, take the difference between the value and the mean, then square it. Average the squared deviations to find the variance. The standard deviation is the square root of the variance.
- Standard Error (of mean): The standard deviation divided by the square of the number of values.
- Quartiles:
- Lower (Q1) is the midpoint between the minimum value and the median value.
- Upper (Q3) is the midpoint between the median value and the maximum value. Both Q1 and Q3 are shown.
- Interquartile Range: The number of values between Q3 and Q1 in the ordered list. Q3-Q1.
Display Multiple Summary Statistics
Multiple summary statistics can be shown at one time for a column and each column may have it's own set. Here is a compound set of statistics on another dataset:
Related Topics
Select Rows
- Select Rows on the Current Page of Data
- Select Rows on Multiple Pages
- Example
- Include a Subset of Data in a View
Select Rows on the Current Page of Data
- To select any single row, click the checkbox at the left side of the row.
- To unselect the row, uncheck the same checkbox.
- The box at the top of the checkbox column allows you to select or unselect all rows on the current page at once.


Changing Page Size
Using the Paging pulldown, you can see the current setting and adjust the number of rows per page.
Select Rows on Multiple Pages
By clicking <<First, < Prev, Next >, or Last >> in the top right of the grid, you can page forward and back in your data and select as many rows as you like, singly or by page, using the same checkbox selection methods as on a single page.In order to see which items are selected across all pages, use Paging > Show Selected. This can be helpful in keeping track of selections in large datasets, but is also needed for some actions which may only apply to rows on the current page which are selected. For example, View Specimens, Delete, and Copy to Study work this way.To assure that an action applies to the set of data you intend, select Paging > Show Selected first to see all selected rows on a single page.Select All Rows on All Pages
To see and select or unselect all rows on all pages at once:- Select Paging > Show All.
- Now the checkbox at the top left will select or unselect all rows in the entire grid at once.
Example
You can see how selection/visibility interact by experimenting with a large dataset, such as the Physical Exam dataset in the interactive example study.- Select an item on the first visible page of data.
- Click Next > to move to the the second page.
- Try clicking QC State > Update State for Selected Rows.
- You will get a popup error asking you to select one or more rows, indicating that the row on the prior page is not considered "selected" by this particular action.
- Click < Prev to return to the previous page, and note that your originally selected row is still selected.
Include a Subset of Data in a Report or Chart
Many reports and charts use as their basis the current data grid, not just items that are selected or items on the visible page.To change the number of items included in a report or chart, create a custom grid that includes a subset of the default datagrid. Use this custom grid as the basis for creating visualizations from a subset of data.Related Topics
- GetData API - Select data using the client API.
Customize Grid Views
Customize a Grid View
To open the grid view customizer for a given dataset, select Grid Views > Customize Grid.
- Tabs: The left-hand tabs specify tools for columns, sorting, and filtering. The Filter and Sort tabs are described in Saved Filters and Sorts.
- Available Fields: Shows the fields available for display. Place a checkmark next to a field to display it. Greyed out items are not fields, but table names. Click + and - buttons to expand/collapse fields in those tables.
- Selected Fields: Shows the list of fields currently displayed in the grid.
- Delete: Deletes the current grid view. You cannot delete the default grid view.
- Revert: Returns the grid view to its original state.
- View Grid: Click to preview your changes. When viewing unsaved changes, hovering over the top bar will reveal save and revert buttons.
- Save: Click to save your changes as the default view or as a new named grid view. Saved grid views appear on the Grid Views dropdown menu.
Add/View/Remove Fields
- To add a field to the grid view, place a checkmark next to the field in the Available Fields pane. The field will be added to the Selected Fields pane.
- Hover over any field name to see a popup with more information about the key and datatype of that field, as well as a description if one has been added.
- To remove a field, hover over the field in the Selected Fields pane, and click the Remove column button.
 You can also remove a column by clicking the column header and selecting Remove Column. Click Save to change the default view. To add the column back, click Revert.
You can also remove a column by clicking the column header and selecting Remove Column. Click Save to change the default view. To add the column back, click Revert.
Reorder Fields
- To reorder the columns in the grid view, drag and drop the fields in the Selected Fields pane. Note that the display order is changed, but no changes happen to the underlying data table.
Edit Column Properties
- Hover over the field in the Selected Fields pane.
- Click the Edit button at the far right side.

- Change the Title if desired.
- Add a column aggregator if desired:
- From the Aggregate dropdown, select the aggregating function to use: Sum, Average, Count, Minimum, or Maximum.

- Click OK to save changes.
Join Fields from other Datasets
- To add fields from other datasets, expand the plus sign next to the field name, and place a checkmark next to the desired fields.
Save a New Named Grid View
- Make the desired changes to a grid view.
- Preview the changes by clicking the View Grid button. Hover over the message "The current grid view is unsaved" to see the options buttons:
- To reject the changes, click Revert.
- To continue editing, click Edit.
- To accept the changes, click Save.

- After clicking the Save button, select Named, and enter a title for the new grid view.
- By default a customized grid is private to you; only you can see it in the drop-down box or modify it. If you have "Editor" permissions (or higher) in the current folder, you can make a grid available to all users by checking the box Make this grid view available to all users.

- The new named grid view is added to the Grid Views dropdown menu. The following image shows grid views available for the Physical Exam dataset in the Demo Study:

Customize the Default Grid View
- To customize the default grid, make the desired changes, and preview the changes by clicking the View Grid button. Hover over the message "The current grid view is unsaved." to reveal buttons:
- To reject the changes, click Revert.
- To continue editing, click Edit.
- To accept the changes, click Save.
- After clicking the Save button, select Default view for this page.
- By default a customized grid is private to you; only you can see it in the drop-down box or modify it. If you have "Editor" (or higher) permissions in the folder, you can make a view available to all users by checking the box Make this grid view available to all users.
Reset the Default Grid View
- To set the default view to an existing view, select Grid Views > Set Default.
- Select the grid you prefer from the list available.
Revert to the Original Default Grid View
- To revert any customizations to the default grid view, open it using Grid Views > default.
- Select Grid Views > Customize Grid.
- Click the Revert button.
Control Visibility of Customized Grid Views
By default a customized grid is private to you; only you can see it, see in the drop-down box, or modify it. If you have "Editor" access or are an administrator in the folder, you can make it visible to all users by checking the box Make this grid view available to all users when you save.Views Web Part
To create a web part listing all the customized views in your folder, an administrator can create an additional web part:- In the lower left, select Views from the Select Web Part dropdown.
- Click Add.
- The webpart will show saved grid views, reports, and charts sorted by categories you assign. For example, in the

Troubleshooting
FAQ: In a study, why can't I customize my grid to show a particular field from another dataset?Background: To customize your grid view of a dataset by adding columns from another dataset, it must be possible to join the two datasets. The columns used for a dataset's key influence how this dataset can be joined to other tables. Certain datasets have more than one key column (in other words, a "compound key"). In a study, you will typically encounter three types of datasets:- Demographic datasets use only one column as a key. Their key is the participantID. This means that only one line of data (for any date) can be associated with a participant in such a dataset.
- Clinical or standard datasets use participant/visit pairs as a compound key. This means that each row is uniquely identified by participant/visit pairs, not by participant identifiers alone.
- Assay datasets copied into a study also use compound keys. Assay datasets use participant/visit/rowID columns as compound keys, so only the trio of these columns uniquely identifies a row. In other words, a participant can have multiple assay rows associated with any individual visit - these are uniquely differentiated only by their rowIDs.
Related Topics
- Saved Filters and Sorts: Using the Filter and Sort tabs.
Saved Filters and Sorts
Define a Saved Sort
- Navigate to the grid view you'd like to modify.
- Select Grid Views > Customize Grid
- Click the Sort tab on the left.
- In the left pane, click the checkbox(es) for fields on which you want to sort.
- In the right pane, specify whether the sort order should be ascending or descending for each sort applied.
- Click Save.

- You may save as a new named grid view or as the default and select whether to make it available to all users.
- In the grid view with the saved sort applied above, sort on a second column, in this example we chose 'Height'.
- Open Grid Views > Customize Grid.
- Click the Sort tab. Note that it shows the number of sorts defined in parentheses.
- To see whether a given sort will be saved with the grid view, hover over the paperclip button on the right.

- Click the paperclip button to toggle whether the given sort is saved with the grid view.
- Remember to Save your grid with these changes applied.
Define a Saved Filter
The process for defining saved filters is very similar. You can filter locally first or directly define saved filters. An important advantage of using the saved filters interface is that when filtering locally, you are limited to two filters on a given column. Saved filters may include any number of separate filtering expressions for a given column, which are all ANDed together.- Select Grid Views -> Customize Grid.
- Click the Filter tab on the left.
- In the left pane, check boxes for the column(s) on which you want to filter.
- In the right pane, specify one or more filtering expressions for each selected column using the Add links.
- Use the paperclip buttons to toggle whether individual filtering expressions are saved with the grid view.
- Hover over a selected column region to see X buttons on the far right; you may delete filtering expressions individually here.

- Save the grid; select whether to make it available to other users.
Apply View Filter
When viewing a data grid, you can enable and disable all saved filters and sorts using the Apply View Filter checkbox in the Views menu. Without using the customize view menu, you cannot pick and choose among saved sorts and filters to apply. If this menu option is not available, no saved filters or sorts have been defined.
Interactions Among Filters and Sorts
Users can perform their own sorting and filtering when looking at a view that also has a saved sort or filter applied.- Sorting: Sorting a grid view while you are looking at it overrides any saved sort order. In other words, the saved sort can control how the data is first presented to the user, but the user can re-sort any way they wish.
- Filtering: Filtering a grid view which has one or more saved filters results in combining the sets of filters with an AND. That is, new local filters happen on the already-filtered data. This can result in unexpected results for the user, if the saved filter excludes data that they are expecting to see. Note that these saved filters are not listed in the filters bar above the data grid, but they can be disabled by unchecking the Grid Views > Apply View Filter checkbox.
Related Topics
Join Columns from Multiple Tables
Create a Lookup Field
An administrator first needs to connect the two tables by creating a lookup column between the two tables. Lookup columns can be created in two ways: either through the graphical user interface, as described in Lookup Columns; or through a SQL query, as described in Lookups: SQL Syntax.Create a Joined Grid View
Once tables are connected by a lookup column, you can create a joined grid view on either table. For example, suppose you wish to create a grid that brings together columns from both the Demographics and the Languages tables. Also, assume that a lookup column has already been defined in the Demographics table that looks up data in the Language table. To create a grid including data from both tables:- Go to the Demographics data grid.
- Select Grid Views > Customize Grid.
- In Available Fields, entries preceded by an expand/collapse "plus" icon (+) represent lookup columns that pull in data from other tables. Expanding these nodes makes the columns in the target ("looked up") table available.
- Click the "plus" icon next to the Languages node -- this reveals the available columns in the Languages table.
- To add a column from the Languages table, place a checkmark next to it. Below two columns have been added: Translator Name and Translator Phone.

- The columns will be added to Selected Fields.
- Save the grid, which now includes data from the target table (Languages).

Related Topics:
- Customize Grid Views
- In SQL terms, this combined grid view is the equivalent of a SQL SELECT query with one or more inner joins. For details on using lookup syntax in SQL queries, see Lookups: SQL Syntax.
- The Tutorial: Cohort Studies uses combined grids using a more complex set of tables joined by multiple foreign key lookups.
- Step 3: Integrate Data from Different Sources
Lookup Columns

Set Up a Lookup Field
To join these tables, add a lookup column to the Demographics dataset definition:- Go to the dataset or list of interest -- the table where you want the lookup to originate. For example, Demographics.
- Click Manage > Edit Definition. (Or Design > Edit Design for lists.) You must have the admin role to see these buttons.
- Click Add Field.
- Enter a Name. This is the system name.
- Enter an optional Label. This will be shown for the column header and other human readable interfaces.
- Click the dropdown under Type and select Lookup.
- In the popup dialog select the target table of the lookup. For example, the lists schema and the Languages table, as show below.

- Click Apply.
- Click Save.
- The lookup column is now available to the grid view customizer (the GUI) and to SQL queries.
- You can now create grids from any of the columns of the two tables, Demographics and Languages. For details on creating such grids see Join Columns from Multiple Tables.
Validating Lookups: Enforcing Lookup Values on Import
When you are importing data into a table that includes a lookup column, you can have the system enforce the lookup values, such that any imported values must appear in the lookup's target table. An error will be displayed whenever you attempt to import a value that is not in the lookup's target table.To set up enforcement:- Go to the definition editor of the table being imported into.
- Select the lookup column in the table.
- Click the Validators tab.
- Click the button Add Lookup Validator.

- Click Save and Close.
Related Topics
Export Data
Export Menu
You can export data in a grid view to an Excel file, a TSV text file, an Excel Web Query, or a variety of different scripts, which can recreate the data grid. Click the Export button above any grid view and use the left-hand tabs to choose between Excel, Text and Script exports, each of which carries a number of appropriate options. After selecting your options, decribed below, and clicking the Export button, you will briefly see visual feedback that the export is in progress:
After selecting your options, decribed below, and clicking the Export button, you will briefly see visual feedback that the export is in progress:
Export Column Headers
Both Excel and Text exports allow you to choose whether Column Headers are exported with the data, and if so, what format is used. Options:- None: Simply export the data table with no column headers.
- Caption: (Default) Include a column header row using the currently displayed column captions as headers.
- Field Key: Use the column name with FieldKey encoding. While less display friendly, these keys are unambiguous and canonical and will ensure clean export and import of data into the same dataset.

Export Selected Rows
If you select one or more rows using the checkboxes on the left, you will activate the Export Selected Rows checkbox. When selected, your exported Excel file will only include the selected rows. Uncheck the box to export all rows. For additional information about selecting rows, see Select Rows.Filter Data Before Export
Another way to export a subset of data records is to filter the grid view before you export it.- Filter Data. Clicking a column header in a grid will open a dialog box that lets you filter and exclude certain types of data.
- Create or select a Custom Grid View. Custom Grids let you store a selected subset as a named grid view.
- View Data From One Visit. You can use the Study Navigator to view the grid of data records for a particular visit for a particular dataset. From the Study Navigator, click on the number at the intersection of the desired visit column and dataset row.
Export to Excel
When you export your data grid to Excel, you can use features within that software to access, sort and present the data as required. If your data grid includes inline images they will be exported in the cell in which they appear in the grid.Export to Text
Select Text tab to export the data grid in a text format. Select tab, comma, colon, or semicolon from the Separator pulldown and single or double from the Quote pulldown. The extension of your exported text file will correspond to the separator you have selected.
Export to Script
You can export the current grid to script code that can be used to access the data from any of the supported client libraries. See Export Data Grid as a Script.The option to generate a Stable URL for the grid is also included on the Export > Script tab.Related Topics
- Export Data Grid as a Script
- Manage an Assay Design - Export assay designs in an XML format.
- Export Chart as JavaScript
Participant Details View

Navigate Between Participants
You can navigate from one participant to the next using the "Previous" and "Next" links above the participant details.Expand Dataset
To expand or contract data listings for the currently displayed participant for any dataset, click on the name of the dataset of interest in the lefthand column.
Add Charts
You can add one or more charts to your participant views using the "Add Chart" link for each dataset. Once you create a chart for one participant in a participant view, the same type of chart is displayed for every participant.
Customize Participant Details View
You can alter the HTML used to create the default participant details page and save alternative ways to display the data using the "Customize View" link. You can leverage the LabKey APIs to tailor your custom page. You can also add the participant.html file via a module: for details see Custom HTML/JavaScript Participant Details View. For further information on data grids, see Data Grids.
For further information on data grids, see Data Grids.
Related Topics
Query Scope: Filter by Folder
Overview
Certain LabKey queries (such as assay designs, issue trackers, and survey designs) can be defined at the project level. Data associated with such queries may be located within individual subfolders. You can adjust the scope of queries on such data to cover all data on the site, all data for a project, or only data located in particular folders. Scope is controlled using the "Filter by Folder" option on the views menu in the webpart.This allows you to organize your data in folders that are convenient to you at the time of data collection (e.g., folders for individual labs or lab technicians). Then you can perform analyses independently of the folder-based organization of your data. You can analyze data across all folders, or just a branch of your folder tree.You can set the scope through either the "Views" menu (above a grid view) or through the client API. In all cases, LabKey security settings remain in force, so users only see data in folders they are authorized to see.Folder Filter Interface
To filter by folder through the user interface, click the Views menu above a grid for an appropriate query (e.g., an assay or issues grid) and choose one of the following:- Current folder
- Current folder and subfolders
- All folders (on the site)

Folder Filters in the JavaScript API
The LabKey API provides developers with even finer grain control over the scope.The containerFilter config property available on many methods on LABKEY.Query (such as LABKEY.Query.executeSql and LABKEY.Query.selectRows) provides fine-grained control over which folders accessed through the query.For example, the LABKEY.Query.executeSql API allow you to use the containerFilter parameter to run custom queries across data from multiple folders at once. This query might (for example) show the count of NAb runs available in each lab’s subfolder if folders are organized by lab.Field Properties Reference
Field Properties Editor
- Use the arrows and X's to the left of each field to reorder or delete fields.
- Click on the Name, Label or Type for any field to edit them.
- Selecting a row brings up the field properties editor: the block of tabs to the right.
- The highlight bar indicates which field is currently selected for editing.
- A wrench icon on the left will indicate a row with unsaved changes.

- Basic Properties
- Display Properties
- Format Properties
- Validators (Field-level Validation)
- Reporting Properties
- Advanced Properties
Basic Properties
Name: This is the name used to refer to the field programmatically. It must start with a character and include only characters and numbers.Label (Optional): The name that users will see displayed for the field. It can be longer and more descriptive than the name and may contain spaces.Type: Fields come in different types, each intended to hold a different kind of data. Once defined, the field type cannot be changed, since the data in the field may not be able to be converted to the new type. To change the field type, you may need to delete and recreate the field. This will delete any data in the field, so re-importing the data will be necessary. The field types are:- Text (String)
- Multi-Line Text
- Boolean (True/False)
- Integer
- Number (Double) - A decimal number.
- Date/Time
- Flag (String)
- File - The File type is only available for certain types of table types, including assay designs and sample sets, see below for a complete list. When a file has been uploaded into this field, it displays a link to the file; for image files, an inline thumbnail is shown. The uploaded file is stored in the file repository, in the assaydata folder.
- Attachment - This type is only available for lists, see below for a complete list. This type allows you to attach documents to individual records in a list. For instance, an image file could be associated with a given row of data in an attachment field, and would show an inline thumbnail. The attached file is not uploaded into the file repository. Maximum file size is 50MB.
- User - This type points to registered users of the LabKey Server system, found in the table core.Users.
- Subject/Participant (String) - This type is only available in a study.
- Lookup - See below.
Field Types Available by Data Structure
The following table show which fields are available in which sort of table/data structure. Notice that Datasets do not support File or Attachment fields. For a workaround technique, see Linking Data Records with External Files.| Field Type | Dataset | List | Sample Set | Assay Design |
|---|---|---|---|---|
| Test (String) | Yes | Yes | Yes | Yes |
| Multi-Line Text | Yes | Yes | Yes | Yes |
| Boolean | Yes | Yes | Yes | Yes |
| Integer | Yes | Yes | Yes | Yes |
| Number (Double) | Yes | Yes | Yes | Yes |
| DateTime | Yes | Yes | Yes | Yes |
| File | No (workaround doc) | No | Yes | Yes |
| Attachment | No (workaround doc) | Yes | No | No |
| User | Yes | Yes | Yes | Yes |
| Subject/Particiant(String) | Yes | Yes | Yes | Yes |
| Lookup | Yes | Yes | Yes | Yes |
Inline Thumbnails for Files and Attachments
Fields of type File and Attachment are available in certain schema including lists, sample sets, and assay run results. When the file or attachment is an image, such as a .png or .jpg file, the cell in the data grid will display a thumbnail of the image. Hovering reveals a larger version. When you export a grid containing these inline images to Excel, the thumbnails remain associated with the cell itself.
When you export a grid containing these inline images to Excel, the thumbnails remain associated with the cell itself.
Lookup
You can populate a field with data via lookup into another table. Click on the Type property for a field, select the Lookup option, then select a source Folder, Schema and Table from the drop-down menus in the popup. These selections identify the source location for the data values that will populate this field. For examples, see the List Tutorial and the Advanced List Demo.A lookup appears as a foreign key (<fk>) in the XML schema generated upon export of this study. An example of the XML generated:<fk>
<fkDbSchema>lists</fkDbSchema>
<fkTable>Reagents</fkTable>
<fkColumnName>Key</fkColumnName>
</fk>
Display Properties
Display properties for a field are shown on the Display tab and control how and when the field is displayed.Description: Verbose description of the field. XML schema name: description. URL: A template for generating hyperlinks for this field. The ${ } syntax may be used to substitute a field's value into the URL. See URL Field Property.Shown In Display Modes: Checkboxes allow you to choose whether or not the column is displayed in certain modes.Format Properties
Format: You can create custom Date, DateTime or Number Formats for displaying values of these types. You can also configure date, datetime, and number formats at the folder, project, or site level for broader consistency. See Date & Number Display Formats.Conditional Formats: Conditional formats let you change the way the data is displayed based on the data value. For details see Conditional FormatsValidators (Field-level Validation)
Field validators ensure that all values entered for a field obey a regular expression and/or fall within a specified range. They can automate checking for reasonableness and catch a broad range of field-level data-entry errors during the upload process.Required: When required, a field cannot be empty. Defaults to "False."Add Regex Validator: Define a regular expression that defines what strings are valid.- Name: Required. A name for this expression.
- Description: Optional. A text description of the expression.
- Regular Expression: Required. A regular expression that this field's value will be evaluated against. All regular expressions must be compatible with Java regular expressions, as implemented in the Pattern class.
- Error message. Optional. The message that will be displayed to the user in the event that validation fails for this field.
- Fail when pattern matches. Optional. By default, validation will fail if the field value does not match the specified regular expression. Check this box if you want validation to fail when the pattern matches the field value, which may be an easier way to express the error cases you want to catch.
- Name: Required. A name for this range requirement.
- Description: Optional. A text description of the range requirement.
- First condition: Required. A condition to this validation rule that will be tested against the value for this field.
- Second condition: Optional. A condition to this validation rule that will be tested against the value for this field. Both the first and second conditions will be tested for this field.
- Error message: Required. The message that will be displayed to the user in the event that validation fails for this field.
Reporting Properties
The reporting tab allows you to set attributes used in creating reports. Select the field of interest in the properties editor, click the Reporting tab and select:Measure: A field identified as a measure contains data useful for charting and other analysis. Measures are typically numeric results/observations, like weight, or CD4 count. Only those columns identified as measures will be listed as options for the y-axis of a time chart, for example.Data Dimension: Data dimensions define logical groupings of measures. For example, 'Gender' could be a dimension for a dataset containing a 'Height' measure, since it may be desirable to study height by gender.Recommended Variable: Define which fields in this table/query/etc. should be prioritized as 'recommended' variables when creating new charts/reports/etc for datasets containing large numbers of columns.Default Scale Type: For numeric field types, defines whether linear or log scales will be used by default for this field.
Advanced Properties
Missing Value Indicators: A field marked with 'Missing Value Indicators', can hold special values to indicate data that has failed review or was originally missing. Defaults to "False." Data coming into the database via text files can contain the special symbols Q and N in any column where "Missing value indicators" is checked. “Q” indicates a QC has been applied to the field, “N” indicates the data will not be provided (even if it was officially required). Default Type: Dataset schemas can automatically supply default values when a user is entering values or when imported data tables have missing values. The "Default Type" property sets how the default value for the field is determined. "Last entered" is the automatic choice for this property if you do not alter it. Note: This property is not included in XML schemas exported from a study.Options:- Editable default: An editable default value will be entered for the user. The default value will be the same for every user for every upload.
- Last entered: An editable default value will be entered for the user's first use of the form. During subsequent uploads, the user will see their last entered value.
- If you have chosen "Editable default," you can set the default value through the Set Values option. Each time the user sees the form, they will see this default value.
- If you have chosen "Last entered" for the default type, the field will show the setting entered previously, but you can still set the initial value of the field through the "Default Value" option.
Related Topics
URL Field Property
Link Format Types
Three link format types for URL property are supported:Full URL: Starts with http:// or https://http://server/path/page.html?id=${Param}https://www.mylabkey.org/home/folder/wiki-page.view?name=${Name}- the link navigates to a different LabKey folder on the current server
- when the URL is a WebDAV link to a file that has been uploaded to current server
/wiki-page.view?name=${Name}Substitution Markers
A URL property can contain markers in the format ${field-name}, where "field-name" is the name of any field that is part of the current query (i.e. the tabular data object that contains the field that has the URL property). When the query is displayed in a grid, the value of the field-name for the current record is substituted into the URL property string in place of the ${field-name} marker. Note that multiple such markers can be used in a single URL property string, and the field referenced by the markers can be any field within the query.Note that substitutions are allowed in any part of the URL, either in the main path, or in the query string. For example, here are two different formats for creating links to an article in wikipedia, here using a "CompanyName" field value:- as part of the path:
- as a parameter value:
Built-in Substitution Markers
The following substitutions markers are built-in and available for any query/dataset. They help you determine the context of the current query.| Marker | Description | Example Value |
|---|---|---|
| ${schemaName} | The schema where the current query lives. | study |
| ${schemaPath} | The schema path of the current query. | assay.General.MyAssayDesign |
| ${queryName} | The name of the current query | Physical Exam |
| ${dataRegionName} | The data region for the current query. | Dataset |
| ${containerPath} | The LabKey Server folder path, starting with the project | /home/myfolderpath |
| ${contextPath} | The Tomcat context path | /labkey |
| ${selectionKey} | Unique string used by selection APIs as a key when storing or retrieving the selected items for a grid | $study$Physical Exam$$Dataset |
Link Display Text
The display text of the link created from a URL property is just the value of the current record in the field which contains the URL property. So in the Gene Ontology example, since the URL property is defined on the Gene_Symbol field, the gene symbol serves as both the text of the link and the value of the search_query parameter in the link address. In many cases you may want to have a constant display text for the link on every row. This text could indicate where the link goes, which would be especially useful if you want multiple such links on each row.In the example above, suppose the researcher wants to be able to look up the gene symbol in both Gene Ontology and EntrezGene. Rather than defining the URL Property on the Gene_Symbol field itself, it would be easier to understand if two new fields were added to the query, with the value in the fields being the same for every record, namely "[GO]" and "[Entrez]". Then set the URL property on these two new fields tofor the GOlink field:http://amigo.geneontology.org/cgi-bin/amigo/search.cgi?search_query=${Gene_Symbol}&action=new-searchhttp://www.ncbi.nlm.nih.gov/gene/?term=${Gene_Symbol} Note that if the two new columns are added to the underlying list, dataset, or schema table directly, the link text values would need to be entered for every existing record. Changing the link text would also be tedious. A better approach is to wrap the list in a query that adds the two fields as constant expressions. For this example, the query might look like:
Note that if the two new columns are added to the underlying list, dataset, or schema table directly, the link text values would need to be entered for every existing record. Changing the link text would also be tedious. A better approach is to wrap the list in a query that adds the two fields as constant expressions. For this example, the query might look like:SELECT TestResults.SampleID,
TestResults.TestRun,
TestResults.Gene_Symbol,
TestResults.ResultValueN,
'[GO]' AS GOlink,
'[Entrez]' AS Entrezlink
FROM TestResults

URL Encoding Options
You can specify the type of URL encoding for a substitution marker, in case the default behavior doesn't work for the URLs needed. This flexibility makes it possible to have one column display the text and a second column can contain the entire href value, or only a part of the href. The fields referenced by the ${ } substitution markers might contain any sort of text, including special characters such as question marks, equal signs, and ampersands. If these values are copied straight into the link address, the resulting address would be interpreted incorrectly. To avoid this problem, LabKey Server encodes text values before copying them into the URL. In encoding, characters such as ? are replaced by their character code %3F. By default, LabKey encodes all special character values except '/' from substitution markers. If you know that a field referenced by a substitution marker needs no encoding (because it has already been encoded, perhaps) or needs different encoding rules, inside the ${ } syntax, you can specify encoding options as described in the topic String Expression Format Functions.Links Without the URL Property
If the data field value contains an entire url starting with an address type designator (http:, https:, etc), then the field value is displayed as a link with the entire value as both the address and the display text. This special case could be useful for queries where the query author could create a URL as an expression column. There is no control over the display text when creating URLs this way, however.Linking To Other Tables
To link two tables, so that records in one table link to filtered views of the other, start with a filtered grid view of the target table, filtering on the target fields of interest. For example, the following URL filters on the fields "WellLocation" and "WellType":/home/demo%20study/study-dataset.view?datasetId=5018&Dataset.WellLocation~eq=AA&Dataset.WellType~eq=XX
/home/demo%20study/study-dataset.view?datasetId=5018&Dataset.WellLocation~eq=${WellLocation}&Dataset.WellType~eq=${WellType}Related Topics
For an example of UI usage, see: Add a URL Property and view an interactive example by clicking here. Hover over a link in the Species column to see the URL, click to view a list filtered to display only demographic data for the specific species.For examples of SQL metadata XML usage, see: JavaScript API Demo Summary Report and the JavaScript API Tutorial.String Expression Format Functions
Reference
The following string formatters can be used when building URLs, or creating unique names for sample sets and DataClasses.
| Name | Synonym | Input Type | Description | Example | |
|---|---|---|---|---|---|
| General | |||||
| defaultValue(string) | any | Use the string argument value as the replacement value if the token is not present or is the empty string. | ${field:defaultValue('missing')} | ||
| passThrough | none | any | Don't perform any formatting. | ${field:passThrough} | |
| URL Encoding | |||||
| encodeURI | uri | string | URL encode all special characters except ',/?:@&=+$#' like JavaScript encodeURI() | ${field:encodeURI} | |
| encodeURIComponent | uricomponent | string | URL uncode all special characters like JavaScript encodeURIComponent() | ${field:encodeURIComponent} | |
| htmlEncode | html | string | HTML encode | ${field:htmlEncode} | |
| jsString | string | Escape carrage return, linefeed, and <>"' characters and surround with a single quotes | ${field:jsString} | ||
| urlEncode | path | string | URL encode each path part preserving path separator | ${field:urlEncode} | |
| String | |||||
| join(string) | collection | Combine a collection of values together separated by the string argument | ${field:join('/'):encodeURI} | ||
| prefix(string) | string, collection | Prepend a string argument if the value is non-null and non-empty | ${field:prefix('-')} | ||
| suffix(string) | string, collection | Append a string argument if the value is non-null and non-empty | ${field:suffix('-')} | ||
| trim | string | Remove any leading or trailing whitespace | ${field:trim} | ||
| Date | |||||
| date(string) | date | Format a date using a format string or one of the constants from Java's DateTimeFormatter. If no format value is provided, the default format is 'BASIC_ISO_DATE' | ${field:date}, ${field:date('yyyy-MM-dd')} | ||
| Array | |||||
| first | collection | Take the first value from a collection | ${field:first:defaultValue('X')} | ||
| rest | collection | Drop the first item from a collection | ${field:rest:join('_')} | ||
| last | collection | Drop all items from the collection except the last | ${field:last:suffix('!')} |
Examples
| Function | Applied to... | Result |
| ${Column1:defaultValue('MissingValue')} | null | MissingValue |
| ${Array1:join('/')} | [apple, orange, pear] | apple/orange/pear |
| ${Array1:first} | [apple, orange, pear] | apple |
| ${Array1:first:defaultValue('X')} | [(null), orange, pear] | X |
Conditional Formats
Specify a Conditional Format
To specify a conditional format, select a field, click the Format tab and click Add Conditional Format. First identify the condition under which you want the conditional format applied. Specifying a condition is just like specifying a filter.
First identify the condition under which you want the conditional format applied. Specifying a condition is just like specifying a filter. Next, you can specify how the field should be formatted when that condition is met. The options are:
Next, you can specify how the field should be formatted when that condition is met. The options are:
- bold
- italic
- strikethrough
- color: click to popup a dialog for setting foreground and background colors

Multiple Conditional Formats
Multiple conditional formats are supported in a single column. Click Add Conditional Format again to specify another conditional format.If a data cell fulfills multiple conditions, then the first condition satisfied is applied, and conditions lower on the list are ignored. You can reorder the list of conditions by dragging and dropping items on the list.For example, suppose you have specified two conditional formats on one field:- If the value is 40 degrees or greater, then display in bold text.
- If the value is 39 degrees or greater, then display in italic text.
41
40
39
38
37
Specify Conditional Formats as Metadata XML
Conditional formats can be specified (1) as part of a table definition and/or (2) as part of a table's metadata XML. When conditional formats are specified in both places, the metadata XML takes precedence over the table definition.You can edit conditional formats as metadata xml source. In the metadata editor, click Edit Source. The sample below shows XML that specifies that values greater than 37 in the Temp_C column should be displayed the bold text.<tables xmlns="http://labkey.org/data/xml">
<table tableName="Physical Exam" tableDbType="NOT_IN_DB">
<columns>
<column columnName="Temp_C">
<conditionalFormats>
<conditionalFormat>
<filters>
<filter operator="gt" value="37"/>
</filters>
<bold>true</bold>
</conditionalFormat>
</conditionalFormats>
</column>
</columns>
</table>
</tables>
Example: Conditional Formats for Human Body Temperature
In the following example, values out of the normal human body temperature range are marked red (too high) or blue (too low). In this example, we use the Physical Exam dataset that is included with the importable demo study.- In a grid view of the Physical Exam dataset, click Manage.
- Click Edit Definition.
- Select a field (in this case Temp_C), click the Format tab, and click Add Conditional Format.
- In the popup, choose Filter Type "Is Greater Than", enter 37.8, and click Ok.
- Click the black/white square icon to select colors:

- Select red in the foreground text panel (to indicate temperature is higher than normal).
- Click Ok.
- Click Add Conditional Format again.
- Choose Filter Type: "Is Less Than", enter 36.1, and click Ok.
- Again select a color format: this time choose blue foreground text (to indicate temperature is lower than normal), and click Ok.
- Scroll back up and click Save.
- Click View Data to return to the data grid.
 When you hover over a formatted value, a pop up dialog will appear explaining the rule behind the format.
When you hover over a formatted value, a pop up dialog will appear explaining the rule behind the format.
Related Topics
- Field Properties Reference
- tableInfo.xsd - The XSD/XML source for table metadata.
Date & Number Display Formats
- Specify how dates are displayed, for example:
- 04/05/2016
- May 4 2016
- Wednesday May 4
- Specify how times are displayed, for example
- 01:23pm
- 1:23pm Pacific Standard Time
- Specify how numbers are displayed, for example
- 1.1
- 1.10
- Determine granularity of the date/time display, for example:
- June 4 2016
- June 4 2016 1pm
- June 4 2016 1:20pm
- Set up formats that apply to the entire site, an entire project, or a folder.
- Override more generally prescribed formats in a particular context, for example, specify that a particular field or folder should follow a different format than the parent container.
- The server checks to see if there is a field-level format set on the field itself. If it finds a field-specific format, it uses that format. If no format is found, it looks to the folder-level format. (To set a field-specific format, see Set Formats on a Per-Field Basis.)
- If a folder-level format is found, it uses that format. If no folder-level format is found, it looks in the parent folder, then that parent's parent folder, etc. until the project level is reached and it looks there. (To set a folder-level default format, see Set Folder Display Formats)
- If a project-level format is found, it uses that format. If no project-level format is found, it looks to the site-level format. (To set a project-level default format, see Set Project Display Formats.)
- To set the site-level format, see Set Formats Globally (Site-Level). Note that if no site-level format is specified, the server will default to these formats:
- Date field: yyyy-MM-dd
- Date-time field: yyyy-MM-dd HH:mm
- Date fields: Year-Month-Date, which is the standard ISO date format, for example 2010-01-31. The Java string format is yyyy-MM-dd
- Date-time fields: Year-Month-Date Hour:Minute, for example 2010-01-31 9:30. The Java string format is yyyy-MM-dd HH:mm
- For date-time fields where displaying a time value would be superfluous, the system overrides the site-wide initial format (Year-Month-Date Hour:Minute) and instead uses a date-only format (Year-Month-Date). Examples include visit dates in study datasets, SpecimenDrawDate in specimens, and BirthDate in various patient schemas. To change the format behavior on these fields, override the query metadata -- see Query Metadata.
yyyy-MM-dd
2000-01-01
Set Formats Globally (Site-Level)
An admin can set formats at the site level by managing look and feel settings.- Select Admin > Site > Admin Console.
- Click Look and Feel Settings.
- Scroll down to Customize date and number formats.

- Enter format strings as desired for date, date-time, or number fields.
- Click Save.
Set Project Display Formats
An admin can standardize display formats at the project level so they display consistently in the intended scope, which does not need to be consistent with site-wide settings.- Navigate to the target project.
- Select Admin > Folder > Project Settings.
- On the Properties tab, scroll down to Customize date and number formats.
- Enter format strings as desired for date, date-time, or number fields.
- Click Save.
Set Folder Display Formats
An admin can standardize display formats at the folder level so they display consistently in the intended scope, which does not need to be consistent with either project or site settings.- Navigate to the target folder.
- Select Admin > Folder > Management.
- Click the Formats tab.
- Enter format strings as desired for date, date-time, or number fields.
- Click Save.
Set Formats on a Per-Field Basis
To do this, you use the field property editor:- Open a grid view of the dataset of interest.
- Click Manage.
- Click Edit Definition.
- Select the field of interest.
- In the field property management panel, select the Format tab.
- Enter the desired format string directly, or use the shortcuts described below.
- Click Save.
Date Format Shortcuts
At the field-level, instead of providing a specific format string, you can use one of the following shortcut values to specify a standard format. A shortcut value tells the server to use the current folder's format setting (a format which may be inherited from the project or site setting).| Format Shortcut String | Description |
|---|---|
| Date | Use the folder-level format setting, specified at Admin > Folder > Management > Formats tab > Default display format for dates. |
| DateTime | Use the folder-level format setting, specified at Admin > Folder > Management > Formats tab > Default display format for date-times. |
| Time | Currently hard-coded to "HH:mm:ss" |

Date and Number Formats Reference
Date and DateTime Format Strings
Format strings used to describe dates and date-times on the LabKey platform must be compatible with the format accepted by the Java class SimpleDateFormat. For more information see the java documentation. The following table has a partial guide to pattern symbols.| Letter | Date/Time Component | Examples |
|---|---|---|
| G | Era designator | AD |
| y | Year | 1996; 96 |
| M | Month in year | July; Jul; 07 |
| w | Week in year | 27 |
| W | Week in month | 2 |
| D | Day in year | 189 |
| d | Day in month | 10 |
| F | Day of week in month | 2 |
| E | Day in week | Tuesday; Tue |
| a | Am/pm marker | PM |
| H | Hour in day (0-23) | 0 |
| k | Hour in day (1-24) | 24 |
| K | Hour in am/pm (0-11) | 0 |
| h ....... | Hour in am/pm (1-12) ....... | 12 ....... |
| m | Minute in hour | 30 |
| s | Second in minute | 33 |
| S | Millisecond | 978 |
| z | Time Zone | Pacific Standard Time; PST; GMT-08:00 |
| Z | Time Zone | -0800 |
| X | Time Zone | -08; -0800; -08:00 |
Format Shortcuts
At the field level, instead of providing a specific format string, you can use a shortcut value for commonly used formats. For details, see Date & Number Display FormatsNumber Format Strings
Format strings for numbers must be compatible with the format that the java class DecimalFormat accepts. A valid DecimalFormat is a pattern specifying a prefix, numeric part, and suffix. For more information see the java documentation. The following table has an abbreviated guide to pattern symbols:| Symbol | Location | Localized? | Meaning |
|---|---|---|---|
| 0 | Number | Yes | Digit |
| # | Number | Yes | Digit, zero shows as absent |
| . | Number | Yes | Decimal separator or monetary decimal separator |
| - | Number | Yes | Minus sign |
| , | Number | Yes | Grouping separator |
Examples
| Format String | Display Result |
|---|---|
| yyyy-MM-dd HH:mm | 2008-05-17 01:45 |
| yyyy-MM-dd HH:mmaa | 2008-05-17 01:45PM |
| MMMM dd yyyy | May 17 2008 |
| hh:mmaa zzzz | 01:45PM Pacific Daylight Time |
| <no string> | 85 |
| .00 | 85.00 |
| 000.000 | 085.000 |
| 000,000 | 085,000 |
| -000,000 | -085,000 |
Java Reference Documents
Dates: http://docs.oracle.com/javase/8/docs/api/java/text/SimpleDateFormat.htmlNumbers: http://docs.oracle.com/javase/8/docs/api/java/text/DecimalFormat.htmlRelated Topics
Date & Number Display FormatsReports and Visualizations
- Report Web Part: Display a Report or Chart - Add a report or chart to a project or folder page.
- Data Views Browser - Display the reports, charts, and data grids available.
Report and Visualization Types
When viewing a data grid, select Charts > Create Chart menu to open the plot editor and create new:- Bar Charts
- Box Plots
- Pie Charts
- Scatter Plots
- Time Charts: Available only in study datasets and queries.
Manage Visualizations
- Manage Reports and Charts - Customize the way reports, charts and grids are listed.
- Manage Categories - Define and use grouping categories.
- Manage Thumbnail Images - Customize thumbnails and mini-icons associated with visualizations.
- Export Chart as JavaScript - Export a report or chart as JavaScript for further modification or insertion in a wiki.
Open a Saved Visualization
Once saved, visualizations are generated by re-running their associated scripts on live data. You can access a visualization either through the Reports or Charts drop-down menu on the data grid, or directly by clicking on the name in the Data Views web part.

Legacy Visualization Types
These visualization types are still available, but are no longer being actively developed.Report Web Part: Display a Report or Chart
- Display a saved report or chart using the Report web part. This topic covers this option.
- Embed a visualization in a wiki page by following the instructions in Embed Live Content in HTML Pages or Messages. See also Web Part Configuration Properties.
- Export a visualization as JavaScript for inclusion in another HTML document. See Export Chart as JavaScript.
- Use the LabKey JavaScript APIs to display reports and views.
Display a Single Report
To display a report on a page:- Click Add Web Part in the lower left, select Report, and click Add.
- On the Customize Report page, enter the following parameters:
- Web Part Title: This is the title that will be displayed in the web part.
- Report or Chart: Select the report or chart to display.
- Show Tabs: Some reports may be rendered with multiple tabs showing.
- Visible Report Sections: Some reports contain multiple sections, such as: images, text, console output. If a list is offered, you can select which section(s) to display by selecting them. If you are displaying an R Report, the sections are identified by the section names from the source script.

- Click Submit.

Change Report Web Part Settings
You can reopen the Customize Report page later to change the name or how it appears.- Select Customize from the triangle pulldown menu next to the name.

- Click Submit.
- Show Tabs: Some views may be rendered with multiple tabs showing. Select this option to only show the primary view.
- Visible Report Sections: Some views contain multiple sections such as: images, text, console output. For these types of views you can select which section(s) to display by selecting them from the list.
Related Topics
Data Views Browser
Add Data Views Browser
To add the Data Views web part to a page:- Select Data Views from the <Select Web Part> pulldown in the lower left.
- Click Add.

- Add Report and Add Chart: Add new reports and charts directly.
- Manage Datasets: Create and manage study datasets.
- Manage Queries: Open the query schema browser.
- Manage Views: Manage reports, queries, and grids, including the option to delete multiple items at once.
- Manage Notifications: Subscribe to receive notifications of report and dataset changes.
- Customize: Customize this web part.
- Permissions: Control who can see this web part.
- Move Up/Down: Change the sequence of web parts on the page.
- Remove From Page: No longer show this web part - note that the underlying data is not affected by removing the web part.
Customize Data Views Browser
- Name: the heading of the web part (the default is "Data Views").
- Display Height: adjust the size of the web part. Options:
- Default (dynamic): by default, the data views browser is dynamically sized to fit the number of items displayed, up to a maximum of 700px.
- Custom: enter the desired web part height. Must be between 200 and 3000 pixels.
- Upgrade note: if an existing data views webpart used one of the prior small, medium, or large options, that height setting will be preserved as a custom height.
- Sort: select an option:
- By Display Order: the default: the order items are returned from the database
- Alphabetical: alphabetize items within categories; categories are explicitly ordered
- View Types: check or uncheck boxes to control whether reports, queries, or datasets are displayed.
- Visible Columns: check and uncheck boxes to control which columns appear in the web part.
- Manage Categories: Click to define and use categories and subcategories for grouping.

- To close the Customize box, select Save or Cancel.
Toggle Edit Mode
- Click the pencil icon in the webpart border to toggle edit mode. Individual pencil icons show which items have metadata you can edit here.
- When active, click the pencil icon for the desired report or query.

- Edit Properties, such as status, author, visibility to others, etc.
- If you want to move the item to a different section of the web part, select a different Category.
- If there are associated thumbnails and mini-icons, you can customize them from the Images tab. See Manage Thumbnail Images for more information.
- Click Save.
Related Topics
Bar Charts
Create a Bar Chart
- Navigate to the data grid you want to visualize.
- Select Charts > Create Chart to open the editor. Click Bar (it is selected by default).
- The columns eligible for charting from your current grid view are listed.
- If you want to plot using a column that is not visible here, return to the data grid and use Grid Views > Customize Grid to add it.
- If your server is configured to restrict charting to columns marked as "measures" or "dimensions", you will only be able to use columns with those designations.
- Select the column of data to use for separating the data into bars and drag it to the X Axis Categories box.

- Only the X Axis Categories field is required to create a basic bar chart. By default, the height of the bar shows the count of rows matching each value in the chosen category.
- To use a different metric for bar height, select another column (here "Lymphs") and drag it to the box for the Y Axis column. Notice that you can select the aggregate method to use. By default, SUM is selected and the label reads "Sum of Lymphs". Here we change to "Mean"; the Y Axis label will update automatically.

- Click Apply.

- To make a more complex grouped bar chart, click Chart Type to reopen the creation dialog.
- Drag a column to the Split Categories By selection box, here "Gender".

- Click Apply to see grouped bars. The "Split" category is now shown along the X axis with a colored bar for each value in the "X Axis Categories" selection chosen earlier.

- Click View Data to see, filter, or export the underlying data.
- Click View Chart to return. If you applied any filters, you would see them immediately reflected in the chart.
- Further customize your visualization using the Chart Type and Chart Layout links in the upper right.
- Chart Type reopens the creation dialog allowing you to:
- Change the "X Axis Categories" column (hover and click the X to delete the current election).
- Remove or change the Y Axis metric, the "Split Categories By" column, or the aggregation method.
- You can also drag and drop columns between selection boxes to change how each is used.
- Note that you can also click another chart type on the left to switch how you visualize the data with the same axes when practical.
- Click Apply to update the chart with the selected changes.
- Chart Layout offers the ability to change the look and feel of your chart.
 There are 3 tabs:
There are 3 tabs:
- General:
- Provide a Title to show above your chart. By default, the dataset name is used; at any time you can return to this default by clicking the refresh icon in the field.
- Provide a Subtitle to print under the chart title.
- Specify the width and height.
- You can also customize the opacity, line width, and line color for the bars.
- Select one of three palettes for bar fill colors: Light, Dark, or Alternate. The array of colors is shown.
- X-Axis/Y-Axis:
- Change the display labels for the axis (notice this does not change which column provides the data).
- The range applied to the Y-axis can also be specified - the default is automatic. Select manual and specify the range if desired.
- Click Apply to update the chart with the selected changes.
- When your chart is ready, click Save.

- Name the chart, enter a description (optional), and choose whether to make it viewable by others. You will also see the default thumbnail which has been auto-generated, and can choose whether to use it. As with other charts, you can later attach a custom thumbnail if desired.
Export Chart
Hover over the chart to reveal export option buttons in the upper right corner: Export your completed chart by clicking an option:
Export your completed chart by clicking an option:
- Script: pop up a window displaying the JavaScript for the chart which you can then copy and paste into a wiki. See Export Chart as JavaScript for a tutorial on this feature.
- PNG: create a PNG image.
- PDF: generate a PDF file.
Videos
- Video Overview: Bar Charts (16.3)
- Video: Using the Chart Designer (16.3)
Related Topics
Box Plots
Create a Box Plot
- Navigate to the data grid you want to visualize.
- Select Charts > Create Chart to open the editor. Click Box.
- The columns eligible for charting from your current grid view are listed.
- If you want to plot using a column that is not visible here, return to the data grid and use Grid Views > Customize Grid to add it.
- If your server is configured to restrict charting to columns marked as "measures" or "dimensions", you will only be able to use columns with those designations.
- Select the column to use on the Y axis and drag it to the Y Axis box.
 Only the Y Axis field is required to create a basic single-box plot, but there are additional options.
Only the Y Axis field is required to create a basic single-box plot, but there are additional options.
- Select another column (here "Study:Cohort") and choose how to use this column:
- X Axis Categories: Create a plot with multiple boxes along the x-axis, one per value in the selected column.
- Color: Display values in the plot with a different color for each column value. Useful when displaying all points or displaying outliers as points.
- Shape: Change the shape of points based on the value in the selected column.

- Here we make it the X-Axis Category and click Apply to see a box plot for each cohort.

- Click View Data to see, filter, or export the underlying data.
- Click View Chart to return. If you applied any filters, you would see them immediately reflected in the plot.
- Customize your visualization using the Chart Type and Chart Layout links in the upper right.
- Chart Type reopens the creation dialog allowing you to:
- Change any column selection (hover and click the X to delete the current election). You can also drag and drop columns between selection boxes to change positions.
- Add new columns, such as to group points by color or shape. Here we've chosen "Country" and "Gender", respectively.
- Click Apply to see your changes and switch dialogs.
- Chart Layout offers options to change the look of your chart, including the option to show all data as points and jitter those points to make the color and shape distinctions we chose clearer.
- Click Apply to update the chart with the selected changes.

- Chart Layout offers the ability to change the look and feel of your chart.

- There are 4 tabs:
- General:
- Provide a Title to show above your plot. By default, the dataset name is used, and you can return to this default at an time by clicking the refresh icon.
- Provide a Subtitle to show below the title.
- Specify the width and height.
- Elect whether to display single points for all data, only for outliers, or not at all.
- Check the box to jitter points.
- You can also customize the colors, opacity, width and fill for points or lines.
- X-Axis/Y-Axis:
- Change the display labels for the axes (notice this does not change which columns provide the data).
- Choose log or linear scale for the Y-axis, and if desired, apply a Range - the default is automatic. Select manual and specify the range if desired.
- Developer: Only available to users that are members of the "Site Developers" permission group.
- Provide a JavaScript function that will be called when a data point in the chart is clicked.
- Click Apply to update the chart with the selected changes.
- When your chart is ready, click Save.

- Name the plot, enter a description (optional), and choose whether to make it viewable by others. You will also see the default thumbnail which has been auto-generated. You can elect None. As with other charts, you can later attach a custom thumbnail if desired.
Export Chart
Hover over the chart to reveal export option buttons in the upper right corner: Export your completed chart by clicking an option:
Export your completed chart by clicking an option:
- Script: pop up a window displaying the JavaScript for the chart which you can then copy and paste into a wiki. See Export Chart as JavaScript for a tutorial on this feature.
- PNG: create a PNG image.
- PDF: generate a PDF file.
Rules Used to Render the Box Plot
The following rules are used to render the box plot. Hover over a box to see a pop-up.- Min/Max are the highest and lowest data points still within 1.5 of the interquartile range.
- Q1 marks the lower quartile boundary.
- Q2 marks the median.
- Q3 marks the upper quartile boundary.
- Values outside of the range are considered outliers and are rendered as dots by default. The options and grouping menus offer you control of whether and how single dots are shown.
Video
Related Topics
Pie Charts
Create a Pie Chart
- Navigate to the data grid you want to visualize.
- Select Charts > Create Chart to open the editor. Click Pie.
- The columns eligible for charting from your current grid view are listed.
- If you want to plot using a column that is not visible here, return to the data grid and use Grid Views > Customize Grid to add it.
- If your server is configured to restrict charting to columns marked as "measures" or "dimensions", you will only be able to use columns with those designations.
- Select the column to visualize and drag it to the Categories box.

- Click Apply. The size of the pie wedges will reflect the count of rows for each unique value in the column selected.

- Click View Data to see, filter, or export the underlying data.
- Click View Chart to return. If you applied any filters, you would see them immediately reflected in the chart.
- Customize your visualization using the Chart Type and Chart Layout links in the upper right.
- Chart Type reopens the creation dialog allowing you to:
- Change the Categories column selection.
- Note that you can also click another chart type on the left to switch how you visualize the data using the same selected columns when practical.
- Click Apply to update the chart with the selected changes.
- Chart Layout offers the ability to change the look and feel of your chart.

- Customize any or all of the following options:
- Provide a Title to show above your chart. By default, the dataset name is used.
- Provide a Subtitle. By default, the categories column name is used. Note that changing this label does not change which column is used for wedge categories.
- Specify the width and height.
- Select a color palette. Options include Light, Dark, and Alternate. Mini squares showing the selected palette are displayed.
- Customizing the radii of the pie chart allows you to size the graph and if desired, include a hollow center space.
- Elect whether to show percentages with the wedges, the display color for them, and whether to hide those annotations when wedges are narrow. The default is to hide percentages when they are under 5%.
- Use the Gradient % slider and color to create a shaded look.
- Click Apply to update the chart with the selected changes.
- When your chart is ready, click Save.

- Name the chart, enter a description (optional), and choose whether to make it viewable by others. You will also see the default thumbnail which has been auto-generated, and can choose whether to use it. As with other charts, you can later attach a custom thumbnail if desired.
Export Chart
Hover over the chart to reveal export option buttons in the upper right corner: Export your completed chart by clicking an option:
Export your completed chart by clicking an option:
- Script: pop up a window displaying the JavaScript for the chart which you can then copy and paste into a wiki. See Export Chart as JavaScript for a tutorial on this feature.
- PNG: create a PNG image.
- PDF: generate a PDF file.
Videos
- Video Overview: Pie Charts (16.3)
- Video: Using the Chart Designer (16.3)
Related Topics
Scatter Plots
Create a Scatter Plot
- Navigate to the data grid you want to visualize.
- Select Charts > Create Chart. Click Scatter.
- The columns eligible for charting from your current grid view are listed.
- If you want to plot using a column that is not visible here, return to the data grid and use Grid Views > Customize Grid to add it.
- If your server is configured to restrict charting to columns marked as "measures" or "dimensions", you will only be able to use columns with those designations.
- Select the X Axis column by drag and drop.
- Select the Y Axis column by drag and drop.

- Only the X and Y Axes are required to create a basic scatter plot. Other options will be explored below.
- Click Apply to see the basic plot.

- Click View Data to see, filter, or export the underlying data.
- Click View Chart to return. If you applied any filters, you would see them immediately reflected in the plot.
- Customize your visualization using the Chart Type and Chart Layout links in the upper right.
- Chart Type reopens the creation dialog allowing you to:
- Change the X or Y Axis column (hover and click the X to delete the current selection).
- Optionally select columns for grouping of points by color or shape.
- Note that you can also click another chart type on the left to switch how you visualize the data with the same axes and color/shape groupings when practical.
- Click Apply to update the chart with the selected changes.
- Here we see the same scatter plot data, with colors varying by cohort and points shaped based on gender. Notice the key in the upper right.

 There are four tabs:
There are four tabs:
- General:
- Provide a title to display on the plot. The default is the name of the source data grid.
- Provide a subtitle to display under the title.
- Specify a width and height.
- Choose whether to jitter points.
- Control the point size and opacity, as well as choose the default color palette. Options: Light (default), Dark, and Alternate. The array of colors is shown under the selection.
- Group By Density: Select either "Always" or "When number of data points exceeds 10,000."
- Grouped Data Shape: Choose either hexagons or squares.
- Density Color Palette: Options are blue & white, heat (yellow/orange/red), or select a single color from the dropdown to show in graded levels. These palettes override the default color palette and other point options in the left column.
- X-Axis/Y-Axis:
- Change the display labels for the axis (notice this does not change which column provides the data).
- Choose log or linear scale for the Y-axis, and specify a range if desired.
- Developer: Only available to users that are members of the "Site Developers" permission group.
- Provide a JavaScript function that will be called when a data point in the chart is clicked.
- Click Chart Layout and change Group By Density to "Always".
- Select Heat as the Density Color Palette and leave the default Hexagon shape selected
- Click Apply to update the chart with the selected changes.

- Notice that when binning is active, a warning message will appear reading: "The number of individual points exceeds the limit set in the Chart Layout options. The data will be displayed according to point density in a heat map." Click Dismiss to remove that message from the display.
- When your chart is finished, click Save.

- Name the chart, enter a description (optional), and choose whether to make it viewable by others. You will also see the default thumbnail which has been auto-generated, and can choose whether to use it. As with other charts, you can later attach a custom thumbnail if desired.
Export Chart
Hover over the chart to reveal export option buttons in the upper right corner: Export your completed chart by clicking an option:
Export your completed chart by clicking an option:
- Script: pop up a window displaying the JavaScript for the chart which you can then copy and paste into a wiki. See Export Chart as JavaScript for a tutorial on this feature.
- PNG: create a PNG image.
- PDF: generate a PDF file.
Video
Related Topics
Time Charts
- Individually select which study participants, cohorts, or groups appear in the chart.
- Refine your chart by defining data dimensions and groupings.
- Export an image of your chart to a PDF or PNG file.
- Export your chart to Javascript (for developers only).
Create a Time Chart
- Navigate to the dataset, view, or query of interest. Time charts are only available in study folders.
- Select Charts > Create Chart. Click Time.
- Whether the X-axis is date based or visit-based is determined by the study type. For a date-based study:
- Choose the Time Interval to plot: Days, Weeks, Months, Years.
- Select the desired Interval Start Date from the drop down menu. All eligible date fields are listed.
- At the top of the right panel is a drop down from which you select the desired dataset or query. Time charts are only supported for datasets/queries in the "study" schema which include columns designated as 'measures' for plotting. Queries must also include both the 'ParticipantId' and 'ParticipantVisit columns to be listed here.
- The list of columns designated as measures available in the selected dataset or query is shown in the Columns panel. Drag the desired selection to the Y-Axis box.
- By default the axis will be shown on the left; click the right arrow to switch sides.

- Click Apply.
- The time chart will be displayed.
- Use the checkboxes in the Filters panel on the left:
- Click a label to select only that participant.
- Click a checkbox to add or remove that participant from the chart.

- Click View Data to see the underlying data.
- Click View Chart(s) to return.
- Customize your visualization using the Chart Type and Chart Layout links in the upper right.
- Chart Type reopens the creation dialog allowing you to:
- Change the X Axis options for time interval and start date.
- Change the Y Axis to plot a different measure, or plot multiple measures at once. Time charts are unique in allowing cross-query plotting. You can select measures from different datasets or queries within the same study to show on the same time chart.
- Remove the existing selection by hovering and clicking the X. Replace with another measure.
- Add a second measure by dragging another column from the list into the Y-Axis box.
- For each measure you can specify whether to show the Y-axis for it on the left or right.
- Open and close information panels about time chart measures by clicking on them.

- Click Apply to update the chart with the selected changes.
- Chart Layout offers the ability to change the look and feel of your chart.
 There are at least 4 tabs:
There are at least 4 tabs:
- On the General tab:
- Provide a Title to show above your chart. By default, the dataset name is used.
- Specify the width and height.
- You can also customize the line width, and elect whether to hide data points along the line.
- Number of Charts: Choose whether to show all data on one chart, or separate by group, or by measure.
- Subject Selection: By default, you select participants from the filter panel. Select Participant Groups to enable charting of data by groups and cohorts using the same checkbox filter panel. Choose at least one charting option for groups:
- Show Individual Lines: show plot lines for individual participant members of the selected groups.
- Show Mean: plot the mean value for each participant group selected. Use the pull down to select whether to include range bars when showing mean. Options are: "None, Std Dev, or Std Err".
- On the X-Axis tab:
- Customize the Label shown on the X-axis. Note that changing this text will not change the interval or range plotted. Use the Chart Type settings to change what is plotted.
- Specify a range of X values to plot, or use the default automatic setting.
- There will be one Y-Axis tab for each side of the plot if you have elected to use both the left and right Y-axes. For each side:
- Customize the Label shown on that Y-axis. Note that changing this text will not change the measure or range plotted.
- Select whether to use a linear or log scale on this axis.
- Range: Options are:
- Automatic across charts
- Automatic within chart
- Manual (specify min and max values)
- For each Measure using that Y-axis, you can choose an Interval End Date. The pulldown menu includes eligible date columns from the source dataset or query.

- On the Developer tab, users with developer access can provide a JavaScript function that will be called when a data point in the chart is clicked.
- Click Apply to update the chart with the selected changes. In this example, we now plot data by participant group. Note that the filter panel now allows you to plot trends for cohorts and other groups. This example shows a plot combining trends for two measures, lymphs and viral load, for two study cohorts.

- When your chart is ready, click Save.
- Name the chart, enter a description (optional), and choose whether to make it viewable by others. You will also see the default thumbnail which has been auto-generated, and can choose whether to use it. As with other charts, you can later attach a custom thumbnail if desired.

- Click Save.

Data Dimensions
By adding dimensions for a selected measure, you can further refine the timechart. You can group data for a measure on any column in your dataset that is defined as a "data dimension". To define a column as a data dimension:- Open a grid view of the dataset of interest.
- Click Manage.
- Click Edit Definition.
- In the Dataset Fields section, select a column.
- Select the Reporting tab.
- Place a checkmark next to Data Dimension.

- Click Save.
- Click View Data to return to your grid view.
- Create a new time chart, or select one from the Charts menu and click Edit.
- Click Chart Layout.
- Select the Y-Axis tab.
- The pulldown menu for Divide Data Into Series By will include the dimensions you have defined.
- Select how you would like duplicate values displayed. Options: Average, Count, Max, Min, Sum.

- Click Apply.
- A new section appears in the filters panel where you can select specific values of the new data dimension to further refine your chart.

Export Chart
Hover over the chart to reveal export option buttons in the upper right corner: Export your completed chart by clicking an option:
Export your completed chart by clicking an option:
- Script: pop up a window displaying the JavaScript for the chart which you can then copy and paste into a wiki. See Export Chart as JavaScript for a tutorial on this feature.
- PNG: create a PNG image.
- PDF: generate a PDF file.
Related Topics
Column Visualizations
- Bar Chart - Histogram displayed above the grid.
- Box & Whisker - Distribution box displayed above the grid.
- Pie Chart - Pie chart displayed above the grid.
 To remove a chart, hover over the chart and click the 'X' in the upper right corner.Available visualization types are determined by whether the column is a Measure and/or a Dimension.
To remove a chart, hover over the chart and click the 'X' in the upper right corner.Available visualization types are determined by whether the column is a Measure and/or a Dimension.
- The box plot option is shown for any column marked as a Measure.
- The bar and pie chart options are shown for any column marked as a Dimension.
Bar Chart
A histogram of the Weight column.
Box and Whisker Plot
A basic box plot report. You can include several column visualizations above a grid simultaneously.
Pie Chart
A pie chart showing prevalence of ARV Regimen types. Filters are also applied to the visualizations displayed. If you filter to hide 'blank' ARV treatment types, the pie chart will update.
Filters are also applied to the visualizations displayed. If you filter to hide 'blank' ARV treatment types, the pie chart will update.
Related Topics
Quick Charts
Create a Quick Chart
- Navigate to a data grid you wish to visualize.
- Click a column header and select Quick Chart. Depending on the content of the column, LabKey Server makes a best guess at the type and arrangement of chart to use as a starting place. A numeric column in a cohort study, for example, might be quickly charted as a box and whisker plot using cohorts as categories.
- You can then alter and refine the chart in the following ways:
- View Data: Toggle to the data grid, potentially to apply filters to the underlying data. Filters are reflected in the plot upon re-rendering.
- Export: Export the chart as a PDF, PNG, or Script.
- Help: Documentation links.
- Chart Type: Click to open the plot editor. You can change the plot type to any of the following and the options for chart layout settings will update accordingly
- Chart Layout: Click to customize the look and feel of your chart; options available vary based on the chart type. See individual chart type pages for a descriptions of options.
- Save: Click to open the save dialog.
Related Topics
Query Snapshot
Create a Query Snapshot
- Go to the query, grid, or dataset you wish to snapshot.
- Select Reports > Create Query Snapshot.

- Name the snapshot.
- Specify manual or scheduled refresh.
- Click Create Snapshot.

R Reports
Topics
- R Report Builder - Create R reports on data using interactive source and preview panes.
- Saved R Reports - Work with pre-existing R reports.
- Datasets in R - Access data using "labkey.data".
- Multi-Panel R Plots - Create multiple plots using R.
- Lattice Plots - Use the "Lattice" R package.
- Participant Charts in R - Work with participant data in R.
- R Reports with knitr - Use the "knitr" R package to create visualizations that include markdown or HTML.
- Input/Output Substitutions Reference - Input and output parameters; implicit variables.
- FAQs for LabKey R Reports - R Reports: Frequently asked questions.
Related Topics
- Rlabkey Package - The LabKey R API
- R Tutorial Video - A video walk-through of LabKey Server's R features.
- Tutorial Video for Custom R Charts - Using SQL queries, R script, and JavaScript.
- Script Pipeline: Running R and Other Scripts in Sequence - Run a sequence of R and other scripts, managed by the processing pipeline.
RStudio and LabKey Server
 Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey

R Report Builder
Create an R Report
Base an R Report on a Data Grid
R reports are ordinarily associated with individual data grids. Choose the dataset of interest and further filter the grid as needed. Only the portion of the dataset visible within this data grid become part of the analyzed dataset.To use the sample dataset we describe in this tutorial, please Step 1: Install the Sample Study if you have not already done so. Alternately, you may simply add the Physical Exam.xls demo dataset to an existing study for completing the tutorial. You may also work with your own dataset, in which case steps and screencaps will differ.- View the "Physical Exam" dataset.
- If you want to filter the dataset and thus select a subset or rearrangement of fields, select or create a custom grid view.
- Select Reports > Create R Report.
Alternative: Create an R report independent of any grid view
R reports do not necessarily need to be associated with individual data grids. You can also create an R report that is independent of any grid:- Select Admin > Manage Views.
- Select Add Report > R Report.
Review the R report builder
The R report builder opens on the Source tab which looks like this: Script Source:Paste an R script for execution or editing into this text box.Checkboxes:
Script Source:Paste an R script for execution or editing into this text box.Checkboxes:
- Make this report available to all users: Enables other users to see your R report and source() its associated script if they have sufficient permissions. Only those with read privileges to the dataset can see your new report based on it.
- If you choose to share your report, you can also opt to Show source tab to all users but it is not required.
- Make this report available in child folders: Make your report available in data grids in child folders where the schema and table are the same as this data grid.
- Run this report in the background as a pipeline job: Execute your script asynchronously using LabKey’s Pipeline module. If you have a big job, running it on a background thread will allow you to continue interacting with your server during execution.
Report Tab
When you select the Report tab, you'll see the resulting graphics and console output for your R report. If the pipeline option is not selected, the script will be run in batch mode on the server.Data Tab
Select the data tab to see the data on which your R report is based. This can be a helpful resource as you write or refine your script.Source Tab
When your script is complete and report is satisfactory, return to the Source tab, scroll down, and click Save to save both the script and the report you generated.A saved report will look similar to the results in the design view tab, minus the help text. Reports are saved on the LabKey Server, not on your local file system. They can be accessed through the Reports drop-down menu on the grid view of you dataset, or directly from the Data Views web part.The script used to create a saved report becomes available to source() in future scripts. Saved scripts are listed under the “Shared Scripts” section of the LabKey R report builder.Additional Options
On the Source Tab you can expand additional option sections:- Knitr: select None, HTML, or Markdown processing of HTML source; include semicolon separated list of dependencies if needed.
- Report Thumbnail: Choose to auto-generate a default thumbnail if desired. You can later edit the thumbnail or attach a custom image. See Manage Views.
- Shared Scripts: Once you save a View, its associated script becomes available to execute using source(“<Script Name>.R”) in future scripts. Check the box next to the appropriate script to make it available for execution.
- Study Options: Participant Chart: A participant chart shows measures for only one participant at a time. Select the participant chart checkbox if you would like this chart to be available for review participant-by-participant.
- Study Options: Enable automatic caching of this report for faster reloading.
Help Tab
This Syntax Reference list provides a quick summary of the substitution parameters for LabKey R. See Input/Output Substitutions Reference for further details.Example
Regardless of where you have accessed the R report builder, you can create a first R report which is data independent. This sample was adapted from the R help files.- Paste the following into the Source tab of the R report builder.
options(echo=TRUE);
# Execute 100 Bernoulli trials;
coin_flip_results = sample(c(0,1), 100, replace = TRUE);
coin_flip_results;
mean(coin_flip_results);
- Click the Report tab to run the source and see your results, in this case the coin flip outcomes.
Note: Echo to Console
By default, most R commands do not generate output to the console as part of your script. To enable output to console, use the following line at the start of your scripts:options(echo=TRUE);
Related Topics
Saved R Reports
Edit a Saved Report's Script
Open your saved R report by clicking the name in the data views web part or by selecting it from the Reports menu above the data grid on which it is based. This opens the R report builder interface on the Data tab. Select the Source tab to edit the script and manage other options. Click Save when finished.
Delete a Saved R Report
You can delete a saved report by first clicking the pencil icon at the top of the Data Views webpart, then click the pencil to the left of the report name. In the popup window, click Delete View. You can also multi-select R reports for deletion on the Manage Views page.Note that deleting a report eliminates its associated script from the “Shared Scripts” list in the R report interface. Make sure that you don’t delete a script that is called (sourced) by other scripts you need.Related Topics
Datasets in R
Access Your Dataset as “labkey.data”
LabKey Server automatically reads your chosen dataset into a data frame called labkey.data; using Input Substitution.A data frame can be visualized as a list with unique row names and columns of consistent lengths. Columns may also be named and their types may differ. You can see the column names for the labkey.data frame by calling:options(echo=TRUE);
names(labkey.data);
labkey.data$<column name>
Use Pre-existig R Scripts
To use a pre-existing R script with LabKey data, try the following procedure:- Copy-and-paste the script into the R Report Builder, for example:
png(filename="${imgout:myscatterplot}", width = 650, height = 480);
plot(x, y, main="Scatterplot Example", xlab="X Axis ", ylab="Y Axis", pch=19)
abline(lm(y~x), col="red") # regression line (y~x)
- Identify the LabKey data columns that you want to be represented by the script, and load those columns into vectors. The following loads the Systolic Blood Pressure and Diastolic Blood Pressure columns into the vectors x and y:
x <- labkey.data$diastolicbloodpressure
y <- labkey.data$systolicbloodpressure
png(filename="${imgout:myscatterplot}", width = 650, height = 480);
plot(x, y, main="Scatterplot Example", xlab="X Axis ", ylab="Y Axis", pch=19)
abline(lm(y~x), col="red") # regression line (y~x)
- Click the View tab to see the result:

Find Simple Means
Once you have loaded your data, you can perform statistical analyses using the functions/algorithms in R and its associated packages. For example:options(echo=TRUE);
names(labkey.data);
labkey.data$pulse;
a <- mean(labkey.data$pulse, na.rm= TRUE);
a;
Find Means for Each Participant
The following simple script finds the average values of a variety of physiological measurements for each study participant.# Get means for each participant over multiple visits;
options(echo=TRUE);
participant_means <- aggregate(labkey.data, list(ParticipantID = labkey.data$participantid), mean, na.rm = TRUE);
participant_means;
Create Functions in R
This script shows an example of how functions can be created and called in LabKey R scripts. Before you can run this script, the Cairo package must be installed on your server. See Install and Set Up R for instructions.Note that the second line of this script creates a "data" copy of the input file, but removes all participant records that contain an NA entry. NA entries are common in study datasets and can complicate display results.library(Cairo);
data= na.omit(labkey.data);
chart <- function(data)
{
plot(data$pulse, data$pulse);
};
filter <- function(value)
{
sub <- subset(labkey.data, labkey.data$participantid == value);
#print("the number of rows for participant id: ")
#print(value)
#print("is : ")
#print(sub)
chart(sub)
}
names(labkey.data);
Cairo(file="${imgout:a}", type="png");
layout(matrix(c(1:4), 2, 2, byrow=TRUE));
strand1 <- labkey.data[,1];
for (i in strand1)
{
#print(i)
value <- i
filter(value)
};
dev.off();
Access Data in Another Dataset
You can access data in another dataset (a dataset not loaded into labkey.data) through the Rlabkey library's selectRows, for example:suppressMessages(library(Rlabkey))
mydata <- labkey.selectRows(
baseUrl="http://localhost:8080/labkey",
folderPath="/home/Demo Study",
schemaName="assay.General.Nab",
queryName="Data",
viewName="",
containerFilter=NULL)
Multi-Panel R Plots
Find Mean Values for Each Participant
Finding the mean value for physiological measurements for each participant across all visits can be done in various ways. Here, we cover three alternative methods.For all methods, we use "na.rm=TRUE" as an argument to aggregate in order to ignore null values when we calculate means.| Description | Code |
|---|---|
| Aggregate each physiological measurement for each participant across all visits; produces an aggregated list with two columns for participantid. | data_means <- aggregate(labkey.data, list(ParticipantID = |
| Aggregate only the pulse column and display two columns: one listing participantIDs and the other listing mean values of the pulse column for each participant | aggregate(list(Pulse = labkey.data$pulse), |
| Again, aggregate only the pulse column, but here results are displayed as rows instead of two columns. | participantid_factor <- factor(labkey.data$participantid); |
Create Single Plots
Next we use R to create plots of some other physiological measurements included in our sample data.Scatter Plot of All Diastolic vs All Systolic Blood Pressures
This script plots diastolic vs. systolic blood pressures without regard for participantIDs. It specifies the "ylim" parameter for plot() to ensure that the axes used for this graph match the next graph's axes, easing interpretation.library(Cairo);
Cairo(file="${imgout:diastol_v_systol_figure.png}", type="png");
plot(labkey.data$diastolicbloodpressure, labkey.data$systolicbloodpressure,
main="R Report: Diastolic vs. Systolic Pressures: All Visits",
ylab="Systolic (mm Hg)", xlab="Diastolic (mm Hg)", ylim =c(60, 200));
abline(lsfit(labkey.data$diastolicbloodpressure, labkey.data$systolicbloodpressure));
dev.off();

Scatter Plot of Mean Diastolic vs Mean Systolic Blood Pressure for Each Participant
This script plots the mean diastolic and systolic blood pressure readings for each participant across all visits. To do this, we use "data_means," the mean value for each physiological measurement we calculated earlier on a participant-by-participant basis.data_means <- aggregate(labkey.data, list(ParticipantID =
labkey.data$participantid), mean, na.rm = TRUE);
library(Cairo);
Cairo(file="${imgout:diastol_v_systol_means_figure.png}", type="png");
plot(data_means$diastolicbloodpressure, data_means$systolicbloodpressure,
main="R Report: Diastolic vs. Systolic Pressures: Means",
ylab="Systolic (mm Hg)", xlab="Diastolic (mm Hg)", ylim =c(60, 200));
abline(lsfit(data_means$diastolicbloodpressure, data_means$systolicbloodpressure));
dev.off();

Create Multiple Plots
There are two ways to get multiple images to appear in the report produced by a single script.Single Plot Per Report Section
The first and simplest method of putting multiple plots in the same report places separate graphs in separate sections of your report. Use separate pairs of device on/off calls (e.g., png() and dev.off()) for each plot you want to create. You have to make sure that the {imgout:} parameters are unique. Here's a simple example:png(filename="${imgout:labkeyl_png}");
plot(c(rep(25,100), 26:75), c(1:100, rep(1, 50)), ylab= "L", xlab="LabKey",
xlim= c(0, 100), ylim=c(0, 100), main="LabKey in R: Report Section 1");
dev.off();
png(filename="${imgout:labkey2_png}");
plot(c(rep(25,100), 26:75), c(1:100, rep(1, 50)), ylab= "L", xlab="LabKey",
xlim= c(0, 100), ylim=c(0, 100), main="LabKey in R: Report Section 2");
dev.off();
Multiple Plots Per Report Section
There are various ways to place multiple plots in a single section of a report. Two examples are given here, the first using par() and the second using layout().Example: Four Plots in a Single Section: Using par()This script demonstrates how to put multiple plots on one figure to create a regression panel layout. It uses standard R libraries for the arrangement of plots, and Cairo for creation of the plot image itself. It creates a single graphics file but partitions the ‘surface’ of the image into multiple sections using the mfrow and mfcol arguments to par().library(Cairo);
data_means <- aggregate(labkey.data, list(ParticipantID =
labkey.data$participantid), mean, na.rm = TRUE);
Cairo(file="${imgout:multiplot.png}", type="png")
op <- par(mfcol = c(2, 2)) # 2 x 2 pictures on one plot
c11 <- plot(data_means$diastolicbloodpressure, data_means$weight_kg, ,
xlab="Diastolic Blood Pressure (mm Hg)", ylab="Weight (kg)",
mfg=c(1, 1))
abline(lsfit(data_means$diastolicbloodpressure, data_means$weight_kg))
c21 <- plot(data_means$diastolicbloodpressure, data_means$systolicbloodpressure, ,
xlab="Diastolic Blood Pressure (mm Hg)",
ylab="Systolic Blood Pressure (mm Hg)", mfg= c(2, 1))
abline(lsfit(data_means$diastolicbloodpressure, data_means$systolicbloodpressure))
c21 <- plot(data_means$diastolicbloodpressure, data_means$pulse, ,
xlab="Diastolic Blood Pressure (mm Hg)",
ylab="Pulse Rate (Beats/Minute)", mfg= c(1, 2))
abline(lsfit(data_means$diastolicbloodpressure, data_means$pulse))
c21 <- plot(data_means$diastolicbloodpressure, data_means$temp_c, ,
xlab="Diastolic Blood Pressure (mm Hg)",
ylab="Temperature (Degrees C)", mfg= c(2, 2))
abline(lsfit(data_means$diastolicbloodpressure, data_means$temp_c))
par(op); #Restore graphics parameters
dev.off();
 Example: Three Plots in a Single Section: Using layout()This script uses the standard R libraries to display multiple plots in the same section of a report. It uses the layout() command to arrange multiple plots on a single graphics surface that is displayed in one section of the script's report.The first plot shows blood pressure and weight progressing over time for all participants. The lower scatter plots graph blood pressure (diastolic and systolic) against weight.
Example: Three Plots in a Single Section: Using layout()This script uses the standard R libraries to display multiple plots in the same section of a report. It uses the layout() command to arrange multiple plots on a single graphics surface that is displayed in one section of the script's report.The first plot shows blood pressure and weight progressing over time for all participants. The lower scatter plots graph blood pressure (diastolic and systolic) against weight.library(Cairo);
Cairo(file="${imgout:a}", width=900, type="png");
layout(matrix(c(3,1,3,2), nrow=2));
plot(weight_kg ~ systolicbloodpressure, data=labkey.data);
plot(weight_kg ~ diastolicbloodpressure, data=labkey.data);
plot(labkey.data$date, labkey.data$systolicbloodpressure, xaxt="n",
col="red", type="n", pch=1);
points(systolicbloodpressure ~ date, data=labkey.data, pch=1, bg="light blue");
points(weight_kg ~ date, data=labkey.data, pch=2, bg="light blue");
abline(v=labkey.data$date[3]);
legend("topright", legend=c("bpsys", "weight"), pch=c(1,2));
dev.off();

Related Topics
Lattice Plots
library("lattice");Display a Volcano
The Lattice Documentation provides a Volcano script to demonstrate the power of Lattice. The script below has been modified to work on LabKey R:library("lattice");
p1 <- wireframe(volcano, shade = TRUE, aspect = c(61/87, 0.4),
light.source = c(10,0,10), zlab=list(rot=90, label="Up"),
ylab= "North", xlab="East", main="The Lattice Volcano");
g <- expand.grid(x = 1:10, y = 5:15, gr = 1:2);
g$z <- log((g$x^g$g + g$y^2) * g$gr);
p2 <- wireframe(z ~ x * y, data = g, groups = gr,
scales = list(arrows = FALSE),
drape = TRUE, colorkey = TRUE,
screen = list(z = 30, x = -60));
png(filename="${imgout:a}", width=500);
print(p1);
dev.off();
png(filename="${imgout:b}", width=500);
print(p2);
dev.off();


Related Topics
Participant Charts in R
Create and View Simple Participant Charts
- Open the "Physical Exam" dataset in a demo study.
- Select Reports > Create R Report.
- On the Source tab, begin with a script that shows data for all participants. Using our "Physical Exam" sample data:
png(filename="${imgout:a}", width=900);
plot(labkey.data$systolicbloodpressure, labkey.data$date);
dev.off();
- Click the Report tab to view the scatter plot data for all participants.
- Return to the Source tab.
- Scroll down and click the triangle to open the Study Options section.
- Check Participant Chart.
- Click Save.
- Name your report "Participant Systolic" or another name you choose.
- Return to the data grid of the "Physical Exam" dataset.
- Select Reports > Participant Systolic (or the name you gave your report).
- Click Previous Participant.
- You will see Next Participant and Previous Participant links that let you step through charts for each participant:

Advanced Example: Create Participant Charts Using Lattice
You can create a panel of charts for participants using the lattice package. If you select the participant chart option on the source tab, you will be able to see each participant's panel individually when you select the report from your data grid.The following script produces lattice graphs for each participant showing systolic blood pressure over time:library(lattice);
png(filename="${imgout:a}", width=900);
plot.new();
xyplot(systolicbloodpressure ~ date| participantid, data=labkey.data,
type="a", scales=list(draw=FALSE));
update(trellis.last.object(),
strip = strip.custom(strip.names = FALSE, strip.levels = TRUE),
main = "Systolic over time grouped by participant",
ylab="Systolic BP", xlab="");
dev.off();
 The following script produces lattice graphics for each participant showing systolic and diastolic blood pressure over time (points instead of lines):
The following script produces lattice graphics for each participant showing systolic and diastolic blood pressure over time (points instead of lines):library(lattice);
png(filename="${imgout:b}", width=900);
plot.new();
xyplot(systolicbloodpressure + diastolicbloodpressure ~ date | participantid,
data=labkey.data, type="p", scales=list(draw=FALSE));
update(trellis.last.object(),
strip = strip.custom(strip.names = FALSE, strip.levels = TRUE),
main = "Systolic & Diastolic over time grouped by participant",
ylab="Systolic/Diastolic BP", xlab="");
dev.off();
 After you save these two R reports with descriptive names, you can go back and review individual graphs participant-by-participant. Use the Reports drop-down available on your data grid.
After you save these two R reports with descriptive names, you can go back and review individual graphs participant-by-participant. Use the Reports drop-down available on your data grid.R Reports with knitr
- Install R and knitr
- Develop knitr Reports
- R/knitr Scripts in Modules
- Declaring Script Dependencies
- HTML Example
- Markdown v2
- Markdown v1 Example
Install R and knitr
- If you haven't already installed R, follow these instructions: Install R.
- Open the R graphical user interface. On Windows, a typical location would be: C:\Program Files\R\R-3.0.2\bin\i386\Rgui.exe
- Select Packages > Install package(s).... Select a mirror site, and select the knitr package.
- OR
- Enter the following:
install.packages('knitr', dependencies=TRUE)
- Select a mirror site and wait for the knitr installation to complete.
Develop knitr Reports
- Go to the dataset you wish to visualize.
- Select Reports -> Create R Report.
- On the Source tab R Report Builder, enter your HTML or Markdown page with knitr code. (Scroll down for example pages.)
- Specify which source to process with knitr. Under knitr Options, select HTML or Markdown.
- Select the Report tab to see the results.
R/knitr Scripts in Modules
R script knitr reports are also available as custom module reports. The script file must have either a .rhtml or .rmd extension, for HTML or markdown documents, respectively. For a file-based module, place the .rhtml/.rmd file in the same location as .r files, as shown below. For module details, see Map of Module Files.MODULE_NAME
reports/
schemas/
SCHEMA_NAME/
QUERY_NAME/
MyRScript.r -- R report
MyRScript.rhtml -- R/knitr report
MyRScript.rmd -- R/knitr report
Declaring Script Dependencies
To fully utilize the report designer (called the "R Report Builder" in the LabKey user interface), you can declare JavaScript or CSS dependencies for knitr reports. This ensures that the dependencies are downloaded before R scripts are run on the "reports" tab in the designer. If these dependencies are not specified then any JavaScript in the knitr report may not run correctly in the context of the script designer. Note that reports that are run in the context of the Reports web part will still render correctly without needing to explicitly define dependencies.Reports can either be created via the LabKey Server UI in the report designer directly or included as files in a module. Reports created in the UI are editable via the Source tab of the designer. Open Knitr Options to see a text box where a semi-colon delimited list of dependencies can be entered. Dependencies can be external (via HTTP) or local references relative to the labkeyWebapp path on the server. In addition, the name of a client library may be used. If the reference does not have a .js or .css extension then it will be assumed to be a client library (somelibrary.lib.xml). The .lib.xml extension is not required. Like local references, the path to the client library is relative to the labkeyWebapp path.File based reports in a module cannot be edited in the designer although the "source" tab will display them. However you can still add a dependencies list via the report's metadata file. Dependencies can be added to these reports by including a <dependencies> section underneath the <R> element. A sample metadata file:<?xml version="1.0" encoding="UTF-8"?>
<ReportDescriptor xmlns="http://labkey.org/query/xml">
<label>My Knitr Report</label>
<description>Relies on dependencies to display in the designer correctly.</description>
<reportType>
<R>
<dependencies>
<dependency path="http://external.com/jquery/jquery-1.9.0.min.js"/>
<dependency path="knitr/local.js"/>
<dependency path="knitr/local.css"/>
</dependencies>
</R>
</reportType>
</ReportDescriptor>
HTML Example
To use this example:- Install the R package ggplot2
- Install the Demo Study.
- Create an R report on the dataset "Physical Exam"
- Copy and paste the knitr code below into the Source tab of the R Report Builder.
- Scroll down to the Knitr Options node, open the node, and select HTML.
- Click the Report tab to see the knitr report.
<table>
<tr>
<td align='center'>
<h2>Scatter Plot: Blood Pressure</h2>
<!--begin.rcode echo=FALSE, warning=FALSE
library(ggplot2);
opts_chunk$set(fig.width=10, fig.height=6)
end.rcode-->
<!--begin.rcode blood-pressure-scatter, warning=FALSE, message=FALSE, echo=FALSE, fig.align='center'
qplot(labkey.data$diastolicbloodpressure, labkey.data$systolicbloodpressure,
main="Diastolic vs. Systolic Pressures: All Visits",
ylab="Systolic (mm Hg)", xlab="Diastolic (mm Hg)", ylim =c(60, 200), xlim=c(60,120), color=labkey.data$temp_c);
end.rcode-->
</td>
<td align='center'>
<h2>Scatter Plot: Body Temp vs. Body Weight</h2>
<!--begin.rcode temp-weight-scatter, warning=FALSE, message=FALSE, echo=FALSE, fig.align='center'
qplot(labkey.data$temp_c, labkey.data$weight_kg,
main="Body Temp vs. Body Weight: All Visits",
xlab="Body Temp (C)", ylab="Body Weight (kg)", xlim=c(35,40), color=labkey.data$height_cm);
end.rcode-->
</td>
</tr>
</table>

Markdown v2
Administrators can enable Markdown v2 when enlisting an R engine through the Views and Scripting Configuration page. When enabled, Markdown v2 will be used when rendering knitr R reports. If not enabled, Markdown v1 is used to execute the reports. Independent installation is required of the following:
Independent installation is required of the following:
- rmarkdown R package (http://rmarkdown.rstudio.com/)
- Pandoc binary (http://pandoc.org/installing.html)
- any other package dependencies on the same server as the R engine
Markdown v1 Example
Scatter Plot: Blood Pressure
----------------------------
>The chart below shows data from all participants
```{r setup, echo=FALSE}
# set global chunk options: images will be 7x5 inches
opts_chunk$set(fig.width=7, fig.height=5)
```
```{r graphic1, echo=FALSE}
plot(labkey.data$diastolicbloodpressure, labkey.data$systolicbloodpressure,
main="Diastolic vs. Systolic Pressures: All Visits",
ylab="Systolic (mm Hg)", xlab="Diastolic (mm Hg)", ylim =c(60, 200));
abline(lsfit(labkey.data$diastolicbloodpressure, labkey.data$systolicbloodpressure));
```
Scatter Plot: Body Temp vs. Body Weight
---------------------------------------
>The chart below shows data from all participants.
```{r graphic2, echo=FALSE}
plot(labkey.data$temp_c, labkey.data$weight_kg,
main="Temp vs. Weight",
xlab="Body Temp (C)", ylab="Body Weight (kg)", xlim=c(35,40));
```
Related Links
Input/Output Substitutions Reference
Input and Output Substitution Parameters
Your R script uses input substitution parameters to generate the names of input files and to import data from your chosen Dataset Grid. It then uses output substitution parameters to either directly place image/data files in your report or to include download links to these files. Substitutions take the form of: ${param} where 'param' is the substitution.| Valid Substitutions: | |
|---|---|
| input_data | LabKey Server automatically reads your input dataset (a tab-delimited table) into the data frame called labkey.data. For tighter control over the method of data upload, or to modify the parameters of the read.table function, you can perform the data table upload yourself: labkey.data <- read.table("${input_data}", header=TRUE); |
| imgout: <name> | An image output file (such as jpg, png, etc.) that will be displayed as a Section of a report on the LabKey Server. The 'imgout:' prefix indicates that the output file is an image and the <name> substitution identifies the unique image produced after you call dev.off(). The following script displays a .png image in a report: png(filename="${imgout:labkeyl_png}"); |
| tsvout: <name> | A TSV text file that is displayed on LabKey Server as a section within a report. No downloadable file is created. For example: write.table(labkey.data, file = "${tsvout:tsvfile}", sep = "t", |
| txtout: <name> | A text file that is displayed on LabKey Server as a section within a report. No downloadable file is created. A CSV example: write.csv(labkey.data, file = "${txtout:csvfile}"); |
| pdfout: <name> | A PDF output file that can be downloaded from the LabKey Server. pdf(file="${pdfout:labkeyl_pdf}"); |
| psout: <name> | A postscript output file that can be downloaded from the LabKey Server. postscript(file="${psout:labkeyl_eps}", horizontal=FALSE, onefile=FALSE); |
| fileout: <name> | A file output that can be downloaded LabKey Server, and may be of any file type. For example, use fileout in the place of tsvout to allow users to download a TSV instead of seeing it within the page:write.table(labkey.data, file = "${fileout:tsvfile}", sep = "t", qmethod = "double", col.names=NA); |
Another example shows how to send the output of the console to a file: options(echo=TRUE); | |
| htmlout: <name> | A text file that is displayed on LabKey Server as a section within a report. The output is different from the txtout: replacement in that no html escaping is done. This is useful when you have a report that produces html output. No downloadable file is created: txt <- paste("<i>Click on the link to visit LabKey:</i> |
| svgout: <name> | An svg file that is displayed on LabKey Server as a section within a report. htmlout can be used to render svg outpust as well, however, using svgout will generate a more appropriate thumbnail image for teh report. No downloadable file is created:svg("${svgout:svg}", width= 4, height=3) |
Implicit Variables
Each R script contains implicit variables that are inserted before your source script. Implicit variables are R data types and may contain information that can be used by the source script.| Implicit variables: | |
|---|---|
| labkey.data | The data frame which the input dataset is automatically read into. The code to generate the data frame is: labkey.data <- read.table("${input_data}", header=TRUE, sep="t", |
| labkey.url.path | The path portion of the current URL which omits the base context path, action and URL parameters. The path portion of the URL: http://localhost:8080/labkey/study/home/test/begin.view would be: /home/test/ |
| labkey.url.base | The base portion of the current URL. The base portion of the URL: http://localhost:8080/labkey/study/home/test/begin.view would be: http://localhost:8080/labkey/ |
| labkey.url.params | The list of parameters on the current URL. The parameters are represented as a list of key / value pairs. |
| labkey.user.email | The email address of the current user |
Cairo or GDD Packages
You may need to use the Cairo or GDD graphics packages in the place of jpeg() and png() if your LabKey Server runs on a "headless" Unix server. You will need to make sure that the appropriate package is installed in R and loaded by your script before calling either of these functions.GDD() and Cairo() Examples. If you are using GDD or Cairo, you might use the following scripts instead:library(Cairo);
Cairo(file="${imgout:labkeyl_cairo.png}", type="png");
plot(c(rep(25,100), 26:75), c(1:100, rep(1, 50)), ylab= "L", xlab="LabKey",
xlim= c(0, 100), ylim=c(0, 100), main="LabKey in R");
dev.off();

library(GDD);
GDD(file="${imgout:labkeyl_gdd.jpg}", type="jpeg");
plot(c(rep(25,100), 26:75), c(1:100, rep(1, 50)), ylab= "L", xlab="LabKey",
xlim= c(0, 100), ylim=c(0, 100), main="LabKey in R");
dev.off();

Additional Reference
Documentation and tutorials about the R language can be found at the R Project website.FAQs for LabKey R Reports
Overview
This page aims to answer common questions about configuring and using the LabKey Server interface for creating R Reports. Remember, an administrator must install and configure R on LabKey Server before users can create and run R scripts on live datasets.Topics:- library(), help() and data() don’t work
- plot() doesn’t work
- jpeg() and png() don’t work
- Does my report reflect live, updated data?
- Output is not printed when I source() a file or use a function
- Scripts pasted from documentation don't work in the LabKey R Script Builder
- LabKey Server becomes very, very slow when scripts execute
- Does R create security risks?
- Any good sources for advice on R scripting?
1. library(), help() and data() don’t work
LabKey Server runs R scripts in batch mode. Thus, on Windows machines it does not display the pop-up windows you would ordinarily see in R’s interpreted/interactive mode. Some functions that produce pop-ups (e.g., library()) have alternatives that output to the console. Some functions (e.g., help() and some forms of data()) do not.Windows Workaround #1: Use alternatives that output to the consolelibrary(): The library() command has a console-output alternative. To see which packages your administrator has made available, use the following:installed.packages()[,0]
2. plot() doesn’t work
Did you open a graphics device before calling plot()?LabKey Server executes R scripts in batch mode. Thus, LabKey R never automatically opens an appropriate graphics device for output, as would R when running in interpreted/interactive mode. You’ll need to open the appropriate device yourself. For onscreen output that becomes part of a report, use jpeg() or png() (or their alternatives, Cairo(), GDD() and bitmap()). In order to output a graphic as a separate file, use pdf() or postscript().Did you call dev.off() after plotting?You need to call dev.off() when you’re done plotting to make sure the plot object gets printed to the open device.3. jpeg() and png() don’t work
R is likely running in a headless Unix server. On a headless Unix server, R does not have access to the appropriate X11 drivers for the jpeg() and png() functions. Your admin can install a display buffer on your server to avoid this problem. Otherwise, in each script you will need to load the appropriate package to create these file formats via other functions (e.g., GDD or Cairo). See also: Determine Available Graphing Functions for help getting unstuck.4. Does my report reflect live, updated data?
Yes. In general, LabKey always re-runs your saved script before displaying its associated report. Your script operates on live, updated data, so its plots and tables reflect fresh data.In study folders, you can set a flag for any script that prevents the script from being re-run unless changes have occurred. This flag can save time when scripts are time-intensive or datasets are large making processing slow. When this flag is set, LabKey will only re-run the R script if:- The flag is cleared OR
- The dataset associated with the script has changed OR
- Any of the attributes associated with the script are changed (script source, options etc.)
5. Output is not printed when I source() a file or use a function
The R FAQ explains:When you use… functions interactively at the command line, the result is automatically printed...In source() or inside your own functions you will need an explicit print() statement.When a command is executed as part of a file that is sourced, the command is evaluated but its results are not ordinarily printed. For example, if you call source(scriptname.R) and scriptname.R calls installed.packages()[,0] , the installed.packages()[,0] command is evaluated, but its results are not ordinarily printed. The same thing would happen if you called installed.packages()[,0] from inside a function you define in your R script.You can force sourced scripts to print the results of the functions they call. The R FAQ explains:
If you type `1+1' or `summary(glm(y~x+z, family=binomial))' at the command line the returned value is automatically printed (unless it is invisible()). In other circumstances, such as in a source()'ed file or inside a function, it isn't printed unless you specifically print it.To print the value 1+1, use
print(1+1);
source("1plus1.R", echo=TRUE);6. Scripts pasted from documentation don't work in the LabKey R report builder
If you receive an error like this:Error: syntax error, unexpected SYMBOL, expecting 'n' or ';'
in "library(Cairo) labkey.data"
Execution halted
7. LabKey Server becomes very, very slow when scripts execute
You are probably running long, computationally intensive scripts. To avoid a slowdown, run your script in the background via the LabKey pipeline. See R Report Builder for details on how to execute scripts via the pipeline.8. Does R Create Security Risks?
Allowing the use of R scripts/reports on a server can be a security risk. A developer could write a script that could read or write any file stored in any SiteRoot, fileroot or pipeline root despite the LabKey security settings for that file.A user must have developer permissions to write a R script or report to be used on the server.R should not be used on a "shared server", that is, a server where users with admin/developer privileges in one project do not have permissions on other projects. Running R on the server could pose a security threat if the user attempts to access the server command line directly. The main way to execute a system command in R is via the 'system(<system call>)' method that is part of the R core package. The threat is due to the permission level of a script being run by the server possibly giving unwanted elevated permissions to the user.9. Any good sources for advice on R scripting?
R Graphics Basics: Plot area, mar (margins), oma (outer margin area), mfrow, mfcol (multiple figures)- Provides good advice how to make plots look spiffy
- This powerpoint provides nice visuals for explaining various graphics parameters in R
- Lectures and labs cover the range - from introductory R to advanced genomic analysis
- Also links to useful example figures and code from several R books
10. Graphics File Formats
If you don’t know which graphics file format to use for your plots, this link can help you narrow down your options..png and .gif
Graphics shared over the web do best in png when they contain regions of monotones with hard edges (e.g., typical line graphs). The .gif format also works well in such scenarios, but it is not supported in the default R installation because of patent issues. The GDD package allows you to create gifs in R..jpeg
Pictures with gradually varying tones (e.g., photographs) are successfully packaged in the jpeg format for use on the web..pdf and .ps or .eps
Use pdf or postscript when you aim to output a graph that can be accessed in isolation from your R report.R Tutorial Video
The Camtasia Studio video content presented here requires JavaScript to be enabled and the latest version of the Macromedia Flash Player. If you are you using a browser with JavaScript disabled please enable it now. Otherwise, please update your version of the free Flash Player by downloading here.
JavaScript Reports
Attachment Reports
Add an Attachment Report
To upload an attachment report, follow these steps:- Create the desired report and save it to your local computer.
- In the Data Views web part, open the triangle pulldown menu.
- Select Add Report > Attachment Report.
- Provide the name, date, etc. for the report.
- Upload the report from your local machine (or point to a document already on the server).

Link Reports
Create a Link Report
- Go to Admin > Manage Views or open the drop down menu in the Data Views web part.
- Select Add Report > Link Report.
- Complete the form. Link to an external or internal resource. For example, link to an external website or to a page within the same LabKey Server.

- Your link report will appear in the Data Browser.

Video Overview
Participant Reports
Create a Participant Report
- Click the Clinical and Assay Data tab.
- Open the triangle menu next to the title of the Data Views web part.
- Click Add Report > Participant Report.
- Click Choose Measures, select one or more measures, then click Select.
- When you first create a report, you will be in "edit mode" and can change your set of chosen measures, but will only see partial results. Close the edit panel by clicking the pencil icon at the top of the report to see more results; you may reopen it at any time to further edit or save the report.
- Clicking the Filter Report chevron to use the filter panel to refine which participants appear in the report.

- Select desired filters. You may hide the filter panel with the chevron, or if you click the X to close it entirely, a Filter Report link will appear on the report menu bar.

- Click the Transpose button to flip the columns and rows in the generated tables, so that columns are displayed as rows and vice versa, as shown below.

- Name and save the report (to access naming and save options, you may need to reopen edit mode by clicking the pencil icon at the top of the report).
- Your new report will appear in the Data Views.
Add the Participant Report as a Web Part
- Select Report from the <Select Web Part>, select Report.
- Name the web part, and select the participant report you created above.
- Click Submit.
Export to Excel File
- Click Export > To Excel.
Related Topics
Query Report
Create a Query Report
- Navigate to the Clinical and Assay Data tab.
- Open the Data Views triangle pulldown menu.
- Select Add Report > Query Report.
 Your report will appear in the Data Views web part.You can customize the thumbnail and mini-icon displayed with your Query Report. See Manage Reports and Charts.
Your report will appear in the Data Views web part.You can customize the thumbnail and mini-icon displayed with your Query Report. See Manage Reports and Charts.Manage Reports and Charts
- View Details
- Edit View Metadata
- Reorder Views and Reports
- Delete Views and Reports
- Manage Notifications
 The Manage Views interface is similar to the Data Views web part, and displays a grid of all the views, queries, and reports available within a folder and allows editing of metadata as well as deletion of multiple reports in one action. The features from the pulldown menu from the data views web part are presented in a row of buttons for adding, managing, and deleting.
The Manage Views interface is similar to the Data Views web part, and displays a grid of all the views, queries, and reports available within a folder and allows editing of metadata as well as deletion of multiple reports in one action. The features from the pulldown menu from the data views web part are presented in a row of buttons for adding, managing, and deleting.
- Hover over the name of an item on the list to see a few details, including the type, creator and source.
- By default you will see all queries and reports you can edit. If you want to view only items you created yourself, click the Mine checkbox in the upper right.
- Click on the name to open the item.
- Click a details link to see more metadata details.
- Notice the pencil icons to the right of charts, reports, and named views. Click to edit the metadata for the item, including thumbnail images shown.
- When managing views within a study, you can click an active link in the Access column to customize permissions for the given visualization.

View Details
Hover over a row to view the source and type of a visualization, with a customizable thumbnail image. Clicking the icon in the Details column for a report or chart opens the Report Details page with the full list of current metadata. The details icon for a query or named view will open the view itself.
Clicking the icon in the Details column for a report or chart opens the Report Details page with the full list of current metadata. The details icon for a query or named view will open the view itself.
Modification Dates
There are two modification dates associated with each report, allowing you to differentiate between property and content changes:- Modified: the date the report was last modified.
- Name, description, author, category, thumbnail image, etc.
- Content Modified: the date the content of the report was modified.
- Underlying script, attachment, link, chart settings, etc.
- Attachment Report:
- Report type (local vs. server) changed
- Server file path updated
- New file attached
- Box Plot, Scatter Plot, Time Chart:
- Report configuration change (measure selection, grouping, display, etc.)
- Link Report:
- URL changed
- Script Reports including JavaScript and R Reports:
- Change to the report code (JavaScript, R, etc.)
- Flow Reports including PositivitFlowReport and ControlsQCReport:
- Change to any of the filter values
Edit View Metadata
Click the pencil icon next to any row to edit metadata to provide additional information about when, how, and why the view or report was created. You can also customize how the item is displayed in the data views panel.View Properties
- Click the pencil icon to open a popup window. The Properties tab allows you to:
- Modify the Name and Description fields.
- Select Author, Status, and Category from pulldown lists of valid values. For more about categories, see Manage Categories.
- Choose a Data Cut Date from the calendar.
- Check whether to share this report with all users and whether to make it visible or hidden.
- Click Save. You could also delete the visualization by clicking Delete View which is confirmed before the view is actually deleted.

View Thumbnails and Mini-icons
When a visualization is created, a default thumbnail is auto-generated and a mini-icon based on the report type is associated with it. For more information about using and customizing these images, see Manage Thumbnail Images.Reorder Reports and Charts
To rearrange the display order of reports and charts, an admin can click Reorder Reports and Charts. Users without administrator permissions will not see this button or be able to access this feature.Click the heading "Reports and Charts" to toggle searching ascending or decending alphabetically. You can also drag and drop to arrange in any order. When the organization is correct, click Done.
When the organization is correct, click Done.Delete Views and Reports
Select any row by clicking an area that is not a link. You can use Shift and Ctrl to multi-select several rows at once. Then click Delete Selected. You will be prompted to confirm the list of the views that will be deleted.
Manage Notifications
If you want to receive email notifications when the content of reports or datasets change, you can subscribe to a daily digest of changes to reports and datasets. You can receive notifications of all changes, or of changes to a given category or subcategory. These notifications are similar to email notifications for messages and file changes at the folder level, but allow finer control of which changes trigger notification. For example, if you want to allow subscription to notifications for a single report, create a singleton subcategory for it. Reports must be both visible and shared to trigger notifications.- Select Manage Notifications from the pulldown menu in the Data Views webpart or by clicking the button on the Manage Views page.
- Select None, All, or By Category.
- If you want to receive notifications by category or subcategory, click checkboxes under Subscribe.

- Click Save.
Related Topics
Manage Categories
Define Categories
- From the Data Views web part, select the customize option.
- Click Manage Categories to pop up the categories pop-up.
 To see subcategories, select a category in the popup. Click New Subcategory to add new ones. Drag and drop to rearrange. Click Done in the category popup when finished.
To see subcategories, select a category in the popup. Click New Subcategory to add new ones. Drag and drop to rearrange. Click Done in the category popup when finished.
Assign Items to Categories
Using the pencil icon dialog in the data views browser or on the manage views page, you can assign items to categories and subcategories using the pulldown menu. You can also assign datasets to categories using a pulldown on the Edit Dataset Properties page.
Related Topics
- Dataset Tagging: Another way to enable easy retrieval of a related group of datasets based on a keyword tag.
- Edit Dataset Properties
Manage Thumbnail Images
View and Customize Thumbnails and Mini-icons
- Enter Edit Mode by clicking the pencil icon in the data views browser or on the manage views page.
- Click the pencil icon for any visualization to open the window for editing metadata.
- Click the Images tab. The current thumbnail and mini-icon are displayed, along with the option to upload different ones from your local machine.
- A thumbnail image will be scaled to 250 pixels high.
- A mini-icon will be scaled to 18x18 pixels.

- Once you have customized the icon or thumbnail, a trash can icon will be shown, allowing you to delete custom thumbnails or icons returning to the defaults for the report type.
- Click Save to save any changes you make.
Extract Thumbnails from Documents
An Attachment Report is created by uploading an external document. Some documents can have embedded thumbnails included, and LabKey Server can in some cases extract those thumbnails to associate with the attachment report.The external application, such as Word, Excel, or PowerPoint, must have the "Save Thumbnail" option set to save the thumbnail of the first page as an extractable jpeg image. When the Open Office XML format file (.docx, .pptx, .xlsx) for an attachment report contains such an image, LabKey Server will extract it from the uploaded file and use it as the thumbnail.Images in older binary formats (.doc, .ppt, .xls) and other image formats, such as EMF or WMF, will not be extracted; instead the attachment report will use the default auto-generated thumbnail image.Related Topics
Measure and Dimension Columns
- Dimension: "dimension" means a column of non-numerical categories that can be included in a chart, such as for grouping into box plots or bar charts.
- Measure: A column with numerical data.
Mark the Desired Column as a Measure/Dimension
Note that you must have editor permissions to change a dataset/list design.- Go to the dataset/list you wish to visualize.
- Click Manage for a dataset or Design for a list.
- Click Edit Definition for a dataset or Edit Design for a list.
- Select the column you wish to visualize.
- Click the Reporting tab.
- Place a checkmark next to either Measure (for numeric columns) or Dimension (for non-numeric columns).
- Click Save.

Turn off the Measure/Dimension Restriction
Note that you must have administrator permissions to change these settings.- Go to Admin > Site > Admin Console.
- Click Look and Feel Settings.
- Scroll down to Restrict charting columns by measure and dimension flags.
- If you see a checkmark next to this option, remove it, and click Save.
Related Topics
Legacy Reports
Advanced Reports / External Reports
Advanced Reports (aka External Reports)
This feature is available to administrators only.An "Advanced Report" lets you launch a command line program to process a dataset. Advanced reports maximize extensibility; anything you can do from the command line you can do via an advanced report.You use substitution strings (for the data file and the output file) to pass instructions to the command line. These substitution strings describe where to get data and where to put data.Access the External Report Builder
- First, navigate to the data grid of interest.
- Select Reports > Create Advanced Report.
- You will now see the External Report Builder page.
- Select the Dataset/Query from the pulldown.
- Define the Program and Arguments using substitution strings as needed.
- Select the Output File Type (txt, tsv, jpg, gif, png).
- Click Submit.
- Enter a name and select the grid from which you want to access this custom report.
- Click Save
Use Substitution Strings
The External Report Builder lets you invoke any command line to generate the report. You can use the following substitution strings in your command line to identify the data file that contains the source dataset and the report file that will be generated.- ${DATA_FILE} This is the file where the data will be provided in tab delimited format. LabKey Server will generate this file name.
- ${REPORT_FILE} If your process returns data in a file, it should use the file name substituted here. For text and tab-delimited data, your process may return data via stdout instead of via a file. You must specify a file extension for your report file even if the result is returned via stdout. This allows LabKey to format the result properly.
Example
This simple example outputs the content of your dataset to standard output (using the cmd shell in Windows).- Open the data grid you want to use.
- Select Reports > Create Advanced Report.
- Select the Dataset/Query from the dropdown (in this example, we use the Physical Exam dataset).
- In the Program field, type:
C:\Windows\System32\cmd.exe
- In the Arguments field, type:
/C TYPE ${DATA_FILE}- Select an Output File Type (in this example, .txt)

- Click Submit. Since we did not name a ${REPORT_FILE} in the arguments, the contents of the dataset will be printed to stdout and appear in this window.
- Scroll all the way down, enter a name for the new custom report (TypeContents in this example).
- Select the dataset where you would like to store this report (Physical Exam in this example).
- Click Save.

Chart Views
Types of Charts
Chart Views are a legacy chart type and let you create several types of graphs for visualizing datasets.Time and Scatter Plots. LabKey provides two types of plots: time plots and scatter plots. A time plot traces the evolution of a particular measurement over time while a scatter plot displays a series of points to visualize relationships between measurements. Chart Views can contain both time plots and scatter plots on a single page.Participant Charts. Ordinary charts display all selected measurements for all participants on a single plot. Participant charts display participant data on a series of separate charts. One chart for one participant is displayed at a time. When a Chart View is composed of participant charts, users can step through the Chart View participant-by-participant to see charts for each individual. Both time plots and scatter plots can be displayed as participant charts.Create a Chart
To create a new chart, you first need to navigate to a dataset grid view, typically by clicking on the name of a dataset on the Study Portal page. You can create charts for subsets of data by first Filtering Data or creating a Custom Grid View.Create Chart View
To open the chart designer, on the dataset grid view, click Charts > Create Chart View. The chart designer lets you can choose whether to create a time plot or a scatter plot.Time Plots. A time plot charts one or more measures (on the Y axis) over time (on the X axis). Lines connect time measurements.Scatter Plots. A scatter plot charts one or more numeric measures (on the Y axis) against a second numeric measure (on the X axis).Horizontal Axis: Time Plots. If you have selected a time plot, you will choose a measure of time for the X measurement. The fields displayed in the list for the X measurement are the dataset fields of type Date/Time.Horizontal Axis: Scatter Plots If you choose a scatter plot, you can select any measurement included in your dataset as the X vector.Vertical Axis. Choose a Y measurement to plot against your chosen X. Note that you can select multiple values by holding down the Ctrl key.Axis Options. You can also choose whether the axes are logarithmic, set the height and width of the plot in pixels.If you select Single plot option, then a single chart will be created, where multiple y-values are plotted against one set of x-values all on the same x- and y-axes, as shown below.
The chart designer lets you can choose whether to create a time plot or a scatter plot.Time Plots. A time plot charts one or more measures (on the Y axis) over time (on the X axis). Lines connect time measurements.Scatter Plots. A scatter plot charts one or more numeric measures (on the Y axis) against a second numeric measure (on the X axis).Horizontal Axis: Time Plots. If you have selected a time plot, you will choose a measure of time for the X measurement. The fields displayed in the list for the X measurement are the dataset fields of type Date/Time.Horizontal Axis: Scatter Plots If you choose a scatter plot, you can select any measurement included in your dataset as the X vector.Vertical Axis. Choose a Y measurement to plot against your chosen X. Note that you can select multiple values by holding down the Ctrl key.Axis Options. You can also choose whether the axes are logarithmic, set the height and width of the plot in pixels.If you select Single plot option, then a single chart will be created, where multiple y-values are plotted against one set of x-values all on the same x- and y-axes, as shown below. If you check the Multiple Y axis checkbox, then a separate metric will be provided for each Y-axis (see below). If left unchecked, a single metric will be provided (see above).
If you check the Multiple Y axis checkbox, then a separate metric will be provided for each Y-axis (see below). If left unchecked, a single metric will be provided (see above). If you select Multiple plot option, then multiple charts will be created, one chart for each set of vertical measurements.
If you select Multiple plot option, then multiple charts will be created, one chart for each set of vertical measurements. Select Refresh Chart to preview the chart(s) to be created.
Select Refresh Chart to preview the chart(s) to be created.
One Chart for All Participants
Select the Participant Chart checkbox to create one chart for each participant instead of graphing all participants' data records on a single chart. If you leave it unchecked, you will see a chart that graphs data for all participants at once.Time Plot. A time plot that shows "Vital Signs" recorded over time: Scatter Plot. A scatter plot that graphs "Diastolic vs. Systolic Blood Pressure":
Scatter Plot. A scatter plot that graphs "Diastolic vs. Systolic Blood Pressure":
Multiple Charts, One for Each Participant
If you select the Subject Chart checkbox, you will see each participant's records graphed separately. You can navigate through the participants in the dataset, displaying the chart as it is plotted for each participant. In the images below, note the Previous Participant and Next Participant links.Time Plot. The same data used to create the "Vital Signs" time plot displayed above produces participant plots like this: For an example of a set of participant charts like the screenshot above, see the following set of charts in the Demo Study: Vital Signs.Scatter Plot. The same data used to create the "Diastolic vs. Systolic Blood Pressure" scatter plot shown earlier can be used to produce participant plots like this:
For an example of a set of participant charts like the screenshot above, see the following set of charts in the Demo Study: Vital Signs.Scatter Plot. The same data used to create the "Diastolic vs. Systolic Blood Pressure" scatter plot shown earlier can be used to produce participant plots like this: For an example of a set of participant charts like the screenshot above, see the following set of charts in the Demo Study: Participant Views: Diastolic/Systolic.Save. The "Save" button, located at the top of the chart designer page, takes you to the Save Chart View dialog. Specify a name for the Chart View and select the appropriate dataset from the drop-down menu (labeled with Add as a Custom View for:). By default, the chart view is associated with the dataset used to create it.Access Chart View. Your newly-created Chart View can be accessed through the Charts drop-down menu on the dataset's grid view. It will also appear on the Clinical and Assay Data tab.
For an example of a set of participant charts like the screenshot above, see the following set of charts in the Demo Study: Participant Views: Diastolic/Systolic.Save. The "Save" button, located at the top of the chart designer page, takes you to the Save Chart View dialog. Specify a name for the Chart View and select the appropriate dataset from the drop-down menu (labeled with Add as a Custom View for:). By default, the chart view is associated with the dataset used to create it.Access Chart View. Your newly-created Chart View can be accessed through the Charts drop-down menu on the dataset's grid view. It will also appear on the Clinical and Assay Data tab.
Creating an Embedded Chart
You can create a chart that is embedded within a dataset. Click on a participant ID in a dataset grid view to display data as a Participant View. Next, expand the dataset of interest and by clicking on its name. Click the Add chart link to display the chart designer. Create a time plot or scatter plot as described above, click Refresh Chart to preview, then click Save to create the chart.In the future, when you go to a Participant View (by clicking on a participantID in a dataset grid view), you will see this chart plotted for each participant when you scroll through participants using the Previous Participant and Next Participant links.This example shows a time plot for one participant:
Related Topic: Enrollment Report
An Enrollment Report is a specialized report available in a visit based study which plots participant enrollment in a study using visit date information provided in a given dataset.Crosstab Reports
- Select Reports > Create Crosstab Report.
- Pick a source dataset and whether to include a particular visit or all visits.
- Then specify the row and column of the source dataset to use, the field for which you would like to see statistics, and the statistics to compute for each row displayed.
SQL Queries
- Create filtered grid views of data.
- Join data from different tables.
- Group data and compute aggregates for each group.
- Add a calculated column to a query.
- Format how data is displayed using query metadata.
- Create staging tables for building reports.
- An intuitive table-joining syntax called lookups. Lookups use a convenient syntax of the form "Table.ForeignKey.FieldFromForeignTable" to achieve what would normally require a JOIN in SQL. For details see LabKey SQL Reference.
- Parameterized SQL statements. Pass parameters to a SQL query via a JavaScript API.
Topics
- LabKey SQL Tutorial - Create a SQL Query.
- SQL Query Browser - A dashboard for all things SQL-related, such as database schemas, tables, columns, and queries.
- LabKey SQL Reference - SQL syntax and reference.
- Create a SQL Query - How to create a database query and view the results.
- Edit SQL Query Source - How to use the SQL source editor.
- Query Metadata - Control how your query is displayed using metadata.
- Query Web Part: Display a Query - How to show query results in your project.
- Add a Calculated Column to a Query - Set a calculated column query.
- Create a Pivot Query - Reshape a table and aggregate data.
- Parameterized SQL Queries - Work with parameterized SQL.
- SQL Examples: JOIN, Calculated Columns, GROUP BY - Sample SQL queries.
- Cross-Folder Queries - Commonly performed tasks, troubleshooting.
Related Topics
- External Schemas and Data Sources - Connect to external database resources.
- Lookup Columns - Use LabKey's graphical user interface to setup lookup columns joining tables.
- Join Columns from Multiple Tables - Use LabKey's graphical user interface to create joined grid views.
- Linked Schemas and Tables - Control data visibility by linking schemas from different folders.
- Modules: SQL Scripts - Manage SQL scripts inside of custom modules.
- XML Schema Reference
LabKey SQL Tutorial
- LabKey SQL: LabKey SQL is a SQL dialect that translates your queries into the native syntax of the SQL database underlying your server, whether it is PostgreSQL or Microsoft SQL Server. This lets you write in one SQL dialect but communicate with many SQL database implementations.
- Lookups: Lookups join tables together using an intuitive syntax.
- Query Metadata: Add additional properties to a query using metadata xml files, such as: column captions, relationships to other tables or queries, data formatting, and links
Create a SQL Query
In this example, we will create a query based on the Users table in the core schema.- Select Admin > Developer Links > Schema Browser.
- Open the core schema in the left hand pane and select the Users table. Then click the button Create New Query. (This tells LabKey Server to create a query based on the table core.Users.)
- On the New Query page:
- Provide a name for the query (in the field "What do you want to call the new query?").
- Confirm that the Users table is selected (in the field "Which query/table do you want this new query to be based on?")
- Click Create and Edit Source.

- LabKey Server will provide a "starter query" on the Users table -- a basic SELECT statement for all of the fields in the table -- essentially a duplicate of the Users table. Typically, you would modify this "starter query" to fit your needs, adding WHERE clauses, JOINs to other tables, or substituting an entirely new SQL statement. But for this tutorial, we will just use the "starter query" unchanged.

- Click Save and Finish.
- The results of the query are displayed in a data grid, similar to the grid shown below -- though yours will show different data.
- Click core Schema to return to the Query Browser.

- Notice that your new query appears under user-defined queries.
Query Metadata
Each query has accompanying XML that defines properties, or metadata, for the query. In this step we will add properties to the query by editing the accompanying XML. In particular we will:- Change the data type of the Users column, making it a lookup into the Users table. By showing a clickable name instead of an integer value, we can make this column more human-readable. We will accomplish this by using the graphical user interface, which will write out the XML automatically.
- Modify the way it is displayed in the grid. We will accomplish this by editing the XML directly.
- Click Edit Metadata.

- On the UserId row, click in the Type column where it shows the value Integer
- In the Choose Field Type dialog, select User. This will create a lookup between your query and the Users table.
- Click Apply.

- Click View Data, and click Save to confirm your changes.

- Notice that the values in User Id column are no longer integers, but linked text -- this reflects the fact that User Id is now a lookup into the Users table. Click a value in the User Id column to see the corresponding record in the Users table (where you can see the actual user ID integer is unchanged). This lookup is defined in the XML metadata document. Click back in your browser to return to the query, and let's see what the XML looks like.
- Click core Schema to return to the Query Browser.
- Click Edit Source and then select the XML Metadata tab.
- The XML metadata will appear in a text editor. Notice the XML between the <fk>...</fk> tags. This tells LabKey Server to create a lookup (aka, a "foreign key") to the Users table in the core schema.
- Next we will modify the XML directly to hide the "Display Name" column in our query. We don't need the this column any longer because the User Id column already displays this user info.
- Add the following XML to the document, directly after the </column> tag (i.e directly before the </columns> tag ending the list of column definitions.
<column columnName="DisplayName">
<isHidden>true</isHidden>
</column>
- Click Save.
- Click the Data tab to see the results without exiting the query editor.
- Notice that the Display Name column is no longer shown.
- Click the XML Metadata tab and now add the following XML. This will display the Email column values in red.
<column columnName="Email">
<conditionalFormats>
<conditionalFormat>
<filters>
<filter operator="isnonblank"/>
</filters>
<textColor>FF0000</textColor>
</conditionalFormat>
</conditionalFormats>
</column>
- Now that you have a SQL query, you can display it directly by using a query web part, or use it as the basis for a report, such as an R report or a visualization. For details, see the Related Topics below.
Related Topics
SQL Query Browser
- Browse and Navigate the Data Model
- Show All Columns vs. Columns in the Default Grid View
- Validate Queries
- Generate Schema Export / Migrate Data to Another Schema
- Browse the tables and queries
- Add new SQL queries
- Discover table relationships to help write queries
- Define external schemas to access new data
- Generate scripts for bulk insertion of data into a new schema
Browse and Navigate the Data Model
To open the Query Schema Browser go to Admin > Developer Links > Schema Browser.The browser displays a list of the available schemas, including external schemas and data sources you have added. Each schema contains a collection of queries and tables. User-defined queries are grouped together separately from the built-in queries. The image below shows the queries and tables in the issues schema (circled). Schemas live in a particular folder on LabKey Server, but can be marked as inheritable, in which case they are accessible in child folders. (For more information on controlling schema heritability in child folders, see Query Metadata.)You can browse column names by clicking on a particular table or query. The image below shows how to discover the column names of the Comments table.
Schemas live in a particular folder on LabKey Server, but can be marked as inheritable, in which case they are accessible in child folders. (For more information on controlling schema heritability in child folders, see Query Metadata.)You can browse column names by clicking on a particular table or query. The image below shows how to discover the column names of the Comments table. Note that the tables and queries displayed are filtered for your permissions within a folder.
Note that the tables and queries displayed are filtered for your permissions within a folder.
Show All Columns vs. Columns in the Default Grid View
For a particular table or query, the browser shows two separate lists. The first list (labeled All columns in this table) shows all of the columns in the table/query, while the second list (labeled Columns in your default view of this query) shows the columns in the default grid view of the table/query. The second list may contain only a subset of all the available columns, or it may contain columns from other related tables.Validate Queries
When you upgrade to a new version of LabKey, change hardware, or database software, you may want to validate your SQL queries. You can perform a validation check of your SQL queries by pressing the Validate Queries button, on the top row of buttons in the Query Schema Browser. Validation runs against all queries in the current folder and checks to see if the SQL queries parse and execute without errors.Generate Schema Export / Migrate Data to Another Schema
If you wish to move data from one LabKey Server schema to another LabKey Server schema, you can do so by generating a migration script. The system will read the source schema and generate:- a set of tab-separated value (TSV) files, one for each table in the source. (Each TSV file is packaged as a .tsv.gz file)
- a script for importing these tables into a target schema.
- Go the Schema Browser: Admin > Developer Links > Schema Browser.
- Click Generate Schema Export.

- Select the data source and schema name.
- Enter a directory path where the script and TSV files will be written, for example: C:\temp\. Note that this directory must already exist on your machine for the export to succeed.
- Click Export.
- The file artifacts will be written to the path you specified.
| Field Name | Description |
|---|---|
| Source Data Source | The data source where the data to export resides. |
| Source Schema | The schema you want to export. |
| Target Schema | The schema where you want to import the data. |
| Path in Script | Optional. If you intend to place the import script and the data files in separate directories, specify a path so that the import script can find the data. |
| Output Directory | Directory on your local machine where the import script and the data files will be written. This directory must already exist on your machine, it will not be created for you. |
SELECT core.bulkImport('assaydata', 'c17d97_pcr_data_fields', 'dbscripts/assaydata/c17d97_pcr_data_fields.tsv.gz');
SELECT core.bulkImport('assaydata', 'c15d80_rna_data_fields', 'dbscripts/assaydata/c15d80_rna_data_fields.tsv.gz');
SELECT core.bulkImport('assaydata', 'c2d326_test_data_fields', 'dbscripts/assaydata/c2d326_test_data_fields.tsv.gz');
SELECT core.bulkImport('assaydata', 'c15d77_pcr_data_fields', 'dbscripts/assaydata/c15d77_pcr_data_fields.tsv.gz');Related Topics
- Create a SQL Query. Create or edit user-defined queries.
- External Schemas and Data Sources. Add external schemas to the query schema browser.
- Discover Lookup Column Names
LabKey SQL Reference
LabKey SQL
LabKey SQL is a SQL dialect that supports (1) most standard SQL functionality and (2) provides extended functionality that is unique to LabKey, including:
- Lookup columns. Lookup columns use an intuitive syntax to access data in other tables to achieve what would normally require a JOIN statement. For example: "SomeTable.ForeignKey.FieldFromForeignTable" For details see Lookups.
- Security. Before execution, all SQL queries are checked against the user's security role/permissions.
- Parameterized SQL statements: the PARAMETERS keyword lets you define parameters for a query. An associated API gives you control over the parameterized query from JavaScript code. See Parameterized SQL Queries.
- Pivot tables: the PIVOT...BY expression provides an intuitive syntax for creating pivot tables. See Create a Pivot Query.
- User-related functions: USERID() and ISMEMBEROF(groupid) lets you control query visibility based on the user's group membership.
Keywords
| Keyword | Description |
| AS | Aliases can be explicitly named using the AS keyword. Note that the AS keyword is optional: the following select clauses both create an alias called "Name":
SELECT LCASE(FirstName) AS Name Implicit aliases are automatically generated for expressions in the SELECT list. In the query below, an output column named "Expression1" is automatically created for the expression "LCASE(FirstName)": SELECT LCASE(FirstName) |
| ASCENDING, ASC | Return results in ascending value order. ORDER BY Weight ASC |
| CAST(AS) | CAST(R.d AS VARCHAR)
Defined valid datatype keywords which can be used as cast/convert targets, and to what java.sql.Types name each keyword maps. Keywords are case-insensitive. BIGINT Examples: CAST(TimeCreated AS DATE) CAST(WEEK(i.date) as INTEGER) as WeekOfYear, |
| DESCENDING, DESC | Return results in descending value order. |
| DISTINCT | Return distinct, non duplicate values. SELECT DISTINCT Country FROM Demographics |
| FALSE | |
| FROM |
The FROM clause in LabKey SQL must contain at least one table. It can also contain JOINs to other tables. Commas are supported in the FROM clause: To refer to tables in LabKey folders other than the current folder, see Cross-Folder Queries. |
| GROUP BY | Used with aggregate functions to group the results. Defines the "for each" or "per". The example below returns the number of records "for each" participant:
SELECT "Physical Exam".ParticipantId, COUNT("Physical Exam".Created) "Number of Records" |
| HAVING | Used with aggregate functions to limit the results. The following example returns participants with 10 or more records in the Physical Exam table: SELECT "Physical Exam".ParticipantId, COUNT("Physical Exam".Created) "Number of Records" FROM "Physical Exam" GROUP BY "Physical Exam".ParticipantId HAVINGCOUNT("Physical Exam".Created) > 10 |
| JOIN, RIGHT JOIN, LEFT JOIN, FULL JOIN |
Example: SELECT "Physical Exam".* FROM "Physical Exam" FULL JOIN "Lab Results" ON "Physical Exam".ParticipantId = "Lab Results".ParticipantId |
| LIMIT | Limits the number or records returned by the query. The following example returns the 10 most recent records:
SELECT * |
| ORDER BY | Often used with LIMIT to improve performance: SELECT "Physical Exam".ParticipantID, "Physical Exam".Height_cm AS Height FROM "Physical Exam" ORDER BY Height DESC LIMIT 5 Troubleshooting: "Why is the ORDER BY clause being ignored?" When authoring queries in LabKey SQL, ORDER BY clauses may appear to not be respected in the results displayed to the user. This is because a LabKey SQL query is typically processed as a subquery within a parent query, and the parent's sort order overrides the ORDER BY clause in the subquery. |
| PARAMETERS | Queries can declare parameters using the PARAMETERS keyword. Default values data types are supported as shown below:
PARAMETERS (X INTEGER DEFAULT 37) Parameter names will override any unqualified table column with the same name. Use a table qualification to disambiguate. In the example below, R.X refers to the column while X refers to the parameter: PARAMETERS(X INTEGER DEFAULT 5) Supported data types for parameters are: BIGINT, BIT, CHAR, DECIMAL, DOUBLE, FLOAT, INTEGER, LONGVARCHAR, NUMERIC, REAL, SMALLINT, TIMESTAMP, TINYINT, VARCHAR Parameter values can be passed via JavaScript API calls to the query. For details see Parameterized SQL Queries. |
| PIVOT BY | Re-visualize a table by rotating or "pivoting" a portion of it, essentially promoting cell data to column headers. See Write a Pivot Query for examples. |
| SELECT | SELECTqueries are the only type of query that can currently be written in LabKey SQL. Sub-selects are allowed both asanexpression,and in the FROM clause.
Aliases are automatically generated for expressions after SELECT. In the query below, an output column named "Expression1" is automatically generated for the expression "LCASE(FirstName)": SELECT LCASE(FirstName) FROM... |
| TRUE | |
| UNION, UNION ALL | The UNION clause is the same as standard SQL. LabKey SQL supports UNION in subqueries. |
| WHERE | Filter the results for certain values. Example: SELECT "Physical Exam".* FROM "Physical Exam" WHERE YEAR(Date) = '2010' |
Operators
| Operator | Description |
| String Operators | |
| || | String concatenation. For example: SELECT Demographics.ParticipantId, Demographics.City || ', ' || Demographics.State AS CityOfOrigin FROM Demographics |
| LIKE | |
| NOT LIKE | |
| Arithmetic Operators | |
| + | Add |
| - | Subtract |
| * | Multiply |
| / | Divide |
| Comparison operators | |
| = | Equals |
| != | Does not equal |
| <> | Does not equal |
| > | Is greater than |
| < | Is less than |
| >= | Is greater than or equal to |
| <= | Is less than or equal to |
| IS NULL | Is NULL |
| IS NOT NULL | Is NOT NULL |
| BETWEEN | Between two values. Values can be numbers, strings or dates. |
| IN | In |
| NOT IN | Not in |
| Bitwise Operators | |
| & | Bitwise AND |
| | | Bitwise OR |
| ^ | Bitwise exclusive OR |
| AND Operators | |
| AND | Logical AND |
| OR | Logical OR |
| LIKE | Like |
| NOT LIKE | Not like |
Operator Order of Precedence
| Order of Precedence | Operators |
| 1 | - (unary) , + (unary), CASE |
| 2 | *, / (multiplication, division) |
| 3 | +, -, & (binary plus, binary minus) |
| 4 | & (bitwise and) |
| 5 | ^ (bitwise xor) |
| 6 | | (bitwise or) |
| 7 | || (concatenation) |
| 8 | <, >, <=, >=, IN, NOT IN, BETWEEN, NOT BETWEEN, LIKE, NOT LIKE |
| 9 | =, IS, IS NOT, <>, != |
| 10 | NOT |
| 11 | AND |
| 12 | OR |
NOTE: Prior to 14.3 bitwise operator precedence varies based on the underlying SQL database. We suggest always using parentheses when using bitwise operators.
Aggregate Functions
| Function | Description |
| COUNT | The special syntax COUNT(*) is supported as of LabKey v9.2. |
| MIN | Minimum |
| MAX | Maximum |
| AVG | Average |
| SUM | Sum |
| STDDEV | Standard deviation |
| GROUP_CONCAT | An aggregate function, much like MAX, MIN, AVG, COUNT, etc. It can be used wherever the standard aggregate functions can be used, and is subject to the same grouping rules. Like the built-in MySQL functionality, it will return a string value which is comma-separated list of all of the values for that grouping. A custom separator, instead of the default comma, can be specified. The example below specifies a semi-colon as the separator: SELECT Participant, GROUP_CONCAT(DISTINCT Category, ';') AS CATEGORIES FROM SomeSchema.SomeTable To use a line-break as the separator, use the following: SELECT Participant, GROUP_CONCAT(DISTINCT Category, chr(10)) AS CATEGORIES FROM SomeSchema.SomeTable |
SQL Functions
Many of these functions are similar to standard SQL functions -- see the JBDC escape syntax documentation for additional information.
| Function | Description |
| abs(value) | Returns the absolute value. |
| acos(value) | Returns the arc cosine. |
| age(date1, date2) |
Supplies the difference in age between the two dates, calculated in years. |
| age(date1, date2, interval) |
The interval indicates the unit of age measurement, either SQL_TSI_MONTH or SQL_TSI_YEAR. |
| age_in_months(date1, date2) | Behavior is undefined if date2 is before date1. |
| age_in_years(date1, date2) | Behavior is undefined if date2 is before date1. |
| asin(value) | Returns the arc sine. |
| atan(value) | Returns the arc tangent. |
| atan2(value1, value2) | Returns the arctangent of the quotient of two values. |
| case | LabKey SQL parser sometimes requires the use of additional parentheses within the statement. CASE (value) WHEN (test1) THEN (result1) ELSE (result2) END CASE WHEN (test1) THEN (result1) ELSE (result2) END |
| ceiling(value) | Rounds the value up. |
| coalesce(value1,...,valueN) | Returns the first non-null value in the argument list. Use to set default values for display. |
| concat(value1,value2) | Concatenates two values. |
| contextPath() | Returns the context path starting with “/” (e.g. “/labkey”). Returns the empty string if there is no current context path. (Returns VARCHAR.) |
| cos(radians) | Returns the cosine. |
| cot(radians) | Returns the cotangent. |
| curdate() | Returns the current date. |
| curtime() | Returns the current time |
| dayofmonth(date) | Returns the day of the month (1-31) for a given date. |
| dayofweek(date) | Returns the day of the week (1-7) for a given date. (Sun=1 and Sat=7) |
| dayofyear(date) | Returns the day of the year (1-365) for a given date. |
| degrees(radians) | Returns degrees based on the given radians. |
| exp(n) | Returns Euler's number e raised to the nth power. e = 2.71828183 |
| floor(value) | Rounds down to the nearest integer. |
| folderName() | LabKey SQL extension function. Returns the name of the current folder, without beginning or trailing "/". (Returns VARCHAR.) |
| folderPath() | LabKey SQL extension function. Returns the current folder path (starts with “/”, but does not end with “/”). The root returns “/”. (Returns VARCHAR.) |
| greatest(a, b, c, ...) | Returns the greatest value from the list expressions provided. Any number of expressions may be used. The expressions must have the same data type, which will also be the type of the result. The LEAST() function is similar, but returns the smallest value from the list of expressions. GREATEST() and LEAST() are not implemented for SAS databases.
When NULL values appear in the list of expressions, different database implementations as follows: Example: SELECT greatest(MyAssay.score_1, MyAssay.score_2, MyAssay.score_3) As HIGH_SCORE |
| hour(time) | Returns the hour for a given date/time. |
| ifdefined(column_name) | IFDEFINED(NAME) allows queries to reference columns that may not be present on a table. Without using IFDEFINED(), LabKey will raise a SQL parse error if the column cannot be resolved. Using IFDEFINED(), a column that cannot be resolved is treated as a NULL value. The IFDEFINED() syntax is useful for writing queries over PIVOT queries or assay tables where columns may be added or removed by an administrator. |
| ifnull(testValue, defaultValue) | If testValue is null, returns the defaultValue. Example: IFNULL(Units,0) |
| isequal | LabKey SQL extension function. ISEQUAL(a,b) is equivalent to (a=b OR (a IS NULL AND b IS NULL)) |
| ismemberof(groupid) | LabKey SQL extension function. Returns true if the current user is a member of the specified group. |
| javaConstant(fieldName) | LabKey SQL extension function. Provides access to public static final variable values. For details see Using SQL Functions in Java Modules. |
| lcase(string) | Convert all characters of a string to lower case. |
| least(a, b, c, ...) | Returns the smallest value from the list expressions provided. For more details, see greatest() above. |
| left(string, integer) | Returns the left side of the string, to the given number of characters. Example: SELECT LEFT('STRINGVALUE',3) returns 'STR' |
| length(string) | Returns the length of the given string. |
| locate(substring, string) locate(substring, string, startIndex) | Returns the location of the first occurrence of substring within string. startIndex provides a starting position to begin the search. |
| log(n) | Returns the natural logarithm of n. |
| log10(n) | Base base 10 logarithm on n. |
| lower(string) | Convert all characters of a string to lower case. |
| ltrim(string) | Trims white space characters from the left side of the string. For example: LTRIM(' Trim String') |
| minute(time) | Returns the minute value for the given time. |
| mod(dividend, divider) | Returns the remainderofthedivisionofdividendbydivider. |
| moduleProperty(module name, property name) |
LabKey SQL extension function. Returns a module property, based on the module and property names. For details see Using SQL Functions in Java Modules. |
| month(date) | Returns the month value (1-12) of the given date. |
| monthname(date) | Return the month name of the given date. |
| now() | Returns the system date and time. |
| overlaps | LabKey SQL extension function. Supported only when Postrgres is installed as the primary database. SELECT OVERLAPS (START1, END1, START2, END2) AS COLUMN1 FROM MYTABLE The LabKey SQL syntax above is translated into the following Postgres syntax: SELECT (START1, END1) OVERLAPS (START2, END2) AS COLUMN1 FROM MYTABLE |
| pi() | Returns the value of π. |
| power(base, exponent) | Returns base raised to the power of exponent. For example, power(10,2) returns 100. |
| quarter(date) | Returns the yearly quarter for the given date where the 1st quarter = Jan 1-March 31, 2nd quarter = April 1-June 30, 3rd quarter = July 1-Sept30, 4th quarter = Oct 1-Dec 31 |
| radians(degrees) | Returns the radians for the given degrees. |
| rand(), rand(seed) | Returns a random number between 0 and 1. |
| repeat(string, count) | Returns the string repeated the given number of times. SELECT REPEAT('Hello',2) returns 'HelloHello'. |
| round(value, precision) | Rounds the value to the specified number of decimal places. ROUND(43.3432,2) returns 43.34 |
| rtrim(string) | Trims white space characters from the right side of the string. For example: RTRIM('Trim String ') |
| second(time) | Returns the second value for the given time. |
| sign(value) | Returns the sign, positive or negative, for the given value. |
| sin(value) | Returnsthesineforthe given value. |
| startswith(string, prefix) | Tests to see if the string starts with the specified prefix. For example, STARTSWITH('12345','2') returns FALSE. |
| sqrt(value) | Returns the square root of the value. |
| substring(string, start, end) | Returns a portion of the string as specified by the start and end locations. |
| tan(value) |
Returns the tangent of the value. |
| timestampadd(interval, number_to_add, timestamp) |
Adds an interval to the given timestamp value. The interval value must be surrounded by quotes. Possible values for interval: SQL_TSI_FRAC_SECOND Example: TIMESTAMPADD('SQL_TSI_QUARTER', 1, "Physical Exam".date) AS NextExam |
| timestampdiff(interval, timestamp1, timestamp2) |
The interval must be surrounded by quotes. This differs from JDBC syntax. Note that PostgreSQL does not support the following intervals: SQL_TSI_FRAC_SECOND As a workaround, use the 'age' functions defined above. Example: TIMESTAMPDIFF('SQL_TSI_DAY', SpecimenEvent.StorageDate, SpecimenEvent.ShipDate) |
| truncate(numeric value, precision) | Truncates the numeric value to the precision specified. This is an arithmetic truncation, not a string truncation. TRUNCATE(123.4567,1) returns 123.4 TRUNCATE(123.4567,2) returns 123.45 TRUNCATE(123.4567,-1) returns 120.0 |
| ucase(string), upper(string) | Converts all characters to upper case. |
| userid() | LabKey SQL extension function. Returns the userid, an integer, of the logged in user. |
| username() | LabKey SQL extension function. Returns the current user display name. VARCHAR |
| week(date) | Returns the week value (1-52) of the given date. |
| year(date) | Return the year of the given date. Assuming the system date is March 4 2023, then YEAR(NOW()) return 2023. |
PostgreSQL Specific FunctionsLabKey SQL supports the following PostgreSQL functions. See the PostgreSQL docs for usage details.
|
MS SQL Server Specific FunctionsLabKey SQL supports the following SQL Server functions. See the SQL Server docs for usage details.
|
General Syntax
| Syntax Item | Description |
| Case Sensitivity | Schema names, table names, column names, SQL keywords, function names are case-insensitive in LabKey SQL. |
| Comments | Comments that use the standard SQL syntax can be included in queries. '--' starts a line comment. Also, '/* */' can surround a comment block:
-- line comment 1 |
| Identifiers | Identifiers in LabKey SQL may be quoted using double quotes. (Double quotes within an identifier are escaped with a second double quote.) SELECT "Physical Exam".* ... |
| Lookups | Lookups columns are columns that see data in other tables. They are essentially foreign key columns that can be managed through an intuitive user interface. See Lookups for details on creating lookup columns. Lookups use a convenient syntax of the form "Table.ForeignKey.FieldFromForeignTable" to achieve what would normally require a JOIN in SQL. Example:
Issues.AssignedTo.DisplayName |
| String Literals | String literals are quoted with single quotes ('). Within a single quoted string, a single quote is escaped with another single quote.
|
| Date/Time Literals |
Date and Timestamp (Date&Time) literals can be specified using the JDBC escape syntax {ts '2001-02-03 04:05:06'} {d '2001-02-03'} |
Lookups: SQL Syntax
Lookup SQL Syntax
Lookups have the general form:Table.ForeignKey.FieldFromForeignTable
Example #1
The following query uses the Datasets table to lookup values in the Demographics table, joining them to the Physical Exam table.SELECT "Physical Exam".ParticipantId,
"Physical Exam".date,
"Physical Exam".Height_cm,
"Physical Exam".Weight_kg,
Datasets.Demographics.Gender AS GenderLookup,
FROM "Physical Exam"
SELECT "Physical Exam".ParticipantId,
"Physical Exam".date,
"Physical Exam".Height_cm,
"Physical Exam".Weight_kg,
Demographics.Gender AS GenderJoin
FROM "Physical Exam"
INNER JOIN Demographics ON "Physical Exam".ParticipantId = Demographics.ParticipantId
Example #2
The following lookup expression shows the Issues table looking up data in the Users table, retrieving the Last Name.Issues.UserID.LastName
SELECT Demographics.ParticipantId,
Demographics.StartDate,
Demographics.Language.LanguageName,
Demographics.Language.TranslatorName,
Demographics.Language.TranslatorPhone
FROM Demographics
SELECT Demographics.ParticipantId,
Demographics.StartDate,
Languages.LanguageName,
Languages.TranslatorName,
Languages.TranslatorPhone
FROM Demographics LEFT OUTER JOIN lists.Languages
ON Demographics.Language = Languages.LanguageId;
...
WHERE VialRequest.Request.Status.SpecimensLocked
AND VialRequest.Vial.Visit.SequenceNumMin = ClinicalData.SequenceNum
AND VialRequest.Vial.ParticipantId = ClinicalData.ParticipantId
...
Discover Lookup Column Names
To discover lookup relationships between tables:- Go to Admin > Developer Links > Schema Browser.
- Select a schema and table of interest.
- Browse lookup fields by clicking the + icon next to a column name which has a lookup table listed.
- In the image below, the column study.Demographics.Language looks up the lists.Languages table joining on the column LanguageId.
- Available columns in the Languages table are listed (in the red box). To reference these columns in a SQL query, use the lookup syntax: Demographics.Language."col_in_lookup_table", i.e. Demographics.Language.TranslatorName, Demographics.Language.TranslatorPhone, etc.

- Note that the values are shown using the slash-delimited syntax, which is used in the selectRows API. For details on using the query API, see LABKEY.Query.
Lookup Column Administration - Adding Lookups to Table/List Definitions
Before lookup columns can be used, they need to be added to definition of a dataset/list. For details on setting up lookup relationships, see Lookup Columns.Related Topics
Create a SQL Query
Create a Custom SQL Query
- Select Admin > Developer Links > Schema Browser.
- From the schema list, select the schema that includes your data tables of interest.
- Click the Create New Query button.
- In the field What do you want to call the new query?, enter a name for your new query. Note: You cannot change this name later.
- In the drop-down field Which query/table do you want this new query to be based on?, select the base query/table for your query.
- Click Create and Edit Source.

- LabKey Server will generate an SQL query for the selected table.
- Refine the source of this query as desired in the SQL source editor.
Related Topics
Edit SQL Query Source
- Go to Admin > Developer Links > Schema Browser.
- Using the navigation tree on the left, browse to the target query and then click Edit Source.

- The SQL source appears in the source editor.

- Select the Data tab or click Execute Query to see the results.

- Return to the Source tab to make your desired changes.
- Clicking Save will check for syntax errors (such as the trailing comma in the above source).
- Return to the Data tab or click Execute Query again to see the revised results.
- Click Save and Finish to save your changes when complete.
Query Metadata
- Format data display
- Add custom buttons menu items that navigate to other pages or call JavaScript methods.
- Disable the standard insert, update, and delete buttons.
- Color coding for values that fall within a numeric range
- Configure lookups on columns
Edit Metadata using the User Interface
The metadata editor offers a subset of the features available in the field properties editor and works in the same way.- Open the schema browser via Admin > Developer Links > Schema Browser.
- Select an individual query/table in the Query Schema Browser and click Edit Metadata.
- When you click anywhere along the row for a field, you activate that field for editing and open the properties editor to the right, which includes three tabs:
- Additional Properties: Edit the description and display properties for the field.
- Format: Add a conditional format if desired.
- Reporting: Set properties used in reporting.

- To change a column's displayed title, edit its Label property.
- In the image above, the displayed text for the column has been changed to read "Average Temperature" (instead of "Average Temp"). Notice the wrench icon on the left indicating unsaved changes.
- You could directly Edit Source or View Data from this interface.
- If you are viewing a built-in table or query, notice the Alias Field button -- this lets you "wrap" a field and display it with a different "alias" field name. This feature is only available for built-in queries.
- Click Save when finished.
Edit Metadata XML Source
The other way to specify and edit query metadata is directly in the source editor. When you set field properties and other options in the UI, the necessary XML is generated for you and you may further edit in the source editor. However, if you wanted to apply a given setting or format to several fields, it might be most efficient to do so directly in the source editor. Changes made to in either place are immediately reflected in the other.- Click Edit Source to open the source editor.
- The Source tab shows the SQL query.
- Select the XML Metadata tab (if it not already open).
- In the screenshot below a conditional format has been applied to the Temp_C column -- if the value is over 37, display the value in red.

- Click the Data tab to see some values displayed in red, then return to the XML Metadata tab.
- You could make further modifications by directly editing the metadata here. For example, change the 37 to 39.
- Click the Data tab to see the result -- fewer red values, if any.
- Restore the 37 value, then click Save and Finish.
<tables xmlns="http://labkey.org/data/xml">
<table tableName="TestDataset" tableDbType="NOT_IN_DB">
<columns>
<column columnName="date">
<isHidden>true</isHidden>
</column>
</columns>
</table>
</tables>
Examples
Reference
- For a detailed reference on query metadata, see tableInfo.xsd.
Query Metadata: Examples
Auditing Level
Set the level of detail recorded in the audit log. The example below sets auditing to "DETAILED" on the Physical Exam table.<tables xmlns="http://labkey.org/data/xml">
<table tableName="Physical Exam" tableDbType="NOT_IN_DB">
<auditLogging>DETAILED</auditLogging>
<columns>
...
</columns>
</table>
</tables>
Conditional Formatting
The following adds a yellow background color to any cells showing a value greater than 72.<tables xmlns="http://labkey.org/data/xml">
<table tableName="Physical Exam" tableDbType="NOT_IN_DB">
<columns>
<column columnName="Pulse">
<columnTitle>Pulse</columnTitle>
<conditionalFormats>
<conditionalFormat>
<filters>
<filter operator="gt" value="72" />
</filters>
<backgroundColor>FFFF00</backgroundColor>
</conditionalFormat>
</conditionalFormats>
</column>
</table>
</tables>
Other Examples
- Query Metadata: Examples - Small snippet examples.
- kinship.query.xml
- Disables the standard insert, update, and delete buttons/links with the empty <insertUrl /> and other tags.
- Configures lookups on a couple of columns and hides the RowId column in some views.
- Adds a custom button "More Actions" with a child menu item "Limit To Animals In Selection" that calls a JavaScript method provided in a referenced .js file.
- Data.query.xml
- Configures columns with custom formatting for some numeric columns, and color coding for the QCFlag column.
- Adds multiple menu options under the "More Actions" button at the end of the button bar.
- Formulations.query.xml
- Sends users to custom URLs for the insert, update, and grid views.
- Retains some of the default buttons on the grid, and adds a "Delete Formulations" button between the "Paging" and "Print" buttons.
- encounter_participants.query.xml
- AssignmentOverlaps.query.xml
- Aliquots.query.xml & performCellSort.html
- Adds a button to the Sample Sets web part. When the user selects samples and clicks the button, the page performCallSort.html is shown, where the user can review the selected records before exporting the records to an Excel file.
- To use this sample, place Aliquots.query.xml in a module's ./resources/queries/Samples directory. Rename Aliquots.query.xml it to match your sample set's name. Edit the tableName attribute in the Aliquots.query.xml to match your sample set's name. Replace the MODULE_NAME placeholder with the name of your module. Place the HTML file in your module's ./resources/views directory. Edit the queryName config parameter to match the sample set's name.
Related Topics
Edit Query Properties
- Go to the Schema Browser (Admin > Developer Links > Schema Browser)
- Select the schema and query/table of interest and then click Edit Properties.
- The Edit query properties page will appear, for example:

Available Query Properties
Name: This value appears as the title of the query/table in the Schema Browser, data grids, etc.Description: Text entered here will be shown with your query in the Schema Browser.Available in child folders: Queries live in a particular folder on LabKey Server, but can be marked as inheritable by setting this property to 'yes'. Note that the query will only be available in child folders containing the matching base schema and table.Hidden from the user: If you set this field to 'yes', then the query will no longer appear in the Schema Browser, or other lists of available queries. It will still appear on the list of available base queries when you create a new query.Query Web Part: Display a Query
- A custom query or grid view.
- A list of all tables in a particular schema.
Add a Query Web Part
- Navigate to where you want to display the query.
- Click Select Web Part drop-down menu at the bottom left of the page, select “Query” and click Add.
- You are now on the Customize Query page.

- Web Part Title: Enter the title for the webpart, which need not match the query name.
- Schema: Pull down to select from available schema.
- Query and View: Choose whether to display a list of all queries for this schema, or the contents of a particular query and grid view of the data. If the former, the following two options will remain inactive.
- Query: If you have chosen to display a particular query, pull down to select it.
- View: By default, the default grid will be shown; pull down if you want to select a custom grid view.
- Allow user to choose query?: If you select "Yes", the web part will allow the user to change which query is displayed. Only queries the user has permission to see will be available.
- Allow user to choose view?: If you select "Yes", the web part will allow the user to change which grid view is displayed. Only grid views the user has permission to see will be available.
- Button bar position: Select whether to display web part buttons at the top, bottom, both, or not at all.
Add a Calculated Column to a Query
Example: Add a Calculated Column
In this example we use SQL to add a column to a query based on the Physical Exam dataset. The column will display "Pulse Pressure" -- the change in blood pressure between contractions of the heart muscle, calculated as the difference between systolic and diastolic blood pressures.Create a Query
- Navigate to Admin > Developer Links > Schema Browser.
- Select a schema to base the query on. (For this example, select the study schema.)
- Click Create New Query.
- Create a query based on some dataset. (For this example, select the Physical Exam dataset.)
Modify the SQL Source
- Adding the following SQL will create a column with the calculated value we seek:
"Physical Exam".SystolicBloodPressure-"Physical Exam".DiastolicBloodPressure as PulsePressure
- The final SQL source should look like the following:
SELECT "Physical Exam".ParticipantId,
"Physical Exam".date,
"Physical Exam".Weight_kg,
"Physical Exam".Temp_C,
"Physical Exam".SystolicBloodPressure,
"Physical Exam".DiastolicBloodPressure,
"Physical Exam".Pulse,
"Physical Exam".Respirations,
"Physical Exam".Signature,
"Physical Exam".Pregnancy,
"Physical Exam".Language,
"Physical Exam".SystolicBloodPressure-"Physical Exam".DiastolicBloodPressure as PulsePressure
FROM "Physical Exam"
- Click Save and Finish.
- Notice that LabKey Server has made a best guess at the correct column label, adding a space to "Pulse Pressure".
Create a Pivot Query
- Select Admin > Developer Links > Schema Browser.
- Select a schema. In this example we chose "study.GenericAssay"
- Click Create New Query.
- Name it and confirm the correct schema is selected.
- Click Create and Edit Source.
Syntax for PIVOT query
A PIVOT query is essentially a SELECT specifying which columns you want and how to PIVOT and GROUP them. To write a pivot query, follow these steps. Our walkthrough example uses the fictional GenericAssay data in the interactive example study.(1) Start with a base SELECT query.FROM GenericAssay
 (2) Identify the data cells you want to pivot and how. In this example, we focus on the values in the Assay Id column (the run name), to separate M1 values for each.(3) Select an aggregating function to handle any non-unique data, even if you do not expect to need it. MAX, MIN, AVG, and SUM are possibilities. If you had only one row for each participant/date/run combination, all would produce the same result, but here we have several sets with multiple values. In this example, we want to display only the maximum value for any given PTID/date/run combination. When aggregating, we can also give the column a new name, here MaxM1.(4) Identify columns which remain the same to determine the GROUP BY clause.
(2) Identify the data cells you want to pivot and how. In this example, we focus on the values in the Assay Id column (the run name), to separate M1 values for each.(3) Select an aggregating function to handle any non-unique data, even if you do not expect to need it. MAX, MIN, AVG, and SUM are possibilities. If you had only one row for each participant/date/run combination, all would produce the same result, but here we have several sets with multiple values. In this example, we want to display only the maximum value for any given PTID/date/run combination. When aggregating, we can also give the column a new name, here MaxM1.(4) Identify columns which remain the same to determine the GROUP BY clause.Max(M1) AS MaxM1
FROM GenericAssay
GROUP BY ParticipantID, date, "Run.Name"
Max(M1) AS MaxM1
FROM GenericAssay
GROUP BY ParticipantID, date, "Run.Name"
PIVOT MaxM1 BY "Run.Name"
 (6) You can focus on particular values using IN. In our example, perhaps we want to see only two runs:
(6) You can focus on particular values using IN. In our example, perhaps we want to see only two runs:Max(M1) AS MaxM1
FROM GenericAssay
GROUP BY ParticipantID, date, "Run.Name"
PIVOT MaxM1 BY "Run.Name" IN ('Run1', 'Run3')
Grouped Headers
You can add additional aggregators and present two pivoted columns, here we show both an average and a maximum M1 for each participant/date/run combination.Min(M1) AS LowM1,
Max(M1) AS MaxM1
FROM GenericAssay
GROUP BY ParticipantID, date, "Run.Name"
PIVOT LowM1, MaxM1 BY "Run.Name" IN ('Run1', 'Run3')

Summary Columns
In a pivot query there are three types of columns:- "Group By" columns
- "Pivoted" columns
- "Summary" columns
SELECT
-- Group By columns
AssignedTo,
Type,
-- Summary columns. Turned into a SUM over the COUNT(*)
COUNT(*) AS Total,
-- Pivoted columns
SUM(CASE WHEN Status = 'open' THEN 1 ELSE 0 END) AS "Open",
SUM(CASE WHEN Status = 'resolved' THEN 1 ELSE 0 END) AS Resolved
FROM issues.Issues
WHERE Status != 'closed'
GROUP BY AssignedTo, Type
PIVOT "Open", Resolved BY Type IN ('Defect', 'Performance', 'Todo')
- a COUNT or SUM aggregate summary column is wrapped with SUM
- a MIN or MAX is wrapped with a MIN or MAX
Examples
Another practical application of a pivot query is to display a list of how many issues of each priority are open for each area.Example 1
See the result of this pivot query: Pivot query on the Issues tableSELECT Issues.Area,
Issues.Priority,
Count(Issues.IssueId) AS CountOfIssues
FROM Issues
GROUP BY Issues.Area, Issues.Priority
PIVOT CountOfIssues BY Priority IN (1,2,3,4)
Example 2
See the result of this pivot query: Pivot query on the Issues tableSELECT
-- Group By columns
AssignedTo,
Type,
-- Summary columns. Turned into a SUM over the COUNT(*)
COUNT(*) AS Total,
-- Pivoted columns
SUM(CASE WHEN Status = 'open' THEN 1 ELSE 0 END) AS "Open",
SUM(CASE WHEN Status = 'resolved' THEN 1 ELSE 0 END) AS Resolved
FROM issues.Issues
WHERE Status != 'closed'
GROUP BY AssignedTo, Type
PIVOT "Open", Resolved BY Type IN ('Defect', 'Performance', 'Todo')
Example 3
See the result of this pivot query: Pivot query with grouped headersSELECT ParticipantId, date, Analyte,
Count(Analyte) AS NumberOfValues,
AVG(FI) AS AverageFI,
MAX(FI) AS MaxFI
FROM "Luminex Assay 100"
GROUP BY ParticipantID, date, Analyte
PIVOT AverageFI, MaxFI BY Analyte
Example 4
SELECT SupportTickets.Client AS Client,
SupportTickets.Status AS Status,
COUNT(CASE WHEN SupportTickets.Priority = 1 THEN SupportTickets.Status END) AS Pri1,
COUNT(CASE WHEN SupportTickets.Priority = 2 THEN SupportTickets.Status END) AS Pri2,
COUNT(CASE WHEN SupportTickets.Priority = 3 THEN SupportTickets.Status END) AS Pri3,
COUNT(CASE WHEN SupportTickets.Priority = 4 THEN SupportTickets.Status END) AS Pri4,
FROM SupportTickets
WHERE SupportTickets.Created >= (curdate() - 7)
GROUP BY SupportTickets.Client, SupportTickets.Status
PIVOT Pri1, Pri2, Pri3, Pri4 BY Status
Parameterized SQL Queries
Example Parameterized SQL Query
The following SQL query defines two parameters, MinTemp and MinWeight:PARAMETERS
(
MinTemp DECIMAL DEFAULT 37,
MinWeight DECIMAL DEFAULT 90
)
SELECT "Physical Exam".ParticipantId,
"Physical Exam".date,
"Physical Exam".Weight_kg,
"Physical Exam".Temp_C
FROM "Physical Exam"
WHERE Temp_C >= MinTemp AND Weight_kg >= MinWeight
Example API Call to the Parametrized Query
You can pass in parameter values via the JavaScript API, as shown below:<div id="div1"></div>
<script type="text/javascript">
// Ensure that page dependencies are loaded
LABKEY.requiresExt3ClientAPI(true, function() {
Ext.onReady(init);
});
function init() {
var qwp1 = new LABKEY.QueryWebPart({
renderTo: 'div1',
title: "Parameterized Query Example",
schemaName: 'study',
queryName: 'ParameterizedQuery',
parameters: {'MinTemp': '36', 'MinWeight': '90'}
});
}
</script>
query.param.MinTemp=36&query.param.MinWeight=90
User Interface for Parameterized SQL Queries
You can also pass in values using a built-in user interface. When you view a parameterized query in LabKey Server, a form is automatically generated, where you can enter values for each parameter.- Go to the Schema Browser: Admin > Developer Links > Schema Browser.
- On the lower left corner, select Show Hidden Schemas and Queries. (Parameterized queries are hidden by default.)
- Locate and select the parameterized query.
- Click View Data.
- You will be presented with a form, where you can enter values for the parameters:

ETLs and Parameterized SQL Queries
You can also use parameterized SQL queries as the source queries for ETLs. Pass parameter values from the ETL into the source query from inside the ETL's config XML file. For details see ETL: Examples.Related Topics
- LabKey SQL Reference - Reference documentation for the PARAMETERS keyword
- LABKEY.QueryWebPart
- LABKEY.Query
- Passing Parameters from an ETL
SQL Examples: JOIN, Calculated Columns, GROUP BY
- GROUP BY
- JOIN Columns from Different Tables
- Join a Calculated Column to Another Query
- Calculate a Column Using Other Calculated Columns
- Filter Calculated Column to Make Outliers Stand Out
GROUP BY
The GROUP BY function is useful when you wish to perform a calculation on a table that contains many types of items, but keep the calculations separate for each type of item. You can use GROUP BY to perform an average such that only rows that are marked as the same type are grouped together for the average.For example, what if you wish to determine an average for each participant in a large study dataset that spans many participants and many visits. Simply averaging a column of interest across the entire dataset would produce a mean for all participants at once, not each participant. Using GROUP BY allows you to determine a mean for each participant individually.A Simple GROUP BY Example
The GROUP BY function can be used on the Physical Exam dataset to determine the average temperature for each participant across all of his/her visits.To set up this query, follow the basic steps described in the Create a SQL Query example to create a new query based on the "Physical Exam" table in the study schema. Name this new query "AverageTempPerParticipant."SELECT "Physical Exam".ParticipantID,
ROUND(AVG("Physical Exam".Temp_C), 1) AS AverageTemp,
FROM "Physical Exam"
GROUP BY "Physical Exam".ParticipantID
 See similar results in our interactive example.
See similar results in our interactive example.
JOIN Columns from Different Tables
Use JOIN to combine columns from different tables.The following query combines columns from the Physical Exam and Demographics tables.SELECT "Physical Exam".ParticipantId,
"Physical Exam".Weight_kg,
"Physical Exam".Temp_C,
"Physical Exam".Pulse,
"Physical Exam".Respirations,
"Physical Exam".Pregnancy,
Demographics.Gender,
Demographics.Height
FROM "Physical Exam" INNER JOIN Demographics ON "Physical Exam".ParticipantId = Demographics.ParticipantId
JOIN a Calculated Column to Another Query
The JOIN function can be used to combine data in multiple queries. In our example, we can use JOIN to append our newly-calculated, per-participant averages to the Physical Exam dataset and create a new, combined query.First, create a new query based on the "Physical Exam" table in the study schema. Call this query "Physical Exam + AverageTemp" and choose to edit it in the SQL Source Editor. Now add edit the SQL such that it looks as follows.SELECT "Physical Exam".ParticipantId,
"Physical Exam".SequenceNum,
"Physical Exam".Date,
"Physical Exam".Day,
"Physical Exam".Weight_kg,
"Physical Exam".Temp_C,
"Physical Exam".SystolicBloodPressure,
"Physical Exam".DiastolicBloodPressure,
"Physical Exam".Pulse,
"Physical Exam".Pregnancy,
AverageTempPerParticipant.AverageTemp,
FROM "Physical Exam"
INNER JOIN AverageTempPerParticipant
ON "Physical Exam".ParticipantID=AverageTempPerParticipant.ParticipantID
 See similar results in the interactive example.
See similar results in the interactive example.
Calculate a Column Using Other Calculated Columns
We next use our calculated columns as the basis for creating yet another calculated column that provides greater insight into our dataset.This column will be the difference between a participant's temperature at a particular visit and the average temperature for all of his/her visits. This "TempDelta" statistic will let us look at deviations from the mean and identify outlier visits for further investigation.Steps:- Create a new query named "Physical Exam + TempDelta" and base it on the "Physical Exam + AverageTemp" query we just created above. We create a new one here, but you could also modify the query above (with slightly different SQL) add the new column to your existing query.
- Add the following SQL expression in the Query Designer:
ROUND(("Physical Exam + AverageTemp".Temp_C-
"Physical Exam + AverageTemp".AverageTemp), 1) AS TempDelta
- Edit the Alias and Caption for the new column:
- Alias: TempDelta
- Caption: Temperature Diff From Average
 See similar results in the interactive example.
See similar results in the interactive example.
Filter Calculated Column to Make Outliers Stand Out
It can be handy to filter your results such that outlying values stand out. This is simple to do in the LabKey grid view UI using the simple filter techniques explained on the Filter Data page.We consider the query above ("Physical Exam + TempDelta") and seek to cull out the visits were a participant's temperature was exceptionally high, possibly indicating a fever. We filter the "Temperature Diff From Average" column for all values greater than 1. Just click on the column name, select "Filter" and choose "Is Greater Than" and type "1", then click OK.This leaves us with a list of all visits where a participant's temperature was more than 1 degree C above the participant's mean temperature at all his/her visits. Notice the total number of filtered records is displayed above the grid. Or see similar results in our interactive example.
Or see similar results in our interactive example.Cross-Folder Queries
Cross-Folder Queries
You can perform cross-folder queries by identifying the folder that contains the data of interest during specification of the dataset. The path of the dataset is composed of the following components, strung together with a period between each item:- Project - This is literally the word Project, which resolves to the current folder's project.
- Path to the folder containing the dataset, surrounded by quotes. This path is relative to the home folder. So a dataset located in the Home->Study->demo subfolder would be referenced using "Study/demo/".
- Schema name - In the example below, this is study
- Dataset name - Surrounded by quotes if there are spaces in the name. In the example below, this is "Physical Exam"
Project."Study/demo/".study."Physical Exam"
Cross-Project Queries
You can perform cross-project queries using the full path for the project and folders that contain the dataset of interest. To indicate that a query is going across projects, use a full path, starting with a slash. The syntax is “/<FULL FOLDER PATH>”.<SCHEMA>.<QUERY>- Full path to the folder containing the dataset, surrounded by quotes. This lets you access an arbitrary folder, not just a folder in the current project. So a dataset located in the Home->Study->demo subfolder would be referenced using "/Home/Study/demo/".
- Schema name - In the example below, this is study
- Dataset name - Surrounded by quotes if there are spaces in the name. In the example below, this is "Physical Exam"
“/Home/Study/demo”.study."Physical Exam"Fields with Dependencies
A few LabKey fields/columns have dependencies. To use a field with dependencies in a custom SQL query, you must explicitly include supporting fields.To use Assay ID in a query, you must include the run's RowId and Protocol columns. You must also use these exact names for the dependent fields. RowId and Protocol provide the Assay ID column with data for building its URL.If you do not include the RowId and Protocol columns, you will see an error for the Run Assay ID field. The error looks something like this:"KF-07-15: Error: no protocol or run found in result set."SQL Synonyms
 Premium Feature — Available in the Professional Plus and Enterprise Editions. Learn more or contact LabKey
Premium Feature — Available in the Professional Plus and Enterprise Editions. Learn more or contact LabKey
- Easier integration with external databases. Naming differences between the client (LabKey Server) and the resource (the database) are no longer a barrier to connection.
- Insulation from changes in the underlying database. If the names of database resources change, you can maintain the connection without changing core client code.
- Hides the underlying database. You can interact with the database without knowing its exact underlying structure.
Set Up
To set up SQL synonyms, first add a new datasource to the labkey.xml file. For details see External Microsoft SQL Server Data Sources.Related Topics
External Schemas and Data Sources
- Overview
- Data Source Configuration
- Load an External Schema/Data Source
- Edit a Previously Defined External Schema
- Reload an External Schema
- Configure for Connection Validation
Overview
An externally-defined schema can provide access to tables that are managed on any PostgreSQL, Microsoft SQL Server, SAS, Oracle, or MySQL database server in your institution. Site Administrators can make externally-defined schemas accessible within the LabKey interface, limiting access to authorized users and, if desired, a subset of tables within each schema. Once a schema is accessible, externally-defined tables become visible as tables within LabKey and LabKey applications can be built using these tables.Furthermore, the external tables are editable within the LabKey interface, if the schema has been marked editable and the table has a primary key. XML meta data can also be added to specify formatting or lookups. Folder-level security is enforced for the display and editing of data contained in external schemas.You can also pull data from an existing LabKey schema in a different folder by creating a "linked schema". You can choose to expose some or all of the tables from the original schema. The linked tables and queries may be filtered such that only a subset of the rows are shown. For details see Linked Schemas and Tables.- Display, analyze, and report on any data stored on any database server within your institution.
- Build LabKey applications using external data without relocating the data.
- Create custom queries that join data from standard LabKey tables with user-defined tables in the same database.
- Publish SAS data sets to LabKey Server, allowing secure, dynamic access to data sets residing in a SAS repository.
Data Source Configuration
Before you define an external schema in LabKey server, you must first configure a new data source resource in LabKey Server. Typically this is done by editing the labkey.xml configuration file, and in some cases, other steps. See the following topics for the preliminary configuration steps, depending on the type of external data source you are using:- External Microsoft SQL Server Data Sources
- External MySQL Data Sources
- External Oracle Data Sources
- External PostgreSQL Data Sources
- External SAS Data Sources
Load an External Schema/Data Source
You can use schemas you have created in external tools (e.g., PGAdmin, SQL or SAS) within your LabKey Server. You will need to tell your LabKey Server about the external schema in order to access it.To load an externally-defined schema:- Click on the folder/project where you would like to place the schema.
- Select Admin -> Developer Links -> Schema Browser.
- On the Query Schema Browser page, click Schema Administration.
- Click New External Schema.
- Fill out the following fields:
- Schema Name – Required. Name of the schema within LabKey Server.
- Data Source - JNDI name of the DataSource associated with this schema.
- Database Schema Name – Required. Name of the physical schema within the underlying database. All external data sources identified in the labkey.xml file are listed as options in this drop-down.
- Show System Schemas - Check the box to show system schemas (such as information_schema in PostgreSQL); by default they are filtered out of this dropdown.
- Editable - Check to allow insert/update/delete operations on the external schema. This option currently only works on MSSQL and Postgres databases, and only for tables with a single primary key.
- Index Schema Meta Data - Determines whether the schema should be indexed for full-text search.
- Tables - Allows you to expose or hide selected tables within the schema. Checked tables are shown in the Query Schema Browser; unchecked tables are hidden.
- Meta Data – You can use a specialized XML format to specify how columns are displayed in LabKey. For example you can specify data formats, column titles, and URL links. This field accepts instance documents of the TableInfo XML schema. In the following example, the AddressLine1 column on the Address table is displayed with the column title "Street Address".
<tables xmlns="http://labkey.org/data/xml">
<table tableName="Address" tableDbType="TABLE">
<columns>
<column columnName="AddressLine1">
<columnTitle>Street Address</columnTitle>
</column>
</columns>
</table>
</tables>

Edit a Previously Defined External Schema
The Schema Administration page displays all schemas that have been defined in the folder and allows you to view, edit, reload, or delete them.Reload an External Schema
External schema meta data is not automatically reloaded. It is cached within LabKey Server for an hour, meaning changes, such as to the number of tables or columns, are not immediately reflected. If you make changes to external schema metadata, you may explicitly reload your external schema immediately using the reload link on the Schema Administration page.Configure for Connection Validation
If there is a network failure or if a database server is restarted, the connection to the data source is broken and must be reestablished. Tomcat can be configured to test each connection and attempt reconnection by specifying a simple validation query. If a broken connection is found, Tomcat will attempt to create a new one. The validation query is specified in your DataSource resource in labkey.xml.For a Microsoft SQL Server or PostgreSQL, data source, add this parameter:validationQuery="SELECT 1"validationQuery="SELECT 1 FROM sashelp.table"validationQuery="/* ping */"Related Topics
- TableInfo.xml. Reference documentation for the XML Meta Data field provided when defining a new schema.
- SQL Query Browser. External data sources populate the tables and fields displayed by the Query Schema Browser.
- The Best of Both Worlds: Integrating a Java Web App with SAS Using the SAS/SHARE Driver for JDBC
- SQL Server
- Linked Schemas and Tables
External MySQL Data Sources
The MySQL Driver
LabKey Server requires the MySQL driver (called "MySQL Connector/J" in the MySQL documentation) to connect to MySQL databases. The LabKey Windows installer and manual install steps will copy the MySQL driver JAR file (mysql.jar) to your Tomcat installation, in <tomcat-home>/lib, making it available to your LabKey Server.Detailed documentation about the driver is available at: MySQL Connector/J Developer Guide.Configure the MySQL Data Source
Add a <Resource> element, to your installation's labkey.xml configuration file. Use the configuration template below as a starting point.Replace USERNAME and PASSWORD with the correct credentials.If you are running LabKey Server against a remote installation of MySQL, change the url attribute to point to the remote server.<Resource name="jdbc/mySqlDataSource" auth="Container"
type="javax.sql.DataSource"
username="USERNAME"
password="PASSWORD"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/?autoReconnect=true&
useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull"
maxActive="15"
maxIdle="7"
useInformationSchema="true"
accessToUnderlyingConnectionAllowed="true"
validationQuery="/* ping */"/>
Define a New Schema
Now define a new schema from the MySQL data source. For details see Set Up an External Schema.Related Topics
com.mysql.jdbc.Driver DocumentationExternal Oracle Data Sources
Oracle JDBC Driver
LabKey Server requires the Oracle JDBC driver to connect to Oracle databases. The driver can be downloaded from the Oracle JDBC/UCP Download page. It is not redistributed with LabKey Server due to licensing restrictions, but it can be downloaded and used for free.<tomcat home>/lib
Configure the Oracle Data Source
Add a <Resource> element to your installation's labkey.xml configuration file. Use the template below as a general starting point, replacing the words in capitals with their appropriate values.<Resource name="jdbc/oracleDataSource" auth="Container"
type="javax.sql.DataSource"
driverClassName="oracle.jdbc.driver.OracleDriver"
url="jdbc:oracle:thin:USERNAME/PASSWORD@SERVER:PORT:SID"
maxActive="8"
maxIdle="4" accessToUnderlyingConnectionAllowed="true"/>
Define a New Schema
Now define a new schema from the Oracle data source. For details see Set Up an External SchemaRelated Documents
External Microsoft SQL Server Data Sources
The MS SQL Server Driver
Use the jTDS JDBC driver for MS SQL Server.Download the driver from jTDS JDBC.Place the driver JAR file in your Tomcat library path:TOMCAT_HOME/lib
Configure the MS SQL Server Data Source
Add a <Resource> element to your installations labkey.xml configuration file. Use the template below as a general starting point, replacing the words in capitals with their appropriate values.<Resource name="jdbc/mssqlDataSource" auth="Container"
type="javax.sql.DataSource"
username="USERNAME"
password="PASSWORD"
driverClassName="net.sourceforge.jtds.jdbc.Driver"
url="jdbc:jtds:sqlserver://localhost:1433/DATABASE_NAME"
maxActive="20"
maxIdle="10"
accessToUnderlyingConnectionAllowed="true"
validationQuery="SELECT 1"/>
Define a New Schema
Now define a new schema from the SQL Server data source. For details see Set Up an External SchemaRelated Topics
External PostgreSQL Data Sources
The PostgreSQL Driver
LabKey Server requires the PostgreSQL driver to connect to PostgreSQL databases. Note that the LabKey Windows installer and manual install steps copies the PostgreSQL driver JAR file (postgresql.jar) to your Tomcat installation, in <tomcat-home>/lib, making it available to your LabKey Server.To install the driver separately, see PostgreSQL JDBC Driver.Configure the PostgreSQL Data Source
Add a <Resource> element, to your installation's labkey.xml configuration file. Use the configuration template below as a starting point.Replace USERNAME and PASSWORD with the correct credentials.If you are running LabKey Server against a remote installation of PostgreSQL, change the url attribute to point to the remote server.<Resource name="jdbc/pgDataSource" auth="Container"
type="javax.sql.DataSource"
username="USERNAME"
password="PASSWORD"
driverClassName="org.postgresql.Driver"
url="jdbc:postgresql://localhost:5432/test"
maxActive="20"
maxIdle="10" accessToUnderlyingConnectionAllowed="true"/>
Define a New Schema
To define a new schema from the PostgreSQL data source see Set Up an External Schema.Related Topics
PostgreSQL JDBC DriverExternal SAS Data Sources
sasshare 5010/tcp #SAS/SHARE server
libname airline 'C:\Program Files\SAS\SAS 9.1\reporter\demodata\airline';
proc server authenticate=optional id=sasshare; run;
<Resource name="jdbc/sasDataSource" auth="Container"
type="javax.sql.DataSource"
driverClassName="com.sas.net.sharenet.ShareNetDriver"
url="jdbc:sharenet://localhost:5010?appname=LabKey"
maxActive="8"
maxIdle="4" accessToUnderlyingConnectionAllowed="true"/>
Related Documentation
- Install SAS/SHARE for Integration with LabKey Server - Provides a broader overview of SAS installation and integration with LabKey Server.
Linked Schemas and Tables
- Private data to be shown only to members of your team.
- Client data and tailored views to be shown to individual clients.
- Public data to be shown on a portal page.
Create a Linked Schema
To create a linked schema in folder B that reveals data from folder A:- Navigate to folder B.
- Select Admin -> Developer Links -> Schema Browser.
- Click Schema Administration.
- Click New Linked Schema and specify the schema properties:
- Schema Name: Provide a name for the new schema.
- Source Container: Select the source folder that holds the originating schema (folder A).
- Schema Template: Select a named schema template in a module. (Optional. See below for details.)
- Source Schema: Select the name of the originating schema.
- Published Tables: To link/publish all of the tables and queries, make no selection. To link/publish a subset of tables, use the multi-select dropdown.
- Meta Data: Provide metadata filters for additional refinement. (Optional. See below for details.)
Metadata Filters
You can add metadata xml that filters the data or modifies how it is displayed on the page.In the following example, a filter is applied to the table People -- a record is shown only when PublicInfo is true.<tables xmlns="http://labkey.org/data/xml" xmlns:cv="http://labkey.org/data/xml/queryCustomView">
<filters name="public-filter">
<cv:filter column="PublicInfo" operator="eq" value="true"/>
</filters>
<table tableName="People" tableDbType="NOT_IN_DB">
<filters ref="public-filter">
</table>
</tables>
Handling Attachment Fields
Attachment fields in the source table are not automatically carried over into the target schema, but you can activate attachment fields by providing a metadata override. For example, the XML below activates attachment field the in the list called "SourceList", which is in the Project/Folder called "SourceFolder". The activated field is called "AttachedDoc". To get the URL pattern, go to the source List and hover over one of the links in the attachment column. Right-click and copy the link.<tables xmlns="http://labkey.org/data/xml">
<table tableName="SourceList" tableDbType="NOT_IN_DB">
<columns>
<column columnName="AttachedDoc">
<url>/labkey/list/SourceFolder/download.view?listId=1&entityId=${EntityId}&name=${AttachedDoc}</url>
</column>
</columns>
</table>
</tables>
Schema Template
Default values can be saved as a "schema template" -- by overriding parts of the template, you can change:- the source schema (for example, while keeping the tables and metadata the same).
- the metadata (for example, to set up different filters for each client).
<LABKEY_HOME>/externalModules/myModuleA/schemas/ClientA.template.xml
<templateSchema xmlns="http://labkey.org/data/xml/externalSchema"
xmlns:dat="http://labkey.org/data/xml"
xmlns:cv="http://labkey.org/data/xml/queryCustomView"
sourceSchemaName="assay.General.Custom Assay">
<tables>
<tableName>Data</tableName>
</tables>
<metadata>
<dat:tables>
<dat:filters name="client-filter">
<cv:filter column="Client" operator="eq" value="A Client"/>
</dat:filters>
<dat:table tableName="Data" tableDbType="NOT_IN_DB">
<dat:filters ref="client-filter"/>
</dat:table>
</dat:tables>
</metadata>
</templateSchema>
 For example, you can create a schema for Client B by (1) creating a new linked schema based on the template for Client A and (2) overriding the metadata xml, as shown below:
For example, you can create a schema for Client B by (1) creating a new linked schema based on the template for Client A and (2) overriding the metadata xml, as shown below:
Related Topics
- Manage Study Security (Dataset-Level Security) - Granular security for study datasets.
- Manage Web Parts - Control the visibility of web parts.
- External Schemas and Data Sources - Set up an external data source.
Manage Remote Connections
- To encrypt the login to the remote server, define an encryption key in the labkey configuration file labkey.xml. On Windows, a typical location for the configuration file is C:\Program Files (x86)\LabKey Server\apache-tomcat-7.0.42\conf\Catalina\localhost\labkey.xml For details on setting a encryption key see labkey.xml Configuration File.
- Select a folder on the accessing server. The data retrieved from the target server will be available in this folder on the accessing server.
- Go to Admin > Developer Links > Schema Browser > Manage Remote Connections.
- Click Create New Connection and complete the form.

- Click Save.
- Click Test to see if the connection is successful.
Related Topics
- ETL: Remote Connections - Use a remote connection as a data source for an ETL module.
LabKey Data Structures
- List
- Assay
- Dataset
- Custom Queries
- Specimen
- Sample Set
- DataClass
- Domain
- External Schema
- Linked Schema
- Management of Simple Tabular Data. Lists are a quick, flexible way to manage ordinary tables of data, such as lists of reagents.
- Integration of Data by Time and Participant for Analysis. Study datasets support the collection, storage, integration, and analysis of information about participants or subjects over time.
- Analysis of Complex Instrument Data. Assays help you to describe complex data received from instruments, generate standardized forms for data collection, and query, analyze and visualize collected data.
Lists
Lists are the simplest and least constrained data type. They are generic, in the sense that the server does not make any assumptions about the kind of data they contain. Lists are not entirely freeform; they are still tabular data and have primary keys, but they do not require participant IDs or time/visit information. There are many ways to visualize and integrate list data, but some specific applications will require additional constraints.Lists data can be imported in bulk as part of a TSV, or as part of a list or folder archive. Lists also allow row-level insert/update/deletes.Lists are scoped to a single folder, and its child workbooks (if any).Assays
Assays capture data from individual experiment runs, which usually correspond to an output file from some sort of instrument. Assays have an inherent batch-run-results hierarchy. They are more structured than lists, and support a variety of specialized structures to fit specific applications. Participant IDs and time information are required.Specific assay types are available, which correspond to particular instruments and offer defaults specific to use of the given assay instrument. Results schema can range from a single, fixed table to many interrelated tables. All assay types allow administrators to configure fields at the run and batch level. Some assay types allow further customization at other levels. For instance, the Luminex assay type allows admins to customize fields at the analyte level and the results level. There is also a general purpose assay type, which allows administrators to completely customize the set of result fields.Usually assay data is imported from a single data file at a time, into a corresponding run. Some assay types allow for API import as well, or have customized multi-file import pathways. Assays result data may also be integrated into a study by aligning participant and time information, or by specimen id.Assay designs are scoped to the current folder, the parent project, or the shared project. Run and result data can be stored in any folder in which the design is in scope.Datasets
Datasets are always part of a study. They always contain information related to participants/subjects/animals/etc. There are different types of datasets with different cardinality: demographic (zero or one row for each subject), “standard”/"clinical" (zero or one row for each subject/timepoint combination), and “extra key”/"assay" (zero or one row for each subject/timepoint/arbitrary field combination).Datasets have special abilities to automatically join/lookup to other study datasets based on the key types, and to create intelligent visualizations based on these sorts of relationships.Datasets can be backed by assay data that has been copied to the study. Behind the scenes, this consists of a dataset with rows that contain the primary key (typically the participant ID) of the assay result data, which is looked up dynamically.Non-assay datasets can be imported in bulk (as part of a TSV paste or a study import), and can also be configurable to allow row-level inserts/updates/deletes.Datasets are typically scoped to a single study in a single folder. In some contexts, however, shared datasets can be defined at the project level and have rows associated with any of its subfolders.Datasets can have special security configuration, where users are granted permission to see (or not see) and edit datasets separately from their permission to the folder itself. As such, permission to the folder is required to see the dataset (i.e., have the Reader role for the folder), but is not necessarily sufficient.A special type of dataset, the query snapshot, can be used to extract data from some other sources available in the server, and create a dataset from it. In some cases, the snapshot is automatically refreshed after edits have been made to the source of the data. Snapshots are persisted in a physical table in the database (they are not dynamically generated on demand), and as such they can help alleviate performance issues in some cases.Custom Queries
A custom query is effectively a non-materialized view in a standard database. It consists of LabKey SQL, which is exposed as a separate, read-only query/table. Every time the data in a custom query is used, it will be re-queried from the database.In order to run the query, the current user must have access to the underlying tables it is querying against.Custom queries can be created through the web interface in the schema browser, or supplied as part of a module.Specimens
Specimens are always part of a study. They consist of multiple tables, including vials, specimens, primary type, etc. In addition to the required fields, administrators can customize the optional fields or add new ones for the specimens themselves.Specimens are almost always loaded in bulk as part of a study or specimen import. It is possible to enable editing of specimens directly through the web UI as well, but this is not common.Specimens support additional workflows around the creation, review, and approval of specimen requests to coordinate cross-site collaboration over a shared specimen repository.The configuration for specimens is scoped to a single folder. Only one set of specimen configuration is supported per folder.Behind the scenes, the server creates an entry in the experiment module’s material table (exp.Materials), which allows specimens to be the inputs or outputs of assay runs.The specimen system is designed to work with millions of vial records.Sample Sets
Sample sets allow administrators to create multiple sets of samples in the same folder, which each have a different set of customizable fields.Sample sets are created by pasting in a TSV of data and identifying one, two, or three fields that comprise the primary key. Subsequent updates can be made via TSV pasting (with options for how to handle samples that already exist in the set), or via row-level inserts/updates/deletes.Sample sets support the notion of a parent sample field. When present, this data will be used to create an experiment run that links the parent and child samples to establish a derivation/lineage history.One sample set per folder can be marked as the “active” set. Its set of columns will be shown in Customize Grid when doing a lookup to a sample table. Downstream assay results can be linked to the originating sample set via a "Name" field -- for details see Sample Sets.Sample sets are scoped based on the current folder, the current project, and the Shared project.DataClass
DataClasses are used to capture complex lineage and derivation information, especially when those derivations include bio-engineering systems like the following:- Reagents
- Gene Sequences
- Proteins
- Protein Expression Systems
- Vectors (used to deliver Gene Sequences into a cell)
- Constructs (= Vectors + Gene Sequences)
- Cell Lines
Similarities with Sample Sets
A DataClass is similar to a Sample Set or a List, in that it has a custom domain. DataClasses are built on top of the exp.Data table, much like Sample Sets are built on the exp.Materials table. Using the analogy syntax:SampleSet : exp.Material :: DataClass : exp.Data
Domain
A domain is a collection of fields. Lists, Datasets, SampleSets, DataClasses, and the Assay Batch, Run, and Result tables are backed by an LabKey internal datatype known as a Domain. A Domain has:- a name
- a kind (e.g. "List" or "SampleSet")
- an ordered set of fields along with their properties.
External Schemas
External schemas allow an administrator to expose the data in a “physical” database schema through the web interface, and programmatically via APIs. They assume that some external process has created the schemas and tables, and that the server has been configured to connect to the database, via a database connection config in the labkey.xml Tomcat deployment descriptor or its equivalent.Administrators have the option of exposing the data as read-only, or as insert/update/delete. The server will auto-populate standard fields like Modified, ModifiedBy, Created, CreatedBy, and Container for all rows that it inserts or updates. The standard bulk option (TSV, etc) import options are supported.External schemas are scoped to a single folder. If an exposed table has a “Container” column, it will be filtered to only show rows whose values match the EntityId of the folder.The server can connect to a variety of external databases, including Oracle, MySQL, SAS, Postgres, and SQLServer. The schemas can also be housed in the standard LabKey Server database.The server does not support cross-database joins. It can do lookups (based on single-column foreign keys learned via JDBC metadata, or on XML metadata configuration) only within a single database though, regardless of whether it’s the standard LabKey Server database or not.Linked Schemas
Linked schemas allow you to expose data in a target folder that is backed by some other data type in a different source folder. These linked schemas are always read-only.This provides a mechanism for showing different subsets of the source data in a different folder, where the user might not have permission to see it in the source folder.The linked schema configuration, set up by an administrator, can include filters such that only a portion of the data in the source schema/table is exposed in the target.Related Topics
Preparing Data for Import
This topic is under construction.
LabKey Server provides a variety of different data structures for different uses: Assay Designs for capturing instrument data, Datasets for integrating heterogeneous clinical data, Lists for general tabular data, etc. Some of these data structures place strong constraints on the nature of the data to imported, for example Datasets make numerous uniqueness constraints on the data; other data structures make few assumptions about incoming data. This topic explains how to best prepare your data for import into each of these data structures in order to meet any constraints set up by the target container.
Summary Table
| Data Structure | Description | Required Columns | Data Constraints | Documentation |
|---|---|---|---|---|
| Demographic Datasets | Demographic data in a folder of type 'Study'. Records permanent (or relatively permanent) features over time, such as birth gender, eye color, etc. |
|
Uniqueness constraint: Participant id values must be unique. | |
| Clinical Datasets | Clinical data in a folder of type 'Study'. Records features that change over time, such as blood pressure, weight. |
|
Uniqueness constraint: Participant id + time point values must be unique. | |
| Study Specimens | Table for holding specimen vial and tissue data. | See Import Specimen Spreadsheet Data | todo | LabKey Data Structures |
| Sample Sets | ||||
| General Assay Type | ||||
| Lists |
Demographic Datasets
todo
Clinical Datasets
todo
Assays
todo
Lists
todo
General Tips
Field name mapping
- On import, the system matches the field names in the file to the field name or label in the target table, or to any import alias that have been configured. Use import alias to be unambiguous.
- Data grid views display field labels (not names). The system adds a space if inner capital letters are found, for example "InnerCapitalLetters" becomes "Inner Capital Letters".
- On export, behavior is target-dependent.
- If exporting to an Excel file, the system uses the field labels.
- If exporting to a text file, the system uses field names. (Use text if just transferring data.)
Field data types
- Use data type 'text' if the field contains inconsistently formatted dates or numbers.
- Field validators can enforce ranges and text patterns.
- If your spreadsheets contain multiple data sets: use cut and paste, or create an assay with an associated transform script.
Column Names
When you import a data table into LabKey Server, it generates both a "name" and a "label" for each column it encounters in the table. The name is used as the internal database field, while the label is used as an external, user-facing field for display. In general special characters and white spaces are stripped out to form the name, while these characters are left in place in the label. The table below provides examples of how LabKey Server generates names and labels from table columns.
| Original Column Name | LabKey Column Name | LabKey Column Label | Notes |
|---|---|---|---|
| Lymphocyte Count (cells/mm3) | Lymphocyte Count _cells_mm3_ | Lymphocyte Count (cells/mm3) | Parentheses are replaced with underscores in names. |
| Signature? | Signature_ | Signature? | Question marks are replaced with underscores in names. |
| blank field | column1 | blank field | Blank columns are given a generic name, "column1", "column2", etc. |
Related Topics
Data Quality Control
| Lists/Data Grids | Study Datasets | Assay Data | Sample Set | Data Class | |
|---|---|---|---|---|---|
| Type Checks | yes | yes | yes | yes | yes |
| Range and Regular Expression Validators | yes | yes | yes | yes | yes |
| Missing Value Indicators | yes | yes | yes | yes | yes |
| Out of Range Value Checking | yes | yes | yes | ||
| Validate Lookups on Import | yes | yes | yes | yes | yes |
| Trigger Scripts (see also Availability) | yes | yes | yes | yes | |
| Dataset Quality Control States | yes | ||||
| Manage Dataset QC States | yes | ||||
| Validate Metadata Entry | yes | ||||
| Improve Data Entry Consistency & Accuracy | yes | ||||
| Programmatically Transform Data on Import | yes |
Other Options
Additional quality control options are available for specific use cases.Specimen Data
- Manual Flagging of Vials
- Adding Comments about Vials or Participants
- Catching Time Stamp Discrepancies
Luminex
Lists
- A place to store and edit data entered by users via forms or editable grids
- Defined vocabularies, which can be used to constrain choices during completion of fields in data entry forms
- Simple workflows that incorporate discussions, documents, and states
- Read-only resources that users can search, filter, sort, and export
Lists Web Part
You will need to enable list management before you can create lists. Add the Lists web part to the project or folder using the Select Web Parts drop-down.Topics
List Tutorial
Steps
To see the results of completing this tutorial, view the interactive example.
Related Topics

First Step
List Tutorial: Setup
Obtain the Sample Data
- Download the LabKeyDemoFiles.zip archive.
- Unzip archive to the location of your choice, which will be referred to as the [LabKeyDemoFiles] directory.
Set Up a Workspace
- If you haven't already installed LabKey Server, follow the steps in the topic Install LabKey Server (Quick Install).
- Open a web browser and navigate to the Home project (or another project of your choice).
- Sign in.
- Create a new folder to work in:
- Go to Admin > Folder > Management.
- Click Create Subfolder.
- Name: "List Tutorial"
- Folder Type: Collaboration.
- Click Next.
- On the Users/Permissions page, make no changes and click Finish.
- Add the Lists Web Part:
- Using the dropdown on the left, select Lists and click Add.
Import a List Archive
- In the Lists web part, click Manage Lists.
- Click Import List Archive.
- Click Choose File and browse to the [LabKeyDemoFiles]/Lists/NIMH directory, and select the list archive: ListDemo_NIMH_ListArchive.lists.zip
- Click Import List Archive.
Start Over | Next Step
Create a Joined Grid
- Click the NIMHSlides list from the Start Page tab.

Create a Joined Grid
- Select Grid Views > Customize Grid.
- Expand SubjectID by clicking on the "+" next to it.
- Place checkmarks next to the Name, Family, and Species fields. (Note that these fields are added to the Selected Fields pane.)
- Click Save and name this view NIMHSlideDataJoinedView
- Click Save.
- You'll now see additional columns in the grid view. To view an interactive example, see: NIMHSlideDataJoinedView

Find a Pattern in the Data
Do positive/negative stains correlate with any other characteristics in our subjects?First, let's do the simplest possible data analysis: sorting the data.- Click the column header Stain Positive to bring up a menu of sorting and filter options.
- Choose Sort Descending.
- Examine the results and notice that almost all of the positive stains came from field mice.
- Looks like we have a pattern worth further investigation.

Previous Step | Next Step
Add a URL Property
Create Links to Filtered Results
- Click the Start Page tab.
- From the Lists web part, click NIMHDemographics to open the grid view of the list.
- Click the column header Species, then Filter.
- Click the label Rat to select only that single value.
- Click OK.
- Notice the URL in your browser, which might look something like this - full path will vary, but the filter you applied is encoded at the end. This will show only rows where the species is Rat.
- Click Design.
- Click Edit Design.
- Select the Species field by clicking in its Name box.
- On the Display tab in the field properties box, enter this value for the URL field:
- The filter portion of this URL replaces "Rat" with the substitution string "${Species}". (If we were to specify "Rat", clicking any species link in the list would filter the list to only show the rats!)
- Scroll up and click Save.
- Click Done.
- Clear the filter by hovering over Filter: (Species = Rat) and then clicking Clear All.
- Click Field mouse and you will see the demographics list filtered to display only rows for field mice.
Create Links to Files
A column value can also include link to a file. All the values in a column could link to a fixed file (such as to a protocol document) or you can make row-specific links to files where a portion of the filename matches a value in the row such as the Subject ID in this example. Open this link in a new browser window: Edit the URL, incrementing the file name 20023.png, 20024.png, 20025.png. These are simply cartoon images of our sample characters stored on a public server, but in actual use you might have slide images or other files of interest stored on your local machine and named by subjectId.Here is a generalized version, using substitution syntax for the URL property, that you can use in the list design:This generalized version is already included in the list design in our example archive.- Click Start Page, then click the NIMHDemographics list in the Lists web part.
- Click Design.
- Click Edit Design.
- Select the CartoonAvailable field by clicking its Name box.
- Notice the URL property for this field. It is the generalized version of the link above.
- Click Cancel and return to the grid for this list.
- Observe that clicking true in the CartoonAvailable column opens an image of the 'subject' in that row.
Related Topics
Previous Step
Create and Populate Lists
- Manually create the list schema
- Use the list designer to add fields to the list and define the schema.
- Populating the list with data is done separately.
- Infer the schema from a datafile
- A best guess at columns and types will be made by reading the file; you may refine the inferred schema.
- During the import process, list fields are defined and the list is also populated with data.
- Import a schema exported from an existing list
- Once a list has been defined, whether or not it is populated with data, you can export the set of fields for use in creating another list.
- Populating the new list is done separately.
- Import a List Archive
- Once you have created a set of lists in a folder, you can export them as a list archive for reimport to another folder.
- Both schema and data contents of the lists are included in the archive, so importing an archive also populates the lists.
- Connect Lists walks through the process of creating a set of interconnected lists and exporting to a list archive.
- A list archive is used to set up the List Tutorial.
Create a List by Defining Fields
- Manually define fields in the list designer. Creates an empty list.
- Infer fields from a sample spreadsheet. Creates an empty list.
- Simultaneously infer fields and populate with data from a spreadsheet
Create a New List
- Navigate to a folder containing a Lists web part.
- Click Manage Lists.
- On the Available Lists page, click Create New List.
- Name the list "Technicians"
- Use default settings for the Primary Key and the Primary Key Type.
- Do not select the Import From File checkbox this time.

- Click Create List.
Add Fields
- Leave the List Properties unchanged for this example.

- Use the Add Field button below the list of fields to add three custom fields to your list design, as shown in the screen capture below. The Key field is a built-in field. If you add an extraneous field, just click the "X" button to the left of the field row you would like to delete.
- The Name, Label and Type for the properties of the three new fields:
- Name: FirstName Label: First Name Type: String
- Name: LastName Label: Last Name Type: String
- Name: ID Label: ID Type: Integer
- Click Save.

Infer a Set of Fields
Instead of creating the list fields one-by-one you can infer the list design from the column headers of a data file. Either upload the file or cut/paste the contents.- Click to download this file Technicians.xls.
- Reach the list designer as described above, but instead of clicking Add Field repeatedly, click Infer Fields From File once.
- Upload the sample file or paste the contents (tab delimited data) into the box.

- Click Submit.
- Note that the field names and types are inferred, but no data is imported from the spreadsheet used in this list design.
Infer Fields and Populate a List from a File
If you want to both infer the fields to design the list and populate the new list with the data from the spreadsheet, follow this shortcut process:- Begin list creation as above, but this time click Import from File.
- Click Browse or Choose File and select the file you downloaded.
- You will see a preview of fields inferred - you may change types or labels here if needed.

- Click Import.
Import/Export Fields
Once you have saved a list design, whether or not you have added data to the actual list, you may export the fields to import into another newly created list.- Click the name of the list in the Lists web part (here, Technicians).
- Click Design.
- Scroll down and click Export Fields.
- Copy the contents of the popup window to your browser clipboard or a notepad file.

- Click Done.
- In the Lists web part, click Manage Lists.
- Click Create New List, name it "TechniciansCopy" and leave other settings as defaults.
- In the List Fields section, click Import Fields.
- Paste the schema you exported above into the provided window:

- You could modify, add, or delete fields from the new design as needed.
- Click Save to save the new design.
Populate a List
- Select Insert > Insert New Row.
- Enter the values for each property.

- Click Submit.
- Select Insert > Import Bulk Data.
- Type the following into the Import Data text box, with a tab between fields.
| First Name | Last Name | ID |
|---|---|---|
| John | Doe | 1 |
| Jane | Doe | 2 |
| John | Smith | 3 |

- Click Submit.

View the List
Your list is now populated. You can see the contents of the list by clicking on the name of the list in the Lists web part. An example:
Import Lookups By Alternate Key
When importing data into a list, you can use the checkbox to Import Lookups by Alternate Key. This allows lookup target rows to be resolved by values other than the target's primary key. It will only be available for lookups that are configured with unique column information. For example, tables in the "samples" schema (representing Sample Sets) use the RowId column as their primary key, but their Name column is guaranteed to be unique as well. Imported data can use either the primary key value (RowId) or the unique column value (Name). This is only supported for single-column unique indices. See Import Sample Sets.Import a List Archive
Export
To export all the lists in a folder to a list archive:- In the folder that contains lists of interest, go to the Lists web part and click Manage Lists.
- Select Export List Archive.
- All lists in the current folder are exported into a zip archive.
Import
To import a list archive:- In the folder where you would like to import the list archive, go to the Lists web part and select Manage Lists.
- Select Import List Archive.
- Browse to the .zip file that contains your list archive and select it.
- Click Import List Archive.
- The imported lists will then be displayed in the Lists web part.
Auto-Increment Key Considerations
Exporting a list with an auto-increment key may result in different key values on import. If you have lookup lists make sure they use an integer or string key instead of an auto-increment key.Related Topics
The List Tutorial uses a list archive preconfigured to connect several lists with lookups between them. A walkthrough of the steps involved in creating that archive from independent lists is covered in Connect Lists.Manage Lists

Manage a Specific List
- Details: View the contents of the list as a grid.
- View Design: View fields and properties that define the list, including allowable actions and indexing.
- View History: See a record of all list events and design changes.
Create a List
Click Create New List to add a new list.Delete Lists
Select one or more lists and click Delete. Removes the list permanently from your server. Both the data and the list design are removed.Import/Export List Archives
You can transfer some or all lists in a folder to a new folder using the Export List Archive and Import List Archive options.List Web Parts
You can display a directory of all the lists in a given folder using a Lists web part. To display the contents of a single list, add a List - Single webpart and choose the list and view to display.Related Topics:
Connect Lists
Import Files into Lists
Create the lists individually by importing spreadsheets. If you already imported the tutorial list archive, you can skip this step, or create a new set of lists in another folder.- Click Manage Lists link in the Lists web part.
- Click Create new list
- Name: "NIMHDemographics"
- Primary Key: "SubjectID"
- Primary Key Type: Integer
- Import from file: Check box.
- Click Create List.
- Browse or Choose File and locate [LabKeyDemoFiles]/Lists/NIMH/NIMHDemographics.xls.
- Assume the inferred fields are correct and click Import.
- Click Lists > above the grid and repeat the Create New List steps for each of the following:
- Name: "NIMHPortions"
- Primary Key: "PortionID"
- Primary Key Type: Integer
- Import from file: Check box.
- Select and import the file named: NIMHPortions.xls
- Name: "NIMHSamples"
- Primary Key: "SampleID"
- Primary Key Type: Integer
- Import from file: Check box.
- Select and import the file named: NIMHSamples.xls
- Name: "NIMHSlides"
- Primary Key: "SlideID"
- Primary Key Type: Integer
- Import from file: Check box.
- Select and import the file named: NIMHSlides.xls
Set Up Lookups
There are columns in common between our lists that can be used as the basis for joins between these lists. In order to setup the lists for joins, we need to identify the columns in common.The steps for editing a list design to make a field into a lookup of a value from another table are as follows. If you are already working with the tutorial list archive, simply examine the list designs where you will already see these changes.- In the Lists web part, click NIMHSamples.
- Click Design then Edit Design.
- Scroll down and for the SubjectID field, click on the Type property and select Lookup.
- Folder: [current folder].
- Schema: lists.
- Table: NIMHDemographics(Integer).
- Click Apply.
- Scroll back up and click Save.
| List | Field | Table for Lookup |
|---|---|---|
| NIMHPortions | SubjectID | NIMHDemographics(Integer) |
| NIMHPortions | SampleID | NIMHSamples(Integer) |
| NIMHSlides | SubjectID | NIMHDemographics(Integer) |
| NIMHSlides | SampleID | NIMHSamples(Integer) |
| NIMHSlides | PortionID | NIMHPortions(Integer) |
Export List Archive
Now that you have created a useful package of interconnected lists, you can package them as an archive for use elsewhere.- From the Lists web part, click Manage Lists.
- Click Export List Archive.
- All the lists in the web part will be included in the zip file that is downloaded.
Import a List Archive
Once you have created and exported an archive, you can reuse it later (as we did in the tutorial example) by importing the archive:- In the Lists web part, click Manage Lists.
- Click Import List Archive.
- Browse to and select the list archive: ListDemo_NIMH_ListArchive_XXXX.lists.zip in [LabKeyDemoFiles]/Lists/NIMH.
- Click Import List Archive.

Edit a List Design
List Properties
The design editor lets you change metadata associated with a list. These metadata are called List Properties.Example. The properties of the NIMHDemographics list in the List Tutorial Demo look like this (when indexing options are selected): Name. The displayed name of the list.Description. An optional description of the list.Title Field. Identifies the field (i.e., the column of data) that is used when other lists or datasets do lookups into this list. You can think of this as the "lookup display column."For example, you may wish to create a defined vocabulary list to guide your users in identifying reagents used in an experiment. To do this, you would create a new list for the reagents, including a string field for reagent names. You would select this string field as the title field for the list. Then the reagent names added to this list will be displayed as drop-down options from other lists doing lookups.Note: If no title field has been chosen (i.e., the <Auto> setting is used, LabKey Server auto-picks the list title field using the following process:
Name. The displayed name of the list.Description. An optional description of the list.Title Field. Identifies the field (i.e., the column of data) that is used when other lists or datasets do lookups into this list. You can think of this as the "lookup display column."For example, you may wish to create a defined vocabulary list to guide your users in identifying reagents used in an experiment. To do this, you would create a new list for the reagents, including a string field for reagent names. You would select this string field as the title field for the list. Then the reagent names added to this list will be displayed as drop-down options from other lists doing lookups.Note: If no title field has been chosen (i.e., the <Auto> setting is used, LabKey Server auto-picks the list title field using the following process:
- LabKey picks the first non-lookup string column (this could be the key).
- If there are no string fields, LabKey uses the key.
- LabKey does not exclude nullable fields from consideration.
- Index each item as a separate document means that each record in the list will appear as a separate search result.
- Standard Title: The standard search result title is <List Name> - <Value of Title Field>
- Custom Title: Customize the search result title using a template that includes your choice of fields, for example: NIMHDemographics - ${SubjectID} ${Name}
- Index all text fields: Values in all text fields will be indexed.
- Index all fields (text, number, date and boolean): Values in all fields will be indexed.
- Index using custom template: Choose the exact set of fields to index, for example: ${SubjectID} ${Name} ${Family} ${Mother} ${Father}
- Index entire list as a single document means that the list as a whole will appear as a search result.
- Metadata only (name and description of list and fields)
- Data only: Not recommend for large lists with frequent updates, since updating any item will cause re-indexing of the entire list
- Metadata and data: Not recommend for large lists with frequent updates, since updating any item will cause re-indexing of the entire list
- Standard title
- Custom title: Any text you want displayed and indexed as the list's search result title.
- Index all text fields
- Index all fields (text, number, date and boolean)
- Index using custom template: Choose the exact set of fields to index, for example: ${SubjectID} ${Name} ${Family} ${Mother} ${Father}
List Fields
You can add, delete or edit the fields of your list in this section. See Field Properties Reference.Example. The field editor for the NIMHDemographics list in the List Tutorial Demo looks like this:
Customize the Order of List Fields
LabKey Server allows customization of the display order of list fields in insert/edit/details grids. This helps users display fields in an order that makes sense for them.By default, the order of fields in the default grid is used to order the fields in insert, edit and details for a list. All fields that are not in the default grid are appended to the end. To see the current order, click Insert New for an existing list.To change the order of fields, modify the default grid by selecting Grid Views > Customize Grid. See Customize Grid Views for further details.Choose a Primary Key
- Enter the name of the "primary key", the column that holds the unique key. Default: Key
- Select the data type of the Primary Key. Default: AutoIncrement Integer.

Search
Search Terms and Operators
The query syntax is very similar to popular search engines such as Google and Bing. To execute a search, enter terms (search words) and operators (search modifiers) in the search box using the following guidelines:Terms- At least one of the terms or phrases you enter must exist somewhere on the returned page. In other words, terms are searched on an OR basis in the absence of operators.
- Example: Searching on NAb assay returns all pages that contain at least one of the terms "NAb" and "assay". Pages that contain both will appear higher in the results than pages that contain just one of the terms.
- Double quotes around phrases indicate that they must be searched as exact phrases instead of as individual terms.
- Example: Searching the quoted phrase "NAb assay" returns only pages that include this two word phrase.
- AND: Search terms separated by the AND operator must both appear on returned pages.
- Example: NAb AND assay returns all pages that contain the term both the term "NAb" and the term "assay".
- +: A search term preceded by the + operator must appear on returned pages.
- Example: NAb +assay returns pages that must contain the term "assay" and may contain the term "NAb".
- NOT: When you separate search terms with the NOT operator, the second term must not appear on returned pages.
- Example: NAb NOT assay returns pages that contain the term "NAb" but do not contain the term "assay".
- -: Works just like the NOT operator. A search term preceded by the - operator must not appear on returned pages.
- Example: NAb -assay returns all pages that contain the term "NAb" but do not contain the term "assay".
- Capitalization is ignored.
- Parentheses can be used to group terms.
- Extraction of root words, also known as stemming, is performed at indexing and query time. As a result, searching for "study", "studies", "studying", or "studied" will yield identical results.
- Wild card searches
- Use the question mark (?) for single character wild card searches. For example, searching for "s?ed" will return both "seed" and "shed".
- Use the asterisk character (*) for multiple character wild card searches. For example, searching for "s*ed" will return both "seed" and "speed".
- Wild card searches cannot be used as the start of the search string. For example, "TestSearch*" is supported, but "*TestSearch" is not.
- Note that stemming (defined above) creates indexes only for words roots, so wild card searches must include a word root (or a shortened version) to yield the intended results.
Content Searched
Data types and sources. The LabKey indexer inventories most data types on your server:- Study protocol document and study description.
- Study dataset metadata (study labels; dataset names, labels, and descriptions; columns names, labels, and descriptions; lab/site labels)
- Assay metadata (assay type, description, name, filenames, etc.)
- List metadata and/or data (You have precise control of which parts of a list are indexed. For details see Edit a List Design.)
- Schema metadata (including external schema)
- Participant IDs
- Wiki pages and attachments
- Messages and attachments
- Issues
- Files
- Automatically includes the contents of all file directories. File directories are where uploaded files are stored by default for each folder on your server. See also: File Terminology
- By default, does not include the contents of pipeline override folders (@pipeline folders). The contents of these folders are only indexed when you set the indexing checkbox for the pipeline override that created them. Files are only stored in pipeline override folders when you have set a pipeline override and thus set up a non-default storage location for uploaded files.
- Folder names, path elements, and descriptions. A separate "Folders" list is provided in search results. This list includes only folders that have your search term in their metadata, not folders where your search term appears in content such as wiki pages.
Participant Search
Participant Searches. Study managers are often particularly interested in seeing all of the data available for a particular individual across all studies. It is easy to search for a particular participant ID on LabKey Server -- just enter the participant ID into the search bar. The appropriate participant page will be the top hit, followed by attachments and other documents that mention this participant. You will only see materials you are pre-authorized to view.Example. Searching labkey.org for participant 249318596 shows these results. The participant page for this individual tops the list, followed by files that include this participant and several pages of documentation. Security rules ensure that only public studies that cover this participant are included in results.Scoping
The search box on the top right of all pages of your LabKey Server site searches across the entire site, returning only results that you have sufficient permissions to see. Search boxes within particular folders (e.g., the search box for the LabKey.org documentation folder) search only within a particular container. They can optionally be set by an admin to search subfolders within that container. Results are always limited by your permissions to view secure content.Advanced Search Options
Advanced search options let you refine your search by specifying the types and locations of documents searched.To access the advanced search options, first perform a search from the web part, then click the + sign next to Advanced Search. Choose one or more Categories to narrow your search to only certain data types. For example, if you select Files you will see only files and attachments in your results.Select a Scope to scope your search to the contents of the entire site, the contents of the current project, the contents of the current folder without it sub-folders, or the contents of the current folder including its sub-folders.The screen shot below shows a search of Files in the current Project.
Choose one or more Categories to narrow your search to only certain data types. For example, if you select Files you will see only files and attachments in your results.Select a Scope to scope your search to the contents of the entire site, the contents of the current project, the contents of the current folder without it sub-folders, or the contents of the current folder including its sub-folders.The screen shot below shows a search of Files in the current Project.
Search URL Parameters
You can define search parameters directly in the URL, for example, the following searches for the term "HIV" in the current folder:You can assign multiple values to a parameter using the plus sign (+). For example, the following searches both files and wikis for the search terms 'HIV' and 'CD4':?q=HIV+DC4&category=File+Wiki
?q="HIV+count"| URL Parameter | Description | Possible Values |
|---|---|---|
| q | The term or phrase to search for. | Any string. |
| category | Determines which sorts of content to search. | File, Wiki, Dataset, Issue, Subject, List, Assay, Message |
| scope | Determines which areas of the server to search. | Project, Folder, FolderAndSubfolders. No value specified searches the entire site. |
| showAdvanced | When the search results are returned, determines whether the advanced options pane is displayed. | true, false |
Additional Resources
- Syntax. LabKey supports additional query syntax that can be used for wildcard searches, fuzzy searches, proximity searches, term boosting, etc. For more details, see Lucene Search Syntax (external link)
- Admin. Please see Search Administration
Search Administration
Full-Text Search Configuration
The Full-Text Search Configuration page allows you to configure the primary index, integrate external indexes, and review statistics about your index.Primary Index Configuration- Set Path. You can change the directory that stores the index (default: <tomcat>/temp/labkey_full_text_index) by entering a new path and clicking the Set Path button. Note that changing the location of the index requires re-indexing all data, which may affect performance. Resetting the path of the index is especially useful if you are running multiple LabKey deployments on the same Tomcat instance, because it allows each LabKey deployment to use a unique index.
- Start/Pause Crawler. The crawler, or document indexer, continually inventories your site when running. You might pause it to diagnose issues with memory or performance.
- Delete Index. You can delete the entire index for your server. Please do this with caution because rebuilding the index can be slow.
- Directory Type. This setting lets you can change the search indexing directory type. The setting marked "Default" allows the underlying search library to choose the directory implementation (based on operating system and 32-bit vs. 64-bit). The other options override the default heuristic and hard-code a specific directory implementation. These are provided in case the "Default" setting causes problems on a specific deployment. Use the default type unless you see a problem with search. Contact LabKey for assistance if full-text indexing or searching seems to have difficulty with the default setting.
- In the field External index description, enter a friendly name for the index.
- In the field Path to external index directory, enter the absolute path to the index folder.
- From the dropdown field Analyzer, select a method for extracting index terms. This analyzer must match the analyzer used at indexing time. Options include:
- SimpleAnalyzer: Splits text at whitespace and special characters such as '!', '@', and '#'. Uppercase words are not included in the index.
- KeywordAnalyzer: Indexes each term as a single word. Useful for zip codes, id numbers, url fragments, etc.
- EnglishAnalyzer: Attempts to extract the "stem" word for each indexable item, so that searches for "study", "studies", "studying", or "studied" will yield identical results.
- IdentifierAnalyzer: A simple, non-stemming analyzer for identifiers. Tokenizes only on whitespace; all punctuation is left intact.
- LabKeyAnalyzer: A hybrid analyzer that uses a non-stemming analyzer for categories and identifier fields, and a stemming English analyzer for all other fields. This is the standard analyzer optimized for LabKey Server usage.

Audit Log
To see the search audit log, click the Admin Console tab and click Audit Log in the "Management" section. Choose the Search option in the dropdown menu at the top of the auditing page. This displays the log of audited search events for your system. For example, you can see the terms entered by users in the search box. If someone has deleted your search index, this event will be displayed in the list, along with information on the user who ordered the delete.Setup for Folder-Specific Search Boxes
By default, a site-wide search box is included on the top right side of every page of your LabKey Server site. You can add additional, scoped search boxes to individual projects or folders.Add Search Web Part. To supply a search box that searches only a particular container, add the Search web part to the Portal page of a project or folder. See Add Web Parts for further details on how to add web parts. To see an example of a search box applied to a particular container, use the search box next to the labkey.org documentation, to the right of this page.Set SubFolder Searching. Administrators can specify whether a search box searches just the current container or the current container and its sub-containers by default. Click on the "..." box on the title bar of the Search web part you've added. Now you can select or unselect "Search Subfolders" and set the default depth of search.Searching List and External Schema Metadata
By default, the search index includes metadata for lists and external schemas (including table names, table descriptions, column names, column labels, and column descriptions).You can turn off indexing of List metadata by unchecking the checkbox Index list meta data when creating or editing a list definition.You can turn off indexing of external schema metadata by unchecking the checkbox Index Schema Meta Data when creating or editing an external schema definition. For details see External Schemas and Data Sources.Include/Exclude a Folder from Search
You may want to exclude the contents of certain folders from searches. For example, you may not want archived folders or work in progress to appear in search results.- Navigate to the folder and select Admin > Folder > Management.
- Select the Search tab.
- Uncheck the checkbox Include this folder's contents in multi-folder search results.
- Click Save.
Exclude a File System Directory from Search
LabKey Server automatically indexes the file system directories associated with projects and folders. It will ignore the contents of directories named ".svn" and ".Trash". To tell the server to not index the content of a directory, you can add a file named ".nocrawl". The content of the file does not matter, an empty text file is sufficient.Laboratory Data
Modeling instrument data in a manageable and meaningful way that provides useful results and permits integration with other data is the role of LabKey Assay Tools. A wide variety of instruments read information from biological samples and output various kinds of structured instrument data. Managing these assays can present some of the biggest challenges in scientific research:
- Massive amounts of data are generated repeatedly and over time.
- Consistent, accurate, reliable tracking of both data and metadata are required.
- Cleaning, validation, transformation by individuals can be a source of inconsistency.
- Integration with other types of related data is difficult to do manually.
- Publishing and sharing selected data in a secure way unlocks collaboration for better outcomes.
Which Assay File Types Does LabKey Server Support?
LabKey Server supports all common tabular file types: Excel formats (XLS, XLSX), Comma Separated Values (CSV), Tab Separated Values (TSV). LabKey Server also recognizes many instrument-specific data files and metadata files, such as FlowJo FCS files, ELISpot formatted XLS files, and many more. In general, if your instrument provides tabular data, then the data can be imported using a GPAT assay type. You maybe also be able to take advantage of other specific assay types, which are designed to make the most of your data. For details, see the documentation below for your instrument class. Contact LabKey if you have problems importing your data or have specific questions about which file types are supported.
Which Assay Instruments Does LabKey Server Support?
Any instrument that outputs tabular data (that is, any data in a format of columns and rows) can be imported into LabKey Server using a General type assay. Assay data imported using a General assay can be analyzed, visualized, and integrated with other data using LabKey Server's standard tools. Many instruments and protocols are supported beyond the General assay type. LabKey Server provides special built-in dashboards and reports to help you make sense of the data, providing specialized tools for NAb, Flow Cytometry, Mass Spectrometry and other assay types. The following table provides a summary of the general and specialized support provided. Both general and instrument-specific assay types are highly-flexible and configurable by the user, so you can extend the reach of any available type to fit your needs.
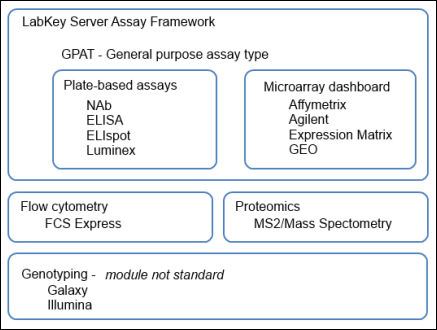
Introduction to Assay Tools
Instrument Data Types
LabKey assay tools simplify complex laboratory workflows and incorporate custom analytics and quality control and trending tools for specific instrument types. Supported types include:
- ELISA - Imports raw data from BioTek Microplate readers.
- ELIspot - Imports raw data files from CTL, Zeiss, and AID instruments.
- Flow Cytometry/FCS Express - Import flow cytometry probe/sample values.
- Fluorospot - Similar to ELISpot, but the detection mechanism uses fluorophores instead of enzymes.
- HPLC - High-Performance Liquid Chromatography assay.
- Luminex - Imports data in the multi-sheet BioPlex Excel file format.
- Microarray - Imports microarray runs from MageML files and gene expression microarrays from a Gene Expression Omnibus series of probe/sample values.
- NAb (Neutralizing Antibody) Assays - Imports results from high- or low-throughput neutralizing antibody assays.
- Affymetrix - Imports microarray runs from GeneTitan Excel files.
- Proteomics - Import mass spectrometry data files, including MzXML, and protein expression experiments.
- Genomics Workflows - Support for DNA sequencing and genotyping examples. Not included in the standard LabKey Server distribution.
Additional Information
Tutorial: Design a General Purpose Assay Type (GPAT)
Overview
This tutorial walks you through importing, annotating and interpreting the tabular results (often provided in a spreadsheet) of a custom assay. You will:- Set up a new assay design, to capture both the core data and the contextual information ("metadata") about the experiment.
- Perform validation as you upload sample data.
- Quickly visualize the data, allowing you to confirm a valid run.
- Integrate quality controlled assay data with other information in a study.
The "General Purpose" Assay Type (GPAT)
As part of this tutorial, we will create an assay design based on a "general purpose assay type", or "GPAT", one of LabKey Server's many tools for working with instrument data. This assay type provides a flexible format for describing your experimental results, so that many sets of experimental results can be imported to LabKey Server using the pattern specified in the design. The structure of an assay design may include:- the type and format of experimental result files
- contextual information about the experiment
- the definition of summaries or visualizations appropriate for sharing
Tutorial Steps
- Step 1: Assay Tutorial Setup
- Step 2: Infer an Assay Design from Spreadsheet Data
- Step 3: Import Assay Data
- Step 4: Work with Assay Data
- Step 5: Data Validation
- Step 6: Integrate Assay Data into a Study
First Step
Step 1: Assay Tutorial Setup
Basic Setup Steps
- Install LabKey Server if you have not already done so.
- Download the sample data: LabKeyDemoFiles.zip
- Unzip the downloaded package.
Create an Assay Folder
- In a web browser go to an available project, such as the Home project, and sign in.
- Create a new folder to work in:
- Go to Admin > Folder > Management and click Create Subfolder.
- On the Create Folder page, enter the following:
- Name: "Assay Tutorial"
- Folder Type: Assay.
- Click Next.
- On the Users/Permissions page, confirm Inherit from Parent Folder is selected, and click Finish.
- You are now on the default tab (Assay Dashboard) of the new assay folder.
Upload Data
Now we will add a file repository to hold the sample assay data you downloaded and unzipped.- In the lower left corner, click the <Select Web Part> menu, select Files and click Add.
- Drag and drop the downloaded (and unzipped) directory [LabKeyDemoFiles]/Assay into the target area of the Files web part.
- When the upload is complete, you will see the "Assay" directory listed in the file repository.
Previous Step | Next Step
Step 2: Infer an Assay Design from Spreadsheet Data
Create a New Assay Design by Inference
LabKey Server can give you a head start on creating your assay design by inferring column names and types from a sample data file, in this case an Excel spreadsheet.- In the Assay List web part, click New Assay Design.
- On the New Assay Design page, select General.
- Select the current folder as the Assay Location and click Next.
- On the General Assay Designer page, in the Name field, enter "GenericAssay".
- Scroll down to the Data Fields section and click Infer Fields for File.

- In the pop up dialog, click Choose File. Note that you may have to scroll up in your browser to see the popup.
- Navigate to the sample files you downloaded and select LabKeyDemoFiles/Assays/Generic/GenericAssay_Run1.xls.
- In the pop up dialog click Submit.

- LabKey Server will examine the Excel file and infer a "best guess" assay design. The server then shows you the inferred columns and their data types. In this tutorial, two extraneous data fields are inferred:
- Delete the inferred fields for "column5" and "column6" by clicking the X to the left of each name.
- In this case the other inferrals are correct. If needed, you could also change field types and set column properties from this page.

Add Fields to the Assay Design
At this point, we could declare the design finished and save a skeleton design capable of uploading any spreadsheets of the same format. But before we finalize the design, we'll add our own fields, in order to capture information about who was operating the instrument and with what settings.An assay design is composed of different fields. There are three types of built-in fields:- Data Fields: Can be read from the uploaded file.
- Run Fields: Are specific to a single file and will be populated by the operator for each file, or run, of data.
- Batch Fields: Apply to groups of runs and are typically populated by the operator once per batch.
- Scroll to the section Batch Fields (If you have already saved and reopened this design, the section will include the assay name, i.e. "GenericAssay Batch Fields.")
- Click Add Field, enter the Name "OperatorEmail".
- Click Add Field, enter the Name "Instrument", and enter the Description: "The diagnostic test instrument."
- In the section Run Fields:
- Click Add Field
- Enter the Name "InstrumentSetting".
- Click the Type field, select Integer in the popup and click Apply.
- Enter the Description: "The configuration settings on the instrument."

- Click Save & Close.
- Your new assay design is now saved and ready to use. We can use it to import as many runs as we like from spreadsheets with the same structure. On the Assay Dashboard tab, you will now see GenericAssay on the assay list.

Example
The original Excel spreadsheet looks like this: The data structure within LabKey Server will look like this after we import the spreadsheet through the assay design in the next step:
The data structure within LabKey Server will look like this after we import the spreadsheet through the assay design in the next step:
Previous Step | Next Step
Step 3: Import Assay Data
Import Multiple Runs in a Batch
- If necessary, return to the main page by clicking the Assay Dashboard tab.
- In the Files webpart in the left panel, navigate to the folder "Assays/Generic".
- Check the boxes for four files:
- GenericAssay_Run1.xls
- GenericAssay_Run2.xls
- GenericAssay_Run3.xls
- GenericAssay_Run4.xls
- Click Import Data.

- In the pop up dialog, select Use GenericAssay (if necessary -- it may already be selected by default). Note that this is the assay design you just created.
- Click Import.
- This will queue up all four files for import into the design.

- On the Batch Properties page, enter the following:
- OperatorEmail: Enter “john.doe@email.com” (or any email you wish).
- Instrument: Enter "ABI QSTAR" (or any name you wish).
- Click Next.

- On the Run Properties and Data File page, notice that the batch properties appear in a read-only section, and the Run Properties panel has been added for entering information. The Run Data section lists the first file and shows a message "(3 more runs available)." Enter values for the first run:
- Assay ID: Enter a custom value here, "Run1".
- Comments: "Test run entered as part of the assay tutorial."
- Instrument Setting: Enter some integer, such as "23".
- Click Save and Import Next File.

- Notice that you skip entering "Batch Properties" and they appear in a "closed" panel above the "Run Properties". This is because these batch properties apply to all files in the batch.
- Notice that the Run Properties page now lists the next file in the series: GenericAssay_Run2.xls.
- Enter values as follows:
- AssayId: "Run2".
- Comments: Enter some comment.
- Instrument Setting: Enter some integer, or keep the value from the last run, "23".
- Click Save and Import Next File.
- Repeat for the remaining two files in the queue: "Run3" and "Run4".
- After you've entered run properties for the fourth and final file, click Save and Finish. The button to save and import next file is no longer available.
- You now see the GenericAssay Runs page, which will look something like this (you may have entered different values).

Related Topics
Previous Step | Next Step
Step 4: Work with Assay Data
- Assay Results: The individual data elements from an instrument, for example the intensity of a spot or well. Assay instruments typically output a lot of results each time a sample is run.
- Assay Runs: Data imported representing a single instrument run, typically but not necessarily contained in a single file. An operator may be required to enter properties at the time of import, depending on the instrument type.
- Assay Batches: A set of runs uploaded in a single session; some properties may be common to the entire batch. A single run can still be considered a batch and still uses batch properties when uploaded by itself.
Assay Runs
Once you have uploaded assay data, you will be taken first to the Runs grid, which is the "middle" level grouping, between Results (the most detailed grid view) and Batches (the most general view).
- Clicking a link in the Assay Id column, such as "Run3", takes you to the Results grid.
- Clicking in the Flag column toggles the flag indicating there is a need to review the run for possible problems. When you flag a row, you may enter a comment. A flagged row shows a colored icon; hover to see the comment entered.
- Clicking the graph link (in the unnamed column between Flag and Assay Id) takes you to details about the run, including a graphical representation of the run. For example, clicking the graph link for Run1 shows the following. Notice that the graph assumes that each unique date in the assay data represents a different specimen.

- Return to the assay runs grid using the back button in your browser, or by clicking Assay Dashboard, then GenericAssay in the assay list.
Assay Results
The Results grid shows actual assay data originally encoded in the Excel files, now captured by the assay design.- From the Runs grid, in the Assay Id column, click Run3.
- You are taken to the assay Results grid. Only results for the selected run are shown. Notice the filter message above the grid reads "Run = 846" (or some other integer) instead of "Run3", as you might expect. The filter message uses the system value, which in this case was 846.
- To see all results across all runs, clear the filter:
- Hover over Filter and a button Clear All will appear. Click the button to clear the filter.

- Use the Results grid to create reports and visualizations.
- To see LabKey Server's best guess visualization for the assay data, click one of the column headers M1, M2, or M3 and select Quick Chart. For the column M2, LabKey Server's best guess is a box and whisker plot that will look something like this:

- Explore the customizations available using the Chart Type and Chart Layout buttons.
- To return to the Results grid, click the Back button on your browser.
- There is much more you can do with the Results grid of assay data -- explore the buttons and menus above the grid, such as Grid Views, Reports, Charts, and Export.
Assay Batches
- From the Assay Dashboard, click GenericAssay, then View Batches to see a grid view of all batches imported.
- The batch grid can be customized, but by default shows the run count as well as properties specified on import.

- Click the batch Name to return to the runs grid, filtered to only show runs from that batch. (Note that if runs were deleted and imported as part of a later batch, the earlier batch will no longer show those runs.)
Previous Step | Next Step
Step 5: Data Validation
- Required fields: prevent operators from skipping critical entries
- Regular expressions: validate entered text against a pattern
- Range validators: catch import of runs containing obviously out of range data
Set Up Validation
Here we add some validation to our GenericAssay design by modifying it. Remember that the assay design is like a map describing how to import and store data. When we change the map, any run data imported using the old design may no longer pass validation.- Click the Assay Dashboard tab.
- In the Assay List section, click the GenericAssay link.
- Select Manage Assay Design > edit assay design.
- Note that if you didn't specify the current subfolder when you defined this tutorial assay, you will get a pop up dialog "This assay is defined in the /home folder. Would you still like to edit it?". Click Ok to continue to the Assay Designer if you are the only user of this assay on the /home folder.
Required Fields
By default, any new field you enter is optional. If you wish, you can make one or more fields required, so that if an operator skips an entry, the upload fails.- Scroll to the GenericAssay Run Fields section.
- Select the InstrumentSetting field (in the "Run Fields" section).
- Click the Validators tab and then click the Required checkbox.

- Click Save and Close.
- If you get the message The required property cannot be changed when rows already exist, this means assay data has already been imported using this design without the instrument setting. You will need to delete the offending assay runs before you can set the field as required.
Regular Expressions
Using a regular expression to check entered text is a flexible form of validation. You could compare text to an expected pattern, or in this example, we can check that special characters like angle brackets are not included in an email address (as could happen in a cut and paste from a contact list).- Reopen Manage Assay Design > edit assay design.
- Select the OperatorEmail field in the "Batch Fields" section. The extended property editor will appear to the right.
- Click the Validators tab and then click Add Regex Validator.
- Enter the following parameters:
- Name: BracketCheck
- Description: Ensure no angle brackets.
- Regular Expression: .*[<>].*
- Error Message: An email address cannot contain the "<" or ">" characters
- Check the box for Fail when pattern matches. Otherwise, you would be requiring that emails contained the offending characters.
- Click OK.

Range Validators
By checking that a given numeric value falls within a given range, you can catch some bad runs at the very beginning of the import process.- Select the M3 field in the "Data Fields" section. The extended property editor will appear to the right.
- Click the Validators tab and then click the Add Range Validator button (which only appears for numeric fields).
- Enter the following parameters:
- Name: M3ValidRange
- First Condition: Select greater than or equals: 5
- Second Condition: Select less than or equals: 100
- Error Message: Valid M3 values are between 5 and 100.
- Click OK.
- Click Save & Close to save the edited GenericAssay design.
Observe Validation in Action
To see how data validation would screen for these issues, we'll intentionally upload some "bad" data which will fail the validators we just defined.- On the Assay Dashboard tab, in the Files web part, select the file [LabKeyDemoFiles]/Assays/Generic/GenericAssay_BadData.xls.
- Click Import Data.
- Select Use GenericAssay and click Import.
- Paste in "John Doe <john.doe@email.com>" as the OperatorEmail. Leave other entries at their defaults, saved from our prior imports.
- Click Next.
- Observe the next red error message: "Value 'John Doe <john.doe@email.com>' for field 'OperatorEmail' is invalid. An email address cannot contain the "<" or ">" characters.
- Correct the email address entry to read only "john.doe@email.com" as before.
- Click Next again and you will no longer see the error.
- Enter an Assay ID for the run, such as "BadRun" and delete the InstrumentSetting value which was autofilled based on your prior upload.
- Click Save and Finish.
- Observe the red error text: "Instrument Setting is required and must be of type Integer."
- Enter a value and click Save and Finish again.
- Observe error message: "Value '4.8' for field 'M3' is invalid. Valid M3 values are between 5 and 100." The invalid M3 value is included in the spreadsheet being imported, so the only way to clear this particular error would be to edit/save/reimport the spreadsheet.
Related Topics
Previous Step | Next Step
Step 6: Integrate Assay Data into a Study
Install the Demo Study
- Complete the instructions in this topic: Step 1: Install the Sample Study.
- Return to your Assay Tutorial folder.
Select Data to Copy
- On the Assay Dashboard page, click GenericAssay in the Assay List web part.
- Check the boxes next to Run1 and Run2 and click the Show results button to see the combined set of results from two runs.
- Since we only wish to copy a subset to our study, we can sort our results to find data of interest. Click the ParticipantID column and choose Sort Ascending.
- Select all four rows for the first participant (249318596).
- Click the Copy to Study button.
- Using the dropdown, select the demo study you installed. For example, if you are working on your own local server, by default it would be "/home/HIV-CD4 Study".
- Click Next.

- Notice that specimens have been matched based on ParticipantIDs and Dates in the demo study. Green checkmarks indicate valid matches.
Confirm Copy
- Click Copy to Study
- You will now see the dataset that has been copied to the demo study. It looks like the assay run results, with an additional column linking back to the source run.
- Notice that in the study, the assay will been renamed "GenericAssay1" if there is a pre-existing dataset named "GenericAssay".

Organize the New Assay Data in Your Study
When the new dataset is copied to the study, it is "uncategorized". You can place this new dataset into the "Assays" category in the target study.- In the target study, click the Clinical and Assay Data tab.
- Click the Data Views pencil icon to enable editing metadata.

- Scroll down and click the pencil icon next to your new dataset in the Uncategorized section. It may be named GenericAssay1 now.
- From the Category pulldown, choose "Assays".
- Click Save.
- Click the Clinical and Assay Data tab (or the pencil icon for the data views web part) to exit edit mode.
- Notice that your copied instrument data now appears in the Assays section.
Integrate with Other Study Data
Now that the data has been copied to the study, we can integrate it with other data. Since we only copied data for a single participant, we won't make elaborate connections here, but we can create a simple combined grid by adding some columns of demographic data which were not available in our assay run upload process.- Click GenericAssay1 on the Clinical and Assay Data tab.
- Select Grid Views > Customize Grid.
- Click the + next to Participant ID to expand columns available in that table.
- Place checkmarks next to Start Date and Treatment Group.
- Click Save.
- Save as the default, or name the new grid.
Related Topics
- Copy Assay Data into a Study - More detail about the copy to study process.
- Data Grids
- Reports and Visualizations
- Study Administrator Guide
Previous Step
ELISA Assay Tutorial
Set up an ELISA Plate Template and Assay Design
First set up an assay folder as a workspace.- Navigate to the Home project.
- Create a new folder to work in.
- Name: "ELISA Experiment".
- Folder Type: Assay.
- Click Next.
- On the Users/Permissions page, make no changes and click Finish.
- In the Assay List web part, click Manage Assays.
- Click Configure Plate Templates.
- Select "New 96 well (8X12) ELISA default template".
- Enter a Template Name, for example, "ELISA Plate 1".
- Review the shape of the template, clicking the Control, Specimen, and Replicate tabs to see the well groupings. Notice that you could edit the template to match alternate well groupings if needed; instructions can be found in Edit Plate Templates. For the purposes of this tutorial, simply save the default.

- When finished, click Save & Close.
- Click the Assay Dashboard tab.
- Click New Assay Design
- Select ELISA and choose the current folder from the Assay Location dropdown, then click Next.
- Provide a Name, for example, "HIV-ENV1 - ELISA Assay".
- Select a Plate Template: "ELISA Plate 1" (it may already be selected by default).
- Scroll down the page and review the data fields. You could add or edit fields, but for this tutorial, leave the default design unchanged.
- Click Save & Close.
Import ELISA Experiment Data
- Download sample data:
- Click the Assay Dashboard tab.
- In the Assay List, click to select your assay design HIV-ENV1 - ELISA Assay.
- Click Import Data.
- Accept the default batch properties by clicking Next.
- In the Run Data field, click Browse or Choose File and select one of the sample data files you just downloaded. Make no other changes on this page, then click Next.
- On the next page, enter Concentrations for Standard Wells as shown here:

- Click Save and Import Another Run. Repeat the import process for the other two files, clicking Save and Finish after the last one.
Visualize the Data
When you are finished importing, you'll see the runs grid showing the files you just uploaded. Since you did not specify any other Assay IDs, the filenames are used. Browse the data and available visualizations:- In the row for Assay Id "biotek_01.xls", click Details.
- You will see a visualization and tabular grid of the data. The server automatically generates a calibration curve for the control values.

Related Topics
ELISpot Assay
Topics
- ELISpot Assay Tutorial - Learn to use the built in ELISpot assay to import data.
- Review ELISpot Data - Review imported results.
Reference
- ELISpot Properties - Explore the default properties in the ELISpot assay.
ELISpot Assay Tutorial
Tutorial Steps
- Import ELISpot Data - Create an assay design and import data.
- Review ELISpot Data - Explore the imported data.
First Step
Import ELISpot Data
- Set Up
- Upload Assay Data
- Configure An ELISpot Plate Template
- Create a New Assay Design Based on the Template
- Import ELISpot Runs
- Explore Imported Data
- Copy Assay Data to the Demo Study (Optional)
Set Up
- Install LabKey Server if you haven't already.
- Download the LabKeyDemoFiles.zip sample data and unzip.
- Navigate to the Home folder
- Create a new folder to work in.
- Name: "ELISpot Tutorial".
- Folder Type: Assay.
- Click Next.
- On the Users/Permissions page, make no changes and click Finish.
- In the lower left, select Files from the <Select Web Part> dropdown.
- Click Add.
Upload Assay Data
- In a desktop file browser, navigate to the LabKeyDemoFiles directory you downloaded and unzipped.
- Drag and drop the directory into the upload area of the Files web part.
Configure An ELISpot Plate Template
- Click Manage Assays in the Assay List web part.
- Click Configure Plate Templates.
- Select New 96 Well (8x12) ELISpot Default Template to open the Plate Template Editor, which allows you to configure the layouts of specimens and antigens on the plate.
- Enter Template name: “ELISpot Template 1”
- Explore the template editor. On the Specimen tab, you will see the layout for specimens:

- Click the Antigen tab. You will see the layout for antigens.
- The Control tab can be used for defining additional well groups. For instance, if you are interested in subtracting background wells, see Background Subtraction for how to define a set of background wells.
- For this tutorial, we will simply use the default template. For customization instructions, see Edit Plate Templates.
- Click Save and Close.
Create a New Assay Design Based on the Template
- Click the Assay Dashboard tab to return to the folder home page.
- In the Assay List webpart, click New Assay Design.
- Select ELISpot, then scroll down and choose "Current Folder (Elispot Tutorial)" as the Assay Location.
- Click Next.
- In the Assay Designer leave all fields unchanged except:
- Name: "ELISpot Assay".
- From the Plate Template dropdown, choose the new "ELISpot Template 1" if it is not already selected.
- Click Save and Close.
Import ELISpot Runs
- In the Files web part, click the icon to show the folder tree.

- Navigate to LabKeyDemoFiles > Assays > ELISpot.
- Select Zeiss_datafile.txt.
- Click Import Data.
- Select Use ELISpot Assay and click Import.
- For Participant/Visit, select Specimen/sample id. (Do not check the box for "I will also provide participant id and visit id".)
- Click Next.
- AssayID: ES1
- Protocol Name: SOP
- LabID: MONT
- PlateID: pl277
- Experiment Date: 2009-03-15
- Plate Reader: Select "Zeiss" from the pulldown list.
- Specimen IDs:
- Specimen id values are often barcoded on labels attached to the plates. Enter these sample barcodes (taken from the file "Specimen Barcodes.pdg" file in LabKeyDemoFiles\Specimens\Specimen Barcodes.pdg):
- 526455390.2504.346
- 249325717.2404.493
- 249320619.2604.640
- 249328595.2604.530
- Click Next.
 Antigen Properties
Antigen Properties
- Fill out the antigen properties according to the table below.
- Press Save and Finish when you are done.
- Notes:
- The cells/well applies to all antigens, so you can just fill in the first box in this column with "40000" and click the "Same" checkbox above the column.
- The antigen names shown are examples only - you may enter any values you wish.

Explore Imported Data
You will see a list of runs for the assay design. See Review ELISpot Data for a walkthrough of the results and description of features for working with this data.Copy Assay Data to the Demo Study (Optional Step)
As described in the general purpose assay tutorial, you can integrate this tutorial ELISpot data into a target study following the steps described in Step 6: Integrate Assay Data into a Study. If you have entered matching participant and specimen IDs, you may simply select all rows to copy.When the copy is complete, you will see the dataset in the target study. It will look similar to this online example in the demo study on labkey.org.Start Over | Next Step
Review ELISpot Data
Explore Uploaded Data
- You will see a list of runs for the assay design. (There is only one run in the list at this point.)
- Click Run Details to see the run you just uploaded.
- You will see two grids, the data, and a well plate summary.
- Note the columns in the first grid include calculated mean and median values for each antigen for each sample well group.

- By default, this view is filtered to show only data from the selected run, but you can clear that filter to see additional data.

- The second grid represents the ELISpot well plate.
- Hover over an individual well to see detailed information about it.

- Use the radio buttons to highlight the location of samples and antigens on the plate.

- Click the Back button in your browser to return to the ELISpotAssay and its list of runs.
- Now click Zeiss_datafile.txt.
- You will see the assay results:
 A similar set of ELISpot assay results may be viewed in the interactive example
A similar set of ELISpot assay results may be viewed in the interactive exampleHandle TNTC (Too Numerous To Count) Values
ELISpot readers sometimes report special values indicating that a certain spot count in a given well is too numerous to count. Some instruments display the special value -1 to represent this concept, others use the code TNTC. When uploaded ELISpot data includes one of these special values instead of a spot count, the LabKey Server well grid representation will show the TNTC code, and exclude that value from calculations. By essentially ignoring these out of range values, the rest of the results can be imported and calculations done using the rest of the data. If there are too many TNTC values for a given well group, no mean or median will be reported.
If there are too many TNTC values for a given well group, no mean or median will be reported.
Background Subtraction
One option for ELISpot data analysis is to subtract a background value from measured results. When enabled, each specimen group will have a single background mean/median value. Then for each antigen group in the sample, the mean/median for the group is calculated, then the background mean/median is subtracted and the count is normalized by the number of cells per well.Enable Background Subtraction
To enable background well subtraction, you first configure the plate template. The main flow of the tutorial did not need this setting, but we return there to add it now.- Return to the Assay Dashboard.
- Click Manage Assays and then Configure Plate Templates.
- Open the plate template editor for "Elispot Template 1" by clicking Edit. Or Edit a copy if you prefer to give it a new name and retain the original version.
- On the Control tab, create a well group called "Background Wells".
- Select the wells you want to use as this background group.
- Save the plate template.
 Once background subtraction calculations have been performed, there is no one-step way to reverse it. Deleting and re-uploading the run without subtraction will achieve this result.
Once background subtraction calculations have been performed, there is no one-step way to reverse it. Deleting and re-uploading the run without subtraction will achieve this result.
Previous Step
ELISpot Properties
ELISpot Assay Properties
ELISpot Assays support import of raw data files from Zeiss, CTL, and AID instruments, storing the data in sortable/filterable data grids.The default ELISpot assay type includes some essential properties beyond the default properties included in general assay designs. You can also add additional properties when you create a new assay design. This topic describes the properties in the default ELISpot assay design and how they are used.Assay Properties
Assay properties are set by an administrator at the time of assay design and apply to all batches and runs uploaded using that design. The default ELISpot assay includes the general assay properties, except for Editable Runs and Import in Background. In addition, ELISpot assays use:- Plate Template.
- Choose an existing template from the drop-down list.
- Edit an existing template or create a new one via the "Configure Templates" button. For further details, see Edit Plate Templates.
Batch Properties
Batch properties are set once during import of a given batch of runs and apply to all runs in the batch. The default ELISpot assay does not add additional properties to the general assay type. Data importers will be prompted to enter:- Participant/Visit
- Target Study (Optional): See Copy Assay Data into a Study for information.
Run Properties
The user is prompted to enter values for run level properties which apply to the data in a single file, or run. Run-level properties are stored on a per-well basis, but used for record-keeping and not for calculations.Included by default:- Assay ID: The unique name of the run - if not provided, the filename will be used.
- Comments
- ProtocolName
- Lab ID
- Plate ID
- Template ID
- Experiment Date
- Background Subtraction: Whether to subtract background values, if a background well group is defined. See Background Subtraction for more information.
- Plate Reader (Required): Select the correct plate reader from the dropdown list. This list is populated with values from the ElispotPlateReader list.
- Run Data (Required): Browse or Choose the file containing data for this run.
- Specimen ID: Enter the specimenID for each group here. These values are often barcoded on labels attached to the plates.
- Sample Description: A sample description for each specimen group. If you click the checkbox, all groups will share the same description.
Antigen Properties
The user will be prompted to enter these properties for each of the antigen well groups in their chosen plate template. Use the Same checkbox to apply the same value to all rows.- Antigen ID: The integer ID of the antigen.
- Antigen Name
- Cells per Well
Flow Cytometry
Overview
[Tutorial: Import a Flow Workspace] [Tutorial: Import Flow Data from FCS Express] [Flow Demo] [Advanced Flow Demo: Peptide Validation]LabKey Server helps researchers automate high-volume flow cytometry analyses, integrate the results with many kinds of biomedical research data, and securely share both data and analyses. The system is designed to manage large data sets from standardized assays that span many instrument runs and share a common gating strategy. It enables quality control and statistical positivity analysis over data sets that are too large to manage effectively using PC-based solutions. LabKey Server supports the import of flow data from popular flow analysis tools, including R, FlowJo, and FCS Express.LabKey's online data environment lets you:- manage workflows and quality control in a centralized repository
- export results to Excel or PDF
- securely share any data subset
- build sophisticated queries and reports
- integrate with other experimental data and clinical data
 FCS Express.
To begin using FCS Express, an investigator first defines a new FCS Express assay design,
and then imports data into that assay design. Once the files have been uploaded, you can take advantage of the online data environment well as LabKey's quality control and workflow tools, including:
FCS Express.
To begin using FCS Express, an investigator first defines a new FCS Express assay design,
and then imports data into that assay design. Once the files have been uploaded, you can take advantage of the online data environment well as LabKey's quality control and workflow tools, including:
- assay progress reports
- assay status and quality control reports
- rich contextual data and metadata capture

LabKey Flow Module
 Researchers
can then define custom queries and views to analyze large result sets.
Gate templates can be modified, and new analyses can be run and
compared. Results can be printed, emailed, or exported to tools such as
Excel or R for further analysis. LabKey Flow enables quality control and statistical
positivity analysis over data sets that are too large to manage
effectively using PC-based solutions.LabKey Flow is not well-suited for highly interactive, exploratory
investigations with relatively small sample sizes. We recommend FlowJo for that type of analysis. LabKey Flow is in production use at the McElrath Lab at FHCRC and the Wilson Lab at the University of Washington.
Researchers
can then define custom queries and views to analyze large result sets.
Gate templates can be modified, and new analyses can be run and
compared. Results can be printed, emailed, or exported to tools such as
Excel or R for further analysis. LabKey Flow enables quality control and statistical
positivity analysis over data sets that are too large to manage
effectively using PC-based solutions.LabKey Flow is not well-suited for highly interactive, exploratory
investigations with relatively small sample sizes. We recommend FlowJo for that type of analysis. LabKey Flow is in production use at the McElrath Lab at FHCRC and the Wilson Lab at the University of Washington.
Documentation Topics
- Flow Cytometry Overview
- Includes:
- Advantages of using LabKey Flow
- How LabKey Flow works with FlowJo
- Two basic pathways for leveraging LabKey Flow for flow analyses.
- Flow Team Members
- Tutorial: Import a Flow Workspace
- Set up a Server and the Flow Demo Project
- Step 3: Import a Flow Workspace and Analysis
- Step 4: Customize Your Grid View
- Step 5: Examine Graphs
- Step 6: Examine Well Details
- Step 7: Export Flow Data
- Tutorial: Perform a LabKey Flow Analysis
- Step 1: Define a Compensation Calculation
- Step 2: Define an Analysis
- Step 3: Apply a Script
- Step 4: View Results
- Custom Flow Queries
Academic papers
Supported FlowJo Versions
Mac FlowJo versions
| FlowJo Version | LabKey Version |
|---|---|
| 9.7.2 | 13.3 |
| 9.6.4 | 13.1 |
| 9.4.1 | 12.1 |
| 9.3.1 | 11.2 |
| 8.5.3 | <11.2 |
Java (Windows/Mac) FlowJo versions
| FlowJo Version | LabKey Version |
|---|---|
| 10.0.8 | 15.2 |
| 10.0.7 | 14.1 |
| 10.0.6 | 14.1 |
| 10.0.5 | 13.1 |
| 7.6.5 | 12.1 |
| 7.5.5 | 12.1 |
| 7.2.5 | 2.1 |
| 5.7.2 | 2.0 |
Flow Cytometry Overview
Introduction
LabKey Server enables high-throughput analysis for several types of assays, including flow cytometry assays. LabKey’s flow cytometry solution provides a high-throughput pipeline for processing flow data. In addition, it delivers a flexible repository for data, analyses and results. This page reviews the FlowJo-only approach for analyzing smaller quantities of flow data, then explains the two ways LabKey Server can help your team manage larger volumes of data. It also covers LabKey Server’s latest enhancement (tracking of background well information) and future enhancements to the LabKey Flow toolkit.Background: Challenges of Using FlowJo Alone
Basic ProcessTraditionally, analysis of flow cytometry data begins with the download of FCS files from a flow cytometer. Once these files are saved to a network share, a technician loads the FCS files into a new FlowJo workspace, draws a gating hierarchy and adds statistics. The product of this work is a set of graphs and statistics used for further downstream analysis. This process continues for multiple plates. When analysis of the next plate of samples is complete, the technician loads the new set of FCS files into the same workspace.ChallengesModerate volumes of data can be analyzed successfully using FlowJo alone; however, scaling up can prove challenging. As more samples are added to the workspace, the analysis process described above becomes quite slow. Saving separate sets of sample runs into separate workspaces does not provide a good solution because it is difficult to manage the same analysis across multiple workspaces. Additionally, looking at graphs and statistics for all the samples becomes increasingly difficult as more samples are added.Solutions: Using LabKey Server to Scale Up
LabKey Server can help you scale up your data analysis process in two ways: by streamlining data processing or by serving as a flexible data repository. When your data are relatively homogeneous, you can use your LabKey Server to apply an analysis script generated by FlowJo to multiple runs. When your data are too heterogeneous for analysis by a single script, you can use your Labkey Server as a flexible data repository for large numbers of analyses generated by FlowJo workspaces. Both of these options help you speed up and consolidate your work.Option 1. Apply One Analysis Script to Multiple Runs within LabKey.LabKey can apply the analysis defined by the FlowJo workspace to multiple sample runs. The appropriate gating hierarchy and statistics are defined once within FlowJo, then imported into LabKey as an Analysis Script. Once created, the Analysis Script can be applied to multiple runs of samples and generate all statistics and graphs for all runs at one time. These graphs and statistics are saved into the LabKey Server’s database, where they can be used in tables, charts and other reports. Within LabKey, flow data can be analyzed or visualized in R. In addition, advanced users can write SQL queries to perform downstream analysis (such as determining positivity). These tables and queries can be exported to formats (e.g., CSV, Excel or Spice) that can be used for documentation or further analysis.Figure 1: Application of an analysis script to multiple runs within LabKey Server Figure 2: A LabKey run with statistics & graphs
Figure 2: A LabKey run with statistics & graphs Option 2. Use LabKey as a Data Repository for FlowJo AnalysesLabKey’s tools for high-throughput flow analysis work well for large amounts of data that can use the same gating hierarchy. Unfortunately, not all flow cytometry data is so regular. Often, gates need to be tweaked for each run or for each individual. In addition, there is usually quite a bit of analysis performed using FlowJo that just needs to be imported, not re-analyzed.To overcome these obstacles, LabKey can also act as a repository for flow data. In this case, analysis is performed by FlowJo and the results are uploaded into the LabKey data store. The statistics calculated by FlowJo are read upon import from the workspace. Graphs are generated for each sample and saved into the database. Technicians can make minor edits to gates through the LabKey online gate editor as needed.Figure 4: LabKey Server as a data repository for FlowJo
Option 2. Use LabKey as a Data Repository for FlowJo AnalysesLabKey’s tools for high-throughput flow analysis work well for large amounts of data that can use the same gating hierarchy. Unfortunately, not all flow cytometry data is so regular. Often, gates need to be tweaked for each run or for each individual. In addition, there is usually quite a bit of analysis performed using FlowJo that just needs to be imported, not re-analyzed.To overcome these obstacles, LabKey can also act as a repository for flow data. In this case, analysis is performed by FlowJo and the results are uploaded into the LabKey data store. The statistics calculated by FlowJo are read upon import from the workspace. Graphs are generated for each sample and saved into the database. Technicians can make minor edits to gates through the LabKey online gate editor as needed.Figure 4: LabKey Server as a data repository for FlowJo
LabKey Interface: The Flow Dashboard
Both of the options described above can be accessed through a single interface, the LabKey Flow Dashboard. You can use LabKey Server exclusively as a data repository (Option 2 above) and “Import results directly from a FlowJo workspace.” Alternatively, you can “Create an Analysis Script from a FlowJo workspace” and apply one analysis script to multiple runs (Option 1 above).Figure 5: LabKey Server Flow Dashboard
Annotation Using Metadata
Extra information can be linked to the run after the run has been imported via either LabKey Flow or FlowJo. Sample information uploaded from an Excel spreadsheet can also be joined to the well. Background wells can then be used to subtract background values from sample wells. Information on background wells is supplied through metadata.Figure 6: Sample and run metadata
Tutorial: Import a Flow Workspace
- Set up a flow cytometry project
- Import flow data
- Create flow datasets
- Create reports based on your data
Tutorial Steps
- Step 1: Set Up a Flow Folder
- Step 2: Upload Files to Server
- Step 3: Import a Flow Workspace and Analysis
- Step 4: Customize Your Grid View
- Step 5: Examine Graphs
- Step 6: Examine Well Details
- Step 7: Export Flow Data
Related Topics
First Tutorial Step
Step 1: Set Up a Flow Folder
Install LabKey Server
- If you haven't already installed LabKey Server, follow the steps in the topic Install LabKey Server (Quick Install).
Create a Flow Project
In this step, you will create a new project inside of LabKey Server to hold your Flow data. Projects are a way to organize your data and set up security so that only authorized users can see the data.- Log in to your server; you will need administrative access to create a new project.
- Create a new project to work in.
- Name: enter a unique name, for example, "My Flow Tutorial".
- Folder Type: Flow.
- Click Next.
- On the Users/Permissions page, make no changes and click Next.
- On the Project Settings page, make no changes and click Finish.
 The Flow Dashboard displays the following four sections (or web parts) by default:
The Flow Dashboard displays the following four sections (or web parts) by default:
- Flow Experiment Management: Describes the user’s progress setting up an experiment and analyzing FCS files. It also includes links to perform actions.
- Flow Analyses: Lists the flow analyses that have been performed in this folder.
- Flow Scripts: Lists analysis scripts. An analysis script stores the gating template definition, rules for calculating the compensation matrix, and the list of statistics and graphs to generate for an analysis.
- Flow Summary: Common actions and configurations.
Start Over | Next Step
Step 2: Upload Files to Server
Obtain the Sample Data Files
- Download the zip file: Flow sample data
- Extract the zip archive to your local hard drive.
Upload to LabKey
- In the Flow Summary section (see the right-hand column of the page) click Upload and Import.
- On your desktop, find the folder labkey-demo (inside the unzipped labkey-flow-demo archive).
- Drag and drop this folder into the LabKey Server file browser, then wait for sample files to be uploaded.
- When complete, you will see the files added to your project's file management system.

Previous Step | Next Step
Step 3: Import a Flow Workspace and Analysis
Import a FlowJo Workspace
- Click the Flow Dashboard tab at the top of the page.
- Click Import FlowJo Workspace Analysis. This will allow you to start the process of importing the compensation and analysis (the calculated statistics) from a FlowJo workspace.
- Select Browse the pipeline.
- In the left panel, click to expand the labkey-demo directory, then click the Workspaces folder.
- In the right panel, select the labkey-demo.xml file, and click Next.

- Notice the two warnings that appear.
Warning:
Sample 118756.fcs (286): 118756.fcs: S/L/-: Count statistic missing
Sample 118756.fcs (286): 118756.fcs: S/L/FITC CD4+: Count statistic missing
- Select Browse the pipeline for the directory of FCS files.
- Click the "labkey-demo" folder to open it.
- In the right panel, check the box for the FACSData folder.

- Click Next.
- The import wizard will attempt to match the imported samples from the FlowJo workspace with the previously imported FCS files. If you were importing samples that matched existing FCS files, such as reimporting a workspace, they would have a green checkmark and unmatched samples would have a red checkmark. To manually correct any mistakes, select the appropriate FCS file from the combobox next to the sample's name. See FCS File Resolution for more on the exact algorithm used to resolve the FCS files.
- Confirm that all samples are selected and click Next.
- Confirm that FlowJo statistics with LabKey Server graphs is selected and click Next.
- Accept the default name of your analysis folder, "Analysis".
- (Optional) Choose a target study folder. If the flow metadata includes PTID and Date/Visit columns matching those in the study, specimen information from the study will be included in the FCSAnalyses table.
- Click Next.
- Review the properties and click Finish to import the workspace.
- Wait for Import to Complete. While the job runs, you will see the current status file growing and have the opportunity to cancel if necessary using the button at the bottom. Import can take several minutes.
- When the import process completes, you will see a datagrid named "labkey-demo.xml." In the next step you will learn how to customize this datagrid to display the columns of your choice.

Previous Step | Next Step
FCS File Resolution
Resolving FCS Files During Import
When importing analysis results from a FlowJo workspace or an external analysis archive, the Flow Module will attempt to find a previously imported FCS file to link the analysis results to.The matching algorithm compares the imported sample from the FlowJo workspace or external analysis archive against previously imported FCS files using the following properties and keywords: FCS file name or FlowJo sample name, $FIL, GUID, $TOT, $PAR, $DATE, $ETIM. Each of the 7 comparisons are weighted equally. Currently, the minimum number of required matches is 2 -- for example, if only $FIL matches and others don't, there is no match.While calculating the comparisons for each imported sample, the highest number of matching comparisons is remembered. Once complete, if there is only a single FCS file that has the max number of matching comparisons, it is considered a perfect match. The import wizard resolver step will automatically select the perfectly matching FCS file for the imported sample (they will have the green checkmark). As long as each FCS file can be uniquely matched by at least two comparisons (e.g, GUID and the other keywords), the import wizard should automatically select the correct FCS files that were previously imported.If there are no exact matches, the imported sample will not be automatically selected (red X mark in the wizard) and the partially matching FCS files will be listed in the combo box ordered by number of matches.Step 4: Customize Your Grid View
Understanding Column Names
In the flow workspace, statistics column names are of the form "subset:stat". For example, "Lv/L:%P" is used for the "Live Lymphocytes" subset and the "percent of parent" statistic.Graphs are of the form "subset(x-axis:y-axis)". For example, "4+(SSC-A:<APC-A>)" for the "4+" subset and the "side scatter" and "compensated APC-A" channels. Channel names in angle brackets are compensated.Customize Your Grid View (Optional)
The columns displayed by default for a dataset are not necessarily the ones you are most interested in, so you can customize which columns are included in the default grid. See Customize Grid Views for general information about customizing grids.In this optional tutorial step, we'll show how you might remove one column, add another, and save this as the new default grid. This topic also explains the column naming used in this sample flow workspace.- From the Flow Dashboard, click Analysis then labkey-demo.xml.
- Select Grid Views > Customize Grid.
- In the Selected Fields pane, hover over "S(SSC-A:FSC-A)" (if present). Notice that you see a tooltip with more information about the field and the cog (rename) and x (remove) icons are activated.
- Click the X to remove the field.

- In the Available Fields pane, open the Statistic node by clicking the '+' sign and place a checkmark next to APC CD3+: Count.

- Click Save.
- Confirm that Default grid view for this page is selected, and click Save.
Previous Step | Next Step
Step 5: Examine Graphs
Review Graphs
- From the Flow Dashboard, click Analysis then labkey-demo.xml to return to the grid.
- Select Show Graphs > Inline.

- The inline graphs are rendered. Note: for large datasets, it may take some time for all graphs to render. Some metrics may not have graphs. See a similar online example.

- Note that graph size options are available at the top of the data table.
- Click on any graph image to make it pop forward in a larger format.
- See thumbnail graphs in columns by selecting Show Graphs > Thumbnail.
- Hide graphs by selecting Show Graphs > None.
Review Other Visualizations
The following pages provide other views and visualizations of the flow data.- Scroll down to the bottom of the labkey-demo.xml page.
- Click Show Compensation to view the compensation matrix. (Compensation Matrix (similar online example))
- Go back to labkey-demo.xml.
- Click Experiment Run Graph and then choose the tab Graph Detail View to see a graphical version of the pipeline process.
- Note that if you don't have dot installed locally, this graph may not display. See a similar online example here.
Previous Step | Next Step
Step 6: Examine Well Details
Access Well Details
- On the labkey-demo.xml page, click a Details link.
- The details view will look something like:

- Collapse the subset hierarchies (in this screencap "L") by clicking the small triangle or simply scroll down to see the graphs.

View Keywords from the FCS File
- At the top of the well details page, click the name of the FCS File, here "119162.fcs".

- Click the Keywords link to expand the list:

Previous Step | Next Step
Step 7: Export Flow Data
Finalize Your Data View
Before you export your dataset, customize your grid to show the columns you want to export. For greater control of the columns included in a view, you can also create custom queries. Topics available to assist you:- Create Custom SQL Queries
- Add Statistics to FCS Queries Using LabKey SQL
- Calculate Suites of Statistics for Every Well
Export to Excel
After you have finalized your grid, you can export the displayed table to an Excel spreadsheet, a text file, a script, or as an analysis.- Open the grid you have customized. For example, from the Flow Dashboard, click Analysis then labkey-demo.xml.
- Click Export.

- Choose the desired format using the tabs on the left, then select options relevant to the format. For this tutorial example, select Excel (the default) and leave the default workbook selected.
- Click Export to Excel.
Previous Step
Tutorial: Perform a LabKey Flow Analysis
Overview
When you perform a LabKey Flow Analysis, the LabKey Flow engine calculates statistics directly. In contrast, when you Step 3: Import a Flow Workspace and Analysis, statistics are simply read from a file. FlowJo is still used to specify the compensation matrix and gates when you perform a LabKey Flow Analysis.This tutorial walks you through the steps necessary to perform a LabKey Flow Analysis using provided sample data.Set Up
To set up this tutorial, complete the instructions in the following topics:- Step 1: Set Up a Flow Folder - Install LabKey Server and set up the flow folder.
- Step 2: Upload Files to Server - Acquire the sample data files and place them on LabKey Server.
- Step 3: Import a Flow Workspace and Analysis - Import the default tutorial workspace as a starting point.
- Return to this topic when you have completed those steps.
- Step 1: Define a Compensation Calculation
- Step 2: Define an Analysis
- Step 3: Apply a Script
- Step 4: View Results
First Step
Step 1: Define a Compensation Calculation
Create a New Analysis Script
- Click the Flow Dashboard tab (in the upper right of the page).
- Click "Create a New Analysis Script".
- Enter the name: "labkey-demo".
- Click Create Analysis Script.

Define a Compensation Calculation
The compensation calculation tells the LabKey Flow engine how to identify the compensation controls in an experiment. It also indicates which gates to apply. A compensation control is identified as having a particular value for a specific keyword.- Click Upload a FlowJo workspace under Define Compensation Calculation.

- Click Choose File.
- Browse to and select the labkey-flow-demo/labkey-demo/Workspaces/labkey-demo.xml file.
- Click Submit.
- Select autocomp from the drop down and the compensation calculation will be automatically populated:

- Scroll down to Choose Source of Gating.
- Select Group labkey-demo-comps from the dropdown menu.
- Click Submit.

- Review the final compensation calculation definition.

Flow Scripts Web Part
Click Flow Dashboard to return to the main page of your project. Scroll down to see the web part that provides easy access to the main script page.
Start Over | Next Step
Step 2: Define an Analysis
- From the Flow Scripts webpart on the Flow Dashboard, click labkey-demo to reopen the script page.
- Click Upload FlowJo workspace under Define Analysis.

- Choose the same 'labkey-flow-demo-123/labkey-demo/Workspaces/labkey-demo.xml' workspace file you uploaded previously.
- Select which statistics you would like to be calculated. Those already defined in the FlowJo workspace are preselected.

- Click Submit.
Select the source of gating for the analysis
- Select the labkey-demo-samples group and click Submit.
 You will once again see the script main page. Now that both the compensation and the analysis have been defined, you have a full set of options for using it to analyze your data.
You will once again see the script main page. Now that both the compensation and the analysis have been defined, you have a full set of options for using it to analyze your data.
Previous Step | Next Step
Step 3: Apply a Script
Initiate Run Analysis
Select which experiment runs should be analyzed, using which script, and where to place the results.- Reopen the script main page by clicking Flow Dashboard and then labkey-demo.
- To apply the script, click Analyze some runs.

- Analysis script to use: This is the script which will be used to define the gates, statistics, and graphs.
- Analysis step to perform: If the script contains both a compensation calculation and an analysis, the user can choose to perform these steps separately.
- Analysis folder to put results in: Either select an existing folder or create a new one.
- Compensation matrix to use: Select one of the following ways of specifying the compensation matrix:
- Calculate new if necessary: If a compensation matrix has not yet been calculated for a given experiment run in the target analysis, it will be calculated.
- Use from analysis 'xxxx': If there is at least one run with a compensation matrix in analysis 'xxxx', it will be used.
- Matrix: 'xxxxx': The named compensation matrix will be used for all runs being analyzed
- Use machine acquired spill matrix: Use the compensation matrix found in the FCS file marked with a "$SPILL" keyword.
- From the Analysis folder to put results in dropdown, select create new. Notice that the runs in the grid are no longer grayed out.
- Select the checkbox associated with the labkey-demo.xml run.
- Then click Analyze Selected Runs.

- Name the new folder: 'labkey-analysis'.

- Click Analyze runs.
- Processing may take a while, and will take even longer for large amounts of data.
- Status will be reported as the analysis runs:

Previous Step | Next Step
Step 4: View Results
 You can also reach this grid from the Flow Dashboard and clicking labkey-analysis in the Flow Analyses web part.
You can also reach this grid from the Flow Dashboard and clicking labkey-analysis in the Flow Analyses web part.
Show Statistics in the Grid
- On the labkey-analysis > Runs page, click the Name "labkey-demo.xml analysis" to show the default data grid for the analysis.
- Select Grid Views > Customize Grid and click the + by "Statistic" in the available fields panel.
- Scroll down to see currently selected fields, and select other statistics you would like shown.
- Drag and drop these rows within on the Selected Fields panel to be in your preferred order. Note that if you make changes here, your results may not match our tutorial screencaps. Click View Grid then reopen for editing to see your customization in progress.

- Remove any you would not like shown from selected fields by hovering over the field name and clicking the 'x' on the right.
- Note that these statistics have been calculated using the LabKey Flow engine (instead of simply read from a file, as they are when you import a workspace).
- Save the grid view as you like it by clicking Save, entering a name, such as "MyStatistics", and clicking Save in the pop-up.
Add Graphs
You can add graphs in line or as thumbnails in columns next to statistics.- Select Grid Views > Customize Grid and open the "Graph" node.
- Scroll and select which graphs will be available.

- Save or use "View Grid" to view without saving.
- Click on the Show Graphs link above the grid to select how you want to see graphs. Options:
- None
- Thumbnails
- Inline - inline graphs may be viewed in three sizes.


Show the Compensation Controls
- In Flow Dashboard > Flow Analyses web part, click labkey-analysis.
- On the "Runs" page, click on "labkey-demo.xml comp" to show the compensation controls.
- The compensation controls page for the flow demo is available here and shown in the screen shot below:
 On the compensation controls page you can also "Show Graphs" as with statistics.
On the compensation controls page you can also "Show Graphs" as with statistics.Flow Reports
There are two types of reports available. Return to the Flow Dashboard and add a Flow Reports web part, then click the create button for either type of report:QC Reports
Provide a name and select available statistics and filters to apply. Select the analysis folder and specify a date range as well to produce the desired quality control report.Positivity Reports
A positivity report requires metadata describing the sample and background information of the flow experiment before it can be run. Select statistics and filters and a date range. Click Save and the report will be displayed.Previous Step
Add Sample Descriptions
Add Sample Descriptions (Sample Sets)
You can associate sample descriptions (sample sets) with flow data and assign additional meanings to keywords.Additional information about groups of FCS files can be uploaded in spreadsheet and associated with the FCS files using keywords.- To upload the data, go to the flow dashboard and click Upload Sample Descriptions.

- Then copy/paste the sample information into the text box, or upload a file directly.
- After pasting in the data or choosing the file, you'll need to identify which column(s) make each sample unique.
- In this case, the "AssayId" and "SampOrd" columns are the uniquely identifying columns for each sample.
- Select a parent column if needed.

- Click Submit.
- Click Flow Dashboard.
- Click Define sample description join fields and specify the join as:
| Sample Property | FCS Property |
|---|---|
| "AssayId" | "EXPERIMENT NAME" |
| "SampOrd" | "Sample Order" |
- Click Update.
 You will now see a new column in the FCSFile table.
You will now see a new column in the FCSFile table.
- Click Flow Dashboard.
- Click on FCS Files in the Flow Summary on the right.
- Click FACSData.
- Then click Grid Views > Customize Grid to open the grid customizer.
- You should now see the columns from the Sample table that you may add to your grid.

Custom Flow Queries
Introductory Topics
- SQL Queries. For those new to custom queries, please start with this section of the documentation.
Flow-Specific Topics
Add Statistics to FCS Queries
- Use the SQL Designer to add/remove "Statistic" fields to a FCS query.
- Use the SQL Editor to call the "Statistic" method on the FCS table of interest.
Example
For this example, we create a query called "StatisticDemo" based on the FCSAnalyses dataset. (You can see a complete version of this query here: StatisticDemo.)Create a New Query
- Select Admin > Developer Links > Schema Browser.
- Click flow to open the flow schema.
- Click Create New Query.
- Call your new query "StatisticDemo"
- Select FCSAnalyses as the base for your new query.
- Click Create and Edit Source.
Add Statistics to the Generated SQL
The generated SQL is:SELECT FCSAnalyses.Name,
FCSAnalyses.Flag,
FCSAnalyses.Run,
FCSAnalyses.CompensationMatrix
FROM FCSAnalyses
SELECT FCSAnalyses.Name,
FCSAnalyses.Flag,
FCSAnalyses.Run,
FCSAnalyses.CompensationMatrix,
FCSAnalyses.Statistic."Count"
FROM FCSAnalyses
Run the Query
To see the generated query, click the Execute Query button. The resulting table includes the "Count" column on the right: View this query applied to a more complex dataset. The dataset used in the Flow Demo has been slimmed down for ease of use. A larger, more complex dataset produces a more interesting "Count" column, as seen in this table and the screenshot below:
View this query applied to a more complex dataset. The dataset used in the Flow Demo has been slimmed down for ease of use. A larger, more complex dataset produces a more interesting "Count" column, as seen in this table and the screenshot below:
Calculate Suites of Statistics for Every Well
Overview
It is possible to calculate a suite of statistics for every well in an FCS file using an INNER JOIN technique in conjunction with the "Statistic" method. This technique can be complex, so we present an example to provide an introduction to what is possible.Example
Create a Query. For this example, we use the FCSAnalyses table in the Peptide Validation Demo, a more complex demo than the one used in the Flow Tutorial. We create a query called "SubsetDemo" using the "FCSAnalyses" table in the "flow" schema and edit it in the SQL Source Editor.SELECT
FCSAnalyses.FCSFile.Run AS ASSAYID,
FCSAnalyses.FCSFile.Sample AS Sample,
FCSAnalyses.FCSFile.Sample.Property.PTID,
FCSAnalyses.FCSFile.Keyword."WELL ID" AS WELL_ID,
FCSAnalyses.Statistic."Count" AS COLLECTCT,
FCSAnalyses.Statistic."S:Count" AS SINGLETCT,
FCSAnalyses.Statistic."S/Lv:Count" AS LIVECT,
FCSAnalyses.Statistic."S/Lv/L:Count" AS LYMPHCT,
FCSAnalyses.Statistic."S/Lv/L/3+:Count" AS CD3CT,
Subsets.TCELLSUB,
FCSAnalyses.Statistic(Subsets.STAT_TCELLSUB) AS NSUB,
FCSAnalyses.FCSFile.Keyword.Stim AS ANTIGEN,
Subsets.CYTOKINE,
FCSAnalyses.Statistic(Subsets.STAT_CYTNUM) AS CYTNUM,
FROM FCSAnalyses
INNER JOIN lists.ICS3Cytokine AS Subsets ON Subsets.PFD IS NOT NULL
WHERE FCSAnalyses.FCSFile.Keyword."Sample Order" NOT IN ('PBS','Comp')
Flow Module Schema
LabKey modules expose their data to the LabKey query engine in one or more schemas. This page outlines the Flow Module's schema, which is helpful to use as a reference when writing custom Flow queries.
Flow Module
The Flow schema has the following tables in it:
Runs Table
This table shows experiment runs for all three of the Flow protocol steps. It has the following columns:
|
RowId |
A unique identifier for the run. Also, when this column is used in a query, it is a lookup back to the same row in the Runs table. That is, including this column in a query will allow the user to display columns from the Runs table that have not been explicitly SELECTed into the query |
|
Flag |
The flag column. It is displayed as an icon which the user can use to add a comment to this run. The flag column is a lookup to a table which has a text column “comment”. The icon appears different depending on whether the comment is null. |
|
Name |
The name of the run. In flow, the name of the run is always the name of the directory which the FCS files were found in. |
|
Created |
The date that this run was created. |
|
CreatedBy |
The user who created this run. |
|
Folder |
The folder or project in which this run is stored. |
|
FilePathRoot |
(hidden) The directory on the server's file system where this run's data files come from. |
|
LSID |
The life sciences identifier for this run. |
|
ProtocolStep |
The flow protocol step of this run. One of “keywords”, “compensation”, or “analysis” |
|
RunGroups |
A unique ID for this run. |
|
AnalysisScript |
The AnalysisScript that was used in this run. It is a lookup to the AnalysisScripts table. It will be null if the protocol step is “keywords” |
|
Workspace |
|
|
CompensationMatrix |
The compensation matrix that was used in this run. It is a lookup to the CompensationMatrices table. |
|
TargetStudy |
|
|
WellCount |
The number of FCSFiles that we either inputs or outputs of this run. |
|
FCSFileCount |
|
|
CompensationControlCount |
|
|
FCSAnalysisCount |
|
CompensationMatrices
This table shows all of the compensation matrices that have either been calculated in a compensation protocol step, or uploaded.
It has the following columns in it:
|
RowId |
A unique identifier for the compensation matrix. |
|
Name |
The name of the compensation matrix. Compensation matrices have the same name as the run which created them. Uploaded compensation matrices have a user-assigned name. |
|
Flag |
A flag column to allow the user to add a comment to this compensation matrix |
|
Created |
The date the compensation matrix was created or uploaded. |
|
Protocol |
(hidden) The protocol that was used to create this compensation matrix. This will be null for uploaded compensation matrices. For calculated compensation matrices, it will be the child protocol “Compensation” |
|
Run |
The run which created this compensation matrix. This will be null for uploaded compensation matrices. |
|
Value |
A column set with the values of compensation matrix. Compensation matrix values have names which are of the form “spill(channel1:channel2)” |
In addition, the CompensationMatrices table defines a method Value which returns the corresponding spill value.
The following are equivalent:
CompensationMatrices.Value."spill(FL-1:FL-2) "
CompensationMatrices.Value('spill(FL-1:FL-2)')
The Value method would be used when the name of the statistic is not known when the QueryDefinition is created, but is found in some other place (such as a table with a list of spill values that should be displayed).
FCSFiles
The FCSFiles table lists all of the FCS files in the folder. It has the following columns:
|
RowId |
A unique identifier for the FCS file |
|
Name |
The name of the FCS file in the file system. |
|
Flag |
A flag column for the user to add a comment to this FCS file on the server. |
|
Created |
The date that this FCS file was loaded onto the server. This is unrelated to the date of the FCS file in the file system. |
|
Protocol |
(hidden) The protocol step that created this FCS file. It will always be the Keywords child protocol. |
|
Run |
The experiment run that this FCS file belongs to. It is a lookup to the Runs table. |
|
Keyword |
A column set for the keyword values. Keyword names are case sensitive. Keywords which are not present are null. |
|
Sample |
The sample description which is linked to this FCS file. If the user has not uploaded sample descriptions, this column will be hidden, and it will be null. This column is a lookup to the SampleSet table. |
In addition, the FCSFiles table defines a method Keyword which can be used to return a keyword value where the keyword name is determined at runtime.
FCSAnalyses
The FCSAnalyses table lists all of the analyses of FCS files. It has the following columns:
|
RowId |
A unique identifier for the FCSAnalysis |
|
Name |
The name of the FCSAnalysis. The name of an FCSAnalysis defaults to the same name as the FCSFile. This is a setting which may be changed. |
|
Flag |
A flag column for the user to add a comment to this FCSAnalysis |
|
Created |
The date that this FCSAnalysis was created. |
|
Protocol |
(hidden) The protocol step that created this FCSAnalysis. It will always be the Analysis child protocol. |
|
Run |
The run that this FCSAnalysis belongs to. Note that FCSAnalyses.Run and FCSAnalyses.FCSFile.Run refer to different runs. |
|
Statistic |
A column set for statistics that were calculated for this FCSAnalysis. |
|
Graph |
A column set for graphs that were generated for this FCSAnalysis. Graph columns display nicely on LabKey, but their underlying value is not interesting. They are a lookup where the display field is the name of the graph if the graph exists, or null if the graph does not exist. |
|
FCSFile |
The FCSFile that this FCSAnalysis was performed on. This is a lookup to the FCSFiles table. |
In addition, the FCSAnalyses table defines the methods Graph, and Statistic.
CompensationControls
The CompensationControls table lists the analyses of the FCS files that were used to calculate compensation matrices. Often (as in the case of a universal negative) multiple CompensationControls are created for a single FCS file.
The CompensationControls table has the following columns in it:
|
RowId |
A unique identifier for the compensation control |
||||||
|
Name |
The name of the compensation control. This is the channel that it was used for, followed by either “+”, or “-“ |
||||||
|
Flag |
A flag column for the user to add a comment to this compensation control. |
||||||
|
Created |
The date that this compensation control was created. |
||||||
|
Protocol |
(hidden) |
||||||
|
Run |
The run that this compensation control belongs to. This is the run for the compensation calculation, not the run that the FCS file belongs to. |
||||||
|
Statistic |
A column set for statistics that were calculated for this compensation control. The following statistics are calculated for a compensation control:
|
||||||
|
Graph |
A column set for graphs that were generated for this compensation control. The names of graphs for compensation controls are of the form: comp(channelName) or comp(<channelName>) The latter is shows the post-compensation graph. |
In addition, the CompensationControls table defines the methods Statistic and Graph.
AnalysisScripts
The AnalysisScripts table lists the analysis scripts in the folder. This table has the following columns:
|
RowId |
A unique identifier for this analysis script. |
|
Name |
The user-assigned name of this analysis script |
|
Flag |
A flag column for the user to add a comment to this analysis script |
|
Created |
The date this analysis script was created |
|
Protocol |
(hidden) |
|
Run |
(hidden) |
Analyses
The Analyses table lists the experiments in the folder with the exception of the one named Flow Experiment Runs. This table has the following columns:
|
RowId |
A unique identifier |
|
LSID |
(hidden) |
|
Name |
|
|
Hypothesis |
|
|
Comments |
|
|
Created |
|
|
CreatedBy |
|
|
Modified |
|
|
ModifiedBy |
|
|
Container |
|
|
CompensationRunCount |
The number of compensation calculations in this analysis. It is displayed as a hyperlink to the list of compensation runs. |
|
AnalysisRunCount |
The number of runs that have been analyzed in this analysis. It is displayed as a hyperlink to the list of those run analyses |
Analysis Archive Format
 In brief, the archive format contains the following files:
In brief, the archive format contains the following files:<root directory>
├─ keywords.tsv
├─ statistics.tsv
|
├─ compensation.tsv
├─ <comp-matrix01>
├─ <comp-matrix02>.xml
|
├─ graphs.tsv
|
├─ <Sample Name 01>/
| └─ <graph01>.png
| └─ <graph02>.svg
|
└─ <Sample Name 02>/
├─ <graph01>.png
└─ <graph02>.pdf
Relationship to ACS Container
Eventually, the analyzed results tsv files could be bundled inside an ACS container. The ACS container format wasn’t sufficient for our current needs -- the ACS table of contents only includes relationships between files and doesn’t include, for example, the population name and channel/parameter used to calculate a statistic or render a graph. If the ACS ToC could include those missing metadata, the graphs.tsv would be made redundant. The statistics.tsv would still be needed, however.Statistics File
The statistics.tsv file is a tab-separated list of values containing stat names and values. The statistic values may be grouped in a few different ways: (a) no grouping (one statistic value per line), (b) grouped by sample (each column is a new statistic), (c) grouped by sample and population (the current default encoding), or (d) grouped by sample, population, and channel.Sample Name
Samples are identified by the value in the sample column so must be unique in the analysis. Usually the sample name is just the FCS file name including the ‘.fcs’ extension (e.g., “12345.fcs”).Population Name
The population column is a unique name within the analysis that identifies the set of events that the statistics were calculated from. A common way to identify the statistics is to use the gating path with gate names separated by a forward slash. If the population name starts with “(” or contains one of “/”, “{”, or “}” the population name must be escaped. To escape illegal characters, wrap the entire gate name in curly brackets { }. For example, the population “A/{B/C}” is the sub-population “B/C” of population “A”.Statistic Name
The statistic is encoded in the column header as statistic(parameter:percentile) where the parameter and percentile portions are required depending upon the statistic type. The statistic part of the column header may be either the short name (“%P”) or the long name (“Frequency_Of_Parent”). The parameter part is required for the frequency of ancestor statistic and for other channel based statistics. The frequency of ancestor statistic uses the name of an ancestor population as the parameter value while the other statistics use a channel name as the parameter value. To represent compensated parameters, the channel name is wrapped in angle brackets, e.g “<FITC-A>”. The percentile part is required only by the “Percentile” statistic and is an integer in the range of 1-99.The statistic value is a either an integer number or a double. Count stats are integer values >= 0. Percentage stats are doubles in the range 0-100. Other stats are doubles. If the statistic is not present for the given sample and population, it is left blank.Allowed Statistics
| Short Name | Long Name | Parameter | Type |
|---|---|---|---|
| Count | Count | n/a | Integer |
| % | Frequency | n/a | Double (0-100) |
| %P | Frequency_Of_Parent | n/a | Double (0-100) |
| %G | Frequency_Of_Grandparent | n/a | Double (0-100) |
| %of | Frequency_Of_Ancestor | ancestor population name | Double (0-100) |
| Min | Min | channel name | Double |
| Max | Max | channel name | Double |
| Median | Median | channel name | Double |
| Mean | Mean | channel name | Double |
| GeomMean | Geometric_Mean | channel name | Double |
| StdDev | Std_Dev | channel name | Double |
| rStdDev | Robust_Std_Dev | channel name | Double |
| MAD | Median_Abs_Dev | channel name | Double |
| MAD% | Median_Abs_Dev_Percent | channel name | Double (0-100) |
| CV | CV | channel name | Double |
| rCV | Robust_CV | channel name | Double |
| %ile | Percentile | channel name and percentile 1-99 | Double (0-100) |
- Count
- Robust_CV(<FITC>)
- %ile(<Pacific-Blue>:30)
- %of(Lymphocytes)
Examples
NOTE: The following examples are for illustration purposes only.No Grouping: One Row Per Sample and Statistic
The required columns are Sample, **Population**, Statistic, and Value. No extra columns are present. Each statistic is on a new line.| Sample | Population | Statistic | Value |
|---|---|---|---|
| Sample1.fcs | S/L/Lv/3+/4+/IFNg+IL2+ | %P | 0.85 |
| Sample1.fcs | S/L/Lv/3+/4+/IFNg+IL2- | Count | 12001 |
| Sample2.fcs | S/L/Lv/3+/{escaped/slash} | Median(FITC-A) | 23,000 |
| Sample2.fcs | S/L/Lv/3+/4+/IFNg+IL2+ | %ile(<Pacific-Blue>:30) | 0.93 |
Grouped By Sample
The only required column is Sample. The remaining columns are statistic columns where the column name contain the population name and statistic name separated by a colon.| Sample | S/L/Lv/3+/4+/IFNg+IL2+:Count | S/L/Lv/3+/4+/IFNg+IL2+:%P | S/L/Lv/3+/4+/IFNg+IL2-:%ile(<Pacific-Blue>:30) | S/L/Lv/3+/4+/IFNg+IL2-:%P |
|---|---|---|---|---|
| Sample1.fcs | 12001 | 0.93 | 12314 | 0.24 |
| Sample2.fcs | 13056 | 0.85 | 13023 | 0.56 |
Grouped By Sample and Population
The required columns are Sample and Population. The remaining columns are statistic names including any required parameter part and percentile part.| Sample | Population | Count | %P | Median(FITC-A) | %ile(<Pacific-Blue>:30) |
|---|---|---|---|---|---|
| Sample1.fcs | S/L/Lv/3+/4+/IFNg+IL2+ | 12001 | 0.93 | 45223 | 12314 |
| Sample1.fcs | S/L/Lv/3+/4+/IFNg+IL2- | 12312 | 0.94 | 12345 | |
| Sample2.fcs | S/L/Lv/3+/4+/IFNg+IL2+ | 13056 | 0.85 | 13023 | |
| Sample2.fcs | S/L/Lv/{slash/escaped} | 3042 | 0.35 | 13023 |
Grouped By Sample, Population, and Parameter
The required columns are Sample, **Population**, and Parameter. The remaining columns are statistic names with any required percentile part.| Sample | Population | Parameter | Count | %P | Median | %ile(30) |
|---|---|---|---|---|---|---|
| Sample1.fcs | S/L/Lv/3+/4+/IFNg+IL2+ | 12001 | 0.93 | |||
| Sample1.fcs | S/L/Lv/3+/4+/IFNg+IL2+ | FITC-A | 45223 | |||
| Sample1.fcs | S/L/Lv/3+/4+/IFNg+IL2+ | <Pacific-Blue> | 12314 |
Graphs File
The graphs.tsv file is a catalog of plot images generated by the analysis. It is similar to the statistics file and lists the sample name, plot file name, and plot parameters. Currently, the only plot parameters included in the graphs.tsv are the population and x and y axes. The graph.tsv file contains one graph image per row. The population column is encoded in the same manner as in the statistics.tsv file. The graph column is the colon-concatenated x and y axes used to render the plot. Again, compensated parameters are surrounded with <> angle brackets. (Future formats may split x and y axes into separate columns to ease parsing.) The path is a relative file path to the image (no “.” or “..” is allowed in the path) and the image name is usually just an MD5-sum of the graph bytes.Multi-sample or multi-plot images are not yet supported.| Sample | Population | Graph | Path |
|---|---|---|---|
| Sample1.fcs | S/L/Lv/3+/4+/IFNg+IL2+ | <APC-A> | sample01/graph01.png |
| Sample1.fcs | S/L/Lv/3+/4+/IFNg+IL2- | SSC-A:<APC-A> | sample01/graph02.png |
| Sample2.fcs | S/L/Lv/3+/4+/IFNg+IL2+ | FSC-H:FSC-A | sample02/graph01.svg |
| ... |
Compensation File
The compensation.tsv file maps sample names to compensation matrix file paths. The required columns are Sample and Path. The path is a relative file path to the matrix (no “.” or “..” is allowed in the path). The comp. matrix file is in the FlowJo comp matrix file format or a GatingML transforms:spilloverMatrix XML document.| Sample | Path |
|---|---|
| Sample1.fcs | compensation/matrix1 |
| Sample2.fcs | compensation/matrix2.xml |
Keywords File
The keywords.tsv lists the keyword names and values for each sample. This file has the required columns Sample, **Keyword**, and Value.| Sample | Keyword | Value |
|---|---|---|
| Sample1.fcs | $MODE | L |
| Sample1.fcs | $DATATYPE | F |
| ... |
FCS Express
Documentation
The following tutorials explain how to set up FCS Express and LabKey Server to work together.- Tutorial: Import Flow Data from FCSExpress -- Set up to LabKey Server to Import from FCS Express.
- Tutorial: Exporting to LabKey Server -- Set up FCS Express to Export Data. (External link to the FCS Express documentation.)
Tutorial: Import Flow Data from FCS Express
Install LabKey Server and FCS Express
If you haven't already installed LabKey Server and FCS Express, use these download links:LabKey Setup: Folder and Assay Design/Protocol
Adding an assay folder provides the basic assay functionality. Enabling FCS Express in that folder provides the FCS Express-specific features. Finally the assay design/protocol provides the fields to receive the data, files, jpegs, etc, coming from the FCS Express client.- First, we will make a folder (of assay type).
- Navigate to a project, such as the Home project: http://localhost:8080/labkey/project/home/begin.view?
- Sign in as an admin.
- Create a subfolder: Admin > Folder > Management, click Create Subfolder.
- Complete the wizard, making sure that you create a folder of type Assay. (You may give the folder any name you wish. For the purposes of this tutorial, we have used the folder name "FCS_Express_Data".)
- Second, enable the FCS Express module.
- Admin > Folder > Management and click the Folder Type tab.
- Under Modules select FCSExpress.
- Click Update Folder.
- Finally, set up the FCS Express assay design/protocol:
- Click the Assay Dashboard tab.
- Click New Assay Design. Select FCSExpress, select the current folder as the assay location, and click Next.
- Enter a Name. (You may enter any name. For the purposes of this tutorial, we have used "My FCS Express Protocol".)
- Before you save this assay design/protocol, scroll down the page to review the data fields. These fields are available to receive data from FCS Express. Note that you can add fields or customize existing fields -- see the end of this tutorial for details on expanding your available data fields.
- Click Save and Close.
FCS Express Set Up: Prepare the FCS Express Report
To kick off a data export from the FCS Express client, you need the following pieces of information:- The export URL -- this URL kicks off the import process (and encodes the target folder)
- The protocol id -- this tells LabKey Server which assay design/protocol to target
- The field names -- these are the target database fields
- To get the export URL and protocol id, go to: Assay Dashboard tab -> your assay design (My FCS Express Protocol) -> Import Data.
- The image below shows an example export URL and the protocol id to use. (These are sample values -- the actual values to use will likely be different than what is shown below.)

- To get the field names, go to: Assay Dashboard tab -> your assay design (My FCS Express Protocol) -> Manage Assay Design -> Edit Assay Design.
- Use any field names that you wish to write data to. (You can also create new fields to receive data. See Export More Kinds of Data below.)
View the Exported Data
- When export is complete, return to LabKey Server to see your data:

What Else Can I Do?
Export More Kinds of Data
Below are listed the fields for a expanded assay design/protocol in order to capture more kinds of data from FCS Express. You can create this expanded design from scratch, or use the XAR shortcut described below. Note that any statistical data in FCS Express can be included in the export.| Column Name | Label | Type |
|---|---|---|
| ParticipantID | Participant ID | Subject/Participant (String) |
| Date | Date | DateTime |
| Events | Gate 1 Events | Integer |
| Percent | M1 Percent | Number (Double) |
| JPEG | Histogram | File |
| FCS | FCS file | File |
| FEY | FCS Express Layout | File |
Shortcut: Assay Design From a XAR File
Use the following XAR file as a starting point: FCSProtocol1.xar- Download the already prepared assay design/protocol: FCSProtocol1.xar
- Click Assay Dashboard -> New Assay Design.
- Click the textual link upload the XAR File directly.
- Complete the wizard, uploading the XAR file.
Make the Comments Field Visible in LabKey Server
When preparing data for export from FCS Express, you can enter comment data that will be included in the exported data. To see this comment data once it has been exported to LabKey Server, follow the instructions below.- Click Assay Dashboard.
- Click your assay design name.
- Click some data run to view the exported data directly.
- Select Grid Views -> Customize Grid.
- Under Available Fields, open the Run node, and place a checkmark next to Comments.
- Save the view. Your exported comment data will appear.
Related Topics
FCS keyword utility
The keywords.jar file attached to this page is a simple commandline tool to dump the keywords from a set of FCS files. Used together with findstr or grep this can be used to search a directory of fcs files.
java -jar keywords.jar *.fcs
This will show you all the 'interesting' keywords from all the files in the current directory (most of the $ keywords are hidden).
java -jar keywords.jar -k "EXPERIMENT ID,Stim,$Tot" *.fcs
will show the EXPERIMENT ID, Stim, and $Tot keywords for each fcs file. You may need to escape the '$' on unix command line shells. For tabular output suitable for import into excel or other tools, use the "-t" switch:
java -jar keywords.jar -t -k "EXPERIMENT ID,Stim,$Tot" *.fcs
To see a list of all options:
java -jar keywords.jar --help
Flow Team Members
Scientific
- Stephen De Rosa, University of Washington, FHCRC, HVTN
- Christoper Wilson, University of Washington
Funding Institutions
- Statistical Center for HIV/AIDS Research Prevention
- HIV Vaccine Trials Network
- Fred Hutchinson Cancer Research Center
- Duke University
- University of Washington
- Immune Tolerance Network
Development
- Matthew Bellew, LabKey
- Kevin Krouse, LabKey
FluoroSpot Assay
- FluoroSpot Assay Set Up
- Importing Data to the FluoroSpot Design
- FluoroSpot Statistics and Plate Summary
FluoroSpot Assay Set Up
The follow instructions explain how to create a new FluoroSpot plate template and assay design (based on the FluoroSpot assay type).- Select Admin > Manage Assays.
- Click Configure Plate Templates.
- Click New 96 Well (8x12) ELISpot Default Template
- Name and configure the plate as fits your experiment. When finished, click Save and Close.
- Select Admin > Manage Assays.
- Click New Assay Design.
- Select ELISpot and the current folder as the Assay Location, then click Next.
- In the Assay Properties section, on the Plate Template dropdown, select a plate template. (If you haven't yet configured a template, you can click Configure Templates, though this will end the Assay Design wizard -- you will need to restart the wizard after you complete the template.)
- In the Assay Properties section, on the Detection Methods dropdown, select 'fluorescent'.

- Set the Batch, Run, Sample, Antigen, and Analyte fields as appropriate to your experiment.
- Click Save and Close.
Importing Data to the FluoroSpot Design
To import data into the assay design, you can use the "Import Data" button, as shown below; or, as an alternative, you can use the Files web part (for details, see Import Data from Files). Note that data import for the FluoroSpot assay is similar to data import for the ELISpot assay -- to compare these processes see: ELISpot Assay Tutorial.- If you wish to use sample data to become familiar with the data import process, download the following sample files:
- On the Assay List, select your FluoroSpot assay design.
- Click Import Data
- Enter any Batch Properties for your experiment.
- If you plan to integrate the assay data into a study, specify how the data maps to other data you have collected. For details see Participant/Visit Resolver. The actual data entry for participants, visits, and/or specimens takes place in the next step.
- Click Next.
- Enter any Run Properties for your experiment, for example, specify the lab which performed the assay runs.
- Select the Plate Reader - note that this field is required. If using our example files, select AID.
- Select Choose File and select the spreadsheet of data to be imported.
- Enter the ParticipantId, VisitId, or SpecimenId, depending on how this information is encoded.
- Click Next.
- Enter the Antigen Properties for your experiment, including the Antigen name(s), id(s) and the number of cells per well.
- Click Next.
- On the Analyte Properties page, enter the cytokine names used in the experiment.
- Click Save and Finish, or Save and Import Another Run if you have more spreadsheets to enter.
FluoroSpot Statistics and Plate Summary
- Once data import is complete, you will be taken to the "Runs" view of your data.
- Click Run Details to view statistics (mean and median) grouped by antigen.

- The Run Details view also displays plate summary information for each analyte. Select the sample and antigen to highlight the applicable wells. Hover over a well to see more details.

Genomics Workflows
 LabKey Server's genotyping and Illumina modules may require significant customization and assistance, so they are not included in standard LabKey distributions. Developers can build these modules from source code in the LabKey repository. Please contact LabKey to inquire about support options.
LabKey Server's genotyping and Illumina modules may require significant customization and assistance, so they are not included in standard LabKey distributions. Developers can build these modules from source code in the LabKey repository. Please contact LabKey to inquire about support options.
- Manage and build dictionaries of reference sequences, including associated sample and run-specific information.
- Import and manage genotyping data: reads, quality scores, metadata, and metrics.
- Analyze reads directly in LabKey Server or export to FASTQ files for use in other tools.
- Initiate genotyping analyses using Galaxy. LabKey sends selected reads, sample information, and reference sequences to Galaxy, and uses the Galaxy web API to load this data into a new Galaxy data library.
- Automatically import results when the Galaxy workflow is complete.
- Store large Illumina sequence data as files in the file system, with links to sample information and ability to export subsets of sequencing data.
Supported Instruments
The genotyping tools are designed to support import, management, and analysis of sequencing data from:- Roche 454 instruments (GS Junior and GS FLX)
- Illumina instruments (for example, MiSeq Benchtop Sequencer)
- PacBio Sequencer by PacBio Systems
Documentation
- Set Up a Genotyping Dashboard
- Example Workflow: LabKey and Galaxy - Manage sequencing resources and interactions with a Galaxy server using data from a Roche 454 Sequencer.
- Example Workflow: LabKey and Illumina - Manage sample and sequencing results from an Illumina MiSeq Benchtop Sequencer.
- Example Workflow: LabKey and PacBio - Import and manage sequencing results from a PacBio Sequencer.
- Example Workflow: O'Connor Module - Perform enhanced experiment management using the O'Connor module.
- Import Haplotype Assignment Data - Import existing haplotype assignment information for integration with other data.
- Work with Haplotype Assay Data - Generate a report of haplotype assignments (and discrepancies).
Resources
- Contact LabKey for more information about these capabilities.
Set Up a Genotyping Dashboard
Add the Genotyping Module
- Acquire and enable the genotyping module zip file (see "Modules" section for details).
- Select Admin > Site > Create Project.
- Give the project a Name, select Genotyping, and click Next.
- Click Next, then Finish to complete basic project creation with default security and project settings. (These can be changed later.)
Get Sample Data
- Download and unzip the sample data.
Import the Reference Sequences, Run Data, and Sample Info
The following lists are added to the database by importing a pre-prepared list archive.- reference sequences
- run-specific data
- sample information
- If necessary, click Genotyping Dashboard tab.
- In the Lists web part, click Manage Lists.
- Click Import List Archive.
- Browse to the unzipped sample data you downloaded and select the gs_archive.lists.zip file.
- Click Import List Archive.
- You will see the contents imported to LabKey Server as part of the lists schema.
Configure Data Resources
Before managing sample information, you must configure the reference sequences, run-specific data, and sample information on the genotyping admin page.- Click Genotyping Dashboard.
- Under Settings click Admin.
- For each row in the Configure Genotyping Queries section, click Configure.
- In the popup, select:
- Schema: "lists"
- Query:
- For "External source of DNA reference sequences," choose "sequences."
- For "Runs," choose "runs."
- For "Samples," choose "libraryDesign."
- For "Haplotype Definitions," choose "mids."
- Leave the View for each set to: [default view].
- Click Submit in the popup.

- When all queries are configured, click Submit on the Genotyping Admin page.
- You will see a warning that "Reference sequences have not been loaded in this folder."
- Click Load Sequences.
Import the Reads
The read data is uploaded and then imported as files in the file system (rather than as lists in the database).- Click View Pipeline Status. (Click Genotyping Dashboard if you don't see this link.)
- Click Process and Import Data.
- Drag and drop the unzipped [genotypingSampleData] directory into the upload region.
- When the upload is complete you will see the list of files.

Where Did the Files Go?
When you upload files via the pipeline, they are stored locally in the file system directory. To see where the file is physically located, show the download link column. Click the arrow next to any column header, select Columns, then check the box for Download Link. The location will be something like: <LABKEY_HOME>\files\<PROJECT_NAME>\@filesNext Steps
Different types of genotyping workflow use the same dashboard setup.Example Workflow: LabKey and Galaxy
- manage reads, samples, and reference sequences
- submit jobs to Galaxy
- export data sets for analysis in other tools

Set Up
Follow the steps in this topic to set up and load some sample genotyping data.Workflow Steps
Here are some ways to use the genotyping dashboard:Load and Browse Sequences
- On the Genotyping Dashboard, click View Reference Sequences.
- Scroll to the right to see all of the data columns.
Load, Browse, and Export Reads
- On the Genotyping Dashboard, click Import Run.
- Select reads.txt and click Import Data.
- Select Import 454 Reads and click Import.
- On the Associated Run dropdown, select 206 and click Import Reads.
- As you wait for the import to finish, you can import another run...
- Click Process and Import Data
- Select secondRead/reads.txt. Note that you will get an error if you try to reimport the same reads.txt as you did above.
- Click Import Data.
- Select Import 454 Reads and click Import.
- On the Associated Run dropdown, select 207 and click Import Reads.
- Wait for the import to finish.
- Click Complete.
- Click Data
- You can now export these results to a FASTQ file by clicking Export > FASTQ > Export to FASTQ. You have the option to filter out low-quality bases.
Configure the Galaxy Server
- On the Genotyping Dashboard, under Settings, click Admin.
- Under Configure Galaxy, enter the URL of the Galaxy server home page, for example, "http://galaxy.myserver.org".
- Click Submit and then Done.
- Under Settings, click My Settings.
- In Galaxy web API key, enter the 32-character hex string.
- Click Submit.
Start a Galaxy Analysis
- In the Sequencing Runs section, click a record, for example: 206.
- Click Add Analysis.
- On the Reference Sequences dropdown, select [default].
- Click Submit.
- LabKey Server will attempt to submit a request to the Galaxy server.
Example Workflow: LabKey and Illumina
- organize sample information, such as sample ids, types, MID tags, experiment-specific data, etc.
- prepare an Illumina sample sheet to be passed to the MiSeq instrument
- automatically associate the Illumina-generated sequence results with the original sample information
- browse and export the sequence files
Set Up a Dashboard
First we will set up a Genotyping dashboard, and import some sample data.- Download genoCleanSamples.folder.zip -- This is a folder archive that contains the Illumina sample data and other files. Don't unzip the file.
- Import the folder archive, as shown below. This will add resources to your existing dashboard
- Navigate to the Home project, or any project convenient for you.
- Create sub-folder in the project: Select Admin > Folder > Management and click Create Subfolder. Create a folder of type Genotyping.
- When the folder is complete, overwrite it with the folder archive you just downloaded: Select Admin > Folder > Management.
- Click the Import tab.
- Under Import Folder From Local Source, confirm Local zip archive is selected and click Choose File.
- Select the file genoCleanSamples.folder.zip.
- Click the button Import Folder.
- The folder archive will be unzipped and its resources added to the folder your just created. Notice also that the folder imports, but with an error -- an error which we will correct in the next step.
- Click the Genotyping Dashboard tab to return to the main dashboard.
Configure Sample Data
Next we will we will tell the dashboard where to find the sequence data, haplotype definitions, and run data.- Under =Settings, click Admin.
- Under Configure Genotyping Queries, next to External source of DNA reference sequences, click Configure.
- In the popup dialog:
- Click the Schema dropdown and select lists.
- Click the Query dropdown and select miseq_libraries.
- Leave the View dropdown at it's default value [default view].
- Click Submit.

- Under Configure Genotyping Queries, repeat for Runs, Samples, and Haplotype Definitions.
- For Runs assign the following values:
- Schema = lists
- Query = runs
- View = [default View]
- For Samples assign the following values:
- Schema = lists
- Query = samples
- View = [default View]
- For Haplotype Definitions assign the following values:
- Schema = lists
- Query = barcodes
- View = [default View]
- Click Submit.
- In the Reference Sequences panel, click Load Sequences.
Prepare an Illumina Sample Sheet
- Under Manage Sample Information, click Samples.
- Select the sample or samples you want to sequence.
- Click Create Illumina Sample Sheet.

- Complete the sample sheet and click Download to download as a CSV file. This CSV sample sheet can be read directly by the Illumina instrument.
- Note the warning provided by the sample sheet validation checker.
- You may save your work as a template for future runs.

Run Samples
- To perform a run, first insert a record into the Runs list. (Go to Tasks > Import Run.)
- Prepare the samples to sequence on your instrument:
- Input (1) the samples and (2) the CSV sample sheet to the Illumina MiSeq instrument, which runs and generates data.
Import Results
- The generated data (FASTQ files) and the sample sheet are then re-imported:
- Go to the Files webpart.
- Select the CSV file.
- Click Import Data.
- Pick Import Illumina Reads.
- Choose which run you associate it with.
- When you hit Import, a pipeline job runs that will import your raw reads. The system assumes that the input FASTQ file have already been binned into separate files per sample (the Illumina instrument handles parsing the barcodes), which will be renamed based on the sample name. Basic metrics are stored for each FASTQ file, like the total read number.
View and Download Files
- For each run, you can view the set of files created, plus sample attributes.
- You can download the files individually, or select multiple files and choose to download a batch of them.
Resources
- Sample Data: download
Example Workflow: LabKey and PacBio
- import sequencing data from a PacBio Sequencer, including sample sheets, barcode identifiers, and table structures
- link sample sets and runs and organize with other information such as ids, types, tags, etc.
- keep different pool data (such as from different lanes) separate
- store multiple fastq files per barcode identifier, and accept fastq files without assuming the need for matching read counts
- browse and export the sequence files
Set Up a Dashboard
First we will set up a Genotyping dashboard, and import some sample data.- Download pacbio.lists.zip -- This is a list archive you will import - do not unzip it.
- Create a new project of type Genotyping. Use the default settings.
- In the Lists webpart click Manage Lists.
- Click Import List Archive.
- Choose or Browse to the pacbio.lists.zip archive and click Import List Archive.
- You will see the lists imported.
- (Optional) Explore the list design of the samples list to notice that the fivemid and threemid columns are configured as lookups into the mids list.
- Click Genotyping Dashboard.
- Under Settings, click Admin.
- Under Configure Genotyping Queries, click Configure next to Runs:
- Schema = lists
- Query = runs
- View = [default View]
- Click Submit
- Click Configure next to Samples:
- Schema = lists
- Query = samples
- View = [default View]
- Click Submit.
- Click Submit again to save the query configuration.
- Download and unzip FilesFromPacBioInstrument.zip - the PacBio sample data - to the location of your choice.
- Click Genotyping Dashboard.
- Under Tasks, click Import Run.
- Drag and drop the pacbio8 folder into the upload area (located in the FilesFromPacBioInstrument package you downloaded).
- Navigate to and select a SampleSheet.csv file. You can find one in each pool of fastq files in the sample data you just uploaded. For instance: pacbio8/pool1_barcoded_fastqs/SampleSheet.csv

- In the pop-up, scroll down to select Import PacBio Reads and click Import.
- Select the Associated Run, and optionally provide a FASTQ Prefix.
- Click Import Reads.
- Evaluate any errors received. For example, the error "Failure to send success notification, but job has completed successfully" can be disregarded.
- Click Genotyping Dashboard when the import is complete.
- Click View Runs and then the run number to see the (small) results from this sample import.

- Click a Sample ID to see the samples associated with this run.

Example Workflow: O'Connor Module
 LabKey Server's O'Connor modules are not included in standard LabKey distributions. Developers can build these modules from source code in the LabKey repository. Please contact LabKey to inquire about support options.
LabKey Server's O'Connor modules are not included in standard LabKey distributions. Developers can build these modules from source code in the LabKey repository. Please contact LabKey to inquire about support options.
OConnor Experiments Web Part
After enabling the OConnorExperiments module in your folder, you can add the OConnorExperiments web part which provides a place to manage your list of experiments. Experiments are numbered and can be of predefined types (see below). They may also optionally display a grant in the web part and have parent/child relationships relationships. The Experiments interface allows you to filter and sort to select specific experiments. Clicking the name of any one opens the associated workbook.
Experiments are numbered and can be of predefined types (see below). They may also optionally display a grant in the web part and have parent/child relationships relationships. The Experiments interface allows you to filter and sort to select specific experiments. Clicking the name of any one opens the associated workbook.
Inventory Lists
The OConnor schema uses lookups for a number of run properties, including ExperimentType and SpecimenType, which look up into persistent lists on the server. Over time these tables can become cluttered with unused values, due to mismatches when migrating old data or past entry of free-form text.To improve consistency, these tables have a boolean field indicating whether the row is active. Any grid views of the lookup target tables will still show all rows whether active or not. However, in insert or update UI, inactive rows will not be included as options, with the one exception that the currently-used value is always offered in an update UI, even if it is marked inactive.The SpecimenType lookup in particular offers an extremely long list of possible values. The dropdown selection UI for this field offers type-ahead for selection of existing values to reduce scrolling.ExperimentType List Cleanup
When you remove extraneous entries from a cluttered ExperimentType list, you must also update existing experiments associated with the extraneous types to use an active type. You can edit the details of any individual experiment, or bulk edit multiple entries at once.- In the Experiments web part, click the checkboxes for the rows to be updated. You might, for example, first filter on the Type column to show only the ExperimentType you wish to remove, then select all rows.
- Click Bulk Edit.
- On the bulk edit page, you can simultaneously reassign the group of experiments to a new type, a new parent, or even give them all the same description if needed.

- Click Submit to apply the change to all selected rows.
Related Topics
Import Haplotype Assignment Data
Set Up
Follow the steps here to set up your project:Configure Animal and Haplotype Tables (Optional)
You may want to store additional information in the Animals and Haplotypes tables by adding new fields such as source, sex, origin, dam, sire, grandDam, grandSire, offspring, comments.- On the Genotyping Dashboard, in the Settings section, click Admin.
- Click Configure next to either Animal or Haplotype.
- Use the Add Field button to add new custom fields to the Animal/Haplotype table by giving the field a name, label, type, etc.
- Click Save when finished.
Haplotype Assay
The default Haplotype Assay type has several default run fields which are used for mapping the column headers in the data you provide with the expected columns in the database.| Name | Label | Type | Description |
|---|---|---|---|
| enabled | enabled | Boolean | |
| labAnimalId | Lab Animal ID | Text (String) | |
| clientAnimalId | Client Animal ID | Text (String) | |
| totalReads | Total # Reads Evaluated | Text (String) | |
| identifiedReads | Total # Reads Identified | Text (String) | |
| mhcAHaplotype1 | MHC-A Haplotype 1 | Text (String) | |
| mhcAHaplotype2 | MHC-A Haplotype 2 | Text (String) | |
| mhcBHaplotype1 | MHC-B Haplotype 1 | Text (String) | |
| mhcBHaplotype2 | MHC-B Haplotype 2 | Text (String) | |
| speciesId | Species Name | Integer | Lookup into the genotyping.Species table |
- Select Admin > Manage Assays.
- Click New Assay Design.
- Choose Haplotype as the assay type, set the folder location to the current folder, and click Next.
- Give the assay design the name of your choice in the Assay Properties section.
- Set the default value for the enabled run field:
- Select by clicking the enabled name.
- Click the Advanced tab on the right.
- Set the Default type to Editable default.
- Click Set Value. A popup will ask you to save changes before setting this value. Click OK.
- Set the default value to true by checking the Initial/Default Value checkbox for the "enabled" row.
- Click Save Defaults to return to editing the assay design.
- To add additional fields, click Add Field in the run or batch sections as needed.
- When you are finished customizing the assay design, click Save & Close.
Add Additional Species
When you import data into a Haplotype Assay, you will select a value for the Species Name from a pulldown list which is a lookup into genotyping.Species table. By default, "rhesus macaques" is the only built in value. An administrator can add additional species to the list of options. For example, you might also have data for "cyno" and "pig-tails".- Select Admin > Developer Links > Schema Browser.
- Click Genotyping.
- Click Species.
- Click View Data.

- Select Insert > Insert New Row.
- Enter "cyno" and click Submit.
- Select Insert > Insert New Row again, enter "pig-tails" and click Submit.
Import Existing Haplotype Assignments
- To import existing haplotype assignment data, go to the Genotyping Dashboard.
- Under Settings, click Admin. Click Haplotype and then Import Data.
- Two files containing sample haplotype assignment data can be downloaded below:
- firstRunData.txt
- secondRunData.txt - This example will only import if you've entered two additional species.
Related Topics
Work with Haplotype Assay Data
Import Haplotype Assay Data
- Select Admin > Manage Assays.
- Click the Haplotype assay design you defined and named above.
- Click Import Data to import a run, entering requested information.
- Once one or more runs have been uploaded, you will see them listed in the runs grid.

Review Haplotype Results
Haplotype Assay results can be viewed on a one animal per file basis. Each row may have information for only a subset of all the haplotypes. When you click the name of a given run, you will View Data as Uploaded which might look something like this: You can also view haplotype results aggregated by animal for a different angle on the same data by clicking View Results:
You can also view haplotype results aggregated by animal for a different angle on the same data by clicking View Results:
View Haplotype Assignment Report
After uploading runs, you may click View Haplotype Assignment Report and enter one or more Animal IDs, then click Submit to generate a report of haplotype assignments.
Report Discrepancies Between STR and Other Haplotype Assignments
Some animals have STR haplotype data generated by an alternative mechanism from the lab's sequencing based analysis. A single STR assignment implies three separate haplotypes (A, B, and DR). To screen for discrepancies between the lab's analysis and the haplotypes predicted by STR assignment, there is color coding of the inconsistent values built into a custom report.Click View STR Discrepancies Report to see the list of animals for which there are discrepancies. Checking the box to ignore subtype distinctions would, for example, cause haplotypes D012 and D012b to be considered as matching. Otherwise they would raise a discrepancy here.
Checking the box to ignore subtype distinctions would, for example, cause haplotypes D012 and D012b to be considered as matching. Otherwise they would raise a discrepancy here.HPLC - High-Performance Liquid Chromatography
- Drag-and-drop file upload.
- Overlays of multiple curve lines.
- Graphical zoom into results.
- Calculation of areas under the curves.
Screen Shots
You can zoom into curve areas of interest, either by manual entering new values, or by directly drawing on the graph. Highlight individual curves and calculate areas under the curves.
Highlight individual curves and calculate areas under the curves.
Related Topics
- HPLC Docs - Detailed documentation on the HPLC module.
- HPLC Module on GitHub - HPLC module source repository.
Luminex
Tutorials
There are two tutorials which introduce the Luminex features using some example data. They are independent of each other, but we recommend completing them in order to learn your way around the tools. The tutorial scenario is that we want to evaluate binding between a panel of HIV envelope proteins (antigens) and plasma immunoglobulin A (antibodies) from participants in a study.Background
LabKey Server supports multiplexed immunoassays based on Luminex xMAP® technology. A Luminex assay multiplexes analysis of up to 500 analytes in each plate well. In contrast, an ELISA requires a separate well for analysis of each individual analyte.Luminex immunoassays often aim to do one or both of the following:- Measure the strength of binding between a set of analytes (e.g., virus envelope antigens) and unknowns (e.g., blood serum samples with unknown antibody activity).
- Find concentrations of unknowns using dose-response curves calculated for titrated standards.
Binding and Concentrations
Each analyte is bound to a different type of bead. Each bead contains a mixture of red and infrared dyes in a ratio whose spectral signature can identify the bead (and thus the analyte).In each plate well, analyte-bound beads of many types are combined with a sample. The sample added to each plate well is typically a replicate for one of the following:- A titrated standard whose concentrations are known and used to calculate a reference curve
- A titrated quality control used for verification
- An unknown, such as serum from a study participant
- A background well, which contains no active compound and is used for subtracting background fluorescence
The LabKey Luminex transform script
The LabKey Luminex tool can be configured to run a custom R transform script that applies custom curve fits to titrated standards. The script also uses these curve fits to find estimated concentrations of samples and other desired parameters.The data used by the script for such analyses can be customized based on the latest lab techniques; for example, the default script allows users to make choices in the user interface that enable subtraction of negative bead FI to account for nonspecific binding to beads.The methods and parameters used for the curve fit can be fully customized, including the weighting used for squared errors to account for trends in variance, the equation used to seed the fitting process, and the optimization technique.Developers can customize the R transform script to use the latest R packages to provide results that reflect the most advanced algorithms and statistical techniques. Additional calculations can be provided automatically by the script, such as calculations of a result’s “positivity” (increase relative to a baseline measurement input by the user).Levey-Jennings plots
Levey-Jennings plots can help labs execute cross-run quality control by visualizing trends and identifying outliers.LabKey Server automatically generates Levey-Jennings plots for a variety of metrics for the curve fits determined from titrations of standards. See Step 5: Track Analyte Quality Over Time for more information.Topics
Luminex Assay Tutorial Level I
- Create a Luminex specific assay design.
- Import Luminex assay data and collect additional, pre-defined analyte, run and batch properties for each run or batch of runs.
- Exclude an analyte's results from assay results, either for a single replicate group of wells or for all wells.
- Import single runs composed of multiple files and associate them as a single run of standards, quality controls and unknowns.
- Copy quality-controlled, specimen-associated assay results into a LabKey study to allow integration with other types of data.
Tutorial Steps
- Setup Luminex Tutorial Project
- Step 1: Create a New Luminex Assay Design
- Step 2: Import Luminex Run Data
- Step 3: Exclude Analytes for QC
- Step 4: Import Multi-File Runs (Optional)
- Step 5: Copy Luminex Data to Study (Optional)
Set Up Luminex Tutorial
Setup Luminex Tutorial Project
Install and Download
- If you haven't already installed LabKey Server, complete these instructions: Install LabKey Server (Quick Install).
- Download and unzip the Luminex sample data:
- LuminexSample.zip
- For LabKey Server versions prior to 14.3 use: Luminex142.zip
- The unzipped file contains a directory named "Luminex", containing sample files.
Create a Folder to Work In
- Select the Home project (or your personal project on a shared server).
- Create a folder inside the Home project: select Admin > Folder > Management > click Create Subfolder.
- On the Create Folder in... page enter the following:
- Name: "Luminex"
- Folder Type: Assay
- Click Next.
- On the Users/Permissions page, make no changes and click Finish.
Upload Tutorial Data Files
- On the bottom left, click the dropdown <Select Web Part> menu. Select Files and click Add.
- In a separate file explorer, locate the Luminex directory you downloaded and unzipped.
- Drag and drop the Luminex directory into the target area of the new Files web part to begin the upload.
Restart Luminex Tutorial | Next Step
Begin the Advanced Luminex Tutorial
Step 1: Create a New Luminex Assay Design
Create a New Default Luminex Design
- On the Assay List web part, click New Assay Design.
- For the assay type, select Luminex.
- At the bottom of the page, for the Assay Location choose Current Folder (Luminex).
- Click Next.
- In the Assay Properties section, for Name enter "Luminex Assay 100".
- Review the properties and fields available, but do not change them.
- Click Save & Close.
Start Over | Next Step
Step 2: Import Luminex Run Data
Start the Import Process
- If necessary, click the Assay Dashboard tab to return to the folder's main page.
- In the Files web part, open the Luminex folder, and then the Runs - Assay 100 folder.
- Select the file 02-14A22-IgA-Biotin.xls by single-clicking it.
- Click Import Data.

- In the Import Data popup window, select Use Luminex Assay 100 (the design you just created).
- Click Import.
Batch Properties
First, we enter batch properties. These are properties which are set once per batch of runs, which in this first example is only a single run.- Participant/Visit and Target Study: Leave the default selections ("Sample information in the data file" and "None". These fields are used for aligning assay data with existing participant and specimen data. We will learn more about these fields later in this tutorial.
- Species: Enter "Human".
- Lab ID: Enter "LabKey".
- Analysis software: Enter "BioPlex"
- Click Next.
Run Properties
Next, we can enter properties specific to this run.- On the page Data Import: Run Properties and Data File, leave all fields unchanged.
- Note that the Run data field points to the Excel file we are about to import: "02-14A22-IgA-Biotin.xls". When you leave the Assay Id field blank (as you do in this step), the name of the imported Excel file will be used as the Assay Id, in this case "02-14A22-IgA-Biotin.xls".
- Click Next.
Analyte Properties
While any assay may have batch or run properties, some properties are particular to the specific type of assay. Analyte properties defined on this page are an example.Well Roles
If a sample appears at several different dilutions, we infer you have titrated it. During the import process for the run, you can indicate whether you are using the titrated sample as a standard, quality control, or unknown.A standard is typically the titration used in calculating estimated concentrations for unknowns based on the standard curve. A quality control is typically a titration used to track values like AUC and EC50 over time for quality purposes. Learn more in Luminex Calculations.Here, we elect to use Standard1 (the standard in the imported file) as a Standard.In this panel you will also see checkboxes for Tracked Single Point Controls. Check a box if you would like to generate a Levey-Jennings report to track the performance of a single-point control. Learn more in the Level II tutorial which includes: Step 5: Track Analyte Quality Over Time and Track Single-Point Controls in Levey-Jennings Plots.Analyte Properties
The Analyte Properties section is used to supply properties that may be specific to each analyte in the run, or shared by all analytes in the run. They are not included in the data file, so need to be entered separately. For example, these properties may help you track the source of the beads used in the experiments, for the purpose of quality control. In the second tutorial we will track two lots of analytes using these properties.- On the page Data Import: Analyte Properties leave the sections Define Well Roles and Analyte Properties unchanged.
- Click Save and Finish.
View Results
The data has been imported, and you can view the results.- In the Luminex Assay 100 Runs table, click 02-14A22-IgA-Biotin.xls to see the imported data for the run.
- The data grid will look something like this:

- You can see a similar page in the interactive example.
Previous Step | Next Step
Step 3: Exclude Analytes for QC
- Exclude Replicate Group: Scope the exclusion to a single replicate group.
- Exclude Analytes: Exclude particular analytes for all wells, irrespective of replicate group.
- Exclude Titrations: Exclude all well groups for a given titration for one or more analytes in one action.
- Exclude Singlepoint Unknowns: Exclude singlepoint samples which are not titrated.
Exclude Analytes for a Replicate Group
Here, you will exclude a single analyte for all sample wells within a replicate group, in this case there are two wells per group.In this example scenario, since the fluorescence intensity reported for an analyte in a well is the median for all beads bound to that analyte in that well, you might exclude the analyte if the reported coefficient of variation for the group was unusually high.Filter Results to a Replicate Group
Filter the results grid so that you see only unknowns, not background, standard or control wells.- On the Luminex Assay 100 Results page, click the column header for the Well Role column.
- Select Filter.
- In the filter popup on the Choose Values tab, select the Unknown option only. Click the label Unknown to select only that checkbox.
- Click OK.

- Customize the results grid to show instrument-reported coefficients of variation for each well:
- Above the grid, select Grid Views > Customize Grid.
- In the Available Fields panel, scroll down, click the box for CV, then click View Grid.
- Scroll to the far right and note that the first two wells for ENV1 (a replicate pair) show much higher CV than the other wells for this analyte.

- Scroll back to the left. Hover over the message "The current <default> grid view is unsaved, click the Save button, confirm that "Default grid view for this page" is selected, and click Save.
Exclude Data for the Replicate Group
To exclude data for a replicate group, click the circle/slash icon for a row in the group. You get to choose whether all analytes for the sample group are excluded, or just the row you picked initially.- Click the circle/slash icon on the second row:

- In the Exclude Replicate Group from Analysis popup:
- Click Exclude selected analytes.
- Check the box for ENV1 to exclude this analyte.
- This exclusion will apply to analyte ENV1 in a replicate group that includes only wells A1 and B1, as listed in the Wells field.
- Click Save.

- A popup message will explain that the exclusion will run in the background, via the pipeline - you have the option to view the pipeline status log to await completion. For this tutorial, just click Yes and continue; this small exclusion will run quickly. Return to the results page by clicking View Results.
View Exclusion Color Coding
Once excluded, the rows are color coded with red/pink and the Flagged As Excluded field changes value from "no" to "yes". Use this field to sort and filter the assay data, if desired. You can also see an example in the
You can also see an example in the Exclude Analytes Regardless of Replicate Group
Next, we exclude a given analyte for all wells in the run. For example, you might wish to exclude all measurements for a particular analyte if you realized that this analyte was bound to beads that came from a problematic lot.- On the Luminex Assay 100 Results grid, select Exclusions > Exclude Analytes.
- Where is the Exclusions menu option? You must have editor or higher permissions to see this option. If you still don't see the option, your results view is probably unfiltered. The button only appears for results that have been filtered to one particular run. To make the button appear, click Luminex Assay 100 Runs at the top of the page, then click a particular run -- this filtered result view will include the Exclusions menu if you have editor or higher permissions.
- In the Exclude Analytes from Analysis popup, select ENV5.
- Notice that there is no Wells field; exclusions apply to all replicate groups.

- Click Save.
- Click No in the popup message offering the option to view the pipeline status.
Exclude Titration
When you exclude data from a well-group within a titration, the assay is re-calculated (i.e. the transform script is rerun and data is replaced). If you want to exclude all well groups for a given titration, you can do so without recalculating by selecting Exclusions > Exclude Titration and specifying which titration to exclude. Note that you cannot exclude a "Standard" titration. The popup lets you select each titration present and check which analytes to exclude for that titration. Note that analytes excluded already for a replicate group, singlepoint unknown, or at the assay level will not be re-included by changes in titration exclusion.
The popup lets you select each titration present and check which analytes to exclude for that titration. Note that analytes excluded already for a replicate group, singlepoint unknown, or at the assay level will not be re-included by changes in titration exclusion.
Exclude Singlepoint Unknowns
To exclude analytes from singlepoint unknown samples, select Exclusions > Exclude Singlepoint Unknowns. The unknown samples are listed, and you can select each one in turn and choose one or more analytes to exclude from only that singlepoint. Note that analytes excluded for a replicate group, titration, or at the assay level will not be re-included by changes in singlepoint unknown exclusions.
Note that analytes excluded for a replicate group, titration, or at the assay level will not be re-included by changes in singlepoint unknown exclusions.
View All Excluded Data
Click View Excluded Data above the results grid to see all exclusions in a single page. This might help you see which data needs to be re-run. You could of course view excluded rows by filtering the grid view on the Flagged as Excluded column, but the summary page gives a summary of exclusions across multiple runs.If you are looking at the results grid for a single run, the View Excluded Data report will be filtered to show the exclusions for that run.- On the results grid, click View Excluded Data
 You can see a similar view in the interactive example.
You can see a similar view in the interactive example.
Reimport Run
Return to the runs view. If you wanted to reimport the run, perhaps to recalculate positivity, you could do so by selecting the run and clicking Reimport Run. Note that the previous run data will be deleted and overwritten with the new run data. You will see the same entry screens for batch and run properties as for a new run, but the values you entered previously will now appear as defaults. You can change them for the rerun as necessary. If exclusions have been applied to the run being replaced, the analyte properties page will include an Exclusion Warning panel.
You will see the same entry screens for batch and run properties as for a new run, but the values you entered previously will now appear as defaults. You can change them for the rerun as necessary. If exclusions have been applied to the run being replaced, the analyte properties page will include an Exclusion Warning panel. The panel lists how many exclusions are applied (in this case one replicate group and one analyte). Click Exclusions Report to review the same report as you saw using the "View Excluded Data" link from the run data grid. Check the Retain matched exclusions box to retain them; then click Save and Finish (or save and import another run if appropriate) to initiate the reimport.If any exclusions would no longer match based on the reimport run data, you will see a red warning message similar to this:
The panel lists how many exclusions are applied (in this case one replicate group and one analyte). Click Exclusions Report to review the same report as you saw using the "View Excluded Data" link from the run data grid. Check the Retain matched exclusions box to retain them; then click Save and Finish (or save and import another run if appropriate) to initiate the reimport.If any exclusions would no longer match based on the reimport run data, you will see a red warning message similar to this: [ Video Overview: Retain Luminex Exclusions on Reimport ]
[ Video Overview: Retain Luminex Exclusions on Reimport ]
Does LabKey Server re-calculate titration curves when I exclude a replicate group?
This happens only when your assay design is associated with a transform script (see: Luminex Assay Tutorial Level II). When you exclude an entire replicate group from a titrated standard or quality control, LabKey Server automatically re-runs the transform script for that run.This is desirable because changing the replicates included in a titration affects the calculations that the script performs for the curve fits and other measure (e.g., EC50, AUC, HighMFI, etc., as defined in Luminex Calculations).If you exclude a replicate group that is not part of a titration (e.g., part of an unknown), the calculations performed by the script will be unaffected, so the script is not re-run.Does LabKey Server do automatic flagging of run data outliers during data import?
During data import, LabKey Server adds a quality control flag to each data row where reported FI is greater than 100 and %CV (coefficient of variation) is outside of a certain threshold. For unknowns, the %CV must be greater than 15 to receive a flag; for standards and quality controls, the %CV must be greater than 20.Columns flagged through this process are highlighted in red. Flagging can be disabled, just like the QC flags described above. When flagging is disabled, the row is no longer highlighted.To see all rows that received flags according to these threshholds, you can add the CVQCFlagsEnabled column to a Luminex data or results view and filter the data using this column. The column is hidden by default.Previous Step | Next Step
Step 4: Import Multi-File Runs
- You have too many unknowns to fit on one plate, so you place them on several different plates that you run together. Since each plate produces an Excel file, you have several Excel files for that run.
- You have one standard plate that you need to associate with several different runs of unknowns. In this case, you run the standards only once on their own plate and associate them with several runs of unknowns. You might do this if you had only a limited supply of an expensive standard.
Import Multi-File Runs
In this example, we want to import two files as a single run. The two files are:- File A (01-11A12a-IgA-Biotin.xls) reports results for the standard.
- File B (01-11A12b-IgA-Biotin.xls) reports results for unknowns that are associated with this standard.
- Click the Assay Dashboard tab.
- In the Assay List web part, click the Luminex Assay 100 assay design.
- Click Import Data.
- Leave the batch property default values in place, and click Next.
- In Run Properties:
- Scroll down to the Run Data property.
- Click the Browse or Choose File button and navigate to the Luminex sample directory you downloaded and unzipped earlier.
- Select the file Luminex/Runs - Assay 100/MultiFile Runs/01-11A12a-IgA-Biotin.xls and click Open.
- Click the + button to upload another file.
- Click the Browse or Choose File button on the new line.
- Select 01-11A12b-IgA-Biotin.xls and click Open.
- Click Next.

- On the Data Import: Analyte Properties page, leave all default values in place, and click Save And Finish.
- The new run, 01-11A12a-IgA-Biotin.xls, appears in the Luminex Assay 100 Runs list. Since we did not provide an Assay ID for this run during the import process, the ID is the name of the first file imported.

Previous Step | Next Step
Step 5: Copy Luminex Data to Study
Install a Target Study
You need a target study for your assay data, so this step creates one based on the LabKey Demo Study.- To install the target study, complete the instructions in this topic: Install the Demo Study
Re-Import a Run
Next we re-import a run, this time indicating a target study and a mapping file for the data.- Return to the Assay Dashboard of your Luminex folder.
- In the Assay List, click Luminex Assay 100.
- On the Luminex Assay 100 Runs list, place a checkmark next to 02-14A22-IgA-Biotin.xls (the original single run we imported).
- Click Re-Import Run.
- Under Batch Properties enter the following:
- Participant/Visit:
- Click the checkbox Sample indices, which map to values in a different data source.
- In the LuminexSample data you downloaded and unzipped, open the Excel file /Luminex/Runs - Assay 100/IndexMap.xls.
- Copy and paste the entire contents of this file (including all column headers and non-blank rows) to the text box under Paste a sample list as a TSV.
- Target Study:
- Select the target study you installed above, by default: /home/HIV-CD4 Study (Interactive Example - Study).
- Click Next.
- On the page Data Import: Run Properties and Data File, scroll down and click Next.
- On the page Data Import: Analyte Properties you may see a warning about previous exclusions; leave the "Retain matched exclusions" checkbox checked if so.
- Scroll down and click Save and Finish.
Select a Subset of Data to Copy
We wish to exclude standards, controls and background wells when we copy. We also want to exclude data that was flagged and excluded as part of the QC process.- On the page Luminex Assay 100 Runs click 02-14A22-IgA-Biotin.xls (reimporting made it the first row).
- Filter the results to show only wells with unknowns (vs standards or controls):
- Click on Well Role column header and select Filter.
- In the popup, select Unknown by clicking its label, and click OK.
- Notice that your data grid now includes values in the Specimen ID, Participant ID, and visitID columns which were not present before we added the mapping during the reimport.
- Filter the results to show only wells with non-excluded data:
- Click on Flagged As Excluded column header and select Filter.
- In the popup, select only false and click OK.
- Select all displayed rows on the current page of the grid using the checkbox at the top of the left column.
- Hover over the "Selected 100 of 350 rows." to display additional options.
- Click SELECT ALL 350 ROWS to select all 350 row in the table
- Click SELECT NONE to de-select the rows

Copy Selected Data to the Study
- Click Copy to Study.
- Note that we have pre-selected our target study: Interactive Example - Study in folder /home/HIV-CD4 Study. The checkbox to "Copy to a different study" is available but unnecessary in this tutorial.
- Click Next.
- The specimen data has been successfully matched to participants/visits in the demo study via specimen IDs. You will see green markers next to each row of data that has been successfully matched, as shown in the screen shot below.
- On the page, Copy to...Study: Verify Results, finalize the copy by clicking Copy To Study.
 If you see the error message 'You must specify a Participant ID (or Date) for all rows.' it means there are unmatched rows. Scroll down to unselect them, then click Copy To Study again.
If you see the error message 'You must specify a Participant ID (or Date) for all rows.' it means there are unmatched rows. Scroll down to unselect them, then click Copy To Study again.View the Copied Data in the Study
- To see the dataset you copied to the study, click the Clinical and Assay Data tab.
- Scroll down to the "Uncategorized" section to find your copied Luminex dataset on the list. Use the pencil icon on the data views webpart to recategorize the dataset, or simply click to view the copied data again.
Previous Step
Continue to the Luminex Level II Tutorial
Luminex Assay Tutorial Level II
- Import Luminex assay data stored in structured Excel files that have been output from a BioPlex instrument.
- Set values during import of pre-defined analyte, run and batch properties for each analyte, run and/or batch of runs.
- Run the LabKey Luminex transform script during import to calculate logistic curve fits and other parameters for standard titrations.
- View curve fits and calculated values for each standard titration.
- Visualize changes in the performance of standards over time using Levey-Jennings plots.
- Determine expected ranges for performance of standards for analyte lots, then flag exceptional values.
Tutorial Steps
- Step 1: Import Lists and Assay Archives
- Step 2: Configure R, Packages and Script
- Step 3: Import Luminex Runs
- Step 4: View 4pl and 5pl Curve Fits
- Step 5: Track Analyte Quality Over Time
- Step 7: Use Guide Sets for QC
- Step 8: Compare Standard Curves Across Runs
First Step
Step 1: Import Lists and Assay Archives
- A set of lists used by the assay design to define lookups for several properties
- A pre-prepared assay design for a Luminex® experiment
Set Up
- If you have not already set up the Luminex tutorial project, follow this topic to do so: Setup Luminex Tutorial Project.
- Return to this page when you have completed the set up.
Import the List Archive
The lists imported here define sets of acceptable values for various properties included in the assay design that you will import in a later step. These acceptable values are used to provide drop-down lists to users importing runs to simplify data entry.Import the List Archive
- Navigate to your Luminex tutorial folder.
- Select Admin > Manage Lists.
- Click Import List Archive.
- Click Browse/Choose File and select /Luminex/Luminex_ListArchive.lists.zip on your local machine.
- Click Import List Archive.

Import the Assay Design Archive
Next, you will import a pre-prepared assay design which will be used to capture Luminex data.- Click the Assay Dashboard tab.
- In the Files web part, double click the Luminex folder.
- Locate and select Luminex Assay 200.xar.
- Click Import Data.
- In the popup dialog, confirm that Import Experiment is selected and click Import.
- Refresh the page by clicking your browsers refresh button (or press F5).
- In the Assay List, the new assay design "Luminex Assay 200" will appear.
Start Over | Next Step
Step 2: Configure R, Packages and Script
- Install and Configure R if you have not already done so.
- Install Necessary Packages.
- Associate the Transform Script with the Assay Design.
- Test Package Configuration if you wish.
Install and Configure R
You will need to install R and configure it as a scripting language on your Labkey Server. If you are on a Windows machine, install R in a directory that does not contain a space (i.e. not the default "C:\Program Files\R" location.Install Necessary R Packages
The instructions in this section describe package installation using the R graphical user interface.Install Ruminex
The transform script requires Ruminex, a custom package not available on CRAN, so you will need to use the zip package provided in the sample files you downloaded. This tutorial was tested using Ruminex 0.1.0 (and 0.0.9); other versions may not work identically.- If you are running R-3.0.0 or later, use Ruminex_0.1.0.zip from the LuminexSample files you downloaded. (Or download it here: Ruminex_0.1.0.zip).
- Launch the R graphical user interface. Use the drop-down menus in the R user interface to select: Packages > Install package(s) from local zip file...
- Open the zip file you downloaded from this page.
Install Additional Packages
- Open your R installation.
- Using the R console, install the packages listed below using commands like the following (you may want to vary the value of repos depending on your geographic location):
install.packages("Rlabkey", repos="http://cran.fhrcr.org")
- Install the following packages:
- Rlabkey
- RCurl
- rjson
- xtable
- drc
- Cairo
- As an alternative to the R console, you can use the R graphical user interface:
- Use the drop-down menus to select Packages > Install package(s)...
- Select your CRAN mirror.
- Select the packages listed above. (You may be able to multi-select by using the Ctrl key.)
- Click OK and confirm that all packages were successfully unpacked and checked.
- alr3
- car
- gtools
- magic
- abind
- plotrix
- bitops
Associate the Transform Script with the Assay Design
Control Access to Scripts
Next, place the transform script and utility script in a server-accessible, protected location.Your script was uploaded into the Files web part earlier; however, we do not recommend running it from this location. If you do so, all users with edit-level permissions on your server will be able to replace/edit the script which runs with very high levels of permission on your server. Before continuing, place a copy of the transform script and its associated utility script in a safer location on your server. If your server runs on Windows, for example:- Locate the LabKey Server directory on your local machine. For example, it might be C:\Program Files\LabKey Server
- Create a new directory named Scripts here.
- Place a copy of each of these files in this new directory: (Copy from the sample data you already downloaded or download a new copy from the Files web part.)
- labkey_luminex_transform.R
- youtil.R
Add Path to Assay Design
Edit the transform script path in the assay design to point to this location.- In the Assay List, click Luminex Assay 200.
- Click Manage Assay Design > edit assay design.
- In the Assay Properties section, for the Transform Script, enter the full path to the scripts you just placed.

- Click Save & Close
Test Package Configuration (Optional)
- Click Assay Dashboard.
- Select /Luminex/Runs - Assay 200/02-14A22-IgA-Biotin.xls in the Files web part.
- Click Import Data.
- Select Use Luminex Assay 200 in the popup and click Import again.

- For Batch properties, leave defaults unchanged and click Next.
- For Run Properties, leave defaults unchanged and click Next.
- Click Save & Finish.
- labkey_luminex_transform.R
- youtil.R
Delete the Imported Run Data
Before continuing with the tutorial, you need to delete any runs you used to test your R configuration.- Go to the Assay List.
- Select Luminex Assay 200.
- Click the top checkbox on the left of the list of runs. This selects all runs.
- Click Delete.
- Click Confirm Delete.
Previous Step | Next Step
Step 3: Import Luminex Runs
Import Batch of Runs
- Click Assay Dashboard.
- In the Files web part, double click the Luminex/Runs - Assay 200 folder to open it. (You may first need to open the Luminex folder to see it.)
- Check the boxes for all 10 run files (the run files begin with a two digit number and end with an .xls suffix).
- Click Import Data.
- Select the Luminex Assay 200 assay design.
- Click Import.
- For Batch Properties, leave default values as provided.
- Click Next.
- In Run Properties, enter the run number (the first two digits of the file name which is listed in the Run Data field) as the Notebook No.

- Click Next.
- In Define Well Roles, leave default boxes checked. For information about these options, see Review Well Roles.
- In Analyte Properties, edit the Lot Number:
- Check the Same box to give the same lot number to all analytes.
- Enter "Lot 437" for all analytes when importing runs #01-05.
- Enter "Lot 815" for all analytes when importing runs #06-10.
- Because the previously entered value will be retained for each import, you only need to edit when importing the first and 6th runs.
- In Analyte Properties, check the box in the Negative Control column for Blank.
- Then select Blank as the Subtract Negative Bead column for all other analytes. These properties are explained here.

- Click Save And Import Next File. Wait for the page to refresh.
- You will return to the Run Properties page with the next file name in the Run Data field. Note that the previously entered Notebook No value is retained; remember to edit it.
- Continue this loop entering the new Notebook No for each run and changing the Analyte Lot message at the 6th run to "Lot 815".
- Click Save And Finish after the 10th run.
View the Imported Runs and Data
When you are finished importing the batch of 10 runs, you'll see the fully populated runs list. It will look something like this. Viewing DataTo see the results for a single run, click one of the links in the Assay ID column on the runs page. For example, if you click 10-13A12-IgA-Biotin.xls, you will see the data just for the tenth (latest) run, as shown here.Above the grid are links for View Batches, View Runs, and View Results.
Viewing DataTo see the results for a single run, click one of the links in the Assay ID column on the runs page. For example, if you click 10-13A12-IgA-Biotin.xls, you will see the data just for the tenth (latest) run, as shown here.Above the grid are links for View Batches, View Runs, and View Results.
- View Batches: The ten runs we just imported were all in one batch; you might have uploaded other runs or batches as well.
- View Runs: Shows the list of all runs you have imported in all batches. This is the view you saw when import was complete.
- View Results: Shows the assay data, or results, for all imported runs in one grid. The results table for all runs has nearly 5,000 rows, as shown here.
Previous Step | Next Step
Step 4: View 4pl and 5pl Curve Fits
View Curve Fits
As an example, here we view one of the 5pl curves generated for the tenth run.- Go to the Assay List and click Luminex Assay 200.
- Click the curve icon in the Curves column for the tenth run (Assay ID 10-13A12-IgA-Biotin.xls).
- Select 10-13A12-IgA-Biotin.Standard1_5PL.pdf.

- Open the file. Depending on your browser settings, it may open directly or download for you to click to open.
- You will see a series of curves like the one below:

- You can open this PDF to see a full set of example curves.
View Calculated Values
Some calculated values are stored in the results grid with other Luminex data, others are part of the titration qc reports for standards and other titrations. For more information about the calculations, see Luminex Calculations.View Calculated Values in Titration QC Reports
For the same tenth run, view calculated values including estimated concentration at 50%, or EC50.- Return to the Assay Dashboard.
- Click Luminex Assay 200.
- In the runs list, click on the Assay ID "10-13A12-IgA-Biotin.xls."
- Click View QC Report > view titration qc report.
- The report shows one row for each analyte in this run. You can see a similar one in the interactive example.
- Scroll to the right to see columns calculated by the script:
- Four Parameter Curve Fit EC50
- Five Parameter Curve Fit EC50
- High MFI
- Trapezoidal Curve Fit AUC
View Calculated Values in Results Grid
- Return to the Assay Dashboard.
- Click Luminex Assay 200.
- In the runs list, click on the Assay ID titled 10-13A12-IgA-Biotin.xls
- In the Results view, scroll to the right to see columns calculated by the script:
- FI-Bkgd-Neg
- Standard for Rumi Calc
- Est Log Conc - Rumi 5 PL
- Est Conc - Rumi 5 PL
- SE - Rumi 5 PL
- Est Log Conc - Rumi 4 PL
- Est Conc - Rumi 4 PL
- SE - Rumi 4 PL
- Slope Param 4 PL
- Lower Param 4 PL
- Upper Param 4 PL
- Inflection Param 4 PL
- Slope Param 5 PL
- Lower Param 5 PL
- Upper Param 5 PL
- Inflection Param 5 PL
- Asymmetry Param 5 PL
Previous Step | Next Step
Step 5: Track Analyte Quality Over Time
Background
Levey-Jennings plots are quality control tools that help you visualize the performance of laboratory standards and quality controls over time, identifying trends and outlying data points. This can help you take corrective measures to ensure that your standards remain reliable yardsticks for your experimental data. See also: Wikipedia article on Laboratory Quality Control.Example usage scenarios for Levey-Jennings plots:- If you see an outlier data point for a standard, you may investigate whether conditions were unusual on the day the data was collected (e.g., building air conditioning was not working). If the standard was not reliable on that day, other data may also be unreliable.
- If you see a trend in the standard (as we will observe below), you may investigate whether experimental conditions are changing (e.g., a reagent is gradually degrading).
- If standard performance changes with analyte lot, you may need to investigate the quality of the new analyte lot and potentially change the preparation or supplier of the lot.
- Click View QC Report > View Levey-Jennings Reports. The screenshot below includes additional single point controls that would only be available if you checked the corresponding boxes during import. See Review Well Roles for additional information.

- Click any link to open the report for the titration or single-point control of interest.
Explore Levey-Jennings Plots for a Standard
The tutorial example includes only a single titration, so we will elect to display Levey-Jennings plots and data for the standard for the ENV2 analyte, IgA isotype and Biotin conjugate trio.- Return to the Assay Dashboard.
- In the Assay List, select Luminex Assay 200.
- Select View QC Report > View Levey-Jennings Reports.
- Click Standard1.
- In the Choose Graph Parameters box on the left side, select ENV2.
- For Isotype, choose "IgA"
- For Conjugate, choose "Biotin".
- Click Apply.
- Note: at this point in the tutorial, it is possible that you will need to add additional packages to your installation of R to support these plots. Refer to the list in Step 2: Configure R, Packages and Script, or add packages as they are requested by error messages in the UI. Retry the plot after each addition.
- In the graph panel, you see a Levey-Jennings plot of EC50 - 4PL for the standard (Standard1).

- Note the downward trend in the EC50 - 4PL, which becomes more pronounced over time and the change from Lot 437 and Lot 815.
Display Levey-Jennings Plots for Other Performance Metrics
Use the tabs above the Levey-Jennings plot to see charts for:- EC50 - 5PL Rumi - the EC50 calculated using a 5-parameter logistic curve and the Ruminex R package
- AUC - the area under the fluorescence intensity curve
- HighMFI - the highest recorded flourescence intensity
- Click on the EC50 - 5PL Rumi tab.
- See a trend that looks quite similar to the trend for EC50 - 4PL, with points in similar positions. The exception is the value for Notebook No 05, well above the general trend.

- Click on the AUC and HighMFI tabs to see the trends in those curves as well.
Generate PDFs for Levey-Jennings plots
If you wish, you can generate a PDF of the curve visible:- Click on the PDF icon in the upper right.
- Depending on your browser settings, you may need to allow popups to run.
- See an example PDF here.
Explore the Tracking Data Table
Below the graph area, you'll find a table that lists the values of all of the data points used in the Levey-Jennings plots above.- Scroll the screen down and to the right.
- Notice the values in the last four columns.

View Levey-Jennings Plots from QC Reports
For quicker review of relevant Levey-Jennings plots without generating the full report, you can access them directly from the QC report for your titration or single point control.- On the Assay Dashboard, click Luminex Assay 200.
- Select View QC Report > View Titration QC Report.
- Click the graph icon in the L-J Plots column of the second row (where the analyte is ENV2 we viewed earlier).
- You can select any of the performance metrics from the dropdown. Click EC50 4PL and you can quickly review that Levey-Jennings plot.

- Notice that the notebook number for the run we selected (01 in this screencap) is shown in red along the x-axis.
Related Topics
Previous Step | Next Step
Step 7: Use Guide Sets for QC
- Run-based: calculated from an uploaded set of runs
- Value-based: defined directly using known values, such as from historical lab data
Define Guide Sets
Earlier in the Luminex Level II tutorial, we assigned five runs to each lot of analytes, so we can now create different guide sets on this data for each lot of the analyte, one run-based and one value-based. When you later select which guide set to apply, you will be able to see the comment field, so it is good practice to use that comment to provide selection guidance.Create a Run-based Guide Set
In this tutorial example consisting of just 5 runs per lot, we use the first three runs as a guide set for the first lot. Ordinarily you would use a much larger group of runs (20-30) to establish statistically valid expected ranges for a much larger pool of data.- On the Assay Dashboard, click Luminex Assay 200.
- Open the Levey-Jennings report for the standard by selecting View QC Report > view levey-jennings reports and clicking Standard1.
- Under Choose Graph Parameters, select ENV2, IgA, Biotin and click Apply.
- Above the graph, notice that there is "No current guide set for the selected graph parameters.
- Click New to Create Guide Set.
- Notice in the upper right corner, Run-based is selected by default.
- In the All Runs panel, scroll down and click the + button next to each of the Assay IDs that begin with 01, 02, and 03 to add them to the guide set.
- Enter the Comment: "Guide Set for Lot 437"

- Click Create.
 Once you define run-based guide sets for a standard, expected ranges are calculated for all performance metrics (AUC, EC50 5PL and HighMFI), not just EC50 4PL. Switch tabs to see graphed ranges for other metrics.
Once you define run-based guide sets for a standard, expected ranges are calculated for all performance metrics (AUC, EC50 5PL and HighMFI), not just EC50 4PL. Switch tabs to see graphed ranges for other metrics.
Create a Value-based Guide Set
If you already have data about expected ranges and want to use these historic standard deviations and means to define your ranges, you create a value-based guide set. Here we supply some known reasonable ranges from our sample data.- Above the graph, click New to Create Guide Set.
- You can only edit the most recent guide set, so you will be warned that creating this new set means you can no longer edit the guide set for Lot 437.
- Click Yes.
- Click Value-based under Guide Set Type.
- Enter values as shown:
| Metric | Mean | Std.Dev. |
|---|---|---|
| EC50 4PL | 3.62 | 0.2 |
| EC50 5PL (Rumi) | 3.5 | 0.2 |
| AUC | 70000 | 1000 |
| High MFI | 32300 | 200 |
- Enter the Comment: "Guide Set for Lot 815"

- Click Create.
Apply Guide Sets
For each run, you can select which guide set to apply. You may switch the association to another guide set, but may not later entirely dissociate the run from all guide sets through the user interface.Apply Run-based Guide Set
Since we used three of our runs for the first analyte lot, we are only able to apply that guide set to the other two runs.- At the bottom of the Levey-Jennings plot, click the checkboxes next to the the runs that begin with the digits 04 and 05.
- Click Apply Guide Set.
- In the popup, notice that you can see the calculated run-based thresholds listed alongside those you entered for the value-based set.
- Select the run-based "Guide Set for Lot 437", then click Apply Thresholds.

- In the Levey-Jennings plot, observe the range bars applied to run 04 and run 05.
- Notice that results for both run 04 and run 05 fall outside of the expected range. We will discuss the QC flags raised by this occurrence in a future step.
Apply Value-based Guide Set
No runs were used to create this set, so we can apply it to all 5 runs that used the second analyte lot.- At the bottom of the Levey-Jennings plot, select the checkboxes next to runs 06-10.
- Click Apply Guide Set.
- In the popup, make sure that the guide set with comment Guide Set for Lot 815 is checked.
- Click Apply Thresholds.
 Explore the guide sets as displayed in the graphs on the other performance metric tabs for EC50 5PL, AUC, and High MFI.
Explore the guide sets as displayed in the graphs on the other performance metric tabs for EC50 5PL, AUC, and High MFI.
Manage Guide Sets
You can view the ranges defined by any guide set by selecting View QC Report > view guide sets and clicking Details. Note that for run-based guide sets, only the calculated range values are shown in the popup. Clicking the Graph link will show you the Levey-Jennings plot where the set is defined.Change Guide Set Associations
Select checkboxes for runs below the Levey-Jennings plot and click Apply Guide Set. You may choose from available guide sets listed. If any selected runs are used to define a run-based guide set, they may not have any guide set applied to them, and requests to do so will be ignored.Edit Guide Sets
Only the most recently defined guide set is editable. From the Levey-Jennings plot, click Edit next to the guide set to change the values or runs which comprise it. For run based guide sets, use the plus and minus buttons for runs; for value-based guide sets, simply enter new values. Click Save when finished.Delete Guide Sets
Over time, when new guide sets are created, you may wish to delete obsolete ones. In the case of run-based guide sets, the runs used to define them are not eligible to have other guide set ranges applied to them unless you first delete the guide set they helped define.- Select View QC Report > view guide sets.
- Check the box for the obsolete guide set. To continue with the tutorial, do not delete the guide sets we just created.
- Click Delete.

- For each guide set selected, you will be shown some information about it before confirming the deletion, including the set of runs which may still be using the given guide set. In this screencap, you see what the confirmation screen would look like if you attempted to delete an old value-based guide set.
 In the case of deleting a run-based guide set, you will see two lists of runs: the "Member runs" used to define the set, and the "User runs" which use it.
In the case of deleting a run-based guide set, you will see two lists of runs: the "Member runs" used to define the set, and the "User runs" which use it.View QC Flags
When guide sets are applied, runs whose values which fall outside expected ranges are automatically flagged for quality control. You can see these tags in the grid at the bottom of the Levey-Jennings page.- Look at the Standard1 Tracking Data grid below the plots.
- Notice red highlighting is applied to any values that fall out of the applied guide set ranges.
- Observe that QC flags have been added to the left hand column for each metric where there are out of range values on each run.

- You can also see this in the interactive example.
Previous Step | Next Step
Step 8: Compare Standard Curves Across Runs
Steps
Return to the Levey-Jennings plot for the ENV2 standard:- Go to the Assay Dashboard.
- Click Luminex Assay 200.
- Select View QC Report > view levey-jennings reports.
- Click Standard1.
- In the Choose Graph Parameters box, select Antigen "ENV2", Isotype "IgA", Conjugate "Biotin" and click Apply.
- Scroll down to the Standard1 Tracking Data for ENV2 - IgA Biotin table.
- Selects all rows. (Click the box at the top of the left hand column.)
- Click View 4pl Curves to generate the overlay plot.
 Using the buttons in the Curve Comparison popup, you can:
Using the buttons in the Curve Comparison popup, you can:
- View Log Y-Axis - Switch between a logarithmic and linear Y-axis. The button will read View Linear Y-Axis when viewing the log(FI) version.
- Export to PDF - Export the overlay plot. The exported pdf includes both FI and log(FI) versions. View a sample here.
- Close the plot when finished.
Related Topics
Previous Step
Track Single-Point Controls in Levey-Jennings Plots
Upload Run with Single Point Control Tracking
When you upload an assay run, the Define Well Roles panel lists the controls available for single point tracking. To briefly explore this feature, you can reimport three of the runs we used for the standard Levey-Jennings plots. Repeat these steps for any three runs:- Go to the Assay Dashboard and select Luminex Assay 200.
- Select a row for a run you imported, and click Reimport Run.

- Notice that as you reimport the run, the values you entered originally are provided as defaults, making it easier to change only what you intend to change.
- Leave Batch Properties unchanged and click Next.
- Leave Run Properties unchanged and click Next.
- In Define Well Roles check the box for IH5672, the only single point control available in this sample data.

- Leave Analyte Properties unchanged and click Save & Finish.
- Repeat for at least two more runs.
View Levey-Jennings Plots for Single Point Controls
- Go to the Assay Dashboard and click Luminex Assay 200.
- Select View QC Reports > view single point control qc report.
- Click the Graph > link next to any row.

- In this example screenshot, there are two tracked controls from Lot 815 and five from Lot 437. Your graph may vary.
- Notice the MFI (Mean Fluorescence Intensity) column in the lower right. This value is the computed average of the FI-Bkgd value for the two wells.
View Levey-Jennings Plots from QC Reports
For quicker review of the single point control Levey-Jennings plots, you can access them directly from the QC report.- On the Assay Dashboard, click Luminex Assay 200.
- Select View QC Report > View Single Point Control QC Report.
- Click the graph icon in the L-J Plots column of any row.
- You can quickly review the plot without visiting the full page.

- The notebook number for the row you selected is shown in red along the x-axis. In this screenshot, notebook 01.
Import Luminex Runs
Define Run-Specific Parameters and Import Data
This page covers run-specific parameters for Luminex assays. It presumes you are working through the overall steps for importing assay data covered on the Import Assay Runs page and you have already entered Batch Properties.Enter Run Properties
Run parameters will be used as metadata for all data imported as part of this Run.Steps:- If you wish to specify a name for the Run, enter it. Otherwise, if you import a file the server will use the file's name for the Run's name. If you paste in a TSV table, the server will automatically generate a name, including the assay's name and today's date.
- You must also provide Run Data. To import a data file, click Browse and select the appropriate file. Currently, the only supported file format is the BioPlex, multi-sheet Excel format.
- Click Next
- You are now on the page titled "Data Import: Analyte Properties."
- On this page, you can supply values for additional fields associated with each analyte in the import file.
Import Runs
You are now ready to finalize import. Note that during import, we import metadata from the start and end of each page in the Luminex Excel file. In addition, we convert some flagged values in the file. See Luminex Conversions for further details.Steps:- Press the “Save and Import Another Run” button to import this set of runs and continue importing additional runs.
- Press Save and Finish when you have finished importing runs. This closes the Batch.
Parsing of the Description Field
The Excel file format includes a single field for sample information, the Description field. LabKey Server will automatically attempt to parse the field to split it into separate fields if it contains information like Participant and Date. Formats supported include:- <SpecimenId>; <PTID>, Visit <VisitNumber>, <Date>, <ExtraInfo>
- <SpecimenId>: <PTID>, Visit <VisitNumber>, <Date>, <ExtraInfo>
- <PTID>, Visit <VisitNumber>, <Date>, <ExtraInfo>
Luminex Calculations
- Background
- Review Calculated Values
- Subtract Negative Control Bead Values
- Skip Ruminex Calculations
- Use Uploaded Positivity Threshold Defaults
Background
LabKey Luminex Transform Script Calculations
The LabKey Luminex transform script uses the Ruminex R package to calculate logistic curve fits for each titration for each analyte. Titrations may be used either as standards or as quality controls. In this tutorial, all titrations are used as standards.Curve fits are calculated using both a 4 parameter logistic (4pl) and a 5 parameter logistic (5pl). Based on these curve fits, the script calculates EC50s ("Expected Concentration at %50") for the standard for each analyte. An EC50 is the concentration or dilution that is expected to produce half of the difference between the asymptotic maximum and minimum fluorescence intensities.For each run, the script outputs a PDF that includes plots for curve fits for each analtye. Each plot shows the dose response curve for fluorescence intensity with increasing concentration or reduced dilution. These plots can be useful for examining how well the curves fit the data.LabKey Server Calculations
LabKey Server itself calculates the AUC ("Area Under the Curve") for each standard titration using a trapezoidal calculation based on observed values. LabKey Server also identifies the HighMFI ("Highest Mean Fluorescence Intensity") for each titration.BioPlex Calculations vs. LabKey Luminex Transform Script Calculations
The Excel run files produced by the BioPlex instrument also include 5-parameter logistic curve fits for each titrated standard and each titrated quality control. These 5pl regressions were calculated by the BioPlex software. The Excel run files also include estimates for sample concentrations generated using each sample's measured FI-Bkgd (fluorescence intensity minus background well fluorescence intensity) and the 5pl regression equations derived for the standards by the instrument software. LabKey Server reports these results alongside all other imported run data, as shown in the Obs Conc BioPlex 5PL column in the default Results view for any run (as shown here for run 10).However, these instrument-generated 5pl regressions and estimates for sample concentrations are not the same as the results given by the LabKey Luminex transform script. The script's results for the parameters of the 5pl regression (Slope Param 5 PL, Lower Param 5 PL, Upper Param 5 PL, Inflection Param 5 PL, and Asymmetry Param 5 PL) and the estimated concentrations of samples (Est Conc - Rumi 5 PL) are reported as columns in the Results view for any run.Using the script for 5pl regression calculations allows subtraction of negative bead fluorescence intensity before fits and other customizations, such as the treatment of negative values, weighting of standard errors, and optional log transforms of data. Users may further customize how the script performs 5pl curve fits as they see fit.Only the 5pl results calculated by the script, not the BioPlex instrument software, are used by LabKey Server. For example, only script-calculated 5pl EC50s are shown in Levey-Jennings plots. All references to 5pl curve fits or EC50s in this tutorial refer to fits and results calculated by the script, not the instrument software, unless specifically noted otherwise.Review Calculated Values
In Step 4: View 4pl and 5pl Curve Fits you reviewed calculated values as they are available in both titration qc reports or in the results grid for the run data. The titration qc report includes summary results for both standards and QC controls for a given run or for all runs. The results grid includes regression parameters for all curve fits.Subtract Negative Control Bead Values
The FI-Bkgd-Neg column shows the fluorescence intensity after both the background well and the negative bead are subtracted. The assay design used in the Luminex Assay Tutorial Level II tells the script (via the StandardCurveFitInput property's default value) to use fluorescence alone (FI), without subtraction, to fit 4pl and 5pl curves to titrated standards. In contrast, the assay design tells the script (via the UnknownFitInput property's default value) to use FI-Bkgd-Neg to estimate concentrations for unknowns using the 4pl and 5pl regression equations calculated from the standards.When calculating the value FI-Bkgd-Negative (fluorescence intensity minus background FI minus a negative bead), you may specify on a per analyte basis what to use as the negative bead. Depending on the study, the negative bead might be blank, or might be a more suitable negative control antigen. For example, in a study of certain HIV antigens, you might subtract MulV gp70 from gp70V1V2 proteins, blank from other antigens, etc. Note that the blank bead is not subtracted by default - it must be explicitly selected like any other negative bead.To enable subtraction of negative control bead values, the assay design must be modified to include a run field of type Boolean named NegativeControl. Then during the assay run import, to select negative beads per analyte, you'll set Analyte Properties when importing data files. First identify specific analytes using checkboxes in the Negative Control column, then select one of these negative beads for each analyte in the Subtract Negative Bead column.
Skip Ruminex Calculations
If you want to have the option to skip the Ruminex calculations of estimated concentration values and generation of standard curve fit PDFs, you can do so by adding a SkipRumiCalculation property to the assay design. All 4PL EC50 and AUC values are calculated regardless of the flag, but when it is defined the user will have the option to check a box on import to skip those calculations.To explore this optional feature, use a copy of the assay design. The tutorial uses the original design and may not work as expected if you skip the Ruminex calculations.- From the Assay Dashboard, click Luminex Assay 200.
- Select Manage Assay Design > copy assay design.
- Click Copy to Current Folder.
- Name the new copy "Luminex Skip Rumi 200".
- In Run Fields, click Add Field and add:
- Name: SkipRumiCalculation (no spaces)
- Type: Boolean

- Click Save and Finish.
- Click Luminex Skip Rumi 200.
- Click Import Data.
- Click Next, then in Run Properties:
- Enter an Assay Id, such as "Run2skip" (since you will be uploading a file you already imported, this name must be unique).
- Check the box for Skip Rumi Calculation, which you just added by defining the property.
- In the Run Data field, click Browse or Choose File
- Select a run from the demo files on your local machine, for example: /Luminex/Runs - Assay 200/02-14A22-IgA-Biotin.xls
- Click Next then Save & Finish.
Use Uploaded Positivity Threshold Defaults
If your lab uses specific positivity cutoff values, you can manually enter them on an antigen-by-antigen basis during upload on the Analyte Properties panel. To simplify user entry and reduce the possibilities of errors during this process, you may specify analyte-specific default values for the PositivityThreshold property on a per folder and assay design combination. The default default value is 100. To specify analyte-specific defaults, add them to the assay design for a given folder as described here using the Luminex Assay Tutorial Level II example:- From the Assay Dashboard, click Luminex Assay 200.
- Select manage assay design > set default values > Luminex Assay 200 Analyte Properties.

- Enter Analyte and desired Positivity Threshold.
- Click the + button to add another.

- You may instead click Import Data to upload a TSV file or copy and paste the data to simplify data entry.
- Click Save Defaults when finished.
Luminex QC Reports and Flags
View QC flags
When guide sets are applied, runs whose values fall outside expected ranges are automatically QC flagged. You can see these flags in the grid at the bottom of the Levey-Jennings page.- Look at the Standard1 Tracking Data grid below the plots.
- Observe red highlighting applied to values in the EC50 - 4PL, EC50 - 5PL Rumi, AUC and HighMFI columns. View the plot for each metric to see the points which lie outside the guide set ranges.
- Observe how QC flags have been added in the left most column for each metric flagged for each run.

- You can see this in the interactive example
Inactivate QC Flags
It is possible to inactivate a single QC flag, in this case we inactivate the flag for EC50 - 5PL Rumi for the tenth run. When you inactivate a flag manually in this manner, it is good practice to add an explanatory comment.- Click on the QC flags (AUC, EC50-4, EC50-5) to the left of the run that begins with the digits 10.
- You now see the Run QC Flags popup.
- In the Enabled column, unselect the checkbox for the EC50-5 flag. This inactivates, but does not delete, the associated QC flag for this data. Notice the red triangle in the corner indicating a change has been made.
- Click the Comment region for that row and type "Manually disabled."

- Click Save in the popup.
- In the Standard1 Tracking Data grid, notice two changes indicating the inactivated flag:
- In the QC Flag column for run 10, the EC50-5 QC flag now has a line through it.
- In the EC50 5pl column for run 10, the value is no longer highlighted in red.
- You can see this in the interactive example.
Disable QC Flagging for a Metric
If your run-based guide set does not have enough valid data for a given metric to usefully flag other runs, you might choose to disable all QC flagging based on that metric. In an extreme example, if only one run in the guide set had a valid EC50-5pl value, then the standard deviation would be zero and all other runs would be flagged, which isn't helpful in assessing trends.- Select View QC Report > view guide sets, then click the Details link for the guide set you want to edit. In this tutorial, the only run-based guide set is the one we created for Lot 437.

- The Num Runs column lists the number of runs in the guide set which have valid data for the given metric. In this example all three runs contain valid data for all metrics.
- To disable QC flagging for one or more metrics, uncheck Use for QC boxes.
- Click Save.
View QC Flags in the QC Report
The same red highlighting appears in the QC Reports available for the entire assay and for each individual run. When you view the QC report for the entire assay, you see red highlighting for all out-of-range values detected using guide sets, not just the ones for a particular analyte (as in the step above). Red highlighting does not appear for any value whose QC flag has been manually inactivated (see the step above).Here, we view the QC report for the entire assay, then filter down to see the results for just one analyte- Click View QC Report > view titration qc report.
- Observe a grid that looks like this one in the interactive example.
- Filter the grid so you see only the rows associated with the same analyte/isotype/conjugate combination that was associated with guide sets in earlier steps:
- Click the Analyte column header.
- Choose Filter.
- Select ENV2.
- Click OK.
- You can now see the same subset of data with the same red highlighting you saw on the Levey-Jennings page in the last step. Formatting may not be identical, i.e. numbers may have additional digits in this view.
Luminex Reference
- Review Luminex Assay Design - Details and built in features of an example Luminex Assay design.
- Luminex Properties - Properties specific to the Luminex technology.
- Luminex File Formats - Output files from Bio-Plex instrument software.
- Import Luminex Runs - Run properties for Luminex assays.
- Review Well Roles - Identify titrations and single point controls.
- Luminex Calculations - Overview of common calculations.
- Luminex Conversions - Substitutions for flagged values during import.
- Customize Luminex Assay for Script - Creating a Luminex Assay design.
- Review Fields for Script - Custom fields for an example Luminex Assay.
- Troubleshoot Luminex Transform Scripts and Curve Fit Results - Tips and advice.
Review Luminex Assay Design
Explore Lookups and Defaults in the Assay Design
Open the assay design and examine how lookups and default values are included as part of this assay design to simplify and standardize data entry:- On the Assay Dashboard, click Luminex Assay 200
- Click Manage Assay Design > edit assay design.
- Scroll down to the Luminex Assay 200 Run Fields section.
- Click on the Type property box for Isotype to select the field and open a popup to see the type.
- To the right, click on the Advanced tab associated with the Isotype field. Note the default value of "IgA" has been set for this lookup property.

- When finished reviewing, be sure to exit with Cancel to discard any changes you may have made.
- Lookup.
- The popup for the Type property shows that Isotype has been pre-defined as a lookup to the Isotype list (which we examined in a step above).
- User-facing result: When importing runs, users will be shown a drop-down list of options for this field, not a free-form data entry box. The options will be the values on the Isotype list.
- Default value
- On the Advanced tab, you can see that the initial Default value for the Isotype field has been set to IgA.
- User-facing result: When users first import runs, the list of drop-down options for Isotype will show a default of IgA. Choosing the default appropriately can speed data entry for the common case.
- Default Type
- On the Advanced tab, you can see that the Default type for the Isotype field has been pre-set to Last entered
- User-facing result: When users import a run, the list of drop-down options will default to the user's "last-entered" value. If the user selected "IgB" for their first run, the next will default to "IgB" instead of the original "IgA".
Review Assay Properties
While you have the assay design open, you may want to review in more detail the properties defined. See further details in Luminex Properties. As with any assay design, an administrator may edit the default design's fields and defaults to suit the specific needs of their data and project. To do so, it is safest to make changes to a copy of the assay design if you want to still be able to use this tutorial. To copy a design:- Choose the assay you want to copy from the Assay List.
- Select Manage Assay Design > copy assay design.
- Choose a destination folder or click Copy to Current Folder.
- Give the new copy a new name, change properties as required.
- Click Save & Close when finished.
Luminex Properties
Assay Properties

Auto-copy Data/Target
If you want the assay to auto-copy results to a target study, specify that here. For more information about copying assay data to studies, see Copy Assay Data into a Study.Transform Scripts
Add any transform script here. For more information, see Transformation Scripts.Import in Background
Using this option is particularly helpful when you have large runs that are slow to upload. If this setting is enabled, assay uploads are processed as jobs in the data pipeline.You will see the Upload Jobs page while these runs are being processed. Your current jobs are marked "Running." When the jobs have completed, you will see "Completed" instead of "Running" for the job status for each. If you see "Error" instead of completed, you can see the log files reporting the problem by clicking on "Error." Luminex assay properties (batch, run, well role/titration settings, and analyte properties) are also written to the log file to assist in diagnosing upload problems.When the Status of all of your jobs is "Completed", click the Description link for one of the runs to see all of the data for this run.Batch Properties
The user is prompted for batch properties once for each set of runs during import. The batch is a convenience to let users set properties once and import many runs using the same suite of properties. Included by default:
Included by default:
- Participant Visit Resolver: Required. This field records the method used to associate the assay with participant/visit pairs. The user chooses a method of association during the assay import process.
- TargetStudy: Including this field simplifies copying assay data to a study, but it is not required. Alternatively, you can create a property with the same name and type at the run level so that you can then copy each run to a different study.
- Network: Enter the network.
- Species: Enter the species under study.
- LabID: The lab where this experiment was performed.
- Analysis Software: The software tool used to analyze results. For LabKey's Luminex tool, this is typically "Bioplex."
Run Properties
The user is prompted to enter run level properties for each imported file. These properties are used for all data records imported as part of a Run. Included by default:
Included by default:
- Assay Id: If not provided, the file name is used.
- Comments: Optional.
- Subtract Negative Bead from All Wells?
- Standards FI Source Column: Select the column for fluorescence intensity in the standard.
- Unknown FI Source Column: Select the column for FI in the unknown.
- Curve Fit Log Transform?
- Isotype
- Conjugate
- Notebook No
- Assay Type: Options:
- Experimental
- Optimization
- Validation
- Experiment Performer
- Run Data: Data files must be in the multi-sheet BioPlex Excel file format.
Well Roles and Analyte Properties
The user is prompted to select well rolls and enter properties for each of the analytes in the imported file. These properties can be helpful for tracking bead lots, analyte batches, etc. for quality control.Included by default:- Well Roles for Standard, QC Control, and Other Control
- Single Point Controls
- Lot Number
- Negative Control: Check the box to identify which bead to use as the negative control.
- Subtract Negative Bead: Elect whether to subtract the bead for any analyte.
- Use Standard: Elect whether to use the standard specified under well roles as the standard for a given analyte.
- PositivityThreshold: The positivity threshold.
- AnalyteWithBead: The name of the analyte including the bead number.
- BeadNumber: The bead number.
Excel File Run Properties
When the user imports a Luminex data file, the server will try to find these properties in the header and footer of the spreadsheet, and does not prompt the user to enter them.Included by default:- File Name
- Acquisition Date (DateTime)
- Reader Serial Number
- Plate ID
- RP1 PMT (Volts)
- RP1 Target
Data Properties
The user is prompted to enter data values for each row of data associated with a run.Not included by default in the design, but should be considered:- SpecimenID: For Luminex files, data sources are uniquely identified using SpecimenIDs, which in turn point to ParticipantID/VisitID pairs. For Luminex Assays, we automatically extract ParticipantID/VisitID pairs from the SpecimenID. If you exclude the SpecimenID field, you will have to enter SpecimenIDs manually when you copy the data to a study.
Additional Properties for the Transform Script
The LabKey Luminex transform script calculates additional values (e.g., curve fits and negative bead subtraction) that are used by the LabKey Luminex tool. Custom batch, run, analyte, and data properties used by this script are covered in these pages: Customize Luminex Assay for Script and Review Fields for Script. Some useful assay properties are listed here:Assay Properties| Field Label | Value | Description |
|---|---|---|
| Transform Script | -- | Path to the LabKey Luminex transform script. The path provided must be specific to your server. The default path provided in a XAR will be usable only on the server where the XAR was created. |
| Import in Background | Unchecked | When selected, runs are imported in the background, allowing you to continue work on the server during import. This can be helpful for importing large amounts of data. This tutorial leaves this value unchecked merely for simplicity of workflow. For further information on what happens when you check this property, see Luminex Properties. |
| Editable Runs | Unchecked | When selected, allows run data to be edited after import by default. If you allow editing of run data, you may wish to uncheck Display > Shown In Display Modes > Update in the domain editor for each field used or calculated by the script. The script runs only on data import, so preventing later editing of such fields is necessary for calculated data to continue matching the values displayed for the fields in the assay. |
Luminex File Formats
General Characteristics
- The file is typically a multi-sheet workbook
- Each spreadsheet (tab) in the workbook reports data for a single analyte. One sheet may report measurements for the blank bead.
- Each sheet contains:
- A header section that reports run metadata (see below for details)
- A data table that reports values for wells
- A footer section that describes data flags and shows curve fits equations and parameters
Run Metadata in the Header
Most of the metadata fields reported in the file header are imported as "Excel File Run Properties." With the exception of Analyte, all of these metadata properties are the same for each sheet in the workbook. Analyte is different for each sheet.- File Name - Imported
- Analyte - The analyte name is also the name of the worksheet (the tab label).
- Acquisition Date - Imported
- Reader Serial Number - Imported
- Standard Lot - Ignored in the header. The standard name also appears in the description for wells that contain the standard. The name of the standard for each analyte can be entered during the import process for each run.
- Expiration Date - Ignored
- Plate ID - Imported
- Signed By - Ignored
- Document ID - Ignored
- RP1 PMT (Volts) - Imported
- RP1 Target - Imported
Well data table
The data table in the middle of each sheet shows how each sample in each well reacted with the single analyte reported on the sheet. In other words, every well (and every sample) appears on every sheet, but each sheet reports on the behavior of a different analyte within that well.File format variants
Samples (particularly unknowns) are typically replicated on a plate, in which case they will appear in multiple wells. How these replicates appear in the Excel file depends on the file format. LabKey Server understands three types of file formats.- Variant A - Summary Data:
- The data table contains one row per sample. This row provides a calculated average of observed values for all sample replicates (all wells where the sample was run).
- The Wells column lists all the wells used to calculate the average.
- Variant B - Raw Data:
- The data table contains one row per well. That means that each sample replicate appears on its own line and the data reported for it is not averaged across sample replicates. Consequently, there are multiple rows for each experimental sample.
- Here, the Wells column shows only a single well.
- LabKey Server infers the presence of Variant B format if a files shows multiple rows for the same sample (so replicates are on different lines). Usually, all samples have the same number of replicates.
- Variant C - Summary and Raw Data:
- Two data tables appear, one following Variant A formatting and the second following Variant B. In other words, tables for both summary sample data and for individual well data both appear.
Data columns
The columns in the well data table:- Analyte
- The analyte name is also the name of the worksheet (the tab label). In the data used in this tutorial, the analyte name is a combination of the analyte name and the number of the bead bound to the analyte.
- Type
- The letter portion of the "Type" indicates the kind of sample; the number portion (if there is one) provides a sample identifier
- B - Background. The average background fluorescence observed in a run's background wells is subtracted from each of the other wells to give the “FI - Bkgd” column
- S - Standard. The titration curve for the standard is used to calculate the concentration of unknowns
- C - Quality control. Used to compare with other runs and track performance
- X - Unknown. These are the experimental samples being studied.
- Well
- The plate location of the well where the sample was run. For file format Variant A, multiple wells may be listed here - these are all the wells for the sample replicate that have been averaged together to produce the average fluorescence intensity for the sample, as reported in FI
- Description
- For an unknown, identifies the source of the unknown sample. This may be a sample identifier or a combination of participant ID and visit number. The following formats are supported, and checked for in this sequence:
- <SpecimenID> - The value is checked for a matching specimen by its unique ID in the target study. If found, the specimen's participant ID and visit/date information is stored in the relevant fields in the Luminex assay data.
- <SpecimenID>: <Any other text> - Any text before a colon is checked for a matching specimen in the target study. If found, the specimen's participant ID and visit/date information is stored in the relevant fields in the Luminex assay data.
- <SpecimenID>; <Any other text> - Any text before a semi-colon is checked for a matching specimen in the target study. If found, the specimen's participant ID and visit/date information is stored in the relevant fields in the Luminex assay data.
- <ParticipantId>, Visit <VisitNumber>, <Date>, <ExtraInfo> - The value is split into separate fields. The "Visit" prefix is optional, as is the ExtraInfo value. The VisitNumber and Date values will be ignored if they cannot be parsed as a number and date, respectively.
- FI
- For file format Variant B, this is the median fluorescence intensity observed for all beads associated with this analyte type in this well.
- For file format Variant A, this value is the mean median fluorescence intensity for all sample replicate wells; in other words, it is a mean of all median FI values for the wells listed in the Wells column.
- FI-Bkgd
- Fluorescence intensity of well minus fluorescence intensity of a "background" (B) well
- Std Dev
- Standard of deviation calculated for replicate wells for file format Variant A
- %CV
- Coefficient of variation calculated for replicate wells for file format Variant A
- Obs Conc
- Observed concentration of the titrated standard, quality control or unknown calculated by the instrument software. Calculated from the observed FI-Bkgd using the 5-parameter logistic regression that is reported at the bottom of the page as Std. Curve.
- Indicators: *Value = Value extrapolated beyond standard range; OOR = Out of Range; OOR> = Out of Range Above; OOR< = Out of Range Below
- Values of Obs Conc flagged as *Value and OOR receive substitutions (to more clearly show ranges) during import to LabKey Server. See: Luminex Conversions
- Exp Conc
- Expected concentration of the titrated standard or quality control. Known from the dilutions performed by the experiment performer. The Std. Curve equation listed at the bottom of the page reports the 5 parameter logistic regression equation that the instrument software fit to the distribution of the titration's FI-Bkgd and Exp Conc. The FitProb and ResVar for this regression are also listed.
- (Obs/Exp)*100
- 100 times the ratio of observed and expected concentrations for titrated standard or quality control
- Indicators: *** = Value not available; --- = Designated as an outlier
- Group
- Not used in this tutorial
- Ratio
- Not used in this tutorial
- Dilution
- Dilution of the sample written as an integer. The actual dilution is a ratio, so a dilution of 1:100 is noted as 100
- Bead Count
- Number of beads in well
- Sampling Errors
- Flags indicate sample errors
- Indicators: 1 - Low bead #; 2 - Agg beads; 3 - Classify %; 4 - Region selection; 5 - Platform temperature
Review Well Roles

Standard vs. Quality Control
In the Define Well Roles section, you can mark a titration as providing both a standard and a quality control. If you check both, you will see twice as many curves (see Step 4: View 4pl and 5pl Curve Fits). Standard titrations are used to calculate the concentrations of samples and the values displayed in Levey-Jennings plots (see Step 5: Track Analyte Quality Over Time). In contrast, quality controls are used in a lab-specific manner to track the performance of the assay over time. For this tutorial, we designate our titrated standards as standards, but not as quality controls.Other Control
In order to have values for EC50, AUC, and other calculations done without adding the selected titration to the Levey-Jennings plot and QC Report, select the Other Control checkbox. This is useful for titrations that will not be tracked using these reporting tools, but still need the transform script to calculate values.Multiple Standards per Analyte
If the data for your run included multiple standard titrations, you would be able to choose which analytes to associate with which standards. Note that you must have marked each standard as a standard in the Define Well Roles section before it will appear as an option. Each standard will appear over a column of checkboxes in the Analyte Properties section. You can select more than one standard for each analyte by selecting the checkboxes in more than one standard’s column. The data for this tutorial includes only one standard, so this option is not explored here.Single-Point Controls
To track performance of a single-point control over time, such as in the case of an antigen panel where the control is not titrated, you can select Tracked Single Point Controls. Check the appropriate boxes in the Define Well Roles panel during run upload. This feature is explored in Track Single-Point Controls in Levey-Jennings Plots.Luminex Conversions
During upload of Luminex files, we perform substitutions for certain flagged values. Other types of flagged values are imported without alteration.
Substitutions During Import for *[number] and OOR
We perform substitutions when Obs. Conc. is reported as OOR or *[number], where [number] is a numeric value. *[number] indicates that the measurement was barely out of range. OOR< and OOR> indicate that measurements were far out of range.
To determine the appropriate substitution, we first determine the lowest and highest "valid standards" for this analyte using the following steps:
- Look at all potentially valid standards for this run. These are the initial data lines in the data table on the Excel page for this Analyte. These lines have either “S” or “ES” listings as their types instead of “X”. These are standards (Ss) instead of experimental results (Xs). Experimental results (Xs) are called Wells in the following table.
- Determine validity guidelines. Valid standards have values in the (Obs/Exp) * 100 column that fall “within range.” The typical valid range is 70-130%, but can vary. The definition of “within range” is usually included at the end of each Excel page on a line that looks like: “Conc in Range = Unknown sample concentrations within range where standards recovery is 70-130%.” If this line does not appear, we use 70-130% as the range.
- Now identify the lowest and highest valid standards by checking the (Obs/Exp) * 100 column for each standard against the "within range" guideline.
N.B. The Conc in Range field will be *** for values flagged with * or OOR.
In the following table, the Well Dilution Factor and the Well FI refer to the Analyte Well (the particular experiment) where the Obs. Conc. was reported as OOR or as *[number].
| When Excel Obs. Conc. is... |
We report Obs. Conc. as... | Where [value] is... |
| OOR < | << [value] | the Well Dilution Factor X the Obs. Conc. of the lowest valid standard |
| OOR > | >> [value] | the Well Dilution Factor X the Obs. Conc of the highest valid standard. |
| *[number] and Well FI is less than the lowest valid standard FI | < [value] | the Well Dilution Factor X the Obs. Conc. of the lowest valid standard. |
| *[number] and Well FI is greater than the highest valid standard FI | > [value] | the Well Dilution Factor X the Obs. Conc of the highest valid standard. |
If a valid standard is not available (i.e., standard values are out of range), [value] is left blank because we do not have a reasonable guess as to the min or max value.
Flagged Values Imported Without Change
| Flag | Meaning | Column |
| --- | Indicates that the investigator marked the well(s) as outliers | Appears in FI, FI Bkgd and/or Obs. Conc. |
| *** | Indicates a Machine malfunction | Appears in FI, FI Bkgd, Std. Dev, %CV, Obs. Conc., and/or Conc.in Range |
| [blank] | No data | Appears in any column except Analyte, Type and Well, Outlier and Dilution. |
Customize Luminex Assay for Script
Create a New Assay Design
These steps assume that you have already created a "Luminex" folder (of type "Assay"), as described in Setup Luminex Tutorial Project.- In the Assay List, click New Assay Design.
- Choose the Luminex assay type.
- At the bottom of the page, in the Assay Location, choose Current Folder. This is important to ensure that lookups to lists in the same folder will work.
- Click Next.
- Give the new assay design a Name.
- Optional: Check the Import in Background box.
- Checking this box means that assay imports will be processed as jobs in the data pipeline, which is helpful because Luminex runs can take a while to load.
- Add fields as described in the following sections before clicking Save & Close.
Add Script-specific Fields
Make sure not to put a space in the Name property for any field you add. See Review Fields for Script page for details about each field.The optional field property settings on tabs in the panel on the right can be used to customize field behavior. For example, you can prevent editing of particular values after a run has been imported in cases where those values are used for calculations/graphs during import. In this case we don't want the user inadvertantly changing the script version each time they run it.Add Batch Fields
- In the Batch Fields section, click the Add Field button for each of the following:
- Add a field for TransformVersion:
- Optional: On the display tab, uncheck the Shown in > Insert option (so that the user is not asked to enter a value).
- Optional: On the advanced tab, change the Default Type to Fixed Value (so that you can specify a fixed value for the default for this field).
- Add a field for RuminexVersion:
- Optional: On the display tab, uncheck the Shown in > Insert option.
- Optional: On the advanced tab, change the Default Type to Fixed Value.
Add Run Fields
- In the Run Fields section:
- Add a field for NotebookNo of type Text (String).
- Add a field for SubtNegativeFromAll of type Boolean.
- Optional: Uncheck the Update box on the display tab.
- Add a field for StndCurveFitInput:
- The type of this field can be either Text (String) or a lookup to a list which has the following three string values: FI, FI-Bkgd, FI-Bkgd-Neg.
- Optional: Uncheck the Update box on the display tab.
- Optional: based on the lab preference, you may want to set this field to either remember the last entered value or to have an editable default value selected (the script defaults to using the “FI” column if no value is specified for the StndCurveFitInput field). When creating this lookup and others, you may find it useful to import the list archive provided in the Setup Luminex Tutorial Project. If you import this archive of lists into the same folder as your assay, you can set this field to target the relevant list.
- Add a field for UnkCurveFitInput:
- The type of this field can be either Text (String) or a lookup to a list which has the following three string values: FI, FI-Bkgd, FI-Bkgd-Neg.
- Optional: Uncheck the Update box on the display tab.
- Optional: Based on the lab preference, you may want to set this field to either remember the last entered value or to have an editable default value selected (the script defaults to using the “FI” column if no value is specified for the UnkCurveFitInput field)
- Add a field for CurveFitLogTransform of type Boolean.
- Optional: Add a field for CalculatePositivity of type Boolean.
- Optional: Add a field for BaseVisit of type Number (Double).
- Optional: Add a field for PositivityFoldChange of type Number (Double).
- Optional: If you would like users to be able to choose whether to skip Ruminex calculations, add a field for SkipRumiCalculation of type Boolean.
Add Analyte Properties
- In the Analyte Properties section:
- Add a field for LotNumber of type Text (String).
- Optional: Add a field for NegativeControl of type Boolean.
Add Data Fields
- In the Assay Data Fields section:
- Add a field for FIBackgroundNegative of type Number (Double).
- Add a field for Standard of type Text (String).
- Add a field for EstLogConc_5pl of type Number (Double).
- Add a field for EstConc_5pl of type Number (Double).
- Add a field for SE_5pl of type Number (Double).
- Add a field for EstLogConc_4pl of type Number (Double).
- Add a field for EstConc_4pl of type Number (Double).
- Add a field for SE_4pl of type Number (Double).
- Optional: Add a field for Positivity of type Text (String).
- Optional:
- Add the optional Data Property fields listed in Appendix D. These are filled in by the transform script and may be interesting to statisticians.
Customize Data Grids
Any properties you add to the assay design can also be added to the various results, run, and batch grid views for the assay using the Grid Views > Customize Grid menu option.Review Fields for Script
Custom Assay Fields for LabKey Luminex Transform Script
To set up a Luminex assay to run the LabKey Luminex transform script used in the Luminex Assay Tutorial Level II, you need to include certain custom fields in the assay design. The script outputs results into these fields. This page provides details on these output fields. Labs may add additional, lab-specific fields when convenient, but only the fields below are used by the Ruminex transform script.
For reference, the fields included by default in a Luminex assay design are listed on the Luminex Properties page.
Appendix A: Custom Batch Fields
| Name | Label | Type | Description |
| TransformVersion | Transform Script Version | Text (String) | Version number of the transform script (to be populated by the transform script) |
| RuminexVersion | Ruminex Version | Text (String) | Version number of the Ruminex R package (to be populated by transform script |
Appendix B: Custom Run Fields
| Name | Label | Type | Description |
| SubtNegativeFromAll | Subtract Negative Bead from All Wells | Boolean | Controls whether or not the negative bead values should be subtracted from all wells or just the unknowns. Values for the negative bead for each run are reported on the Negative (Bead Number) tab of the run's Excel file. |
| StndCurveFitInput | Standards/Controls FI Source Column | Text (String) | The source column to be used by the transform script for the analyte/titration curve fit calculations of Standards and QC Controls (if lookup configured, choices include: FI, FI-Bkgd, and FI-Bkgd-Neg). |
| UnkCurveFitInput | Unknowns FI Source Column | Text (String) | The input source column to be used by the transform script when calculating the estimated concentration values for non-standards (if lookup configured, choices include: FI, FI-Bkgd, and FI-Bkgd-Neg). |
| CurveFitLogTransform | Curve Fit Log Transform | Boolean | Whether or not to take the log transform of the FI data for the curve fits. When set to true, FI (minus any chosen background subtractions for background wells or negative beads) is log transformed before calculation of curve fit regression parameters and interpolation of unknowns from the curve. |
| NotebookNo | Notebook Number | Text (String) | Notebook number |
| AssayType | Assay Type | Text (String) lookup | Lookup into lists.AssayType |
| ExpPerformer | Experiment Performer | Text (String) | Who performed the experiment |
| CalculatePositivity | Calculate Positivity | Boolean | Whether or not the calculate the positivity for this run |
| BaseVisit | Baseline Visit | Number (Double) | The baseline visit for positivity calculations |
| PositivityFoldChange | Positivity Fold Change | Number (Integer) - lookup with 3x and 5x | Fold change used to determine positivity |
| SkipRumiCalculation | Skip Rumi Calculation | Boolean | Set to true to allow calculation of 4PL EC50 and AUC on upload without running the Ruminex calculation |
Appendix C: Custom Excel File Run Properties
| Name | Label | Type | Description |
| FileName | File Name | Text (String) | The file name |
| AcquisitionDate | Acquisition Date | DateTime | |
| ReaderSerialNumber | Reader Serial Number | Text (String) | |
| PlateID | Plate ID | Text (String) | |
| RP1PMTvolts | RP1 PMT (Volts) | Number (Double) | |
| RP1Target | RP1 Target | Text (String) |
Appendix D: Custom Analyte Properties
| Name | Label | Type | Description |
| LotNumber | Lot Number | Text (String) | The lot number for a given analyte |
| NegativeControl | Negative Control | Boolean | Indicates which analytes are to be treated as negative controls (i.e. skip curve fit calculations, etc.) |
Appendix E: Custom Data Fields
The optional fields in this section are not required for the Ruminex script to run. They are specific curve fit parameters returned by the transform script. They may be useful to statisticians.
| Name | Label | Type | Description |
| FIBackgroundNegative | FI-Bkgd-Neg | Number (Double) | The value calculated by the transform script by subtracting the FI-Bkgd of the negative bead from the FI-Bkgd of the given analyte bead |
| Standard | Standard for Rumi Calc | Text (String) | The name of the standard used for the transform script estimated concentration calculations based on the rumi curve fits |
| EstLogConc_5pl | Est Log Conc Rumi 5 PL | Number (Double) | The transform script calculated estimated log concentration value using a 5PL curve fit |
| EstConc_5pl | Est Conc Rumi 5 PL | Number (Double) | The transform script calculated estimated concentration value using a 5PL curve fit |
| SE_5pl | SE Rumi 5 PL | Number (Double) | The transform script calculated standard error value using a 5PL curve fit |
|
EstLogConc_4pl |
Est Log Conc Rumi 4 PL |
Number (Double) | The transform script calculated estimated log concentration value using a 4PL curve fit |
|
EstConc_4pl |
Est Conc Rumi 4 PL |
Number (Double) | The transform script calculated estimated concentration value using a 4PL curve fit |
|
SE_4pl |
SE Rumi 4 PL |
Number (Double) | The transform script calculated standard error value using a 4PL curve fit |
| Positivity | Positivity | Text (String) | The transform script calculated positivity value for unknowns |
| Slope_4pl | Slope Param 4 PL | Number (Double) | Optional. The transform script calculated slope parameter of the 4PL curve fit for a given analyte/titration |
| Lower_4pl | Lower Param 4 PL | Number (Double) | Optional. The transform script calculated lower/min parameter of the 4PL curve fit for a given analyte/titration |
| Upper_4pl | Upper Param 4 PL | Number (Double) | Optional. The transform script calculated upper/max parameter of the 4PL curve fit for a given analyte/titration |
| Inflection_4pl | Inflection Param 4 PL | Number (Double) | Optional. The transform script calculated inflection parameter of the 4PL curve fit for a given analyte/titration |
| Slope_5pl | Slope Param 5 PL | Number (Double) | Optional. The transform script calculated slope parameter of the 5PL curve fit for a given analyte/titration |
| Lower_5pl | Lower Param 5 PL | Number (Double) | Optional. The transform script calculated lower/min parameter of the 5PL curve fit for a given analyte/titration |
| Upper_5pl | Upper Param 5 PL | Number (Double) | Optional. The transform script calculated upper/max parameter of the 5PL curve fit for a given analyte/titration |
| Inflection_5pl | Inflection Param 5 PL | Number (Double) | Optional. The transform script calculated inflection parameter of the 5PL curve fit for a given analyte/titration |
| Asymmetry_5pl | Asymmetry Param 5 PL | Number (Double) | Optional. The transform script calculated asymmetry parameter of the 5PL curve fit for a given analyte/titration |
Troubleshoot Luminex Transform Scripts and Curve Fit Results
This page provides tips on interpreting and fixing error messages from Luminex transform scripts. In addition, it includes troubleshooting advice for issues you may encounter when reviewing assay data and calculated values output from such scripts.
Transform Script Upload Errors
"An error occurred when running the script [script-filename.R] (exit code: 1)"
- This message indicates that an error has occurred in the R transform script and has halted the script execution. In most case, if you look further down in the upload log file, you will see the details of the actual R error message.
"Error in library(xtable) : there is no package called 'xtable' - Calls: source -> withVisible -> eval -> eval -> library - Execution halted"
- The named library cannot be located. You may need to download an additional package or check that your downloaded packages are in the R library directory. If you are using the R graphical user interface on Windows, you may need to hand copy the downloaded packages from a temp directory into the R/library directory. See the R documentation for more information about troubleshooting R in Windows.
"Error in plot.window(...) : need finite 'xlim' values"
- This error message is usually the result of a problem in the Ruminex package when Ruminex tries to plot a curve fit PDF and encounters an x-axis or y-axis min/max value that is Infinity or Negative Infinity (for example, as a result of taking the log of a zero value). Check to see if you have zero values in the Expected Concentration column for one of your titrated standards.
"Illegal argument (4) to SQL Statement: NaN is not a valid parameter"
"Zero values not allowed in dose (i.e. ExpConc/Dilution) for Trapezoidal AUC calculation"
- When the server attempts to calculate the area under the curve value for each for the selected titrations using the trapezoidal method, it uses the log of the ExpConc or Diliution values. For this reason, zero values are not allowed in either of these columns for the titrations that will have an AUC calculated.
"ERROR: For input string: 1.#INFE+000"
- There is at least one bad value in the uploaded Excel file. That value cannot be properly parsed for the expected field type (i.e. number).
"NAs are not allowed in subscripted assignments"
- This error has already been fixed to give a better error message. This error is an indication that values in the ExpConc column for some of the wells do not match between Analyte tabs of the Excel file. Verify that the ExpConc and Dilution values are the same across analytes for each of your well groups. Missing descriptions in control wells can also cause this error.
"Error in Ops.factor(analyte.data$Name, analytePtids$name[index])"
- This error message indicates that there is a mis-match between the analyte name on the Excel file worksheet tab and the analyte name in the worksheet content (i.e. header and analyte column). Check that the bead number is the same for both.
Issues with uploaded results, curve fit calculations, plots, etc.
Missing values for AUC or EC50
- When a curve fit QC metric (such as AUC or EC50) is blank for a given analyte, there are a few reasons that could be the cause (most of which are expected):
- Check the curve fit's failure flag to make sure the parameters weren't out of range (e.g. 'AnalyteTitration/FiveParameterCurveFit/FailureFlag')
- Check to see if Max(FI) of the curve fit points are less than 1000 - in which case the curve fit won't be run
- Check to make sure that the AUC column being displayed is from the 'Trapezoidal Curve Fit' method and EC50 column is from the 'Five Parameter' or 'Four Parameter' fit method
- Was the titration selected as QC Control or Standard on upload? (Check 'Well Role' column)
Levey-Jennings report showing too many or too few points on the default graph
- The default Levey-Jennings report will show the last 30 uploaded results for the selected graph parameters. You can set your desired run date range using the controls above the graph to view more/less records.
Levey-Jennings Comparison plots and/or Curve Fit PDF plots showing curves sloping in different directions
- QC Control titrations are plotted with dilution as the x-axis whereas Standard titrations are plotted with expected concentration on the x-axis. Make sure that your titrations were correctly set as either a QC Control or Standard on the well-role definition section of the Luminex upload wizard.
Incorrect positivity calls
- When you encounter an unexpected or incorrect positivity call value, there are a few things to check:
- Check that the Visit values are parsing correctly from the description field by looking at the following columns of the imported assay results: Specimen ID, Participant ID, Visit ID, Date, and Extra Specimen Info
- Check that the run settings for the positivity calculation are as expected for the following fields: Calculate Positivity, Baseline Visit, and Positivity Fold Change
- When the "Calculate Positivity" run property is set, the Analyte properties section will contain input fields for the "Positivity Thresholds" for each analyte. Check to make sure those values were entered correctly
- Positivity calls for titrated unknowns will be made using only the data for the lowest dilution of the titration
Microarray
Microarray Data File, Sample, and Other Metadata Tracking
The Microarray module supports workflows for both Agilent and Affymetrix.For Agilent, the server automates running the Feature Extractor software on the instrument generated TIFF file, and then associates the resulting MAGE-ML data file, along with a PDF QC report, a JPEG thumbnail, and other outputs with sample information and customizable, user-entered run-level metadata.For Affymetrix, the server expects to receive an Excel file with sample and file information, along with the .cel files generated by the instrument. The implementation has been used successfully with the GeneTitan instrument.For both Agilent and Affymetrix, the raw content of the data files are not imported into the LabKey Server database. The files remain available for download and analysis in R other other tools. Administrators can define the exact set of fields tracked for each sample associated with a microarray run.Tutorial: Microarray Assay Tutorial - Demonstrates import of Agilent MAGE-ML files.Microarray Expression Matrix Import
The "Expression Matrix" assay imports a normalized expression and associates each value with a sample and its feature or probe from the array. Administrators upload metadata about the probes being used, with their associated gene information. Users can upload sample information (including whatever fields might be of interest), along with expression data. Since the full expression data is imported, users can filter and view data based on genes or samples of interest. Additionally, the data is available to hand off to R, LabKey Server's standard visualization tools, and more.Tutorial: Expression Matrix Assay TutorialMicroarray Assay Tutorial
- Set up
- Create a Microarray Folder
- Upload Sample Microarray Data
- Create a Microarray Assay Design
- Import Run Data to the Design (2 methods)
- Review Run Data
- Copy Data to the Demo Study (Optional Step)
Set Up
- Install LabKey Server and set up the demo study if you have not already done so as part of another tutorial. These instructions assume your demo study is named HIV-CD4 Study, but you can substitute any name you used.
- Download the sample data and unzip the LabKeyDemoFiles directory to the location of your choice. You will upload from that location.
Create a Microarray Folder
In this tutorial, you set up a separate subfolder within your demo study for the microarray experiment and associated web parts. You could instead incorporate these web parts directly in a study folder, but that option is not described here.- Navigate to the home page of the demo study, HIV-CD4 Study.
- Select Admin > Folder > Management and click Create Subfolder.
- Name: "Microarray Staging"
- Type: Select Microarray.
- Click Next.
- On the Permissions page, confirm that Inherit From Parent Folder is checked, and click Finish.

Upload Microarray Files via the Pipeline
- In the Data Pipeline web part, click Process and Import Data.
- Drag and drop the unzipped sample file folder [LabKeyDemoFiles]\Assays\Microarray into the pipeline file panel to begin the upload.
Create a Microarray Assay Design
- Click the Microarray Dashboard tab.
- In the Assay List web part, click Manage Assays.
- Click New Assay Design.
- Select Microarray, choose "Current Folder (Microarray Staging)" as the Assay Location and click Next.
- On the "Microarray Assay Designer" page. Enter the name "Microarray Test" and leave all other Assay Properties with their default values.
- Scroll down to the Run Fields section, and for each row below, click Add Field and enter the values given.
| Name | Label | Description |
|---|---|---|
| Producer | Producer | /MAGE-ML/Descriptions_assnlist/Description/Annotations_assnlist/ |
| Version | Version | /MAGE-ML/Descriptions_assnlist/Description/Annotations_assnlist/ |
| Protocol_Name | Protocol_Name | /MAGE-ML/BioAssay_package/BioAssay_assnlist/MeasuredBioAssay/FeatureExtraction_assn/ |
| RunPropWithoutXPath | RunPropWithoutXPath | [leave blank] |
- If you select the Producer field again, the section will look like this:

- When finished, click Save & Close.
Set up a Sample Set
- Click Microarray Dashboard.
- Add a Sample Sets web part, using the web part drop-down menu at the lower left.
- In the new web part, click Import Sample Set
- Name this new sample set "Microarray Sample Set".
- Paste the following three lines into the Sample Set Data text box:
| Name |
|---|
| Microarray 1 |
| Microarray 2 |
- Click Submit at the bottom of the page to finish.
Import Microarray Runs
- Click Microarray Dashboard.
- In the Assay List web part, click the assay design you created above: Microarray Test.
- Click Import Data. You will now see the Microarray directory that you uploaded to your server in an earlier step.
- Double click Microarray to open the folder. This folder contains MAGE-ML files.
- Place check marks next to the files test1_MAGEML.xml and test2_MAGEML.xml.
- Click Import Data.
- In the popup dialog, confirm that Use Microarray Test is selected and click Import. This will start to import the selected files into the "Microarray Test" design that you created earlier.
Specify Properties
You will now see the "Data Import: Batch Properties" page.Properties that contain XPaths in the descriptions for their fields will be populated automatically from your files. Additional bulk, run or data properties can be populated using one of two methods by selecting one of the two radio buttons:- Option 1: Enter run properties for each run separately by entering values into a form.
- Option 2: Specify run properties for all runs at once with tab-separated values (TSV).
- Confirm that "Enter run properties for each run separately by entering values into a form" is selected.
- Click Next to advance to the "Data Import: Run Properties and Data File" page.
- Enter "1" for the RunPropWithoutXPath.
- For "Sample 1" select "Microarray 1" in the Sample Name column, and for "Sample 2" select "Microarray 2" as shown:

- Click Save and Import Next File.
- Enter "2" for the RunPropWithoutXPath.
- Leave "Microarray 1" selected for "Sample 1" and "Microarray 2" for "Sample 2."
- Select Save and Finish.
 Notice the values you entered in the RunPropWithoutXPath column.
Notice the values you entered in the RunPropWithoutXPath column.- First delete previously imported runs by selecting both checkboxes and clicking Delete and confirming.
- Repeat the steps described in the "Import Microarray Runs" section above.
- This time, select "Specify run properties for all runs at once with tab-separated values (TSV)" on the "Data Import: Batch Properties" page.
- Click Download Excel Template and open it in Excel. This spreadsheet shows the barcodes associated with the two files we have chosen to upload. It allows you to specify the sample set for each dye for each file, plus the RunPropWithoutXPath. The other run properties (Producer, Version, Protocol_Name) are still populated automatically using the XPaths you provided in the assay design.
- Fill in this table with the following information (as shown in the screenshot below and available in the bulkproperties1.xls spreadsheet in your [LabKeyDemoFiles]\Assays\Microarray folder), then paste it into the Run Properties textbox.
| Barcode | ProbeID_Cy3 | ProbeID_Cy5 | RunPropWithoutXPath |
| 251379110131_A01 | Microarray 1 | Microarray 2 | 1 |
| 251379110137_A01 | Microarray 1 | Microarray 2 | 2 |

- Click Next.
Review Run Data
You will now bypass entering any more information and see the "Microarray Test Runs" grid view. You can later reach this grid from the dashboard by clicking on the name of the assay in the Assay List. See a similar grid in this interactive example. The following items are numbered in the picture of the runs grid shown above:
The following items are numbered in the picture of the runs grid shown above:
- QC Flag icon: click to activate indicating a possible problem with the run.
- Experiment run graph icon: click to see more information about the source sample.
- Name (Assay ID): click for details about all files related to the MAGEML.
- Additional columns: additional metadata for the runs.
- Batch: displays the batch name. Click to see all of the MAGEMLs that were uploaded together as part of one batch.
Integrate Data into a Study (Optional Step)
You can integrate your microarray assay into a study and align it with other data for the particular participant and data collection date. To show you how, we integrate the tutorial data into the HIV-CD4 Study demo study:- Click the Microarray Dashboard tab.
- Click Microarray Test in the Assay List web part.
- Select the runs you would like to copy to a study using the checkboxes on the left side of the grid view. For this demo, we select both runs.
- Click Copy to Study.
- Select the demo study, HIV-CD4 Study, as the target study and click Next.
- You will notice 'X's in the match column. To match these runs to specimens present in the demo study, enter participant IDs and visit dates for each run you have selected. Enter these values for both runs:
- ParticipantID: 249320489
- Date: 2008-12-03

- Click Re-validate to confirm that the given participant/visit pairs already exist in the study. You will see green validation markers in the specimen match column, indicating successful matches to Participant/Visit pairs in the demo study:

- To finalize the copy, click Copy to Study.
- Click the Manage tab.
- Click Manage Datasets.
- Click your assay (Microarray Test1).
- Click Edit Definition.
- Category: Type “Assays” for the category.
- Label: Edit the label to read "Microarray Assay"
- Show in Overview: Confirm this box is checked.
- Click Save.
- Click the Clinical and Assay Data tab.
- Notice that your renamed assay dataset has been added to the Assays section.
Related Topics
Expression Matrix Assay Tutorial
- Metadata about features/probes (typically at the plate level)
- Sample information
- Actual expression data (often called a "series matrix" file)
Enable the Expression Matrix Module
The Expression Matrix assay is part of the microarray module.Review File Formats
In order to use the assay, you will need three sets of data: a run file, a sample set, and a feature annotation file.The run file will have one column for probe ids (ID_REF) and a variable number of columns named after a sample found in your sample set. The ID_REF column in the run file will contain probe ids that will be found in your feature annotation file, under the Probe_ID column. All of the other columns in your run file will be named after samples, which must be found in your sample set.In order to import your run data, you must first import your sample set and your feature annotation set. Your run import will fail if we are unable to find a match for your ID_REF value or for a sample in your sample set.Set up the Expression Matrix Assay
- Create a new folder of type Microarray.
- Add the Sample Sets web part to the Microarray Dashboard tab.
- Click the Import Sample Set button.
- On the Import Sample Set page, name your sample set ExpressionMatrixSamples.
- In the sample set data text area, paste in a TSV of all your samples.
- In the Id Columns section, make the appropriate Name column an ID column.
- Save your sample set.
- Return to the Microarray Dashboard.
- Add a Feature Annotation Sets web part at the bottom of the left column.
- Click Import Feature Annotation Set.
- Enter the name, vendor, description, folder.
- Browse to select the annotation file. These can be from any manufacturer (i.e. Illumina or Affymetrix), but must be a TSV file with the following column headers:
Probe_ID
Gene_Symbol
UniGene_ID
Gene_ID
Accession_ID
RefSeq_Protein_ID
RefSeq_Transcript_ID
- Click Upload.
Create a New Assay Design
- Select the ExpressionMatrix assay type
- Name your assay and save it
Import a Run
Runs will be in the TSV format and have a variable number of columns.- The first column will always be ID_REF, which will contain a probe id that matches the Probe_ID column from your feature annotation set.
- The rest of the columns will be for samples from your imported sample set (ExpressionMatrixSamples).
ID_REF GSM280331 GSM280332 GSM280333 GSM280334 GSM280335 GSM280336 GSM280337 GSM280338 ...
1007_s_at 7.1722616266753 7.3191207236008 7.32161337343459 7.31420082996567 7.13913363545954 ...
- Navigate to your ExpressionMatrix assay
- Import run data
View Run Results
After the run is imported, to view the results:- Click the file name in the runs grid
- Select Admin > Developer Links > Schema Browser
- Browse to Assay > ExpressionMatrix > [YOUR_ASSAY_NAME] > FeatureDataBySample
Microarray Properties
Assay Properties
- Name. Required. Name of the assay design.
- Description. Optional.
- Channel Count XPath. Optional. XPath for the MageML that defines the number of channels for the microarray run. The server uses this value to determine how many samples it needs to get from the user. Defaults to:
/MAGE-ML/BioAssay_package/BioAssay_assnlist/MeasuredBioAssay/FeatureExtraction_assn/FeatureExtraction/
ProtocolApplications_assnlist/ProtocolApplication/SoftwareApplications_assnlist/SoftwareApplication/ParameterValues_assnlist/
ParameterValue[ParameterType_assnref/Parameter_ref/@identifier='Agilent.BRS:Parameter:Scan_NumChannels']/@value
- Barcode XPath. Optional. XPath for the MageML that defines the barcode for the run. The server uses this value to match MageML files with associated samples. Defaults to:
/MAGE-ML/BioAssay_package/BioAssay_assnlist/MeasuredBioAssay/FeatureExtraction_assn/FeatureExtraction/
ProtocolApplications_assnlist/ProtocolApplication/SoftwareApplications_assnlist/SoftwareApplication/ParameterValues_assnlist/
ParameterValue[ParameterType_assnref/Parameter_ref/@identifier='Agilent.BRS:Parameter:Scan_NumChannels']/@value
- Barcode Field Names. Optional. The name of the field in a sample set that contains a barcode value that should be matched to the Barcode XPath's value. Multiple field names may be comma separated, and the server will use the first one that has a matching value.
- Cy3 Sample Field Name. Optional. This is the name of the column whose cells contain Cy3 sample names. It is only used if you are using "Bulk Properties" (specifying the run properties in bulk). Defaults to: ProbeID_Cy3.
- Cy5 Sample Field Name. Optional. This is the name of the column whose cells contain Cy5 sample names. It is only used if you are using "Bulk Properties" (specifying the run properties in bulk). Defaults to: ProbeID_Cy5.
XPaths
For Bulk, Run and Data Properties, you can include an XPath in the "Description" property for any field you include. This XPath will tell LabKey Server where to automatically find values for this field in the MAGEML file. Since this information is provided automatically, you are not prompted for the information while importing files. See the Microarray Assay Tutorial for examples of using XPaths.Batch Properties
The user is prompted for batch properties once for each set of runs during import. The batch is a convenience to let users set properties once and import many runs using the same suite of properties. Typically, batch properties are properties that rarely change.Properties included by default: None.Run Properties
The user is prompted to enter run level properties for each imported file. These properties are used for all data records imported as part of a Run. This is the second step of the import process. You may enter an XPath expression in the description for the property. If you do, when importing a run the server will look in the MAGEML file for the value.Properties included by default: None.Data Properties
The user is prompted to select a MAGEML file that contains the data values. If the spot-level data within the file contains a column that matches the data column name here, it will be imported.Properties included by default: None.Finish Assay Design
After making changes, be sure to click Save or Save & Close at the bottom of the page.NAb (Neutralizing Antibody) Assays
Tutorial
- NAb Assay Tutorial - Includes working with High-Throughput NAb Data
Topics
- Work with Low-Throughput NAb Data
- Use NAb Data Identifiers
- NAb Assay QC
- Work with Multiple Viruses per Plate
- NAb Plate File Formats
- Customize NAb Plate Template
- NAb Properties
Related Resources
- The LabKey NAb tool is also described in LabKey Server NAb: A tool for analyzing, visualizing and sharing results from neutralizing antibody assays, Piehler, et al., 2011: http://www.biomedcentral.com/1471-2172/12/33
NAb Assay Tutorial
Tutorial Steps
- Step 1: Create a NAb Assay Design
- Step 2: Import NAb Assay Data
- Step 3: View High-Throughput NAb Data
- Step 4: Explore NAb Graph Options
First Step
Step 1: Create a NAb Assay Design
Set Up
This tutorial assumes you can create a working folder where you have administrative permissions. If you install a local evaluation server on your own machine, you will have those permissions. Otherwise, work with a local admin to find a suitable location for completing this tutorial.- Download and unzip the sample data package LabKeyDemoFiles.zip. You will upload files from this unzipped [LabKeyDemoFiles] location later.
- Log in and navigate to the Home project.
- Create a new folder to work in:
- Go to Admin > Folder > Management and click Create Subfolder.
- On the Create New Folder page, enter the Name: "NAb Assay Tutorial"
- Select the Folder Type "Assay".
- Click Next.
- On the Users/Permissions page, make no changes, and click Finish.
Create a New NAb Plate Template
Assay designs may be created from scratch, or we can use pre-configured designs for specific assay types which are already customized with commonly used fields for the specific type of assay. In the case of a plate-based assay like NAb, first we create a plate template, which describes the contents in each well of the plate.- In the Assay List web part, click Manage Assays.
- Click Configure Plate Templates.
- Select "New 384 Well (16x24) NAb High-Throughput (Single Plate Dilution) Template"

- In the Plate Template Editor:
- Enter Template Name: "NAb High Plate 1".
- Make no other changes.
- Click Save & Close.
Create a New NAb Assay Design
Next we create a new assay design which uses our new plate template. Our sample data is from a high-throughput NAb assay in which dilutions occur within a single plate. In addition, the instrument used here provides metadata about the experiment in its own file separate from the data file. For more about metadata input options, see NAb Plate File Formats.- Click the tab Assay Dashboard to get to the main folder page.
- Click New Assay Design.
- Choose TZM-bl Neutralization (NAb), High-throughput (Single Plate Dilution) as your assay type.
- Select "Current Folder (NAb Assay Tutorial)" as your Assay Location.
- Click Next.
- On the Assay Designer page, under Assay Properties:
- Name: "NAb High/Single Assay".
- From the Plate Template pulldown, confirm that "NAb High Plate 1" is selected.
- Confirm that the Metadata Input Format is "File Upload (metadata only)".
- Review the other properties, but leave all at their default settings for this tutorial.
- Click Save & Close.
Related Topics
Start Over | Next Step
Step 2: Import NAb Assay Data
Import Data
When you import assay data, you declare how you will identify your data for later integration with other related data. See Data Identifiers for more details. In this case we'll use SpecimenIDs provided in the sample file, which match SpecimenIDs used in our LabKey demo study.Locate the LabKeyDemoFiles package you downloaded and unzipped in the prior tutorial step. The two files you will upload in this step are in the [LabKeyDemoFiles]/Assays/NAb/ directory.- Click the tab Assay Dashboard to return to the tutorial home page.
- In the Assay List web part, click NAb High/Single Assay.
- Click Import Data.
- For Participant/Visit (i.e. how you will identify your data):
- Select Specimen/sample id.
- Do not check the box for providing participantID and visitID.
- You do not need to select a target study at this time.
- Click Next.
- On the data import page:
- Leave the Assay ID blank. The run data file name will be used as the AssayID.
- For Cutoff Percentage (1) enter 50.
- From the Curve Fit Method pulldown, select Five Parameter.
- For Sample Metadata:
- Click Browse or Choose File.
- Select "NAb_highthroughput_metadata.xlsx" from the [LabKeyDemoFiles]/Assays/NAb/ directory.
- For Run Data, select "NAb_highthroughput_testdata.xlsx" from the same sample location.
- Click Save and Finish.
- View the run summary screen.

Previous Step | Next Step
Step 3: View High-Throughput NAb Data
Review NAb Dashboard
After uploading a NAb run, you will see the NAb Dashboard. The Run Summary section includes the percent neutralization for each dilution or concentration, calculated after subtraction of background activity. The NAb tool fits a curve to the neutralization profile using the method you specified when uploading the run (in this tutorial example a five-parameter fit). It uses this curve to calculate neutralizing antibody titers and other measures. The tool also calculates “point-based” titers by linearly interpolating between the two replicates on either side of the target neutralization percentage.The percent coefficient of variation (%CV) is shown on the neutralization curve charts as vertical lines from each data point.If you are not working through the tutorial on your own server, you can view a similar dashboard in the interactive example. Below the graphs, a data summary by specimen and participant includes:
Below the graphs, a data summary by specimen and participant includes:
- AUC -- Area Under the Curve. This is the total area under the curve based on the titrations, with negative regions counting against positive regions.
- PositiveAUC -- Positive Area Under the Curve. This figure represents only the areas under the curve that are above the y-axis.
 Even lower on the page, you'll find even more detailed specimen and plate data.
Even lower on the page, you'll find even more detailed specimen and plate data.
Quality Control
An administrator can review and mark specific wells for exclusion from calculations. See NAb Assay QC for details.Previous Step | Next Step
Step 4: Explore NAb Graph Options
Explore Graph Options
The Change Graph Options menu at the top of the run details page offers a variety of viewing options for your data:- Curve Type: See what the data would look like if you had chosen a different curve fit (see below).
- Graph Size: Small, medium, or large graphs as desired.
- Samples Per Graph: Choose more graphs each containing fewer samples, or fewer more complex graphs. Options: 5, 10, 15, 20 samples per graph.
- Graphs Per Row: Control the width of the results layout. Options 1, 2, 3, or 4 graphs per row.
- Data Identifiers: If you provided multiple ways of identifying your data, you may select among them here.
- From the Change Graph Options menu, select a different Curve Type and view the resulting graph.
- You can experiment with how the graph would appear using a different curve fit method without changing the run data. For example, select Polynomial. The top graph will look something like this:
 Note that this alternate view shows you your data with another curve type selected, but does not save this alternate view. If you want to replace the current run data with the displayed data, you must delete and reimport the run with the different Curve Type setting.
Note that this alternate view shows you your data with another curve type selected, but does not save this alternate view. If you want to replace the current run data with the displayed data, you must delete and reimport the run with the different Curve Type setting.
http://localhost:8080/labkey/home/NAb Tutorial/details.view?rowId=283
&sampleNoun=Virus&maxSamplesPerGraph=10&graphsPerRow=3&graphWidth=425&graphHeight=300
What's Next?
LabKey's NAb Assay tools provide quick feedback after the upload of each run. Once you confirm that the particular run of data is valid you might want to quickly share the results with colleagues via URLs or printable browser view. You could also copy your data to a LabKey study where it could be integrated with other information about the same specimens or samples. Connecting differing neutralization rates to different cohorts or treatment protocols could enable discoveries that improve results.You have now completed the process of setting up for, importing, and working with NAb data. You might proceed directly to designing the plate template and assay that would suit your own experimental results. If you are working with low-throughput 96-well data, you can learn more in this topic: Work with Low-Throughput NAb Data.Previous Step
Work with Low-Throughput NAb Data
Create a New NAb Assay Design
- In the Assay List web part, click Manage Assays.
- Click Configure Plate Templates, then select New 96 Well (8x12) NAB Single-Plate Template.

- Specify the following in the plate template editor:
- Provide a Template Name, for example: "NAb Plate 1"
- Leave all other settings at their default values (in order to create the default NAb plate).
- Click Save and Close.
- Click Assay Dashboard to get back to your folder.
- Click New Assay Design.
- Select TZM-bl Neutralization (NAb), select the current folder (NAb Tutorial) as the Assay Location, and click Next.
- Specify the following in the assay designer:
- Name: "NAbAssayDesign"
- Plate Template: NAb Plate 1
- Metadata Input Format: Confirm Manual is selected for this tutorial.
- Leave all other fields at their default values.
- Click Save and Close.
Import Data
When importing runs for this tutorial, you provide metadata, in this case sample information, manually through the UI. If instead you had a file containing that sample information, you could upload it using the File Upload option for Metadata Input Format. See NAb Properties for more information.- Return to the Assay Dashboard page.
- On the Assay List, click NAbAssayDesign, then Import Data.
- For Participant/Visit, select Specimen/sample id. Do not check the box to also provide participant/visit information.
- Click Next and enter experiment data as follows:
| Property | Value |
|---|---|
| Assay Id | Leave blank. This field defaults to the name of the data file import. |
| Cutoff Percentage (1) | 50 |
| Cutoff Percentage (2) | 80 |
| Host Cell | T |
| Experiment Performer | <your name> |
| Experiment ID | NAb32 |
| Incubation Time | 30 |
| Plate Number | 1 |
| Curve Fit Method | Five parameter |
| Virus Name | HIV-1 |
| Virus ID | P392 |
| Run Data | Browse to the file: [LabKeyDemoFiles]\Assays\NAb\NAbresults1.xls |
| Specimen IDs | Enter the following (in the row of fields below the run data file): |
| Specimen 1 | 526455390.2504.346 |
| Specimen 2 | 249325717.2404.493 |
| Specimen 3 | 249320619.2604.640 |
| Specimen 4 | 249328595.2604.530 |
| Specimen 5 | 526455350.4404.456 |
| Initial Dilution | Place a checkmark and enter 20 |
| Dilution Factor | Place a checkmark and enter 3 |
| Method | Place a checkmark and enter Dilution |
- Click Save and Finish.
NAb Dashboard
When the import is complete, you can view detailed information about any given run right away, giving quick confirmation of a good set of data or identifying any potential issues. The run summary dashboard looks something like this: The percent coefficient of variation (%CV) is shown on the neutralization curve charts as vertical lines from each data point. Additional quality control, including excluding particular wells from calculations is available for NAb assays. See NAb Assay QC for details.As with high-throughput NAb data you can customize graphs and views before integrating or sharing your results. Once a good set of data is confirmed, it could be copied to a study or data repository for further analysis and integration.
The percent coefficient of variation (%CV) is shown on the neutralization curve charts as vertical lines from each data point. Additional quality control, including excluding particular wells from calculations is available for NAb assays. See NAb Assay QC for details.As with high-throughput NAb data you can customize graphs and views before integrating or sharing your results. Once a good set of data is confirmed, it could be copied to a study or data repository for further analysis and integration.
Related Topics
Use NAb Data Identifiers
Data Identifiers
[ Video Overview: Data Identifiers in NAb Run Details ]When you upload a NAb run and enter batch properties, you declare how you will identify the data by selecting an identifier known as a Participant/Visit Resolver. Choices include:- Participant id and visit id. If VisitID is not specified, it is set to null.
- Participant id and date.
- Participant id, visit id, and date. If VisitID is not specified, it is set to null.
- Specimen/sample id. If you choose this option, you may also provide participant id and visit id.
- Sample indices, which map to values in a different data source. This option allows you to assign a mapping from your own specimen numbers to participants and visits. The mapping may be provided by pasting data from a tab-separated values (TSV) file, or by selecting an existing list. Either method must include an 'Index' column and using the values of the columns 'SpecimenID', 'ParticipantID', and 'VisitID'. To use the template available from the Download template link, fill in the values, copy and paste the entire spreadsheet including column headers into the text area provided.
 Options on this menu will only be enabled when there is enough data provided to use them. The tutorial example does not include providing this second set of identifiers, but you may try this feature yourself with low-throughput NAb data. Note that the data identifier selection is included as a URL parameter so that you may share data with or without this graph option.
Options on this menu will only be enabled when there is enough data provided to use them. The tutorial example does not include providing this second set of identifiers, but you may try this feature yourself with low-throughput NAb data. Note that the data identifier selection is included as a URL parameter so that you may share data with or without this graph option.NAb Assay QC
Review and Mark Data for Exclusion
- Open the details view of the run you want to review. From the Assay List, click the assay name, then Run Details for the desired row.
- Select View QC > Review/QC Data. If you do not see this menu option, you do not have permission to perform this step.

- The review page shows the run result data, with checkboxes for each item.
QC Review Page
The page is divided into sections which may vary based on the type and complexity of data represented. In this example, a single low-throughput plate containing 5 specimens at varying dilutions is represented with a section for the plate controls, followed by a series of graphs and specific data, one set for each specimen.
- Place a checkmark in the box for any data you would like to exclude, then scroll to the bottom of the page and click Next.
- The QC summary page allows you to enter a comment for each exclusion and shows the plate with excluded wells highlighted:

- If you notice other data you would like to exclude, you can click Previous and return to the selection page to add or delete checkmarks. When you return to the summary by clicking Next, any previously entered comments have been preserved.
- Click Finish when finished to save the exclusions and recalculate results and curve fits.
View Excluded Data
After some data has been excluded, users with access to view the run details page will be able to tell at a glance that it has been reviewed for quality control by noticing the Last Reviewed for QC notation in the page header.- On the run details page, the user and date are now shown under Last Reviewed for QC and excluded wells are highlighted in red.

- Hovering over an excluded well will show a tooltip containing the exclusion comment. If none was entered the tooltip will read: "excluded from calculations".
Related Topics
Work with Multiple Viruses per Plate
Configure a Multi-Virus Plate Template
The built-in NAb Multi-virus Plate Template is divided in half between two viruses with 10 samples (in replicate) per virus, each with their own separate control wells. The samples on each plate are identical between the two viruses. By customizing this built-in default plate template, it is further possible to add additional viruses or otherwise customize the template to fit alternate arrangements of well groups and plates.- From the Assay Dashboard, click Manage Assays.
- Click Configure Plate Templates.
- Select New 384-well (16x24) NAb Multi-Virus Plate Template.
- Notice the Virus tab which will show you the default layout of the two viruses.

- After making any changes necessary, name your template.
- Click Save & Close.
Define a Multi-Virus Single-Plate Assay Design
Select the appropriate NAb assay type as you create a new named assay design.- From the Assay Dashboard, click New Assay Design.
- Select the assay type.
- Name the design.
- Select the named multi-virus plate template you just created.
- Notice that Virus Fields including virus name, virus id, and host cell, are predefined and will appear as run-level properties in the assay design.
- Add additional fields as needed.
- Click Save & Close.
Import Multi-Virus NAb Data
During upload of data, the upload wizard will request the virus specific information and other metadata necessary to correctly associate data from each well with the correct virus. Dilution and neutralization information is also grouped by virus.
Explore Multi-Virus Results
In the resulting run details report, each sample/virus combination will have its own set of dilution curves, cutoffs, AUC, fit errors, etc.
NAb Plate File Formats
- Low-throughput assays typically have 96 wells in a single plate, prepared with five specimens in eight dilutions of two replicates each. Low-throughput samples are diluted within a single plate.
- High-throughput assays typically have 384 wells per plate and may consist of up to eight plates. High-throughput assays have two options for dilution:
- Cross Plate Dilution: Each well on a given plate has the same dilution level; dilutions occur across plates.
- Single Plate Dilution: Dilutions occur within a single plate.
- Multi-Virus NAb assays include multiple viruses within a single plate and may be either low- or high-throughput and either single- or cross-plate dilution.
Low-Throughput NAb Assay Formats
LabKey's low-throughput NAb assay supports a few different formats. Files containing these formats may be of any type that the TabLoader can parse: i.e. Excel, tsv, csv, txt.- format1.xls has the plate data in a specific location on the second sheet of the workbook. The 96 wells of plate data must be in exactly the same location every time, spanning cells A7-L14.
- SpectraMax.csv contains plate data identified by a "Plate:" cell header.
- format2.xls follows a more general format. It can have the plate data on any sheet of the workbook, but the rows and columns must be labeled with 1-12 and A-H.
- format3.tsv is the most general format. It is a file file that just contains the plate data without row or column headers.
Metadata Input Format
For low-throughput NAb assays, sample and virus metadata input may be done manually via form input at assay import time, or may be uploaded as a separate file to simplify the import process and reduce user error. For example, if you are using a FileMaker database you can export the information and upload it directly. The file upload option supports Excel, tsv, csv, or txt file types.High-Throughput NAb Assay Formats - Metadata Upload
In order to support different plate readers for high-throughput 384-well NAb assays, LabKey tools support two methods of uploading metadata. Some instruments output metadata and run data in separate spreadsheets, others generate a combined file which contains both. As part of new LabKey Assay design, you select a Metadata Input Format of either:- File Upload (metadata only): upload the metadata in a separate file.
- Combined File Upload (metadata & run data): upload both in a single file.
Multi-Virus NAb Assay Format
When working with multiple viruses on a single plate, the assay design can be configured to specify multiple virus and control well groups within a single plate design so that a run may be uploaded at once but results viewed and graphed on a per-virus basis. See Work with Multiple Viruses per Plate for details.Customize NAb Plate Template
TZM-bl Neutralization
The default, low-throughput NAb plate template is called "NAb: 5 specimens in duplicate" and corresponds to the following plate layout: This plate tests five samples in duplicate for inhibition of infection and thus decreased luminescence. The first column of eight wells provides the background signal, measured from the luminescence of cells alone, the “Virus Control.” The second column of eight wells, the “Cell Control” column, provides the maximum possible signal. This is measured from cells treated with the virus without any antibody sample present to inhibit infection. These two columns define the expected range of luminescence signals in experimental treatments. The next five pairs of columns are five experimental treatments, where each treatment contains a serial dilution of the sample.
This plate tests five samples in duplicate for inhibition of infection and thus decreased luminescence. The first column of eight wells provides the background signal, measured from the luminescence of cells alone, the “Virus Control.” The second column of eight wells, the “Cell Control” column, provides the maximum possible signal. This is measured from cells treated with the virus without any antibody sample present to inhibit infection. These two columns define the expected range of luminescence signals in experimental treatments. The next five pairs of columns are five experimental treatments, where each treatment contains a serial dilution of the sample.
Create a New NAb Assay Plate Template
- In the Assay List web part, select Manage Assays.
- Click Configure Plate Templates.
- Choose one of the links to start from one of the built-in NAb templates. The correct link to choose depends on the number of wells, layout, and dilution method you used for your experiments.
- Once you've selected a place to start, you will see the plate editor.
- Name the template. Even if you make no changes, you need to name the base template to create a usable instance of it.
- Edit if required as described below.
- Click Save and Close.
Customize a NAb Assay Plate Template
Customize an assay plate template to match the specific plate and well layout used by your instrument.- In the Assay List web part, select Manage Assays.
- Click Configure Plate Templates.
- The plate templates already defined are listed, you can either:
- Edit to edit the existing template.
- Edit a Copy to create a new variant of an existing template.
- Choose one of the built-in NAb templates to start a new template.
- You will see the plate editor (see examples below).
- Explore the Control, Specimen, Replicate, and Other tabs.
- Edit as desired on any of the tabs. For instance, on the specimen tab, you can select a specimen (using the color coded radio buttons under the layout) and then drag across the plate template editor to “paint” with the chosen specimen. There are also buttons to shift the entire array Up, Down, Left, or Right.
- Well Group Properties may be added in the column on the right. For instance, you can reverse the direction of dilution for a given well group.
- Warnings, if any, will be shown as well. For example, if you identify a given well as both a specimen and control group, a warning will be raised.
- Click Save and Close.
Reverse Dilution Direction
Single-plate NAb assays assume that specimens get more dilute as you move up or left across the plate. High-throughput NAb assays assume that specimens are more dilute as you move down or right across the plate. To reverse the default dilution direction for a specimen well group, select it and add a well group property named 'ReverseDilutionDirection' with the value 'true.'
Example Plate Template Editors
The plate template editor for low-throughput NAb assays, showing control layout: The plate template editor for a high-throughput NAb assay with cross plate dilution, showing specimen layout:
The plate template editor for a high-throughput NAb assay with cross plate dilution, showing specimen layout:
NAb Properties
TZM-bl Neutralization (NAb) Assay Properties
Default NAB assay designs include properties beyond the default properties included in general assay designs. For any TZM-bl Neutralization (NAb) assays, the following additional properties can be set.Assay Properties
- Plate Template: The template that describes the way your plate reader outputs data. You can:
- Choose an existing template from the drop-down list.
- Edit an existing template or create a new one via the Configure Templates button.
- Metadata Input Format: Assays that support more than one method of adding sample/virus metadata during the data import process can be configured by selecting among possible options. Not all options are available for all configurations:
- Manual: Metadata is entered manually at the time of data import. Available for low-throughput NAb assays only.
- File Upload (metadata only): Metadata is uploaded in a separate file from the actual run data at the time of data import.
- Combined File Upload (metadata & run data): Upload a combined file containing both metadata and run data. Available only for some high-throughput NAb assays.
Run Properties
- Cutoff Percentages 1 (required), 2, and 3
- Host Cell
- Study Name
- Experiment Performer
- Experiment ID
- Incubation Time
- PlateNumber
- Experiment Date
- FileID
- Lock Graph Y-Axis (True/False): Fixes the Y axis from -20% to 120%, useful for generating graphs that can easily be compared side-by-side. If not set, axes are set to fit the data, so may vary between graphs.
- Curve Fit Method. Required. The assay's run report (accessed through the details link) generates all graph, IC50, IC80 and AUC information using the selected curve fit method. You can choose from the following types of curve fits:
- Five parameter
- Four parameter
- Polynomial: This algorithm allows you to quantifying a sample’s neutralization behavior based on the area under a calculated neutralization curve, commonly abbreviated as “AUC”.
Sample Fields
For each run, the user will be prompted to enter a set of properties for each of the sample well groups in their chosen plate template. In addition to general assay data property fields, which include date and participant/visit resolver information, NAb assays include:- Sample Description. Optional.
- Initial Dilution. Required. Sample value: 20.0. Used for calculation.
- Dilution Factor. Required. Sample value: 3.0. Used for calculation.
- Method. Required. Dilution or Concentration.
Proteomics
 Analyzed results can be dynamically displayed, enabling you to filter, sort, customize, compare, and export experiment runs. You can share data securely with collaborators inside or outside your organization, with fine-grained control over permissions.A data pipeline imports and processes MS/MS data from raw and mzXML data files. The pipeline searches the data file for peptides using the X!Tandem search engine against the specified FASTA database. Once the data has been searched and scored (using X! Tandem scoring or a pluggable scoring algorithm), the pipeline optionally runs PeptideProphet, ProteinProphet, and XPRESS quantitation analyses on the search results.The data pipeline can also load results that have been processed externally by some other programs. For example, it can load quantitation data processed by Q3.
Analyzed results can be dynamically displayed, enabling you to filter, sort, customize, compare, and export experiment runs. You can share data securely with collaborators inside or outside your organization, with fine-grained control over permissions.A data pipeline imports and processes MS/MS data from raw and mzXML data files. The pipeline searches the data file for peptides using the X!Tandem search engine against the specified FASTA database. Once the data has been searched and scored (using X! Tandem scoring or a pluggable scoring algorithm), the pipeline optionally runs PeptideProphet, ProteinProphet, and XPRESS quantitation analyses on the search results.The data pipeline can also load results that have been processed externally by some other programs. For example, it can load quantitation data processed by Q3.
Documentation Topics
- Proteomics Tutorial
- Work with MS2 Data
- Loading Public Protein Annotation Files
- Using Custom Protein Annotations
- Using ProteinProphet
- Using Quantitation Tools
- Protein Expression Matrix Assay
- Link Protein Expression Data with Annotations
- Spectra Counts
- MS1
- Proteomics Team
- Panorama - Targeted Proteomics - Panorama is a LabKey Server module that provides tools for targeted proteomics experiments
Proteomics Installations
LabKey Server powers proteomics repositories at the following institutions:- Fred Hutchinson Cancer Research Center
- Harvard Partners
- USC Center for Applied Molecular Medicine
- Stanford Canary Center for Cancer Early Detection
- Mallick Lab at Stanford University
- University of Washington
- Molecular Imaging Program at Stanford, and others
Integrated Tools



Proteomics Tutorial
Tutorial Steps:
- Step 1: Set Up for Proteomics Analysis
- Step 2: Search mzXML Files
- Step 3: View PeptideProphet Results
- Step 4: View ProteinProphet Results
- Step 5: Compare Runs
- Step 6: Search for a Specific Protein
First Step
Step 1: Set Up for Proteomics Analysis
Obtain the Sample MS2 Data Files
Download the sample data files. (Choose either zip or tar format, whatever is most convenient for you.)- If you haven't already, install LabKey Server: Install LabKey Server (Quick Install)
- In the installation wizard, on the Install Proteomics Libraries page, make sure to place a checkmark next to Download proteomics analysis tools. (If you are building the server from source code, obtain the proteomics analysis tools using these instructions.)

- Navigate to http://localhost:8080/labkey/ and log in.
- Download Sample Files (zip format)
- OR
- Download Sample Files (tar format)
- Extract the archive to your local hard drive. You can put them anywhere you like, but this tutorial will assume that you extract them into the following directory:
C:/ProteomicsDemo
Create a Proteomics Folder for the Sample Data
Create a new project or folder inside of LabKey server to store the demo data.- Select the Home project (or any project where you can create a subfolder).
- Create a new folder to work in:
- Go to Admin > Folder > Management and click Create Subfolder.
- Name: "Proteomics Tutorial"
- Folder type: MS2, which will automatically set up the folder for proteomics analysis.
- Click Next.
- On the Users/Permissions page, make no changes and click Finish.
Set Up the Pipeline
Finally, we'll configure the data "pipeline", so that LabKey Server knows where to look for files/data to process.- In the Data Pipeline section, click Setup.
- In the Data Processing Pipeline Setup web part, select Set a pipeline override.
- Enter the path to the sample files you download and extracted. (For example: C:/ProteomicsDemo)
- Click Save.
- Look for the confirmation message (in green text): "The pipeline root was set to..."
Start Over | Next Step
Step 2: Search mzXML Files
- X! Tandem
- SEQUEST
- Mascot
- Comet
Run an X! Tandem Search
- Click the MS2 Dashboard tab.
- In the Data Pipeline panel, click Process and Import Data.
- The Files panel appears and already contains the files that you downloaded in the previous step, now viewed through the file management system.
- Open the folder Peroxisomal_ICAT by clicking in the left panel.
- Select the three files in the folder and click X!Tandem Peptide Search. If you don't see the link to click, try making your browser window wider.
Select the Analysis Protocol
Next, you'll choose the FASTA file against which you wish to search and configure other parameters, like quantitation. Save the information as a protocol for use with future searches.The sample contains an Analysis Protocol which is already configured to search an ICAT MS2 run and which instructs X! Tandem to use the k-score scoring algorithm.- Select the Analysis Protocol named k_Yeast_ICAT
- Click Search to launch the X! Tandem search.
- You will be returned to the MS2 Dashboard.
Check the Search Status
While the X! Tandem search is underway, the status of search jobs is shown in the Data Pipeline panel.- In the Data Pipeline panel, click links in the Status column to view detailed status and the pipeline log for that job.
- Note that as the jobs are completed, the results appear in the MS2 Runs panel below.
Previous Step | Next Step
Step 3: View PeptideProphet Results
View the PeptideProphet Results
- Refresh the MS2 Dashboard by clicking the "refresh page" button (or the F5 key) in your browser.
- In the MS2 Runs section, click Peroxisomal_ICAT/MM_clICAT13 (k_Yeast_ICAT).
View Peptide Details
- In the Peptides and Proteins section, under the Scan or Peptide columns, click a link for a peptide sequence.
- You'll see a page that shows spectra information, as well as quantitation results, as shown below.
- Experiment with the control panel on the left to control the visualizations on the right.

View Peptide Scores with Highest and Lowest Certainty
To view the peptides scored with the highest certainty by PeptideProphet:- Click back to the results page for Peroxisomal_ICAT/MM_clICAT13 (k_Yeast_ICAT).
- In the Peptides section, locate the PepProphet column.
- Click the column heading and choose Sort Descending to see the scores with highest certainty.
- Choose Sort Ascending to see the scores with lowest certainty.

Manage Peptide Views
In the Peptides web part, by selecting Grid Views > Customize Grid, you can manage how peptide and protein data is displayed. Add, remove, or rearrange columns, then apply sorts and filters to columns. Once you've modified the grid to your liking, you can save it as a custom grid. Custom grids can be applied to any MS/MS data set, and can be public or private. In addition to saving a custom grid, you can use options in the View web part to specify more options for how to view peptides. In each section, select a value and click Go.
In addition to saving a custom grid, you can use options in the View web part to specify more options for how to view peptides. In each section, select a value and click Go.
- Grouping: offers options for aggregating peptide data. You can specify whether peptides are viewed by themselves or grouped by the protein assigned by the search engine or by ProteinProphet group. Options include:
- Standard offers access to additional data like protein annotations and experimental annotations using LabKey Server's Query interface.
- Protein Groups displays proteins grouped by ProteinProphet protein groups.
- The other three options are for backwards compatibility with previous versions of LabKey Server.
- Hyper charge filters: Specify minimum Hyper values for peptides in each charge state (1+, 2+, 3+).
- Minimum tryptic ends: By default, zero is selected and all peptides are shown. Click 1 or 2 if you only want to see peptides where one or both ends are tryptic.
- Highest score filter: Check the box to show only the highest score for Hyper.
Previous Step | Next Step
Step 4: View ProteinProphet Results
Group Peptides by Protein
- In the View section, under Grouping, select Standard and click Go
- In the Peptides section, click Grid Views and select ProteinProphet.
 Note that there may often be more than one protein per group, but the sample data contains only one protein per group. The following image shows the expanded protein group.To see how the individual peptides found map to the protein sequence, click the protein name link as circled above.The peptides found are highlighted in the sequence.Hover over and click the highlighted area of the sequence for details.
Note that there may often be more than one protein per group, but the sample data contains only one protein per group. The following image shows the expanded protein group.To see how the individual peptides found map to the protein sequence, click the protein name link as circled above.The peptides found are highlighted in the sequence.Hover over and click the highlighted area of the sequence for details.
Previous Step | Next Step
Step 5: Compare Runs
Choose Runs and Comparison Paradigm
- Click the MS2 Dashboard tab.
- In the MS2 Runs section, select all three runs.
- Click the Compare button, and then choose how you want to compare the runs. You can compare by peptide, by protein as chosen by the search engine, or by protein as chosen by ProteinProphet. Additionally, you can use a comparison built on top of a custom grid view, or do a comparison based on spectra counting. For this tutorial, select the ProteinProphet comparison option.
- Accept the default options and click Compare.
View the Comparison Overview Venn Diagram
At the top of the page, you can expand the Comparison Overview section to see a Venn diagram of how the runs overlap:
Filter for High Confidence Matches
You can filter the list to show only high confidence matches.- In the Comparison Details section, select Grid Views > Customize Grid.
- Click the Filter tab on the left side to see any current filters (initially, there aren't any).
- Open the Protein Group node (click the "+" symbol) and check the box for Prob.
- Then, in the drop-down list that appears on the right side, select Is Greater Than Or Equal To and enter 0.8 in the text field.
- Click Save.
- In the Save Custom Grid dialog, ensure that Default grid for this page is selected, and click Save.
Understand the New Comparison Results
You'll notice that there are fewer proteins in the list now. Since you created a filter on the protein group probability, the table will only show proteins where at least one run in the list has a probability meeting your threshold.Previous Step | Next Step
Step 6: Search for a Specific Protein
Specify Your Search
- Click on the MS2 Dashboard tab at the top of the page.
- Locate the Protein Search section.
- Enter the name of the protein you want to find in the Protein Name text box. For this tutorial, enter FOX2_YEAST, one of the peroxisomal proteins identified.
- You can set a minimum ProteinProphet probability or error rate if you like, but for now just leave them blank.
- Click on Search.
Understand the Results
The results page shows you two lists. Click the "+" next to expand the first list, Matching Proteins. Matching Proteins, shows all the proteins that LabKey Server knows about that have that name. It will only show proteins that appear in FASTA files that were used for runs in the current folder. However, this top list will show proteins even if they weren't actually found in any of your runs. This helps you validate that you didn't mistype when entering the name.The second list, Protein Group Results, shows all the ProteinProphet protein groups that contain any of the proteins in the top list. You can see the probability, the run it came from, and so on.You can use the Customize Grid option under the Grid Views option to add or remove columns from the search results.
Matching Proteins, shows all the proteins that LabKey Server knows about that have that name. It will only show proteins that appear in FASTA files that were used for runs in the current folder. However, this top list will show proteins even if they weren't actually found in any of your runs. This helps you validate that you didn't mistype when entering the name.The second list, Protein Group Results, shows all the ProteinProphet protein groups that contain any of the proteins in the top list. You can see the probability, the run it came from, and so on.You can use the Customize Grid option under the Grid Views option to add or remove columns from the search results.
Previous Step
Proteomics Video
The Camtasia Studio video content presented here requires JavaScript to be enabled and the latest version of the Macromedia Flash Player. If you are you using a browser with JavaScript disabled please enable it now. Otherwise, please update your version of the free Flash Player by downloading here.
Work with MS2 Data
- Search MS2 Data Via the Pipeline: Upload MS2 data for analysis, performing processing steps at the same time.
- configMs2search: Select specific search engine.
- Search and Process MS2 Data: Configure parameters.
- Import Existing Analysis Results
- Trigger MS2 Processing Automatically
- Set Proteomics Search Tools Version
- Explore the MS2 Dashboard
- View an MS2 Run
- Compare MS2 Runs
- Export MS2 Runs
- View, Filter and Export All MS2 Runs
Related Topics
- Proteomics Tutorial: Explore the basics using sample data in our tutorial.
- Run Groups
Search MS2 Data Via the Pipeline
- The X! Tandem search engine, which searches tandem mass spectra for peptide sequences. You can configure X! Tandem search parameters from within LabKey Server to specify how the search is run.
- PeptideProphet, which validates peptide assignments made by the search engine, assigning a probability that each result is correct. - ProteinProphet, which validates protein identifications made by the search engine on the basis of peptide assignments.
- XPRESS, which performs protein quantification.
Set Up MS2 Search Engines
- Set Up Mascot - Install and configure Mascot search.
- Set Up Sequest - Install and configure Sequest search.
- Set Up Comet - Install and configure Comet search.
- Working with mzML files - Enable .mzXML.gz handling by MSInspect.
Set Up Mascot
Configure Mascot Support
If you are not familiar with your organization's Mascot installation, you will want to recruit the assistance of your Mascot administrator.
Before you configure Mascot support, have the following information ready:
- Mascot Server Name: Typically of the form mascot.server.org
- User: The user id for logging in to your Mascot server (leave blank if your Mascot server does not have security configured)
- Password: The password to authenticate you to your Mascot server (leave blank if your Mascot server does not have security configured)
- HTTP Proxy URL: Typically of the form http://proxyservername.domain.org:8080/ (leave blank if you are not using a proxy server).
Enter this information in the site-wide or project/folder specific Mascot settings, as described below.
Site-Wide Configuration
To configure Mascot support across all projects on the site:
- Select Admin > Admin Console
- In the Configuration section, click the Mascot Server link.
- Specify the Mascot server name, the user name and password used to authenticate against the Mascot server, if Mascot security is enabled. Optionally, specify the HTTP Proxy URL, if your network setup requires it.
Project and Folder Specific Configuration
You configure Mascot support for a specific project or folder that overrides any site-wide configuration. To configure project or folder specific Mascot support:
- Create or navigate to project or folder of type MS2.
- In the Data Pipeline web part, click Setup.
- Click Configure Mascot Server.
- By default, the project/folder will inherit the Mascot settings from the site-wide configuration. To override these settings for this project/folder, specify the Mascot server name, the user name and password used to authenticate against the Mascot server, if Mascot security is enabled. Optionally, specify the HTTP Proxy URL, if your network setup requires it.
Test the Mascot Configuration
To test your Mascot support configuration, select Admin > Admin Console, then click the Mascot Server link. Click Test Mascot Settings. A window will open to report the status of the testing.
If the test is successful, LabKey displays a message indicating success and displaying the settings used and the Mascot server configuration file (mascot.dat).
If the test fails, LabKey displays an error message, followed by one of the following additional messages to help you troubleshoot.
- is not a valid user: Check that you have entered the correct user account. Contact your Mascot administrator for help if problem persists.
- You have entered an invalid password: Check that you have entered the right password. Ensure that your CAPS lock and NUM lock settings are correct. Contact your Mascot administrator for help if problem persists.
- Failure to interact with Mascot Server: LabKey cannot contact the Mascot server. Please check that the Mascot server is online and that your network is working.
Set Up Sequence Database Synchronization
The Perl script labkeydbmgmt.pl supports the download of sequence database from your Mascot server. To download the Perl script, click: here The database is needed to translate the Mascot result (.dat file) to pepXML (.pep.xml file).
- Copy the Perl script labkeydbmgmt.pl to the folder /cgi/.
- Open labkeydbmgmt.pl in a text editor and change the first line to refer to your Perl executable full path. (See your copy of /cgi/search_form.pl for the correct path.)
- If your Mascot runs on a *nix system, you need to set the execution attribute. (Command: chmod a+rx labkeydbmgmt.pl).
Supported and Tested Mascot Versions
To get your Mascot server version number check with your Mascot administrator. You can use the helper application at /bin/ms-searchcontrol.exe to determine your version. Usage: ./ms-searchcontrol.exe –version.
If your Mascot Server version is v2.1.03 or later, LabKey should support it with no additional requirements. If your Mascot Server version is v2.0.x or v2.1.x (earlier than v2.1.03), you must perform the following upgrade: - Visit the Matrix Science website for the free upgrade (http://www.matrixscience.com/distiller_support.html#CLIENT). - Ask your Mascot administrator to determine the correct platform upgrade file to use and to perform the upgrade. Remember to back up all files that are to be upgraded beforehand. - As the Mascot result is retrieved via the MIME format, you must make the following highlighted changes to client.pl:
140: close(SOCK);
141: print @temp;
142:
143:# WCH: 28 July 2006
# Added to support the retrieval of Mascot .dat result file in MIME format
# This is necessary if you are using Mascot version 2.0 or 2.1.x (< v 2.1.03) and
# have upgraded to the version 2.1 Mascot daemon
} elsif (defined($thisScript->param('results'))
|| defined($thisScript->param('xmlresults'))
|| defined($thisScript->param('result_file_mime'))) {
# END - WCH: 28 July 2006
144:
145: if ($taskID < 1) {
146: print "problem=Invalid task ID - $taskID\n";
147: exit 1;
148: }
149:
150: # Same code for results and xmlresults except that the latter requires
151: # reporttop and different command to be passed to ms-searchcontrol
152: my ($cmnd, $reporttop);
153: if (defined($thisScript->param('xmlresults'))) {
154: $cmnd = "--xmlresults";
155: if (!defined($thisScript->param('reporttop'))) {
156: print "problem=Invalid reporttop\n";
157: exit 1;
158: } else {
159: $reporttop = "--reporttop " . $thisScript->param('reporttop');
160: }
# WCH: 28 July 2006
# Added to support the retrieval of Mascot .dat result file in MIME format
# This is necessary if you are using v2.0 Mascot Server and
# have upgraded to the version 2.1 Mascot Daemon
} elsif (defined($thisScript->param('result_file_mime'))) {
$cmnd = "--result_file_mime";
# END - WCH: 28 July 2006
161: } else {
162: $cmnd = "--results";
163: }
164:
165: # Call ms-searchcontrol.exe to output search results to STDOUT
Note: LabKey has not been tested against Mascot version 1.9.x or earlier. Versions earlier than 1.9.x are not supported or guaranteed to work. If you are interested in using an earlier version, you will need commercial-level support. This level of assistance is available from the LabKey technical services team. Please contact LabKey.
Related Topics
Set Up Sequest
Install the LabKey Remote Pipeline Server on an existing computer with Proteome Discoverer
In this option, you will install LabKey Remote Pipeline Server software on a computer that is currently running Proteome Discoverer software. This is our recommended solution. See Enterprise Pipeline for more information on the Enterprise Pipeline.Install JAVA on the computer running Proteome Discoverer 1.1
This software will be installed on the computer running Proteome Discoverer 1.1.- Download the Java Runtime Environment (JRE) from http://www.oracle.com/technetwork/java/javase/downloads/index.html
- Install the JRE to the chosen directory.
- Create the JAVA_HOME environmental variable to point at your installation directory.
Install the LabKey Remote Pipeline Server Software
Follow the instructions at Configure Remote Pipeline Server to install the LabKey Remote Pipeline Server on the server running Proteome Discover.Define the Location of the Remote Pipeline Server
In order for the newly installed Remote Pipeline Server to start accepting tasks from the LabKey Server, we will need to define a server location. This is configured in the pipelineConfig.xml. Open the pipelineConfig.xml file you created in the previous step and change<property name="remoteServerProperties">
<bean class="org.labkey.pipeline.api.properties.RemoteServerPropertiesImpl">
<property name="location" value="mzxmlconvert"/>
</bean>
</property>
<property name="remoteServerProperties">
<bean class="org.labkey.pipeline.api.properties.RemoteServerPropertiesImpl">
<property name="location" value="sequest"/>
</bean>
</property>
Enable Sequest Integration
Open the configuration file ms2Config.xml, that was created in the previous step, with your favorite editor. At the bottom of the file, you will want to change the text<!-- Enable Sequest integration and configure it to run on a remote pipeline server (using "sequest" as its location
property value in its pipelineConfig.xml file). Give pointers to the directory where Sequest is installed,
and a directory to use for storing FASTA index files. -->
<!--
<bean id="sequestTaskOverride" class="org.labkey.ms2.pipeline.sequest.SequestSearchTask$Factory">
<property name="location" value="sequest"/>
<property name="sequestInstallDir" value="C:\Program Files (x86)\Thermo\Discoverer\Tools\Sequest" />
<property name="indexRootDir" value="C:\FastaIndices" />
</bean>
-->
<!-- Enable Sequest integration and configure it to run on a remote pipeline server (using "sequest" as its location
property value in its pipelineConfig.xml file). Give pointers to the directory where Sequest is installed,
and a directory to use for storing FASTA index files. -->
<bean id="sequestTaskOverride" class="org.labkey.ms2.pipeline.sequest.SequestSearchTask$Factory">
<property name="location" value="sequest"/>
<property name="sequestInstallDir" value="C:\Program Files (x86)\Thermo\Discoverer\Tools\Sequest" />
<property name="indexRootDir" value="C:\FastaIndices" />
</bean>
- Find all places in the file that contain a line that starts with <property name="location"...
- Do not change location value in the sequestTaskOverride bean, shown above, that should stay as sequest
- On each line, change the value to be webserver
- Save the file
Install a JMS Queue for use with the Enterprise Pipeline
Follow the instructions at JMS Queue. We recommend installing this software on your LabKey Server.Configure your LabKey Server to use the Enterprise Pipeline
The changes below will be made on your LabKey Server.1) Enable Communication with the ActiveMQ JMS Queue:You will need to uncomment the JMS configuration settings in the LabKey configuration file (labkey.xml). The labkey.xml is normally located in CATALINA_HOME/conf/Catalina/localhost/labkey.xml. Change<!-- <Resource name="jms/ConnectionFactory" auth="Container"
type="org.apache.activemq.ActiveMQConnectionFactory"
factory="org.apache.activemq.jndi.JNDIReferenceFactory"
description="JMS Connection Factory"
brokerURL="vm://localhost?broker.persistent=false&broker.useJmx=false"
brokerName="LocalActiveMQBroker"/> -->
<Resource name="jms/ConnectionFactory" auth="Container"
type="org.apache.activemq.ActiveMQConnectionFactory"
factory="org.apache.activemq.jndi.JNDIReferenceFactory"
description="JMS Connection Factory"
brokerURL="tcp://@@JMSQUEUE@@:61616"
brokerName="LocalActiveMQBroker"/>
- where @@JMSQUEUE@@ is the hostname or IP address of the server where you installed the ActiveMQ software.
<!-- Pipeline configuration -->
<!-- <Parameter name="org.labkey.api.pipeline.config" value="C:\proj\labkey\docs\mule\config-demo"/> -->
<!-- Pipeline configuration -->
<Parameter name="org.labkey.api.pipeline.config" value="@@LABKEY_HOME@@\config"/>
- where @@LABKEY_HOME@@\config is the configuration directory location. The default setting is LABKEY_HOME\config. (i.e., replace @@LABKEY_HOME@@ with the full path to the LABKEY_HOME directory for your installation)
Restart your LabKey Server
All the configuration changes have been made to your LabKey Server. Now restart your LabKey Server and you can start testing.Install Proteome Discoverer on LabKey Server
In this option, you will install the Proteome Discoverer software on your LabKey Server. NOTE: You can only use this option if your LabKey Server is installed on a Windows XP or Windows 7 computer.Install Proteome Discoverer 1.1
Install the Proteome Discoverer software on your LabKey Server following the vendor's instructions. Ensure that the directory that contains sequest.exe and makedb.exe is placed on the PATH environment variable for the server.Download and Expand the Enterprise Pipeline Configuration files
- Goto the LabKey Download Page
- Download the Pipeline Configuration(zip) zip file
- Expand the downloaded file.
Enable SEQUEST support in LabKey Server
Create the Enterprise Pipeline configuration directory- Open Windows Explorer and goto the installation directory for your LabKey Server
- Create a new directory named config
- Write down the full path of this new directory
- Goto to the Enterprise Pipeline Configuration files that were downloaded above.
- Open the webserver directory
- Copy the ms2Config.xml file to configuration directory created in the previous step
<!-- Enable Sequest integration and configure it to run on a remote pipeline server (using "sequest" as its location
property value in its pipelineConfig.xml file). Give pointers to the directory where Sequest is installed,
and a directory to use for storing FASTA index files. -->
<!--
<bean id="sequestTaskOverride" class="org.labkey.ms2.pipeline.sequest.SequestSearchTask$Factory">
<property name="location" value="sequest"/>
<property name="sequestInstallDir" value="C:\Program Files (x86)\Thermo\Discoverer\Tools\Sequest" />
<property name="indexRootDir" value="C:\FastaIndices" />
</bean>
-->
<!-- Enable Sequest integration and configure it to run on a remote pipeline server (using "sequest" as its location
property value in its pipelineConfig.xml file). Give pointers to the directory where Sequest is installed,
and a directory to use for storing FASTA index files. -->
<bean id="sequestTaskOverride" class="org.labkey.ms2.pipeline.sequest.SequestSearchTask$Factory">
<property name="location" value="sequest"/>
<property name="sequestInstallDir" value="C:\Program Files (x86)\Thermo\Discoverer\Tools\Sequest" />
<property name="indexRootDir" value="C:\FastaIndices" />
</bean>
- change the sequestInstallDir property value to be the installation of the Sequest binary on your server.
- change the location value to be webserver
- Find all places in the file that contain a line that starts with <property name="location"...
- On each line, change the value to be webserver
- Save the file
Enable the Enterprise Pipeline configuration directory
To configure the Enterprise Pipeline configuration directory, open the LabKey configuration file (labkey.xml) and change<!-- Pipeline configuration -->
<!-- <Parameter name="org.labkey.api.pipeline.config" value="C:\proj\labkey\docs\mule\config-demo"/> -->
<!-- Pipeline configuration -->
<Parameter name="org.labkey.api.pipeline.config" value="@@LABKEY_HOME@@\config"/>
- where @@LABKEY_HOME@@\config is the configuration directory location. The default setting is LABKEY_HOME\config. (i.e., replace @@LABKEY_HOME@@ with the full path to the LABKEY_HOME directory for your installation)
Restart your LabKey Server
All the configuration changes have been made to your LabKey Server. Now restart your LabKey Server and you can start testing.Supported versions of Proteome Discoverer
LabKey currently only supports Proteome Discoverer 1.1. While other versions of Proteome Discoverer may work, they have not been tested by LabKey.How to Upgrade the Enhanced Sequest MS2 Pipeline
This page is currently under development: If you need assistance with an upgrade, please contact us on the Support Discussion BoardAdditional Features
- The Enhanced MS2 Sequest Pipeline includes the capability of indexing FASTA files using the makedb.exe utility. This makes your searches faster. It only works for Sequest. To tell Sequest to use indexed FASTA files, set the appropriate parameter on the MS2 search settings dialog. See the following for more information
- API for submitting jobs
Set Up Comet
Configure Comet Defaults
To configure the Comet default parameters:- Go to the MS2 Dashboard.
- In the Data Pipeline panel, click Setup.
- Under Comet specific settings, click Set defaults.
- Edit the XML configuration file using the Comet parameter reference.
Working with mzML files
<!-- mzML support via JNI -->
<Parameter name="org.labkey.api.ms2.mzmlLibrary" value="pwiz_swigbindings"></Parameter>
Search and Process MS2 Data
- First set up the pipeline root. See Set a Pipeline Override.
- Click the Process and Import Data button.
- Navigate through the file system hierarchy beneath the pipeline root to locate your mzXML file.
- On the MS2 Dashboard click New Assay Design in the Assay List web part.
- Select Mass Spec Metadata and specify the current folder as the location unless you want your protocol available more widely.
- Name your new protocol.
- Specify the appropriate properties and fields. Options including inferring fields from a sample file can help.
- Click Save & Close.
- Click Data Pipeline > Process and Import Data.
- Click the Admin button on the toolbar.
- In the Describe Samples section, click the box for Show on Toolbar for your newly defined protocol.
- Click Submit.
- A name for the new protocol.
- A description.
- A FASTA file to search against. The FASTA files listed are those found in the FASTA root that you specified during the Set a Pipeline Override process.
- For XTandem and Mascot searches, you can select multiple FASTAs to search against simultaneously.
- Any search engine parameters that you want to specify, if you wish to override the defaults.
Configure Common Parameters
Pipeline Parameters
The LabKey Server data pipeline adds a set of parameters specific to the web site. These parameters are defined on the pipeline group. Most of these are set in the tandem.xml by the Search MS2 Data form, and will be overwritten if specified separately in the XML section of this form.
| Parameter | Description |
|---|---|
|
pipeline, database |
The path to the FASTA sequence file to search. Sequence Database field. |
| pipeline, protocol name | The name of the search protocol defined for a data file or set of files. Protocol Name field. |
| pipeline, protocol description | The description for the search protocol. Protocol Description field. |
|
pipeline, email address |
Email address to notify of successful completion, or of processing errors. Automatically set to the email of the user submitting the form. |
| pipeline, load folder | The project folder in the web site with which the search is to be associated. Automatically set to the folder from which the search form is submitted. |
| pipeline, load spectra | Prevents LabKey Server from loading spectra data into the database. Using this parameter can significantly improve MS2 run load time. If the mzXML file is still available, LabKey Server will load the spectra directly from the file when viewing peptide details. For example:
|
| pipeline, data type |
Flag for determining how spectrum files are searched, processed and imported. The allowed (case insensitive) values are:
|
PeptideProphet and ProteinProphet Parameters
The LabKey data pipeline supports a set of parameters for controlling the PeptideProphet and ProteinProphet tools run after the peptide search. These parameters are defined on the pipeline prophet group.
| Parameter | Description |
|---|---|
|
pipeline prophet, min probability |
The minimum PeptideProphet probability to include in the pepXML file (default - 0.05). For example:
|
| pipeline prophet, min protein probability |
The minimum ProteinProphet probability to include in the protXML file (default - 0.05). For example:
|
| pipeline prophet, decoy tag | The tag used to detect decoy hits with a computed probability based on the model learned. Passed to xinteract as the 'd' argument |
| pipeline prophet, use hydrophobicity | If set to "yes", use hydrophobicity / retention time information in PeptideProphet. Passed to xinteract as the 'R' argument |
| pipeline prophet, use pI |
If set to "yes", use pI information in PeptideProphet. Passed to xinteract as the 'I'argument |
| pipeline prophet, accurate mass | If set to "yes", use accurate mass binning in PeptideProphet. Passed to xinteract as the 'A' argument |
| pipeline prophet, allow multiple instruments | If set to "yes", emit a warning instead of exit with error if instrument types between runs is different. Passed to xinteract as the 'w' argument |
| pipeline prophet, peptide extra iterations | If set, the number of extra PeptideProphet iterations. Defaults to 20. |
| pipeline, import prophet results | If set to "false", do not import PeptideProphet or ProteinProphet results after the search. Defaults to "true". |
Pipeline Quantitation Parameters
The LabKey data pipeline supports a set of parameters for running quantitation analysis tools following the peptide search. These parameters are defined on the pipeline quantitation group:
| Parameter | Description |
|---|---|
|
pipeline quantitation, algorithm |
This parameter must be set to run quantitation. Supported algorithms are xpress, q3, and libra. |
|
pipeline quantitation, residue label mass |
The format is the same as X! Tandem's residue, modification mass. There is no default value. For example:
|
| pipeline quantitation, mass tolerance | The default value is 1.0 daltons. |
| pipeline quantitation, mass tolerance units | The default value is "Daltons"; other options are not yet implemented. |
| pipeline quantitation, fix | Possible values "heavy" or "light". |
| pipeline quantitation, fix elution reference | Possible values "start" or "peak". The default value is "start". |
| pipeline quantitation, fix elution difference | A positive or negative number. |
| pipeline quantitation, metabolic search type | Possible values are "normal" or "heavy". |
| pipeline quantitation, q3 compat | If the value is "yes", passes the --compat argument when running Q3. Defaults to "no". |
| pipeline quantitation, libra config name | Name of Libra configuration file. LabKey Server supports up to 8 channels. Must be available on server's file system in <File Root>/.labkey/protocols/libra. Example file. |
| pipeline quantitation, libra normalization channel | Libra normalization channel. Should be a number (integer) from 1-8. |
ProteoWizard msconvert Parameters
LabKey Server can be configured to use ProteoWizard's msconvert tool to convert from instrument vendor binary file formats to mzXML. As of version 12.1, the Windows installer configures the server to automatically use msconvert for converting Thermo .RAW files to .mzXML, and 15.3 adds support for SciEx .wiff files.
| Parameter | Description |
|
pipeline msconvert, conversion bits |
Number of bits of precision to use when converting spectra to mzXML. Possible values are "32" or "64". Defaults to not specifying a bit depth, leaving it to the msconvert default (64). |
|
pipeline msconvert, mz conversion bits |
Number of bits of precision to use for encoding m/z values. Possible values are "32" or "64". Defaults to not specifying a bit depth, leaving it to the msconvert default (64). (Added in 15.3) |
| pipeline msconvert, intensity conversion bits | Number of bits of precision to use for encoding intensity values. Possible values are "32" or "64". Defaults to not specifying a bit depth, leaving it to the msconvert default (32). (Added in 15.3) |
| pipeline msconvert, index | Pass-through parameters to control --filter arguments to msconvert. (Added in 15.3) |
| pipeline msconvert, precursorRecalculation | |
| pipeline msconvert, precursorRefine | |
| pipeline msconvert, peakPicking | |
| pipeline msconvert, scanNumber | |
| pipeline msconvert, scanEvent | |
| pipeline msconvert, scanTime | |
| pipeline msconvert, sortByScanTime | |
| pipeline msconvert, stripIT | |
| pipeline msconvert, msLevel | |
| pipeline msconvert, metadataFixer | |
| pipeline msconvert, titleMaker | |
| pipeline msconvert, threshold | |
| pipeline msconvert, mzWindow | |
| pipeline msconvert, mzPrecursors | |
| pipeline msconvert, defaultArrayLength | |
| pipeline msconvert, chargeStatePredictor | |
| pipeline msconvert, activation | |
| pipeline msconvert, analyzerType | |
| pipeline msconvert, analyzer | |
| pipeline msconvert, polarity | |
| pipeline msconvert, zeroSamples |
ProteoWizard mspicture Parameters
LabKey Server can be configured to use ProteoWizard's mspicture tool to generate images from MS data files.
| Parameter | Description |
|
pipeline mspicture, enable |
Calls mspicture as part of the workflow and associates the resulting images with the rest of the run. For example:
|
MS2 Search Engine Parameters
For information on settings specific to particular search engines, see:
Configure X! Tandem Parameters
X! Tandem is an open-source search engine that matches tandem mass spectra with peptide sequences. LabKey Server uses X! Tandem to search an mzXML file against a FASTA database and displays the results in the MS2 viewer for analysis.
Modifying X! Tandem Settings in LabKey Server
For many applications, the X! Tandem default settings used by LabKey Server are likely to be adequate, so you may not need to change them. If you do wish to override some of the default settings, you can do so in one of two ways:
- You can modify the default X! Tandem parameters for the pipeline, which will set the defaults for every search protocol defined for data files in the pipeline (see Set Up the LabKey Pipeline Root).
- You can override the default X! Tandem parameters for an individual search protocol (see Search and Process MS/MS Data).
Note: When you create a new search protocol for a given data file or set of files, you can override the default parameters. In LabKey Server, the default parameters are defined in a file named default_input.xml file, at the pipeline root. You can modify the default parameters for the pipeline during the pipeline setup process, or you can accept the installed defaults. If you are modifying search protocol parameters for a specific protocol, the parameter definitions in the XML block on the search page are merged with the defaults at runtime.
If you're just getting started with LabKey Server, the installed search engine defaults should be sufficient to meet your needs until you're more familiar with the system.
X! Tandem Search Parameters
See the section entitled "Search Parameter Syntax" under Search and Process MS2 Data for general information on parameter syntax. Most X! Tandem parameters are defined in the X! Tandem documentation, available here:
http://www.thegpm.org/TANDEM/api/index.html
LabKey Server provides additional parameters for X! Tandem for working with the data pipeline and for performing quantitation. For further details, please see: Configure Common Parameters.
Selecting a Scoring Technique
X!Tandem supports pluggable scoring implementations. The version of X!Tandem included with the LabKey Server Windows installer includes both X!Tandem's native scoring (the default), and k-score. You can choose an alternate scoring implementation with this parameter:
<note label="scoring, algorithm" type="input">k-score</note>
Examples of Commonly Modified Parameters
As you become more familiar with LabKey Server and X! Tandem, you may wish to override the default X! Tandem parameters to hone your search more finely. Note that the X! Tandem default values provide good results for most purposes, so it's not necessary to override them unless you have a specific purpose for doing so.
The get started tutorial overrides some of the default X! Tandem parameters to demonstrate how to change certain ones. The override values are stored with the tutorial's ready-made search protocol, and appear as follows:
<?xml version="1.0" encoding="UTF-8"?>
<bioml>
<!-- Override default parameters here. -->
<note label="spectrum, parent monoisotopic mass error minus" type="input">2.1</note>
<note label="spectrum, fragment mass type" type="input">average</note>
<note label="residue, modification mass" type="input">227.2@C</note>
<note label="residue, potential modification mass" type="input">16.0@M,9.0@C</note>
<note label="pipeline quantitation, residue label mass" type="input">9.0@C</note>
<note label="pipeline quantitation, algorithm" type="input">xpress</note>
</bioml>
Taking each parameter in turn:
- spectrum, parent monoisotopic mass error minus: The default is 2.0; 2.1 is specified here to allow for the mass spectrometer being off by two peaks in its pick of the precursor parent peak in the first MS phase.
- spectrum, fragment mass type: The default value is "monoisotopic"; "average" specifies that a weighted average is used to calculate the masses of the fragment ions in a tandem mass spectrum.
- residue, modification mass: A comma-separated list of fixed modifications.
- residue, potential modification mass: A comma-separated list of variable modification.
- pipeline quantitation, residue label mass: Specifies that quantitation is to be performed.
- pipeline quantitation, algorithm: Specifies that XPRESS should be used for quantitation.
Configure Mascot Parameters
Modifying Mascot Settings in LabKey Server
For many applications, the Mascot default settings used by LabKey Server are likely to be adequate, so you may not need to change them. If you do wish to override some of the default settings, you can do so in one of two ways:- You can modify the default Mascot parameters for the pipeline, which will set the defaults for every search protocol defined for data files in the pipeline (see Set a Pipeline Override).
- You can override the default Mascot parameters for an individual search protocol (see Search and Process MS2 Data).
Configuring MzXML2Search parameters
You can control some of the MzXML2Search parameters from LabKey Server, which are used to convert mzXML files to MGF files before submitting them to Mascot.<note type="input" label="spectrum, minimum parent m+h">MIN_VALUE</note><note type="input" label="spectrum, maximum parent m+h">MAX_VALUE</note>These settings control the range of MH+ mass values that will be included in the MGF file.
Using X! Tandem Syntax for Mascot parameters
You don't have to be knowledgeable about XML to modify Mascot parameters in LabKey Server. You only need to find the parameter that you need to change, determine what value you want to set it to, and paste the correct line into the Mascot XML section when you create your MS2 search protocol.The Mascot parameters that you see in a standard Mascot search page are defined here:| GROUP | NAME | Default | Notes | |
|---|---|---|---|---|
| mascot | peptide_charge | 1+, 2+ and 3+ | Peptide charge state to search if not specified | |
| mascot | enzyme | Trypsin | Enzyme (see /<mascot dir>/config/enzymes) | |
| mascot | comment | n.a. | Search Title or comments | |
| pipeline | database | n.a. | Database (see /<mascot dir>/config/mascot.dat) | |
| spectrum | path | n.a. | Data file | |
| spectrum | path type | Mascot generic | Data format | |
| mascot | icat | off | Treat as ICAT data? (value: off / on) | |
| mascot | decoy | off | Perform automatic decoy search (value: off / on) | |
| mascot | instrument | Default | Instrument | |
| mascot | variable modifications | n.a. | Variable modifications (see /<mascot dir>/config/mod_file) | |
| spectrum | fragment mass error | n.a. | MS/MS tol. (average mass) | |
| spectrum | fragment monoisotopic mass error | n.a. | MS/MS tol. (monoisotopic mass) | |
| spectrum | fragment mass error units | n.a. | MS/MS tol. unit (average mass, value: mmu / Da) | |
| spectrum | fragment monoisotopic mass error units | n.a. | MS/MS tol. unit (monoisotopic mass, value: mmu / Da) | |
| spectrum | fragment mass type | n.a. | mass (value: Monoisotopic / Average) | |
| mascot | fixed modifications | n.a. | Fixed modifications (see /<mascot dir>/config/mod_file) | |
| mascot | overview | Off | Provide overview in Mascot result | |
| scoring | maximum missed cleavage sites | 1 | Missed cleavages | |
| mascot | precursor | n.a. | Precursor | |
| mascot | report top results | n.a. | Specify the number of hits to report | |
| mascot | protein mass | n.a. | Protein Mass | |
| protein | taxon | n.a. | taxonomy (See /<mascot dir>/config/taxonomy) | |
| spectrum | parent monoisotopic mass error plus | n.a. | Peptide tol. maximum of plus and minus error | |
| spectrum | parent monoisotopic mass error minus | n.a. | Peptide tol. | |
| spectrum | parent monoisotopic mass error units | n.a. | Peptide tol. unit (value: mmu / Da / % / ppm) | |
| mascot | import dat results | false | Import Mascot search results directly from .dat file (value: true / false) |
- <note type="input" label="GROUP, NAME">VALUE</note>
- <note type="input" label="mascot, instrument">MALDI-TOF-TOF</note>
Pipeline Parameters
The LabKey Server data pipeline adds a set of parameters specific to the web site. Please see Pipeline Parameters section in Configure X! Tandem Parameters.Pipeline Prophet Parameters
The LabKey Server data pipeline supports a set of parameters for controlling the PeptideProphet and ProteinProphet tools run after the peptide search. Please see Pipeline Prophet Parameters section in Configure X! Tandem Parameters.Pipeline Quantitation Parameters
The LabKey Server data pipeline supports a set of parameters for running quantitation analysis tools following the peptide search. Please see Pipeline Quantitation Parameters section in Configure X! Tandem Parameters.Some examples
Example 1Perform MS/MS ion search with the followings: Enzyme "Trypsin", Peptide tol. "2.0 Da", MS/MS tol. "1.0 Da", "Average" mass and Peptide charge "2+ and 3+".<?xml version="1.0"?>
<bioml>
<!-- Override default parameters here. -->
<note type="input" label="mascot, enzyme" >Trypsin</note>
<note type="input" label="spectrum, parent monoisotopic mass error plus" >2.0</note>
<note type="input" label="spectrum, parent monoisotopic mass error units" >Da</note>
<note type="input" label="spectrum, fragment mass error" >1.0</note>
<note type="input" label="spectrum, fragment mass error units" >Da</note>
<note type="input" label="spectrum, fragment mass type" >Average</note>
<note type="input" label="mascot, peptide_charge" >2+ and 3+</note>
</bioml>
<?xml version="1.0"?>
<bioml>
<!-- Override default parameters here. -->
<note type="input" label="scoring, maximum missed cleavage sites" >2</note>
<note type="input" label="spectrum, fragment mass type" >Monoisotopic</note>
<note type="input" label="mascot, report top results" >50</note>
</bioml>
<?xml version="1.0"?>
<bioml>
<!-- Override default parameters here. -->
<note label="pipeline quantitation, residue label mass" type="input">9.0@C</note>
<note label="spectrum, parent monoisotopic mass error plus" type="input">2.1</note>
<note label="spectrum, parent monoisotopic mass error units" type="input">Da</note>
<note label="mascot, variable modifications" type="input">ICAT_heavy,ICAT_light</note>
<!-- search, comp is optional and result could be slightly different -->
<note label="search, comp" type="input">*[C]</note>
</bioml>
Configure Sequest Parameters
Sequest, by Thermo Sciences, is a search engine that matches tandem mass spectra with peptide sequences. LabKey Server uses Sequest to search an mzXML file against a FASTA database and displays the results in the MS2 viewer for analysis.
Because LabKey Server can search with several different search engines, a common format was chosen for entering search parameters. The format for the search parameters is based on the input.xml format, developed for X!Tandem. LabKey Server includes a set of default Sequest search parameters. These default parameters can be overwritten on the search form.
Topics:
- Sequest Parameters
- MzXML2Search Parameters
- Pipeline Parameters
- Examples of Commonly Modified Parameters
The Sequest/LabKey Server integration was made possible by:
![]()
![]()
![]()
Sequest Parameters
Modifying Sequest Settings in LabKey Server
Sequest settings are based on the sequest.params file (See your Sequest documentation). For many applications, the Sequest default settings used by LabKey Server are likely to be adequate, so you may not need to change them. If you do wish to override some of the default settings, you can do so in one of two ways:
-
You can modify the default Sequest parameters for the pipeline, which will set the defaults for every search protocol defined for data files in the pipeline (see Set the LabKey Pipeline Root).
-
You can override the default Sequest parameters for an individual search protocol (see Search and Process MS/MS Data).
Sequest takes parameters specified in XML format. In LabKey Server, the default parameters are defined in a file named sequest_default.input.xml, at the pipeline root. When you create a new search protocol for a given data file or set of files, you can override the default parameters. Each search protocol has a corresponding Sequest Sequest analysis definition file, and any parameters that you override are stored in the file, named sequest.xml by default.
Note: If you are modifying a sequest.xml file by hand, you don't need to copy parameter values from the sequest_default_input.xml file. The parameters definitions in these files are merged by LabKey Server at runtime.
Using X!Tandem Syntax for Sequest Parameters
You don't have to be knowledgeable about XML to modify Sequest parameters in LabKey Server. You only need to find the parameter that you need to change, determine the value want to set it to, and paste the correct line into the Sequest XML section when you create your MS2 search protocol.
When possible the Sequest parameters will use the same tags already defined for X!Tandem. Most X!Tandem tags are defined in the X!Tandem documentation, available here:
http://www.thegpm.org/TANDEM/api/index.html
As you'll see in the X!Tandem documentation, the general format for a parameter is as follows:
<note type="input" label="GROUP, NAME">VALUE</note>
For example, in the following entry, the parameter group is residue, and the parameter name is modification mass. The value given for the modification mass is 227.2 daltons at cysteine residues.
<note type="residue, modification mass">227.2@C</note>
LabKey Server provides additional parameters for Sequest where X!Tandem does not have an equivlent parameter, for working with the data pipeline and for performing quantitation, described in the following sections.
The Sequest parameters the you see in a standard sequest.params file are defined here:
| sequest.params name | GROUP | NAME | Default | Notes |
| first_database_name | pipeline | database | n.a. | Entered through the search form. |
| peptide_mass_tolerance | spectrum |
parent monoisotopic mass error plus parent monoisotopic mass error minus |
2.0f | They must be set to the same value |
| use an indexed ("pre-digested") fasta file | pipeline |
use_index |
0 (no) | If set, the SEQUEST pipeline will use a fasta file index to perform the search. If the index does not already exist, the pipeline will invoke makedb.exe to create the index. 1 means yes |
| name of indexed fasta file | pipeline |
index_name |
empty | (Optional). Specifies the name of the index to generate and use. If no name is specified, the SEQUEST pipeline will create a name based on the values of the search parameters, in particular the enzyme_info. |
| peptide_mass_units | spectrum | parent monoisotopic mass error units | Daltons | The value for this parameter may be 'Daltons' or 'ppm': all other values are ignored |
| ion_series | scoring |
a ions |
no yes no no yes no |
On is 1 and off is 0. No fractional values. |
| sequest |
d ions |
no |
||
| fragment_ion_tolerance | spectrum | fragment mass error | 1.0 | |
| num_output_lines | sequest | num_output_lines | 10 | |
| num_results | sequest | num_results | 500 | |
| num_description_lines | sequest | num_description_lines | 5 | |
| show_fragment_ions | sequest | show_fragment_ions | 0 | |
| print_duplicate_references | sequest | print_duplicate_references | 40 | |
| enzyme_info | protein | cleavage site |
[RK]|{P} |
|
|
max_num_differential_AA_per_mod |
sequest | max_num_differential_AA_per_mod | 3 | |
| max_num_differential_per_peptide | sequest | max_num_differential_per_peptide | 3 | |
| diff_search_options | residue | potential modification mass | none | |
| term_diff_search_options | refine |
potential N-terminus modifications potential C-terminus modifications |
none | |
| nucleotide_reading_frame | n.a | n.a | 0 | Not settable. |
| mass_type_parent | sequest | mass_type_parent | 0 | 0=average masses 1=monoisotopic masses |
| mass_type_fragment | spectrum | fragment mass type | 1 | 0=average masses 1=monoisotopic masses |
| normalize_xcorr | sequest | normalize_xcorr | 0 | |
|
remove_precursor_peak |
sequest | remove_precursor_peak | 0 | 0=no 1=yes |
| ion_cutoff_percentage | sequest | ion_cutoff_percentage | 0 | |
| max_num_internal_cleavage_sites | scoring | maximum missed cleavage sites | 2 | |
| protein_mass_filter | n.a. | n.a. | 0 0 | Not settable. |
| match_peak_count | sequest | match_peak_count | 0 | |
| match_peak_allowed_error | sequest | match_peak_allowed_error | 1 | |
| match_peak_tolerance | sequest | match_peak_tolerance | 1 | |
| create_output_files | n.a. | n.a. | 1 |
Not settable. |
| partial_sequence | n.a. | n.a. | none | Not settable. |
| sequence_header_filter | n.a. | n.a. | none | Not settable. |
| add_Cterm_peptide | protein | cleavage C-terminal mass change | 0 | |
| add_Cterm_protein | protein | C-terminal residue modification mass | 0 | |
| add_Nterm_peptide | protein | cleavage N-terminal mass change | 0 | |
| add_Nterm_protein | protein | protein, N-terminal residue modification mass | 0 | |
|
add_G_Glycine |
residue | modification mass | 0 |
MzXML2Search Parameters
The mzXML data files must be converted to Sequest .dta files to be accepted by the Sequest application. The MzXML2Search executable is used to convert the mzXML files and can also do some filtering of the scans that will be converted to .dta files. Arguments are passed to the MzXML2Search executable the same way that parameters are passed to Sequest. The available MzXML2Search parameters are:
| MzXML2Search argument | GROUP | NAME | Default | Notes |
| -F<num> | MzXML2Search | first scan | none | Where num is an int specifying the first scan |
| -L<num> | MzXML2Search | last scan | none | Where num is an int specifying the last scan |
| -C<n1>[-<n2>] | MzXML2Search | charge | 1,3 | Where n1 is an int specifying the precursor charge state to analyze and n2 is the end of a charge range (e.g. 1,3 will include charge states 1 thru 3). |
Examples of Commonly Modified Parameters
As you become more familiar with LabKey proteomics tools and Sequest, you may wish to override the default Sequest parameters to hone your search more finely. Note that the Sequest default values provide good results for most purposes, so it's not necessary to override them unless you have a specific purpose for doing so.
The get started tutorial overrides some of the default X! Tandem parameters to demonstrate how to change certain ones. Below are the override values to use if sequest is the search engine:
<?xml version="1.0" encoding="UTF-8"?>
<bioml>
<!-- Override default parameters here. -->
<note label="spectrum, parent monoisotopic mass error plus" type="input">2.1</note>
<note label="spectrum, parent monoisotopic mass error minus" type="input">2.1</note>
<note label="spectrum, fragment mass type" type="input">average</note>
<note label="residue, modification mass" type="input">227.2@C</note>
<note label="residue, potential modification mass" type="input">16.0@M,9.0@C</note>
<note label="pipeline quantitation, residue label mass" type="input">9.0@C</note>
<note label="pipeline quantitation, algorithm" type="input">xpress</note>
</bioml>
Taking each parameter in turn:
- spectrum, parent monoisotopic mass error minus: The default is 2.0; 2.1 is specified here. Sequest requires a symetric value so bothe plus and minus must be set to the same value.
- spectrum, fragment mass type: The default value is "monoisotopic"; "average" specifies that a weighted average is used to calculate the masses of the fragment ions in a tandem mass spectrum.
- residue, modification mass: A comma-separated list of fixed modifications.
- residue, potential modification mass: A comma-separated list of variable modification.
- pipeline quantitation, residue label mass: Specifies the residue and weight difference for quantitation.
- Specifies that quantitation is to be performed (using XPRESS).
Configure Comet Parameters
Search Using Comet
To search using Comet:
- Go the MS2 Dashboard.
- In the Data Pipeline panel, click Process and Import Data.
- In the Files panel, select one or more mass spec data files.
- Click Comet Peptide Search.
- Then select or create an analysis protocol to use and click **Search**.
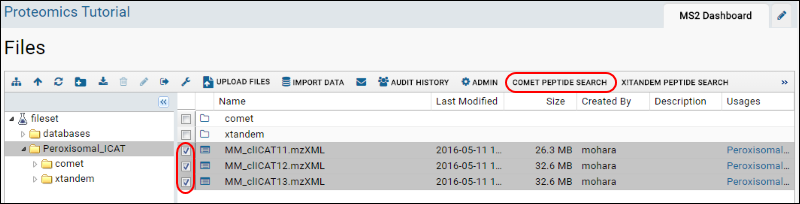
Comet Versions
LabKey Server 16.1 supports parameters from Comet 2015 and 2014 releases. Prior versions only support Comet 2014. By default, 2015 will be assumed, but you can specify that the server should generate a comet.params for 2014 versions using:
<note label="comet, version" type="input">2014</note>
Comet Parameters
To set the value of a parameter, add a line to your search protocol such as:
<note label="comet, activation_method" type="input">CID</note>
For details on setting default (and overriding) Comet parameters, see Set Up Comet.
| comet.params parameter | Description | LabKey Server search protocol parameter | Comet Version |
| activation_method = ALL |
activation method; used if activation method set; |
comet, activation_method | 2014 and later |
| add_A_alanine = 0.0000 | added to A - avg. 71.0779, mono. 71.03711 | residue, modification mass | 2014 and later |
| add_B_user_amino_acid = 0.0000 | added to B - avg. 0.0000, mono. 0.00000 | residue, modification mass | 2014 and later |
| add_C_cysteine = 57.021464 | added to C - avg. 103.1429, mono. 103.00918 | residue, modification mass | 2014 and later |
| add_Cterm_peptide = 0.0 | residue, modification mass | 2014 and later | |
| add_Cterm_protein = 0.0 | residue, modification mass | 2014 and later | |
| add_D_aspartic_acid = 0.0000 | added to D - avg. 115.0874, mono. 115.02694 | residue, modification mass | 2014 and later |
| add_E_glutamic_acid = 0.0000 | added to E - avg. 129.1140, mono. 129.04259 | residue, modification mass | 2014 and later |
| add_F_phenylalanine = 0.0000 | added to F - avg. 147.1739, mono. 147.06841 | residue, modification mass | 2014 and later |
| add_G_glycine = 0.0000 | added to G - avg. 57.0513, mono. 57.02146 | residue, modification mass | 2014 and later |
| add_H_histidine = 0.0000 | added to H - avg. 137.1393, mono. 137.05891 | residue, modification mass | 2014 and later |
| add_I_isoleucine = 0.0000 | added to I - avg. 113.1576, mono. 113.08406 | residue, modification mass | 2014 and later |
| add_J_user_amino_acid = 0.0000 | added to J - avg. 0.0000, mono. 0.00000 | residue, modification mass | 2014 and later |
| add_K_lysine = 0.0000 | added to K - avg. 128.1723, mono. 128.09496 | residue, modification mass | 2014 and later |
| add_L_leucine = 0.0000 | added to L - avg. 113.1576, mono. 113.08406 | residue, modification mass | 2014 and later |
| add_M_methionine = 0.0000 | added to M - avg. 131.1961, mono. 131.04048 | residue, modification mass | 2014 and later |
| add_N_asparagine = 0.0000 | added to N - avg. 114.1026, mono. 114.04293 | residue, modification mass | 2014 and later |
| add_Nterm_peptide = 0.0 | residue, modification mass | 2014 and later | |
| add_Nterm_protein = 0.0 | residue, modification mass | 2014 and later | |
| add_O_ornithine = 0.0000 | added to O - avg. 132.1610, mono 132.08988 | residue, modification mass | 2014 and later |
| add_P_proline = 0.0000 | added to P - avg. 97.1152, mono. 97.05276 | residue, modification mass | 2014 and later |
| add_Q_glutamine = 0.0000 | added to Q - avg. 128.1292, mono. 128.05858 | residue, modification mass | 2014 and later |
| add_R_arginine = 0.0000 | added to R - avg. 156.1857, mono. 156.10111 | residue, modification mass | 2014 and later |
| add_S_serine = 0.0000 | added to S - avg. 87.0773, mono. 87.03203 | residue, modification mass | 2014 and later |
| add_T_threonine = 0.0000 | added to T - avg. 101.1038, mono. 101.04768 | residue, modification mass | 2014 and later |
| add_U_user_amino_acid = 0.0000 | added to U - avg. 0.0000, mono. 0.00000 | residue, modification mass | 2014 and later |
| add_V_valine = 0.0000 | added to V - avg. 99.1311, mono. 99.06841 | residue, modification mass | 2014 and later |
| add_W_tryptophan = 0.0000 | added to W - avg. 186.0793, mono. 186.07931 | residue, modification mass | 2014 and later |
| add_X_user_amino_acid = 0.0000 | added to X - avg. 0.0000, mono. 0.00000 | residue, modification mass | 2014 and later |
| add_Y_tyrosine = 0.0000 | added to Y - avg. 163.0633, mono. 163.06333 | residue, modification mass | 2014 and later |
| add_Z_user_amino_acid = 0.0000 | added to Z - avg. 0.0000, mono. 0.00000 | residue, modification mass | 2014 and later |
| allowed_missed_cleavage = 2 | maximum value is 5; for enzyme search | scoring, maximum missed cleavage sites | 2014 and later |
| clear_mz_range = 0.0 0.0 | for iTRAQ/TMT type data; will clear out all peaks in the specified m/z range | comet, clear_mz_range | 2014 and later |
| clip_nterm_methionine = 0 | 0=leave sequences as-is; 1=also consider sequence w/o N-term methionine | comet, clip_nterm_methionine | 2014 and later |
| database_name = c:\temp\comet\Bovine_mini.fasta | pipeline, database | 2014 and later | |
| decoy_prefix = DECOY_ | comet, decoy_prefix | 2014 and later | |
| decoy_search = 0 | 0=no (default), 1=concatenated search, 2=separate search | comet, decoy_search | 2014 and later |
| digest_mass_range = 600.0 5000.0 | MH+ peptide mass range to analyze | comet, digest_mass_range | 2014 and later |
| fragment_bin_offset = 0.4 | offset position to start the binning (0.0 to 1.0) | comet, fragment_bin_offset | 2014 and later |
| fragment_bin_tol = 1.0005 | binning to use on fragment ions | spectrum, fragment mass error | 2014 and later |
| isotope_error = 0 | 0=off, 1=on -1/0/1/2/3 (standard C13 error), 2= -8/-4/0/4/8 (for +4/+8 labeling) | comet, isotope_error | 2014 and later |
| mass_offsets | one or more mass offsets to search (values substracted from deconvoluted precursor mass) | comet, mass_offsets | 2015 and later |
| mass_type_parent = 1 | 0=average masses, 1=monoisotopic masses | comet, mass_type_parent | 2014 and later |
| max_fragment_charge = 3 | set maximum fragment charge state to analyze (allowed max 5) | comet, max_fragment_charge | 2014 and later |
| max_precursor_charge = 6 | set maximum precursor charge state to analyze (allowed max 9) | comet, max_precursor_charge | 2014 and later |
| max_variable_mods_in_peptide = 5 | comet, max_variable_mods_in_peptide | 2014 and later | |
| minimum_intensity = 0 | minimum intensity value to read in | comet, minimum_intensity | 2014 and later |
| minimum_peaks = 10 | minimum num. of peaks in spectrum to search (default 10) | comet, minimum_peaks | 2014 and later |
| ms_level = 2 | MS level to analyze, valid are levels 2 (default) or 3 | comet, ms_level | 2014 and later |
| nucleotide_reading_frame = 0 | 0=proteinDB, 1-6, 7=forward three, 8=reverse three, 9=all six | N/A | 2014 and later |
| num_enzyme_termini = 2 | valid values are 1 (semi-digested), 2 (fully digested, default), 8 N-term, 9 C-term | comet, num_enzyme_termini | 2014 and later |
| num_output_lines = 5 | num peptide results to show | comet, num_output_lines | 2014 and later |
| num_results = 50 | number of search hits to store internally | comet, num_results | 2014 and later |
| num_threads = 0 | 0=poll CPU to set num threads; else specify num threads directly (max 32) | comet, num_threads | 2014 and later |
| override_charge | 0=no, 1=override precursor charge states, 2=ignore precursor charges outside precursor_charge range, 3=see online | comet, override_charge | 2015 and later |
| peptide_mass_tolerance = 3.00 | spectrum, parent monoisotopic mass error minus spectrum, parent monoisotopic mass error plus |
2014 and later | |
| peptide_mass_units = 0 | 0=amu, 1=mmu, 2=ppm | spectrum, parent monoisotopic mass error units | 2014 and later |
| precursor_charge = 0 0 | precursor charge range to analyze; does not override mzXML charge; 0 as 1st entry ignores parameter | comet, precursor_charge | 2014 and later |
| precursor_tolerance_type = 0 | 0=MH+ (default), 1=precursor m/z | comet, precursor_tolerance_type | 2014 and later |
| print_expect_score = 1 | 0=no, 1=yes to replace Sp with expect in out & sqt | comet, print_expect_score | 2014 and later |
| remove_precursor_peak = 0 | 0=no, 1=yes, 2=all charge reduced precursor peaks (for ETD) | comet, remove_precursor_peak | 2014 and later |
| remove_precursor_tolerance = 1.5 | +- Da tolerance for precursor removal | comet, remove_precursor_tolerance | 2014 and later |
| require_variable_mod | N/A | 2015 and later | |
| sample_enzyme_number = 1 | Sample enzyme which is possibly different than the one applied to the search. | protein, cleavage site | 2014 and later |
| scan_range = 0 0 | start and scan scan range to search; 0 as 1st entry ignores parameter | comet, scan_range | 2014 and later |
| search_enzyme_number = 1 | choose from list at end of this params file | protein, cleavage site | 2014 and later |
| show_fragment_ions = 0 | 0=no, 1=yes for out files only | comet, show_fragment_ions | 2014 and later |
| skip_researching = 1 | for '.out' file output only, 0=search everything again (default), 1=don't search if .out exists | N/A | 2014 and later |
| spectrum_batch_size = 0 | max. of spectra to search at a time; 0 to search the entire scan range in one loop | comet, spectrum_batch_size | 2014 and later |
| theoretical_fragment_ions = 1 | 0=default peak shape, 1=M peak only | comet, theoretical_fragment_ions | 2014 and later |
| use_A_ions = 0 | scoring, a ions | 2014 and later | |
| use_B_ions = 1 | scoring, b ions | 2014 and later | |
| use_C_ions = 0 | scoring, c ions | 2014 and later | |
| use_NL_ions = 1 | 0=no, 1=yes to consider NH3/H2O neutral loss peaks | comet, use_NL_ions | 2014 and later |
| use_sparse_matrix = 0 | N/A | 2014 and later | |
| use_X_ions = 0 | scoring, x ions | 2014 and later | |
| use_Y_ions = 1 | scoring, y ions | 2014 and later | |
| use_Z_ions = 0 | scoring, z ions | 2014 and later | |
| variable_C_terminus = 0.0 | residue, potential modification mass | 2014 | |
| variable_C_terminus_distance = -1 | -1=all peptides, 0=protein terminus, 1-N = maximum offset from C-terminus | comet, variable_N_terminus_distance | 2014 |
| variable_mod1 = 15.9949 M 0 3 | residue, potential modification | 2014 | |
| variable_mod2 = 0.0 X 0 3 | |||
| variable_mod3 = 0.0 X 0 3 | |||
| variable_mod4 = 0.0 X 0 3 | |||
| variable_mod5 = 0.0 X 0 3 | |||
| variable_mod6 = 0.0 X 0 3 | |||
| variable_N_terminus = 0.0 | residue, potential modification mass | 2014 | |
| variable_N_terminus_distance = -1 | -1=all peptides, 0=protein terminus, 1-N = maximum offset from N-terminus | comet, variable_N_terminus_distance | 2014 |
| variable_mod01 = 15.9949 M 0 3 -1 0 0 | <mass> <residues> <0=variable/else binary> <max_mods_per_peptide> <term_distance> <n/c-term> <required> |
residue, potential modification |
2015 and later |
| variable_mod02 = 0.0 X 0 3 -1 0 0 | |||
| variable_mod03 = 0.0 X 0 3 -1 0 0 | |||
| variable_mod04 = 0.0 X 0 3 -1 0 0 | |||
| variable_mod05 = 0.0 X 0 3 -1 0 0 | |||
| variable_mod06 = 0.0 X 0 3 -1 0 0 | |||
| variable_mod07 = 0.0 X 0 3 -1 0 0 | |||
| variable_mod08 = 0.0 X 0 3 -1 0 0 | |||
| variable_mod09 = 0.0 X 0 3 -1 0 0 |
Import Existing Analysis Results
- After you've set up the pipeline root (see Set a Pipeline Override), click the Process and Import Data button.
- Navigate through the file system hierarchy beneath the pipeline root to locate your data files file.
 In the Import Data pop up dialog, click Import to confirm the pipeline job.
In the Import Data pop up dialog, click Import to confirm the pipeline job. LabKey Server supports importing the following MS2 file types:
LabKey Server supports importing the following MS2 file types:
- *.pep.xml (MS2 search results, PeptideProphet results)
- *.prot.xml (ProteinProphet results)
- *.dat (Mascot search results)
- *.xar.xml (Experiment archive metadata)
- *.xar (Compressed experiment archive with metadata)
Trigger MS2 Processing Automatically
Overview of the MS2 Notification APIs
LabKey Server includes two server APIs and associated java-language wrappers that support automatic processing of MS spectra files as they are produced by the mass spectrometer, without operator intervention. This document describes their configuration and use: MS2 Notification APIs.docxA few excerpts from this document:The LabKey Server Enterprise Pipeline is designed to be used in a shared file system configuration with the MS instrument. In this configuration data files are copied from the instrument to a directory shared with the LabKey Server and with its remote task runners. From the LabKey Server's perspective, this directory lives under the Pipeline root directory for a given folder. Once the raw data files are copied, the Pipeline web part can be used to manually select a search protocol and initiate search processing. Alternately, these notification APIs can be called by a batch processing step after the copy to the shared pipeline directory is complete.- The StartSearchCommand initiates MS2 searching on one or more specified data files using a named, pre-configured search protocol. If a data file is not found in the specified location at the time this command is called, the search job will still be initiated and will enter a "File Waiting" status.
- The FileNotificationCommand tells LabKey Server to check for any jobs in a given folder that are in the File Waiting status. A File Waiting status is cleared if the specified file being waited for is found in the expected pipeline location. If the waited-for file is not present the File Waiting status remains until it is checked again the next time a FileNotificationCommand is called on that folder.
- The MS2SearchClient class takes data file and protocol information from a CSV file and uses it to call StartSearchCommand one or more times. The CSV file contents are also saved at the server using the SubmitAssayBatches API. MS2SearchClient is designed to be called in a batch file.
- The PipelineFileAvailableClient is a simple wrapper over FileNotificationCommand to enable calling from a batch file.
Set Proteomics Search Tools Version
Introduction
The LabKey Enterprise Pipeline gives you are the ability to specify the version of Proteomics Search tools to be used during your analysis. The version of the Proteomics Search tools to be used can be set at the Server, Pipeline and/or individual search level. The tools covered on this page:- X!Tandem
- Trans Proteomic Pipeline
- msconvert and other ProteoWizard tools
- Server-wide default version of tools
- Pipeline-default version of tools
- Version used during a Search
Prerequisites
The new version(s) of the Search Tools must be installed on your Enterprise Pipeline Servers.The name of the installation directory for each tool is very important. LabKey uses the following naming convention for each of the tools:- X!Tandem
- Installation directory name = `tandem.VERSIONNUMBER`
- where VERSIONNUMBER is the version of the X!Tandem binary contained in the directory (e.g.. `tandem.2009.10.01.1`)
- Trans Proteomic Pipeline
- Installation directory name = `tpp.VERSIONNUMBER`
- where VERSIONNUMBER is the version of the TPP binaries contained in the directory (e.g. `tpp.4.3.1`)
How to Change the Server-Wide Default Versions of the Tools
X!TandemFor the sake of this documentation, let's assume- Version 2009.10.10.1 will be the new default version
- Version 2009.10.01.1 is installed in the directory `/opt/labkey/bin/tandem.2009.10.01.1`
/opt/labkey/bin/tandem/tandem.exe
- Ensure that no Enterprise Pipeline jobs are currently running
- Stop all Pipeline jobs from running on the cluster using your cluster management tools
- Perform the following steps
sudo su - labkey
cd /opt/labkey/bin/
mv tandem/ tandem.old
cp -R tandem.2009.10.01.1 tandem
- The default version of X!Tandem has now been changed. Please perform a test search and verify that is working properly.
- After testing is complete run
rm -r tandem.old
- Version 4.3.1 will be the new default version
- Version 4.3.1 is installed in the directory `/opt/labkey/bin/tpp.4.3.1`
/opt/labkey/bin/tpp/bin
- Log into medusa.tgen.org
- Ensure that no Enterprise Pipeline jobs are currently running
- Stop all Pipeline jobs from running on the cluster using your cluster management tools
- Perform the following steps
sudo su - labkey
cd /opt/labkey/bin/
mv tpp/ tpp.old
cp -R tpp.4.3.1 tpp
- The default version of TPP has now been changed. Please perform a test search and verify that is working properly.
- After testing is complete run
rm -r tpp.old
- Version 4.3.1 will be the new default version
- Version 4.3.1 is installed in the directory `c:labkeybin`
c:labkeybinReAdW.exe
- Log into cpas-xp-conv01 using RDP
- Stop the LabKey Remote Pipeline Server
- Open a command prompt window
- execute
net stop "LabKey Remote Pipeline Server"- Make a backup of the Enterprise Pipeline Configuration file `c:labkeyconfigms2config.xml`
- Edit `c:labkeyconfigms2config.xml`
[change]
<bean class="org.labkey.api.pipeline.cmd.EnumToCommandArgs">
<property name="parameter" value="pipeline, readw version"/>
<property name="default" value="1.2"/>
[to]
<bean class="org.labkey.api.pipeline.cmd.EnumToCommandArgs">
<property name="parameter" value="pipeline, readw version"/>
<property name="default" value="4.3.1"/>
- Start the LabKey Remote Pipeline Server
- Open a command prompt window
- execute
net start "LabKey Remote Pipeline Server"- Review the log file at `c:labkeylogsoutput.log` for any error messages. If the server starts without any problems then
- Copy the `c:labkeyconfigms2config.xml` to
- `c:labkeyconfigms2config.xml` on cpas-web01
- `/opt/labkey/config/msconfig.xml` on medusa.tgen.org
- The default version of ReAdW has now been changed. Please perform a test search and verify that is working properly.
How to Change the Pipeline Default Versions of the Tools
For the sake of this documentation, let's assume we will be setting the default options on the pipeline for the MyAdmin project- Log on to your LabKey Server as a user with Site Admin privileges
- Goto to the Database Pipeline Setup Page for the pipeline you would like to edit
- Click on the Set Defaults link under "X! Tandem specific settings:"
- Verify that there are no defaults set already by searching in the text box for
<note type="input" label="pipeline tandem, version">
- If there is a default already configured, then change the version specified. The result should look like
<note type="input" label="pipeline tandem, version">2009.10.01.1</note>
- If there is no default configured, then add the following text to the bottom of the file, above the line containing`</bioml>`
<note type="input" label="pipeline tandem, version">2009.10.01.1</note>
<note>Set the default version of X!Tandem used by this pipeline</note>
- Verify that there are no defaults set already by searching in the text box for
<note type="input" label="pipeline tpp, version">
- If there is a default already configured, then change the version specified. The result should look like
<note type="input" label="pipeline tpp, version">4.3.1</note>
- If there is no default configured, then add the following text to the bottom of the file, above the line containing`</bioml>`
<note type="input" label="pipeline tpp, version">4.3.1</note>
<note>Set the default version of TPP used by this pipeline</note>
- Verify that there are no defaults set already by searching in the text box for
<note type="input" label="pipeline, readw version">
- If there is a default already configured, then change the version specified. The result should look like
<note type="input" label="pipeline, readw version">4.3.1</note>
- If there is no default configured, then add the following text to the bottom of the file, above the line containing`</bioml>`
<note type="input" label="pipeline, readw version">4.3.1</note>
<note>Set the default version of ReAdW used by this pipeline</note>
How to Change the version of the tools to use for an individual search
When a search is being submitted, you are able to specify the version of the Search tool on the Search MS2 Data page, where you specify the MS2 Search Protocol to be used for this search. X!TandemEnter the following configuration settings in the X! Tandem XML: text box. Enter it below the line containing `<!-- Override default parameters here. -->`<note type="input" label="pipeline tandem, version">VERSIONNUMBER</note>
<note type="input" label="pipeline tpp, version">VERSIONNUMBER</note>
<note type="input" label="pipeline, readw version">VERSIONNUMBER</note>
Explore the MS2 Dashboard
- Data Pipeline: A list of jobs processed by the data Data Processing Pipeline, including currently running jobs; jobs that have terminated in error; and all successful and unsuccessful jobs that have been run for this folder. Click on a pipeline job for more information about the job.
- MS2 Runs A list of processed and imported runs. Click on the description of a run to view it in detail, or look across runs using the comparison and export functionality. It also integrates experiment information.
- Protein/Peptide Search: Provides a quick way to search for a protein or peptide identification in any of the runs in the current folder, or the current folder and all of its subfolders.
- MS2 Sample Preparation Runs: A list of runs conducted to prepare the MS/MS sample.
- Run Groups: A list of groups associated with MS2 runs. Click on a run group's name to view its details.
- Run Types: A list of links to experiment runs by type.
- Sample Sets: A list of sample sets present, if any.
- Assay List: A list of assay designs defined in the folder or inherited from the project level.
- Pipeline Protocols: A list of pipeline protocols present, if any.
MS2 Runs
The MS2 Runs web part displays a list of the runs in this folder. Click a run for more details. The following image shows this web part displaying sample data from the Proteomics Tutorial. Here you can:
Here you can:
View an MS2 Run

Run Overview
The run overview provides metadata about the run and how the search was performed. This information is derived from the pepXML file associated with the run. Or for COMET searches, this metadata comes from a comet.def (definitions) file within the tar.gz file.Information shown includes:- Search Enzyme: The enzyme applied to the protein sequences by the search tool when searching for possible peptide matches (not necessarily the enzyme used to digest the sample).
- Search Engine: The search tool used to make peptide and protein matches.
- Mass Spec Type: The type of MS instrument used to analyze the sample.
- Quantitation: The source of quantitation algorithms used.
- File Name: The name of the file where the search results are stored.
- Path: The location of the file named above.
- FASTA File: The name and location of the copy of the protein sequence database searched.
- rename the run
- show protein modifications
- show the tandem.xml search protocol definition file used by the search engine
- show peptide or protein prophet details
View
Ways of grouping and filtering your results can be saved as a named 'view' of the data, which can later be applied to other similar datasets. Select among existing saved views and click Go or create and save your own.Use the options in the View section, or make grid based changes in the Peptides and Proteins section.Grouping
Options for grouping the Peptides and Proteins grid include:- Standard lists all the peptides from the run. See additional filters below.
- Protein Groups shows information from the ProteinProphet groups.
- Peptides (Legacy) lists all the peptides from the run and the corresponding columns of peptide information without nesting them.
- Protein (Legacy) displays a summary of the protein matches from the run, as assigned by the search engine, and the corresponding columns of protein information.
- ProteinProphet (Legacy) displays a summary the results of the ProteinProphet analysis, including a confidence score that the protein has been identified correctly.
View Filters
There are special filters available in the View section that offer specialized features not available in typical grid filtering. Not all options are available in all Groupings of data.- Hyper charge filter allows you to filter by charge, select the minimum Hyper value for peptides in charge states 1+, 2+ and 3+, then click Go.
- Minimum tryptic ends specifies how many ends of the peptide are required to match a tryptic pattern: 0 means all peptides will be displayed; 1 means the peptide must have at least one tryptic end; and 2 means both ends must be tryptic.
- Highest score filter allows you to filter out all except the highest Hyper score for a peptide.
- RawScore filter offered for the COMET search engine specifies different raw score thresholds for each charge state. For example, if you enter 200, 300, and 400 in these three text boxes, you are specifying 1+ peptides with raw scores greater than 200, 2+ peptides with raw scores greater than 300, and 3+ peptides with raw scores greater than 400.
Saving Views
You can save a specific combination of grouping, filtering parameters, column layout, and sorting as a named view. Click Save View to do so. Later selecting that saved view from the menu will apply those same parameters to other runs or groups of runs. This makes it easier to keep your analysis consistent across different datasets.Manage Views
To delete an existing view, select a default, or indicate whether you want to use the current view the next time you look at another MS2 run, click Manage Views.
Peptides and Proteins Section
The Peptides/Proteins section displays the peptides and/or proteins from the run according to the sorting, filtering, and grouping options you select.You can customize the display and layout of the Peptides/Proteins section, as with other data grids:- Choose which columns of information are displayed, and in what order, by selecting Grid Views > Customize Grid. See Peptide Columns and Protein Columns for more information.
- Sort the grid, including sorting by multiple columns at once.
- Filter the grid using the column header menu option Filter.
- Click the Scan number or the Peptide name to go to the Peptide Spectrum page, which displays the MS2 spectrum of the fragmented peptide.
- Click the Protein name to go to the Protein Details page, which displays information on that protein and the peptides from the run that matched it.
- Click the dbHits number to go to the Protein Hits page, which displays information on all the proteins from the database that the peptide matched.

Customize Display Columns
Peptide Columns
To specify which columns to display for peptide results:
- Navigate to the run you would like to work with (see Viewing an MS2 Run).
- In the Peptides section, select Grid Views > Customize Grid.
- In the Available Fields pane, select which columns to display in the current view.
- Click Save to save the grid, either as the default, or as a separate named grid.
Available Peptide Columns
The following table describes some of the available peptide columns which are applicable to all search engines.
| Peptide Column | Column Abbrev | Description |
|---|---|---|
|
Scan |
The number of the machine scan from the run. |
|
|
RetentionTime |
RetTime | The peptide's elution time. |
| Run | A unique integer identifying the run. | |
| RunDescription | A description of the run, including the pep.xml file name and the search protocol name | |
|
Fraction |
The id for a particular fraction, as assigned by the MS2 Viewer. Note that a single run can be comprised of multiple fractions (e.g., if a sample was fractionated to reduce its complexity, and the fractions were interrogated separately on the MS machine, a technician can combine the results for those fractions in a single run file for analysis and upload to the MS2 Viewer). |
|
| FractionName | The name specified for a given fraction. | |
|
Charge |
Z |
The assumed charge state of the peptide featured in the scan. |
|
IonPercent |
Ion% |
The number of theoretical fragment ions that matched fragments in the experimental spectrum divided by the total number of theoretical fragment ions, multiplied by 100; higher value indicates a better match. |
|
Mass |
CalcMH+ |
The singly protonated mass of the peptide sequence in the database that was the best match. |
|
DeltaMass |
dMass |
The difference between the MH+ observed mass and the MH+ theoretical mass of this peptide; a lower number indicates a better match. |
|
DeltaMassPPM |
dMassPPM |
The difference between the theoretical m/z and the observed m/z , scaled by theoretical m/z and expressed in parts per million; this value gives a measure of the mass accuracy of the MS machine. |
| FractionalDeltaMass | fdMass | The LTQ-FT mass spectrometer may register the C13 peak in error in place of the monoisotopic peak. The FractionalDeltaMass indicates the absolute distance to nearest integer of the DeltaMass, thereby correcting for these errors. |
| FractionalDeltaMassPPM | fdMassPPM | The FractionalDeltaMass expressed in parts per million. |
|
PrecursorMass |
ObsMH+ |
The observed mass of the precursor ion, expressed as singly protonated (MH+). |
|
MZ |
ObsMZ |
The mass-to-charge ratio of the peptide. |
| PeptideProphet | PepProphet | The score assigned by PeptideProphet. This score represents the probability that the peptide identification is correct. A higher score indicates a better match. |
| PeptideProphetErrorRate | PPErrorRate | The error rate associated with the PeptideProphet probability for the peptide. A lower number indicates a better match. |
|
Peptide |
The sequence of the peptide match. The previous and next amino acids in the database sequence are printed before/after the identified peptide, separated by periods. |
|
|
StrippedPeptide |
The peptide sequence (including the previous amino acid and next amino acid, if applicable) filtered of all extra characters (no dot at the beginning or end, and no variable modification characters). |
|
|
PrevAA |
The amino acid immediately preceding the peptide in the protein sequence; peptides at the beginning of the protein sequence will have a dash (-) as this value. |
|
|
TrimmedPeptide |
The peptide sequence without the previous and next amino acids. |
|
|
NextAA |
The amino acid immediately following the peptide in the protein sequence; peptides at the end of the protein sequence will have a dash (-) as this value. |
|
|
ProteinHits |
SeqHits |
The number of protein sequences in the protein database that contain the matched peptide sequence. |
|
SequencePosition |
SeqPos |
The position in the protein sequence where the peptide begins. |
|
H |
Theoretical hydrophobicity of the peptide calculated using Krokhin’s algorithm (Anal. Chem. 2006, 78, 6265). |
|
|
DeltaScan |
dScan |
The difference between actual and expected scan number, in standard deviations, based on theoretical hydrophobicity calculation. |
|
Protein |
A short name for the protein sequence identified by the search engine as a possible source for the identified peptide. |
|
|
Description |
A short phrase describing the protein sequence identified by the search engine. This name is derived from the UniProt XML or FASTA file from which the sequence was taken). |
|
|
GeneName |
The name of the gene that encodes for this protein sequence. |
|
| SeqId | A unique integer identifying the protein sequence. |
Peptide Columns Populated by ProteinProphet
The following table describes the peptide columns that are populated by ProteinProphet.
| Peptide Column | Column Abbrev | Description |
|---|---|---|
| NSPAdjustedProbability | NSPAdjProb | PeptideProphet probability adjusted for number of sibling peptides. |
| Weight | Share of peptide contributing to the protein identification. | |
| NonDegenerateEvidence | NonDegenEvid | True/false value indicating whether peptide is unique to protein (true) or shared (false). |
| EnzymaticTermini | Number of expected cleavage termini (valid 0, 1 or 2) consistent with digestion enzyme. | |
| SiblingPeptides | SiblingPeps | A calculation, based on peptide probabilities, to quantify sibling peptides (other peptides identified for this protein). |
| SiblingPeptidesBin | SiblingPepsBin | A bin or histogram value used by ProteinProphet. |
| Instances | Number of instances the peptide was identified. | |
| ContributingEvidence | ContribEvid | True/false value indicating whether the peptide is contributing evidence to the protein identification. |
| CalcNeutralPepMass | Calculated neutral mass of peptide. |
Peptide Columns Populated by Quantitation Analysis
The following table describes the peptide columns that are populated during the quantitation analysis.
| Peptide Column | Description |
|---|---|
| LightFirstScan | Scan number of the start of the elution peak for the light-labeled precursor ion. |
| LightLastScan | Scan number of the end of the elution peak for the light-labeled precursor ion |
| LightMass | Precursor ion m/z of the isotopically light-labeled peptide. |
| HeavyFirstScan | Scan number of the start of the elution peak for the heavy-labeled precursor ion. |
| HeavyLastScan | Scan number of the end of the elution peak for the heavy-labeled precursor ion. |
| HeavyMass | Precursor ion m/z of the isotopically heavy-labeled peptide. |
| Ratio | Light-to-heavy ratio, based on elution peak areas. |
| Heavy2LightRatio | Heavy-to-light ratio, based on elution peak areas. |
| LightArea | Light elution peak area. |
| HeavyArea | Heavy elution peak area. |
| DecimalRatio | Light-to-heavy ratio expressed as a decimal value. |
Peptide Columns Specific to X! Tandem
The following table describes the peptide columns that are specific to results generated by the X! Tandem search engine.
| Peptide Column | Description |
|---|---|
| Hyper | Tandem’s hypergeometric score representing the quality of the match of the identified peptide; a higher score indicates a better match. |
| B | Tandem’s b-ion score. |
| Next | The hyperscore of the 2nd best scoring peptide. |
| Y | Tandem’s y-ion score. |
| Expect | Expectation value of the peptide hit. This number represents how many identifications are expected by chance to have this hyperscore. The lower the value, the more likely it is that the match is not random. |
Peptide Columns Specific to Mascot
The following table shows the scoring columns that are specific to Mascot:
| Peptide Column | Description |
|---|---|
|
Ion |
Mascot ions score representing the quality of the match of the identified peptide; a higher score indicates a better match. |
|
Identity |
Identity threshold. An absolute threshold determines from the distribution of random scores to highlight the presence of non-random match. When ions score exceeds identity threshold, there is a 5% chance that the match is not exact. |
|
Homology |
Homology threshold. A lower, relative threshold determines from the distribution of random scores to highlight the presence of non-random outliners. When ions score exceeds homology threshold, the match is not random, spectrum may not fully define sequence and the sequence may be close but not exact. |
|
Expect |
Expectation value of the peptide hit. This number represents how many identifications are expected by chance to have this ion score or higher. The lower the value, the more likely it is that the match is significant. |
Peptide Columns Specific to SEQUEST
The following table shows the scoring columns that are specific to SEQUEST:
| Peptide Column | Description |
|---|---|
| SpRank | Rank of the preliminary SpScore, typically ranging from 1 to 500. A value of 1 means the peptide received the highest preliminary SpScore so lower rankings are better. |
| SpScore | The raw value of the preliminary score of the SEQUEST algorithm. The score is based on the number of predicted CID fragments ions that match actual ions and on the predicted presence of immonium ions. An SpScore is calculated for all peptides in the sequence database that match the weight (+/- a tolerance) of the precursor ion. Typicaly only the top 500 SpScoress are assigned a SpRank and are passed onto the cross correlation analysis for XCorr scoring. |
| XCorr | The cross correlation score from SEQUEST is the main score that is used to rank the final output. Only the top N (where N normally equals 500) peptides that survive the preliminary SpScoring step undergo cross correlation analysis. The score is based on the cross correlation analysis of a Fourier transform pair ceated from a simulated spectrum vs. the actual spectrum. The higher the number, the better. |
| DeltaCn | The difference of the normalized cross correlation scores of the top hit and the second best hit (e.g., XC1 - XC2, where XC1 is the XCorr of the top peptide and XC2 is the XCorr of the second peptide on the output list). In general a difference greater than 0.1 indicates a successful match between sequesce and spectrum. |
Peptide Columns Specific to COMET
The following table shows the scoring columns that are specific to COMET:
| Peptide Column | Description |
|---|---|
|
RawScore |
Number between 0 and 1000 representing the quality of the match of the peptide feature in the scan to the top COMET database search result; higher score indicates a better match. |
|
ZScore |
The number of standard deviations between the best peptide match's score and the mean of the top 100 peptide scores, calculated using the raw dot-product scores; higher score indicates a better match. |
|
DiffScore |
The difference between the normalized (normalized from 0.0 to 1.0) RawScore values of the best peptide match and the second best peptide match; greater DiffScore tends to indicate a better match. |
Protein Columns
To specify which columns to display for peptide results:
- Navigate to the run you would like to work with (see Viewing an MS2 Run).
- In the Peptides section, select Grid Views > ProteinProphet.
- Then Grid Views > Customize Grid.
- In the Available Fields pane, select which columns to display in the current grid.
- Click Save to name and save the grid.
The currently displayed columns appear in the Selected Fields pane. You can edit the columns that appear in this list manually for finely tuned control over which columns are displayed in what order.
Available Protein Columns
The following table describes some of the available protein columns. Not all columns are available for all data sets.
| Protein Column | Column Abbrev | Description |
|---|---|---|
| Protein | The name of the sequence from the protein database. | |
| SequenceMass | The mass of the sequence calculated by adding the masses of its amino acids. | |
| Peptides | PP Peps | The number of filtered peptides in the run that were matched to this sequence. |
| UniquePeptides | PP Unique | The number of unique filtered peptides in the run that were matched to this sequence. |
| AACoverage | The percent of the amino acid sequence covered by the matched, filtered peptides. | |
| BestName | A best name, either an accession number or descriptive word, for the identified protein. | |
| BestGeneName | The most useful gene name associated with the identified protein. | |
| Description | Short description of the protein’s nature and function. | |
| GroupNumber | Group | A group number assigned to the ProteinProphet group. |
| GroupProbability | Prob | ProteinProphet probability assigned to the protein group. |
| PctSpectrumIds | Spectrum Ids | Percentage of spectrum identifications belonging to this protein entry. As a semi-quantitative measure, larger numbers reflects higher abundance. |
| ErrorRate | The error rate associated with the ProteinProphet probability for the group. | |
| ProteinProbability | Prob | ProteinProphet probability assigned to the protein(s). |
| FirstProtein | ProteinProphet entries can be composed of one or more indistinguishable proteins and are reflected as a protein group. This column represents the protein identifier, from the protein sequence database, for the first protein in a protein group. | |
| FirstDescription | Protein description of the FirstProtein. | |
| FirstGeneName | Gene name, if available, associated with the FirstProtein. | |
| FirstBestName | The best protein name associated with the FirstProtein. This name may come from another protein database file. | |
| RatioMean | L2H Mean | The light-to-heavy protein ratio generated from the mean of the underlying peptide ratios. |
| RatioStandardDev | L2H StdDev | The standard deviation of the light-to-heavy protein ratio. |
| RatioNumberPeptides | Ratio Peps | The number of quantified peptides contributing to the protein ratio. |
| Heavy2LightRatioMean | H2L Mean | The heavy-to-light protein ratio generated from the mean of the underlying peptide ratios. |
| Heavy2LightRatioStandardDev | H2L StdDev | The heavy-to-light standard deviation of the protein ratio. |
View Peptide Spectra
Finding Related MS1 Features or Other Peptide Identifications
You can click on the Find Features button to search for MS1 runs that identified features that were linked to the same peptide sequence. It will also present a list of all the peptide identifications with the same sequence in other MS2 runs from the same folder, or the same folder and its subfolders.Ion Fragment Table
The table on the right side of the screen displays the expected mass values of the b and y ion fragments (for each of the possible charge states, +1, +2, and +3) for the putative peptide. The highlighted values are those that matched fragments observed in the spectrum.Zooming in on a Spectrum
You can zoom in on a spectrum using the "X start" and "X end" text boxes. Change the values to view a smaller mz range.Quantitation Elution Profiles
If your search protocol included labeled quantitation analysis using XPRESS or Q3 and you are viewing a peptide which had both light and heavy identifications, you will see three elution graphs. The light and heavy elution profiles will have their own graphs, and there will also be a third graph that shows the two overlaid. You can click to view the profiles for different charge states.CMT and DTA Files
For COMET runs loaded via the analysis pipeline, you will see Show CMT and Show DTA buttons. For SEQUEST runs, you will see Show OUT and Show DTA buttons. The CMT and OUT files contain a list of other possible peptides for this spectrum; these are not uploaded in the database. The DTA files contain the spectrum for each scan; these are loaded and displayed, but intensities are not displayed in the Viewer. If you click the Show CMT, Show OUT, or Show DTA button, the MS2 module will retrieve these files from the file server and display them in your browser.Note: These buttons will not appear for X!Tandem search results since those files are not associated with X!Tandem results.View Protein Details
Grouping: Standard
In most cases, you will use the Standard option in the Grouping box in the View section of the page.After you have chosen this option and clicked the Go button next to it, you can customize the grid using one of the built-in custom grids available on the Grid Views menu in the Peptide web part. Or you may use Customize Grid to create your own version.If you wish to see information on the proteins selected as matches by the search engine, choose Grid Views > SearchEngineProtein. In the resulting grid view, the putative protein appears under the Database Sequence Name column.If you wish to see the protein-level scores calculated by the ProteinProphet tool, choose Grid Views > ProteinProphet. Each row of the resulting grid view shows a protein. Expand the "+" next to any row to show the peptides that were matched to the particular protein.Grouping: Protein Groups
The Protein Groups option in the Grouping box under the Views web part is more narrowly useful than the Standard option. Use it if you want to drill into the members of the particular protein groups.If you have selected this option in the Grouping box and clicked the Go button next to it, results appear in a grid view in the Protein Groups web part below. Each row of this grid view shows a protein group. Expand the "+" next to a row to show the proteins that are members of that group. Use the Expanded box in the View section and click Go to expand all proteins.Protein Details
The Protein Details page displays the following information about the protein:- The protein sequence's name, or names in the case of indistinguishable proteins
- The sequence mass, which is the sum of the masses of the amino acids in the protein sequence
- The amino acid (AA) coverage, which is the number of amino acids in the peptide matches divided by the number of amino acids in the protein and multiplied by 100
- The mass coverage, which is the sum of the masses of the amino acids in the peptide matches divided by the sequence mass of the protein and multiplied by 100

Peptides
The Peptides section of the page displays information about the peptide matches from the run, according to any currently applied sorting or filtering parameters.Tip: If you’re interested in reviewing the location of certain peptides in the sequence or wish to focus on a certain portion of the sequence, try sorting and filtering on the SequencePosition column in the PeptideProphet results view.Annotations
The Annotations section of the page displays annotations for the protein sequence, including (if available):- The sequence name
- The description of the sequence
- Name of the gene or genes that encodes the sequence
- Organisms in which the sequence occurs
- Links to various external databases and resources
View Gene Ontology Information


Experimental Annotations for MS2 Runs
Loading Sample Sets
Sample sets contain a group of samples and properties for those samples. In the context of an MS2 experiment, these are generally the samples that are used as inputs to the mass spectrometer, often after they have been processed in some way.Sample sets are scoped to a particular project inside of LabKey Server. You can reference sample sets that are in other folders under the same project, or sample sets in the "Shared" project.To set up a sample set, first navigate to a target folder. Click on the Experiment tab, or the MS2 Dashboard as appropriate. By default, there will be a Sample Sets web part. It will show all of the existing sample sets that are available in that folder. If the sample set you want to use is already loaded, select the check box in front of it and click on the Make Active button. This will make it accessible when loading an MS2 run or for display in the grids.If the sample set you want is not already loaded, you will need to enter the data in a tab separated format (TSV). The easiest way to do this is to use a spreadsheet like Excel. One of the columns should be the name of the sample, and the other columns should be properties of interest (the age of the participant, the type of cancer, the type of the sample, etc). Each of the columns should have a header.Select all of the cells that comprise your sample set, including the headers, and copy them to the clipboard.In the Sample Sets web part, click Import Sample Set. Give the set a useful name. Then, either cut and paste in the sample set data, or select "File" and click Upload to select upload the spreadsheet. Click on the drop down for Id Column #1. It should contain the column headers for your sample set. Choose the column that contains the sample name or id. In most cases, you shouldn't need to enter anything for the other Id Columns. Click on Submit. If necessary, correct any errors. One the next page, click on the Set as Active button if it hasn't already been marked as the active sample set.Describing mzXML files
The next step is to tie mzXML files to samples. LabKey Server will prompt you to do this when you initiate an MS2 search through the pipeline.Go to the Pipeline tab or the pipeline section of the MS2 dashboard and click on Process and Upload Data. Browse to the mzXML file(s) you want to search. Click Describe Samples.If you've already described the mzXML files, you have the option to delete the existing information and enter the data again. This is useful if you made a mistake when entering the data the first time or want to make other changes.If you haven't already created a protocol for your experimental procedure, click on create a new protocol. Depending on your configuration, you may be given a list of templates from which to start. For example, you may have worked with someone at LabKey to create a custom protocol to describe a particular fractionation approach. Select a template, if needed, and fill in a description of the protocol.Then select the relevant protocol from the list. If you started from a directory that contains multiple mzXML files, you will need to indicate if the mzXML files represent fractions of a larger sample.The next screen asks you to identify the samples that were inputs to the mass spectrometer. The active sample set for the current LabKey Server folder, if any, is selected as the default sample set. It is strongly recommended that you use the active sample set or no sample set. You can change the default name for the runs. For each run, you are asked for the Material Sample ID. You can use the text box to type in a name if it is not part of a sample set. Otherwise, choose the name of the sample from the drop down.Once you click on Submit, LabKey Server will create a XAR file that includes the information you entered and load it in the background.Kicking off an MS2 search
To initiate an MS2 search, return to the Data Pipeline and browse back to the mzXML files. This is described in the Search and Process MS2/MS2 Data topic.Viewing Annotation Data
There are a number of different places you can view the sample data that you associated with your mzXML files. First, it's helpful to understand a little about how LabKey Server stores your experimental annotations.A set of experimental annotations relating to a particular file or sample is stored as an experiment run. Each experiment run has a protocol, which describes the steps involved in the experimental procedure. For MS2, LabKey Server create an experiment run that describes going from a sample to one or more mzXML files. Each time you do a search using the mzXML files creates another experiment run. LabKey Server can tie the two types of runs because it knows that the output of the first run, the mzXML files, are the inputs to the search run.You can see the sample data associated with a search run using the Enhanced MS2 Run view, or by selecting the "MS2 Searches" filter in the Experiment tab's run list. This view will only show MS2 runs that have experimental data loaded. In some cases, such as if you moved MS2 runs from another folder using LabKey Server 1.7 or earlier, or if you directly loaded a pep.xml file, no experimental data will be loaded.Click on the Customize View button. This brings up the column picker for the run list. Click to expand the Input node. This shows all the things that might be inputs to a run in the current folder. Click to expand the mzXML node. This shows data for the mzXML file that was an input to the search run. Click to expand the Run node. This shows the data that's available for the experiment run that produced the mzXML file. Click to expand the Input node. This shows the things that might be inputs to the run that produced the mzXML file. If you used a custom template to describe your mass spectrometer configuration, you should expand the node that corresponds to that protocol's inputs. Otherwise, click to expand the Material node. Click to expand the Property node, which will show the properties from the folder's active sample set. Click to add the columns of interest, and then Save the column list. You can then filter and sort on sample properties in the run.You can also pull in sample information in the peptides/proteins grids by using the new Query grouping. Use the column picker to go to Fraction->Run->Experiment Run. At this point, you can follow the instructions above to chain through the inputs and get to sample properties.
You can then filter and sort on sample properties in the run.You can also pull in sample information in the peptides/proteins grids by using the new Query grouping. Use the column picker to go to Fraction->Run->Experiment Run. At this point, you can follow the instructions above to chain through the inputs and get to sample properties.Protein Search
Performing a Protein Search
There are a number of different places where you can initiate a search. If your folder is configured as an MS2 folder, there will be a Protein Search web part on the MS2 Dashboard. You can also add the Protein Search web part to the portal page on other folder types, or click on the MS2 tab within your folder.Type in the name of the protein. The server will search for all of the proteins that have a matching annotation within the server. Sources of protein information include FASTA files and UniProt XML files. See Loading Public Protein Annotation Files for more details.You may also specify a minimum ProteinProphet probability or a maximum ProteinProphet error rate filter to filter out low-confidence matches. You can also indicate whether subfolders of the current folder or project should be included in the search and whether or not to only include exact name matches. If you do not restrict to exact matches, the server will include proteins that start with the name you entered.To add a custom filter on your search results, select the radio button and click Create or edit view to select columns, filters, and sorts to apply to your search results.Understanding the Search Results
The results page is divided into two sections.The top section shows all of the proteins that match the name, regardless of whether they have been found in a run. This is useful for making sure that you typed the name of the protein correctly.The bottom section shows all of the ProteinProphet protein groups that match the search criteria. A group is included if it contains one or more proteins that match. From the results, you can jump directly to the protein group details, to the run, or to the folder.You can customize either section to include more details, or export them for analysis on other tools.Mass Spec Search Web Part
If you will be searching for both proteins and peptides in a given folder, you may find it convenient to add the Mass Spec Search (Tabbed) web part which combines Protein Search and Peptide Search in a single tabbed web part.Peptide Search
Performing a Peptide Search
There are a number of different places where you can initiate a search. If your folder is configured as an MS1 or MS2 folder, there may be a Peptide Search web part on the MS1 or MS2 Dashboard. You can also add the Peptide Search web part to the portal page yourself. In some configurations, there may be a Manage Peptide Inventory web part configured to allow searching and pooling of peptides.Type in the peptide sequence to find. You may include modification characters if you wish. If you select the Exact Match checkbox, your results will only include peptides that match the exact peptide sequence, including modification characters.Understanding the Search Results
The results page is divided into two sections.The top section shows all of the MS1 features that have been identified, linked to MS2 peptides that match the search sequence, and loaded.The bottom section shows all of the MS2 peptide identifications that match the search criteria, regardless of whether they match MS1 features.You can apply filters to either section, customize the view to add or remove columns, or export them for analysis on other tools.Mass Spec Search Web Part
If you will be searching for both proteins and peptides in a given folder, you may find it convenient to add the Mass Spec Search (Tabbed) web part which combines Protein Search and Peptide Search in a single tabbed web part.MS2 Runs With Peptide Counts
The MS2Extensions module contains an additional MS2 Runs With Peptide Counts web part offering enhanced protein search capabilities, including filtering by multiple proteins simultaneously and the ability to focus on high-scoring identifications by using peptide filters. The runs list is preceded by a section for defining Comparison and Export Filters:
The runs list is preceded by a section for defining Comparison and Export Filters:
- Target Protein: Enter one or more comma separated strings to identify proteins of interest.
- Match Criteria: Select how to match the above string(s). Options: Exact, Prefix, Suffix, Substring.
- Peptide Filter: Click Create or Edit View to define a peptide filter.
 Click Continue.
Click Continue.Compare MS2 Runs
Compare Runs within a Single Folder
You can compare peptides, proteins, or ProteinProphet results across two or more runs.- Navigate to the MS2 Dashboard.
- In the MS2 Experiment Runs web part, click the checkboxes next to the runs you want to compare.
- Click Compare and select a method of comparison. Options include:
- ProteinProphet: your comparison will be based on the proteins assignments made by ProteinProphet. See Compare ProteinProphet.
- Peptide: choose whether to include all peptides, those which exceed a given ProteinProphet probability, or those which meet the filter criteria in a saved grid. You can also opt to require a sequence map against a specific protein.
- Search Engine Protein: indicate whether you want to display unique peptides, or all peptides. If you use a saved view, the comparison will respect both peptide and protein filters.
- Peptide (Legacy): choose which columns to include in the comparison results. If you use a saved view created when examining a single run, the comparison will only use the peptide filters.
- ProteinProphet (Legacy): specify which columns to display in the comparison grid. If you use a saved grid created when examining a single run, the comparison will only use the protein group filters.
- Spectra Count: choose how to group results and how to filter the peptide identifications.
- After specifying necessary options, click Compare.
- There is a summary of how the runs overlap at the top of the page for most types of comparison. It allows you to see the overlap of individual runs, or to combine the runs based on the run groups to which they are assigned and see how the groups overlap. Click the [+] to expand the section
- Depending on the type of comparison, the format of Comparison Details will differ.
- Select Grid Views > Customize Grid to add columns to the comparison. Find the column you'd like to add (for example, protein quantitation data can be found under Protein Group->Quantitation in the tree on the left). Place a check mark next to the desired columns and click Save to create a saved grid.
- Select Grid Views > Customize Grid and click on the Filter tab to apply filters. On the left side, place a check mark next to the column on which you'd like to filter, and then specify your filter criteria. Click Save to save the filters with your grid.
- The comparison grid will show a protein or a peptide if it meets the filter criteria in any one of the runs. Therefore, the values shown for the protein or peptide in one of the runs may not meet the criteria.
- For more information on setting and saving grids, see the View an MS2 Run help page. If you compare without picking a grid, the comparison results will be displayed without filters.
Compare Runs across Folders
- On the MS2 Dashboard in the MS2 Runs web part, click Grid Views > Folder Filter > Current folder and subfolders.
- The MS2 Experiment Runs list now contains runs in the current folder and subfolders, so you can select the runs of your choice for comparison, just as described above for a single folder.
Compare ProteinProphet
In this view, the comparison results are based on the proteins assignments made by ProteinProphet.
There are a number of options for how to perform the comparison:
Protein group filters
These filters allow to you to optionally filter data based on protein group criteria, such as ProteinProphet probability. You can also create a custom grid view to filter groups based on other data, like quantitation ratios or other protein group properties.
Peptide filters
These filters allow you to optionally exclude protein groups based on the peptides that have been assigned to each group. A protein group must have at least one peptide that meets the criteria to qualify for the comparison. You may choose not to filter, to filter based on a PeptideProphet probability, or to create a custom grid view to filter on other peptide properties, like charge state, scoring engine specific scores, quantitation ratios, and more.
Inclusion criteria
This setting lets you choose if you want to see protein results for a run, even if the results don't meet your filter criteria for that run. Consider a scenario in which run A has protein P1 with ProteinProphet probability 0.97, and protein P2 with probability 0.71, and run B has protein P1 with ProteinProphet probability 0.86, and P2 with probability 0.25. Assume that you set a protein group probability filter of 0.9. Protein P2 will not be shown in the comparison because it doesn't meet the filter in either run. P1 will be included because it meets the threshold in run A. This option lets you choose if it is also shown in run B, where it didn't meet the probability threshold. Depending on your analysis, you may wish to see it, or to exclude it.
Protein group normalization
This option allows you to normalize protein groups across runs, where there may be runs that do not share identical ProteinProphet protein/protein group assignments. Consider the following scenario:
| Run name | Protein group | Proteins | Probability |
|---|---|---|---|
| A | 1 | a | 1.0 |
| A | 2 | b, c | 1.0 |
| A | 3 | d | 0.95 |
| A | 4 | e, f, g | 0.90 |
| B | 1 | a, b | 1.0 |
| B | 2 | d | 1.0 |
| B | 3 | e | 0.94 |
| B | 4 | h | 0.91 |
If you do not choose to normalize protein groups, the comparison result will show one row per protein, even if there are multiple proteins assigned to a single protein group. This has the advantage of unambiguously aligning results from different runs, but has the disadvantage of presenting what is likely an inflated set of protein identifications. The results would look like this:
| Protein | Run A Group | Run A Prob | Run B Group | Run B Prob |
|---|---|---|---|---|
| a | 1 | 1.0 | 1 | 1.0 |
| b | 2 | 1.0 | 1 | 1.0 |
| c | 2 | 1.0 | ||
| d | 3 | 0.95 | 2 | 1.0 |
| e | 4 | 0.90 | 3 | 0.94 |
| f | 4 | 0.90 | ||
| g | 4 | 0.90 | ||
| h | 4 | 0.91 |
Note that this result presents proteins e, f, and g as three separate rows in the result, even though based on the ProteinProphet assignments, it is likely that only one of them was identified in run A, and only e was identified in run B.
If you choose to normalized protein groups, LabKey Server will align protein groups across runs A and B based on any shared protein assignments. That is, if a group in run A contains any of the same proteins as a group in run B, it will be shown as a single, unified row in the comparison. This has the advantage of aligning what were likely the same identifications in different runs, with the disadvantage of potentially misaligning in some cases. The results would look like this:
| Proteins | Run A Group Count | Run A First Group | Run A Prob | Run B Group Count | Run B First Group | Run B Prob |
|---|---|---|---|---|---|---|
| a, b, c | 2 | 1 | 1.0 | 1 | 1 | 1.0 |
| d | 1 | 3 | 0.95 | 2 | 2 | 1.0 |
| e, f, g | 1 | 4 | 0.90 | 1 | 3 | 0.94 |
| h | 1 | 4 | 0.91 |
The group count column shows how many protein groups were combined from each run to make up the normalized group. For example, run A had two groups, 1 and 2, that shared the proteins a and b with group 1 from run B, so those groups were normalized together. Normalization will continue to combine groups until there are no more overlapping identifications within the set of runs to be compared.
Export MS2 Runs
- Navigate to the MS2 Runs web part on the MS2 Dashboard. Alternatively, add the MS2 Runs web part to a folder page.
- Select the run or runs to export.
- Click MS2 Export from the web part menu.
- Select a view to apply to the exported data. The subset of data matching the protein and peptide filters and the sorting and grouping parameters from your selected view will be exported to Excel.
- Select the desired export format.
- Click Export.
- Before you export, make sure the view you have applied includes the data you want to export. For more information on setting and saving views, see View an MS2 Run. If you click Export without picking a view, LabKey Server will attempt to export all data from the run or runs. The export will fail if your runs contain more data than Excel can accommodate.
- Select the individual results you wish to export using the row selectors, and click the Export Selected button.
- To select all visible rows, click the box at the top of the checkbox column, then select Export Selected.
- Click Export All to export all results that match the filter, including those that are not displayed.
Export Formats
You can export to the following formats:- Excel
- TSV
- AMT
- DTA/PKL
- MS2 Ions TSV
- Bibliospec
Exporting to an Excel file
You can export any peptide or protein information displayed on the page to an Excel file to perform further analysis. The MS2 module will export all rows that match the filter, not just the first 1,000 or 250 rows displayed in the Peptides/Proteins section. As a result, the exported files could be very large, so use caution when applying your filters. Note that Excel may have limits on the number of rows or columns it is able to import.Exporting to a TSV file
You can export data to a TSV (tab-separated values) file to load peptide or protein data into a statistical program for further analysis.You can only export peptide data to TSV files at this time so you must select Grouping: None in the View section of the page to make the TSV export option available.Exporting to a DTA/PKL file
You can export data to DTA/PKL files to load MS/MS spectra into other analysis systems such as the online version of Mascot (available at http://www.matrixscience.com).You can export to DTA/PKL files from any ungrouped list of peptides, but the data must be in runs uploaded through the analysis pipeline. The MS2 module will retrieve the necessary data for these files from the archived tar.gz file on the file server.For more information, see http://www.matrixscience.com/help/data_file_help.html#DTA and http://www.matrixscience.com/help/data_file_help.html#QTOF.Exporting to an AMT File
You can export data to the AMT, or Accurate Mass & Time, format. This is a TSV format that exports a fixed set of columns -- Run, Fraction, CalcMHPlus, Scan, RetTime, PepProphet, and Peptide -- plus information about the hydrophobicity algorithm used and names & modifications for each run in the export.Bibliospec
See Export Spectra Libraries for details on exporting to a Bibliospec spectrum library.Working with Small Molecule Targets
- Small Molecule Precursor List
- Small Molecule Summaries
- Small Molecule Details, including Chromatograms
Importing Small Molecule Documents
- Create or navigate to a Panorama type Folder.
- Configure the Panorama folder for Experimental Data. (For details see Configure Panorama Folder.)
- Click the Data Pipeline tab. In the Data Pipeline web part, click Process and Import Data.
- Drag and drop the individual Skyline documents or .zip file into the Files web part.
- When the documents have been uploaded, select the documents and click Import Data.
- In the Import Data popup menu, confirm that Import Skyline Results is selected, and click Import.
- When the import job is complete, click the Panorama Dashboard tab.
- In the Targeted MS Runs web part, click a Skyline document for views and details on the contents.
Available Views
The Small Molecule Precursor List shows a summary of the document contents.
- Click a value under the Custom Ion Name column for a details page.
- Click the value under Molecule Label to see a summary page for the molecule group ("PC" in this case) which includes charts showing peak area and retention time information.
 Clicking the triangle next to the title Small Molecule Precursor List displays a link to the Small Molecule Transitions List.
Clicking the triangle next to the title Small Molecule Precursor List displays a link to the Small Molecule Transitions List. The Small Molecule Transition List is shown below.
The Small Molecule Transition List is shown below.
Ion Details
The following screen shot shows details and chromatograms for an ion.
Related Topics
- Use a Panorama QC folder to track the performance of instruments and reagents using Levey-Jennings plots, Pareto plots, and other tools for both proteomics and small molecule data.
Other Resources
Export Spectra Libraries
Export Spectra for Multiple Runs
To export spectra data for whole runs at a time:- Go to the MS2 Runs web part.
- Select the desired runs from the list.
- Click MS2 Export.

- On the Export Runs page, select BiblioSpec spectra library file and click Export.
- A spectra library file is generated and downloaded to your local machine.

Export Spectra for Selected Peptides
To export spectra data from individual peptides:- In the Peptides web part, select the peptides of interest.
- Select Export Selected > Bibliospec.
- A spectra library file is generated and downloaded to your local machine.

Export Spectra for a Filtered List Peptides
- In the Peptides web part, filter the list peptides to the items of interest.
- Select Export All > Bibliospec.
- LabKey Server will generate a spectra library from the entire list of peptides (respecting the current filters) and downloaded it to your local machine.
View, Filter and Export All MS2 Runs
Set Up the Web Part
- In a folder of type MS2, add the web part MS2 Runs Browser from the <Select Web Part> pulldown in the lower left.
- The new web part is titled MS2 Runs Overview and displays all Folders containing MS2 runs on the server. The count of the number of runs in each folder is also displayed.
- You can see an example in the proteomics demo folder.
Search runs
- Use checkboxes on the Folders containing MS2 runs list to select where to search for runs.
- Then select the Search Engine Type and the FASTA File from the dropdown menus to the right of the folder list.
- When you are done selecting filters, click Show Matching MS2 Runs.

Review Matching Runs
- After you have executed a search, you will see a list of matching runs in the Matching MS2 Runs section of the Runs Overview web part. An example is shown in the screenshot above.
Select Result Filters
- First use the checkbox to select one or more Matching MS2 Runs to filter. If you click the run name, you will open the results outside of this browser view.
- Use the checkboxes available in the Result Filters section of the web part to narrow your results.
- Optionally filter by probability or
- Use the Switch to Proteins/Peptides button to switch between peptides and proteins.
- Click the Preview Results button when you would like to see the results of your filters. An example is shown in the screenshot below.

Export runs
- To export, use the Export Results button at the bottom of the Result Filters section, or the Export button above the Results list.
- Only your filtered list of results will be exported. Results are exported to an Excel spreadsheet.
Related Topics
Work with Mascot Runs
View/Export Mascot Results
Viewing/Exporting Mascot results occurs in two stages. First, make a rough selection of the runs you are interested in. Second, refine the results of interest by filtering on probability, charge, etc. Finally view or export the results.To View Mascot Runs:
- Locate runs of interest using an MS2 Runs Overview web part.
- If you don't already have one, select MS2 Runs Browser from the web part dropdown.
- Select the folder(s) containing the desired results.
- In the Search Engine Type dropdown, select MASCOT. (The server will remember your choice when you revisit the page.)
- Select the FASTA File.
- Click Show Matching MS2 Results.
- The runs will appear in the panel directly below labeled Matching MS2 Runs.

To View/Export Mascot Results:
- Use the panel under Matching MS2 Runs to filter which results to display or export.
- Select the runs to display, the columns to display, set the probability, and the charge, and then click Preview Results.
- Note that Mascot-specific columns are available in the Matching MS2 Runs panel: MascotFile and DistillerRawFile.
- Also, Mascot-specific peptide columns are available: QueryNumber, HitRank, and Decoy.

Run Details View
To view details of a particular run, click the run name. The run details page for a mascot run is very similar to that for any MS2 run. See View an MS2 Run for details on common sections.In addition, with Mascot runs, when there are multiple matches, you can elect to display only the hit with the highest (best) Ion score for each duplicate by checking the "Highest score filter" box in the View section. This option works with the Standard view and will not be displayed for legacy views. You can use this option with custom grid views, including built in grids like SearchEngineProtein. Note that this filter is applied prior to other filters on the peptide sequence. If you apply a filter which removes the highest ion score match, you would not see the next highest match using this filter; you'd simply see no matches for that peptide sequence.
Note that this filter is applied prior to other filters on the peptide sequence. If you apply a filter which removes the highest ion score match, you would not see the next highest match using this filter; you'd simply see no matches for that peptide sequence.
Retention Time
You can display retention time by adding the RetTime column to your grid. In addition, the "Retention Time Minutes" column offers you the option to display that retention time in minutes instead of the default seconds. To add columns, use Grid Views > Customize Grid.
Peptide Details View
To view the details for a particular peptide, click the run name, then the peptide name For Mascot peptides, the details view shows whether the peptide is a decoy, the HitRank, and the QueryNumber. Below the spectra plot, if one exists, the grid of peptides labeled All Matches to This Query is filtered on the current fraction/scan/charge. Click values in the Peptide column to view other potential identifications of the same peptide.
Below the spectra plot, if one exists, the grid of peptides labeled All Matches to This Query is filtered on the current fraction/scan/charge. Click values in the Peptide column to view other potential identifications of the same peptide.
Decoy Summary View
The Decoy Summary is shown only for Mascot runs that have decoy peptides in them. Non-Mascot runs, or those with no decoy peptides, will not show this section.P Value: The probability of a false positive identification. Default is <0.05.Ion Threshold (Identity Score): The Identity score threshold is determined by the P Value. Conversion between P Value and Identity score is: Identity = -10 * log10(p-value)This yields 13.1 for p-value = .05In Target and In Decoy: The target and decoy counts for the initial calculation are the count of peptides with hit rank = 1 with Identity score >= 13.1FDR: FDR = Decoy count / Target countAdjust FDR To: The "Adjust FDR To" dropdown finds the identity score at which the FDR value is closest to the selected percentage. Initially, the dropdown is set to the FDR with the default Identity threshold (13.1). Selecting a different option finds the closest FDR under that value, and displays the corresponding p-value and Identity scores, FDR, target count, decoy count. If there is no FDR under the selected value, we display the lowest FDR over that value, along with a message that there is no FDR under the value. Only the peptide Identity scores and with hitRank = 1 are considered.Only show Ion >= this threshold checkbox:
If there is no FDR under the selected value, we display the lowest FDR over that value, along with a message that there is no FDR under the value. Only the peptide Identity scores and with hitRank = 1 are considered.Only show Ion >= this threshold checkbox: By default, all peptides are shown, whether they are over or under the designated threshold. Checking this box filters out all lower ions. Note that if you check this box, then change the FDR filter values, the box will become unchecked. To propagate your FDR filter to the peptide display, check the box labelled "Only show ions >= this threshold" in the decoy panel, and your peptide display will be refreshed with this filter applied.
By default, all peptides are shown, whether they are over or under the designated threshold. Checking this box filters out all lower ions. Note that if you check this box, then change the FDR filter values, the box will become unchecked. To propagate your FDR filter to the peptide display, check the box labelled "Only show ions >= this threshold" in the decoy panel, and your peptide display will be refreshed with this filter applied.Loading Public Protein Annotation Files
- UniProtKB Species Suffix Map. Used to determine the genus and species of a protein sequence from a swiss protein suffix.
- The Gene Ontology (GO) database. Provides the cellular locations, molecular functions, and metabolic processes of protein sequences.
- UniProtKB (SwissProt and TrEMBL). Provide extensively curated protein information, including function, classification, and cross-references.
- FASTA. Identifies regions of similarity among Protein or DNA sequences.
UniProtKB Species Suffix Map
LabKey ships with a version of the UniProt organism suffix map and loads it automatically the first time it is required by the guess organism routines. It can also be manually (re)loaded from the MS2 admin page; however, this is not something LabKey administrators or users need to do. The underlying data change very rarely and the changes are not very important to LabKey Server. Currently, this dictionary is used to guess the genus and species from a suffix (though there are other potential uses for this data).The rest of this section provides technical details about the creation, format, and loading of the SProtOrgMap.txt file.The file is derived from the Uniprot Controlled Vocabulary of Species list:http://www.uniprot.org/docs/speclistThe HTML from this page was hand edited to generate the file. The columns are sprotsuffix (swiss protein name suffix), superkingdomcode, taxonid, fullname, genus, species, common name and synonym. All fields are tab delimited. Missing species are replaced with the string "sp.". Swiss-Protein names (as opposed to accession strings) consist of 1 to 5 alphanumerics (uppercase), followed by an underscore and a suffix for the taxon. There are about 14,000 taxa represented in the file at present.The file can be (re)loaded by visiting the Admin Console -> Protein Databases and clicking the "Reload SWP Org Map" button. LabKey will then load the file named ProtSprotOrgMap.txt in the MS2/externalData directory. The file is inserted into the database (prot.SprotOrgMap table) using the ProteinDictionaryHelpers.loadProtSprotOrgMap(fname) method.Gene Ontology (GO) Database
LabKey loads five tables associated with the GO (Gene Ontology) database to provide details about cellular locations, molecular functions, and metabolic processes associated with proteins found in samples. If these files are loaded, a "GO Piechart" button will appear below filtered MS2 results, allowing you to generate GO charts based on the sequences in your results.The GO databases are large (currently about 10 megabytes) and change on a monthly basis. Thus, a LabKey administrator must load them and should update them periodically. This is a simple, fast process.To load the most recent GO database, go to Admin > Site > Admin Console, click Protein Databases and click the Load / Reload Gene Ontology Data button. LabKey Server will automatically download the latest GO data file, clear any existing GO data from your database, and upload new versions of all tables. On a modern server with a reasonably fast Internet connection, this whole process takes about three minutes. Your server must be able to connect directly to the FTP site listed below.Linking results to GO information requires loading a UniProt or TREMBL file as well (see below).The rest of this section provides technical details about the retrieval, format, and loading of GO database files.LabKey downloads the GO database file from: ftp://ftp.geneontology.org/godatabase/archive/latest-fullThe file has the form go_yyyyMM-termdb-tables.tar.gz, where yyyyMM is, for example, 201205. LabKey unpacks this file and loads the five files it needs (graph_path, term.txt, term2term.txt, term_definition, and term_synonym) into five database tables (prot.GoGraphPath, prot.GoTerm, prot.GoTerm2Term, prot.GoTermDefinition, and prot.GoTermSynonym). The files are tab-delimited with the mySQL convention of denoting a NULL field by using a "\N". The files are loaded into the database using the FtpGoLoader class.Note that GoGraphPath is relatively large (currently 1.9 million records) because it contains the transitive closure of the 3 GO ontology graphs. It will grow exponentially as the ontologies increase in size.Java 7 has known issues with FTP and the Windows firewall. Administrators must manually configure their firewall in order to use certain FTP commands. Not doing this will prevent LabKey from automatically loading GO annotations. To work around this problem, use the manual download option or configure your firewall as suggested in the these links:- http://www.enterprisedt.com/forums/viewtopic.php?t=3768&sid=4ddc012abd8b101b98b351d0dd9ee6ca
- http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=7077696
UniProtKB (SwissProt and TrEMBL)
Note that loading these files is functional and reasonably well tested, but due to the immense size of the files, it can take many hours or days to load them on even high performing systems. When funding becomes available, we plan to improve the performance of loading these files.The main source for rich annotations is the EBI (the European Biomolecular Institute) at:ftp://ftp.uniprot.org/pub/databases/uniprot/current_release/knowledgebase/completeThe two files of interest are:- uniprot_sprot.xml.gz, which contains annotations for the Swiss Protein database. This database is smaller and richer, with far fewer entries but many more annotations per entry.
- uniprot_trembl.xml.gz, which contains the annotations for the translated EMBL database (a DNA/RNA database). This database is more inclusive but has far fewer annotations per entry.
- Download the file of interest (uniprot_sprot.xml.gz or uniprot_trembl.xml.gz)
- Unpack the file to a local drive on your LabKey web server
- Visit Admin Console -> Protein Databases
- Under Protein Annotations Loaded, click the Import Data button
- On the Load Protein Annotations page, type the full path to the annotation file
- Select uniprot type.
- Click the button Load Annotations.
FASTA
When LabKey loads results that were searched against a new FASTA file, it loads the FASTA file, including all sequences and any annotations that can be parsed from the FASTA header line. Every annotation is associated with an organism and a sequence. Guessing the organism can be problematic in a FASTA file. Several heuristics are in place and work fairly well, but not perfectly. Consider a FASTA file with a sequence definition line such as:>xyzzyYou can not infer the organism from it. Thus, the FastaDbLoader has two attributes: DefaultOrganism (a String like "Homo sapiens" and OrganismIsToBeGuessed (a boolean) accessible through getters and setters setDefaultOrganism, getDefaultOrganism, setOrganismToBeGuessed, isOrganismToBeGuessed. These two fields are exposed on the insertAnnots.post page.Why is there a "Should Guess Organism?" option? If you know that your FASTA file comes from Human or Mouse samples, you can set the DefaultOrganism to "Homo sapiens" or "Mus musculus" and tell the system not to guess the organism. In this case, it uses the default. This saves tons of time when you know your FASTA file came from a single organism.Important caveat: Do not assume that the organism used as the name of the FASTA file is correct. The Bovine_Mini.fasta file, for example, sounds like it contains data from cows alone. In reality, it contains sequences from about 777 organisms.Using Custom Protein Annotations
Uploading Custom Protein Annotations
To add custom protein annotations:- Navigate to the MS2 Dashboard.
- Select Admin > Manage Custom Protein Lists.
- If you want to define your protein list at the project-wide level, click annotations in the project; otherwise your protein list will only be loaded in the current folder.
- Click the Import Custom Protein List button.
Viewing Your Annotations
Click on the name of the set to view its contents. You'll see a grid with all of the data that you uploaded.To see which the proteins in your custom set match up with a protein that the server has already loaded from a FASTA or Uniprot file, click on the "Show with matching proteins loaded into this server" link.Using Your Annotations
You can add your custom annotations to many of the MS2 pages. To see them while viewing a MS2 run:- Select queryPeptidesView from the Select a saved view dropdown.
- Select Grid Views > Customize Grid.
- Find and expand the node for your custom annotation set as follows:
- If you want to use the search engine-assigned protein, expand the "Search Engine Protein > Custom Annotations > Custom List" node.
- For a ProteinProphet assigned protein, expand the "Protein Prophet Data > Protein Group > First Protein > Custom Annotations > Custom Lists" node.
- Lookup String is the name you used for the protein in your uploaded file.
- Select the properties you want to add to the grid, and click Save.
- They will then show up in the grid.
- When viewing a single MS2 run under the queryProteinGroupView grouping, expand the Proteins > Protein > Custom Annotations node.
- When viewing Protein Search results, in the list of protein groups expand the First Protein > Custom Annotations node.
- In the Compare Runs query view, expand the Protein > Custom Annotations node.
Using ProteinProphet
- Run ProteinProphet automatically within LabKey Server as part of protein searches.
- Run ProteinProphet outside of LabKey Server and manually uploading results.
- General Upload Steps
- Specific Example Upload Steps
- View ProteinProphet Results Uploaded Manually
Automatically Run ProteinProphet and Load Results via LabKey Server
If you initiate a search for proteins from within your site, LabKey Server will automatically run ProteinProphet for you and load the results.Run ProteinProphet Outside LabKey Server and Upload Results Manually
You can use LabKey Server functionality on MS2 runs that have been processed previously outside of LabKey Server. You will need to upload processed runs manually to LabKey Server after running ProteinProphet and/or ProteinProphet separately.General Upload Steps: Set up Files and the Local Directory Structure for Upload- Place the ProteinProphet(protXML), PeptideProphet(pepXML), mzXML and FASTA files into a directory within your Pipeline Root.
- Make sure the FASTA file's path is correct in the protXML file. The FASTA file location must be available on the path specified in the file, if it is not available, the import will fail.
- Set up the Pipeline. Make sure that the data pipeline for your folder is configured to point to the directory on your file system that contains your ProteinProphet result files. On the Pipeline tab, click the "Process and Upload Data" button and browse to the directory containing your ProteinProphet results.
- Import Results. Click on the corresponding "Import ProteinProphet" button. LabKey Server will load the MS2 run from the .pep.xml file, if needed, and associate the ProteinProphet data with it. LabKey Server recognizes protXML and pepXML files as ProteinProphet data.
- Load the PeptideProphet results from the pepXML file
- Place the pepXML, protXML, mzXML and FASTA file(s) in the directory: i:\S2t
- Verify that the path to the FASTA file within the protXML file correctly points to the FASTA file in step #1
- In the "MS2 Dashboard > Process and Upload" window, click on the "Import Protein Prophet" button located next to pepXML.
View ProteinProphet Results Uploaded Manually
To view uploaded ProteinProphet results within LabKey Server, navigate to the MS2 run of interest within LabKey Server. If the data imported correctly, there will be a new grouping option, "Protein Prophet". Select one of them to see the protein groups, as well as the indistinguishable proteins in the groups. The expanded view will show you all of the peptides assigned to that group, or you can click to expand individual groups in the collapsed view.There are additional peptide-level and protein-level columns available in the ProteinProphet views. Click on either the Pick Peptide Columns or Pick Protein Columns buttons to view the full list and choose which ones you want to include.Using Quantitation Tools
Add Quantitation Columns
When viewing runs with quantitation data, you will want to add the columns that hold the quantitation data.Add Peptide Quantitation Columns- Navigate to the run you would like to modify.
- In the Peptides section, select Grid Views > Customize Grid
- To add XPRESS or Q3 peptide quantitation columns, expand the Quantitation node.
- To add Libra peptide quantitation columns, expand the iTRAQ Quantitation node.
- Choose columns.
- Save the grid.
- Navigate to the run you would like to modify.
- In the Peptides section, select Grid Views > ProteinProphet.
- Then Grid Views > Customize Grid.
- Open the nodes Protein Prophet Data > Protein Group > Quantitation or iTRAQ Quantitation.
- Choose columns.
- Save the grid.
Excluding Specific Peptides from Quantitation Results
If you have XPRESS or Q3 quantitation data, you can exclude specific peptides from the quantitation results. The server will automatically recalculate the rollup quantitation values at the protein group level. Follow these steps:Exclude Specific Peptides- Add the peptide quantitation columns (see above).
- Navigate to the peptide you would like to exclude. (Expand a particular protein record to see the peptides available and then click the name of the peptide.)

- On the peptide's details page, scroll down and click the Invalidate Quantitation Results button.
- Refresh the run page and note that the peptide's Invalidated column now has the value "true" and the quantitation rollup values for the protein have been recalculated.
- To include a previously excluded peptide, navigate to the peptide's details page, and click the Revalidate Quantitation Results button.
Related Topics
Label-Free QuantitationProtein Expression Matrix Assay
- Go to Admin > Manage Assays and click New Assay Design.
- Select Protein Expression Matrix and click Next.
- Enter a Name for the design.
- Click Save and Close.
Related Topics
Link Protein Expression Data with Annotations
Set Up an MS2 Folder
An MS2 folder makes the protein annotation data available to be linked with the protein expression data. You can create a new folder, or change an existing folder to type "MS2".- To create a new folder:
- Navigate to the parent location.
- Select Admin > Folder > Management and click Create Subfolder.
- Give the folder a Name and for Folder Type select MS2 and click Next.
- Complete the wizard by clicking Finish.
- To change an existing folder:
- Navigate to it and select Admin > Folder > Management.
- Select the Folder Type tab
- Select MS2 and click Update Folder.
Download Sample Files
- Download the following sample files:
- Sample UniProt XML file: Uniprot_rat.xml
- Sample FASTA file: rat.fasta
- Sample protein expression matrix dataset: ExpressionMatrix_Rat.xlsx
Import Annotation Data
Imported annotation data is parsed into a more readily useable format, i.e. into various tables in the 'proteins' schema. Once you've imported the annotation data below, you can see resulting data tables by going to Admin > Developer Links > Schema Browser and selecting the proteins schema in the lefthand pane. Select a table, such as Annotations or GOCellularLocation, and click View Data.- Go to Admin > Site > Admin Console. Under Management click Protein Databases.
- Under Protein Annotations Loaded click Import Data.
- Enter the Full file path to rat.fasta, for Type select "fasta".
- Either enter the default organism, or check the box to allow the server to try to guess.
- Click Load Annotations.
- Go to Admin > Site > Admin Console. Under Management click Protein Databases.
- Under Protein Annotations Loaded click Import Data.
- Enter the Full file path to the UniProt XML file, for Type select "uniprot".
- Click Load Annotations. (To get the latest UniProt XML files, go to http://www.uniprot.org/, or you can use Uniprot_rat.xml as a sample file.)
- Click Load Gene Ontology Data under Protein Annotations Loaded.
Import Protein Expression Data
- Create a new Protein Expression Matrix assay design. The default assay design will work with sample expression data provided here. For details, see Protein Expression Matrix Assay.
- Import the sample protein expression data into the assay design:
- Select Admin > Manage Assays.
- In the Assay List, click the expression assay you just created.
- Click Import Data.
- For FASTA/Uniprot File, select "rat.fasta".
- Click Choose File and select the file: ExpressionMatrix_Rat.xlsx.
- Click Save and Finish.
Create Joined Views
Now that the expression and annotation data is in place, you can create views that join the two together.- Navigate to the expression data results table. (From the runs table, click the Assay ID link text ExpressionMatrix_Rat.xlsx.)
- Select Grid Views > Customize Grid.
- Under Available Fields open the Protein node. The fields inside the Protein node hold annotation data you imported earlier. Select the fields of interest to add them to the view, for example, select Sequence. Also scroll down to see GO annotation fields, such GO Metabolic Processes, GO Cellular Processes, GO Molecular Functions.

- Once you have selected the desired fields, click Save, and Save again, to save the view as the default view.
- The joined view will be displayed as a grid:

Create a Custom Query on the Data
You can also create more sophisticated queries on the expression data / GO data. Below we will create an example query.- Go to Admin > Developer Links > Schema Browser.
- Open the nodes assay and then ProteinExpressionMatrix in the lefthand pane, and then select the name of your assay design.
- Click Create New Query.
- Give the query a name, such as "Protein Counts"
- The table/query you base your custom query on can be any value, as we will overwrite the default query.
- Click Create and Edit Source.
- Delete the default SQL query that is provided, and copy and paste the SQL query below into the text area:
SELECT AVG(D.Value) AS Average,
a.SeqId,
a.AnnotVal AS Location,
COUNT(d.SeqId) AS ProteinCount,
D.SampleId,
a.AnnotTypeId.Name
FROM Data d, Protein.Annotations a
WHERE a.SeqId = d.SeqId
GROUP BY a.AnnotVal, D.SampleId, a.AnnotTypeId.Name, a.SeqId
- Click Execute Query to see the results (shown on the Data tab):

- Return to the Source tab.
- Click Save and Finish to finalize the query.
Related Topics
- Protein Expression Matrix Assay
- For details about importing public Gene Ontology and protein annotations, see: Loading Public Protein Annotation Files.
Spectra Counts
Label-Free Quantitation
Label-Free Quantitation Using Spectra Counts
When given two unlabeled samples that are input to a mass spectrometer, it is often desirable to assess whether a given protein exists in higher abundance in one sample compared to the other. One strategy for doing so is to count the spectra identified for each sample by the search engine. This technique requires a statistical comparison of multiple, repeated MS2 runs of each sample. LabKey Server makes handling the data from multiple runs straightforward.Example Data Set
To illustrate the technique, we will use mzXML files that were described in this paper as the "Variability Mix":Jacob D. Jaffe, D. R. Mani, Kyriacos C. Leptos, George M. Church, Michael A. Gillette, and Steven A. Carr, "PEPPeR, a Platform for Experimental Proteomic Pattern Recognition", Molecular and Cellular Proteomics; 5: 1927 - 1941, October 2006The datasets are derived from two sample protein mixes, alpha and beta, with varied concentrations of a specific list of 12 proteins. The samples were run on a Thermo Fisher Scientific LTQ FT Ultra Hybrid mass spectrometer. The resulting datafiles were converted to the mzXML format that was downloaded from Tranche.The files named VARMIX_A through VARMIX_E were replicates of the Alpha mix. The files named VARMIX_K through VARMIX_O were the Beta mix.You can see the examples in our online demo project.Running the MS2 Search
The mzXML files provided with the PEPPeR paper included both MS1 and MS2 scan data. The first task is to get an MS2 search protocol that correctly identifies the 12 proteins spiked into the samples. The published data do not include the FASTA file to use as the basis of the search, so this has to be created from the descriptions in the paper. The paper did provide the search parameters used by the authors, but these were given for the SpectrumMill search engine, which is not freely available nor accessible from LabKey Server. So the SpectrumMill parameters are translated into their approximate equivalents on the X!Tandem search engine that is included with LabKey Server.Creating the right FASTA file
The PEPPeR paper gives the following information about the protein database against which they conducted their search:Data from the Scale Mixes and Variability Mixes were searched against a small protein database consisting of only those proteins that composed the mixtures and common contaminants… Data from the mitochondrial preparations were searched against the International Protein Index (IPI) mouse database version 3.01 and the small database mentioned above.The spiked proteins are identified in the paper by common names such as "Aprotinin". The paper did not give the specific protein database identifiers such as IPI numbers or SwissProt.. The following list of 13 SwissProt names is based on Expasy searches using the given common names as search terms. (Note that "alpha-Casein" became two SwissProt entries).| Common Name | Organism | SprotName | Conc. In A | Conc. In B |
|---|---|---|---|---|
| Aprotinin | Cow | BPT1_BOVIN | 100 | 5 |
| Ribonuclease | Cow | RNAS1_BOVIN | 100 | 100 |
| Myoglogin | Horse | MYG_HORSE | 100 | 100 |
| beta-Lactoglobulin | Cow | LACB_BOVIN | 50 | 1 |
| alpha-Casein S2 | Cow | CASA2_BOVIN | 100 | 10 |
| alpha-Casein S1 | Cow | CASA1_BOVIN | 100 | 10 |
| Carbonic anhydrase | Cow | CAH2_BOVIN | 100 | 100 |
| Ovalbumin | Chicken | OVAL_CHICK | 5 | 10 |
| Fibrinogen beta chain | Cow | FIBB_BOVIN | 25 | 25 |
| Albumin | Cow | ALBU_BOVIN | 200 | 200 |
| Transferrin | Human | TRFE_HUMAN | 10 | 5 |
| Plasminogen | Human | PLMN_HUMAN | 2.5 | 25 |
| beta-Galactosidase | E. Coli | BGAL_ECOLI | 1 | 10 |
- The spiked proteins as listed in the table, using SwissProt identifiers
- The Mouse IPI fasta database, using IPI identifiers
- The cRAP list of common contaminants from www.thegpm.org, minus the proteins that overlapped with the spiked proteins (including other species versions of those spiked proteins. This list used a different format of SwissProt identifiers.
Loading the PEPPeR data as a custom protein list
When analyzing a specific set of identified proteins as in this exercise, it is very useful to load the known data about the proteins as a custom protein annotation list. To add custom protein annotations using our example file attached to this page:- Navigate to the MS2 Dashboard.
- Select Admin > Manage Custom Protein Lists.
- Click Import Custom Protein List.
- Download the attached file PepperProteins.tsv and open it.
- Select all rows and all columns of the content, and paste into the text box on the Upload Custom Protein Annotations page. The first column is a “Swiss-Prot Accession” value.
- Click Submit.

X!Tandem Search Parameters
Spectra counts rely on the output of the search engine, and therefore the search parameters will likely affect the results. The original paper used SpectrumMill and gave its search parameters. For LabKey Server, the parameters must be translated to X!Tandem. These are the parameters applied:<bioml>
<!-- Carbamidomethylation (C) -->
<note label="residue, modification mass" type="input">57.02@C</note>
<!-- Carbamylated Lysine (K), Oxidized methionine (M) -->
<note label="residue, potential modification mass" type="input">43.01@K,16.00@M</note>
<note label="scoring, algorithm" type="input">k-score</note>
<note label="spectrum, use conditioning" type="input">no</note>
<note label="pipeline quantitation, metabolic search type" type="input">normal</note>
<note label="pipeline quantitation, algorithm" type="input">xpress</note>
</bioml>
- The values for the fixed modifications for Carbamidomethylation and the variable modifications for Carbamylated Lysine (K) and Oxidized methionine (M) were taken from the Delta Mass database.
- Pyroglutamic acid (N-termQ) was another modification set in the SpectrumMill parameters listed in the paper, but X!Tandem checks for this modification by default.
- The k-score pluggable scoring algorithm and the associated “use conditioning=no” are recommended as the standard search configuration used at the Fred Hutchinson Cancer Research Center because of its familiarity and well-tested support by PeptideProphet.
- The metabolic search type was set to test the use of Xpress for label-free quantitation, but the results do not apply to spectra counts.
- These parameter values have not been reviewed for accuracy in translation from SpectrumMill.
Reviewing Search Results
One way to assess how well the X!Tandem search identified the known proteins in the mixtures is to compare the results across all 50 runs, or for the subsets of 25 runs that comprise the Alpha Mix set and the Beta Mix set. To enable easy grouping of the runs into Alpha and Beta mix sets, create two Run Groups (for example AlphaRunGroup and BetaRunGroup) and add the runs to them. Creating run groups is a sub function of the Add to run group button on the MS2 Runs (enhanced) grid. After the run groups have been created, and runs assigned to them, it is easy to compare the protein identifications in samples from just one of the two groups by the following steps:
After the run groups have been created, and runs assigned to them, it is easy to compare the protein identifications in samples from just one of the two groups by the following steps:- Navigate to the MS2 Dashboard and the MS2 Runs web part.
- If you do not see the Run Groups column, use Grid Views > Customize Grid to add it.
- Filter to show only the runs from one group by clicking it's name in the Run Groups column. If the name is not a link, you can use the column header filter option as usual.
- Select all the filtered runs using the checkbox at the top of the selection box column.
- Select Compare > ProteinProphet.
- On the options page choose "Peptides with PeptideProphet probability >=" and enter ".75".
- Click Compare.

The Spectra Count views
The wide format of the ProteinProphet view is designed for viewing on-line. It can be downloaded to an Excel or TSV file, but the format is not well suited for further client-side analysis after downloading. For example, the existence of multiple columns of data under each run in Excel makes it difficult to reference the correct columns in formulas. The spectra count views address this problem. These views have a regular column structure with Run Id as just a single column.- Return to the MS2 Runs web part on the MS2 Dashboard and select the same filtered set of runs.
- Select Compare > Spectra Count.
- Peptide sequence: Results are grouped by run and peptide. Use this for quantitation of peptides only
- Peptide sequence, peptide charge: Results grouped by run and peptide charge. Used for peptide quantitation if you need to know the charge state (for example, to filter or weight counts based on charge.state)
- Peptide sequence, ProteinProphet protein assignment: The run/peptide grouping joined with the ProteinProphet assignment of proteins for each peptide.
- Peptide sequence, search engine protein assignment: The run/peptide grouping joined with the single protein assigned by the search engine for each peptide.
- Peptide sequence, peptide charge, ProteinProphet protein assignment: Adds in grouping by charge state
- Peptide sequence, peptide charge, search engine protein assignment: Adds in grouping by charge state
- Search engine protein assignment: Grouped by run/protein assigned by the search engine.
- ProteinProphet protein assignment: Grouped by run/protein assigned by ProteinProphet. Use with protein group measurements generated by ProteinProphet
Understanding the spectra count data sets
Because the spectra count output is a single rectangular result set, there will be repeated information with some grouping options. In the peptide, protein grid, for example, the peptide data values will be repeated for every protein that the peptide could be matched to. The table below illustrates this type of grouping:| (row) | Run Id | Alpha Run Grp | Peptide | Charge States Obsv | Tot Peptide Cnt | Max PepProph | Protein | Prot Best Gene Name |
|---|---|---|---|---|---|---|---|---|
| 1 | 276 | false | K.AEFVEVTK.L | 2 | 16 | 0.9925 | ALBU_BOVIN | ALB |
| 2 | 276 | false | K.ATEEQLK.T | 2 | 29 | 0.9118 | ALBU_BOVIN | ALB |
| 3 | 276 | false | K.C^CTESLVNR.R | 1 | 18 | 0.9986 | ALBU_BOVIN | ALB |
| 4 | 276 | false | R.GGLEPINFQTAADQAR.E | 1 | 4 | 0.9995 | OVAL_CHICK | SERPINB14 |
| 5 | 276 | false | R.LLLPGELAK.H | 1 | 7 | 0.9761 | H2B1A_MOUSE | Hist1h2ba |
| 6 | 276 | false | R.LLLPGELAK.H | 1 | 7 | 0.9761 | H2B1B_MOUSE | Hist1h2bb |
| 7 | 276 | false | R.LLLPGELAK.H | 1 | 7 | 0.9761 | H2B1C_MOUSE | Hist1h2bg |
| 8 | 299 | true | K.AEFVEVTK.L | 2 | 16 | 0.9925 | ALBU_BOVIN | ALB |
| 9 | 299 | true | K.ECCHGDLLECADDR.A | 1 | 12 | 0.9923 | ALBU_MOUSE | Alb |
| 10 | 299 | true | R.LPSEFDLSAFLR.A | 1 | 1 | 0.9974 | BGAL_ECOLI | lacZ |
| 11 | 299 | true | K.YLEFISDAIIHVLHSK.H | 2 | 40 | 0.9999 | MYG_HORSE | MB |
- Row 1 contains the total of all scans (16) that matched the peptide K.AEFVEVTK.L in Run 276, which was part of the Beta Mix. There were two charge states identified that contributed to this total, but the individual charge states are not reported separately in this grouping option. 0.9925 was the maximum probability calculated by PeptideProphet for any of the scans matched to this peptide The K.AEFVEVTK.L is identified with the ALBU_BOVIN (bovine albumin), which has a gene name of ALB.
- Rows 2 and 3 are different peptides in run 276 that also belong to Albumin.. Row 4 matches to a different protein, ovalbumin.
- Rows 5-7 are 3 different peptides in the same run that could represent any one of 3 mouse proteins, H2B1x_MOUSE. ProteinProphet assigned all three proteins into the same group. Note that the total peptide count for the peptide is repeated for each protein that it matches. This means that simply adding up the total peptide counts would over count in these cases. This is just the effect of a many-to-many relationship between proteins and peptides that is represented in a single result set.
- Rows 8-11 are from a different run that was done from an Alpha mix sample.
Using Excel Pivot Tables for Spectra Counts
An Excel pivot table is a useful tool for consuming the datasets returned by the Spectra count comparison in LabKey Server. It is very fast, for example, for rolling up the Protein grouping data set and reporting ProteinProphet’s “Total Peptides” count, which is a count of spectra with some correction for the potential pitfalls in mapping peptides to proteins.Using R scripts for spectra counts
The spectra count data set can also be passed into an R script for statistical analysis, reporting and charting. R script files which illustrate this technique can be downloaded here. Note that column names are hard coded and may need adjustment to match your data.- SpectraCountFunctions_v8_1.R: utility script - define and select it as a shared when executing other scripts.
- SimpleExec.R
- DoExampleRunScoring.R
- DoSASPECT.R
Combine XTandem Results
- Go to the Data Pipeline at Admin > Go To Module > Pipeline and click Process and Import Data.
- Select the filename.xtan.xml files you want to combine and click Fraction Rollup Analysis.

- Select an existing Analysis protocol. (Or select <new protocol> and provide a Name.)
- Complete the protocol details and click Search. For details on configuring a protocol, see Configure Common Parameters.

- The job will be passed to the pipeline. Job status is displayed in the Data Pipeline web part.
- When complete, the results will appear as a new record in the MS2 Runs web part.

- Click the protocol name in MS2 Runs for detailed data.

Related Topics
MS1
- Users may import msInspect "Feature" files to server via the pipeline. Each file will be imported as a new experiment run.
- If a corresponding peaks XML file is supplied with the Features file, its contents will also be imported into the database.
- After import, users can view the set of MS1-specific experiment runs and click the Features link to view the features from a particular run.
 The features list is a LabKey query grid, meaning that it supports all the standard sorting, filtering, export, print and customize functionality.
The Similar link for each feature allows you to search for similar features.
The features list is a LabKey query grid, meaning that it supports all the standard sorting, filtering, export, print and customize functionality.
The Similar link for each feature allows you to search for similar features.
- If a corresponding "peaks" XML file was supplied, each feature will also offer two links: one to view the features details; and one to view the peaks that contributed to that feature.
- The peaks view is another query grid, complete with all the standard functionality.
- The feature details view displays provided peak information in a series of charts.

Related Documentation
- Documentation for msInspect is available on the msInspect site.
- MS1 Pipelines
MS1 Pipelines
Overview
LabKey currently provides two MS1 Pipelines:
- Pipeline #1: msInspect Find Features
- peakaboo peak finding
- msInspect feature finding
- Pipeline #2 : msInspect Find Features and Match Peptides
- peakaboo peak finding
- msInspect feature finding
- pepmatch MS1 feature-MS2 peptide linking
For information on how to download and build peakaboo and pepmatch, please view this documentation.
Each pipeline makes use of Tasks. These currently include:
- peakaboo
- msInspect
- pepmatch
Pipeline #1: Find MS1 Features
- Button: msInspect Find Features
- Protocol Folder: inspect
- Initial type: .mzXML
- Output type: .features.tsv (.peaks.xml)
Flow Diagram: msInspect Feature Finding Analysis

Flow Diagram: msInspect Feature Finding Analysis with Peakaboo peaks analysis

Pipeline #2: Match MS1 Features to Peptides
- Button: msInspect Find Features and Match Peptides
- Protocol Folder: ms1peptides
- Initial type: .pep.xml
- Output type: .peptides.tsv (.peaks.xml)
Flow Diagram: msInspect Feature Peptide Matching Analysis

Flow Diagram: msInspect Feature Peptide Matching with Peakaboo peaks Analysis

Task: peakaboo (not included in default installation)
Extensions:
inputExtension = .mzXML
outputExtension = .peaks.xml
Usage:
peakaboo [options] [files]+
| Parameter | Arguments | Description | Command Line Help |
| pipeline, peakaboo enabled | Enables/disables Peakaboo execution as part of pipeline. Values are true/false. Defaults to true. | ||
| pipeline, import peaks | Skips importing peak data into the database. Values are true/false. Defaults to true. | ||
| peakaboo, start scan | --scanBegin arg (=1) | Minimum scan number (default 1). | beginning scan |
| peakaboo, end scan | --scanEnd arg (=2147483647) | Maximum scan number (default last). | ending scan |
| peakaboo, minimum m/z | --mzLow arg (=200) | Minimum M/Z value (default: the minimum m/z value in the file). set mz low cutoff | set mz low cutoff |
| peakaboo, maximum m/z | --mzHigh arg (=2000) | Maximum M/Z value (default: the maximum m/z value in the file). | set mz high cutoff |
Example:
<?xml version="1.0"?>
<bioml>
<note type="input" label="peakaboo, minimum m/z">100</note>
<note type="input" label="peakaboo, maximum m/z">300</note>
</bioml>
Task: msInspect
Extensions:
inputExtension = .mzXML
outputExtension = .features.tsv
Usage:
--findPeptides [--dumpWindow=windowSize] [--out=outfilename] [--outdir=outdirpath] [--start=startScan][--count=scanCount] [--minMz=minMzVal] [--maxMz=maxMzVal] [--strategy=className] [--noAccurateMass] [--accurateMassScans=<int>]
[--walkSmoothed] mzxmlfile
Details:
The findpeptides command finds peptide features in an mzXML file, based on the criteria supplied
Argument Details: ('*' indicates a required parameter)
*(unnamed ...): Input mzXML file(s)
| Parameter | Argument | Description |
| msinspect findpeptides, start scan | start | Minimum scan number (default 1) |
| msinspect findpeptides, scan count | count | Number of scans to search, if not all (default 2147483647) |
| msinspect findpeptides, minimum m/z | minmz | Minimum M/Z Value (default: the minimum m/z value in the file) |
| msinspect findpeptides, maximum m/z | maxmz | Maximum M/Z Value (default: the maximum m/z value in the file) |
| msinspect findpeptides, strategy | strategy | Class name of a feature-finding strategy implementation |
| msinspect findpeptides, accurate mass scans | accuratemassscans | When attempting to improve mass-accuracy, consider a neighborhood of <int> scans (default 3) |
| msinspect findpeptides, no accurate mass | noaccuratemass | Do not attempt mass-accuracy adjustment after default peak finding strategy (default false) |
| msinspect findpeptides, walk smoothed | walksmoothed | When calculating feature extents, use smoothed rather than wavelet-transformed spectra) (default false) |
Example:
<?xml version="1.0"?>
<bioml>
<note type="input" label="msinspect findpeptides, minimum m/z">100</note>
<note type="input" label="msinspect findpeptides, maximum m/z">300</note>
</bioml>
Task: pepmatch
Extensions:
inputExtension = .features.tsv
outputExtension = .peptides.tsv
Usage:
pepmatch <pepXML file> <feature file> [options]
| Parameter | Arguments | Description | Command Line Help |
| ms1 pepmatch, window | -w<window> | Filters on the specificed mz-delta window (default 1.0) | filters on the specified mz-delta window. |
| ms1 pepmatch, min probability | -p<min> | Minimum Peptide Prophet probability to match. Min = 0.0. Max = 1.0 | minimum PeptideProphet probability to match. |
| ms1 pepmatch, require match charge | -c | Discard matches where pepXML assumed charge does not match MS1 data (values are true/false) | discard matches where pepXML assumed charge does not match MS1 data |
Example:
<?xml version="1.0"?>
<bioml>
<note type="input" label="ms1 pepmatch, require match charge">true</note>
</bioml>
Panorama - Targeted Proteomics
- Easy aggregation and curation of results
- Guidance for new experiments based on insights from previous experiments
- Search and review over a large collection of experiments
- Secure sharing of results
- Panorama can be installed by laboratories and organizations on their own servers. It is included as part of a standard LabKey Server installation.
Documentation
- Configure Panorama Folder
- Panorama QC Dashboard
- Panorama QC Plots
- Panorama Plot Types
- Panorama QC Annotations
- Panorama QC Guide Sets
- Pareto Plots
- Panorama: Clustergrammer Heat Maps
- Panorama Document Revision Tracking
PanoramaWeb Documentation
Configure Panorama Folder
- Experimental data: A repository of Skyline documents, useful for collaborating, sharing and searching across multiple experiments.
- Chromatogram library: Curated precursor and product ion expression data for use in designing and validating future experiments. Check Rank peptides within proteins by peak area if your data contains relative peptide expression for proteins.
- QC: Quality control metrics of reagents and instruments.
Experimental Data
The Sharing Skyline Documents Tutorial on the PanoramaWeb site provides an introduction to using Panorama and covers the following areas:- Requesting a project on panoramaweb.org
- Data organization and folder management in Panorama
- Publishing Skyline documents to Panorama
- Data display options and searching results uploaded to Panorama
- Providing access to collaborators and other groups
- Panorama: Clustergrammer Heat Maps
- Panorama Document Revision Tracking
Chromatogram Library
In the Panorama Chromatogram Libraries Tutorial you will go through the steps of creating a library folder in Panorama for storing curated, targeted results.- Build a chromatogram library in Panorama
- Use it in Skyline to select peptides and product ions to measure in a new experimental setting
- Compare library chromatograms with new data to validate peptide indentifications.
Panorama QC Folder
- Panorama QC Dashboard: Overview of the Panorama QC Folder
- Panorama QC Plots: Panorama QC Plots
Panorama QC Dashboard
Panorama Dashboard
The Panorama Dashboard tab shows the QC Summary and QC Plots.QC Summary
On the Panorama Dashboard, the QC Summary section shows a tile for the current folder and each immediate subfolder the user can access. Typically a folder would represent an individual instrument, and the dashboard gives an operator an easy way to immediately scan all the machines for status. The count of the number of Skyline documents (targetedms.runs) and sample files (targtedms.samplefile) are scoped to the current container. Each tile lists the number of files that have been uploaded, the number of precursors that are being tracked, and summary details for the last 3 sample files uploaded, including their acquired date and whether any outliers were identified. Both proteomics and small molecule data outliers are tracked, and a combined count of outliers is presented. Tiles also include a visual indicator of AutoQC status.
AutoQC
The TargetedMS module uses the AutoQC tool to ping the server to check if a given container exists. The QC Summary web part displays a color indicator:- Gray - AutoQC has never pinged.
- Red - AutoQC has pinged, but not recently.
- Green - AutoQC has pinged recently. The default timeout for "recently" is 15 minutes.
 AutoQC also facilitates the ongoing collection of data in a Panorama QC folder. Each sample is uploaded incrementally and automatically by AutoQC. AutoQC adds new samples to an existing Skyline document, rotating out and archiving old data to prevent the active file from getting too large. As new files are received, they are automatically coalesced to prevent storing redundant copies across multiple files. Whenever a PanoramaQC file receives a new file to import, by the end of that import we have the most recent copy of the data for each sample contained in the file, even if it had been previously imported.
AutoQC also facilitates the ongoing collection of data in a Panorama QC folder. Each sample is uploaded incrementally and automatically by AutoQC. AutoQC adds new samples to an existing Skyline document, rotating out and archiving old data to prevent the active file from getting too large. As new files are received, they are automatically coalesced to prevent storing redundant copies across multiple files. Whenever a PanoramaQC file receives a new file to import, by the end of that import we have the most recent copy of the data for each sample contained in the file, even if it had been previously imported.
Sample File Details
The display tile shows the acquired date/time for the latest 3 sample files along with indicators of which QC metrics have outliers in the Levey-Jennings report, if any. Hover over the icon for a sample file in the QC Summary web part to see popover details about that file. The hover details for a sample file with outliers show the per metric "out of guide set range" information with links to view the Levey-Jennings plot for that container and metric.
The hover details for a sample file with outliers show the per metric "out of guide set range" information with links to view the Levey-Jennings plot for that container and metric.
Delete a Sample File
To delete an unwanted sample file, such as one you imported accidentally, click the link showing the number of sample files in the folder to open a grid, select the relevant row, and click Delete. The data from that sample file will be removed from the plot.QC Plots
The QC Plots webpart shows one graph per precursor for a selected metric and date range. Choose from a variety of different available plot types, sizes, and other options. For more details, see Panorama QC Plots.
Related Topics
Panorama QC Plots
QC Plots Web Part
The QC Plots webpart shows one graph per precursor. The web part header allows yoou to specify a number of options, including selecting one or more type of plot using checkboxes. Hover over a plot name to learn more. This topic uses the default Levey-Jennings plot to illustrate features.QC Plot Types
- Levey-Jennings: (Default) Levey-Jennings plots plot quality control data to give a visual indication of whether a laboratory test is working well. The distance from the mean (expected value) is measured in standard deviations (SD).
- Moving Range (MR): Plots the moving range over time to monitor process variation for individual observations by using the sequential differences between two successive values as a measure of dispersion.
- CUSUMm: A CUSUM plot is a time-weighted control plot that displays the cumulative sums of the deviations of each sample value from the target value. CUSUMm (mean CUSUM) plots two types of CUSUM statistics: one for positive mean shifts and one for negative mean shifts.
- CUSUMv: The CUSUMv (variability or scale CUSUM) plots two types of CUSUM statistics: one for positive variability shifts and one for negative variability shifts. Variability is a transformed standardized normal quantity which is sensitive to variability changes.
QC Plot Features
Metrics
Select the metric to plot using the pulldown menu in the web part header. Each type of plot can be shown for the following metrics:- Full Width at Base (FWB)
- Full Width at Half Maximum (FWHM)
- Light/Heavy Ratio (when data is available)
- Mass Accuracy
- Peak Area
- Retention Time
- Transition/Precursor Area Ratio
- Transition/Precursor Areas

- Metric: Select the desired metric from the pulldown.
- Date Range: Default is "All dates". Other options range from last 7 days to last year, or you can specify a custom range.
- Plot Size: When multiple plots are selected, you will have the following options:
- Small: Display 2 plots across the page.
- Large: Show full width plots, one per row.
- QC Plot Type: Check one or more boxes for plot type. Options outlined above.
- Y-Axis Scale: Linear or logarithmic.
- Group X-Axis Values by Date: Check this box to scale acquisition times based on the actual dates. When this box is not checked, acquisition times are spaced equally, and multiple acquisitions for the same date will be shown as distinct points.
- Show All Series in Single Plot: Check this box to show all fragments in one plot.
Transition/Precursor Areas
To show both precursor and fragment values in the same plot, select the metric option Transition/Precursor Areas. The plot is more complex when all fragments are shown. Use the legend for reference, and you can also hover over any point to see a tool tip with more information about that point.
The plot is more complex when all fragments are shown. Use the legend for reference, and you can also hover over any point to see a tool tip with more information about that point.
View Legend
To see the legends used for all plots click View Legend.
Export a Plot
You can export any of the plots by hovering to expose the buttons in the upper right, then clicking the icon for:- PNG: Export to a PNG image file.
- PDF: Export as a PDF document.
 Exported plots will always include the legends, whether they appear on the display plot or not.
Exported plots will always include the legends, whether they appear on the display plot or not.
QC Metric Settings Persistence
The next time the user views the plots on the dashboard, they will see the same metric they were most recently viewing. Persisted values are metric, y-axis scale, group x-axis checkbox, and show single plot checkbox. The start and end dates previously selected do not persist, as it is most useful to come back to the full range.Small Molecule Data
The same Levey-Jennings, MR, CUSUM, and Pareto plot features apply to both proteomics (peptide/protein) data and small molecule data. Data from both types may be layered together on the same plot when displaying plots including all fragments. Counts of outliers and sample files include both types of data.When visualizing small molecule data, you are more likely to encounter warnings if the number of precursors exceeds the count that can be usefully displayed. This screenshot shows an example plot with small molecule data. Note that the legend for this illegibly-dense plot does not list all 50 precursors.
Note that the legend for this illegibly-dense plot does not list all 50 precursors.
Related Topics
Panorama Plot Types
Levey-Jennings Plots
The default plot in a Panorama QC folder is the Levey-Jennings plot which is helpful in visualizing and analyzing trends and outliers. The distance between a given observation and the mean (expected value) is measured in standard deviations (SD). For a walkthrough of plotting features featuring these plots, see Panorama QC Plots.Moving Range Plots
The moving range can be plotted over time to monitor process variation for individual observations by using the sequential differences between two successive values as a measure of dispersion. Moving Range (MR) plots can be displayed alongside Levey-Jennings plots for integrated analysis of changes. To create a Moving Range plot, check the box in the QC Plots webpart.In this screencap, both the Levey-Jennings and Moving Range plots are shown side by side. Notice the two elevated points on the moving range plot highlight the one peak (two large changes). Otherwise the value for retention time remained quite consistent. The plotting features outlined in Panorama QC Plots also apply to Moving Range plots.
The plotting features outlined in Panorama QC Plots also apply to Moving Range plots.
CUSUM Plots
A Cumulative Sum (CUSUM) plot is a time-weighted control plot that displays the cumulative sums of the deviations of each sample value from the target value. This can highlight a problem when seemingly small changes combine to make a substantial difference over time.Clicking View Legend will show the legend for the dotted and solid lines in a CUSUM plot:- CUSUM- is a solid line
- CUSUM+ is a dotted line
CUSUMm (Mean CUSUM)
The CUSUMm (mean CUSUM) plots two types of CUSUM statistics: one for positive mean shifts and one for negative mean shifts.
CUSUMv (Variable CUSUM)
The CUSUMv (variability or scale CUSUM) plots two types of CUSUM statistics: one for positive variability shifts and one for negative variability shifts. Variability is a transformed standardized normal quantity which is sensitive to variability changes.A sample CUSUMv plot, shown with no other plot type selected:
Related Topics
Panorama QC Annotations
Quality Control Annotations
Color coded date markers can be used to annotate the QC plots with information about the timing of various changes. The annotated plot will show colored Xs noting the time there was a change in instrumentation, reagent, etc. Click View Legend to see which color corresponds to which type of annotation.Hovering over an annotation pops up a tooltip showing information about when the annotation event occurred, the description of the event, and who added it.
Add Annotations
Select the Annotations tab to define and use annotations.
Define Types of Annotations
If you wish to add new categories of annotations, use Insert > Insert New Row in the QC Annotation Types section. Each type has a name, description, and color to use. There are three built-in categories which are shared by all Panorama folders on the server. You may change them or the colors they use, but be aware that other projects may be impacted by your changes. Annotation Types defined in the "Shared" project are available throughout the server. Types defined at the project level are available in all subfolders.- Instrumentation Change
- Reagent Change
- Technician Change
Add New Annotations to Plots
To enter a new annotation, use Insert > Insert New Row in the QC Annotations section. Select the type of event (such as Reagent Change), enter a description to show in hover text ("new batch of reagent", and enter when it occurred. Dates that include a time of day should be of the form "2013-8-21 7:00", but a simple date is sufficient. Return to the Panorama Dashboard tab to view the plots with your new annotation applied.The annotation symbol is placed on the x-axis above the tick mark for the date on which the event occurred. If there are multiple tickmarks for that date, the annotation will appear above the leftmost one. If an annotation occurred on a date for which there is no other data, a new tick mark will be added to the x-axis for that date.Related Topics
Panorama QC Guide Sets
Quality Control Guide Sets
Guide sets give you control over which data points are used to establish the expected range of values in a QC plot. Instead of calculating the expected ranges based on all data points in the view, you can specify guide sets based on a subset of data points.You create a guide set by specifying two dates:- training start date
- training end date

Define Guide Sets
You can create guide sets directly from the QC plot. To add a new guide set, click Create Guide Set, drag to select an area directly on the graph, and click the Create button that appears over the selected area. Note: a warning will be given if fewer than 5 data points are selected. You cannot create overlapping guide sets.Alternatively, you can create guide sets by entering the start and end dates manually: click the Guide Sets tab and click Insert New to manually enter a new guide set. Note that you must have been granted the Editor role or greater to create guide sets from either of these two methods.
Note: a warning will be given if fewer than 5 data points are selected. You cannot create overlapping guide sets.Alternatively, you can create guide sets by entering the start and end dates manually: click the Guide Sets tab and click Insert New to manually enter a new guide set. Note that you must have been granted the Editor role or greater to create guide sets from either of these two methods.
Edit or Delete Guide Sets
To edit or delete guide sets, click the tab Guide Set. To edit, click Edit next to a guide set that has already been created. To delete, place a checkmark next to the target guide set and click the Delete button.
Related Topics
Pareto Plots
Pareto Plots
Pareto plots combine a bar plot and a line plot, and are used to quickly identify which metrics are most indicative of a quality control problem. Each bar in the plot represents a metric (see metric code below). Metric bars are ordered by decreasing incidence of outliers, where outliers are defined as the number of instances where each metric falls outside of the +/- 3 standard deviation range. The line shows the cumulative outliers by percentage. There are separate pareto plots for each guide set and plot type (Levey-Jennings, Moving Range, CUSUMm, and CUSUMv) combination.Other items to note in Pareto plots:
There are separate pareto plots for each guide set and plot type (Levey-Jennings, Moving Range, CUSUMm, and CUSUMv) combination.Other items to note in Pareto plots:
- Hover over dots in the line plot to show the cumulative %.
- Hover over a metric bar to show the number of outliers.
- Click a metric bar to see the relevant QC plot and guide set for that metric.
- Click on the PNG or PDF button (hover to reveal buttons in the upper right) to export the Pareto plot for that guide set.
- FWB - Fill Width at Base
- FWHM - Fill Width at Half Maximum
- MA - Mass Accuracy
- PA - Peak Area
- P Area - Precursor Area
- RT - Retention Time
- T Area - Transition Area
- T/PA Ratio - Transition/Precursor Area Ratio
Related Topics
Panorama: Clustergrammer Heat Maps
Generate a Clustergrammer Heat Map
- Navigate to the Panorama runs list of interest.
- Select the runs of interest and click Clustergrammer Heatmap.
- Adjust the auto-generated title and description if desired, or accept the defaults.
- Click Save.

- You'll be asked to confirm that you consent to publish the information to Clustergrammer. Clustergrammer is a third-party service, so all data sent will be publicly accessible. Click Yes if you wish to continue.
- The heat map will be generated and shown:


Panorama Document Revision Tracking
Automatically Link Skyline Documents
The server will automatically link Skyline documents together at import time (beginning with LabKey Server 16.1), provided that the Skyline documents provide a document ID. When importing a Skyline document whose ID matches one already in the folder, the incoming document will automatically be linked to the previous document(s) as the newest version in the document chain.The document’s import log file will indicate if it was attached as a new version in the document chain. This functionality is now part of the Skyline-daily builds (beta), and will be part of the next regular release (Skyline 3.6).Document Details
You can view a detailed profile for each document in Panorama by clicking the document name in Targeted MS Runs web part.The profile provides:- a Document Summary panel showing key data points. (Click Rename to rename the document.)
- a Document Versions panel which shows the document's position in the series of versions.
- a Precursor List/Transition List panel which shows different views of the protein/peptide breakdown. (Click the dropdown next to Precursor List to select Transition List.)

Link Document Versions
To chain together a series of document versions, select them in the Targeted MS Runs web part and click Link Versions.The Link Versions panel will appear. You can drag and drop the documents into the preferred order and click Save.Note that an individual document can be incorporated into only one document series -- it cannot be incorporated into different document series simultaneously.
Add Comments
To add comments to a document, click in the Flag column.The Review panel will appear. Enter the comment and click Ok. Comments are displayed in the Document Versions panel as notes.
Comments are displayed in the Document Versions panel as notes.
Proteomics Team
- Martin McIntosh, FHCRC
- Jimmy Eng, University of Washington
- Parag Mallick, Stanford University
- Mike MacCoss, University of Washington
- Brendan MacLean, University of Washington
- Phillip Gafken, FHCRC
- Josh Eckels, LabKey
- Cory Nathe, LabKey
- Adam Rauch, LabKey
- Vagisha Sharma, University of Washington
- Kaipo Tamura, University of Washington
- Yuval Boss, University of Washington
Signal Data Assay
 LabKey Server's Signal module is not included in standard LabKey distributions. Developers can build the module from source code in the LabKey GitHub repository. If you are not a developer, please contact LabKey to inquire about support options.
LabKey Server's Signal module is not included in standard LabKey distributions. Developers can build the module from source code in the LabKey GitHub repository. If you are not a developer, please contact LabKey to inquire about support options.
- Drag-and-drop file upload.
- Overlays of multiple curve lines.
- Graphical zoom into results.
- Calculation of areas under the curves.
Screen Shots
You can zoom into curve areas of interest, either by manual entering new values, or by directly drawing on the graph. Highlight individual curves and calculate areas under the curves.
Highlight individual curves and calculate areas under the curves.
Related Topics
- Signal Data Docs - Detailed documentation on the Signal Data module.
- Signal Data Module on GitHub - Signal Data module source repository.
Assay Administrator Guide
Organize Assay Workspaces
Customize Assay Tools
- Design a New Assay
- Participant/Visit Resolver
- Manage an Assay Design
- Set up a Data Transformation Script
Improve User Experience
Publish and Share Results
Assay Feature Matrix
Summary of features supported by each assay type.
- 'Y' indicates that the assay type supports the feature.
- 'N' indicates that the assay type does not support the feature.
|
Module
| |||||||
|---|---|---|---|---|---|---|---|
| Luminex | luminex | Y | Y | N | N | Y | Y |
| Affymetrix | microarray | N | Y | N | N | N | Y |
| FCSExpress | fcsexpress | N | Y | N | N | N | Y |
| General ("GPAT") | experiment | Y | Y | Y | N | Y | Y |
| Microarray | microarray | N | Y | N | N | N | Y |
| ELISA | elisa | Y | Y | N | Y | N | Y |
| ELISpot | elispot | Y | Y | N | Y | N | Y |
| NAb | nab | Y | Y | N | Y | N | Y |
| NAb, high-throughput, cross plate dilution | nab | Y | Y | N | Y | N | Y |
| NAb, high-thoughput, single plate dilution | nab | Y | Y | N | Y | N | Y |
| Mass Spec 1 | ms1 | N | N | N | N | N | N |
| Mass Spec 2 | ms2 | N | N | N | N | N | N |
| Mass Spec Metadata | ms2 | N | Y | N | N | N | Y |
| Flow Cytometry | flow | N | N | N | N | N | Y |
Set Up Folder For Assays
Set Up an Assay Folder
An Admin must set up a folder with the necessary assay web parts.- Create a folder. Create a folder of type Assay or Study.
- Assay-type. Creating an assay-type folder allows you to set up a staging area for assays, separate from other types of data. If you choose to set up an assay-type folder, you will need to set up a separate study folder (steps described below) before you can publish quality-controlled assay data to a study.
- Study-type. Creating a study-type folder places all assay and study data in one place and does not provide a separate staging area for assay data. If you do not care about separating assay data before it has undergone review, you can choose this option.
- View or add the "Assay List" web part. The assay list provides a summary of available assays.
- For assay-type folders: This web part is automatically included.
- For study-type folders: Choose Assay List from the Select Web Part drop-down menu, then click Add.
Assay List
The Assay List web part is the starting place for digging deeper into information about assays contained within the folder or related folders. It lists assays located in any of the following places:- Current folder
- Folders in the same project, including non-parent folders
- The Shared project
Other Assay Web Parts
Additional assay web parts can be added to a portal to display information for specific assays:- Assay Batches - Displays a list of batches for a specific assay.
- Assay Runs - Displays a list of runs for a specific assay.
- Assay Results - Displays a list of results for a specific assay.
Copy to Study
You can copy quality-controlled assay results into a study when these results are ready for broader sharing and integration with other data types. The target study can exist in the same folder as your assay list or in a separate one. Assay results are copied into a study as datasets.If you plan to publish your assay data to a study, create or customize a study-type folder. If you want to avoid creating a separate study folder you may also enable study-features in an existing assay-type folder:- Select Admin > Folder > Management.
- Choose the Folder Type tab.
- Select Study and click Update.
Assay Designs and Types
Assay Terminology
- Assay type: Structure defined by developers for a specific technology or instrument type which functions like a template for creating specific designs. Built-in assay types include Luminex, Elispot, Microarray, etc. There is also a general purpose assay type that can be customized by an administrator to capture any sort of experimental data. A developer may define and add a new assay type if required.
- Assay design: A specific named instance of an assay type, defined by an administrator and typically customized to include properties specific to a particular use or project. The design is like a pre-prepared map of how to interpret data imported from the instrument.
- Assay run: Import of data from one instrument run using an assay design. Runs are created by researchers and lab technicians who enter values for properties specified in the design.
- Assay batch: A set of runs uploaded in a single session. Some properties in a design apply to entire batches of runs.
- Assay results or assay data: Individual data elements of the run, for example the intensity of a spot or well.
Assay Types and Designs
An assay type (or "provider") corresponds to a class of instrument or file format. For example, the Flow assay type provides a basic framework for capturing experimental results from a flow cytometry instrument. Assay types include a foundational database schema that can be further customized to form a database design.An assay design is based on an assay type. When you create an assay design, you start with an assay type, and customize it to the specifics of your experiment, so it is capable of capturing the core data, and the contextual data, of your results.When you import instrument data into LabKey server, the assay design describes how to interpret the uploaded data, and what additional input to request about the run.Included in the assay design are:- the column names
- the column datatypes (integer, text, etc.)
- optional validation or parsing/formatting information
- the contextual data (also known as "metadata") about your assay, such as who ran the assay, on what instrument, and for which client/project.
Import Assay Design
Import Assay Design Archive (.XAR)
- Upload the XAR file to the Files web part to your assay project.
- In the Files web part, select the XAR file and click Import Data.
- In the popup dialog select Import Experiment and click Import.
- Refresh your Assay List web part.
- The new assay will appear in list of available designs. If it does not appear immediately, it is still being uploaded, so wait a moment and refresh your browser window again.
Example
An example XAR file is included in the LabKeyDemoFiles at LabKeyDemoFiles/Assays/Generic/GenericAssayShortcut.xar.Download: LabKeyDemoFiles.zip.Design a New Assay
Assay Types
Every assay type includes a set of required fields, or properties and may include other optional ones. The General assay type includes by default only the minimal fields that are also required by any assay. It may be extended to describe data structures in Excel or TSV files. Instrument-specific assay types are also built in to LabKey Server and include specialized, pre-defined fields in addition to these general assay fields. Customizing an assay type that is the most similar to your specific instrument data requirement will simplify the process of designing the assay you require. The following pages describe the fields pre-defined for some of the built-in assay types:Create an Assay Design
- Click on New Assay Design in the Assay List Web Part.
- Select the type of Assay (e.g., "Luminex") from the menu.
- Select the Assay Location -- this determines where the assay design is available.
- Click Next. You’ll now see the Assay Designer.
- Properties and fields common to many assay types are covered in General Properties.
- The assay-specific pages listed above describe additional fields, properties and notes for the particular assay type.
- You can also add additional fields as needed.
- Click Save and Close. Your new assay is now listed in the Assay List web part.
General Properties
Assay Properties
These assay properties are included in all assay designs:- Name: Required text. Each assay design must have a unique name.
- Description Optional text.
- Auto-copy Data: If enabled, when new runs are imported, data rows are automatically copied to the specified target study. Only rows that include subject and visit/date information will be copied. For details, see Copy Assay Data into a Study.
- Auto-copy Target: If "Auto-copy Data" above is enabled, when new runs are imported, these runs are automatically copied to the study specified here.
- Transform Scripts: For details, see Transformation Scripts.
- Save Script Data: Typically transform and validation script data files are deleted on script completion. For debug purposes, it can be helpful to be able to view the files generated by the server that are passed to the script. If this checkbox is checked, files will be saved to a subfolder named: "TransformAndValidationFiles", located in the same folder that the original script is located.
- Editable Runs: If enabled, users with sufficient permissions can edit values at the run level after the initial import is complete. These changes will be audited.
- Editable Results: If enabled, users with sufficient permissions can edit and delete at the individual results row level after the initial import is complete. These changes will be audited. New result rows cannot be added to existing runs.
- Upload in Background: If enabled, assay uploads will be processed as jobs in the data pipeline. If there are any errors during the upload, they can be viewed from the log file for that job.
Batch Properties
The user is prompted for batch properties once for each set of runs during import. The batch is a convenience to let users set properties once and import many runs using the same suite of properties. Typically, batch properties are properties that rarely change. Default properties:- Participant Visit Resolver This field records the method used to associate the assay with participant/visit pairs. The user chooses a method of association during the assay import process. See also Participant/Visit Resolver.
- TargetStudy. If this assay data is copied into a study, it will go to this study. This is the only pre-defined Batch property field for General Assays. It is optional, but including it simplifies the copy-to-study process. Alternatively, you can create a property with the same name and type at the run level so you can then publish each run to a different study. Note that "TargetStudy" is a special property which is handled differently than other properties.
Run Properties
Run properties are set once for all data records imported as part of a given run.- No default run properties are defined for General Assays.
Data Properties
Data properties apply to individual rows within the uploaded data.The pre-defined Data Property fields for General Assays are:- SpecimenID
- ParticipantID
- VisitID
- Date
Files and Attachments
Assay datasets can associate a given row of data with a file using a field of one of these types:- File: A field that creates a link to a file. The file will be stored in the file root on the server, and will be associated with an assay result.
- Attachment: A field that will associated an image file with a row of data in a list.
Design a Plate-Based Assay
- Enzyme-Linked Immunosorbent Assay (ELISA)
- Enzyme-Linked Immunosorbent Spot Assay (ELISpot)
- Neutralizing Antibody Assays (NAb)
Plate Templates
When you create any type of plate-based assay design, the assay properties section includes a place to specify the template used to map spots or wells on the plate to data fields. To populate the dropdown list of available templates, you create at least one named template with or without modifications from the default:- Click Configure Templates.

- Select one of the pre-defined plate templates available.

- Make any necessary modifications in the Plate Template Editor so that it correctly maps the layout of your plate to the appropriate specimens, etc.
- Give the template a name, whether you modified it or not.

- Click Save and Close.
- From the Assay Dashboard, click New Assay Design.
- Select the appropriate assay type and location.
- Click Next.
- Name the assay design (required).
- The Plate Template pulldown will include the templates visible from this location.
- Make other assay design changes as required.
- Click Save & Close.
Edit Plate Templates
Detailed instructions on using the plate template editor can be found here:Plate-Based Assay Examples
For a detailed walkthrough of using a plate template, try one of these tutorials:Edit Plate Templates
Plate Templates
From the Assay Dashboard, click Manage Assays to see the list of currently defined assays. Click Configure Plate Templates to open the Plate Templates page, which lists all plate templates currently defined (if any) and gives options for each to:- Edit: Open the defined template in the plate template editor.
- Edit a copy: This option opens a copy of the template for editing, leaving the original unchanged.
- Copy to another folder
- Delete: Only available if more than one template is defined. You cannot delete the final template.

Plate Template Editor
The Plate Template Editor lets you lay out the design of your experiment by associating plate wells with experimental groups. This walkthrough uses the 8x12 NAb Single Plate template as a representative example.Create a Plate Template
- From the Assay Dashboard, click Manage Assays.
- Click Configure Plate Templates.
- Select "New 96 Well (8x12) NAb Single Plate Template**.

- Enter a unique Template Name. This is required even if you make no changes to the default layout.
- Click Save.
Create and Edit Well Groups
If you are editing an existing template, you may see color-coded, predefined groups. You can add additional groups by entering a group name in the New box and clicking Create. You may delete and restore existing well groups as follows:- Open the plate template for editing, or edit a copy to avoid changing a working template.
- To delete and restore a given well group, first note the name so you can recreate a match, then:
- Select the desired group and click the Delete button next to it (and confirm the deletion). The associated squares in the grid above will turn white to show that they are no longer associated with any group.
- Type the name into the New textbox at the bottom of the page to create the same group again. Click Create.
- Click on the white boxes to associate them with this "new" group.
- Note that deleting/restoring a group may change the color associated with it.
- Click Save and Close when finished.
Associate Wells with Groups
In order to associate wells with experimental groups, you first need to select the active group. Use the radio button next to the group name to select the active group. You can then associate a grid cell in the plate template with the active group by clicking on the grid cell of interest or dragging to paint a region. In the screenshot below , the purple "CELL_CONTROL_SAMPLE" group is the active group, so when you click on a well, it associated with the CELL_CONTROL_SAMPLE group and painted purple. You can enter groups and associate wells with groups for the "Virus", "Control," "Specimen," "Replicate" and "Other" plates. The Up, Down, Left, and Right buttons can be used to shift the entire layout if desired.
You can enter groups and associate wells with groups for the "Virus", "Control," "Specimen," "Replicate" and "Other" plates. The Up, Down, Left, and Right buttons can be used to shift the entire layout if desired.
Define Well Group Properties
In the section on the right, you can define new Well Group Properties using the "Add a new property" button.For example, single-plate NAb assays assume that specimens get more dilute as you move up or left across the plate. High-throughput NAb assays assume that specimens are more dilute as you move down or right across the plate. Adding a well group property named 'ReverseDilutionDirection' with the value 'true' will reverse this default behavior for a given specimen well group.
View Warnings
If any Warnings exist, for example, if you identify a single well as belonging to both a specimen sample and control group (which we did in the above screenshot), the tab label will be red with an indication of how many warnings exist. Click the tab to see the warnings.
Save & Close
When you wish to save your changes, click "Save" and continue to edit. When you have finished editing, click Save & Close to exit the template editor.Return to the Assay Dashboard and click New Assay Design to use your new plate template in a new assay design.Participant/Visit Resolver
Participant/Visit Resolver
When uploading runs of instrument data, the operator selects from a set of options which may include:- Sample information in the data file (may be blank).
- Participant id and visit id.
- Participant id and date.
- Participant id, visit id, and date.
- Specimen/sample id.
- Sample indices, which map to values in a different data source.
Mapping Sample Indices
The "Sample indices, which map to values in a different data source" option allows you to use an existing indexed list of participant, visit, date, and sample information for your data. At upload time, the user will enter a single index number for each specimen; the target data source will contain the required mapping values. The sample indices list must have your own specimen identifier as its primary key, and uses the values of the 'SpecimenID', 'ParticipantID', 'Date', and 'VisitID' columns.You can specify a mapping either by pasting a TSV file or by selecting a specific folder, schema, and list. Either method can be used during each upload or specified as a default. To paste a TSV file containing the mapping, you can first click Download Template to obtain a correctly typed template. After populating it with your data, cut and paste the entire spreadsheet (including column headers) into the box provided: To specify an existing list, use the selection dialog pulldowns to choose the folder, schema, and specific query (list) containing your mapping:
To specify an existing list, use the selection dialog pulldowns to choose the folder, schema, and specific query (list) containing your mapping:
Using Default Values
The operator may specify the mapping each time data is uploaded, but in some cases you may want to set automatic defaults. For example, you might always want to use a specific source list for the participant/visit identifier, such as a thaw list populated at the time samples are removed from the freezer for testing. The operator could specify the list at the time of each batch upload, but by including the default list as part of your assay design you can simplify upload and improve consistency.- Select Manage Assay Design > Set Default Values > [design name] Batch Fields.

- Select Sample indices, which map to values in a different data source.
- Either paste the contents of a TSV file or select Use an existing list and select the Folder, Schema, and Query containing your list.

- Click Save Defaults.
- Click Save and Close.
Related Topics
Manage an Assay Design
Manage an Existing Assay Design
Open the list of currently defined assays by navigating to the Assay List web part or by selecting Admin > Manage Assays. Click on the name of any assay to open the runs page. The Manage Assay Design menu provides the following options:- Edit the assay design. - Add, delete, or change properties or structure. Note that all current users of the assay design, including those in subfolders, will be impacted by these changes.
- Copy the assay design. - This option lets you create a new assay design based on design of the current assay, but not affecting the original design or its users.
- Delete the assay design.
- Export the assay design to a XAR file.
- Set default values. - See below.
Set Default Values
An assay design can directly specify defaults for properties using the property fields editor. The assay design may be then be inherited in subfolders, which may override these parent defauts if needed using the Set Default Values option. These folder defaults will, in turn, be inherited by sub-folders that do not specify their own defaults.You can set defaults for:
- Batch fields
- Run fields
- Properties specific to the assay type. For example, for an Luminex assay, additional items would include "analyte" and "Excel run file" properties.

Assay Data Auditing and Tracking Changes
Some assays, like the General assay type, allow you to make run and data rows editable individually. Editability at the run or result level is enabled in the assay design by an administrator. Any edits are audited, with values before and after the change being captured. See the audit log's Assay/Experiment events. Upon deleting assay data, the audit log records that a deletion has occurred, but does not record what data was deleted.Some assays like Luminex and the General type allow you to upload a replacement copy of a file/run. This process is called "re-import" of assay data. The server retains the previous copy and the new one, allowing you to review any differences.See the Assay Feature Matrix for details on which assay support editable runs/results and re-import.Improve Data Entry Consistency & Accuracy
- Use lookups to constrain user input to only pre-defined vocabularies
- Set default values to reduce repetitive user input.
- Step 5: Data Validation
Use Lookups to Constrain Input
When users upload assay data, they often need to enter information about the data and might use different names for the same thing. For instance, one user might enter "ABI-Qstar" and another simply "Qstar" for the same machine. By defining a lookup for an assay field, you can eliminate this confusion by only allowing a pre-set vocabulary of options for that field.In this scenario, we want users to choose from a dropdown list of instruments, rather than name them instrument themselves when they upload a run. We modify the assay design to constrain the instrument field to only values available on a given list. The example GeneralAssay design used here comes from the design a general purpose assay tutorial, so if you have completed that tutorial you may follow these steps yourself. The named files will be in the [LabKeyDemoFiles]/Assays/Generic/ directory whereever you unzipped the sample data.Create a List to Define Lookup Vocabulary
First you need to create the list from which you want dropdown values to be chosen.- Select Admin > Manage Lists.
- Click the Create New List button.
- Name: Lab Instruments
- Primary Key: InstrumentID
- Primary Key Type: Text (string)
- Import from file checkbox: Checked
- Click Create List.
- Click Browse or Choose File and select the file [LabKeyDemoFiles]/Assays/Generic/Instruments.xls.
- Click Import.
Edit the Assay Design
Change the assay design so that the instruments field no longer asks for open user entry, but is a dropdown instead:- Click Assay Dashboard, then click Manage Assays.
- Click GenericAssay.
- Select Manage Assay Design > edit assay design.
- In the Batch Fields section, in the Instruments field, click the Type dropdown menu.
- Select Lookup.
- Folder: /home/Assay Tutorial
- Schema: lists
- Table: Lab Instruments
- Click Apply.
- Click Save and Close.
Demonstration
If you have now made these changes in your tutorial project, you can see how it will work by pretending you will import an additional run:- Navigate to the GenericAssay Runs page.
- Click Import Data.
- On the Batch Properties page notice that the Instruments field is now a dropdown list instead of a simple text field.

Set Default Values
When the user must enter the same fixed values repeatedly, or you want to allow prior entries to become new defaults for given fields, you can do so using built in default values for fields. Default values may be scoped to a specific folder or subfolder, which can be useful in a situation where an assay design is defined at the project level, the overall design can be shared among many subfolders, each of which may have different default value requirements.Configure Data Validation
Field level validation can programmatically ensure that specific fields are required, entries follow given regular expressions, or are within valid ranges.Set up a Data Transformation Script
Overview
It can be useful to transform data columns during the process of importing data to LabKey Server. For example, you can add a column that is calculated from several other columns in the dataset. For this simple example, we add a column that contains a randomly selected value.Topics:- Set up the Perl Scripting Engine
- Set up a New Assay Design
- Import Data and Observe the Data Transformation
Set up the Perl Scripting Engine
Before you can run transform scripts, you need to set up the appropriate scripting engine. You only need to set up a scripting engine once per type of script (e.g., R or perl). You will need a copy of Perl running on your instrument to set up the engine.- Select the Admin -> Site -> Admin Console.
- Click Views and Scripting.
- Click Add -> New Perl Engine.
- Name: Perl Scripting Engine
- Language: Perl
- Language Version: Leave this blank
- File Extension: pl
- Program Path: Provide the path to the perl program on your instrument, including the name of the program. For example, on labkey.org, this is "/usr/bin/perl". A typical path on Windows is "C:\perl\bin\perl.exe".
- Program Command: Leave this blank
- Output File Name: Leave this blank
- Enabled: Confirm this is checked.
- Click "Submit"

Locate the Transform Script
To add a transform script to an assay design, you will need to enter a full path to it on your local machine. For example, if you are completing the assay tutorial on a local windows machine and uploaded the LabKeyDemoFiles package, you might find our sample perl script using a path like:C:/Program Files (x86)/LabKey Server/files/home/Assay Tutorial/@files/LabKeyDemoFiles/Assays/Generic/GenericAssay_Transform.pl
Set up a New Assay Design
We create a new assay design in order to avoid losing the original GenericAssay design. Using this transform script requires adding a column to the design.Copy the GenericAssay Design.- Navigate to the Assay Tutorial project page.
- Click GenericAssay in the Assay List section.
- Select Manage Assay Design > Copy Assay Design.
- Click Copy to Current Folder.
- Set these properties in the Assay Properties section.
- Name: GenericAssay_Transformed
- Transform Script: Click Add Script and enter the full path to the perl transform script, GenericAssay_Transform.pl, on your local machine.
- In the Data Fields section:
- Add a field named "Animal" of type "string."
- Click "Save and Close."
Import data and observe the transformed column
Start Import- On the portal page, in the Files section, locate the file LabKeyDemoFiles/AssayData/Generic/GenericAssay_Run4.xls.
- Click the Import Data button.
- Select Use GenericAssay_Transformed and click Import.
- OperatorEmail: john@company.com
- Instrument: ABI QSTAR
- Click Next.
- Assay ID: Enter "Run4"
- Comment: Enter whatever you wish.
- Instrument setting: 24 (or any integer)
- Press Save and Finish.
 Next... Step 6: Integrate Assay Data into a Study.
Next... Step 6: Integrate Assay Data into a Study.Copy Assay Data into a Study
- Easily integrate assay data with other assay and clinical data.
- Create a broader range of visualizations, such as time charts.
- Utilize qc and workflow tools.
What Copying Happens During this Process?
Despite the name, your assay data is not duplicated in any way. Assay data records are mapped to VisitID/ParticipantID pairs either manually or using participant/visit resolvers. The assay data is then linked to the study dataset as a lookup.Manual Copy of Assay Data to a Study
- Navigate to the grid view of the assay run.

- Select the appropriate records (data rows), or use the checkbox in the column header to select all records.

- Click Copy to Study.
- Select the target study from the drop down list.
- Click Next.
- Each row will show an icon indicating whether it can resolved to data in that study. In this screencap, one participantID is missing a digit, so the match fails. Cancel and correct the error or select just the matching rows and click Copy to Study to complete the integration.

Automatic Copy-to-Study Upon Import
By default, assay data must first be imported and then, as a second step, manually selected and copied to a study. You can change this default behavior to have assay data copied automatically as part of the original data import.- Navigate to your Assay Runs page.
- Click Manage Assay Design > Edit Assay Design.
- Placed a checkmark next to Auto-copy Data.
- Select a target study from the Auto-copy Target dropdown list.

View Copied Datasets
After you have successfully copied an assay's data to a study dataset, your new dataset will appear at the bottom of the list on the Clinical and Assay Data tab in the target study. Click the title to see the data; the "Assay" link preceding each record will take you to the source assay for that data record.Recall Copied Rows
If you have permission to delete from the assay's dataset in a particular study, you can also recall rows from the dataset's grid view. Select one or more dataset rows and click the Recall button on the tool bar.
View Copy-to-Study History
Please see Copy-To-Study History to learn how to view the publication history for assays or datasets.Copy-To-Study History
View and Manage Copy-To-Study History
Once you have copied assay records to a study dataset, you can view the log of copy-to-study events. You can also 'undo' by deleting (recalling) copied data from a dataset.Access Copy-To-Study History
After you have copied data from an assay to a study, you can view copy-to-study history for the assay from either the source or destination grid.From the Assay ItselfFrom a datagrid view for the assay, click the "View Copy-To-Study History" link: The history is displayed in a grid showing who copied what and to where.
The history is displayed in a grid showing who copied what and to where. From the Target Study DatasetTo access copy-to-study history from a study dataset to which you have copied assay data, click View Source Assay above the grid, then proceed as above.
From the Target Study DatasetTo access copy-to-study history from a study dataset to which you have copied assay data, click View Source Assay above the grid, then proceed as above. From the Site Admin ConsoleIf you are a site administrator, you can also view all copy-to-study events for all assays within the site. Select Admin > Site > Admin Console. Under Management click Audit Log. Select "Copy-to-Study Assay Events" from the dropdown.Site copy-to-study events may be filtered by target study, or sorted by assay type using the column headers as in other data grids.
From the Site Admin ConsoleIf you are a site administrator, you can also view all copy-to-study events for all assays within the site. Select Admin > Site > Admin Console. Under Management click Audit Log. Select "Copy-to-Study Assay Events" from the dropdown.Site copy-to-study events may be filtered by target study, or sorted by assay type using the column headers as in other data grids.
View Copy-to-Study History Details
Once you have reached the Copy-To-Study History page, click on the "details" link to see all the rows copied from the assay: You now see the Copy-To-Study History Details page:
You now see the Copy-To-Study History Details page:
Recall Copied Data (Undo Copy)
You can recall (or delete) copied assay data from a dataset, essentially undoing the copy. Select the rows that you would like to remove from the dataset and select the "Recall Selected Rows" button. Next, click "Okay" in the popup that requests confirmation of your intent to delete dataset rows.Rows recalled from the study dataset are deleted from that target dataset, but are not deleted from the source assay itself. You can copy these rows to the dataset again if needed.Recall events will be appear in the Copy-To-Study History.Experiment Descriptions & Archives (XARs)
Overview
LabKey Server's Experiment module provides a framework for describing experimental procedures and for transferring experiment data into and out of a LabKey Server system. An experiment is a series of steps that are performed on specific inputs and produce specific outputs. Experiments can be described, archived and transferred in experiment descriptor files.Basic Topics
XAR.xml Topics
- XAR Files
- Uses of XAR.xml Files
- Import a XAR.xml
- Example 1: Review a Basic XAR.xml
- Examples 2 & 3: Describe Protocols
- Examples 4, 5 & 6: Describe LCMS2 Experiments
- Design Goals and Directions
- Overview of Life Sciences IDs
Related Topics
Experiment Terminology
Objects that Describe an Experiment
The basic terms and concepts in the LabKey Server experiment framework are taken from the Functional Genomics Experiment (FuGE) project. The xar.xml format only encompasses a small subset of the FuGE object model, and is intended to be compatible with the FuGE standard as it emerges. More details on FuGE can be found at http://fuge.sourceforge.net.The LabKey Server experiment framework uses the following primary objects to describe an experiment.- Sample or Material: These terms are synonyms. A Sample object refers to some biological sample or processed derivative of a sample. Examples of Sample objects include blood, tissue, protein solutions, dyed protein solutions, and the content of wells on a plate. Samples have a finite amount and usually a finite life span, which often makes it important to track measurement amounts and storage conditions for these objects. Samples can be included in the description of an experiment as the input to a run. The derivation of Samples can be tracked.
- Sample Set A Sample Set is group of Samples accompanied by a suite of properties that describe shared characteristics of all samples in the group.
- Data: A Data object refers to a measurement value or control value, or a set of such values. Data objects can be references to data stored in files or in database tables, or they can be complete in themselves. Data objects can be copied and reused a limitless number of times. Data objects are often generated by instruments or computers, which may make it important to keep track of machine models and software versions in the applications that create Data objects.
- Protocol or Assay: These terms are synonyms. A Protocol object is a description of how an experimental step is performed. A Protocol object describes an operation that takes as input some Sample and/or Data objects, and produces as output some Sample and/or Data objects. In LabKey Server, Protocols are nested one level--an experiment run is associated with a parent protocol. A parent protocol contains n child protocols which are action steps within the run. Each child protocol has an ActionSequence number, which is an increasing but otherwise arbitrary integer that identifies the step within the run. Child protocols also have one or more predecessors, such that the outputs of a predecessor are the inputs to the protocol. Specifying the predecessors separately from the sequence allows for protocol steps that branch in and out. Protocols also may have ParameterDeclarations, which are intended to be control settings that may need to be set and recorded when the protocol is run.
- ProtocolApplication: The ProtocolApplication object is the application of a protocol to some specific set of inputs, producing some outputs. A ProtocolApplication is like an instance of the protocol. A ProtocolApplication belongs to an ExperimentRun, whereas Protocol objects themselves are often shared across runs. When the same protocol is applied to multiple inputs in parallel, the experiment run will contain multiple ProtocolApplications object for that Protocol object. ProtocolApplications have associated Parameter values for the parameters declared by the Protocol.
- ExperimentRun: The ExperimentRun object is a unit of experimental work that starts with some set of input materials or data files, executes a defined sequence of ProtocolApplications, and produces some set of outputs. The ExperimentRun is the unit by which experimental results can be loaded, viewed in text or graphical form, deleted, and exported. The boundaries of an ExperimentRun are up to the user.
- RunGroup or Experiment: These terms are synonyms. LabKey Server's user interface calls these entities RunGroups while XAR.xml files call them Experiments. A RunGroup is a grouping of ExperimentRuns for the purpose of comparison or export. The relationship between ExperimentRuns and RunGroups is many-to-many. A RunGroup can have many ExperimentRuns and a single ExperimentRun can belong to many RunGroups.
- Xar file: A compressed, single-file package of experimental data and descriptions. A Xar file expands into a single root folder with any combination of subfolders containing experimental data and settings files. At the root of a Xar file is a xar.xml file that serves as a manifest for the contents of the Xar as well as a structured description of the experiment that produced the data.
Relationships Between xar.xml Objects
At the core of the data relationships between objects is the cycle of ProtocolApplications and their inputs and outputs, which altogether constitute an ExperimentRun.- The cycle starts with either Sample and/or Data inputs. Examples are a tissue sample or a raw data file output from an LCMS machine.
- The starting inputs are acted on by some ProtocolApplication, an instance of a specific Protocol that is a ProtocolAction step within the overall run. The inputs, parameters, and outputs of the ProtocolApplication are all specific to the instance. One ProtocolAction step may be associated with multiple ProtocolApplications within the run, corresponding to running the same experimental procedure on different inputs or applying different parameter values.
- The ProtocolApplication produces sample and/or data outputs. These outputs are usually inputs into the next ProtocolAction step in the ExperimentRun, so the cycle continues. Note that a Data or Sample object can be input to multiple ProtocolApplications, but a Data or Sample object can only be output by at most one ProtocolApplication.

XAR Files
Topics
- Uses of XAR.xml Files
- Import a XAR.xml
- Troubleshoot XAR Import (Optional)
- Import XAR Files Using the Data Pipeline (Optional)
- Example 1: Review a Basic XAR.xml
- Examples 2 & 3: Describe Protocols
- Examples 4, 5 & 6: Describe LCMS2 Experiments
- Design Goals and Directions
Related Topics
Uses of XAR.xml Files
Background
The information requirements of biological research change rapidly and are often unique to a particular experimental procedure. The LabKey Server experiment framework is designed to be flexible enough to meet these requirements. This flexibility, however, means that the purpose of an experiment description needs to be determined up-front, before creation of a xar.xml.For example, the granularity of experimental procedure descriptions, how data sets are grouped into runs, and the types of annotations attached to the experiment description are all up to the author of the xar.xml. The appropriate answers to these design decisions depend on the uses intended for the experiment description.Uses of the Experiment Framework
One reason to describe an experiment in xml is to enable the export and import of experimental results. If this is the author's sole purpose, the description can be minimal—a few broadly stated steps.The experiment framework also serves as a place to record lab notes so that they are accessible through the same web site as the experimental results. It allows reviewers to drill in on the question, "How was this result achieved?" This use of the experiment framework is akin to publishing the pages from a lab notebook. When used for this purpose, the annotations can be blocks of descriptive text attached to the broadly stated steps.A more ambitious use of experiment descriptions is to allow researchers to compare results and procedures across whatever dimensions they deem to be relevant. For example, the framework would enable the storage and comparison of annotations to answer questions such as:- What are all the samples used in our lab that identified protein X with an expectation value of Y or less?
- How many samples from mice treated with substance S resulted in an identification of protein P?
- Does the concentration C of the reagent used in the depletion step affect the scores of peptides of type T?
Import a XAR.xml
Create a New Project
To create a new project in LabKey Server for working through the XAR tutorial samples, follow these steps:- Make sure you are logged into your LabKey Server site with administrative privileges.
- Select Admin > Site > Create Project.
- Enter a name for your new project and create it with default permissions and settings.
- Select Admin > Folder > Management and click Create Subfolder.
- Choose the Custom folder type. While not strictly necessary, doing so makes for easier clean-up and reset.
- Confirm that the Experiment and Pipeline modules are selected.
- Set the default tab to Experiment.
- Save, and accept the default folder permissions.
Set Up the Data Pipeline
Next, you need to set up the data pipeline. The data pipeline is the tool that you use to import the sample xar.xml file. It handles the process of converting the text-based xar.xml file into database objects that describe the experiment. When you are running LabKey Server on a production server, it also handles queueing jobs -- some of which may be computationally intensive and take an extended period of time to import -- for processing.To set up the data pipeline, follow these steps:- Download either XarTutorial.zip or XarTutorial.tar.gz and extract to your computer.
- Select the Pipeline tab, and click Setup.
- Click Set a pipeline override.
- Enter the path to the directory where you extracted the files.
- Click Save.
Import Example1.xar.xml
You will need to import each example xar.xml file that you wish to use in this tutorial. This section covers how to import Example1.xar.xml. The process is the same for Examples 2 and 3. Examples 4, 5 and 6 use a different mechanism that is covered on the page that describes them.To import the tutorial sample file Example1.xar.xml, follow these steps:- Click on the Experiment tab.
- Click Upload XAR.
- Click Browse or Choose File and locate the Example1.xar.xml file on your computer (in the same unpacked archive you downloaded).
- Click Upload. You'll be taken to the Pipeline tab, where you'll see an entry for the imported file, with a status indication (e.g., LOADING EXPERIMENT or WAITING). If the status doesn't change soon to either COMPLETE or ERROR, you may need to refresh your browser window.
- Click the Experiment tab.
- In the Experiment Runs section, click on Tutorial Examples to display the Experiment Details page.
- Click on the Example 1 (Using Export Format) link under Experiment Runs to show the summary view.
- Click the ERROR link.
- On the Job Status page, you will see log information. See: Troubleshoot XAR Import.
Import Via Pipeline
You can also import a xar.xml file via the data pipeline as follows:- On the Pipeline tab, click Process and Import Data.
- By default you will see the contents of the pipeline override directory you set above.
- Select the desired file in the file tree and click Import Data.
- Select Import Experiment and click Import.
Troubleshoot XAR Import
- Often the actual error message is cryptic, but the success/info messages above it should give you an indication of how far the import progressed before it encountered the error.
- The most common problem in importing xar.xml files is a duplicate LSID problem. In example 1 of the XAR Tutorial, the LSIDs have fixed values. This means that this xar.xml can only be imported in one folder on the whole system. If you are sharing access to a LabKey Server system with some other user of this tutorial you will encounter this problem. Subsequent examples in the tutorial will show you how to address this.
- A second common problem is clashing LSID objects at the run level. If an object is created by a particular ProtocolApplication and then a second ProtApp tries to output an object with the same LSID, an error will result.
- LabKey Server does not offer the ability to delete protocols or starting inputs or in a folder, except for deleting the entire folder. This means that if you import a xar.xml in a folder and then change a protocol or starting input without changing its LSID , you won't see your changes. The XarReader currently checks first to see if the protocols in a xar.xml have already been defined, and if so will silently use the existing protocols rather than the (possibly changed ) protocol descriptions in the xar.xml. See example 3 in the XAR Tutorial for a suggestion of how to avoid problems with this.
- Sometimes a xar.xml will appear to import correctly but report an error when you try to view the summary graph. This seems to happen most often because of problems in referencing the Starting Inputs.
Import XAR Files Using the Data Pipeline
Example 1: Review a Basic XAR.xml
Experiment runs are described by a researcher as a series of experimental steps performed on specific inputs, producing specific outputs. The researcher can define any attributes that may be important to the study and can associate these attributes with any step, input, or output. These attributes are known as experimental annotations. Experiment descriptions and annotations are saved in an XML document known as an eXperimental ARchive or xar (pronounced zar) file.
The best way to understand the format of a xar.xml document is to walk through a simple example. The example experiment run starts with a sample (Material) and ends up with some analysis results (Data). In LabKey Server, this example run looks like the following:
|
|
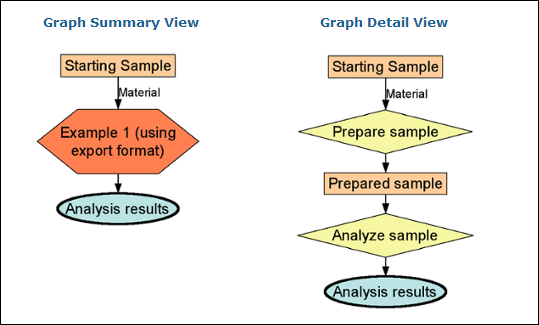
In the summary view, the red hexagon in the middle represents the Example 1 experiment run as a whole. It starts with one input Material object and produces one output Data object. Clicking on the Example 1 node brings up the details view, which shows the protocol steps that make up the run. There are two steps: a "prepare sample" step which takes as input the starting Material and outputs a prepared Material, followed by an "analyze sample" step which performs some assay of the prepared Material to produce some data results. Note that only the data results are designated as an output of the run (i.e. shown as an output of the run in the summary view, and marked with a black diamond and the word "Output" in details view). If the prepared sample were to be used again for another assay, it too might be marked as an output of the run. The designation of what Material or Data objects constitute the output of a run is entirely up to the researcher.
The xar.xml file that produces the above experiment structure is shown in the following table. The schema doc for this Xml instance document is XarSchema_minimum.xsd. (This xsd file is a slightly pared-down subset of the schema that is compiled into the LabKey Server source project; it does not include some types and element nodes that are being redesigned).
Table 1: Xar.xml for a simple 2-step protocol
|
First, note the major sections of the document, highlighted in yellow:
ExperimentArchive (root): the document node, which specifies the namespaces used by the document and (optionally) a path to a schema file for validation.
Experiment: a section which describes one and only one experiment which is associated with the run(s) described in this xar.xml
ProtocolDefinitions: the section describes the protocols that are used by the run(s) in this document. These protocols can be listed in any order in this section. Note that there are 4 protocols defined for this example: two detail protocols (Sample prep and Example analysis) and two “bookend” protocols. One bookend represents the start of the run (Example 1 protocol, of type ExperimentRun) and the other serves to mark or designate the run outputs (the protocol of type ExperimentRunOutput).
Also note the long string highlighted in blue, beginning with “urn:lsid:…”. This string is called an LSID, short for Life Sciences Identifier. LSIDs play a key role in LabKey Server. The highlighted LSID identifies the Protocol that describes the run as a whole. The run protocol LSID is repeated in several places in the xar.xml ; these locations must match LSIDs for the xar.xml to load correctly. (The reason for the repetition is that the format is designed to handle multiple ExperimentRuns involving possibly different run protocols.) |
<?xml version="1.0" encoding="UTF-8"?> <exp:ExperimentArchive xmlns:exp="http://cpas.fhcrc.org/exp/xml" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://cpas.fhcrc.org/exp/xml XarSchema_minimum.xsd"> <exp:Experiment rdf:about="${FolderLSIDBase}:Tutorial"> <exp:Name>Tutorial Examples</exp:Name> <exp:Comments>Examples of xar.xml files.</exp:Comments> </exp:Experiment> <exp:ProtocolDefinitions> <exp:Protocol rdf:about="urn:lsid:localhost:Protocol:MinimalRunProtocol.FixedLSID"> <exp:Name>Example 1 protocol</exp:Name> <exp:ProtocolDescription>This protocol is the "parent" protocol of the run. Its inputs are …</exp:ProtocolDescription> <exp:ApplicationType>ExperimentRun</exp:ApplicationType> <exp:MaxInputMaterialPerInstance xsi:nil="true"/> <exp:MaxInputDataPerInstance xsi:nil="true"/> <exp:OutputMaterialPerInstance xsi:nil="true"/> <exp:OutputDataPerInstance xsi:nil="true"/> </exp:Protocol> <exp:Protocol rdf:about="urn:lsid:localhost:Protocol:SamplePrep"> <exp:Name>Sample prep protocol</exp:Name> <exp:ProtocolDescription>Describes sample handling and preparation steps</exp:ProtocolDescription> <exp:ApplicationType>ProtocolApplication</exp:ApplicationType> <exp:MaxInputMaterialPerInstance>1</exp:MaxInputMaterialPerInstance> <exp:MaxInputDataPerInstance>0</exp:MaxInputDataPerInstance> <exp:OutputMaterialPerInstance>1</exp:OutputMaterialPerInstance> <exp:OutputDataPerInstance>0</exp:OutputDataPerInstance> </exp:Protocol> <exp:Protocol rdf:about="urn:lsid:localhost:Protocol:Analyze"> <exp:Name>Example analysis protocol</exp:Name> <exp:ProtocolDescription>Describes analysis procedures and settings</exp:ProtocolDescription> <exp:ApplicationType>ProtocolApplication</exp:ApplicationType> <exp:MaxInputMaterialPerInstance>1</exp:MaxInputMaterialPerInstance> <exp:MaxInputDataPerInstance>0</exp:MaxInputDataPerInstance> <exp:OutputMaterialPerInstance>0</exp:OutputMaterialPerInstance> <exp:OutputDataPerInstance>1</exp:OutputDataPerInstance> <exp:OutputDataType>Data</exp:OutputDataType> </exp:Protocol> <exp:Protocol rdf:about="urn:lsid:localhost:Protocol:MarkRunOutput"> <exp:Name>Mark run outputs</exp:Name> <exp:ProtocolDescription>Mark the output data or materials for the run. Any and all inputs…</exp:ProtocolDescription> <exp:ApplicationType>ExperimentRunOutput</exp:ApplicationType> <exp:MaxInputMaterialPerInstance xsi:nil="true"/> <exp:MaxInputDataPerInstance xsi:nil="true"/> <exp:OutputMaterialPerInstance>0</exp:OutputMaterialPerInstance> <exp:OutputDataPerInstance>0</exp:OutputDataPerInstance> </exp:Protocol> </exp:ProtocolDefinitions>
|
|
The next major section of xar.xml is the ProtocolActionDefinitions: This section describes the ordering of the protocols as they are applied in this run. A ProtocolActionSet defines a set of “child” protocols within a parent protocol. The parent protocol must be of type ExperimentRun. Each action (child protocol) within the set (experiment run protocol) is assigned an integer called an ActionSequence number. ActionSequence numbers must be positive, ascending integers, but are otherwise arbitrarily assigned. (It is useful when hand-authoring xar.xml files to leave gaps in the numbering between Actions to allow the insertion of new steps in between existing steps, without requiring a renumbering of all nodes. The ActionSet always starts with a root action which is the ExperimentRun node listed as a child of itself. |
<exp:ProtocolActionDefinitions> <exp:ProtocolActionSet ParentProtocolLSID="urn:lsid:localhost:Protocol:MinimalRunProtocol.FixedLSID"> <exp:ProtocolAction ChildProtocolLSID="urn:lsid:localhost:Protocol:MinimalRunProtocol.FixedLSID" ActionSequence="1"> <exp:PredecessorAction ActionSequenceRef="1"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="urn:lsid:localhost:Protocol:SamplePrep" ActionSequence="10"> <exp:PredecessorAction ActionSequenceRef="1"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="urn:lsid:localhost:Protocol:Analyze" ActionSequence="20"> <exp:PredecessorAction ActionSequenceRef="10"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="urn:lsid:localhost:Protocol:MarkRunOutput" ActionSequence="30"> <exp:PredecessorAction ActionSequenceRef="20"/> </exp:ProtocolAction> </exp:ProtocolActionSet> </exp:ProtocolActionDefinitions>
|
Examples 2 & 3: Describe Protocols
Experiment Log format and Protocol Parameters
The ExperimentRun section of the xar.xml for Example 1 contains a complete description of every ProtocolApplication instance and its inputs and outputs. If the experiment run had been previously loaded into a LabKey Server repository or compatible database, this type of xar.xml would be an effective format for exporting the experiment run data to another system. This document will use the term "export format" to describe a xar.xml that provides complete details of every ProtocolApplication as in Example 1. When loading new experiment run results for the first time, export format is both overly verbose and requires the xar.xml author (human or software) to invent unique IDs for many objects.
To see how an initial load of experiment run data can be made simpler, consider how protocols relate to protocol applications. A protocol for an experiment run can be thought of as a multi-step recipe. Given one or more starting inputs, the results of applying each step are predictable. The sample preparation step always produces a prepared material for every starting material. The analyze step always produces a data output for every prepared material input. If the xar.xml author could describe this level of detail about the protocols used in a run, the loader would have almost enough information to generate the ProtocolApplication records automatically. The other piece of information the xar.xml would have to describe about the protocols is what names and ids to assign to the generated records.
Example 1 included information in the ProtocolDefinitions section about the inputs and outputs of each step. Example 2 adds pre-defined ProtocolParameters to these protocols that tell the LabKey Server loader how to generate names and ids for ProtocolApplications and their inputs and outputs. Then Example 2 uses the ExperimentLog section to tell the Xar loader to generate ProtocolApplication records rather than explicitly including them in the Xar.xml. The following table shows these differences.
Table 2: Example 2 differences from Example 1
|
The number and base types of inputs and outputs for a protocol are defined by four elements, MaxInput…PerInstance and Output…PerInstance.
The names and LSIDs of the ProtocolApplications and their outputs can be generated at load time. The XarTemplate parameters determine how these names and LSIDs are formed.
Note new suffix on the LSID, discussed under Example 3. |
<exp:Protocol rdf:about="urn:lsid:localhost:Protocol:SamplePrep.WithTemplates"> <exp:Name>Sample Prep Protocol</exp:Name> <exp:ProtocolDescription>Describes sample handling and preparation steps</exp:ProtocolDescription> <exp:ApplicationType>ProtocolApplication</exp:ApplicationType> <exp:MaxInputMaterialPerInstance>1</exp:MaxInputMaterialPerInstance> <exp:MaxInputDataPerInstance>0</exp:MaxInputDataPerInstance> <exp:OutputMaterialPerInstance>1</exp:OutputMaterialPerInstance> <exp:OutputDataPerInstance>0</exp:OutputDataPerInstance> <exp:ParameterDeclarations> <exp:SimpleVal Name="ApplicationLSIDTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.ApplicationLSID" ValueType="String">urn:lsid:localhost:ProtocolApplication:DoSamplePrep.WithTemplates</exp:SimpleVal> <exp:SimpleVal Name="ApplicationNameTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.ApplicationName" ValueType="String">Prepare sample</exp:SimpleVal> <exp:SimpleVal Name="OutputMaterialLSIDTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputMaterialLSID" ValueType="String">urn:lsid:localhost:Material:PreparedSample.WithTemplates</exp:SimpleVal> <exp:SimpleVal Name="OutputMaterialNameTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputMaterialName" ValueType="String">Prepared sample</exp:SimpleVal> </exp:ParameterDeclarations> </exp:Protocol>
|
|
Example 2 uses the ExperimentLog section to instruct the loader to generate the ProtocolApplication records. The Xar loader uses the information in the ProtocolDefinitions and ProtocolActionDefinitions sections to generate these records.
Note the ProtocolApplications section is empty. |
<exp:ExperimentRuns> <exp:ExperimentRun rdf:about="urn:lsid:localhost:ExperimentRun:MinimalExperimentRun.WithTemplates"> <exp:Name>Example 2 (using log format)</exp:Name> <exp:ProtocolLSID>urn:lsid:localhost:Protocol:MinimalRunProtocol.WithTemplates</exp:ProtocolLSID> <exp:ExperimentLog> <exp:ExperimentLogEntry ActionSequenceRef="1"/> <exp:ExperimentLogEntry ActionSequenceRef="10"/> <exp:ExperimentLogEntry ActionSequenceRef="20"/> <exp:ExperimentLogEntry ActionSequenceRef="30"/> </exp:ExperimentLog> <exp:ProtocolApplications/> </exp:ExperimentRun> </exp:ExperimentRuns> |
ProtocolApplication Generation
When loading a xar.xml using the ExperimentLog section, the loader generates ProtocolApplication records and their inputs/outputs. For this generation process to work, there must be at least one LogEntry in the ExperimentLog section of the xar.xml and the GenerateDataFromStepRecord attribute of the ExperimentRun must be either missing or have an explicit value of false.
The xar loader uses the following process:
- Read an ExperimentLogEntry record in with its sequence number. The presence of this record in the xar.xml indicates that step has been completed. These LogEntry records must be in ascending sequence order. The loader also gets any optional information about parameters applied or specific inputs (Example 2 contains none of this optional information).
- Lookup the protocol corresponding to the action sequence number, and also the protocol(s) that are predecessors to it. This information is contained in the ProtocolActionDefinitions.
- Determine the set of all output Material objects and all output Data objects from the ProtocolApplication objects corresponding to the predecessor protocol(s). These become the set of inputs to the current action sequence. Because of the ascending sequence order of the LogEntry records, these predecessor outputs have already been generated. (If we are on the first protocol in the action set, the set of inputs is given by the StartingInputs section).
- Get the MaxInputMaterialPerInstance and MaxInputDataPerInstance values for the current protocol step. These numbers are used to determine how many ProtocolApplication objects ("instances") to generate for the current protocol step. In the Example 2 case there is only one starting Material that never gets divided or fractionated, so there is only one instance of each protocol step required. (Example 3 will show multiple instances. ) The loader iterates through the set of Material or Data inputs and creates a ProtocolApplication object for every n inputs. The input objects are connected as InputRefs to the ProtocolApplications.
- The name and LSID of each generated ProtocolApplication is deterimined by the ApplicationLSIDTemplate and ApplicationNameTemplate parameters. See below for details on these parameters.
- For each generated ProtocolApplication, the loader then generates output Material or Data objects according to the Output…PerInstance values. The names and LSIDs or these generated objects are determined by the Output…NameTemplate and Output…LSIDTemplate parameters.
- Repeat until the end of the ExperimentLog section.
Instancing properties of Protocol objects
As described above, four protocol properties govern how many ProtocolApplication objects are generated for an ExperimentLogEntry, and how many output objects are generated for each ProtocolApplication:
|
Property |
Allowed values |
Effect of property value |
|
MaxInputMaterialPerInstance MaxInputDataPerInstance |
0 |
The protocol does not accept [ Material | Data ] objects as inputs |
|
1 |
For every [ Material | Data ] object output by a predecessor step, create a new ProtocolApplication for this protocol |
|
|
>1 |
For every n [ Material | Data ] objects output by a predecessor step, create a new ProtocolApplication. If the number of [ Material | Data ] objects output by predecessors does not divide evenly by n, a warning is written to the log |
|
|
xsi:nil="true" |
Equivalent to "unlimited". Create a single ProtocolApplication object and assign all [ Material | Data ] outputs of predecessors as inputs to this single instance |
|
|
Combined constraint |
If both MaxInputMaterialPerInstance and MaxInputDataPerInstance are not nil, then at least one of the two values must be 0 for the loader to automatically generate ProtocolApplication objects. |
|
|
OutputMaterialPerInstance OutputDataPerInstance |
0 |
An application of this Protocol does note create [ Material | Data ] outputs |
|
1 |
Each ProtocolApplication of this Protocol "creates" one [ Material | Data ] object |
|
|
n >1 |
Each ProtocolApplication of this Protocol "creates" n [ Material | Data ] objects |
|
|
xsi:nil="true" |
Equivalent to "unknown". Each ProtocolApplication of this Protocol may create 0, 1 or many [ Material | Data ] outputs, but none are generated automatically. Its effect is currently equivalent to a value of 0, but in a future version of the software a nil value might be the signal to ask a custom load handler how many outputs to generate. |
Protocol parameters for generating ProtocolApplication objects and their outputs
A ProtocolParameter has both a short name and a fully-qualified name (the "OntologyEntryURI" attribute). Currently both need to be specified for all parameters. These parameters are declared by including a SimpleVal element in the definition. If the SimpleVal element has non-empty content, the content is treated as the default value for the parameter. Non-default values can be specified in the ExperimentLogEntry node, but Example 2 does not do this.
|
Name |
Fully-qualified name |
Purpose |
|
ApplicationLSIDTemplate |
terms.fhcrc.org#XarTemplate.ApplicationLSID |
LSID of a generated ProtocolApplication |
|
ApplicationNameTemplate |
terms.fhcrc.org#XarTemplate.ApplicationName |
Name of a generated ProtocolApplication |
|
OutputMaterialLSIDTemplate |
terms.fhcrc.org#XarTemplate.OutputMaterialLSID |
LSID of an output Material object |
|
OutputMaterialNameTemplate |
terms.fhcrc.org#XarTemplate.OutputMaterialName |
Name of an output Material object |
|
OutputDataLSIDTemplate |
terms.fhcrc.org#XarTemplate.OutputDataLSID |
LSID of an output Data object |
|
OutputDataNameTemplate |
terms.fhcrc.org#XarTemplate.OutputDataName |
Name of an output Data object |
|
OutputDataFileTemplate |
terms.fhcrc.org#XarTemplate.OutputDataFile |
Path name of an output Data object, used to set the DataFileUrl property . Relative to the OutputDataDir directory, if set; otherwise relative to the directory containing the xar.xml file |
|
OutputDataDirTemplate |
terms.fhcrc.org#XarTemplate.OutputDataDir |
Directory for files associated with output Data objects, used to set the DataFileUrl property . Relative to the directory containing the xar.xml file |
Substitution Templates and ProtocolApplication Instances
The LSIDs in Example 2 included an arbitrary ".WithTemplates" suffix, where the same LSIDs in Example 1 included ".FixedLSID" as a suffix. The only purpose of these LSID endings was to make the LSIDs unique between Example 1 and 2. Otherwise if a user tried to load Example 1 onto the same LabKey Server system as Example 2, the second load would fail with a "LSID already exists" error in the log. The behavior of the Xar loader when it encounters a duplicate LSID already in the database depends on the object it is attempting to load:
- Experiment, ProtocolDefinitions, and ProtocolActionDefinitions will use existing saved objects in the database if a xar.xml being loaded uses an existing LSID. No attempt is made to compare the properties listed in the xar.xml with those properties in the database for objects with the same LSID.
- An ExperimentRun will fail to load if its LSID already exists unless the CreateNewIfDuplicate attribute of the ExperimentRun is set to true. If this attribute is set to true, the loader will add a version number to the end of the existing ExperimentRun LSID in order to make it unique.
- A ProtocolApplication will fail to load (and abort the entire xar.xml load) if its LSID already exists. (This is a good reason to use the ${RunLSIDBase} template described below for these objects.)
- Data and Material objects that are starting inputs are treated like Experiment and Protocol objects—if their LSIDs already exist, the previously loaded definitions apply and the Xar.xml load continues.
- Data and Material objects that are generated by a ProtocolApplication are treated like ProtocolApplication objects—if a duplicate LSID is encountered the xar.xml load fails with an error.
Users will encounter problems and confusion when LSIDs overlap or conflict unexpectedly. If a protocol reuses an existing LSID unexpectedly, for example, the user will not see the effect of protocol properties set in his or her xar.xml, but will see the previously loaded properties. If an experiment run uses the same LSID as a previously loaded run, the new run will fail to load and the user may be confused as to why.
Fortunately, the LabKey Server Xar loader has a feature called substitution templates that can alleviate the problems of creating unique LSIDs. If an LSID string in a xar.xml file contains one of these substitution templates, the loader will replace the template with a generated string at load time. A separate document called Life Sciences Identifiers (LSIDs) in LabKey Server details the structure of LSIDs and the substitution templates available. Example 3 uses these substitution templates in all of its LSIDs.
Example 3 also shows a fractionation protocol that generates multiple output materials for one input material. In order to generate unique LSIDs for all outputs, the OutputMaterialLSIDTemplate uses ${OutputInstance} to append a digit to the generated output object LSIDs. Since the subsequent protocol steps operate on only one input per instance, the LSIDs of all downstream objects from the fractionation step also need an instance number qualifier to maintain uniqueness. Object names also use instance numbers to remain distinct, though there is no uniqueness requirement for object Names.
Graph view of Example 3
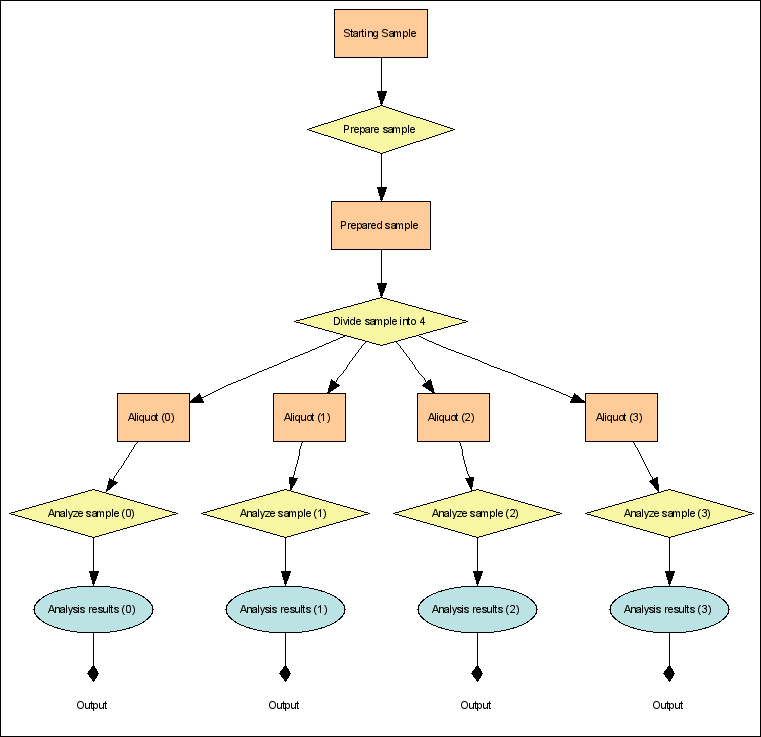
Table 3: Example 3 differences from Example 2
|
The Protocol objects in Example 3 use the ${FolderLSIDBase} substitution template. The Xar loader will create an LSID that looks like
urn:lsid:proteomics.fhcrc.org
The integer “3017” in this LSID is unique to the folder in which the xar.xml load is being run. This means that other xar.xml files that use the same protocol (i.e. the Protocol element has the same rdf:about value, including template) and are loaded into the same folder will use the already-loaded protocol definition.
If a xar.xml file with the same protocol is loaded into a different folder, a new Protocol record will be inserted into the database. The LSID of this record will be the same except for the number encoded in the “Folder-xxxx” portion of the namespace.
|
… <exp:Experiment rdf:about="${FolderLSIDBase}:Tutorial"> <exp:Name>Tutorial Examples</exp:Name> </exp:Experiment>
<exp:ProtocolDefinitions> <exp:Protocol rdf:about="${FolderLSIDBase}:Example3Protocol"> <exp:Name>Example 3 Protocol</exp:Name> <exp:ProtocolDescription>This protocol and its children use substitution strings to generate LSIDs on load.</exp:ProtocolDescription> <exp:ApplicationType>ExperimentRun</exp:ApplicationType> <exp:MaxInputMaterialPerInstance xsi:nil="true"/> <exp:MaxInputDataPerInstance xsi:nil="true"/> <exp:OutputMaterialPerInstance xsi:nil="true"/> <exp:OutputDataPerInstance xsi:nil="true"/> <exp:ParameterDeclarations> <exp:SimpleVal Name="ApplicationLSIDTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.ApplicationLSID" ValueType="String"> <exp:SimpleVal Name="ApplicationNameTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.ApplicationName" ValueType="String">Application of MinimalRunProtocol</exp:SimpleVal> </exp:ParameterDeclarations> </exp:Protocol> … |
|
The records that make up the details of an experiment run-- ProtocolApplication objects and their Data or Material outputs—are commonly loaded multiple times in one folder. This happens, for example, when a researcher applies the exact same protocol to different starting samples in different runs. To keep the LSIDs of the output objects of the runs unique, the ${RunLSIDBase} template is useful. It does the same thing as the FolderLSIDBase except that the namespace contains a integer unique to the run being loaded. These LSIDs look like
urn:lsid:proteomics.fhcrc.org
|
<exp:Protocol rdf:about="${FolderLSIDBase}:Divide_sample"> <exp:Name>Divide sample</exp:Name> <exp:ProtocolDescription>Divide sample into 4 aliquots</exp:ProtocolDescription> <exp:ApplicationType>ProtocolApplication</exp:ApplicationType> <exp:MaxInputMaterialPerInstance>1</exp:MaxInputMaterialPerInstance> <exp:MaxInputDataPerInstance>0</exp:MaxInputDataPerInstance> <exp:OutputMaterialPerInstance>4</exp:OutputMaterialPerInstance> <exp:OutputDataPerInstance>0</exp:OutputDataPerInstance> <exp:OutputDataType>Data</exp:OutputDataType> <exp:ParameterDeclarations> <exp:SimpleVal Name="ApplicationLSIDTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.ApplicationLSID" ValueType="String"> <exp:SimpleVal Name="ApplicationNameTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.ApplicationName" ValueType="String">Divide sample into 4</exp:SimpleVal>
|
|
Example 3 also includes an aliquot step, taking an input prepared material and producing 4 output materials that are measured portions of the input. In order to model this additional step, the xar.xml needs to include the following in the Protocol of the new step:
· set the OutputMaterialPerInstance to 4 · use ${OutputInstance} in the LSIDs and names of the generated Material objects output. This will range from 0 to 3 in this example. · use ${InputInstance} in subsequent Protocol definitions and their outputs.
Using ${InputInstance} in the protocol applications that are downstream of the aliquot step is necessary because there will be one ProtocolApplication object for each output of the previous step.
|
<exp:SimpleVal Name="OutputMaterialLSIDTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputMaterialLSID" ValueType="String"> <exp:SimpleVal Name="OutputMaterialNameTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputMaterialName" ValueType="String"> </exp:ParameterDeclarations> </exp:Protocol>
<exp:Protocol rdf:about="${FolderLSIDBase}:Analyze"> <exp:Name>Example analysis protocol</exp:Name> … <exp:ParameterDeclarations> <exp:SimpleVal Name="ApplicationLSIDTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.ApplicationLSID" ValueType="String"> <exp:SimpleVal Name="ApplicationNameTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.ApplicationName" ValueType="String"> <exp:SimpleVal Name="OutputDataLSIDTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputDataLSID" ValueType="String"> <exp:SimpleVal Name="OutputDataNameTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputDataName" ValueType="String"> </exp:ParameterDeclarations> </exp:Protocol>
|
|
When adding a new protocol step to a run, the xar.xml author must also add a ProtocolAction element that gives the step an ActionSequence number. This number must fall between the sequence numbers of its predecessor(s) and its successors. In this example, the Divide_sample step was inserted between the prepare and analyze steps and assigned a sequence number of 15. The succeeding step (Analyze) also needed an update of its PredecessorAction sequence ref, but none of the other action definition steps needed to be changes. (This is why it is useful to leave gaps in the sequence numbers when hand-editing xar.xml files.).
|
<exp:ProtocolActionDefinitions> <exp:ProtocolActionSet ParentProtocolLSID="${FolderLSIDBase}:Example3Protocol"> .. <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:Divide_sample" ActionSequence="15"> <exp:PredecessorAction ActionSequenceRef="10"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:Analyze" ActionSequence="20"> <exp:PredecessorAction ActionSequenceRef="15"/> </exp:ProtocolAction> … </exp:ProtocolActionSet> </exp:ProtocolActionDefinitions> |
|
One other substitution template that is useful is the ${XarFileId}. On load, this template becomes an integer unique to the xar.xml file. In example 3, the Starting_Sample gets a new LSID for every new xar.xml it is loaded from. |
<exp:StartingInputDefinitions> <exp:Material rdf:about="${FolderLSIDBase}.${XarFileId}:Starting_Sample"> <exp:Name>Starting Sample</exp:Name> </exp:Material> </exp:StartingInputDefinitions> |
Example 3 illustrates the difference between LogEntry format and export format more clearly. The file Example3.xar.xml uses the log entry format. It has 120 lines altogether, of which 15 are in the ExperimentRuns section. The file Example3_exportformat.xar.xml describes the exact same experiment but is 338 lines long. All of the additional lines are in the ExperimentRun section, describing the ProtocolApplications and their inputs and outputs explicitly.
Examples 4, 5 & 6: Describe LCMS2 Experiments
Connected Experiment Runs
Examples 4 and 5 are more “real world” examples. They describe an MS2 analysis that will be loaded into LabKey Server. These examples use the file Example4.mzXML in the XarTutorial directory. This file is the output of an LCMS2 run, a run which started with a physical sample and involved some sample preparation steps. The mzXML file is also the starting input to a peptide search process using X!Tandem. The search process is initiated by the Data Pipeline, and produces a file named Example4.pep.xml. When loaded into the database, the pep xml becomes an MS2 Run with its associated pages for displaying and filtering the list of peptides and proteins found in the sample. It is sometimes useful to think of the steps leading up to the mzXML file as a separate experiment run from the peptide search analysis of that run, especially if multiple searches are run on the same mzXML file. The Data Pipeline follows this approach.
To load both experiment runs, follow these steps.
- Download the file Example4.zip. Extract the files into a directory that is accessible to your LabKey Server, such as \\server1\piperoot\Example4Files. This folder will now contain a sample mzXML file from an LCMS2 run, as well as a sample xar.xml file and a FASTA file to search against.
- Because Example4 relies on its associated files, it must be loaded using the data pipeline (rather than the "upload xar.xml" button. Make sure the Data Pipeline is set to a root path above or including the Example4 folder.
- Select the Process and Upload Data button from the Pipeline tab.
- Select Import Experiment next to Example4.xar.xml. This loads a description of the experimental steps that produced the Example4.mzXML file.
- Return to the Process and Upload Data button on the Pipeline tab. This time select the Search for Peptides button next to the Example4.mzXML file. (Because these is already a xar.xml file with the same base name in the directory, the pipeline skips the page that asks the user to describe the protocol that produced the mzXML file.)
- The pipeline presents a dialog entitled Search MS2 Data. Choose the “Default” protocol that should appear in the dropdown. Press Search.
The peptide search process may take a minute or so. When completed, there should be a new experiment named “Default experiment for folder”. Clicking on the experiment name should show two runs belonging to it. When graphed, these two runs look like the following
Connected runs for an MS2 analysis (Example 4)
|
|
|
|
Example 4 Run (MS2) Summary View |
XarTutorial/Example4 (Default) Summary View |
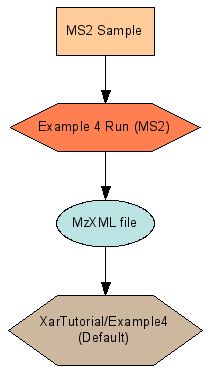
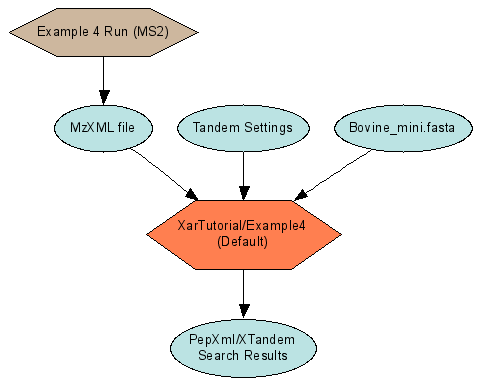
Referencing files for Data objects
The connection between the two runs is the Example4.mzXML file. It is the output of the run described by Example4.xar.xml. It is the input to a search run which has a xar.xml generated by the data pipeline, named XarTutorial\xtandem\Default\Example4.search.xar.xml. LabKey Server knows these two experiment runs are linked because the marked output of the first run is identified as a starting input to the second run. The file Example4.mzXML is represented in the xar object model as a Data object with a DataFileUrl property containing the path to the file. Since both of the runs are referring to the same physical file, there should be only one Data object created. The ${AutoFileLSID} substitution template serves this purpose. ${AutoFileLSID} must be used in conjunction with a DataFileUrl value that gives a path to a file relative to the xar.xml file’s directory. At load time the LabKey Server loader checks to see if an existing Data object points to that same file. If one exists, that object’s LSID is substituted for the template. If none exists, the loader creates a new Data object with a unique LSID. Sharing the same LSID between the two runs allows LabKey Server to show the linkage between the two, as in Figure 4.
Table 4: Example 4 LCMS2 Experiment description
|
Example4.xar.xml
The OutputDataLSID of the step that produces the mzXML file uses the ${AutoFileLSID} template. A second parameter, OutputDataFileTemplate, gives the relative path to the file from the xar.xml’s directory (in this case the file is in the same directory). |
<exp:Protocol rdf:about="${FolderLSIDBase}:ConvertToMzXML"> <exp:Name>Convert to mzXML</exp:Name> <exp:ApplicationType>ProtocolApplication</exp:ApplicationType> <exp:MaxInputMaterialPerInstance>0</exp:MaxInputMaterialPerInstance> <exp:MaxInputDataPerInstance>1</exp:MaxInputDataPerInstance> <exp:OutputMaterialPerInstance>0</exp:OutputMaterialPerInstance> <exp:OutputDataPerInstance>1</exp:OutputDataPerInstance> <exp:OutputDataType>Data</exp:OutputDataType> <exp:ParameterDeclarations> <exp:SimpleVal Name="ApplicationLSIDTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.ApplicationLSID" ValueType="String">${RunLSIDBase}:${InputLSID.objectid}.DoConvertToMzXML</exp:SimpleVal> <exp:SimpleVal Name="ApplicationNameTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.ApplicationName" ValueType="String">Do conversion to MzXML</exp:SimpleVal> <exp:SimpleVal Name="OutputDataLSIDTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputDataLSID" ValueType="String">${AutoFileLSID}</exp:SimpleVal> <exp:SimpleVal Name="OutputDataFileTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputDataFile" ValueType="String">Example4.mzXML</exp:SimpleVal> <exp:SimpleVal Name="OutputDataNameTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputDataName" ValueType="String">MzXML file</exp:SimpleVal> </exp:ParameterDeclarations> </exp:Protocol> |
|
Example4.search.xar.xml
Two of the protocols in the generated xar.xml use the ${AutoFileLSID} template including the Convert to PepXml step shown. But note here that the OutputDataFileTemplate parameter is declared but does not have a default value. |
<exp:Protocol rdf:about="${FolderLSIDBase}:MS2.ConvertToPepXml"> <exp:Name>Convert To PepXml</exp:Name> <exp:ApplicationType>ProtocolApplication</exp:ApplicationType> <exp:MaxInputMaterialPerInstance>0</exp:MaxInputMaterialPerInstance> <exp:MaxInputDataPerInstance>1</exp:MaxInputDataPerInstance> <exp:OutputMaterialPerInstance>0</exp:OutputMaterialPerInstance> <exp:OutputDataPerInstance>1</exp:OutputDataPerInstance> <exp:ParameterDeclarations> <exp:SimpleVal Name="ApplicationLSIDTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.ApplicationLSID" ValueType="String">${RunLSIDBase}::MS2.ConvertToPepXml</exp:SimpleVal> <exp:SimpleVal Name="ApplicationNameTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.ApplicationName" ValueType="String">PepXml/XTandem Search Results</exp:SimpleVal> <exp:SimpleVal Name="OutputDataLSIDTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputDataLSID" ValueType="String">${AutoFileLSID}</exp:SimpleVal> <exp:SimpleVal Name="OutputDataFileTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputDataFile" ValueType="String"/> <exp:SimpleVal Name="OutputDataNameTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputDataName" ValueType="String">PepXml/XTandem Search Results</exp:SimpleVal> </exp:ParameterDeclarations> <exp:Properties/> </exp:Protocol>
|
|
The StartingInputDefintions use the ${AutoFileLSID} template. This time the files referred to are in different directories from the xar.xml file. The Xar load process turns these relative paths into paths relative to the Pipeline root when checking to see if Data objects already point to them. |
<exp:StartingInputDefinitions> <exp:Data rdf:about="${AutoFileLSID}"> <exp:Name>Example4.mzXML</exp:Name> <exp:CpasType>Data</exp:CpasType> <exp:DataFileUrl>../../Example4.mzXML</exp:DataFileUrl> </exp:Data> <exp:Data rdf:about="${AutoFileLSID}"> <exp:Name>Tandem Settings</exp:Name> <exp:CpasType>Data</exp:CpasType> <exp:DataFileUrl>tandem.xml</exp:DataFileUrl> </exp:Data> <exp:Data rdf:about="${AutoFileLSID}"> <exp:Name>Bovine_mini.fasta</exp:Name> <exp:CpasType>Data</exp:CpasType> <exp:DataFileUrl>..\..\databases\Bovine_mini.fasta</exp:DataFileUrl> </exp:Data> </exp:StartingInputDefinitions>
|
|
The ExperimentLog section of this xar.xml uses the optional CommonParametersApplied element to give the values for the OutputDataFileTemplate parameters. This element has the effect of applying the same parameter values to all ProtocolApplications generated for the current action. |
<exp:ExperimentLog> <exp:ExperimentLogEntry ActionSequenceRef="1"/> <exp:ExperimentLogEntry ActionSequenceRef="30"> <exp:CommonParametersApplied> <exp:SimpleVal Name="OutputDataFileTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputDataFile" ValueType="String">Example4.xtan.xml</exp:SimpleVal> </exp:CommonParametersApplied> </exp:ExperimentLogEntry> <exp:ExperimentLogEntry ActionSequenceRef="40"> <exp:CommonParametersApplied> <exp:SimpleVal Name="OutputDataFileTemplate" OntologyEntryURI="terms.fhcrc.org#XarTemplate.OutputDataFile" ValueType="String">Example4.pep.xml</exp:SimpleVal> </exp:CommonParametersApplied> </exp:ExperimentLogEntry> <exp:ExperimentLogEntry ActionSequenceRef="50"/> </exp:ExperimentLog> |
After using the Data Pipeline to generate a pep.xml peptide search result, some users may want to integrate the two separate connected runs of Example 4 into a single run that starts with a sample and ends with the peptide search results. Example 5 is the result of this combination.
Combine connected runs into an end-to-end run (Example 5)
|
|
|
|
Summary View |
Details View |
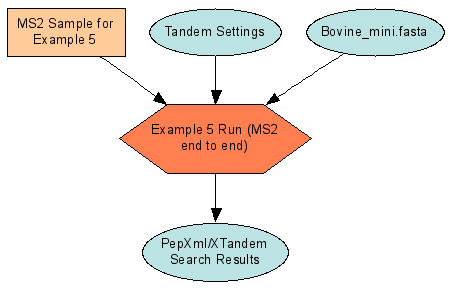
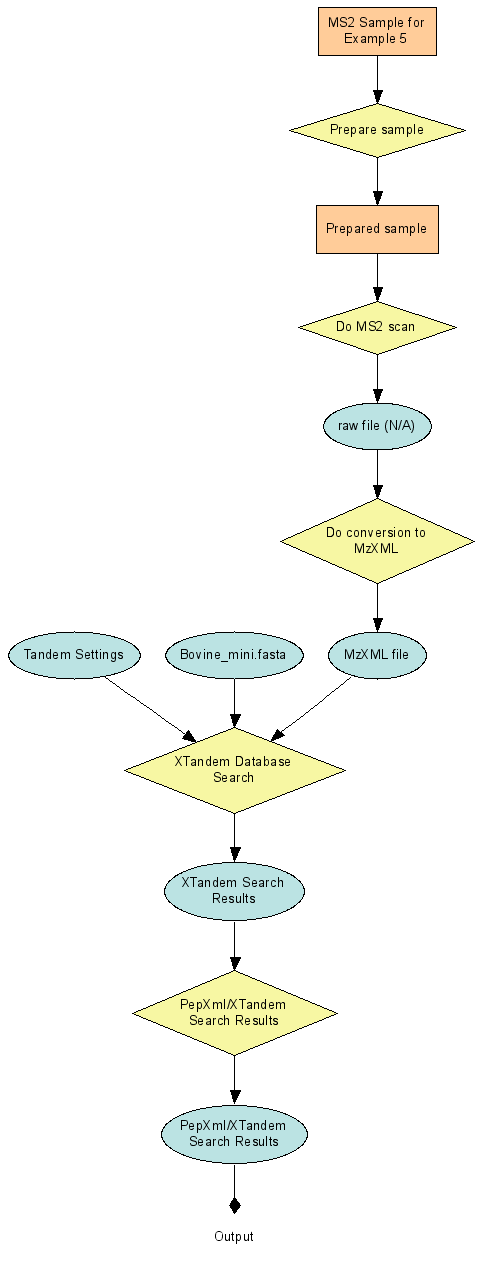
Table 5: Highlights of MS2 end-to-end experiment description (Example5.xar.xml)
|
The protocols of example 5 are the union of the two sets of protocols in Example4.xar.xml and Example4.search.xar.xml. A new run protocol becomes the parent of all of the steps.
Note that the ActionDefinition section has one unusual addition: the XTandemAnalyze step has both the MS2EndToEndProtocol (first) step and the ConvertToMzXML steps as predecessors. This is because it takes as inputs 3 files: the mzXML file output by step 30 and the tandem.xml and bovine_mini.fasta files. The latter two files are not produced by any step in the protocol and so must be included in the StartingInputs section. Adding step 1 as a predecessor is the signal that the XTandemAnalyze step uses StartingInputs. |
<exp:ProtocolActionDefinitions> <exp:ProtocolActionSet ParentProtocolLSID="${FolderLSIDBase}:MS2EndToEndProtocol"> <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:MS2EndToEndProtocol" ActionSequence="1"> <exp:PredecessorAction ActionSequenceRef="1"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:SamplePrep" ActionSequence="10"> <exp:PredecessorAction ActionSequenceRef="1"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:LCMS2" ActionSequence="20"> <exp:PredecessorAction ActionSequenceRef="10"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:ConvertToMzXML" ActionSequence="30"> <exp:PredecessorAction ActionSequenceRef="20"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:XTandemAnalyze" ActionSequence="60"> <exp:PredecessorAction ActionSequenceRef="1"/> <exp:PredecessorAction ActionSequenceRef="30"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:ConvertToPepXml" ActionSequence="70"> <exp:PredecessorAction ActionSequenceRef="60"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:MarkRunOutput" ActionSequence="1000"> <exp:PredecessorAction ActionSequenceRef="70"/> </exp:ProtocolAction> </exp:ProtocolActionSet> </exp:ProtocolActionDefinitions> |
Describing pooling and fractionation
Some types of MS2 experiments involve combining two related samples into one prior to running LCMS2. The original samples are dyed with different markers so that they can be distinguished. Example 6 demonstrates how to do this in a xar.xml.
Sample pooling and fractionation (Example 6)
|
|
|
Details View |
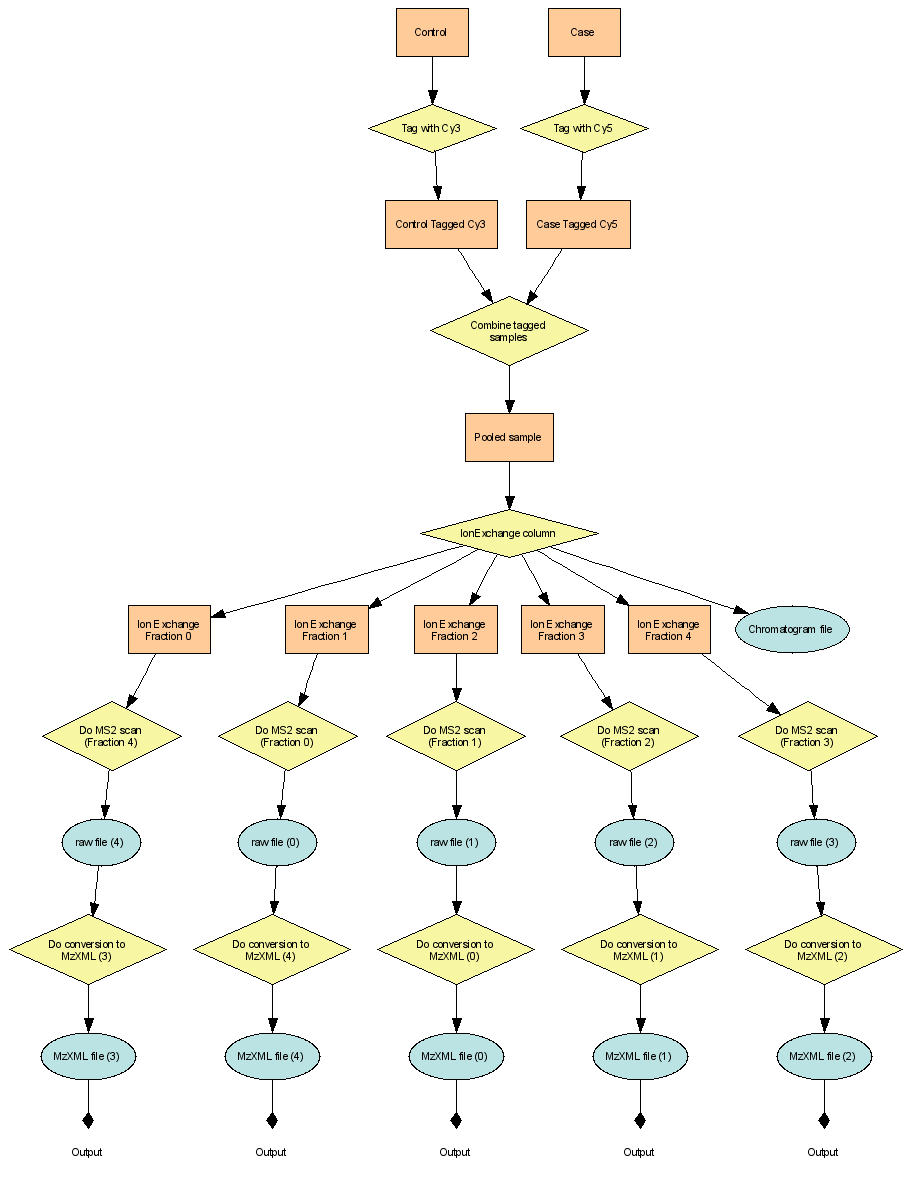
{kind=link}
{kind=link}
Table 6: Describing pooling and fractionation (Example6.xar.xml)
|
There are two different tagging protocols for the two different dye types.
The PoolingTreatment protocol has a MaxInputMaterialPerInstance of 2 and an Output of 1
|
<exp:Protocol rdf:about="${FolderLSIDBase}:TaggingTreatment.Cy5"> <exp:Name>Label with Cy5</exp:Name> <exp:ProtocolDescription>Tag sample with Amersham CY5 dye</exp:ProtocolDescription> … </exp:Protocol> <exp:Protocol rdf:about="${FolderLSIDBase}:TaggingTreatment.Cy3"> <exp:Name>Label with Cy3</exp:Name> … </exp:Protocol> <exp:Protocol rdf:about="${FolderLSIDBase}:PoolingTreatment"> <exp:Name>Combine tagged samples</exp:Name> <exp:ProtocolDescription/> <exp:ApplicationType/> <exp:MaxInputMaterialPerInstance>2</exp:MaxInputMaterialPerInstance> <exp:MaxInputDataPerInstance>0</exp:MaxInputDataPerInstance> <exp:OutputMaterialPerInstance>1</exp:OutputMaterialPerInstance> <exp:OutputDataPerInstance>0</exp:OutputDataPerInstance> … </exp:Protocol> |
|
Both tagging steps are listed as having the start protocol (action sequence =1) as predecessors, meaning that they take StartingInputs.
The pooling step lists both the tagging steps as predecessors. |
<exp:ProtocolActionDefinitions> <exp:ProtocolActionSet ParentProtocolLSID="${FolderLSIDBase}:Example_6_Protocol"> <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:Example_6_Protocol" ActionSequence="1"> <exp:PredecessorAction ActionSequenceRef="1"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:TaggingTreatment.Cy5" ActionSequence="10"> <exp:PredecessorAction ActionSequenceRef="1"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:TaggingTreatment.Cy3" ActionSequence="11"> <exp:PredecessorAction ActionSequenceRef="1"/> </exp:ProtocolAction> <exp:ProtocolAction ChildProtocolLSID="${FolderLSIDBase}:PoolingTreatment" ActionSequence="15"> <exp:PredecessorAction ActionSequenceRef="10"/> <exp:PredecessorAction ActionSequenceRef="11"/> </exp:ProtocolAction> |
|
The two starting inputs need to be assigned to specific steps so that the xar records which dye was applied to which sample. So this xar.xml uses the ApplicationInstanceCollection element of the ExperimentLogEntry to specify which input a step takes. Since there is only one instance of step 10 (or 20) there is one InstanceDetails block in the collection. The InstanceInputs refer to an LSID in the StartingInputDefinitions block. Instance-specific parameters could also be specified in this section. |
<exp:StartingInputDefinitions> <exp:Material rdf:about="${FolderLSIDBase}:Case"> <exp:Name>Case</exp:Name> </exp:Material> <exp:Material rdf:about="${FolderLSIDBase}:Control"> <exp:Name>Control</exp:Name> </exp:Material> </exp:StartingInputDefinitions>
<exp:ExperimentLog> <exp:ExperimentLogEntry ActionSequenceRef="1"/> <exp:ExperimentLogEntry ActionSequenceRef="10"> <exp:ApplicationInstanceCollection> <exp:InstanceDetails> <exp:InstanceInputs> <exp:MaterialLSID>${FolderLSIDBase}:Case</exp:MaterialLSID> </exp:InstanceInputs> </exp:InstanceDetails> </exp:ApplicationInstanceCollection> </exp:ExperimentLogEntry> <exp:ExperimentLogEntry ActionSequenceRef="11"> <exp:ApplicationInstanceCollection> <exp:InstanceDetails> <exp:InstanceInputs> <exp:MaterialLSID>${FolderLSIDBase}:Control</exp:MaterialLSID> </exp:InstanceInputs> </exp:InstanceDetails> </exp:ApplicationInstanceCollection> </exp:ExperimentLogEntry> <exp:ExperimentLogEntry ActionSequenceRef="15"/> |
Full Example: Lung Adenocarcinoma Study description
The file LungAdenocarcinoma.xar.xml is a fully annotated description of an actual study. It uses export format because it includes custom properties attached to run outputs. Properties of generated outputs cannot currently be described using log format.
Design Goals and Directions
- Custom properties defined by an individual researcher
- Properties described in a shared vocabulary (also known as an ontology)
- Complete, structured, standardized descriptions of experiments
- Many of the basic terms and concepts in the LabKey SErver framework are borrowed from the FuGE model. In particular, the base Material, Data, Protocol and ProtocolApplication objects have essentially the same roles and relationships in xar.xml and in FuGE.
- Like FuGE, objects in a xar.xml are identified by Life Sciences Identifiers (LSIDs).
- The ontology-defined annotations (properties) are compatible and could be attached to objects in either framework
Life Science Identifiers (LSIDs)
Constructing LSIDS
LSIDs are multi-part strings with the parts separated by colons. They are of the form:urn:lsid:<AuthorityID>:<NamespaceID>:<ObjectID>:<RevisionID>The variable portions of the LSID are set as follows:- <AuthorityID>: An Internet domain name
- <NamespaceID>: A namespace identifier, unique within the authority
- <ObjectID>: An object identifier, unique within the namespace
- <RevisionID>: An optional version string
LSID Example
Here is an example of a valid LabKey LSID:urn:lsid:labkey.org:Protocol.Folder-2994:SamplePrep.BiotinylationThis LSID identifies a specific protocol for a procedure called biotinylation. This LSID was created on a system with the LSID authority set to labkey.org. The namespace portion indicates that Protocol is the base type of the object, and the suffix value of Folder-2994 is added so that the same protocol can be loaded in multiple folders without a key conflict (see the discussion on substitution templates below). The ObjectId portion of the LSID can be named in whatever way the creator of the protocol chooses. In this example, the two-part ObjectId is based on a sample preparation stage (SamplePrep), of which one specific step is biotinylation (Biotinylation).LSID Substitution Templates
The extensive use of LSIDs in LabKey Server requires a system for generating unique LSIDs for new objects. LSIDs must be unique because they are used as keys to identify records in the database. These generated LSIDs should not inadvertently clash for two different users working in separate contexts such as different folders. On the other hand, if the generated LSIDs are too complex – if, for example, they guarantee uniqueness by incorporating large random numbers – then they become difficult to remember and difficult to share among users working on the same project.
LabKey Server allows authors of experiment description files (xar.xml files) to specify LSIDs which include substitution template values. Substitution templates are strings of the form
${<substitution_string>}
where <substitution_string> is one of the context-dependent values listed in the table below. When an experiment description file is loaded into the LabKey Server database, the substitution template values are resolved into final LSID values. The actual values are dependent on the context in which the load occurs.
Unless otherwise noted, LSID substitution templates are supported in a xar.xml file wherever LSIDs are used. This includes the following places in a xar.xml file:
- The LSID value of the rdf.about attribute. You can use a substitution template for newly created objects or for references to objects that may or may not exist in the database.
- References to LSIDs that already exist, such as the ChildProtocolLSID attribute.
- Templates for generating LSIDs when using the ExperimentLog format (ApplicationLSID, OuputMaterialLSID, OutputDataLSID).
A limited subset of the substitution templates are also supported in generating object Name values when using the ExperimentLog format (ApplicationName, OutputMaterialName, and OutputDataName). These same templates are available for generating file names and file directories (OutputDataFile and OutputDataDir). Collectively these uses are listed as the Name/File ProtocolApplication templates in the table below.
Note: The following table lists the primitive, single component substitution templates first. The most powerful and useful substitution templates are compound substitutions of the simple templates. These templates are listed at the bottom of the table.
Table: LSID Substition Templates in LabKey Server
|
${LSIDAuthority} |
||
|
|
Expands to |
Server-wide value set on the Customize Site page under Site Administration. The default value is localhost. |
|
|
Where valid |
|
|
|
||
|
${LSIDNamespace.prefix} |
||
|
|
Expands to |
Base object name of object being identified by the LSID; e.g., Material, Data, Protocol, ProtocolApplication, Experiment, or ExperimentRun |
|
|
Where valid |
|
|
|
||
|
${Container.RowId} |
||
|
|
Expands to |
Unique integer or path of project or folder into which the xar.xml is loaded. Path starts at the project and uses periods to separate folders in the hierarchy. |
|
|
Where valid |
|
|
|
||
|
${XarFileId} |
||
|
|
Expands to |
Xar- + unique integer for xar.xml file being loaded |
|
|
Where valid |
|
|
|
||
|
${UserEmail},${UserName} |
||
|
|
Expands to |
Identifiers for the logged-on user initiating the xar.xml load |
|
|
Where valid |
|
|
|
||
|
${ExperimentLSID} |
||
|
|
Expands to |
rdf:about value of the Experiment node at the top of the xar.xml being loaded |
|
|
Where valid |
|
|
|
||
|
${ExperimentRun.RowId} |
||
|
|
Expands to |
The unque integer, LSID, and Name of the ExperimentRun being loaded |
|
|
Where valid |
|
|
|
||
|
${InputName},${InputLSID} |
||
|
|
Expands to |
The name and lsid of the Material or Data object that is the input to a ProtocolApplication being generated using ExperimentLog format. Undefined if there is not exactly one Material or Data object that is input. |
|
|
Where valid |
|
|
|
||
|
${InputLSID.authority} |
||
|
|
Expands to |
The individual parts of an InputLSID, as defined above. The namespacePrefix is defined as the namespace portion up to but not including the first period, if any. The namepsaceSuffix is the remaining portion of the namespace after the first period. |
|
|
Where valid |
|
|
|
||
|
${InputInstance},${OutputInstance} |
||
|
|
Expands to |
The 0-based integer number of the ProtocolApplication instance within an ActionSequence. Useful for any ProtocolApplication template that includes a fractionation step. Note that InputInstance is > 0 whenever the same Protocol is applied multiple times in parallel. OutputInstance is only > 0 in a fractionation step in which multiple outputs are generated for a single input. |
|
|
Where valid |
|
|
|
||
|
${FolderLSIDBase} |
||
|
|
Expands to |
urn:lsid:${LSIDAuthority}: |
|
|
Where valid |
|
|
|
|
|
|
${RunLSIDBase} |
||
|
|
Expands to |
urn:lsid:${LSIDAuthority}:${LSIDNamespace.Prefix} |
|
|
Where valid |
|
|
|
||
|
${AutoFileLSID} |
||
|
|
Expands to |
urn:lsid:${LSIDAuthority} See Data object in next section for behavior and usage |
|
|
Where valid |
|
Common Usage Patterns
In general, the primary object types in a Xar file use the following LSID patterns:
Experiment, ExperimentRun, Protocol
These three object types typically use folder-scoped LSIDs that look like
${FolderLSIDBase}:Name_without_spaces
In these LSIDs the object name and the LSID’s objectId are the same except for the omission of characters (like spaces) that would get encoded in the LSID.
ProtocolApplication
A ProtocolApplication is always part of one and only one ExperimentRun, and is loaded or deleted with the run. For ProtocolApplications, a run-scoped LSID is most appropriate, because it allows multiple runs using the same protocol to be loaded into a single folder. A run-scoped LSID uses a pattern like
${RunLSIDBase}:Name_without_spaces
Material
Material objects can be divided into two types: starting Materials and Materials that are created by a ProtocolApplication. If the Material is a starting material and is not the output of any ProtocolApplication, its scope is outside of any run. This type of Material would normally have a folder-scoped LSID using ${FolderLSIDBase}. On the other hand, if the Material is an output of a ProtocolApplication, it is scoped to the run and would get deleted with the run. In this case using a run-scoped LSID with ${RunLSIDBase} would be more appropriate.
Data
Like Material objects, Data objects can exist before any run is created, or they can be products of a run. Data objects are also commonly associated with physical files that are on the same file share as the xar.xml being loaded. For these data objects associated with real existing files, it is important that multiple references to the same file all use the same LSID. For this purpose, LabKey Server provides the ${AutoFileLSID} substitution template, which works somewhat differently from the other substitution templates. An ${AutoFileLSID} always has an associated file name on the same object in the xar.xml file:
- If the ${AutoFileLSID} is on a starting Data object, that object also has a DataFileUrl element.
- If the ${AutoFileLSID} is part of a XarTemplate.OutputDataLSID parameter, the XarTemplate.OutputDataFile and XarTemplate.OutputDataDir specify the file
- If the ${AutoFileLSID} is part of a DataLSID (reference), the DataFileUrl attribute specifies the file.
When the xar.xml loader finds an ${AutoFileLSID}, it first calculates the full path to the specified file. It then looks in the database to see if there are any Data objects in the same folder that already point to that file. If an existing object is found, that object’s LSID is used in the xar.xml load. If no existing object is found, a new LSID is created.
Assay User Guide
- An administrator will set up the appropriate assay design. The assay design specifies how to interpret the specific data to be imported.
- Import Assay Runs: Users can then use this design as a specific import pipeline for importing data. Most assays will include instrument-specific properties or processes. For a sampling see:
- Depending on the type of instrument, tools and grids offer various analysis options to the user. An administrator can add and configure what is available. For a sampling of possibilities, see Tutorials for specific instrument types.
- Reimport Assay Runs: When necessary, the user can also reimport assay runs.
Related Topics
- Tutorials are available for many specific instrument data types.
Import Assay Runs
Prerequisite: Create an Assay Design
Before you import data into an assay design, you need a target assay design in your project. If you don't already have an assay design in your project, an administrator can either (1) create a new assay design from scratch or (2) you can import a pre-existing assay design. Once you have an assay design you can begin the process of uploading and importing the data into the design.Upload Data Files to LabKey Server
- Add the Files web part to your assay project.
- Upload your data files into the Files web part. See Using the Files Repository for details.
Consider File Naming Conventions
Before uploading data files, consider how your files are named, in order to take advantage of LabKey Server's file grouping feature.When you import data files into an assay design, LabKey Server tries to group together files that have the same name (but different file extensions). For example, if you are importing an assay data file named MyAssayRun1.csv, LabKey will group it together with other files (such as JPEGs, CQ files, metadata files, etc.), provided they have the same name as the data record file.Files grouped together in this way will be rendered together in the graphical flow chart (see below) and they can be exported together as a zip file.Import Data into an Assay
- In the Files web part, navigate to and select the files you want to import.
- Click Import Data.

- In the popup dialog, select the target assay design and click Import.

Enter Batch Properties
You are now on the page titled Data Import: Batch Properties. A batch is a group of runs, and batch properties will be used as metadata for all runs imported as part of this group. You can define which batch properties appear on this page when you design a new assay.- Enter any assay-specific properties for the batch.
- Click Next.
Enter Run-Specific Properties and Import Data
The next set of properties are collected per-run, and while there are some commonalities, they can vary widely by type of assay, so please see the pages appropriate for your instrument. Review run-specific properties and documentation for importing data appropriate for your assay type:- Step 3: Import Assay Data. Server simply reads in tab-separated values that conform to your assay's schema.
- ELISpot Properties
- Import Luminex Runs. Server parses a Luminex file, extracts metadata and deals with out-of-range values and other value flags.
- NAb Assay Tutorial
- Enter run-specific properties and specify the file(s) containing the data.
- For some types of instrument data, there will be a Next link, followed by an additional page (or more) of properties to enter.
- Click Save and Finish (or Save and Import Next File) to initiate the actual import.
Explore the Data
When the import is complete, you'll see the runs page listing all runs imported so far for the given assay design. Each line lists a run and represents a group of data records imported together.To see and explore the data records for a particular run, click the run's name. To see a graphical picture of the run and associated files, click the graph icon.
To see a graphical picture of the run and associated files, click the graph icon. A flow chart of the run is rendered, showing the input data and file outputs. Note that the elements of the flowchart are clickable links.
A flow chart of the run is rendered, showing the input data and file outputs. Note that the elements of the flowchart are clickable links.
- Switch tabs above the graph for the Graph Details and Text View of the run.
- Return to the Assay Dashboard by clicking the tab at the top of the page.
- You can reach the runs page by clicking the name of your assay in the Assay List.
- For specific instrument assays, the runs list may show additional columns.
Assay Data and Original Files
In the case of a successful import, the original Excel file will be attached to the run so you can refer back to it. The easiest way to get to it is usually to click on the flow chart icon for the run in the grid view. You'll see all of the related files on that page.Once you have imported a file you cannot import it, or another file of the same name, using the same method. If you need to repeat an import, either because the data in the file has been updated or to apply an updated import process, use the process covered in Reimport Assay Runs.For failed import attempts, the server will leave a copy of the file at yourFolder/assaydata/uploadTemp. The subdirectories under uploadTemp have GUIDs for names -- identify your file based on the created/modified date on the directory itself.Related Topics
Specific import processes for specific instrument data types:Reimport Assay Runs
- Neutralizing Antibody (NAb) Assays - See details below.
- Luminex Reimport - When exclusions have been applied, reimporting Luminex runs offers the option to retain the exclusions. A walkthrough of this process is included in the Luminex tutorial. See Reimport Luminex Runs for more information.
- Some assay types, including ELISA, ELISpot, and FluoroSpot do not offer a reimport option. If the reimport link or button is not available, the only way to reimport a run is to delete it and import it again from the original source file.
Reimport Assay Data
To reimport a run:- Navigate to the Runs view of the assay data.
- Select the run to reimport using a checkbox on the left. In this example, an incorrect "AssayId" value was entered for a run in the general assay tutorial.
- Click Reimport Run. Note that the reimport link will only be active when a single run is checked.

- The import process will be run again, often providing the previously entered import properties as defaults. Change properties as needed, click Next to advance import screens.
- The Run Data section offers options on reimport:
- Click Show Expected Data Fields to display them for reference.
- Click Download Spreadsheet Template to download the expected format.
- Choose one of the upload options:
- Paste new data into the text area.
- Select Use the data file(s) already uploaded to the server. When you select this option, the name of the file will be shown.
- Check Upload a data file to upload and use a new data file. Note: If you select the same file (or any file with the same name as a file already imported) a warning message will tell you that the file you upload will be renamed with a "-1." before the extension (or higher incremented number). The server stores the names of files associated with runs and these names must be unique. To avoid this automated incremented renaming, you can rename the file on your file system and choose the new file before proceeding.
- Click Save and Finish.
Reimport NAb Assay Data
A specific scenario in which Neutralizing Antibody runs must be reimported is to apply alternate curve fits to the data.NAb assay data must be deleted before it can be rerun, and the run may consist of multiple files - a metadata and run data file. NAb assay tools do not offer the multi-select general runs grid option outlined above. Instead, each Run Details page includes a Delete and Reimport button. The tools remember which file or files were involved in the metadata and run data import.To reimport a NAb run:- Navigate to the NAb Assay Runs list.
- Click Run Details for the run to reimport.
- Click Delete and Reimport.
- The previously entered import properties and files will be offered as defaults. Make changes as needed, then click Next and if needed, make other changes.
- Click Save and Finish.
Sample Sets
Uses of Sample Sets
- A sample set can be included in the description of an experiment as the inputs to a run.
- A sample set can be used to quickly apply shared properties to a group of samples instead of adding these properties to each sample individually.
- Samples can be linked with downstream assay results, using a lookup field in the assay design. For details, see Link Assay Data to Sample Sets.
- The derivation of a sample into aliquots, or samples that are mixtures of multiple parent samples, can be tracked. For details, see Parent Samples: Derivation and Lineage.
Samples vs. Specimens
The terms sample and specimen refer to two different methods of tracking the same types of physical materials (such as blood draws or tissue).- Specimens. LabKey's specimen infrastructure is tightly woven into the study module, enabling integration of specimen information with other types of study data. The study module also provides a specimen request and tracking system for specimens. However, specimen information imported to LabKey Server must conform to a constrained format with a defined set of fields.
- Samples. Samples are less constrained than specimens. Administrators can define sample properties and fields tailored to their particular experiments. Sample infrastructure is provided by LabKey's experiment module. It supports tracking the derivation history of these materials but does not support request tracking. Samples are used by LabKey's Flow, MS2 and Microarray modules.
Topics
Import Sample Sets
Import A New Sample Set
Before you create a new sample set, consider how you will provide unique ids for each sample. For options, see Samples: Unique IDs.- In the Sample Sets web part, click Import Sample Set.
- Enter:
- Name: This is the name for the overall sample set. (Not to be confused with the Name column in a sample set, which has special meaning to the server. For details see Samples: Unique IDs.) It will appear as a record in the Sample Sets web part. Clicking on this name will bring you to a grid of the individual samples in the set.
- Upload Type: Select either 'Cut/Paste' or 'File'.
- If you select 'File', click Upload TSV, XLS, or XLSX File. Browse to the file you wish to upload.
- If you select 'Cut/Paste', then paste the data into Sample Set Data. The data must be formatted as tab separated values (TSV). Copy/paste from Microsoft Excel works well. The first row should contain column names, and subsequent rows should contain the data.
- ID Columns. Select columns in your data to form a concatenated unique id. Individual columns need not contain unique ids, but the concatenated value must for a unique value for each row. The concatenated values (with dash separators) will be written to the Name column, even if no Name column is provided in your original data. These dropdowns will be populated after you select a file or paste sample data. For details see, Samples: Unique IDs.
- Parent Column. Deprecated. The Parent Column dropdown, though still available, is considered deprecated as of LabKey Server version 16.2. Instead of indicating parent samples using the dropdown, use a column name with the pattern "MaterialInputs/<NameOfSample>". For syntax details, see Indicating Sample Parentage on Import.
- Click Submit.
Add an Individual Sample to an Existing Sample Set
Add a single sample to a sample set:- When viewing an individual sample set, select Insert > Insert New Row from the grid menu.
- Enter the properties of the new sample.
- Click Submit.
Add More Samples to an Existing Sample Set
- When viewing an individual sample set, click the Import more samples button.
- Choose how the uploaded samples should be merged with the existing samples. Your options:
- Insert only new samples; error if trying to update an existing sample.
- Insert only new samples; ignore any existing samples.
- Insert any new samples and update existing samples.
- Update only existing samples with new values; error if sample doesn't already exist.
- By default, any additional columns in the uploaded sample data will be ignored. Check the box to add any new columns found in the uploaded sample data to the existing sample set columns.
- Either upload a TSV, XLS or XLSX file, or cut/paste sample set data into the box. You can click Download an Excel Template Workbook to use to ensure correct formatting.
- After uploading/pasting, indicate one or more Id columns.
- Click Submit.
Next Step
Samples: Unique IDs
- Name Column - If you provide a "Name" column in the uploaded data, the server will consider this a unique identifier for each sample record.
- ID columns - Identify up to three ID columns in your uploaded data. The server will concatenate the selected columns to generate a unique sample name.
- Name Expressions - Create a unique id by concatenating a variety of elements, including fixed strings, data from the current record, and special tokens (see below for details).
- Name Expressions: Examples - Example uses of name expressions to form ids.
Name Column
If you provide a 'Name' column in your sample set, the server will make it the unique identifier for your sample records. If the Name column contains duplicate values, the server will not be able to import your data. An example sample set using the 'Name' column:| Name | Type | Volume | VolumeUnit |
|---|---|---|---|
| S-100 | Plasma | 100 | mL |
| S-200 | Plasma | 100 | mL |
| S-300 | Plasma | 100 | mL |
| S-400 | Plasma | 100 | mL |

ID Columns
You can build a unique identifier out of the data in your table by selecting up to three id columns. The columns you select will be concatinated together to form the id. If the resulting concatenated value is not unique, the server will not be able to import the data. Below is an example sample set that uses "Lab" and "Date" to build the unique id:| Lab | Date | Type | Volume | VolumeUnit |
|---|---|---|---|---|
| Hanson | 2010-10-10 | Plasma | 100 | mL |
| Hanson | 2010-10-11 | Plasma | 100 | mL |
| AmeriLab | 2010-10-10 | Plasma | 100 | mL |
| AmeriLab | 2010-10-11 | Plasma | 100 | mL |

Name Expressions
Name expressions let you build unique ids out of a variety of different elements, including: values drawn from the sample data, string constants, random numbers, etc. See the examples of name expressions below.In additional to column names, the following tokens can be used:- Inputs: A collection of all DataInputs and MaterialInputs for the current sample. You can concatenate using one or more value from the collection.
- DataInputs: A collection of all DataInputs for the current sample. You can concatenate using one or more value from the collection.
- MaterialInputs: A collection of all MaterialInputs for the current sample. You can concatenate using one or more value from the collection.
- now: The current date, which you can format using string formatters.
- batchRandomId: A four digit random number applied to the entire set of incoming sample records. On each import event, this random batch number will be regenerated.
- randomId: A four digit random number for each sample row.
- dailySampleCount: An incrementing counter, starting with the integer '1', that resets each day.
- weeklySampleCount: An incrementing counter, starting with the integer '1', that resets each week.
- montlySampleCount: An incrementing counter, starting with the integer '1', that resets each month.
- yearlySampleCount: An incrementing counter, starting with the integer '1', that resets each year.

Example Name Expressions
| Name Expression | Example Output | Description |
|---|---|---|
| ${ParticipantId}_${Barcode} | P1_189 P2_190 P3_191 P4_192 | ParticipantId + Barcode. |
| ${Lab:defaultValue('Unknown')}_${Barcode} | Hanson_189 Hanson_190 Krouse_191 Unknown_192 | Lab + Barcode. If the Lab value is null, then use the string 'Unknown'. |
| S_${randomId} | S_3294 S_1649 S_9573 S_8843 | Random numbers. |
| S_${now:date}_${dailySampleCount} | S_20170202_1 S_20170202_2 S_20170202_3 S_20170202_4 | Date + incrementing integer. |
| Barcode | Type | DrawDate | ParticipantId | MaterialInputs/Reagents | Lab |
|---|---|---|---|---|---|
| 189 | Plasma | 1/1/2010 | P1 | RegA | Hanson |
| 190 | Plasma | (null) | P2 | RegB | Hanson |
| 191 | Plasma | 1/3/2010 | P3 | (null) | Krouse |
| 192 | Plasma | 1/4/2010 | P4 | RegD, RegX, RegY | (null) |
Name Expressions Used with String Modifiers
The following name expressions are used in combination with string modifiers.| Name Expression00000000000000000000000000000000000000000000000 | Example Output000000000000000000 | Description |
|---|---|---|
| S_${Column1}_${Column2} | S_101_102 | Create an id from the letter 'S' and two values from the current row of data, separated by underscore characters. |
| S-${Column1}-${now:date}-${batchRandomId} | S-1-20170103-9001 | |
| S-${Column1:suffix('-')}${Column2:suffix('-')}${batchRandomId} | S-2-4-5862 | |
| ${Column1:defaultValue('S')}-${now:date('yy-MM-dd')}-${randomId} | 2-17-01-03-1166 | ${Column1:defaultValue('S')} means 'Use the value of Column1, but if that is null, then use the default: the letter S' |
| ${DataInputs:first:defaultValue('S')}-${Column1} | Nucleotide1-5 | ${DataInputs:first:defaultValue('S')} means 'Use the first DataInput value, but if that is null, use the default: the letter S' |
| ${DataInputs:join('_'):defaultValue('S')}-${Column1} | Nucleotide1_Nucleotide2-1 | ${DataInputs:join('_'):defaultValue('S')} means 'Join together all of the DataInputs separated by undescores, but if that is null, then use the default: the letter S' |
View SampleSets and Samples
View All Sample Sets
You can add the Sample Sets web part to any folder that has the Experiment module enabled. See another example in LabKey's proteomics demo.
See another example in LabKey's proteomics demo.
View an Individual Sample Set
Clicking on the name of any sample set brings you to the individual view of the set and it's properties (metadata). For example, clicking on the Yeast Sample Set in the web part shown above brings you here: Options on this page:
Options on this page:
- Make Active: Make the current sample set active.
- Edit Fields: Add or modify the metadata fields associated with this sample set. See Field Properties Reference.
- Edit Set: Change the description.
- Delete Set: Delete the sample set.
- Import More Samples: See Import Sample Sets.
View an Individual Sample
Clicking on the name of any sample in the sample set brings you to a detailed view of the sample. The Sample Set Contents page shows you:
The Sample Set Contents page shows you:
- Standard properties. These are properties defined for a group of samples at the sample-set level.
- Custom properties. These are properties of this individual sample.
- Parent samples. The current sample was derived from these samples.
- Child samples. The current sample has been used to derive the listed child samples. This might happen (for example) if you have subdivided the sample into smaller aliquots.
- Runs using this material or derived material. All listed runs use this sample as an input.
- Edit the properties of the sample.
- Derive samples from this sample. This is covered in the next topic.
Link Assay Data to Sample Sets
Linking Assay Data to Sample Sets
To create a link between your assay data and its source sample, create a lookup column in the assay design that points to the source sample.When creating a lookup column that points to a sample set, you can choose to lookup either the RowID (an integer) or the Name field (a string). In most cases, you should lookup to the Name (String) field, since your assay data probably refers to the string id, not the integer RowID (which is a system generated value). Both fields are guaranteed to be unique within a sample set. When creating a new lookup column, you will see the same table listed twice with different types offered, String and Integer, as shown below. Choosing the integer option will create a lookup on the RowId, choosing String will give you a lookup on the Name.
Choosing the integer option will create a lookup on the RowId, choosing String will give you a lookup on the Name.
Resolve Samples in Multiple Locations
[ Video Overview: Resolving Samples in Other Locations ] The lookup definition includes the target location. If you select a specific folder, the lookup only matches samples within that folder. If you leave the lookup target as the default location, the search for a match proceeds as follows:- First the current folder is searched for a matching name. If no match:
- Look in the parent of the current folder, and if no match there, continue to search up the folder tree to the project level, or whereever the sample set itself is defined. If there is still no match:
- Look in the Shared project (but not in any of its subfolders).
Related Topics
Parent Samples: Derivation and Lineage
- Indicate Sample Parentage Using the User Interface
- Indicate Sample Parentage On Import
- Indicate Sample Parentage Through the API
- Display the Parent Column
- Lineage Graphs
Indicate Sample Parentage Using the User Interface
You can capture sample aliquoting using the user interface.- From a Sample Set, select one or more samples to use as parents, and click Derive samples.
- Specify Source Materials:
- Name. The source samples are listed here.
- Role. Roles allow you to label each input with a unique purpose.
- Number of Derived Samples. You can create multiple derived samples at once.
- Target Sample Set. You have the option to make derived samples part of an existing sample set.

- Click Next.
- Enter properties specific to the Output Sample(s) if needed.
- Click Submit.
Indicate Sample Parentage On Import
When importing samples, you can indicate a parent sample by including a column named "MaterialInputs/<NameOfSampleSet>", where <NameOfSampleSet> refers to some existing sample set, either a different sample set, or the current one. For example, the following indicates that DerivedSample-1 has a parent named M-100 in the sample set RawMaterials.| Name | MaterialInputs/RawMaterials |
|---|---|
| DerivedSample-1 | M-100 |
| Name | MaterialInputs/MySampleSet |
|---|---|
| ParentSample-1 | |
| ChildSample-1 | ParentSample-1 |
| Name | MaterialInputs/RawMaterials |
|---|---|
| DerivedSample-2 | M-100, M-200 |
| Name | MaterialInputs/RawMaterials | MaterialInputs/Reagents |
|---|---|---|
| DerivedSample-3 | M-100, M-200 | R-100 |
| Name | DataInputs/ExpressionSystems |
|---|---|
| DerivedSample-4 | ES-100 |
Indicate Sample Parentage Through the API
You can create a LABKEY.Exp.Run with parent samples as inputs and child derivatives as outputs.Display the Parent Column
By default a sample set does not display the parent columns, either the Material Inputs or the Data Inputs. To show these columns:- Go the relevant sample set.
- In the panel Sample Set Contents, click Grid Views > Customize Grid.
- Select Show Hidden Fields.
- Open the nodes Inputs > Data or the nodes Inputs > Materials.
- Select the field you would like to show.
- Save the grid, either for your own viewing, or for sharing with others.

Lineage Graphs
Derived samples are represented graphically using "lineage graphs". Sample are represented as rectangles and the derivation steps are shown as diamonds. Note that elements in the graph are clickable links that navigate to details pages for other samples. To view a derivation graph:
To view a derivation graph:
- Go to the sample set of interest.
- Click the individual sample name or id.
- On the sample details page, under Standard Properties > Lineage Graph, click the link Lineage for <Your Sample>. If there is no parentage information, there will be no link and no graph.
 Note that lineage graphs can differ depending on the way that the data is entered. When you manually derive multiple child samples from a parent via the Derive Samples button, the lineage graph summary view will show these child samples on one graph, as shown below in a case where two additional samples have been derived from the "Derived Yeast Sample".
Note that lineage graphs can differ depending on the way that the data is entered. When you manually derive multiple child samples from a parent via the Derive Samples button, the lineage graph summary view will show these child samples on one graph, as shown below in a case where two additional samples have been derived from the "Derived Yeast Sample". When the sample parent/child relationships are imported via copy-and-paste or via the API, separate lineage graphs will be rendered for each parent/child relationship, as shown below. A single graph showing all the child sample simultaneously will not be available.
When the sample parent/child relationships are imported via copy-and-paste or via the API, separate lineage graphs will be rendered for each parent/child relationship, as shown below. A single graph showing all the child sample simultaneously will not be available.
Related Topics
Sample Sets: Examples
Blood Samples - Live Version
A sample set recording the original blood draws and aliquots (derived child samples) for a clinical study. The original parent vials for the aliquots are indicated by the column "MaterialInput/Blood Samples".| Name | Description | Volume | VolumeUnit | SampleType | MaterialInputs/Blood Samples |
|---|---|---|---|---|---|
| S1 | Baseline blood draw | 10 | mL | Whole Blood | |
| S2 | Baseline blood draw | 10 | mL | Whole Blood | |
| S3 | Baseline blood draw | 10 | mL | Whole Blood | |
| S4 | Baseline blood draw | 10 | mL | Whole Blood | |
| S1.100 | Aliquot from original vial S1 | 2 | mL | Whole Blood | S1 |
| S1.200 | Aliquot from original vial S1 | 2 | mL | Whole Blood | S1 |
| S1.300 | Aliquot from original vial S1 | 6 | mL | Whole Blood | S1 |
| S2.100 | Aliquot from original vial S2 | 2 | mL | Whole Blood | S2 |
| S2.200 | Aliquot from original vial S2 | 4 | mL | Whole Blood | S2 |
| S2.300 | Aliquot from original vial S2 | 4 | mL | Whole Blood | S2 |

Cocktails - Live Version
A sample set capturing cocktail recipes. The column "MaterialInputs/Cocktails" refers to multiple parent ingredient for each recipe.| Name | Description | MaterialType | MaterialInputs/Cocktails |
|---|---|---|---|
| Vodka | Liquor | Liquid | |
| Gin | Liquor | Liquid | |
| Bourbon | Liquor | Liquid | |
| Bitters | Mixer | Liquid | |
| Vermouth | Mixer | Liquid | |
| Ice | Garnish | Solid | |
| Olive | Garnish | Solid | |
| Orange Slice | Mixer | Garnish | |
| Martini | Classic Cocktail | Liquid | Gin, Vermouth, Ice, Olive |
| Vespers | Classic Cocktail | Liquid | Gin, Vodka, Vermouth, Ice |
| Old Fashioned | Classic Cocktail | Liquid | Bourbon, Bitters, Orange Slice |

Beer Recipes
This example is consists of four different tables:- Beer Ingredient Types: a DataClass used to capture the different kinds of ingredients that go into beer, such as Yeast and Hops. In order to keep this example simple, we have consolidated all of the ingredient types into one large DataClass. But you could also split out each of these types into separate DataClasses, resulting in four different DataClases: Yeast Types, Hops Types, Water Types, and Grain Types.
- Beer Recipe Types: a DataClass used to capture the different kinds of beer recipes, such as Lager, IPA, and Ale.
- Beer Ingredient Samples: a Sample Set that instantiates the ingredient types.
- Beer Samples: a Sample Set that captures the final result: samples of beer mixed from the ingredient samples and recipes.
 Tables used in the sample:
Tables used in the sample:
Beer Ingredient Types - Live Version
| Name | Description | Form |
|---|---|---|
| Water | Water from different sources. | liquid |
| Yeast | Yeast used for fermentation. | granular |
| Grain | Grain types such as wheat, barley, oats, etc. | solid |
| Hops | Various hop strains | solid |
Beer Recipe Types - Live Version
| Name | Recipe Text |
|---|---|
| Lager | Mix and bottom ferment. |
| Ale | Mix and use wild yeast from the environment. |
| IPA | Mix using lots of hops. |
Beer Ingredient Samples - Live Version
| Name | Description | Volume | VolumeUnits | DataInputs/Beer Ingredient Types |
|---|---|---|---|---|
| Yeast.1 | Sample derived from Beer Ingredient Types | 10 | grams | Yeast |
| Yeast.2 | Sample derived from Beer Ingredient Types | 10 | grams | Yeast |
| Yeast.3 | Sample derived from Beer Ingredient Types | 10 | grams | Yeast |
| Water.1 | Sample derived from Beer Ingredient Types | 1000 | mL | Water |
| Water.2 | Sample derived from Beer Ingredient Types | 1000 | mL | Water |
| Grain.1 | Sample derived from Beer Ingredient Types | 100 | grams | Grain |
| Grain.2 | Sample derived from Beer Ingredient Types | 100 | grams | Grain |
| Hops.1 | Sample derived from Beer Ingredient Types | 3 | grams | Hops |
| Hops.2 | Sample derived from Beer Ingredient Types | 3 | grams | Hops |
Beer Samples - Live Version
| Name | MaterialInputs/Beer Ingredient Samples | DataInputs/Beer Recipe Types |
|---|---|---|
| Lager.1 | Yeast.1, Water.2, Grain.1, Hops.2 | Lager |
| Ale.1 | Yeast.2, Water.1, Grain.1, Hops.1 | Ale |
| IPA.1 | Yeast.3, Water.2, Grain.2, Hops.2 | IPA |
Related Topics
- Parent Samples: Derivation and Lineage - Syntax for capturing parentage and lineage
- DataClasses - Set and use Data Classes
- Sample Sets Interactive Example
'Active' Sample Set
Run Groups
Create Run Groups and Associate Runs with Run Groups
From a list of runs, select the runs you want to add to the group and click on the "Add to run group" button. You'll see a popup menu. If you haven't already created the run group, click on "Create new run group." This will bring you a page that asks you information about the run group. You must give it a name, and can provide additional information if you like. Clicking on "Submit" will create the run group, and add the runs you selected to it. It will then return you to the list of runs.Continue this process to define all the groups that you want. You can also add runs to existing run groups.The "Run Groups" column will show all of the groups to which a run belongs.
This will bring you a page that asks you information about the run group. You must give it a name, and can provide additional information if you like. Clicking on "Submit" will create the run group, and add the runs you selected to it. It will then return you to the list of runs.Continue this process to define all the groups that you want. You can also add runs to existing run groups.The "Run Groups" column will show all of the groups to which a run belongs.
Viewing Run Groups
You can click on the name of a run group in the "Run Groups" column within a run list to see its details. You can also add the "Run Groups" web part to your folder, or access it through the Experiment module (Admin > Go to Module > More Modules > Experiment).You can edit the run group's information, as well as view all of the run group's runs. LabKey Server will attempt to determine the most specific type of run that describes all of the runs in the list and give you the related set of options.Viewing Group Information from an Individual Run
From either the text or graphical view of an experiment run, you have access to a list of all the run groups in the current folder.
Filtering a Run List by Run Group Membership
You can add columns to your list of runs that let you filter by run group membership. In the MS2 Runs web part, select Grid View > Customize Grid. Expand the "Run Group Toggle" node in the tree. Check the boxes for the group or groups that you want to add (in this example, we choose both "K Score" and "Native Score"). Click Save.Your run list will now include columns with checkboxes that show if a run belongs to the group. You can toggle the checkboxes to change the group memberships. You can also add a filter where the value is equal to TRUE or FALSE to restrict the list of runs based on group membership.
DataClasses
DataClass Lineage & Derivation
When importing data into a Sample Set, to indicate a DataClass parent, provide a column named "DataInputs/<NameOfDataClass>", where <NameOfDataClass> is some DataClass. Values entered under this column indicate the parent the sample is derived from. You can enter multiple parent values separated by commas. For example to indicate that sample-1 has three parents, two in DataClassA, and one in DataClassB import the following.| Name | DataInputs/DataClassA | DataInputs/DataClassB |
|---|---|---|
| sample-1 | data-parent1,data-parent2 | data-parent3 |
| Name | DataInputs/DataClassA | DataInputs/DataClassB |
|---|---|---|
| protein-1 | data-parent1,data-parent2 | data-parent3 |
| protein-2 | protein-1 | |
| protein-3 | protein-1 | |
| protein-4 | protein-1 |
Name Expressions
You can specify a name expression when a DataClass is created. The name expression can be concatenated from (1) fixed strings, (2) an auto-incrementing integer indicated by ${genid}, and (3) values from other columns in the DataClass. The following name expression is concatenated from three parts: "FOO" (a fixed string value), "${genid}" (an auto-incrementing integer), and ${barcode} (the value from the barcode column).FOO-${genid}-${barcode}Aliases
You can specify aliases names for records in a DataClass. On import, you can select one or more alias names. These aliases are intended to be used as "friendly" names, or tags; they aren't intended to be an alternative set of unique names. You can import a set of available aliases only via the client API. No graphical UI is currently available.LABKEY.Query.insertRows({
schemaName: "exp.data",
queryName: "myQuery",
rows: [{
barcode: "barcodenum",
alias: ["a", "b", "c", "d"]
}]
});DataClass User Interface
The web part "DataClasses" displays a list of the DataClasses in the current folder.To create a new DataClass, click the Insert New button. You can create a DataClass from scratch or from a domain templateCreating a DataClass from scratch, you are presented with four fields:
You can create a DataClass from scratch or from a domain templateCreating a DataClass from scratch, you are presented with four fields:
- Name: Required.
- Description: Optional.
- Name Expression: Optional. Specify an alternative naming system, concatenated from fixed strings, auto-incrementing integers, and column values. See above for details.
- Material Source ID: Optional. The default SampleSet where new samples will be created. (Currently not implemented.)

Related Topics
Electronic Laboratory Notebooks (ELN)
Using LabKey Server as an Electronic Lab Notebook
LabKey Server offers the functionality of a simple Electronic Laboratory Notebook (ELN), including:- Documentation of experimental procedures and results.
- Management of file-based content.
- Organization of lab notes and observations.
- Workbooks: Use workbooks as containers for experimental results, work areas for uploading files, and holding lab notes.
- Assays: Use assay designs to hold your instrument data in a structured format.
- Sample Sets: Use sample sets to track and organize the materials used in laboratory experiments, including their derivation history.
- Audit History: LabKey Server's extensive audit log can help you meet compliance challenges.
- Wikis: Wiki pages can handle any sort of textual information, including laboratory free text notes, grant information, and experimental procedures.
- Files: Manage your file-based content.
- Search: Locate resources using full-text search.
Getting Started with ELN Functionality
See the ELN tutorial to begin building a basic electronic lab notebook. The tutorial shows you how to model a basic lab workflow which links together freezer inventories, samples, and downstream assay results. Use this example application as a starting point to extend and refine for your own workflows.Related Topics
- Tutorial: Electronic Lab Notebook - Step-by-step instructions for creating a basic ELN.
- Example Workflow: O'Connor Module
- DISCVR
Tutorial: Electronic Lab Notebook
- Tracking sample vials and their freezer locations
- Capture of experimental/assay result data
- Linkage between vials and downstream experimental data
- Basic lab workflows, such as the intake and processing of sample vials
- Vial status, such as "Consumed", "Ready for processing", "Contaminated", etc.

Tutorial Steps
The tutorial has the following four steps:- Step 1: Create the User Interface - Set up tabs and dashboards.
- Step 2: Import Lab Data - Configure the data tables to capture your data.
- Step 3: Link Assays to Samples - Link the new tables together.
- Step 4: Using and Extending the ELN - How to use the completed ELN, and how to extend it's capabilities.
First Step
Step 1: Create the User Interface
Folder Structure
First, create a new folder as a workspace.- Navigate to a project on your server where you have permission to create a new folder. The image below shows the project named "My Project".
- Create a new subfolder. Hover over your chosen project's folder menu and click the "New Subfolder" button, as illustrated in the animation below.

- On the Create Folder page:
- Name the folder "ELN",
- Select the Assay folder type.
- Click Next.

- On the Users/Permissions page:
- Retain the default selection Inherit From Parent Folder
- Click Finish.
Tabs
Add three tabs to the folder to reflect the basic workflow: the lab begins with Vials, which are run through different Experiments, which finally provide Assay Results.- Add the following tabs:
- "Vials"
- "Experiments".
- To add a tab:
- Click the "pencil" icon in the upper right.
- This will toggle on the "plus" icon next to it.
- Click the "plus" icon to create a new tab, as shown in the animation below.

- Rename the tab "Assay Dashboard" to "Assay Results" and move it to the far right.


- You should now have three tabs in this order: Vials, Experiments, Assay Results.
- Click the pencil icon again to hide the '+' icon.

Web Parts
Finally add web parts to the tabs. These web parts allow users to manage the inventory, samples, and assay data.- Click the Vials tab.
- On the Vials tab, click the dropdown labeled <Select Web Part> on the left and select Sample Sets.
- Click Add.

- Click the Experiments tab.
- On the Experiments tab, click the dropdown labeled <Select Web Part> on the left and select Files.
- Click Add.
Related Topics
- File Repository Tutorial - A more detailed tutorial on working with files.
- Web Part Inventory - A list of available web parts (UI panels).
Start Over | Next Step
Step 2: Import Lab Data
- Plasma sample inventory: an Excel spreadsheet that describes different vials of plasma specimens.
- Assay result data: an Excel spreadsheet that holds the experimental results of assaying the plasma.
Add Sample Set - Plasma
We will import information about the individual sample vials, such as the tissues stored and the barcode of each vial, like the table shown below.Sample Set - Plasma| Name | Type | Status | LocationId |
|---|---|---|---|
| vl-100 | Plasma | Received | i-123456 |
| vl-200 | Plasma | Preserved | i-123457 |
| vl-300 | Plasma | Contaminated | i-123458 |
| vl-400 | Plasma | Results Verified | i-123459 |
| vl-500 | Plasma | Results Verified | i-123460 |
| vl-600 | Plasma | Results Verified | i-123461 |
- Download the sample file Plasma.xlsx from this page.
- Click the Vials tab.
- On the Samples Sets panel, click Import Sample Set.
- Provide the name: "Plasma"
- Select File and click Upload TSV, XLS, or XLSX File.
- Navigate to and select the Excel file Plasma.xlsx.
- Click Submit.

Import Assay Data - Immune Scores
Next, we import the data generated by assays performed on these plasma vials. The data includes:- Participant IDs - The subjects from which the samples were drawn.
- Specimen IDs - Note these values match the Name column in the Plasma table. This fact makes it possible to link these two tables (Assay and Sample Set) together.
- Experimental measurements - Columns M1, M2, M3.
| ParticipantId | SpecimenId | Date | M1 | M2 | M3 |
|---|---|---|---|---|---|
| pt-1 | vl-100 | 4/4/2020 | 1 | 0.8 | 0.12 |
| pt-1 | vl-200 | 6/4/2020 | 0.9 | 0.6 | 0.22 |
| pt-1 | vl-300 | 8/4/2020 | 0.8 | 0.7 | 0.32 |
| pt-2 | vl-400 | 4/4/2020 | 0.77 | 0.4 | 0.33 |
| pt-2 | vl-500 | 6/4/2020 | 0.99 | 0.5 | 0.44 |
| pt-2 | vl-600 | 8/4/2020 | 0.98 | 0.55 | 0.41 |
| pt-3 | vl-700 | 4/4/2020 | 0.94 | 0.3 | 0.32 |
| pt-3 | vl-800 | 6/4/2020 | 0.8 | 0.77 | 0.21 |
- Download the file immune-score.xlsx from this page. This is the data-bearing file. It holds the data results of your experiment, that is, the values measured by the instrument.
- Click the Experiments tab.
- Drag-and-drop this file into the Files panel.
- In the Files panel select the file immune-score.xlsx and click Import Data.

- In the Import Data pop-up dialog, select Create New General Assay Design and click Import.

- On the General Assay Import page:
- In the Name field, enter "Immune Scores"
- Set the Location to Current Folder (ELN).
- Click Begin Import.

- On the Data Import: Batch Properties page, do not change any values and click Next.
- On the Data Import: Run Properties and Data File page, do not change any values and click Save and Finish.
Related Topics
- Sample Sets - General documentation for capturing sample data.
- Tutorial: Design a General Purpose Assay Type (GPAT) - A more detailed tutorial on capturing assay data.
- Assay Designs and Types - Detailed information on how the server captures assay data.
Previous Step | Next Step
Step 3: Link Assays to Samples
 To create the lookup, follow the instructions below:
To create the lookup, follow the instructions below:- Click the Assay Results tab.
- Click the Immune Scores assay design.
- Click Manage Assay Design and select edit assay design.
- Scroll down to the SpecimenID field:
- In the SpecimenID row, click the dropdown Type (String).
- In the Choose Field Type pop-up menu, select Lookup.
- On the Schema dropdown, select samples.
- On the Table dropdown, select Plasma (String).
- Click Apply.

- To save changes to the assay design, click Save and Close.
- This creates a link between the SpecimenId field and the Plasma sample set, creating a link between assay result data and the particular vial that produced the results.
- To test these links, click a value in the SpecimenId field. Notice that the links take you a detailed dashboard describing the original vial.

Previous Step | Next Step
Step 4: Using and Extending the ELN

Using the ELN
Here are some ways you can use the Electronic Lab Notebook:Importing New Samples
When new sample arrive at the lab, register/import them on the Vials tab. You can import them in one of two ways:- as a new Sample Set (click Import Sample Set).
- or as new records in an existing Sample Set (click the target Sample Set and then click Import More Samples).
Import Assay Results
New assay results can be imported using the Experiments tab.- Drag-and-drop any new files into the Files web part.
- Once they have been uploaded, select the new files, click Import Data, and select a target assay design.
Discover Which Vial Generated Assay Results
When samples and assay results have been imported, the ELN automatically links the two together (provided that you use the same id values in the Name and SpecimenId fields). To navigate from assay results to the original vial:- Click the Assay Results tab
- Then click the assay design (like Immune Scores)
- Then click View Results.
Extending the ELN
Here some ways you can extend the functionality of the ELN:- Add freezer/inventory tracking of the vials.
- Add status tracking for individual vials, such as "In Transit", "Received", "Used", "Ready for Processing", etc.
- Add links from a vial to the results that were generated by it.
Track Freezer/Inventory Locations
This inventory list records the freezer/location of the sample vials. Import the inventory list as follows:- Download the list: FreezerInventory.xlsx, similar to the data below.
| InventoryID | Freezer | Shelf | Box | RowAndColumn |
|---|---|---|---|---|
| i-123456 | A | A | C11 | D/2 |
| i-123457 | C | 1 | C12 | E/4 |
| i-123458 | B | B | C4 | A/9 |
- Go to Admin > Manage Lists.
- On the Available Lists page, click Create New List.
- On the Create new List page, enter the following:
- Name: FreezerInventory
- Primary Key: InventoryId
- Primary Key Type: Text (String)
- Import from file: <place a checkmark>
- Click Create List.

- Click Browse or Choose File and select the FreezerInventory.xlsx file you downloaded.
- Click Import.
Link Plasma to the FreezerInventory
Next you will create a lookup from the Plasma samples to the FreezerInventory list, making it easy to find a vial's location in the lab's freezers.- Click the Vials tab.
- Click the Plasma sample set, and click Edit Fields.
- On the page Edit Fields in Plasma, select the LocationId field and click the dropdown Type (String).
- In the Choose Field Type pop-up menu:
- Select Lookup:
- Schema dropdown, select lists
- Table dropdown, select FreezerInventory (String).
- Click Apply and then Save.
- The Plasma samples now link to matching records in the Inventory table.
Track Sample Status
Vials have different states throughout a lab workflow: first they are received by the lab, then they are stored somewhere, later they are processed to generate result data. The following list of states is used to track the different events in a vial's life cycle in the lab. The list of status states is not fixed, you can modify it as best fits your lab workflow.- Download the list: Status.xlsx, similar to the table below.
| Status |
|---|
| In Transit |
| Received |
| Preserved |
| Contaminated |
| Job Assigned |
| Job Cancelled |
| Results Verified |
| Results Invalid |
| Results Published |
- Go to Admin > Manage Lists.
- On the Available Lists page, click Create New List.
- On the Create new List page, enter the following:
- Name: Status
- Primary Key: Status
- Primary Key Type: Text (String)
- Import from file: <place a checkmark>
- Click Create List.
- Click Browse or Choose File and select the Status.xlsx file you downloaded.
- Click Import.
Link Plasma to the Status List
Next you will create a lookup from the Plasma samples to the Status list, making it easy to find the vial's state with respect to the basic lab workflow.- Click the Vials tab.
- Click the Plasma sample set, and click Edit Fields.
- On the page Edit Fields in Plasma, select the Status field and click the dropdown Type (String).
- In the Choose Field Type pop-up menu:
- Select Lookup:
- Schema dropdown, select lists
- Table dropdown, select Status (String).
- Click Apply and then Save.
- The Plasma samples now link to matching records in the Status table.
Improved User Interface
To save yourself clicking through the UI each time you want to see the Plasma samples and the Assay results, you can add these tables directly to the Vials and Assay Results tabs respectively.To add the Plasma table directly to the Vials tab:- Go the Vials tab.
- Add the web part: Query.
- On the Customize Query page, enter the following:
- Web Part Title: Plasma Samples
- Schema: samples
- Select "Show the contents of a specific query and view."
- Query: Plasma
- Click Submit.

- Go the Assay Results tab.
- Add the web part: Assay Results.
- On the Customize Assay Results page, enter the following:
- Assay: select "General: Immune Scores"
- Show button in web part: leave the checkmark in place.
- Click Submit.
Improve Link from Assay Results to Vial Details
Currently, the SpecimenID field in the assay data displays a link to the original vial that generated the data. By default, these links take you to a details page for the vial, for example: But this is somewhat of a dead end in the application. The problem is that the vial details page does not contain any useful links.To correct this, we will override the target of the link: we will redirect it to a more useful view of vial details, a details view that includes links into the inventory and status information. In particular, we will link to a filtered view of the Plasma sample set, like this:- Go to the assay designer view:
- Select Admin > Manage Assays.
- In the Assay List click Immune Scores.
- Select Manage Assay Design > edit assay design.
- Scroll down to the SpecimenID field.
- In the Specimen field, click in the Name or Label text boxes. (If you click in the Type box, this will bring up a pop up menu. If you accidentally do this, close the pop up.)
- On the right hand side, notice the Display tab contains the URL text box.
- By entering URL patterns in this box, you can override the target of links for the SpecimenID field.
- In the URL text box, enter the following URL pattern. This URL pattern filters the sample set table to one selected SpecimenID, referenced by the token ${SpecimenID}.
project-begin.view?pageId=Vials&qwp2.Name~eq=${SpecimenID}- Scroll up and click Save & Close.
- Test your new link by going to the assay result view, and click a link in the SpecimenID field. You will see the plasma samples grid filtered to show only the particular specimen you clicked.
- To see the entire Plasma sample set unfiltered, hover in the grid header area, and click Clear All.

Previous Step
Assay Request Tracker
 Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
- the sample(s) to be processed
- the kind of assay to be run (NAb, Luminex, ELISA, etc.)
- the lab technician responsible for completing the assay processing
- the original requester who will sign off on the completed work
- Assay Request Tracker: User Documentation - How to use the assay tracker.
- Assay Request Tracker: Administrator Documentation - How to set up the assay tracker.
Assay Request Tracker: User Documentation
The assay request module lets the user:
- Request a specific assay to be performed on a given sample.
- Assign the assay request to others users for fulfillment.
- Track the progress of the requested job and assign workflow states (incomplete, complete, results invalid, etc.)
- Navigate easily between assay requests, the associated samples, and data results.
Using the Assay Request Tracker (User Documentation)
From a user's perspective, the the assay request tracker functions much like the LabKey issue tracker. A typical workflow looks like the following:
- A user begins the process by creating a request for assays to be run, and assigns the request to a lab techician for fulfillment. Specify the type of assay to be run by selecting from the Assay dropdown.
- Once the assays has been run and the data is available, the request is "resolved" and assigned back to the original requester.
- If the original requester is satisfied that the work is complete, then the request is "closed".
The assay tracker also provides for adverse events in the workflow. For example, duplicate requests for assay runs can be resolved as "Duplicate", or requests can be resolved as "Rejected" if for some reason the request cannot be completed. The available resolution states are not fixed, and can be adjusted by an administrator (see the Administrator docs for documentation).
To create a new assay request:
- Click the New Assay Request button.
- Fill out the form on Insert New Assay Request.
- Set the Assay dropdown to indicate the desired assay design.
- Indicate the samples to be assayed using the Sample Ids text box. For documentation on other fields in this form, see Using the Issue Tracker.
- Requested Sample Count indicates the number of samples to be run through the assays. It is intended to be filled out by the request originator.
- Completed Sample Count indicates the number of samples actually run through the assay. It is intended to be filled out by the request fulfiller.
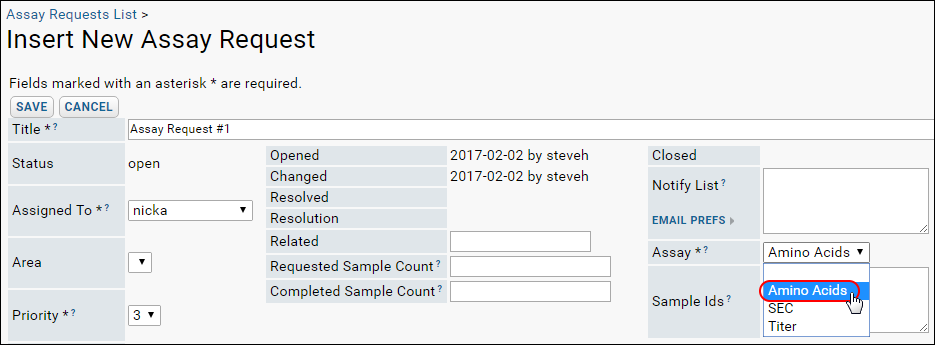
Once the request has been submitted, the person you have assigned it to will be notified by email.
You can navigate to the assay data by clicking on the Assay field.
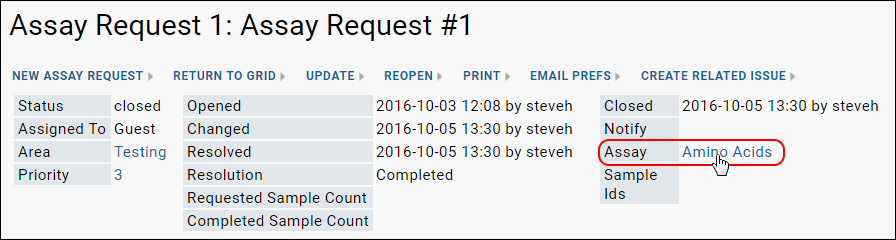
When the assay data has been generated, lab technicians can indicate which assay request is being fulfilled when they import the data. In the data import wizard, select the particular assay request from the dropdown labled Assay Request.
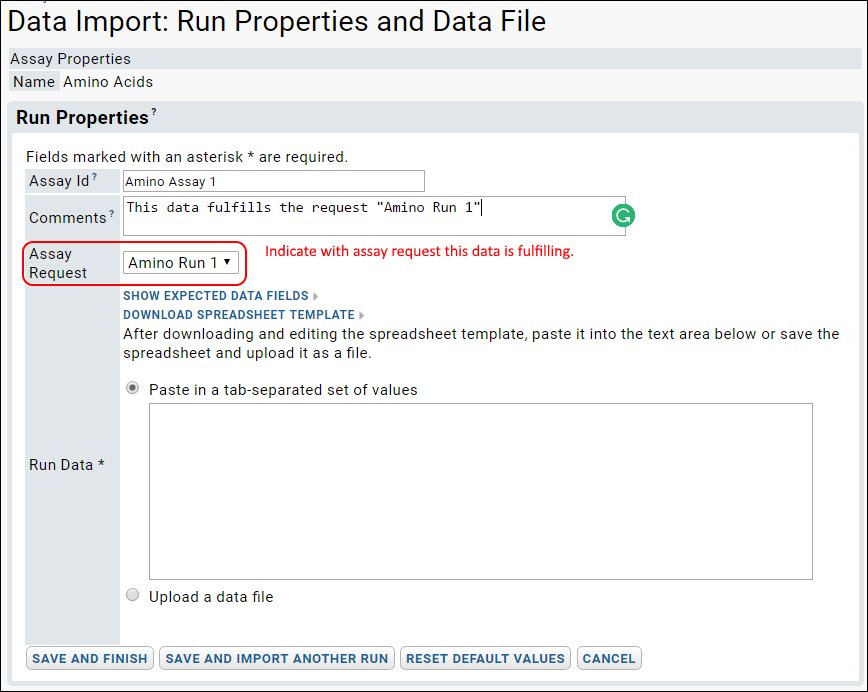
Related Topics
Assay Request Tracker: Administrator Documentation
This topic explains how to set up a new assay request tracker.
To set up a new Assay Request tracker, first you define a new issues list (of type Assay Request Tracker), then you add the tracker user interface.
Define a New Issues List
- First, enable the AssayRequest module in your project or folder. (For details, see Enable a Module in a Folder)
- Go to Admin > Go To Module > Assay Request.
- On the Issue List Definitions page, click Insert New Row.
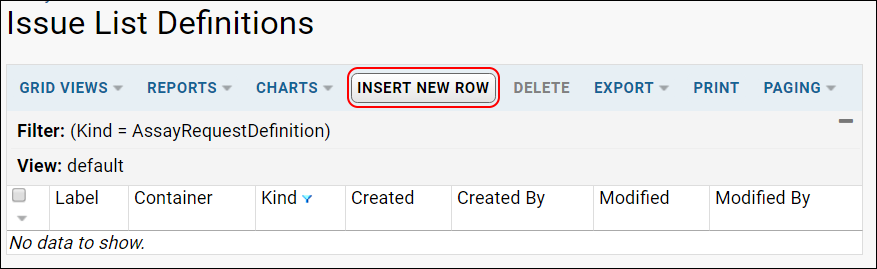
- Under Insert Issue List Definitions:
- Enter a Label, for example "Assay Jobs"
- For Kind select Assay Request Tracker.
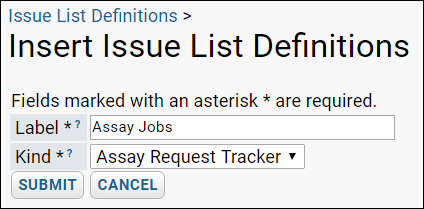
- Click Yes, when prompted by the popup dialog titled Create Issue List Definition?
- You will be taken to the administration and configuration page for your assay request tracker.
- Click Save to use the default configuration. You can return to this page later to refine the configuration.
- Now you have defined a new tracker list. Now you can add it to your folder.
Add the Assay Tracker UI to a Folder
- Go to the folder where you wish to place the assay jobs list.
- Add the web part Issues List.
- On the Customize Issues List page, on the Issue List Definition dropdown, select the label of the list you entered previously, for example "assayjobs". Notice that your label has been converted to a single lowercase string without whitespace. Click Submit.
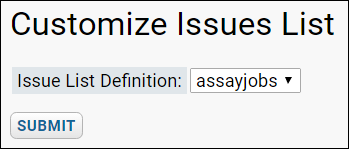
- Your assay tracker is ready for use.
- For user documentation see: Assay Request Tracker: User Documentation
- To refine and customize the tracker click Admin. Documentation is available below.
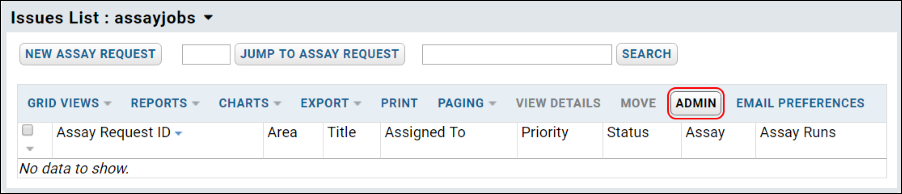
Administration and Configuration
Administrators can customize the assay request tracker in the following ways:
- Set the available values in dropdowns on the request form, including the priority ratings, the request groupings, and resolution states. (For details, see below.)
- Link assay requests, specimens, and result data for easy navigation. (For details, see below.)
- Select the noun used to identify the request or issue. By default the AssayRequest modules uses "Assay Request", but this can be changed as desired. For details, see Administering the Issue Tracker.
- Configure the users who can be assigned requests. For details, see Administering the Issue Tracker.
- Select the default user (if any) to be assigned new requests. For details, see Administering the Issue Tracker.
- Change the display labels for fields, and many other field properties. For details, see Administering the Issue Tracker.
- Customize email notification templates. For details see Customize Email Notifications.
Controlling Dropdown Values
When a new assay request tracker is created, three lists are created that hold the dropdown values for the following fields: 'Area', 'Priority', 'Resolution'.
An administrator can alter these lists to provide dropdown values that best fit their project. To change these lists, go to Admin > Manage Lists. Select one of the lists, and update as desired.
| Dropdown Field | List Name | Description |
|---|---|---|
| Area | list.assayrequests-area-lookup | Holds different groupings of issues/requests, for example, 'HPLC', 'Sequencing', and 'Viability'. |
| Priority | list.assayrequests-priority-lookup |
This list holds possible priority rankings for a request/issue. By default, the list includes numbers 1 through 5, where priority 1 is intended to mean highest priority, and priority 5 the lowest priority. |
| Resolution | list.assayrequests-resolution-lookup |
This list holds possible resolution states for a request. By default three resolution states are included: 'Complete', 'Duplicate', and 'Rejected'. |
Linking Requests to Assay Data
Each assay request tracker contains a lookup field, named "Assay", that points to the assay designs in scope of the current folder. In particular, the lookup points to the table assay.AssayList, which lists all of the assay designs that reside in the current folder, in the current project, and those in the Shared project. When creating an assay request, this list is presented to the user as a dropdown used to specify which assay is to be run against the samples. To control the items in the Assay dropdown, add or delete assay designs from the current folder (or the current project, or the Shared folder).
Linking Assay Data to Requests
Assay data can also link back to the originating request. To provide links from assay data/designs to the request tracker, add a lookup to the issue tracker:
- Go the Run or Result view on the assay you wish to modify.
- Open the assay designer. From the Run or Result view of the assay data, select Manage Assay Design > Edit Assay Design.
- In the Assay Designer, scroll down to the Run Fields area.
- Add a new run field by clicking Add Field.
- Name the field "assayRequest" and set the data type to 'lookup' by clicking the dropdown under Type.
- In the popup dialog box, select Lookup and then set the target of the lookup as follows:
- Schema: set to issues
- Table: set to assayrequests
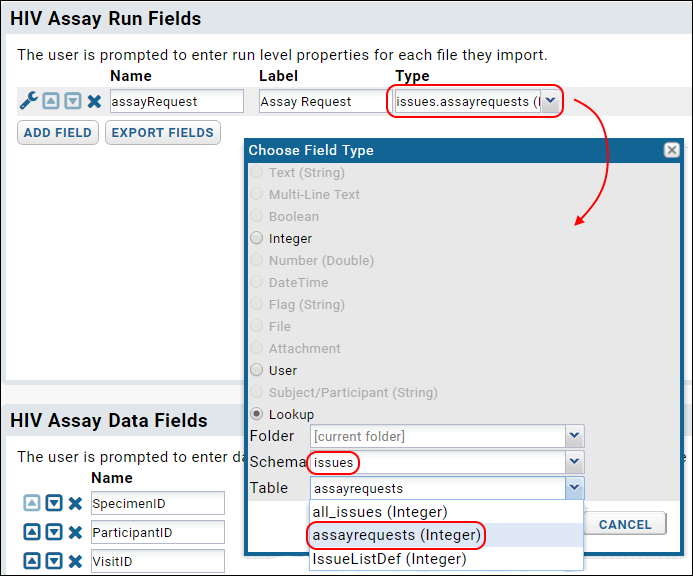
Once the lookup column has been added, people working with the assay data, can point to the originating request when importing the assay runs.
Related Topics
Reagent Inventory
 The reagent inventory module may require significant customization and assistance, so it is not included in standard LabKey distributions. Developers can build these modules from source code in the LabKey repository. Please contact LabKey to inquire about support options.
The reagent inventory module may require significant customization and assistance, so it is not included in standard LabKey distributions. Developers can build these modules from source code in the LabKey repository. Please contact LabKey to inquire about support options.
Introduction
The Reagent database helps you organize your lab's reagents. It can help you track:- Reagent suppliers
- Current reagent inventory and expiration dates
- Current reagent locations (such as a particular freezer, box, etc.)
- Reagent lot numbers and manufacturers
Installation
Install
- Acquire the reagent module (see note above)
- Stop LabKey server
- Copy the reagent.module file into your /modules directory.
- Restart the server.
Setup
- Create a new folder or navigate to a folder where you'd like to install the reagent database.
- On the folder portal page, choose Query from the Select Web Part dropdown menu and click Add.
- On the Customize Query page, enter the following values:
- Web Part Title: <leave blank>
- Schema: "reagent"
- Query and View: Select the radio button Show the contents of a specific table and view and, from the dropdown menu, select "Reagents".
- Allow user to choose query?: "Yes"
- Allow user to choose view?: "Yes"
- Button bar position: Both
- Click Submit.
- Populate the database with data by navigating to the following URL (substituting <server:port>, <project-name> and <folder-path> with appropriate values):
http://<server:port>/labkey/reagent/<project-name>/<folder-path>/initialize.view
- For example, if you have LabKey Server installed locally, your project is named "myProject" and your folder is named "myFolder", you would navigate to the URL:
http://localhost:8080/labkey/reagent/myProject/myFolder/initialize.view?
Use the Reagent Database
Navigation
The reagent database contains the following tables:- Antigens
- Labels
- Lots
- Manufacturers
- Reagents
- Species (holds species reactivity data)
- Titrations
- Vials

Customize Tables
You can add custom fields (for example, "Expires" or "Price") to the Lots, Reagents, Titrations, and Vials tables.To add a new field, navigate to the target table, and click Edit Fields, then click Add FieldAdd New Reagents and Lots
To add new reagents and lots to the database, first you need to add information to these tables:- Antigens
- Labels
- Manufacturers
- Species (optional)
Add New Vials and Titrations
To add new vials and titrations, first you need to add lot data, then navigate to the vials table and select Insert > Insert New Row.Bulk Edits
To edit multiple rows simultaneously, place checkmarks next to the rows you wish to edit, and click Bulk Edit. Only changed values will be saved to the selected rows.Research Studies
Longitudinal Study Tools
For large-scale studies and research projects, success depends on:- Integrating many different kinds of information, including clinical, assay, and specimen data
- Tracking progress of the protocol and associated research projects
- Presenting your results in a secure way to colleagues
Integrate
LabKey Server knows how to integrate the diverse range of research data, including demographic, clinical, experimental, and specimen data.
Track Progress
Progress tracking tools help you put all the pieces together.
Present Results
Present your research using LabKey's rich analytic and visualization tools.
Learn More
Use the following topics to get started:- Study Tour - Tour a sample research project
- Tutorial: Cohort Studies - Learn how to use LabKey's tools for observational studies
- Study Administrator Guide - Administrator's guide
- Study User Guide - Researcher's guide
Study Tour
Collaborative Research Dashboard
Within a study folder, tabs and subfolders can be used to encapsulate functional sets of the tools available. You can define custom tabs and place tools (webparts) on them as desired, or use the default set of study tabs:- Overview: title, abstract, protocol, and other basic info.
- Participants: clinical and demographic data for participants, cohorts and groups.
- Clinical and Assay Data: browse available datasets, reports, and visualizations.
- Specimen Data: specimen request and tracking system.
- Manage (visible to admins only): a dashboard of project properties.
 See a similar interactive example.
See a similar interactive example.
Overview
The Study Overview webpart displays the investigator, grant, description, and other customizable Study Properties you define.The Study Navigator helps you track the status of each part of the study. It shows how much data is available for each dataset at each point in time. Time in a study can be organized by visit or by date-based timepoints which can either be fixed relative to the study start data or based on individual participant start dates.Search
The ability to search across all aspects of the data is one of the most powerful features of a LabKey Study. Data from clinic visits, lab results, and instrument-derived assay data can be integrated in ways that support discovery of relationships and trends that can be connected to give a broad vision of how to improve treatment protocols. You can also focus on particular pieces of data in a complete way.Study-wide search is supported from the Overview tab: For example, if you enter a phrase or even a participantID such as 249318596, you will see links to all documents and datasets that include reference to that participant. Context-specific searches are available as well, such as for all the whole blood specimens available for a given participant.Participants
Study participants can be grouped by cohort, demographic information, or other groups you define. Hovering over a label will highlight cohort members on the participant list. Custom participant views can be defined to show relevant pieces of data including charts and graphs that are dynamically updated as new data is integrated.Clicking a participantID will open the details page for that individual. You may also create a Participant Detail web part for a specific participant of interest to display that detail on any portal page.
Custom participant views can be defined to show relevant pieces of data including charts and graphs that are dynamically updated as new data is integrated.Clicking a participantID will open the details page for that individual. You may also create a Participant Detail web part for a specific participant of interest to display that detail on any portal page.
Clinical and Assay Data
A study dataset is like a list that has been rationalized with participantIDs and dates. Dataset views can be customized to integrate columns from different sources and fields can be customized with validators, lookups, and other programmatic quality control features.Visualizations
Graphs and charts, like the following time chart and scatter plot, can be created using LabKey Server's data visualization tools. Customize to show the specific measures and participants or cohorts that best illustrate your research. Browse the list of datasets and charts in the interactive example.
Browse the list of datasets and charts in the interactive example.
Specimen Data
LabKey Server provides configurable tools for managing specimen data and request systems. For more information, start here: Specimen Tracking. You can also explore some of the features in our live interactive example.Manage
The Study administrator uses the tools and options on the Manage tab to track and control many aspects of the study. The Study Schedule offers a broad view of progress and current status: Among the available options, study reloading can be configured to automatically incorporate new data from an external source on a regular schedule, participant groups and cohorts can be defined, security and schedules can be defined and tracked. Protected health information can be obscured in a demonstration mode or aliased to offer the ability to share data and results without compromising privacy of study partipants. Studies can also be exported, imported, published, and ancillary studies can be created with selected participants and datasets from the source study.
Among the available options, study reloading can be configured to automatically incorporate new data from an external source on a regular schedule, participant groups and cohorts can be defined, security and schedules can be defined and tracked. Protected health information can be obscured in a demonstration mode or aliased to offer the ability to share data and results without compromising privacy of study partipants. Studies can also be exported, imported, published, and ancillary studies can be created with selected participants and datasets from the source study.
Related Topics
The following tutorials give step-by-step instructions for building the Demo Study:Tutorial: Cohort Studies
- Collected basic demographic and physiological data from your study participants.
- Performed a number of blood tests and assays on the participants over time.
- Imported and configured the data into a study in LabKey Server.
Tutorial Steps
- Step 1: Install the Sample Study
- Step 2: Study Data Dashboards
- Step 3: Integrate Data from Different Sources
- Step 4: Compare Participant Performance
Related Topics
First Step
Step 1: Install the Sample Study
- 200+ participant profiles, including birth gender, age, initial height, etc.
- Physiological snapshots over a three year period (blood pressure, weight, respiration)
- Lab tests (HIV status, lymphocyte and CD4+ levels, etc.)
- Specimen repository
Set up Steps
- If you haven't already installed LabKey Server, complete the following instructions: Install LabKey Server (Quick Install).
- Download the sample data zip file -- but do not unzip it: ImportableDemoStudy.folder.zip
- Go to a project where you can create a new folder. On your local server, you can use the Home project: http://localhost:8080/labkey/project/home/begin.view?
- Sign in.
- Create a new folder to work in:
- Go to Admin > Folder > Management and click Create Subfolder.
- Name the folder "HIV-CD4 Study" (or anything you wish).
- Set the folder type to Study. (This enables the study-related tools in the folder.)
- Click Next.
- Confirm that Inherit from Parent Folder is selected and click Finish.
Import the Pre-prepared Study
- On the New Study page, click Import Study.
- Confirm Local zip archive is selected, then click Choose File. Navigate to and select the "ImportableDemoStudy..." zip file you downloaded.
- Uncheck "Validate All Queries After Import." Do not check the box for "Use advanced import options."
- Click Import Study.
- Wait for LabKey Server to process the file: you will see a status notification of Complete when it is finished. You might see a status of Import Folder Waiting. If the page doesn't update automatically after a few minutes, refresh your browser window manually.
- Click the Overview tab to go to the home page of your new study.
Start Over | Next Step
Step 2: Study Data Dashboards

Study Tabs
Tabs within the study provide convenient groupings of content.- Overview: The study home page. Displays the title, abstract, a link to the protocol document, and other basic information.
- Participants: Browse individual participant data. Select by cohort or other filter.
- Clinical and Assay Data: The Data Views browser shows datasets, reports, and visualizations.
- Specimen Data Browse specimen data in the study.
- The Manage tab (visible to admins only) contains a dashboard for setting study properties.
Study Navigator
The Study Navigator displays a grid overview of your study datasets over time, providing a convenient jumping-off point to specific perspectives. Each dataset is listed as a row; each timepoint or visit is listed as a column; the cells indicate how much data is available for each dataset for that particular visit. The navigator gives an overview of whether participants are completing visits and can help confirm that the necessary data is being gathered for the purpose of the study.- Click the Study Navigator link.
 The full-sized view shows a breakdown of the datasets and timepoints.
The full-sized view shows a breakdown of the datasets and timepoints.
View Data By Timepoint or Visit
- Click the link at the intersection of the Physical Exam row and the Month 2 column.
- The resulting data grid shows all physical exams conducted in the second month of participation for each participant. "Month 2" is relative to each participant's enrollment date in the study, so the "Month 2" visits fall on different dates for each person.
 Notice that the Systolic Blood Pressure column in this data set makes use of Conditional Formats to display values configured to be noteworthy in orange and red.
Notice that the Systolic Blood Pressure column in this data set makes use of Conditional Formats to display values configured to be noteworthy in orange and red.View Data for Individual Participants
- Click one of the id's under the Participant ID column.
- The participant page shows demographic data and a list of datasets available for an individual subject.

- Click the [+] next to 5004: Physical Exam to open details of this dataset for this participant.
- You can highlight data by adding visualizations. We have added a graph of the participant's weight over time. Click Add Chart to add another. You must have at least editor permissions to see the Add Chart link.

- To scroll through the different subjects, click Next Participant and Previous Participant.
Previous Step | Next Step
Step 3: Integrate Data from Different Sources
Examine the Two Source Datasets
- Click the Clinical and Assay Data tab.
- Open these two datasets in different browser tabs so you can view and compare side by side. Right-click the datasets below and select "Open in New Tab" to open separate tabs:
- Physical Exam - This dataset captures the vital signs of the study participants: blood pressure, pulse and respiration rates, etc.
- Lab Results - This dataset captures the laboratory work done on the blood samples provided by the participants: lymphocyte levels, HIV counts, etc.
Create a Combined Grid
Here we create a joined grid view combining all of the blood-related data:- In the Physical Exam dataset, select Grid Views > Customize Grid.
- In the Available Fields pane, scroll down and click the + symbol next to DataSets.
- Scroll down and click the + symbol next to Lab Results.
- Place checkmarks next to all of these blood-related fields: CD4+, Lymphs, Hemoglobin, Viral Load.
- Scroll back up and remove checkmarks next to: Clinician Signature/Date, Pregnancy, Form Language (to remove clutter).
- Click Save, select Named and name the grid "Hema/Cardio Data".
- Check the box to Make this grid available to all users.
- Click Save.
Create a Visualization
We now have an integrated grid view of the all of the participants' hematological data, which you can see by selecting Grid Views > Hema/Cardio Data. Values from the Lab Results dataset are added to the Physical Exam dataset if available for the same participant and date combination. Now we can start making soundings into this combined data to see if there are any relationships to be discovered.First let's create a scatter plot to see if there is a relationship between the lymphocyte levels and the blood pressure levels.- If necessary, return to the Physical Exam dataset and select Grid Views > Hema/Cardio Data.
- Select Charts > Create Chart to open the plot creation dialog.
- Click Scatter on the left.
- Drag and drop the Systolic Blood Pressure column as the X Axis.
- Drag and drop the Lymphs (cells/mm3) column as the Y Axis.
- Click Apply.
- The scatter plot is displayed. (A quick visual check suggests there is no relationship, at least not in this data.)

- Save the plot with the name of your choice.
- Experiment with the chart tools to see if you can discover any relationship within the data.
- Chart Type lets you add grouping or point shaping by other columns, such as cohort or demographic
- For instance, try dragging the "Treatment Group" column to the "Color" field.
- Chart Layout provides more options for changing the chart title, size, coloring, etc.
- You can save or save as a new copy.
Previous Step | Next Step
Step 4: Compare Participant Performance
- How do mean CD4 levels vary for different individuals over time?
- How do mean CD4 levels vary for different groups/cohorts over time?
Create a Time Chart
- Click the tab Clinical and Assay Data.
- In the Data Views web part, click Lab Results.
- Select Charts > Create Chart. Click Time on the left.
- Drag CD4+ (cells/mm3) from the column list on the right into the Y Axis box.
- Click Apply.
- You will see a time chart like the following:

- In the left hand Filters panel, you can select individual participants to include in the chart. Clicking any value label will select only the given participant, checking/unchecking the box allows you to toggle participants on and off the chart. Note that our sample data may include participants with incomplete data for whom lines will not be drawn.
- Include any four participants and click Save.
- Name the chart: "CD4 Levels, Individual Participants", and click Save.
Visualize Performance of Participant Groups
In this step we will create a chart comparing the CD4 levels for different treatment groups.- Click Edit, then click Chart Layout.
- Under Subject Selection, choose Participant Groups and confirm that the box for Show Mean is checked and the pulldown is set to None.
- Click Apply.
- The filters panel now shows checkboxes for participant groups you can select among.
- Check Treatment Group and uncheck any other categories that were selected by default (Cohorts). Depending on the width of your browser window, the chart may be very crowded at this stage.
- Click Chart Type.
- In the X Axis box, change the Time Interval to "Months".
- Click Apply. Fewer data points make the chart simpler.
- The X-axis label may still read "Days Since Start Date" - to change it, click Chart Layout, select the X-Axis tab, and edit the X-axis label to read Months instead of Days. Click Apply.
- Click Save As, name the report "Mean CD4 Levels Per Treatment Group", and click Save.
- You now have a chart comparing the mean CD4+ levels of the different treatment groups over time.

Add More Data to the Chart
- Click Edit, then Chart Type.
- Drag another interesting data measure, like Lymphs, to the Y Axis box. Notice that a second panel is created; the original Y axis selection is not replaced.
- Click the right-pointing arrow to switch the Y Axis Side to the right for this measure. Notice as well that the measure lists the query from which it came. You could use the pulldown above the column name listing to select a different query from which to join a different column.
- Click Apply. The new chart will have a second set of lines for each treatment group using the second measure.
- Click Save As and save your new version of this chart as "CD4 and Lymph Levels Per Treatment Group".
- Refine your chart exploring the menus and options available for time charts.
- If at any time you find yourself elsewhere in the study, you can find your chart again by clicking the Clinical and Assay Data tab and then selecting the chart name. Click Edit to make further changes.
Related Resources
The following articles describe TrialShare, a collaborative application for managing multiple cohort studies, based on LabKey Server.- Participant-Level Data and the New Frontier in Trial Transparency (NEJM)
- Covers innovations in data transparency and openness: contrasts TrialShare's low bar for data access with the higher bar used by pharmaceutical companies for sharing trial data.
- http://www.nejm.org/doi/full/10.1056/NEJMe1307268
- Efficacy of Remission-Induction Regimens for ANCA-Associated Vasculitis (NEJM)
- A report on the results of the RAVE clinical trial. Includes several links to data and visualizations on TrialShare.
- http://www.nejm.org/doi/full/10.1056/NEJMoa1213277
Previous Step
Tutorial: Set Up a New Study
Tutorial Aim
This tutorial is primarily about 'putting the pieces together': data integration. It shows you how to join together disconnected datasets into a single, analyzable whole, so you can ask questions that span the whole data landscape. It shows you how to combine heterogeneous datasets (datasets with different shapes and sources), compare cohort performance, and view trends over time.Starting with Excel spreadsheets, the tutorial assembles a LabKey "study": a repository of integrated data that you can explore and analyze.Tutorial Scenario
Imagine you are studying treatments for HIV infection. Your aim is to evaluate the effectiveness of anti-retroviral (ARV) treatments in human subjects, using viral load, blood lymphocytes, and cytokine production as measures of successful treatment. You have already collected specimens and data over two years, and are now ready to perform an analysis and evaluation of the data, to get answers to your key questions:- How do the ARV treated participants compare to the untreated participants?
- How do the ARV treatments perform compared to one another?
- What trends emerge over time for the key measures (viral load, lymphocyte percentage, and cytokine production)?
How Data Integration Works
LabKey Server aligns data using the following data columns:- ParticipantID columns
- Date or VisitID columns
- SpecimenID columns
Tutorial Steps
- Step 1: Define Study Properties
- Step 2: Import Datasets
- Step 3: Assign Cohorts
- Step 4: Import Specimens
- Step 5: Visualizations and Reports
First Step
Step 1: Define Study Properties
Participants
A study repository lets you choose the name used for Participants. The name you choose typically reflects the organism being studied, for example, "Mouse", "Mosquito", "Subject", etc. for the study below, we will use the name "Participant".Time
LabKey Server provides three different "timepoint styles" for your data:- Dates means that the data is grouped into time periods bounded by calendar dates. If your study has a variety of visits across patients, and no set naming system for visits, a Date-based style works best.
- Assigned Visits means that the data is grouped into named visit periods. No calendar dates need be present in the data, as the sequence of visit periods is determined by a series of decimal numbers, recorded in the "Sequence Number" field. Visit labels can be assigned to the Sequence numbers, for example, "Baseline Visit" can be the visit label for the Sequence number "0". If the participants in your study have a fixed number of visits, with a small amount of variability, a Visit-based style works best.
- Continuous is intended for open-ended observational studies that have no determinate end date or stopping point. This style is useful for electronic health record (EHR) data. If the study is ongoing with no strong concept of dividing time into fixed visits, then a continuous style works best.
Specimens
A study repository provides two different ways to handle specimens:- Standard specimen repository. The specimen inventory is simply copied to the server and linked to assays and participants.
- Advanced specimen repository. The specimen inventory is made available to outside investigators using a "shopping cart". Outside researchers can request specimen vials from your repository for their own testing. Requests are evaluated and fulfilled using a built-in workflow.
Set Up
- If you haven't already installed LabKey Server, do so: Install LabKey Server (Quick Install).
- Download and unzip the sample research data to the location of your choice. LabKeyDemoFiles.zip
Create a New Study Folder
Study folders contain tools to help you manage your study, organize your data and set up security so that only authorized users can see the data.- Sign in to your LabKey Server and navigate to the Home project.
- Create a new folder to work in:
- Go to Admin > Folder > Management and click Create Subfolder.
- For the Name enter "Demo".
- For Folder Type select "Study".
- Click Next.
- On the Users/Permissions page, make no changes, and click Finish
- If you instead click Finish and Configure Permissions you will see the project configuration permission page. Make no changes there and click Save and Close to continue).
- Click the Create Study button.
Set Study Properties
Study properties allow you to store some basic information about your study, including a label, identifying information, a protocol document. You may also customize how individual participants in a study are described.- Timepoint Style: Dates
- Start Date: 2008-01-01
- Default Timepoint Duration: 28 (days)
- Repository Type: Standard Specimen Repository
- Security Mode: Basic security with editable datasets

- Click the Create Study button to finish creating your study.
- You will initially land on the Manage tab.
- Name: the name of your study appears in the top banner.
- Subject Noun: The subject noun typically indicates the organism being investigated, for examples, "Mouse", "Mosquito", "Participant". This noun will be used throughout the user interface of the study.
- Subject Column Name: The is the default column name containing subject ids. Your data does not need to conform to this column name. It is only the default used by the server.
- Specimen Repository Type: The Standard repository integrates your specimen data with the other datasets. Advanced repositories provide an additional specimen request management system.
- Security Mode: Provides security pre-configuration. You can change the security settings later on.
Start Over | Next Step
Step 2: Import Datasets
Study Datasets
The datasets in a study repository come in three different types:- Demographic. Demographic datasets record permanent characteristics of the participants which are collected only once for a study. Characteristics like birth gender, birth date, and enrollment date will not change over time. (From a database point of view, demographic datasets have one primary key, the participantId. Demographic datasets contain up to one row of data for each participant.)
- Clinical. Clinical datasets record participant characteristics that vary over time in the study, such as physical exam data and simple lab test data. Typical data includes weight, blood pressure, or lymphocyte counts. This data is collected at multiple times over the course of the study. (From a database point of view, clinical datasets have two primary keys, the participantId and a time point. Clinical datasets may contain up to one row of data per subject/time point pair.)
- Assay/Specimen. These datasets record the assay and specimen data in the study. Not only is this data typically collected repeatedly over time, but more than one of each per time point is possible, if, for example, multiple vials of blood are tested. (From a database point of view, assay/specimen datasets have the same primary keys as Clinical data, plus an optional third key. Multiple rows per subject/time point are allowed.)
Create one or more Demographic Datasets
Each study needs at least one demographic dataset identifying the participants in the study. Our example data files includes two: Demographics and Consent.- Click the Manage tab.
- Click Manage Datasets.
- Click Create New Dataset.
- On the Define Dataset screen:
- Short Dataset Name: Enter "Demographics"
- Leave the "Define Dataset Id Automatically" box checked.
- Select the Import from File checkbox.
- Click Next.
- Click Choose File.
- Browse to the sample directory you unzipped and select the file: [LabKeyDemoFiles]\Datasets\Demographics.xls.
- You will see a preview of the imported dataset. Notice that the sample files we provide already have columns that are mapped to the required server columns "ParticipantId" and "Visit Date". When importing your own datasets, you may need to explicitly set these pulldowns which establish dataset keys.
- Review the field names and data types and click Import.

- You will see this dataset:

- Click Manage in the link bar above the grid to manage this dataset.
- Click Edit Definition.
- Check the Demographic Data checkbox. (This indicates that the dataset is collected only once for this participant and applies for all time.)
- Click Save.
Import Clinical Datasets
The other .xls files provided in the sample datasets folder contain clinical data. Each time a new test or exam is performed on the participant, a new row of data is generated for that date. There will be multiple rows per participant, but only one row per participant and date combination.- HIV Test Results.xls
- Lab Results.xls
- Physical Exam.xls
- Click the Manage tab.
- Click Manage Datasets.
- Click Create New Dataset.
- On the Define Dataset screen:
- Short Dataset Name: Enter the name of the XLS file being imported (without the file extension).
- Select the checkbox Import from File.
- Click Next.
- Browse to the file, select it, and ensure that all fields are being imported properly.
- Click Import.
Previous Step | Next Step
Step 3: Assign Cohorts
Assign Cohorts
Cohorts can be used to group participants by particular characteristics, such as disease state, for efficient analysis. Participants may be assigned manually to cohorts, or automatically by using a dataset field of type string, as in this tutorial.- Click the Manage tab and then click Manage Cohorts.
- On the Participant/Cohort Dataset dropdown menu, select Demographics.
- On the Cohort Field Name dropdown menu, select Group Assignment.
- Click Update Assignments.

- You will see the list of cohorts defined by the designated column followed by a list showing which participants are assigned to which cohort. In this case, only participants with group assignments will be assigned to cohorts.

Previous Step | Next Step
Step 4: Import Specimens
Import a Specimen Archive
First you upload the specimen archive to the server, then import the data into the database.- Click the Specimen Data tab.
- In the Specimens web part, click Import Specimens.

- In Excel, open [LabKeyDemoFiles]/Specimens/SimpleSpecimenRepository.xls.
- Select the entire spreadsheet, including column headings.
- Copy and paste the contents into the Upload Specimens window
- Click Submit.

- When you see the message "Specimens uploaded successfully," click Specimens to see the data.

Explore Specimen Data
- Click the Specimen Data tab.
- In the Specimens web part, expand the Specimen Reports item by clicking the "+".
- Click View Available Reports.

- From this page you can view a variety of reports.
- For example, next to Type Summary Report, click View.
- Notice that here you see the number of specimens present for each time point.
- You can view by cohort as well as select different ways to view the specimen data.
- Clicking any link in the Summary table will itemize the specimen vials that make up that total count.
Previous Step | Next Step
Step 5: Visualizations and Reports
Quick Chart: CD4 Levels by Cohort
We would expect that the CD4 levels for the two cohorts would differ: the HIV+ group should have overall lower CD4 levels compared to the HIV- group. Below we will confirm this using a quick visualization.- Click the Clinical and Assay Data tab.
- Click the Lab Results dataset.
- Click the column CD4+ (cells/mm3) and select Quick Chart.
- LabKey Server will make a "best guess" visualization of the CD4 column. It puts the CD4 values on the Y axis, and puts the Cohorts on the X axis, assuming that you want to compare the CD4 values against the most important category in the study: the cohorts. The plot confirms that CD4 levels are lower for the Acute HIV-1 group. Notice there is a third box plotted for participants not assigned to either cohort in the study.

- Click Save, name the chart "CD4+ by Cohort", and click Save.
- Click the Clinical and Assay Data tab. Notice that the chart has been added to the list.
Custom Grid Views: Joined Tables
It would also be interesting to see how the CD4+ and Viral Load measures compare against one another. To do this, we will combine data from two different datasets: Lab Results and HIV Test Results.- Click the Clinical and Assay Data tab.
- Click the Lab Results dataset.
- Select Grid Views > Customize Grid.
- This brings you to the grid customization panel, where you can pull in columns from other tables to form joined grids.
- In the Available Fields panel, scroll down and open the node Datasets. Never mind that Datasets is greyed out -- this only means that you cannot select it directly, but you can select the columns it contains.
- Open the node HIV Test Results and select (place a checkmark next to) Viral Load Quantified (copies/ml). This indicates that you wish to add the Viral Load Quantified column to the current dataset, the Lab Results dataset.
- Click Save.
- In the Save Custom Grid dialog, select Named and enter Lab Results with Viral Load. Click Save.
- On the joined grid select Charts > Create Chart and click Scatter.
- For the X axis, select CD4 by dragging it from the list of columns on the right into the appropriate box.
- For the Y axis, select Viral Load Quantified.
- Click Apply.
- Next render the Y axis with a log scale to get a better view.
- Click Chart Layout and click "Y axis" on the left.
- Select log, and click Apply.

- The resulting scatter plot gives you a sense that the two measures are in inverse relationship to one another, which you would expect. To refine the chart, you could click View Data, filter the viral load quantified column to only show rows for values that are greater than 0, and click View Chart to return to the chart which is immediately filtered to reflect your change.
- Click Save, give it the name "Viral Load / CD4 Scatter Plot", and click Save.
Time-based Reports
Next let's get a sense of how the cohorts perform over the course of the study. Below we will create a chart that shows the cohorts CD4 levels over the course of the study. This is a two step process: first we need to tell the server which columns are "measures", that is, which columns are available on the Y axis of a time-based chart; (2) then we will create the chart.- Click the Clinical and Assay Data tab.
- Click the Lab Results dataset.
- Click Manage in the header bar of the grid, then click Edit Definition.
- Scroll down to the Dataset Fields and click inside the text box containing CD4.
- Notice the tabs that appear to the right. Select the Reporting tab, and check the box next to Measure.
- Click Save.
- Now we are ready to make a time-chart on the CD4 levels.
- Click View Data.
- On the Lab Results dataset, select Charts > Create Chart.
- Click Time.
- Drag the CD4+ column (the only column marked as a measure) to the Y Axis box.
- Click Apply.
- The server initially renders a time chart of the CD4 levels for the first 5 individual participants in the study.
- To see how the cohorts compare, click Chart Layout, select Participant Groups and click Apply.There are now two lines, one for each cohort.
- To simplify the chart, click Chart Type and change the Time Interval to Months, and click Apply.
- The resulting visualization shows a clear performance difference between the two cohorts over time.
- Save the report under the name: "CD4 Levels over Time".

Next Steps
This tutorial has given you a quick tour of LabKey Server's data integration features. There are many features that we haven't looked at, including:- Custom participant groups. You can create groups that are independent of the cohorts and compare these groups against one another. For example, it would be natural to compare those receiving ARV treatment against those not receiving ARV treatment. For details see Participant Groups.
- Assay data. We have yet to add any assay data to our study. For details on adding assay data to a study, see Tutorial: Design a General Purpose Assay Type (GPAT). You can treat this assay tutorial as a continuation of this tutorial: simply use the same study repository and continue on to the assay tutorial.
- R reports. You can build R reports directly on top of the integrated study data. For details see R Reports. For an example see our online demo study.
Previous Step
Study User Guide
Study Navigation
The Study Folder
The Study Folder provides the jumping-off point for working with datasets in a Study. By default, the main study folder page includes five tabs:
By default, the main study folder page includes five tabs:
- The Overview tab displays the title, abstract, a link to the protocol document, and other basic info. Including a link to the study navigator.
- The Participants tab shows the demographics of the study subjects.
- The Clinical and Assay Data tab shows important visualizations and a data browser to all study data. Clicking on a dataset brings you to the dataset's grid view. Also all of the views and reports are listed.
- The Specimen Data tab provides links to the specimen search and tracking systems.
- The Manage tab contains the study management dashboard and is visible to administrators only.
The Study Navigator

Examine the Study Navigator
The Study Navigator shows all of the datasets in the study that you have sufficient permissions to view. The following image shows the Study Navigator for the LabKey.org demo study:
- Each dataset is listed as a row in the Study Navigator.
- Each timepoint or visit is displayed as a column and the column headings are timepoint labels or visit numbers.
- By default, the squares display the participant count, or the number of participants for which data is available for each dataset for that particular visit. Use the checkboxes to switch to a row count instead.
- The Navigator also displays a total tally of the number of participants or rows available for each dataset, across all visits, at the beginning of each dataset row under the heading "All."
View Data By Visit
To display information collected at a particular visit, click the number at the intersection of the dataset and visit you are interested in. All data collected for this particular dataset at this particular visit are displayed. For example, click on the number at the intersection of the "Month 2" column and the Physical Exam row (circled in red in the screencap above). The resulting data grid view shows all physical exams conducted in the second month of participation in the study for each participant. Each participant started the study on a different date, so the "Month 2" visits fall on different dates for each person. You can also see this grid view in the interactive example.From this grid view, you can:- Sort and filter on columns in the grid.
- Customize the default grid view, or create a new custom saved view.
- Create Reports and Charts.
- View data by participant. Click on the participantID in the first column of the data grid. See Data Grids for further info.

Hover for Visit Descriptions
If you have added Description fields to your visit or timepoint definitions, you can see them by hovering over the ? next to the visit column heading. See Edit Visits or Timepoints for details.
Study Data Browser
Data Views within a Study
The Data Views web part within a study offers a convenient listing of your datasets, views, and reports. You can customize the web part size and groupings as described in Data Views Browser.
Related Topics
Cohorts

Filter Data by Cohort
The Cohorts option on the Groups drop-down menu above each dataset lets you display only those participants who belong to a desired cohort: The Physical Exam dataset in the interactive example can be filtered by cohort in this way. Click the following links to see:
The Physical Exam dataset in the interactive example can be filtered by cohort in this way. Click the following links to see:
- The original unfiltered dataset
- The dataset filtered to include only "Group 1: Acute HIV-1"
- The dataset filtered to include only "Group 2: HIV-1 Negative"
View Individual Participants by Cohort
Time-invariant cohorts. You can display per-participant details exclusively for participants within a particular cohort. Steps:- Display a dataset of interest.
- Filter it by the desired cohort using the Groups > Cohorts drop-down menu.
- Click a participantID.
- You now see a per-participant details view for this member of the cohort. Click "Next Participant" or "Previous Participant" to step through participants who are included in this cohort.
- All per-participant views
- Per-participant view only for members of "Group 1: Acute HIV-1"
- Per-participant view only for members of "Group 2: HIV-1 Negative"
- Initial cohort. You will see all participants that began the study in the selected cohort.
- Current cohort. You will see all participants that currently belong to the selected cohort.
- Cohort as of data collection. You will see participants who belonged to the selected cohort at the time when the data or a specimen was obtained.

Customize Grid to Add a Cohort Column
Cohort membership can be displayed as an extra column in a datagrid by creating a custom grid.- Display the dataset of interest.
- Select Grid Views > Customize Grid.
- You will now see the Custom Grid designer, as shown here:

- On the left-hand side of the designer, expand the ParticipantID node by clicking on the "+" sign next to it.
- Place a checkmark next to Cohort.
- In the Selected Fields panel, you can reorder the fields by dragging and dropping.
- Click Save and name your custom grid, or make it the default for the page.
- The new grid will display a Cohort column that lists the cohort assigned to each participant.
Participant Groups
- To highlight a scientifically interesting group of participants, such as participants who have a certain condition, medical history, or demographic property.
- To mark off a useful group from a study management point of view, such as participants who have granted specimen consent, or participants who visited such-and-such a lab during such-and-such a time period.
Create a Participant Group: Method 1
You can create a participant group by filtering for the participants you want to include.- Go to any data grid in your study that includes a ParticipantID column.
- Filter the data grid to show the participants you want to include in the group.
- Select Groups > Create Participant Group > From All Participants.
- Specify a name and click Save.
Create a Participant Group: Method 2
You can create a participant group by individually selecting participants from any data grid in your study.- Go to any data grid in your study that includes a ParticipantID column.
- Individually select the participants you want to include in the group using the checkbox selectors.
- Select Groups > Create Participant Group > From Selected Participants.
- Specify a name and click Save.
Create a Participant Group: Method 3
You can create a participant group using the dialog Define Participant Group.- On your Study home page, click Manage Study > Manage Participant Groups > Create.
- In the Define Participant Group dialog:
- Name the group.
- Enter participant identifiers directly, or use the dropdown Select Participants from to select the table from which to select participants. Filter/select and click Add Selected, or just click Add All.
- Set the Participant Category in one of these ways:
- Select an existing category from the dropdown menu for the field.
- Manually type a new category name in the field. Manual entries are automatically added as new items in the dropdown menu, available for selection the next time you create a participant group. --- If you leave the category field blank, the uncategorized group will be listed on the top level menu.
- Check the box to control whether the category will be shared with others making participant groups.
- Click Save.
 In the above screencap, the "My Little Group" we created in the "Treatment Group" category is shown on the nested menu. The group "Genetic Consent Granted" was created without a category.
In the above screencap, the "My Little Group" we created in the "Treatment Group" category is shown on the nested menu. The group "Genetic Consent Granted" was created without a category.
- Shared/Not Shared applies directly to the category and only indirectly to the participant groups within a category.
- Administrators and editors can create shared or private groups; everyone with read access can create private groups.
- Admins and editors can delete shared groups, otherwise you have to be the owner to delete a group.
- Anyone with read access to a folder can see shared groups.
Filter Using a Participant Group
Once a participant group has been created you can filter any of the datasets using that group, just as you can filter using a cohort.- Click the Groups menu button for a list of available cohort-based and group-based filters, including any groups you have created or have been shared with you.

Delete a Participant Group
- Open the Manage tab.
- Select Manage Participant Groups.
- Highlight the participant group you wish to delete, then click Delete Selected.
Related Topics
Comments
- Per-Participant or Per-Participant/Visit Comments
- Per-Specimen or Per-Vial Comments
- Move or Copy Specimen-Level and Vial-Level Comments
- Where to Store Comments?
- Audit Comments
- Join Comment Columns to Datasets
Per-Participant or Per-Participant/Visit Comments
Typically, per-participant and per-participant-visit comments are added by editing the comment column in the appropriate dataset directly. The dataset must be editable and you must have edit-level permissions to add comments after import of the dataset. When a dataset is editable, an edit link appears at the beginning of each row of the dataset's grid view.Required setup. An administrator must set up per-participant and/or per-participant commenting before you can add such comments. For further information, see: Manage Comments.Simple editing example: If you have installed a local copy of the demo study, you can set up addition of comments there, and then the comment "Latex Allergy" can be added to any participant by anyone with dataset-level edit permissions.- Navigate to the Clinical and Assay Data tab of the demo study.
- Click Demographics to open that dataset.
- Click the Edit link on the row for the participant of interest.
- Enter the string "Latex Allergy" in the Comments box.
- Click Submit.
- The comment will appear in the dataset for the given row.

 View comments. You can view the comment in any specimen or vial view that includes specimens or vials associated with the participant of interest. The comment appears in the "Comment" column with the prefix "Participant," indicating that the comment is a study-wide, per-participant comment.
View comments. You can view the comment in any specimen or vial view that includes specimens or vials associated with the participant of interest. The comment appears in the "Comment" column with the prefix "Participant," indicating that the comment is a study-wide, per-participant comment.
Per-Specimen or Per-Vial Comments
Comments are added to individual specimens and vials through links available above specimen and vial grid views.- Display a grid view with specimens or vials of interest (e.g., click on By Individual Vial in the View All Specimens section of the Specimens web part).
- Click the Enable Comments/QC button above the displayed grid view if you have not already done so. You must have Specimen Coordinator permissions or higher. Once clicked, the button becomes a Comments and QC pulldown menu.
- Select a vial or specimen using the checkboxes to the left of the grid rows.
- Click Comments and QC above the grid view and select Set Vial Comment or QC State for Selected.
- Enter comments in the Comments box and click Save Changes.
- The comments you enter are applied to all vials selected.
View Comments
Once added, vial comments appear in the "Comments" column in a comma separated list with any per-participant and per-participant-visit comments described above. All types of comments are preceded with a tag (e.g. "Vial" or "Participant"). Here is a screen shot of comments for two vials that have been assigned both a vial-level and study-wide, participant-level comments.
Replace or Append Comments
If you choose "Set Vial Comment or QC State for Selected" again for a single vial that already has vial-level comments, you can edit the comment originally provided.If you select a number of vials, some of which already have vial-level comments, you will have additional options in the Set vial comments UI. Use the radio buttons to determine what action to perform on vials with existing comments:- Replace existing comments with new comments.
- Append new comments to existing comments.
- Do not change comments for vials with existing comments. Note that this means that the comments you add now will only affect selected vials that do not yet have comments.

Move or Copy Specimen-Level and Vial-Level Comments
To move individual comments:- On a specimen or vial grid view, select the row that contains the comment you wish to copy or move.
- On the Set vial comments page, click Copy or move comment and use its menu options to select where to copy or move of the comment.

Where to Store Comments?
Since comments can be associated with vials, specimens, participants or participant/visit pairs, you will need to consider where it makes the most sense to store different categories of comments.When deciding where to store a comment, consider whether you would like new vials or specimens to contain the comment. If you assign the comment at the vial level, the comment will remain with the individual vial, but will not be added to new vials that come into the system.To ensure that the comment is added to new vials that come into the system for a particular participant, make sure that the comment is assigned at the participant level. This makes it easy to track persistent participant-specific issues, allergies for example, across all vials without copying and pasting.Audit Comments
All changes to comments are logged in the site audit log. If you are an admin, you can review the log:- Go to Admin > Site > Admin Console
- In the Management section, click Audit Log
- Select Specimen Comments and QC from the dropdown menu.
Join Comment Columns to Datasets
Comment columns can also be joined into ordinary datasets by customizing the grid view.Related Topics
Dataset Quality Control States
Overview
Studies integrate many different types of research data, so they often contain datasets of that have passed through different levels of quality control (QC). Dataset QC states allow you to track the extent of quality control that has been performed on each dataset. This facilitates human approval of study data.LabKey's dataset QC features allow you to mark incoming datasets with the level of quality control executed before incorporation of the dataset into a study. Once datasets are part of a study, the QC markers for individual rows in (or entire datasets) can be changed to recognize subsequent rounds of quality control.For example, consider a study where CRF datasets have been carefully reviewed, but assay datasets copied to the study have not gone through review. The CRF datasets can be marked as fully reviewed during import, while the assay datasets can be automatically marked as raw data when copied to the study. During subsequent quality control reviews of the assay datasets, the datasets can be marked as reviewed at the dataset or row-by-row level.Feature summary for dataset QC:- The quality control process allows study administrators to define a series of approval and review states for data. These states can be associated with "public" or "nonpublic" settings that define the default visibility of the data.
- Different data approval states (and thus approval pathways) can be defined for data added to a study through different pathways (e.g., assay data copied to a study, CRF data imported via the Pipeline or TSV data inserted directly into a study dataset).
- Reviewers can the filter overview data grid by Quality Control State and thus find all data requiring review from a single screen.
- All quality control actions are audited.
- Admin Guide for Dataset QC. Provides setup instructions to help Admins define QC states. Must be completed before users can change QC states.
- User Guide for Specimen QC. Specimen QC is simpler but less customizable than dataset QC.
- Validators and Range Checks for Individual Fields. Provides data-type and data-range checks, defined in the assay design.
Filter datasets by QC state
You can use filtering to review only data rows that are currently in a particular quality control state. This option is available to all users once an admin has set up dataset-level QC and defined QC states.Steps:- Go to the dataset of interest.
- Click QC States. (If the "QC States" button is not visible above your dataset, ask your admin to set up dataset-level QC.)
- Choose one of the pre-defined states listed in the first section of the dropdown menu, All Data or Public/approved Data.

Change the QC State
You can change the QC state for dataset rows if you have sufficient levels of permissions on the dataset.Steps:- Go to the dataset and select one, many or all lines of data.
- Click QC States > Update state of selected data. If the "QC States" button is not visible above your dataset, ask your admin to set up dataset-level QC.
- Choose one of your pre-defined QC states from the drop-down menu New QC State.
- Enter a comment.
- Click Update Status.

Study Administrator Guide
Topics
- Create a Study - Create a new study. (Also see Tutorial: Set Up a New Study.)
- Use Visits or Timepoints/Dates - Configure how the study schedule is defined and tracked.
- Create and Populate Datasets - Define datasets and import data.
- Manage a Study - Manage study participants, datasets, visits, cohorts, quality control, and security.
- Create a Vaccine Study Design - Design a study which can be used as a template to create additional studies with the same parameters.
- Import, Export, and Reload a Study - These operation make it easy to transfer studies between servers, duplicate them within a server, synchronize them with a master database, and more.
- Publish a Study - Publish a selected subset of data from a study.
- Publish a Study: Protected Health Information - Handle protected health information when publishing a study.
- Publish a Study: Refresh Snapshots - Refresh data in a published study from the original source study.
- Ancillary Studies - Select a subset of data from study to explore new hypotheses and/or set up follow up studies.
Create a Study
Create the Study Container
First we create an empty container for the study data to live in. We recommend creating studies inside subfolders, not directly inside of projects.- Navigate to a project, in which you will create a subfolder.
- Create an empty "study" type subfolder:
- Go to Admin > Folder > Management. Click the button Create Subfolder.
- Enter a Name for the study, choose the folder type Study, and click Next.
- On the Users/Permissions page, click Finish. (You can configure permissions later by selecting Admin > Folder > Permissions.)
Create or Import the Study
You are now on the overview tab of your new study folder. You have the option to create a study from scratch, or importing an pre-existing study.- Click Create Study to begin the process of creating a study from scratch.
- OR
- Click Import Study to import a pre-existing study archive that was previously exported.

Set Study Properties
- Look and Feel: Name your study and choose how to refer to subjects.
- Visit/Timepoint Tracking: Choose whether your study tracks time by date or visit. See Continuous Studies for studies which use neither.
- Specimen Management: Declare the type of specimen repository you will use.
- Security: Select basic or custom security and whether to allow edits to datasets.
 When you are finished, click the Create Study button to create a study in your new project or folder.If you would like to create additional custom study properties, you can do so at the project level. A project administrator can define properties that are available to all studies within the project. For more information, see Custom Study Properties.
When you are finished, click the Create Study button to create a study in your new project or folder.If you would like to create additional custom study properties, you can do so at the project level. A project administrator can define properties that are available to all studies within the project. For more information, see Custom Study Properties.
Design a Vaccine Study
A vaccine study is specialized to collect data about specific vaccine protocols, associated immunogens, and adjuvants. A team can agree upon the necessary study elements in advance and design a study which can be used as a template to create additional studies with the same pre-defined study products, treatments, and expected schedule, if desired. This can be particularly helpful when your workflow includes study registration by another group after the study design is completed and approved.Once you have created a study, whether directly or via import, you can standardize shared vaccine study features among multiple studies.[ Video Overview: Study Designer - treatment data and assay schedule]- Select the Manage tab and return to it after setting up each of the following:
- Click Manage Study Products.
- Click Manage Treatments.
- Click Manage Assay Schedule.
Related Topics
- Create a Vaccine Study Design : Covers the specialized case of using a CAVD folder type to design a vaccine study.
Create and Populate Datasets
Topics
- Create a Dataset from a File - Define and populate a dataset from a file, such as an Excel or text file.
- Create a Dataset by Defining Fields - Define a dataset and it's fields manually before importing data.
- Create Multiple Dataset Definitions from a TSV File - Define a set of datasets (= a schema) in one step.
- Import Data to a Dataset - Import data to an existing dataset.
- Import Study Data From REDCap Projects - Import data from an existing REDCap project.
Related Topics
- Field Properties Reference - Edit properties of individual fields
- Edit Dataset Properties - Edit properties of datasets
- Dataset System Fields - In addition to any custom fields included, a dataset definition will automatically include certain pre-defined fields.
- Date & Number Display Formats - Set the default formats for displaying dates and numbers.
- Dataset Properties
Create a Dataset from a File
Create a Dataset from a File
In this example, we define a Physical Exam dataset by importing an Excel file. In order to follow these steps yourself, download Physical Exam-- Dataset.xls. Note that this file is intended for import into a visit-based study.- From the Manage tab in a study folder, click Manage Datasets.
- Click Create New Dataset.
- Give the dataset a short, unique name.
- The dataset ID is an integer number that must be unique for each dataset in a study. By default, dataset IDs are defined automatically for you, but you may uncheck the box and specify your own if you prefer.
- Select the Import From File checkbox.

- Click Next.
- Browse to the file that contains the data you wish to import. Here, the "Physical Exam-- Dataset.xls" file you downloaded earlier.
- Once you select it, column and type information will be automatically inferred and displayed for you.

- Before clicking import, you may make changes to the inferred dataset:
- Uncheck the box at the top of a column to ignore during import.
- Correct types if required; for instance, if a column you intend to be a numeric type happens to only contain integers, the server will infer it as an integer field.
- In the column mapping section you can pull down to select mappings between columns in the dataset you are creating and existing columns in the study domain.
- Click Import.
View Dataset
When your dataset has finished importing, it will appear as a grid view and will look something like this:
Create a Dataset by Defining Fields
Overview
You have two options for creating and populating a single dataset:- Directly import a dataset from a file. In this case, the shape of your data file will define the shape of the dataset. The dataset fields are defined at the same time the dataset is populated during the data import process.
- Define dataset fields, then populate the dataset. Specify the shape of the dataset by adding fields to the dataset's definition. These fields correspond to the columns of the resulting dataset. After you have specified the name, key value and shape of the dataset, you can populate the dataset with data.
Create a Dataset
You can create a single dataset schema by manually defining its fields. To get started:- Click the Manage tab, then Manage Datasets.
- Click Create a New Dataset.
- Enter a Short Dataset Name for the dataset. Required.
- Optional: Enter a Dataset ID. The dataset ID is an integer number that must be unique for each dataset in a study. If you do not wish to specify a dataset ID (the usual case), simply leave the default "Define Dataset ID Automatically" checkbox checked.
- Do not check Import from File. You would use this option to upload a spreadsheet as a dataset (see: Create a Dataset from a File).
- Click Next.
Enter Dataset Properties
Enter dataset properties in the top section of the "Edit Dataset Definition" page. A full listing of options is available here: Dataset Properties in the first section.Define Dataset Fields
LabKey Server automatically includes standard system fields as part of every schema. These are the Dataset System Fields.You have the following options for defining custom dataset fields:- Option 1: Define dataset fields manually by adding fields in the "Dataset Fields" section of the page.
- Option 2: Import dataset fields by pasting a tab-delimited text file that describes the fields. Click the Import Fields button in the Dataset Fields section.
- Option 3: Import dataset fields by inferring fields from a tabular format file such as an Excel file, TSV, or CSV file. Click Infer Fields from File in the Dataset Fields section. Note that you should avoid adding dataset reserved fields via this option. These fields are: ParticipantId (or whichever field you specified on study creation), Visit, SequenceNum, and Date, as these fields can put the designer into a dead end state. If you do get into a dead end state, cancel the designer, delete the dataset, and start over.
- Property (aka "Name") - Required. This is the field Name for this Property (not the dataset itself). The name must start with a character and include only characters and numbers
- Format - Optional. Set the format for Date and/or Number output. See Date and Number Formats Reference for acceptible format strings.
- RangeURI - This identifies the type of data to be expected in a field. It is a string based on the XML Schema standard data type definitions. The prefix "xsd" is an alias for the formal namespace http://www.w3.org/2001/XMLSchema# , which is also allowed. The RangeURI must be one of the following values:
- xsd:int – integer
- xsd:double – floating point number
- xsd:string – any text string
- xsd:dateTime – date and time
- xsd:boolean – boolean
- Label - Optional. Name that users will see for the field. It can be longer and more descriptive than the Property Name.
- NotNull (aka "Required") - Optional. Set to TRUE if this value is required. Required fields must have values for every row of data imported.
- Hidden - Optional. Set to TRUE if this field should not be shown in default grid views
- LookupSchema - Optional. If there is a lookup defined on this column, this is the target schema
- LookupQuery - Optional. If there is a lookup defined on this column, this is the target query or table name
- Description - Optional. Verbose description of the field
Import Data Records
After you enter and save a dataset definition, you will see the property page for your new Dataset. From here you can Import Data Records Via Copy/Paste by selecting the "Import Data" button.Edit Dataset Properties
In addition to importing data, you can also Edit Dataset Properties.Create Multiple Dataset Definitions from a TSV File
You can define many datasets at once using a schema.TSV file. To upload dataset fields in bulk, paste in a tab-delimited file that includes the five required columns and any additional columns.
To use the Bulk Import page:
- Navigate to some folder of type Study.
- Click the Manage tab.
- Modify your browser's URL, replacing "manageStudy.view?" with "bulkImportDataTypes.view?", for example, http://localhost:8080/labkey/study/MyStudy/bulkImportDataTypes.view?
- On the Bulk Import page, paste in tab-delimited text (copy and paste from Excel works well). The first row of the spreadsheet contains column headers. Each subsequent row of the spreadsheet describes one field from a dataset. See an example below.
Dataset Properties
These columns describe dataset-wide properties -- they have the same value for all fields in a given dataset.
|
DatasetNameHeader |
Required. The name of the dataset being defined. This column can have any heading; the column header must match what you type in the Column Containing Dataset Name field. |
|
DatasetLabelHeader |
Required. The display name or label to use for the dataset. This may include any characters. This column can have any heading; the column header must match what you type in the Column Containing Dataset Label text box. |
|
DatasetIdHeader |
Required. The integer id of the dataset being defined. This column can have any heading; the column header must match what you type in the Column Containing Dataset Id text box. |
|
Hidden |
Optional. Indicates whether this dataset should be hidden. Defaults to false. Sample value: true |
|
Category |
Optional. Indicates the category for this dataset. Each dataset can belong to one category. Categories are used to organize datasets. Sample value: CRF Data |
Field Properties
These columns describe field-specific properties, which will change within each dataset.
|
Property |
Required. This is the name of the field being defined. When importing data, this name will match the column header of the data import file. This should be a short name made of letters and numbers. It should not include spaces. |
|
RangeURI |
Required. This tells the type of data to be expected in a field. It is a string based on the XML Schema standard data type definitions. It must be one of the following values:
Note: xsd is an alias for the formal namespace http://www.w3.org/2001/XMLSchema# |
|
ConceptURI |
Each property can be associated with a concept. Fields with the same concept have the same meaning even though they may not have the same name. The concept has a unique identifier string in the form of a URI and can have other associated data. |
|
Key |
Indicates that this column is an extra key (int, max 1 per dataset). Sample value: 0 |
|
AutoKey |
Indicates that this extra key column should be auto-incrementing, and managed by the server. Sample value: false |
|
MvEnabled |
Indicates whether this column supports missing value indicators (e.g. "Q" or "N"). See the Missing Value Indicator documentation page. Sample value: false |
|
Label |
The display name to use for the field. This may include any characters. |
|
Required |
Indicates whether this field is required. |
Example
The following schema.TSV file defines two datasets, Demographics and AbbreviatedPhysicalExam.
| DatasetName | DatasetId | DatasetLabel | Property | Label | RangeURI |
| Demographics | 1 | Demographics | DEMdt | Contact Date | xsd:dateTime |
| Demographics | 1 | Demographics | DEMbdt | Date of Birth | xsd:string |
| Demographics | 1 | Demographics | DEMsex | Gender | xsd:string |
| AbbreviatedPhysicalExam | 136 | Abbreviated Physical Exam | APXdt | Exam Date | xsd:dateTime |
| AbbreviatedPhysicalExam | 136 | Abbreviated Physical Exam | APXwtkg | Weight | xsd:double |
| AbbreviatedPhysicalExam | 136 | Abbreviated Physical Exam | APXtempc | Body Temp | xsd:double |
| AbbreviatedPhysicalExam | 136 | Abbreviated Physical Exam | APXbpsys | BP systolic xxx/ | xsd:int |
| AbbreviatedPhysicalExam | 136 | Abbreviated Physical Exam | APXbpdia | BP diastolic /xxx | xsd:int |
Import Data to a Dataset
Import Data Records
There are three ways to import data records into a dataset:- Import via Copy/Paste. Copy and paste tab-delimited data.
- Import From a Dataset Archive. Import dataset files using the pipeline.
Import via Copy/Paste
- Navigate to the dataset of interest.
- Select Insert > Import Bulk Data above the dataset grid. You are now on the "Import Data" page.
- To confirm that the data structures will match, click the Download Template button to obtain an empty spreadsheet containing all of the fields defined. Fill in your data, or compare to your existing spreadsheet and adjust until the spreadsheet format will match the dataset.
- To import the data either:
- Click Upload File to select and upload the .xls, .csv, or .txt file.
- Copy and paste tabular data into the Copy/paste text box.
- Click Submit.
Validation and Error Checking
Only one row with a combination of participant/sequenceNum/key values is permitted within each dataset. If you attempt to import another row with the same key, an error occurs.Data records are checked for errors or inconsistencies, including:- Missing data in required fields
- Data that cannot be converted to the right datatype
- Data records that duplicate existing records and are not marked to replace those records
Import From a Dataset Archive
Create Pipeline Configuration File
Create a Pipeline Configuration File
To control the operation of the dataset import, you can create a pipeline configuration file. The configuration file for dataset import is named with the .dataset extension and contains a set of property/value pairs.The configuration file specifies how the data should be handled on import. For example, you can indicate whether existing data should be replaced, deleted, or appended to when new data is imported into the same named dataset. You can also specify how to map data files to datasets using file names or a file pattern. The pipeline will then handle importing the data into the appropriate dataset.Note that we automatically alias the names ptid, visit, dfcreate, and dfmodify to participantid, sequencenum, created, and modified.File Format
The following example shows a simple .dataset file:1.action=REPLACE
1.deleteAfterImport=FALSE
# map a source tsv column (right side) to a property name or full propertyURI (left)
1.property.ParticipantId=ptid
1.property.SiteId=siteid
1.property.VisitId=visit
1.property.Created=dfcreate
default.property.SiteId=siteidparticipant.file=005.tsv
participant.property.SiteId=siteId
Properties
The properties and their valid values are described below.actionThis property determines what happens to existing data when the new data is imported. The valid values are REPLACE, APPEND, DELETE. DELETE deletes the existing data without importing any new data. APPEND leaves the existing data and appends the new data. As always, you must be careful to avoid importing duplicate rows (action=MERGE would be helpful, but is not yet supported). REPLACE will first delete all the existing data before importing the new data. REPLACE is the default.enrollment.action=REPLACEdeleteAfterImportThis property specifies that the source .tsv file should be deleted after the data is successfully imported. The valid values are TRUE or FALSE. The default is FALSE.enrollment.deleteAfterImport=TRUEfileThis property specifies the name of the tsv (tab-separated values) file which contains the data for the named dataset. This property does not apply to the default dataset. In this example, the file enrollment.tsv contains the data to be imported into the enrollment dataset.enrollment.file=enrollment.tsvfilePatternThis property applies to the default dataset only. If your dataset files are named consistently, you can use this property to specify how to find the appropriate dataset to match with each file. For instance, assume your data is stored in files with names like plate###.tsv, where ### corresponds to the appropriate DatasetId. In this case you could use the file pattern "plate(\d\d\d).tsv". Files will then be matched against this pattern, so you do not need to configure the source file for each dataset individually.default.filePattern=plate(\d\d\d).tsvpropertyIf the column names in the tsv data file do not match the dataset property names, the property property can be used to map columns in the .tsv file to dataset properties. This mapping works for both user-defined and built-in properties. Assume that the ParticipantId value should be loaded from the column labeled ptid in the data file. The following line specifies this mapping:enrollment.property.ParticipantId=ptidNote that each dataset property may be specified only once on the left side of the equals sign, and each .tsv file column may be specified only once on the right.sitelookupThis property applies to the participant dataset only. Upon importing the particpant dataset, the user typically will not know the LabKey internal code of each site. Therefore, one of the other unique columns from the sites must be used. The sitelookup property indicates which column is being used. For instance, to specify a site by name, use participant.sitelookup=label. The possible columns are label, rowid, ldmslabcode, labwarelabcode, and labuploadcode. Note that internal users may use scharpid as well, though that column name may not be supported indefinitely.Participant Dataset
The virtual participant dataset is used as a way to import site information associated with a participant. This dataset has three columns in it: ParticipantId, EnrollmentSiteId, and CurrentSiteId. ParticipantId is required, while EnrollmentSiteId and CurrentSiteId are both optional.As described above, you can use the sitelookup property to import a value from one of the other columns in this table. If any of the imported value are ambiguous, the import will fail.Import Study Data From REDCap Projects
Dataset Properties
 Buttons offer the following options:
Buttons offer the following options:
- View Data: see the current contents of the dataset.
- Edit Associated Timepoints: select the visits where data will be collected.
- Delete Dataset: delete the selected dataset including its definition and properties as well as all rows and visitmap entries. You will be asked for confirmation as this action cannot be undone.
- Delete All Rows: deletes all rows, but the dataset definition and properties will remain. You will be asked for confirmation as this action cannot be undone.
- Show Import History: see a list of all previous uploads to this dataset.
- Edit Definition: modify dataset properties and add or modify the dataset fields.
Related Topics
Edit Dataset Properties

- Name: Required. This name must be unique. It is used when identifying datasets during data upload.
- Label: The name of the dataset shown to users. If no Label is provided, the Name is used.
- Cohort Association: Datasets may be cohort specific, or associated with all cohorts.
- Additional Key Column: If the dataset has more than one row per participant/visit, an additional key field must be provided. There can be at most one row in the dataset for each combination of participant, visit, and key. See below for more information. Options:
- None: No additional key.
- Data Field: A user-managed key field.
- Managed Field: A numeric or string field that is managed by the server to make each new entry unique. Numbers will be assigned auto-incrementing integer values, strings will be assigned globally unique identifiers (GUIDs).
- Demographic Data: Whether this is a demographic dataset, which has only a single row per participant in the study.
- Show In Overview: Check to show this dataset in the overview grid by default.
- ID: Required. The unique, numerical identifier for your dataset. It is defined automatically during dataset creation and cannot be modified. The combination of container and dataset is the primary key.
- Category: Assigning a category to a dataset will group it with similar datasets in the navigator and data browser.
- Dataset Tag: An additional, flexible, way to categorize datasets. For instance, you might tag certain datasets as "Reference" for easy retrieval as a set across categories.
- Description: An optional longer description of your dataset. The Description can only be specified when you Edit Dataset Properties, not at the time of dataset creation.
Details: Additional Key Columns
Some datasets may have more than one row for each participant/visit pairing. For example, a sample might be tested for neutralizing antibodies to several different virus strains. Each test (sample/date/virus combination) could then become a single unique row of a dataset. In order to upload multiple rows of data for a single participant/visit, an additional key field must be specified for tracking within the database. Consider the following data:| ParticipantId | SequenceNum (=Visit) | VirusId | Value | Percent |
|---|---|---|---|---|
| 12345 | 101 | Virus127 | 3127.877 | 70% |
| 12345 | 101 | Virus228 | 788.02 | 80% |
Related Topics
Dataset System Fields
| System Column | Data Type | Description |
|---|---|---|
| DatasetId | int | A number that corresponds to a defined dataset. |
| ParticipantId | string | A user-assigned string that uniquely identifies each participant throughout the Study. |
| VisitDate | date/time | The date that a visit occurred (only defined in visit-based study datasets). |
| Created | date/time | A date/time value that indicates when a record was first created. If this time is not explicitly specified in the imported dataset, LabKey will set it to the date/time that the data file was last modified. |
| CreatedBy | int | An integer representing the user who created the record. |
| Modified | date/time | A date/time value that indicates when a record was last modified. If this time is not explicitly specified in the imported dataset, LabKey will set it to the date/time that the data file was last modified. |
| ModifiedBy | int | An integer representing the user who last modified the record. |
| SequenceNum | float | A number that corresponds to a defined visit within a Study. This is a floating-point number. In general, you can use a visit ID here, but keep in mind that it is possible for a single visit to correspond to a range of sequence numbers. |
| Date | date/time | The date associated with the record. Note this field is included in datasets for both timepoint and visit based studies. |
Related Topics
Use Visits or Timepoints/Dates
- Visits: Data is organized by sequence number provided into a series of defined visits or events. Visit based studies do not need to contain calendar date information, nor do they need to be in temporal order. Even if the data collection is not literally based on a person visiting a clinic a series of times, sequence numbers can be used to map data into sequential visits regardless of how far apart the collection dates are.
- Timepoints/Dates: A timepoint is a range of dates, such as weeks or months, rather than a literal "point" in time. The interval can be customized, and the start-date can be either study-wide or per-participant. For example, using timepoints aligned by particpant start date might reveal that a given reaction occured in week 7 of a treatment regimen regardless of the calendar day of enrollment.
Visits
When setting up a visit-based study, you define a mapping for which datasets will be gathered when. Even if your study is based on a single collection per participant, we recommend that you still define a minimum of two visits for your data. One visit to store demographic data that occurs only once for each participant; the second visit for all experimental or observational data that might include multiple rows per participant visit, such as in the case of results from two rounds of tests on a single collected vial.You have two options for defining visits and mapping them to datasets:- Create Visits. Manually define visits and declare required datasets.
- Import Visit Map. Import visit map XML file to quickly define a number of visits and the required datasets for each.
Timepoints
When you define a study to use timepoints, you can manually create them individually, or you can specify a start date and duration and default timepoints will be automatically created when datasets are uploaded.There are two ways timepoints can be used:- Relative to the Study Start Date: All data is tracked relative to the study start date. Timepoints might represent calendar months or years.
- Relative to Participant Start Dates: Each participant can have an individual start date, such that all data for given participant are relativized to his/her individual start date. On this configuration, timepoints represent the amount of time each subject has been in the study since their individuals start dates, irrespective of the study's overarching start date. To set up: Include a StartDate column in a dataset marked as demographic.

Related Topics
Create Visits
Create a Visit or Timepoint
- From the Study Dashboard, select the Manage tab.
- Click Manage Visits (or Manage Timepoint).
- Click Create New Visit (or Timepoint).

- Define the properties of the visit or timepoint (see below).
- Click Save.
Visit Properties
- Label: Descriptive name for this visit. This label will appear in the Study Overview.
- VisitId/Sequence Range: Each row of data is assigned to a visit using a sequence number. A visit can be defined as a single sequence number or a range. If no second value is provided, the range is the single first value. When viewing the study schedule, the first value in the range is displayed along with the visit label you define.
- Description: An optional short text description of the visit which (if defined) will appear as hover text on visit headers in the study navigator and the visit column in datasets.
- Type: Visit types are described below.
- Visit Handling (advanced): You may specify that unique sequence numbers should be based on visit date. This is for special handling of some log/unscheduled events. Make sure that the sequence number range is adequate (e.g #.0000-#.9999)
- Show By Default: Check to make this Visit visible in the Study Overview.
- Cohort (not shown in visit creation UI): If the visit is associated with a particular cohort, you can select it here from the list of cohorts already defined in the study.
- Protocol Day (not shown in visit creation UI): The expected day for this visit according to the protocol, used for study alignment.
Timepoint Properties
- Label: Text name for this timepoint.
- Day Range: Days from start date encompassing this visit, i.e. days 8-15 would represent Week 2.
- Description: An optional short text description of the visit which (if provided) will appear as hover text on visit headers in the study navigator and the timepoint column in datasets.
- Type: Timepoint types are described below.
- Show By Default: Check to make this timepoint visible in the Study Overview.
- Cohort (not shown in timepoint creation UI): If the timepoint is associated with a particular cohort, you can select it here from the list of cohorts already defined in the study.
- Protocol Day (not shown in timepoint creation UI): The expected day for this visit according to the protocol, used for study alignment.
Visit and Timepoint Types
A visit or timepoint can be one of the following types:- Screening
- Pre-baseline visit
- Baseline
- Scheduled follow-up
- Optional follow-up
- Required by time of next visit
- Cycle termination visit
- Required by time of termination visit
- Early termination of current cycle
- Abort all cycles
- Final visit (terminates all cycles)
- Study termination window
Associate Datasets with Visits or Timepoints
To mark which datasets are required for which visits or timepoints, use the Study Schedule view.- From the Manage tab, click Study Schedule.
- Click the radio buttons at the intersection of dataset/visit pairs you want to define as requirements.
- Click Save Changes.
Map Datasets to Visits
To specify which datasets should be collected at each visit:- From the Manage tab, click Manage Visits.
- Click the edit link for the desired visit.
- For each associated dataset listed, you can select Required or Optional from the pulldown.
- Click Save.
Map Visits to Datasets
To specify the associated visits for a dataset, follow these steps:- From the Manage tab, click Manage Datasets.
- Click the label for the dataset of interest.
- Click the Edit Associated Visits button.
- Under Associated Visits, specify whether the dataset is required or optional for each visit. By default, datasets are not expected at every visit.
- Click Save.
Visit Dates
A single visit may have multiple associated datasets. The visit date is generally included in one or more of these datasets. In order to import and display your study data correctly, it's necessary to specify which dataset, and which property within the dataset, contains the visit date. Alignment of visit dates is also helpful in cross-study alignment.Once one or more datasets are required for a given visit, you can specify the visit date as follows:- From the Manage tab, click Manage Visits.
- Edit the visit.
- From the Visit Date Dataset pulldown, select the dataset (only datasets marked as required are listed here.
- Specify a Visit Date Column Name. The date in this column will be used to assign the visit date.
- Click Save.
Protocol Day
The Protocol Day is the expected day for this visit according to the protocol, used for study alignment. It cannot be set explicitly when defining new visits or timepoints, but can be edited later. For a date-based study, the default protocol day is the median of the timepoint range. For a visit-based study, the default is 0.Related Topics
- To hide the "Date" field in visit-based studies, see the message board thread: Hiding the Date Field in a Visit Based Study
Edit Visits or Timepoints
Edit a Visit or Timepoint
Click the "Edit" link next to the name of a visit or timepoint on the list to change the properties of the given visit. In addition to the properties available when you first create visits or timepoints, you can edit some additional properties, and there are further properties associated with visits and timepoints that are defined internally.Cohort
If the visit is associated with a particular cohort, you can select it here. The pulldown lists cohorts already defined in the study.Protocol Day
The Protocol Day is the expected day for this visit according to the protocol, used for study alignment. It cannot be set explicitly when defining new visits or timepoints, but can be edited after creation. For a date-based study, the default protocol day is the median of the timepoint range. For a visit-based study, the default is 0.Edit Multiple Visits From One Page
Using the Change Properties link on the "Manage Visits" page, you can change the label, cohort, type, and visibility of multiple visits from a single page. This option is not available for timepoints.Note that this link only allows you to change a subset of visit properties while the "Edit" link lets you change all properties for a single visit at a time.Hover to View Descriptions
If you add descriptions to visits or timepoints, you will be able to hover over the value in the Visit column to view the description.
Related topics
Import Visit Map
- From the Manage tab, click Manage Visits.
- Click Import Visit Map.
- Paste the contents of the visit map XML file into the box.
- Click Import.
Visit Map XML Format
The visit map lists which visits make up the study, which sequence numbers are assigned to them, and additional properties as required. The same options are available as when you create a single visit in the UI. The format of the imported visit map XML must match the study serialization format used by study import/export.For full details, review the visitMap XML source.Sample visit_map.xml
The following sample defines 4 visits, including a baseline.<?xml version="1.0" encoding="UTF-8"?>
<visitMap xmlns="http://labkey.org/study/xml">
<visit label="Baseline" sequenceNum="0.0" protocolDay="0.0" sequenceNumHandling="normal"/>
<visit label="Month 1" sequenceNum="1.0" maxSequenceNum="31.0" protocolDay="16.0" sequenceNumHandling="normal"/>
<visit label="Month 2" sequenceNum="32.0" maxSequenceNum="60.0" protocolDay="46.0" sequenceNumHandling="normal"/>
<visit label="Month 3" sequenceNum="61.0" maxSequenceNum="91.0" protocolDay="76.0" sequenceNumHandling="normal"/>
</visitMap>
DEPRECATED: DataFax Visit Map
The DataFax format visit map is no longer supported and has been replaced with the XML format described above.If you import a DataFax visit map with lines look something like "0|B|Baseline|1|9 (mm/dd/yy)|0|0| 1 2 3 4 5 6 7 8||99", you will receive an error reading "Unable to parse the visit map format: visit map XML file is not valid: 1:1: Unexpected element: CDATA"Import Visit Names / Aliases
- "Month 1"
- "M1"
- "Day 30"
- "First Month"
Create Alias/Sequence Number Mapping
- Prepare your mappings as a tab separated list with two columns: Name and SequenceNum, like the example below. You can map as many names as needed to a given sequence number:
| Name | SequenceNum |
|---|---|
| Two Week Checkup | 14 |
| Three Week Checkup | 21 |
| Seven Week Evaluation | 49 |
| Seven Week Checkup | 49 |
- From the Manage tab, click Manage Visits.
- Click Visit Import Mapping
- Click Import Custom Mapping (or if an existing custom map is defined you can Replace Custom Mapping).
- Copy and paste the tab separated list into the text area.

- Click Submit.
Importing Data Using Alias Visit Names
Once the mapping is in place, you can import data using a name for the visit, instead of the sequence number value. Place the string values/alias in a column named "Visit". On import, the server will convert the string values in the Visit column to integers for internal storage. For example, the following table import physical exam data using string values in the Visit column:| ParticipantID | Visit | Temperature | Weight | |
|---|---|---|---|---|
| PT-101 | Two Week Checkup | 37 | 80 | |
| PT-101 | Three Week Checkup | 37 | 81 | |
| PT-101 | Seven Week Checkup | 38 | 81 |
Manage a Study
Manage Your Study
 Administrators can use the links under the "General Study Settings" heading to manage many study properties and settings:
Administrators can use the links under the "General Study Settings" heading to manage many study properties and settings:
- Change Study Properties: Set values which appear on the Study Overview tab.
- Edit Definition: Edit additional properties defined for the study, if any.
- Manage Reloading: Configure reloading of the Study, if desired.
- Manage Datasets: Create or Edit Datasets and their Schemas.
- Manage Visits or Timepoints: Create, Map and Edit Timepoints or Visits.
- Study Schedule: Manage the schedule and track study progress.
- Manage Locations: Create and Edit Labs and Sites.
- Manage Location Types: Define which types of locations can make requests.
- Manage Cohorts: Assign Study Participants to Cohorts.
- Manage Participant Groups: Define participant groups.
- Manage Alternate Participant IDs and Aliases. Configure how alternate participant IDs and aliases are generated.
- Manage Study Security (Dataset-Level Security): Manage access to your Study, Datasets, Assays and Specimens. Assign all users to groups with specific permissions. Grant Permissions (e.g., view or edit) to groups on a per-study or per-report level.
- Manage Views: Manage Reports, Charts, and Views and their metadata.
- Manage Dataset QC States: Manage quality control states.
- Manage Comments: Set up comment fields for participants.
- Manage Study Products: Define immunogen and adjuvant information for vaccines.
- Manage Treatments: Configure immunization treatments and schedule.
- Manage Assay Schedule: Define Assay/Specimen Configurations, Timepoint Mapping and an Assay Plan.
- Demo Mode: Obscure participant IDs on many pages for demonstration purposes.
Manage Specimen Repository and Request Settings
Additional Helpful Settings
You may also find it useful to Manage Missing Value Indicators / Out of Range Values. These indicators can be managed using site and folder administration options.Custom Study Properties
- Open the Manage tab.
- Click Edit Definition.
- Click Add Field and specify the name, label, type, and field properties as required.
- Reorder or delete custom fields using the arrow and X buttons on the left.
- Click Save.
 Once added you will be able to set values for them via the Change Study Properties link from the Manage tab. Custom properties appear at the end of the list after the built in study properties.
Once added you will be able to set values for them via the Change Study Properties link from the Manage tab. Custom properties appear at the end of the list after the built in study properties.
Manage Datasets

Study Schedule
View the study schedule and associated datasets. See Study Schedule.Change Display Order
Datasets can be displayed in any order. To change their order, select a dataset and press the Move Up or Move Down buttons. Click Save.The Reset Order button will automatically order datasets by category, and then by their ID within each category. Once confirmed, the reset order action cannot be undone.Change Properties
Edit the label, category, cohort, status, and visibility of multiple datasets from one screen using this link. To edit additional properties for individual datasets, click the dataset name instead. See Edit Dataset Properties.Delete Multiple Datasets
An administrator can select multiple datasets at once for deletion.Manage Dataset Security
Security can be configured at a per-dataset level. See also: Security and Manage Study Security (Dataset-Level Security).Create New Dataset
You can add new datasets to the study at any time. See also Create a Dataset by Defining Fields.Date/Time/Number Formatting
The default date-time and number formats for the study are shown and can be changed by clicking the Folder Settings Page link. You can choose the default formats for all datasets together or customize formats for individual dataset fields. See Date & Number Display Formats.For details on valid format strings for dates, times and numbers, see Date and Number Formats Reference.Datasets Web Part
If you would like to display a simple directory of datasets by category, select Datasets from the <Select Web Part> pulldown in the lower left.
Related Topics
Manage Visits or Timepoints
- To reach this page, click the study's Manage tab.
- Select either Manage Visits or Manage Timepoints.
Manage Visits

- Study Schedule
- Change Visit Order: Change the display order and/or chronological order of visits
- Change Properties: The label, cohort, type, and default visibility of multiple visits can be edited at the same time.
- Delete Multiple Visits: Select the visits you want to delete. Note this will also delete any related dataset and specimen rows. The number of rows associated with each visit are shown for reference.
- Delete Unused Visits: If there are any visits not associated with any data, you can delete them. You will see a list of unused visits and confirm the deletion.
- Recalculate Visit Dates: The number of rows updated is shown after recalculating.
- Import Visit Map: Import a visit map in XML format.
- Visit Import Mapping: Define a mapping between visit names and numbers so that data containing only visit names can be imported.
- Create New Visit.
Change Visit Order
Display order determines the order in which visits appear in reports and views for all study and specimen data. By default, visits are displayed in order of increasing visit ID for visit-based studies, which is often, but not necessarily the same as date order as used in timepoint-based studies. You can also explicitly set the display order.Chronological visit order is used to determine which visits occurred before or after others. Visits are chronologically ordered when all participants move only downward through the visit list. Any given participant may skip some visits, depending on cohort assignment or other factors. It is generally not useful to set a chronological order for date-based studies.To explicitly set either order, check the box, then use the "Move Up" or "Move Down" buttons to adjust the order if needed. Click "Save" when you are done.
Manage Timepoints

- Study Schedule
- Recompute Timepoints: If you edit the day range of timepoints, use this link to assign dataset data to the correct timepoints. The number of rows changed will be reported.
- Delete Multiple Timepoints: Select the timepoints you want to delete. Note this will also delete any related dataset and specimen rows. The number of rows associated with each timepoint are shown for reference.
- Create New Timepoint
- Timepoint Configuration: Set the study start date and duration for timepoints. Used to assign a row to the correct timepoint when only a date field is provided.
- A timepoint is assigned to each dataset row by computing the number of days between a subject's start date and the date supplied in the row.
- Each subject can have an individual start date specified by providing a StartDate field in a demographic dataset.
- If no start date is available for a subject, the study start date specified here is used.
- If dataset, specimen, or other data is imported that is not associated with an existing timepoint, a new timepoint will automatically be created.
- The default timepoint duration will determine the number of days included in automatically created timepoints.
Related Topics
- Edit Visits or Timepoints: Edit individual visits or timepoints
Study Schedule
- understand study requirements.
- set required datasets for each time point.
- set the status of each dataset (Draft, Final, Locked, Unlocked) and other properties (Author, Data Cut Date, Category, Description, and Visibility).
 To mark a dataset as required, click a cell within the grid, as show below.
To mark a dataset as required, click a cell within the grid, as show below. To edit dataset metadata status, click the pencil button, as show below.
To edit dataset metadata status, click the pencil button, as show below. Dataset status is shown in the Data Views Browser.
Dataset status is shown in the Data Views Browser.Manage Locations
Manage Locations
Managing locations and changing location definitions requires folder or project administrator permissions. However, the contents of the table can be made visible to anyone with read permissions by adding a locations query web part.- Click the study's Manage tab.
- Select Manage Locations.

Add a Location
Click Insert New, enter information as required, then click Save. Fields include:- Location Id: The unique LDMS identifier assigned to each location, if imported from an LDMS system.
- External Id: The external identifier for each location, if imported from an external data source.
- Labware Lab Code: The unique Labware identifier assigned to each location, if imported from a Labware system.
- Lab Upload Code: The upload code for each location.
- Label: The name of the location.
- Description: A short description of each location.
- Location Types: Check boxes to select which type of location this is (more than one may apply): SAL (Site-Affiliated Laboratory), Repository, Endpoint, Clinic.
- Address Information: Physical location.
Edit an Existing Location
Click Edit to change any information associated with an existing location.Delete Unused Locations
Locations which are not in use may be deleted from the Manage Locations page, shown above. The grid shows which locations are currently in use, meaning other tables within the study refer to them. For example, locations are in use if they are:- Original collection locations or current storage locations of specimens in the repository.
- Involved in specimen requests.
Labs TSV File
Another way to manage locations used within a study is to directly modify the labs.tsv file located in the specimen archive. The structure of this tab-separated values file is very similar to the grid shown in the location management interface. The format is documented on this page and a sample file is available here: labs.tsv.Offer Read Access
To show the contents of the table to anyone with read access, place a query web part in the folder or tab of your choice:- Select Query from the Select Web Part dropdown in the lower left.
- Click Add.
- Give the web part the title of your choice.
- Select Schema "study" and check the box to show the contents of a specific query.
- Select Query "Location" and choose the desired view and choose other options as needed.
- Click Submit.
Manage Location Types
If you are using a specimen request repository within LabKey Server, you may choose to allow only certain types of location to make requests.- Click the study's Manage tab.
- Select Manage Location Types.
- Click checkboxes for the types of location you want to allow to be requesting locations:
- Repository
- Clinic
- Site Affiliated Lab (SAL)
- Endpoint Lab
- Click Save.
Manage Cohorts
Manage Cohorts
Administrators can access the "Manage Cohorts" page via these routes:- From within a study, click the Manage tab, and then click Manage Cohorts.
- From any datagrid, select Participant Groups > Manage Cohorts.

Assignment Mode: Simple or Advanced
- Simple: Participants are assigned to a single cohort throughout the study. For example, gender or demographic cohorts set up to track the impact of a given treatment on different categories of individual.
- Advanced: Participants may change cohorts mid-study. For example, if your cohorts are based on disease progression or treatment regimen, participants would potentially move from cohort to cohort based on test results during the term of the study. Note that advanced cohort management requires automatic assignment via a study dataset that can include multiple participant/visit pairs (i.e. not a demographic dataset).
Assignment Type: Automatic or Manual
Participants can be assigned to cohorts manually, or automatically based on a field you specify in a dataset. If you are automatically assigning cohorts, you will also see a section here for specifying the dataset and field. See Assign Participants to Cohorts for further information.Defined Cohorts
The Defined Cohorts section lists all cohorts currently defined for the study. You can insert new cohorts, delete unused ones, and export information about current cohorts in various formats.Each defined cohort has an Edit link you may use to specify whether the members of that cohort are considered enrolled in the study, the expected or target subject count, and a short text description of the cohort.
 If desired, you can also add to the default fields that define a cohort by clicking Edit Cohort Definition and specifying additional fields. The new fields you define can then be specified using the per-cohort Edit links as above.
If desired, you can also add to the default fields that define a cohort by clicking Edit Cohort Definition and specifying additional fields. The new fields you define can then be specified using the per-cohort Edit links as above.
Participant-Cohort Assignments
The bottom of the "Manage Cohorts" page shows a list of the participants within the current study and the cohort associated with each participant.Assign Participants to Cohorts
Automatic Cohort Assignment
The Automatic option for mapping participants to cohorts allows you to use the value of a dataset field to determine cohort membership. The field used must be of type string.- Select the name of the mapping dataset ("Demographics" in this example) from the Participant/Cohort Dataset drop-down menu.
- Select the Cohort Field Name you wish to use ("Treatment Group" in this example).
- Click Update Assignments.
Manual Cohort Assignment
If you wish to manually associate participants with cohorts, and do not need to use time-varying cohorts, select "Manual" from the radio buttons. For each participant, choose a cohort using the dropdown menu which lists available cohorts. Scroll down to click Save when you have finished assigning participants to cohorts.
Use Cohorts
For information on using cohorts and filtering datasets based on cohorts, see the User Guide for Cohorts.Manage Participant IDs
- Alternate Participant IDs - Merge inconsistently named ids in your data.
- Alias Participant IDs - Associate multiple names for the same organism, while maintaining the original data.
Alternate Participant IDs
Merging Participant Data
Suppose you discover that two participant IDs in your data actually refer to the same actual participant. Perhaps naming conventions changed, or someone accidentally entered data with the incorrect participant id. They meant to enter data for Participant "LK002-123", but accidently entered the data under the ID "LK002-1". Now LabKey Server thinks there are two participants, when in fact there is only one actual participant. To fix these sort of naming mistakes and merge the data associated with the "two" participants into one, LabKey Server can systematically search for an id and replace it with a new id value.- Go to Admin > Manage Study > Manage Alternate Participant IDs and Aliases.
- Click Change or Merge ParticipantID.
- Enter both the id value to be replaced and the replacing id value.
- Click Preview.
- LabKey Server searches all of the data in the folder and presents a list of datasets to be changed.
- Click link text in the report to see filtered views of the data to be changed.
- If conflicts are found, i.e., when a table contains both ids, LabKey Server gives you a chance to choose between the old values or the new values for that table. For each table, select either Use old Id value or Use new Id value.

- Click Merge to run the search and replace.
- If your folder contains a configured alias mapping table, you can optionally convert the old name to an alias by selecting Create an Alias for the old ParticipantId. When this option is selected, a new row will be added to the alias table. For details on configuring an alias table, see Alias Participant IDs.
- If an alias is defined for an old id, the server won't update it on the merge. A warning is provided in the preview table: "Warning: <old id> has existing aliases".

Related Topics
- Publish a Study - Export randomized dates; hold back protected data columns.
- Alias Participant IDs - Align participant data from sources that use different names for the same subject.
Alias Participant IDs
- merging records with different ids for the same animal
- consolidating search results around a central id
- retaining data as originally provided by a client
Merge Data Containing Participant Alias Names
To set up alias ids, point to a dataset that contains the aliases for each participant, where one column contains the aliases for a given participant and other column which contains the source organizations that use those aliases.- Add a dataset containing the alias and source organization information. See below for an example file.
- Go to Admin > Manage Study > Manage Alternate Participant IDs and Aliases.
- Point to the dataset using the dropdown field Dataset Containing Aliases.
- Point to the column containing alias names using Alias Column.
- Point to the column containing the source organization using Source Column.
- Click Save Changes and Done.
| ParticipantId | Aliases | SourceOrganization | Date |
|---|---|---|---|
| 101344 | Primate 44 | ABC Labs | 10/10/2010 |
| 101344 | Macaque 1 | Research Center A | 10/10/2010 |
| 103505 | Primate 45 | ABC Labs | 10/10/2010 |
| 103866 | Primate 46 | ABC Labs | 10/10/2010 |
Resolving Naming Conflicts
What if incoming data contains a id that is already used being used in the system to refer to a different subject? To resolving naming conflicts like this, you can systematically search and replace a given id, and optional retain one of the conflicting names as alias. For details see Alternate Participant IDs.One you have an alias dataset in place, you can add more records to it by clicking Import Aliases.To clean all alias mappings, but leave the alias dataset in place, click Clear All Alias Settings.Manage Comments
- Specimen-level and vial-level comments.
- Participant-level and participant-visit-level comments
- Comment user guide. Provides an overview of use cases for comments.
Enable per-vial and per-specimen comments
If you only need to set comments on a per-vial or per-specimen basis, setup is simple. Steps:- Go to a specimen or vial view (e.g., click on "By Individual Vial" in the "View All Specimens" section of the Specimens web part).
- Click the "Enable Comments/QC" button above the grid view.
Enable per-participant and/or per-participant-visit comments
Setting up comments on a per-participant and/or participant-visit basis takes more steps than setting up vial-level and specimen-level comments.The comments associated with a Participant or Participant/Visit are saved as fields in datasets. Each of the datasets can contain multiple fields, but only one field can be designated to hold the comment text. Comment fields must be of type text or multi-line text. Comments will appear automatically in colums for the specimen and vial views.You will need to set up dedicated fields to hold participant and participant/visit comments. You do not need to set up both types of comments if you only wish to use one of them.Create or add comment fieldsFor holding participant-level comments, create a demographic-type dataset that includes a column for comments. Alternatively, you can add a column for comments to a pre-existing demographic dataset.For holding participant-visit-level comments, create non-demographic-type dataset that includes a column for comments. Alternatively, you can add a column for comments to a pre-existing, non-demographic dataset.Note: Only users with read access to the selected dataset(s) will be able to view comment information. Make sure your users have appropriate permissions on comment datasets.Access the "Manage Comments" UIAccess the "Manage Comments" page by going to the study's portal page, selecting "Manage Study" and then choosing "Manage Comments." The "Manage Comments" page for the Demo Study looks as follows: Identify the datasets and columns/fields that will hold comments.Participant Comment Assignment
Identify the datasets and columns/fields that will hold comments.Participant Comment Assignment
- Comment Dataset - The dataset selected must be a demographics dataset.
- Comment Field Name - This dropdown identifies the field in the selected dataset that holds participant-level comments.
- Comment Dataset - The dataset selected cannot be a demographics dataset.
- Comment Field Name - This dropdown identifies the field in the selected dataset that holds participant-visit-level comments.
Manage Study Security (Dataset-Level Security)
Configure Study/Dateset-level Security
Before you configure dataset-level security for a given group, you must first ensure that they have at least "Reader" permissions on the folder containing the study datasets. Follow these steps:- Navigate to the folder containing the study and choose Admin > Folder > Permissions.
- On the Permissions page, grant "Reader" access or higher to the target group. Click Save and Finish. Return to the study folder if no new access is needed.
- Select the Manage tab, then click Manage Security.
- On the Study Security page, use the dropdown Study Security Type to select a study security "style", described below.
Study Security Types
Type 1: Basic Security with Read-Only Datasets- Uses the security settings of the containing folder for dataset security. Only administrators can import or delete dataset data.
- Users with read-only or update permissions on the folder can see all datasets, but cannot edit, import, update, or delete them.
- Identical to Basic Read-Only Security, except that individuals with UPDATE permission can edit, update, and delete data from datasets.
- Users with read-only access to the folder will see a view identical to "Basic Security with Read-only Datasets" above. Only users with update permission will see the edit option.
- Allows the configuration of security on individual datasets.
- Only administrators can import or delete dataset data.
- Users with read access to the folder may also be granted access to read certain datasets.
- No edit permissions can be granted and edit options are not visible.
- Per-dataset read-only access can be granted or revoked at on the study dataset security page (see below for further info).
- This security type is identical to the one above, except that users with folder access may also be granted "edit" permissions on selected datasets.
Configure General Dataset Permissions
The Study Security section lets you specify general dataset access for each group.These options are available only for "Custom Security" types (types 3 and 4 above).- In the Study Security section, specify "Read" and possibly "Edit" permissions for each group in the project:
- Edit All. Members of the group may view and edit all rows in all datasets. (Only available with Custom security with editable datasets is selected (type 4 above).)
- Read All. Members of the group may view all rows in all datasets.
- Per-Dataset. Members of the group may view and possibly edit rows in some datasets; permissions are configured per-dataset.
- None. Members of the group may not view or edit any rows in any datasets. They will be able to view some summary data for the study.
- Note that these options override the general Reader access granted at the folder level.
 Note the red exclamation mark at the end of the All site users row -- this indicates that they lack folder-level read permissions to the study.
Note the red exclamation mark at the end of the All site users row -- this indicates that they lack folder-level read permissions to the study.
Configure Per Dataset Permissions
The Per Dataset Permissions section lets you specify access for specific datasets.- For a given group you can grant edit or read access for each individual dataset by setting the dropdown to Read or Edit.
- You can block access to a dataset by setting the dropdown to None.
- Note that these options override the general Reader access granted at the folder level.

Configure Report Permissions
Please see Configure Permissions for Reports & Views.Configure Permissions for Reports & Views
Explore Permissions and Project Groups
To explore these features, you will first need to set up a few users and groups. If you are working on a server where you have administrative permissions, such as your own evaluation installation, but have not already set up site users and site groups, complete the steps on this page: Secure Your Data.- Navigate to your Study home page and select Admin > Folder > Permissions. - If you created the Researchers site group and gave them Editor permissions, you will see that they also have Editor permissions on the contents of this folder.
- In the Editor row, pulldown the Add user or group... box and select joe_public1 from the list as shown:

- Then select the Project Groups tab.
- Type "Reviewers" in the New Group Name box and click Create New Group.

- In the popup window, add joe_public1 and joe_public2 as members, then click Done.
- Return to the Permissions tab and add the new "Reviewers" group to the Reader Role so that they will have access to datasets in the project.
- Click Save and Finish.
View and Set Report Permissions
- From the study home page, do either of the following:
- Select the Manage tab, then click Manage Views.
- Select the Clinical and Assay Data tab, and from the pulldown on the Data Views web part, select Manage Views.
- Scroll down to a report or view of interest, such as "My View: Systolic vs. Diastolic" created as part of the study tutorial.
- Click the link in the Access column for the given row.

- Default : this dynamic view will be readable only by users who have permission to the source datasets
- Custom : set permissions per group; then check boxes to give access to groups
- Private : this view is only visible to you
 In the lists of site and project groups, an enabled group indicates that the group already has READ access to the dataset (and to this report) through the project permissions. If a group is disabled, the group does not have READ access to the dataset and cannot be granted access through this view. If the checkbox is selected, the group has been given explicit access through this view.Consider the scenario where one of our visualizations, in this case "My View: Systolic vs. Diastolic" is in draft state and we do not want the group of reviewers to be able to see it in the current form.
In the lists of site and project groups, an enabled group indicates that the group already has READ access to the dataset (and to this report) through the project permissions. If a group is disabled, the group does not have READ access to the dataset and cannot be granted access through this view. If the checkbox is selected, the group has been given explicit access through this view.Consider the scenario where one of our visualizations, in this case "My View: Systolic vs. Diastolic" is in draft state and we do not want the group of reviewers to be able to see it in the current form.- Click the Custom button to enable per group selections.
- Uncheck the box for Reviewers.
- Click Save.
- Notice that the link in the Access column now reads "custom".
- To test this setting, impersonate the reviewers group by clicking your account login in the upper right and choosing Impersonate > Groups > Reviewers from the menu that appears.
- Notice that now the Manage Views web part does not include the "My View: Systolic vs. Diastolic" item we just restricted. The Reviewers can still see other views based on the dataset as well as the dataset itself.
- To stop impersonating, click again on your username and choose Stop Impersonating.
Matrix of Permissions
Dataset-Level and Folder-Level Permissions
The following table lists the level of access granted for study dataset when folder-level permissions are set according to the top row and dataset-level permissions are set according to the left column.| Admin | Editor | Author | Reader | Submitter | No permissions | |
|---|---|---|---|---|---|---|
| None | Limited editing. Admins can always Import and Delete by default. | None | None | None | None | None |
| Read | No additional permissions on top of those granted to Admins by default. | View | View | View | None | None |
| Edit | Full Edit permissions (Insert, New, and Edit) added on top of default permissions. | View and edit | View and edit | View and edit | None | None |
Related Topics
Securing Portions of a Dataset (Row and Column Level Security)
Create a Filtered Report/View
Disallow direct access to the dataset, and create a report/view that shows only a subset of rows or columns in the dataset. Then grant access to this report/view as appropriate. For details, see Configure Permissions for Reports & Views.Linked Schemas
In a separate folder, expose a query that only includes a subset of the rows or columns from the source dataset using a Linked Schema. For details see Linked Schemas and Tables.Protected Columns
Mark the sensitive columns as "protected". Using the Publish Study wizard, publish a version of the study that excludes those columns. The published study will be exposed in a separate folder; grant access to the separate folder as appropriate. For details see Publish a Study: Protected Health Information.Manage Dataset QC States
- User Guide for Dataset QC. Provides an overview of dataset-level quality control, filtering by QC state and updating QC states.
- User Guide for Specimen QC. Specific QC options for specimen data.
Set Up Dataset QC
To navigate to the QC management area:- From the study home page, select the Manage tab.
- Click Manage Dataset QC States.
 Currently Defined QC States. You can define an arbitrary number of QC states and determine whether data in these categories will be shown to users by default or not using the "Public" checkbox. When a QC state is not marked public, data in this state will be hidden if the "Dataset Visibility" option is set to "Public Data."Default states for study data. These settings allow different default QC states depending on data source. If set, all imported data without an explicit QC state will have the selected state automatically assigned. You can set QC states for the following:
Currently Defined QC States. You can define an arbitrary number of QC states and determine whether data in these categories will be shown to users by default or not using the "Public" checkbox. When a QC state is not marked public, data in this state will be hidden if the "Dataset Visibility" option is set to "Public Data."Default states for study data. These settings allow different default QC states depending on data source. If set, all imported data without an explicit QC state will have the selected state automatically assigned. You can set QC states for the following:
- Pipeline-imported datasets
- Assay data copied to this study
- Directly inserted/updated dataset data
- The default setting is "Public Data," so QC states defined above that do not have a check in the "Public" box will not be displayed
- Datasets that have been incorporated into your study before you set up QC states will not have a QC state and will not be considered public. This means that they will be hidden unless the "Dataset Visibility" setting reads "All Data." Please see the next section for further details.
Restore Hidden, Pre-Existing Datasets
The default value of "Dataset Visibility" is "Public Data." This means that only "Public" data will be displayed if you set up QC states and leave this setting at its default. Pre-existing datasets are not automatically assigned a QC state and are not considered public, so they will cease to be visible.To make pre-existing data visible, you can simply set "Default Visibility" to "All Data." However, if you'd like to restore pre-existing datasets while still hiding non-public datasets, follow these steps:- In "Manage QC States", set "Default Visibility" to "All Data".
- For each pre-existing dataset:
- Select all rows
- Choose "QC State -> Update state of selected rows."
- Choose one of your pre-defined QC states from the drop-down menu "New QC State"
- Enter a comment
- Click "Update Status"
- Return to "Manage QC States" and set "Default Visibility" to "Public Data."
Manage Study Products
- Go to the Vaccine Design tab.
- Click Manage Study Products.
Populate Dropdown Options
When you insert new Immunogens, Adjuvants, and Challenges you select values for Challenge Type, Immunogen Type, Gene, SubType, and Route from lists specified either at the project- or folder-level. When defined at the project level, the values stored are made available in all studies within the project. This walkthrough suggests defining folder level tables; to define at the project level, simply select the Project branch of each configure option.- Select Configure > Folder > Challenge Types.

- A new browser tab will open on the schema browser.
- Use Insert > Insert New Row (or Import Bulk Data) to populate the StudyDesignChallengeTypes table.
- When all additions to the table have been submitted, click the Vaccine Design tab, then Manage Study Products.
- Repeat for each:
- Configure > Folder > Immunogen Types to populate the StudyDesignImmunogenTypes table.
- Configure > Folder > Genes to populate the StudyDesignGenes table.
- Configure > Folder > SubTypes to populate the StudyDesignSubTypes table.
- Configure > Folder > Routes to populate the StudyDesignRoutes table.
- Click the Vaccine Design tab, then Manage Study Products again.
Define Study Products
Each immunogen, adjuvant, and challenge used in the study should have a unique name and be listed in the panels on this page. Enter information to each panel and click Save when finished.Define Immunogens
The immunogen description should include specific sequences of HIV antigens included in the immunogen if possible. You should also list all the expected doses and routes that will be used throughout the study. When you add the immunogen to an immunization treatment, you will select one of the doses you listed here. Click Add new row to open the data entry fields - initially only "Label" and "Type" will be shown. Click Add new row under "HIV Antigens" and "Doses and Routes" to add values to the associated fields.You can delete immunogens or any component rows by clicking the trash can icon to the left of the fields to delete. You will be asked to confirm the deletion before it occurs.
Click Add new row to open the data entry fields - initially only "Label" and "Type" will be shown. Click Add new row under "HIV Antigens" and "Doses and Routes" to add values to the associated fields.You can delete immunogens or any component rows by clicking the trash can icon to the left of the fields to delete. You will be asked to confirm the deletion before it occurs.
Define Adjuvants
Click Add new row in the Adjuvants panel and enter the label for each adjuvant. Click Add new row to add dose and route information. Again, list all the expected doses and routes that will be used throughout the study. When you add the adjuvant to an immunization treatment, you will select one of the doses you listed here. You can delete an adjuvant or dose/route information by clicking the trash can icon for the fields. You will be asked to confirm before deletion occurs.
You can delete an adjuvant or dose/route information by clicking the trash can icon for the fields. You will be asked to confirm before deletion occurs.
Define Challenges
Click Add new row in the Challenges panel to add each challenge required. Click Add new row for "Doses and Routes" to add all the options you will want to have available when you later add this challenge to a treatment.
Next Step
Once you have defined study products, remember to click Save. Then you can package them into specific immunization protocols, or treatments.Additional Resources
- [ Video Overview: Study Designer - treatment data and assay schedule - March, 2014 ]
Manage Treatments
- Open the Immunizations tab.
- Click Manage Treatments.
Populate Options
You should already have defined Immunogens, Adjuvants, and Challenges on the Manage Study Products page. This process includes populating the dropdown menus for various fields used in defining treatments.Your study should also have already defined the cohorts and timepoints or visits you plan to use for the vaccine treatment schedule. Note that whether your study is visit- or time-based, the process in setting up the treatment schedule is the same. The exception is that with visits, you have the additional option to change the order in which they appear on your treatment schedule.Define Treatments
Treatments are defined as some combination of the immunogens, adjuvants, and challenges already defined in your folder. A treatment must have at least one adjuvant or immunogen, but both are not required.- Click Add new row in the "Treatments" section.
- Enter the Label and Description.
- Click Add new row for the relevant section to add Immunogens, Adjuvants, and/or Challenges to this treatment. Note that if there are no products defined for one of these categories, the category will not be shown.
- Select from the dropdowns listing the products and dose and route information you provided when defining the product.

- Click Save when finished.
Define Treatment Schedule
Once you've defined the contents of each treatment, you can set the schedule for when treatments will be given and to whom. Participant groups, or cohorts may already be defined in your study or you can define cohorts directly from this page by giving them a name and participant count.- The initial treatment schedule is prepopulated with the cohorts defined in your study.
- To add additional cohorts, click Add new row and enter the name and count.

- In the Treatment Schedule section, click Add new visit.

- In the Add Visit popup, either:
- Select an existing study visit from the dropdown or
- Create a new study visit providing a label and range.
- Click Select or Submit respectively to add a new column for the visit to the treatment schedule.
- For each cohort who will receive a treatment at that visit, use the pulldown menu to select one of the treatments you defined.

- Repeat the process of adding new visit columns and selecting treatments for each cohort as appropriate for your study.
- Click Save. Only the visits for which at least one cohort receives a treatment will be saved.
- View the Treatment Schedule on the Immunizations tab.
- Hover over the ? next to any treatment on the schedule to see the definition in a tooltip.

CAVD Folder Treatment Schedule
In a CAVD folder, study products are not rolled into a "Treatments" table prior to defining the Treatment Schedule. Instead, after adding cohort rows and visit (or timepoint) columns to the treatment schedule, the user clicks an entry field to directly enter the components of the immunization treatment given to that cohort at that time. The popup lists all defined products with checkboxes to select one or more components. Click OK to save the treatment, then Save to save the treatment schedule. The schedule will show a concatenated list of product names; hover over the "?" to see details including dose and route information for each product included.
Click OK to save the treatment, then Save to save the treatment schedule. The schedule will show a concatenated list of product names; hover over the "?" to see details including dose and route information for each product included.
Additional Resources
Next Step
Manage Assay Schedule
- Open the Assays tab.
- Click Manage Assay Schedule.
Populate Dropdown Options
Before you can define your assay schedule, you will need to populate dropdown options for the Assay Name, Lab, SampleType, and Units fields. They can be set at the folder level as described here. You can also view or set project-level settings by selecting Configure > Project > [field_name].- Select Configure > Folder > Assays.
- Use Insert > Insert New Row (or Import Bulk Data) to populate the StudyDesignAssays table.
- Repeat for:
- Configure > Folder > Labs to populate the StudyDesignLabs table.
- Configure > Folder > SampleTypes to populate the StudyDesignSampleTypes table.
- Configure > Folder > Units to populate the StudyDesignUnits table.
Define Assay Configurations
Each assay you add will become a row on your assay schedule.- Return to the Manage Assay Schedule page.
- In the Assay Schedule panel, click Add new row.
- Select an Assay Name and complete the Description, Lab, Sample Type, Quantity, and Units fields.

Define Assay Schedule
Next you will add a column for each visit in your study during which an assay you defined will be run. Note that if you are using a time-based study, the word "visit" will be replaced with "timepoint" in the UI. If you do not already havve visits defined in your study, you may add them from this page.- Click Add new visit.

- In the popup, either:
- Select an existing study visit from the dropdown, or
- Create a new study visit providing a label and range.
- Click Select or Submit respectively to add a new column for the visit to the assay schedule.
- Each visit you add will become a column - check the boxes to identify which assays will be run at this visit.
- Continue to add rows for assays and columns for visits as appropriate.
- Click Save to save the schedule. Note that columns without data (such as visits added which will not have any assays run) will not be saved or shown.
Assay Plan
Enter a text description of the assay plan. Click Save when finished. The assay plan is optional to the study tools, but may be required for some workflow applications. If provided, it will be displayed with the assay schedule in the study.Display Assay Schedule
You may now choose to add an Assay Schedule web part to any tab or page within your study. The web part includes a Manage Assay Schedule link, giving users with Editor permissions the ability to manage the assay schedule without having access to the Manage tab.- From the Select Web Part dropdown, choose Assay Schedule.
- Click Add.

Additional Resources
Demonstration Mode
- show your data to anyone who should not see participant IDs
- display your data on a projection screen
- take screen shots for slide show presentations

Turn On/Off Demonstration Mode
To turn on demonstration mode:- the address bar (when viewing individual participant pages or using URL filters)
- the status bar (when hovering over links to participant views, etc.)
- free-form text that happens to include participant IDs, for example, comments or notes fields, PDFs, wikis, or messages
Related Topics
Create a Vaccine Study Design
Create Vaccine Study Folder
If you have a custom module containing a CAVD Study folder type, you can directly create a folder of that custom type named "Vaccine Study" and skip to the next section.Otherwise, you can set up your own Vaccine Study folder as follows:- If you do not already have a local server to use for this tutorial, Install LabKey Server (Quick Install)
- Download this folder archive: vaccineStudy.folder.zip
- Create a new folder of type Study, and, to match the screencaps in this walkthrough, name it "Vaccine Study".
- Click Import Study.
- Confirm Local zip archive is selected, then click Browse or Choose File and select the zipped archive you just downloaded.
- Click Import Study.
- When the pipeline import is complete, click Overview to return to the home page of your new study.
Other Admin Tasks
Administrator access is required to populate the Overview tab with specific information about the study. This tab need not be filled in to complete other study steps, but it is a useful place to present summmary information.- Click the Manage tab.
- Click Change Study Properties.
- Enter Label, Investigator, Description and other study details as desired.
- Click Submit.
Set Up Vaccine Design Tab
On the Vaccine Design tab, click Manage Study Products. Define the products you will study, including immunogens, adjuvants, and antigens, as described in this topic. Return to this page when finished.Set Up Immunizations Tab
Select the Immunizations tab and click Manage Treatments to define immunization treatments and schedule, as described in this topic:Set Up Assays Tab
Select the Assays tab and click Manage Assay Schedule. Follow the instructions in this topic:Next Steps
Your study is now ready for data collection, integration, and research. If you intend to generate multiple vaccine study folders using this one as a template, follow the steps in Export / Import a Folder.Additional Resources
Continuous Studies
 The study still utilizes a start date and may also have an end date, though it is not required. To see and adjust these dates, select Admin > Manage Study.Proceed to create a new study and set up the datasets you require, though skipping any steps related to visit or timepoint mapping. Note that the resulting study will not have some features like the study schedule. Creating visualizations based on time will also not always work as in timepoint or visit based study.
The study still utilizes a start date and may also have an end date, though it is not required. To see and adjust these dates, select Admin > Manage Study.Proceed to create a new study and set up the datasets you require, though skipping any steps related to visit or timepoint mapping. Note that the resulting study will not have some features like the study schedule. Creating visualizations based on time will also not always work as in timepoint or visit based study.
Changing the timepoint style for a study
Once you have selected the timepoint style for your study, it cannot be changed within the user interface. If you made a mistake and need to change it right away, you may be able to export the study, change the value of timepointType in the study.xml file, and reimport the archive. Other adjustments within your study will likely be required after making this type of fundamental change.Import, Export, and Reload a Study
- Studies can be reloaded to transfer a study from a staging environment to a live platform.
- A snapshot of one study can be exported and imported into several new studies so that they share a common baseline.
- A brand new study can be generated with the exported structure (with or without the data) of an existing study. This allows very rapid creation of new studies based on templates.
- The structure of an existing set of studies can also be standardized by importing selected structural elements from a common template.
- A study can be exported masking all identifying information enabling the sharing of results without sharing PHI or any patient or clinic details.
- Studies can be set up to reload nightly from a remote master data depot.
Export
To export a study folder, go to Admin > Manage Study and click the Export Study button at the bottom of the page. This page is also accessible through the Admin > Folder > Management page on the Export tab and is described in Export / Import a Folder.Details about the study objects can be found here: Export Study Objects.Import
Importing a study archive is the same as importing any folder archive with a few additional considerations. Like other imports, you first create a folder of type "Study", then navigate to it before importing. You can import from an exported archive, or from another study folder on the same server. Selecting which study objects to import from either source gives you, for example, the ability to import an existing study's configuration and structure without including the actual dataset data from the archive. If you do want to import dataset data or specimen data to a new study, you must use the archive import option as the folder template method does not support data transfer.Validate All Queries After Import
By default, queries will be validated upon import of a study archive and any failure to validate will cause the import job to raise an error. To suppress this validation step, uncheck the Validate all queries after import option. If you are using the check-for-reload action in the custom API, there is a suppress query validation parameter that can be used to achieve the same effect as unchecking this box in the check for reload action.Fail Import for Undefined Visits
By default, new visit rows will be created in the study during import for any dataset or specimen rows which reference a new, undefined visit. If you want the import to instead fail if it would create visits that are not already in the destination study or imported visit map, you can check the box to "Fail Import for Undefined Visits".Overlapping Visit Ranges
If you are importing a new visit map for a visit-based study, the import will fail if the new map causes overlapping visit.Study Templates
A study minus the actual dataset data can be used as a template for generating new studies of the same configuration, structure and layout. To generate one, you can either:- Create a specific template study with all the required elements but no data.
- Export an existing study, but exclude "Dataset Data" on export.
- Select Admin > Folder > Management and click the Import tab.
- Click Choose File or Browse and select the study template archive.
- Check the box for "Use advanced import options".
- Click Import from local zip archive.
- Check the box for "Select specific objects to import".
- Select the elements to import; if you are using an archive as a template, check that "Dataset Data" and other data objects are not checked. Objects not available or not eligible for import are grayed out.

- Click Start Import.
Reload
A study can be configured to reload study data from the pipeline root, either manually or automatically at pre-set intervals, which can be useful for refreshing studies whose data is managed externally. For example, if the database of record is SAS, a SAS script could automatically generate TSVs nightly to be reloaded into LabKey Server. This simplifies the process of using LabKey tools for administration, analysis, reporting, and data integration without forcing migration of existing storage or data collection frameworks.- Open the Manage tab and select Manage Reloading.
- Check the Allow Study Reload box.
- Manual Reload: Set the "Reload Interval" to <Never>.
- Automatic Reload: Set the "Reload Interval" to a time interval. A reload is attempted automatically each time the specified interval elapses.
- Click Update.
- Once you have enabled reloading, whether manual or automatic, a reload attempt can be initiated at any time by an administrator clicking the Attempt Reload Now button or by an external script invoking that same URL.
- Read dataset, specimen, and other important study data from a master database and/or specimen LIMS system.
- Write the data to the file system in the LabKey study archive format.
- Touch the studyload.txt file to update the timestamp to the current date/time.
- Signal to the LabKey Server that the archive is ready to load.
Related Topics
- LabKey XML Schema Reference
- Study Import/Export Files and Formats - Formats of the exported files
- Export / Import a Folder
Export Study Objects
- To export a study:
- From the Manage tab, click the Export Study button.
- Or select Admin > Folder > Management and click the Export tab.
- Select the checkboxes for folder and study objects you wish to export. The list will look something like the following:

Assay Datasets
This option exports assay dataset information, writing metadata to "datasets_manifest.xml" and data to .tsv files. See Study Import/Export Files and Formats for more details.Assay Schedule
Exports assay schedule .tsv files to a directory parallel to datasets in the archive including definitions of which assays are included in the study and expectations for which visits assay data will be uploaded.Categories
This option exports the Categories for report grouping to "view_categories.xml."Cohort Settings
This option exports the cohort definitions to "cohorts.xml." If defined, SubjectCount and Description for cohorts are included.CRF Datasets
This option exports Case Report Form dataset information, writing meta data to "datasets_manifest.xml" and "datasets_metadata.xml" files and data to .tsv files. See Study Import/Export Files and Formats for more details.Custom Participant View
For a study where the admin has pasted in a custom Participant HTML page, the custom participant view is exported as participant.html.Dataset Data
Export data in datasets; omitting this object creates a study template for use creating new matching but empty studies.Participant Comment Settings
This option exports participant comment settings, if present.Participant Groups
This option exports the study's participant groups. In addition to label, type, and datasetID, the autoUpdate attribute will record whether the group should be updated automatically. The file generated is "participant_groups.xml."Protocol Documents
This option exports the study protocol documents to a "protocolDocs" folder.QC State Settings
This option exports a "quality_control_states.xml" file that includes QC state definitions including custom states, descriptions, default states for the different import pathways and the default blank QC state.Specimen Settings
This option exports a "specimen_settings.xml" file containing the groupings, location types, statuses, actors, and requirements you have defined. If you later import that archive into an existing specimen repository, any new specimen settings will be added. Any status or actor that is currently in use in the specimen repository will not be replaced from the imported archive. When you import an in-use actor, the membership emails for that actor will be replaced.Note that there are some settings associated with specimen repositories which are not covered by this option. For example, custom properties defined for specimen tables are only exported in a full study archive.For additional information about specimen repository settings and options, see Specimens: Administrator Guide.Specimens
This option exports a "specimens" directory containing the specimen archive itself as a .specimens file. For more about specimen archives, see Specimen Archive File Reference. Note that this archive includes the data only - select export of specimen repository settings separately as described above.Treatment Data
Include information about study products and immunization treatments including immunogens, adjuvants, doses, and routes.Visit Map
This option exports a "visit_map.xml" file detailing the baseline and visit schedule for the exported study.More: For more information about export options and study schema, see Study Import/Export Files and Formats.Study Import/Export Files and Formats
XML Formats
Exporting a study using the XML formats produces a set of XML/XSD files that describe the study's settings and associated data. Some of these files are contained in similarly-named folders rather than at the top level. Key .xml and .xsd files are listed here and linked to their schema documentation pages:- study.xml -- Top level study schema XML file.
- cohorts.xsd -- Describes the cohorts used in the study. A cohort.xml file is exported only when you have manually assigned participants to cohorts.
- datasets.xsd -- Describes the study dataset manifest. Includes all study dataset-specific properties beyond those included in tableInfo.xsd. Used to generate dataset_manifests.xml.
- study.xsd -- A manifest for the serialized study. It includes study settings, plus the names of the directories and files that comprise the study.
- studyDesign.xsd -- Includes studyDesign table information including immunogens, adjuvants, sample types, immunization schedule.
- visit_map.xsd -- Describes the study visit map. It is used to generate the visitMap.xml file, which describes the study's visits and includes all of the information that can be set within the "Manage Visit" UI within "Manage Study."
- data.xml -- An XML version of dataset schemas.
- tableInfo.xsd -- Describes metadata for any database table in LabKey Server, including lists and datasets. A subset of this schema's elements are used to serialize lists for import/export. Similarly, a subset of this schema's elements are used to generate the datasets_metadata.xml file for dataset import/export. Note that a complementary schema file, datasets.xsd, contains additional, dataset-specific properties and is used to generate and read datasets_manifest.xml during dataset import/export. These properties are not included in tableInfo.xsd because of their specificity to datasets.
- query.xml -- Describe the queries in the study.
- report.xsd -- Describe the reports in the study.
- Additional information on query, view, and report schemas can be found on the Modules: Queries, Views and Reports page.
- specimen_settings.xml -- Contains the specimen repository settings including specimen webpart groupings, location types, request statuses, request actors, and default requirements.
Related Topics
Serialized Elements and Attributes of Lists and Datasets
Study export/import requires the serialization of several different types of data. XSD files are used to describe these serialization formats, but are also used to provide metadata for a wide range of tables and views in the LabKey database.
The tableinfo.xsd file contains elements and attributes that are used for List (L) and/or Dataset (D) serialization.
Both Datasets and Lists
The list below covers attributes & elements defined in tableInfo.xsd that are exported/imported for both datasets and lists.
Complex Type: dat:ColumnType
Attributes:
columnName (type: xs:string), D, L
Complex Type: dat:TableType
Attributes:
tableName (type: xs:string), D, L
Datasets
The list below covers attributes & elements defined in tableInfo.xsd that are exported/imported for datasets, but not for lists. Additional attributes & elements for datasets are provided in datasets.xsd, which is used to generate datasets_manifest.xml.
Complex Type: dat:TableType
Lists
The list below covers attributes & elements defined in tableInfo.xsd that are exported/imported for lists, but not for datasets.
Complex Type: dat:TableType
Publish a Study
- Participant Groups
- Datasets and Lists
- Timepoints and Visit Dates
- Specimens
- Views and Reports
- Settings (Folder, Study, and Specimen)
What Happens When You Publish a Study?
Data that is selected for publication is packaged as a new study in a new folder. (This is similar to creating an ancillary study, with slightly different options and behaviors.) The security settings for the destination folder can be configured independently of the original source folder, allowing you to maintain restricted access to the source study, while opening up access to the destination folder. By default, the new destination folder inherits its security settings from whatever parent folder is specified. To change the security configuration of the destination folder, define user groups for the folder and map roles (access levels) to those groups. For details see Security Tutorial and Configure Permissions.Protected Health Information
You can provide another layer of security to the published data by randomizing participant ids, dates, and clinic names. You can also hold back specified columns of data.For details see Publish a Study: Protected Health Information.Publish Data in a Study
To publish a study, follow these instructions:- In the study folder, click the Manage tab.
- At the bottom of the page, click the Publish Study button.
- Note: If there were already studies published from this one, you will have the option to use Previous Settings as defaults.
- The wizard lets you select the following options:
- General Setup - Specify a name and description for the published study, provide a protocol document, and select the destination folder. By default the destination folder is created as a child folder of the source study. You can select a different parent folder by clicking the Change button next to the Location field.
- Participants - Select at least one participant group.
- Datasets - You can optionally include any datasets in the source study. For details on refreshing these datasets, see Publish a Study: Refresh Snapshots.
- Timepoints - Select at least one timepoint.
- Lists/Views/Reports - These are all optional items.
- Specimens - If specimens are selected for publication, you have the option to refresh the data daily to capture ongoing changes to the source specimen data, or you can use a one-time, non-refreshable snapshot. For details on refreshing specimen data, see Publish a Study: Refresh Snapshots.

- Publish Options - These options let you randomize, mask, and hold back certain data when publishing. For details, see Publish a Study: Protected Health Information.
Republish a Study using Previous Settings
When you publish a study, the settings are retained and can be used later as defaults when republishing the same study. For example, an administrator might use exactly the same settings to republish a study with corrected data, or might update some settings such as to publish a 36-month snapshot of a trial in the same way as an 18-month snapshot was published.- Go to the Manage tab.
- Click Publish Study.
- The first option in the publication wizard is to select either:
- Republish starting with the settings from a previous publication: Choose from the list.
- Publish new study from scratch

- Click Next and continue with the wizard, noting the previous settings are provided as defaults.
Study Snapshot
Information about the creation of every ancillary and published study is stored in the study.studySnapshot table. This table contains a row for each ancillary or published study that was created from the study in the current folder. You can view this table in the schema browser, or add a query web part to any tab. Only users with administrator permissions will see any data. You may also add this snapshot to a tab in your folder:- Select Query from the Select Web Part dropdown in the lower left and click Add.
- Choose the schema "study" and click "Show the contents of a specific query or view".
- Select the query: "StudySnapshot".
- Click Submit.
- The default grid shows the settings used to publish the study; this column has been hidden to simplify this screencap:


Related Topics
Publish a Study: Protected Health Information
- Replace all participant IDs with alternate, randomly generated participant IDs.
- Apply random date shifts/offsets.
- Exclude specially marked "protected" columns from being copied to the published study.
- Mask clinic names with a generic name to hide any identifying features in the original clinic name.
Publish Options
The following screen shot shows one panel from a larger wizard used to publish a study. For details on starting this dialog, see Publish a Study.
Remove All Columns Tagged as Protected
Selecting this option will exclude all dataset, list, and specimen columns that have been previously tagged as "protected".- Navigate to the dataset/list that contains the column you want to protect.
- Edit the dataset/list definition.
- In the designer, select the column you wish to protect.
- Click the Advanced tab, place a check mark next to Protected, and click Save.

Shift Participant Dates
Selecting this option will shift published dates for associated participants by a random offset between 1 and 365 days. A separate offset is generated for each participant and that offset is used for all dates associated with that participant (except for exclusions, see below). This obscures the exact dates, protecting potentially identifying details, but maintains the relative differences between them, so that much of their scientific value is preserved. Note that the date offset used for a given participant is persisted in the source study and reused for each new published study.- Go to the dataset that includes the date column.
- Edit the dataset definition.
- In the designer, select the date column, then the Advanced tab.
- Place a checkmark next to Exclude From Shifting.
- Click Save.
Use Alternate Participant IDs
Selecting this option replaces the participant IDs throughout the published data with alternate, randomly generated ids. Like date offsets, the alternate id used for each participant is persisted in the source study and reused for each new published study. Admins can set the prefix and number of digits used in this alternate id if desired. See Alternate Participant IDs for details.Mask Clinic Names
When this option is selected, actual clinic names will be replaced with a generic label. This helps prevent revealing neighborhood or other details that might identify individuals. For example, "South Brooklyn Youth Clinic" is masked with the generic value "Clinic".All locations that are marked as a clinic type (including those marked with other types) will be masked in the published data. More precisely, both the Label and Labware Lab Code will be masked. Location types are specified by directly editing the labs.tsv file. For details see Manage Locations.Publish a Study: Refresh Snapshots
Refresh Datasets
To refresh a dataset in the published study, follow the same instructions for refreshing an ancillary study. For details, see Ancillary Studies.Refresh Specimens
If you want the published specimen data to reflect any changes/updates in the source study, the published study can be set to refresh automatically each day. If you want the published specimen data to remain static, you can specify that a one-time snapshot be made.You can set the refresh behavior either when you create the published study or after it has been created. To change the refresh behavior after the creation of the published study: go to the published study folder, click the Manage tab, and click the View Settings button. On the Published Study Settings page, use the Refresh Specimens checkbox to indicate whether or not specimens are refreshed nightly.The specimen refresh occurs as a part of system maintenance, which by default occurs at 2am. To set a different time of day, go to Admin > Site > Admin Console, click System Maintenance, choose a new time from the drop-down list, and click the Save button.Specimen Refresh: User Credentials
LabKey Server refreshes the specimen data using the security credentials of the user who last modified the specimen refresh settings. The user who initiated the study publication is the initial "modified by" user. If this user is no longer able to refresh specimens (for example, they leave the research organization or their security credentials fall below folder administrator), then subsequent specimen refreshes will fail. In this situation, a different user with at least folder admin permissions in the published study should update the specimen refresh settings:- Login as (or impersonate) a user with at least folder permissions
- Navigate to the published study folder
- Go to the Published Study Settings page by clicking the Manage tab and then clicking View Settings
- To perform specimen snapshot updates, LabKey Server uses the account identified in the Modified By field
- Click Update to update the Modified By field
- This will change the Modified By field to the current logged in user. LabKey Server will perform future specimen refreshes under this user account.
Ancillary Studies
Create an Ancillary Study
- In your parent study, click the Manage tab.
- Click Create Ancillary Study.
- Supply the ancillary study's name, description, protocol document.
- Select the participants to include.
- Select the datasets to include and set the data refresh style.
- Click Finish.
Refresh Data Snapshots in an Ancillary Study
To update the data in the ancillary (or published) study datasets:- Go to the dataset grid view that you would like to update.
- Select Views -> Edit Snapshot.
- On the Edit Query Snapshot page, click Update Snapshot.
View Previously Created Ancillary Studies
Information about the creation of every ancillary and published study is stored in the study.studySnapshot table for the parent study. For further information, see View Published Study Snapshot.Create New Ancillary Study with Previous Settings
Using the settings stored in the study.studySnapshot table, you may also create a new ancillary study using previous settings as defaults. For further information, see Republish Using Previous Settings.Shared Datasets and Timepoints
- Share the same dataset definitions and timepoints across multiple studies. This lets you define datasets at the project level and use the same definitions in the child folders. On this option, data is not shared across studies, only the dataset definitions. This is similar to defining an assay design at the project level so the same design can be available in child folders. In both cases, you can ensure that the same table definitions are being used across multiple containers, and control those definitions from a central source.
- Share demographic datasets, both the definitions and the actual data within them, with child folders. Demographic data in the child folders is automatically added to the shared dataset in the parent project, creating a union table out of the child datasets.
- View combined data across multiple studies. Combined data views are available at the parent/project-level.
Shared Definitions and Timepoints
Shared dataset definitions and timepoints are defined at the project-level and are available in any "sub-studies", that is, studies in the project's child folders. Any datasets and timepoints you define in the parent project will automatically appear in the child folders. Also any changes you make to the parent definitions and timepoints will cascade into the child folder, for example:- Any fields added to the dataset definition in the project will also appear in the child studies.
- Any visits added to the project will also appear in the child studies.
- Create a project of type Study. This project will form the source of the shared definition and timepoint structure.
- Once the empty study project is created, click Create Study.
- On the Create Study page, define your study properties and scroll down to the Experimental Features section. Enable Shared Datasets and/or Shared Timepoints. Note that these options are only available when creating a new study in a project; the options will not appear when creating a new study in a folder.

- Once Shared Datasets and/or Shared Timepoints have been enabled, change the folder type from Study to Dataspace.
- Create subfolders to this project, each of type Study.
- Now any definitions or timepoints in the project will also appear in the child studies.
Shared Demographic Datasets
Once shared datasets and shared timepoints have been enabled, you can enable shared data, not just shared definitions.Enable data sharing means that any individual records entered at the folder level will appear at the project level. In effect, the project level dataset become a union of the data in the child datasets. Note that inserting data directly in the project level dataset is disabled.- Navigate to the dataset definition in the top level project.
- Edit the dataset definition.
- In the dataset designer, ensure there is a checkmark next to Demographic Data.
- Use the dropdown Share Demographic Data to enable data sharing:
- When No is selected (the default) each child study folder 'owns' its own data rows.
- If the study has shared visits/timepoints, then Share by Participants means that data rows are shared across the project, and studies will only see data rows for participants that are part of that study. todo ???

The Dataspace Container
Note that the project-level container that shares its datasets and timepoints with children sub-studies does not behave like an "ordinary" study. If fact is it is a different container type: a Dataspace container, which does not follow the same rules and constraints that are enforced in regular studies. This is especially true of the uniqueness constraints that are normally associated with demographic datasets. This uniqueness contraint does not apply to datasets in the top-level Dataspace project, so it is possible to have a demographics table with duplicate participant ids, and similar unexpected behavior.If the same participant id occurs in multiple studies, participants groups may exhibit unexpected behavior. Participant groups do not track containers, they are merely a list of strings (participant ids), and cannot distinguish the same participant id in two different containers.When viewed from the project-level study, participants may have multiple demographics datasets that report different information about the same id, there might be different dates or cohort membership for the same visit, etc.Data Aliasing
- A lab provides assay data which uses different participant ids than those used in your study. (Using different participant ids is often desirable and intentional, as it provides a layer of PHI protection for the lab and the study.)
- Excel files have different column names for the same data, for example some files have the column "Immune Rating" and other have the column "Immune Score".
- The source files have a variety of names for the same visit id, for example, "M1", "Milestone #1", and "Visit 1".
Study Data Model
Study Entities
The core entities of a Study (its "keys") are Participants (identified by "Participant IDs") and Visits (identified by "Visit IDs" or "SequenceNums").Participants appear at planned locations (Sites) at expected points in time (Visits) for data collection. At such Visits, scientific personnel collect Datasets (including Clinical and Assay Datasets) and Specimens. These are all uploaded or copied to the Study.Participant/Visit pairs are used to uniquely identify Datasets and Specimens. Optionally, Sites can also be used as "keys." In this case, Participant/Visit/Site triplets uniquely identify Specimens.A Study also tracks and manages Specimen Requests from Labs, plus the initial delivery of Specimens from Sites to the Specimen Repository.
Customization
Studies can be customized via the flexible definition of Visits (time points), Visit Maps (measurements collected at time points) and Schemas (data types and relationships).The project team is free to define the additional Study entities as needed.Linking Data Records with External Files
Scenario
 Suppose you have a dataset where each of row of data refers to some image or file. For example, you have a dataset called Biopsies, where you want each row of data to link to an image depicting a tissue section. Below is an example Biopsies table:
Suppose you have a dataset where each of row of data refers to some image or file. For example, you have a dataset called Biopsies, where you want each row of data to link to an image depicting a tissue section. Below is an example Biopsies table:
Biopies
| ParticipantId | Date | TissueType | TissueSlide |
|---|---|---|---|
| PT-101 | 10/10/2010 | Liver | slide1.jpg |
| PT-102 | 10/10/2010 | Liver | slide2.jpg |
| PT-103 | 10/10/2010 | Liver | slide3.jpg |
Solution
To achieve this linking behavior, follow these steps:- Upload the target images to the File Repository.
- Import a dataset where one column contains the image names.
- Build a URL that links from the image names to the image files.
- Use this URL in the dataset.
Upload Images to the File Repository
- Navigate to your study folder.
- Go to Admin > Go To Module > File Content.
- Drag-and-drop your files into the File Repository. You can upload the images directly into the root directory, or you can upload the images inside a subfolder. For example, the screenshot below, shows a folder called images, which contains all of the slide JPEGs.
- Acquire the URL to your image folder: In the File Repository, open the folder where your images reside, and scroll down to the WebDav URL.
- Open Notepad, or any text editor, and paste in the URL, for example:
https://myserver.labkey.com/_webdav/myproject/%40files/images/

Import Dataset
You dataset should include a column which holds the file names of your target images. See "Biopsies" above for an example.For details on importing a study dataset, see Import Datasets.Build the URL
To build the URL to the images, do the following:- In your dataset, determine which column holds the image names. In our example the column is "TissueSlides".
- In Notepad, or some text editor, type out this column name as a "substitution token", by placing it in curly brackets preceded by a dollar sign, as follows:
${TissueSlides}- In Notepad, append this substitution token to the end of the WebDav URL, for example:
https://myserver.labkey.com/_webdav/myproject/%40files/images/${TissuesSlide}- You now have a URL that can link to any of the images in the File Repository.
Use the URL
- Go the dataset grid view and click Manage.
- On the Dataset Properties page, click Edit Definition.
- Scroll down to the field which holds the image names, in this example, "TissueSlide".
- Select Name or Label, but not Type. If you accidentally select Type, close the popup dialog that appears.
- On the Display tab, locate the URL field.

- Copy and paste the URL you just created, including the substitution token, into the URL field.
- Scroll up and click Save.
- On the Dataset Properties page, click View Data.
- Notice that the filenames in the TissueSlide field are now links. Click a link to see the corresponding image file.
If you prefer that the link results in a file download, add the following to the end of the URL in the dataset definition.?contentDisposition=attachment
https://myserver.labkey.com/_webdav/myproject/%40files/images/${TissuesSlide}?contentDisposition=attachmentRelated Topics
Specimen Tracking
Overview
LabKey Server helps research teams bring together specimen data from separate systems, integrate specimen information with other data types, and securely manage the allocation and transfer of scarce specimen resources between labs, sites and repositories. LabKey Server can act as the database of record for specimens, the integration point for information from external systems, or a combination of both.
LabKey Server can act as the database of record for specimens, the integration point for information from external systems, or a combination of both.
- If you need heavy-duty management of specimen information (e.g., freezer layouts, etc), we typically recommend the use of a third-party, fully-featured Laboratory Information Systems (LIMS) as the specimen database of record. LabKey Server can then serve as the point of data integration and the central portal for managing specimen requests across multiple sites with separate LIMS.
- If your specimen information is relatively simple, you can avoid adopting another information management system and use LabKey Server as the database of record for specimens. You can import, enter, and edit specimen information within LabKey Server, and integrate this data with other kinds of data.
Specimen Repository Types
LabKey Server supports two types of repositories.- The Standard Specimen Repository supports import of spreadsheet data and a variety of viewing and reporting options.
- The Advanced (External) Specimen Repository integrates with existing data archives and offers additional features such as specimen request tracking and optional data modification without re-importing the entire repository. The Advanced Specimen Repository can act as a lightweight LIMS (Laboratory Information Management System).
Specimen Tutorial
The Specimen Tutorial walks through the process of configuring and using a specimen repository. In practice, different users play different roles in the process, but it may be helpful for any user to review the entire process.Specimen Repository Roles
Administrator: The specimen repository is set up and managed by a folder administrator who configures the repository, imports and updates data, assigns permissions and roles to other users, and exports specimen archives. In addition to the options covered in the tutorial, administrator tasks are outlined here: Specimen Request Coordinator: If you are using an Advanced Specimen Repository configured to support request and tracking features, the administrator can assign the role of "Specimen Request Coordinator" to the person who will manage actors, requests, and notifications. This person does not have full administrator permissions on the folder, but performs configuration and tracking tasks for specimen requests. Researchers and Requesters: Those who have been granted specific Specimen Requester permissions can also request specimen vials if enabled.Next... Specimen Request TutorialSpecimen Request Tutorial
- Administrator: the person who configures and populates the repository.
- Specimen Repository Coordinator: the person configures and administers the request system.
- Users/Requesters: project users granted additional permission to request specimens.
Tutorial Steps
- Step 1: Repository Setup (Admin)
- Step 2: Request System (Specimen Coordinator)
- Step 3: Request Specimens (User)
- Step 4: Track Requests (Specimen Coordinator)
First Step
Step 1: Repository Setup (Admin)
Select Specimen Repository Settings
Basic options like the type and editability of your repository are covered by the options in the Specimen Repository Settings section of the manage menu.
Change Repository Type
- Navigate to the home page of the sample study.
- Click the Manage tab.
- Under Specimen Repository Settings, select Change Repository Type.
- Select Advanced (External) Specimen Repository (if it is not already selected). Two advanced options are available:
- Specimen Data options are:
- Read-only: Specimen data is read-only and can only be changed by importing a specimen archive.
- Editable: Specimen data is editable.
- Specimen Requests options are:
- Enabled: The system will allow users with appropriate permissions to request specimens, and will show counts of available specimens.
- Disabled: Specimen request features such as the specimen shopping cart will not appear in the specimen tracking user interface.
- For this tutorial, Advanced Specimen Repository, Read-only, and Enabled should be selected.
- Click Submit.
Edit Specimen Properties
This option allows you to modify the default specimen properties. You can assign custom labels, add new properties, and remove unused ones to best suit your specimen repository. For this tutorial, make no changes. For more information, see Specimen Properties and Rollup Rules.Manage Display and Behavior
- Click the Manage tab.
- Under Specimen Repository Settings, select Manage Display and Behavior.
- Review options available (described below).
- For this tutorial, make no changes.
- Click Cancel to avoid saving accidental changes.
- Comments and Quality Control:
- Default Mode: The specimen system can function in two modes. Users with appropriate permissions can always manually switch modes.
- Request Mode: Vials are requested and requests are managed.
- Comments Mode: Vial information itself can be modified.
- Manual QC flagging/unflagging: Vials are automatically flagged for QC at time of import if a vial's history contains conflicting information. Enable manual QC flagging/unflagging to allow these states to be changed without updating the underlying specimen data. Once a vial's QC state is set manually, it will no longer be updated automatically during the import process.
- Low Vial Warnings. If enabled, the specimen request system can display warning icons when supplies of any primary specimen are very low (zero or one available). An icon will appear next to all vials of that primary specimen.
- Display one available vial warning: Select whether to show for all users, administrators only, or never.
- Display zero available vial warning: Select whether to show for all users, administrators only, or never.
Configure Specimen Groupings
You can decide which specimen groupings to display by default in the Specimens web part. The default groupings are sufficient for this tutorial. To read about the options available, see Customize Specimens Web Part.Populate the Repository
The administrator loads specimen data into the repository, either from a spreadsheet or from a specimen archive. For this tutorial, the specimen archive has already been imported with the sample study. For more about uploading data, see Import a Specimen Archive.Assign Specimen Requester and Coordinator Permissions
Specimen data can be made available to others via the usual read or edit permissions within the given study folder. Two additional permission levels are provided to support specimen request tracking:- Specimen Requester permission is required to place a request or view the status of requests in process.
- Specimen Coordinator permission is offered as an intermediate administrative level for the individual tracking requests through the approval and fulfillment process without requiring full administrative permissions throughout the study.
- Click the Overview tab (so you start on a page that a Reader can view).
- From the pulldown menu for your username (in the top right corner), select Impersonate > Roles.
- In the popup, click the boxes for both Reader and Specimen Coordinator.
- Click Impersonate.
Start Over | Next Step
Step 2: Request System (Specimen Coordinator)
Set Up Specimen Request Tracking
From the study home page, open the Specimen Data tab and click Settings. This tutorial will walk through some of the Specimen Request Settings section. For more information about all of the options available, see Specimen Coordinator Guide.
- Statuses: Define the different stages of the request approval process.
- Actors: Define people or groups who might be involved in a specimen request.
- Request Requirements: Define default requirements for new requests.
- Request Form: Customize the information collected from users when they generate a new specimen request.
- Notifications: Configure emails and notifications sent to users during the specimen request workflow.
- Requestability Rules: Manage the rules used to determine specimen availability for request.
Statuses
A specimen request goes through a number of states from start to finish. Request statuses help a specimen coordinator organize and track requests through the system and communicate progress to requesters. States are numbered sequentially, but not all requests need to pass through all states.- Click the Specimen Data tab.
- Click Settings in the Specimen Tools web part.
- Click Manage Request Statuses under Specimen Request Settings.
- If they are not already defined, add the "Processing Request", "Pending Approval", "Complete", and "Rejected" statuses as show below (including the checkmark columns to the right).
- Click Save after each addition.
- When finished, click Done.
 Notice the option to Allow requests to be built over multiple searches before submission. This is a convenience for requesters, but requires the coordinator to watch for abandoned unsubmitted requests that may have locked specimens needed by others.
Notice the option to Allow requests to be built over multiple searches before submission. This is a convenience for requesters, but requires the coordinator to watch for abandoned unsubmitted requests that may have locked specimens needed by others.
Actors
Each person or group involved in processing a specimen request should have an Actor defined to represent them in the specimen repository tracking system. Examples include:- Specimen requesters, such as lab technicians or principal investigators
- Reviewers of requests, such as oversight boards or leadership groups
- Those responsible for storing and shipping specimens, such as repository owners
- One Per Study: There is one group of people representing this actor in the study, specified by a single list of email addresses.
- Multiple Per Study (Location Affiliated): There may be multiple groups representing this actor at multiple sites. Each site/actor combination has a separate list of member email addresses.
- slg_member@fakemail.com
- highpoint_board1@fakemail.com
- highpoint_board2@fakemail.com
- Click the Specimen Data tab and click Settings.
- Click Manage Actors and Groups.
- Fill out the form as show below. Click Save after each addition.

- Click Update Members on the Scientific Leadership Group row and add a fictional user email such as "slg_member@fakemail.com".
- Uncheck the Send notification emails to all users box for this tutorial.
- Click Update Members.
- Click Update Members on the Institutional Review Board row.
- Select a Site for this new (fictional) member (here "High Point Clinic"), then enter the fictional user "highpoint_board1@fakemail.com".
- Uncheck the Send notification emails to all users box.
- Click Update Members.
- By clicking Update Members again for any actor or actor/site combination, you can review the current list, remove, or add new members.

Request Requirements, Notifications and Rules.
The coordinator can also configure the following. For this tutorial, all the defaults are sufficient, but for more information, see Specimen Coordinator Guide.- Default requirements for new specimen requests
- Customize the request form itself to gather required information from requesters
- Define the email notification process and content
- Set requestability rules for specimens
Next Steps
Now your basic repository is ready for users to make some sample requests. You can continue to the next tutorial step as an Admin, Specimen Coordinator, or impersonate the role of Specimen Requester (remember to first impersonate the Reader role). After some requests are made, you can return to the role of coordinator to track and approve them.Previous Step | Next Step
Step 3: Request Specimens (User)
View and Search for Specimens
The Specimen Data tab includes search and display options which can be configured by the administrator to present the most useful groupings and options for users. Even if you are not a specimen requester, you can search and view specimens here. Expand groupings in the Specimens section using the + buttons next to the types. Note that the tools use 'vial' terminology, even if your specimen aliquots are something else, such as blocks of tissue.
Create a New Specimen Request
First identify specimens of interest.- Click on the Specimen Data tab.
- Click on Urine under Vials by Primary Type in the Specimens web part.
- Choose any specimen with multiple samples available to request, and click on its shopping cart.

- If you have not yet opened a specimen request, you will see a popup confirming the creation of a new request. Click Yes.
- Fill in the New Specimen Request page. For example:
- From the Requesting Location dropdown, select a demo value, for example, Northgate Diagnostics.
- Under Assay Plan, enter "Analyze specimens".
- Under Shipping Information, enter "123 Research Lane".
- Notice that the specimen you selected is listed at the bottom of the request.
- Click Create and View Details
- Click Specimen Data, then Urine in the Specimens section to return to the prior vial search results.
- Notice that the number of vials of the specimen you added to your request has gone down by one. The shopping cart icon is also no longer present, indicating that you do not need to "shop" further for that specimen.
- If you do not see a shopping cart icon, but instead see a red target, there are no samples available for the given specimen.
- If you do not see anything between the checkbox column and history column, you may need to log in again, or you may not have Specimen Requester permissions.
Request More Specimens
You can add other specimens to the request before submitting it.- Go to the Vial Search panel on the Specimen Data tab.
- Select Urine from the Primary Type pulldown.
- Click Search.
- Click a shopping cart icon to request that specimen.
- The Request Vial popup window lists the specimens already included in the request.
- If you have multiple open requests, you can select among them using the Select request pulldown. You can also click Create New Request to start another new one.
- Review the list of vials currently in the request to confirm you want to add the newly selected one to this list. Then click one of the buttons:
- Add [Vial Number] to Request.
- Remove Checked Vials. Clicking the checkbox to the left of any vial lets you select it for deletion. Click Remove checked vials to delete.
- Manage Request. Provides access to Request Details, Submit Request, and Cancel Request options.

- Click Add [Vial number] to Request.
- Click OK.
Add Multiple Specimens to Existing or New Request
You can add multiple specimens to a specimen request simultaneously using the checkboxes next to each specimen row.- Select two (or more) specimen checkboxes.
- Use the Request Options drop-down menu to select Add to Existing Request.
- Confirm that the desired request is selected at the top of the popup window and click Add 2 Vials to Request.
Submit the Request
- Click the Specimen Data tab.
- In the Specimens web part, open the Specimen Requests option.
- Click View Current Requests.
- Click Details to view a request. Note that any requirements that will need to be completed before the request can be filled will be marked in bold red as Incomplete.
- When you confirm the request is complete, click Submit Request.
- Click OK in the popup window. Once a request is submitted you can no longer modify the list of specimens it is requesting.
Previous Step | Next Step
Step 4: Track Requests (Specimen Coordinator)
View and Track Specimen Requests
List Current Requests
To access the list of existing specimen requests:- Click the Specimen Data tab.
- Expand Specimen Requests in the Specimens panel.
- Click View Current Requests.
- You will see a list of existing specimen requests, their current statuses, and options for managing them, depending on your permissions level and the status of the requests.

Filter Requests
You can choose to filter requests by using the My Requests link and/or Filter by Status pulldown on the top row. Remember, you can always use LabKey's sorting and filtering tools to sort and filter any grid like this one.Customize Grid
You can also customize this grid, as you can any data grid. See Customize Grid Views.Manage an Existing Specimen Request
Select the Details link next to any existing request to see the current status of the request. If the request has not yet been submitted, and you have appropriate permissions, you will have options for managing the request.Request Information
- View History: A list of all changes to the request.
- Update Request: Options for update, including attachment of supporting information.
- Originating Location Specimen Lists: Configure and send email notifications to the location where the specimen was originally drawn or collected.
- Providing Location Specimen Lists: Configure and send email notifications to the location which currently possesses the specimen aliquot and will mail it out after full approval has been granted.

Manage Requirements
The Current Requirements section lists the current status of all approval requirements associated with this request. Click any Details link for information and options, including the addition of comments and sending of notifications to the members of the associated Actor.Use the Manage Requirement page to approve specimen requirements. Once all requirements are met, the request can be approved.- Complete Requirements
- Submit Final Notification for Approval
- Email Specimen Lists to Originating and Providing Locations
- Update Request Status to Indicate Completion
Specimen Request Management Console
- Navigate to the Specimen Data tab of your study.
- Expand the Specimen Requests section of the Specimens web part.
- Click View Current Requests.
- Click the Details button next to the specimen request listing.
Completion of Requirements
Prior to approval, each requirement must be completed by the associated Actor.- To mark a requirement completed, click on the Details link.
- Check Complete, add any comments, attachments, or additional notifications and click Save Changes and Send Notifications.

Final Notification Steps for Approval
After all requirements are completed, the list of next three steps will be listed at the top of the specimen request detail page.- Email specimen lists to their originating locations: [Originating Location Specimen Lists]
- Email specimen lists to their providing locations: [Providing Location Specimen Lists]
- Update request status to indicate completion: [Update Request]
Update Request Status to Indicate Completion
- To finalize the request, click the Update Request link
- Select Complete from the Status drop-down menu.
- Add any supporting documents and select actors to notify.
- Click Save Changes and Send Notifications.

Previous Step
Specimens: Administrator Guide
Import Specimen Data
LabKey Server supports two types of repository and two methods for bringing specimen data into a LabKey study:The simplest method is to use a Standard Specimen Repository and paste data from a specimen spreadsheet. An Advanced Specimen Repository allows you to upload and import a specimen archive, and then manage the transfer of specimens between labs.Customize Specimen Properties
Customize the Specimen UI
- Customize Specimens Web Part
- Customize Specimen Report Web Parts - Flag Specimens for Quality Control
Administer a Specimen Archive
These features and options are applicable to Advanced Specimen Repositories.Import Specimen Spreadsheet Data
Select Standard Specimen Repository
- On the Study project home page, select the Manage tab.
- Under Specimen Repository Settings, click Change Repository Type.
- Select Standard Specimen Repository.
- Click Submit.
Import Specimen Spreadsheet Data
- Go to the Study project home page and select the Specimen Data tab.
- In the Specimens webpart, expand the Administration topic.
- Click Import Specimens to open the Upload Specimens page.
Show Expected Data Fields
To view data fields expected in the upload, click Show Expected Data Fields. This will expand a display of column names, types, brief descriptions, and whether the field is required for a successful upload. If your study is set up to use visits instead of date-based timepoints, you will see a Visit field here in addition to Draw Timestamp and draw timestamps will not be required.Note that in cases where the Sample ID and/or Participant ID are the same as your Global Unique ID, you need only supply the Global Unique ID and leave the others null. They are still required fields, but will be populated on import automatically.
This will expand a display of column names, types, brief descriptions, and whether the field is required for a successful upload. If your study is set up to use visits instead of date-based timepoints, you will see a Visit field here in addition to Draw Timestamp and draw timestamps will not be required.Note that in cases where the Sample ID and/or Participant ID are the same as your Global Unique ID, you need only supply the Global Unique ID and leave the others null. They are still required fields, but will be populated on import automatically.
Download a Template Workbook
- Select Download a Template Workbook.
- Open this spreadsheet to confirm that your column headings match those in the template.
- Copy and paste your data into this template spreadsheet. In practice you could download this template in advance and enter the original data into it.
Select Replace or Merge
When uploading specimen data from a spreadsheet, you can either replace the existing repository with the new data, or merge new data into the existing repository. The merge option will use the primary key to determine if a row is in the repository already. If so, it will delete and replace it. Otherwise, it will add new rows but leave any unchanged rows in place.Copy and Upload Data
- Copy the contents of the filled-in template file and paste this data into the text box on the Upload Specimens page.
- Select Replace or Merge, and click Submit.
- When the import is complete, click Specimens to see a grid view of all imported specimens.
Import a Specimen Archive
- Review the Specimen Archive File Format here.
- Review the details of how imported data will be represented in destination tables here.
Upload a Specimen Archive
- Click the Specimen Data tab.
- In the Specimens web part, expand the Administration link if present.
- Click Import Specimens. A file browser will open showing the files already uploaded to the study. If your specimen archive is already uploaded to the file browser, skip the rest of this step.
- In a separate file explorer window, locate your specimen archive.
- Drag and drop it into the LabKey Server file browser panel.
Import the Specimen Archive
- Select the files you wish to import, and click the Import Data link on the menu bar.

- On the Import Data pop up, select the specific import job you wish to run, by default Import Specimen Data and click Import.
- On the Import Study Batch page, you will see a list of files to be imported. If you are importing an archive to a folder already containing a previous archive, select either:
- Replace: Replace all of the existing specimens.
- Merge: Insert new specimens and update existing specimens.
- Replace: Replaces the previous repository. Any changes you made to existing data will be lost.
- Merge: Any attempt to update specimens currently in the repository will result in an error. This only allows new specimens to be added and preserves all changes you may have made.
- Click Start Import.
Import Specimen Settings
If specimen settings were exported with the repository, the archive will include a specimen_settings.xml file containing Groupings, Location Types, Statuses, Actors, and Default Requirements. If you are importing that archive into an existing specimen repository, any new specimen settings will be added. Any status or actor that is currently in use in the specimen repository will not be replaced, however. When you import an in-use Actor, the membership emails for that actor will be replaced.Other Topics
- Export a Specimen Archive - How to export specimen data to a .specimen archive file.
- Flag Specimens for Quality Control - offers options for flagging specimen data on import for possible issues.
Specimen Archive File Reference
Specimen Archive File Format
A specimen archive is a collection of tab-separated values (.tsv) files packaged as a zip archive with a .specimens extension. The archive can contain any file names or directory structure. For example, a typical archive might have the following structure and file names:
- mySpecimenArchive.specimens
- additives.tsv
- derivatives.tsv
- labs.tsv
- primary_types.tsv
- specimens.tsv
When these files are imported into LabKey Server, the data is stored in a hierarchy of tables described in more detail in Specimen Data Destinations.
Each TSV file contains required and optional columns. The required columns are primary/foreign key values and other data that are used to drive the system. The remaining optional columns are included for your convenience and can be left blank or filled with data as desired. Set up custom grids to show, hide, and reorder these columns as desired.
LabKey Server recognizes and imports data from five types of specimen TSV files. The type of file is indicated by the text on the first line of the file. Each specimen data file contained within the archive must begin with one of the "hashtags" listed in the table below. (Note the space following each "#" sign.)
| File Type | Description | Hashtag for First Line |
| specimen | Contains the primary specimen data. | # specimens |
| primary types | A list of primary specimen types. | # primary_types |
| labs | A list of labs. | # labs |
| derivatives | A list of derivative types. | # derivates |
| additives | A list of additives. | # additives |
ExternalId
Each file has a primary key (additive_id, derivative_id, primary_type_id, etc), collectively referred to as the ExternalId property. Each file must have a value for the primary key column in each row. If not, an error message will be raised indicating that "ExternalId" is a required property. No file contains a column by that name per se, but the error message will indicate which file is misconfigured.
For example, if there is a problem with the derivative_id column in derivatives.tsv, the error message would read:
"ExternalId: Missing value for required property: ExternalId (File:derivatives)".
File Type: specimens
This file type contains one row for each time each location has possessed each specimen sample, in this case a vial. For example, if a vial has passed from a clinic on to a repository and finally to a lab, three entries for this vial (one for each location) will appear in this file. Required fields are shown with a grey background.
Column Name |
Data Type |
Max Characters |
Required? |
Description |
Attribute Of... |
| record_id | int | Y | Primary key | Draw | |
| global_unique_specimen_id | text | 50 | Y | LIMS-generated global unique specimen ID. Used for joins to results and request data (clinical data joined based on participant/visit). | Vial |
| lab_id | numeric | Y | LIMS lab number. Labeled "Site Name" in specimen grid views. Foreign key into the lab list. This field should contain only values found in the lab_id column in the labs.tsv file. | Event | |
| ptid | text | 32 | Y | Participant/subject identifier. Only needs to be unique within the study. | Draw |
| draw_timestamp | date/time | Y | Date and time specimen was drawn | Draw | |
| visit_value | numeric | Y | Visit value | Draw | |
| volume | numeric | Y | Aliquot volume value. May differ across LIMS records; the largest value found is stored in the database. This usage is based on the assumption that volume may decrease as specimen is consumed, so the original volume is what should be tracked by the system. | Draw | |
| volume_units | text | 20 | Y | Volume units | Draw |
| primary_specimen_type_id | int | N | Foreign key into primary type table. This field should contain only values found in the primary_type_id column in the primary_types.tsv file. See footnote 2. | Draw | |
| derivative_type_id | int | N | Foreign key into derivative table. This field should contain only values found in the derivative_id column in the derivatives.tsv file. See footnote 2. | Draw | |
| derivative_type_id2 | int | N | A second foreign key into the derivative table. Functioning identically to derivative_type_id. This field should contain only values found in the derivative_id column in the derivatives.tsv file. Not used by most installations, but available if a single vial/aliquot/slide contained multiple derivative types. |
Draw | |
| additive_type_id | int | N | Foreign key into additive type list. This field should contain only values found in the additive_id column in the additives.tsv file. See footnote 2. | Draw | |
| storage_date | date/time | N | Date that specimen was stored in LIMS at each lab. See footnote 1. | Event | |
| ship_date | date/time | N | Date that specimen was shipped. See footnote 1. | Event | |
| lab_receipt_date | numeric | N | Date that specimen was received at subsequent lab. Should be equivalent to storage date. See footnote 1. | Event | |
| record_source | text | 20 | N | Indicates providing LIMS (generally "ldms" or "labware") | Event |
| originating_location | numeric | N |
LIMS lab number. Labeled "Clinic" in specimen grid views. Foreign key into the lab list. This field should contain only values found in the lab_id column in the labs.tsv file. This field can be used when vials are poured from a specimen at a location different than the location where the specimen was originally obtained. It can record the location where the specimen itself was obtained while the lab_id records the site of vial separation. |
Draw | |
| unique_specimen_id | text | 50 | N | Unique specimen number | Event |
| parent_specimen_id | numeric | N | Parent unique specimen number | Event | |
| sal_receipt_date | date/time | N | Date that specimen was received at site-affiliated lab | Draw | |
| specimen_number | text | 50 | N | LIMS-generated specimen number | Event |
| class_id | text | 20 | N | Group identifier | Draw |
| protocol_number | text | 20 | N | Protocol number | Draw |
| visit_description | text | 10 | N | Visit description. The system does not actively use this field, but it still appears in vial and collection grid views by default. | Event |
| other_specimen_id | text | 50 | N | Other specimen ID | Event |
| stored | date/time | N | LIMS-specific integer code for storage status | Event | |
| storage_flag | numeric | N | Storage flag | Event | |
| ship_flag | numeric | N | Shipping flag | Event | |
| ship_batch_number | numeric | N | LIMS generated shipping batch number | Event | |
| imported_batch_number | numeric | N | Imported batch number | Event | |
| expected_time_value | numeric | N | Expected time value for PK or metabolic samples | Draw | |
| expected_time_unit | text | 15 | N | Expected time unit for PK or metabolic samples. | Draw |
| group_protocol | numeric | N | Group/protocol field | Draw | |
| sub_additive_derivative | text | 50 | N | Sub additive/derivative. Appears in vial and collection grid views. | Draw |
| comments | text | 500 | N | Up to 500 characters are passed through from the comment field in the LIMS | Event |
| specimen_condition | text | 30 | N | Condition string | Event |
| sample_number | int | N | ignored | ||
| x_sample_origin | text | 50 | N | ignored | |
| external_location | text | 50 | N | ignore | |
| update_timestamp | date/time | N | Date of last update to this specimen’s LIMS record | Event | |
| freezer | text | 200 | N | Freezer where vials are stored. | Event |
| fr_level1 | text | 200 | N | Level where vials are stored. | Event |
| fr_level2 | text | 200 | N | Level where vials are stored. | Event |
| fr_container | text | 200 | N | Container where vials are stored. | Event |
| fr_position | text | 200 | N | Position where vials are stored. | Event |
| shipped_from_lab | text | 32 | N | Shipped from lab string. | Event |
| shipped_to_lab | text | 32 | N | Shipped to lab string. | Event |
| frozen_time | date/time | N | Date / time when frozen. | Event | |
| primary_volume | numeric | N | volume value | Vial | |
| primary_volume_units | text | 20 | N | volume unit | Vial |
| processed_by_initials | text | 32 | N | Initials of sample processor. | Event |
| processing_date | date/time | N | Date when processed. | Event | |
| processing_time | date/time | N | Time when processed. | Event | |
| total_cell_count | int | N | Total cell count. | Vial | |
| tube_type | text | 32 | N | Specimen tube type. | Vial |
| requestable | nullable boolean | Not Recommended |
Provides a mechanism for overriding built-in requestability rules. Can be used if the requestability rule cannot be built into the system for some reason, or if a user wants to entirely manage requestability in an external system. We generally recommend using built-in functions for this instead. When NULL, this flag has no effect. |
Vial |
Columns that are "attributes of" the draw, vial or event. Columns in the specimen file can describe the "draw" of the specimen (a.k.a. its "collection"), a "vial" subdivision of a specimen, or an "event" that marks its transfer or processing. These three types of columns exhibit different visibility in the LabKey Server UI:
- Columns associated with the "draw" are stored in the Specimens table and show up in the LabKey Server UI when you choose to view specimens by Vial Group.
- Columns associated with the "vial" are stored in the Vial table and show up in the UI when you choose to view specimens by Individual Vials. Certain columns associated with the "draw" appear in this grid as well.
- Columns associated with an "event" are stored in the SpecimenEvent table and show up when you choose to view the History of a vial. Certain columns associated with the "draw" and the "vial" appear in the history grid as well.
If additional fields are added to the specimen tables, values for those fields will be included in the exported archive, however values need not be specified for non-required fields in order to successfully import an archive.
File Type: additives
This file type has one row per additive.
Column Name |
Data Type |
Max Characters |
Required? |
Description |
|---|---|---|---|---|
| additive_id | int | Y | Primary key | |
| additive | text | 100 | Y | Descriptive label |
| ldms_additive_code | text | 30 | N | LIMS abbreviation |
| labware_additive_code | text | 30 | N | LabWare abbreviation |
File Type: derivatives
This file type has one row per derivative.
Column Name |
Data Type |
Max Characters |
Required |
Description |
|---|---|---|---|---|
| derivative_id | int | Y | Primary key | |
| derivative | text | 100 | Y | Descriptive label |
| ldms_derivative_code | text | 20 | N | LIMS abbreviation |
| labware_derivative_code | text | 20 | N | LabWare abbreviation |
File Type: primary_types
This file type has one row per primary type.
Column Name |
Data Type |
Max Characters |
Required? |
Description |
|---|---|---|---|---|
| primary_type_id | int | Y | Primary key | |
| primary_type | text | 100 | Y | Descriptive label |
| primary_type_ldms_code | text | 5 | N | LIMS abbreviation |
| primary_type_labware_code | text | 5 | N | LabWare abbreviation |
File Type: labs
This file type has one row per lab.
Column Name |
Data Type |
Max Characters |
Required? |
Description |
|---|---|---|---|---|
| lab_id | int | Y | Primary key | |
| lab_name | text | 200 | Y | Lab name |
| ldms_lab_code | int | N | LIMS lab code | |
| labware_lab_code | text | 20 | N | LabWare lab code |
| lab_upload_code | text | 10 | N | Lab upload code |
| is_sal | boolean | N | Indicates whether this lab is a site affiliated lab | |
| is_repository | boolean | N | Indicates whether this lab is a repository. In order to use specimen tracking, at least one lab must be marked as a repository. | |
| is_clinic | boolean | N | Indicates whether this site is a clinic | |
| is_endpoint | boolean | N | Indicates whether this lab is an endpoint lab | |
| street_address | text | 200 | N | Street address |
| city | text | 200 | N | City |
| governing_district | text | 200 | N | Governing district |
| country | text | 200 | N | Country |
| postal_area | text | 50 | N | Postal area |
| description | text | 500 | N | Description |
Footnotes
1. At least one of storage_date, ship_date, or lab_receipt_date is needed to accurately order records chronologically. The system will tolerate records with all nulls for these dates, but incorrect ordering may result.
2. Type information is not required (the system will display the type as "unknown"), but the data may not be useful without the type info.
Template Spreadsheet
Use the following spreadsheet as a template when creating new specimen archive files: template spreadsheet.
Data Inconsistencies and Quality Control Flags
When records in the specimens table disagree about a property of a draw or vial that should be consistent, LabKey Server displays the property as blank. It also flags the records with red highlighting to indicate that quality control is needed for that record. For further details, see Specimen Quality Control.
Sample Specimen Archive
A sample specimen archive file is available in the LabKey Server demonstration samples. Download the samples here: LabKeyDemoFiles.zip
Specimen Archive Data Destinations
- The Specimens table holds information about the group of vials that comprise a specimen. You see fields from this table when you view specimens "by vial group."
- The Vial table holds all the information about a single vial or aliquot. You see fields from this table when you view specimens "by individual vial." There can be many Vial rows for any given Specimen row.
- The SpecimenEvent table closely matches the specimen archive file and contains fields that describe each individual event for a given vial or other aliquot. There can be many SpecimenEvent rows for a given Vial row. If you view History for an individual vial, you are seeing fields from this event table.
File-by-File Overview
Data destinations for each file in the specimen import archive:- labs.tsv: This data is imported directly into the study.site table.
- primary_types.tsv: This data is imported directly into the study.specimenprimarytype table.
- derivatives.tsv: This data is imported directly into the study.specimenderivative table.
- additives.tsv: This data is imported directly into the study.additive table.
- specimens.tsv: See below.
Details for Specimens.tsv
The file import process for specimen.tsv is the most complex.All fields from this file go into the study.specimenevent table, which is accessed through the 'history' links in the vial view or directly via the specimenevent table in the schema browser.The subset of fields that should be constant across locations (such as vial ID, vial volume, etc.) are also inserted into the study.vial table.Fields that are not expected to be the same across location (freezer information, for example) are found only in study.specimenevent.Aggregating up one more level from study.vial, the study.specimen table (accessible via the 'group by vial' links in LabKey Server) summarizes the data by collection. This table contains all fields from study.vial that are expected to be the same across all vials from a given collection (such as subject ID, visit, type, and draw timestamp).Note that study.vial and study.specimen also contain a number of calculated fields that are not found in the import data. These fields are used in a variety of places within the system.Troubleshoot Specimen Import
Interpret Errors in the .log File
First, view the .log file. If your specimen archive does not upload correctly, you will see "ERROR" as the final status for the pipeline task on the "Data Pipeline" page. To view the error log, click on the word "ERROR" to reach the "Job Status" page.
Next, identify the error. To determine which file in the .specimens archive caused problems during import, look at the lines immediately preceding the first mention of an "ERROR." You will see the type of data (e.g., "Specimens" or "Site") that was not imported properly. Note that the name of the uploaded file (e.g., "labs.tsv") does not necessarily have a 1-to-1 mapping to the type of data imported (e.g., "labs.tsv" provides "Site" data).
Example. Consider the log file produced by failed import of a specimen archive that included a labs.tsv file with bad data (unacceptably long site names). In the .log file excerpted below, you can see that the data type mentioned just above the "ERROR" line is "Site." Since "labs.tsv" contains "Site" data, you can conclude that the labs.tsv file caused the error. Note that earlier lines in the .log file mention "Specimens," indicating that the specimens.tsv file was imported successfully before an error was hit while importing the labs.tsv file.
Excerpt from this log file, with highlighting added:
06 Mar 2008 23:27:39,515 INFO : Specimen: Parsing data file for table...
06 Mar 2008 23:27:39,515 INFO : Specimen: Parsing complete.
06 Mar 2008 23:27:39,890 INFO : Populating temp table...
06 Mar 2008 23:27:40,828 INFO : Temp table populated.
06 Mar 2008 23:27:40,828 INFO : Site: Parsing data file for table...
06 Mar 2008 23:27:40,828 INFO : Site: Parsing complete.
06 Mar 2008 23:27:40,828 INFO : Site: Starting merge of data...
06 Mar 2008 23:27:40,828 ERROR: Unexpected processing specimen archive
Import FreezerPro Data
 Premium Feature — Available in the Professional Plus and Enterprise Editions. Also available as an Add-on to the Professional Edition. Learn more or contact LabKey
Premium Feature — Available in the Professional Plus and Enterprise Editions. Also available as an Add-on to the Professional Edition. Learn more or contact LabKey
- Enable FreezerPro
- Connect to the FreezerPro Server
- Select Specimen Types and Map Fields
- Filtering FreezerPro Data
- Manual Configuration Via XML
- Manual Triggering of Reload
- Scheduling Automatic Reload
Enable FreezerPro
To add FreezerPro functionality to your project or folder, enable the FreezerPro module in that project or folder.- Begin with a folder of type Study. (Only study type folders support FreezerPro.)
- Select Admin > Folder > Management.
- Click the Folder Type tab.
- Select the checkbox on the right to enable the FreezerPro module.
- Click Update Folder.
Connect to the FreezerPro Server
- Navigate to the study folder where the FreezerPro module enabled.
- Click the Manage tab. Under the heading Specimen Repository Settings, click Configure FreezerPro.
- On the Connection tab, enter the following:
- FreezerPro Server Base URL. This is the URL where you log in to FreezerPro, plus the suffix "/api".
- Enter the User Name and Password you want to use to connect to the remote FreezerPro server.
- Click Test Connection to confirm the ability to connect using these entries. A popup message will confirm a successful connection or indicate a possible problem to resolve before proceding.

Select Specimen Types and Map Fields
After adding the credentials and server information, configure which sample types you want to import and the field mappings between FreezerPro and LabKey Server.- Click the Specimen Fields tab.
- Click the pencil icon to open the field configuration panel.
- A list of available sample types is shown. Select the sample types you want to import and click Next.

- A list of destination LabKey fields is shown next to a list of source FreezerPro fields. Select which FreezerPro fields you want to match to the corresponding LabKey fields. (Note that the list of available field options is filtered based on the field type. For example, a LabKey date field only shows FreezerPro date fields as mapping options.)
- If no LabKey field shown is appropriate for a FreezerPro field of interest, click the arrow button to open the Add Custom LabKey Field panel.
- Enter the name, label, and select the appropriate type.
- Click Add to add the field to the list.
- Assign a mapping to your new field.
- Click Apply when finished. Custom fields are validated to ensure that the field name doesn't have spaces and doesn't already exist in the current folder, but will not be added to the specimen tables until you click Save on the specimen fields tab.

- A summary of selected sample types and field mappings is shown.
- An "Exclamation Point" icon is shown next to any mapped FreezerPro fields that are no longer available from the FreezerPro server. Mouse over the icon for the warning message: "This field is no longer available from the configured FreezerPro server for the selected sample type. Please adjust the specimen mapping."
- Once the types and mappings are configured as desired, click Save. Custom fields will now be added to the study.SpecimenEvent and study.Vial table in the current folder.)

Filtering FreezerPro Data
You can configure filters that limit the data exported from FreezerPro via the Filters tab.To add filters:- On the FreezerPro Configuration page, click the Filters tab.
- Click Add New Filter.
- Using the dropdowns, select a FreezerPro field to filter and an operator.
- Using the text box, add a criteria value.
- Add multiple filters as desired.
- Click Save when finished.

Manual Configuration Via XML
You can manually edit the configuration XML for more complex cases, such as loading data into multiple LabKey studies, mapping columns that are not universally present in the sample types chosen, and skipping location information. Editing the XML manually will replace any configurations added through the user interface. If you later choose to go back to configuration via the user interface, the manually configured XML is translated into configurations supported by the graphical user interface, but any configurations not supported by the graphical user interface will be lost.Some XML common elements to use:- filterString: return all rows which contain the given string anywhere in the imported row.
- columnFilters: return rows which have an exact match for the specified value in the column of the given name. Multiple columnFilters rows are ANDed together.
- columnMap: map data in the FreezerPro field sourceName into the LabKey field destName. The destName field must be defined on both the SpecimenEvent and Vial tables.
XML Config Example
- In your study, click the Manage tab, and then click Configure Freezerpro.
- Select the Advanced tab.
- Select "Configure manually via XML". As long as this option is selected, the configuration options on the specimen fields and filters tabs will be read-only.
- Edit or add the XML metadata to provide the filtering and mapping required. For example, paste the following code block to import only records containing a keyword "validated" for the INS-4074 Study Protocol, and map FreezerPro field "Cells/Vial" to LabKey field "CellsVial", etc.
<?xml version="1.0" encoding="UTF-8"?>
<freezerProConfig xmlns="http://labkey.org/study/xml/freezerProExport">
<filterString>validated</filterString>
<columnFilters>
<filter name="Study Protocol" value="INS-4074"/>
</columnFilters>
<columnMap>
<column sourceName="subject_id" destName="ptid"/>
<column sourceName="Cells/Vial" destName="CellsVial"/>
</columnMap>
</freezerProConfig>
- Click Save.

- Click Test Configuration if desired to confirm an active connection.
- Click Reload Now to reload applying the new filters and mapping.
Manual Triggering of Reload
This step assumes you have already configured a connection with a FreezerPro server instance. For details see above.- On the Configure FreezerPro page, click the Connection tab.
- Click Test Connection to confirm the ability to connect using these entries. A popup message will confirm a successful connection or indicate a possible problem to resolve before attempting reload.
- Click Reload Now to pull data from FreezerPro. You'll see the pipeline import screen, which will show COMPLETE when finished.
- Return to the Specimen Data tab to view the loaded freezerpro data.
Scheduling Automatic Reload
You may also have FreezerPro data automatically reloaded on a regular schedule. Reloading is configured at the study-level and different studies may have different schedules for the day(s) on which reloading occurs, but all automatic reloading is done at the same time of day, along with other site-wide system maintenance tasks.- On the Configure Freezerpro page click the Connection tab.
- Click the box for Enable Reloading.
- Specify the Load on date - the date to start automatic reloading.
- Set Repeat (days) for the number of days between automatic reloads. Use 1 for daily reloading, 7 for weekly pulls.
- Select Admin > Admin Console.
- Click System Maintenance.
- While FreezerPro automatic reloading is performed with these tasks on this schedule, it is not part of every installation, so does not appear as one of the options listed on the page.

- If you want to confirm that the FreezerPro Upload Task will be run with the checked tasks, click Run all tasks and you will see a progress log of tasks as they start and complete.

Related Topics
Delete Specimens
- In the study folder, click the Manage tab.
- In the section Specimen Repository Settings, click Change Repository Type.
- Select Advanced (External) Specimen Repository.
- In the section Specimen Data, select Editable, and click the link Specimen Detail.
- On the Specimen Detail grid, select the records to delete. You may select all records using the checkbox at the top of the grid view.
- Click Delete.
Specimen Properties and Rollup Rules
Edit Specimen Properties
There are some columns which are used internally or optimized based on specific naming and ordering thus cannot be altered or removed, but for others you can optionally:- Assign custom labels (for example, "Used" or "Unused")
- Define field properties like custom descriptions and validators
- Reorder properties
- Add new properties
- Remove unused properties
- Click the Manage tab.
- In the Specimen Repository Settings section, click Edit Specimen Properties.

- Current Specimen Properties are listed by table, each starting with required built-in fields that cannot be edited. Built-in fields which can be edited or removed if desired follow.
- By clicking Add Field it is possible to add new user-defined specimen fields to each table. New fields will be added after the field you select, so to add fields to the end of the table, first select the last built-in field as shown:

- To reorder properties, use the up and down arrows, if available. If the arrow boxes are inactive (gray) reordering is not permitted.
- To remove a property, click the x to the left of the name. Use caution since when you delete a property, you will delete all of its data as well.
- After changing fields as required, click Save and Close.
Define Specimen Property Rollups
A single specimen, or sample, is collected at a given time and place and then divided into many vials, or other aliquots, which then have various events happen to them. Sometimes you are interested in aggregated or sequenced results, such as the total volume in all vials for a given specimen. Events are also ordered by date, so maybe you sometimes want to see who first processed a given vial, and other times need to know the last person to process it.There are three specimen tables with a hierarchical relationship: each Specimen table row represents a collected sample and can have multiple rows in the Vial table (portions of the same specimen sample), and each Vial can in turn have multiple rows in the SpecimenEvent table (every change in status or location is an event). For additional details, see Specimen Archive Data Destinations.Using specific naming pre- and post-fixes on these tables, properties may roll values "up" from the event to vial or from the vial to specimen tables using group by clauses. There are built-in rollups already defined, and you may also define new rollup properties from either new custom properties you define, or from existing built-in properties.Rollup Examples:
Built-in rollup of built-in property: "ProcessedByInitials" on the event table rolls up into "FirstProcessedByInitials" on the vial table.User-defined rollup of built-in property: You could add "LatestProcessedByInitials" on the vial table, as there is no restriction on multiple rollups from the same field. Or you might rollup the built-in vial field "PrimaryVolume" into a new "TotalPrimaryVolume" field on the specimen table.User-defined rollup of user-defined property: You might add a text field "Barcode" on the event and vial tables, then use "MaxBarcode" and "MinBarcode" on the specimen table to give you the ability to ensure all barcodes matched across all events and all vials by ensuring the two values were the same.Multi-level rollups: If desired, you can also rollup a field from vial to specimen that is already a rollup from event. For instance, you could watch for a diminishing resource by defining "MinLatestYield" on the specimen table that would store the minimum value of "LatestYield" across all vials of that specimen.Rollups from SpecimenEvent to Vial Table
Events are ordered by date; sequence fields like 'first' and 'latest' apply to the date order of event rows, not to the order in the table itself.| Prefix | Postfix Option? | From Type (on Event) | To Type (on Vial) | Behavior |
|---|---|---|---|---|
| First | no | any | must match | Vial property contains the value of the base property from the first event. |
| Latest | no | any | must match | Vial property contains the value of the root property from the latest event. |
| LatestNonBlank | no | any | must match | Vial property contains the latest non blank value of the root property. |
| Combine | no | numeric | must be promotable from "From Type" | All non-empty values are summed. |
| Combine | no | text | must match | All non-empty values are concatenated together in event order separated by a comma and space. |
Rollups from Vial to Specimen Table
Vials are not ordered by date, so the useful rollups from the Vial to Specimens table are different kinds of aggregation:| Prefix | Postfix Option? | From Type (on Vial) | To Type (on Specimen) | Behavior |
|---|---|---|---|---|
| Count | yes | boolean | integer | Keeps a count of all 'true' settings of the root property on the vials for that specimen. |
| Total | yes | numeric | must be promotable from "From Type" | Sum of root property settings on all vials for that specimen. |
| SumOf | no | numeric | must be promotable from "From Type" | Sum of root property settings on all vials for that specimen (same as "Total" but can only be used as a prefix). |
| Max | yes | numeric | must be promotable from "From Type" | Contains the maximum value of the root field for all vials. |
| Max | yes | text | must match | Contains the alphabetically 'last' value (useful where all vials are expected to have the same value. |
| Min | yes | numeric | must be promotable from "From Type" | Contains the minimum value of the root field for all vials. |
| Min | yes | text | must match | Contains the alphabetically 'first' value. |

Customize Aliquot Types (optional)
Different types of specimen material may be divided in different ways. A common specimen aliquot is a vial, and that terminology is used by default in the LabKey tools. If the specimen is divided in another way, such as into blocks of tissue, which may be further subdivided into many slides, you may edit the column (field) names to better describe the aliquots involved. This step is optional whether your specimens are vials or not and does not affect the underlying data tables, just the display names.- Select Admin > Developer Links > Schema Browser.
- Open the Study folder and Specimen Detail spreadsheet.
- Select Edit Metadata.
- Customize the Label for any given column.
- Click Save when finished.
- Click Specimen Data and select any view to see your revised column headings.
Customize Specimens Web Part
Configure Specimen Groupings
On the Specimen Data tab of your study, the Specimens web part contains grouping nodes to offer quick shortcuts to various views of available specimen data. As the administrator, you can configure these groupings to present the views most likely to be of use to your particular research teams. For example: To customize which groupings are displayed:
To customize which groupings are displayed:- Open the Manage tab.
- Click Configure Specimen Groupings.
- Each grouping offers three levels of sorting. Select as shown:

- Click Save.
- Open the Specimen Data tab.
- You can now click the + to expand the specimen groupings:

- Click any item within the grouping to see the corresponding data view.
Flag Specimens for Quality Control
Guidelines for Flagging
Conflicting information on specimen data will trigger a flag, the conflicting column will be left blank, and the row will have color highlighting. Example flag situations:- An imported specimen's globalUniqueID is associated with more than one primary type, as could occur if a clinic and repository entered different information pre- and post-shipment.
- A single sample is simultaneously at multiple locations, which can occur in normal operations when an information feed from a single location is delayed, but in other cases may indicate an erroneous or reused globalUniqueID on a vial or other aliquot.
- Conflicting Draw Timestamps are detected. See below for more about this case.
- A saliva specimen present in a protocol that only collects blood (indicating a possibly incorrect protocol or primary type).
- Primary specimen aliquoted into an unexpectedly large number of vials, based on protocol expectations for specimen volume (indicating a possibly incorrect participantID, visit, or type for the specimen).
How to Work With Specimen QC Flags
Enable Specimen QC
To enable Specimen QC, go to a specimen grid and click the Enable Comments/QC button.
Review Flagged Vials
You may choose to save a custom grid that filters for vials with the Quality Control Flag marked True in order to identify and manage vials that import with conflicts.Change Quality Control Flags
- After you have enabled specimen QC in a grid, check boxes for specimens of interest.
- Click Comments and QC and select Set Vial Comment or QC State for Selected.
- In Quality Control Flags, change the radio button:
- Do not change quality control state
- Add quality control flag
- If any of the specimens you have selected already have existing comments, you will have the option to replace them, append new comments to them, or leave existing comments unchanged.
- Add Comments if you wish.
- Click Save Changes.
- Return to the grid to see red highlighting on flagged vials:

Review Audit Log
All specimen QC and comment actions are logged in the site audit log. If you are an admin, you can review the log:- Select Admin > Site > Admin Console.
- Click Audit Log.
- Select Specimen Comments and QC from the dropdown menu.

Flagging Draw Timestamp Discrepancies
[ 14.1 Demo Video: Draw Timestamp Changes ]The Draw Timestamp for a specimen vial is expected to remain constant over time. However, as specimens are moved among labs sometimes the time portion is lost. Also, occasionally time corrections are made to the repository but it is difficult to change all events associated with a specimen. Whenever the Draw Timestamp differs among events the specimen is flagged with a QC flag and the Draw Timestamp is not shown.To provide more information about possible discrepancies, upon import to the SpecimenEvent table, the DrawTimestamp field value is used to generate new DrawDate and DrawTime fields in the Vial and Specimen tables (the SpecimenEvent table retains the existing DrawTimestamp field only). QC Flagging will apply individually to the DrawDate and DrawTime fields on the Vial table, allowing the administrator to still import the row but be able to determine whether the discrepancy is significant.Related Topics
For more information about quality control settings for study datasets, see Manage Dataset QC States.Edit Specimen Data
- Select the Manage tab.
- Click Select Repository Type.
- Check the radio button for Editable.
- Click Submit.
Edit Specimen Data
- Open the desired individual specimen view.
- Click Edit next to the specimen you wish to edit.
- Change fields as desired in the SpecimenDetail view:

- Click Submit.
Add New Specimen Data
- Click Insert New in the individual vial view
- Complete the available fields on the Insert SpecimenDetail page.
- Any fields which do not have an entry option, such as Processing Location are populated automatically from other sources.
- Participant Id and Sequence Num are required.
- Click Submit.
Customize the Specimen Request Email Template
- From the study Manage tab, click Manage Notifications.
- Click Edit Email Template.

- Confirm that Specimen request notification is selected from the Email type pulldown.
- Note: You could also reach this page from anywhere in the study by selecting Admin > Site > Admin Console, clicking Email Customization and choosing Specimen request notification from the Email Type pulldown.
<div>
<br>
Specimen request #^specimenRequestNumber^ was ^simpleStatus^ in ^studyName^.
<br>
<br>
</div>
<table width="500px">
<tr>
<td valign="top"><b>Request Details</b></td>
</tr>
<tr>
<td valign="top"><b>Specimen Request</b></td>
<td align="left">^specimenRequestNumber^</td>
</tr>
<tr>
<td valign="top"><b>Destination</b></td>
<td align="left">^destinationLocation^</td>
</tr>
<tr>
<td valign="top"><b>Status</b></td>
<td align="left">^status^</td>
</tr>
<tr>
<td valign="top"><b>Modified by</b></td>
<td align="left">^modifiedBy^</td>
</tr>
<tr>
<td valign="top"><b>Action</b></td>
<td align="left">^action^</td>
</tr>
^attachments|<tr><td valign="top"><b>Attachments</b></td><td align="left">%s</td></tr>^
</table>
^comments|<p><b>Current Comments</b><br>%s</p>^
<p>
^requestDescription^
</p>
^specimenList^
Export a Specimen Archive
- Navigate to the Manage tab of your study.
- Click the Export Study button at the bottom of the page.
- Select Study from the Folder Objects list.
- Unselect all the study objects except Specimens and Specimen Settings.
- Under Options, select the desired behavior.
- Under Export To, select Pipeline root export directory, as individual files.
- Click Export.
- Under Files, navigate to export > study > specimens. Look for a file named <StudyName>.specimens, where <StudyName> is the name of your study. This is the specimen archive. It is a .zip file, renamed as a .specimen file.
- Download the .specimen file to your machine.
Exporting and Importing Specimen Settings
Some but not all specimen settings are exported in a standalone archive. To determine which settings are included, you can unpack the zipped archive and view the contents of the included .xml files. To include custom properties and request settings, for example, you must export the entire study archive.Upon reimport of a specimen repository, some rules about some settings are observed. For example, any status or actor that is currently in use in the specimen repository will not be replaced. When you import an in-use Actor, the membership emails for that actor will be replaced.The full XML schema description can be found in: LabKey XML Schema Reference.Specimen Coordinator Guide

Statuses
A specimen request goes through a number of states from start to finish. For example:- New Request
- Processing
- Completed
 Each request will begin with step number 1, but will not necessarily pass through the other states in strict order or necessarily completing each one. For example, a given request would end up as either Complete or Rejected but not one before the other. You could also define a custom status like Pending Confirmation of Location that would only apply to first requests from that location but never to repeat requests.For each status, two additional flags may be set:
Each request will begin with step number 1, but will not necessarily pass through the other states in strict order or necessarily completing each one. For example, a given request would end up as either Complete or Rejected but not one before the other. You could also define a custom status like Pending Confirmation of Location that would only apply to first requests from that location but never to repeat requests.For each status, two additional flags may be set:
- Final State - this flag indicates that no further processing will take place.
- Lock Specimens - this flag will prevent other requests from being made for the same items while the request is in this state.
Actors
Actors are individuals or groups who can be involved in a specimen request. Examples include:- Specimen requesters, such as lab technicians or principal investigators
- Reviewers of requests, such as oversight boards or leadership groups
- Those responsible for storing and shipping specimens, such as repository owners
- Study-affiliated Actors (such as an oversight board for that particular study) are defined as One Per Study and you can specify the email address(es) associated with that actor.
- Site-affiliated actors, who may participate in multiple studies, are defined as Multiple per study and you define the site affiliation for the actor.
- From the Specimen Data tab and click Settings.
- Click Manage Actors and Groups.
- Define the Actors required and declare their affiliations
- Click Update Members and add email addresses for each study-affiliated actor.
- Click Done.
Request Requirements
You can configure default requirements for new specimen requests. General requirements are those events that must happen once per specimen request, regardless of the details/locations of the specimens.In addition, default requirements can be tied to various specimen-specific locations, such as originating location, providing location, and requesting location. Location-specific requirements are often related to legal and shipment notifications.
Request Form
You can customize the information collected from users when they generate a new specimen request. The only required part of the standard form is a drop-down list from which the user selects the destination site; this list appears first on the form and cannot be removed or customized.Manage New Request Form allows you to specify a number of inputs, such as assay plan, shipping information, etc, each with:- Title
- Help Text - The instructive caption such as "Please enter your shipping address"
- Multiline - Check to allow multiple lines of input
- Required - Whether the given information must be provided to submit the request
- Remember by Site - If checked, the input will be pre-populated with the previous value entered for the destination location. This is useful for things like the shipping address.
 Reorder or delete input fields using the arrows and X links to the left of each field.
Reorder or delete input fields using the arrows and X links to the left of each field.
Notifications
Next configure the options for content and process for email notifications sent during the request approval process:- Reply-to Address: The address that will receive replies and error messages, so it should be a monitored address. Can be fixed or set to reply to the administrator who generates each notification.
- Edit Email Template: The subject line and body of the email can be controlled using a configurable template. Administrative permissions are required to edit the email template.
- Subject Suffix: The subject line will always begin with the name of the study, followed by whatever value is specified as the subject suffix.
- Send Notification of New Requests - if checked, specify who to notify.
- Always Send CC: If specified, mail addresses listed for this property will receive a copy of every email notification. Security issues should be kept in mind when adding users to this list.
- Default Email Recipients: Specify which actors will receive notification email, provided the coordinator does not explicitly override. Possible values: All / None / Notify Actors Involved.
- Include Requested Specimens Table: In each notification email, a table of requested specimens can be included in the email body, or as an attachment, or not at all. Possible values: In the email body / As Excel attachment / As text attachment / Never. For information about customizing the data shown, see Email Specimen Lists.
Requestability Rules
Whether a given specimen is requestable is determined by running a series of configurable rules during import. Different types of specimen and request workflows may require different sets of rules. For example, if the specimen is divided into a limited number of vials, the "Locked in request" rule would prevent multiple requests for the same item. However, if the specimen aliquot is a block of tissue, and it is possible to generate multiple slides from the same block, that rule would not apply. A common specimen aliquot is a vial, so that terminology is used in the tools even if you have customized the aliquot field names.- Each specimen with requestability set via these queries is annotated so that users and administrators can determine why the aliquot is or is not requestable.
- Administrators can specify the order in which the queries are run in order to resolve potential conflicts.
- Rules are run in order, so the last rule applied to a given aliquot will determine it's final state.
- Rules are run exclusively during import, so changing them will not affect the requestability of aliquots currently stored in the system until the next specimen import.
- Click Settings in the right column on the home page of your study.
- Under the Specimen Request Settings heading, click Manage Requestability Rules.
- The Active Rules interface allow you to view, delete and reorder existing rules, or configure new ones:

- From the Add Rule dropdown, you can also configure a Custom Query by specifying a Schema
- When you are finished editing rules, click Save.
Other Topics
- Email Specimen Lists - Email lists as attachments, such as to the originating lab.
Email Specimen Lists
Send An Email
- On the Specimen Data tab of your study, expand the Specimen Requests section of the Specimens webpart.
- Click View Current Requests.
- Click the Details button next to any request.
- Click either Originating Location Specimen Lists or Providing Location Specimen Lists.
- Check the boxes next to the desired email recipients (See note below).
- Add any comments, attachments, and supporting documents you wish.
- Click Send Email.

Customize the Specimen List
On the Manage Notifications page, you can choose whether to include the specimen list as an attachment or directly in the email body. To customize the data shown by either method, create a custom grid called SpecimenEmail on the SpecimenDetail table.- Go to Admin > Developer Links > Schema Browser.
- Browse to: study > Built-In Queries and Tables > Specimen Detail.

- To optionally edit column labels or types, click Edit Metadata. When finished, click Save.
- Click View Data.
- Click Grid Views > Customize Grid.
- Using the grid customizer, you can control which fields are shown in what order and how filters and sorting are applied.
- When you have customized the grid to your liking, click Save.
- Select Named, name the grid SpecimenEmail, and decide how you want the grid shared and inherited.
- Click Save.
Edit Metadata (optional)
If desired, you can configure the column headings and datatypes of the attached list by modifying the metadata for the study.SpecimenDetail table before creating your SpecimenEmail grid view.
Customize Grid
For instructions on using the grid customizer see: Customize Grid Views.For broader notification configuration settings see Specimen Coordinator Guide.View Specimen Data
Explore Specimen Repository Data
A study folder has a Specimen Data tab containing two default web parts:- Vial Search: A web part for selecting specific specimens of interest.
- Specimens: This web part contains links to view all specimens by vial or group as well as a number of predefined groupings.
Vial Groupings
The specimen repository automatically groups together aliquots/vials into one specimen, using the following fields. When two aliquots/vials have identical values in the following fields, the system groups them together in the same specimen. (The system concatenates these values together to form a "SpecimenHash" value; aliquots with the same SpecimenHash are considered part of the same specimen.)- AdditiveTypeId
- ClassId
- DerivativeTypeId
- DerivativeTypeId2
- DrawTimestamp
- OriginatingLocationId
- ParticipantId
- PrimaryTypeId
- ProtocolNumber
- SalReceiptDate
- SubAdditiveDerivative
- VisitDescription
- VisitValue
- VolumeUnits
Search for Specimens
The Vial Search web part offers many options for searching for specific specimens of interest. For example the following image shows a search request for all blood specimens from participant 249318596. If you would like to add a vial search web part to a page that does not already contain one, select Specimen Search from the Add Web Part pulldown.
If you would like to add a vial search web part to a page that does not already contain one, select Specimen Search from the Add Web Part pulldown.
View Selected Specimens
- Navigate to the study home page on your own server, or open this page in a new browser window.
- Click the Specimen Data tab.
- In the Specimens web part, pictured below, expand the Vials By Primary Type and Vials by Derivative Type sections as shown. Click the + button to the left of an item to expand it.

- Click By Vial Group under View All Specimens for a view of data to explore.

Specimen Vial History
Events and flags that occur with each specimen data row, such as requests or updates, are tracked and recorded. If you are using your own locally installed study, you will only be able to see the history if you have enabled the advanced specimen repository. To enable it, select Manage > Change Repository Type then choose the Advanced (External) Specimen Repository option.- Open any individual vial view from the Specimens web part, or click the Show Individual Vials link at the top of a group view.
- Click History on any vial to view a summary and history including relevant requests if any.

Related Topics
Generate Specimen Reports
View and Customize Reports
- Open the Specimen Data tab.
- Click the Specimen Reports link icon in the right panel. Built-in report types are listed here.

- Click Show Options next to any report type.

- Select desired options, click View to see your report.
Export/Print Reports
After viewing any report, you can select either Print View or Export to Excel.Share Results Online
You can share a customized specimen report with colleagues by sharing the URL of the customized report page.Specimen Report Webpart
For easy access to a specific specimen report directly from a folder or tab, an administrator may add a customized web part. These specimen report web parts may be embedded in wikis and messages like any other web part.- In the lower left, select Specimen Report from the Select Web Part drop down, then click Add.
- Choose a report option from the drop down, such as Participant Summary.

- Click Submit.

- Readers can now see this report directly on the page.
Laboratory Information Management System (LIMS)
Specimen Management
The LabKey Specimen Tracking and Request systems are ideally suited to customization to suit your particular sample management needs. You can track the movement of samples between locations, record notes and quality control flags, and generate reports required. Customize the approval process, make sure your specific data gathering and analysis steps happen in the correct order, and track metrics about performance to aid in streamlining any lab.For example, a single specimen drawn from a subject might be distributed to many different laboratories, which then generate different datasets from the original specimen. This presents a number of problems for the researcher: How do you track a vial's history from the original clinical site, to the labs, and finally link the specimen to the generated datasets? Moreover, how do you connect the various datasets residing in independent storage systems, including the CRFs describing the subjects, the vial inventory systems, and the assay results generated from the specimens?LabKey Server solves these issues by importing and connecting data from the different systems, including subject CRF data, specimen inventories from LIMS and lab tracking systems, and downstream assay results. The integrated data provides answers to questions that would be difficult to approach when the data is separated, questions such as:What assays have been run on this specimen?What is the current location of the specimens that generated these assay results?
Which specimens originated from subjects with such-and-such clinical characteristics?LabKey Server connects and aligns the separate datasets using key fields, especially subject ids, timepoints, and specimen ids/barcodes. Links between the datasets can take a number of different forms: assay results and CRFs can be linked to specimen information using subject ids, or using vial barcodes/specimen ids. The resulting integrated datasets allow for the creation of reports and views that would not be possible otherwise. For example, when clinical, assay, and specimen data are brought together, researchers can navigate from a given vial to its downstream assay results, or they can navigate from a set of assay results back to the originating vial and subject. Similarly, integrated data views can be used as the basis for complex analyses and visualizations. LabKey's specimen management system is designed to complement, not replace, existing lab workflows and LIMS systems. LabKey Server typically works by syncing with data from existing systems, without the need to transform LabKey Server into the "database of record". This allows labs to retain their existing workflows and avoid transferring their data to a new platform. LabKey can also link together different naming systems, so that datasets with different ids for the same subjects and specimens cab be brought together, like an "honest broker" system. With LabKey Premium Editions, you can also integrate with automate refresh of specimen and sample data from external tools like FreezerPro.
Instrument Integration
No matter what instrumentation you are using to extract research data from your samples, you can design a LabKey assay to represent the schema and facilitate integration of your data with other information about the sample, or about other samples from the same patient. Tracking metadata about the data can also be made programmatic and quality control tools will help improve the reproducibility and reliability of the data obtained.Electronic Data Capture and Exchange
Create your own custom application for electronic data capture, combining survey-style user-entered information with automatically processed instrument data for a complete programmatic process for your specific research requirements.With LabKey Premium Editions, integrate with existing systems using tools like RedCap and DATStat.Laboratory Workflow Management
When the sequence of activities in your research lab can be incorporated into a workflow application, you can improve performance and results. By customizing a LabKey application to closely match existing tools, adoption into busy labs becomes easier.Using tabs, webparts, and existing LabKey tools, you can create a custom solution to manage your laboratory data and provide workflow guidance. A simple system of named web parts can direct individual operators to their specific tasks, and more involved task list applications can help share the work across a larger group.Additional Functions
- Audit Management
- Barcode Handling
- Chain of Custody
- Compliance
- Customer relationship management - link demographic information and manage communications
- Document management - track distribution and manage access
- Instrument calibration and maintenance - track tasks and keep detailed records
- Manual and Electronic data entry
- Quality Control
- Reports
Contact LabKey
If you are interested in learning more, or in partnering with LabKey to solve laboratory information management problems, please contact LabKey.Electronic Health Records (EHR)
- EHR: Animal History: Search for Particular Animals
- EHR: Animal Search: Search for Animals by Criteria
- EHR: Data Entry
- EHR: Administration
- EHR Team
 Task buttons:
Task buttons:
EHR: Animal History
Search for Particular Animals by ID
The animal history search page offers a list of different types of searches (specific options may vary by center). Choose the type of search, enter the ID or IDs of interest, and click Update Report. The search results yield a set of results, displayed on a tiered set of tabs. Choose a primary (top row) tab to see the options for the secondary row of tabs. Both rows can be scrolled using the left and right arrows. The specific tabs offered will vary by center and each tab can be customized to the needs of your research lab. Some examples of primary/secondary tabs that might show useful grids:
The search results yield a set of results, displayed on a tiered set of tabs. Choose a primary (top row) tab to see the options for the secondary row of tabs. Both rows can be scrolled using the left and right arrows. The specific tabs offered will vary by center and each tab can be customized to the needs of your research lab. Some examples of primary/secondary tabs that might show useful grids:| Primary Tab | Secondary Tab |
|---|---|
| General | Blood Draw History |
| Lab Results | Hematology |
| Clinical | Medication Orders |
| Behavior | Cagemate History |
| Genetics | Pedigree Plot |
Animal History Reporting
You can generate visualizations or other reports on top of the data in the search results. Individual fields may also contain links to other grids - for instance, clicking a value in a "Cage" column on one tab could open the profile of that cage from another tab (that might include links to the specific animals currently in it).As another example, on the Genetics > Kinship tab, you might see a tool for exporting a kinship matrix, which you could then print to CSV. Entry fields could allow you to further filter the result.
EHR: Animal Search
Search for Animals by Criteria
Select the Search Animals tab. The specific options and links available will vary by center, but the tab will look similar to the following: The Browse section of customized links to pre-defined views or reports may or may not be included on this tab. Such links can be added by an administrator.The Search Criteria panel offers a list of ways users can filter by values in one or more categories to find animals of interest. The list of criteria here may vary by center, and the filtering expressions available on pulldown menus will vary by data type. A full list of expressions is available here: Filtering Expressions.
The Browse section of customized links to pre-defined views or reports may or may not be included on this tab. Such links can be added by an administrator.The Search Criteria panel offers a list of ways users can filter by values in one or more categories to find animals of interest. The list of criteria here may vary by center, and the filtering expressions available on pulldown menus will vary by data type. A full list of expressions is available here: Filtering Expressions.
View Selection
The only required search criterion is View, typically listed last. This selection determines the view of the demographics dataset to search. Built in options typically include "Alive at Center" and "All" (which would include all animals, including ones which are dead or no longer at the center). Users with sufficient permission may add additional custom views and make them available for others.Once you have selected a view and optionally entered any criteria to use for filtering, click Submit to run the search.Search Results
Search results are presented as a grid view of the Demographics table. You can further apply traditional filtering, sorting, grid view customization, and export features as with any LabKey dataset.Related Topics
EHR: Data Entry
Entering Data
From the Overview tab, click Enter Data. Your login will be associated with your task assignment, i.e. the permission roles you require. These roles will determine which forms are available. You can also select the My Tasks or All Tasks tabs for a list of pending tasks requiring data entry. Click a link to open the form. Use Add or Add Batch to enter data. Entry forms can be customized to aid data entry by showing required fields with highlighting, guidance text or labels, and some fields will be drop down selectors to limit input to values contained in another table. For example, a Blood Draw entry form could look like this:
Click a link to open the form. Use Add or Add Batch to enter data. Entry forms can be customized to aid data entry by showing required fields with highlighting, guidance text or labels, and some fields will be drop down selectors to limit input to values contained in another table. For example, a Blood Draw entry form could look like this:
Related Topics
EHR: Administration
Colony Management
Track birth records, cagemate history, death records, housing history, potential parents, and produce reports about these and other aspects of colony management.Notification System
The notification system can be configured to send email alerts automatically when certain events occur. You could send daily or weekly updates, and notify interested parties of things like weight drops, clinical rounds, or compliance notifications.Click the EHR Admin Page link near the bottom of the Overview tab, then click Notification Admin. The list of notification emails that can be enabled for an EHR system includes a brief description of when each will be sent, to whom, and why. Each can be individually enabled or disabled. You can also click to run each report within the browser for a preview of the information.
The list of notification emails that can be enabled for an EHR system includes a brief description of when each will be sent, to whom, and why. Each can be individually enabled or disabled. You can also click to run each report within the browser for a preview of the information.
Related Topics
EHR Team
- Wisconsin National Primate Research Center (WNPRC), University of Wisconsin - Madison
- Oregon National Primate Research Center (ONPRC), Oregon Health and Sciences University
- Southwest National Primate Research Center (SNPRC), Texas Biomedical Research Institute
- California National Primate Research Center (CNPRC), University of California - Davis
- Binal Patel, LabKey
- Josh Eckels, LabKey
- Marty Pradere, LabKey
- Daniel Nicolalde, UW-Madison
- Jon Richardson, UW-Madison
- Tom Lynch, UW-Madison
- Ben Bimber, OSHU
- Gary Jones, OHSU
- Lakshmi Kolli, OHSU
- Patrick Leyshock, OHSU
- Raymond Blasa, OHSU
- Wayne Borum, OHSU
- R Mark Sharp, Texas Biomedical
- Scott Rouse, Texas Biomedical
- Terry Hawkins, Texas Biomedical
- Alex de Bruin, UC-Davis
- Joseph Acac, UC-Davis
- Michael Lucas, UC-Davis
- Steve Fisher, UC-Davis
Collaboration
- File management -- Share and manage files using a secure repository
- Message boards -- Facilitate team discussions about your project.
- Issue tracking -- Solve multi-step problems requiring input from many team members.
- Wiki pages -- Document and contextualize your project.
- Electronic Data Capture -- Design and integrate surveys for electronic data capture (EDC).
- RedCap Integration -- Integrate RedCap survey data.
- Adjudication Module -- Tools for increased diagnosis confidence through independent determinations.
- Tours for New Users -- Create guided tours of your application for your users.
- Contacts -- When enabled, create a user contacts page.

Tutorial
Collaboration TutorialRelated Topics
Security -- Learn more about the LabKey security model and how to use it.Collaboration Tutorial
Tutorial Steps
First Step
Step 1: Use the Message Board
Example Message
Researchers often use the message board to announce new content and updates to their work. Here a fictional example message, announcing new data and press resources: Notice that each message contains:
Notice that each message contains:
- A title
- The author's name
- The date posted
- The body of the message
- A link to post a response message.
Set up a New Message Board
To set up a workspace and message board of your own:- Navigate to a location on your LabKey Server in which you have administrative access and can create a new folder.
- If you haven't already installed LabKey Server, follow the steps in this topic Install LabKey Server (Quick Install). You will create a local demonstration server on which you will be the site administrator. You can use the home project on your own local server: http://localhost:8080/labkey/project/home/begin.view
- Sign in.
- Create a new folder workspace:
- Go to Admin > Folder > Management and click Create Subfolder.
- Name: "Collaboration Tutorial".
- Folder Type: Collaboration.
- Click Next.
- On the Permissions page, confirm "inherit from parent folder" is selected and click Finish.
- Notice that the page contains two main sections or "web parts": a Wiki web part and a Messages web part.

Start a Conversation on the Message Board
- In the Messages web part, click New.
- On the New Message page, make the following changes:
- In the Title field, enter "First Announcement".
- In the Body field, enter "This is the first announcement of the collaboration project."
- Notice the Render As pulldown. Options:
- Plain Text (default): Leave this selected for the tutorial.
- Wiki Page: Supports the use of wiki syntax to format the page.
- HTML: Supports HTML editing.
- Notice the option to attach a file attachment (but skip this option for the tutorial).
- Click Submit.
- Notice that the Messages web part contains a new listing titled First Announcement.
Continue the Conversation
When you submit the message, you are returned to the main page of your tutorial and see the message in the Messages web part. To open the message for editing or responding, click the message title or the View Message Or Respond link.On the page for this message, you have a few additional options: you can print (to a new browser window) or view the message on a list. As the creator of the message, and an administrator, you will also see "Edit" or "Delete Message" options. You are also automatically "subscribed" to any responses - an "unsubscribe" link is available.- Click View Message or Respond to open the message page.
- Click Respond.
- In the Body field, enter "This is a response to the first announcement."
- Click Submit.
- Notice that the response is displayed underneath the announcement. Other responses can be added to form a longer conversation.

Configure the Message Board
- Click the Start Page tab to return to the main page.
- In the Messages web part, click the dropdown arrow at the top of the web part and then Admin.

- In the Board name field, replace the text "Messages" with the text "Message Board".
- In the Conversation name field, replace the text "Message" with "Announcement".
- Review but do not change the other customization options.
- Click Save.
- Notice that the web part has a new name: "Message Board", and now is showing "all announcments".

- See an example version of the message board you just built: Message Board
- Look at a live message board with lots of content: Developer Message Board
Related Topics
Start Over | Next Step
Step 2: Collaborate Using a Wiki
Example Page
The following example wiki page is shown as an administrator would see it.- The page includes a title in large font.
- Buttons are shown for editing the page, creating a new one, viewing the history of changes, etc. These buttons are shown only to users with appropriate permissions.
- Links and images can be included in the body of the page.
 The following steps will take you through the mechanics of creating and updating wiki pages.
The following steps will take you through the mechanics of creating and updating wiki pages.
Create an HTML Page
- Navigate to the Start Page tab of your Collaboration Tutorial project.
- In the Wiki web part, click Create a new wiki page. If this link is not present, i.e. another wiki already exists in the folder, use the triangle menu for the wiki web part and select New.
- In the New Page form, make the following changes:
- In the Name field, enter "projectx".
- In the Title field, enter "Project X".
- On the Visual tab, enter the following text: "Project X data collection proceeds apace, we expect to have finished the first round of collection and quality control by..."
- You can switch to the Source tab to see the HTML for this simple text page.
- Click Save & Close.
- Notice that the Pages web part in the right hand column shows a link to your new page.
Create a Wiki Page
Wiki pages are written in "wiki code", a simple syntax that is easier to read and write than HTML. Wiki pages are especially useful for composing text and presenting content clearly and simply. When a user calls up your wiki page in a browser, LabKey Server parses the wiki code and renders it as HTML to the user.- In the Pages web part (on the right when viewing the Start Page tab), click the dropdown arrow, and select New.

- Click Convert To....
- In the Change Format pop up dialog, confirm that Wiki Page is selected, and click Convert. Notice there is only a single panel for the body of text. The "Visual" and "Source" tabs are only used for HTML format pages.
- In the New Page form, make the following changes:
- In the Name field, enter "projecty".
- In the Title field, enter "Project Y".
- Copy the following and paste into the Body field:
**Project Y Synopsis**
Project Y consists of 3 main phases
- **Phase 1: Goals and Resources.**
-- Goals: We will determine the final ends for the project.
-- Resources: What resources are already in place? What needs to be created from scratch?
- **Phase 2: Detailed Planning and Scoping.**
- **Phase 3: Implementation.**
We anticipate that Phase 1 will be complete by the end of 2014, with Phase 2 \\
completed by June 2015. Implementation in Phase 3 must meet the end of funding \\
in Dec 2016.
- Click Save & Close

- In the Pages web part, click Project Y.
- Click the Manage button.

- Using the Parent dropdown, select "Project X (projectx)". This makes Project X the parent topic for Project Y. Notice Project X is no longer listed as a sibling of Project Y. Sibling pages can be reordered with the buttons.
- Click Save when finished.
- Notice the Pages web part: any parent page now has a small + or - button for expanding and contracting the table of contents.
View the History / Compare Versions
All changes to wiki and HTML pages are tracked and versioned, so you can see how a document has developed and have a record of who made changes. To see these features, first make an edit to one of your pages, in order to build an editing history for the page.- In the Pages menu, click Project Y.
- Click Edit. (If you do not see the edit link, you may need to log in again.)
- Make some changes and click Save & Close.
- Click History to see the list of edits.
- Click Version 1.
- Click Compare With... and then select Latest Version to see the exact changes made between the two revisions.
Previous Step | Next Step
Step 3: Track Issues
Life Cyle of an Issue/Bug
Issues have three statuses/phases:- The open phase - The issue has been identified, but a solution has not yet been applied.
- The resolved phase - A solution has been applied, but it is not yet confirmed.
- The closed phase - The solution is confirmed, so the issue is put to rest.
 Steve notices a problem and opens an issue which needs attention. Once someone else has resolved it, Steve double checks the work before marking the issue closed.Notice:
Steve notices a problem and opens an issue which needs attention. Once someone else has resolved it, Steve double checks the work before marking the issue closed.Notice:
- The issue contains three main areas: a title section (with action links), a properties/status report area, and series of comments.
- Each comment includes the date, the contributing user, life-cycle status updates, and the body of the comment, which can include file attachments.
- This issue has gone through the entire life-cycle: open, resolved, and finally closed.
Set Up and Use an Issue Tracker
First we add the issue tracker to the folder. There can be several different types of issue tracker, and issue definitions are used to define the fields and settings. In this case we need only a general one that uses default properties.- Click the Start Page tab to return to the main page.
- From the <Select Web Part> dropdown at the bottom left of the page, select Issues Definitions and click Add.
- Click Insert New Row in the new web part.
- Give the new definition a name, such as "Default Tracker", and leave "General Issue Tracker" selected.
- Click Submit.
- Review the properties and naming conventions on the admin page, but make no changes.
- Click Save.
- Click the Start Page tab to return to the main page.
- From the <Select Web Part> dropdown at the bottom left of the page, select Issues List and click Add.
- Confirm that your new default definition is selected and click Submit.
- From the menu in the upper right, select Admin > Folder > Permissions.
- Click the Project Groups tab.
- Unless it already exists, type "Users" in the New Group Name box and click Create New Group.
- In the Add user or group... dropdown, select yourself.
- Click Done in the pop-up.
- Select Admin > Folder > Permissions.
- If necessary, uncheck Inherit permissions from parent.
- Using the dropdown next to the Editor role, select "Users". This means that anyone in that group can open and edit an issue.
- Click the tab Project Groups.
- Click Users. Notice that Editor is now listed under Effective Roles.
- Click Done.
- Click Save and Finish.
- In the Issues List web part, click the New Issue button.
- On the Insert New Issue page:
- In the Title field: "Some Task That Needs to be Completed"
- From the Assign To dropdown, select yourself.
- In the Comment field, enter "Please complete the task."
- Notice that the other required field, Priority, has a default value of 3 already.
- Click Save.
- You will see the details page for your new issue.
- Click the Start Page tab return to the main tutorial page.
- Update: Add additional information without changing the issue status. For example, you could assign it to someone else using an update.
- Resolve: Mark the issue resolved and assign to someone else, possibly but not necessarily the person who originally opened it, to confirm.
- Close (available for resolved issues): Confirm the resolution of the issue closes the matter.
- Open the detail view of the issue by clicking the title in the issue list.
- Click Resolve.
- By default the Assigned to field will switch to the user who originally opened the issue (you); you may change it if needed, so that a different person can confirm the fix.
- Enter a message like "I fixed it!" and click Save.
- Notice that instead of a resolve link, there is a link reading Close; click it.
- Enter a message if you like ("Well done.") and click Save.
- Your issue is now closed.
- See a live example of a similar issue: Issues List.
- See the LabKey issues list, where the LabKey staff tracks development issues: LabKey Issues List
Related Topics
Previous Step
File Repository Tutorial

Problems with Files
Researchers and scientists often have to manage large numbers of files with a wide range of sizes and formats. Some of these files are relatively small, such as spreadsheets containing a few lines of data; others are huge, such as large binary text files. Some have a generic format, such as tab-separated data tables; while others have instrument-specific, proprietary formats, such as Luminex assay files -- not to mention image-based data files, PowerPoint presentations, grant proposals, longitudinal study protocols, and so on.Often these files are scattered across many different computers in a research team, making them difficult to locate, search over, and consolidate for analysis. Worse, researchers often share these files via email, which puts your data security at risk and can lead to further duplication and confusion.Solutions: LabKey Server File Repository
LabKey Server addresses these problems with a secure, web-accessible file repository, which serves both as a searchable storage place for files, and as a launching point for importing data into the database (for integration with other data, querying, and analysis).In particular, the file repository provides:- A storage, indexing and sharing location for unstructured data files like Word documents. The search indexer scans and pulls out words and phrases to enable finding files with specific content.
- A launching point for structured data files like Excel files, that can be imported into the LabKey Server database for more advanced analysis.
- A staging point for files that are opaque to the search indexer, such as biopsy image files.
Tutorial Steps
- Step 1: Set Up a File Repository
- Step 2: File Repository Administration
- Step 3: Search the Repository
- Step 4: Import Data from the Repository
- Install a local evaluation server on your own machine (described in the first step).
- Or, have your server administrator grant you folder or project level admin permissions.
First Step
Step 1: Set Up a File Repository
Set up a File Repository
First we will set up the user interface for the repository, which lets you upload, browse, and interact with the files in the repository.- If you haven't already installed LabKey Server, follow the steps in the topic Install LabKey Server (Quick Install).
- In a web browser go to an available project, such as the Home project, and sign in.
- Create a new folder to work in, a blank slate:
- Go to Admin > Folder > Management and click Create Subfolder.
- Name: "File Repository"
- Folder Type: "Collaboration" (the default) and click Next.
- Confirm Inherit from Parent Folder is selected and click Finish.
- You are now on the default tab (Start Page) of the new folder.
- Add the file repository user interface:
- From the Select Web Part dropdown in the lower left, select Files and click Add.
- The user interface panel for the file repository is added to the page.
- The files web part window is now a drag-and-drop target area.

Upload Files to the Repository
With the user interface in place, you can add content to the repository. For the purposes of this tutorial we have supplied sample files including a variety of presentations (unstructured data) from the LabKey Server user conferences, each showing some application of LabKey Server to a particular problem or project. There is also tabular data in the form of Excel files (structured data).- Download FileRepositoryTutorialData.zip.
- Unzip the folder to the location of your choice.
- Open an explorer window on the unzipped folder FileRepositoryTutorialData and open the subfolders.
- Notice that the directory structure and file names contain inherent keywords and metadata (which will be captured by full text search).
FileRepositoryTutorialData
DataForImport
Lab Results.xls
UserConferenceSlides
2011
Adapting LabKey To Pathogen Research_VictorJ Pollara_Noblis.pdf
Adjuvant Formulations_Quinton Dowling_IDRI.pdf
Katze Lab and LabKey 1_Richard Green_Katze.pdf
. . .
2012
. . .
2013
. . .
- Drag and drop the two folders DataForImport and UserConferenceSlides, onto the target area on the File Repository.
- Notice the progress bar displays the status of the import.
- Click the Toggle Folder Tree button on the far left to Show or hide the folder tree.

- When uploaded, these two folders should appear at the root of the file directory, directly under the fileset node.
Securing and Sharing the Repository (Optional)
Now you have a secure, shareable file repository. Setting up security for the repository is beyond the scope of this tutorial. To get a sense of how it works, go to Admin > Folder > Permissions. The Permissions page lets you grant different levels of access, such as Reader, Editor, Submitter, etc., to specified users or groups of users. For details on configuring security, see Tutorial: Security.Start Over | Next Step
Step 2: File Repository Administration
- Add and delete files.
- Customize which actions are exposed in the user interface.
- Audit user activity, such as when users have logged in and where they have been inside the repository.
Browse and Download Files (Client Users)
- If the file upload panel is open, click the Upload Files button to close it.
- Click the folder tree toggle to show the folder tree on the left.
- Notice that the button bar may overflow to a >> pulldown menu on the right if there are more buttons visible than fit across the panel.

- Click into the subfolders and files to see what sort of files are in the repository.
- Double-click an item to download it (depending on your browser settings, some types of files may open directly).
Customize the Button Bar (Administrators)
You can add, remove, and rearrange the buttons in the Files web part toolbar. Both text and icons are optional for each button shown.- Return to the folder home page by clicking the Start Page tab.
- In the Files web part toolbar, click Admin. (Note that when more buttons are displayed than fit across the files panel, overflow buttons will be on a >> pulldown menu to the right).
- Select the Toolbar and Grid Settings tab.
- The Configure Toolbar Options shows current toolbar settings; you can select whether and how the available buttons (listed on the right) will be displayed.
- Uncheck the Shown box for the Rename button. Notice that unsaved changes are marked with red corner indicators.
- You can also drag and drop to reorder the buttons. In this screenshot, the parent folder button is being moved to the right of the refresh button.

- Make a few changes and click Submit.
- You may want to undo your changes before continuing, but it is not required as long as you can still see the necessary buttons. To return to the original file repository button bar:
- Click Admin.
- Return to the Toolbar and Grid Settings tab.
- Click Reset to Default.
Configure Grid Column Settings
Grid columns may be hidden and reorganized using the pulldown menu on the right edge of any column header, or you can use the toolbar Admin interface. This interface offers control over whether columns can be sorted as well.- From the Toolbar and Grid Settings tab, scroll down to Configure Grid Column Settings.
- Using the checkboxes, select whether you want each column to be hidden and/or sortable.
- Reorder columns by dragging and dropping.
- Click Submit when finished.
- If needed, you may also Reset to Default.
Audit History (Administrators)
- In the Files webpart, click Audit History. The report tells you when each file was created or deleted and who executed the action. In this case you will see when you uploaded the sample directory.
- See an interactive example.
Previous Step | Next Step
Step 3: Search the Repository
Add Search User Interface
- Return to the Start Page tab where you installed the Files web part.
- At the bottom of the left side of the page, click Select Web Part, select Search and click Add.
- Pull down the web part control menu and select Move Up to move it above the Files web part.

- Using the pulldown webpart menus, you could also "Remove from page" the Wiki and Messages webparts; they are included in a default "Collaboration" folder but not used in this tutorial.
Search the Data
- Enter "serum" and click Search.
- The search results show a variety of documents that contain the search term "serum".
- Click the links to view the contents of these documents.

- Try other search terms and explore the results. Some suggested search terms: "cancer" and "HIV". Try "Mendel" for an empty result (we'll come back to this term in a the next tutorial step.)
- Click the + symbol next to Advanced Search for more options including:
- narrowing your search to selected categories of data.
- specifying the desired project and folder scope.
- See an interactive example: Search LabKey documentation for "serum".

File Tagging
In many cases it is helpful to tag your files with custom properties to aid in searching, for example, when the desired search text is not already part of the file itself. For example, you might want to tag files in your repository under their appropriate project code names, say "Darwin" and "Mendel", and later retrieve files tagged for that project.To tag files with custom properties, follow these steps:Define a 'Project' Property
- Navigate back to Files by clicking the Start Page tab.
- Click Admin. If you don't see it, try the >> pulldown menu.
- Select the File Properties tab.
- Select Use Custom File Properties.
- Click Edit Properties.
- In the Files Property Designer make the following changes:
- In the Name field, enter "Project".
- In the Label field, enter "Project".
- In the Description field on the Display tab, enter "Enter the project this file belongs to:".

- Click Save & Close.
Apply the Property to Files
- Open the folder tree toggle and expand directories.
- Select two files by placing a checkmark next to their filenames.
- Click Edit Properties, or it may be shown only as a wrench-icon. (Hover over any icon-only buttons to see a tooltip with the text. You might need to use the Admin > Toolbar and Grid Settings interface to make it visible.)

- In the Project field you just defined, enter "Darwin" for the first file.
- Click Next and enter "Mendel" for the next.
- Click Save.
Retrieve Tagged Files
- In the Search web part, enter "Darwin" and click Search.
- Your tagged file will be retrieved (along with any other file containing the string "Darwin").
- Enter "Mendel" and search again to retrieve the other file you tagged.
Turn Search Off (Optional)
The full-text search feature can search content in all folders where the user has read permissions. There may be cases when you want to disable global searching for some content which is otherwise readable. For example, you might disable searching of a folder containing archived versions of documents so that only the more recent versions to appear in project-wide search results.- To turn the search function off in a given folder, first navigate there.
- Select Admin > Folder > Management, and click the Search tab.
- Remove the checkmark and click Save.
Previous Step | Next Step
Step 4: Import Data from the Repository
- Create visualizations and SQL queries of selected data.
- Import assay runs to an analysis dashboard.
- Run an analysis on a genetic sequence file.
- Pass the file to an R script sequence you define.
Import Data for Visualization
First, import some file you want to visualize. You can pick a file of interest to you, or follow this walkthrough using the sample file provided. When you "import" a file into LabKey Server, you add its contents to the database. This makes the data available to a wide variety of analysis/integration tools and dashboard environments inside LabKey Server. In the steps below we will import some data of interest and visualize it using an assay analysis dashboard.- In the Files web part, open the folder DataForImport.
- Select the file Lab Results.xls
- Click Import Data.
- Select Create New General Assay Design.

- Click Import.
- Enter a Name, for example "Preliminary Lab Data".
- Select the current folder as the Location.
- Notice the import preview area below. Let's assume the inferred columns are correct and accept all defaults.
- Click Begin Import, then Next to accept the default batch properties, then Save and Finish.
- When the import completes, you see the list of runs, consisting of the one file we just imported.
- To make it easier to access this data later, we can add a web part to show it:
- Click the Start Page tab.
- At the lower left of the screen, click <Select Web Part>, select Query, and click Add.
- Web Part Title: Enter "Preliminary Data" or whatever you would like the title to be.
- Schema: Select "assay.General.Preliminary Lab Data" (or whatever you named your assay when you defined it above).
- Click "Show the contents of a specific query and view."
- Query: Select "Data."
- Leave the default settings for View and the other remaining options.
- Click Submit.
- Scroll down to see your new data grid.
Create a Box Plot
- Explore the new Preliminary Data web part (or whatever name you gave your web part).
- Select Charts > Create Chart. Click Box.
- Drag the column "Cohort" to the X Axis Grouping box.
- Drag the column "CD4+" to the Y Axis box.
- Click Apply and you will see a box and whisker plot for the CD4+ levels of each cohort.

- Explore more chart options via the Chart Type and Chart Layout buttons. You can also return to the data grid and explore more visualization options on the Reports menu.
Previous Step
Files
- Browser-based, secure upload of files to LabKey Server where you can archive, search, store, and share.
- Structured import of data into the LabKey database, either from files already uploaded or from files stored outside the server. The imported data can be analyzed and integrated with other data.
- Browser-based, secure sharing and viewing of files and data produced on your LabKey Server.

Basic Functions
Once files have been uploaded to the repository, they can be securely searched, shared and viewed, or downloaded.Scientific Functions
Once data has been imported into the database, team members can integrate it across source files, analyze it in grid views (using sort, filter, charting, export and other features), perform quality control, or use domain specific tools (eg., NAb, Flow, etc.). The basic functions described above (search, share, download and view) remain available for both the data and its source files.Application Examples
Members of a research team might upload experimental data files into the repository during a sequence of experiments. Other team members could then use these files to identify a consistent assay design and import the data into the database later in a consistent manner. Relevant tutorials: Alternatively, data can be imported into the database in a single step bypassing individual file upload. Relevant tutorials:Related Topics
Using the Files Repository
Drag-and-Drop Upload
The Files web part provides a built-in drag-and-drop upload interface. Open a browser window and drag the desired file or files onto the drag-and-drop target area.Folders, along with any sub-folders, can also be uploaded via drag-and-drop. Empty folders are ignored and not uploaded. While files are uploading, a countdown of files remaining is displayed in the uploader. This message disappears on completion.
While files are uploading, a countdown of files remaining is displayed in the uploader. This message disappears on completion.
Create Directories in the File Repository
You can create directories in the File Repository by clicking the folder button: Enter the name of the directory in the popup dialog, and click Submit:
Enter the name of the directory in the popup dialog, and click Submit: Note that directory names must follow these naming rules:
Note that directory names must follow these naming rules:
- The directory name must not start with an ampersand character: @
- The directory name must not contain any of the following characters: / ; : ? < > * | " ^
Related Topics
- Upload Files: WebDAV - Upload files using a 3rd party WebDAV client.
- Data Processing Pipeline - Upload files using the data processing pipeline.
Share and View Files
File Download Link
For flexible sharing of a file you have uploaded to LabKey Server, you can generate a download link allowing others to see or download a copy.- Navigate to the Files webpart showing the file.
- Make the Download Link column visible using the triangle menu for any current column, as shown here:

- Right click the link for the file of interest and select Copy link address.

- The URL is now saved to your clipboard and might look something like:
- This URL can be pasted into an email, Wikis, or external page to provide your users with a link to download the file of interest.
Link to a Specific Directory in the File Repository
To link to a specific directory in the file repository, append the directory path to the base WebDAV URL. To get the base URL, go to Admin > Go To Module > FileContent. The base URL is displayed at the bottom of the File Repository window, as shown below: To get the link for a specific directory in the repository, navigate to that directory and copy the value from the WebDAV URL field. For example, the following URL points to the directory "UserConferenceSlides/2015" in the repository.
To get the link for a specific directory in the repository, navigate to that directory and copy the value from the WebDAV URL field. For example, the following URL points to the directory "UserConferenceSlides/2015" in the repository.
File Preview
If you hover over the icon for a file in the Files web part, a pop-up showing a preview of the contents will be displayed for a few seconds. This is useful for quickly differentiating between files with similar names, such as in this screencap showing exported datasets as numbered tsv files.
File Display in Browser
Double-clicking will open some files (i.e. images or some simple text files) directly, depending on browser settings.It is also possible to edit the URL of a download link to display some types of content in the browser inside the standard LabKey template by removing this portion of the URL (if present):?contentDisposition=attachment
Related Topics
File Sharing and URLs
Controlling File Display via the URL
For example, if you set the file content root for the Home project toC:\myfiles
C:\myfiles\test.html
- renderAs=FRAME - Cause the file to be rendered within an IFRAME. This is useful for returning standard HTML files.
- renderAs=INLINE - Render the content of the file directly into a page. This is only useful if you have files containing fragments of HTML, and those files link to other resources on the LabKey Server, and links within the HTML will also need the renderAs=INLINE to maintain the look.
- renderAs=TEXT - Renders text into a page, preserves line breaks in text files.
- renderAs=IMAGE - For rendering an image in a page.
- renderAs=PAGE - Show the file unframed.
Named File Sets
If the target files are in a named file set, you must add the fileSet parameter to the URL. For example, if you are targeting the file set named "store1", then use a URL like the following:Related Topics
Import Data from Files
Import Data from Files
Before you can import data files into LabKey data structures, you must first upload your files to the LabKey file system using the Files web part.After you have uploaded data files, select a file of interest and click the Import Data button in the Files web part. In the Import Data pop up dialog, you can select from available options for the type of data you are importing. For example, the folder must support the study module in order for you to be able to import specimens.Click Import to confirm the import.
In the Import Data pop up dialog, you can select from available options for the type of data you are importing. For example, the folder must support the study module in order for you to be able to import specimens.Click Import to confirm the import. Some data import options will continue with additional pages requesting more input or parameters.
Some data import options will continue with additional pages requesting more input or parameters.File Administrator Guide
File Admin Topics
Files Web Part Administration
- Customize the user interface
- Define metadata properties
- Configure email alerts

Customize the User Interface
Actions Tab
The Actions tab lets you add common design action and data import options such as importing datasets, specimen data, creating assay designs, etc. The Import Data button is always visible to admins, but you can choose whether to show it to non-admin users. For each other action listed, checking the Enabled box makes it available as a pipeline job. Checking Show in Toolbar adds a button to the Files web part toolbar.File Properties Tab
The File Properties tab lets you define properties that can be used to tag files. Once a property is defined, users are asked to provided property values when files are uploaded.- To define a property, select Use Custom File Properties and then click the Edit Properties button.
- To reuse properties defined in the parent folder, select Use Same Settings as Parent.
Toolbar and Grid Settings Tab
The Toolbar and Grid Settings tab controls the appearance of the file management browser.Configure Toolbar Options: Toolbar buttons are in display order, from top to bottom; drag and drop to rearrange. Available buttons which are not currently displayed are listed at the end. Check boxes to show and hide text and icons independently. Configure Grid Columns Settings (scroll down): lists grid columns in display order from top to bottom; drag and drop to rearrange. The columns can be reorganized by clicking and dragging their respective rows, and checkboxes can make columns Hidden or Sortable.
Configure Grid Columns Settings (scroll down): lists grid columns in display order from top to bottom; drag and drop to rearrange. The columns can be reorganized by clicking and dragging their respective rows, and checkboxes can make columns Hidden or Sortable. You can also change which columns are displayed directly in the Files web part. Pulldown the arrow in any column label, select Columns and use checkboxes to show and hide columns. For example, this screenshot shows adding the Download Link column:
You can also change which columns are displayed directly in the Files web part. Pulldown the arrow in any column label, select Columns and use checkboxes to show and hide columns. For example, this screenshot shows adding the Download Link column: Local Path to FilesUse the following procedure to find the local path to files that have been uploaded via the Files web part.
Local Path to FilesUse the following procedure to find the local path to files that have been uploaded via the Files web part.- Go to Admin > Site > Admin Console > Files.
- Under Summary View for File Directories, locate and open the folder where your Files web part is located.
- The local path to your files appears in the Directory column. It should end in @files.

General Settings Tab
Select whether to show the file upload panel by default. You may drag and drop files into the file browser region to upload them whether or not the panel is shown.Configure Default Email Alerts
To control the default email notification for the folder where the Files web part resides, see Manage Projects and Folders. Email notifications can be sent for file uploads, deletions, changes to metadata properties, etc. Note that project users will have the option to override or accept the folder's default notification setting. Project users can override or accept the folder's default notification setting by clicking the Email Preferences button in the Files web part toolbar.Upload Files: WebDAV
- Example Setup for Cyberduck WebDAV Client
- Native Windows WebDAV Client
- Native MacOSX WebDAV Client
- Linux WebDAV Clients
Example Setup for Cyberduck WebDAV Client
To set up Cyberduck to access a file repository on LabKey Server, follow these instructions:- First, get the URL for the target repository:
- On LabKey Server, go to the target file repository.
- If necessary, add the Files web part.
- Open the Upload Files panel, then click the "i" badge.
- The File Upload Help dialog appears.
- The URL used by WebDAV appears in this dialog. Copy the URL to the clipboard.

- Set up Cyberduck (or another 3rd party WebDAV client).
- Click Open Connection (or equivalent in another client).
- Enter the URL and your username/password.
- Click Connect.
- You can now drag-and-drop clients into the file repository using the 3rd party WebDAV client.
Native Windows WebDAV Client (WebDAV Redirector)
A WebDAV client called "WebDAV Redirector" is built into Windows 8. Assuming your server is configured to use SSL, you can connect from Windows directly to a LabKey Server file repository. (I.e., any LabKey Server folder that has a Files web part.) Configuring the WebDAV Redirector to work over non-SSL connections is not recommended.To connect, you can use the Window Explorer to map a network drive to the file repository URL, using the URL shown below.To connect using a Windows Command prompt, use "net use". For example:| Command line item | Description |
|---|---|
| Y: | The drive letter that will allow the client to copy multiple files to the LabKey Server using familiar Windows commands . It can’t be in use at the time; if it is, either choose a different drive letter or issue a net use Y: /D command first to disconnect the Y: drive. |
| https://hosted.labkey.com/labkey/_webdav/myProject/myFolder/@files/ | The URL to the WebDAV root. Use double quotes if there are spaces in the URL. (To get this URL, see the screen shot above.) |
| _webdav | This component of the URL applies to all WebDAV connections into LabKey Server. |
| myProject | The LabKey Server project name. |
| myFolder | The folder name within the project - the location of the Files web part. |
| @files | The directory root for the file content. This folder is viewed by the Files web part in a LabKey Server folder. Files managed by the pipeline component appear under a root directory called @pipeline. |
| johndoe@labkey.com | the same user email you would use to sign into LabKey Server from a browser. |
| * | Causes Windows to prompt for your LabKey password. |
| /PERSISTENT:YES | Causes Windows to remember the drive letter mapping between restarts of the system. |
Native MacOSX WebDAV Client
When using OSX, you do not need to install a 3rd party WebDAV client. You can mount a WebDAV share via the dialog at Go > Connect to Server. Enter a URL of the form:https://<username%40domain.com>@<www.sitename.org>/_webdav/<projectname>/
- <username%40domain.com> - The email address you use to log in to your LabKey Server, with the @ symbol replaced with %40. Example: Use username%40labkey.com for username@labkey.com
- <www.sitename.org> - The URL of your LabKey Server. Example: www.mysite.org
- <projectname> - The name of the project you would like to access. If you need to force a login, this project should provide no guest access. Example: _secret
Linux WebDAV Clients
Tested clients:- Gnome Desktop: Nautilus file browser can mount a WebDAV share like an NFS share.
- KDE Desktop: Has drop down for mounting a WebDAV share like an NFS share.
- cadaver: Command line tool. Similar to FTP.
Set File Roots
Site-wide File Root
The site-wide file root is the top of the directory structure for files you upload. By default it is the same as the LabKey Server installation directory, but you may choose to place it elsewhere if required for backup or permissions reasons.During server setup, a directory structure is created mirroring the structure of your LabKey Server projects and folders. Each project or folder is a directory containing a "@files" subdirectory.You can specify a site-wide file root at installation or to access the "Configure File System Access" page on an existing installation, use Admin > Site > Admin Console > Files. When you change the site-wide file root for an existing installation, files located under that site-wide file root will be automatically moved to the new location. The server will also update paths in the database for all of the core tables. If you are storing file paths in tables managed by custom modules, the custom module will need register an instance of org.labkey.api.files.FileListener with org.labkey.api.files.FileContenService.addFileListener(), and fix up the paths stored in the database when its fileMoved() method.Files located in projects that use pipeline overrides or set their own project-level file roots will not be moved. Please see Troubleshoot File Roots and Pipeline Overrides for more information.
When you change the site-wide file root for an existing installation, files located under that site-wide file root will be automatically moved to the new location. The server will also update paths in the database for all of the core tables. If you are storing file paths in tables managed by custom modules, the custom module will need register an instance of org.labkey.api.files.FileListener with org.labkey.api.files.FileContenService.addFileListener(), and fix up the paths stored in the database when its fileMoved() method.Files located in projects that use pipeline overrides or set their own project-level file roots will not be moved. Please see Troubleshoot File Roots and Pipeline Overrides for more information.
Project-level File Roots
You can override the site-wide root on a project-by-project basis. A few reasons you might wish to do so:- Separate file storage for a project from your LabKey Server. You might wish to enable more frequent backup of files for a particular project.
- Hide files. You can hide files previously uploaded to a project or its subfolders by selecting the "Disable File Sharing" option for the project.
- Provide a window into an external drive. You can set a project-level root to a location on a drive external to your LabKey Server.
- From your project:
- Select Admin > Folder > Project Settings.
- Click the Files tab.

- Click Save.
Named File Sets
Named file sets are additional file stores for a LabKey web folder. They exist alongside the default file root for a web folder, enabling web sharing of files in directories that do not correspond exactly to LabKey containers. You can add multiple named file sets for a given LabKey web folder, displaying each in its own web part. The server considers named file sets as "non-managed" files systems, so moving either the site or the folder file root does not have any effect on named file sets. File sets are a single directory and do not include any subdirectories.To add a named file root:- On the Files web part, click the dropdown triangle next to Files and select Customize

- On the Customize Files page, click Configure File Roots.
- Under File Sets, enter a Name and a Path to the file directory on your local machine.
- Click Add File Set.

- Add additional file sets are required.
- To display a named file set in the Files web part, click the dropdown triangle on the Files web part, and select Customize.
- On the File Root dropdown, select your named file set, and click Submit.

- The Files web part will now display the files in your named file set.
Summary View of File Roots and Overrides
You can view an overview of settings and full paths from the "Summary View for File Directories" section of the "Configure File System Access" page that is available through Admin > Site > Admin Console > Files. A screenshot: File directories, named file sets and pipeline directories can be viewed on a project/folder basis through the "Summary View." The 'Default' column indicates whether the directory is derived from the site-level file root or has been overriden. To view or manage files in a directory, double click on a row or click on the 'Browse Selected' button. To configure an @file or an @pipeline directory, select the directory and click on the 'Configure Selected' button in the toolbar.
File directories, named file sets and pipeline directories can be viewed on a project/folder basis through the "Summary View." The 'Default' column indicates whether the directory is derived from the site-level file root or has been overriden. To view or manage files in a directory, double click on a row or click on the 'Browse Selected' button. To configure an @file or an @pipeline directory, select the directory and click on the 'Configure Selected' button in the toolbar.Related Topics
- File Terminology
- Data Processing Pipeline. If you are using the pipeline, see also Set a Pipeline Override. A pipeline override supersedes settings described on this page for file roots.
- Troubleshoot File Roots and Pipeline Overrides
Troubleshoot File Roots and Pipeline Overrides
Files Not Visible
If you do not see the right files in the "Files" web part, check whether you have set up project-level file roots or set up pipeline overrides. A project may also be configured with file sharing disabled. Since these are inherited by subfolders, you may not realize that they have been applied to your folder.You can quickly check whether a particular project has unexpected settings by going to Admin > Folder > Project Settings and clicking the Files tab. Alternatively, you can see an overview of site-wide settings for all folders by going to Admin > Site > Admin Console and clicking Files.No "Import Data" Button Available
If you are using a pipeline override for a folder that differs from the file directory, you will not see an "Import Data" button in the Files web part. You may either to change project settings to use the default site-level file root or you can import files via the Data Pipeline instead of the "Files" web part. To access the pipeline UI, go to: Admin > Go to Module > Pipeline.Project-level Files Not Moved When Site-wide Root is Changed
When the site-wide root changes, files in projects that use the default, site-wide root are moved automatically to a new location and deleted from in their original locations. Also the file paths recorded in core tables are updated to reflect the new locations.Files located in projects that have project-level roots or pipeline overrides are not deleted when you change the site-wide file root. If you have set project-level roots or pipeline overrides, files in these projects and their subfolders must be moved separately.User Cannot Upload Files When Pipeline Override Set
In general, a user who is an Editor or Author for a folder should be able to upload files. This is true for the default file management tool location, or file attachments for issues, wikis, messages, etc.The exception is when you have configured a folder (or its parent folders) to use a pipeline override. In that case, you will need to explicitly assign permissions for the pipeline override directory.To determine whether a pipeline override is set up and to configure permissions if it is:- Navigate to the folder in question.
- Select Admin > Go to Module > Pipeline.
- Click Setup.
- If the "Set a pipeline override" option is selected, you have two choices:
- Keep the override and use the choices under the Pipeline Files Permissions heading to set permissions for the appropriate users.
- Remove the override and use normal permissions for the folder. Select "Use a default based on the site-level root" instead of a pipeline override.
- Adjust folder permissions if needed using Admin > Folder > Permissions.
File Terminology
Integrating S3 Cloud Data Storage
Cloud Data Storage
Cloud Services offer the ability to upload and post large data files in the cloud, and LabKey Server can interface with this data allowing users to integrate it smoothly with other data for seamless use by LabKey analysis tools. In order to use these features, you must have installed the Cloud Module in your LabKey Server.Cloud Storage services store data in buckets which are typically limited to a certain number by user account, but can contain unlimited files. LabKey server Cloud Storage uses a single bucket with a directory providing a pseudo-hierarchy so that multiple structured folders can appear as a multi-bucket storage system.Configure LabKey Server to use Cloud Storage
Before you can use your Cloud Storage account from within LabKey server, you must first create the bucket you intend to use and the user account must have "list" as well as "upload/delete" permissions on the bucket. It is possible to have multiple cloud store services per account. To configure your account for cloud storage:- Navigate to Admin > Site > Admin Console.
- Select Cloud Settings. If you do not see this option, you do not have a cloud module installed.
- Configure Cloud Accounts.

- Select a Provider.
- Enter your Identity and Credential.
- Click Update.
- Select Create Storage Config.

- Provide a Config Name.
- Select the Account you just created from the pulldown.
- Provide the Bucket name.
- Select Enabled.
- Click Create.
Enable Cloud Storage
In each folder where you want to access cloud data, configure the filesystem to use your cloud storage. If a cloud store is disabled at the site-level it will not be possible to enable it within a folder.- Open Admin > Folder Management.
- Select the Files tab.
- Under Enable Cloud Store, enable and disable the available cloud stores using the checkboxes. Note that this enables cloud storage at the folder level, not the site level.

- Click Save.
- Return to the Files web part.
- Select Customize from the pulldown arrow in the upper left.
- Select the cloud in File Root.
- Click Submit.

Use Files from the Cloud
The Files web part will now display the cloud storage files as if they are local, as in the case of the .fcs file shown here: The file is actually located in cloud storage as shown here:
The file is actually located in cloud storage as shown here: When a download request for a cloud storage file comes through LabKey server, the handle is passed to the client so the client can download the file directly.
When a download request for a cloud storage file comes through LabKey server, the handle is passed to the client so the client can download the file directly.
Future Directions
This feature is currently under development and not yet suitable for deployment in a production environment. In addition to supporting production deployment, some other possible future directions include:- An upload widget that can perform "multi-part" uploads directly to the cloud storage back end to support large files.
- Performance improvements.
- Mirror/replication between buckets for remote sites.
- Execute pipeline jobs via cloud compute/execute service.
Data Processing Pipeline
- Automating data upload
- Performing bulk import of large data files
- Performing sequential transformations on data during import to the system
View Data Pipeline Grid
The Data Pipeline grid displays information about current and past pipeline jobs. You can add a Data Pipeline web part to a page, or view the site-wide pipeline grid:- Select Admin > Site > Admin Console.
- Click Pipeline.

- Select the checkbox for a row to enable Retry, Delete, and Cancel options for that job.
- Click Process and Import Data to initiate a new job.
- Navigate to and select the intended file or folder. If you navigate into a subdirectory tree to find the intended files, the pipeline file browser will remember that location when you return to import other files later.
- Click Import.
Delete a Pipeline Job
To delete a pipeline job, click the checkbox for the row on the data pipeline grid, and click Delete. You will be asked to confirm the deletion. If there are associated experiment runs that were generated, you have the option to delete them at the same time. In addition, if there are no usages of files in the pipeline analysis directory when the pipeline job is deleted (i.e., files attached to runs as inputs or outputs), we will delete the analysis directory from the pipeline root. The files are not actually deleted, but moved to a ".deleted" directory that is hidden from the file-browser.
If there are associated experiment runs that were generated, you have the option to delete them at the same time. In addition, if there are no usages of files in the pipeline analysis directory when the pipeline job is deleted (i.e., files attached to runs as inputs or outputs), we will delete the analysis directory from the pipeline root. The files are not actually deleted, but moved to a ".deleted" directory that is hidden from the file-browser.
Cancel a Pipeline Job
To cancel a pipeline job, select the checkbox for the intended row and click Cancel. The job status will be set to "CANCELLED" and excecution halted.Use Pipeline Override to Mount a File Directory
You can configure a pipeline override to identify a specific location for the storage of files for usage by the pipeline.Set Up Email Notifications (Optional)
If you or others wish to be notified when a pipeline job succeeds or fails, you can configure email notifications at the site, project, or folder level. Email notification settings are inherited by default, but this inheritance may be overridden in child folders.- Open the Email Notifications panel at the desired level:
- At the site level, select Admin > Site > Admin Console, then click Pipeline Email Notification.
- At the project or folder level, select Admin > Go To Module > Pipeline, then click Setup.

- Check the appropriate box(es) to configure notification emails to be sent when a pipeline job succeeds and/or fails.
- Check the "Send to owner" box to automatically notify the user initiating the job.
- Add additional email addresses and select the frequency and timing of notifications.
- In the case of pipeline failure, there is a second option to define a list of escalation users. If configured, these users can be notified from the pipeline job details view directly using the Escalate Job Failure button.
- Click Update.
Related Topics
- MS2: Pipeline Upload of MS2 Files - You can use the LabKey data pipeline to search and process LC-MS/MS run data stored in an mzXML file. You can also process pepXML files, which are stored results from a search for peptides on an mzXML file against a protein database. Results are displayed by the MS2 module for analysis.
- Study: Study Import via the Pipeline - Allow import to complete in the background or point the pipeline to an outside source.
- Experiment: Pipeline Upload for .XAR Files - The data pipeline can upload experiment description (.xar) files.
- Script Pipeline: Running R and Other Scripts in Sequence - Process files through chained R scripts. Import the results to an assay design.
- Pipeline Protocols - Pipelines making use of analysis protocols can offer users a selection of upload protocols.
Set a Pipeline Override
Single Machine Setup
These steps will help you set up the pipeline, including an override directory, for usage on a single computer. For information on setup for a distributed environment, see the next section.- Go to Admin > Go to Module > Pipeline.
- Now click Setup.
- You will now see the "Data Processing Pipeline Setup" page.
- Click Set a pipeline override.
- Specify the Primary Directory from which your dataset files will be loaded.
- Click the Searchable box if you want the pipeline override directory included in site searches. By default, the materials in the pipeline override directory are not indexed.
- For MS2 Only, you have the option to include a Supplemental Directory from which dataset files can be loaded. No files will be written to the supplemental directory.
- You may also choose to customize Pipeline Files Permissions using the panel to the right.
- Click Save.

Include Supplemental File Location (Optional)
MS2 projects that set a pipeline override can specify a supplemental, read-only directory, which can be used as a repository for your original data files. If a supplemental directory is specified, LabKey Server will treat both directories as sources for input data to the pipeline, but it will create and change files only in the first, primary directory.Set Pipeline Files Permissions (Optional)
By default, pipeline files are not shared. To allow pipeline files to be downloaded or updated via the web server, check the Share files via web site checkbox. Then select appropriate levels of permissions for members of global and project groups.Configure Network Drive Mapping (Optional)
If you are running LabKey Server on Windows and you are connecting to a remote network share, you may need to configure network drive mapping for LabKey Server so that LabKey Server can create the necessary service account to access the network share. For more information, see labkey.xml Configuration File.Additional Options for MS2 Runs
Set the FASTA Root for Searching Proteomics Data
The FASTA root is the directory where the FASTA databases that you will use for peptide and protein searches against MS/MS data are located. FASTA databases may be located within the FASTA root directory itself, or in a subdirectory beneath it.- On the MS2 Dashboard, click Setup in the Data Pipeline webpart.
- Under MS2 specific settings, click Set FASTA Root.
- By default, the FASTA root directory is set to point to a /databases directory nested in the directory that you specified for the pipeline override. However, you can set the FASTA root to be any directory that's accessible by users of the pipeline.
- Click Save.
Set X! Tandem, Sequest, or Mascot Defaults for Searching Proteomics Data
You can specify default settings for X! Tandem, Sequest or Mascot for the data pipeline in the current project or folder. On the pipeline setup page, click the Set defaults link under X! Tandem specific settings, Sequest specific settings, or Mascot specific settings.The default settings are stored at the pipeline override in a file named default_input.xml. These settings are copied to the search engine's analysis definition file (named tandem.xml, sequest.xml or mascot.xml by default) for each search protocol that you define for data files beneath the pipeline override. The default settings can be overridden for any individual search protocol. See Search and Process MS2 Data for information about configuring search protocols.Setup for Distributed Environment
The pipeline that is installed with a standard LabKey installation runs on a single computer. Since the pipeline's search and analysis operations are resource-intensive, the standard pipeline is most useful for evaluation and small-scale experimental purposes.For institutions performing high-throughput experiments and analyzing the resulting data, the pipeline is best run in a distributed environment, where the resource load can be shared across a set of dedicated servers. Setting up the LabKey pipeline on a server cluster currently demands some customization as well as a high level of network and server administrative skill. If you wish to set up the LabKey pipeline for use in a distributed environment, contact LabKey.Pipeline Protocols
Define Protocols
Analysis protocols are defined during import of a file and can be saved for future use in other imports.- In the Data Pipeline web part, click Process and Import Data.
- Select the file(s) to import and click Import Data.
- In the popup, select the specific import pipeline to associate with the new protocol and click Import.
- On the next page, the Analysis Protocol pulldown lists any existing protocols. Select "<New Protocol>" to define a new protocol.
- Enter a unique name and the defining parameters for the protocol.
- Check the box to "Save protocol for future use."

- Continue to define all the protocols you want to offer your users.
- You may need to delete the imported data after each definition to allow reimport of the same file and definition of another new protocol.
Manage Protocols
Add a Pipeline Protocols web part. All the protocols defined in the current container will be listed. The Pipeline column shows the specific data import pipeline where the protocol will be available. Click the name of any protocol to see the saved xml file, which includes the parameter definitions included.Select one or more rows and click Archive to set their status to "Archived". Archived protocols will not be offered to users uploading new data. No existing data uploads (or other artifacts) will be deleted when you archive a protocol. The protocol definition itself is also preserved intact.Protocols can also be returned to the list available to users by selecting the row and clicking Unarchived.
Click the name of any protocol to see the saved xml file, which includes the parameter definitions included.Select one or more rows and click Archive to set their status to "Archived". Archived protocols will not be offered to users uploading new data. No existing data uploads (or other artifacts) will be deleted when you archive a protocol. The protocol definition itself is also preserved intact.Protocols can also be returned to the list available to users by selecting the row and clicking Unarchived.
Use Protocols
A user uploading data through the same import pipeline will be able to select one of the currently available and unarchived protocols from a dropdown.
Related Topics
Enterprise Pipeline
- Install Prerequisites for the Enterprise Pipeline
- Working installation of LabKey Server
- JMS Queue (ActiveMQ)
- RAW to mzXML Converters (convert MS2 output to mzXML). Optional. Only required if you plan to convert files to mzXML format in your pipeline
- Configure LabKey Server to use the Enterprise Pipeline
- Use the Enterprise Pipeline
- Troubleshoot the Enterprise Pipeline
- All files (both sample files and result files from searches) will be stored on a Shared File System
- LabKey Server is running on a Windows Server
- LabKey Server will mount the Shared File System
- Conversion of RAW files to mzXML format will be included in the pipeline processing
- Conversion Server will mount the Shared File System
- MS1 and MS2 pipeline analysis tools (xtandem, tpp, msInspect, etc) will be executed on Cluster
- Cluster execution nodes will mount the Shared File System
- Instructions for SGE and PBS based clusters are available.
Install Prerequisites for the Enterprise Pipeline
- Installation of LabKey Server
- JMS Queue (ActiveMQ)
- Conversion Service (convert MS2 output to mzXML). Optional. Only required if you plan to convert files to mzXML format in your pipeline
JMS Queue
JMS: Installation Steps
- Choose a server on which to run the JMS Queue
- Install the Java Runtime Environment
- Install and Configure ActiveMQ
- Test the ActiveMQ Installation
Choose a server to run the JMS Queue
ActiveMQ supports all major operating systems (including Windows, Linux, Solaris and Mac OSX). (For example, the Fred Hutchinson Cancer Research Institute runs ActiveMQ on the same linux server as the GRAM Server.) For this documentation we will assume you are installing on a Linux based server.Install the Java Runtime Environment
- Download the Java Runtime Environment (JRE) from http://java.sun.com/javase/downloads/index.jsp
- Install the JRE to the chosen directory.
- Create the JAVA_HOME environmental variable to point at your installation directory.
Install and Configure ActiveMQ
Download and Unpack the distribution
- Download ActiveMQ from ActiveMQ's download site
- Unpack the binary distribution from into /usr/local
- This will create /usr/local/apache-activemq-5.1.0
- Create the environmental variable <ACTIVEMQ_HOME> and have it point at /usr/local/apache-activemq-5.1.0
Configure logging for the ActiveMQ server
To log all messages sent through the JMSQueue, add the following to the <broker> node in the config file located at <ACTIVEMQ-HOME>/conf/activemq.xml<plugins>
<!-- lets enable detailed logging in the broker -->
<loggingBrokerPlugin/>
</plugins>
#log4j.rootLogger=DEBUG, stdout, out
log4j.rootLogger=INFO, stdout, out
Authentication, Management and Configuration
- Configure JMX to allow us to use Jconsole and the JMS administration tools monitor the JMS Queue
- We recommend configuring Authentication for your ActiveMQ server. There are number of ways to implement authentication. See http://activemq.apache.org/security.html
- We recommend configuring ActiveMQ to create the required Queues at startup. This can be done by adding the following to the configuration file <ACTIVEMQ-HOME>/conf/activemq.xml
<destinations>
<queue physicalName="job.queue" />
<queue physicalName="status.queue" />
</destinations>
Start the server
To start the ActiveMQ server, you can execute the command below. This command will start the ActiveMQ server with the following settings- Logs will be written to <ACTIVEMQ_HOME>/data/activemq.log
- StdOut will be written to /usr/local/apache-activemq-5.1.0/smlog
- JMS Queue messages, status information, etc will be stored in <ACTIVEMQ_HOME>/data
- job.queue Queue and status.queue will be durable and persistant. (I.e., messages on the queue will be saved through a restart of the process.)
- We are using AMQ Message Store to store Queue messages and status information
<ACTIVEMQ_HOME>/bin/activemq-admin start xbean:<ACTIVEMQ_HOME>/conf/activemq.xml > <ACTIVEMQ_HOME>/smlog 2>&1 &
Monitoring JMS Server, Viewing JMS Queue configuration and Viewing messages on a JMS Queue.
Using the ActiveMQ management tools
Browse the messages on queue by running<ACTIVEMQ_HOME>/bin/activemq-admin browse --amqurl tcp://localhost:61616 job.queue
<ACTIVEMQ_HOME>/bin/activemq-admin query
Using Jconsole
Here is a good quick description of using Jconsole to test your ActiveMQ installation. Jconsole is an application that is shipped with the Java Runtime. The management context to connect to isservice:jmx:rmi:///jndi/rmi://localhost:1099/jmxrmi
RAW to mzXML Converters
Installation Requirements
- Choose a Windows-based server to run the Conversion Service
- Install the Oracle Java Runtime Environment
- Install ProteoWizard. (ReAdW.exe is also supported for backward compatibility for ThermoFinnigan instruments)
- Test the Converter Installation
Choose a server to run the Conversion Service
The Conversion server must run the Windows Operating System (Vendor software libraries currently only run on the Windows OS).
Install the Java Runtime Environment
- Download the Java Runtime Environment (JRE) 1.7 from http://www.oracle.com/technetwork/java/javase/downloads/index.html
- Install the JRE to the chosen directory. On Windows the default installation directory is C:\Program Files\Java.
Notes:
- The JDK includes the JRE, so if you have already installed the JDK, you don't need to also install the JRE.
Install the Vendor Software for the Supported Converters
Currently LabKey Server supports the following vendors
- ThermoFinnigan
- Waters
Install ProteoWizard
Download the converter executables from the ProteoWizard project
Install the executables, and copy them into the directory <LABKEY_HOME>\bin directory
- Create the directory c:\labkey to be the <LABKEY_HOME> directory
- Create the binary directory c:\labkey\bin
- Place the directory <LABKEY_HOME>\bin directory on the PATH System Variable using the System Control Panel
- Install the downloaded files and copy the executable files to <LABKEY_HOME>\bin
Test the converter installation.
For the sake of this document, we will use an example of converting a RAW file using the msconvert. Testing for other vendor formats is similar.
- Choose a RAW file to use for this test. For this example, the file will be called convertSample.RAW
- Place the file in a temporary directory on the computer. For this example, we will use c:\conversion
- Open a Command Prompt and change directory to c:\conversion
- Attempt to convert the sample RAW file to mzXML using msconvert.exe. Note that the first time you perform a conversion, you may need to accept a license agreement.
C:\conversion> dir
Volume in drive C has no label.
Volume Serial Number is 30As-59FG
Directory of C:\conversion
04/09/2008 12:39 PM <DIR> .
04/09/2008 12:39 PM <DIR> ..
04/09/2008 11:00 AM 82,665,342 convertSample.RAW
C:\conversion>msconvert.exe convertSample.RAW --mzXML
format: mzXML (Precision_64 [ 1000514:Precision_64 1000515:Precision_32 ], ByteOrder_LittleEndian, Compression_None) indexed="true"
outputPath: .
extension: .mzXML
contactFilename:
filters:
filenames:
convertSample.raw
processing file: convertSample.raw
writing output file: ./convertSample.mzXML
C:\conversion> dir
Volume in drive C has no label.
Volume Serial Number is 20AC-9682
Directory of C:\conversion
04/09/2008 12:39 PM <DIR> .
04/09/2008 12:39 PM <DIR> ..
04/09/2008 11:15 AM 112,583,326 convertSample.mzXML
04/09/2008 11:00 AM 82,665,342 convertSample.RAW
Resources
Converters.zipConfigure LabKey Server to use the Enterprise Pipeline
- Configure the LabKey Server to use the Enterprise Pipeline
- Create the LabKey Tool directory (which contains the MS1 and MS2 analysis tools to be run on the cluster execution nodes)
Assumptions
The Enterprise Pipeline does not support all possible configurations of computational clusters. It is currently written to support a few select configurations. The following configurations are supported
- Use of a Network File System: The LabKey web server, LabKey Conversion server and the cluster nodes must be able to mount the following resources
- Pipeline directory (location where mzXML, pepXML, etc files are located)
- Pipeline Bin directory (location where third-party tools (TPP, Xtandem, etc) are located.
- MS1 and MS2 analysis tools will be run on either a PBS or SGE based cluster.
- Java 8 or greater is installed on all cluster execution node
- You have downloaded or built from the subversion tree the following files
- LabKey Server Enterprise Edition v8.3 or greater
- Labkey Server v8.3 Enterprise Pipeline Configuration files
Verify the version of your LabKey Server.
The Enterprise Pipeline is supported in the LabKey Server Enterprise Edition v8.3 or greater.To verify if you are running the Enterprise Edition follow the instructions below
- Log on to your LabKey Server using a Site Admin account
- Open the Admin Console
- Under the Module Information section verify that the following modules are installed
- BigIron
Enable Communication with the ActiveMQ JMS Queue.
You will need to add the following settings to the LabKey configuration file (labkey.xml). This is typically located at <CATALINA_HOME>/conf/Catalina/localhost/labkey.xml
<Resource name="jms/ConnectionFactory" auth="Container"
type="org.apache.activemq.ActiveMQConnectionFactory"
factory="org.apache.activemq.jndi.JNDIReferenceFactory"
description="JMS Connection Factory"
brokerURL="tcp://@@JMSQUEUE@@:61616"
brokerName="LocalActiveMQBroker"/>
Set the Enterprise Pipeline configuration directory (Optional)
By default, the system looks for the pipeline configuration files in the following directory: LABKEY_HOME/config.To specify a different location, add the following parameter to the LabKey configuration file (labkey.xml, typically located at <CATALINA_HOME>/conf/Catalina/localhost/labkey.xml), for example:
<Parameter name="org.labkey.api.pipeline.config" value="C:/path-to-config"/>
Create the Enterprise Pipeline Configuration Files for the Web Server.
- Unzip LabKey Server Enterprise Pipeline Configuration distribution and copy the webserver configuration files to the Pipeline Configuration directory specified in the last step (ie <LABKEY_HOME>/config)
- Configuration files.
- ms2config.xml: This is used to configure
- where MS2 searches will be performed (on the cluster, on a remote server or locally)
- where the Conversion of raw files to mzXML will occur (if required)
- which analysis tools will be executed during a MS2 search
- ms1config.xml: This is used to configure
- where MS1 searches will be performed (on the cluster, on a remote server or locally)
- which analysis tools will be executed during a MS1 search
- Edit the file ms2Config.xml
- Documentation is under development.
- Edit the file ms1Config.xml
- Documentation is under development.
Restart the LabKey Server.
In order for the LabKey Server to use the new Enterprise Pipeline configuration settings, the Tomcat process will need to be restarted.Once the server has been restarted. You will want to ensure that the server the server started up with no errors.
- Log on to your LabKey Server using a Site Admin account
- Open the Admin Console: Admin -> Site -> Admin Console.
- In the Diagnostics Section click on view all site errors
- Check to see that no errors have occurred after the restart
Create the LABKEY_TOOLS directory that will be used on the Cluster.
The <LABKEY_TOOLS> directory will contain all the files necessary to perform the MS2 searches on the cluster execution nodes. This directory must be accessible from all cluster execution nodes. We recommend that the directory be mounted on the cluster execution nodes as well as the Conversion Server. The directory will contain
- Required LabKey software and configuration files
- TPP tools
- XTandem search engine
- msInspect
- Additional MS1 and MS2 analysis tools
Create the <LABKEY_TOOLS> directory
Create the <LABKEY_TOOLS> directory.- This directory must be accessible from all cluster execution nodes.
- We recommend that the directory created on Shared File System which will be mounted on the cluster nodes as well as the Conversion Server.
Download the required LabKey software
- Unzip the LabKey Server Enterprise Edition distribution into the directory <LABKEY_TOOLS>/labkey/dist
- Unzip the LabKey Server Pipeline Configuration distribution into the directory <LABKEY_TOOLS>/labkey/dist/conf
Install the LabKey software into the <LABKEY_TOOLS> directory
Copy the following to the <LABKEY_TOOLS>/labkey directory- The directory <LABKEY_TOOLS>/labkey/dist/LabKey<VERSION>-Enterprise-Bin/labkeywebapp
- The directory <LABKEY_TOOLS>/labkey/dist/LabKey<VERSION>-Enterprise-Bin/modules
- The directory <LABKEY_TOOLS>/labkey/dist/LabKey<VERSION>-Enterprise-Bin/pipeline-lib
- The file <LABKEY_TOOLS>/labkey/dist/LabKey<VERSION>-Enterprise-Bin/tomcat-lib/labkeyBootstrap.jar
cd <LABKEY_TOOLS>/labkey/
java -jar labkeyBootstrap.jar
Install Enterprise Pipeline configuration files into the <LABKEY_TOOLS> directory
Copy the following to the <LABKEY_TOOLS>/labkey/config directory- All files in the directory <LABKEY_TOOLS>/labkey/dist/LabKey8.3-xxxxx-PipelineConfig/cluster
Create the Enterprise Pipeline Configuration Files for use on the Cluster.
- There are 3 configuration files.
- Description of configuration files is under development.
- Edit the file pipelineConfig.xml
- Documentation is under development.
- Edit the file ms2Config.xml
- Documentation is under development.
- Edit the file ms1Config.xml
- Documentation is under development.
- Install the MS1 and MS2 analysis tools on the Cluster
These tools will be installed in the <LABKEY_TOOLS>/bin directory.Documentation is under development
Test the Configuration
There are a few simple tests that can be performed at this stage to verify that the configuration is correct. These tests are focused on ensure that a cluster node can perform an MS1 or MS2 search
- Can the cluster node see the Pipeline Directory and the <LabKey_Tools> directory
- Test under development
- Can the cluster node execute Xtandem
- Test under development
- Can the cluster node execute the java binary
- Test under development
- Can the cluster node execute a Xtandem search against an mzXML file located in the Pipeline Directory?
- Test under development
- Can the cluster node execute a PeptideProphet search against the resultant pepXML file
- Test under development
- Can the cluster node execute the Xtandem search again, but this time using the LabKey java code located on the cluster node
- Test under development
Configure the Conversion Service
Assumptions
This documentation will describe how to configure the LabKey Server Enterprise Pipeline to convert native instrument data files (such as .RAW) files to mzXML using the msconvert software that is part of ProteoWizard.
- The Conversion Server can be configured to convert from native acquisition files for a number of manufacturers.
- Use of a Shared File System: The LabKey Conversion server must be able to mount the following resources
- Pipeline directory (location where mzXML, pepXML, etc files are located)
- Oracle Java 8 is installed
- You have downloaded (or built from the Subversion source control system) the following files
- LabKey Server
- Labkey Server Enterprise Pipeline Configuration files
Download and Expand the LabKey Conversion Server Software
- Create the <LABKEY_HOME> directory (LabKey recommends you use c:\LabKey )
- Unzip the LabKey Server distribution into the directory <LABKEY_HOME>\dist
- Unzip the LabKey Server Pipeline Configuration distribution into the directory <LABKEY_HOME>\dist
Install the LabKey Software
Copy the following to the <LABKEY_HOME> directory
- The directory <LABKEY_HOME>\dist\LabKeyX.X-xxxxx-Bin\labkeywebapp
- The directory <LABKEY_HOME>\dist\LabKeyX.X-xxxxx-Bin\modules
- The directory <LABKEY_HOME>\dist\LabKeyX.X-xxxxx-Bin\pipeline-lib
- The file <LABKEY_HOME>\dist\LabKeyX.X-xxxxx-Bin\tomcat-lib\labkeyBootstrap.jar
- All files in the directory <LABKEY_HOME>\dist\LabKeyX.X-xxxxx-PipelineConfig\remote
cd <LABKEY_HOME>
java -jar labkeyBootstrap.jar
Create the Tools Directory
This is the location where the Conversion tools (msconvert.exe, etc) binaries are located. For most installations this should be set to <LABKEY_HOME>\bin
- Place the directory <LABKEY_HOME>bin directory on the PATH System Variable using the System Control Panel
- Copy the conversion executable files to <LABKEY_HOME>bin
Edit the Enterprise Pipeline Configuration File (pipelineConfig.xml)
The pipelineConfig.xml file enables communication with: (1) the the JMS queue, (2) the RAW files to be converted, and (3) the tools that perform the conversion.An example pipelineConfig.xml File
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd">
<bean id="activeMqConnectionFactory" class="org.apache.activemq.ActiveMQConnectionFactory">
<constructor-arg value="tcp://localhost:61616"/>
<property name="userName" value="someUsername" />
<property name="password" value="somePassword" />
</bean>
<bean id="pipelineJobService" class="org.labkey.pipeline.api.PipelineJobServiceImpl">
<property name="workDirFactory">
<bean class="org.labkey.pipeline.api.WorkDirectoryRemote$Factory">
<!--<property name="lockDirectory" value="T:/tools/bin/syncp-locks"/>-->
<property name="cleanupOnStartup" value="true" />
<property name="tempDirectory" value="c:/temp/remoteTempDir" />
</bean>
</property>
<property name="remoteServerProperties">
<bean class="org.labkey.pipeline.api.properties.RemoteServerPropertiesImpl">
<property name="location" value="mzxmlconvert"/>
</bean>
</property>
<property name="appProperties">
<bean class="org.labkey.pipeline.api.properties.ApplicationPropertiesImpl">
<property name="networkDriveLetter" value="t" />
<property name="networkDrivePath" value="\\someServer\somePath" />
<property name="networkDriveUser" value="someUser" />
<property name="networkDrivePassword" value="somePassword" />
<property name="toolsDirectory" value="c:/labkey/build/deploy/bin" />
</bean>
</property>
</bean>
</beans>
Enable Communication with the JMS Queue
Edit the following lines in the <LABKEY_HOME>\config\pipelineConfig.xml<bean id="activeMqConnectionFactory" class="org.apache.activemq.ActiveMQConnectionFactory">
<constructor-arg value="tcp://@@JMSQUEUE@@:61616"/>
</bean>
Configure the WORK DIRECTORY
The WORK DIRECTORY is the directory on the server where RAW files are placed while be converted to mzXML. There are 3 properties that can be set- lockDirectory: This config property helps throttle the total number of network file operations running across all machines. Typically commented out.
- cleanupOnStartup: This setting tells the Conversion server to delete all files in the WORK DIRECTORY at startup. This ensures that corrupted files are not used during conversion
- tempDirectory: This is the location of the WORK DIRECTORY on the server
<property name="workDirFactory">
<bean class="org.labkey.pipeline.api.WorkDirectoryRemote$Factory">
<!-- <property name="lockDirectory" value="T:/tools/bin/syncp-locks"/> -->
<property name="cleanupOnStartup" value="true" />
<property name="tempDirectory" value="c:/TempDir" />
</bean>
</property>
Configure the Application Properties
There are 2 properties that must be set- toolsDirectory: This is the location where the Conversion tools (msconvert.exe, etc) are located. For most installations this should be set to <LABKEY_HOME>\bin
- networkDrive settings: These settings specify the location of the shared network storage system. You will need to specify the appropriate drive letter, UNC PATH, username and password for the Conversion Server to mount the drive at startup.
- @@networkDriveLetter@@ - Provide the letter name of the drive you are mapping to.
- @@networkDrivePath@@ - Provide a server and path to the shared folder, for example: \\myServer\folderPath
- @@networkDriveUser@@ and @@networkDrivePassword@@ - Provide the username and password of the shared folder.
- @@toolsDirectory@@ - Provide the path to the bin directory, for example: C:\labkey\bin
<property name="appProperties">
<bean class="org.labkey.pipeline.api.properties.ApplicationPropertiesImpl">
<!-- If the user is mapping a drive, fill in this section with their input -->
<property name="networkDriveLetter" value="@@networkDriveLetter@@" />
<property name="networkDrivePath" value="@@networkDrivePath@@" />
<property name="networkDriveUser" value="@@networkDriveUser@@" />
<property name="networkDrivePassword" value="@@networkDrivePassword@@" />
<!-- Enter the bin directory, based on the install location -->
<property name="toolsDirectory" value="@@toolsDirectory@@" />
</bean>
</property>
Edit the Enterprise Pipeline MS2 Configuration File (ms2Config.xml)
The MS2 configuration settings are located in the file <LABKEY_HOME>\config\ms2Config.xmlAn example configuration for running msconvert on a remote server named "mzxmlconvert":
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd">
<bean id="ms2PipelineOverrides" class="org.labkey.api.pipeline.TaskPipelineRegistrar">
<property name="factories">
<list>
<!-- This reference and its related bean below enable RAW to mzXML conversion -->
<ref bean="mzxmlConverterOverride"/>
</list>
</property>
</bean>
<!-- Enable Thermo RAW to mzXML conversion using msConvert. -->
<bean id="mzxmlConverterOverride" class="org.labkey.api.pipeline.cmd.ConvertTaskFactorySettings">
<constructor-arg value="mzxmlConverter"/>
<property name="cloneName" value="mzxmlConverter"/>
<property name="commands">
<list>
<ref bean="msConvertCommandOverride"/>
</list>
</property>
</bean>
<!-- Configuration to customize behavior of msConvert -->
<bean id="msConvertCommandOverride" class="org.labkey.api.pipeline.cmd.CommandTaskFactorySettings">
<constructor-arg value="msConvertCommand"/>
<property name="cloneName" value="msConvertCommand"/>
<!-- Run msconvert on a remote server named "mzxmlconvert" -->
<property name="location" value="mzxmlconvert"/>
</bean>
</beans>
Install the LabKey Remote Server as a Windows Service
LabKey uses procrun to run the Conversion Service as a Windows Service. This means you will be able to have the Conversion Service start up when the server boots and be able to control the Service via the Windows Service Control Panel.
Set the LABKEY_ROOT environment variable.
In the System Control Panel, create the LABKEY_ROOT environment variable and set it to <LABKEY_HOME>. (Where <LABKEY_HOME> is the target install directory.) This should be a System Environment Variable.Install the LabKey Remote Service
- Copy *.exe and *.bat from the directory <LABKEY_HOME>\dist\LabKeyX.X-xxxxx-PipelineConfig\remote to <LABKEY_HOME>\bin
- For 32-bit Windows installations, install the service by running the following from the Command Prompt:
set LABKEY_ROOT=<LABKEY_HOME>
<LABKEY_HOME>\bin\installServiceWin32.bat
- For 64-bit Windows installations, install the service by running the following from the Command Prompt:
set LABKEY_ROOT=<LABKEY_HOME>
<LABKEY_HOME>\bin\installServiceWin64.bat
set LABKEY_ROOT=c:\labkey
How to uninstall the LabKey Remote Pipeline Service
- For 32-bit Windows installations, run the following:
<LABKEY_HOME>\bin\service\removeServiceWin32.bat
- For 64-bit Windows installations, run the following:
<LABKEY_HOME>\bin\service\removeServiceWin64.bat
- Uninstall the service as described above.
- Reboot the server.
- Edit <LABKEY_HOME>\bin\service\installServiceWin32.bat or <LABKEY_HOME>\bin\service\installServiceWin64.bat as appropriate, and make the necessary changes and run
<LABKEY_HOME>\bin\service\installService.bat
How to Manage the LabKey Remote Windows Service
How to start the service:From the command prompt you can runnet start LabKeyRemoteServer
net start LabKeyRemoteServer
Where are the log files located
All logs from the LabKey Remote Server are located in <LABKEY_HOME>\logs\output.logNOTE: If running Windows XP, this service cannot be run as the Local System user. You will need to change the LabKey Remote Pipeline Service to log on as a different user.Configure Remote Pipeline Server
This page explains how to configure the LabKey Server Enterprise Pipeline Remote Server. The Remote Server can be used to execute X!Tandem or SEQUEST MS/MS searches on a separate computer from LabKey Server. It can also be used run a raw data file to mzXML conversion server, or run other pipeline configured tools.
Assumptions
- Use of a Shared File System: The LabKey Conversion Server must be able to mount the following resources
- Pipeline directory (location where mzXML, pepXML, etc files are located)
- Oracle Java 8 or greater is installed
- You have downloaded (or built from the subversion tree) the following files
- LabKey Server
- Labkey Server Enterprise Pipeline Configuration files
Install the Enterprise Pipeline Remote Server
Download and expand the LabKey Software
NOTE: You will use the same distribution software for this server as you use for the LabKey Server. We recommend simply copying the downloaded distribution files from your LabKey Server
- Create the <LABKEY_HOME> directory
- On Windows: LabKey recommends you use c:\LabKey
- On Linux, Solaris or MacOSX: LabKey recommends you use /usr/local/labkey
- Unzip the LabKey Server distribution into the directory <LABKEY_HOME>\src
Install the LabKey Software
Copy the following to the <LABKEY_HOME> directory
- The directory <LABKEY_HOME>\src\LabKeyX.X-xxxxx-Bin\labkeywebapp
- The directory <LABKEY_HOME>\src\LabKeyX.X-xxxxx-Bin\modules
- The directory <LABKEY_HOME>\src\LabKeyX.X-xxxxx-Bin\pipeline-lib
- The directory <LABKEY_HOME>\src\LabKeyX.X-xxxxx-Bin\bin
- The file <LABKEY_HOME>\src\LabKeyX.X-xxxxx-Bin\tomcat-lib\labkeyBootstrap.jar
Create the Configuration directory
- Create the directory <LABKEY_HOME>\config
Create the Temporary Working directory for this server
- Create the directory <LABKEY_HOME>\RemoteTempDirectory
Create the directory to hold the FASTA indexes for this server
- Create the directory <LABKEY_HOME>\FastaIndices
Create the logs directory
- Create the directory <LABKEY_HOME>\logs
Install the Pipeline Configuration Files
There are currently 3 important configuration files that need to be configured on the Remote Server. The configuration settings will be different depending on the use of the LabKey Remote Pipeline Server.
Download the Enterprise Pipeline Configuration Files
- Goto the Download Page
- Download the Pipeline Configuration(zip) zip file
- Unzip the LabKey Server distribution into the directory <LABKEY_HOME>\src
Configuration Settings for using the Enhanced Sequest MS2 Pipeline
pipelineConfig.xml This file holds the configuration for the pipeline. To install,
- Copy <LABKEY_HOME>\src\LabKeyX.X-xxxxx-PipelineConfig\remote\pipelineConfig.xml to <LABKEY_HOME>\config
- Copy <LABKEY_HOME>\src\LabKeyX.X-xxxxx-PipelineConfig\webserver\ms2Config.xml to <LABKEY_HOME>\config
There are a few important settings that may need to be changed
- tempDirectory: set to <LABKEY_HOME>\RemoteTempDirectory
- toolsDirectory: set to <LABKEY_HOME>\bin
- location: set to sequest
-
Network Drive Configuration: You will need to the set the variables in this section of the configuration. In order for the Enhanced SEQUEST MS2 Pipeline to function, the LabKey Remote Pipeline Server will need to be able to access same files as the LabKey Server via a network drive. The configuration below will allow the LabKey Remote Pipeline Server to create a new Network Drive.
<property name="appProperties"> <bean class="org.labkey.pipeline.api.properties.ApplicationPropertiesImpl"> <property name="networkDriveLetter" value="t" /> <property name="networkDrivePath" value="\\@@SERVER@@\@@SHARE@@" /> <!-- Map the network drive manually in dev mode, or supply a user and password --> <property name="networkDriveUser" value="@@USER@@" /> <property name="networkDrivePassword" value="@@PASSWORD@@" />
-
Enable Communication with the JMS Queue by changing @@JMSQUEUE@@ to be the name of your JMS Queue server in the code that looks like
<bean id="activeMqConnectionFactory" class="org.apache.activemq.ActiveMQConnectionFactory"> <constructor-arg value="tcp://@@JMSQUEUE@@:61616"/> </bean>
- Change @@JMSQUEUE@@ to be the hostname of the server where you installed the ActiveMQ software.
ms2Config.xml This file holds the configuration settings for MS2 searches. Change the configuration section
<bean id="sequestTaskOverride" class="org.labkey.ms2.pipeline.sequest.SequestSearchTask$Factory"> <property name="location" value="sequest"/> </bean>
to
<bean id="sequestTaskOverride" class="org.labkey.ms2.pipeline.sequest.SequestSearchTask$Factory"> <property name="sequestInstallDir" value="C:\Program Files (x86)\Thermo\Discoverer\Tools\Sequest"/> <property name="indexRootDir" value="C:\FastaIndices"/> <property name="location" value="sequest"/> </bean>
Configuration Settings for executing X!Tandem searches on the LabKey Remote Pipeline Server
If you are attempting to enable this configuration, you may find assistance by searching the inactive Proteomics Discussion Board, or contact us on the Community Support Forum.
Install the LabKey Remote Server as a Windows Service
If you are installing the Remote Server on a non-Windows operating system, see the next section, Configure the LabKey Remote Server to start at boot-time on Linux Server.
LabKey uses procrun to run the Conversion Service as a Windows Service. This means you will be able to have the Conversion Service start up when the server boots and be able to control the Service via the Windows Service Control Panel.
Set the LABKEY_ROOT environment variable.
In the System Control Panel, create the LABKEY_ROOT environment variable and set it to <LABKEY_HOME> . This should be a System Environment Variable.
Install the LabKey Remote Service on 32bit Windows
- Copy *.exe and *.bat from the directory <LABKEY_HOME>\dist\LabKeyX.X-xxxxx-PipelineConfig\remote to <LABKEY_HOME>\bin
-
Install the Windows Service by running the following from the Command Prompt
set LABKEY_ROOT=<LABKEY_HOME> <LABKEY_HOME>\bin\service\installService.bat
where<LABKEY_HOME>
is the directory where labkey is installed. For example, if installed in c:\labkey, then the command isset LABKEY_ROOT=c:\labkey
If the installService.bat command succeeded then it should have created a new Windows Service named LabKeyRemoteServer
Install the LabKey Remote Service on 64bit Windows
If you are running a a 64bit version of Windows, then you will need to follow the instructions below
- Copy *.bat from the directory <LABKEY_HOME>\dist\LabKeyX.X-xxxxx-PipelineConfig\remote to <LABKEY_HOME>\bin
- Download the latest version of the Apache Commons Daemon to <LABKEY_HOME>\dist
- Expand the downloaded software
- Copy the following from the expanded directory to <LABKEY_HOME>\bin
- prunmgr.exe to <LABKEY_HOME>\bin\prunmgr.exe
- amd64\prunsrv.exe to <LABKEY_HOME>\bin\amd64\prunsrv.exe
- amd64\prunsrv.exe to <LABKEY_HOME>\bin\amd64\procrun.exe
-
Install the Windows Service by running the following from the Command Prompt
set LABKEY_ROOT=<LABKEY_HOME> <LABKEY_HOME>\bin\service\installService.bat
where<LABKEY_HOME>
is the directory where labkey is installed. For example, if installed in c:\labkey, then the command isset LABKEY_ROOT=c:\labkey
If the installService.bat command succeeded, it should have created a new Windows Service named LabKeyRemoteServer.
Starting and Stopping the LabKey Remote Windows Service
To start the service, from a command prompt, run:
net start LabKeyRemoteServer
To stop the service, from a command prompt, run:
net stop LabKeyRemoteServer
Log File Locations
All logs from the LabKey Remote Server are located in <LABKEY_HOME>\logs\output.log
Configure the LabKey Remote Server to start at boot-time on Linux Server
If you are attempting to enable this configuration, please contact us on the Support Discussion Board
Configure Pipeline Path Mapping
Pipeline Root
First decide the location of the pipeline root (= the source location for job files to be submitted to the Remote Pipeline Server).For example, assume that the pipeline root is on a Linux machine running LabKey Server:/john
Shared File System
Next, share out this pipeline root directory so that the machine running the Remote Pipeline Server can map to it.Network Share/labkey/pipeline
//lkweb/john
\\labkey\\pipeline\\myfile.txt
T:\\myfile.txt
Use the Enterprise Pipeline
Before you performing the tasks below, you must:
- Install Prerequisites for the Enterprise Pipeline
- Configure LabKey Server to use the Enterprise Pipeline
Create a new Project to test the Enterprise Pipeline
You can skip this step if a Project already exists that you would rather use.
- Log on to your LabKey Server using a Site Admin account
- Create a new Project with the following options
- Project Name = PipelineTest
- Select MS2 Folder Type radio button
- Choose the default settings during the Project Creation.
Configure the Project to use the Enterprise Pipeline
The following information will be required in order to configure this Project to use the Enterprise Pipeline
- Pipeline Root Directory
- Pass Phrase for User Key File
Setup the Pipeline
- Click on the Setup button in the Data Pipeline Webpart
- Enter in the following information
- Path to the desired Pipeline Root directory on the Web Server
- Specific settings and parameters for the relevant section
- Click on the Set button
- Goto the MS2 Dashboard, by clicking the PipelineTest link in the upper left pane
Testing the Enterprise Pipeline
To test the Enterprise Pipeline, simply
- Click on the Process and Upload Data button in the Data Pipeline Webpart
- Navigate to an mzXML file with the Pipeline Root Directory and hit the X!Tandem Pepitide Search button to the right of the filename.
Troubleshoot the Enterprise Pipeline
Determine Which Jobs and Tasks Are Actively Running
Each job in the pipeline is composed of one or more tasks. These tasks are assigned to run at a particular location. Locations might include the web server, cluster, remote server for RAW to mzXML conversion, etc. Each location may have one or more worker threads that runs the tasks. A typical installation might have the following locations that run the specified tasks:| Location | # of threads | Tasks |
|---|---|---|
| Web Server | 1 | CHECK FASTA IMPORT RESULTS |
| Web Server, high priority | 1 | MOVE RUNS |
| Conversion server | 1+ | MZXML CONVERSION |
| Cluster | 1+ | SEARCH ANALYSIS |
Messages
Topics
- Use Message Boards: Post messages for public discussion.
- Administer Message Boards: Administer and customize message boards.
Related Topics
Use Message Boards
 (2) The Messages List web part displays a sortable and filterable grid view of all messages, as shown below.
(2) The Messages List web part displays a sortable and filterable grid view of all messages, as shown below. Messages board users can post new messages, respond to continue conversations, subscribe to conversations, and configure their own notification preferences. Users with Editor or higher permissions can also edit existing messages. For information about configuring the message board itself, see Administer Message Boards.
Messages board users can post new messages, respond to continue conversations, subscribe to conversations, and configure their own notification preferences. Users with Editor or higher permissions can also edit existing messages. For information about configuring the message board itself, see Administer Message Boards.
Post New Messages
To post a new message, author permissions or higher are required.- Click New.
- Enter the Title and Body. The body is optional for quick subject alerts.
- Use the Render As drop-down menu to specify one of:
- Plain Text
- Wiki Page
- HTML
- To add an attachment, click Attach a file. Attachments should not exceed 250MB per message.
View, Edit, and Delete Messages
The beginning of the message text is displayed in the Messages web part - you can expand the text within the webpart by clicking More. To open the message for other features, click View Message or Respond. You can also open the message by clicking the title in a Message List web part. The original message is followed by any responses; all are marked with the username and date of the post. If you have sufficient permissions, you will also have links to Edit or Delete the individual message and responses. Buttons for Respond and Delete Message are below.By clicking Subscribe in the upper right, you can enable notifications for the specific thread, or the entire forum.
The original message is followed by any responses; all are marked with the username and date of the post. If you have sufficient permissions, you will also have links to Edit or Delete the individual message and responses. Buttons for Respond and Delete Message are below.By clicking Subscribe in the upper right, you can enable notifications for the specific thread, or the entire forum.
Configure Email Preferences
The message board administrator can specify default email notification policy for the project or folder. Each user can choose to override the default settings as follows:To set your email preferences:- Click the dropdown arrow at the top right of the Messages web part.
- Select Email > Preferences.
- Choose which messages should trigger emails (none, mine, or all) and whether you prefer each individual message or a daily digest.
 Check the box if you want to Reset to folder default setting.
Check the box if you want to Reset to folder default setting.Additional Message Fields (Optional)
The following message fields are turned off by default but can be activated by an administrator: Status, Assigned To, Members, and Expires. Status: Track whether messages are "Active", i.e. requiring further work or attention, or "Closed". Once a message is closed, it is no longer displayed on the Messages or Messages List web parts.Assigned To: Assign an issue to a particular team member for further work, useful for sharing multi-part tasks or managing workflow procedures.Members: List of team members to receive email notification whenever there are new postings to the message. The Members field is especially useful when a subset of team members or a project manager needs to keep track of an evolving issue.
Expires: Set the date on which the message will disappear, by default one month from the day of posting. Once the expiration date has passed, the message will no longer appear in either the Messages or Messages List web parts, but it will still appear in the unfiltered message list. You can use this feature to display only the most relevant or urgent messages, while still preserving all messages. If you leave the Expires field blank, the message will never expire.
Status: Track whether messages are "Active", i.e. requiring further work or attention, or "Closed". Once a message is closed, it is no longer displayed on the Messages or Messages List web parts.Assigned To: Assign an issue to a particular team member for further work, useful for sharing multi-part tasks or managing workflow procedures.Members: List of team members to receive email notification whenever there are new postings to the message. The Members field is especially useful when a subset of team members or a project manager needs to keep track of an evolving issue.
Expires: Set the date on which the message will disappear, by default one month from the day of posting. Once the expiration date has passed, the message will no longer appear in either the Messages or Messages List web parts, but it will still appear in the unfiltered message list. You can use this feature to display only the most relevant or urgent messages, while still preserving all messages. If you leave the Expires field blank, the message will never expire.
Related Topics
Administer Message Boards
Message Board Security
Consider security and notification settings for your message boards when defining them. A user with "Editor" permissions on the folder can edit any message posted to the message board. Users with the "Message Board Contributor" role can add new messages to discussions and edit or delete their own messages, but cannot edit or delete the messages added by others.If a board is configured to email all users, you may want to restrict posting access. Users can also customize their own email notification settings on a per-message board basis.Message Board Web Parts
There are two web parts available for displaying messages:- The Messages web part displays the first few lines of text of most recent messages. Each message is labeled with its author and the date it was posted, and includes a link to view or respond to the message.
- The Messages List displays a grid view of all messages posted on this message board.
Messages Web Part

Customize a Message Board
To customize a message board, click the triangle next to the web part title and choose Admin. Note that the "Customize" option on the web part menu lets you customize the web part itself as described below. Board name: The name used to refer to the entire message board. Examples: "Team Discussions," "Building Announcements," etc.Conversation name: The term used by your team to refer to a conversation. Example: "thread" or "discussion."Conversation sorting: Whether to sort by initial post on any given conversation (appropriate for announcements or blogs) or most recent update or response (suitable for discussion boards).Security: By default, security is "OFF": conversations are visible to anyone with read permissions, content can be modified after posting, and content will be sent via email (if enabled by users). Turning "ON" security limits access so that only editors and those on the member list can view conversations, content cannot be modified after posting, and is never sent by email, even if users have set their preferences to request email.Allow Editing Title: Check to enable editing the title of a message.Include Member List: Check to enable the member list field, allowing the selection of members to notify about the conversation. On a secure message board, you can use the member list to notify a user who does not have editor permissions on the message board itself.Include Status: Enables a drop-down for the status of a message, "active" or "closed", for workflow applications.Include Expires: Allows the option to indicate when a message expires and is no longer displayed in the messages web part. The default is one month after posting. Expired messages are still accessible in the Message List.Include Assigned To: Displays a drop-down list of project users to whom the message can be assigned as a task or workflow item. You can specify a default member for all new messages.Include Format Picker: Displays a drop-down list of options for message format: Wiki Page, HTML, or Plain Text. If the format picker is not displayed, new messages are posted as plain text.Show poster's groups, link user name to full details (admins only): Check this box to provide only admins with access to view the group memberships of whoever posted each message.Email templates: Click links to:
Board name: The name used to refer to the entire message board. Examples: "Team Discussions," "Building Announcements," etc.Conversation name: The term used by your team to refer to a conversation. Example: "thread" or "discussion."Conversation sorting: Whether to sort by initial post on any given conversation (appropriate for announcements or blogs) or most recent update or response (suitable for discussion boards).Security: By default, security is "OFF": conversations are visible to anyone with read permissions, content can be modified after posting, and content will be sent via email (if enabled by users). Turning "ON" security limits access so that only editors and those on the member list can view conversations, content cannot be modified after posting, and is never sent by email, even if users have set their preferences to request email.Allow Editing Title: Check to enable editing the title of a message.Include Member List: Check to enable the member list field, allowing the selection of members to notify about the conversation. On a secure message board, you can use the member list to notify a user who does not have editor permissions on the message board itself.Include Status: Enables a drop-down for the status of a message, "active" or "closed", for workflow applications.Include Expires: Allows the option to indicate when a message expires and is no longer displayed in the messages web part. The default is one month after posting. Expired messages are still accessible in the Message List.Include Assigned To: Displays a drop-down list of project users to whom the message can be assigned as a task or workflow item. You can specify a default member for all new messages.Include Format Picker: Displays a drop-down list of options for message format: Wiki Page, HTML, or Plain Text. If the format picker is not displayed, new messages are posted as plain text.Show poster's groups, link user name to full details (admins only): Check this box to provide only admins with access to view the group memberships of whoever posted each message.Email templates: Click links to:
- Customize site-wide template. You can also select Email > Site-Wide Email Template directly from the messages web part menu.
- Customize template for this project. You can also select Email > Project Email Template directly from the messages web part menu.
Email Notifications for Messages
Preferences
Users who have read permissions on a message board can choose to receive emails containing the content of messages posted to the message board. A user can set their own preferences by selecting Email > Preferences.Administration
Project administrators can set the defaults for the message board's email notification behavior for individual users or for all users at the folder level. Any user can override the preferences set for them if they choose to do so.- Click the dropdown arrow in the Messages web part border and select Email > Administration to open the folder notifications tab.
- See Manage Email Notifications for more information.
- Options available:
- Select desired Default Settings and click Update.
- Select one or more users using the checkboxes to the left and click Update User Settings.
Customize the Messages Web Part
You can switch the display in the web part between a simple message presentation and full message display by selecting Customize from the drop down menu.Messages Web Part Permission
Like any web part, you can control which users can see the Messages web part by selecting Permissions from the triangle menu. See Web Parts: Permissions Required to View for more information.Messages List Web Part
The Messages List offers a grid view of all the messages in the current board. It can be filtered and sorted, new messages can be added by clicking New and the contents of any existing message can be accessed by clicking the conversation title.Example Scenario: Email All Site Users
In some cases you may want to set up a mechanism for emailing periodic broadcast messages to all users, such as notification of a server upgrade affecting all projects. You would probably want to limit the permission to send such wide broadcasts to only users who would need to do so. Individual users can still opt-out of these email notifications.- Create a folder for your broadcast announcements and grant Read permissions to All Site Users.
- Grant Author or greater permissions only to individuals or groups who should be able to send broadcast messages.
- Create a new message board.
- Select Email > Administration.
- Set Default Setting for Messages to "All conversations."
- Create a new message. Notice that there is an alert above the Submit button indicating the number of people that will be emailed.
Related Topics
- Manage Projects and Folders
- Email Template Customization: Tailor the email notifications sent to message board subscribers.
- Manage Email Notifications
- Object-Level Discussions
Object-Level Discussions
- Start new discussion: With author (or higher) permissions, you can create a new message board discussion on this page.
- Start email discussion: Anyone with reader (or higher) permissions may also begin an email discussion directly.
- Email preferences: Control when you receive email notifications about this discussion. See Configure Email Preferences for details.
- Email admin: (Administrators only) Control the default notification behavior for this discussion, which applies to any user who has not set their own overriding preferences. See Manage Email Notifications for more information.
- Customize: (Administrators only) Allows you to customize the discussion board itself.
 Once a discussion has been created, the link will read See Discussions with a count of how many messages are included. You will now have additional options to open and read any existing discussions on that specific page or other object.All discussions created within a single folder can be accessed through a single Messages web part or Messages List in that folder. The message will include the title of the object it was created to discuss.
Once a discussion has been created, the link will read See Discussions with a count of how many messages are included. You will now have additional options to open and read any existing discussions on that specific page or other object.All discussions created within a single folder can be accessed through a single Messages web part or Messages List in that folder. The message will include the title of the object it was created to discuss.
Discussion Roles
The permissions granted to the user determine how they can participate in discussions.- Reader: read discussions
- Message Board Contributor: reply to discussions, edit or delete their own comments only
- Author: all of the above, plus start new discussions
- Editor: all of the above, plus edit or delete any comments
- Admin: all of the above, delete message boards, enable/disable object-level discussions, assign permissions to others
Related Topics
Wikis
- Wiki Admin Guide. Learn how to set up a wiki. (Admins Only)
- Wiki User Guide. Learn how to write, edit and manage wiki pages.
Wiki Admin Guide
Wiki Web Parts
In order to access wiki features, you usually Add a Wiki Web Part to a folder that has been created or customized to contain the wiki module.The wiki module provides three kinds of wiki web parts:- The wide Wiki web part displays one wiki page in the main panel of the page.
- The narrow Wiki web part displays one wiki page on the right side.
- The Wiki Table of Contents (TOC) web part displays links to all the wiki pages in the folder on the right side of the page.
Special Wiki Pages
You can also create a specially-named wiki page to display custom "Terms of Use" and require a use to agree to these terms before gaining access. For more information, see Establish Terms of Use.Customizing the Wiki Web Part
To specify the page to display in the Wiki web part, first add a Wiki Web Part using the Select Web Part drop-down menu. You must be logged in as an Admin to add web parts. After you have added the Wiki Web Part, click either Choose an existing page to display or Create a new wiki page.Choose an Existing Page
First specify the project or folder where the page is located, then select the page name from the second drop-down list. The title bar of the Wiki web part always displays the title of the selected page.You can use this feature to display content that is stored in a folder with different permissions than the one in which it is displayed.Create a New Wiki Page
This option directly opens the wiki editor in the current folder. See Wiki User Guide.The Wiki Module Versus the Wiki Web Part
It's helpful to understand the difference between the Wiki module and the Wiki web part. The Wiki module displays all of your wiki pages for that project or folder on the Wiki tab. The Wiki web part, on the other hand, appears only on the Portal page and displays only one page, either the default page or another page that you have designated.When you are viewing the Wiki module, the Wiki tab is always active, and you'll always see the Wiki TOC on the right side of the page. When you are viewing the Wiki web part on the Portal page, the Portal tab is active and the Wiki TOC can be added optionally.If you have created a project or folder with the folder type set to Custom, you must explicitly display the Wiki tab or add a Wiki web part in order to add wiki content.Related Topics
- Manage Web Parts: details on removing, moving and maximizing web parts.
Copy Wiki Pages
LabKey provides several tools for copying all or part of the wiki documentation from one project or folder to another. You must have administrative privileges on the folder to use any of these tools.
Copy all wiki pages to another folder
To copy all pages, follow these steps:
- Create the destination folder, if it does not already exist.
- From the source folder, select Copy from the triangle pulldown menu on the wiki TOC web part.
- Click the destination folder from the tree.
If a page with the same name already exists in the destination wiki, the page will be given a new name in the destination folder (e.g., page becomes page1).
Copy all or some pages to another folder
You can copy all or a portion of the pages in a wiki to another folder from the URL. The URL action is copyWiki.
The following table describes the available parameters.
| URL Parameter | Description |
| sourceContainer | The path to the container containing the pages to be copied. |
| destContainer | The path to the destination container. If the container does not exist, it will be created. |
| path | If destContainer is not specified, path is used to determine the destination container. |
| pageName |
If copying only a branch of the wiki, specifies the page from which to start. This page and its children will be copied. |
Example:
This URL copies the page named default and any children to the destination container docs/newfolder, creating that folder if it does not yet exist.
http://localhost:8080/labkey/Wiki/docs/copyWiki.view?destContainer=docs/newfolder&pageName=default
Copy a single page to another folder
You can copy a single page to another folder from the URL. The URL action is copySinglePage.
The following table describes the available parameters.
| URL Parameter | Description |
| sourceContainer | The path to the container containing the pages to be copied. |
| destContainer | The path to the destination container. If the container does not exist, it will be created. |
| path | If destContainer is not specified, path is used to determine the destination container. |
| pageName | The name of the page to copy. |
Example:
This URL copies only the page named config (and not its children) to the destination container docs/newfolder, creating that folder if it does not yet exist.
http://localhost:8080/labkey/Wiki/docs/copySinglePage.view?pageName=config&destContainer=docs/newfolder
Wiki User Guide
What is a Wiki?
A wiki is a collection of documents that multiple users can edit. Wiki pages can be written in HTML, plain text or a specialized wiki language. On LabKey Server, you can use a wiki to include formatted content in a project or folder. You can even embed live data in this content.This User Guide will help you create, manage and edit wiki pages. A typical wiki page will show the current page in the main window, an expandable Table of Contents listing of Pages in a column to the right, and a Search box above the Table of Contents.Navigate Using the Table of Contents
Wiki pages display a Table of Contents (TOC) in the right-hand column, titled Pages, to help you navigate through the tree of wiki documents. You can see pages that precede and follow the page you are viewing, which will appear in bold italics (for this page, Wiki User Guide). Click on a page to open it.Expand/Collapse TOC Sections. Wiki documents are organized into parent/child page trees. To expand section and view child pages, click on the "+" sign next to a page name. To condense a TOC section, click on the "-" sign next to it.Expand/Collapse All. You can use the Expand All and Collapse All links at the end of a wiki table of contents to collapse or expand the entire table.Create or Edit a Wiki Page
To create a new wiki page, click the New link. To edit an existing page, click the Edit link at the top of the displayed page. This brings you to the wiki editor, whose features will be discussed in the following sections.
This brings you to the wiki editor, whose features will be discussed in the following sections. Name. Required.
The page Name identifies it uniquely within the wiki. The URL address for a wiki page includes the page name. Although you can create page names with spaces, we recommend using short but descriptive page names with no spaces and no special characters.The first page you see in a new wiki has the page name set to "default." This designates that page as the default page for the wiki. The default page is the page that appears by default in the wiki web part. Admins can change this page later on (see Customizing the Wiki Web Part).Title. The page Title appears in the title bar above the wiki page.Index. Uncheck if the content on this page should not be searchable.Parent. The page under which your page should be categorized in the table of contents. You cannot immediately specify the order in which a new page will appear among its siblings under its new parent. After you have saved your new page, you can adjust its order among its siblings using its Manage link (see the Manage a Wiki Page section below for further details). If you do not specify a parent, the page will appear at the top of your wiki's table of contents.Body. You must include at lease one character of initial text in the Body section of your new page. The body section contains the main text of your new wiki page. For details on formatting and linking syntax, see:
Render Mode: The "Convert To..." Button. This button, located on the upper right side of the page, allows you to change how the wiki page is rendered. Options:
Name. Required.
The page Name identifies it uniquely within the wiki. The URL address for a wiki page includes the page name. Although you can create page names with spaces, we recommend using short but descriptive page names with no spaces and no special characters.The first page you see in a new wiki has the page name set to "default." This designates that page as the default page for the wiki. The default page is the page that appears by default in the wiki web part. Admins can change this page later on (see Customizing the Wiki Web Part).Title. The page Title appears in the title bar above the wiki page.Index. Uncheck if the content on this page should not be searchable.Parent. The page under which your page should be categorized in the table of contents. You cannot immediately specify the order in which a new page will appear among its siblings under its new parent. After you have saved your new page, you can adjust its order among its siblings using its Manage link (see the Manage a Wiki Page section below for further details). If you do not specify a parent, the page will appear at the top of your wiki's table of contents.Body. You must include at lease one character of initial text in the Body section of your new page. The body section contains the main text of your new wiki page. For details on formatting and linking syntax, see:
Render Mode: The "Convert To..." Button. This button, located on the upper right side of the page, allows you to change how the wiki page is rendered. Options:
- Wiki page: The default rendering option. A page rendered as a wiki page will display special wiki markup syntax as formatted text. See Wiki Syntax for the wiki syntax reference.
- HTML: A wiki page rendered as HTML will display HTML markup as formatted text. Any legal HTML syntax is permitted in the page.
- Plain text, with links: A wiki page rendered as plain text will display text exactly as it was entered for the wiki body, with the exception of links. A recognizable link (that is, one that begins with http://, https://, ftp://, or mailto://) will be rendered as an active link.
- Many pages contain elements that are not supported by the visual editor. You will be warned before switching that such elements would be lost if you converted.
- To insert an image, you cannot use the Visual Editor. Use the Source Editor and syntax like the following:
<img src="FILENAME.PNG"/> - To view the visual editor full-screen, click the screen icon in the editor tool bar.
Manage a Wiki Page
Click the "Manage" link to manage the properties of a wiki page. On the Manage page, you can change the wiki page name or title, specify its parent, and specify its order in relation to its siblings. Note that if you change the page name, you will break any existing links to that page.You can also delete the wiki page from the Manage page. Note: When you click the Delete Page button, you are deleting the page that you are managing, not the page that's selected in the Sibling Order box. Make sure you double-check the name of the page that you're deleting on the delete confirmation page, so that you don't accidentally delete the wrong page.Add Images
After you have attached an image file to a page, you need to refer to it in your page's body for the image itself to appear on your page. If you do not refer to it in your page's body, only a link to the image appears at the bottom of your page.Wiki-Language. To add images to a wiki-language page, you must first add the image as an attachment, then refer to it in the body of the wiki page using wiki syntax such as the following: [FILENAME.PNG].HTML. To insert an image on page rendered as HTML, you cannot use the HTML Visual Editor. After attaching your image, use the Source Editor and syntax such as the following: <img src="FILENAME.PNG"/> to show the image.Add Live Content by Embedding Web Parts
You can embed "web parts" into any HTML wiki page to display live data or the content of other wiki pages. You can also embed clients dependencies (references to JavaScript or CSS files) in HTML wiki pages. Please see Embed Live Content in HTML Pages or Messages for more details.View History
You can see earlier versions of your wiki page by clicking on the "History" link at the top of any wiki page. Select the number to the left of the version of the page you would like to examine.If you wish to make this older version of the page current, select the "Make Current" button at the bottom of the page. You can also access other numbered version of the page from the links at the bottom of any older version of the page.Note that you will not have any way to edit a page while looking at its older version. You will need to return to the page by clicking on its name in the wiki TOC in order to edit it.Copy Pages
Print All
You can print all wiki pages in the current folder using the Print All option on the triangle menu above the Table of Contents. Note that all pages are concatenated into one continuous document."Discussion" Link
You can use the "Discussion >" link at the bottom of a wiki page to start a conversation via email or a message board specific to that page. Note that this feature can be disabled at the site level by an administrator, and that when enabled, the role "Message Board Contributor" is required to participate in message board discussions.Check for Broken Links
You can use ordinary link checking software on a LabKey Server wiki. For example, their are a variety of in-browser plugin in link checkers that work well.Tips for efficiency in using link checking (when available):- Set it to exclude URLs that represent the execution of common actions on wiki pages. For example, when checking LabKey.org's documentation (at https://www.labkey.org/wiki/home/Documentation/page.view?name=default), exclude:
- https://www.labkey.org/Project/home/Documentation/expandCollapse.view
- https://www.labkey.org/wiki/home/Documentation/printBranch.view
- Reduce the search depth.
- Turn off prompts for login certifications when checking a wiki whose content is intended to be public.
Add a Link to the Source of a Wiki Page
It is sometimes useful to include a "view source" link on wiki pages used to demonstrate the use of LabKey APIs. For example, you will see a "view source" link in the upper right of this API tutorial page.If you replace the "page" portion of the URL for a wiki page with "source", the URL will lead to the HTML source of the wiki page.It may also be useful to open a separate page for viewing the source. In these examples, replace "default" with the appropriate page name:- Open a LabKey-bordered copy of the source:
<div align="right">
[<a onClick="window.open('source.view?name=default')" href="#">view source<a>]
</div>
- Open a page that includes only the source, without a LabKey border:
<div align="right">
[<a onClick="window.open('source.view?name=default&_template=none')" href="#">view source<a>]
</div>
Related Topics
Wiki Syntax
If you choose to render a page as type Wiki Page, use wiki syntax to format the page. The following table shows commonly used wiki syntax designations. See the Advanced Wiki Syntax page for further options.
| markup | effect |
|---|---|
| [tutorials] | Tutorials - Link to another page, named 'tutorials', in this wiki |
| [Display Text|tutorials] | Display Text - Link with custom text |
| http://www.google.com/ | www.google.com - Links are detected automatically |
| {link:Google|http://www.google.com/} | Google - Link to an external page with display text |
| {link:**Google**|http://www.google.com/} | Google - Link to an external page with display text in bold |
| {mailto:somename@domain.com} | Include an email link which creates new email message with default mail client |
| [attach.jpg] | Display an attached image |
| {image:http://www.google.com/images/logo.gif} | Display an external image |
| **bold** | bold |
| __underline__ | underline |
| ~~italic~~ | italic |
| strike through | See Advanced Wiki Syntax. |
| ---- | horizontal line |
| \ | the escape char |
| \\ | line break ( ) |
| \\\ | a single \ (e.g., backslash in a Windows file path) |
| blank line | new paragraph |
| 1 Title |
Title |
| 1.1 Subtitle |
Subtitle |
| - item1 - item2 |
|
| - item1 -- subitem1 -- subitem2 |
|
|
1. item1 |
Numbered list. (Note that all items in the wiki code are numbered "1.") 1. item1 |
| {table} header|header|header cell|cell|cell {table} |
Create an html table |
| {div} - some wiki code {div} |
Renders as an HTML <div>. Wrap wiki code in {div}'s to apply (1) inline CSS styles or (2) CSS classes.
See examples at Advanced Wiki Syntax. |
|
{comment} |
Content inside the {comment} tags is not rendered in the final HTML. |
Wiki Syntax: Macros
List of Macros
The following macros work when encased in curly braces. Parameters values follow the macro name, separated by colons. Escape special characters such as "[" and "{" within your macro text using a backslash. For example, {list-of-macros} was used to create the following table:| Macro | Description | Parameters |
|---|---|---|
| anchor | Anchor Tag | name: anchor name. |
| api | Generates links to Java or Ruby API documentation. | 1: class name, e.g. java.lang.Object or java.lang.Object@Java131 2: mode, e.g. Java12, Ruby, defaults to Java (optional) |
| api-docs | Displays a list of known online API documentations and mappings. | none |
| asin | Generates links to DVD/CD dealers or comparison services. Configuration is read from conf/asinservices.txt | 1: asin number |
| code | Displays a chunk of code with syntax highlighting, for example Java, XML and SQL. The none type will do nothing and is useful for unknown code types. | 1: syntax highlighter to use, defaults to java. Options include none, sql, xml, and java (optional) |
| comment | Wraps comment text (which will not appear on the rendered wiki page). | none |
| div | Wraps content in a div tag with an optional CSS class and/or style specified. | class: the CSS class that should be applied to this tag. style: the CSS style that should be applied to this tag. |
| file-path | Displays a file system path. The file path should use slashes. Defaults to windows. | 1: file path |
| h1 | Wraps content in a h1 tag with an optional CSS class and/or style specified. | class: the CSS class that should be applied to this tag. style: the CSS style that should be applied to this tag. |
| hello | Say hello example macro. | 1: name to print |
| image | Displays an image file. | img: the path to the image. alt: alt text (optional) align: alignment of the image (left, right, flow-left, flow-right) (optional) |
| inter-wiki | Displays a list of known InterWiki mappings. | none |
| isbn | Generates links to book dealers or comparison services. Configuration is read from conf/bookservices.txt. | 1: isbn number |
| labkey | Base LabKey macro, used for including data from the LabKey Server portal into wikis. | tree : renders a LabKey navigation menu. treeId: the id of the menu to render can be one of the following: core.projects, core.CurrentProject, core.projectAdmin, core.folderAdmin, core.SiteAdmin |
| link | Generate a weblink. | unexplained, lazy programmer, probably [funzel] |
| list-of-macros | Displays a list of available macros. | unexplained, lazy programmer, probably [funzel] |
| mailto | Displays an email address. | 1: mail address |
| new-tab-link | Displays a link that opens in a new tab. | 1. Text to display 2. Link to open in a new tab |
| quote | Display quotations. | 1: source (optional) 2: displayed description, default is Source (optional) |
| rfc | Generates links to RFCs. | unexplained, lazy programmer, probably [funzel] |
| span | Wraps content in a span tag with an optional CSS class and/or style specified. | class: the CSS class that should be applied to this tag. style: the CSS style that should be applied to this tag. |
| study | See study macro documentation for description of this macro. | See study macro documentation for description of this macro. |
| table | Displays a table. | none |
| video | Embeds a video from a link. | video: the video URL width: width of the video frame (optional) height: height of the video frame (optional) |
| xref | Generates links to Java Xref source code. | 1: class name, e.g. java.lang.Object or java.lang.Object@Nanning 2: line number (optional) |
Example: Using the Code Formatting Macro
Encase text that you wish to format as code between two {code} tags. Note that the text will be placed inside <pre> tags, so it will not line-wrap. For example,{code:java}
// Hello World in Java
class HelloWorld {
static public void main( String args[] ) {
System.out.println( "Hello World!" );
}
}
{code}// Hello World in Java
class HelloWorld {
static public void main( String args[] ) {
System.out.println( "Hello World!" );
}
}
Example: Strike Through
The following wiki code...{span:style=text-decoration:line-through}Strike through this text.
{span}...renders text with a line through it. Strike through this text.
Example: Using the {div} Macro to Apply Inline CSS Styles
The {div} macro lets you inject arbitrary CSS styles into your wiki page, either as an inline CSS style, or as a class in a separate CSS file.The following example demonstrates injecting inline CSS styles to the wiki code.The following wiki code...{div:style=background-color: #FCAE76;border:1px solid #FE7D1F;
padding-left:20px; padding-right:15px;
margin-left:25px; margin-right:25px}
- list item 1
- list item 2
- list item 3
{div}...renders in the browser as shown below:
- list item 1
- list item 2
- list item 3
Example: Using the {div} Macro to Apply CSS Classes
To apply a CSS class in wiki code, first create a CSS file that contains your class:.bluebox {
background-color: #edf0f1;
border:1px solid #dee0e1;
padding-left:20px; padding-right:15px;
margin-left:25px; margin-right:25px
}{div:class=bluebox}
- list item 1
- list item 2
- list item 3
{div}Example: Using the {anchor} Macro
To define a target anchor:{anchor:someName}[Link to anchor|#someName]
[Link to anchor|docName#someName]
Example: Colored Text Inline
- To create RED TEXT:
{div:style=color:red;display:inline-block}RED TEXT{div}Special Wiki Pages
Underscores in Wiki Names
Wikis whose names start with an underscore (for example: "_hiddenPage") do not appear in the wiki table of contents, for non-admin users. For admin users, the pages are visible in the table of contents._termsOfUse
A wiki page named "_termsOfUse" will require users to agree to a terms of use statement as part of the login process. For details, see Establish Terms of Use._header
A wiki page named "_header" will replace the default "LabKey Server" logo and header. Adding the _header wiki to a project means it will be applied to all of the folders within that project.Embed Live Content in HTML Pages or Messages
- Embed a web part or visualization in an HTML wiki page or message.
- Combine static and dynamic content in a single page. This eliminates the need to write custom modules even when complex layout is required.
- Embed wiki page content in other wiki pages to avoid duplication of content (and thus maintenance of duplicate content). For example, if a table needs to appear in several wiki pages, you can create the table on a separate page, then embed it in multiple wiki pages.
- Indicate JavaScript or CSS files that are required for code or styles on the page; LabKey will ensure that these dependencies are loaded before your code references them.
- The displaying page.
- The source container for the content inserted in the page.
Embed Web Parts
To embed a web part in an HTML wiki page, open the page for editing and go to the HTML Source tab. (Do not try to preview using the Visual tab, because this will cause <p> tags to be placed around your script, breaking it.) Use the following syntax, substituting appropriate values for the substitution parameters in single quotes:${labkey.webPart(partName='PartName', showFrame='true|false', namedParameters…)}Web Parts
You can find the web part names to use as the 'partName' argument in the Web Part Inventory. These names also appear in the UI in the Select Web Part drop-down menu.Configuration Properties for Web Parts
The Web Part Configuration Properties page covers the configuration properties that can be set for various types of web parts inserted into a web page using the syntax described aboveExamples and Demos
See Examples: Embedded Web Parts. That page includes a link to the HTML source for its samples.Wiki Example. To include a wiki page in another wiki page, use:${labkey.webPart(partName='Wiki', showFrame='false', name='includeMe')}${labkey.webPart(partName='Wiki', showFrame='false', webPartContainer='aa644cac-12e8-102a-a590-d104f9cdb538' name='includeMe')}${labkey.webPart(partName='Search', showFrame='false', location='right',
includeSubFolders='false')}<div id='fileDiv'/>
<script type="text/javascript">
LABKEY.requiresScript("fileBrowser.js");
LABKEY.requiresScript("FileContent.js");
var wikiWebPartRenderer = new LABKEY.WebPart({
partName: 'Files',
renderTo: 'fileDiv'
});
wikiWebPartRenderer.render();
</script>
${labkey.webPart(partName='Wiki Table of Contents', showFrame='false')}Embed Client Dependencies
You can also embed dependencies on other JavaScript or CSS files into your wiki using similar syntax.${labkey.dependency(path='path here')}${labkey.dependency(path='myFolder/myFile.js')}
${labkey.dependency(path='myFolder/stylesheet.css')}<div id='tocDiv'/><br/>
<div id='searchDiv'/>
<script type="text/javascript">
var tocRenderer = new LABKEY.WebPart({
partName: 'Wiki TOC',
renderTo: 'tocDiv'
})
tocRenderer .render();
var tocRenderer = new LABKEY.WebPart({
partName: 'Search',
renderTo: 'searchDiv'
})
tocRenderer .render();
</script>
Related Topics
Examples: Embedded Web Parts
This wiki page contains embedded web parts.
Click view source to review the syntax that inserts each of these web parts.
Embedded Query Web Part
Embedded Doc Search Box
Embedded Content from Another Wiki
LabKey Server's genotyping and Illumina modules may require significant customization and assistance, so they are not included in standard LabKey distributions. Developers can build these modules from source code in the LabKey repository. Please contact LabKey to inquire about support options.
- Manage and build dictionaries of reference sequences, including associated sample and run-specific information.
- Import and manage genotyping data: reads, quality scores, metadata, and metrics.
- Analyze reads directly in LabKey Server or export to FASTQ files for use in other tools.
- Initiate genotyping analyses using Galaxy. LabKey sends selected reads, sample information, and reference sequences to Galaxy, and uses the Galaxy web API to load this data into a new Galaxy data library.
- Automatically import results when the Galaxy workflow is complete.
- Store large Illumina sequence data as files in the file system, with links to sample information and ability to export subsets of sequencing data.
Supported Instruments
The genotyping tools are designed to support import, management, and analysis of sequencing data from:- Roche 454 instruments (GS Junior and GS FLX)
- Illumina instruments (for example, MiSeq Benchtop Sequencer)
- PacBio Sequencer by PacBio Systems
Documentation
- Set Up a Genotyping Dashboard
- Example Workflow: LabKey and Galaxy - Manage sequencing resources and interactions with a Galaxy server using data from a Roche 454 Sequencer.
- Example Workflow: LabKey and Illumina - Manage sample and sequencing results from an Illumina MiSeq Benchtop Sequencer.
- Example Workflow: LabKey and PacBio - Import and manage sequencing results from a PacBio Sequencer.
- Example Workflow: O'Connor Module - Perform enhanced experiment management using the O'Connor module.
- Import Haplotype Assignment Data - Import existing haplotype assignment information for integration with other data.
- Work with Haplotype Assay Data - Generate a report of haplotype assignments (and discrepancies).
Resources
- Contact LabKey for more information about these capabilities.
Embedded Table of Contents
Embedded Files Web Part
Web Part Configuration Properties
Properties Common to All Web Parts
Two properties exist for all web parts. These properties can be set in addition to the web-part-specific properties listed above.The showFrame property indicates whether or not the title bar for the web part is displayed. When the showFrame='true' (as it is by default), the web part includes its title bar and the title bar's usual features. For example, for wiki pages, the title bar includes links such as "Edit" and "Manage" for the inserted page. You will want to set showFrame='false' when you wish to display one wiki page's content seamlessly within another page without a separator.- showFrame='true|false'. Defaults to True.
- location='right' displays the narrow version of a web part. Default value is '!content', which displays the wide web part.
Properties Specific to Particular Web Parts
Properties specific to particular web parts are listed in this section, followed by acceptable values for each. All listed properties are optional, except where indicated. Default values are used for omitted, optional properties. Issues Web Part Summary of issues in the current folder's issue tracker- title - Title of the web part. Useful only if showFrame is true. Default: "Issues Summary."
- title - title to use on the web part. Default: "[schemaName] Queries" (e.g., "CustomProteinAnnotations Queries")
- schemaName - Name of schema that this query is going to come from. It is Required.
- queryName - Query or Table Name to show. Unspecified by Default.
- viewName - Custom view associated with the chosen queryName. Unspecified by Default.
- buttonBarPosition - Determines how the button bar is displayed. By default, the button bar is displayed above and below the query grid view. To make the button bar appear only above or below the grid view, set this parameter to either 'top' or 'bottom', respectively. You can suppress the button bar by setting buttonBarPosition to 'none'.
- allowChooseQuery - If the button bar is showing, this boolean determines whether or not the button bar should be include a button to let the user choose a different query.
- allowChooseView - If the button bar is showing, this boolean determines whether or not the button bar should be include a button to let the user choose a different view.
- reportId - The ID of the report you wish to display. You can find the ID for the report by hovering over a link to the report and reading the reportID from the report's URL. If the URL includes 'db:151', the reportID would be 151.
- schemaName, queryName and reportName. You can use these three properties together as an alternative to reportId. This is a handy alternative when you develop a report on a test system and reference the report using the LabKey JavaScript API. If you were to use reportID in your script and deploy to production, you would have to edit the calling code -- the reportID would have changed.
- showSection - The section name of the R report you wish to display. Optional. Section names are the names given to the replacement parameters in the source script. For example, in the replacement '${imgout:image1}' the section name is 'image1'. If a section name is specified, then the specified section will be displayed without any headers or borders. If no section name is specified, all sections will be rendered. Hint: When you use the report web part from a portal page, you will see a list of all the reports available. When you select a particular report, you will see all section names available for the particular report.
- includeSubFolders - 'true|false'. Search this folder or this and all sub folders. Defaults to 'true'.
- partConfig - todo - documentation under construction
- fileSet - todo - documentation under construction
- name - Title name of the page to include. Required.
- webPartContainer - The ID of the container where the wiki pages live. If this param is not supplied, the current container is used.
- webPartContainer - Same as the "webPartContainer" parameter for the wiki web part described above.
- title - Title for the web part. Only relevant if showFrame is TRUE. "Pages" is used as the default when this parameter is not specified.
Related Topics
- Embed Live Content in HTML Pages or Messages
- Examples: Embedded Web Parts. This page provides a link to the HTML source for its samples.
Add Screenshots to a Wiki
How to Add Screenshots to a Wiki
Screen captures can help you highlight parts of your site that are particularly interesting to users. Screen captures can also help to you visualize the steps you're asking users to follow on support or help pages. Adding screen captures is quite simple. This page covers how to:- Obtain an image editor.
- Get a screen capture into the editor.
- Crop the image.
- Draw a red circle on the image to call out an interesting feature. Optional.
- Resize the image. Optional.
- Add a border to the image. Optional.
- Save the image.
- Add your image to a wiki-language wiki.
- Add your image to an HTML-language wiki. Optional.
- Download and install a basic image editing program. This tutorial assumes that you will use Paint.Net, a simple, free program that works well for screen captures. The following screen capture shows Paint.Net in action and includes circles around key features discussed below.
 Get a screen capture into the editor.
Get a screen capture into the editor.
- Do a screen capture for your desktop. The correct key combo varies by keyboard. On many keyboards, the correct key combo is Fn+F11, where F11 is labeled as the "Print Screen" button. An image of the desktop and any open windows is now contained in the clipboard.
- Within Paint.Net, press CTRL+V to paste the clipboard into an open, blank image canvas. You will often be asked to enlarge canvas to fit the dimensions of the image on your clipboard. Accept the invitation to enlarge the canvas.
- In the "Tools" floating menu, select the "Rectangle Select," which is represented by a dashed rectangle and is located at the top left of the menu.
- Click and drag the selection rectangle across the region of interest in your desktop screenshot.
- Press CTRL+Shift+X to crop the image neatly to the rectangle you selected.
- You may wish to repeat this process a few times to refine the selected region. Remember, CTRL+Z can quickly undo an overzealous crop.
- In the "Colors" floating menu, click on the top square to allow yourself to select the primary color. Then click on the tiny red square to pick red as the primary color.
- In the "Tools" menu, select the "Rounded Rectangle," the second option from the bottom in the right column.
- Click on your image and drag the rounded rectangle across the image to add a red oval to the image. Remember, CTRL+Z can quickly undo a wayward oval.
- Use the "Image" drop-down to select "Resize."
- Make sure that "Maintain aspect ratio" is checked to allow the image to be shrunk in a uniform way in all directions.
- Choose a new size for the image. The LabKey documentation wiki typically keeps images smaller than 800 pixels wide.
- In the "Colors" floating menu, click on the bottom, large square to allow yourself to select the secondary color. Then click on the tiny black square in the color palette to pick black as the secondary color. This color will be used for the border of the image.
- Use the "Image" drop-down to select "Canvas Size."
- Make sure that the image icon in the "Anchor" section of the popup is centered in its grid. This ensures that the canvas will be expanded in equal amounts on all sides.
- Increase "Width" and "Height" in the "Pixel size" section by 2 pixels each. This adds a one-pixel border on each side of the image. Often, you will not be able to see the new border until you incorporate your image into another document. To quickly see whether the border you've added is correct, copy/paste the image into a Word file.
- Download one of the cursor images:


- Select "Layers" -> "Import from File" and browse to the downloaded cursor image.
- Position the cursor image as appropriate.
- To flatten the image select "Image" -> "Flatten".
- Typically, save the image as a .png for use on a web site. This compact format displays well on the web.
- Open a wiki page for editing
- Add the saved file as an attachment to the wiki.
- Uncheck the "Show attachments" box.
- At the point in the text where you would like to display the image, enter the name of the image file enclosed in square brackets. Example: [myImage.png].
- Save and close the wiki.
- Open a wiki page for editing
- Add the saved file as an attachment to the wiki.
- Make sure that the "Show attachments" box is checked.
- Save and close the wiki.
- You will see a hyperlink to the uploaded image below the text of the wiki page. Copy the URL for the image.
- Open the wiki page for editing again.
- Uncheck the "Show attachments" box.
- At the point in the text where you would like to display the image, click the Image icon in the wiki editor (it looks like an image of a tree).
- Enter the copied URL for the image. Optionally, enter a description. Select "Insert" in the dialog to save your changes. Note that you may be warned that you have not entered a description if you left one out. Entering a description is optional.
- Save and close the wiki.
Manage Wiki Attachment List
Wiki Attachment List
The list of file attachments to a wiki page is displayed at the end of a wiki page by default. You can hide this list by selecting the "Show Attached Files" checkbox above the attachment browsing UI on a wiki edit page.It is often handy to hide this list when the attachments to a page are images displayed on the page. The interesting part of the files is their display within the text, not the list of images.Wiki Attachment List Divider
This section provides a method for hiding the bar above the list of attached files on an individual or an entire site.The "Attached Files" divider often appears above the list of attachments to wiki pages. This divider appears when the page has attachments and the "Show Attached Files" checkbox is checked for the page.You can conditionally hide the divider using CSS that affects the unique ID of the HTML element that surrounds that divider and text. You can hide the divider on a page-by-page basis (for HTML, not wiki-syntax pages), or via a project stylesheet (which will affect all pages in the project). If you're using a site-wide stylesheet, you can put the CSS there as well.The CSS rule looks like this:<style>
.lk-wiki-file-attachments-divider
{
display: none;
}
</style>
Issue/Bug Tracking
 Topics
Topics
Using the Issue Tracker
Issue Workflow
An issue has one of three possible states: it may be open, resolved, or closed.Opening and Assigning Issues
When you open an issue, you provide the title and any other necessary information, and a unique issue ID is automatically generated. You also must assign the issue to someone from the Assigned To pulldown list, which is configured by an administrator. Other site users, i.e. stakeholders, may be added to the Notify List now or when the issue is updated later.The person to whom the issue is assigned and all those on the notify list will receive notification any time the issue is updated.Updating an Issue
When an issue is assigned to you, you might be able to resolve it in some manner right away. If not, you can update it with additional information, and optionally assign it to someone else if you need them to do something before you can continue.For example, if you needed test data to resolve an issue, you could add a request to the description, reassign the issue to someone who has that data, and add yourself to the notify list if you wanted to track the issue while it was not assigned directly to you.You can update an open or a resolved issue. Updating an issue does not change its status.Resolving an Issue
Declaring an issue resolved will automatically reassign it back to the user who opened it who will decide whether to reopen, reassign, further update, or ultimately close the issue.Options for resolution include: Fixed, Won't Fix, By Design, Duplicate, or Not Repro (meaning that the problem can't be reproduced by the person investigating it). An administrator may add additional resolution options as appropriate.When you resolve an issue as a Duplicate, you provide the ID of the other issue and a comment is automatically entered in both issue descriptions.Closing an Issue
When a resolved issue is assigned back to you, if you can verify that the resolution is satisfactory, you then close the issue. Closed issues remain in the Issues module, but they are no longer assigned to any individual.The Issues List
The Issues List displays a list of the issues in the issue tracker and can be sorted, filtered, and customized. Some data grid features that may be particularly helpful in issue management include:View Selected Details
To view the details pages for two or more issues, select the desired issues in the grid and click View Selected Details. This option is useful for comparing two or more related or duplicate issues on the same screen.Specify Email Preferences
Click the Email Preferences button to specify how you prefer to receive workflow email from the issue tracker. You can elect to receive no email, or you can select one or more of the following options:- Send me email when an issue is opened and assigned to me.
- Send me email when an issue that's assigned to me is modified.
- Send me email when an issue I opened is modified.
- Send me email when any issue is created or modified.
- Send me email notifications when I create or modify an issue.
Issues Summary
The Issues Summary web part displays a summary of the issues by user. Click the View Open Issues link to navigate to the full list of issues. Note that a given project or folder has only one associated Issues module, so if you add more than one Issues List or Summary web part, both will display the same data.Not Supported
Deleting Issues
LabKey Server does not support deleting issues through the user interface. Typically, simply closing an issue is sufficient to show that an issue is no longer active.Related Topics
Administering the Issue Tracker
- Set Up an Issue Tracker
- Configuration Options
- Customize Fields
- Define Selection Options
- Customize Notification Emails
Set Up an Issue Tracker
- Navigate to, or create, an Issue Definitions web part in the desired location.
- Click Insert New and enter the name to use for your issue tracker.
- Select the Kind of issue tracker you are creating (default is "General Issue Tracker").
- Click Submit. If an issue tracker with the same name exists in the current folder, project, or "Shared" project (searched in that order), your new tracker will share the same definition. You'll be asked to confirm before the tracker is created.
- Make any customizations necessary on the Issues Admin Page. These changes will apply to all trackers created using this named definition.
- Click Save.
- Click the name of the new tracker to open it.

Configuration Options
[ Video Overview: Improved Issues List Customization ]To customize the issue tracker, click the Admin button on the issues list grid border. The issues admin page looks like this:
The issues admin page looks like this: After making any changes as described below, click Save at the top of the page.
After making any changes as described below, click Save at the top of the page.
Flexible Naming and Ordering
The Singular item name and Plural item name fields control the display name for an "issue" across the Issues module. For example, you might instead refer to issues as "Bugs" or "Opportunities" instead of "Issues".By default, comments on an issue are shown in the order they are added, oldest first. Change the Comment Sort Direction to newest first if you prefer."Assign To" Options
You can control the names that appear as options on the Assigned To dropdown field. By default, the drop-down contains all project users, that is, every user who is a member of at least one project security group. You can populate the dropdown from a single group using the Specific Group drop-down to select the group. Both site-level and project-level groups are available.In some workflows it is useful to have a default user to whom all issues are assigned, such as for initial triage and balancing assignments across a group.Customize Fields
The issue tracker includes a set of commonly used fields by default, and you can use the field properties customizer to add additional fields and modify as needed to suit any application. Fields can be reordered, and any field showing an "X" is not required by the system and may be deleted. Customize labels and define field types, use lookups and validation to simplify user entry and data consistency.When you make a field a lookup, shown here in the case of the "Resolution" property, the user updating an issue will be shown a picklist of items on the list given, here "mynewtracker-resolution-lookup"Required Fields
You can specify that a field must have a value before a new issue can be submitted by checking the Required box on the Validators tab. When a user creates or edits an issue, required fields are marked with an asterisk (*).Default Values
To set a default value for a field, highlight the field and select the Advanced Tab. The default can be fixed, editable, or based on the last value entered. Click Set Value to set the default value. All fields with default values enabled may be edited simultaneously:
Protect Fields
To require that a user have insert (editor) or higher permissions in order to see a given field, use the Protected checkbox on the Advanced tab. Anything without that box checked can be viewed by anyone with read permissions.Selection Lists
If you want a list to offer the user a "pick list" of options, you will populate a list with the desired values and add a field with the type Lookup into the appropriate list. Built in fields that use selection options (or pick lists) include:- Type: the type of issue or task
- Area: the area or category under which this issue falls
- Priority: the importance of this issue
- Milestone: the targeted deadline for resolving this issue, such as a release version
- Resolution: ways in which an issue can be resolved, such as 'fixed' or 'not reproducible'
 When a user is entering a new issue, the pulldown for the Type field will look like this:
When a user is entering a new issue, the pulldown for the Type field will look like this: To add, change, or remove options, select Admin > Manage Lists and edit the appropriate list.
To add, change, or remove options, select Admin > Manage Lists and edit the appropriate list.
Move an Issue to another Issue Tracker
If you organize issues into different folders, such as to divide by client or project, you may want to be able to move them. As long as the two issue lists share the same issue definition, you can move issues between them. Select the issue and click Move. The popup will show a drop-down list of valid destination issue lists.
Inherit Issue Tracker Settings
In some cases, such using multiple issue trackers in many different folders for multiple client projects, you may want to have these issue trackers share a single definition, i.e. have the same set of custom fields and options that you can update in one place. Issue definitions are not automatically "inherited" by subfolders, they must be defined in each folder locally. To share an issue definitions, define the "template" issue definition in a parent context and use the same name in the local context where you want to use the issue tracker. If you want to create a site-wide definition, define it in the "Shared" project.When you define a new issue tracker definition in any folder, the name you select is compared first in the current folder, then the containing project, and finally the "Shared" project. If a matching name is found, a dialogue box asks you to confirm whether you wish to share that definition. If no match is found, a new unique definition is created.Customize Notification Emails
Click Customize Email Template at the top of the issue administration page to edit the notification email that will be sent (based on notification rules and settings) whenever an issue is created or edited. By default, these emails are automatically sent to the user who created the issue, the user the issue is currently assigned to, and all users on the Notify List.This email is built from a template consisting of a mix of plain text and substitution variables marked out by caret characters, for example, ^issueId^ and ^title^. Variables are replaced with plain text values before the email is sent.For example, the variables in the following template sentence...Related Topics
Workflow Module
BPMN 2.0
Business Process Modeling & Notation 2.0 is a graphical notation for representing business processes. The LabKey workflow module is built on the open-source Activiti BPM Platform. Process diagrams like the following show the work proceeding along the arrows. Tasks are shown in rectangles with a cog icon indicating a system task; a person is shown for a human task. Events (such as starts, stops, messages exchanged among processes) are shown as circles. Gateways (decisions) are shown as diamonds - an 'X' indicates an exclusive gateway (only one outcome is possible) while a '+' indicates a parallel gateway enabling the launch of parallel processes from that point. Activiti implements a large subset of the full BPMN 2.0 standard, including many more options than those shown above. For more options, see Activiti BPMN 2.0 Constructs
.
Activiti implements a large subset of the full BPMN 2.0 standard, including many more options than those shown above. For more options, see Activiti BPMN 2.0 Constructs
.
Workflow Module
The workflow module includes:- API: a wrapper around Activiti objects, with interfaces and base classes for various types of workflow activities.
- Database: holds the workflow schema in which tables are created.
- Resources: the workflow process definitions.
- Permissions Handler
- Email Notifier: enables sending of email from a workflow process.
- System Task Runner
- Boundary Event Handlers
Topics
Workflow Tutorial
Tutorial Scenario
Consider the work flow in a lab where scientists receive sample material and run one or both of two assays on it, depending on the needs of the requester. The assay(s) must be run, results reviewed, and decisions made along the way, including potentially rerunning the assay entirely. Many simultaneous requests might be in process at the same time, and if certain steps aren't completed in a timely way, you want to be able to catch that and make sure the request isn't forgotten. Each process ends when the original requested assay results are approved and returned to the requestor.- Step 1: Set Up Workflow Tutorial
- Step 2: Run Sample Workflow Process
- Step 3: Workflow Process Definition
- Step 4: Customize Workflow Process Definition
First Step
Step 1: Set Up Workflow Tutorial
Set Up a LabKey Workspace
Sample Package
Using a sample workflow application will help illustrate some basic features and options for customization. We use in this case a multiple assay workflow simply named "labWork".- Download and unzip labWork.zip from this page.
Install Modules
- Obtain and install the workflow module in your optionalModules directory.
- Install the "labWork" module from the sample data package by copying the unzipped folder to your optionalModules directory.
- Rebuild your server, start it, and sign in as an administrator.
Create Workspace
- Create a new project named "Workflow Tutorial."
- Choose folder type "Collaboration" and click Next.
- On the Users/Permissions page, choose "My User Only", and click Next.
- Check "Use Default" on the project settings page and click Finish.
- Enable the workflow and labWork modules in your new project:
- Select Admin > Folder > Management and click the Folder Type tab.
- Check the boxes for both "LabWork" and "Workflow" in the column on the right.
- Click Update Folder.
Set Up Activiti Workflow Engine
Download and install the latest stable release of the Activiti engine . You must already have a working Java runtime environment, Apache Tomcat installation, and the JAVA_HOME variable must be set. These will all be in place already when you are running a local LabKey Server.- Download and unpack the .zip package to the location of your choice.
- Place the included activiti-explorer.war in the webapps directory of your Tomcat installation.
- Restart Tomcat.
- When Tomcat is running, go to http://localhost:8080/activiti-explorer.
- Log in using the demo user "kermit" with password "kermit".
Go Back | Next Step
Step 2: Run Sample Workflow Process
Run A Sample Workflow Process
- In a new browser window, open http://localhost:8080/labkey and navigate to the Workflow Tutorial container you created earlier.
- Select Admin > Go To Module > LabWork. This opens the module "labWork" you installed and enabled in your project.
- You will see the very basic UI which would kick off our sample process:

- Select one or two assays and click Make Request.

- Click links to see:
- All Workflows: a listing of all workflows currently deployed in this container.
- Multiple Assay Workflow: a listing of current instances of this workflow.
- Process Instance List: a listing of all process instances. This top level assay request has spawned additional processes (to actually run the assays requested).
- My Tasks: a listing of tasks assigned to the current user.
Workflow List Webpart
To make the workflow easier to initiate from the home project:- Return to the Start Page tab and add a new Workflow List web part to your workflow tutorial folder. It gives you ready access to all workflows deployed in the container.

Previous Step | Next Step
Step 3: Workflow Process Definition
Explore Process Definition
Process definitions have a unique process identifier, a short string used as part of the file name. The file is named:[process identifier].bpmn20.xml
...[LabKey Home]/server/optionalmodules/labWork/resources/workflow/model/[process identifier].bpmn20.xml
- Go to http://localhost:8080/activiti-explorer. Log in using the demo user "kermit" with password "kermit" if necessary.
- Click Processes.
- Click Model Workspace.

- Click Import.
- Select the sample file [labWork]/resources/workflow/model/labWorkflow.bpmn20.xml. You can find this file in the sample package you downloaded, or it will now also be installed in your server/optionalmodules directory on the same path.
- Click Open.
- Click Edit to see the process diagram.

- Open the labWorkflow.bpmn20.xml file in a separate text editor window to compare the xml version of the workflow with the Activiti diagram.
Previous Step | Next Step
Step 4: Customize Workflow Process Definition
Customize a Process Definition
In the Activiti Explorer you can graphically develop your workflow process and elements. Learn how by using our example as a starting place. First, we'll change the process identifier so that the changes you make will not overwrite the tutorial process definition. The process identifier is the first part of the filename.- Go to http://localhost:8080/activiti-explorer. Log in using the demo user "kermit" with password "kermit" if necessary.
- Click Processes, then Model Workspace.
- This view shows you the current workflow process, titled "Multiple Assay Workflow". If that title is not showing, click Import and import "labWorkflow.bpmn20.xml" again.
- Click Edit.
- Click "labWorkflow" next to Process identifier to activate an entry panel. Edit the string to read "myTutorialWorkflow" or any unique string you like. Remember that this will be part of the file name.

- Click the file icon in the upper left to save the changes, ensuring that any further changes you make will not overwrite the original tutorial workflow.
- To change the name of the process printed above the diagram, and displayed in the Workflow List Webpart within LabKey, edit the "Name" field (which initially reads "Multiple Assay Workflow".
- Click any element in the diagram to see details about it displayed below the diagram, as well as reveal tools for adding additional workflow elements.

- Explore the editing options, and make any changes you like. You are not overwriting the original sample, so don't worry about making irrevocable changes.
- Double clicking on any text label, for instance, will allow you to edit it.
- Add a new element or pathway by clicking and dragging.
- Click the file icon in the upper left to save your revision.
- In the popup, change the Name to read "My Assay Workflow" or another name of your choice.
- Click Save and close editor.
- Notice the process diagram window on the model workspace pane now shows your revisions.
Export a Process XML File
- Using the Model action pulldown, select Export model and a new myTutorialWorkflow.bpmn20.xml file will be downloaded.
Add Your Own Workflow Process
By working back and forth between the two methods, you can tailor a new workflow to suit your needs. Once you have a final process diagram exported to an .xml file, install it in the /resources/workspace/model directory of the module in which you will run it.Related Topics
Workflow Process DefinitionPrevious Step
Workflow Process Definition
Sample XML
Using a sample process definition will help illustrate some basic features, in this case a multiple assay workflow.- Review the contents of labWorkflow.bpmn20.xml.
- If you download and unzipped the "labWork" module as part of the Workflow Tutorial, find this file in the /labWork/resources/workflow/model/ directory.
- If not, download it here labWorkflow.bpmn20.xml.
- Open in an editor to review the features described below.
Definitions
The first section loads namespace and language definitions. One of the attributes of the <definitions> element is the targetNamespace. Change this to be a URN of the form "urn:lsid:labkey.com:workflow:[module with the workflow resource]". The workflow engine uses this to find permissions handlers, if any, that are used for the workflow. If your workflow does not use permissions handlers then this is less important, but in future, this part of the definition could be used for finding other module-specific resources. Replace "LabWork" with the name of your module in this line:targetNamespace="urn:lsid:labkey.com:workflow:LabWork"><process id="labWorkflow" name="Multiple Assay Workflow" isExecutable="true">
<startEvent id="startLabWork" name="Start"></startEvent>
userTask
<userTask id="runAssayA" name="Run Assay"></userTask>
serviceTask
Service, or system tasks, carry more information about the work required. Typically these are defined as classes to encapsulate similar tasks. In this example, an email notifier extended for workflow use:<serviceTask id="notifyScientists" name="Notify Scientists" activiti:class="org.labkey.workflow.delegate.EmailNotifier">
<extensionElements>
<activiti:field name="notificationClassName">
<activiti:string><![CDATA[org.labkey.labwork.workflow.WorkNotificationConfig]]></activiti:string>
</activiti:field>
</extensionElements>
</serviceTask>
Java Classes for Service Tasks
The following Java classes are available in the workflow module for handling different types of service tasks. The Activiti extensions for BPMN 2.0 allow you to provide the Java class name and the configuration data within the XML files.DataManager
DataManager handles access to data. It expects as part of the configuration in the .bpmn20.xml definition a class that extends the abstract org.labkey.api.workflow.DataManagerConfig class.EmailNotifier
EmailNotifier is used for sending email notifications. It expects as part of the configuration in the .bpmn20.xml definition, a class that extends the abstract org.labkey.api.workflow.NotificationConfig where you set the users and the email template.SystemTaskManager
SystemTask Manager handles executing system tasks of any kind. It expects as part of the configuration in the .bpmn20.xml definition, a class that extends org.labkey.api.workflow.SystemTaskRunnerElectronic Data Capture (EDC)
Survey Topics
- Survey Designer: Basics - Set up a new EDC survey.
- Survey Designer: Customization - Format questions and default responses.
- Survey Designer: Reference - Reference topic for survey/question properties.
- Survey Designer: Example Questions - Sample question metadata.
- REDCap Survey Data Integration - Import data from a RedCap project
Survey Designer: Basics
Survey Designer Set Up
First enable survey functionality in a folder. Each user taking the survey will need to have at least Editor permissions, so you will typically create a new folder such as My Project > Conference Attendee Surveys to avoid wider access to other parts of your project.- Go to or create a folder for your survey.
- Configure Editor permissions for each user.
- Select Admin > Folder > Management and click the Folder Type tab.
- Under Modules, place a checkmark next to Survey.
- Click Update Folder.
- Create a new Lists web part.
- Click Manage Lists, then Create New List.
- Name your list SurveyResults.
- Change the Primary Key? identifier to "ParticipantID". (This will allow the survey to be integrated directly with demographic information.)
- Leave Primary Key Type? unchanged (as Auto-Increment Integer).
- Leave Import from File unchecked.
- Click Create List.
- Leave the defaults in List Properties.
- Under List Fields, add the following fields. For each line, enter the information as shown and click Add Field.

- Click Save at the top of the page, then Done
Survey Design
The next step is to design the survey so that it will request the information needed in the correct types for your results table. The survey designer generates simple input fields labeled with the column name as the default questions presented to the person taking the survey.- Click Start Page to return to your folder.
- Add a Survey Designs web part.
- Click Create Survey Design.
- Provide a Label (such as ConferenceAdvance in this example) and Description.
- From the Schema dropdown, select lists.
- From the Query dropdown, select your list, in this example: SurveyResults.
- Click Generate Survey Questions above the entry panel.
- Default survey questions are generated using the field information you used when you created your SurveyResults list. Notice the lower left panel contains documentation of the survey configuration options. It is possible to customize the survey at this point, but for now just use the defaults.
- Click Save Survey.
Create and Populate The Survey
Create the Survey:- Click Select Web Part, select Surveys, click Add.
- Survey Design dropdown: select your survey design (ConferenceAdvance).
- Click Submit.

- Click Create Survey to launch the survey wizard and present the default questions based on your results table.
- Enter values for the given fields.

- Click Submit Completed Form to finish. There is also a Save button allowing the user to pause without submitting incomplete data. In addition, the survey is auto-saved periodically.
Next step
Survey Designer: Customization
- the parameters of default survey questions
- the parameters of the survey method itself
- metadata for more specific or complex question types
Customize Default Survey Questions
For a more traditional and user-friendly survey, you can add more description, write survey questions in a traditional sense, and control which fields are optional.- Go back to your survey folder.
- Click Edit next to the ConferenceAdvance survey design you created in the previous step. The main panel contains the JSON code to generate the basic survey. Below the label and description on the right, there is documentation of the configuration options available within the JSON.
- Make changes as follows:
- Change the caption for the First Name field to read "First name to use for nametag".
- Change required field for Last Name to true.
- Change the caption for the Reception field to read "Check this box if you plan to attend the reception:".
- Change the caption for the GuestPasses field to read "How many guests will you be bringing?"
- Change the width for the GuestPasses field to 400.
- Change the hidden paramenter for Title to true (perhaps you decided you no longer plan to print titles on nametags).
- In the Gender field, change the caption to "Gender (please enter Male or Female) and change the width to 600.

- Click Save Survey.
Customize the Survey
You can make various changes to the overall design and layout using parameters to survey outlined in the Survey Configuration Options panel. For example, you can use a card format and change the Survey Label the user sees where they are expected to enter the primary key for your results table.- Return to your folder and again open the ConferenceAdvance survey design for editing.
- In the json panel, change "layout" to "card" and add a new parameter: "labelCaption" : "Attendee Registration Number". All parameters must be comma separated.

- Click Save Survey.
- In the Surveys: ConferenceAdvance web part, click Create Survey and note the new format and start tab.
Customize Question Metadata
In addition to the survey question types directly based on field datatypes, there are additional options for more complex questions. For example, for a given text field such as title, you might constrain allowable input by using a lookup from a table of three letter abbreviations (Ms., Mr., Mrs, Dr., Hon) to format evenly on nametags. To do so, you would create a list of allowable options, and add a "Combobox" question to your survey.- Click Edit for your ConferenceAdvance survey design.
- Open the Question Metadata Examples panel on the right by clicking the small chevron button in the upper right.

- Click the name of any question type and an example json implementation will appear in a scrollable panel below the bar.
- You can cut and paste the json from the middle panel in place of one of your default questions. Watch for result type mismatches.
- Customize the parameters as with default questions. In our title lookup example you would specify the table and column (containerPath and query name) from which the value should be selected.
Survey Designer: Reference
Survey Designer Metadata Options
The following properties are available when customizing a survey to adjust layout, style, question formatting, and defaults. This documentation is also available directly from the survey designer on the Survey Configuration Options panel.
The indenting of the 'Parameter' column below shows the structure of the JSON objects.
| Parameter |
Datatype | Description | Default Value |
| beforeLoad | object | Object to hold a javascript function. | |
| fn | string |
A javascript function to run prior to creating the survey panel. |
|
| footerWiki | object | Configuation object for a wiki that will be displayed below the survey panel. | |
| containerPath | string | Container path for the footer wiki. Defaults to current container. | current container path |
| name | string | Name of the footer wiki. | |
| headerWiki | object | Configuration object for a wiki that will be displayed above the survey panel. | |
| containerPath | string | The container path for the header wiki. Defaults to current container. | current container path |
| name | string | Name of the header wiki. | |
| layout | string | Possible values: • auto - vertical layout of sections • card - wizard layout |
auto |
| mainPanelWidth | integer | In card layout, the width of the main section panel. | 800 |
| sections | array | An array of survey section panel config objects. | |
| border | boolean | Set to 'true' to display a 1px border around the section. Defaults to false. | false |
| collapsed | boolean | If layout is auto, set to true to begin the section panel in a collapsed state. | false |
| collapsible | boolean | If layout is auto, set to true to allow the section panel to be collapsed. Defaults to true. | true |
| defaultLabelWidth | integer | Default label width for questions in this section. | 350 |
| description | string | Description to show at the beginning of the section panel. | |
| extAlias | string | For custom survey development, the ext alias for a custom component. | |
| header | boolean | Whether to show the Ext panel header for this section. | true |
| initDisabled | boolean | In card layout, disables the section title in the side bar. Defaults to false. | false |
| layoutHorizontal | boolean | If true, use a table layout with numColumns providing the number of columns. | false |
| numColumns | integer | The number of columns to use in table layout for layoutHorizontal=true. | 1 |
| padding | integer | The padding to use between questions in this section. Defaults to 10. | 10 |
| questions | array | The array of questions. Note that the 'questions' object is highly customizable because it can hold ExtJS config objects to render individual questions. | |
| extConfig | object | An ExtJS config object. | |
| required | boolean | Whether an answer is required before results can be submitted. | false |
| shortCaption | string | The text to display on the survey end panel for missing required questions. | |
| hidden | boolean | The default display state of this question (used with listeners). | false |
| listeners | object | JavaScript listener functions to be added to questions for skip logic or additional validation (currently on 'change' is supported). |
auto |
| change | object | Listener action. | |
| question | string or array | Name(s) of parent question(s). | |
| fn | string | JavaScript function to be executed on parent. | |
| title | string | The title text to display for the section (auto layout displays title in header, card layout displays title in side bar). | |
| showCounts | boolean | Whether to show count of completed questions. | false |
| sideBarWidth | integer | In card layout, the width of the side bar (i.e. section title) panel. | 250 |
| start | object | Configuration options for the first section of the survey. | |
| description | string | Description appears below the 'survey label' field, in the start section, i.e., the first section of the survey. | |
| labelCaption | string | Label that appears to the left of the 'survey label' field, defaults to "Survey Label". | "Survey Label" |
| labelWidth | integer | Pixels allotted for the labelCaption. | |
| sectionTitle | string | The displayed title for the start section, defaults to "Start". | "Start" |
| useDefaultLabel | boolean | If true, the label field will be hidden and populated with the current date/time. | false |
Survey Designer: Example Questions
- Auto Populate from an Existing Record
- Auto Populate with the Current User's Email
- Hidden Radio Group
- Hidden Question
- Radio Buttons / Rendering Images
- Likert Scale
- Concatenate Values
- Checkbox (with Conditional/Skip Logic)
- Text Field (with Conditional/Skip Logic)
- Time Dropdown
- Calculated Fields
- Hiding "Default Label"
- Checkbox Group (ExtJS)
- Combobox (Lookup)
- Combobox (ExtJS)
- Date Picker
- Number Range (ExtJS)
- Survey Grid Question (ExtJS)
- Survey Header/Footer Wiki
- Other Examples
Auto Populate from an Existing Record
The following example assumes you have a List named "Participants" with the following fields:- SSN (this is your Primary Key, which is a string)
- FirstName
- LastName
- Phone

Auto Populate with the Current User's Email
When a user changes the Patient Id field, the email field is auto populated using the currently logged on user's info.Download the JSON code for this survey: survey-Emailautopop.json
Hidden Radio Group
When Option A is selected, a hidden radio group is shown below.Download the JSON code for this survey: survey-hiddenRadioGroup.json
Hidden Question
A hidden question appears when the user enters particular values in two previous questions. In this example, when the user enters 'Yes' to questions 1 and 2, a 3rd previously hidden question appears.Download the JSON code for this survey: TwoQuestions.json
Radio Buttons / Rendering Images
The following example renders radio buttons and an image. The 'questions' object holds an 'extConfig' object, which does most of the interesting work.The 'start' object hides the field "Survey Label" from the user.Download the JSON code for this survey: survey-RadioImage.json
Likert Scale
The following example offers Likert scale questions as radio buttons.Download the JSON code for this survey: survey-Likert.json
Concatenate Values
When three fields are filled in, they auto-populate another field as a concatenated value.Download the JSON code for this survey: survey-Concat.json
Checkbox with Conditional/Skip Logic
Two boxes pop-up when the user picks Other or Patient Refused. The boxes are text fields where an explanation can be provided. Download the JSON code for this example: survey-Skip1.json
Download the JSON code for this example: survey-Skip1.json
Text Field (w/ Skip Logic)
Shows conditional logic in a survey. Different sets of additional questions appear later in the survey, depending on whether the user enters "Yes" or "No" to an earlier question.Download the JSON code for this example: survey-Skip2.json
Time Dropdown
The following example presents a dropdown to select a time in 15 minutes increments.Download the JSON code for this example: survey-timedropdown.json
Calculated Fields
The following example calculates values from some fields based on user entries in other fields:- Activity Score field = the sum of the Organ/Site scores, multiplied by 2 if Damage is Yes, plus the Serum IgG4 Concentration.
- Total number of Urgent Organs = the sum of Urgent fields set to Yes.
- Total number of Damaged Organs = the sum of Damaged fields set to Yes.

Hiding "Default Label"
Add the following start object before the sections to hide the "Label" question.{
"survey" : {
"start": {
"useDefaultLabel": true
},
"sections" : [{
...Checkbox Group (ExtJS)
{
"extConfig": {
"xtype": "fieldcontainer",
"width": 800,
"hidden": false,
"name": "checkbox_group",
"margin": "10px 10px 15px",
"fieldLabel": "CB Group (ExtJS)",
"items": [{
"xtype": "panel",
"border": true,
"bodyStyle":"padding-left:5px;",
"defaults": {
"xtype": "checkbox",
"inputValue": "true",
"uncheckedValue": "false"
},
"items": [
{
"boxLabel": "CB 1",
"name": "checkbox_1"
},
{
"boxLabel": "CB 2",
"name": "checkbox_2"
},
{
"boxLabel": "CB 3",
"name": "checkbox_3"
}
]
}]
}
}Combobox (Lookup)
Constrain the answers to the question to the values in a specified column in a list.{
"jsonType": "int",
"hidden": false,
"width": 800,
"inputType": "text",
"name": "lkfield",
"caption": "Lookup Field",
"shortCaption": "Lookup Field",
"required": false,
"lookup": {
"keyColumn": "Key",
"displayColumn": "Value",
"schemaName": "lists",
"queryName": "lookup1",
"containerPath": "/Project/..."
}
}Combobox (ExtJS)
{
"extConfig": {
"width": 800,
"hidden": false,
"xtype": "combo",
"name": "gender",
"fieldLabel": "Gender (ExtJS)",
"queryMode": "local",
"displayField": "value",
"valueField": "value",
"emptyText": "Select...",
"forceSelection": true,
"store": {
"fields": ["value"],
"data" : [
{"value": "Female"},
{"value": "Male"}
]
}
}
}Date Picker
{
"jsonType": "date",
"hidden": false,
"width": 800,
"inputType": "text",
"name": "dtfield",
"caption": "Date Field",
"shortCaption": "Date Field",
"required": false
}Number Range (ExtJS)
{
"extConfig": {
"xtype": "fieldcontainer",
"fieldLabel": "Number Range",
"margin": "10px 10px 15px",
"layout": "hbox",
"width": 800,
"items": [
{
"xtype": "numberfield",
"fieldLabel": "Min",
"name": "min_num",
"width": 175
},
{
"xtype": "label",
"width": 25
},
{
"xtype": "numberfield",
"fieldLabel": "Max",
"name": "max_num",
"width": 175
}
]
}
}Survey Grid Question (ExtJS)
{
"extConfig": {
"xtype": "surveygridquestion",
"name": "gridquestion",
"columns": {
"items": [{
"text": "Field 1",
"dataIndex": "field1",
"width": 350,
"editor": {
"xtype": "combo",
"queryMode": "local",
"displayField":"value",
"valueField": "value",
"forceSelection": true,
"store": {
"fields": ["value"],
"data" : [{
"value": "Value 1"
}, {
"value": "Value 2"
}, {
"value": "Value 3"
}]
}
}
},
{
"text": "Field 2",
"dataIndex": "field2",
"width": 200,
"editor": {
"xtype": "textfield"
}
},
{
"text": "Field 3",
"dataIndex": "field3",
"width": 200,
"editor": {
"xtype": "textfield"
}
}]
},
"store": {
"xtype": "json",
"fields": [
"field1",
"field2",
"field3"
]
}
}
}Survey Header/Footer Wiki
{"survey":{
"headerWiki": {
"name": "wiki_name",
"containerPath": "/Project/..."
},
"footerWiki": {
"name": "wiki_name",
"containerPath": "/Project/..."
},
...
}Other Examples
Download these examples of whole surveys.- CustomSurveyMetadata.json - When a user enters '1' in the field LK Field, a file picker is shown.
- Survey Simple Example.txt
- Survey Simple Example with comments.txt
REDCap Survey Data Integration
 Premium Feature — Available in the Professional Plus and Enterprise Editions. Also available as an Add-on to the Professional Edition. Learn more or contact LabKey
Premium Feature — Available in the Professional Plus and Enterprise Editions. Also available as an Add-on to the Professional Edition. Learn more or contact LabKey
| REDCap data object | LabKey Server data object | Notes |
|---|---|---|
| form00000000000000 | dataset0000000000000000000000 | Forms are imported as Labkey Server study datasets. You can specify which forms should be imported as demographic datasets using the configuration property demographic. |
| event | visit or date | Events are imported as either LabKey Server visits or dates. You can specify 'visit' or 'date' import using the configuration property timepointType. |
| multichoice fields | lookups | Multiple choice fields are imported as lookups. Possible values are imported into separate Lists. |
Enable the REDCap Module
- In your study folder, go to: Admin > Folder > Management and click the Folder Type tab.
- Under Modules, place a checkmark next to REDCap.
- Click Update Folder.
Connect and Configure REDCap Projects
- In your study folder, click the Manage tab.
- Click Manage External Reloading.
- Click Configure REDCap.
- Configure connections and reloading on the three tabs: Authentication, Reloading, and Configuration Setting.
- token: A hexidecimal value used by the REDCap server to authenticate the identity of LabKey Server as a client. (Get the token value from your REDCap server, located on the REDCap API settings page of the project you are exporting from.)
- project: The name of the target REDCap project. This value should match the project name in the configuration XML specified in the Configuration Setting tab.
 ReloadingOn the Reloading tab, enable data reloading on a repeating schedule.
ReloadingOn the Reloading tab, enable data reloading on a repeating schedule.
- Enable Reloading: Place a checkmark here to start reloading.
- Load On: Set the start date for the reloading schedule.
- Repeat (days): Repeat the reload after this number of days.
- Click Save to confirm your changes.
- Click Reload Now to manually reload the data.
 Configuration SettingsEnter configuration information in the text box. Use the example XML as a template. Available configuration options are described below:
Configuration SettingsEnter configuration information in the text box. Use the example XML as a template. Available configuration options are described below:
- serverUrl: Required. The URL of the REDCap server api (https://redcap.test.org/redcap/api/).
- projectName: Required. The name of the REDCap project (used to look up the project token from the netrc file). The projectName must match the project name entered on the Authentication tab.
- subjectId: Required. The field name in the REDCap project that corresponds to LabKey Server's participant id column.
- timepointType: Optional. the timepoint type (possible values are either 'visit' or 'date'), the default value is: 'date'.
- matchSubjectIdByLabel: Optional. Boolean value. If set to true, the import process will interpret 'subjectId' as a regular expression. Useful in situations where there are slight variations in subject id field names across forms in the REDCap project.
- duplicateNamePolicy: Optional. How to handle duplicate forms when exporting from multiple REDCap projects. If the value is set to 'fail' (the default), then the import will fail if duplicate form names are found in the projects. If the value is set to 'merge', then the records from the duplicate forms will be merged into the same dataset in LabKey Server (provided the two forms have an identical set of column names).
- formName: Optional. The name of a REDCap form to import into LabKey Server as a dataset.
- dateField: Optional. The field that holds the date information in the REDCap form.
- demographic: Optional. Boolean value indicating whether the REDCap form will be imported into LabKey Server as a 'demographic' dataset.
 Example Configuration File
Example Configuration File<red:redcapConfig xmlns:red="http://labkey.org/study/xml/redcapExport">
<red:projects>
<red:project>
<red:serverUrl>https://redcap.test.org/redcap/api/</red:serverUrl>
<red:projectName>MyCaseReports</red:projectName>
<red:subjectId>ParticipantId</red:subjectId>
<red:matchSubjectIdByLabel>true</red:matchSubjectIdByLabel> <!--Optional-->
<red:demographic>true</red:demographic> <!--Optional-->
<red:forms> <!--Optional-->
<red:form>
<red:formName>IntakeForm</red:formName>
<red:dateField>StartDate</red:dateField>
<red:demographic>true</red:demographic>
</red:form>
</red:forms>
</red:project>
</red:projects>
<red:timepointType>visit</red:timepointType> <!--Optional-->
<red:duplicateNamePolicy>merge</red:duplicateNamePolicy> <!--Optional-->
</red:redcapConfig>
Related Resources
Adjudication Module
 LabKey Server's adjudication module may require significant customization and assistance, so it is not included in standard LabKey distributions. Developers can build this module from source code in the LabKey repository. Please contact LabKey to inquire about support options.
LabKey Server's adjudication module may require significant customization and assistance, so it is not included in standard LabKey distributions. Developers can build this module from source code in the LabKey repository. Please contact LabKey to inquire about support options.
| Role | Description |
|---|---|
| Adjudication-Folder-Administrator | The person who configures and maintains the adjudication folder. This person must have Administrator permissions on the folder or project, and will assign all the other roles via the Adjudication Users table. Note that the administrator does not hold those other roles, which means they cannot see tabs or data in the folder reserved for the specialized roles. |
| Adjudication Lab Personnel | One or more people who upload assay data to create or amend adjudication cases, and can view the adjudication dashboard to track and review case determination progress. |
| Adjudicators | People who evaluate the lab data provided and make independent determinations about infection status. Each individual is assigned to a single team. |
| Infection Monitor | One or more people who can view the infection monitor tab or use queries to track confirmed infections. They receive notifications when adjudication determinations identify an infection. |
| Adjudication Data Reviewer | One or more people who can view the adjudication dashboard to track case progress. They receive notifications when cases are created, when determinations are updated, and when assay data is updated. |
| Additional people to be notified | Email notifications can be sent to additional people who do not hold any of the above roles. |
Topics
- Set Up an Adjudication Folder - Adjudication Folder Administrator
- Initiate an Adjudication Case - Adjudication Lab Personnel
- Make an Adjudication Determination - Adjudicator (each completes independently)
- Monitor Adjudication - Adjudication Lab Personnel, Adjudication Data Reviewer
- Infection Monitor - Adjudication Infection Monitor
Role Guides
Topics covering the tasks and procedures applicable to individual roles within the process:Set Up an Adjudication Folder
- Set Up the Adjudication Folder
- Assign Adjudication Roles and Permissions
- Assign Adjudicator Team Members
- Specify Supported Assay Kits
- Customize Case File Format
Set Up the Adjudication Folder
- Create a new folder of type Adjudication.
- All users with folder read permissions are able to view the Overview tab. The wiki there is intended to be customized with protocol documents or other framing information, but should not reveal anything not intended for all adjudicators and lab personnel.
- The available tabs and which users can see them are shown in the following table:
| Tab Name | Adjudication Roles Granting Access |
|---|---|
| Overview | All users with Read access to the folder. |
| Administrator Dashboard | Administrators, Lab Personnel, Infection Monitors, Data Reviewers |
| Upload | Lab Personnel |
| Case Determination | Adjudicators |
| Infection Monitor | Administrators, Infection Monitors |
| Manage | Administrators |
Manage Adjudication Options
The Manage Adjudication web part on the Manage tab allows you to:- Specify the file prefix used for uploaded cases. Options are:
- Parent Folder Name
- Parent Study Name (requires that the adjudication folder be a study subfolder).
- Text: Enter expected text in the box, such as "VTN703" here.
- Select the number of Adjudicator Teams (from 1 to 5, default is 2).
- Specify whether HIV-1, HIV-2, or both determinations are required (default is HIV-1 only)
- Configure the assay results table to include additional columns if necessary.
 The format of a case filename is PREFIX_PTID_DDMMMYYYY.txt. PTID is the patient ID. For instance, VTN703_123456782_01Aug2015.txt as used in our example. Prefixes are checked for illegal characters, and if you leave the text box blank, the filename is expected to be _PTID_DDMMMYYY.txt.Once a case exists in the adjudication folder you will no longer be able to edit the admin settings, so the web part will simply display the selections in force.
The format of a case filename is PREFIX_PTID_DDMMMYYYY.txt. PTID is the patient ID. For instance, VTN703_123456782_01Aug2015.txt as used in our example. Prefixes are checked for illegal characters, and if you leave the text box blank, the filename is expected to be _PTID_DDMMMYYY.txt.Once a case exists in the adjudication folder you will no longer be able to edit the admin settings, so the web part will simply display the selections in force.
Assign Adjudication Roles and Permissions
In the adjudication process, the objective is adjudication determinations which are reached independently and blinded to each other. Each Adjudicator Team can be a single person, or may include an additional backup person in case they are unavailable. Both team members are equally empowered to make the determination for the team.The Adjudication Users table on the Manage tab is used to give access and roles to users within this folder. No user can appear twice in the table, and when you insert a new user and grant one of the adjuication roles, you assign the relevant permissions automatically. No explicit setting of folder permissions is required.You will need to identify at least one member of lab personnel and at least one member of each adjudication team. Additionally, you can assign the other roles for notification and data access purposes. Additional people to be notified may also be specified and carry no distinguishing role.- Click the Manage tab.
- Click Insert New Row on the Adjudication Users table.
- Select the user from the dropdown.
- Select the role from the dropdown. Options are:
- Adjudicator
- Data Reviewer
- Folder Administrator
- Infection Monitor
- Lab Personnel
- To Be Notified
- Click Submit.
- Repeat to add other necessary personnel to fully populate the table.
Assign Adjudicator Team Members
The Adjudicator Team Members web part is populated with the defined number of teams and pulldowns for eligible users. Users given the role Adjudicator in the Adjudication Users webpart will be available to select from the team member pulldowns. You must select at least one adjudicator per team. If you select a second, or "backup" adjudicator for one or more teams, no distinction is made between the back-up and primary adjudicator within the tools; either may make the adjudication determination for the team.Use the Send notifications checkboxes to select which adjudicators will receive notifications for each team. In circumstances where both adjudicators are available and receiving notifications, they will communicate about who is 'primary' for making decisions. If one is on vacation or otherwise unavailable, unchecking their checkbox will quiet notifications until they are available again.This screencap shows the two webparts populated using example users assigned to the roles. The Name column shows the Role Name, not the user name. There is one of each role, plus a total of four adjudicators. Adjudicators 1 and 3 make up team 1, and adjudicators 2 and 4 are team 2. To change adjudication team assignments, first delete or reassign the current team members using the edit or delete links on the table, then add new users. You can only have two users on each team at any time. When you assign a user to a role in this table, the associated permission is automatically granted; you need not separately set folder permissions. Likewise, when you remove a user from any role in this table, the associated permission is automatically retracted.
To change adjudication team assignments, first delete or reassign the current team members using the edit or delete links on the table, then add new users. You can only have two users on each team at any time. When you assign a user to a role in this table, the associated permission is automatically granted; you need not separately set folder permissions. Likewise, when you remove a user from any role in this table, the associated permission is automatically retracted.
Specify Supported Assay Kits
The folder administrator also defines which assays, or assay kits, are expected for the cases. All assay kits available are listed in the Kits table. The Manage tab Supported Assay Kits web part shows kits for this folder. To add a kit to this list:- Click Insert New Row in the Supported Assay Kits web part.
- Select the desired kit from the pulldown.

- Click Submit.

Customize Case File Format
The uploaded case file must be named with the correct prefix, and must include all these columns at a minimum:- ParticipantID
- Visit
- AssayKit (kits must be on the supported list)
- DrawDate
- Result
Next Steps
The adjudication lab personnel can now use their tools within the folder to initiate a case. See Initiate an Adjudication Case for the steps they will complete.If additional columns are necessary, or changes must be made to assigned personnel later in the process, you (or another folder administrator) will need to perform the necessary updates.Initiate an Adjudication Case
Upload an Adjudication Case
Click the Upload tab to see the Upload Wizard web part for uploading an adjudication case. This topic includes an example case for use in learning how the process works.Data required for adjudication may include:- Data from the following assays kits: Elisa, DNA PCR, RNA PCR, Multispot, Western Blot, Open Discretionary, BioRad Geenius assay, HIV-1 Total Nucleic Acid assay
- All assay data for these kits will be uploaded as part of one spreadsheet (one row per participant/visit/assay).
- Additional data can be attached to a case.
- If a PTID has multiple dates where adjudication is needed, all data will be viewable in one case, with data separated by visit.
- If a PTID has multiple uploads for the same date, the case creator will be prompted whether to replace the existing data, append the new data, or create a new case. When re-uploading a case, the case filename is case-insensitive (i.e. vtn703_123456782_01Aug2015.txt will be an update for VTN703_123456782_01Aug2015.txt).
Step 1: Upload Adjudication Data File
- Click Browse and select the adjudication data file to upload. You can download and use this example for demonstration purposes: VTN703_123456780_01Aug2015.txt
- Rename the file if your folder is configured to require a different prefix.
- The number of rows of data imported will be displayed.
- If the case requires evaluation of data from multiple dates, all data will be included in the same case, separated by visit.
- Click Next.
Step 2: Adjudication Case Creation
Before you can complete this step, the folder administrator must already have assigned the appropriate number of adjudicators to teams.- Enter a case comment as appropriate.
- Click Next.
Step 3: Upload Additional Information
- Optionally add additional information to the case.

- Click Next.
Step 4: Summary of Case Details
The final wizard screen shows the case details for your review. Confirm accuracy and click Finish.The Adjudication Review page shows summary information and result data for use in the adjudication process. Scroll down to see the sections which will later contain the Adjudication Determinations for the case. The adjudicators are listed for each team by userID for your reference.Next Step: Adjudication
The adjudicators can now access the folder, review case information you provided and make determinations via an Adjudication tab that Lab Personnel cannot access. See Make an Adjudication Determination for the process they follow.You and other lab personnel monitor the progress of this and other cases as described in Monitor Adjudication.Related Topics
Make an Adjudication Determination
- Lab personnel upload a new case; adjudicators receive UI notifications and email, if enabled.
- Adjudicators review the case details and one member of each team makes a diagnosis determination or requests additional information.
- If lab personnel update or add new data, adjudicators receive another notification via email and in the UI.
- When all adjudicator teams have made independent determinations:
- If all agree (and not that further testing is required), all are notified that the case is complete.
- If not, all adjudicators are notified in one email that case resolution is required. This resolution typically consists of a discussion among adjudicators and may result in the need for additional testing, updated determinations, or an entirely new round of adjudication.
Adjudication Determinations
Each adjudicator logs in to the adjudication project and sees a personal dashboard of cases awaiting their review on the Case Determination tab. Notifications about cases requiring their action are shown in the UI, as is a case summary report.
Dashboard
The View dropdown on the right allows you to select All, Complete, or Active Adjudications.The Status column can contain one of the following:- "Not started" - neither adjudicator has made a determination.
- "You made determination" or "Adjudicator in other team made determination". If the team to which you are assigned contains a second adjudicator you could also see "Other adjudicator in same team made determination."
- "Resolution required" - all adjudicator teams have made determinations and they disagree or at least one gave an inconclusive status.
- "Further testing required" - if further testing was requested by either adjudicator.
- Click Update for the case or View for the notification to see case details.
- You can select another case from the "Change Active Case" pulldown if necessary.
- Scroll to review the provided case details - click to download any additional files included.

- When you reach a decision, click Make Determination near the bottom of the page. The folder administrator configures whether you are required to provide HIV-1, HIV-2, or both diagnoses.

- In the pop-up, use pulldowns to answer questions. Determinations of whether the subject is infected are:
- Yes
- No
- Final Determination is Inconclusive
- Further Testing Required
- If you select "Yes", then you must provide a date of diagnosis (selected from the pulldown provided - in cases where there is data from multiple dates provided, one of those dates must be chosen).
- Comments are optional but can be helpful.
- Click Submit.
Related Topics
Monitor Adjudication
Dashboard
When cases are active in the folder, the dashboard web part offers the ability to view current status of active and completed cases at a glance.
- Click the Administrator Dashboard to find the Dashboard web part.
- Select whether to view Active, Complete, or All Adjudications using the View dropdown.
- In the Active Adjudication table:
- Click the details link for more information on the CaseID for the listed participant ID.
- The number of days since case creation are displayed here, as are any notes entered.
- The Status column can contain the following:
- “Not started” (if no adjudicator has made a determination)
- “# of # adjudicators made determinations”
- “Resolution required” (if all adjudicators have made determinations, but need follow up because their answers disagree or because they have chosen an “inconclusive” status)
- “Further testing required” (if further testing has been requested)
- Note: The “closed” status is not displayed, because the case will just be moved to the "complete" table
- In the Complete table:
- The beginning and end dates of the adjudication are listed for each case.
- The righthand column will record the date when the adjudication determination was recorded back in the lab.
Case Summary Report
Displays a summary of active/completed cases and how long cases have been taking to complete to assist lab personnel in planning and improving process efficiency.
Notifications
The Notifications web part displays active alerts that require the attention of the particular user viewing the web part. The user can click to dismiss the UI notification when action has been taken. If there are no UI notifications pending for this user, the web part will not be displayed. Each UI notification has a link to View details, and another to Dismiss the message from the web part.The adjudication tools also send email notification messages to subscribed individuals, including lab personnel, data reviewers, infection monitors, and others identified as "to be notified." The email includes a direct link to the adjudication review page for the case.Whether emails are sent, UI notifications are displayed, or both is governed by assigned roles.UI Notification Types
For each type of UI notification, the rules for when it is added and dismissed vary somewhat.- Adjudication Case Created
- Added on new case creation (i.e. upload by lab personnel)
- Dismissed via clicking "dismiss" or viewing the details or determination page for the given case
- Adjudication Case Assay Data Updated
- Added on upload of appended assay data to an existing case
- Dismissed via clicking "dismiss" or viewing the details or determination page for the given case
- Adjudication Case Completed
- Added on case completion (i.e. agreement among all adjudication team determinations)
- Dismissed via clicking "dismiss" or viewing the details or determination page for the given case
- Adjudication Case Ready For Verification
- Added on case completion for lab personnel only
- Dismissed for all lab personnel on click of the “Verify Receipt of Determination” button on the details page for a given case
- Adjudication Case Resolution Required
- Added when case status changes to ‘Resolution Required’ (i.e. adjudication determinations disagree) for all adjudicators
- Dismissed for all adjudicators when the case has an updated determination made (note: if updated determinations still disagree, this would then activate a new set of "resolution required" notifications)
| Notification Type | Lab Personnel | Adjudicators | Folder Admin | Infection Monitor | Data Reviewer | "To Be Notified" users |
|---|---|---|---|---|---|---|
| Case Created | yes | yes | yes | no | no | no |
| Case Assay Data Updated | yes | yes | yes | no | no | no |
| Case Completed | no | no | yes | yes - if infection present | no | no |
| Case Ready for Verification | yes | no | no | no | no | no |
| Case Resolution Required | no | yes | no | no | no | no |
Notifications Sent Via Email
This table shows which roles receive email notifications for each type:| Notification Type | Lab Personnel | Adjudicators* | Folder Admin | Infection Monitor | Data Reviewer | "To Be Notified" users |
|---|---|---|---|---|---|---|
| Case Created | yes | yes | yes | no | yes | yes |
| Case Assay Data Updated | yes | yes | yes | no | yes | yes |
| Case Completed | yes | yes | yes | no | no | yes |
| Case Determination Updated | yes | no | yes | yes - if infection present | yes | yes |
| Case Resolution Required | no | yes** | no | no | no | no |
Verify Determination
When all adjudicators have made determinations and are in agreement, a notification goes to the lab personnel. The final step in the process is for them to verify the determination.- Click to the Administrator Dashboard and click View next to the "Case Ready for Verification" notification.
- If the notification has been dismissed, you can also click Details next to the row in the "Completed Cases" table. Note that there is no date in the "Adj Recorded at Lab" column for the two cases awaiting verification in this screencap:

- On the details page, scroll to the bottom, review the determinations, and click Verify Receipt of Determination.

Update Case Data
When an update to a case is required, perhaps because additional assay data is provided in response to any adjudicator indicating additional testing is required, a member of Lab Personnel can reupload the case. When re-uploading, the case filename is case-insensitive (i.e. vtn703_123456782_01Aug2015.txt will be an update for VTN703_123456782_01Aug2015.txt).Any time a case has multiple uploads for the same date, the user will be prompted whether to merge (append) the new data, or replace the existing data and create a new case.- Merge: Add the assay results from the uploaded TXT file to the existing case. This does not remove any previously uploaded assay results, case details, or determinations. Note that if the updated TXT file is cumulative, i.e. includes everything previously uploaded, you will have two copies of the previously uploaded assay results.
- Replace: This option will delete the current case including the previously uploaded assay results, the case details, and any determinations. A new case will then be created with the new TXT file data.
- Cancel: Cancel this upload and exit the wizard.
 When you upload additional data, all assigned adjudicators will receive notification that there is new data to review.Case data can also be updated by lab personnel after the case determination is made. When that happens, the case data is flagged with an explanatory message and the case remains closed.
When you upload additional data, all assigned adjudicators will receive notification that there is new data to review.Case data can also be updated by lab personnel after the case determination is made. When that happens, the case data is flagged with an explanatory message and the case remains closed.
Related Topics
Infection Monitor
Infection Monitor Tab
The Infection Monitor tab is visible only to administrators and users assigned the Infection Monitor role. The Case Determination panel displays all cases, whether (and when) they have been completed, what the diagnosis status was, and pn which visit/date the subject was infected.
Infection Monitor Queries
Infection monitors can also access the data programmatically using the built in adjudication schema query CaseDeterminations which includes the columns listed below by source table.- AdjudicationCase: CaseID, ParticipantID, Created, Completed
- Determination: Hiv1Infected, Hiv2Infected, Hiv1InfectedVisit, Hiv2InfectedVisit
- Determinations With User Info: Hiv1InfectedDate, Hiv2InfectedDate
Related Topics
Role Guide: Adjudicator
Role Description
An Adjudicator is an individual who reviews details of assigned cases and makes diagnosis determinations. Each adjudicator is assigned to a numbered Adjudication Team which may or may not have a second 'backup' person assigned. The team of one or two people is considered a single "adjudicator" and either person assigned may make the determination for the team. There are usually two, but may be up to 5 teams making independent decisions on each case. Each team makes a determination independently and only when all teams have returned decisions are they compared and reviewed by lab personnel.If any or all teams make the determination that further testing is required, lab personnel will be notified and when that testing is completed and new data uploaded, all teams will receive notification that a new review and determination is required.If all teams return matching diagnosis determinations, the case is completed and the diagnosis confirmed and reported to the lab.If determinations differ, all adjudicators are notified that further review is required. They would typically meet to discuss the details of the case and decide how to handle the case. They might agree to request additional data, or might agree on a diagnosis and update the disagreeing determination(s).Task List
The basic work flow for an adjudicator is a looping procedure:- Receive and Review Notifications
- Review Case Data
- Make Determination
- Receive Further Notification - either of case closure or need to return to step 1.
Receive and Review Notifications
Notifications can be emailed to adjudicators and also appear in the UI. Email notifications may be turned off by an administrator in case of vacation or other reason to quiet the notifications.- Log in to the adjudication folder.
- Click the Case Determination folder.
- Review the list of Notifications.
Review Case Data
- Click View to see the case details. You can also reach the same information clicking Update for any Active Adjudication case listed.

- Scroll through the provided information. Click links to download any additional information attached to the case.
Make Determination
- Scroll to the bottom of the case detail page.
- Click Make Determination.
- In the pop-up window, use pulldowns to enter your determination and add comments as appropriate.
 When finished, click Submit.
When finished, click Submit.Receive Further Notification
The case will now appear completed to you, and the original UI notification will have disappeared. The actual status of the case is pending until all adjudicators have made their determinations. When that occurs, you will receive one of the following notifications via email as well as in the Notifications panel on the Case Determination tab:- The case is now closed: agreed diagnosis is considered final and reported to the lab.
- Additional data has been uploaded: you will need to return to review the updated case details.
- Resolution is required: There is disagreement among the adjudicators about the determination. A conversation outside the tools will be required to resolve the case.
Update Determination
If you decide you need to change your determination before a case is closed, either because additional data was provided, or because you have reached a consensus in a resolution conversation after disagreeing determinations were reached, you may do so:- Return to the Case Determination tab and click Update next to the case.
- Scroll to the bottom of the case review page.
- Click Change Determination to open the adjudication determination page.
- Review details as needed.
- Click Change Determination to review your previous determination.
- Change entries as appropriate and click Submit.
Related Topics
- Make an Adjudication Determination - More detailed instructions and elaboration of available options.
- Adjudication Module - Overview of the adjudication process for all roles.
Role Guide: Adjudication Lab Personnel
Role Description
Adjudication Lab Personnel are the individuals who upload case details, monitor their progress through adjudication, and report final diagnosis determinations back to the lab when the process is complete. The role is granted by the adjudication folder administrator.The format of case data, and types of assay data that may be included, are prescribed within the folder by an administrator. Cases are assigned to and receive diagnosis determinations from 2-5 adjudicator teams, each consisting of one person, plus a backup person in case they are unavailable. Determinations made by each adjudicator (team) are blinded to the lab personnel and other teams until all determinations have been recorded.If any adjudicator requests additional testing or other information, lab personnel are notified so that the additional data can be acquired and the case updated.When all adjudication decisions are entered, lab personnel will be notified. If determinations differ, the adjudicators will need to meet to decide whether to request additional testing or one or more may decide to change their determinations so that they are in agreement. Once all determinations are entered and agree on a diagnosis, lab personnel will report the result back to the lab.Task List
There may be one or many adjudication lab personnel working with a given adjudication folder. All users granted this role may equally perform all of the steps in the progress of a case through the process; coordination outside the tools is advised to avoid duplication of effort if many people are working together.- Upload Adjudication Case Data
- Monitor Case Progress
- Update Case Data (if necessary)
- Report Diagnosis to Lab
Upload Adjudication Case Data
The format and filename of the uploaded case data file are determined by settings configured by the folder administrator. Only assay kits explicitly enabled within the folder can be included. Only columns included in the assay results table will be stored. If you need additional kits enabled or columns added to the assay results table in your folder, contact the administrator.If any of the adjudication teams are empty at the time of upload, you may still proceed, but the administrator must assign adjudicators before the case can be completed. For a more detailed walkthrough of the upload process, see Initiate an Adjudication Case.- Log in to the adjudication folder and click the Upload tab.
- Step 1: Upload Adjudication Data File: click Browse and select the adjudication data file.
- The number of rows of data imported will be displayed.
- If the case requires evaluation of data from multiple dates, all data will be included in the same case, separated by visit.
- If the case has multiple uploads for the same date, the user will be prompted whether to replace the existing data, append the new data, or create a new case.
- Click Next.
- Step 2: Adjudication Case Creation: Prior to this step, the folder administrator must have assigned adjudicators to teams. If any remain empty, you will see a warning, but can still proceed with case creation.
- Enter a case comment as appropriate.
- Click Next.
- Step 3: Upload Additional Information: click insert to add information to the case if necessary.

- Click Next.
- Step 4: Summary of Case Details: Confirm accuracy and click Finish.
Monitor Case Progress
After uploading at least one case, you will be able to review case status on the Administrator Dashboard tab. This screencap shows 4 notifications to view or dismiss, the dashboard showing active and completed cases, and a case summary report in the upper right which tracks the time it takes to complete cases and return results to the lab. For more information about each webpart, see Monitor Adjudication.As adjudicators enter determinations, you can see progress toward case completion. In the screencap, case 48 is awaiting the last determination. If you click the Details link for the case, you can scroll to the bottom to see who is assigned to the team that still needs to make a determination.
This screencap shows 4 notifications to view or dismiss, the dashboard showing active and completed cases, and a case summary report in the upper right which tracks the time it takes to complete cases and return results to the lab. For more information about each webpart, see Monitor Adjudication.As adjudicators enter determinations, you can see progress toward case completion. In the screencap, case 48 is awaiting the last determination. If you click the Details link for the case, you can scroll to the bottom to see who is assigned to the team that still needs to make a determination.
Update Case Data
If any adjudicator indicates that additional testing is required, you will need to obtain those new results and update the case in question. If the case has multiple uploads for the same date, the user will be prompted whether to replace the existing data, append the new data, or create a new case. When re-uploading a case, the case filename is case-insensitive (i.e. vtn703_123456782_01Aug2015.txt will be an update for VTN703_123456782_01Aug2015.txt). When you upload additional data, all assigned adjudicators will receive notification that there is new data to review.
When you upload additional data, all assigned adjudicators will receive notification that there is new data to review.
Report Diagnosis to Lab
After all adjudicators have agreed on a diagnosis, your final task for that case is to record the result in the lab. In the screencap above, case 50 is completed, but no decision has been recorded yet. Click the Details link for the case, scroll to review the diagnosis determinations, and click Verify Receipt of Determination to close the case and clear the notification.Related Topics
- Initiate an Adjudication Case - More information about uploading and updating case data.
- Monitor Adjudication - More information about monitoring case progress and verifying determinations.
- Adjudication Module - Overview of the adjudication process for all roles.
Tours for New Users
Tour Overview
The tour annotations appear as pop over 'bubbles' above the page contents. Each can be dismissed using an X or may contain one or more action buttons. Typically, click next to go to the next tour annotation. A tour may provide a series of annotations which change pages or tabs within a folder, or change folders within a project.Once defined, tours can be run by selecting Help > Tours > [name of tour]. Each may also be configured to run automatically when a user reaches the folder.To see an example tour of a LabKey demo study, visit this project in another browser window: Annotated Study.
Tour Builder
The tour builder allows an administrator to create, edit, export, and import tours. Navigate to the project or folder of interest and open the list of available tours:- Select Admin > Developer Links > Schema Browser.
- Open the announcements schema.
- Select Tours.
- Click View Data.
Build a Tour
Above the list of available tours, select Insert > Insert New Row. Note that if any tours are set to "Run Always" they may also run in the tour builder UI, depending on selectors they use. Simply click the X in the first box to stop the tour.
- Title: Enter a title for your tour. The title will be displayed in the Help > Tours menu.
- Description: Enter a description, which will only be shown in the grid of tours and within the builder.
- Mode: Select whether you want your tour to run automatically. No matter what this setting, the user can always run a tour from the help>tours menu. Options are:
- Run Always: Each time the user reaches the container, the tour will run.
- Run Once: Run it the first time the user reaches the container.
- Off: Never run unless the user selects it from the menu. This option may be the most practical during development.
Selectors and Steps
The body of the tour is defined in a numbered series of steps. Each step is accompanied by an HTML selector which defines what element of the page it is attached to. In a typical annotation, the popover annotation may "point" to the selector element, though you have the option to adjust position/location/direction of pointers and bubbles in a variety of ways relative to the chosen selector. Identify your selector by using "right click>Inspect" in your browser.For example, the selector for the first step in the study tour is "td.study-properties"; the content of the Study Overview web part which appears in HTML as <td class="study-properties" valign="top">.The definition of the step includes using options to place the bubble on top of the element, offset the position by an X and Y value and center the arrow in the center:{
content: "<br>Welcome! <br> A LabKey Study integrates and aligns diverse clinical research data...",
placement: "top",
xOffset: 150,
yOffset: 50,
arrowOffset: "center",
title: "Guided Study Tour"
} For more about the options available in step definitions, see the Hopscotch options list.To have a tour span multiple pages, the step before the page switch should include "multipage:true" and define "onNext". For instance, the second step in the sample tour shows the Study Navigator; clicking Next moves the tour to the Participants tab for the third step. The second step definition is:
For more about the options available in step definitions, see the Hopscotch options list.To have a tour span multiple pages, the step before the page switch should include "multipage:true" and define "onNext". For instance, the second step in the sample tour shows the Study Navigator; clicking Next moves the tour to the Participants tab for the third step. The second step definition is:
{
content: "<br>Visual overview of study progress and data...." ,
placement: "left",
title: "Study Navigator",
multipage: true,
yOffset: -20,
arrowOffset:60,
onNext: function (){LABKEY.help.Tour.continueAtLocation
('/project/home/Study/Annotated%20Study/begin.view?pageId=study.PARTICIPANTS');}
}Export/Import/Edit a Tour
Export a Tour
Exporting the JSON for a tour gives you a convenient way to jumpstart the process of creating additional tours. Click Export for the tour we just created. A popup window showing the tour definition will appear. Copy the contents of that window to your browser clipboard or an offline file.Import a Tour
Import the tour we just exported into a new tour.- Return to the tours view and select Insert > Insert New Row.
- Click Import.
- Paste the exported tour into the popup window.
- Click Import.
- The imported tour will populate the builder.
- You may need to change the name of the "newly imported" tour to avoid overwriting the old one.
- Click Save and proceed to edit, or Save and Close.
Edit a Tour
Click Edit for the tour. Make changes as needed.Clicking Add Step will add a new empty selector and step at the end of the existing tour.If you need to reorder the steps in a tour, add an additional one early in a long tour, or remove one or more from the middle, the easiest way to do so is to export the tour, make changes directly in the JSON export, and reimport with the steps in the new order.Contacts
- Make sure you are logged in to the LabKey Server installation.
- Open the pulldown menu showing your username in the top right corner of the page.
- Select My Account to show your contact information.
- Click Edit to make changes.
Development

Client API Applications
Create applications by adding API-enhanced content (such as JavaScript) to wiki or HTML pages in the file system. Application features can include custom reports, SQL query views, HTML views, R views, charts, folder types, assay definitions, and more.- LabKey Client APIs - Write simple customization scripts or sophisticated integrated applications for LabKey Server.
- Tutorial Video: Building Views and Custom User Interfaces - SQL queries, R reports, and JavaScript UI.
- Tutorial: JavaScript/HTML Application - Create an application to manage reagent requests, including web-based request form, confirmation page, and summary report for managers. Reads and write to the database.
- Tutorial: JavaScript Chart APIs - Select data from the database and render as a chart using the JavaScript API.
Scripting and Reporting
LabKey Server also includes 'hooks' for using scripts to validate and manipulate data during import, and allows developers to build reports that show data within the web user interface- Assay transformation scripts (which operate on the full file) can be written in virtually any language.
- Trigger scripts which operate at the row-level, are written in JavaScript and supported for most data types.
- Using R scripts, you can produce visualizations and other analysis on the fly, showing the result to the user in the web interface.
- Pipeline support for script sequences: Script Pipeline: Running R and Other Scripts in Sequence.
Module Applications
Developers can create larger features by encapsulating them in modules- Modules: Query, Views, Reports - Create a module with multiple resources: SQL queries, R reports, HTML views, etc.
- Module-based Assay - Create custom assay types and interfaces.
- Develop Modules - Package your custom code as a portable module.
LabKey Server Open Source Project
- Set Up a Dev Machine - Set up a machine to build LabKey Server from source.
- Common Dev Tasks - Often performed development tasks and application building blocks.
- LabKey Open Source Project - An overview of the improvement process for LabKey Server and how you can contribute.
LabKey Client APIs
Overview
The LabKey client libraries provide secure, auditable, programmatic access to LabKey data and services.The purpose of the client APIs is to let developers and statisticians write scripts or programs in various programming languages to extend and customize LabKey Server. The specifics depend on the exact type of integration you hope to achieve. For example, you might:- Analyze and visualize data stored in LabKey in a statistical tool such as R or SAS
- Perform routine, automated tasks in a programmatic way.
- Query and manipulate data in a repeatable and consistent way.
- Enable customized data visualizations or user interfaces for specific tasks that appear as part of the existing LabKey Server user interface.
- Provide entirely new user interfaces (web-based or otherwise) that run apart from the LabKey web server, but interact with its data and services.
Related Topics:
JavaScript API
- Add JavaScript to a LabKey HTML page to create a custom renderer for your data, transforming and presenting the data to match your vision.
- Upload an externally-authored HTML page that uses rich UI elements such as editable grids, dynamically trees, and special purpose data entry controls.
- Create a series of HTML/JavaScript pages that provide a custom workflow packaged as a module.
Topics
- JavaScript API Reference
- Tutorial: Create Applications with the JavaScript API
- Tutorial: Use URLs to Pass Data and Filter Grids
- Tutorial Video: Building Reports and Custom User Interfaces
- JavaScript API - Samples
- Adding Report to a Data Grid with JavaScript
- Export Data Grid as a Script
- Export Chart as JavaScript
- Custom HTML/JavaScript Participant Details View
- Custom Button Bars
- Insert into Audit Table via API
- Declare Dependencies
- Loading ExtJS On Each Page
- Licensing for the ExtJS API
- Search API Documentation
- Naming & Documenting JavaScript APIs
Additional Resources:
Tutorial: Create Applications with the JavaScript API
- Provides web-based access to users and system managers.
- Allows users to enter, edit, and review their requests (for reagent materials) .
- Allows reagent managers to review requests in a variety of ways to help them optimize their fulfillment system.
- JavaScript/HTML pages - Provides the user interface pages.
- Several Lists - Holds the requests, reagent materials, and user information.
- Custom SQL queries - Filtered views on the Lists.
- R Reports - Provides visualization of user activity.
Requirements
To complete this tutorial, you will need:- Admin or Developer permissions on a LabKey Server installation.
- To complete the R step, your LabKey Server instance must be configured to use R.
- Step 1: Create Request Form
- Step 2: Confirmation Page
- Step 3: R Histogram (Optional)
- Step 4: Summary Report For Managers
First Step
Step 1: Create Request Form

Folders and Permissions
First create a separate folder where your target users are granted "insert" permissions. Creating a separate folder allows you to grant these expanded permissions to all site users only for the scope needed and not to more sensitive information. Further, insertion of data into the lists can then be carefully controlled and granted only through admin-designed forms.- Log in to your server (with Admin or Developer permissions) and navigate to the project you want to work in.
- Create a new folder to work in:
- Go to Admin > Folder > Management > click Create Subfolder.
- Name it "Reagent Request Tutorial" (confirm it is of type Collaboration).
- Click Next.
- On the User/Permissions page, click Finish and Configure Permissions.
- Uncheck Inherit permissions from parent.
- Next to Submitter, select All Site Users.
- Click Save and Finish.
Import Lists
The reagent request application will use two lists. One records the available reagents, the other records the incoming requests. Below you import the lists in one pass, using a "list archive". (We've pre-populated these lists to simulate a system in actual use.)- Download this list archive: ReagentTutorial.lists.zip
- Go to Admin > Manage Lists.
- Click Import List Archive.
- Click Browse or Choose File and select the list archive you just downloaded.
- Click Import List Archive.
Create the Request Page
Requests submitted via this page will be inserted into the Reagent Requests list.- Click the Start Page tab to return to the main folder page.
- In the Wiki web part, click Create a new wiki page.
- Give it the name "reagentRequest" and the title "Reagent Request Form".
- Click the Source tab.
- Scroll down to the Code section of this page.
- Copy and paste the HTML/JavaScript code block into the Source tab.
- Click Save and Close.
Notes on the source code
The following example code uses LABKEY.Query.selectRows and LABKEY.Query.insertRows to handle traffic with the server. For example code that uses Ext components, see LABKEY.ext.Store.To view the source code, click the pencil icon, or view similar source in the interactive example. Search for the items in orange text to observe any or all of the following:- Initialization. The init() function, triggered by Ext.onReady, pre-populates the web form with several pieces of information about the user.
- User Info. User information is provided by LABKEY.Security.currentUser API. Note that the user is allowed to edit some of the user information obtained through this API (their email address and name), but not their ID.
- Dropdown. The dropdown options are extracted from the Reagent list. The LABKEY.Query.selectRows API is used to populate the dropdown with the contents of the Reagents list.
- Data Submission. To insert requests into the Reagent Requests list, we use LABKEY.Query.insertRows. The form is validated before being submitted.
- Asynchronous APIs. The success in LABKEY.Query.insertRows is used to move the user on to the next page only after all data has been submitted. The success function executes only after rows have been successfully inserted, which helps you deal with the asynchronous processing of HTTP requests.
- Default onFailure function. In most cases, it is not necessary to explicitly include an onFailure function for APIs such as LABKEY.Query.insertRows. A default failure function is provided automatically; create one yourself if you wish a particular mode of failure other than the simple, default notification message.
Code
<div align="right" style="float: right;">
<input value='View Source' type='button' onclick='gotoSource()'><br/>
<input value='Edit Source' type='button' onclick='editSource()'>
</div>
<form name="ReagentReqForm">
<table cellspacing="0" cellpadding="5" border="0">
<tr>
<td colspan="2">Please use the form below to order a reagent.
All starred fields are required.</td>
</tr>
<tr>
<td colspan="2"><div id="errorTxt" style="display:none;color:red"></div></td>
</tr>
<tr>
<td valign="top" width="100"><strong>Name:*</strong></td>
<td valign="top"><input type="text" name="DisplayName" size="30"></td>
</tr>
<tr>
<td valign="top" width="100"><strong>E-mail:*</strong></td>
<td valign="top"><input type="text" name="Email" size="30"></td>
</tr>
<tr>
<td valign="top" width="100"><strong>UserID:*</strong></td>
<td valign="top"><input type="text" name="UserID" readonly="readonly" size="30"></td>
</tr>
<tr>
<td valign="top" width="100"><strong>Reagent:*</strong></td>
<td valign="top">
<div>
<select id="Reagent" name="Reagent">
<option>Loading...</option>
</select>
</div>
</td>
</tr>
<tr>
<td valign="top" width="100"><strong>Quantity:*</strong></td>
<td valign="top"><select id="Quantity" name="Quantity">
<option value="1">1</option>
<option value="2">2</option>
<option value="3">3</option>
<option value="4">4</option>
<option value="5">5</option>
<option value="6">6</option>
<option value="7">7</option>
<option value="8">8</option>
<option value="9">9</option>
<option value="10">10</option>
</select></td>
</tr>
<tr>
<td valign="top" width="100"><strong>Comments:</strong></td>
<td valign="top"><textarea cols="23" rows="5" name="Comments"></textarea></td>
</tr>
<tr>
<td valign="top" colspan="2">
<div align="center">
<input value='Submit' type='button' onclick='submitRequest()'>
</td>
</tr>
</table>
</form>
<script type="text/javascript">
// Ensure that page dependencies are loaded
LABKEY.requiresExt3ClientAPI(true, function() {
Ext.onReady(init);
});
// Navigation functions. Demonstrates simple uses for LABKEY.ActionURL.
function gotoSource() {
window.location = LABKEY.ActionURL.buildURL("wiki", "source", LABKEY.ActionURL.getContainer(), {name: 'reagentRequest'});
}
function editSource() {
window.location = LABKEY.ActionURL.buildURL("wiki", "edit", LABKEY.ActionURL.getContainer(), {name: 'reagentRequest'});
}
// Initialize the form by populating the Reagent drop-down list and
// entering data associated with the current user.
function init() {
LABKEY.Query.selectRows({
schemaName: 'lists',
queryName: 'Reagents',
success: populateReagents
});
document.getElementById("Reagent").selectedIndex = 0;
// Set the form values
var reagentForm = document.getElementsByName("ReagentReqForm")[0];
reagentForm.DisplayName.value = LABKEY.Security.currentUser.displayName;
reagentForm.Email.value = LABKEY.Security.currentUser.email;
reagentForm.UserID.value = LABKEY.Security.currentUser.id;
}
// Populate the Reagent drop-down menu with the results of
// the call to LABKEY.Query.selectRows.
function populateReagents(data) {
var el = document.getElementById("Reagent");
el.options[0].text = "<Select Reagent>";
for (var i = 0; i < data.rows.length; i++) {
var opt = document.createElement("option");
opt.text = data.rows[i].Reagent;
opt.value = data.rows[i].Reagent;
el.options[el.options.length] = opt;
}
}
// Enter form data into the reagent request list after validating data
// and determining the current date.
function submitRequest() {
// Make sure the form contains valid data
if (!checkForm()) {
return;
}
// Insert form data into the list.
LABKEY.Query.insertRows({
schemaName: 'lists',
queryName: 'Reagent Requests',
rowDataArray: [{
"Name": document.ReagentReqForm.DisplayName.value,
"Email": document.ReagentReqForm.Email.value,
"UserID": document.ReagentReqForm.UserID.value,
"Reagent": document.ReagentReqForm.Reagent.value,
"Quantity": parseInt(document.ReagentReqForm.Quantity.value),
"Date": new Date(),
"Comments": document.ReagentReqForm.Comments.value,
"Fulfilled": 'false'
}],
success: function(data) {
// The set of URL parameters.
var params = {
"name": 'confirmation', // The destination wiki page. The name of this parameter is not arbitrary.
"userid": LABKEY.Security.currentUser.id // The name of this parameter is arbitrary.
};
// This changes the page after building the URL. Note that the wiki page destination name is set in params.
var wikiURL = LABKEY.ActionURL.buildURL("wiki", "page", LABKEY.ActionURL.getContainer(), params);
window.location = wikiURL;
}
});
}
// Check to make sure that the form contains valid data. If not,
// display an error message above the form listing the fields that need to be populated.
function checkForm() {
var result = true;
var ob = document.ReagentReqForm.DisplayName;
var err = document.getElementById("errorTxt");
err.innerHTML = '';
if (ob.value == '') {
err.innerHTML += "Name is required.";
result = false;
}
ob = document.ReagentReqForm.Email;
if (ob.value == '') {
if(err.innerHTML != '')
err.innerHTML += "<br>";
err.innerHTML += "Email is required.";
result = false;
}
ob = document.ReagentReqForm.Reagent;
if (ob.value == '') {
if(err.innerHTML != '<Select Reagent>')
err.innerHTML += "<br>";
err.innerHTML += "Reagent is required.";
result = false;
}
if(!result)
document.getElementById("errorTxt").style.display = "block";
return result;
}
init();
</script>
Start Over | Next Step
Step 2: Confirmation Page
 See a live example.
See a live example.
Create a Confirmation Page
- Return to the main folder page by clicking Start Page.
- Click the dropdown menu on Reagent Request Form (look for the small triangle) and select New.
- Name: "confirmation" (this page name is embedded in the code for the request page, and is case sensitive).
- Title: "Reagent Request Confirmation".
- Confirm that the Source tab is selected.
- Copy and paste the contents of the code section below into the source panel.
- Click Save & Close.
- You will see a grid displayed. Submit some sample requests to add data to the table. (To begin submitting requests, click Start Page.)
Notes on the JavaScript Source
LABKEY.Query.executeSql is used to calculate total reagent requests and total quantities of reagents for the current user and for all users. These totals are output to text on the page to provide the user with some idea of the length of the queue for reagents.Note: The length property (e.g., data.rows.length) is used to calculate the number of rows in the data table returned by LABKEY.Query.executeSql. It is used instead of the rowCount property because rowCount returns only the number of rows that appear in one page of a long dataset, not the total number of rows on all pages.LABKEY.QueryWebPart is used to display grid of the user's requests.Code
<p>Thank you for your request. It has been added to the request queue and will be filled promptly.</p>
<div id="totalRequests"></div>
<div id="allRequestsDiv"></div>
<div id="queryDiv1"></div>
<script type="text/javascript">
// Ensure that page dependencies are loaded
LABKEY.requiresExt3ClientAPI(true, function() {
Ext.onReady(init);
});
function init() {
var qwp1 = new LABKEY.QueryWebPart({
renderTo: 'queryDiv1',
title: 'Your Reagent Requests',
schemaName: 'lists',
queryName: 'Reagent Requests',
buttonBarPosition: 'top',
// Uncomment below to filter the query to the current user's requests.
// filters: [ LABKEY.Filter.create('UserID', LABKEY.Security.currentUser.id)],
sort: '-Date'
});
// Extract a table of UserID, TotalRequests and TotalQuantity from Reagent Requests list.
LABKEY.Query.executeSql({
schemaName: 'lists',
queryName: 'Reagent Requests',
sql: 'SELECT "Reagent Requests".UserID AS UserID, ' +
'Count("Reagent Requests".UserID) AS TotalRequests, ' +
'Sum("Reagent Requests".Quantity) AS TotalQuantity ' +
'FROM "Reagent Requests" Group BY "Reagent Requests".UserID',
success: writeTotals
});
}
// Use the data object returned by a successful call to LABKEY.Query.executeSQL to
// display total requests and total quantities in-line in text on the page.
function writeTotals(data)
{
var rows = data.rows;
// Find overall totals for all user requests and quantities by summing
// these columns in the sql data table.
var totalRequests = 0;
var totalQuantity = 0;
for(var i = 0; i < rows.length; i++) {
totalRequests += rows[i].TotalRequests;
totalQuantity += rows[i].TotalQuantity;
}
// Find the individual user's total requests and quantities by looking
// up the user's id in the sql data table and reading off the data in the row.
var userTotalRequests = 0;
var userTotalQuantity = 0;
for(i = 0; i < rows.length; i++) {
if (rows[i].UserID === LABKEY.Security.currentUser.id){
userTotalRequests = rows[i].TotalRequests;
userTotalQuantity = rows[i].TotalQuantity;
break;
}
}
document.getElementById('totalRequests').innerHTML = '<p>You have requested <strong>' +
userTotalQuantity + '</strong> individual bottles of reagents, for a total of <strong>'
+ userTotalRequests + '</strong> separate requests pending. </p><p> We are currently '
+ 'processing orders from all users for <strong>' + totalQuantity
+ '</strong> separate bottles, for a total of <strong>' + totalRequests
+ '</strong> requests.</p>';
}
</script>
Previous Step | Next Step
Step 3: R Histogram (Optional)

Set Up R
If you have not already configured your server to use R, follow these instructions before continuing: Install and Set Up R.Create an R Histogram
- Click Start Page.
- Go to Admin > Manage Lists.
- On the Available Lists page, click Reagent Requests.
- Select Reports > Create R Report.
- Paste the following code onto the Source tab (replace the default contents).
if(length(labkey.data$userid) > 0){
png(filename="${imgout:histogram}")
hist(labkey.data$quantity, xlab = c("Quantity Requested By ", labkey.url.params$displayName),
ylab = "Count", col="lightgreen", main= NULL)
dev.off()
} else {
write("No requests are available for display.", file = "${txtout:histogram}")
}
- Check the "Make this report available to all users" checkbox.
- Scroll down and click Save.
- Enter a Report Name, such as "Reagent Histogram".
- Click OK.
- From the data grid, select Reports > "Reagent Histogram"
- Click OK.
- Click the Report tab to see the R report.
- Notice the reportId in the URL. You will need this number to reference the report in your confirmation page. In this URL example, the reportId is 90:
http://localhost:8080/labkey/list/home/Request%20Reagent%20Tutorial/grid.view?listId=1&query.reportId=db%3A90
http://localhost:8080/labkey/list/home/Reagent Request Tutorial/grid.view?listId=1&query.reportId=db:90
Update the Confirmation Page
- Open the confirmation wiki page for editing.
- Add the following to the block of <div> tags at the top of the page:
<div id="reportDiv">Loading...</div>- Add the following to the init() function:
// Draw a histogram of the user's requests.
var reportWebPartRenderer = new LABKEY.WebPart({
partName: 'Report',
renderTo: 'reportDiv',
frame: 'title',
partConfig: {
title: 'Reagent Request Histogram',
reportId: 'db:XX',
showSection: 'histogram',
'query.UserID~eq' : LABKEY.Security.currentUser.id,
displayName: LABKEY.Security.currentUser.displayName
}
});
reportWebPartRenderer.render();
- Note the reference "db: XX". Replace XX with the report number for your R report.
- Click Save and Close.
Previous Step | Next Step
Step 4: Summary Report For Managers
 See a live example.
See a live example.
Create Custom SQL Queries
We create three custom SQL queries over the "Reagent Requests" list in order to distill the data in ways that are useful to reagent managers. We create custom SQL queries using the LabKey UI, then use LABKEY.QueryWebPart to display the results as a grid. As part of writing custom SQL, we can add Metadata XML to provide a URL link to the subset of the data listed in each column.Query #1: Reagent View
First we define a query that returns all the reagents, the number of requests made, and the number requested of each.- Click the Start Page tab.
- Select Admin > Developer Links > Schema Browser.
- Select the lists schema.
- Click the Create New Query button.
- Define your first of three SQL queries:
- What do you want to call the new query?: Enter "Reagent View"
- Which query/table do you want this new query to be based on?: Select Reagent Requests
- Click the Create and Edit Source button.
- Paste this SQL onto the Source tab (replace the default text):
SELECT
"Reagent Requests".Reagent AS Reagent,
Count("Reagent Requests".UserID) AS TotalRequests,
Sum("Reagent Requests".Quantity) AS TotalQuantity
FROM "Reagent Requests"
Group BY "Reagent Requests".Reagent
- Click the XML Metadata tab and paste the following:
<tables xmlns="http://labkey.org/data/xml">
<table tableName="Reagent View" tableDbType="NOT_IN_DB">
<columns>
<column columnName="TotalRequests">
<fk>
<fkTable>/list/grid.view?name=Reagent%20Requests;query.Reagent~eq=${Reagent}</fkTable>
</fk>
</column>
<column columnName="TotalQuantity">
<fk>
<fkTable>/list/grid.view?name=Reagent%20Requests;query.Reagent~eq=${Reagent}</fkTable>
</fk>
</column>
</columns>
</table>
</tables>
- Click Save and Finish to see the results.
- Depending on what requests have been entered, the results might look something like this:

Query #2: User View
The next query we add will return the number of requests made by each user.- Return to the lists schema in the Query Browser. (Notice your new "Reagent View" request is now included.)
- Click Create New Query.
- Call this query "User View" and again base it on Reagent Requests.
- Click Create and Edit Source.
- Paste this into the source tab:
SELECT
"Reagent Requests".Name AS Name,
"Reagent Requests".Email AS Email,
"Reagent Requests".UserID AS UserID,
Count("Reagent Requests".UserID) AS TotalRequests,
Sum("Reagent Requests".Quantity) AS TotalQuantity
FROM "Reagent Requests"
Group BY "Reagent Requests".UserID, "Reagent Requests".Name, "Reagent Requests".Email
- Paste this into the XML Metadata tab:
<tables xmlns="http://labkey.org/data/xml">
<table tableName="Reagent View" tableDbType="NOT_IN_DB">
<columns>
<column columnName="TotalRequests">
<fk>
<fkTable>/list/grid.view?name=Reagent%20Requests;query.Name~eq=${Name}</fkTable>
</fk>
</column>
<column columnName="TotalQuantity">
<fk>
<fkTable>/list/grid.view?name=Reagent%20Requests;query.Name~eq=${Name}</fkTable>
</fk>
</column>
</columns>
</table>
</tables>
- Click Save and Finish to see the results.
Query #3: Recently Submitted
- Return to the lists schema in the Query Browser.
- Click Create New Query.
- Name the query "Recently Submitted" and again base it on the list Reagent Requests.
- Paste this into the source tab:
SELECT Y."Name",
MAX(Y.Today) AS Today,
MAX(Y.Yesterday) AS Yesterday,
MAX(Y.Day3) AS Day3,
MAX(Y.Day4) AS Day4,
MAX(Y.Day5) AS Day5,
MAX(Y.Day6) AS Day6,
MAX(Y.Day7) AS Day7,
MAX(Y.Day8) AS Day8,
MAX(Y.Day9) AS Day9,
MAX(Y.Today) + MAX(Y.Yesterday) + MAX(Y.Day3) + MAX(Y.Day4) + MAX(Y.Day5)
+ MAX(Y.Day6) + MAX(Y.Day7) + MAX(Y.Day8) + MAX(Y.Day9) AS Total
FROM
(SELECT X."Name",
CASE WHEN X.DayIndex = DAYOFYEAR(NOW()) THEN X.C ELSE 0 END AS Today,
CASE WHEN X.DayIndex = DAYOFYEAR(NOW()) - 1 THEN X.C ELSE 0 END AS Yesterday,
CASE WHEN X.DayIndex = DAYOFYEAR(NOW()) - 2 THEN X.C ELSE 0 END AS Day3,
CASE WHEN X.DayIndex = DAYOFYEAR(NOW()) - 3 THEN X.C ELSE 0 END AS Day4,
CASE WHEN X.DayIndex = DAYOFYEAR(NOW()) - 4 THEN X.C ELSE 0 END AS Day5,
CASE WHEN X.DayIndex = DAYOFYEAR(NOW()) - 5 THEN X.C ELSE 0 END AS Day6,
CASE WHEN X.DayIndex = DAYOFYEAR(NOW()) - 6 THEN X.C ELSE 0 END AS Day7,
CASE WHEN X.DayIndex = DAYOFYEAR(NOW()) - 7 THEN X.C ELSE 0 END AS Day8,
CASE WHEN X.DayIndex = DAYOFYEAR(NOW()) - 8 THEN X.C ELSE 0 END AS Day9,
CASE WHEN X.DayIndex = DAYOFYEAR(NOW()) - 9 THEN X.C ELSE 0 END AS Day10
FROM
(
SELECT Count("Reagent Requests".Key) AS C,
DAYOFYEAR("Reagent Requests".Date) AS DayIndex, "Reagent Requests"."Name"
FROM "Reagent Requests"
WHERE timestampdiff('SQL_TSI_DAY', "Reagent Requests".Date, NOW()) < 10
GROUP BY "Reagent Requests"."Name", DAYOFYEAR("Reagent Requests".Date)
)
X
GROUP BY X."Name", X.C, X.DayIndex)
Y
GROUP BY Y."Name"
- There is nothing to paste into the XML Metadata tab.
- Click Save and Finish.
- Manually edit the dates in the list to occur within the last 10 days.
- Edit the source XLS to bump the dates to occur within the last 10 days, and re-import the list.
- Create a bunch of recent requests using the reagent request form.
Create Summary Report Wiki Page
- Click the Start Page tab.
- On the Pages web part, click the dropdown triangle (look for a small triangle in the upper right of the Page web part) and select New.
- Enter the following:
- Name: reagentManagers
- Title: "Summary Report for Reagent Managers"
- Scroll down to the Code section of this page.
- Copy and paste the code block into the Source tab.
- Click Save & Close.
Notes on the JavaScript Source
You can reopen your new page for editing or view the source code below to observe the following parts of the JavaScript API.Check User Credentials
The script uses the LABKEY.Security.getGroupsForCurrentUser API to determine whether the current user has sufficient credentials to view the page's content.Display Custom Queries
We use the LABKEY.QueryWebPart API to display our custom SQL queries in the page. Note the use of aggregates to provide sums and counts for the columns of our queries.Display All Data
Lastly, we display a grid view of the entire "Reagent Requests" lists on the page using the LABKEY.QueryWebPart API, allow the user to select and create views using the buttons above the grid.Code
The source code for the reagentManagers page.<div align="right" style="float: right;">
<input value='View Source' type='button' onclick='gotoSource()'>
<input value='Edit Source' type='button' onclick='editSource()'>
</div>
<div id="errorTxt" style="display:none; color:red;"></div>
<div id="listLink"></div>
<div id="reagentDiv"></div>
<div id="userDiv"></div>
<div id="recentlySubmittedDiv"></div>
<div id="plotDiv"></div>
<div id="allRequestsDiv"></div>
<script type="text/javascript">
// Ensure that page dependencies are loaded
LABKEY.requiresExt3ClientAPI(true, function() {
Ext.onReady(init);
});
// Navigation functions. Demonstrates simple uses for LABKEY.ActionURL.
function gotoSource() {
thisPage = LABKEY.ActionURL.getParameter("name");
window.location = LABKEY.ActionURL.buildURL("wiki", "source", LABKEY.ActionURL.getContainer(), {name: thisPage});
}
function editSource() {
editPage = LABKEY.ActionURL.getParameter("name");
window.location = LABKEY.ActionURL.buildURL("wiki", "edit", LABKEY.ActionURL.getContainer(), {name: editPage});
}
function init() {
// Ensure that the current user has sufficient permissions to view this page.
LABKEY.Security.getGroupsForCurrentUser({
successCallback: evaluateCredentials
});
// Check the group membership of the current user.
// Display page data if the user is a member of the appropriate group.
function evaluateCredentials(results)
{
// Determine whether the user is a member of "All Site Users" group.
var isMember = false;
for (var i = 0; i < results.groups.length; i++) {
if (results.groups[i].name == "All Site Users") {
isMember = true;
break;
}
}
// If the user is not a member of the appropriate group,
// display alternative text.
if (!isMember) {
var elem = document.getElementById("errorTxt");
elem.innerHTML = '<p>You do '
+ 'not have sufficient permissions to view this page. Please log in to view the page.</p>'
+ '<p>To register for a labkey.org account, please go <a href="http://www.labkey.com/forms/register-to-download-labkey-server">here</a></p>';
elem.style.display = "inline";
}
else {
displayData();
}
}
// Display page data now that the user's membership in the appropriate group
// has been confirmed.
function displayData()
{
// Link to the Reagent Request list itself.
LABKEY.Query.getQueryDetails({
schemaName: 'lists',
queryName: 'Reagent Requests',
success: function(data) {
var el = document.getElementById("listLink");
if (data && data.viewDataUrl) {
var html = '<p>To see an editable list of all requests, click ';
html += '<a href="' + data.viewDataUrl + '">here</a>';
html += '.</p>';
el.innerHTML = html;
}
}
});
// Display a summary of reagents
var reagentSummaryWebPart = new LABKEY.QueryWebPart({
renderTo: 'reagentDiv',
title: 'Reagent Summary',
schemaName: 'lists',
queryName: 'Reagent View',
buttonBarPosition: 'none',
aggregates: [
{column: 'Reagent', type: LABKEY.AggregateTypes.COUNT},
{column: 'TotalRequests', type: LABKEY.AggregateTypes.SUM},
{column: 'TotalQuantity', type: LABKEY.AggregateTypes.SUM}
]
});
// Display a summary of users
var userSummaryWebPart = new LABKEY.QueryWebPart({
renderTo: 'userDiv',
title: 'User Summary',
schemaName: 'lists',
queryName: 'User View',
buttonBarPosition: 'none',
aggregates: [
{column: 'UserID', type: LABKEY.AggregateTypes.COUNT},
{column: 'TotalRequests', type: LABKEY.AggregateTypes.SUM},
{column: 'TotalQuantity', type: LABKEY.AggregateTypes.SUM}]
});
// Display how many requests have been submitted by which users
// over the past 10 days.
var resolvedWebPart = new LABKEY.QueryWebPart({
renderTo: 'recentlySubmittedDiv',
title: 'Recently Submitted',
schemaName: 'lists',
queryName: 'Recently Submitted',
buttonBarPosition: 'none',
aggregates: [
{column: 'Today', type: LABKEY.AggregateTypes.SUM},
{column: 'Yesterday', type: LABKEY.AggregateTypes.SUM},
{column: 'Day3', type: LABKEY.AggregateTypes.SUM},
{column: 'Day4', type: LABKEY.AggregateTypes.SUM},
{column: 'Day5', type: LABKEY.AggregateTypes.SUM},
{column: 'Day6', type: LABKEY.AggregateTypes.SUM},
{column: 'Day7', type: LABKEY.AggregateTypes.SUM},
{column: 'Day8', type: LABKEY.AggregateTypes.SUM},
{column: 'Day9', type: LABKEY.AggregateTypes.SUM},
{column: 'Total', type: LABKEY.AggregateTypes.SUM}
]
});
// Display the entire Reagent Requests grid view.
// Note that the returnURL parameter is temporarily necessary due to a bug.
var allRequestsWebPart = new LABKEY.QueryWebPart({
renderTo: 'allRequestsDiv',
title: 'All Reagent Requests',
schemaName: 'lists',
queryName: 'Reagent Requests',
returnURL: encodeURI(window.location.href),
aggregates: [{column: 'Name', type: LABKEY.AggregateTypes.COUNT}]
});
}
}
</script>
Related Topics
Previous Step
Repackaging the App as a Module
- Download jstutorial.module
- Copy jstutorial.module to the LABKEY_HOME/externalModules directory of your LabKey Server installation.
- The module will be automatically deployed to the server.
- Enable the module in some folder.
- Visit the following URL to see the reagent request form, where <path_to_folder> is the path to the folder where you enabled the module, for example, "home/myfolder":
Tutorial: Use URLs to Pass Data and Filter Grids
- Pass parameters between pages via a URL
- Filter a grid using a received URL parameter
Set Up
First, set up the underlying data and pages.- Go to the Home project.
- Create a new folder to work in:
- Go to Admin > Folder > Management.
- Click Create Subfolder.
- Name: "URL Tutorial".
- Folder Type: Collaboration.
- Click Next.
- On the Users/Permissions page, confirm that Inherit from Parent Folder is checked, and click Finish.
- Download the following sample data: URLTutorial.lists.zip (This is a set of TSV files packaged as a list archive, and must remain zipped)
- Import it to your folder by selecting Admin > Manage Lists. Click Import List Archive.
- Click Choose File.
- Select the URLTutorial.lists.zip file, and click Import List Archive.
- The archive is unzipped and the lists inside are added to your folder.
- Click URL Tutorial to return to the work folder.
First Step
Related Topics
Choose Parameters
Create an HTML Page
- In the Wiki section, click Create a new wiki page.
- Name: 'chooseParams' (Replace the 'default' value provided.)
- Title: 'Choose Parameters'
- Click the Source tab and copy and paste the code below.
- Click Save and Close.
<script type="text/javascript">
var displayName = "";
function buttonHandler()
{
if (displayName.length > 0)
{
//Set the name of the destination wiki page,
//and the text we'll use for filtering.
var params = {};
params['name']= 'showFilter';
params['displayName'] = displayName;
// Build the URL to the destination page.
// In building the URL for the "Show Filtered Grid" page, we use the following arguments:
// controller - The current controller (wiki)
// action - The wiki controller's "page" action
// containerPath - The current container
// parameters - The parameter array we just created above (params)
window.location = LABKEY.ActionURL.buildURL(
"wiki",
"page",
LABKEY.ActionURL.getContainer(),
params);
}
else
{
alert('You must enter a value to submit.');
}
}
Ext.onReady(function() {
var filterField = new Ext.form.TextField({
id : 'filter-field',
fieldLabel : 'Search text',
style : { margin: '10px' },
labelStyle : 'margin:10px;',
listeners : {
// Set the global variable whenever the field is changed.
change : function(field, newVal, oldVal) {
displayName = newVal;
}
}
});
var submitBtn = new Ext.Button({
text : 'Submit',
style : {
margin : '10px',
float : 'right'
},
handler : buttonHandler
});
var theForm = new Ext.form.FormPanel({
id : 'the-form',
renderTo : 'theFormDiv',
title : 'Enter search text for filtering the list',
autoHeight: true,
width : 400,
items : [ filterField , submitBtn ]
});
});
</script>
<div id="theFormDiv"></div>
- name -- The name of the destination wiki page (which doesn't exist yet).
- displayName -- The text we'll use for filtering on the next page. Provided through user input on the current page.
Build the URL and Navigate
- In the Choose Parameters section, enter some text, for example, "a", and click Submit.
- The destination page (showFilter) doesn't exist yet, so you will see an error. But notice the URL in the browser address bar built from the parameters provided, especially 'name=showFilter&displayName=a'. (By the way, the text after the '?' is called the 'query string'.)
Previous Step | Next Step
Show Filtered Grid
Create a Destination HTML Page
- Click URL Tutorial to return to the work folder.
- In the Pages section to the right, click the small triangle icon and select New.
- Create a new HTML page with the following properties:
- Name: showFilter
- Title: Show Filtered List
- Click the Source tab and copy and paste the following code into it.
- Click Save and Close.
- Notice that the entire list is displayed because no filter has been applied yet.
<script type="text/javascript">
Ext.onReady(function(){
// We use the 'displayName' parameter contained in the URL to create a filter.
var myFilters = [];
if (LABKEY.ActionURL.getParameter('displayName'))
{
var myFilters = [ LABKEY.Filter.create('Reagent',
LABKEY.ActionURL.getParameter('displayName'),
LABKEY.Filter.Types.STARTS_WITH) ]
}
// In order to display the filtered list,
// we render a QueryWebPart that uses the 'myFilters' array (created above) as its filter.
// Note that it is recommended to either use the 'renderTo' config option
// (as shown above) or the 'render( renderTo )' method, but not both.
// These both issue a request to the server, so it is only necessary to call one of them.
var qwp = new LABKEY.QueryWebPart({
schemaName : 'lists',
queryName : 'Reagents', // Change to use a different list, for example: 'Instruments'
renderTo : 'filteredTable',
filters : myFilters
});
});
</script>
<div id="filteredTable"></div>
Display a Filtered Grid
Now we are ready to use our parameterized URL to filter the data.- Click URL Tutorial to return to the work folder.
- In the new Choose Parameters wiki page, enter search text, for example 'a' and click Submit.
- The URL is constructed and takes you to the data grid page.
- Notice that only those reagents that start with 'a' are shown in the grid.
- Notice that you can change the URL directly in the address bar to see different results. For example, change the value from 'a' to 't' to see all of the reagents that begin with 't'.
Previous Step
Tutorial Video: Building Reports and Custom User Interfaces
You can use the custom interface shown in the video in the Proteomics Tutorial demo folder. The SQL queries, the R script, and the JavaScript user interface are available for download as attachments on this page.
The Camtasia Studio video content presented here requires JavaScript to be enabled and the latest version of the Macromedia Flash Player. If you are you using a browser with JavaScript disabled please enable it now. Otherwise, please update your version of the free Flash Player by downloading here.
JavaScript API - Samples
Other JavaScript API Samples
- The LabKey JavaScript API Reference contains additional sample scripts.
- Sample Visualization Page: demo_script.js
Show a QueryWebPart
Displays a query in the home/ProjectX folder. The containerFilter property broadens the scope of the query to pull data from all folders on the site.<div id='queryDiv1'/>
<script type="text/javascript">
var qwp1 = new LABKEY.QueryWebPart({
renderTo: 'queryDiv1',
title: 'Some Query',
schemaName: 'someSchema',
queryName: 'someQuery',
containerPath: 'home/ProjectX',
containerFilter: LABKEY.Query.containerFilter.allFolders,
buttonBarPosition: 'top',
maxRows: 25
});
</script>
Files Web Part - Named File Set
Displays the named file set 'store1' as a Files web part.<div id="fileDiv"></div>
<script type="text/javascript">
// Displays the named file set 'store1'.
var wp1 = new LABKEY.WebPart({
title: 'File Store #1',
partName: 'Files',
partConfig: {fileSet: 'store1'},
renderTo: 'fileDiv'
});
wp1.render();
</script>
Inserting a Wiki Web Part
Note that the Web Part Configuration Properties covers the configuration properties that can be set for various types of web parts inserted into a wiki page.<div id='myDiv'>
<script type="text/javascript">
var webPart = new LABKEY.WebPart({partName: 'Wiki',
renderTo: 'myDiv',
partConfig: {name: 'home'}
});
webPart.render();
</script>
Retrieving the Rows in a List
This script retrieves all the rows in a user-created list named "People." Please see LABKEY.Query.selectRows for detailed information on the parameters used in this script.<script type="text/javascript">
function onFailure(errorInfo, options, responseObj)
{
if(errorInfo && errorInfo.exception)
alert("Failure: " + errorInfo.exception);
else
alert("Failure: " + responseObj.statusText);
}
function onSuccess(data)
{
alert("Success! " + data.rowCount + " rows returned.");
}
LABKEY.Query.selectRows({
schemaName: 'lists',
queryName: 'People',
columns: ['Name', 'Age'],
success: onSuccess,
error: onFailure,
});
</script>
var someValue = 'Test value';
LABKEY.Query.selectRows({
schemaName: 'lists',
queryName: 'People',
columns: ['Name', 'Age'],
success: function (data)
{
alert("Success! " + data.rowCount + " rows returned and value is " + someValue);
},
failure: onFailure
});
Displaying a Grid
Adding Report to a Data Grid with JavaScript
JavaScript Reports
A JavaScript report links a specific data grid with code that runs in the user's browser. The code can access the underlying data, transform it as desired, and render a custom visualization or representation of that data (for example, a chart, grid, summary statistics, etc.) to the HTML page. Once the new JavaScript report has been added, it is accessible from the Reports menu on the grid.Create a JavaScript Report
To create a JavaScript report:- Navigate to the data grid of interest.
- Select Reports > Create JavaScript Report.
- Note the "starter code" provided on the Source tab. This starter code simply retrieves the data grid and displays the number of rows in the grid. The starter code also shows the basic requirements of a JavaScript report. Whatever JavaScript code you provide must define a render() function that receives two parameters: a query configuration object and an HTML div element. When a user views the report, LabKey Server calls this render() function to display the results to the page using the provided div.
- Modify the starter code, especially the onSuccess(results) function, to render the grid as desired. See an example below.

- If you want other users to see this report, place a checkmark next to Make this report available to all users.
- Elect whether you want the report to be available in child folders on data grids where the schema and table are the same as this data grid.
- Click Save, provide a name for the report, and click OK.
- Confirm that the JavaScript report has been added to the grid's Reports menu.

GetData API
There are two ways to retrieve the actual data you wish to see, which you control using the JavaScript Options section of the source editor, circled in red at the bottom of the following screenshot.
- If Use GetData API is selected (the default setting), you can pass the data through one or more transforms before retrieving it. When selected, you pass the query config to LABKEY.Query.GetData.getRawData().
- For details see LABKEY.Query.GetData API.
- If Use GetData API is not selected, you can still configure columns and filters before passing the query config directly to LABKEY.Query.selectRows()
- For details see LABKEY.Query.selectRows().
Modifying the Query Configuration
Before the data is retrieved, the query config can be modified as needed. For example, you can specify filters, columns, sorts, maximum number of rows to return, etc. The example below specifies that only the first 25 rows of results should be returned:queryConfig.maxRows = 25;
. . .
queryConfig.success = onSuccess;
queryConfig.error = onError;
. . .
function onSuccess(results)
{
. . .Render results as HTML to div. . .
}
function onError(errorInfo)
{
jsDiv.innerHTML = errorInfo.exception;
}
Scoping
Your JavaScript code is wrapped in an anonymous function, which provides unique scoping for the functions and variables you define; your identifiers will not conflict with identifiers in other JavaScript reports rendered on the same page.Sample
This sample can be attached to any dataset or list. To run this sample, select a dataset or list to run it against, create a JavaScript report (see above), pasting this sample code into the Source tab.var jsDiv;
// When the page is viewed, LabKey calls the render() function, passing a query config
// and a div element. This sample code calls selectRows() to retrieve the data from the server,
// and displays the data inserting line breaks for each new row.
// Note that the query config specifies the appropriate query success and failure functions
// and limits the number of rows returned to 4.
function render(queryConfig, div)
{
jsDiv = div;
queryConfig.success = onSuccess;
queryConfig.error = onError;
// Only return the first 4 rows
queryConfig.maxRows = 4;
LABKEY.Query.GetData.getRawData(queryConfig);
//LABKEY.Query.selectRows(queryConfig);
}
function onSuccess(results)
{
var data = "";
// Display the data with white space after each column value and line breaks after each row.
for (var idxRow = 0; idxRow < results.rows.length; idxRow++)
{
var row = results.rows[idxRow];
for (var col in row)
{
if (row[col] && row[col].value)
{
data = data + row[col].value + " ";
}
}
data = data + "<br/>";
}
// Render the HTML to the div.
jsDiv.innerHTML = data;
}
function onError(errorInfo)
{
jsDiv.innerHTML = errorInfo.exception;
}
Related Topics
Export Data Grid as a Script
Export/Generate Scripts
LabKey Server provides a rich API for building client applications on top of LabKey Server -- for example, applications that retrieve and interact with data from the database. To get started building a client application, LabKey Server can generate a client script that retrieves a grid of data from the database. Adapt and extend the scripts capabilities to meet your needs. You can generate a script snippet for any data grid. The following script languages are supported:- Java
- JavaScript
- Perl
- Python
- R
- SAS
- Stable URL
- Navigate to the grid view of interest and click the Export button.
- Select the Script tab and select an available language: Java, JavaScript, Perl, Python, R, or SAS.
- Click Create Script to generate a script.

<script type="text/javascript">
LABKEY.Query.selectRows({
requiredVersion: 9.1,
schemaName: 'study',
queryName: 'Physical Exam',
columns: 'ParticipantId,date,height_cm,Weight_kg,Temp_C,SystolicBloodPressure,DiastolicBloodPressure,Pulse,
Respirations,Signature,Pregnancy,Language,ARV,ARVtype',
filterArray: null,
sort: null,
success: onSuccess,
error: onError
});
function onSuccess(results)
{
var data = "";
var length = Math.min(10, results.rows.length);
// Display first 10 rows in a popup dialog
for (var idxRow = 0; idxRow < length; idxRow++)
{
var row = results.rows[idxRow];
for (var col in row)
{
data = data + row[col].value + " ";
}
data = data + "n";
}
alert(data);
}
function onError(errorInfo)
{
alert(errorInfo.exception);
}
</script>
Use Exported Scripts
JavaScript Examples.- You can paste a script into a <script> block in an HTML wiki.
- For a better development experience, you can create a custom module. HTML pages in that module can use the script to create custom interfaces.
- Use the script in a custom R view.
- Use the script within an external R environment to retrieve dat from LabKey Server. Paste the script into your R console. See documentation on the Rlabkey CRAN package.
Related Topics
- Adding Report to a Data Grid with JavaScript - A JavaScript view allows you to associate JavaScript code with a grid view.
- Export Chart as JavaScript
Export Chart as JavaScript
- load the dependencies necessary for visualization libraries
- load the data to back the chart
- render the chart
Create a Chart and Export to JavaScript
We will start by making a time chart grouped by treatment group as follows:- Navigate to the home page of your sample study, "HIV-CD4 Study."
- Click the Clinical and Assay Data tab.
- Open the Lab Results data set.
- Select Charts > Create Chart.
- Click Time.
- Drag CD4+ from the column list to the Y Axis box.
- Click Apply.
- You will see a basic time chart. Before exporting the chart to Javascript, we can customize it within the wizard.
- Click Chart Type.
- In the X Axis box, change the Time Interval to "Months".
- Click Apply and notice the X axis now tracks months.
- Click Chart Layout, then change the Subject Selection to "Participant Groups". Leave the default "Show Mean" checkbox checked.
- Change the Number of Charts to "One per Group".

- Click Apply.
- In the Filters > Groups panel on the left, select Treatment Group and deselect anything that was checked by default. The chart will now be displayed as a series of four individual charts in a scrollable window, one for each treatment group:

- Hover over the chart to reveal the Export buttons, and click to Export as Script.
- You will see a popup window containing the HTML for the chart, including the JavaScript code.

- Select All within the popup window and Copy the contents to your browser clipboard. For safekeeping, you can paste to a text file.
- Click Close. Then Save your chart with the name of your choice.
Copy JavaScript to Wiki
You can embed the chart without further modifications into a Wiki or any other HTML page.- Click the Overview tab to go to the home page of your study, or navigate to any tab where you would like to place this exported chart.
- Select Wiki from the <Select Web Part> pulldown in the lower left, then click Add.
- Create a new wiki:
- If the folder already contains a wiki page named "default", the new webpart will display it. Choose New from the triangle menu next to the webpart name.
- Otherwise, click Create a new wiki page in the new wiki webpart.
- Give the page the name of your choice. Wiki page names must be unique, so be careful not to overwrite something else unintentionally.
- Enter a Title such as "Draft of Chart".
- Click the Source tab. Note: if there is no Source tab, click Convert To..., select HTML and click Convert.
- Paste the JavaScript code you copied above onto the source tab.

- You could also add additional HTML to the page before or after the pasted JavaScript of the chart.
- Caution: Do not switch to the Visual tab. The visual editor does not support this JavaScript element, so switching to that tab would cause the chart to be deleted. You will be warned if you click the Visual tab. If you do accidentally lose the chart, you should be able to recover it using the History of the wiki page, or by pasting the exported script again.
- Scroll up and click Save and Close.
- Return to the tab where you placed the new wiki. If it does not already show your chart, select Customize from the triangle menu next to the title and change the Name and title of the page to display to the name of the wiki you just created.
- Notice that the new wiki now contains the series of single timecharts as created in the wizard.

Edit JavaScript
The chart wizard itself offers a variety of tools for customizing your chart. However, by editing the exported JavaScript for the chart directly you can have much finer grained control as well as make modifications that are not provided by the wizard. In this step we will modify the chart to use an accordian layout and change the size to better fit the page.- Open your wiki for editing by clicking the pencil icon or Edit button.
- Confirm that the Source tab is selected. Reminder: Do not switch to the Visual tab.
- Scroll down to the end of the chart validation section and paste the following code defining the accordian panel. It is good practice to mark your additions with comments such as those shown here.
...
if (!validation.success)
{
renderMessages(CHART_ID, messages);
return;
}
// ** BEGIN MY CODE **
var accordionPanel = Ext4.create('Ext.panel.Panel', {
renderTo: CHART_ID,
title: 'Time Chart: CD4 Levels per Treatment Group',
width: 760,
height: 500,
layout: 'accordion',
items: []
});
// ** END MY CODE **
// For time charts, we allow multiple plots to be displayed by participant, group...
- Next, scroll to the portion of script defining plotConfig.
- Before and after that definition, paste two new sections as shown below.
- Also edit the lines shown in the section below marked CHANGED THIS LINE to match this example:
...
var data = plotConfigsArr[configIndex].individualData ? plotConfigsArr[configIndex].individualData :
plotConfigsArr[configIndex].aggregateData;
// ** BEGIN MY CODE **
var divId = 'TimeChart' + configIndex;
var plotPanel = Ext4.create('Ext.panel.Panel', {
html: '<div id="' + divId + '"></div>',
title: labels.main.value
});
accordionPanel.add(plotPanel);
// ** END MY CODE **
var plotConfig = {
renderTo: divId, // ** CHANGED THIS LINE **
clipRect: clipRect,
width: 750, // ** CHANGED THIS LINE **
height: 350, // ** CHANGED THIS LINE **
labels: labels,
aes: aes,
scales: scales,
layers: layers,
data: data
};
// ** BEGIN MY CODE **
plotConfig.labels.main.value = "";
plotConfig.scales.yRight.tickFormat = function(v) {
return v.toExponential();
};
// ** END MY CODE **
var plot = new LABKEY.vis.Plot(plotConfig);
plot.render();
- Click Save and Close to view your new chart. Notice that by clicking the - and + buttons on the right, you can switch between the individual charts in the display panel.

Displaying a Chart with Minimal UI
To embed an exported chart without surrounding user interface, create a simple file based module where your chart is included in a simple myChart.html file. Create a myChart.view.html file next to that page with the following content. This will load the necessary dependencies and create a page displaying only the simple chart. (To learn how to create a simple module, see Tutorial: Hello World Module.)<view xmlns="http://labkey.org/data/xml/view" template="print" frame="none">
</view>
Related Topics
- Export Data Grid as a Script
- For more detail about editing JavaScript to make custom charts, see Adding Report to a Data Grid with JavaScript.
- See LABKEY.vis.GenericChartHelper in the JavaScript API docs.
- Develop Modules
- Tutorial: Hello World Module
Custom HTML/JavaScript Participant Details View
MODULE_NAME
resources
views
participant.html
Example Custom Participant.html
The following page grabs the participantid from the URL, queries the database for the details about that participant, and builds a custom HTML view/summary of the data with a different appearance than the default.<style type="text/css">
div.wrapper {
/*margin-left: auto;*/
/*margin-right: auto;*/
margin-top: -10px;
width : 974px;
}
div.wrapper .x4-panel-body {
background-color: transparent;
}
div.main {
background-color: white;
padding: 10px 20px 20px 20px;
margin-top: 10px;
box-shadow: 0 1px 1px rgba(0,0,0,0.15), -1px 0 0 rgba(0,0,0,0.06), 1px 0 0 rgba(0,0,0,0.06), 0 1px 0 rgba(0,0,0,0.12);
}
div.main h2 {
display: inline-block;
text-transform: uppercase;
font-weight: normal;
background-color: #126495;
color: white;
font-size: 13px;
padding: 9px 20px 7px 20px;
margin-top: -20px;
margin-left: -20px;
}
div.main h3 {
text-transform: uppercase;
font-size: 14px;
font-weight: normal;
padding: 10px 0px 10px 50px;
border-bottom: 1px solid darkgray;
}
#demographics-content .detail {
font-size: 15px;
padding-left: 30px;
padding-bottom: 5px;
}
#demographics-content .detail td {
font-size: 15px;
}
#demographics-content h3 {
margin-bottom: 0.5em;
margin-top: 0.5em;
}
#demographics-content td {
padding: 3px;
}
#demographics-content td.label,
td.label, div.label, a.label {
font-size: 12px;
color: #a9a9a9;
vertical-align: text-top;
}
div.main-body {
margin-top: 0.5em;
}
#assays-content .detail td {
font-size: 15px;
padding: 3px;
}
.thumb.x-panel-header {
background-color: transparent;
}
</style>
<div id="participant-view"></div>
<script type="text/javascript">
LABKEY.requiresExt4Sandbox();
</script>
<script type="text/javascript">
LABKEY.requiresScript('clientapi/ext4/Util.js');
LABKEY.requiresScript('clientapi/ext4/data/Reader.js');
LABKEY.requiresScript('clientapi/ext4/data/Proxy.js');
LABKEY.requiresScript('clientapi/ext4/data/Store.js');
</script>
<script type="text/javascript">
var outer_panel = null;
var subject_accession = null;
Ext4.onReady(function(){
Ext4.QuickTips.init();
subject_accession = LABKEY.ActionURL.getParameter('participantId') || 'SUB112829';
outer_panel = Ext4.create('Ext.panel.Panel', {
renderTo : 'participant-view',
border : false, frame : false,
cls : 'wrapper',
layout : 'column',
items : [{
xtype : 'container',
id : 'leftContainer',
columnWidth : .55,
padding: 10,
items : []
},{
xtype : 'container',
id : 'rightContainer',
columnWidth : .45,
padding: 10,
items : []
}]
});
getDemographicCfg();
});
function getDemographicCfg()
{
var tpl = new Ext4.XTemplate(
'<div id="demographics" class="main">',
'<h2>Information</h2>',
'<div id="demographics-content">',
'<h3>Demographics</h3>',
'<table class="detail" style="margin-left: 30px">',
'<tr><td class="label" width="120px">ParticipantId</td><td>{ParticipantId:this.renderNull}</td></tr>',
'<tr><td class="label" width="120px">Gender</td><td>{Gender:this.renderNull}</td></tr>',
'<tr><td class="label" width="120px">StartDate</td><td>{StartDate:this.renderNull}</td></tr>',
'<tr><td class="label" width="120px">Country</td><td>{Country:this.renderNull}</td></tr>',
'<tr><td class="label" width="120px">Language</td><td>{Language:this.renderNull}</td></tr>',
'<tr><td class="label" width="120px">TreatmentGroup</td><td>{TreatmentGroup:this.renderNull}</td></tr>',
'<tr><td class="label" width="120px">Status</td><td>{Status:this.renderNull}</td></tr>',
'<tr><td class="label" width="120px">Height</td><td>{Height:this.renderNull}</td></tr>',
'</table>',
'</div>',
'</div>',
{
renderNull : function(v) {
return (v == undefined || v == null || v == "") ? "--" : v;
}
}
);
Ext4.getCmp('leftContainer').add({
xtype : 'component',
id : 'demographics-' + subject_accession,
tpl : tpl,
border : false, frame : false,
data : {}
});
var sql = "SELECT Demographics.ParticipantId, " +
"Demographics.date, " +
"Demographics.StartDate, " +
"Demographics.Country, " +
"Demographics.Language, " +
"Demographics.Gender, " +
"Demographics.TreatmentGroup, " +
"Demographics.Status, " +
"Demographics.Height " +
"FROM Demographics " +
"WHERE Demographics.ParticipantId='" + subject_accession + "'";
var demo_store = Ext4.create('LABKEY.ext4.data.Store', {
schemaName : 'study',
sql : sql,
autoLoad : true,
listeners : {
load : function(s) {
var c = Ext4.getCmp('demographics-' + subject_accession);
if (c) { c.update(s.getAt(0).data); }
},
scope : this
},
scope : this
});
}
</script>
Custom Button Bars
- LABKEY.QueryWebPart JavaScript API
- XML metadata
- Example of a button bar defined in custom XML metadata
LABKEY.QueryWebPart JavaScript API
The LABKEY.QueryWebPart's buttonBar parameter can be used to build custom button bars. For example:var qwp1 = new LABKEY.QueryWebPart({
renderTo: 'queryTestDiv1',
title: 'My Query Web Part',
schemaName: 'lists',
queryName: 'People',
buttonBar: {
includeStandardButtons: true,
items:[
LABKEY.QueryWebPart.standardButtons.views,
{text: 'Test', url: LABKEY.ActionURL.buildURL('project', 'begin')},
{text: 'Test Script', onClick: "alert('Hello World!'); return false;"},
{text: 'Test Handler', handler: onTestHandler},
{text: 'Test Menu', items: [
{text: 'Item 1', handler: onItem1Handler},
{text: 'Fly Out', items: [
{text: 'Sub Item 1', handler: onItem1Handler}
]},
'-', //separator
{text: 'Item 2', handler: onItem2Handler}
]},
LABKEY.QueryWebPart.standardButtons.exportRows
]
}
});
- A custom button can get selected items from the current page of a grid view and perform a query using that info. Note that only the selected options from a single page can be manipulated using onClick handlers for custom buttons. Cross-page selections are not currently recognized.
- The allowChooseQuery and allowChooseView configuration options for LABKEY.QueryWebPart effect the buttonBar parameter.
XML metadata
In addition to setting buttons from the API, an administrator can set additional buttons in the metadata of a table using XML syntax. When clicked, custom buttons can:- Navigate the user to a custom URL (see the "Google" button in the example below).
- Execute an action using the onClick handler (see the "OnClickButton" below).
- Invoke JavaScript functions (see the "View Chart" button in the next section's example). The JavaScript function is located in an included .js file.
- buttonBarOptions element
- ButtonBarOptions type
- ButtonBarItem type
- URL Actions. Also covers customized URL actions.
<tables xmlns="http://labkey.org/data/xml">
<table tableName="ListName" tableDbType="NOT_IN_DB">
<columns></columns>
<buttonBarOptions position="top" includeStandardButtons="true" >
<item text="ButtonTitle">
<item text="OnCLickButton">
<onClick>alert('Hello');</onClick>
</item>
<item text="Google">
<target>http://www.google.com</target>
</item>
</item>
</buttonBarOptions>
</table>
</tables>
Example of a button bar defined in custom XML metadata
The example XML below creates a custom button bar that includes some standard buttons along with a custom button. It is excerpted below. Things to note:- The XML includes standard buttons by including a string that matches the standard button's caption ("originalText").
- It also includes a custom "View Chart" button.
- The onClick behavior for the custom button is defined in the button bar's included script ("studyButtons.js").
<query xmlns="http://labkey.org/data/xml/query">
<metadata>
<tables xmlns="http://labkey.org/data/xml">
<table tableName="StudyData" tableDbType="TABLE">
<columns>
<column columnName="Description">
<isHidden>false</isHidden>
<displayWidth>300</displayWidth>
</column>
</columns>
<buttonBarOptions position="both" includeStandardButtons="false">
<includeScript>/EHR_Reporting/studyButtons.js</includeScript>
<item text="Insert New">
<originalText>Insert New</originalText>
</item>
<item text="Views">
<originalText>Views</originalText>
</item>
<item text="Cohorts">
<originalText>Cohorts</originalText>
</item>
<item text="QC State">
<originalText>QC State</originalText>
</item>
<item requiresSelection="true" text="View Chart">
<onClick>
historyHandler(dataRegion, dataRegionName);
</onClick>
</item>
</buttonBarOptions>
</table>
</tables>
</metadata>
</query>
Insert into Audit Table via API
LABKEY.Query.insertRows({
schemaName: 'auditLog',
queryName: 'Client API Actions',
rows: [ {
comment: 'Test event insertion via client API',
int1: 5
} ]
});Declare Dependencies
- Module-Scoped Dependencies
- File-Scoped Dependencies
- LABKEY.requiresScript()
- Custom Client Libraries
- Troubleshooting: Dependencies on Ext3
Declare Module-Scoped Dependencies
To declare dependencies for all the pages in a module, do the following:First, create a config file named "module.xml" at the module's root folder:myModule/module.xml
<module xmlns="http://labkey.org/moduleProperties/xml/">
<clientDependencies>
<dependency path="Ext4"/>
<dependency path="https://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js" />
<dependency path="extWidgets/IconPanel.css" />
<dependency path="extWidgets/IconPanel.js" />
</clientDependencies>
</module>
Declare File-Scoped Dependencies
For each HTML file in a file-based module, you can create an XML file with associated metadata. This file can be used to define many attributes, including the set of script dependencies. The XML file allows you to provide an ordered list of script dependencies. These dependencies can include:- JS files
- CSS files
- libraries
myModule/
queries/
reports/
views/
Overview.html
Overview.view.xml
web/
<view xmlns="http://labkey.org/data/xml/view">
<dependencies>
<dependency path="Ext4"/>
<dependency path="/myModule/Utils.js"/>
<dependency path="/myModule/stylesheet.css"/>
</dependencies>
</view>
- Ext3: Will load the Ext3 library and dependencies. Comparable to LABKEY.requiresExt3()
- Ext4: Will load the Ext4 library and dependencies. Comparable to LABKEY.requiresExt4Sandbox()
- clientapi: Will load the LABKEY Client API. Comparable to LABKEY.requiresClientAPI()
Using LABKEY.requiresScript()
From javascript on an HTML view or wiki page, you can load scripts using LABKEY.requiresScript() or LABKEY.requiresCss(). Each of these helpers accepts the path to your script or CSS resource. In addition to the helpers to load single scripts, LabKey provides several helpers to load entire libraries:- LABKEY.requiresExt3ClientAPI(): Will load the ExtJS 3.4 JavaScript library.
- LABKEY.requiresExt4Sandbox(): Will load the ExtJS 4.2.1 JavaScript library.
<script type="text/javascript">
// Require that ExtJS 4 be loaded
LABKEY.requiresExt4Sandbox(true, function() {
// List any JavaScript files here
var javaScriptFiles = ["/myModule/Utils.js"];
LABKEY.requiresCss('/myModule/stylesheet.css');
LABKEY.requiresScript(javaScriptFiles, true, function() {
// Called back when all the scripts are loaded onto the page
alert("Ready to go!");
});
});
</script>
Create Custom Client Libraries
If you find that many of your views and reports depend on the same set of javascript or css files, it may be appropriate to create a library of those files so they can be referred to as a group. To create a custom library named "mymodule/mylib", create a new file "mylib.lib.xml" in the web/mymodule directory in your module's resources directory. Just like dependencies listed in views, the library can refer to web resources and other libraries:<libraries xmlns="http://labkey.org/clientLibrary/xml/">
<library>
<script path="/mymodule/Utils.js"/>
<script path="/mymodule/stylesheet.css"/>
</library>
<dependencies>
<dependency path="Ext4"/>
<dependency path="https://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js"/>
</dependencies>
</libraries>
Troubleshooting: Dependencies on Ext3
Past implementations of LabKey Server relied heavily on Ext3, and therefore loaded the ExtJS v3 client API on each page by default. This resulted in the ability to define views, pages, and scripts without explicitly declaring client dependencies. Beginning with version LabKey Server v16.2, DataRegion.js is no longer dependent on ext3, so it is no longer loaded and these views may break at run time.Symptoms: Either a view will fail to operate properly, or a test or script will fail with a JavaScript alert about an undefined function (e.g. "LABKEY.ext.someFn").Workaround: Isolate and temporarily work around this issue by forcing the inclusion of ext3 on every page. Note that this override is global and not an ideal long term solution.- Open Admin > Site > Admin Console > Site Settings.
- Check one or both boxes to "Require ExtJS v3… be loaded on each page."
Override getClientDependencies()
For views that extend HttpView, you can override getClientDependencies() as shown in this example from QueryView.java:@NotNull
@Override
public LinkedHashSet<ClientDependency> getClientDependencies()
{
LinkedHashSet<ClientDependency> resources = new LinkedHashSet<>();
if (!DataRegion.useExperimentalDataRegion())
resources.add(ClientDependency.fromPath("clientapi/ext3"));
resources.addAll(super.getClientDependencies());
.
.
.
Override in .jsp views
Note the <%! syntax when declaring an override as shown in this example from core/project/projects.jsp.<%!
public void addClientDependencies(ClientDependencies dependencies)
{
dependencies.add("Ext4ClientApi"); // needed for labkey-combo
dependencies.add("/extWidgets/IconPanel.js");
dependencies.add("extWidgets/IconPanel.css");
}
%>
Related Topics
Loading ExtJS On Each Page
- Go to Admin > Site > Site Console > click Site Settings.
- Scroll down to Customize LabKey system properties.
- Two checkboxes, for two different libraries, are available:
- Require ExtJS v3.4.1 be loaded on each page
- Require ExtJS v3.x based Client API be loaded on each page
Licensing for the ExtJS API
"Based on the "Quid Pro Quo" principle, if you wish to derive a commercial advantage by not releasing your application under an open source license, you must purchase an appropriate number of commercial licenses from Ext. By purchasing commercial licenses, you are no longer obligated to publish your source code."
Search API Documentation
Naming & Documenting JavaScript APIs
Naming Conventions for JavaScript APIs
Avoid web resource collisions
The web directory is shared across all modules so it is a best practice to place your module's resources under a unique directory name within the web directory. It is usually sufficient to use your module's name to scope your resources. For example,mymodule/
├── module.properties
└── resources
├── web
│ └── **mymodule**
│ ├── utils.js
│ └── style.css
└── views
└── begin.html
Choose concise names
General guidelines:- Avoid:
- Adding the name of the class before the name of a property, unless required for clarity.
- Adding repetitive words (such as "name" or "property") to the name of a property, unless required for clarity.
- Consider:
- Creating a class to hold related properties if you find yourself adding the same modifier to many properties (e.g., "lookup").
- "domainId" -- should exclude the name of the class, so should be "id" -- see LABKEY.Domain.DomainDesign
- "propertyId" -- should exclude the word "property", so should be "id" -- see LABKEY.Domain.DomainDesign#fields
- "chartType" -- should exclude the name of the class, so should be "type" -- see LABKEY.Chart
- "id" -- see LABKEY.Assay.AssayDesign
Choose consistent names
These follow Ext naming conventions.Listener method names- Document failure as the name of a method that listens for errors.
- Also support: failureCallback and errorCallback but not "errorListener"
- Document success as the name of a method that listens for success.
- Also support: successCallback
- Use error as the first parameter (not "errorInfo" or "exceptionObj"). This should be a JavaScript Error object caught by the calling code.
- This object should have a message property (not "exception").
- Use response as the second parameter (not "request" or "responseObj"). This is the XMLHttpRequest object that generated the request. Make sure to say "XMLHttpRequest" in explaining this parameter, not "XMLHttpResponse," which does not exist.
Use consistent capitalization
General guidelines:- Use UpperCamelCase for the names of classes.
- Use lowercase for the names of events.
- Use lowerCamelCase for the names of methods, fields and properties. See the special cases for acronyms below.
- Treat as words and use lowerCamelCase
- Examples:
- config.titleHref -- see LABKEY.WebPart
- config.lsid -- see LABKEY.Exp.ExpObject
- Use upper case for all letters when the acronym is used as the second word in a compound name.
- Lower case when the acronym stands alone or is the first word in a compound name.
- Examples:
- domainURI -- see LABKEY.Domain.DomainDesign
- typeURI -- see LABKEY.Assay.AssayDesign
- getURLSuffix -- see LABKEY.Filter.FilterDefinition#getURLSuffix
- Always treat "ID" a word and lowerCamelCase accordingly, just like four-letter acronyms.
- Note that API capitalization is a different kettle of fish than UI capitalization – please remember to use “ID” in UI.
- Examples:
- config.id -- see LABKEY.Exp.ExpObject
- metadata.id -- see LABKEY.Query.ExtendedSelectRowsResults
- rowId, globalUniqueId, etc. -- see LABKEY.Specimen.Vial
How to Generate JSDoc
Overview
LabKey's JavaScript API reference files are generated automatically when you build LabKey Server. These files can be found in the ROOT\build\clientapi_docs directory, where ROOT is the directory where you have placed the files for your LabKey Server installation.Generating API docs separately can come in handy when you wish to customize the JSDoc compilation settings or alter the JSDoc template. This page helps you generate API reference documentation from annotated javascript files. LabKey uses the open-source JsDoc Toolkit to produce reference materials.Use the Ant Build Target
From the ROOT\server directory, use the following to generate the JavaScript API docs:ant clientapi_docs
Use an Alternative Build Method
You can also build the documents directly from within the jsdoc-toolkit folder.First, place your annotated .js files in a folder called "clientapi" in the jsdoc-toolkit folder (<JSTOOLKIT> in the code snippet below). Then use a command line similar to the following to generate the docs:C:\<JSTOOLKIT>>java -jar jsrun.jar app\run.js clientapi -t=templates\jsdoc
Further Info on JsDocs and Annotating Javascript with Tags
JsDoc Annotation Guidelines
- Follow LabKey's JavaScript API naming guidelines.
- When documenting objects that are not explicitly included in the code (e.g., objects passed via successCallbacks), avoid creating extra new classes.
- Ideally, document the object inline as HTML list in the method or field that uses it. LABKEY.Security contains many examples.
- If you do need to create an arbitrary class to describe an object, use the @name tag. See LABKEY.Domain.DomainDesign for a simple example. You'll probably need to create a new class to describe the object IF:
- Many classes use the object, so it's confusing to doc the object inline in only one class.
- The object is used as the type of many other variables.
- The object has (or will have) both methods and fields, so it would be hard to distinguish them in a simple HTML list.
- Caution: Watch for a bug if you use metatags to write annotations once and use them across a group of enclosed APIs. If you doc multiple, similar objects that have field names in common, you may have to fully specify the name of the field-in-common. If this bug is problematic, fields that have the same names across APIs will not show links.
- An example of a fix: Query.js uses fully specified @names for several fields (e.g., LABKEY.Query.ModifyRowsOptions#rows).
- When adding a method, event or field, please remember to check whether it is correctly marked static.
- There are two ways to get a method to be marked static, depending on how the annotations are written:
- Leave both "prototype" and "#" off of the end of the @scope statement (now called @lends) for a @namespace
- Leave both "prototype" and "#" off of the end of the @method statement
- Note: If you have a mix of static and nonstatic fields/methods, you may need to use "prototype" or "#" on the end of a @fieldOf or @memeberOf statement to identify nonstatic fields/methods.
- As of 9.3, statics should all be marked correctly.
- Check out the formatting of @examples you’ve added – it’s easy for examples to overflow the width of their boxes, so you may need to break up lines.
- Remember to take advantage of LabKey-defined objects when defining types instead of just describing the type as an {Object}. This provides cross-linking. For example, see how the type is defined for LABKEY.Specimen.Vial#currentLocation.
- Use @link often to cross-reference classes. For details on how to correctly reference instance vs. static objects, see NamePaths.
- Cross-link to the main doc tree on labkey.org whenever possible.
- Deprecate classes using a red font. See GridView for an example. Note that a bug in the toolkit means that you may need to hard-code the font color for the class that’s listed next in the class index (see Message for an example).
Java API
Overview
The client-side library for Java developers is a separate JAR from the LabKey Server code base. It can be used by any Java program, including another Java web application.Resources:Prototype LabKey JDBC Driver
Overview
We have created a prototype JDBC driver for LabKey Server that allows clients to query against the schemas, tables, and queries that LabKey Server exposes using LabKey SQL. It only implements a subset of the full JDBC functionality, but it is enough to allow third-party tools to connect, retrieve metadata, and execute queries. It has been successfully used from DbVisualizer, for example.The driver is included in the standard Java client API JAR file.Containers (projects and folders) are exposed as JDBC catalogs. Schemas within a given container are exposed as JDBC schemas. In DbVisualizer, double-click a given catalog/container to set it to be active.Driver Usage
- Classpath: You must include both the LabKey Java client API JAR, and its dependencies. They are included in the Java client distribution. Version numbers may vary, but here is a guide (note that newer releases of the Java client API also include a single JAR that includes all dependencies, with a "-all" suffix in the file name):
- labkey-client-api-14.1.jar
- commons-codec-1.2.jar
- commons-httpclient-3.1.jar
- commons-logging.jar
- commons-logging-api.jar
- json_simple-1.1.jar
- log4j-1.2.8.jar
- opencsv-2.0.jar
- Driver class: org.labkey.remoteapi.query.jdbc.LabKeyDriver
- Database URL: The base URL of the web server, including any context path, prefixed with "jdbc:labkey:". Examples include "jdbc:labkey:http://localhost:8080/labkey" and "jdbc:labkey:https://www.labkey.org/". You may include a folder path after a # to set the default target, without the need to explicitly set a catalog through JDBC. For example, "jdbc:labkey:http://localhost:8080/labkey#/MyProject/MyFolder"
- Username: Associated with an account on the web server
- Password: Associated with an account on the web server
Timeouts
The driver currently supports one other property, "Timeout". This can be set either in Java code by setting it in the Properties handed to to DriverManager.getConnection(), or by setting it on the Connection that is returned by calling setClientInfo(). In DbVisualizer, you may set the Timeout in the Properties tab on the connection configuration. The default timeout is 60 seconds for any JDBC command. You may set it to 0 to disable the timeout, or the specific timeout you'd like, in milliseconds.Example Java code
Class.forName("org.labkey.remoteapi.query.jdbc.LabKeyDriver");
Connection connection = DriverManager.getConnection("jdbc:labkey:https://www.labkey.org/", "user@labkey.org", "mypassword");
connection.setClientInfo("Timeout", "0");
connection.setCatalog("/home");
ResultSet rs = connection.createStatement().executeQuery("SELECT * FROM core.Containers");
Remote Login API
Remote Login API Overview
This document describes the simple remote login and permissions service available in LabKey Server.
The remote login/permissions service allows cooperating websites to:
- Use a designated LabKey server for login
- Attach permissions to their own resources based on permissions to containers (folders) on the Labkey Server.
The remote login/permissions service has two styles of interaction:
- Simple URL/XML based API which can be used by any language
- Java wrapper classes that make the API a little more convenient for people building webapps in java.
- PHP wrapper classes that make the API a little more convenient for people building webapps in PHP.
The remote login/permissions service supports the following operations
- Get a user email and opaque token from the LabKey server. This is accomplished via a web redirect and the LabKey server’s login api will be shown if the user does not currently have a logged-in session active in the browser.
- Check permissions for a folder on the labkey server.
- Invalidate the token, so that it cannot be used for further permission checking.
Base URL
A labkey server has a base URL that we use throughout this API description. This is of the form
<protocol>//<server>[:<port>]/[contextPath]
Such as
http://localhost:8080/labkey
In the above example, the port is 8080 and the contextpath is labkey. On some servers (such as labkey.org) there is no context path. This doc will use ${baseurl} to refer to this base URL.
URL/XML API
There are 3 main actions supported by the Login controller
createToken.view
To ensure that a user is logged in and to get a token for further calls, a client must redirect the browser to the URL:
${baseurl}/login/createToken.view?returnUrl=${url of your page}
Where ${url of your page} is a properly encoded url parameter for a page in the client web application where control will be returned. After the user is logged in (if necessary) the browser will be redirected back to <url of your page> with the following 2 extra parameters which your page will have to save somewhere (usually session state).
- labkeyToken – this is a hex string that your web application will pass into subsequent calls to check permissions.
- labkeyEmail – this is the email address used to log in. It is not required to be passed in further calls
Example
To create a token for the web page
http://localhost:8080/logintest/permissions.jsp
You would use the following URL
https://www.labkey.org/login/createToken.view?returnUrl=http%3A%2F%2Flocalhost%3A8080%2Flogintest%2Fpermissions.jsp
After the login the browser would return to your page with additional parameters:
http://localhost:8080/logintest/permissions.jsp?labkeyToken=7fcfabbe1e1f377ff7d2650f5427966e&labkeyEmail=marki%40labkey.com
verifyToken.view
This action is not intended to be used from the browser (though you certainly can do so for testing). This URL returns an XML document indicating what permissions are available for the logged in user on a particular folder.
Your web app will access this URL (Note that your firewall configuration must allow your web server to call out to the LabKey server) and parse the resulting page. The general form is
${baseurl}/login/${containerPath}/verifyToken.view?labkeyToken=${token}
Where ${containerPath} is the path on the labkey server to the folder you want to check permisisons against and ${token} is the token sent back to your returnUrl from createToken.view.
Example
To check permissions for the home folder on www.labkey.org, here’s what you’d request:
https://www.labkey.org/login/home/verifyToken.view?labkeyToken=7fcfabbe1e1f377ff7d2650f5427966e
An XML document is returned. There is currently no XML schema for the document, but it is of the form
<TokenAuthentication success="true" token="${token}" email="${email}" permissions="${permissions}" />
Where permissions is an integer with the following bits turned on for permissions to the folder.
READ: 0x00000001 INSERT: 0x00000002 UPDATE: 0x00000004 DELETE: 0x00000008 ADMIN: 0x00008000
If the token is invalid the return will be of the form
<TokenAuthentication success="false" message="${message}">
invalidateToken.view
This URL invalidates a token and optionally returns to another URL. It is used as follows
${baseurl}/login/createToken.view?labkeyToken=${token}&returnUrl=${url of your page}
Where ${token} is the token received from createToken.view and returnUrl is any page you would like to redirect back to. returnUrl should be supplied when calling from a browser and should NOT be supplied when calling from a server.
Java API
The Java API wraps the calls above with some convenient java classes that
- store state in web server session
- properly encode parameters
- parse XML files and decode permissions
- cache permissions
The Java API provides no new functionality over the URL/XML API
To use the Java API store the remoteLogin.jar in the WEB-INF/lib directory of your web application. The API provides two main classes:
- RemoteLogin – contains a static method to return a RemoteLoginHelper instance for the current request.
- RemoteLoginHelper – Interface providing methods for calling back to the server.
Typically a protected resource in a client application will do something like this
RemoteLoginHelper rlogin = RemoteLogin.getHelper(request, REMOTE_SERVER);
if (!rlogin.isLoginComplete())
{
response.sendRedirect(rlogin.getLoginRedirect());
return;
}
Set<RemoteLogin.Permission> permissions = rlogin.getPermissions(FOLDER_PATH);
if (permissions.contains(RemoteLogin.Permission.READ))
//Show data
else
//Permission denied
The API is best described by the Javadoc and the accompanying sample web app.
HTTP and Certificates
The Java API uses the standard Java URL class to connect to server and validates certificates from the server. To properly connect to an https server, clients may have to install certificates in their local certificate store using keytool.
Help can be found here: http://java.sun.com/javase/6/docs/technotes/tools/windows/keytool.html
The default certificate store shipped with Java JDK 1.6 supports more certificate authorities than previous jdk’s. It may be easier to run your web app under 1.6 than install a certificate on your client JDK. The labkey.org certificate is supported under JDK 1.6.
Security Bulk Update via API
Bulk Update
Operations available:- Create and Populate a Group
- Ensure Group and Update, Replace, or Delete Members
- email - specifies a user; if the user does not already exist in the system, it will be created and will be populated with any of the additional data provided
- userId - specifies a user already in the system. If the user does not already exist, this will result in an error message for that member. If both email and userId are provided, this will also result in an error.
- groupId - specifies a group member. If the group does not already exist, this will result in an error message for that member.
public static class GroupForm
{
private Integer _groupId; // Nullable; used first as identifier for group;
private String _groupName; // Nullable; required for creating a group
private List<GroupMember> _members; // can be used to provide more data than just email address; can be empty;
// can include groups, but group creation is not recursive
private Boolean _createGroup = false; // if true, the group should be created if it doesn't exist;
//otherwise the operation will fail if the group does not exist
private MemberEditOperation _editOperation; // indicates the action to be performed with the given users in this group
}
public enum MemberEditOperation {
add, // add the given members; do not fail if already exist
replace, // replace the current members with the new list (same as delete all then add)
delete, // delete the given members; does not fail if member does not exist in group;
//does not delete group if it becomes empty
};
Sample JSON
{
‘groupName’: ‘myNewGroup’,
‘editOperation’: ‘add’,
‘createGroup’: ‘true’,
‘members’: [
{‘email’ : ‘me@here.org’, ‘firstName’:’Me’, ‘lastName’:’Too’}
{‘email’ : ‘you@there.org’, ‘firstName’:’You’, ‘lastName’:’Too’}
{‘email’ : ‘@invalid’, ‘firstName’:’Not’, ‘lastName’:’Valid’},
{‘groupId’ : 1234},
{‘groupId’: 314}
]
}{
‘groupName’: ‘myNewGroup’,
‘editOperation’: ‘add’,
‘createGroup’: ‘true’,
‘members’: [
{‘email’ : ‘me@here.org’}
{‘email’ : ‘you@there.org’}
{‘email’ : ‘invalid’}
]
}{
‘id’: 123,
‘name’: ‘myNewGroup’,
‘newUsers’ : [ {email: ‘you@there.org’, userId: 3123} ],
‘members’ : {
‘added’: [{‘email’: ‘me@here.org’, ‘userId’: 2214}, {‘email’: ‘you@there.org’, ‘userId’: 3123},
{‘name’: ‘otherGroup’, ‘userId’ : 1234}],
‘removed’: []
}
‘errors’ :[
‘invalid’ : ‘Invalid email address’,
‘314’ : ‘Invalid group id. Member groups must already exist.’
]
}- CreateGroupAction, which includes in its response just the id and name in a successful response
- AddGroupMemberAction, which includes in its response the list of ids added
- RemoveGroupMemberAction, which includes in its response the list of ids removed
- CreateNewUserAction, which includes in its response the userId and email address for users added as well as a possible message if there was an error
Error Reporting
Invalid requests may have one of these error messages:- Invalid format for request. Please check your JSON syntax.
- Group not specified
- Invalid group id <id>
- validation messages from UserManager.validGroupName
- Group name required to create group
- You may not create groups at the folder level. Call this API at the project or root level.
- Invalid user id. User must already exist when using id.
- Invalid group id. Member groups must already exist.
- messages from exceptions SecurityManager.UserManagementException or InvalidGroupMembershipException
Perl API
Overview
Contributed by Ben Bimber, University of WisconsinLabKey's Perl API allows you to query, insert and update data on a LabKey Server from Perl. The API provides functionality similar to the following LabKey JavaScript APIs:- LABKEY.Query.selectRows()
- LABKEY.Query.executeSql()
- LABKEY.Query.insertRows()
- LABKEY.Query.updateRows()
- LABKEY.Query.deleteRows()
Documentation
- LabKey::Query, available on CPAN.
Configuration Steps
- Install Perl, if needed.
- Most Unix platforms, including Macintosh OSX, already have a Perl interpreter installed.
- Binaries are available here.
- Install the Query.pm Perl module from CPAN:
- perl -MCPAN -e "install LabKey::Query"
- To upgrade from a prior version of the module:
- perl -MCPAN -e "upgrade"
- NOTE: The module name has changed from Labkey::Query in 1.03 to LabKey::Query in 1.04. You may have to upgrade the module using the command: perl -MCPAN -e "install LABKEY/LabKey-Query-1.04.tar.gz"
- Create a .netrc or _netrc file in the home directory of the user running the Perl script.
- The netrc file provides credentials for the API to use to authenticate to the server, required to read or modify tables in secure folders.
Python API
 LabKey's Python APIs allow you to query, insert and update data on a LabKey Server from Python.
LabKey's Python APIs allow you to query, insert and update data on a LabKey Server from Python.
Documentation
- Python API - Docs for the most recent version on GitHub.
- Python API (Archive) - Docs for the older version in the LabKey doc archive.
Rlabkey Package
Overview
The LabKey client library for R makes it easy for R users to load live data from a LabKey Server into the R environment for analysis, provided users have permissions to read the data. It also enables R users to insert, update, and delete records stored on a LabKey Server, provided they have appropriate permissions to do so. The Rlabkey APIs use HTTP requests to communicate with a LabKey Server.All requests to the LabKey Server are performed under the user's account profile, with all proper security enforced on the server. User credentials are obtained from a separate location than the running R program so that R programs can be shared without compromising security.The Rlabkey library can be used from the following locations:- Within an instance of R external to LabKey
- Within the LabKey R interface.
- By scripts included in LabKey Modules
Documentation
- Rlabkey documentation (pdf)
- Rlabkey Users Guide
- Rlabkey Package Vignette
- Troubleshooting Rlabkey Connections
- For full documentation on using R on the LabKey platform, please see R Reports.
- For instructions on how to export an R script that recreates a LabKey grid view, see Export Data Grid as a Script.
Configuration Steps
Typical configuration steps for a user of Rlabkey include:- Install R from http://www.r-project.org/
- Install the Rlabkey package once using the following command in the R console. (You may want to change the value of repos depending on your geographical location.)
install.packages("Rlabkey", repos="http://cran.fhcrc.org")
- Load the Rlabkey library at the start of every R script using the following command:
library(Rlabkey)
- Create a .netrc or _netrc file to set up authentication.
- Necessary if you wish to modify a password-protected LabKey Server database through the Rlabkey macros.
- Note that Rlabkey handles sessionid and authentication internally. Rlabkey passes the sessionid as an HTTP header for all API calls coming from that R session. LabKey Server treats this just as it would a valid JSESSIONID parameter or cookie coming from a browser.
Scenarios
The Rlabkey package supports the transfer of data between a LabKey Server and an R session.- Retrieve data from LabKey into a data frame in R by specifying the query schema information (labkey.selectRows and getRows) or by using SQL commands (labkey.executeSql).
- Update existing data from an R session (labkey.updateRows).
- Insert new data either row by row (labkey.insertRows) or in bulk (labkey.importRows) via the TSV import API.
- Delete data from the LabKey database (labkey.deleteRows).
- Use Interactive R to discover available data via schema objects (labkey.getSchema).
- Connect to a LabKey Server.
- Use metadata queries to show which schemas are available within a specific project or sub-folder.
- Use metadata queries to show which datasets are available within a schema and query of interest in a folder.
- Create colSelect and colFilter parameters for the labkey.selectRows command on the selected schema and query.
- Retrieve a data frame of the data specified by the current url, folder, schema, and query context.
- Perform transformations on this data frame locally in your instance of R.
- Save a data frame derived from the one returned by the LabKey Server back into the LabKey Server.
Troubleshooting Rlabkey Connections
Diagnostic Tests
Check Basic Installation Information
The following will gather basic information about the R configuration on the server. Run the following in an R view. To create an R view: from any data grid, select Views > Create > R View.library(Rlabkey)
cat("Output of SessionInfo \n")
sessionInfo()
cat("\n\n\nOutput of Library Search path \n")
.libPaths()
Test HTTPS Connection
The following confirms that R can make a HTTPS connection to known good server. Run the following in an R View:library(Rlabkey)
cat("\n\nAttempt a connection to Google. If it works, print first 200 characters of website. \n")
x = getURLContent("https://www.google.com")
substring(x,0,200)
Diagnose RCurl or Rlabkey
Next check if the problem is coming from the RCurl library or the Rlabkey library. Run the following in an R View, replacing "DOMAIN.org" with your server:library(Rlabkey)
cat("\n\n\nAttempt a connection to DOMAIN.org using only RCurl. If it works, print first 200 characters of website. \n")
y = getURLContent("https://DOMAIN.org:8443")
substring(y,0,200)
Certificate Test
The 4th test is to have R ignore any problems with certificate name mis-matches and certificate chain integrity (that is, using a self-signed certificate or the certificate is signed by a CA that the R program does not trust. In an R view, add the following line after library(Rlabkey)labkey.setCurlOptions(ssl.verifypeer=FALSE, ssl.verifyhost=FALSE)
openssl s_client -showcerts -connect DOMAIN.org:8443
Common Issues
TLSv1 Protocol Replaces SSLv3
By default, Rlabkey will connect to LabKey Server using the TLSv1 protocol. If your attempt to connect fails, you might see an error message similar to one of these:Error in function (type, msg, asError = TRUE) :
error:1408F10B:SSL routines:SSL3_GET_RECORD:wrong version number
Error in function (type, msg, asError = TRUE) :
error:1411809D:SSL routines:SSL_CHECK_SERVERHELLO_TLSEXT:tls invalid ecpointformat list
labkey.setCurlOptions(sslversion=1)
(Windows) Failure to Connect
Rlabkey uses the package RCurl to connect to the LabKey Server. On Windows, older versions of the RCurl package are not configured for SSL by default. In order to connect, you may need to perform the following steps:1. Create or download a "ca-bundle" file.We recommend using ca-bundle file that is published by Mozilla. See http://curl.haxx.se/docs/caextract.html. You have two options:- Download the ca-bundle.crt file from the link named "HTTPS from github:" on http://curl.haxx.se/docs/caextract.html
- Create your own ca-bundle.crt file using the instructions provided on http://curl.haxx.se/docs/caextract.html
- create a directory named `labkey` in your home directory
- copy the ca-bundle.crt into the `labkey` directory
- create a directory named `c:\labkey`
- copy the ca-bundle.crt into the `c:\labkey` directory
- Select Computer from the Start menu.
- Choose System Properties from the context menu.
- Click Advanced system settings > Advanced tab.
- Click on Environment Variables.
- Under System Variables click on the new button.
- For Variable Name: enter RLABKEY_CAINFO_FILE
- For Variable Value: enter the path of the ca-bundle.crt you created above.
- Hit the Ok buttons to close all the windows.
- Drag the Mouse pointer to the Right bottom corner of the screen.
- Click on the Search icon and type: Control Panel.
- Click on -> Control Panel -> System and Security.
- Click on System -> Advanced system settings > Advanced tab.
- In the System Properties Window, click on Environment Variables.
- Under System Variables click on the new button.
- For Variable Name: enter RLABKEY_CAINFO_FILE
- For Variable Value: enter the path of the ca-bundle.crt you created above.
- Hit the Ok buttons to close all the windows.
Self-Signed Certificate Authentication
If you are using a self-signed certificate, and connecting via HTTPS on a Mac or Linux machine, you may see the following issues as Rlabkey attempts unsuccessfully to validate that certificate.Peer Verification
If you see an error message that looks like the following, you can tell Rlabkey to ignore any failures when checking if the server's SSL certificate is authentic.> rows <- labkey.selectRows(baseUrl="https://SERVERNAME", folderPath="home",schemaName="lists", queryName="myFavoriteList")
Error in function (type, msg, asError = TRUE) :
SSL certificate problem, verify that the CA cert is OK. Details:
error:14090086:SSL routines:SSL3_GET_SERVER_CERTIFICATE:certificate verify failed
labkey.setCurlOptions(ssl.verifypeer=FALSE)
Certificate Name Conflict
It is possible to tell Rlabkey to ignore any failures when checking if the server's name used in baseURL matches the one specified in the SSL certificate. An error like the following could occur when the name on the certificate is different than the SERVERNAME used.> rows <- labkey.selectRows(baseUrl="https://SERVERNAME", folderPath="home",schemaName="lists", queryName="ElispotPlateReader")
Error in function (type, msg, asError = TRUE) :
SSL peer certificate or SSH remote key was not OK
labkey.setCurlOptions(ssl.verifyhost=FALSE)
Troubleshoot .netrc / _netrc Files
For details see: Create a .netrc or _netrc fileSAS Macros
Introduction
The LabKey Client API Library for SAS makes it easy for SAS users to load live data from a LabKey Server into a native SAS dataset for analysis, provided they have permissions to read those data. It also enables SAS users to insert, update, and delete records stored on a LabKey Server, provided they have appropriate permissions to do so.All requests to the LabKey Server are performed under the user's account profile, with all proper security enforced on the server. User credentials are obtained from a separate location than the running SAS program so that SAS programs can be shared without compromising security.The SAS macros use the Java Client Library to send, receive, and process requests to the server. They provide functionality similar to the Rlabkey Package.Topics
- SAS Setup
- SAS Macros
- SAS Security
- SAS Demos
- Export Data Grid as a Script. You can export a SAS script that will recreate a grid view.
Related Topics
Downloads
SAS Setup
Set up SAS to use the SAS/LabKey Interface
The LabKey/SAS client library is a set of SAS macros that retrieve data from an instance of LabKey Server as SAS data sets. The SAS macros use the Java Client Library to send, receive, and process requests to the server.Configure your SAS installation to use the SAS/LabKey interface:- Install SAS
- Retrieve the latest ClientAPI-SAS.zip file (e.g., LabKey15.3-41022.16-ClientAPI-SAS.zip) from the "All Downloads" tab on the LabKey Server download page.
- Extract this file to a local directory (these instructions assume "c:\sas"). The directory should contain a number of .jar files (the Java client library and its dependencies) and 12 .sas files (the SAS macros).
- Open your default SAS configuration file, sasv9.cfg (e.g., in c:\Program Files\SASHome\x86\SASFoundation\9.3\nls\en)
- In the -SET SASAUTOS section, add the path to the SAS macros to the end of the list (e.g., "C:\sas")
- Configure your Java Runtime Environment (JRE) based on your SAS version:
- Instructions for SAS 9.1.x (NO LONGER SUPPORTED)
- SAS 9.1.x installs a 1.4 JRE; you must install a 7.0 JRE and change -Dsas.jre.home= to point to it
- In the JREOPTIONS section of sasv9.cfg, add -Dsas.app.class.path= full paths to all .jar files separated by ;
- Instructions for SAS 9.2 (NO LONGER SUPPORTED)
- SAS 9.2 installs a 5.0 JRE; you must install a 7.0 JRE and change -Dsas.jre.home= to point to it
- Set the system CLASSPATH environment variable to the full paths to all jar files separated by ;
- Instructions for SAS 9.3
- Install the SAS update TS1M2, in order to run it with Java 7, instead of Java 6 (which is the default for SAS 9.3)
- Near the top of sasv9.cfg, add -set classpath "<full paths to all .jar files separated by ; (on Windows) or : (on Mac)>" (see below)
- Instructions for SAS 9.4
- No configuration of the Java runtime is necessary on SAS 9.4 since it runs a private Java 7 JRE, installed in the SASHOME directory
- Near the top of sasv9.cfg, add -set classpath "<full paths to all .jar files separated by ; (on Windows) or : (on Mac)>"; (see below)
-set classpath "C:\sas\commons-codec-1.6.jar;C:\sas\commons-logging-1.1.3.jar;C:\sas\fluent-hc-4.3.5.jar;C:\sas\httpclient-4.3.5.jar;C:\sas\httpclient-cache-4.3.5.jar;
C:\sas\httpcore-4.3.2.jar;C:\sas\httpmime-4.3.5.jar;C:\sas\json_simple-1.1.jar;C:\sas\opencsv-2.0.jar;C:\sas\labkey-client-api-15.2.jar"-set classpath "/sas/commons-codec-1.6.jar:/sas/commons-logging-1.1.3.jar:/sas/fluent-hc-4.3.5.jar:/sas/httpclient-4.3.5.jar:/sas/httpclient-cache-4.3.5.jar:
/sas/httpcore-4.3.2.jar:/sas/httpmime-4.3.5.jar:/sas/json_simple-1.1.jar:/sas/opencsv-2.0.jar:/sas/labkey-client-api-15.2.jar"- On your local version of LabKey Server, configure a list called "People" in your home folder and import demo.xls to populate it with data
- Configure your .netrc or _netrc file in your home directory. For further information, see: Create a .netrc or _netrc file.
- Run SAS
- Execute "proc javainfo; run;" in a program editor; this command should display detailed information about the java environment in the log. Verify that java.version matches the JRE you set above.
- Load demo.sas
- Run it
Related Topics
External SAS Data Sources.SAS Macros
SAS/LabKey Library
The SAS/LabKey client library provides a set of SAS macros that retrieve data from an instance of LabKey Server as SAS data sets and allows modifications to LabKey Server data from within SAS. All requests to the LabKey Server are performed under the user's account profile, with all proper security enforced on the server.The SAS macros use the Java Client Library to send, receive and process requests to the server. This page lists the SAS macros, parameters and usage examples.Related topics:The %labkeySetDefaults Macro
The %labkeySetDefaults macro sets connection information that can be used for subsequent requests. All parameters set via %labkeySetDefaults can be set once via %labkeySetDefaults, or passed individually to each macro.The %labkeySetDefaults macro allows the SAS user to set the connection information once regardless of the number of calls made. This is convenient for developers, who can write more maintainable code by setting defaults once instead of repeatedly setting these parameters.Subsequent calls to %labkeySetDefaults will change any defaults set with an earlier call to %labkeySetDefaults.%labkeySetDefaults accepts the following parameters:| Name | Type | Required? | Description |
|---|---|---|---|
| baseUrl | string | n | The base URL for the target server. This includes the protocol (http, https) and the port number. It will also include the context path (commonly “/cpas” or “/labkey”), unless LabKey Server has been deployed as the root context. Example: "http://localhost:8080/labkey" |
| folderPath | string | n | The LabKey Server folder path in which to execute the request |
| schemaName | string | n | The name of the schema to query |
| queryName | string | n | The name of the query to request |
| userName | string | n | The user's login name. Note that the NetRC file includes both the userName and password. It is best to use the values stored there rather than passing these values in via a macro because the passwords will show up in the log files, producing a potential security hole. However, for chron jobs or other automated processes, it may be necessary to pass in userName and password via a macro parameter. |
| password | string | n | The user's password. See userName (above) for further details. |
| containerFilter | string | n | This parameter modifies how the query treats the folder. The possible settings are listed below. If not specified, "Current" is assumed. |
- Current -- The current container
- CurrentAndSubfolders -- The current container and any folders it contains
- CurrentPlusProject -- The current container and the project folder containing it
- CurrentAndParents -- The current container and all of its parent containers
- CurrentPlusProjectAndShared -- The current container, its project folder and all shared folders
- AllFolders -- All folders to which the user has permission
%labkeySetDefaults(baseUrl="http://localhost:8080/labkey", folderPath="/home",
schemaName="lists", queryName="People");
The %labkeySelectRows Macro
The %labkeySelectRows macro allows you to select rows from any given schema and query name, optionally providing sorts, filters and a column list as separate parameters.Parameters passed to an individual macro override the values set with %labkeySetDefaults.Parameters are listed as required when they must be provided either as an argument to %labkeySelectRows or through a previous call to %labkeySetDefaults.This macro accepts the following parameters:| Name | Type | Required? | Description |
|---|---|---|---|
| dsn | string | y | The name of the SAS dataset to create and populate with the results |
| baseUrl | string | y | The base URL for the target server. This includes the protocol (http, https), the port number, and optionally the context path (commonly “/cpas” or “/labkey”). Example: "http://localhost:8080/labkey" |
| folderPath | string | y | The LabKey Server folder path in which to execute the request |
| schemaName | string | y | The name of the schema to query |
| queryName | string | y | The name of the query to request |
| viewName | string | n | The name of a saved custom grid view of the given schema/query. If not supplied, the default grid will be returned. |
| filter | string | n | One or more filter specifications created using the %makeFilter macro |
| columns | string | n | A comma-delimited list of column name to request (if not supplied, the default set of columns are returned) |
| sort | string | n | A comma-delimited list of column names to sort by. Use a “-“ prefix to sort descending. |
| maxRows | number | n | If set, this will limit the number of rows returned by the server. |
| rowOffset | number | n | If set, this will cause the server to skip the first N rows of the results. This, combined with the maxRows parameter, enables developers to load portions of a dataset. |
| showHidden | 1/0 | n | By default hidden columns are not included in the dataset, but the SAS user may pass 1 for this parameter to force their inclusion. Hidden columns are useful when the retrieved dataset will be used in a subsequent call to %labkeyUpdate or %labkeyDetele. |
| userName | string | n | The user's login name. Please see the %labkeySetDefaults section for further details. |
| password | string | n | The user's password. Please see the %labkeySetDefaults section for further details. |
| containerFilter | string | n | This parameter modifies how the query treats the folder. The possible settings are listed in the %labkeySetDefaults macro section. If not specified, "Current" is assumed. |
%labkeySelectRows(dsn=all, baseUrl="http://localhost:8080/labkey",
folderPath="/home", schemaName="lists", queryName="People");
%labkeySetDefaults(baseUrl="http://localhost:8080/labkey", folderPath="/home",
schemaName="lists", queryName="People");
%labkeySelectRows(dsn=all2);
%labkeySelectRows(dsn=limitRows, columns="First, Last, Age",
sort="Last, -First", maxRows=3, rowOffset=1);
The %labkeyMakeFilter Macro
The %labkeyMakeFilter macro constructs a simple compare filter for use in the %labkeySelectRows macro. It can take one or more filters, with the parameters listed in triples as the arguments. All operators except "MISSING and "NOT_MISSING" require a "value" parameter.| Name | Type | Required? | Description |
|---|---|---|---|
| column | string | y | The column to filter upon |
| operator | string | y | The operator for the filter. See below for a list of acceptable operators. |
| value | any | y | The value for the filter. Not used when the operator is "MISSING" or "NOT_MISSING". |
- EQUAL
- NOT_EQUAL
- NOT_EQUAL_OR_MISSING
- DATE_EQUAL
- DATE_NOT_EQUAL
- MISSING
- NOT_MISSING
- GREATER_THAN
- GREATER_THAN_OR_EQUAL
- LESS_THAN
- LESS_THAN_OR_EQUAL
- CONTAINS
- DOES_NOT_CONTAIN
- STARTS_WITH
- DOES_NOT_START_WITH
- IN
- NOT_IN
- CONTAINS_ONE_OF
- CONTAINS_NONE_OF
/* Specify two filters: only males less than a certain height. */
%labkeySelectRows(dsn=shortGuys, filter=%labkeyMakeFilter("Sex", "EQUAL", 1,
"Height", "LESS_THAN", 1.2));
proc print label data=shortGuys; run;
/* Demonstrate an IN filter: only people whose age is specified. */
%labkeySelectRows(dsn=lateThirties, filter=%labkeyMakeFilter("Age",
"IN", "36;37;38;39"));
proc print label data=lateThirties; run;
/* Specify a grid and a not missing filter. */
%labkeySelectRows(dsn=namesByAge, viewName="namesByAge",
filter=%labkeyMakeFilter("Age", "NOT_MISSING"));
proc print label data=namesByAge; run;
The %labkeyExecuteSql Macro
The %labkeyExecuteSql macro allows SAS users to execute arbitrary LabKey SQL, filling a SAS dataset with the results.Required parameters must be provided either as an argument to %labkeyExecuteSql or via a previous call to %labkeySetDefaults.This macro accepts the following parameters:| Name | Type | Required? | Description |
|---|---|---|---|
| dsn | string | y | The name of the SAS dataset to create and populate with the results |
| sql | string | y | The LabKey SQL to execute |
| baseUrl | string | y | The base URL for the target server. This includes the protocol (http, https), the port number, and optionally the context path (commonly “/cpas” or “/labkey”). Example: "http://localhost:8080/labkey" |
| folderPath | string | y | The folder path in which to execute the request |
| schemaName | string | y | The name of the schema to query |
| maxRows | number | n | If set, this will limit the number of rows returned by the server. |
| rowOffset | number | n | If set, this will cause the server to skip the first N rows of the results. This, combined with the maxrows parameter, enables developers to load portions of a dataset. |
| showHidden | 1/0 | n | Please see description in %labkeySelectRows. |
| userName | string | n | The user's login name. Please see the %labkeySetDefaults section for further details. |
| password | string | n | The user's password. Please see the %labkeySetDefaults section for further details. |
| containerFilter | string | n | This parameter modifies how the query treats the folder. The possible settings are listed in the %labkeySetDefaults macro section. If not specified, "Current" is assumed. |
/* Set default parameter values to use in subsequent calls. */
%labkeySetDefaults(baseUrl="http://localhost:8080/labkey", folderPath="/home",
schemaName="lists", queryName="People");
/* Query using custom SQL… GROUP BY and aggregates in this case. */
%labkeyExecuteSql(dsn=groups, sql="SELECT People.Last, COUNT(People.First)
AS Number, AVG(People.Height) AS AverageHeight, AVG(People.Age)
AS AverageAge FROM People GROUP BY People.Last");
proc print label data=groups; run;
/* Demonstrate UNION between two different data sets. */
%labkeyExecuteSql(dsn=combined, sql="SELECT MorePeople.First, MorePeople.Last
FROM MorePeople UNION SELECT People.First, People.Last FROM People ORDER BY 2");
proc print label data=combined; run;
The %labkeyInsertRows, %labkeyUpdateRows and %labkeyDeleteRows Macros
The %labkeyInsertRows, %labkeyUpdateRows and %labkeyDeleteRows macros are all quite similar. They each take a SAS dataset, which may contain the data for one or more rows to insert/update/delete.Required parameters must be provided either as an argument to %labkeyInsert/Update/DeleteRows or via a previous call to %labkeySetDefaults.Parameters:| Name | Type | Required? | Description |
|---|---|---|---|
| dsn | dataset | y | A SAS dataset containing the rows to insert/update/delete |
| baseUrl | string | y | The base URL for the target server. This includes the protocol (http, https), the port number, and optionally the context path (commonly “/cpas” or “/labkey”). Example: "http://localhost:8080/labkey" |
| folderpath | string | y | The folder path in which to execute the request |
| schemaName | string | y | The name of the schema |
| queryName | string | y | The name of the query within the schema |
| userName | string | n | The user's login name. Please see the %labkeySetDefaults section for further details. |
| password | string | n | The user's password. Please see the %labkeySetDefaults section for further details. |
/* Set default parameter values to use in subsequent calls. */
%labkeySetDefaults(baseUrl="http://localhost:8080/labkey", folderPath="/home",
schemaName="lists", queryName="People");
data children;
input First : $25. Last : $25. Appearance : mmddyy10. Age Sex Height ;
format Appearance DATE9.;
datalines;
Pebbles Flintstone 022263 1 2 .5
Bamm-Bamm Rubble 100163 1 1 .6
;
/* Insert the rows defined in the children data set into the "People" list. */
%labkeyInsertRows(dsn=children);
Quality Control Values
The SAS library accepts special values in datasets as indicators of the quality control status of data. The QC values currently available are:- 'Q': Data currently under quality control review
- 'N': Required field marked by site as 'data not available'
SAS Security
SAS Demos
Simple Demo
You can select Export > Script > SAS above most query views to export a script that selects the columns shown in any view. For example, performing this operation on the custom grid shown here: Grid View: Join for Cohort Views in the Demo Study produces the following SQL:
For example, performing this operation on the custom grid shown here: Grid View: Join for Cohort Views in the Demo Study produces the following SQL:%labkeySelectRows(dsn=mydata,
baseUrl="https://www.labkey.org",
folderPath="/home/Study/demo",
schemaName="study",
queryName="Lab Results",
viewName="Grid View: Join for Cohort Views");
Full SAS Demo
The sas-demo.zip archive attached to this page provides a SAS script and Excel data files. You can use these files to explore the selectRows, executeSql, insert, update, and delete operations of the SAS/LabKey Library.Steps for setting up the demo:- Make sure that you or your admin has Set Up SAS on your LabKey Server.
- Make sure that you or your admin has set up a .netrc file to provide you with appropriate permissions to insert/update/delete. For further information, see Create a .netrc or _netrc file.
- Download and unzip the demo files: sas-demo.zip. The zip folder contains a SAS demo script (demo.sas) and two data files (People.xls and MorePeople.xls). The spreadsheets contain demo data that goes with the script.
- Add the "Lists" web part to a portal page of a folder on your LabKey Server if it has not yet been added to the page.
- Create a new list called “People” and choose the “Import from file” option at list creation time to infer the schema and populate the list from People.xls.
- Create a second list called “MorePeople” and “Import from file” using MorePeople.xls.
- Change the two references to baseUrl and folderPath in the demo.sas to match your server and folder.
- Run the demo.sas script in SAS.
HTTP Interface
Topics
- Overview
- Calling API Actions from Client Applications and Scripts
- Query Controller API Actions
- Project Controller API Actions
- Assay Controller API Actions
- Troubleshooting Tips
Overview
If a client library does not yet exist for the language of your choice, you can interact with a LabKey Server through HTTP requests from the client-side language of your source (e.g., PHP). However, using a client library is strongly recommended.The HTTP Interface exposes a set of URLs (or "links") that return raw data instead of nicely-formatted HTML (or "web") pages. These may be called from any program capable of making an HTTP request and decoding the JSON format used for the response (e.g., C++, C#, etc.).This document describes the API actions that can be used by HTTP requests, detailing their URLs, inputs and outputs. For information on using the JavaScript helper objects within web pages, see JavaScript API. For an example of using the HTTP Interface from Perl, see Example: Access APIs from Perl.Calling API Actions from Client Applications and Scripts
The API actions documented below may be used by any client application or script capable of making an HTTP request and handling the response. Consult your programming language’s or operating environment’s documentation for information on how to submit an HTTP request and process the response. Most languages include support classes that make this rather simple.Several actions accept or return information in the JavaScript Object Notation (JSON) format, which is widely supported in most modern programming languages. See http://json.org for information on the format, and to obtain libraries/plug-ins for most languages.Most of the API actions require the user to be logged in so that the correct permissions can be evaluated. Therefore, client applications and scripts must first make an HTTP POST request to the LabKey login handler. To login, do an HTTP POST request for the following URL:http://<MyServer>/<LabkeyRoot>/login/login.post
email=<UserEmailAddress>&password=<UserPassword>
Query Controller API Actions
selectRows ActionThe selectRows action may be used to obtain any data visible through LabKey’s standard query grid views.Example URL:http://<MyServer>/labkey/query/<MyProj>/selectRows.api?schemaName=lists&query.queryName=my%20list
| Parameter | Description |
| schemaName | Name of a public schema. |
| query.queryName | Name of a valid query in the schema. |
| query.viewName | (Optional) Name of a valid custom grid view for the chosen queryName. |
| query.columns | (Optional) A comma-delimited list of column names to include in the results. You may refer to any column available in the query, as well as columns in related tables using the 'foreign-key/column' syntax (e.g., 'RelatedPeptide/Protein'). If not specified, the default set of visible columns will be returned. |
| query.maxRows | (Optional) Maximum number of rows to return (defaults to 100) |
| query.offset | (Optional) The row number at which results should begin. Use this with maxRows to get pages of results. |
| query.showAllRows | (Optional) Include this parameter, set to true, to get all rows for the specified query instead of a page of results at a time. By default, only a page of rows will be returned to the client, but you may include this parameter to get all the rows on the first request. If you include the query.showAllRows parameter, you should not include the query.maxRows nor the query.offset parameters. Reporting applications will typically set this parameter to true, while interactive user interfaces may use the query.maxRows and query.offset parameters to display only a page of results at a time. |
| query.sort | (Optional) Sort specification. This can be a comma-delimited list of column names, where each column may have an optional dash (-) before the name to indicate a descending sort. |
| query.<column-name>~<oper>=<value> | (Optional) Filter specification. You may supply multiple parameters of this type, and all filters will be combined using AND logic. The list of valid operators are as follows: eq = equals neq = not equals gt = greater-than gte = greater-than or equal-to lt = less-than lte = less-than or equal-to dateeq = date equal (visitdate~dateeq=2001-01-01 is equivalent to visitdate >= 2001-01-01:00:00:00 and visitdate < 2001-01-02:00:00:00) dateneq = date not equal neqornull = not equal or null isblank = is null isnonblank = is not null contains = contains doesnotcontain = does not contain startswith = starts with doesnotstartwith = does not start with in = equals one of a semi-colon delimited list of values ('a;b;c'). For example, query.BodyTemperature~gt=98.6 |
- metaData
- columnModel
- rows
- rowCount
| Property | Description |
| root | The name of the property containing rows (“rows”). This is mainly for the Ext grid component. |
| totalProperty | The name of the top-level property containing the row count (“rowCount”) in our case. This is mainly for the Ext grid component. |
| sortInfo | The sort specification in Ext grid terms. This contains two sub-properties, field and direction, which indicate the sort field and direction (“ASC” or “DESC”) respectively. |
| id | The name of the primary key column. |
| fields | an array of field information. name = name of the field type = JavaScript type name of the field lookup = if the field is a lookup, there will be three sub-properties listed under this property: schema, table, and column, which describe the schema, table, and display column of the lookup table (query). |
http://<MyServer>/labkey/query/<MyProj>/updateRows.api
{"schemaName": "lists",
"queryName": "Names",
"rows": [
{"Key": 5,
"FirstName": "Dave",
"LastName": "Stearns"}
]
}{ "schemaName": "lists",
"queryName": "Names",
"command": "update",
"rowsAffected": 1,
"rows": [
{"Key": 5,
"FirstName": "Dave",
"LastName": "Stearns"}
]
}- schemaName
- queryName
- command
- rowsAffected
- rows
http://<MyServer>/labkey/query/<MyProj>/insertRows.api
http://<MyServer>/labkey/query/<MyProj>/deleteRows.api
http://<MyServer>/labkey/query/<MyProj>/executeSql.api
{
schemaName: 'study',
sql: 'select MyDataset.foo, MyDataset.bar from MyDataset'
}Project Controller API Actions
getWebPart ActionThe getWebPart action allows the client to obtain the HTML for any web part, suitable for placement into a <div> defined within the current HTML page.Example URL:http://<MyServer>/labkey/project/<MyProj>/getWebPart.api?webpart.name=Wiki&name=home
Assay Controller API Actions
assayList ActionThe assayList action allows the client to obtain a list of assay definitions for a given folder. This list includes all assays visible to the folder, including those defined at the folder and project level.Example URL:http://<MyServer>/labkey/assay/<MyProj>/assayList.api
| Property | Description |
| Name | String name of the assay |
| id | Unique integer ID for the assay. |
| Type | String name of the assay type. "ELISpot", for example. |
| projectLevel | Boolean indicating whether this is a project-level assay. |
| description | String containing the assay description. |
| plateTemplate | String containing the plate template name if the assay is plate based. Undefined otherwise. |
| domains | An object mapping from String domain name to an array of domain property objects. (See below.) |
| Property | Description |
| name | The String name of the property. |
| typeName | The String name of the type of the property. (Human readable.) |
| typeURI | The String URI uniquely identifying the proeprty type. (Not human readable.) |
| label | The String property label. |
| description | The String property description. |
| formatString | The String format string applied to the property. |
| required | Boolean indicating whether a value is required for this property. |
| lookupContainer | If this property is a lookup, this contains the String path to the lookup container or null if the lookup in the same container. Undefined otherwise. |
| lookupSchema | If this property is a lookup, this contains the String name of the lookup schema. Undefined otherwise. |
| lookupQuery | If this property is a lookup, this contains the String name of the lookup query. Undefined otherwise. |
Troubleshooting Tips
If you hit an error, here are a few "obvious" things to check:Spaces in Parameter Names. If the name of any parameter used in the URL contains a space, you will need to use "%20" or "+" instead of the space.Controller Names: "project" vs. "query" vs "assay." Make sure your URL uses the controller name appropriate for your chosen action. Different actions are provided by different controllers. For example, the "assay" controller provides the assay API actions while the "project" controller provides the web part APIs.Container Names. Different containers (projects and folders) provide different schemas, queries and grid views. Make sure to reference the correct container for your query (and thus your data) when executing an action.Capitalization. The parameters schemaName, queryName and viewName are case sensitive.Examples: Controller Actions
Overview
This page provides a supplemental set of examples to help you get started using the HTTP Interface.Topics:- The API Test Tool. Use the API Test Tool to perform HTTP "Get" and "Post" operations.
- Define a List. Design and populate a List for use in testing the Action APIs.
- Query Controller API Actions:
- getQuery Action
- updateRows Action
- insertRows Action
- deleteRows Action
- Project Controller API Actions:
- getWebPart Action
- Assay Controller API Actions:
- assayList Action
The API Test Tool
Please note that only admins have access to the API Test Tool. To reach the test screen for the HTTP Interface, enter the following URL in your browser, substituting the name of your server for "<MyServer>" and the name of your project for "<MyProject>:"http://<MyServer>/labkey/query/<MyProject>/apiTest.view?
Define a List
You will need a query table that can be used to exercise the HTTP Interface. In this section, we create and populate a list to use as our demo query table.Steps to design the list:- You will need to add the "Lists" web part via the Select Web Parts dropdown menu at the bottom of the page.
- Click the "Manage Lists" link in the new Lists web part.
- Click "Create a New List."
- Name the list "API Test List" and retain default parameters.
- Click "Create List."
- Now add properties to this list by clicking the "edit fields" link.
- Add two properties:
- FirstName - a String
- Age - an Integer
- Click "Save"
- Name: API Test List
- Key Type: Auto-Increment Integer
- Key Name: Key
- Other fields in this list:
- FirstName: String
- Age: Integer
- Click the "upload list items" link on the same page where you see the list definition.
- Paste the information in the following table into the text box:
| FirstName | Age |
|---|---|
| A | 10 |
| C | 20 |
Query Controller API Actions: getQuery Action
The getQuery action may be used to obtain any data visible through LabKey’s standard query views.Get Url:/labkey/query/home/getQuery.api?schemaName=lists&query.queryName=API%20Test%20List
{
"rows": [
{
"Key": 1,
"FirstName": "A",
"Age": 10
},
{
"Key": 2,
"FirstName": "B",
"Age": 20
}
],
"metaData": {
"totalProperty": "rowCount",
"root": "rows",
"fields": [
{
"type": "string",
"name": "FirstName"
},
{
"type": "int",
"name": "Age"
},
{
"type": "int",
"name": "Key"
}
],
"id": "Key"
},
"rowCount": 2,
"columnModel": [
{
"editable": true,
"width": "200",
"required": false,
"hidden": false,
"align": "left",
"header": "First Name",
"dataIndex": "FirstName",
"sortable": true
},
{
"editable": true,
"width": "60",
"required": false,
"hidden": false,
"align": "right",
"header": "Age",
"dataIndex": "Age",
"sortable": true
},
{
"editable": false,
"width": "60",
"required": true,
"hidden": true,
"align": "right",
"header": "Key",
"dataIndex": "Key",
"sortable": true
}
],
"schemaName": "lists",
"queryName": "API Test List"
}Query Controller API Actions: updateRows Action
The updateRows action allows clients to update rows in a list or user-defined schema. This action may not be used to update rows returned from queries to other LabKey module schemas (e.g., ms1, ms2, flow, etc). To interact with data from those modules, use API actions in their respective controllers.Post Url:/labkey/query/home/updateRows.api?
{ "schemaName": "lists",
"queryName": "API Test List",
"rows": [
{"Key": 1,
"FirstName": "Z",
"Age": "100"}]
}{
"keys": [1],
"command": "update",
"schemaName": "lists",
"rowsAffected": 1,
"queryName": "API Test List"
}| FirstName | Age |
|---|---|
| Z | 100 |
| B | 20 |
Query Controller API Actions: insertRows Action
Post Url:/labkey/query/home/insertRows.api?
{ "schemaName": "lists",
"queryName": "API Test List",
"rows": [
{"FirstName": "C",
"Age": "30"}]
}{
"keys": [3],
"command": "insert",
"schemaName": "lists",
"rowsAffected": 1,
"queryName": "API Test List"
}| FirstName | Age |
|---|---|
| Z | 100 |
| B | 20 |
| C | 30 |
Query Controller API Actions: deleteRows Action
Post Url:/labkey/query/home/deleteRows.api?
{ "schemaName": "lists",
"queryName": "API Test List",
"rows": [
{"Key": 3}]
}{
"keys": [3],
"command": "delete",
"schemaName": "lists",
"rowsAffected": 1,
"queryName": "API Test List"
}| FirstName | Age |
|---|---|
| Z | 100 |
| B | 20 |
Project Controller API Actions: getWebPart Action
NB: Remember, the URL of Project Controller actions includes "project" instead of "query," in contrast to the Query Controller Actions described above.Lists. The web part we created when we created our list:/labkey/project/<MyProject>/getWebPart.api?webpart.name=Lists
 Wiki. Web parts can take the name of a particular page as a parameter, in this case the page named "home":
Wiki. Web parts can take the name of a particular page as a parameter, in this case the page named "home":/labkey/project/<MyProject>/getWebPart.api?webpart.name=Wiki&name=home
/labkey/project/home/getWebPart.api?webpart.name=Assay%20List
Example: Access APIs from Perl
#!/usr/bin/perl -w
use strict;
# Fetch some information from a LabKey server using the client API
my $email = 'user@labkey.com';
my $password = 'mypassword';
use LWP::UserAgent;
use HTTP::Request;
my $ua = new LWP::UserAgent;
$ua->agent("Perl API Client/1.0");
# Setup variables
# schemaName should be the name of a valid schema.
# The "lists" schema contains all lists created via the List module
# queryName should be the name of a valid query within that schema.
# For a list, the query name is the name of the list
# project should be the folder path in which the data resides.
# Use a forward slash to separate the path
# host should be the domain name of your LabKey server
# labkeyRoot should be the root of the LabKey web site
# (if LabKey is installed on the root of the site, omit this from the url)
my $schemaName="lists";
my $queryName="MyList";
my $project="MyProject/MyFolder/MySubFolder";
my $host="localhost:8080";
my $labkeyRoot = "labkey";
my $protocol="http";
#build the url to call the selectRows.api
#for other APIs, see the example URLs in the HTTP Interface documentation at
#https://www.labkey.org/wiki/home/Documentation/page.view?name=remoteAPIs
my $url = "$protocol://$host/$labkeyRoot/query/$project/" .
"selectRows.api?schemaName=$schemaName&query.queryName=$queryName";
#Fetch the actual data from the query
my $request = HTTP::Request->new("GET" => $url);
$request->authorization_basic($email, $password);
my $response = $ua->request($request);
# use JSON 2.07 to decode the response: This can be downloaded from
# http://search.cpan.org/~makamaka/JSON-2.07/
use JSON;
my $json_obj = JSON->new->utf8->decode($response->content);
# the number of rows returned will be in the 'rowCount' propery
print $json_obj->{rowCount} . " rows:n";
# and the rows array will be in the 'rows' property.
foreach my $row(@{$json_obj->{rows}}){
#Results from this particular query have a "Key" and a "Value"
print $row->{Key} . ":" . $row->{Value} . "n";
}
Compliant Access via Session Key
Configure Session Keys
- Select Admin > Site > Admin Console.
- Under "Configuration", click Site Settings.
- Under "Configure Security", check the box for Allow API session keys.

- Click Save.
Access and Use a Session Key
Once enabled, the user can log in, providing all the necessary compliance information, then retrieve their unique session key from the username pulldown menu: The session ID is a long, randomly generated token that is valid for only this single browser session. Click Copy to Clipboard to grab it. Then click Done.You can then paste this key into a script or other API access of data. Your use of the data will be logged with all the same data access information you provided when you logged in.For example, if you were accessing data via R, you could run the following command in your R interface to enable access to the protected data.
The session ID is a long, randomly generated token that is valid for only this single browser session. Click Copy to Clipboard to grab it. Then click Done.You can then paste this key into a script or other API access of data. Your use of the data will be logged with all the same data access information you provided when you logged in.For example, if you were accessing data via R, you could run the following command in your R interface to enable access to the protected data.labkey.setDefaults(apiKey="the_long_string_session_id_copied_from_clipboard")Video
Related Topics
Set up a Development Machine
- Checklist
- Obtain the LabKey Source Files
- Install Java, Tomcat, and a Database
- Environment Variables and System PATH
- Install IntelliJ IDEA
- Build and Run LabKey
- Post-installation Steps
- Modules on GitHub
- Install Optional Components
- Troubleshooting
Checklist
Obtain the LabKey Source Files
Install TortoiseSVN
- Download the latest version of TortoiseSVN.
- Install TortoiseSVN on your local computer.
- On the list of features to install, include the command line client tools.
- Add the TortoiseSVN/bin directory to your PATH.
Checkout LabKey Source Files
- Create a new directory in the Windows file system for the source files, for example, C:\dev\labkey\trunk
- In Windows Explorer, right-click the new directory and select SVN Checkout.
- Enter the URL for the LabKey repository: https://hedgehog.fhcrc.org/tor/stedi/trunk
- The user/password is cpas/cpas
- Click OK to checkout the source files. At this point all the LabKey source files, tests, and sample data will be copied to your computer.
Install Java, Tomcat, and a Database
Java
Download the Oracle JDK version 8 and install it.Tomcat
Download the most recent release of Tomcat 8.5.x. Download a ZIP or TAR.GZ distribution, not the Windows Service Installer. To install Tomcat, unzip it to a chosen directory (for example, C:\apache\tomcat).LabKey supports older versions of Tomcat as well; find more information about supported versions here. If using Tomcat 7.0.x, follow instructions on this page: Encoding in Tomcat 7Install a Database
Install one of the following database servers: PostgreSQL or Microsoft SQL ServerPlatform-specific installation instructions:Environment Variables and System PATH
JAVA_HOME
Create or modify the system environment variable JAVA_HOME so it points to your JDK installation location (for example, %ProgramFiles%\Java\jdk1.8.0_xx).If you've already set the JAVA_HOME variable to point to your installation of the JRE, you should modify it to point to the JDK.
CATALINA_HOME
Create or modify the system environment variable CATALINA_HOME so that it points to your Tomcat installation (for example, C:\apache\tomcat).PATH
Add the following locations to your system PATH, where LABKEY_HOME is the root of your SVN enlistment.- <LABKEY_HOME>/external/ant/bin
- <LABKEY_HOME>/build/deploy/bin (This directory won't exist yet, but add it to the PATH anyways.)
These directories contain Apache Ant for building the LabKey source, as well as a number of executable files used by LabKey.
The build process creates build/deploy/bin, so it may not exist initially.Apache Ant is included in the project as a convenience. If you have a recent version of Ant already installed you can use that instead. Ant 1.9.3 or newer is required to build.For example, on OSX, place the environment variables in your .bash_profile:
export JAVA_HOME=`/usr/libexec/java_home -v 1.8`
export CATALINA_HOME=$HOME/apps/tomcat
export LABKEY_HOME=$HOME/labkey/trunk
export LABKEY_GWT_USER_OVERRIDE="gwt-user-firefox"
export PATH=$LABKEY_HOME/external/ant/bin:$LABKEY_HOME/build/deploy/bin:$PATH
GWT_HOME
Installing and configuring GWT is required only if you plan to modify existing or develop new GWT components. If you do not plan to develop with GWT you can disable IntelliJ's notifications by going to File > Project Structure. Click Facets and disable framework detection (remove the checkmark at the top of the dialog).Open the LabKey Project in IntelliJ
Download and install IntelliJ IDEA.
Configure the LabKey Project in IntelliJ
- Create the workspace.xml file.
- Copy the file <LABKEY_HOME>/server/.idea/workspace.template.xml. Rename the copy to create a file called <LABKEY_HOME>/server/.idea/workspace.xml
- This file configures the debug information for LabKey project. To review the debug settings go to Run > Edit Configurations in IntelliJ.
- Open the LabKey project.
- Launch IntelliJ.
- If your IntelliJ install is brand new, you will see the "Welcome to IntelliJ" pop up screen. Click Open. If you have previously installed IntelliJ, select File > Open.
- Select the LabKey IntelliJ project directory, <LABKEY_HOME>/server
- Set CATALINA_HOME
- Select File > Settings > Appearance & Behavior > Path Variables.
- Click the green plus icon in the upper right. Set the CATALINA_HOME path variable to the root directory of your Tomcat installation, for example, C:\apache\apache-tomcat-8.0.28.
- Click OK to close the Settings window.
- Set the Classpath
- Select Run > Edit Configurations. (If the menu is greyed-out, wait until IntelliJ finishes indexing the project files.)
- Confirm that LabKey Development is the selected Application in the left panel.
- Confirm that the dropdown labeled Use classpath of module is set to LabKey.
- Click OK, to close the Run/Debug Configurations window.
- Configure the Target JDK
- In IntelliJ, select File > Project Structure.
- Under Project Settings, click Project.
- Under Project SDK click New and then click JDK.
- Browse to the path of your JDK, for example, (C:\Program Files (x86)\Java\jdk1.8.0_66), and click OK.
- Click Edit. Change the name of the JDK to "labkey".
- Click Ok to close the Project Structure window.
- Verify the Target JDK for Ant
- In IntelliJ, select View > Tool Windows > Ant Build.
- In the Ant Build panel (on the far right), click the Properties button (which is directly left of the Help question mark '?' button).
- Click the Execution tab.
- Verify that Use project default Ant is selected.
- Verify that Run under JDK drop-down is set to "Project JDK (labkey)".
- Click OK.
Build and Run LabKey
Configure the Appropriate .properties File
The LabKey source includes two configuration files, one for use with PostgreSQL (pg.properties) and one for use with Microsoft SQL Server (mssql.properties), each specifying JDBC settings, including URL, port, user name and password, etc.- If using PostgreSQL, open the file LABKEY_HOME/server/configs/pg.properties
- If using MS SQL Server, open the file LABKEY_HOME/server/configs/mssql.properties
- Edit the appropriate file, adding your values for the jdbcUser and jdbcPassword. (This password is the one you specified when installing PostgreSQL or MS SQL Server. If your password contains an ampersand or other special XML characters, you will need to escape it in the .properties file, as the value will be substituted into an XML template without encoding. For example, if your JDBC password is "this&that", then use the escaped version "this&that".)
Run pick_pg or pick_mssql
- In a command window, go to the directory LABKEY_HOME/server
- Run "ant pick_pg" or "ant pick_mssql" to configure labkey.xml with the corresponding database settings.
Build LabKey
To build LabKey, invoke the Ant build targets from the command line in the <LABKEY_HOME>/server directory.To control which modules are included in the build, see Customizing the Build.The most important targets:| Ant Targetooooooooooooooooo | Description |
|---|---|
| ant pick_pg ant pick_mssql | Specify the database server to use. The first time you build LabKey, you need to invoke one of these targets to configure your database settings. If you are running against PostgreSQL, invoke the pick_pg target. If you are running against SQL Server, invoke the pick_mssql target. These Ant targets copy the settings specified in the pg.properties or mssql.properties file, which you previously modified, to the LabKey configuration file, labkey.xml. |
| ant build | Build the LabKey Server source for development purposes. This is a fast, development-only build that skips many important steps needed for production environments, including GWT compilation for popular browsers, gzipping of scripts, production of Java & JavaScript API documentation, and copying of important resources to the deployment location. Builds produced by this target will not run in production mode. |
| ant <module_name> | For convenience, we've added targets to build each of the standard modules. If your changes are restricted to a single module then building just that module is a faster option than a full build. Examples: 'ant study', 'ant query', or 'ant api'. |
| ant production | Build the LabKey Server source for deployment to a production server. This build takes longer than ant build but results in artifacts that are suitable and optimized for production environments. |
| ant clean | Delete all artifacts from previous builds. |
| ant rebuild | Delete all artifacts from previous builds and build the LabKey Server from source. This build target is sometimes required after certain updates. |
Post-installation Steps
Install R
Install and configure the R programming languageRun the Basic Test Suite
Run the command 'ant drt' from within your <labkey-home>/server directory, to initiate automated tests of LabKey's basic functionality. Note that 'R' must first be configured for these tests to run. Other automated tests are available as Ant targets. For details, see Running Automated Tests.Modules on GitHub
Many optional modules are available from the LabKey repository on GitHub. To included these modules in your build, install a Git client and clone individual modules into the LabKey Server source.Install a Git Client
- Install GitHub, or another Git client:
Clone Modules from LabKey's GitHub Repository
- To add a GitHub module to your build, clone the desired module into trunk/labkey/server/optionalModules. For example, to add the 'workflow' module:
C:\svn\trunk\server\optionalModules>git clone https://github.com/LabKey/workflow.gitManage GitHub Modules via IntelliJ
Once you have cloned a GitHub module, you can have IntelliJ handle any updates:To add the GitHub-based module to IntelliJ:- In IntellJ, go to File > Project Structure.
- Under Project Settings, select Modules.
- Click the green plus sign (top of the second column) and select Import Module.
- Navigate to the module you've cloned from the GitHub repository and select its .iml file, for example, NLP.iml., and click OK.
- To have IntelliJ handle source updates from GitHub, go to File > Settings.
- Select Version Control.
- In the Directory panel, select the target module and set its VCS source as Git, if necessary.
- Note that IntelliJ will sometimes think that embedded 'test' modules have their sources in SVN instead of Git. You can safely delete these embedded 'test' modules using the Directory panel.
- To sync to a particular GitHub branch: in IntelliJ, go to VCS > Git > Branches. A popup menu will appear listing the available Git modules. Use the popup menu to select the branch to sync to.
Install Optional Components
GWT
Installing and configuring GWT is required only if you plan to modify existing or develop new Google Web Toolkit (GWT) components.Please see GWT Integration for instructions on installation and configuration of GWT.Mass Spec and Proteomics Tools
LabKey Server's mass spectrometry and proteomics binaries are provided as a separate (and optional) enlistment. To add these binaries, follow the instructions in the topic: Enlisting Proteomics BinariesTroubleshooting
1. Tomcat
If Tomcat fails to start successfully, check the steps above to ensure that you have configured your JDK and development environment correctly. Some common errors you may encounter include:org.postgresql.util.PSQLException: FATAL: password authentication failed for user "<username>" or java.sql.SQLException: Login failed for user '<username>'These error occurs when the database user name or password is incorrect. If you provided the wrong user name or password in the .properties file that you configured above, LabKey will not be able to connect to the database. Check that you can log into the database server with the credentials that you are providing in this file.java.net.BindException: Address already in use: JVM_Bind:<port x>:This error occurs when another instance of Tomcat or another application is running on the same port. Specifically, possible causes include:- Tomcat is already running under IntelliJ.
- Tomcat is running as a service.
- Microsoft Internet Information Services (IIS) is running on the same port.
- Another application is running on the same port.
- Shut down the instance of Tomcat or the application that is running on the same port.
- Change the port for the other instance or application.
- Edit the Tomcat server.xml file to specify a different port for your development installation of Tomcat.
or
Error: Could not find or load main class com.intellij.rt.execution.application.AppMain:In certain developer configurations, you will need to add an IntelliJ utility JAR file to your classpath.
- Edit the Debug Configuration in IntelliJ.
- Under the "VM Options" section, find the "-classpath" argument.
- Find your IntelliJ installation. On Windows machines, this is typically "C:\Program Files\JetBrains\IntelliJ IDEA <Version Number>" or similar. On Mac OSX, this is typically "/Applications/IntelliJ IDEA <Version Number>.app" or similar.
- The required JAR file is in the IntelliJ installation directory, and is ./lib/idea_rt.jar. Add it to the -classpath argument value, separating it from the other values with a ":" on OSX and a ";" on Windows.
- Save your edits and start Tomcat.
2. Database State
If you build the LabKey source yourself from the source tree, you may need to periodically delete and recreate your LabKey database. The daily drops often include SQL scripts that modify the data and schema of your database.3. IntelliJ Warnings and Errors
- Warning: Class "org.apache.catalina.startup.Bootstrap" not found in module "LabKey": You may ignore this warning in the Run/Debug Configurations dialog in IntelliJ.
- Error: Could not find or load main class org.apache.catalina.startup.Bootstrap on OSX (or Linux): you might see this error in the console when attempting to start LabKey server. Update the '-classpath' VM option for your Run/Debug configuration to have Unix (:) path separators, rather than Windows path separators (;).
- Certain lines in build.xml files and other Ant build files may be incorrectly flagged as errors.
- Can't find workspace.template.xml? On older enlistments of LabKey, for example version 15.3, copy <LABKEY_HOME>/server/LabKey.iws.template to LabKey.iws instead.
4. IntelliJ Slow
You can help IntelliJ run faster by increasing the amount of memory allocated to it. To increase memory:- Go to C:\Program Files\JetBrains\IntelliJ IDEA <Version Number>\bin, assuming that your copy of IntelliJ is stored in the default location on a Windows machine.
- Right click on the idea.exe.vmoptions file and open it in notepad.
- Edit the first two lines of the file to increase the amount of memory allocated to IntelliJ. For example, on a 2 Gig machine, it is reasonable to increase memory from 32m to 512m. The first two lines of this file then read:
-Xms512m
-Xmx512m
- Save the file
- Restart IntelliJ
error: unmappable character for encoding ASCIIexport JAVA_TOOL_OPTIONS=-Dfile.encoding=UTF8
Enlisting in the Version Control Project
Install TortoiseSVN (Recommended for Windows)
- Download TortoiseSVN version 1.9.x from the TortoiseSVN download page.
- Install TortoiseSVN on your local computer.
- On the list of features to install to the local hard drive, include the command line tools
- Add the TortoiseSVN/bin directory to your PATH
Check Out Source Files Using TortoiseSVN
TortoiseSVN integrates with the Windows file system UI. To use the TortoiseSVN commands, open Windows Explorer, right-click a file or folder, and select a SVN command.- Create a new directory in the Windows file system. This will be the root directory for your enlistment.
- In Windows Explorer, right-click the new directory and select SVN Checkout...
- Enter the URL for the LabKey repository
- Make sure that the checkout directory refers to the location of your root directory.
- Click OK to create a local enlistment. Note that at this point all the LabKey source files, tests, and sample data will be copied to your computer.
Install Command Line SVN Client (Recommended for Non-Windows Operating Systems)
- Download a Subversion 1.9.x package by visiting the Apache Subversion Packages page and choosing the appropriate link for your operation system.
- Install Subversion on your local computer following instructions from the Apache Subversion website. Provide the server and account information from above.
- Extensive Subversion documentation is available in the Subversion Book.
Check Out Source Files Using Command Line SVN
Use the svn checkout command, for example:svn checkout --username cpas --password cpas https://hedgehog.fhcrc.org/tor/stedi/trunk c:\labkey(Optional) Add the Mass Spec and Proteomics Binaries
LabKey Server's mass spectrometry and proteomics binaries are provided as a separate (and optional) enlistment. To add these binaries, follow the instructions in the topic: Enlisting Proteomics BinariesRead-Only Access
Read-only access is available using the following configuration:- LabKey 17.1 release: https://hedgehog.fhcrc.org/tor/stedi/branches/release17.1
- Next release (unstable): https://hedgehog.fhcrc.org/tor/stedi/trunk
- Username: cpas
- Password: cpas
Modules on GitHub
Note that the Subversion repository above only provides a minimal set of core LabKey Server modules. Many optional and specialty modules are located on GitHub. For a list of available modules see:https://github.com/LabKeyThese modules can be added to your build on a module-by-module basis. For details on installing a Git client and cloning individual modules see:https://www.labkey.org/home/Documentation/wiki-page.view?name=build#gitSupported Versions
If you are running a production LabKey server, you should install only official releases of LabKey on that server. Subversion access is intended for developers who wish to peruse, experiment with, and debug LabKey code against a test database. Daily drops of LabKey are not stable and, at times, may not even build. We cannot support servers running any version other than an officially released version of LabKey.More Information
- For more information about using Subversion, see the official Subversion site.
- For information on building the LabKey source code, see our development documentation.
- For source code archives, see Source Code.
Enlisting Proteomics Binaries
svn co https://hedgehog.fhcrc.org/tor/stedi/binaries/proteomics/comet
svn co https://hedgehog.fhcrc.org/tor/stedi/binaries/proteomics/labkey
svn co https://hedgehog.fhcrc.org/tor/stedi/binaries/proteomics/msinspect
svn co https://hedgehog.fhcrc.org/tor/stedi/binaries/proteomics/pwiz
svn co https://hedgehog.fhcrc.org/tor/stedi/binaries/proteomics/tpp
Customizing the Build
- Modify your local standard.modules file to remove modules that you never use, speeding up your build.
- Add your custom module directories to an existing build location (e.g., /server/modules) to automatically include them in the standard build.
- Create a custom .modules file (say, "mine.modules") with a list of just your custom module directories. Invoke "ant build -DmodulesFile=mine.modules" to build just your modules.
Machine Security
We (The LabKey Software Foundation) require that everyone committing changes to the source code repository exercise reasonable security precautions.
Virus Scanning
It is the responsibility of each individual to exercise reasonable precautions to protect their PC(s) against viruses. We recommend that all committers:
- Run with the latest operating system patches
- Make use of software and/or hardware firewalls when possible
- Install and maintain up-to-date virus scanning software
Password Protection
It is the responsibility of each individual to ensure that their PC(s) are password protected at all times. We recommend the use of strong passwords that are changed at a minimum of every six months.
We reserve the right to revoke access to any individual found to be running a system that is not exercising reasonable password security.
Notes on Setting up a Mac for LabKey Development
Software Installation
- Install the Apple Mac OS X developer tools. This contains a number of important tools you will need.
- Java for Mac OS X (FAQs for your reference: https://www.java.com/en/download/faq/java_mac.xml#havejava)
- Mac OS X 10.6 and below: Apple's Java comes pre-installed with your Mac OS.
- Mac OS X 10.7 (Lion) and above: Java is not pre-installed with Mac OS X versions 10.7 and above. To get the latest Java from Oracle, you will need Mac OS X 10.7.3 and above.
- Open the Java Preferences application in /Applications/Utilities and ensure that Java SE 8 is at the top of the Java Applications list.
- Setup Environment variables:
- CATALINA_HOME = <your_tomcat_home>
- PATH = <labkey-root>/external/ant/bin:<labkey-root>/external/osx/bin:<your-normal-path>
export JAVA_HOME=`/usr/libexec/java_home -v 1.8`
export CATALINA_HOME=$HOME/apps/tomcat
export LABKEY_ROOT=$HOME/labkey/trunk
export LABKEY_GWT_USER_OVERRIDE="gwt-user-firefox"
export PATH=$LABKEY_ROOT/external/ant/bin:$LABKEY_ROOT/build/deploy/bin:$PATH
- Create the env vars shown above
- logout and in
Ant
Yosemite does not include ant. LabKey includes ant in LabKey/trunk/external/ant. To use this version of ant, add the following line to your .bash_profile file (located in /Users/<username>): export PATH=/LabKey/trunk/external/ant/bin:$PATH (You'll need to restart Terminal for these changes to take effect across all terminal windows). (Replace '/LabKey/trunk/external/ant/bin' with wherever your ant is located, of course). Package managers can be used to install other tools such as git, subversion, etc. Homebrew works pretty well for this : http://brew.sh/IntelliJ IDEA
The setup for IntelliJ is described in the common documentation, but a few additional troubleshooting notes may be helpful: Run/Debug LabKey Error:- Could not find or load main class org.apache.catalina.startup.Bootstrap
- You might see this error in the console when attempting to start LabKey server. Update the '-classpath' VM option for your Run/Debug configuration to have Unix (:) path separators, rather than Windows path separators (;).
- Problems while loading file history: svn: E175002
- Notes on upgrading on Yosemite, with Subversion 1.8.13:
- From terminal, execute these commands:
- Get Brew, if you don't have it already: $ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
- Uninstall svn: $ brew uninstall svn
- Install svn: $ brew install svn
- Link: $ brew link --overwrite subversion
- Test the version: $ svn --version (without successful linking, svn won't be recognized as a valid command)
- Configure IntelliJ to use the installed binary (https://www.jetbrains.com/idea/help/subversion.html)
- from Terminal execute : which svn
- In IntelliJ, go to 'IntelliJ IDEA' menu --> Preferences --> Version Control --> Subversion --> Under "Use command line client:", copy the resultant path from 'which svn' command --> Apply.
VirtualBox
To do development or testing using a database that is not supported on the Mac (e.g., SQL Server or Oracle), it is recommended to set up a VirtualBox instance for the target operating system (Windows or Linux). (This is generally preferred for developers over using Parallels, but the installation instructions once you have an OS installed are the same regardless. )- Download and install Virtual Box : https://www.virtualbox.org/wiki/Downloads
- Create a new Virtual Box VM and install the desired OS on it. The easiest way is to download an ISO file for the OS and use it as the installation media for your VM.
- Once the ISO file is downloaded start Virtual Box and create a new VM for your target OS (most defaults are acceptable).
- Start the new VM for the first time.
- When a VM gets started for the first time, another wizard -- the "First Start Wizard" -- will pop up to help you select an installation medium. Since the VM is created empty, it would otherwise behave just like a real computer with no operating system installed: it will do nothing and display an error message that no bootable operating system was found.
- Select the ISO file that was previously downloaded, this should result in the installation wizard getting run.
- You may also want to install the Guest Additions for the VM so the window can be expanded to a more usable size (https://www.virtualbox.org/manual/ch04.html#idp95956608). This will also enable you to share files between your Mac and the VM, which can sometimes be helpful.
- Once the OS is installed, you can install your target database on it. See below for specifics on SQLServer or Oracle.
- To allow for remote access to the database you've installed, you will need to create a hole for the database connections in the firewall. For Windows, follow the instructions in the "TCP Access" section of this TechNet note using the port number appropriate for your database installation.
- You also need to configure Virtual Box so that a connection to the database can be made from the instance of LabKey running on your mac. The easiest way to do this is through port forwarding over NAT.
 Create a new record using TCP, and localhost (127.0.0.1). Set the host and guest port to be the same as the configuration in your mssql.properties file (typically 1433) Note: To get the IP address of the Guest OS, you can run "ipconfig" in a command window on the Windows VM. You will want the IPv4 address.
Create a new record using TCP, and localhost (127.0.0.1). Set the host and guest port to be the same as the configuration in your mssql.properties file (typically 1433) Note: To get the IP address of the Guest OS, you can run "ipconfig" in a command window on the Windows VM. You will want the IPv4 address. 
SQL Server on VM
Typically SQL Server Express is adequate for development. Follow the instructions here for the installation. Note that you should not need to do the extra steps to get GROUP_CONCAT installed. It will be installed automatically when you start up LabKey server for the first time pointing to your SQL Server database.SQL Server Browser Setup
During the installation, you will want to set the SQL Server Browser to start automatically. You can do this from within the SQL Server Configuration Manager. Under SQL Server Services, right click on the SQL Server Browser and open the Properties window Go to the Service tab and change the Start Mode to "Automatic."Remote Access to SQL Server
To allow for remote access to SQL Server, you will need to:- Create a hole for SQL Server in the Windows firewall. Follow the instructions in the "TCP Access" section of this TechNet note.
- make some configuration changes to allow remote connections and set up a login for LabKey server to use:
- Open SQL Server Management Studio (which is not the same as the SQL Server Configuration Manager)
- Right click on the <Server Name> and choose Properties -->Connections, check "Allow remote connections to this server"
- From <Server Name> --> Properties, --> Security, set Server Authentication to “SQL Server & Windows Authentication mode”
- Click OK and Close the Properties window
- Choose Security --> Logins --> double click on 'sa' --> Status, set Login to Enabled. This is the user that will be used by LabKey server, so set the password and take note of it.
- From Sql Server Configuration Manager, select SQL Server Network Configuration --> Protocols for MSSQLSERVER.
- Enable TCP/IP (If not enabled already).
- Right Click on TCP/IP --> Properties --> IP Addresses tab
- Make sure ports with IP Addresses of 127.0.0.1 and other other IP Address (thats used in Port Forwarding that you found using ipconfig), are Enabled.
- Restart your computer.
- Restart SQL Server & SQL Server Browser from the Services control panel.
LabKey Properties Files
- Edit the mssql.properties config file under /Labkey/server/configs. If you have setup the NAT forwarding mentioned above, then set the databaseDefaultHost to 127.0.0.1. Otherwise, set the databaseDefaultHost to the windows IP (use ipconfig to find out what this is; you want the IPv4 address) (seems like this is necessary; just using the name of the host instead doesn't seem to work). If you have multiple datasources defined in your labkey.xml file, the IP address needs to be used for those data sources as well.
- Edit the mssql.properties config file further by updating the jdbcUser and jdbcPassword information. This is where you use the "sa" user and the password you had setup during the SQL Server install.
- Pick SQL Server for LabKey (run "ant pick_mssql" - either from the command line or within IntelliJ)
- Restart your LabKey server instance.
Oracle on VM
Oracle Express Edition is probably sufficient for development and testing purposes. Follow the instructions in the installation docs on Oracle's site and then refer to the page for using Oracle as an external data source for some LabKey specifics.Remote Access to Oracle
After the initial installation, Oracle Database XE will be available only from the local server, not remotely. Be sure to follow the steps for making Oracle available to Remote Clients. In particular, you will need to run the following command from within SQL*Plus connected as the system userSQL> EXEC DBMS_XDB.SETLISTENERLOCALACCESS(FALSE);
SQL Developer (Oracle Client UI).
For troubleshooting and development, you will probably want to install a version of SQL Developer, the Oracle client application. There is a version of the client that works for the Mac, so it is probably easiest to download and install on your Mac. It may also be useful to install a version on the VM. If installing on the VM, Java is required unless you get the version of SQL Developer that also bundles Java.Creating Production Builds
BuildType: Production
Related Topics
Encoding in Tomcat 7
URIEncoding="UTF-8"Related Topics
Gradle Build
Developers who build LabKey Server from source will not be able to use the Ant build targets starting in 17.2 (July 2017). Instead, the Gradle build framework will be used. This topic is intended for early adopters who want to begin the process of migrating from Ant to Gradle early, before it is required.
For the latest news on the migration to Gradle, see Gradle Developer Discussion Thread.
- Summary
- General Setup
- Artifactory Setup
- Your First Gradle Commands
- Changing the Set of Projects
- Building from Source (or not)
- Command Line
- IntelliJ Setup
- Troubleshooting
- Global Properties Template
- Resources
Summary
It is assumed in what follows that you have a standard LabKey SVN enlistment. We use LABKEY_ROOT to refer to the directory into which you check out your enlistment (i.e., the parent of the server directory). (You may also have git modules checked out, but the first step will be to get a build using SVN modules going.)
General Setup
Create a gradle properties file to contain information about global settings for your gradle build
- Create a .gradle directory in your home directory (e.g., /Users/<you>/.gradle on a Mac or C:\Users\<you>\.gradle on Windows). Note: the windows file explorer may not allow you to create a folder beginning with a period. To solve this navigate to C:\Users\<you>\ in the command prompt and type mkdir .gradle.
- Create a gradle.properties file in the .gradle directory using the template given below (or you can copy this from the LABKEY_ROOT/global_gradle.properties_template file)
- Substitute your tomcat home directory for the value after systemProp.tomcat.home
On Windows, use forward slashes, not backslashes, for the Tomcat path. For example:
systemProp.tomcat.home=C:/apache/apache-tomcat-8.5.11
Artifactory Setup (LabKey Staff Only)
This step is only for LabKey Software internal staff. If you are not a LabKey employee, skip this step.
- Get your password or API key for the Artifactory server.
EITHER
- Log in to the Artifactory server using your GitHub credentials
- Let Susan or Brian know so your permissions can be set up to be able to read all necessary artifacts
- Click on your display name in the “Welcome, <user>” text in the upper right to go to your profile.
- Click the gear next to the API key input field to generate your API key
- Capture the API key so you can paste it in your properties file
OR
- Request an internal account on the Artifactory server from either Susan or Brian
- Log in to the Artifactory server
- Click on your display name in the “Welcome, <user>” text in the upper right to go to your profile.
- Enter your password there to unlock the page and then scroll down to the Authentication Settings section. The icons next to the Encrypted Password box allow you to see the encrypted value or copy it to the clipboard.
2. Modify the gradle properties file
- Substitute your (case-sensitive) artifactory user name (e.g., labkey-susanh) and either your API key (if you logged in to artifactory with GitHub) or your encrypted password (if you used an internal Artifactory account) within this file. Note that the text shown in the “Welcome, <user>” is a display name for your artifactory account, which is not the same as your user name, at least as far as casing is concerned. You want to use your user name, not the display name in the properties file. This value is likely to be all lower case (e.g., for GitHub, this will be something like labkey-susanh).
Your First Gradle Commands
- Clean out the ant build directories and files
ant clean
- Put the Gradle script file in your operating system path. This file (either gradlew or gradlew.bat) is included in the SVN sync and is already in the <LABKEY_ROOT> directory.
- For Windows, do the following:
- Open the start menu and type system environment variables then enter to open the system properties window.
- Click the button at the bottom labelled “Environment Variables...:”
- This will open another menu with two lists of variables. Find the variable “path” in the “System Variables” list.
- Clicking Edit will open a new menu, which enumerates all the items on your path.
- Click New then browse. Navigate to the <LABKEY_ROOT> directory.
- For Mac, add a line similar to the following in your ~/.bash_profile file
export PATH=<LABKEY_ROOT>:$PATH and then open a new terminal window.
- Execute a gradle command to show you the set of currently configured projects (modules)
- On the command line, type gradlew projects (or gradlew.bat projects)
- Execute a gradle command to build and deploy the application
gradlew deployApp
This will take some time as it needs to pull down many resources to initialize the local caches. Subsequent builds will be much faster.
Changing the Set of Projects
Gradle uses the <LABKEY_ROOT>/settings.gradle file to determine which projects (modules) are included in the build. (This is an analog of the various .modules files used in the ant build.) To include a different set of projects in your build, you will need to edit this file. By default, only modules in the server/modules directory and the server/test and server/test/modules directories are included in the build. See the file for examples of different ways to include different subsets of the modules.
Building from Source (or not)
This feature is currently only for LabKey Software internal staff. If you are not a LabKey employee, skip this section.
N.B. As of 12 January 2017, there is a bug related to the buildFromSource parameter in conjunction with a dev build having to do with the .lib.xml files and client libraries, which means this probably won’t work as advertised here just yet.
Which modules are built from source is controlled by the buildFromSource property. This property can be set at the LABKEY_ROOT level, at the project level, at the global (user) level, or on the command line (with overrides happening in the order given).
The default properties file in LABKEY_ROOT/gradle.properties has the following property defined
buildFromSource=true
This setting will cause a build command to construct all the jars and the .module files that are necessary for a server build. But if you are not changing code, you do not need to build everything from source. The following table illustrates how you can specify the properties to build just the source code you need to build.
|
If you want to... |
.. then ... |
|
build nothing from source |
Set buildFromSource=false In one of:
Then run gradlew deployApp |
|
Build everything from source |
Set buildFromSource=true In one of
Then run gradlew deployApp |
|
Build a single module from source |
Set buildFromSource=false In LABKEY_ROOT/gradle.properties Then EITHER (most efficient) run deployModule command for that module (e.g., gradlew :server:opt:cds:deployModule) OR (Less efficient)
|
|
Build a subset of modules from source |
Set buildFromSource=false In LABKEY_ROOT/gradle.properties Then EITHER (most efficient) run deployModule command for the modules you wish to build (e.g., gradlew :server:opt:cds:deployModule) OR (Less efficient)
|
Command Line
Ant-to-Gradle Command Line Mapping
The following table provides a mapping between the most popular (I assume) ant commands and their Gradle counterparts. Note that while a mapping is provided for the ‘ant clean’ and ‘ant rebuild’ commands to get you oriented, these commands should no longer be used automatically with each new day or each new sync from SVN. Gradle handles checking for needed updates much better and so you do not need to proactively clean as often.
|
Ant Command |
Gradle Command |
Directory |
|
ant build |
gradlew deployApp |
trunk or server |
|
ant clean |
gradlew cleanBuild |
trunk or server |
|
ant rebuild |
gradlew cleanBuild deployApp |
trunk or server |
|
ant pick_pg |
gradlew pickPg |
trunk or server |
|
ant pick_mssql |
gradlew pickMSSQL |
trunk or server |
|
ant dist |
gradlew distribution |
trunk |
|
ant wiki |
gradlew :server:modules:wiki:deployModule |
Any directory |
|
ant wiki |
gradlew deployModule |
server/modules/wiki |
|
ant test |
gradlew :server:test:uiTest |
Any directory |
|
ant drt |
gradlew :server:test:uiTest -Psuite=DRT |
Any directory |
|
ant production |
gradlew deployApp -PdeployMode=prod |
trunk or server |
Tips
Here we include a few bits of information that may be useful for learning to use the Gradle command line.
- Use gradlew -h to see the various options available for running gradle commands
- If working offline, you will want to use the --offline option to prevent it from contacting the artifact server (You won’t have success if you do this for your first build.)
- By default, gradle outputs information related to the progress in building and which tasks it considers as up to date or skipped. If you don’t want to see this, or any other output about progress of the build, you’ll want to add the -q flag:
./gradlew -q projects
Now might be a good time to set up an alias if you’re a command-line kind of person who can’t abide output to the screen.
- If doing development in a single module, it is most efficient to do builds from the module’s directory as that will cause Gradle to do the least amount of building and configuration. There is a command available to you that can be sort of a one-stop shopping experience:
gradlew deployModule
This will build the jar files, and the .module file and then copy it to the build/deploy/modules directory, which will cause Tomcat to refresh.
- Gradle commands can (generally) be executed from anywhere within the project directory structure. You need only provide the gradle path (Gradle paths use colons as separators instead of slashes in either direction) to the project as part of the target name. For example, from the server/modules directory, you can build the announcements module using the command
gradlew announcements:module
And from the server/modules/announcements directory, you can build the wiki module using
gradlew :server:modules:wiki:module
One exception to this is that in directories that have subprojects declared in a build.gradle file, (e.g., the root directory or the server directory), you can run commands such as “deployModule” and “clean” and it will run the corresponding tasks in all the subdirectories. These global tasks are not executable from other directories.
- Gradle provides many helpful tasks to advertise the capabilities and settings within the build system. Start with this and see where it leads you
gradlew tasks
- Gradle automatically understands shortcuts and when you mistype a target name it will suggest possible targets nearby. For example, you can build the announcements module with this command:
gradlew :se:m:an:b
And when you switch back to ant task mode momentarily and type
gradlew pick_pg
Gradle responds with:
* What went wrong:
Task 'pick_pg' not found in project ':server'. Some candidates are: 'pickPg'.
Cleaning
First, you should know that Gradle is generally very good about keeping track of when things have changed and so you can, and should, get out of the habit of wiping things clean and starting from scratch because it just takes more time. If you find that there’s some part of the process that does not recognize when its inputs have changed or its outputs are up-to-date, please file a bug or post to the [developer support board|https://www.labkey.org/home/Support/Developer%20Forum/project-begin.view?] so we can get that corrected. (As of Feburary 2017, there is one known issue with the GWT compiler up-to-date check.)
The gradle tasks also provide much more granularity in cleaning. Generally, for each task that produces an artifact, we try to have a corresponding cleaning task that removes that artifact. This leads to a plethora of cleaning tasks, but there are only a few that you will probably ever want to use. We summarize the most commonly useful ones here.
Module Cleaning
The two most important tasks for cleaning modules are:
- undeployModule - removes all artifacts for this module from the staging and deploy directories. This should always be used when switching between feature branches if you have set the includeVcs property.
- reallyClean - removes the build directory for the module as well as all artifacts for this module from the staging and deploy directories. Use this to remove all evidence of your having built a module.
undeployModule - This is the opposite of deployModule. deployModule copies artifacts from the build directories into the staging (LABKEY_ROOT/build/staging) and then the deployment (LABKEY_ROOT/build/deploy) directories, so undeployModule removes the artifacts for this module from the staging and deployment directories. This will cause a restart of a running server since tomcat will recognized that the deployment directory is changed. This command should always be used when switching between feature branches because the artifacts created in a feature branch will have the feature branch name in their version number and thus will look different from artifacts produced from a different branch. If you don’t do the undeployModule, you’ll likely end up with multiple versions of your .module file in the deploy directory and thus in the classpath, which will cause confusion.
|
directory |
gradle command |
result |
|
trunk |
clean |
All build directories for all projects are removed |
|
any |
:server:modules:wiki:undeployModule |
LABKEY_ROOT/build/staging/modules/wiki* and /build/deploy/modules/wiki* will be removed |
|
server/modules/wiki |
undeployModule |
LABKEY_ROOT/build/staging/modules/wiki* and /build/deploy/modules/wiki* will be removed |
clean - This task comes from the standard Gradle lifecycle. Its purpose, generally, is to remove the build directory for a project. For our modules, these are the directories under LABKEY_ROOT/build/modules. Note that this will have little to no effect on a running server instance. It will simply cause gradle to forget about all the building it has previously done so the next time it will start from scratch.
|
directory |
gradle command |
result |
|
trunk |
clean |
All build directories for all projects are removed |
|
any |
:server:modules:wiki:clean |
LABKEY_ROOT/build/modules/wiki is removed. |
|
server/modules/wiki |
clean |
LABKEY_ROOT/build/modules/wiki is removed |
reallyClean - combines undeployModule and clean to remove the build, staging and deployment directories for a module.
Application Cleaning
cleanBuild - Removes the build directory entirely. This will also stop the tomcat server if it is running. This is the big hammer that you should avoid using unless there seems to be no other way out.
cleanDeploy - Removes the build/deploy directory. This will also stop the tomcat server if it is running.
cleanStaging - Removes the build/staging directory. This does not affect the running server.
IntelliJ Setup
Follow these steps in order to make IntelliJ able to find all the source code and elements on the classpath as well as be able to run tests.
- Upgrade to the latest version of IntelliJ. Version 2016.1.x has issues with Gradle. 2016.3.4 has been tested and works.
- Be sure that IntelliJ has enough heap memory. The default max is OK if you’re just dealing with the core modules, but you will likely need to raise the limit if you’re adding in customModules, optionalModules, etc. 3GB seems sufficient.
- Enable the Gradle plugin in IntelliJ
- Go to File -> Preferences/Settings -> Plugins and choose “Gradle”
- Gradle is enabled by default, so this may not be necessary.
- Create the workspace.xml file for the IntelliJ project in LABKEY_ROOT (NOTE: this is a different project than the one in the LABKEY_ROOT/server directory, which will be removed after transition has happened. If you want to use the workspace.xml file that currently resides in the LABKEY_ROOT/server/.idea directory, you will need to edit this file and adjust the paths that refer to $PROJECT_DIR$ such that they are accurate for the root being at LABKEY_ROOT instead of LABKEY_ROOT/server)
- Copy the file LABKEY_ROOT/.idea/workspace.template.xml. Rename the copy to create a file called LABKEY_ROOT/.idea/workspace.xml
- This file configures the debug information for LabKey project. To review the debug settings go to Run > Edit Configurations in IntelliJ.
- Close the current IntelliJ project
- If your IntelliJ install is brand new, you will see the "Welcome to IntelliJ" pop up screen. Click Open. If you have previously installed IntelliJ, select File > Open.
- Select the LabKey IntelliJ project directory, <LABKEY_HOME>
- If asked about an “Unlinked Gradle project”, DO NOT “Import Gradle project” in the default way from IntelliJ.
- If your project is new, make sure your Project SDK is set correctly. This is under “Project Structure”.
- Open the Gradle tool window (using icon shown on the right)

- Then click the Refresh icon in that window. (This will take a while, perhaps 15-30 minutes. After a few minutes, you should start seeing messages about its progress. If not, something is probably hung up.)

- After your Gradle Sync is done, edit the Run / Debug Configuration:
- Go to Run -> Edit Configurations. Select LabKey Dev.
- VM options: Confirm that the path separators are appropriate for your operating system. On Windows, ensure that the paths to the jar files are separated by semicolons. For example: "./bin/bootstrap.jar;./bin/tomcat-juli.jar;C:/Program Files (x86)/JetBrains/IntelliJ IDEA 2016.3.3/lib/idea_rt.jar"
- Confirm that ‘api_main’ is chosen for the setting “Use classpath of module”.
Troubleshooting
Problem: Gradle Sync in IntelliJ has no effect on project structure after the settings.gradle file is updated.
Cause: Name conflict between the gel_test project and the gel_test IntelliJ module that would be created from the gel project’s ‘test’ source set. (IDEA-168284)
Workarounds: Do one of the following
- Remove gel_test from the test of projects you are including in your settings.gradle file and the do the Gradle Sync.
- Within IntelliJ do the following
- Preferences -> Build, Execution, Deployment -> Build Tools -> Gradle
- Uncheck the setting “Create separate module per source set”
- Click “OK”
- Do the Gradle Sync in the Gradle window
- Preferences -> Build, Execution, Deployment -> Build Tools -> Gradle
- Check the setting “Create separate module per source set”
- Click “OK”
- Do the Gradle Sync in the Gradle window
Problem: Running tests within IntelliJ for the first time, you will likely encounter a problem related to not being able to find apache httpmime classes.
Cause: A bug in IntelliJ, related to our project structure which marks some dependencies as “Runtime” instead of “Compile”.
Solution: To fix this, you will need to go to File-> Project Structure -> Modules -> remoteapi -> java -> java_main -> Dependencies. You will see that there are a few dependencies designated as “Runtime” instead of “Compile”. Choose “Compile” and then click “OK”. After that your tests should be runnable. Unfortunately, you’ll need to make this modification every time you manually sync from the Gradle window, but fortunately that shouldn’t be needed all that often.
Problem: My passwords to PostgreSQL and MS SQL Server aren't working.
Solution: Unlike Ant, the Gradle build system will automatically escape any special XML characters, such as quotes and ampersand symbols in the pg.properties / mssql.properties files. When migrating these files from Ant to Gradle, replace any escaped ampersands (&) with plain text ampersands (&).
Global Properties Template
deployMode=dev # When set to true, Gradle will run the build with remote debugging enabled, listening on port 5005. # Note that this is the equivalent of adding -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=5005 to the JVM command line # and will suspend the virtual machine until a debugger is attached. #org.gradle.debug=true #We need to know the tomcat home directory for some of the dependencies in our build process. IntelliJ does not #pick up the CATALINA_HOME environment variable, so if working with the IDE, you need to set the tomcat.home #system property either here as shown below on the command line with -Dtomcat.home=/path/to/tomcat/home #Regardless of OS, use the forward slash (/) as a file separator in the path (yes, even on Windows) systemProp.tomcat.home=/path/to/tomcat/installation artifactory_user=<your user> # the encrypted password or API key artifactory_password=<your password or API key> # uncomment to enable population of VCS revision number and url in module.properties file # for localhost installation #includeVcs #svn_user=<your svn user name> #svn_password=<your svn password>
Resources
- Gradle documentation - A basic introduction to the command line.
- Gradle Developer Discussion Thread - Current news on the migration to Gradle.
Develop Modules
Module Functionality
| Functionalityoooooooo | Description | Docsooooooooooooooooooooooooooo |
|---|---|---|
| Queries, Views, and Reports | A module that includes queries, reports, and/or views directories. Create file-based SQL queries, reports, views, web parts, and HTML/JavaScript client-side applications. No Java code required, though you can easily evolve your work into a Java module if needed. | Modules: Queries, Views and Reports |
| Assay | A module with an assay directory included, for defining a new assay type. | Modules: Assay Types |
| Extract-Transform-Load | A module with an etl directory included, for configuring data transfer and synchronization between databases. | Modules: ETLs |
| Script Pipeline | A module with a pipeline directory included, for running scripts in sequence, including R scripts, JavaScript, Perl, Python, etc. | Script Pipeline: Running R and Other Scripts in Sequence |
| Java | A module with a Java src directory included. Develop Java-based applications to create server-side code. | Modules: Java |
Do I Need to Compile Modules?
Modules do not need to be compiled, unless they contain Java code. Most module functionality can be accomplished without the need for Java code, including "CRUD" applications (Create-Retrieve-Update-Delete applications) that provide views and reports on data on the server, and provide some way for users to interact with the data. These applications will typically use some combination of the following client APIs: LABKEY.Query.selectRows, insertRows, updateRows, and deleteRows.Also note that client-side APIs are generally guaranteed to be stable, while server-side APIs are not guaranteed to be stable and are liable to change as the LabKey Server code base evolves -- so modules based on the server API may require changes to keep them up to date.More advanced client functionality, such as defining new assay types, working with the security API, and manipulating studies, can also be accomplished with a simple module without Java.To create your own server actions (i.e., code that runs on the server, not in the client), Java is generally required. Trigger scripts, which run on the server, are are an exception: trigger scripts are a powerful feature, sufficient in many cases to avoid the need for Java code. Note that Java modules require a build/compile step, but modules without Java code don't need to be compiled before deployment to the server.Module Development Setup
Use the following topic to set up a development machine for building LabKey modules: Set up a Development MachineTopics
The topics below show you how to create a module, how to develop the various resources within the module, and how to package and deploy it to LabKey Server.- Map of Module Files - An overview of the features and file types you can include in modules.
- Example Modules - Representative example modules from the LabKey Server open source project.
- Modules: Queries, Views and Reports - Build a more complex file-based module.
- Modules: Assay Types - Module-based custom assay types, to base assay designs on.
- Modules: ETLs - Module-based Extract-Transform-Load functionality.
- Modules: Java - Including Java in modules.
- Modules: Folder Types - Module-based custom folder types.
- Modules: SQL Scripts - Running SQL scripts on module load.
- Deploy Modules to a Production Server - Deploying modules for production.
- Upgrade Modules - How to handle module upgrades.
- MiniProfiler - Developer tool shows which queries were run on a page, and performance information for each query.
- Main Credits Page - Include a credits page.
- Module Properties Reference - Reference for module.properties/module.xml files.
Tutorial: Hello World Module
- Create a new assay type to capture data from a new instrument.
- Add a new set of tables and relationships (= a schema) to the database by running a SQL script.
- Develop file-based SQL queries, R reports, and HTML views.
- Build a sequence of scripts that process data and finally insert it into the database.
- Define novel folder types and web part layouts.
- Set up Extract-Transform-Load (ETL) processes to move data between databases.
Set Up a Development Machine
In this step you will set up a test/development machine, which compiles LabKey Server from its source code.If you already have a working build of the server, you can skip this step.- If necessary, uninstall any instances of LabKey Server that were installed using the Windows Graphical Installer, as an installer-based server and a source-based server cannot run together simultaneously on the same machine. Use the Windows uninstaller at: Control Panel > Uninstall a program. If you see LabKey Server in the list of programs, uninstall it.
- Download the server source code and complete an initial build of the server by completing the steps in the following topic: Set up a Development Machine
- Before you proceed, build and deploy the server. Confirm that the server is running by visiting the URL http://localhost:8080/labkey/project/home/begin.view?
- For the purposes of this tutorial, we will call the location where you have synced the server source code LABKEY_SRC. On Windows, a typical location for LABKEY_SRC would be C:/dev/trunk
Module Properties
In this step you create the main directory for your module and set basic module properties.- Go to LABKEY_SRC, the directory where you synced to the server source code, and locate the directory externalModules.
- Inside LABKEY_SRC/externalModules, create a directory named "helloworld".
- Inside the helloworld directory, create a file named "module.properties".
- Add the following property/value pairs to module.properties. This is a minimal list of properties needed for deployment and testing. You can add a more complete list of properties later on, including your name, links to documentation, required server and database versions, etc. For a complete list of available properties see Module Properties Reference.
Name: HelloWorld
ModuleClass: org.labkey.api.module.SimpleModule
Version: 1.0
Build and Deploy the Module
- Open the file LABKEY_SRC/server/standard.modules (This file controls which modules are included in the build.)
- Add this line to the file:
externalModules/helloworld
- Build the server.
- Open a command window.
- Go to directory LABKEY_SRC/server
- Call the ant task:
ant build
- Start the server, either in IntelliJ by click the "Debug" button, or by running the Tomcat startup script appropriate for your operating system (located in TOMCAT_HOME/bin).
Confirm the Module Has Been Deployed
- In a browser go to: http://localhost:8080/labkey/project/home/begin.view?
- Sign in.
- Confirm that HelloWorld has been deployed to the server by going to Admin > Site > Admin Console. Scroll down to Module Information (in the right hand column). Open the node HelloWorld. Notice the module properties you specified are displayed here: Name: HelloWorld, Version: 1.0, etc.

Add a Default Page
Each module has a default home page called "begin.view". In this step we will add this page to our module. The server interprets your module resources based on a fixed directory structure. By reading the directory structure and the files inside, the server knows their intended functionality. For example, if the module contains a directory named "assays", this tells the server to look for XML files that define a new assay type. Below, we will create a "views" directory, telling the server to look for HTML and XML files that define new pages and web parts.- Inside helloworld, create a directory named "resources".
- Inside resources, create a directory named "views".
- Inside views, create a file named "begin.html". (This is the default page for any module.)
helloworld
│ module.properties
└───resources
└───views
begin.html
- Open begin.html in a text editor, and add the following HTML code:
<p>Hello, World!</p>
Test the Module
- Build the server by calling 'ant build'.
- Wait for the server to redeploy.
- Enable the module in some test folder:
- Navigate to some test folder on your server.
- Go to Admin > Folder > Management and click the Folder Type tab.
- In the list of modules on the right, place a checkmark next to HelloWorld.
- Click Update Folder.
- Confirm that the view has been deployed to the server by going to Admin > Go to Module > HelloWorld.
- The following view will be displayed:

Modify the View with Metadata
You can control how a view is displayed by using a metadata file. For example, you can define the title, framing, and required permissions.- Add a file to the views directory named "begin.view.xml". Note that this file has the same name (minus the file extension) as begin.html: this tells the server to apply the metadata in begin.view.xml to being.html.
helloworld
│ module.properties
└───resources
└───views
begin.html
begin.view.xml
- Add the following XML to begin.view.xml. This tells the server to: display the title 'Begin View', display the HTML without any framing, and that Reader permission is required to view it.
<view xmlns="http://labkey.org/data/xml/view"
title="Begin View"
frame="none">
<permissions>
<permission name="read"/>
</permissions>
</view>
- Refresh your browser to see the result. (You do not need to rebuild or restart the server.)
- The begin view now looks like the following:

- Experiment with other possible values for the 'frame' attribute:
- portal (If no value is provided, the default is 'portal'.)
- title
- dialog
- div
- left_navigation
- none
- When you are ready to move to the next step, set the 'frame' attribute back to 'portal'.
Hello World Web Part
You can also package the view as a web part using another metadata file.- In the helloworld/resources/views directory add a file named "begin.webpart.xml". This tells the server to surface the view inside a webpart. Your module now has the following structure:
helloworld
│ module.properties
└───resources
└───views
begin.html
begin.view.xml
begin.webpart.xml
- Paste the following XML into begin.webpart.xml:
<webpart xmlns="http://labkey.org/data/xml/webpart"
title="Hello World Web Part">
<view name="begin"/>
</webpart>
- Return to your test folder using the hover menu in the upper left.
- In your test folder, click the dropdown <Select Web Part>.
- Select the web part Hello World Web Part and click Add.
- The following web part will be added to the page:

Hello User View
The final step provides more interesting view which uses the JavaScript API to retrieve information about the current users.- Open begin.html and replace the HTML with the following.
- Refresh the browser to see the changes. (You can directly edit the file begin.html in the module -- the server will pick up the changes without needing to rebuild or restart.)
<p>Hello, <script>
document.write(LABKEY.Security.currentUser.displayName);
</script>!</p>
<p>Your account info: </p>
<table>
<tr><td>id</td><td><script>document.write(LABKEY.Security.currentUser.id); </script><td></tr>
<tr><td>displayName</td><td><script>document.write(LABKEY.Security.currentUser.displayName); </script><td></tr>
<tr><td>email</td><td><script>document.write(LABKEY.Security.currentUser.email); </script><td></tr>
<tr><td>canInsert</td><td><script>document.write(LABKEY.Security.currentUser.canInsert); </script><td></tr>
<tr><td>canUpdate</td><td><script>document.write(LABKEY.Security.currentUser.canUpdate); </script><td></tr>
<tr><td>canUpdateOwn</td><td><script>document.write(LABKEY.Security.currentUser.canUpdateOwn); </script><td></tr>
<tr><td>canDelete</td><td><script>document.write(LABKEY.Security.currentUser.canDelete); </script><td></tr>
<tr><td>isAdmin</td><td><script>document.write(LABKEY.Security.currentUser.isAdmin); </script><td></tr>
<tr><td>isGuest</td><td><script>document.write(LABKEY.Security.currentUser.isGuest); </script><td></tr>
<tr><td>isSystemAdmin</td><td><script>document.write(LABKEY.Security.currentUser.isSystemAdmin); </script><td></tr>
</table>
- Once you've refreshed the browser, the web part will display the following.

Make a .module File
You can distribute and deploy a module to production server by making a helloworld.module file (a renamed .zip file).- In anticipation of deploying the module on a production server, add the property 'BuildType: Production' to the module.properties file:
Name: HelloWorld
ModuleClass: org.labkey.api.module.SimpleModule
Version: 1.0
BuildType: Production
- Then build the module:
ant build
- The build process creates a helloworld.module file at:
LABKEY_SRC/build/deploy/modules/helloworld.module
Related Topics
These tutorials show more functionality that you can package as a module:Map of Module Files
Module Directories and Files
The following directory structure follows the pattern for modules as they are checked into source control. The structure of the module as deployed to the server is somewhat different, for details see below and the topic Module Properties Reference. If your module contains Java code or Java Server Pages (JSPs), you will need to compile it before it can be deployed.Items shown in lowercase are literal values that should be preserved in the directory structure; items shown in UPPERCASE should be replaced with values that reflect the nature of your project.Module Layout - As Source
If you are developing your module inside the LabKey Server source, use the following layout. The standard build targets will automatically assemble the directories for deployment. In particular, the standard build target makes the following changes to the module layout:- Moves the contents of /resources one level up into /mymodule.
- Uses module.properties to create the file config/module.xml via string replacement into an XML template file.
- Compiles the Java /src dir into the /lib directory.
mymodule
├───module.properties
├───resources
│ ├───assay
│ ├───etls
│ ├───folderTypes
│ ├───queries
│ ├───reports
│ ├───schemas
│ ├───views
│ └───web
└───src (for modules with Java code)
Module Layout - As Deployed
The standard build targets transform the source directory structure above into the form below for deployment to Tomcat.mymodule
├───assay
├───config
│ └───module.xml
├───etls
├───folderTypes
├───lib (holds compiled Java code)
├───queries
├───reports
├───schemas
├───views
└───web
Related Topics
Example Modules
| Module Location | Description / Highlights |
|---|---|
| server/customModules | This directory contains numerous client modules, in most cases Java modules. |
| server/modules | The core modules for LabKey Server are located here, containing the core server action code (written in Java). |
| server/test | The test module runs basic tests on the server. Contains many basic examples to clone from. |
| externalModules | Other client modules. |
Other Resources
- Creating a New Java Module - Using an Ant target, create a template Java module that you can build out from.
- Getting Started with the Demo Module - A sample module demonstrates Java module development.
- Trigger Scripts - Module-based trigger scripts, schemas created by SQL scripts.
- Community Modules - Descriptions of the modules in the standard distribution of LabKey Server.
Modules: Queries, Views and Reports
The Scenario
Suppose that you want to present a series of R reports, database queries, and HTML views. The end-goal is to deliver these to a client as a unit that can be easily added to their existing LabKey Server installation. Once added, end-users should not be able to modify the queries or reports, ensuring that they keep running as expected. The steps below show how to fulfill these requirements using a file-based module.Steps:- Module Directories Setup
- Module Query Views
- Module SQL Queries
- Module R Reports
- Module HTML and Web Parts
Use the Module on a Production Server
This tutorial is designed for developers who build LabKey Server from source. But even if you are not a developer and do not build the server from source, you can get a sense of how modules by work by installing the module that is the final product of this tutorial. To install the module, download reportDemo.module and copy the file into the directory LABKEY_HOME\externalModules (on a Windows machine this directory is typically located at C:\Program Files(x86)\LabKey Server\externalModules). Notice that the server will detect the .module file and unzip it, creating a directory called reportDemo, which is deployed to the server. Look inside reportDemo to see the resources that have been deployed to the server. Read through the steps of the tutorial to see how these resources are surfaced in the user interface.First Step
Module Directories Setup
- queries - Holds SQL queries and views.
- reports - Holds R reports.
- views - Holds user interface files.
Set Up a Dev Machine
Complete the topics below. This will set up a machine that can build LabKey Server (and the proteomics tools) from source.Install Sample Data
- Install the Proteomics sample data by following the instructions in these topics:
Create Directories
- Go to the externalModules/ directory, and create the following directory structure and standard.modules file:
reportDemo
│ module.properties
└───resources
├───queries
├───reports
└───views
Module Class: org.labkey.api.module.SimpleModule
Name: ReportDemo
Build the Module
- Open the file module.properties and add the following line:
externalModules/reportDemo
- In a command shell, go to the 'server' directory, for example, 'cd C:\dev\labkey-src\trunk\server'.
- Call 'ant build' to build the module.
- Restart the server to deploy the module.
Enable Your Module in a Folder
To use a module, enable it in a folder.- Go to the LabKey Server folder where you want add the module functionality.
- Select Admin -> Folder -> Management -> Folder Type tab.
- Under the list of Modules click on the check box next to ReportDemo to activate it in the current folder.
Start Over | Next Step
Module Query Views
- SQL queries on the database (.SQL files)
- Metadata on the above queries (.query.xml files).
- Named views on pre-existing queries (.qview.xml files)
- Trigger scripts attached to a query (.js files) - these scripts are run whenever there an event (insert, update, etc.) on the underlying table.
Create an XML-based SQL Query
- Add two directories (ms2 and Peptides) and a file (High Prob Matches.qview.xml), as shown below.
- The directory structure tells LabKey Server that the view is in the "ms2" schema and on the "Peptides" table.
View Source
The view will display peptides with high Peptide Prophet scores (greater than or equal to 0.9).- Save High Prob Matches.qview.xml with the following content:
<customView xmlns="http://labkey.org/data/xml/queryCustomView">
<columns>
<column name="Scan"/>
<column name="Charge"/>
<column name="PeptideProphet"/>
<column name="Fraction/FractionName"/>
</columns>
<filters>
<filter column="PeptideProphet" operator="gte" value="0.9"/>
</filters>
<sorts>
<sort column="PeptideProphet" descending="true"/>
</sorts>
</customView>
- The root element of the qview.xml file must be <customView> and you should use the namespace indicated.
- <columns> specifies which columns are displayed. Lookups columns can be included (e.g., "Fraction/FractionName").
- <filters> may contain any number of filter definitions. (In this example, we filter for rows where PeptideProphet >= 0.9). (docs: <filter>)
- <sorts> section will be applied in the order they appear in this section. In this example, we sort descending by the PeptideProphet column. To sort ascending simply omit the descending attribute.
See the View
To see the view on the ms2.Peptides table:- Build and restart the server.
- Go to the Peptides table and click Grid Views -- the view High Prob Matches has been added to the list. (Admin > Developer Links > Schema Browser. Open ms2, scroll down to Peptides. Select Grid Views > High Prob Matches.)
Previous Step | Next Step
Module SQL Queries
- Add two .sql files in the queries/ms2 directory, as follows:
SELECT
COUNT(Peptides.TrimmedPeptide) AS UniqueCount,
Peptides.Fraction.Run AS Run,
Peptides.TrimmedPeptide
FROM
Peptides
WHERE
Peptides.PeptideProphet >= 0.9
GROUP BY
Peptides.TrimmedPeptide,
Peptides.Fraction.Run
SELECT
pc.UniqueCount,
pc.TrimmedPeptide,
pc.Run,
p.PeptideProphet,
p.FractionalDeltaMass
FROM
PeptideCounts pc
INNER JOIN
Peptides p
ON (p.Fraction.Run = pc.Run AND pc.TrimmedPeptide = p.TrimmedPeptide)
WHERE pc.UniqueCount > 1
See the SQL Queries
- Build and restart the server.
- To view your SQL queries, go to the schema browser at Admin -> Developer Links -> Schema Browser.
- On the left side, open the nodes ms2-> user-defined queries -> PeptideCounts.
Previous Step | Next Step
Module R Reports
- In the reports/ directory, create the following subdirectories: schemas/ms2/PeptidesWithCounts, and a file named "Histogram.r", as shown below:
- Open the Histogram.r file, enter the following script, and save the file. (Note that .r files may have spaces in their names.)
png(
filename="${imgout:labkeyl_png}",
width=800,
height=300)
hist(
labkey.data$fractionaldeltamass,
breaks=100,
xlab="Fractional Delta Mass",
ylab="Count",
main=NULL,
col = "light blue",
border = "dark blue")
dev.off()
Report Metadata
Optionally, you can add associated metadata about the report. See Modules: Report Metadata.Test your SQL Query and R Report
- Go to the Query module's home page (Admin -> Go to Module -> Query). Note that the home page of the Query module is the Query Browser.
- Open the ms2 node, and see your two new queries in the user-defined queries section.
- Click on PeptidesWithCounts and then View Data to run the query and view the results.
- While viewing the results, you can run your R report by selecting Views -> Histogram.

Previous Step | Next Step
Module HTML and Web Parts
Add an HTML Page
Under the views/ directory, create a new file named reportdemo.html, and enter the following HTML:<p>
<a id="pep-report-link"
href="<%=contextPath%><%=containerPath%>/query-executeQuery.view?schemaName=ms2&query.queryName=PeptidesWithCounts">
Peptides With Counts Report</a>
</p>
Use contextPath and containerPath
Note the use of the <%=contextPath%> and <%=containerPath%> tokens in the URL's href attribute. These tokens will be replaced with the server's context path and the current container path respectively. For syntax details, see LabKey URLs.Since the href in this case needs to refer to an action in another controller, we can't use a simple relative URL, as it would refer to another action in the same controller. Instead, use the contextPath token to get back to the web application root, and then build your URL from there.Note that the containerPath token always begins with a slash, so you don't need to put a slash between the controller name and this token. If you do, it will still work, as the server automatically ignores double-slashes.Define a View Wrapper
This file has the same base-name as the HTML file, "reportdemo", but with an extension of ".view.xml". In this case, the file should be called reportdemo.view.xml, and it should contain the following:<view xmlns="http://labkey.org/data/xml/view"
frame="none" title="Report Demo">
</view>
Define a Web Part
To allow this view to be visible inside a web part create our final file, the web part definition. Create a file in the views/ directory called reportdemo.webpart.xml and enter the following content:<webpart xmlns="http://labkey.org/data/xml/webpart" title="Report Demo">
<view name="reportdemo"/>
</webpart>
externalModules/
ReportDemo/
resources/
reports/
schemas/
ms2/
PeptidesWithCounts/
Histogram.r
queries/
ms2/
PeptideCounts.sql
PeptidesWithCounts.sql
Peptides/
High Prob Matches.qview.xml
views/
reportdemo.html
reportdemo.view.xml
reportdemo.webpart.xml
Set Required Permissions
You might also want to require specific permissions to see this view. That is easily added to the reportdemo.view.xml file like this:<view xmlns="http://labkey.org/data/xml/view" title="Report Demo">
<permissions>
<permission name="read"/>
</permissions>
</view>
Previous Step
Modules: JavaScript Libraries
- Acquire the library .js file want to use.
- In your module resources directory, create a subdirectory named "web".
- Inside "web", create a subdirectory with the same name as your module. For example, if your module is named 'helloworld', create the following directory structure:
- Copy the library .js file into your directory structure. For example, if you wish to use a JQuery library, place the library file as shown below:
- For any HTML pages that use the library, create a .view.xml file, adding a "dependencies" section.
- For example, if you have a page called helloworld.html, then create a file named helloworld.view.xml next to it:
- Finally add the following "dependencies" section to the .view.xml file:
<view xmlns="http://labkey.org/data/xml/view" title="Hello, World!">
<dependencies>
<dependency path="helloworld/jquery-2.2.3.min.js"></dependency>
</dependencies>
</view>
Remote Dependencies
In some cases, you can declare your dependency using an URL that points directly to the remote library, instead of copying the library file and distributing it with your module:<dependency path="https://code.jquery.com/jquery-2.2.3.min.js"></dependency>Related Topics
Modules: Assay Types
Topics
- Tutorial: Define an Assay Type in a Module - Get started writing module-based assays.
- Assay Custom Domains - Create a custom result domain.
- Assay Custom Views - Add custom HTML details views.
- Example Assay JavaScript Objects - JavaScript examples for assay modules.
- Assay Query Metadata - Provide additional properties to a query.
- Transformation Scripts - Transform data before updates and inserts using scripts.
- Customize Batch Save Behavior - Customize batch save behavior using Java.
- Suggestions for Extensible Assays - An informative discussion from the LabKey Support Boards
Examples: Module-Based Assays
There are a handful of module-based assays in the LabKey SVN tree. You can find the modules in <LABKEY_ROOT>/server/customModules. Examples include:- <LABKEY_ROOT>/server/customModules/exampleassay/resources/assay
- <LABKEY_ROOT>/server/customModules/iaviElisa/elisa/assay/elisa
- <LABKEY_ROOT>/server/customModules/idri/resources/assay/particleSize
File Structure
The assay consists of an assay config file, a set of domain descriptions, and view html files. The assay is added to a module by placing it in an assay directory at the top-level of the module. The assay has the following file structure:
How to Specify an Assay "Begin" Page
Module-based assays can be designed to jump to a "begin" page instead of a "runs" page. If an assay has a begin.html in the assay/<name>/views/ directory, users are directed to this page instead of the runs page when they click on the name of the assay in the assay list.Tutorial: Define an Assay Type in a Module
Download
First download a pre-packed .module file and deploy it to LabKey Server.- Download exampleassay.module. (This is a renamed .zip archive the contains the source files for the assay module.)
Add the Module to your LabKey Server Installation
- On a local build of LabKey Server, copy exampleassay.module to a module deployment directory, such as <LABKEY_HOME>\build\deploy\modules\
- Or
- On a local install of LabKey Server, copy exampleassay.module to this location: <LABKEY_HOME>\externalModules\
- Restart your server. The server will explode the directory.
- Examine the files in the exploded directory. You will see the following structure:
exampleassay
└───assay
└───example
│ config.xml
│
├───domains
│ batch.xml
│ result.xml
│ run.xml
│
└───views
upload.html
- upload.html contains the UI that the user will see when importing data to this type of assay.
- batch.xml, result.xml, and run.xml provide the assay's design, i.e., the names of the fields, their data types, whether they are required fields, etc.
Enable the Module in a Folder
The assay module is now available through the UI. Here we enable the module in a folder.- Create or select a folder to enable the module in, for example, a subfolder in the Home project.
- Select Admin > Folder > Management and then click the Folder Type tab.
- Place a checkmark next to the exampleassay module (under the "Modules" column on the right).
- Click the Update Folder button.
Use the Module's Assay Design
Next we create a new assay design based the module.- Select Admin > Manage Assays.
- On the Assay List page, click New Assay Design.
- Select LabKey Example and click Next.
- Name this assay "FileBasedAssay"
- Leave all other fields at default values and click Save and Close.
Import Data to the Assay Design
- Download these two sample assay data files:
- Click on the new FileBasedAssay in the Assay List.
- Click the Import Data button.
- Note that instead of the standard UI for importing data, you will see the custom UI for importing data defined by upload.html in exampleassay\assay\example\views.
- Also note the URL to the custom upload page. It follows the pattern: http://myserver.org/labkey/myproject/myfolder/assay-moduleAssayUpload.view?rowId=1
- Enter a value for Batch Name, for example, "Batch 1"
- Click Add Excel File and select GenericAssay_Run1.xls. (Wait a few seconds for the file to upload.)
- Notice that the Created and Modified fields are filled in automatically, as specified in the module-based assay's upload.html file.
- Click Import Data and repeat the import process for GenericAssay_Run2.xls.
- Click Done.

Review Imported Data
- Click on the first run (GenericAssayRun1.xls) to see the data it contains. You will see data similar to the following:

- You can now integrate this data into any available target studies.
Related Topics
Assay Custom Domains
assay/<assay-name>/domains/<domain-name>.xml
<ap:domain xmlns:exp="http://cpas.fhcrc.org/exp/xml"
xmlns:ap="http://labkey.org/study/assay/xml">
<exp:Description>This is my data domain.</exp:Description>
<exp:PropertyDescriptor>
<exp:Name>SampleId</exp:Name>
<exp:Description>The Sample Id</exp:Description>
<exp:Required>true</exp:Required>
<exp:RangeURI>http://www.w3.org/2001/XMLSchema#string</exp:RangeURI>
<exp:Label>Sample Id</exp:Label>
</exp:PropertyDescriptor>
<exp:PropertyDescriptor>
<exp:Name>TimePoint</exp:Name>
<exp:Required>true</exp:Required>
<exp:RangeURI>http://www.w3.org/2001/XMLSchema#dateTime</exp:RangeURI>
</exp:PropertyDescriptor>
<exp:PropertyDescriptor>
<exp:Name>DoubleData</exp:Name>
<exp:RangeURI>http://www.w3.org/2001/XMLSchema#double</exp:RangeURI>
</exp:PropertyDescriptor>
</ap:domain>
Assay Custom Views
Add a Custom Details View
Suppose you want to add a [details] link to each row of an assay run table, that takes you to a custom details view for that row. You can add new views to the module-based assay by adding html files in the views/ directory, for example:assay/<assay-name>/views/<view-name>.html
1 <table>
2 <tr>
3 <td class='labkey-form-label'>Sample Id</td>
4 <td><div id='SampleId_div'>???</div></td>
5 </tr>
6 <tr>
7 <td class='labkey-form-label'>Time Point</td>
8 <td><div id='TimePoint_div'>???</div></td>
9 </tr>
10 <tr>
11 <td class='labkey-form-label'>Double Data</td>
12 <td><div id='DoubleData_div'>???</div></td>
13 </tr>
14 </table>
15
16 <script type="text/javascript">
17 function setValue(row, property)
18 {
19 var div = Ext.get(property + "_div");
20 var value = row[property];
21 if (!value)
22 value = "<none>";
23 div.dom.innerHTML = value;
24 }
25
26 if (LABKEY.page.result)
27 {
28 var row = LABKEY.page.result;
29 setValue(row, "SampleId");
30 setValue(row, "TimePoint");
31 setValue(row, "DoubleData");
32 }
33 </script>
Add a custom view for a run
Same as for the custom details page for the row data except the view file name is run.html and the run data will be available as the LABKEY.page.run variable. See Example Assay JavaScript Objects for a description of the LABKEY.page.run object.Add a custom view for a batch
Same as for the custom details page for the row data except the view file name is batch.html and the run data will be available as the LABKEY.page.batch variable. See Example Assay JavaScript Objects for a description of the LABKEY.page.batch object.Example Assay JavaScript Objects
LABKEY.page.assay = {
"id": 4,
"projectLevel": true,
"description": null,
"name": <assay name>,
// domains objects: one for batch, run, and result.
"domains": {
// array of domain property objects for the batch domain
"<assay name> Batch Fields": [
{
"typeName": "String",
"formatString": null,
"description": null,
"name": "ParticipantVisitResolver",
"label": "Participant Visit Resolver",
"required": true,
"typeURI": "http://www.w3.org/2001/XMLSchema#string"
},
{
"typeName": "String",
"formatString": null,
"lookupQuery": "Study",
"lookupContainer": null,
"description": null,
"name": "TargetStudy",
"label": "Target Study",
"required": false,
"lookupSchema": "study",
"typeURI": "http://www.w3.org/2001/XMLSchema#string"
}
],
// array of domain property objects for the run domain
"<assay name> Run Fields": [{
"typeName": "Double",
"formatString": null,
"description": null,
"name": "DoubleRun",
"label": null,
"required": false,
"typeURI": "http://www.w3.org/2001/XMLSchema#double"
}],
// array of domain property objects for the result domain
"<assay name> Result Fields": [
{
"typeName": "String",
"formatString": null,
"description": "The Sample Id",
"name": "SampleId",
"label": "Sample Id",
"required": true,
"typeURI": "http://www.w3.org/2001/XMLSchema#string"
},
{
"typeName": "DateTime",
"formatString": null,
"description": null,
"name": "TimePoint",
"label": null,
"required": true,
"typeURI": "http://www.w3.org/2001/XMLSchema#dateTime"
},
{
"typeName": "Double",
"formatString": null,
"description": null,
"name": "DoubleData",
"label": null,
"required": false,
"typeURI": "http://www.w3.org/2001/XMLSchema#double"
}
]
},
"type": "Simple"
};LABKEY.page.batch = new LABKEY.Exp.RunGroup({
"id": 8,
"createdBy": <user name>,
"created": "8 Apr 2009 12:53:46 -0700",
"modifiedBy": <user name>,
"name": <name of the batch object>,
"runs": [
// array of LABKEY.Exp.Run objects in the batch. See next section.
],
// map of batch properties
"properties": {
"ParticipantVisitResolver": null,
"TargetStudy": null
},
"comment": null,
"modified": "8 Apr 2009 12:53:46 -0700",
"lsid": "urn:lsid:labkey.com:Experiment.Folder-5:2009-04-08+batch+2"
});
LABKEY.page.run = new LABKEY.Exp.Run({
"id": 4,
// array of LABKEY.Exp.Data objects added to the run
"dataInputs": [{
"id": 4,
"created": "8 Apr 2009 12:53:46 -0700",
"name": "run01.tsv",
"dataFileURL": "file:/C:/Temp/assaydata/run01.tsv",
"modified": null,
"lsid": <filled in by the server>
}],
// array of objects, one for each row in the result domain
"dataRows": [
{
"DoubleData": 3.2,
"SampleId": "Monkey 1",
"TimePoint": "1 Nov 2008 11:22:33 -0700"
},
{
"DoubleData": 2.2,
"SampleId": "Monkey 2",
"TimePoint": "1 Nov 2008 14:00:01 -0700"
},
{
"DoubleData": 1.2,
"SampleId": "Monkey 3",
"TimePoint": "1 Nov 2008 14:00:01 -0700"
},
{
"DoubleData": 1.2,
"SampleId": "Monkey 4",
"TimePoint": "1 Nov 2008 00:00:00 -0700"
}
],
"createdBy": <user name>,
"created": "8 Apr 2009 12:53:47 -0700",
"modifiedBy": <user name>,
"name": <name of the run>,
// map of run properties
"properties": {"DoubleRun": null},
"comment": null,
"modified": "8 Apr 2009 12:53:47 -0700",
"lsid": "urn:lsid:labkey.com:SimpleRun.Folder-5:cf1fea1d-06a3-102c-8680-2dc22b3b435f"
});
LABKEY.page.result = {
"DoubleData": 3.2,
"SampleId": "Monkey 1",
"TimePoint": "1 Nov 2008 11:22:33 -0700"
};Assay Query Metadata
Query Metadata for Assay Tables
You can associate query metadata with an individual assay design, or all assay designs that are based on the same type of assay (e.g., "NAb" or "Viability").Example. Assay table names are based upon the name of the assay design. For example, consider an assay design named "Example" that is based on the "Viability" assay type. This design would be associated with three tables in the schema explorer: "Example Batches", "Example Runs", and "Example Data."Associate metadata with a single assay design. To attach query metadata to the "Example Data" table, you would normally create a /queries/assay/Example Data.query.xml metadata file. This would work well for the "Example Data" table itself. However, this method would not allow you to re-use this metadata file for a new assay design that is also based on the same assay type ("Viability" in this case).Associate metadata with all assay designs based on a particular assay type. To permit re-use of the metadata, you need to create a query metadata file whose name is based upon the assay type and table name. To continue our example, you would create a query metadata file callled /assay/Viability/queries/Data.query.xml to attach query metadata to all data tables based on the Viability-type assay.As with other query metadata in module files, the module must be activated (in other words, the appropriate checkbox must be checked) in the folder's settings.See Modules: Queries, Views and Reports and Modules: Query Metadata for more information on query metadata.Customize Batch Save Behavior
<saveHandler>org.labkey.icemr.assay.tracking.TrackingSaveHandler</saveHandler>.
- Create the skeleton framework for a Java module. This consists of a controller class, manager, etc. See Creating a New Java Module for details on autogenerating the boiler plate Java code.
- Add an assay directory underneath the Java src directory that corresponds to the file-based assay you want to extend. For example: myModule/src/org.labkey.mymodule/assay/tracking
- Implement the AssaySaveHandler interface. You can choose to either implement the interface from scratch or extend default behavior by having your class inherit from the DefaultAssaySaveHandler class. If you want complete control over the JSON format of the experiment data you want to save, you may choose to implement the AssaySaveHandler interface entirely. If you want to follow the pre-defined LABKEY experiment JSON format, then you can inherit from the DefaultAssaySaveHandler class and only override the specific piece you want to customize. For example, you may want custom code to run when a specific property is saved. (See below for more implementation details.)
- Reference your class in the assay's config.xml file. For example, notice the <ap:saveHandler/> entry below. If a non-fully-qualified name is used (as below) then LabKey Server will attempt to find this class under org.labkey.[module name].assay.[assay name].[save handler name].
<ap:provider xmlns:ap="http://labkey.org/study/assay/xml">
<ap:name>Flask Tracking</ap:name>
<ap:description>
Enables entry of a set of initial samples and then tracks
their progress over time via a series of daily measurements.
</ap:description>
<ap:saveHandler>TrackingSaveHandler</ap:saveHandler>
<ap:fieldKeys>
<ap:participantId>Run/PatientId</ap:participantId>
<ap:date>MeasurementDate</ap:date>
</ap:fieldKeys>
</ap:provider>
- The interface methods are invoked when the user chooses to import data into the assay or otherwise calls the SaveAssayBatch action. This is usually invoked by the Experiment.saveBatch JavaScript API. On the server, the file-based assay provider will look for an AssaySaveHandler specified in the config.xml and invoke its functions. If no AssaySaveHandler is specfied then the DefaultAssaySaveHandler implementation is used.
SaveAssayBatch Details
The SaveAssayBatch function creates a new instance of the SaveHandler for each request. SaveAssayBatch will dispatch to the methods of this interface according to the format of the JSON Experiment Batch (or run group) sent to it by the client. If a client chooses to implement this interface directly then the order of method calls will be:- beforeSave
- handleBatch
- afterSave
- beforeSave
- handleBatch
- handleProperties (for the batch)
- handleRun (for each run)
- handleProperties (for the run)
- handleProtocolApplications
- handleData (for each data output)
- handleProperties (for the data)
- handleMaterial (for each input material)
- handleProperties (for the material)
- handleMaterial (for each output material)
- handleProperties (for the material)
- afterSave
Related Topics
SQL Scripts for Module-Based Assays
exampleassay
├───assay
│ └───example
│ │ config.xml
│ │
│ ├───domains
│ │ batch.xml
│ │ result.xml
│ │ run.xml
│ │
│ └───views
│ upload.html
│
└───schemas
│ SCHEMA_NAME.xml
│
└───dbscripts
├───postgresql
│ SCHEMA_NAME-X.XX-Y.YY.sql
└───sqlserver
SCHEMA_NAME-X.XX-Y.YY.sql
DROP SCHEMA IF EXISTS myreagents CASCADE;
CREATE SCHEMA myreagents;
CREATE TABLE myreagents.Reagents
(
RowId SERIAL NOT NULL,
ReagentName VARCHAR(30) NOT NULL
);
ALTER TABLE ONLY myreagents.Reagents
ADD CONSTRAINT Reagents_pkey PRIMARY KEY (RowId);
INSERT INTO myreagents.Reagents (ReagentName) VALUES ('Acetic Acid');
INSERT INTO myreagents.Reagents (ReagentName) VALUES ('Baeyers Reagent');
INSERT INTO myreagents.Reagents (ReagentName) VALUES ('Carbon Disulfide');
<exp:PropertyDescriptor>
<exp:Name>Reagent</exp:Name>
<exp:Required>false</exp:Required>
<exp:RangeURI>http://www.w3.org/2001/XMLSchema#int</exp:RangeURI>
<exp:Label>Reagent</exp:Label>
<exp:FK>
<exp:Schema>myreagents</exp:Schema>
<exp:Query>Reagents</exp:Query>
</exp:FK>
</exp:PropertyDescriptor>
<ns:column columnName="Lsid">
<ns:datatype>lsidtype</ns:datatype>
<ns:isReadOnly>true</ns:isReadOnly>
<ns:isHidden>true</ns:isHidden>
<ns:isUserEditable>false</ns:isUserEditable>
<ns:isUnselectable>true</ns:isUnselectable>
<ns:fk>
<ns:fkColumnName>ObjectUri</ns:fkColumnName>
<ns:fkTable>Object</ns:fkTable>
<ns:fkDbSchema>exp</ns:fkDbSchema>
</ns:fk>
</ns:column>
function editDomain(queryName)
{
var url = LABKEY.ActionURL.buildURL("property", "editDomain", null, {
domainKind: "ExtensibleTable",
createOrEdit: true,
schemaName: "myreagents",
queryName: queryName
});
window.location = url;
}
Transformation Scripts
Topics
- Use Transformation Scripts
- How Transformation Scripts Work
- Example Workflow: Develop a Transformation Script (perl)
- Example Transformation Scripts (perl)
- Transformation Scripts in R
- Transformation Scripts in Java
- Transformation Scripts for Module-based Assays
- Run Properties Reference
- Transformation Script Substitution Syntax
- Warnings in Tranformation Scripts
Use Transformation Scripts
Each assay design can be associated with one or more validation or transformation scripts which are run in the order specified. The script file extension (.r, .pl, etc) identifies the script engine that will be used to run the transform script. For example: a script named test.pl will be run with the Perl scripting engine. Before you can run validation or transformation scripts, you must configure the necessary Scripting Engines.- Open the assay designer for a new assay, or edit an existing assay design.
- Click Add Script.
- Enter the full path to the script in the Transform Scripts field.
- You may enter multiple scripts by clicking Add Script again.

- Confirm that other Properties required by your assay type are correctly specified.
- Click Save and Close.
- Client API calls are not supported in transform scripts.
- Columns populated by transform scripts must already exist in the assay definition.
- Executed scripts show up in the experimental graph, providing a record that transformations and/or quality control scripts were run.
- Transform scripts are run before field-level validators.
- The script is invoked once per run upload.
- Multiple scripts are invoked in the order they are listed in the assay design.
How Transformation Scripts Work
Script Execution Sequence
Transformation and validation scripts are invoked in the following sequence:- A user uploads assay data.
- The server creates a runProperties.tsv file and rewrites the uploaded data in TSV format. Assay-specific properties and files from both the run and batch levels are added. See Run Properties Reference for full lists of properties.
- The server invokes the transform script by passing it the information created in step 2 (the runProperties.tsv file).
- After script completion, the server checks whether any errors have been written by the transform script and whether any data has been transformed.
- If transformed data is available, the server uses it for subsequent steps; otherwise, the original data is used.
- If multiple transform scripts are specified, the server invokes the other scripts in the order in which they are defined.
- Field-level validator/quality-control checks (including range and regular expression validation) are performed. (These field-level checks are defined in the assay definition.)
- If no errors have occurred, the run is loaded into the database.
Passing Run Properties to Transformation Scripts
Information on run properties can be passed to a transform script in two ways. You can put a substitution token into your script to identify the run properties file, or you can configure your scripting engine to pass the file path as a command line argument. See Transformation Script Substitution Syntax for a list of available substitution tokens.For example, using perl:Option #1: Put a substitution token (${runInfo}) into your script and the server will replace it with the path to the run properties file. Here's a snippet of a perl script that uses this method:# Open the run properties file. Run or upload set properties are not used by
# this script. We are only interested in the file paths for the run data and
# the error file.
open my $reportProps, '${runInfo}';
- Go to Admin > Site > Admin Console.
- Select the Views and Scripting.
- Select and edit the perl engine.
- Add ${runInfo} to the Program Command field.
Example Workflow: Develop a Transformation Script (perl)
- transform run data
- transform run properties
Script Engine Setup
Before you can develop or run validation or transform scripts, configure the necessary Scripting Engines. You only need to set up a scripting engine once per type of script. You will need a copy of Perl running on your machine to set up the engine.- Select Admin > Site > Admin Console.
- Click Views and Scripting.
- Click Add > New Perl Engine.
- Fill in as shown, specifying the "pl" extension and full path to the perl executable.

- Click Submit.
Add a Script to the Assay Design
Create a new empty .pl file in the development location of your choice and include it in your assay design.- Navigate to the Assay Tutorial.
- Click GenericAssay in the Assay List web part.
- Select Manage Assay Design > copy assay design.
- Click Copy to Current Folder.
- Enter a new name, such as "TransformedAssay".
- Click Add Script and type the full path to the new script file you are creating.
- Check the box for Save Script Data.
- Confirm that the batch, run, and data fields are correct.
- Click Save and Close.
Obtain Test Data
To assist in writing your transform script, you will next obtain sample "runData.tsv" and "runProperties.tsv" files showing the state of your data import 'before' the transform script would be applied. To generate useful test data, you need to import a data run using the new assay design.- Open and select the following file (if you have already imported this file during the tutorial, you will first need to delete that run):
LabKeyDemoFiles/Assays/Generic/GenericAssay_Run4.xls
- Click Import Data.
- Select the TransformedAssay design you just defined, then click Import.
- Click Next, then Save and Finish.
- When the import completes, select Manage Assay Design > edit assay design.
- You will now see a Download Test Data button that was not present during initial assay design.
- Click it and unzip the downloaded "sampleQCData" package to see the .tsv files.
- Open the "runData.tsv" file to view the current fields.
Date VisitID ParticipantID M3 M2 M1 SpecimenID
12/17/2013 1234 demo value 1234 1234 1234 demo value
12/17/2013 1234 demo value 1234 1234 1234 demo value
12/17/2013 1234 demo value 1234 1234 1234 demo value
12/17/2013 1234 demo value 1234 1234 1234 demo value
12/17/2013 1234 demo value 1234 1234 1234 demo value
Save Script Data
Typically transform and validation script data files are deleted on script completion. For debug purposes, it can be helpful to be able to view the files generated by the server that are passed to the script. When the Save Script Data checkbox is checked, files will be saved to a subfolder named: "TransformAndValidationFiles", in the same folder as the original script. Beneath that folder are subfolders for the AssayId, and below that a numbered directory for each run. In that nested subdirectory you will find a new "runDataFile.tsv" that will contain values from the run file plugged into the current fields.participantid Date M1 M2 M3
249318596 2008-06-07 00:00 435 1111 15.0
249320107 2008-06-06 00:00 456 2222 13.0
249320107 2008-03-16 00:00 342 3333 15.0
249320489 2008-06-30 00:00 222 4444 14.0
249320897 2008-05-04 00:00 543 5555 32.0
249325717 2008-05-27 00:00 676 6666 12.0
Define the Desired Transformation
The runData.tsv file gives you the basic fields layout. Decide how you need to modify the default data. For example, perhaps for our project we need an adjusted version of the value in the M1 field - we want the doubled value available as an integer.Add Required Fields to the Assay Design
- Select Manage Assay Design > edit assay design.
- Scroll down to the Data Fields section and click Add Field.
- Enter "AdjustM1", "Adjusted M1", and select type "Integer".
- Click Save and Close.
Write a Script to Transform Run Data
Now you have the information you need to write and refine your transformation script. Open the empty script file and paste the contents of the Modify Run Data box from this page: Example Transformation Scripts (perl).Iterate over the Sample Run
Re-import the same run using the transform script you have defined.- From the run list, select the run and click Re-import Run.
- Click Next.
- Under Run Data, click Use the data file(s) already uploaded to the server.
- Click Save and Finish.
 Until the results are as desired, you will edit the script and use Reimport Run to retry.Once your transformation script is working properly, re-edit the assay design one more time to uncheck the Save Script Data box - otherwise your script will continue to generate artifacts with every run and could eventually fill your disk.
Until the results are as desired, you will edit the script and use Reimport Run to retry.Once your transformation script is working properly, re-edit the assay design one more time to uncheck the Save Script Data box - otherwise your script will continue to generate artifacts with every run and could eventually fill your disk.
Debugging Transformation Scripts
If your script has errors that prevent import of the run, you will see red text in the Run Properties window. If you fail to select the correct data file, for example: If you have a type mismatch error between your script results and the defined destination field, you will see an error like:
If you have a type mismatch error between your script results and the defined destination field, you will see an error like:
Errors File
If the validation script needs to report an error that is displayed by the server, it adds error records to an error file. The location of the error file is specified as a property entry in the run properties file. The error file is in a tab-delimited format with three columns:- type: error, warning, info, etc.
- property: (optional) the name of the property that the error occurred on.
- message: the text message that is displayed by the server.
| type | property | message |
|---|---|---|
| error | runDataFile | A duplicate PTID was found : 669345900 |
| error | assayId | The assay ID is in an invalid format |
Example Transformation Scripts (perl)
- Modify Run Data
- Modify Run Properties
Modify Run Data
This script is used in the Example Workflow: Develop a Transformation Script (perl) and populates a new field with data derived from an existing field in the run.#!/usr/local/bin/perl
use strict;
use warnings;
# Open the run properties file. Run or upload set properties are not used by
# this script. We are only interested in the file paths for the run data and
# the error file.
open my $reportProps, '${runInfo}';
my $transformFileName = "unknown";
my $dataFileName = "unknown";
my %transformFiles;
# Parse the data file properties from reportProps and save the transformed data location
# in a map. It's possible for an assay to have more than one transform data file, although
# most will only have a single one.
while (my $line=<$reportProps>)
{
chomp($line);
my @row = split(/t/, $line);
if ($row[0] eq 'runDataFile')
{
$dataFileName = $row[1];
# transformed data location is stored in column 4
$transformFiles{$dataFileName} = $row[3];
}
}
my $key;
my $value;
my $adjustM1 = 0;
# Read each line from the uploaded data file and insert new data (double the value in the M1 field)
# into an additional column named 'Adjusted M1'. The additional column must already exist in the assay
# definition and be of the correct type.
while (($key, $value) = each(%transformFiles)) {
open my $dataFile, $key or die "Can't open '$key': $!";
open my $transformFile, '>', $value or die "Can't open '$value': $!";
my $line=<$dataFile>;
chomp($line);
$line =~ s/r*//g;
print $transformFile $line, "\t", "Adjusted M1", "\n";
while (my $line=<$dataFile>)
{
$adjustM1 = substr($line, 27, 3) * 2;
chomp($line);
$line =~ s/r*//g;
print $transformFile $line, "\t", $adjustM1, "\n";
}
close $dataFile;
close $transformFile;
}
Modify Run Properties
You can also define a transform script that modifies the run properties, as show in this example which parses the short filename out of the full path:#!/usr/local/bin/perl
use strict;
use warnings;
# open the run properties file, run or upload set properties are not used by
# this script, we are only interested in the file paths for the run data and
# the error file.
open my $reportProps, $ARGV[0];
my $transformFileName = "unknown";
my $uploadedFile = "unknown";
while (my $line=<$reportProps>)
{
chomp($line);
my @row = split(/\t/, $line);
if ($row[0] eq 'transformedRunPropertiesFile')
{
$transformFileName = $row[1];
}
if ($row[0] eq 'runDataUploadedFile')
{
$uploadedFile = $row[1];
}
}
if ($transformFileName eq 'unknown')
{
die "Unable to find the transformed run properties data file";
}
open my $transformFile, '>', $transformFileName or die "Can't open '$transformFileName': $!";
#parse out just the filename portion
my $i = rindex($uploadedFile, "\\") + 1;
my $j = index($uploadedFile, ".xls");
#add a value for fileID
print $transformFile "FileID", "\t", substr($uploadedFile, $i, $j-$i), "\n";
close $transformFile;
Transformation Scripts in R
Overview
Users importing instrument-generated tabular datasets into LabKey Server may run into the following difficulties:- Instrument-generated files often contain header lines before the main dataset, denoted by a leading # or ! or other symbol. These lines usually contain useful metadata about the protocol or reagents or samples tested, and in any case need to be skipped over to find the main data set.
- The file format is optimized for display, not for efficient storage and retrieval. For example, columns that correspond to individual samples are difficult to work with in a database.
- The data to be imported contains the display values from a lookup column, which need to be mapped to the foreign key values for storage.
Identifying the Path to the Script File
Transform scripts are designated as part of a assay by providing a fully qualified path to the script file in the field named at the top of the assay instance definition. A convenient location to put the script file is to upload it using a File web part defined in the same folder as the assay definition. Then the fully qualified path to the script file is the concatenation of the file root for the folder (for example, "C:\lktrunk\build\deploy\files\MyAssayFolderName\@files\", as determined by the Files page in the Admin console) plus the file path to the script file as seen in the File web part (for example, "scripts\LoadData.R". For the file path, LabKey Server accepts the use of either backslashes (the default Windows format) or forward slashes.When working on your own developer workstation, you can put the script file wherever you like, but putting it within the scope of the File manager will make it easier to deploy to a server. It also makes iterative development against a remote server easier, since you can use a Web-DAV enabled file editor to directly edit the same file that the server is calling.If your transform script calls other script files to do its work, the normal way to pull in the source code is using the source statement, for examplesource("C:\lktrunk\build\deploy\files\MyAssayFolderName\@files\Utils.R")source("${srcDirectory}/Utils.R");Accessing and Using the Run Properties File
The primary mechanism for communication between the LabKey Assay framework and the Transform script is the Run Properties file. Again a substitution token tells the script code where to find this file. The script file should contain a line likerpPath<- "${runInfo}"gDarkStdDev 1.98223 java.lang.Double- a. runDataUploadedFile: the raw data file that was selected by the user and uploaded to the server as part of an import process. This can be an Excel file, a tab-separated text file, or a comma-separated text file.
- b. runDataFile: the imported data file after the assay framework has attempted to convert the file to .tsv format and match its columns to the assay data result set definition. The path will point to a subfolder below the script file directory, with a path value similar to <property value> <java property type>. The AssayId_22\42 part of the directory path serves to separate the temporary files from multiple executions by multiple scripts in the same folder.
C:\lktrunk\build\deploy\files\transforms\@files\scripts\TransformAndValidationFiles\AssayId_22\42\runDataFile.tsv
- c. AssayRunTSVData: This file path is where the result of the transform script will be written. It will point to a unique file name in an “assaydata” directory that the framework creates at the root of the files tree. NOTE: this property is written on the same line as the runDataFile property.
- d. errorsFile: This path is where a transform or validation script can write out error messages for use in troubleshooting. Not normally needed by an R script because the script usually writes errors to stdout, which are written by the framework to a file named “<scriptname>.Rout”.
- e. transformedRunPropertiesFile: This path is where the script writes out the updated values of batch- and run-level properties that are listed in the runProperties file.
Choosing the Input File for Transform Script Processing
The transform script developer can choose to use either the runDataFile or the runDataUploadedFile as its input. The runDataFile would be the right choice for an Excel-format raw file and a script that fills in additional columns of the data set. By using the runDataFile, the assay framework does the Excel-to-TSV conversion and the script doesn’t need to know how to parse Excel files. The runDataUploadedFile would be the right choice for a raw file in TSV format that the script is going to reformat by turning columns into rows. In either case, the script writes its output to the AssayRunTSVData file.Transform Script Options
There are two useful options presented as checkboxes in the Assay designer.- Save Script Data tells the framework to not delete the intermediate files such as the runProperties file after a successful run. This option is important during script development. It can be turned off to avoid cluttering the file space under the TransformAndValidationFiles directory that the framework automatically creates under the script file directory.
- Upload In Background tells the framework to create a pipeline job as part of the import process, rather than tying up the browser session. It is useful for importing large data sets.
Connecting Back to the Server from a Transform Script
Sometimes a transform script needs to connect back to the server to do its job. One example is translating lookup display values into key values. The Rlabkey library available on CRAN has the functions needed to connect to, query, and insert or update data in the local LabKey Server where it is running. To give the connection the right security context (the current user’s), the assay framework provides the substitution token ${rLabkeySessionId}. Including this token on a line by itself near the beginning of the transform script eliminates the need to use a config file to hold a username and password for this loopback connection. It will be replaced with two lines that looks like:labkey.sessionCookieName = "JSESSIONID" labkey.sessionCookieContents = "TOMCAT_SESSION_ID"where TOMCAT_SESSION_ID is the actual ID of the user's HTTP session.Debugging an R Transform Script
You can load an R transform script into the R console/debugger and run the script with debug(<functionname> commands active. Since the substitution tokens described above ( ${srcDirectory} , ${runInfo}, and ${rLabkeySessionId} ) are necessary to the correct operation of the script, the framework conveniently writes out a version of the script with these substitutions made, into the same subdiretory as the runProperties.tsv file is found. Load this modified version of the script into the R console.Example Script
Setup- Create a new project, type Assay
- Add the following Web parts:
- Files
- Lists
- Data Pipeline
- Sample Sets (narrow)
- Copy the scripts folder from the data folder to the root of the Files web part tree
- Create a sample set called ExampleSamples
- Click on header of Sample Sets web part
- Select Import Sample Set
- Open the file samples.txt in a text editor or Excel (Click to download from page.)
- Copy and paste the contents into the import window , select sampleId as the key field
- Create a list called probesources by importing ProbeSourcesListArchive.zip (Click to download.)
- Create a GPAT assay with transform script
- Import the file ExampleAssayWithRTransform.xar (Click to download.)
- Fix up the path to the script file TransformScriptExample.R (Click to download.)
- Run the assay
- Click on assay name
- Import data button on toolbar
- Select probe source from list, leave property Prefix, press Next
- Column Names Row: 65
- Sample Set: ExampleSamples
- Run Data: Upload a data file. Choose file GSE11199_series_matrix_200.txt (Click to download.)
- Save and finish
A Look at the Code
This transform script example handles the data output from an Affymetrics microarray reader. The data file contains 64 lines of metadata before the chip-level intensity data. The metadata describes the platform, the experiment, and the samples used. The spot-level data is organized with one column per sample, which may be efficient for storage in a spreadsheet but isn’t good for querying in a database.The transform script does the following tasks:- Reads in the runProperties file
- Gets additional import processing parameters from a lookup list, such as the prefix that designates a comment line containing a property-value pair
- Fills in run properties that are read from the data file header (marked by the prefix). Writes the transformed run properties to the designated file location so they get stored with the assay.
- Converts sample identifiers to sample set key values so that a lookup from result data to sample set properties works.
- Skips over a specified number of rows to the beginning of the spot data.
- Reshapes the input data so that the result set is easier to query by sample
options(stringsAsFactors = FALSE)
source("${srcDirectory}/ExampleUtils.R")
baseUrl<-"http://localhost:8080/labkey"
${rLabkeySessionId}
rpPath<- "${runInfo}"
## read the file paths etc out of the runProperties.tsv file
params <- getRunPropsList(rpPath, baseUrl)
## read the input data frame just to get the column headers.
inputDF<-read.table(file=params$inputPathUploadedFile, header = TRUE,
sep = "\t", quote = "\"",
fill=TRUE, stringsAsFactors = FALSE, check.names=FALSE,
row.names=NULL, skip=(params$loaderColNamesRow -1), nrows=1)
cols<-colnames(inputDF)
## create a Name to RowId map for samples
keywords <- as.vector(colnames(inputDF)[-1])
queryName=params$sampleSetName
keywordMap<- getLookupMap( keywords, baseUrl=baseUrl, folderPath=params$containerPath,
schemaName="Samples", queryName=queryName, keyField="rowId",
displayField="SampleId")
doRunLoad(params=params, inputColNames=cols, outputColNames=c( "ID_REF", "sample", "val"),
lookupMap=keywordMap)
getRunPropsList<- function(rpPath, baseUrl)
{
rpIn<- read.table(rpPath, col.names=c("name", "val1", "val2", "val3"), #########
header=FALSE, check.names=FALSE, ## 1 ##
stringsAsFactors=FALSE, sep="\t", quote="", fill=TRUE, na.strings=""); #########
## pull out the run properties
params<- list(inputPathUploadedFile = rpIn$val1[rpIn$name=="runDataUploadedFile"],
inputPathValidated = rpIn$val1[rpIn$name=="runDataFile"],
##a little strange. AssayRunTSVData is the one we need to output to
outputPath = rpIn$val3[rpIn$name=="runDataFile"],
containerPath = rpIn$val1[rpIn$name=="containerPath"],
runPropsOutputPath = rpIn$val1[rpIn$name=="transformedRunPropertiesFile"],
sampleSetId = as.integer(rpIn$val1[rpIn$name=="sampleSet"]),
probeSourceId = as.integer(rpIn$val1[rpIn$name=="probeSource"]),
errorsFile = rpIn$val1[rpIn$name=="errorsFile"])
## lookup the name of the sample set based on its number
if (length(params$sampleSetId)>0)
{
df<-labkey.selectRows(baseUrl=baseUrl,
folderPath=params$containerPath, schemaName="exp", queryName="SampleSets",
colFilter=makeFilter(c("rowid", "EQUALS", params$sampleSetId)))
params<- c(params, list(sampleSetName=df$Name))
}
## This script reformats the rows in batches of 1000 in order to reduce
## the memory requirements of the R calculations
params<-c(params, list(loaderBatchSize=as.integer(1000)))
## From the probesource lookup table, get the prefix characters that
## identify property value comment lines in the data file, and the starting
## line number of the spot data table within the data file
dfProbeSource=labkey.selectRows(baseUrl=baseUrl, folderPath=params$containerPath, #########
schemaName="lists", queryName="probesources", ## 2 ##
colFilter=makeFilter(c("probesourceid", "EQUALS", params$probeSourceId))) #########
params<-c(params, list(propertyPrefix=dfProbeSource$propertyPrefix,
loaderColNamesRow=dfProbeSource$loaderColNamesRow))
if (is.null(params$loaderColNamesRow) | is.na(params$loaderColNamesRow))
{
params$loaderColNamesRow <- 1
}
## now apply the run property values reported in the header
## of the data tsv file to the corresponding run properties
conInput = file(params$inputPathUploadedFile, "r")
line<-""
pfx <- as.integer(0)
fHasProps <- as.logical(FALSE)
if (!is.na(params$propertyPrefix))
{ #########
pfx<-nchar(params$propertyPrefix) ## 3 ##
} #########
while(pfx>0)
{
line<-readLines(conInput, 1)
if (nchar(line)<=pfx) {break}
if (substring(line, 1, pfx) != params$propertyPrefix) {break}
strArray=strsplit(substring(line, pfx+1, nchar(line)) ,"\t", fixed=TRUE)
prop<- strArray[[1]][1]
val<- strArray[[1]][2]
if (length(rpIn$name[rpIn$name==prop]) > 0 )
{
## dealing with dates is sometimes tricky. You want the value pushed to rpIn
## to be a string representing a date but in the default date format This data
## file uses a non-defualt date format that we explicitly convert to date using
## as.Date and a format string.
## Then convert it back to character using the default format.
if (rpIn$val2[rpIn$name==prop]=="java.util.Date")
{
val<-as.character(as.Date(val, "%b%d%y"))
}
rpIn$val1[rpIn$name==prop]<-val
fHasProps <- TRUE
}
}
if (fHasProps)
{
## write out the transformed run properties to the file that
## the assay framework will read in
write.table(rpIn, file=params$runPropsOutputPath, sep="\t", quote=FALSE
, na="" , row.names=FALSE, col.names=FALSE, append=FALSE)
}
return (params)
}
getLookupMap<- function(uniqueLookupValues, baseUrl, folderPath, schemaName,
queryName, keyField, displayField, otherColName=NULL, otherColValue=NULL)
{
inClauseVals = paste(uniqueLookupValues, collapse=";") #########
colfilt<-makeFilter(c(displayField, "EQUALS_ONE_OF", inClauseVals)) ## 4 ##
if (!is.null(otherColName)) #########
{
otherFilter=makeFilter(c(otherColName, "EQUALS", otherColValue))
colfilt = c(colfilt, otherFilter)
}
colsel<- paste(keyField, displayField, sep=",")
lookupMap <-labkey.selectRows(baseUrl=baseUrl, folderPath=folderPath,
schemaName=schemaName, queryName=queryName,
colSelect=colsel, colFilter=colfilt, showHidden=TRUE)
newLookups<- uniqueLookupValues[!(uniqueLookupValues %in% lookupMap[,2])]
if (length(newLookups)>0 && !is.na(newLookups[1]) )
{
## insert the lookup values that we haven't already seen before
newLookupsToInsert<- data.frame(lookupValue=newLookups, stringsAsFactors=FALSE)
colnames(newLookupsToInsert)<- displayField
if (!is.null(otherColName))
{
newLookupsToInsert<-cbind(newLookupsToInsert, otherColValue)
colnames(newLookupsToInsert)<- c(displayField, otherColName)
}
result<- labkey.insertRows(baseUrl=baseUrl, folderPath=folderPath,
schemaName=schemaName, queryName=queryName, toInsert= newLookupsToInsert)
lookupMap <-labkey.selectRows(baseUrl=baseUrl, folderPath=folderPath,
schemaName=schemaName, queryName=queryName,
colSelect=colsel, colFilter=colfilt, showHidden=TRUE)
}
colnames(lookupMap)<- c("RowId", "Name")
return(lookupMap)
}
doRunLoad<-function(params, inputColNames, outputColNames, lookupMap)
{
folder=params$containerPath
unlink(params$outputPath)
cIn <- file(params$inputPathUploadedFile, "r")
cOut<- file(params$outputPath , "w")
## write the column headers to the output file
headerDF<-data.frame(matrix(NA, nrow=0, ncol=length(outputColNames)))
colnames(headerDF)<- outputColNames
write.table(headerDF, file=cOut, sep="\t", quote=FALSE, row.names=FALSE, na="",
col.names=TRUE, append=FALSE)
# the fisrt read from the input file skips rows up to and including the header
skipCnt<-params$loaderColNamesRow
## read in chunks of batchSize, which are then transposed and written to the output file. #########
## blkStart is the 1-based index of the starting row of a chunk ## 5 ##
#########
blkStart <- skipCnt + 1
rowsToRead <- params$loaderBatchSize
while(rowsToRead > 0)
{
inputDF <- read.table(file=cIn, header = FALSE, sep = "\t", quote = "\"",
na.strings = "---", fill=TRUE, row.names=NULL,
stringsAsFactors = FALSE, check.names=FALSE,
col.names=inputColNames ,skip=skipCnt, nrows=rowsToRead)
cols<-colnames(inputDF)
if(NROW(inputDF) >0)
{
idVarName<-inputColNames[1]
df1 <- reshape(inputDF, direction="long", idvar=idVarName,,
v.names="Val",timevar="Name"
,times=cols[-1], varying=list(cols[-1]) ) #########
## 6 ##
df2<- merge(df1, lookupMap) #########
reshapedRows<- data.frame(cbind(df2[,idVarName], df2[,"RowId"],
df2[,"Val"], params$probeSourceId ), stringsAsFactors=FALSE)
reshapedRows[,2] <- as.integer(reshapedRows[,2])
reshapedRows[,4] <- as.integer(reshapedRows[,4])
nonEmptyRows<- !is.na(reshapedRows[,3])
reshapedRows<-reshapedRows[nonEmptyRows ,]
reshapedRows<- reshapedRows[ do.call(order, reshapedRows[1:2]), ]
colnames(reshapedRows)<- outputColNames
## need to double up the single quotes in the data
reshapedRows[,3]<-gsub("'", "''", reshapedRows[,3],fixed=TRUE)
write.table(reshapedRows, file=cOut, sep="\t", quote=TRUE, na="" ,
row.names=FALSE, col.names=FALSE, append=TRUE)
df1<-NULL
df2<-NULL
reshapedRows<-NULL
recordsToInsert<-NULL
}
if (NROW(inputDF)< rowsToRead)
{
##we've hit the end of the file, no more to read
rowsToRead <- 0
}
else
{
## now look where the next block will start, and read up to the end row
blkStart <- blkStart + rowsToRead
}
## skip rows only on the first read
skipCnt<-0
}
inputDF<-NULL
close(cIn)
close(cOut)
}
Transformation Scripts in Java
Overview
LabKey Server supports transformation scripts for assay data at upload time. This feature is primarily targeted for Perl or R scripts; however, the framework is general enough that any application that can be externally invoked can be run as well, including a Java program.Java appeals to programmers who desire a stronger-typed language than most script-based languages. Most important, using a Java-based validator allows a developer to leverage the remote client API and take advantage of the classes available for assays, queries, and security.This page outlines the steps required to configure and create a Java-based transform script. The ProgrammaticQCTest script, available in the BVT test, provides an example of a script that uses the remote client API.Configure the Script Engine
In order to use a Java-based validation script, you will need to configure an external script engine to bind a file with the .jar extension to an engine implementation.To do this:- Go to the Admin Console for your site.
- Select the [views and scripting configuration] option.
- Create a new external script engine.
- Set up the script engine by filling in its required fields:
- File extension: jar
- Program path: (the absolute path to java.exe)
- Program command: -jar "${scriptFile}" "${runInfo}"
- scriptFile - The full path to the (processed and rewritten) transform script. This is usually in a temporary location the server manages.
- runInfo - The full path to the run properties file the server creates. For further info on this file, see the "Run Properties File" section of the Transformation Scripts documentation.
- srcDirectory - The original directory of the transform script (usually specified in the assay definition).
 The program command configured above will invoke the java.exe application against a .jar file passing in the run properties file location as an argument to the java program. The run properties file contains information about the assay properties including the uploaded data and the location of the error file used to convey errors back to the server. Specific details about this file are contained in the data exchange specification for Programmatic QC.
The program command configured above will invoke the java.exe application against a .jar file passing in the run properties file location as an argument to the java program. The run properties file contains information about the assay properties including the uploaded data and the location of the error file used to convey errors back to the server. Specific details about this file are contained in the data exchange specification for Programmatic QC.
Implement a Java Validator
The implementation of your java validator class must contain an entry point matching the following function signature:public static void main(String[] args)
public class AssayValidator
{
private String _email;
private String _password;
private File _errorFile;
private Map<String, String> _runProperties;
private List<String> _errors = new ArrayList<String>();
private static final String HOST_NAME = "http://localhost:8080/labkey";
private static final String HOST = "localhost:8080";
public static void main(String[] args)
{
if (args.length != 1)
throw new IllegalArgumentException("Input data file not passed in");
File runProperties = new File(args[0]);
if (runProperties.exists())
{
AssayValidator qc = new AssayValidator();
qc.runQC(runProperties);
}
else
throw new IllegalArgumentException("Input data file does not exist");
}
Create a Jar File
Next, compile and jar your class files, including any dependencies your program may have. This will save you from having to add a classpath parameter in your engine command. Make sure that a ‘Main-Class’ attribute is added to your jar file manifest. This attribute points to the class that implements your program entry point.Set Up Authentication for Remote APIs
Most of the remote APIs require login information in order to establish a connection to the server. Credentials can be hard-coded into your validation script or passed in on the command line. Alternatively, a .netrc file can be used to hold the credentials necesasry to login to the server. For further information, see: Create a .netrc or _netrc file.The following sample code can be used to extract credentials from a .netrc file:private void setCredentials(String host) throws IOException
{
NetrcFileParser parser = new NetrcFileParser();
NetrcFileParser.NetrcEntry entry = parser.getEntry(host);
if (null != entry)
{
_email = entry.getLogin();
_password = entry.getPassword();
}
}
Associate the Validator with an Assay Instance
Finally, the QC validator must be attached to an assay. To do this, you will need to editing the assay design and specify the absolute location of the .jar file you have created. The engine created earlier will bind the .jar extension to the java.exe command you have configured.
Transformation Scripts for Module-based Assays
<assay>
|_domains
|_views
|_scripts
|_config.xml
Run Properties Reference
Run Properties Format
The runProperties file has three (or four) tab-delimited columns in the following order:- property name
- property value
- data type – The java class name of the property value (java.lang.String). This column may have a different meaning for properties like the run data, transformed data, or errors file. More information can be found in the property description below.
- transformed data location – The full path to the location where the transformed data are rewritten in order for the server to load them into the database.
Generic Assay Run Properties
| Property Name | Data Type | Property Description |
|---|---|---|
| assayId | String | The value entered in the Assay Id field of the run properties section. |
| assayName | String | The name of the assay design given when the new assay design was created. |
| assayType | String | The type of this assay design. (GenericAssay, Luminex, Microarray, etc.) |
| baseUrl | URL String | For example, http://localhost:8080/labkey |
| containerPath | String | The container location of the assay. (for example, /home/AssayTutorial) |
| errorsFile | Full Path | The full path to a .tsv file where any validation errors are written. See details below. |
| protocolDescription | String | The description of the assay definition when the new assay design was created. |
| protocolId | String | The ID of this assay definition. |
| protocolLsid | String | The assay definition LSID. |
| runComments | String | The value entered into the Comments field of the run properties section. |
| runDataUploadedFile | Full Path | The original data file that was selected by the user and uploaded to the server as part of an import process. This can be an Excel file, a tab-separated text file, or a comma-separated text file. |
| runDataFile | Full Path | The imported data file after the assay framework has attempted to convert the file to .tsv format and match its columns to the assay data result set definition. |
| transformedRunPropertiesFile | Full Path | File where the script writes out the updated values of batch- and run-level properties that are listed in the runProperties file. |
| userName | String | The user who created the assay design. |
| workingDir | String | The temp location that this script is executed in. (e.g. C:\AssayId_209\39\) |
errorsFile
Validation errors can be written to a TSV file as specified by full path with the errorsFile property. This output file is formatted with three columns:- Type - "error" or "warn"
- Property - the name of the property raising the validation error
- Message - the actual error message
Additional Assay Specific Run Properties
ELISpot
| Property Name | Data Type | Property Description |
|---|---|---|
| sampleData | String | The path to a file that contains sample data written in a tab-delimited format. The file will contain all of the columns from the sample group section of the assay design. A wellgroup column will be written that corresponds to the well group name in the plate template associated with this assay instance. A row of data will be written for each well position in the plate template. |
| antigenData | String | The path to a file that contains antigen data written in a tab-delimited format. The file contains all of the columns from the antigen group section of the assay design. A wellgroup column corresponds to the well group name in the plate template associated with this assay instance. A row of data is written for each well position in the plate template. |
Luminex
| Property Name | Data Type | Property Description |
|---|---|---|
| Derivative | String | |
| Additive | String | |
| SpecimenType | String | |
| DateModified | Date | |
| ReplacesPreviousFile | Boolean | |
| TestDate | Date | |
| Conjugate | String | |
| Isotype | String |
NAb (TZM-bl Neutralizing Antibody) Assay
| Property Name | Data Type | Property Description |
|---|---|---|
| sampleData | String | The path to a file that contains sample data written in a tab-delimited format. The file contains all of the columns from the sample group section of the assay design. A wellgroup column corresponds to the well group name in the plate template associated with this assay instance. A row of data is written for each well position in the plate template. |
General Purpose Assay Type (GPAT)
| Property Name | Data Type | Property Description |
|---|---|---|
| severityLevel (reserved) | String | This is a property name used internally for error and warning handling. Do not define your own property with the same name in a GPAT assay. |
| maximumSeverity (reserved) | String | This is a property name reserved for use in error and warning handling. Do not define your own property with the same name in a GPAT assay. See Warnings in Tranformation Scripts for details. |
Transformation Script Substitution Syntax
| Script Syntax | Description | Substitution Value |
|---|---|---|
| ${runInfo} | File containing metadata about the run | Full path to the file on the local file system |
| ${srcDirectory} | Directory in which the script file is located | Full path to parent directory of the script |
| ${rLabkeySessionId} | Information about the current user's HTTP session | labkey.sessionCookieName = "COOKIE_NAME" labkey.sessionCookieContents = "USER_SESSION_ID" Note that this is multi-line. The cookie name is typically JSESSIONID, but is not in all cases.) |
| ${httpSessionId} | The current user's HTTP session ID | The string value of the session identifier, which can be used for authentication when calling back to the server for additional information |
| ${sessionCookieName} | The name of the session cookie | The string value of the cookie name, which can be used for authentication when calling back to the server for additional information. |
| ${baseServerURL} | The server's base URL and context path | The string of the base URL and context path. (ex. "http://localhost:8080/labkey") |
| ${containerPath} | The current container path | The string of the current container path. (ex. "/ProjectA/SubfolderB") |
Warnings in Tranformation Scripts
Enable Support for Warnings in a Transformation Script
To raise a warning from within your transformation script, set maximumSeverity to WARN within the transformedRunProperties file. To report an error, set maximumSeverity to ERROR. To display a specific message with either a warning or error, write the message to errors.html in the current directory. For example, this snippet from an R transformation script defines a warning and error handler:# writes the maximumSeverity level to the transformRunProperties file and the error/warning message to the error.html file.
# LK server will read these files after execution to determine if an error or warning occurred and handle it appropriately
handleErrorsAndWarnings <- function()
{
if(run.error.level > 0)
{
fileConn<-file(trans.output.file);
if(run.error.level == 1)
{
writeLines(c(paste("maximumSeverity","WARN",sep="t")), fileConn);
}
else
{
writeLines(c(paste("maximumSeverity","ERROR",sep="t")), fileConn);
}
close(fileConn);
# This file gets read and displayed directly as warnings or errors, depending on maximumSeverity level.
if(!is.null(run.error.msg))
{
fileConn<-file("errors.html");
writeLines(run.error.msg, fileConn);
close(fileConn);
}
quit();
}
}
Workflow for Warnings from Transformation Scripts
When a warning is triggered during assay import, the user will see a screen similar to this with the option to Proceed or Cancel the import after examining the output files: After examining the output and transformed data files, if the user clicks Proceed the transform script will be rerun and no warnings will be raised the on second pass. Quieting warnings on the approved import is handled using the value of an internal property called severityLevel in the run properties file. Errors will still be raised if necessary.
After examining the output and transformed data files, if the user clicks Proceed the transform script will be rerun and no warnings will be raised the on second pass. Quieting warnings on the approved import is handled using the value of an internal property called severityLevel in the run properties file. Errors will still be raised if necessary.
Priority of Errors and Warnings:
- 1. Script error (syntax, runtime, etc...) <- Error
- 2. Script returns a non-zero value <- Error
- 3. Script writes ERROR to maximumSeverity in the transformedRunProperties file <- Error
- If the script also writes a message to errors.html, it will be displayed, otherwise a server generated message will be shown.
- 4. Script writes WARN to maximumSeverity in the transformedRunProperties file <- Warning
- If the script also writes a message to errors.html, it will be displayed, otherwise a server generated message will be shown.
- The Proceed and Cancel buttons are shown, requiring a user selection to continue.
- 5. Script does not write a value to maximumSeverity in transformedRunProperties but does write a message to errors.html. This will be interpreted as an error.
Modules: ETLs
[ Video Update: ETL Enhancements in LabKey Server v15.1 ]Extract-Transform-Load functionality lets you encapsulate some of the most common database tasks, especially (1) extracting data from a database, (2) transforming it, and finally (3) loading it into another database. LabKey Server ETL modules let you:
- Assemble data warehouses that integrate data from multiple data sources.
- Normalize data from different systems.
- Move data in scheduled increments.
- Log and audit migration processes.
- Tutorial: Extract-Transform-Load (ETL) - Develop an ETL module.
- ETL: Configuration and Schedules - Configure the refresh schedule.
- ETL: Column Mapping - Transform columns in an ETL process.
- ETL: Stored Procedures - Use a stored procedure as a transformation.
- ETL: SQL Scripts - Create table schemas with sql scripts.
- ETL: Logs and Error Handling - Logging and error reporting.
- ETL: Remote Connections - Extract data via a remote connection.
- ETL: Examples - Example ETL modules.
- ETL: Reference - File references, directory structure.
Related Topics
Tutorial: Extract-Transform-Load (ETL)
Data Warehouse
This tutorial shows you how to create a simple ETL as a starting point for further development.As you go through the tutorial, imagine you are a researcher who wants to collect a group of participants for a research study. The participants must meet certain criteria to be included in the study, such as having a certain condition or diagnosis. You already have the following in place:- You have a running installation of LabKey Server.
- You already have access to a large database of Demographic information of candidate participants. This database is continually being updated with new data and new candidates for your study.
- You have an empty table called "Patients" on your LabKey Server which is designed to hold the study candidates.
Tutorial Steps
- ETL Tutorial: Set Up - Set up a sample ETL workspace.
- ETL Tutorial: Run an ETL Process - Run an ETL.
- ETL Tutorial: Create a New ETL Process - Add a New ETL for a New Query.
First Step
ETL Tutorial: Set Up
- a basic workspace for working with ETL processes
- a working ETL module that can move data from the source database into the Patients table on your system.
Download
- Download the folder archive:
- ETLWorkspace.folder.zip (Don't unzip. This archive contains an ETL workspace and sample data to work with.)
- Download the server module:
Set Up ETL Workspace
In this step you will import a pre-configured workspace in which to develop ETL processes. (Note that there is nothing mandatory about the way this workspace has been put together -- your own ETL workspace may be different, depending on the needs of your project. This particular workspace has been configured especially for this tutorial as a shortcut to avoid many set up steps, steps such as connecting to source datasets, adding an empty dataset to use as the target of ETL scripts, and adding ETL-related web parts.)- Go the LabKey Server Home project (or any project convenient for you).
- Create a subfolder of type Study to use as a workspace:
- Go to Admin > Folder > Management.
- Click Create Subfolder.
- On the Create Folder page, enter the Name "ETL Workspace".
- Under Folder Type, select Study.
- Click Next.
- On the Users/Permissions page, click Finish.
- Import ETLWorkspace.folder.zip into the folder:
- In the Study Overview panel, click Import Study.
- On the Folder Management page, confirm Local zip archive is selected and click Choose File.
- Select the folder archive that you have already downloaded: ETLWorkspace.folder.zip.
- Click Import Folder.
- When the import is complete, click ETL Workspace to see the workspace.
- A LabKey Study with various datasets to use as data sources
- An empty dataset named Patients to use as a target destination
- The ETLs tab provides an area to manage and run your ETL processes. Notice that this tab contains three panels/"web parts":
- Data Transforms shows the available ETL processes. Currently it is empty because there are none defined.
- The Patients dataset (the target dataset for the process) is displayed, also empty because no ETL process has been run yet. When you run an ETL process in the next step the the empty Patients dataset will begin to fill with data.
- The Demographics dataset (the source dataset for this tutorial) is displayed with more than 200 records.

Add the ETL Module
ETL processes are added to LabKey Server as part of a "module". Modules are packets of functionality that are easy to distribute to other LabKey Servers. Modules can contain a wide range of functionality, not just ETL-related functionality. For example, they can include HTML pages, SQL queries, R script reports, and more. Module resources are for the most part "file-based", that is, they contain files such as .HTML, .SQL, and .R files which are deployed to the server and surfaced in various places in the user interface where users can interact with them. For deployment to the server, the module files are zipped up into a .zip archive, which is renamed as a ".module" file. In this case, the module you will deploy contains two resources:- An ETL configuration file (called "FemaleARV.xml") which defines how the ETL process works
- A SQL query which defines the source data for the ETL process
- If you are a developer working with the LabKey Server source code directly, then:
- Copy the file etlModule.module to the directory /build/deploy/modules and restart the server.
- If you are working with an installer-based version of LabKey Server, then:
- Copy the file etlModule.module to the directory LABKEY_HOME/externalModules and restart the server. (On Windows you can restart the server using the Services panel.)
- Enable the module in your workspace folder:
- In the "ETL Workspace" folder, go to Admin > Folder > Management. (You need to be logged in as an admin to complete this step.)
- Click the Folder Type tab.
- In the Modules list (on the right) place a checkmark next to ETLModule.
- Click Update Folder.
- The ETL script is now ready to run. Notice it has been added to the list under Data Transforms.

Start Over | Next Step
ETL Tutorial: Run an ETL Process
ETL User Interface
The web part Data Transforms lists all of the ETL processes that are available in the current folder. It lets you review current status at a glance, and run any transform manually or on a set schedule. You can also reset state after a test run. For details on the ETL user interface, see ETL: User Interface.
For details on the ETL user interface, see ETL: User Interface.
Run the ETL Process
- If necessary, click the ETLs tab, to return to the main page including the Data Transforms web part.
- Click Run Now for the "Demographics >>> Patients" row to transfer the data to the Patients table.
- You will be taken to the ETL Job page, which provides updates on the status of the running job.
- Refresh your browser until you see the Status field shows the value COMPLETE

- Click the ETLs tab to see the records that have been added to the Patients table. Notice that 36 records (out of over 200 in the source Demographics query) have been copied into the Patients query. The ETL process is filtering to show female members of the ARV treatment group.

Experiment with ETL Runs
Now that you have a working ETL process, you can experiment with different scenarios.- First, roll back the rows added to the target table (that is, delete the rows and return the target table to its original state) by selecting Reset State > Truncate and Reset.

- Confirm the deletion in the popup window.
- Rerun the ETL process by clicking Run Now.
- The results are the same because we did not in fact change any source data yet. Next you can actually make some changes to show that they will be reflected.
- Edit the data in the source table Demographics:
- Click the ETLs tab.
- Scroll down to the Demographics dataset - remember this is our source data.
- Click Edit next to a record where the Gender is M and the Treatment Group is ARV. You could also apply column filters to find this set of records.
- Change the Gender to "F" and save.
- Rerun the ETL process by first selecting Reset > Truncate and Reset, then click Run Now.
- The resulting Patients table will now contain the additional matching row for a total count of 37 matching records.
Previous Step | Next Step
ETL Tutorial: Create a New ETL Process
Create a New Source Query
- Locate the source code for the ETL module. Depending on where you deployed it, go to either LABKEY_HOME/externalModules/etlmodule or build/deploy/modules/etlmodule.
- Go to the directory etlmodule/queries/study.
- In that directory, create a file named "MaleNC.sql".
- Open the file in a text editor and copy and paste the following code into the file:
SELECT Demographics.ParticipantId,
Demographics.StartDate,
Demographics.Gender,
Demographics.PrimaryLanguage,
Demographics.Country,
Demographics.Cohort,
Demographics.TreatmentGroup
FROM Demographics
WHERE Demographics.Gender = 'm' AND Demographics.TreatmentGroup = 'Natural Controller'
- Save the file.
- Restart the server.
Create a New ETL Process
ETL processes are defined by XML configuration files that specify the data source, the data target, and other properties. Here we create a new configuration that draws from the query we just created above.- In the etlmodule/etls directory, create a new XML file called "MaleNC.xml".
- Copy the following into MaleNC.xml, and save.
<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>Demographics >>> Patients (Males)</name>
<description>Update data for study on male patients.</description>
<transforms>
<transform id="males">
<source schemaName="study" queryName="MaleNC"/>
<destination schemaName="study" queryName="Patients" targetOption="merge"/>
</transform>
</transforms>
<schedule>
<poll interval="1h"/>
</schedule>
</etl>
- Notice that this configuration file has our query (MaleNC) as its source, and the Patients query as its target.
- Refresh the browser. Notice that the system will add your new module to the server. Click Next if necessary to complete the update.
- In the "ETL Workspace" folder, notice our new ETL process is now listed in the Data Transforms web part.
Run the ETL Process
- Click Run Now next to the new process name. You will need to sign in to see this button.
- Refresh in the pipeline window until the job completes, then click the ETLs tab.
- New records will have been copied to the Patients table, making a total of 43 records (42 if you skipped the step of changing the gender of a participant in the previous tutorial step).

Previous Step
ETL: User Interface
ETL User Interface
The web part Data Transforms lists all of the ETL processes that are available in the current folder.- Columns:
- Name - This column displays the name of the process.
- Source Module - This column tells you module where the configuration file resides.
- Schedule - This column shows you the reload schedule. In this case the ETL process is configured to run once every hour.
- Enabled - This checkbox controls whether the automated schedule is enabled: when unchecked, the ETL process must be run manually.
- Last Status, Successful Run, Checked - These columns record the latest run of the ETL process.
- Set Range - (Available only in devMode) The Set Range column is displayed only in dev mode and is intended for testing purposes during ETL module development. The Run button is only displayed for ETL processes with a filter strategy of RunFilterStrategy or ModifiedSinceFilterStrategy; the button is not displayed for the filter strategy SelectAllFilterStrategy. Click Run to set a date or row version window range to use for incremental ETL filters, overriding any persisted or initial values.

- Last Transform Run Log Error - Shows the last error logged, if any exists.
- Buttons:
- Run Now - This button immediately activates the ETL process.
- Reset State - This button returns the ETL process to its original state, deleting its internal history of which records are, and are not, up to date. There are two options:
- Reset
- Truncate and Reset
- View Processed Jobs - This button shows you a log of all previously run ETL jobs, and their status.
Run an ETL Process Manually
The Data Transforms web part lets you:- Run jobs manually. (Click Run Now.)
- Enable/disable the recurring run schedule, if such a schedule has been configured in the ETL module. (Check or uncheck the column Enabled.)
- Reset state. (Select Reset State > Reset resets an ETL transform to its initial state, as if it has never been run.)
- See the latest error raised in the Last Transform Run Log Error column.
Cancel and Roll Back Jobs
While a job is running you can cancel and roll back the changes made by the current step by pressing the Cancel button.The Cancel button is available on the Job Status panel for a particular job, as show below: To roll back a run and delete the rows added to the target by the previous run, view the Data Transforms webpart, then select Reset State > Truncate and Reset. Note that rolling back an ETL which outputs to a file will have no effect, that is, the file will not be deleted or changed.
To roll back a run and delete the rows added to the target by the previous run, view the Data Transforms webpart, then select Reset State > Truncate and Reset. Note that rolling back an ETL which outputs to a file will have no effect, that is, the file will not be deleted or changed.
See Run History
The Data Transform Jobs web part provides a detailed history of all executed ETL runs, including the job name, the date and time when it was executed, the number of records processed, the amount of time spent to execute, and links to the log files.To add this web part to your page, scroll down to the bottom of the page and click the dropdown <Select Web Part>, select Data Transform Jobs, and click Add. When added to the page, the web part appears with a different title: "Processed Data Transforms". Click Run Details for fine-grained details about each run, including a graphical representation of the run.
Click Run Details for fine-grained details about each run, including a graphical representation of the run.

ETL: Configuration and Schedules
Schedules
You can set a polling schedule to check the source database for new data and automatically run the ETL process when new data is found. The schedule below checks every hour for new data:<schedule><poll interval="1h" /></schedule><!-- run at 10:15 every day -->
<schedule><cron expression="0 15 10 ? * *"/></schedule>
<!-- run at 3:30am every day -->
<schedule><cron expression="0 30 3 * * ?"/></schedule>
Target Options
When the data is loaded into the destination database, there are three options for handling cases when the source query returns key values that already exist in the destination:- Append: Appends new rows to the end of the existing table. Fails on duplicate primary key values.
- Merge: Merges data into the destination table. Matches primary key values to determine insert or update. Target tables must have a primary key.
- Truncate: Deletes the contents of the destination table before inserting the selected data.
<destination schemaName="vehicle" queryName="targetQuery" targetOption="merge" />
Filter Strategy
The filter strategy, defined in the incrementalFilter tag, is how the ETL process identifies new rows in the source database. The strategy allows a special value on the destination table to be compared to the source and only pulls over new rows based on that value. Using an incrementalFilter allows you to use the append option to add new rows to your target table and not accidentally run into any duplicate record conflicts. There are three options:- SelectAllFilterStrategy: Apply no further filter to the source; simply transform/transfer all rows returned by the query.
- RunFilterStrategy: Check a specified column, typically an increasing integer column (e.g. Run ID), against a given or stored value. For instance, any rows with a higher value than when the ETL process was last run are transformed.
- ModifiedSinceFilterStrategy: Use a specified date/timestamp column (timeStampColumnName) to identify the new records. Rows changed since the last run will be transformed.
<incrementalFilter className="ModifiedSinceFilterStrategy" timestampColumnName="Date" />
Incremental Deletion of Target Rows
When incrementally deleting rows based on a selective filter strategy, use the element deletedRowsSource to correctly track the filtered values for deletion independently of the main query. Even if there are no new rows in the source query, any new records in the "deleteRowsSource" will still be found and deleted from the source. Using this method, the non-deleted rows will keep their row ids, maintaining any links to other objects in the target table.File Targets
An ETL process can load data to a file, such as a comma separated file (CSV), instead of loading data into a database table. For example, the following ETL configuration element directs outputs to a tab separated file named "report.tsv". rowDelimiter and columnDelimiter are optional, if omitted you get a standard TSV file.<destination type="file" dir="etlOut" fileBaseName="report" fileExtension="tsv" />
Transaction Options
<destination schemaName="study" queryName="demographics" useTransaction="false" />
<destination schemaName="study" queryName="demographics" bulkLoad="true" batchSize="500" />
Command Tasks
Once a command task has been registered in a pipeline task xml file, you can specify the task as an ETL step.<transform id="ProcessingEngine" type="ExternalPipelineTask"
externalTaskId="org.labkey.api.pipeline.cmd.CommandTask:myEngineCommand"/>
ETL: Column Mapping
- Column Mapping
- Constants
- Creation and Modification Columns
- Data Integration Columns
- Transformation Java Classes
Column Mapping
If your source and target tables have different column names, you can configure a mapping between the columns, such that data from one column will be loaded into the mapped column, even if it has a different name. For example, suppose you are working with the following tables:| Source Table Columns | Target Table Columns |
|---|---|
| ParticipantId | SubjectId |
| StartDate | Date |
| Gender | Sex |
| TreatmentGroup | Treatment |
| Cohort | Group |
<transform id="transform1">
<source schemaName="study" queryName="Participants"/>
<destination schemaName="study" queryName="Subjects" targetOption="merge">
<columnTransforms>
<column source="ParticipantId" target="SubjectId"/>
<column source="StartDate" target="Date"/>
<column source="Gender" target="Sex"/>
<column source="TreatmentGroup" target="Treatment"/>
<column source="Cohort" target="Group"/>
</columnTransforms>
</destination>
</transform>
Container Columns
Container columns can be used to integrate data across different containers within LabKey Server. For example, data gathered in one project can be referenced from other locations as if it were available locally. However, ETL processes are limited to running within a single container. You cannot map a target container column to anything other than the container in which the ETL process is run.Constants
To assign a constant value to a given target column, use a constant in your ETL configuration .xml file. For example, this sample would write "schema1.0" into the sourceVersion column of every row processed:<constants>
<column name="sourceVersion" type="VARCHAR" value="schema1.0"/>
</constants>
- The top level of your ETL xml: the constant is applied for every step in the ETL process.
- At an individual transform step level: the constant is only applied for that step and overrides any global constant that may have been set.
<destination schemaName="vehicle" queryName="etl_target">
<constants>
<column name="sourceVersion" type="VARCHAR" value="myStepValue"/>
</constants>
</destination>
Creation and Modification Columns
If the source table includes the following columns, they will be populated in the target table with the same names:- EntityId
- Created
- CreatedBy
- Modified
- ModifiedBy
DataIntegration Columns
Adding the following data integration ('di') columns to your target table will enable integration with other related data and log information.| Column Name | PostresSQL Type | MS SQL Server Type | Notes |
|---|---|---|---|
| diTransformRunId | INT | INT | |
| diRowVersion | TIMESTAMP | DATETIME | |
| diModified | TIMESTAMP | DATETIME | Values here may be updated in later data mergers. |
| diModifiedBy | USERID | USERID | Values here may be updated in later data mergers. |
| diCreated | TIMESTAMP | DATETIME | Values here are set when the row is first inserted via a ETL process, and never updated afterwards |
| diCreatedBy | USERID | USERID | Values here are set when the row is first inserted via a ETL process, and never updated afterwards |
Transformation Java Classes
The ETL pipeline allows Java developers to add a transformation java class to a particular column. This Java class can validate, transform or perform some other action on the data values in the column. For details and an example, see ETL: ExamplesReference
ETL: Queuing ETL Processes
<transforms>
...
<transform id="QueueTail" type="TaskrefTransformStep">
<taskref ref="org.labkey.di.steps.QueueJobTask">
<settings>
<setting name="transformId" value="{MODULE-NAME}/MaleNC"/>
</settings>
</taskref>
</transform>
...
</transforms>
<transform id="requeueNlpTransfer" type="TaskrefTransformStep">
<taskref ref="org.labkey.di.steps.QueueJobTask"/>
</transform>
Handling Generated Files
If file outputs are involved (for example, if one ETL process outputs a file, and then queues another process that expects to use the file in a pipeline task), all ETL configurations in the chain must have the attribute loadReferencedFile="true” in order for the runs to link up properly.<etl xmlns="http://labkey.org/etl/xml" loadReferencedFiles="true">
...
</etl>
Standalone vs. Component ETL Processes
ETL processes can be set as either "standalone" or "sub-component":- Standalone ETL processes:
- Appear in the Data Transforms web part
- Can be run directly via the user or via another ETL
- Sub-Component ETL processes or tasks:
- Not shown in the Data Transforms web part
- Cannot be run directly by the user, but can be run only by another ETL process, as a sub-component of a wider job.
- Cannot be enabled or run directly via an API call.
<transform id="MySubComponent" standalone="false">
...
</transform>
ETL: Stored Procedures
Stored Procedures as Source Queries
Instead of extracting data directly from a source query and loading it into a target query, an ETL process can call one or more stored procedures that themselves move data from the source to the target (or the procedures can transform the data in some other way). For example, the following ETL process runs a stored procedure to populate the Patients table.<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>Populate Patient Table</name>
<description>Populate Patients table with calculated and converted values.</description>
<transforms>
<transform id="ExtendedPatients" type="StoredProcedure">
<description>Calculates date of death or last contact for a patient, and patient ages at events of interest</description>
<procedure schemaName="patient" procedureName="PopulateExtendedPatients" useTransaction="true">
</procedure>
</transform>
</transforms>
<!-- run at 3:30am every day -->
<schedule><cron expression="0 30 3 * * ?"/></schedule>
</etl>
Special Behavior for Different Database Implementations
ETL: Stored Procedures in MS SQL Server
Example - Normalize Data
The following ETL process uses the stored procedure normalizePatientData to modify the source data.<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>Target #1 (Normalize Gender Values - Stored Procedure)</name>
<description>Runs a stored procedure.</description>
<transforms>
<transform id="storedproc" type="StoredProcedure">
<description>Runs a stored procedure to normalize values in the Gender column.</description>
<procedure schemaName="target1" procedureName="normalizePatientData">
</procedure>
</transform>
</transforms>
</etl>
CREATE procedure [target1].[normalizePatientData] (@transformRunId integer)
as
begin
UPDATE Patients SET Gender='Female' WHERE (Gender='f' OR Gender='F');
UPDATE Patients SET Gender='Male' WHERE (Gender='m' OR Gender='M');
end
GO
Parameters
The <procedure> element can have <parameter> child elements that specify the initial seed values passed in as input/output parameters. Note that The "@" sign prefix for parameter names in the ETL xml configuration is optional.<procedure … >
<parameter name="@param1" value="100" override="false"/>
<parameter name="@param2" value="200" override="false"/>
</procedure>
<procedure schemaName="external" procedureName="etlTestRunBased">
<parameter name="@femaleGenderName" value="Female" override="false"/>
<parameter name="@maleGenderName" value="Male" override="false"/>
</procedure>
CREATE procedure [target1].[normalizePatientData] (@transformRunId integer,
@maleGenderName VARCHAR(25),
@femaleGenderName VARCHAR(25))
as
begin
UPDATE Patients SET Gender=@femaleGenderName WHERE (Gender='f' OR Gender='F');
UPDATE Patients SET Gender=@maleGenderName WHERE (Gender='m' OR Gender='M');
end
GO
Parameters - Special Processing
The following parameters are given special processing.| Name | Direction | Datatype | Notes |
|---|---|---|---|
| @transformRunId | Input | int | Assigned the value of the current transform run id. |
| @filterRunId | Input or Input/Output | int | For RunFilterStrategy, assigned the value of the new transfer/transform to find records for. This is identical to SimpleQueryTransformStep’s processing. For any other filter strategy, this parameter is available and persisted for stored procedure to use otherwise. On first run, will be set to -1. |
| @filterStartTimestamp | Input or Input/Output | datetime | For ModifiedSinceFilterStrategy with a source query, this is populated with the IncrementalStartTimestamp value to use for filtering. This is the same as SimpleQueryTransformStep. For any other filter strategy, this parameter is available and persisted for stored procedure to use otherwise. On first run, will be set to NULL. |
| @filterEndTimestamp | Input or Input/Output | datetime | For ModifiedSinceFilterStrategy with a source query, this is populated with the IncrementalEndTimestamp value to use for filtering. This is the same as SimpleQueryTransformStep. For any other filter strategy, this parameter is available and persisted for stored procedure to use otherwise. On first run, will be set to NULL. |
| @containerId | Input | GUID/Entity ID | If present, will always be set to the id for the container in which the job is run. |
| @rowsInserted | Input/Output | int | Should be set within the stored procedure, and will be recorded as for SimpleQueryTransformStep. Initialized to -1. Note: The TransformRun.RecordCount is the sum of rows inserted, deleted, and modified. |
| @rowsDeleted | Input/Output | int | Should be set within the stored procedure, and will be recorded as for SimpleQueryTransformStep. Initialized to -1. Note: The TransformRun.RecordCount is the sum of rows inserted, deleted, and modified. |
| @rowsModified | Input/Output | int | Should be set within the stored procedure, and will be recorded as for SimpleQueryTransformStep. Initialized to -1. Note: The TransformRun.RecordCount is the sum of rows inserted, deleted, and modified. |
| @returnMsg | Input/Output | varchar | If output value is not empty or null, the string value will be written into the output log. |
| @debug | Input | bit | Convenience to specify any special debug processing within the stored procedure. May consider setting this automatically from the Verbose flag. |
| Return Code | special | int | All stored procedures must return an integer value on exit. “0” indicates correct processing. Any other value will indicate an error condition and the run will be aborted. |
Log Rows Modified
Use special parameters to log the number of rows inserted, changed, etc. as follows:CREATE procedure [target1].[normalizePatientData] (@transformRunId integer
, @parm1 varchar(25) OUTPUT
, @gender varchar(25) OUTPUT
, @rowsInserted integer OUTPUT
, @rowCount integer OUTPUT
, @rowsDeleted integer OUTPUT
, @rowsModified integer OUTPUT
, @filterStartTimestamp datetime OUTPUT)
as
begin
SET @rowsModified = 0
UPDATE Patients SET Gender='Female' WHERE (Gender='f' OR Gender='F');
SET @rowsModified = @@ROWCOUNT
UPDATE Patients SET Gender='Male' WHERE (Gender='m' OR Gender='M');
SET @rowsModified += @@ROWCOUNT
end
Optional Source
An optional source must be used in combination with the RunFilterStrategy or ModifiedSinceFilterStrategy filter strategies.<transforms>
<transform id="storedproc" type="StoredProcedure">
<description>
Runs a stored procedure to normalize values in the Gender column.
</description>
<!-- Optional source element -->
<!-- <source schemaName="study" queryName="PatientsWarehouse"/> -->
<procedure schemaName="target1" procedureName="normalizePatientData">
</procedure>
</transform>
</transforms>
Transactions
By default all stored procedures are wrapped as transactions, so that if any part of the procedure fails, any changes already made are rolled back. For debugging purposed, turn off the transaction wrapper setting useTransaction to "false":<procedure schemaName="target1" procedureName="normalizePatientData" useTransaction="false">
</procedure>
ETL: Functions in PostgreSQL
ETL XML Configuration File
<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>Stored Proc Normal Operation</name>
<description>Normal operation</description>
<transforms>
<transform id="callfunction" type="StoredProcedure">
<procedure schemaName="patient" procedureName="postgresFunction" useTransaction="false">
<parameter name="inoutparam" value="before"/>
</procedure>
</transform>
</transforms>
</etl>
Function and Parameter Requirements
PostgreSQL functions called by an ETL process must meet the following requirements:- The Postgres function must be of return type record.
- Parameter names, including the Special Processing parameters (see table below), are case-insensitive.
- There can be an arbitrary number of custom INPUT and/or INPUT/OUTPUT parameters defined for the function.
- There can be at most one pure OUTPUT parameter. This OUTPUT parameter must be named "return_status" and must be of type INTEGER. If present, the return_status parameter must be assigned a value of 0 for successful operation. Values > 0 are interpreted as error conditions.
- Function overloading of differing parameter counts is not currently supported. There can be only one function (procedure) in the Postgres database with the given schema & name combination.
- Optional parameters in PostgreSQL are not currently supported. An ETL process using a given function must provide a value for every custom parameter defined in the function.
- Postgres does not have a "print" statement. Writing to the ETL log can be accomplished with a "RAISE NOTICE" statement, for example:
RAISE NOTICE '%', 'Test print statement logging';
- The "@" sign prefix for parameter names in the ETL configuration xml is optional (for both SQL Server and Postgres). When IN/OUT parameters are persisted in the dataintegration.transformConfiguration.transformState field, their names are consistent with their native dialect (an "@" prefix for SQL Server, no prefix for Postgres).
Parameters - Special Processing
The following parameters are given special processing.Note that the output values of INOUT's are persisted to be used as inputs on the next run.| Name | Direction | Datatype | Notes |
|---|---|---|---|
| transformRunId | Input | int | Assigned the value of the current transform run id. |
| filterRunId | Input or Input/Output | int | For RunFilterStrategy, assigned the value of the new transfer/transform to find records for. This is identical to SimpleQueryTransformStep's processing. For any other filter strategy, this parameter is available and persisted for functions to use otherwise. On first run, will be set to -1. |
| filterStartTimestamp | Input or Input/Output | datetime | For ModifiedSinceFilterStrategy with a source query, this is populated with the IncrementalStartTimestamp value to use for filtering. This is the same as SimpleQueryTransformStep. For any other filter strategy, this parameter is available and persisted for functions to use otherwise. On first run, will be set to NULL. |
| filterEndTimestamp | Input or Input/Output | datetime | For ModifiedSinceFilterStrategy with a source query, this is populated with the IncrementalEndTimestamp value to use for filtering. This is the same as SimpleQueryTransformStep. For any other filter strategy, this parameter is available and persisted for functions to use otherwise. On first run, will be set to NULL. |
| containerId | Input | GUID/Entity ID | If present, will always be set to the id for the container in which the job is run. |
| rowsInserted | Input/Output | int | Should be set within the function, and will be recorded as for SimpleQueryTransformStep. Initialized to -1. Note: The TransformRun.RecordCount is the sum of rows inserted, deleted, and modified. |
| rowsDeleted | Input/Output | int | Should be set within the functions, and will be recorded as for SimpleQueryTransformStep. Initialized to -1. Note: The TransformRun.RecordCount is the sum of rows inserted, deleted, and modified. |
| rowsModified | Input/Output | int | Should be set within the functions, and will be recorded as for SimpleQueryTransformStep. Initialized to -1. Note: The TransformRun.RecordCount is the sum of rows inserted, deleted, and modified. |
| returnMsg | Input/Output | varchar | If output value is not empty or null, the string value will be written into the output log. |
| debug | Input | bit | Convenience to specify any special debug processing within the stored procedure. |
| return_status | special | int | All functions must return an integer value on exit. “0” indicates correct processing. Any other value will indicate an error condition and the run will be aborted. |
Example Postgres Function
CREATE OR REPLACE FUNCTION patient.postgresFunction
(IN transformrunid integer
, INOUT rowsinserted integer DEFAULT 0
, INOUT rowsdeleted integer DEFAULT 0
, INOUT rowsmodified integer DEFAULT 0
, INOUT returnmsg character varying DEFAULT 'default message'::character varying
, IN filterrunid integer DEFAULT NULL::integer
, INOUT filterstarttimestamp timestamp without time zone DEFAULT NULL::timestamp without time zone
, INOUT filterendtimestamp timestamp without time zone DEFAULT NULL::timestamp without time zone
, INOUT runcount integer DEFAULT 1
, INOUT inoutparam character varying DEFAULT ''::character varying
, OUT return_status integer)
RETURNS record AS
$BODY$
BEGIN
/*
*
* Function logic here
*
*/
RETURN;
END;
$BODY$
LANGUAGE plpgsql;
ETL: Check For Work From a Stored Procedure
<transform id="checkToRun" type="StoredProcedure">
<procedure schemaName="patient" procedureName="workcheck" useTransaction="false">
<parameter name="StagingControl" value="1" noWorkValue="-1"/>
</procedure>
</transform>
<transform id="queuedJob">
<source schemaName="patient_source" queryName="etl_source" />
<destination schemaName="patient_target" queryName="Patients" targetOption="merge"/>
</transform>
<parameter name="batchId" noWorkValue="${batchId}"/>
Example
In the ETL transform below, the gating procedure checks if there is a new ClientStagingControlID to process. If there is, the ETL job goes into the queue. When the job starts, the procedure is run again in the normal job context; the new ClientStagingControlID is returned again. The second time around, the output value is persisted into the global space, so further procedures can use the new value. Because the gating procedure is run twice, don’t use this with stored procedures that have other data manipulation effects! There can be multiple gating procedures, and each procedure can have multiple gating params, but during the check for work, modified global output param values are not shared between procedures.<transform id="CheckForWork" type="StoredProcedure">
<description>Check for new batch</description>
<procedure schemaName="patient" procedureName="GetNextClientStagingControlID">
<parameter name="ClientStagingControlID" value="-1" scope="global" noWorkValue="${ClientStagingControlID}"/>
<parameter name="ClientSystem" value="LabKey-nlp-01" scope="global"/>
<parameter name="StagedTable" value="PathOBRX" scope="global"/>
</procedure>
</transform>
ETL: SQL Scripts
Directory Structure
LabKey Server will automatically run SQL scripts that are packaged inside your module in the following directory structure:SQL Script Names
Script names are formed from three components: (1) schema name, (2) previous module version, and (3) current module version, according to the following pattern:Schema XML File
LabKey will generate an XML schema file for a table schema by visiting a magic URL of the form:http://<server>/labkey/admin/getSchemaXmlDoc.view?dbSchema=<schema-name>Examples
This script creates a simple table and a stored procedure for MS SQL Server dialect.CREATE SCHEMA target1;
GO
CREATE procedure [target1].[normalizePatientData] (@transformRunId integer)
as
begin
UPDATE Patients SET Gender='Female' WHERE (Gender='f' OR Gender='F');
UPDATE Patients SET Gender='Male' WHERE (Gender='m' OR Gender='M');
end
GO
CREATE TABLE target1.Patients
(
RowId INT IDENTITY(1,1) NOT NULL,
Container ENTITYID NOT NULL,
CreatedBy USERID NOT NULL,
Created DATETIME NOT NULL,
ModifiedBy USERID NOT NULL,
Modified DATETIME NOT NULL,
PatientId INT NOT NULL,
Date DATETIME NOT NULL,
LastName VARCHAR(30),
FirstName VARCHAR(30),
MiddleName VARCHAR(30),
DateVisit DATETIME,
Gender VARCHAR(30),
PrimaryLanguage VARCHAR(30),
Email VARCHAR(30),
Address VARCHAR(30),
City VARCHAR(30),
State VARCHAR(30),
ZIP VARCHAR(30),
Diagnosis VARCHAR(30),
CONSTRAINT PatientId PRIMARY KEY (RowId)
);
---------------
-- schema1 --
---------------
DROP SCHEMA schema1 CASCADE;
CREATE SCHEMA schema1;
CREATE TABLE schema1.patients
(
patientid character varying(32),
date timestamp without time zone,
startdate timestamp without time zone,
country character varying(4000),
language character varying(4000),
gender character varying(4000),
treatmentgroup character varying(4000),
status character varying(4000),
comments character varying(4000),
CONSTRAINT patients_pk PRIMARY KEY (patientid)
);
CREATE OR REPLACE FUNCTION changecase(searchtext varchar(100), replacetext varchar(100)) RETURNS integer AS $$
UPDATE schema1.patients
SET gender = replacetext
WHERE gender = searchtext;
SELECT 1;
$$ LANGUAGE SQL;
Related Topics
- Tutorial: Extract-Transform-Load (ETL) - Other SQL scripts are included in the ETL samples at patientetl/schemas/dbscripts.
- Modules: SQL Scripts - Details on SQL scripts in modules.
ETL: Remote Connections
<transform type="RemoteQueryTransformStep" id="step1">
<source remoteSource="EtlTest_RemoteConnection" schemaName="study" queryName="etl source" />
...
</transform>
<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>Remote Test</name>
<description>append rows from "remote" etl_source to etl_target</description>
<transforms>
<transform type="RemoteQueryTransformStep" id="step1">
<description>Copy to target</description>
<source remoteSource="EtlTest_RemoteConnection" schemaName="study" queryName="etl source" />
<destination schemaName="study" queryName="etl target" targetOption="truncate"/>
</transform>
</transforms>
<incrementalFilter className="ModifiedSinceFilterStrategy" timestampColumnName="modified" />
</etl>
Related Topics
ETL: Logs and Error Handling
Logging
Messages and/or errors inside an ETL job are written to a log file named for that job, located atLABKEY_HOME/files/PROJECT/FOLDER_PATH/@files/etlLogs/ETLNAME_DATE.etl.log
C:/labkey/files/MyProject/MyFolder/@files/etlLogs/myetl_2015-07-06_15-04-27.etl.log
 File Path shows the log location.
File Path shows the log location. ETL processes check for work (= new data in the source) before running a job. Log files are only created when there is work.
If, after checking for work, a job then runs, errors/exceptions throw a PipelineJobException. The UI shows only the error message; the log captures the stacktrace.XSD/XML-related errors are written to the labkey.log file, located at TOMCAT_HOME/logs/labkey.log.
ETL processes check for work (= new data in the source) before running a job. Log files are only created when there is work.
If, after checking for work, a job then runs, errors/exceptions throw a PipelineJobException. The UI shows only the error message; the log captures the stacktrace.XSD/XML-related errors are written to the labkey.log file, located at TOMCAT_HOME/logs/labkey.log.
DataIntegration Columns
To record a connection between a log entry and rows of data in the target table, add the 'di' columns listed here to your target table.Error Handling
If there were errors during the transform step of the ETL process, you will see the latest error in the Transform Run Log column.- An error on any transform step within a job aborts the entire job. “Success” in the log is only reported if all steps were successful with no error.
- If the number of steps in a given ETL process has changed since the first time it was run in a given environment, the log will contain a number of DEBUG messages of the form: “Wrong number of steps in existing protocol”. This is an informational message and does not indicate anything was wrong with the job.
- Filter Strategy errors. A “Data Truncation” error may mean that the xml filename is too long. Current limit is module name length + filename length - 1, must be <= 100 characters.
- Stored Procedure errors. “Print” statements in the procedure appear as DEBUG messages in the log. Procedures should return 0 on successful completion. A return code > 0 is an error and aborts job.
- Known issue: When the @filterRunId parameter is specified in a stored procedure, a default value must be set. Use NULL or -1 as the default.
ETL: All Jobs History

ETL: Examples
- Interval - 1 Hour
- Interval - 5 Minutes
- Cron - 1 Hour
- Merge
- Merge By Run ID
- Merge with Alternate Key
- Append with Two Targets
- Truncate
- Passing Parameters to a SQL Query
- Truncate the Target Query
- Java Transforms
Interval - 1 Hour
<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>Patient - Merge</name>
<description>Merges patient data to the target query.</description>
<transforms>
<transform id="1hour">
<source schemaName="external" queryName="etl_source" />
<destination schemaName="patient" queryName="etl_target" targetOption="merge"/>
</transform>
</transforms>
<incrementalFilter className="ModifiedSinceFilterStrategy" timestampColumnName="modified" />
<schedule><poll interval="1h"></poll></schedule>
</etl>
Interval - 5 Minutes
<schedule><poll interval="5m" /></schedule>
Cron - 1 Hour
Check at midnight every day.<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>Cron on the hour</name>
<transforms>
<transform id="eachHour">
<description>valid</description>
<source schemaName="external" queryName="etl_source" />
<destination schemaName="patient" queryName="etl_target" targetOption="merge"/>
</transform>
</transforms>
<incrementalFilter className="ModifiedSinceFilterStrategy" timestampColumnName="modified" />
<schedule><cron expression="0 0 * * * ?" /></schedule>
</etl>
Merge
<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>Merge</name>
<description>Merge rows from etl_source to etl_target.</description>
<transforms>
<transform id="merge">
<description>Merge to target.</description>
<source schemaName="external" queryName="etl_source" />
<destination schemaName="patient" queryName="etl_target" targetOption="merge"/>
</transform>
</transforms>
<incrementalFilter className="ModifiedSinceFilterStrategy" timestampColumnName="modified" />
</etl>
Merge by Run ID
<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>MergeByRunId</name>
<description>Merge by run id.</description>
<transforms>
<transform id="step1">
<description>Copy to target</description>
<source schemaName="patient" queryName="etlsource" />
<destination schemaName="target" queryName="etltarget" />
</transform>
</transforms>
<incrementalFilter className="RunFilterStrategy" runTableSchema="patient"
runTable="Transfer" pkColumnName="Rowid" fkColumnName="TransformRun" />
<schedule>
<poll interval="15s" />
</schedule>
</etl>
Merge with Alternate Key
Specify an alternate key to use for merging when the primary key is not suitable, i.e. would cause duplicates or orphaned data.<destination schemaName="vehicle" queryName="etl_target2" targetOption="merge">
<alternateKeys>
<!-- The pk of the target table is the "rowId" column. Use "id" as an alternate match key -->
<column name="id"/>
</alternateKeys>
</destination>
Append with Two Targets
For example, you might want to ensure that a given stored procedure is executed (step1) before loading the data into the destination (step2).<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>Append</name>
<description>append rows from etl_source to etl_target and etl_target2</description>
<transforms>
<transform id="step1">
<description>Copy to target</description>
<source schemaName="external" queryName="etl_source" timestampcolumnname="modfiied" />
<destination schemaName="patient" queryName="etl_target" />
</transform>
<transform id="step2">
<description>Copy to target two</description>
<source schemaName="external" queryName="etl_source" />
<destination schemaName="patient" queryName="etl_target2" />
</transform>
</transforms>
<incrementalFilter className="SelectAllFilterStrategy"/>
</etl>
Truncate
<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>Truncate</name>
<description>Clear target and append rows from etl_source.</description>
<transforms>
<transform id="step1">
<description>Copy to target</description>
<source schemaName="patient" queryName="etl_source" />
<destination schemaName="patient" queryName="etl_target" targetOption="truncate"/>
</transform>
</transforms>
<incrementalFilter className="ModifiedSinceFilterStrategy" timestampColumnName="modified" />
<schedule>
<poll interval="15s" />
</schedule>
</etl>
Passing Parameters to a SQL Query
The following ETL process passes parameters (MinTemp=99 and MinWeight=150) into its source query (a parameterized query).<?xml version="1.0" encoding="UTF-8" ?>
<etl xmlns="http://labkey.org/etl/xml">
<name>PatientsToTreated</name>
<description>Transfers from the Patients table to the Treated table.</description>
<transforms>
<transform id="step1">
<description>Patients to Treated Table</description>
<source queryName="Patients" schemaName="study"/>
<destination schemaName="study" queryName="Treated"/>
</transform>
</transforms>
<parameters>
<parameter name="MinTemp" value="99" type="DECIMAL" />
<parameter name="MinWeight" value="150" type="DECIMAL" />
</parameters>
<schedule>
<poll interval="1h"/>
</schedule>
</etl>
Truncate the Target Query
The following truncates the target table, without copying any data from a source query. Note the lack of a <source> element.<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>Truncate Patients Table</name>
<description>Update data for study on male patients.</description>
<transforms>
<transform id="trunc">
<destination schemaName="study" queryName="Patients" targetOption="truncate"/>
</transform>
</transforms>
<schedule>
<poll interval="1h"/>
</schedule>
</etl>
Java Transforms
Java developers can add a Java class to handle the transformation step of an ETL process. The column to be transformed points to the Java class as follows:<columnTransforms>
<column source="columnToTransform" transformClass="org.labkey.di.columnTransforms.MyJavaClass"/>
</columnTransforms>
ETL.xml
<?xml version="1.0" encoding="UTF-8"?>
<etl xmlns="http://labkey.org/etl/xml">
<name>Append Transformed Column</name>
<description>Append rows from etl_source to etl_target, applying column transformation using a Java class.</description>
<transforms>
<transform id="step1" type="org.labkey.di.pipeline.TransformTask">
<description>Copy to target</description>
<source schemaName="vehicle" queryName="etl_source" />
<destination schemaName="vehicle" queryName="etl_target">
<columnTransforms>
<column source="name" transformClass="org.labkey.di.columnTransforms.TestColumnTransform"/>
</columnTransforms>
<constants>
<column name="myConstant" type="varchar" value="aConstantValue"/>
</constants>
</destination>
</transform>
</transforms>
<incrementalFilter className="SelectAllFilterStrategy" />
</etl>
TestColumnTransform.java
package org.labkey.di.columnTransforms;
import org.labkey.api.di.columnTransform.AbstractColumnTransform;
/**
* An example of Java implementing a transform step.
* Prepends the value of the "id" column of the source query
* to the value of the source column specified in the ETL configuration xml,
* then appends the value of the "myConstant" constant set in the xml.
*/
public class TestColumnTransform extends AbstractColumnTransform
{
@Override
protected Object doTransform(Object inputValue)
{
Object prefix = getInputValue("id");
String prefixStr = null == prefix ? "" : prefix.toString();
return prefixStr + "_" + inputValue + "_" + getConstant("myConstant");
}
}
ETL: Reference
Directory Structure of an ETL Module
The directory structure for an ETL module is shown below. Note that the "queries" and "schemas" directories are optional, and not required for ETL functionality. Items shown in lowercase are literal values that should be preserved in the directory structure. Items shown in uppercase should be replaced with values that reflect the nature of your project.MODULE_NAME
├───etls
│ ETL1.xml
│ ETL2.xml
│
├───queries
│ └───SCHEMA_NAME
│ QUERY_NAME.sql
│
└───schemas
│ SCHEMA_NAME.xml
│
└───dbscripts
├───postgresql
│ SCHEMA_NAME-X.XX-Y.YY.sql
│
└───sqlserver
SCHEMA_NAME-X.XX-Y.YY.sql
- ETL1.xml - The main config file for an ETL process. Defines the sources, targets, transformations, and schedules for the transfers. Any number of ETL processes and tasks can be added. For examples see ETL: Examples.
- QUERY_NAME.sql - SQL queries for data sources and targets.
- schemas - Optional database schemas. Optional sql scripts for bootstrapping a target database.
ETL Configuration Reference
For details see ETL XML Reference.Reference Links
- etl.xml Reference - xml reference docs for ETL config files.
- etl.xsd - The XSD schema file on which the XML config files are based.
Modules: Java
- Module Architecture
- Getting Started with the Demo Module
- Creating a New Java Module
- Deprecated Components
- The LabKey Server Container
- CSS Design Guidelines
- Implementing Actions and Views
- Implementing API Actions
- Integrating with the Pipeline Module
- Integrating with the Experiment Module
- GWT Integration
- GWT Remote Services
- Java Testing Tips
Module Architecture
Deploy Modules
At deployment time, a LabKey module consists of a single .module file. The .module file bundles the webapp resources (static content such as .GIF and .JPEG files, JavaScript files, SQL scripts, etc), class files (inside .jar files), and so forth.The built .module file should be copied into your /modules directory. This directory is usually a sibling directory to the webapp directory.At server startup time, LabKey Server extracts the modules so that it can find all the required files. It also cleans up old files that might be left from modules that have been deleted from the modules directory.Build Modules
The build process for a module produces a .module file and copies it into the deployment directory. The standalone_build.xml file can be used for modules where the source code resides outside the standard LabKey source tree. It's important to make sure that you don't have the VM parameter -Dproject.root specified if you're developing this way or LabKey won't find all the files it loads directly from the source tree in dev mode (such as .sql and .gm files).The create_module Ant target will prompt you for the name of a new module and a location on the file system where it should live. It then creates a minimal module that's an easy starting point for development. You can add the .IML file to your IntelliJ project and you're up and running. Use the build.xml file in the module's directory to build it.Each module is built independently of the others. All modules can see shared classes, like those in API or third-party JARs that get copied into WEB-INF/lib. However, modules cannot see one another's classes. If two modules need to communicate with each other, they must do so through interfaces defined in the LabKey Server API, or placed in a module's own api-src directory. Currently there are many classes that are in the API that should be moved into the relevant modules. As a long-term goal, API should consist primarily of interfaces and abstract classes through which modules talk to each other. Individual modules can place third-party JARs in their lib/ directory.Dependencies
The LabKey Server build process enforces that modules and other code follow certain dependency rules. Modules cannot depend directly on each other's implementations, and the core API cannot depend on individual modules' code. A summary of the allowed API/implementation dependencies is shown here:
Upgrade Modules
See Upgrade Modules.Delete Modules
To delete an unused module, delete both the .module file and the expanded directory of the same name from your deployment. The module may be in either the /modules or /externalModules directory.Getting Started with the Demo Module
About the Demo Module
The Demo module is a simple sample module that displays names and ages for some number of individuals. Its purpose is to demonstrate some of the basic data display and manipulation functionality available in LabKey Server.You can enable the Demo module in a project or folder to try it out:- Select Admin -> Folder -> Management and choose the Folder Type tab
- Enable the Demo module
- Add the Demo Summary web part to your project or folder. A web part is an optional component that can provide a summary of the data contained in your module.
A Tour of the Demo Module
In the following sections, we'll examine the different files and classes that make up the Demo module.Take a look at the source code at: <labkey-home>\modules. The modules\ directory contains the source code for all of the modules, each sub-directory is an individual module.The LabKey Server web application uses a model-view-controller (MVC) architecture based on Spring.You may also want to look at the database component of the Demo module. The Person table stores data for the Demo module.The Object Model (Person Class)
The Person class comprises the object model for the Demo module. The Person class can be found in the org.labkey.demo.model package (and, correspondingly, in the <labkey-home>\modules\server\demo\src\org\labkey\demo\model directory). It provides methods for setting and retrieving Person data from the Person table. Note that the Person class does not retrieve or save data to the database itself, but only stores in memory data that is to be saved or has been retrieved. The Person class extends the Entity class, which contains general methods for working with objects that are stored as rows in a table in the database.The Controller File (DemoController Class)
Modules have one or more controller classes, which handle the flow of navigation through the UI for the module. A controller class manages the logic behind rendering the HTML on a page within the module, submitting form data via both GET and POST methods, handling input errors, and navigating from one action to the next.A Controller class is a Java class that defines individual action classes, all of which are auto-registered with the controller's ActionResolver. Action classes can also be defined outside the controller, in which case they must be registered with the ActionResolver. Action classes are annotated to declare permissions requirements.The controller for the Demo module, DemoController.java, is located in the org.labkey.demo package (that is, in <labkey-home>\server\modules\demo\src\org\labkey\demo). If you take a look at some of the action classes in the DemoController class, you can see how the controller manages the user interface actions for the module. For example, the BeginAction in the DemoController displays data in a grid format. It doesn't write out the HTML directly, but instead calls other methods that handle that task. The InsertAction class displays a form for inserting new Person data when GET is used and calls the code that handles the database insert operation when POST is used.A module's controller class should extend the SpringActionController class, Labkey's implementation of the Spring Controller class.The primary controller for a module is typically named <module-name>Controller.The Module View
The module controller renders the module user interface and also handles input from that user interface. Although you can write all of the necessary HTML from within the controller, we recommend that you separate out the user interface from the controller in most cases and use the LabKey Server rendering code to display blocks of HTML. LabKey Server primarily uses JSP files templates to render the module interface.The bulkUpdate.jsp FileThe bulkUpdate.jsp file displays an HTML form that users can use to update more than one row of the Person table at a time. BulkUpdateAction renders the bulkUpdate.jsp file and accepts posts from that HTML form. The data submitted by the user is passed to handlePost() as values on an object of type BulkUpdateForm. The form values are accessible via getters and setters on the BulkUpdateForm class that are named to correspond to the inputs on the HTML form.The bulkUpdate.jsp file provides one example of how you can create a user interface to your data within your module. Keep in mind that you can take advantage of a lot of the basic data functionality that is already built into LabKey Server, described elsewhere in this section, to make it easier to build your module. For example, the DataRegion class provides an easy-to-use data grid with built-in sorting and filtering.The DemoWebPart ClassThe DemoWebPart class is located in the org.labkey.demo.view package. It comprises a simple web part for the demo module. This web part can be displayed only on the Portal page. It provides a summary of the data that's in the Demo module by rendering the demoWebPart.jsp file. An object of type ViewContext stores in-memory values that are also accessible to the JSP page as it is rendering.The web part class is optional, although most modules have a corresponding web part.The demoWebPart.jsp FileThe demoWebPart.jsp file displays Person data on an HTML page. The JSP retrieves data from the ViewContext object in order to render that data in HTML.The Data Manager Class (DemoManager Class)
The data manager class contains the logic for operations that a module performs against the database, including retrieving, inserting, updating, and deleting data. It handles persistence and caching of objects stored in the database. Although database operations can be called from the controller, as a design principle we recommend separating this layer of implementation from the navigation-handling code.The data manager class for the Demo module, the DemoManager class, is located in the org.labkey.demo package. Note that the DemoManager class makes calls to the LabKey Server table layer, rather than making direct calls to the database itself.The Module Class (DemoModule Class)
The DemoModule class is located in the org.labkey.demo package. It extends the DefaultModule class, which is an implementation of the Module interface. The Module interface provides generic functionality for all modules in LabKey Server and manages how the module plugs into the LabKey Server framework and how it is versioned.The only requirement for a module is that it implement the Module interface. However, most modules have additional classes like those seen in the Demo module.The Schema Class (DemoSchema Class)
The DemoSchema class is located in the org.labkey.demo package. It provides methods for accessing the schema of the Person table associated with the Demo module. This class abstracts schema information for this table, so that the schema can be changed in just one place in the code.Database Scripts
The <labkey-home>\server\modules\demo\webapp\demo\scripts directory contains two subdirectories, one for PostgreSQL and one for Microsoft SQL Server. These directories contain functionally equivalent scripts for creating the Person table on the respective database server.Note that there are a set of standard columns that all database tables in LabKey Server must include. These are:- _ts: the timestamp column
- RowId: an autogenerated integer field that serves as the primary key
- CreatedBy: a user id
- Created: a date/time column
- ModifiedBy: a user id
- Modified: a date/time column
- Owner: a user id
Creating a New Java Module
The main build.xml file on your LabKey Server contains an Ant target called create_module. This target makes it easy to create a template Java module with the correct file structure and template Controller classes. We recommend using it instead of trying to copy an existing module, as renaming a module requires editing and renaming many files.When you invoke the create_module target, it will prompt you for two things:
- The module name. This should be a single word (or multiple words concatenated together), for example MyModule, ProjectXAssay, etc.
- A directory in which to put the files.
- "Test"
- "C:\labkey\server\localModules\Test"
C:\labkey\server\localModules\Test
│ module.properties
│ Test.iml
│
├───lib
├───resources
│ ├───schemas
│ │ │ test.xml
│ │ │
│ │ └───dbscripts
│ │ ├───postgresql
│ │ │ test-XX.XX-YY.YY.sql
│ │ │
│ │ └───sqlserver
│ │ test-XX.XX-YY.YY.sql
│ │
│ └───web
└───src
└───org
└───labkey
└───test
│ TestContainerListener.java
│ TestController.java
│ TestManager.java
│ TestModule.java
│ TestSchema.java
│
└───view
hello.jsp
If you are using IntelliJ, you can import MyModule.iml as an IntelliJ module to add your LabKey Server module to the IntelliJ project.lib directory
JAR files required by your module but not already part of the LabKey Server distribution can be added to the ./lib directory. At compile time and run time, they will be visible to your module but not to the rest of the system. This means that different modules may use different versions of library JAR files.Manager class
In LabKey Server, the Manager classes encapsulate much of the business logic for the module. Typical examples include fetching objects from the database, inserting, updating, and deleting objects, and so forth.Module class
This is the entry point for LabKey Server to talk to your module. Exactly one instance of this class will be instantiated. It allows your module to register providers that other modules may use.Schema class
Schema classes provide places to hook in to the LabKey Server Table layer, which provides easy querying of the database and object-relational mapping.Schema XML file
This provides metadata about your database tables and views. In order to pass the developer run test (DRT), you must have entries for every table and view in your database schema. To regenerate this XML file, see Modules: Database Transition Scripts. For more information about the DRT, see Check in to the Source Project.Controller class
This is a subclass of SpringActionController that links requests from a browser to code in your application.web directory
All of that static web content that will be served by Tomcat should go into this directory. These items typically include things like .gif and .jpg files. The contents of this directory will be combined with the other modules' webapp content, so we recommend adding content in a subdirectory to avoid file name conflicts..sql files
These files are the scripts that create and update your module's database schema. They are automatically run at server startup time. See the Modules: SQL Scripts for details on how to create and modify database tables and views. LabKey Server currently supports Postgres and Microsoft SQL Server.module.properties
At server startup time, LabKey Server uses this file to determine your module's name, class, and dependencies.
Deploy the Java Module
The main build target will build and deploy your custom module, assuming its source directory is referenced in the "standard.modules" file (either explicitly or implicitly via wildcards). The main build will compile your Java files and JSPs, package all code and resources into a .module file, and deploy it to the server.Add a Module API
A module may define its own API which is available to the implementations of other modules. To add an API to an existing module:- Create a new api-src directory in the module's root.
- In IntelliJ, File->New Module. Choose Java as the module type. Call it MODULENAME-API, make the module's api-src directory the content root, and use the root of the module as the module file location.
- In IntelliJ, File->Project Structure. Select your new API module from the list. In the Sources tab, remove the "src" directory as a source root, and make the api-src directory as a source root. In the Dependencies tab, add a Module Dependency on the "Internal" module and check the box to Export it. Find your original module from the list. Remove the dependency on the Internal module, and add a Module Dependency on your new API module.
- Remove the "src" directory under the api-src directory.
- Create a new package under your api-src directory, "org.labkey.MODULENAME.api" or similar.
- Add Java classes to the new package, and reference them from within your module.
- Add a Module Dependency to any other modules that depend on your module's API.
- Develop and test.
- Commit your new Java source files, the new .IML file, any .IML files for existing modules that you changed, and the reference to your new .IML API in LabKey.ipr.
The LabKey Server Container
The Container on the URL
The container hierarchy is always included in the URL, following the name of the controller. For example, the URL below shows that it is in the /Documentation folder beneath the /home project:https://www.labkey.org/home/Documentation/wiki-page.view?name=buildingModuleThe getExtraPath() method of the ViewURLHelper class returns the container path from the URL. On the Container object, the getPath() method returns the container's path.The Root Container
LabKey Server also has a root container which is not apparent in the user interface, but which contains all other containers. When you are debugging LabKey Server code, you may see the Container object for the root container; its name appears as "/".In the core.Containers table in the LabKey Server database, the root container has a null value for both the Parent and the Name field.You can use the isRoot() method to determine whether a given container is the root container.Projects Versus Folders
Given that they are both objects of type Container, projects and folders are essentially the same at the level of the implementation. A project will always have the root container as its parent, while a folder's parent will be either a project or another folder.You can use the isProject() method to determine whether a given container is a project or a folder.Useful Classes and Methods
Container Class MethodsThe Container class represents a given container and persists all of the properties of that container. Some of the useful methods on the Container class include:- getName(): Returns the container name
- getPath(): Returns the container path
- getId(): Returns the GUID that identifies this container
- getParent(): Returns the container's parent container
- hasPermission(user, perm): Returns a boolean indicating whether the specified user has the given level of permissions on the container
- create(container, string): Creates a new container
- delete(container): Deletes an existing container
- ensureContainer(string): Checks to make sure the specified container exists, and creates it if it doesn't
- getForId(): Returns the container with this EntityId (a GUID value)
- getForPath(): Returns the container with this path
Implementing Actions and Views
- the Model is implemented as one or more Java classes, such as standard JavaBean classes
- the View is implemented as JSPs, or other technologies
- the Controller is implemented as Java action classes
- ViewServlet receives the request and directs it to the appropriate module.
- The module passes the request to the appropriate Controller which then invokes the requested action.
- The action verifies that the user has permission to invoke it in the current folder. (If the user is not assigned an appropriate role in the folder then the action will not be invoked.) Action developers typically declare required permissions via a @RequiresPermission() annotation.
- The Spring framework instantiates the Form bean associated with the action and "binds" parameter values to it. In other words, it matches URL parameters names to bean property names; for each match, it converts the parameter value to the target data type, performs basic validation, and sets the property on the form by calling the setter.
- The Controller now has data, typed and validated, that it can work with. It performs the action, and typically redirects to a results page, confirmation page, or back to the same page.
Example: Hello World JSP View
The following action takes a user to a static "Hello World" JSP view.helloWorld.jsp:<%= h("Hello, World!") %>// If the user does not have Read permissions, the action will not be invoked.
@RequiresPermission(ReadPermission.class)
public class HelloWorldAction extends SimpleViewAction
{
@Override
public ModelAndView getView(Object o, BindException errors) throws Exception
{
JspView view = new JspView("/org/labkey/javatutorial/view/helloWorld.jsp");
view.setTitle("Hello World");
return view;
}
@Override
public NavTree appendNavTrail(NavTree root)
{
return root;
}
}
Example: Submitting Forms to an Action
The following action processes a form submitted by the user.helloSomeone.jspThis JSP is for submitting posts, and displaying responses, on the same page:<%@ taglib prefix="labkey" uri="http://www.labkey.org/taglib" %>
<%@ page import="org.labkey.api.view.HttpView"%>
<%@ page import="org.labkey.javatutorial.JavaTutorialController" %>
<%@ page import="org.labkey.javatutorial.HelloSomeoneForm" %>
<%@ page extends="org.labkey.api.jsp.JspBase" %>
<%
HelloSomeoneForm form = (HelloSomeoneForm) HttpView.currentModel();
%>
<labkey:errors />
<labkey:form method="POST" action="<%=urlFor(JavaTutorialController.HelloSomeoneAction.class)%>">
<h2>Hello, <%=h(form.getName()) %>!</h2>
<table width="100%">
<tr>
<td class="labkey-form-label">Who do you want to say 'Hello' to next?: </td>
<td><input name="name" value="<%=h(form.getName())%>"></td>
</tr>
<tr>
<td><labkey:button text="Go" /></td>
</tr>
</table>
</labkey:form>
// If the user does not have Read permissions, the action will not be invoked.
@RequiresPermission(ReadPermission.class)
public class HelloSomeoneAction extends FormViewAction<HelloSomeoneForm>
{
public void validateCommand(HelloSomeoneForm form, Errors errors)
{
// Do some error handling here
}
public ModelAndView getView(HelloSomeoneForm form, boolean reshow, BindException errors) throws Exception
{
return new JspView<>("/org/labkey/javatutorial/view/helloSomeone.jsp", form, errors);
}
public boolean handlePost(HelloSomeoneForm form, BindException errors) throws Exception
{
return true;
}
public ActionURL getSuccessURL(HelloSomeoneForm form)
{
// Redirect back to the same action, adding the submitted value to the URL.
ActionURL url = new ActionURL(HelloSomeoneAction.class, getContainer());
url.addParameter("name", form.getName());
return url;
}
public NavTree appendNavTrail(NavTree root)
{
root.addChild("Say Hello To Someone");
return root;
}
}
package org.labkey.javatutorial;
public class HelloSomeoneForm
{
public String _name = "World";
public void setName(String name)
{
_name = name;
}
public String getName()
{
return _name;
}
}
Example: Export as Script Action
This action exports a query as a re-usable script, either as JavaScript, R, Perl, or SAS. (The action is surfaced in the user interface on a data grid, at Export > Script.)public static class ExportScriptForm extends QueryForm
{
private String _type;
public String getScriptType()
{
return _type;
}
public void setScriptType(String type)
{
_type = type;
}
}
@RequiresPermission(ReadPermission.class)
public class ExportScriptAction extends SimpleViewAction<ExportScriptForm>
{
public ModelAndView getView(ExportScriptForm form, BindException errors) throws Exception
{
ensureQueryExists(form);
return ExportScriptModel.getExportScriptView(QueryView.create(form, errors),
form.getScriptType(), getPageConfig(), getViewContext().getResponse());
}
public NavTree appendNavTrail(NavTree root)
{
return null;
}
}
Example: Delete Cohort
The following action deletes a cohort category from a study (provided it is an empty cohort). It then redirects the user back to the Manage Cohorts page.@RequiresPermission(AdminPermission.class)
public class DeleteCohortAction extends SimpleRedirectAction<CohortIdForm>
{
public ActionURL getRedirectURL(CohortIdForm form) throws Exception
{
CohortImpl cohort = StudyManager.getInstance().getCohortForRowId(getContainer(), getUser(), form.getRowId());
if (cohort != null && !cohort.isInUse())
StudyManager.getInstance().deleteCohort(cohort);
return new ActionURL(CohortController.ManageCohortsAction.class, getContainer());
}
}
Packaging JSPs
JSPs can be placed anywhere in the src directory, but by convention they are often placed in the view directory, as shown below:mymodule
├───lib
├───resources
└───src
└───org
└───labkey
└───javatutorial
│ HelloSomeoneForm.java
│ JavaTutorialController.java
│ JavaTutorialModule.java
└───view
helloSomeone.jsp
helloWorld.jsp
Implementing API Actions
Overview
This page describes how to implement API actions within the LabKey Server controller classes. It is intended for Java developers building their own modules or working within the LabKey Server source code.API actions build upon LabKey’s controller/action design. They include the “API” action base class whose derived action classes interact with the database or server functionality. These derived actions return raw data to the base classes, which serialize raw data into one of LabKey’s supported formats.Leveraging the current controller/action architecture provides a range of benefits, particularly:- Enforcement of user login for actions that require login, thanks to reuse of LabKey’s existing, declarative security model (@RequiresPermission annotations).
- Reuse of many controllers’ existing action forms, thanks to reuse of LabKey’s existing Spring-based functionality for binding request parameters to form beans.
API Action Design Rules
In principle, actions are autonomous, may be named, and can do, whatever the controller author wishes. However, in practice, we suggest adhering to the following general design rules when implementing actions:- Action names should be named with a verb/noun pair that describes what the action does in a clear and intuitive way (e.g., getQuery, updateList, translateWiki, etc.).
- Insert, update, and delete of a resource should all be separate actions with appropriate names (e.g., getQuery, updateRows, insertRows, deleteRows), rather than a single action with a parameter to indicate the command.
- Wherever possible, actions should remain agnostic about the request and response formats. This is accomplished automatically through the base classes, but actions should refrain from reading the post body directly or writing directly to the HttpServletResponse unless they absolutely need to.
- For security reasons, ApiActions that respond to GET should not mutate the database or otherwise change server state. ApiActions that change state (e.g., insert, update, or delete actions) should respond to POST and extend MutatingApiAction.
API Actions
An APIAction is a Spring-based action that derives from the abstract base class org.labkey.api.action.ApiAction. API actions do not implement the getView() or appendNavTrail() methods that view actions do. Rather, they implement the execute method. MyForm is a simple bean intended to represent the parameters sent to this action.@RequiresPermission(ReadPermission.class)
public class GetSomethingAction extends ApiAction<MyForm>
{
public ApiResponse execute(MyForm form, BindException errors) throws Exception
{
ApiSimpleResponse response = new ApiSimpleResponse();
// Get the resource...
// Add it to the response...
return response;
}
}
JSON Example
A basic API action class looks like this:@RequiresPermission(ReadPermission.class)
public class ExampleJsonAction extends ApiAction<Object>
{
public ApiResponse execute(Object form, BindException errors) throws Exception
{
ApiSimpleResponse response = new ApiSimpleResponse();
response.put("param1", "value1");
response.put("success", true);
return response;
}
}
{
"success" : true,
"param1" : "value1"
}Example: Set Display for Table of Contents
@RequiresLogin
public class SetTocPreferenceAction extends MutatingApiAction<SetTocPreferenceForm>
{
public static final String PROP_TOC_DISPLAYED = "displayToc";
public ApiResponse execute(SetTocPreferenceForm form, BindException errors)
{
//use the same category as editor preference to save on storage
PropertyManager.PropertyMap properties = PropertyManager.getWritableProperties(
getUser(), getContainer(),
SetEditorPreferenceAction.CAT_EDITOR_PREFERENCE, true);
properties.put(PROP_TOC_DISPLAYED, String.valueOf(form.isDisplayed()));
PropertyManager.saveProperties(properties);
return new ApiSimpleResponse("success", true);
}
}
Execute Method
public ApiResponse execute(FORM form, BindException errors) throws Exception
return new ApiSimpleResponse("rowsUpdated", rowsUpdated);
Form Parameter Binding
If the request uses a standard query string with a GET method, form parameter binding uses the same code as used for all other view requests. However, if the client uses the POST method, the binding logic depends on the content-type HTTP header. If the header contains the JSON content-type (“application/json”), the ApiAction base class parses the post body as JSON and attempts to bind the resulting objects to the action’s form. This code supports nested and indexed objects via the BeanUtils methods.For example, if the client posts JSON like this:{ "name": "Lister",
"address": {
"street": "Top Bunk",
"city": “Red Dwarf",
"state": “Deep Space"},
"categories” : ["unwashed", "space", "bum"]
}form.setName("Lister");
form.getAddress().setStreet("Top Bunk");
form.getAddress().setCity("Red Dwarf");
form.getAddress().setState("Deep Space");
form.getCategories().set(0) = "unwashed";
form.getCategories().set(1) = "space";
form.getCategories().set(2) = "bum";
Jackson Marshalling (Experimental)
Experimental Feature: Instead of manually unpacking the JSONObject from .getJsonObject() or creating a response JSONObject, you may use Jackson to marshall a Java POJO form and return value. To enable Jackson marshalling, add the @Marshal(Marshaller.Jackson) annotation to your Controller or ApiAction class. When adding the @Marshal annotation to a controller, all ApiActions defined in the Controller class will use Jackson marshalling. For example,@Marshal(Marshaller.Jackson)
@RequiresLogin
public class ExampleJsonAction extends ApiAction<MyStuffForm>
{
public ApiResponse execute(MyStuffForm form, BindException errors) throws Exception
{
// retrieve resource from the database
MyStuff stuff = ...;
// instead of creating an ApiResponse or JSONObject, return the POJO
return stuff;
}
}
Error and Exception Handling
If an API action adds errors to the errors collection or throws an exception, the base ApiAction will return a response with status code 400 and a json body using the format below. Clients may then choose to display the exception message or react in any way they see fit. For example, if an error is added to the errors collection for the "fieldName" field of the ApiAction's form class with message "readable message", the response will be serialized as:{
"success": false,
"exception": "readable message",
"errors": [ {
"id" : "fieldName",
"msg" : "readable message",
} ]
}Integrating with the Pipeline Module
Integration points
org.labkey.api.pipeline.PipelineProviderPipelineProviders let modules hook into the Pipeline module's user interface for browsing through the file system to find files on which to operate. This is always done within the context of a pipeline root for the current folder. The Pipeline module calls updateFileProperties() on all the PipelineProviders to determine what actions should be available. Each module provides its own URL which can collect additional information from the user before kicking off any work that needs to be done.For example, the org.labkey.api.exp.ExperimentPipelineProvider registered by the Experiment module provides actions associated with .xar and .xar.xml files. It also provides a URL that the Pipeline module associates with the actions. If the users clicks to load a XAR, the user's browser will go to the Experiment module's URL.PipelineProviders are registered by calling org.labkey.api.pipeline.PipelineServer.registerPipelineProvider().org.labkey.api.pipeline.PipelineJob
PipelineJobs allow modules to do work relating to a particular piece of analysis. PipelineJobs sit in a queue until the Pipeline module determines that it is their turn to run. The Pipeline module then calls the PipelineJob's run() method. The PipelineJob base class provides logging and status functionality so that implementations can inform the user of their progress.The Pipeline module attempts to serialize the PipelineJob object when it is submitted to the queue. If the server is restarted while there are jobs in the queue, the Pipeline module will look for all the jobs that were not in the COMPLETE or ERROR state, deserialize the PipelineJob objects from disk, and resubmit them to the queue. A PipelineJob implementation is responsible for restarting correctly if it is interrupted in the middle of processing. This might involve resuming analysis at the point it was interrupted, or deleting a partially loaded file from the database before starting to load it again.For example, the org.labkey.api.exp.ExperimentPipelineJob provided by the Experiment module knows how to parse and load a XAR file. If the input file is not a valid XAR, it will put the job into an error state and write the reason to the log file.PipelineJobs do not need to be explicitly registered with the Pipeline module. Other modules can add jobs to the queue using the org.labkey.api.pipeline.PipelineService.queueJob() method.
Integrating with the Experiment Module
Integration points
org.labkey.api.exp.ExperimentDataHandlerThe ExperimentDataHandler interface allows a module to handle specific kinds of files that might be present in a XAR. When loading from a XAR, the Experiment module will keep track of all the data files that it encounters. After the general, Experiment-level information is fully imported, it will call into the ExperimentDataHandlers that other modules have registered. This gives other modules a chance to load data into the database or otherwise prepare it for later display. The XAR load will fail if an ExperimentDataHandler throws an ExperimentException, indicating that the data file was not as expected.Similarly, when exporting a set of runs as a XAR, the Experiment module will call any registered ExperimentDataHandlers to allow them to transform the contents of the file before it is written to the compressed archive. The default exportFile() implementation, provided by AbstractExperimentDataHandler, simply exports the file as it exists on disk.The ExperimentDataHandlers are also interrogated to determine if any modules provide UI for viewing the contents of the data files. By default, users can download the content of the file, but if the ExperimentDataHandler provides a URL, it will also be available. For example, the MS2 module provides an ExperimentDataHandler that hands out the URL to view the peptides and proteins for a .pep.xml file.Prior to deleting a data object, the Experiment module will call the associated ExperimentDataHandler so that it can do whatever cleanup is necessary, like deleting any rows that have been inserted into the database for that data object.ExperimentDataHandlers are registered by implementing the getDataHandlers() method on Module.org.labkey.api.exp.RunExpansionHandler
RunExpansionHandlers allow other modules to modify the XML document that describes the XAR before it is imported. This means that modules have a chance to run Java code to make decisions on things like the number and type of outputs for a ProtocolApplication based on any criteria they desire. This provides flexibility beyond just what is supported in the XAR schema for describing runs. They are passed an XMLBeans representation of the XAR.RunExpansionHandlers are registered by implementing the getRunExpansionHandlers() method on Module.org.labkey.api.exp.ExperimentRunFilter
ExperimentRunFilters let other modules drive what columns are available when viewing particular kinds of runs in the experiment run grids in the web interface. The filter narrows the list of runs based on the runs' protocol LSID.Using the Query module, the ExperimentRunFilter can join in additional columns from other tables that may be related to the run. For example, for MS2 search runs, there is a row in the MS2Runs table that corresponds to a row in the exp.ExperimentRun table. The MS2 module provides ExperimentRunFilters that tell the Experiment module to use a particular virtual table, defined in the MS2 module, to display the MS2 search runs. This virtual table lets the user select columns for the type of mass spectrometer used, the name of the search engine, the type of quantitation run, and so forth. The virtual tables defined in the MS2 schema also specify the set of columns that should be visible by default, meaning that the user will automatically see some of files that were the inputs to the run, like the FASTA file and the mzXML file.ExperimentRunFilters are registered by implementing the getExperimentRunFilters() method on Module.Generating and Loading XARs
When a module does data analysis, typically performed in the context of a PipelineJob, it should generally describe the work that it has done in a XAR and then cause the Experiment module to load the XAR after the analysis is complete.It can do this by creating a new ExperimentPipelineJob and inserting it into the queue, or by calling org.labkey.api.exp.ExperimentPipelineJob.loadExperiment(). The module will later get callbacks if it has registered the appropriate ExperimentDataHandlers or RunExpansionHandlers.API for Creating Simple Protocols and Experiment Runs
Version 2.2 of LabKey Server introduces an API for creating simple protocols and simple experiment runs that use those protocols. It is appropriate for runs that start with one or more data/material objects and output one or more data/material objects after performing a single logical step.To create a simple protocol, call org.labkey.api.exp.ExperimentService.get().insertSimpleProtocol(). You must pass it a Protocol object that has already been configured with the appropriate properties. For example, set its description, name, container, and the number of input materials and data objects. The call will create the surrounding Protocols, ProtocolActions, and so forth, that are required for a full fledged Protocol.To create a simple experiment run, call org.labkey.api.exp.ExperimentService.get().insertSimpleExperimentRun(). As with creating a simple Protocol, you must populate an ExperimentRun object with the relevant properties. The run must use a Protocol that was created with the insertSimpleProtocol() method. The run must have at least one input and one output. The call will create the ProtocolApplications, DataInputs, MaterialInputs, and so forth that are required for a full-fledged ExperimentRun.
Using SQL in Java Modules
Ways to Work with SQL
Options for working with SQL from Java code:Table Class
Using Table.insert()/update()/delete() with a simple Java class/bean works well when you want other code to be able to work with the class, and the class fields map directly with what you're using in the database. This approach usually results in the least lines of code to accomplish the goal. See the demoModule for an example of this approach.SQLFragment/SQLExecutor
SQLFragment/SQLExecutor is a good approach when you need more control over the SQL you're generating. It's also used for operations that work on multiple rows at a time.Prepared SQL Statements
Use prepared statements when you're dealing with many data rows and want the performance gain from being able to reuse the same statement with different values.Client-Side Options
You can also develop SQL applications without needing any server-side Java code by using the LABKEY.Query.saveRows() and related APIs from JavaScript code in the client. In this scenario, you'd expose your table as part of a schema, and rely on the default server implementation. This approach gives you the least control over the SQL that's actually used.Utility Functions
LabKey Server provides a number of SQL function extensions to help Java module developers:- access various properties
- keep Java code and SQL queries in sync
moduleProperty(MODULE_NAME, PROPERTY_NAME)
Returns a module property, based on the module and property names. Arguments are strings, so use single quotes not double.ExamplesmoduleProperty('EHR','EHRStudyContainer')SELECT *
FROM Site.{substitutePath moduleProperty('EHR','EHRStudyContainer')}.study.myQuery
javaConstant(FULLY_QUALIFIED_CLASS_AND_FIELD_NAME)
Provides access to public static final variable values. The argument value should be a string.Fields must be either be on classes in the java.lang package, or tagged with the org.labkey.api.query.Queryable annotation to indicate they allow access through this mechanism. Other fields types are not supported.ExamplesjavaConstant('java.lang.Integer.MAX_VALUE')
javaConstant('org.labkey.mymodule.MyConstants.MYFIELD')public class MyConstants
{
@Queryable
public static final String MYFIELD = "some value";
}
GWT Integration
LabKey Server uses the Google Web Toolkit (GWT) to create web pages with rich UI. GWT compiles java code into JavaScript that runs in a browser. For more information about GWT see the GWT home page.
We have done some work to integrate GWT into the LabKey framework:
- The org.labkey.api.gwt.Internal GWT module can be inherited by all other GWT modules to include tools that allow GWT clients to connect back to the LabKey server more easily.
- There is a special incantation to integrate GWT into a web page. The org.labkey.api.view.GWTView class allows a GWT module to be incorporated in a standard LabKey web page.
- GWTView also allows passing parameters to the GWT page. The org.labkey.api.gwt.client.PropertyUtil class can be used by the client to retrieve these properties.
- GWT supports asynchronous calls from the client to servlets. To enforce security and the module architecture a few classes have been provided to allow these calls to go through the standard LabKey security and PageFlow mechanisms.
- The client side org.labkey.api.gwt.client.ServiceUtil class enables client->server calls to go through a standard LabKey action implementation.
- The server side org.labkey.api.gwt.server.BaseRemoteService class implements the servlet API but can be configured with a standard ViewContext for passing a standard LabKey url and security context.
- Create an action in your controller that instantiates your servlet (which should extend BaseRemoteService) and calls doPost(getRequest(), getResponse()). In most cases you can simply create a subclass of org.labkey.api.action.GWTServiceAction and implement the createService() method.
- Use ServiceUtil.configureEndpoint(service, "actionName") to configure client async service requests to go through your PageFlow action on the server.
Examples of this can be seen in the study.designer and plate.designer packages within the Study module.
The checked-in jars allow GWT modules within Labkey modules to be built automatically. Client-side classes (which can also be used on the server) are placed in a gwtsrc directory parallel to the standard src directory in the module.
While GWT source can be built automatically, effectively debugging GWT modules requires installation of the full GWT toolkit (we are using 2.5.1 currently). After installing the toolkit you can debug a page by launching GWT's custom client using the class com.google.gwt.dev.DevMode, which runs java code rather than the cross-compiled javascript. The debug configuration is a standard java app with the following requirements
- gwt-user.jar and gwt-dev.jar from your full install need to be on the runtime classpath. (Note: since we did not check in client .dll/.so files, you need to point a manually installed local copy of the GWT development kit.)
- the source root for your GWT code needs to be on the runtime classpath
- the source root for the LabKey GWT internal module needs to be on the classpath
- Main class is com.google.gwt.dev.DevMode
- Program parameters should be something like this:
-noserver -startupUrl "http://localhost:8080/labkey/query/home/metadataQuery.view?schemaName=issues&query.queryName=Issues" org.labkey.query.metadata.MetadataEditor
- -noserver tells the GWT client not to launch its own private version of tomcat
- the URL is the url you would like the GWT client to open
- the last parameter is the module name you want to debug
For example, here is a configuration from a developer's machine. It assumes that the LabKey Server source has is at c:\labkey and that the GWT development kit has been extracted to c:\JavaAPIs\gwt-windows-2.5.1. It will work with GWT code from the MS2, Experiment, Query, List, and Study modules.
- Main class: com.google.gwt.dev.DevMode
- VM parameters:
-classpath C:/labkey/server/internal/gwtsrc;C:/labkey/server/modules/query/gwtsrc;C:/labkey/server/modules/study/gwtsrc;C:/labkey/server/modules/ms2/gwtsrc;C:/labkey/server/modules/experiment/gwtsrc;C:/JavaAPIs/gwt-2.5.1/gwt-dev.jar; C:/JavaAPIs/gwt-2.5.1/gwt-user.jar;c:\labkey\external\lib\build\gxt.jar;C:/labkey/server/modules/list/gwtsrc;C:\labkey\external\lib\server\gwt-dnd-3.2.0.jar
- Program parameters:
-noserver -startupUrl "http://localhost:8080/labkey/query/home/metadataQuery.view?schemaName=issues&query.queryName=Issues" org.labkey.query.metadata.MetadataEditor
- Working directory: C:\labkey\server
- Use classpath and JDK of module: QueryGWT
A note about upgrading to future versions of GWT: As of GWT 2.6.0 (as of this writing, the current release), GWT supports Java 7 syntax. It also stops building permutations for IE 6 and 7 by default. However, it introduces a few breaking API changes. This means that we would need to move to GXT 3.x, which is unfortunately a major upgrade and requires significant changes to our UI code that uses it.
GWT Remote Services
Integrating GWT Remote services is a bit tricky within the LabKey framework. Here's a technique that works.
1. Create a synchronous service interface in your GWT client code:
import com.google.gwt.user.client.rpc.RemoteService;
import com.google.gwt.user.client.rpc.SerializableException;
public interface MyService extends RemoteService
{
String getSpecialString(String inputParam) throws SerializableException;
}
2. Create the asynchronous counterpart to your synchronous service interface. This is also in client code:
import com.google.gwt.user.client.rpc.AsyncCallback;
public interface MyServiceAsync
{
void getSpecialString(String inputParam, AsyncCallback async);
}
3. Implement your service within your server code:
import org.labkey.api.gwt.server.BaseRemoteService;
import org.labkey.api.gwt.client.util.ExceptionUtil;
import org.labkey.api.view.ViewContext;
import com.google.gwt.user.client.rpc.SerializableException;
public class MyServiceImpl extends BaseRemoteService implements MyService
{
public MyServiceImpl(ViewContext context)
{
super(context);
}
public String getSpecialString(String inputParameter) throws SerializableException
{
if (inputParameter == null)
throw ExceptionUtil.convertToSerializable(new
IllegalArgumentException("inputParameter may not be null"));
return "Your special string was: " + inputParameter;
}
}
4. Within the server Spring controller that contains the GWT action, provide a service entry point:
import org.labkey.api.gwt.server.BaseRemoteService;
import org.labkey.api.action.GWTServiceAction;
@RequiresPermission(ACL.PERM_READ)
public class MyServiceAction extends GWTServiceAction
{
protected BaseRemoteService createService()
{
return new MyServiceImpl(getViewContext());
}
}
5. Within your GWT client code, retrive the service with a method like this. Note that caching the service instance is important, since construction and configuration is expensive.
import com.google.gwt.core.client.GWT;
import org.labkey.api.gwt.client.util.ServiceUtil;
private MyServiceAsync _myService;
private MyServiceAsync getService()
{
if (_testService == null)
{
_testService = (MyServiceAsync) GWT.create(MyService.class);
ServiceUtil.configureEndpoint(_testService, "myService");
}
return _testService;
}
6. Finally, call your service from within your client code:
public void myClientMethod()
{
getService().getSpecialString("this is my input string", new AsyncCallback()
{
public void onFailure(Throwable throwable)
{
// handle failure here
}
public void onSuccess(Object object)
{
String returnValue = (String) object;
// returnValue now contains the string returned from the server.
}
});
}
Java Testing Tips
HotSwapping Java classes
- Do an Ant build.
- In IntelliJ, do Build->Make Project. This gets IntelliJ's build system primed.
- Start up Tomcat, and use the webapp so that the class you want to change is loaded (the line breakpoint icon will show a check in the left hand column once it's been loaded).
- Edit the class.
- In IntelliJ, do Build->Compile <MyClass>.java.
- If you get a dialog, tell the IDE to HotSwap and always do that in the future.
- Make your code run again. Marvel at how fast it was.
Deprecated Components
Deprecated Components
Older versions of LabKey supported components that have been deprecated. Developers creating new modules or updating existing modules should remove dependencies on these deprecated components:- PostgreSQL 8.1, 8.2
- Microsoft SQL Server 2000, 2005, 2008 (pre-R2)
- Beehive PageFlows (ViewController, @Jpf.Action, @Jpf.Controller)
- Struts (FormData, FormFile, StrutsAttachmentFile)
- Groovy (.gm files, GroovyView, GroovyExpression, BooleanExpression)
- ACL-based permissions
Modules: Folder Types
- The name of the folder type.
- Description of the folder type.
- A list of tabs (provide a single tab for a non-tabbed folder).
- A list of the modules enabled by default for this folder.
- Whether the menu bar is enabled by default. If this is true, when the folderType is activated in a project (but not a subfolder), the menu bar will be enabled.
- The name and caption for the tab.
- An ordered list of 'required webparts'. These webparts cannot be removed.
- An ordered list of 'preferred webparts'. The webparts can be removed.
- A list of permissions required for this tab to be visible (ie. READ, INSERT, UPDATE, DELETE, ADMIN)
- A list of selectors. These selectors are used to test whether this tab should be highlighted as the active tab or not. Selectors are described in greater detail below.
Define a Custom Folder Type
Module LocationThe easiest way to define a custom folder type is via a module, which is just a directory containing various kinds of resource files. Modules can be placed in the standard modules/ directory, or in the externalModules/ directory. By default, the externalModules/ directory is a peer to the modules/ directory.To tell LabKey Server to look for external modules in a different directory, simply add the following to your VM parameters:-Dlabkey.externalModulesDir="C:/externalModules"MyModule
└───resources
└───folderTypes
MyModule
└───resources
└───folderTypes
myType1.foldertype.xml
myType2.foldertype.xml
myType3.foldertype.xml
Example #1
The full XML schema (XSD) for folder type XML is documented and available for download. However, the complexity of XML schema files means it is often simpler to start from an example. The following XML defines a simple folder type:<folderType xmlns="http://labkey.org/data/xml/folderType">
<name>My XML-defined Folder Type</name>
<description>A demonstration of defining a folder type in an XML file</description>
<requiredWebParts>
<webPart>
<name>Query</name>
<location>body</location>
<property name="title" value="A customized web part" />
<property name="schemaName" value="study" />
<property name="queryName" value="SpecimenDetail" />
</webPart>
<webPart>
<name>Data Pipeline</name>
<location>body</location>
</webPart>
<webPart>
<name>Experiment Runs</name>
<location>body</location>
</webPart>
</requiredWebParts>
<preferredWebParts>
<webPart>
<name>Sample Sets</name>
<location>body</location>
</webPart>
<webPart>
<name>Run Groups</name>
<location>right</location>
</webPart>
</preferredWebParts>
<modules>
<moduleName>Experiment</moduleName>
<moduleName>Pipeline</moduleName>
</modules>
<defaultModule>Experiment</defaultModule>
</folderType>
<requiredWebParts>
<webPart>
<name>Query</name>
<modules>
<moduleName>Experiment</moduleName>
<moduleName>Pipeline</moduleName>
</modules>
<defaultModule>Experiment</defaultModule>
Example #2 - Tabs
This is another example of an XML file defining a folder type:<folderType xmlns="http://labkey.org/data/xml/folderType" xmlns:mp="http://labkey.org/moduleProperties/xml/">
<name>Laboratory Folder</name>
<description>The default folder layout for basic lab management</description>
<folderTabs>
<folderTab>
<name>overview</name>
<caption>Overview</caption>
<selectors>
</selectors>
<requiredWebParts>
</requiredWebParts>
<preferredWebParts>
<webPart>
<name>Laboratory Home</name>
<location>body</location>
</webPart>
<webPart>
<name>Lab Tools</name>
<location>right</location>
</webPart>
</preferredWebParts>
</folderTab>
<folderTab>
<name>workbooks</name>
<caption>Workbooks</caption>
<selectors>
</selectors>
<requiredWebParts>
</requiredWebParts>
<preferredWebParts>
<webPart>
<name>Workbooks</name>
<location>body</location>
</webPart>
<webPart>
<name>Lab Tools</name>
<location>right</location>
</webPart>
</preferredWebParts>
</folderTab>
<folderTab>
<name>data</name>
<caption>Data</caption>
<selectors>
<selector>
<controller>assay</controller>
</selector>
<selector>
<view>importData</view>
</selector>
<selector>
<view>executeQuery</view>
</selector>
</selectors>
<requiredWebParts>
</requiredWebParts>
<preferredWebParts>
<webPart>
<name>Data Views</name>
<location>body</location>
</webPart>
<webPart>
<name>Lab Tools</name>
<location>right</location>
</webPart>
</preferredWebParts>
</folderTab>
<folderTab>
<name>settings</name>
<caption>Settings</caption>
<selectors>
<selector>
<view>labSettings</view>
</selector>
</selectors>
<requiredWebParts>
</requiredWebParts>
<preferredWebParts>
<webPart>
<name>Lab Settings</name>
<location>body</location>
</webPart>
<webPart>
<name>Lab Tools</name>
<location>right</location>
</webPart>
</preferredWebParts>
<permissions>
<permission>org.labkey.api.security.permissions.AdminPermission</permission>
</permissions>
</folderTab>
</folderTabs>
<modules>
<moduleName>Laboratory</moduleName>
</modules>
<menubarEnabled>true</menubarEnabled>
</folderType>
- If there is 'pageId' param on the URL that matches a tab's name, this tab is selected. This most commonly occurs after directly clicking a tab.
- If no URL param is present, the tabs are iterated from left to right, checking the selectors provided by each tab. If any one of the selectors from a tab matches, that tab is selected. The first tab with a matching selector is used, even if more than 1 tab would have a match.
- If none of the above are true, the left-most tab is selected
- View: This string will be matched against the viewName from the current URL (ie. 'page', from the current URL). If they are equal, the tab will be selected.
- Controller: This string will be matched against the controller from the current URL (ie. 'wiki', from the current URL). If they are equal, the tab will be selected.
- Regex: This is a regular expression that must match against the full URL. If it matches against the entire URL, the tab will be selected.
Modules: Query Metadata
Examples
See the Examples section of the main query metadata topic.The sample below adds table- and column-level metadata to a SQL query.<query xmlns="http://labkey.org/data/xml/query">
<metadata>
<tables xmlns="http://labkey.org/data/xml">
<table tableName="ResultsSummary" tableDbType="NOT_IN_DB">
<columns>
<column columnName="Protocol">
<fk>
<fkColumnName>LSID</fkColumnName>
<fkTable>Protocols</fkTable>
<fkDbSchema>exp</fkDbSchema>
</fk>
</column>
<column columnName="Formulation">
<fk>
<fkColumnName>RowId</fkColumnName>
<fkTable>Materials</fkTable>
<fkDbSchema>exp</fkDbSchema>
</fk>
</column>
<column columnName="DM">
<formatString>####.#</formatString>
</column>
<column columnName="wk1">
<columnTitle>1 wk</columnTitle>
<formatString>####.#</formatString>
</column>
<column columnName="wk2">
<columnTitle>2 wk</columnTitle>
<formatString>####.###</formatString>
</column>
</columns>
</table>
</tables>
</metadata>
</query>
Metadata Overrides
Metadata is applied in the following order:- JDBC driver-reported metadata.
- Module schemas/<schema>.xml metadata.
- Module Java code creates UserSchema and FilteredTableInfo.
- Module queries/<schema>/<query>.query.xml metadata.
- First .query.xml found in the active set of modules in the container.
- User-override query metadata within LabKey database, specified through the Query Schema Browser.
- First metadata override found by searching up container hierarchy and Shared container.
- For LABKEY.QueryWebPart, optional metadata config parameter.
Related Topics
Modules: Report Metadata
Example Report
Suppose you have a file-based R report on a dataset called "Physical Exam". The R report (MyRReport.r) is packaged as a module with the following directory structure.externalModules
TestModule
queries
reports
schemas
study
Physical Exam
MyRReport.r
Report Metadata
To add metadata to the report, create a file named MyRReport.report.xml in the "Physical Exam" directory:externalModules
TestModule
queries
reports
schemas
study
Physical Exam
MyRReport.r
MyRReport.report.xml
<?xml version="1.0" encoding="UTF-8" ?>
<ReportDescriptor>
<label>My R Report</label>
<description>A file-based R report.</description>
<category>Reports</category>
<hidden>true</hidden>
</ReportDescriptor>
Modules: Custom Footer
mymodule
resources
views
_footer.html
Images and CCS Files
Associated images and CSS files can be located in the same module, as follows:mymodule
resources
web
mymodule
myimage.png
Example
The following _footer.html file references myimage.png.<p align="center">
<img src="<%=contextPath%>/customfooter/myimage.png"/> This is the Footer Text!
</p>
Choosing Between Multiple Footers
If _footer.html files are contributed by multiple modules, you can select which footer to display from the Admin Console. Go to Admin > Site > Admin Console. Click Configure Footer. The dropdown list is populated by footers residing in modules deployed on the server (including both enabled and un-enabled modules).
The dropdown list is populated by footers residing in modules deployed on the server (including both enabled and un-enabled modules).
- Core will show the standard LabKey footer "Powered by LabKey".
- Default will display the footer with the highest priority, where priority is determined by module dependency order. If module A depends on module B, then the footer in A has higher priority. Note that only modules that are enabled in at least one folder will provide a footer to the priority ranking process.
Modules: SQL Scripts
SQL Script Manager
You must name your SQL scripts correctly and update your module versions appropriately, otherwise your scripts might not run at all, scripts might get skipped, or scripts might run in the wrong order. The LabKey SQL Script Manager gets called when a new version of a module gets installed. Specifically, a module gets updated at startup time if (and only if) the version number listed for the module in the database is less than the current version in the code. The module version in the database is stored in core.Modules; the module version in code is returned by the getVersion() method in each Module class (Java module) or listed in version.properties (file-based module).Rule #1: The module version must be bumped to get any scripts to run.When a module is upgraded, the SQL Script Manager automatically runs the appropriate scripts to upgrade to the new schema version. It determines which scripts to run based on the version information encoded in the script name. The scripts are named using the following convention: <dBschemaName>-<fromVersion #.00>-<toVersion #.00>.sqlRule #2: Use the correct format when naming your scripts; anything else will get ignored.Use dashes, not underscores. Use two (or three, if required) decimal places for version numbers (0.61, 1.00, 12.10). We support three decimal places for very active modules, those that need more than 10 incremental scripts per point release. But most modules should use two decimal places.Some examples:- foo-0.00-1.00.sql: Upgrades foo schema from version 0.00 to 1.00
- foo-1.00-1.10.sql: Upgrades foo schema from version 1.00 to 1.10
- foo-1.10-1.20.sql: Upgrades foo schema from version 1.10 to 1.20
- foo-0.00-1.20.sql: Upgrades foo schema from version 0.00 to 1.20
- Determine installed module version number ("old") and new module version number ("new").
- Find all scripts in the directory that start at or above "old" and end at or below "new". Eliminate any scripts that have already been run on this database (see the core.SqlScripts table).
- Of these scripts, find the script(s) with the lowest "from" version. If there's just a single script with this "from" version, pick it. If there are more than one, pick the script with the highest "to" version.
- Run that script. Now the schema has been updated to the "to" version indicated in the script just run.
- Determine if more scripts need to be run. To do this, treat the "to" version of the script just run as the currently installed version.
- Repeat all the steps above (create list of scripts in the new range, eliminate previously run scripts, choose the script with the lowest starting point having the greatest range, and run it) until there are no more scripts left.
| Installed Module Version | New Module Version | Script(s) Run |
|---|---|---|
| 0.00 (not installed) | 1.10 | foo-0.00-1.00.sql, foo-1.00-1.10.sql |
| 0.00 (not installed) | 1.20 | foo-0.00-1.20.sql |
| 1.00 | 1.20 | foo-1.00-1.10.sql, foo-1.10-1.20.sql |
| 1.10 | 1.20 | foo-1.10-1.20.sql |
| 1.11 | 1.20 | None of these scripts |
- Finalize and test your script contents.
- Do an svn update to get current on all files. This ensures that no one else has bumped the version or checked in an incremental script with the same name.
- Find the current version number returned by the FooModule getVersion() method. Let's say it's 1.02.
- Name your script "foo-1.02-1.03.sql". (Incrementing by 0.01 gives you room to get multiple schema changes propagated and tested during the development period between major releases.)
- Bump the version number returned by FooModule.getVersion() to 1.03.
- Build, test, and commit your changes.
Hints and Advanced Topics
- Modules are upgraded in dependency order, which allows schemas to safely depend on each other.
- Modules can (optionally) include two special scripts for each schema: <schema>-create.sql and <schema>-drop.sql. The drop script is run before all module upgrades and the create script is run after that schema's scripts are run. The primary purpose is to create and drop SQL views in the schema. The special scripts are needed because some databases don't allow modifying tables that are used in views. So LabKey drops all views, modifies the schema, and re-creates all views on every upgrade.
- Java upgrade code. Some schema upgrades require code. One option is to implement and register a class in your module that implements UpgradeCode and invoke its methods from inside a script via the core.executeJavaUpgradeCode stored procedure. This works well for self-contained code that assumes a particular schema structure; the code is run once at exactly the right point in your upgrade sequence.
- After schema update. Another option for running Java code is to call it from the Module afterUpdate() method. This can be useful if the upgrade code needs to call library methods that change based on the current schema. Be very careful here; the schema could be in a completely unknown state (if the server hasn't upgraded in a while then your code could execute after two years of future upgrade scripts have run).
- ant bootstrap. On a developer machine: shut down your server, run "ant bootstrap", and restart your server to initiate a full bootstrap on your currently selected database server. This is a great way to test SQL scripts on a clean install. Use "ant pick_pg" and "ant pick_mssql" to test against the other database server.
- The Admin Console provides other helpful tools. The "Sql Scripts" link shows all scripts that have run and those that have not run on the current server. From there, you can choose to "Consolidate Scripts" (e.g., rolling up incremental scripts into version upgrade scripts or creating bootstrap scripts, <schema>-0.00-#.00.sql). While viewing a script you have the option to "Reorder" the script, which attempts to parse and reorder all the statements to group all modifications to each table together. This can help streamline a script (making redundant or unnecessary statements more obvious), but is recommended only for advanced users.
- In addition to these scripts, you will need to create a schema XML file. This file is located in the /scripts folder of your module. There is one XML file per schema. This file can be auto-generated for an existing schema. To get an updated XML file for an existing schema, go to the Admin Console then pick 'Check Database'. There will be a menu to choose the schema and download the XML. If you would like to download an XML file for a schema not yet visible to labkey, you can use a URL along these lines directly: http://localhost:8080/labkey/admin/getSchemaXmlDoc.view?dbSchema=<yourSchemaName>. Simply replace the domain name & port with the correct values for your server. Also put the name of your schema after 'dbSchema='. Note: Both the schema XML file name and 'dbSchema=' value are case-sensitive. They must match the database schema name explicitly.
- LabKey offers automated tests that will compare the contents of your schema XML file with the actual tables present in the DB. To run this test, visit a URL similar to: http://localhost:8080/labkey/junit/begin.view?, but substitute the correct domain name and port. Depending on your server configuration, you may also need to omit "/labkey" if labkey is run as the root webapp. This page should give a list of all Junit test. Run the test called "org.labkey.core.admin.test.SchemaXMLTestCase".
- Schema delete. When developing a new module, schemas can change rapidly. During initial development, it may be useful to completely uninstall / reinstall a module in order to rebuild the schema from scratch, rather than make changes via a large number of incremental scripts. Uninstalling a module requires several steps: drop the schema, delete the entry in the core.Modules table, delete all the associated rows in the core.SqlScripts table. The "Module Details" page (from the Admin Console) provides a quick way to uninstall a module; when your server is restarted, the module will be reinstalled and the latest scripts run. Use extreme caution… deleting a schema or module should only be done on development machines. Also note that while this is useful for development, see warnings above about editing scripts once checked into subversion and/or otherwise made available to other instances of LabKey.
Script Conventions
The conventions below are designed to help everyone write better scripts. They 1) allow developers to review & test each other's scripts and 2) produce schema that can be changed easily in the future. The conventions have been developed while building, deploying, and changing production LabKey installations over the last eight years; we've learned some lessons along the way.Databases & Schemas
Most modules support both PostgreSQL and Microsoft SQL Server. LabKey Server uses a single primary database (typically named "labkey") divided into 20 - 30 "schemas" that provide separate namespaces, usually one per module. Note that, in the past, SQL Server used the term "owner" instead of "schema," but that term is being retired.Capitalization
SQL keywords should be in all caps. This includes SQL commands (SELECT, CREATE TABLE, INSERT), type names (INT, VARCHAR), and modifiers (DEFAULT, NOT NULL).Identifiers such as table, view, and column names are always initial cap camel case. For example, ProtInfoSources, IonPercent, ZScore, and RunId. Note that we append 'Id' (not 'ID') to identity column names.We use a single underscore to separate individual identifiers in compound names. For example, a foreign key constraint might be named 'FK_BioSource_Material'. More on this below.Constraints & Indexes
Do not use the PRIMARY KEY modifier on a column definition to define a primary key. Do not use the FOREIGN KEY modifier on a column definition to define a foreign key. Doing either will cause the database to create a random name that will make it very difficult to drop or change the index in the future. Instead, explicitly declare all primary and foreign keys as table constraints after defining all the columns. The SQL Script Manager will enforce this convention.- Primary Keys should be named 'PK_<TableName>'
- Foreign Keys should be named 'FK_<TableName>_<RefTableName>'. If this is ambiguous (multiple foreign keys between the same two tables), append the column name as well
- Unique Constraints should be named 'UQ_<TableName>_<ColumnName>'
- Normal Indexes should be named 'IX_<TableName>_<ColumnName>'
- Defaults are also implemented as constraints in some databases, and should be named 'DF_<TableName>_<ColumnName>'
Keep Your SQL as Database-Independent as Possible
You may prefer using PostgreSQL over SQL Server (or vice versa), but don't forget about the other database… write your scripts to work with both databases and you'll save yourself many headaches. Test your scripts on both databases.Statement Endings
Every statement should end with a semicolon, on both PostgreSQL and SQL Server. In older versions of SQL Server, "GO" statements needed to be interjected frequently within SQL scripts. They are rarely needed now, except in a few isolated cases:- After creating a new user-defined type (sp_addtype), which is rare
- Before and after a stored procedure definition; SQL Server requires each stored procedure definition to be executed in its own block
- After a DROP and re-CREATE
- After an ALTER statement, if the altered object is referenced later in the scripts
Scripting from SQL Server
It is often convenient to create SQL Server objects or data via visual tools first, and then have SQL Server generate the correct CREATE, INSERT, etc scripts. This is fine; however be aware that the script will have a "USE database name" statement at the top. Be sure to remove this before committing your upgrade script, as the database name in other environments is entirely arbitrary.Related Topics
Modules: Database Transition Scripts
Generate a schema
You can generate a basic version of the schema file for an existing schema by navigating to a magic URL:http://<server>/labkey/admin/getSchemaXmlDoc.view?dbSchema=<schema-name>
Store schema transition scripts
Schema transition scripts should live in the schemas/dbscripts/<db-type>/ directory of your module. Currently, the following database types are supported:| Database Type | Directory |
|---|---|
| PostgreSQL | schemas/dbscripts/postgresql/ |
| Microsoft SQL Server | schemas/dbscripts/sqlserver/ |
externalModules/resources/schemas/dbscripts/postgresql/ReportDemo-0.0-1.0.sql
externalModules/resources/schemas/dbscripts/postgresql/ReportDemo-1.0-1.1.sql
Related Topics
See Modules: SQL Scripts, which describes these files in detail.Modules: Domain Templates
- a name
- a set of columns
- an optional set of indices (to add a uniqueness constraint)
- an optional initial data file to import upon creation
- domain specific options (e.g, for SampleSet, the list of columns that make the Name column unique.)
<templates
xmlns="http://labkey.org/data/xml/domainTemplate"
xmlns:dat="http://labkey.org/data/xml"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<template xsi:type="ListTemplateType">
<table tableName="Category" tableDbType="NOT_IN_DB" hidden="true">
<dat:columns>
<dat:column columnName="category" mandatory="true">
<dat:datatype>varchar</dat:datatype>
<dat:scale>50</dat:scale>
</dat:column>
</dat:columns>
</table>
<initialData>
<file>/data/category.tsv</file>
</initialData>
<options>
<keyCol>category</keyCol>
</options>
</template>
</templates>
LABKEY.Domain.create({
domainGroup: "todolist",
importData: false
});LABKEY.Domain.create({
domainGroup: "todolist",
domainTemplate: "Category",
importData: false
});LABKEY.Domain.create({
domainGroup: "biologics",
domainTemplate: "CellLine",
domainKind: "SampleSet",
createDomain: false,
importData: true
});Deploy Modules to a Production Server
Related Topics
Upgrade Modules
-Dlabkey.externalModulesDir=/MY/OTHER/DIRECTORY
Main Credits Page
Modules can contribute content to the main credits page on your LabKey Server.
To add a credits page to your module, create a jars.txt file documenting all jars and drop it in the following directory: <YOUR MODULE DIRECTORY>\src\META-INF\<YOUR MODULE NAME>.
The jars.txt file must be written in wiki language and contain a table with appropriate columns. See the following example:
{table}
Filename|Component|Version|Source|License|LabKey Dev|Purpose
annotations.jar|Compiler
annotations|1.0|{link:JetBrains|http://www.jetbrains.com/}|{link:Apache
2.0|http://www.apache.org/licenses/LICENSE-2.0}|adam|Annotations to enable compile-time checking for null antlr-3.1.1.jar|ANTLR|3.1.1|{link:ANTLR|http://www.antlr.org/}|{link:BSD|http://www.antlr.org/license.html}|mbellew|Query
language parsing
axis.jar|Apache
Axis|1.2RC2|{link:Apache|http://ws.apache.org/axis/}|{link:Apache
2.0|http://www.apache.org/licenses/LICENSE-2.0}|jeckels|Web service implementation
{table}
Module Properties Reference
myModule
│ module.properties
└───resources
├───...
├───...
└───...
Name: HelloWorld
ModuleClass: org.labkey.api.module.SimpleModule
Version: 1.0
ModuleClass: org.labkey.issue.IssuesModule
ModuleDependencies: Wiki, Experiment
Label: Issue Tracking Service
Description: The LabKey Issues module provides an issue tracker, a centralized workflow system for tracking issues or tasks across the lifespan of a project. Users can use the issue tracker to assign tasks to themselves or others, and follow the task through the work process from start to completion.
URL: https://www.labkey.org/wiki/home/Documentation/page.view?name=issues
Organization: LabKey
OrganizationURL: https://www.labkey.com/
License: Apache 2.0
LicenseURL: http://www.apache.org/licenses/LICENSE-2.0
Properties Reference
Available properties for modules. Note that property names vary slightly between module.property and module.xml files.| Property Name (in module.xml) | Property Name (in module.properties) | Description |
|---|---|---|
| class | ModuleClass | Main class for the module. For modules without Java code, use org.labkey.api.module.SimpleModule |
| name | Name | The display name for the module. |
| version | Version | The module version. |
| requiredServerVersion | RequiredServerVersionooo | The minimum required version for LabKey Server. |
| moduleDependencies | ModuleDependencies | A comma-delimited list of other module names this module depends upon. This determines module initialization order and controls the order in which SQL scripts run. For example, suppose your module includes a foreign key to a table in the Experiment module. In this case you could declare a dependency on the Experiment module, so that you can be sure that the target table exists before you try to create your foreign key. LabKey Server will give an error if you reference a module that doesn't exist, or if there's a circular dependency, for example, if ModuleA depends on ModuleB, which itself depends on ModuleA. |
| supportedDatabases | SupportedDatabases | Add this property to indicate that your module runs only on a particular database. Possible values: "pgsql" or "mssql". |
| label | Label | One line description of module's purpose (display capitalized and without a period at the end). |
| description | Description | Multi-line description of module. |
| url | URL | The homepage URL for additional information on the module. |
| author | Author | Comma separated list of names and, optionally, email addresses: e.g. "Adam Rauch <adamr@labkey.com>, Kevin Krouse" |
| maintainer | Maintainer | Comma separated list of names and, optionally, email addresses: e.g. "Adam Rauch <adamr@labkey.com>, Kevin Krouse" |
| organization | Organization | The organization responsible for the module. |
| organizationURL | OrganizationURL | The organization's URL/homepage. |
| license | License | License name: e.g. "Apache 2.0", "GPL-2.0", "MIT" |
| licenseURL | LicenseURL | License URL: e.g. "http://www.apache.org/licenses/LICENSE-2.0" |
| vcsRevision | VcsRevision | This value is set internally by the build, and does not need to be provided by the developer in module.properties. The SVN revision number of the module. This will be displayed next to the module in the site admin console. |
| vcsUrl | VcsURL | This value is set internally by the build, and does not need to be provided by the developer in module.properties. The URL to the SVN server that manages the source code for this module. This will be displayed next to the module in the site admin console. |
| buildOS | BuildOS | This value is set internally by the build, and does not need to be provided by the developer in module.properties. The operating system upon which the module was built. This will be displayed next to the module in the site admin console. |
| buildPath | BuildPath | This value is set internally by the build, and does not need to be provided by the developer in module.properties. The file path in which the module was built. This will be displayed next to the module in the site admin console. |
| buildTime | BuildTime | This value is set internally by the build, and does not need to be provided by the developer in module.properties. The date and time the module was built. This will be displayed next to the module in the site admin console. |
| buildType | BuildType | Possible values are "Development" or "Production". "Development" modules will not deploy on a production machine. To build modules destined for a production server, run 'ant production', or add the following to your module.properties file: 'BuildType=Production'. |
| buildUser | BuildUser | This value is set internally by the build, and does not need to be provided by the developer in module.properties. The name of the user that built the module. This will be displayed next to the module in the site admin console. |
| sourcePath | SourcePath | This value is set internally by the build, and does not need to be provided by the developer in module.properties. The location of the module source code. |
| resourcePath | ResourcePath | This value is set internally by the build, and does not need to be provided by the developer in module.properties. |
| buildNumber | BuildNumber | This value is set internally by the build, and does not need to be provided by the developer in module.properties. The build number. |
| enlistmentId | EnlistmentId | This value is set internally by the build, and does not need to be provided by the developer in module.properties. Used to determine whether the module was built on the current server. |
Properties Surfaced in the Admin Console
Module properties are surfaced in the user interface at Admin > Site > Admin Console, under the heading Module Information. Click an individual module name to see its properties. If you having problems loading/reloading a module, check the properties Enlistment ID and Source Path. When the server is running in devMode, these properties are displayed in green text if the values in module.xml match the values found the on the server; they are displayed in the red text if there is a mismatch. The properties for deployed modules are available in the table core.Modules, where they can be accessed by the client API.
The properties for deployed modules are available in the table core.Modules, where they can be accessed by the client API.
Generation of module.xml
When you run the standard Ant build targets in the open source project, the property/value pairs in module.properties are extracted and used to populate a module.xml file (via string substitution into module.template.xml). The resulting module.xml file is copied to the module's config subdirectory (MODULE_NAME/config/module.xml) and finally packaged into the built .module file. At deployment time, the server loads properties from config/module.xml, not module.properties (which the server ignores). Note that modules that contain Java code must be built using the standard build targets in the open source project.<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd">
<bean id="moduleBean" class="org.labkey.api.module.SimpleModule">
<property name="name" value="mymodule"/>
<property name="version" value="0.0"/>
<property name="requiredServerVersion" value="0.0"/>
<property name="moduleDependencies" value="Wiki"/>
<property name="label" value="My Module"/>
<property name="description">
<value><![CDATA[My module helps users solves problems related to...]]></value>
</property>
<property name="url" value="https://www.mywebsite.com"/>
<property name="author">
<value><![CDATA[Jane Doe <janedoe@email.com>]]></value>
</property>
<property name="maintainer">
<value><![CDATA[John Doe <johndoe@email.com>]]></value>
</property>
<property name="organization" value="My Software Inc."/>
<property name="organizationUrl" value="https://www.my-software-inc.com/"/>
<property name="license" value="Apache 2.0"/>
<property name="licenseUrl" value="http://www.apache.org/licenses/LICENSE-2.0"/>
</bean>
</beans>
Related Topics
Common Development Tasks
- Tutorial Video: Building Reports and Custom User Interfaces
- Custom Button Bars
- Modules: Folder Types
- Trigger Scripts
- Modules: SQL Scripts
- LabKey URLs and Context Paths
- Modules: Report Metadata
- Modules: Query Metadata
- URL Actions
- How To Find schemaName, queryName & viewName
- HTML Encoding
- Deploy Modules to a Production Server
- Upgrade Modules
- Study Data Model
- LabKey/Rserve Setup Guide
- Main Credits Page
Trigger Scripts
Trigger Scripts
Trigger scripts are attached to a database table or query. Trigger scripts are different from "transformation scripts", which are attached to an assay design and are intended for transformation/validation of incoming assay data.Trigger scripts can be configured to run on a per-row basis whenever there is a insert/update/delete event on the table (with a few exceptions). They are called on a per-HTTP request basis (or in other contexts like ETLs), either before or after the request is executed. Typical uses for trigger scripts are (1) to alter incoming data or (2) to set off cascading changes in other tables.- When importing Sample Sets.
- When importing a study or folder archive.
- When bulk importing datasets.
- Trigger Script Location
- Order of Execution
- Shared Scripts / Libraries
- Script Execution
- Functions
- Parameters and Return Values
- Sample Script #1
- Sample Script #2
Trigger Script Location
The trigger script attached to a particular table needs be placed in the folder associated with the table's schema. The script must be named after its associated table or query. For example, a QUERY_NAME.js script would be placed in:Lists:
MODULE_NAME/queries/lists/QUERY_NAME.js
Data Classes:
MODULE_NAME/queries/exp.data/QUERY_NAME.js
Study Datasets:
MODULE_NAME/queries/study/QUERY_NAME.js
Custom Schemas:
MODULE_NAME/queries/SCHEMA_NAME/QUERY_NAME.js
Order of Execution
When multiple trigger scripts are defined in different modules for the same table/dataset, they will be executed in reverse module dependency order. For example, assume module A has a dependency on module B and both modules have trigger scripts defined for myTable. When a row is inserted into myTable, module A's trigger script will fire first, and then module B's trigger script will fire.Shared Scripts / Libraries
Trigger scripts can pull in functionality from other shared libraries.Shared libraries should be located in a LabKey module in the following directory:MODULE_NAME/scripts/MODULE_NAME/SCRIPT_FILE.js
var sampleVar = "value";
function sampleFunc(arg)
{
return arg;
}
var hiddenVar = "hidden";
function hiddenFunc(arg)
{
throw new Error("Function shouldn't be exposed");
}
exports.sampleFunc = sampleFunc;
exports.sampleVar = sampleVar;
var shared = require("myModule/shared");
function init() {
shared.sampleFunc("hello");
}
- LABKEY.ActionURL
- LABKEY.Ajax
- LABKEY.Filter
- LABKEY.Message
- LABKEY.Query
- LABKEY.Security
- LABKEY.SecurityPolicy
- LABKEY.Utils (only non-browser related functions)
var LABKEY = require("labkey");
function sendEmail()
{
var userEmail = "messagetest@validation.test";
// need a user to send email to/from
LABKEY.Security.createNewUser({
email: userEmail,
sendEmail: false,
containerPath: "/Shared/_junit"
});
var msg = LABKEY.Message.createMsgContent(LABKEY.Message.msgType.plain, "Hello World");
var recipient = LABKEY.Message.createRecipient(LABKEY.Message.recipientType.to, userEmail);
var response = LABKEY.Message.sendMessage({
msgFrom:userEmail,
msgRecipients:[recipient],
msgContent:[msg]
});
}
var console = require("console");
console.log("** evaluating shared.js script");
Script Execution
The script will be evaluated once per request. In other words, any state you collect will disappear after the request is complete.If your script runs for more than 60 seconds, the script will be terminated with an error indicating that it timed out.Functions
- init(event, errors)
- complete(event, errors)
- The init and complete functions are called once before or after insert/update/delete for a set of rows.
- The event parameter is one of "insert", "update" or "delete".
- The errors object for the init and complete functions is an array of error objects.
- beforeInsert(row, errors)
- beforeUpdate(row, oldRow, errors)
- beforeDelete(row, errors)
- afterInsert(row, errors)
- afterUpdate(row, oldRow, errors)
- afterDelete(row, errors)
- Use these functions to transform and/or validate data at the row or field level before or after insert/update/delete.
Parameters and Return Values
- row - The row that is being inserted, updated or deleted.
- row.FIELD - A field in the row being inserted, updated, or deleted. Modifiable by the script.
- errors - During the update/insert/delete process, you may add a message to this parameter to indicate that a field or an entire row has an error. Can be an array of errors. When any error messages are added to the error object, the insert/update/delete will be canceled.
- errors.FIELD - The field that has the error. Can be an array to indicate that many fields have errors.
- errors[null] - If you assign an error message to the null property of error, the message is returned for the entire row.
- return false - Returning false from any of these functions will cancel the insert/update/delete with a generic error message for the row.
function beforeInsert(row, errors)
{
console.log("beforeInsert got triggered");
console.log("row is: " + row);
row.Email = "example@example.com";
console.log("edited row is: " + row);
}
Sample Scripts #1
The sample module, testtriggers.module, shows how to attach a trigger script to a table/query.To run the sample:- Download the .module file: testtriggers.module.
- Copy the .module file to the diretory LabKey Server/externalModules/. (For developers who have downloaded the src code and are running the server --> stop the server --> put this .module file under <src code>/build/deploy/externalModules (create externalModules dir if you don't have it) --> re-start the server)
- Turn on the JavaScript Console: Admin -> Developer Links -> Server JavaScript Console.
- Enable the module in a folder.
- Navigate to the the module-enabled folder.
- Go to the Items table: Admin > Developer Links > Schema Browser > testtrigger > Items > View Data > Insert New.
- Insert a new record.
- On the server's internal JavaScript console (Admin > Developer Links > Server JavaScript Console), monitor which trigger scripts are run.
- Repeat by editing or deleting records.
Sample Scripts #2
Other sample scripts are available in the module "simpletest", which can be downloaded here: simpletest.zip.To add the module, copy simpletest/ into <LabKey_Home>/externalModules/ and then enable the module in your project.The following sample scripts are available:- simpletest/scripts/simpletest/Debug.js - a shared script
- simpletest/scripts/simpletest/ScriptValidationExports.js - a shared script
- simpletest/scripts/validationTest/... - contains many trigger scripts that utilize the shared scripts and the LabKey libraries.
- simpletest/queries/vehicle/colors.js - a largely stand alone trigger script
- simpletest/queries/lists/People.js - a largely stand alone list example
Related Topics
Availability of Server-side Trigger Scripts
Server-side trigger scripts are not available for all LabKey data types and all import pathways. Present availability is summarized below, where import pathways are shown as columns, and data types are shown as rows:
| "Insert New" Button (single record) | "Import Data" button on data grids (TSV / Excel import) | Import via Client APIs | Import via Folder/Study/List/XAR Archive | |
| Lists | yes | yes | yes | yes |
| Datasets | yes | no | yes | no |
| Module/External Schemas | yes | yes | yes | N/A |
| Assay | N/A | no | no | no |
| Sample Set | no | no | no | no |
| DataClass | yes | yes | yes | no |
Script Pipeline: Running R and Other Scripts in Sequence
- Simplify procedures and reduce errors
- Standardize and reproduce analyses
- Track inputs, script versions, and outputs
Set Up
Before you use the script pipeline, confirm that your target script engine is enlisted with LabKey Server. For example, if you intend to use an R script, enlist the R engine as described in the topic Configure Scripting Engines.Tasks
Tasks are defined in a LabKey Server module. They are file-based, so they can be created from scratch, cloned, exported, imported, renamed, and deleted. Tasks declare parameters, inputs, and outputs. Inputs may be files, parameters entered by users or by the API, a query, or a user selected set of rows from a query. Outputs may be files, values, or rows inserted into a table. Also, tasks may call other tasks.Module File Layout
The module directory layout for sequence configuration files (.pipeline.xml), task configuration files (.task.xml), and script files (.r, .pl, etc.) has the following shape. (Note: the layout below follows the pattern for modules as checked into LabKey Server source control. Modules not checked into source control have a somewhat different directoy pattern. For details see Map of Module Files.)<module>
resources
pipeline
pipelines
job1.pipeline.xml
job2.pipeline.xml
job3.pipeline.xml
...
tasks
RScript.task.xml
RScript.r
PerlScript.task.xml
PerlScript.pl
...
File Operation Tasks
Exec Task
An example command line .task.xml file that takes .hk files as input and writes .cms2 files:<task xmlns="http://labkey.org/pipeline/xml" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="ExecTaskType" name="mytask" version="1.0">
<exec>
bullseye -s my.spectra -q ${q}
-o ${output.cms2} ${input.hk}
</exec>
</task>
Script Task
An example task configuration file that calls an R script:<task xmlns="http://labkey.org/pipeline/xml"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:type="ScriptTaskType"
name="generateMatrix" version="0.0">
<description>Generate an expression matrix file (TSV format).</description>
<script file="RScript.r"/>
</task>
Parameters
Parameters, inputs, and outputs can be explicitly declared in the .task.xml file (or in the .pipeline.xml, if it includes an inline task).<task xmlns="http://labkey.org/pipeline/xml"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:type="ScriptTaskType"
name="someTask" version="0.0">
<inputs>
<file name="input.txt" required="true"/>
<text name="param1" required="true"/>
</inputs>
<task xmlns="http://labkey.org/pipeline/xml" name="mytask" version="1.0">
<exec>
bullseye -s my.spectra -q ${q}
-o ${output.cms2} ${input.hk}
</exec>
</task>
Inputs and Outputs
File inputs are identified by file extension. For example, the following configures the task to accept .txt files:<inputs>
<file name="input.txt"/>
</inputs>
- The task name must be unique (no other task with the same name). For example: <task xmlns="http://labkey.org/pipeline/xml" name="myUniqueTaskName">
- An input must be declared, either implicitly or explicitly with XML configuration elements.
- Input and output files must not have the same file extensions. For example, the following is not allowed, because .tsv is declared for both input and output:
<inputs>
<file name="input.tsv"/>
</inputs>
<outputs>
<file name="output.tsv"/> <!-- WRONG - input and output cannot share the same file extension. -->
</outputs>
<inputs>
<file name="input.tsv"/>
<text name="param1" required="true"/>
</inputs>
Implicitly Declared Parameters, Inputs, and Outputs
Implicitly declared parameters, inputs, and outputs are allowed and identified by the dollar sign/curly braces syntax, for example, ${param1}.- Inputs are identified by the pattern: ${input.XXX} where XXX is the desired file extension.
- Outputs are identified by the pattern: ${output.XXX} where XXX is the desired file extension.
- All others patterns are considered parameters: ${fooParam}, ${barParam}
- ${input.txt} - Input files have 'txt' extension.
- ${output.tsv} - Output files have 'tsv' extension.
- ${skip-lines} - An integer indicating how many initial lines to skip.
# reads the input file and prints the contents to stdout
lines = readLines(con="${input.txt}")
# skip-lines parameter. convert to integer if possible
skipLines = as.integer("${skip-lines}")
if (is.na(skipLines)) {
skipLines = 0
}
# lines in the file
lineCount = NROW(lines)
if (skipLines > lineCount) {
cat("start index larger than number of lines")
} else {
# start index
start = skipLines + 1
# print to stdout
cat("(stdout) contents of file: ${input.txt}n")
for (i in start:lineCount) {
cat(sep="", lines[i], "n")
}
# print to ${output.tsv}
f = file(description="${output.tsv}", open="w")
cat(file=f, "# (output) contents of file: ${input.txt}n")
for (i in start:lineCount) {
cat(file=f, sep="", lines[i], "n")
}
flush(con=f)
close(con=f)
}
Assay Database Import Tasks
The built-in task type AssayImportRunTaskType looks for TSV and XSL files that were output by the previous task. If it finds output files, it uses that data to update the database, importing into whatever assay runs tables you configure.An example task sequence file with two tasks: (1) generate a TSV file, (2) import that file to the database: scriptset1-assayimport.pipeline.xml.<pipeline xmlns="http://labkey.org/pipeline/xml"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
name="scriptset1-assayimport" version="0.0">
<!-- The description text is shown in the Import Data selection menu. -->
<description>Sequence: Call generateMatrix.r to generate a tsv file,
import this tsv file into the database. </description>
<tasks>
<!-- Task #1: Call the task generateMatrix (= the script generateMatrix.r) in myModule -->
<taskref ref="myModule:task:generateMatrix"/>
<!-- Task #2: Import the output/results of the script into the database -->
<task xsi:type="AssayImportRunTaskType" >
<!-- Target an assay by provider and protocol, -->
<!-- where providerName is the assay type -->
<!-- and protocolName is the assay design -->
<!-- <providerName>General</providerName> -->
<!-- <protocolName>MyAssayDesign</protocolName> -->
</task>
</tasks>
</pipeline>
Pipeline Task Sequences
Pipelines consist of a configured sequence of tasks. A "job" is a pipeline instance with specific input and outputs files and parameters. Task sequences are defined in files with the extension ".pipeline.xml".Note the task references, for example "myModule:task:generateMatrix". This is of the form <ModuleName>:task:<TaskName>, where <TaskName> refers to a task config file at /pipeline/tasks/<TaskName>.task.xmlAn example pipeline file: job1.pipeline.xml, which runs two tasks:<pipeline xmlns="http://labkey.org/pipeline/xml"
name="job1" version="0.0">
<description> (1) Normalize and (2) generate an expression matrix file.</description>
<tasks>
<taskref ref="myModule:task:normalize"/>
<taskref ref="myModule:task:generateMatrix"/>
</tasks>
</pipeline>
Invoking Pipeline Sequences from the File Browser
Configured pipeline jobs/sequences can be invoked from the Pipeline File browser by selecting an input file(s) and clicking Import Data. The list of available pipeline jobs is populated by the .pipeline.xml files.
Overriding Parameters
The default UI provides a panel for overriding default parameters for the job.<?xml version="1.0" encoding="UTF-8"?>
<bioml>
<!-- Override default parameters here. -->
<note type="input" label="pipeline, protocol name">geneExpression1</note>
<note type="input" label="pipeline, email address">steveh@labkey.com</note>
</bioml>
Providing User Interface
You can override the default user interface by setting <analyzeURL> in the .pipeline.xml file.<pipeline xmlns="http://labkey.org/pipeline/xml"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
name="geneExpMatrix-assayimport" version="0.0">
<description>Expression Matrix: Process with R, Import Results</description>
<!-- Overrides the default UI, user will see myPage.view instead. -->
<analyzeURL>/pipelineSample/myPage.view</analyzeURL>
<tasks>
...
</tasks>
</pipeline>
Invoking from JavaScript
Example JavaScript that invokes a pipeline job through LABKEY.Pipeline.startAnalysis().Note the value of taskId: 'myModule:pipeline:generateMatrix'. This is of the form <ModuleName>:pipeline:<TaskName>, referencing a file at /pipeline/pipelines/<PipelineName>.pipeline.xmlfunction startAnalysis()
{
var protocolName = document.getElementById("protocolNameInput").value;
if (!protocolName) {
alert("Protocol name is required");
return;
}
var skipLines = document.getElementById("skipLinesInput").value;
if (skipLines < 0) {
alert("Skip lines >= 0 required");
return;
}
LABKEY.Pipeline.startAnalysis({
taskId: "myModule:pipeline:generateMatrix",
path: path,
files: files,
protocolName: protocolName,
protocolDescription: "",
jsonParameters: {
'skip-lines': skipLines
},
saveProtocol: false,
success: function() {
window.location = LABKEY.ActionURL.buildURL("pipeline-status", "showList.view")
}
});
}
Execution Environment
When a pipeline job is run, a job directory is created named after the job type and a another child directory is created inside named after the protocol, for example, "create-matrix-job/protocol2". Log and output files are written to this child directory.Also, while a job is running, a work directory is created, for example, "run1.work". This includes:- Parameter replaced script.
- Context 'task info' file with server URL, list of input files, etc.
Other Resources
- LABKEY.Pipeline.html
- Pipeline XML Config Reference
- Example script pipelines from the LabKey Server automated tests. Download these .module files and deploy them to a production server. Copy these files to LABKEY_HOME/externalModules (on a Windows system, this is typically at C:\Program Files(x86)\LabKey Server\externalModules) and restart the server. Once deployed, enable these modules in your folder.
- pipelinetest.module (The source files for this module can be found at: https://cpas:cpas@hedgehog.fhcrc.org/tor/stedi/trunk/server/test/modules/pipelinetest )
- pipelinetest2.module (The source files for this module can be found at: https://cpas:cpas@hedgehog.fhcrc.org/tor/stedi/trunk/server/test/modules/pipelinetest2 )
LabKey URLs
https://example.com/labkey/home/study-begin.view
<protocol>://<domain>/<contextpath>/<containerpath>/<controller>-<action>
| URL Part | Example | Description |
|---|---|---|
| protocol | https:// | Supported protocols are http or https (for secure sockets). |
| domain | www.labkey.org | Your server's host domain name. |
| contextpath | labkey | This is the root of the LabKey web application on the server, and is accessible by developers if they need to build URLs that include it. In the JavaScript API library, see LABKEY.ActionURL.getContextPath(). In Java module code, this is accessible from AppProps.getInstance().getContextPath(). |
| containerpath | home/myproject/myfolder | This may consist of multiple parts if the current container is a sub-folder (e.g., “/project/folder/subfolder/”). This helps the LabKey Server know which container the user is working in. The current container information is also available to developers. In the JavaScript API library, see LABKEY.ActionURL.getContainer(). In Java module code, you can get this information from the Container object returned from the getContainer() method on your action base class. (For details on the container hierarchy reflected in the container path, see Site Structure: Best Practices.) |
| controller | study | The term "controller" comes from the Model-View-Controller (MVC) design pattern, where a controller coordinates user interaction with the model (data) as seen through a particular view of that data. The LabKey Server uses the industry-standard Spring framework for its MVC implementation. In the LabKey Server, the name of the controller typically matches the name of the module. The system assumes that the controller name is the same as the module name unless the module has explicitly registered other controllers. |
| action | begin.view | Modules/controllers may expose one or more actions, each of which may do several things. Simple actions may return a read-only view, while more complex actions may return an HTML form and handle the posted data, updating the database as necessary. Actions typically have the extension “.view” or “.post”. |
Setting the Default URL Pattern
As of version 16.1, new server installations use the following URL pattern by default:New URL Pattern<protocol>://<domain>/<contextpath>/<containerpath>/<controller>-<action>
<protocol>://<domain>/<contextpath>/<controller>/<containerpath>/<action>
- https://www.labkey.org/home/Study/demo/study-overview.view? (new pattern, version 16.1 and after)
- https://www.labkey.org/study/home/Study/demo/overview.view? (old pattern, before version 16.1)
Folder/Container-Relative Links
The new URL pattern supports folder-relative links in wikis and static files. For example, a static HTML page in a module can use the following to link to the default page for the current folder/container.<a href="./project-begin.view">Home Page</a>Token Replacement and Context Paths
Token replacement/expansion is applied to html files before they are rendered in the browser. Available tokens include:- contextPath - The token "<%=contextPath%>" will expand to the context root of the labkey server (e.g. "/labkey")
- containerPath - The token "<%=containerPath%>" will expand to the current container (eg. "/MyProject/MyFolder").
- webpartContext - The token <%=webpartContext%> is replaced by a JSON object of the form:
{
wrapperDivId: <String: the unique generated div id for the webpart>,
id: <Number: webpart rowid>,
properties: <JSON: additional properties set on the webpart>
}<img src="<%=contextPath%>/my-image.png" />Build URLs Using the LabKey API
You can build URLs using the LABKEY.ActionURL.buildURL() API.window.location = LABKEY.ActionURL.buildURL("wiki", "source", LABKEY.ActionURL.getContainer(), {name: 'url'});
window.location = LABKEY.ActionURL.buildURL("study", "begin");
window.location = LABKEY.ActionURL.buildURL("study", "begin", "/myproject/mystudyfolder");
URL Parameters
LabKey URLs can also include additional parameters that provide additional instructions to an action. For example, some actions accept a returnUrl parameter. This parameter allows you to tell the action where to forward the user after it is finished.Some parameters are listed on the Web Part Configuration Properties page.URL parameters can be written explicitly as part of an href link, or provided by LabKey APIs.HREF Example:Suppose you want to have a user input content to a list, then see a specific page after saving changes to the list.The following snippet executes an insert action in a specified list ('queryName=lists&schemaName=MyListName'). After clicking the link, the user first sees the appropriate insert page for this list. Once the user has entered changes and pressed "Save," the user is delivered to the returnUrl page ('/MyProject/project-begin.view').<a href="https://www.labkey.org/MyProject/query-insertQueryRow.view?queryName=lists&
schemaName=MyListName&returnUrl=/project/MyProject/begin.view">
Click here to request specimens</a>
window.location = LABKEY.ActionURL.buildURL(
"query",
"insertQueryRow",
LABKEY.ActionURL.getContainer(),
{schemaName: "lists",
queryName: "MyListName",
returnUrl: window.location}
);
- Step 3: R Histogram (Optional) - Creates a report in a LABKEY.WebPart by passing URL parameters to R to draw a histogram.
URL Encoding
Substitution syntax for inserting a field value into a URL is covered in URL Field Property.URL Actions
Customize URLs for actions
You can use a custom URL for an action to redirect a user to a custom page when the user executes the action. You can customize actions that lead to insert, update, grid and details views. To set these URLs, add metadata XML to the table. An example of overriding the updateUrl on a DbUserSchema table:<table tableName="testtable" tableDbType="TABLE">
<updateUrl>/mycontroller/foo.view?rowid=${rowid}</updateUrl>
</table>
- insertUrl - used to control the target of the Insert New (single row) button
- updateUrl - used to control the target of the update link
- deleteUrl - used to control the target of the Delete button
- importUrl - used to control the target of the Import Data (bulk entry) button
- gridUrl - used to control the default grid view of a table
- tableUrl - used to control the target of the details link
Turn off default URL actions
insertUrl, updateUrl, tableUrl, deleteUrl, and importUrl may be set to a blank value to turn off the corresponding UI for a table.For example:<insertUrl />
How To Find schemaName, queryName & viewName
Overview
Many of the view-building APIs make use of data queries (e.g., dataset grid views) on your server. In order reference a particular query, you need to identify its schemaName and queryName. To reference a particular custom view of a query such as a grid view, you will also need to specify the viewName parameter.This section helps you determine which schemaName, queryName and viewName to use to properly identify your data source.N.B. Check the capitalization of the values you use for these three properties; all three properties are case sensitive.Query Schema Browser
You can determine the appropriate form of the schemaName, queryName and viewName parameters by using the Query Schema Browser.To view the Query Schema Browser, go to the upper right corner of the screen and click Admin -> Developer Links -> Schema Browser from the dropdown menus.Schema List
The Query Schema Browser shows the list of schemas (and thus schemaNames) available in this container. Identify the schemaName of interest and move on to finding possible queryNames (see "Query List" section below).Example: The Demo Study container defines the following schemas:- assay
- auditLog
- core
- CustomProteinAnnotations
- CustomProteinAnnotationsWithSequences
- EHR
- exp
- flow
- issues
- mothership
- ms1
- ms2
- Nab
- pipeline
- Samples
- study
Query List
To find the names of the queries associated with a particular schema, click on the schemaName of interest. You will see a list of User-Defined Queries and a list of Built-in Queries and Tables. These are the queryNames you can use with this schemaName in this container.Example. For the Demo Study example, click on the study schema in the Query Schema Browser. (As a shortcut you can visit this URL: https://www.labkey.org/query/home/Study/demo/begin.view?schemaName=study#sbh-ssp-study)You will see a list of User-Defined Queries:- AverageTempPerParticipant
- Physical Exam + AverageTemp
- Physical Exam + TempDelta
- Physical Exam Query
- Cohort
- DataSetColumn
- DataSets
- Demographics
- ELISpotAssay
- FileBasedAssay
- ...etc...
Custom Grid View List
The last (optional) step is to find the appropriate viewName associated with your chosen queryName. To see the custom grids associated with a query, click on the query of interest, and then click [view data]. This will take you to a grid view of the query. Finally, click the Grid Views drop-down menu to see a list of all custom grids (if any) associated with this query.Example. For the Demo Study example, click on the Physical Exam query name on this page. Next, click [view data]. Finally, click the Grid Views drop-down to see all custom grids for the Physical Exam query (a.k.a. dataset). You'll see at least the following query (more may have been added since completion of this document):- Grid View: Physical + Demographics
- schemaName: 'study',
- queryName: 'Physical Exam',
- viewName: 'Grid View: Physical + Demographics'
LabKey/Rserve Setup Guide
- Set Up
- Rserve Machine (RS-MAC): Install Rserve
- Run Rserve Securely
- LabKey Machine (LK-PC): Setup Report and Data Shares
- Rserve Machine (RS-MAC): Connect to Report and Data Shares
- LabKey Machine (LK-PC): Enabling Scripting Using Rserve
- Rserve Machine (RS-MAC): Start Your Rserve Instance
- Client Code Changes
- Running Rserve and Labkey on the Same Machine
- Setting Default R Engines, Local or Remote
- White Listing Functions
- Direct Execution of R Functions - LABKEY.Report.executeFunction
- Troubleshooting
- A remote Rserve server frees up resources on your local machine, which otherwise might be clogged with expensive R processes.
- It provides faster overall results, because there is no need to recreate a new R session for each process.
- There is no need to wait for one process to end to begin another, because LabKey Server can handle multiple connections to Rserve at one time.
Set Up
This document provides instructions for enabling LabKey Server to execute R reports against a remote Rserve instance. Below, the "Rserve machine" refers to the machine running the Rserve instance; "LabKey machine" will refer to the LabKey web server. This document assumes a working knowledge of R. This document also covers required changes to client code to take advantage of the Rserve integration features. Note that Rserve integration is currently only available as an experimental feature that must be enabled on the LabKey machine. See Experimental Features.For illustration purposes a concrete example will be used throughout this setup guide. In particular, we assume a configuration where LabKey Server is running on a Windows PC (called "LK-PC") and the Rserve instance is running on a Mac (called "RS-MAC"). Note that setup instructions will vary depending upon the operating systems of the machines used. Values indicated by colored text are used in multiple places and must be consistent between the two machines.Rserve Machine (RS-MAC): Install Rserve
First step is to install R if you haven’t already. Rserve uses your R installation, so any packages, environments, and libraries you have already installed as part of your R installation are used by Rserve.Information and installation of Rserve can be found here: http://www.rforge.net/Rserve/. There is a lot of good info on that site about Rserve, so it’s worth reading through the FAQs and documentation. Note that running Rserve on a Windows machine is not advised. From the download page pick the binary that matches your OS or you can install from within R:install.packages('Rserve',,'http://www.rforge.net/')Run Rserve Securely
We recommend running Rserve under a user account with restricted privileges (i.e., not an administrator or root user). This will help limit the damage a malicious R script can do to the machine.Second, we recommend that the Rserve configuration specify “auth required” and “plaintext disable”. This will prevent unauthorized users from connecting to the Rserve box in the first place. Note that the login required for Rserve may or may not be the same user account under which Rserve is run.The Rserve configuration is loaded from an /etc/rserv.conf file. By default Rserve won’t accept connections from a different machine so you must edit/create the configuration file above.Example rserv.conf TSV file:remote enable
auth required
encoding utf8
plaintext disable
pwdfile /users/shared/rserve/logins
rserve_usr
rserve_pwd
LabKey Machine (LK-PC): Setup Report and Data Shares
In the context of running R reports, LabKey Server needs access to two roots:- A reports root under which temporary files are created when an R report request gets serviced
- A pipeline data root where any external data is read (if required)
Rserve Machine (RS-MAC): Connect to Report and Data Shares
Connect to the file share you created above. You need to create one “drive” for the reports_temp directory and, if your R script references pipeline data, then one for the pipeline data directory.For the concrete example, create a volume that references the LK-PC using smb. In the finder menu, connect to smb://LK-PC. Note that this may be the ip address of LK-PC as well. Be sure to connect to the reports_temp and, if applicable, data shares using the RserveShare account and password created on LK-PC. From RS-MAC’s point of view, these shares are mounted as volumes, respectively accessed as /volumes/reports_temp and /volumes/data.LabKey Machine (LK-PC): Enabling Scripting Using Rserve
Ensure your LabKey webserver is up and running. You’ll need admin access to your server to setup the scripting engine to use Rserve. This feature is still in the experimental stage so you need to turn the feature on first.- Sign in as an admin.
- Go to Admin > Site > Admin Console.
- Click Experimental Features.
- Under Rserve Reports, click Enable.
- Go to Admin > Site > Admin Console.
- Click Views and Scripting.
- If there is already an ‘R Scripting Engine’ configuration, select and delete it.
- Add a new R Scripting Engine configuration. The table below shows properties and sample values for the running example.
| Setting | Sample value | Description |
|---|---|---|
| machine name | RS-MAC | Machine name or IP address of running Rserve instance |
| port | 6311 | Port that the Rserve instance is listening on |
| Rserve data volume root | /volumes/data | The name of an optional pipeline data share as referenced by the Rserve machine. This is where data files are read in from the pipeline root, for example: /volumes/data/ |
| Rserve report volume root | /volumes/reports_temp | The name of the required reports share as referenced by the Rserve machine. This is where report output files get written: for example, /volumes/reports_temp |
| Rserve user | RserveShare | Name of the user allowed to connect to an RServe instance. This user is managed by the admin of the Rserver machine. |
| Rserve password | RserveShare_pwd | Password for the Rserve user |
Rserve Machine (RS-MAC): Start Your Rserve Instance
You need to start the server to accept incoming connections. You can start Rserve from your shell by typing:rserve --no-restore --no-save --slave
Client Code Changes
R Script Changes
For the most part, an R script executing locally will execute just fine when running remotely. However, there are a few things to keep in mind: 1. There is no implicit printing or plotting. To guarantee that you write to the graphics device you must wrap these statements with print(). This is because LabKey will be using R’s source command and nested commands do not automatically print. So, instead of xyplot(..), for example, you should use print(xyplot(..));2. If you are accessing data shares from within your R script, you cannot access them as if you were running on the LabKey machine. For parameter substitutions like ${imgout:graph.png}, LabKey will replace this parameter with a file reference relative to the /volumes/reports_temp directory you setup above. However, for referencing data pipeline files, you need to do your own file mapping. To assist with this, the prolog of your script file will contain two new values:- labkey.pipeline.root: the root directory as accessed by the labkey machine (LK-PC)
- labkey.remote.pipeline.root: the root as accessed by the Rserve machine (RS-MAC).
rootPath <- labkey.makeRemotePath(labkey.pipeline.root, labkey.remote.pipeline.root, labkey.url.params$path);
if (exists(“flowGraph.session”)) {...}.JavaScript Changes
If you want to take advantage of R session sharing then you’ll need to acquire and pass a reportSessionId parameter into the reports web part config. Very briefly, your Javascript needs to create a session using LABKEY.Report.createSession() API. On success this function will return a data object containing a unique report session identifier that can be used in subsequent report web part invocations:reportWebPartConfig.reportSessionId = data.reportSessionId;
Running Rserve and Labkey on the Same Machine
You can run Rserve on the same machine as LabKey. This puts more burden on your LabKey web server but in some cases it can provide very quick response times as data does not need to be moved between machines. Following the concrete example, let’s assume we want to run everything on RS-MAC. To do this:- Install Rserve but you don’t need to enable remote in your Rserv.conf file.
- Enable the Rserve Reporting feature as before in LabKey
- You don’t need to setup any data shares but you do need to ensure that whatever account you are running Rserve under has access to the data.
- You don’t need to translate any data pipeline paths in your R script itself
- Your R scripting engine configuration values would look like the following:
| Setting | Sample value | Description |
|---|---|---|
| machine name | localhost | Machine name or IP address of running Rserve instance |
| port | 6311 | Port that Rserve instance is listening on |
| Rserve data volume root | The name of an optional pipeline data share as referenced by the Rserve machine. This is where data files are read in from the pipeline root, for example: /volumes/data | |
| Rserve report volume root | The name of the required reports share as referenced by the Rserve machine. This is where report output files get written: for example, /volumes/reports_temp | |
| Rserve user | RserveShare | Name of the user allowed to connect to an RServe instance. This user is managed by the admin of the Rserver machine. |
| Rserve password | RserveShare_pwd | Password for the Rserve user |
Setting Default R Engines, Local or Remote
You can register both remote and local R engines, using one or the other as desired. If two engines are registered, and a report job does not specify which to use, LabKey Server will try the local server by default. You can configure LabKey to try the remote server by default by providing a metadata XML file for the report in question. The XML file should follow this naming pattern: <R-Report-Name>.report.xml. The XML file for the script/report should include a <scriptEngine> element, as follows:<?xml version="1.0" encoding="UTF-8"?>
<ReportDescriptor>
<description>setup the R session</description>
<reportType>
<R>
<scriptEngine remote="true"/>
<functions>
<function name="getStats"/>
</functions>
</R>
</reportType>
</ReportDescriptor>
White Listing Functions
The <functions> list above is a "white list" of allowed functions, that is, an approved list functions, to ensure that arbitrary R code cannot be invoked. If your function name is not found in the list, a ScriptException is thrown.Direct Execution of R Functions - LABKEY.Report.executeFunction
You can use the LABKEY.Report.executeFunction API to "directly" invoke a function without the need for a backing report to execute. This is both convenient in many cases, and can save time, especially if you need to call the function multiple times within a session, because the report does not need to loaded every time you call the function.executeFunction takes a config object with the following properties:- containerPath: The container in which to make the request, defaults to the current container.
- scope: The scope to use when calling the callbacks (defaults to this).
- functionName: The name of the function to execute.
- reportSessionId: A valid report session returned by Report.createSession.
- inputParams: An optional object with properties for input parameters.
- success: A function to call if the operation is successful. The callback will receive an object with the following properties:
- console: A string[] of information written by the script to the console.
- errors: An array of errors returned by the script or LabKey.
- outputParams: An array of length 1 that contains a single JSON output parameter value.
- failure: A function to call if an error preventing script execution occurs. This function will receive one parameter which is the exception message.
- Make sure the Rserve experimental feature is enabled.
- Call LABKEY.Report.createSession to create a report session.
- Call LABKEY.Report.execute with this session and call your setup.R module report. This will load the report and run it, putting all it’s work in the session passed in.
- Call the function "getStats" via LABKEY.Report.executeFunction using the same report session. This will execute the function in the session without needing to load any reports.
Troubleshooting
java.lang.RuntimeException: Could not connect to: rs-mac:6311
- Can you ping “rs-mac”? i.e. is the name resolved?
- Is rs-mac the correct machine running Rserve? if not, you’ll need to change your R scripting engine configuration setting
- Is the Rserve instance running on rs-mac?
- Is Rserve listening on the port 6311?
java.lang.RuntimeException: eval failed, request status: error code: 127 Error in file (filename, “r”, encoding=encoding) : cannot open the connection
- Have you setup the data share and mounted a volume on the Rserve machine? i.e. are reports_temp and /volumes/reports_temp setup correctly?
- Did you connect to the shares with the correct account? RserveShare
java.lang.RuntimeException: could not login to Rserve with user: foo_bar
- Verify your R script engine configuration settings have the correct user name and password
java.lang.RuntimeException: eval failed, request status: error code: 127 …
- This usually means a script evaluation failed. This could be a syntax error in your R script (try running it in R to see if there is an issue with your script)
- You can also run rserve.dbg for better output on the server side (DAX-MAC) to see better error information.
javax.script.ScriptException: The report session is invalid
- The reportSessionId you passed in is no longer valid. Did you get the reportSessionId from a call to LABKEY.Report.createSession()?
- The web session expired out from underneath you. This could happen because the session timeout expired (default timeout is 30 minutes in tomcat) or you signed out. You’ll need to refresh the page hosting the reports web part and call LABKEY.Report.createSession() to get a new session.
This feature requires the “Rserve Reporting” experimental feature be turned on
Related Topics
Web Application Security
Common Security Risks
When developing dynamic web pages in LabKey Server, you should be careful not to introduce unintentional security problems that might allow malicious users to gain unauthorized access to data or functionality. The following booklet provides a quick overview of the ten most critical web application security risks that developers commonly introduce:https://www.owasp.org/index.php/Category:OWASP_Top_Ten_ProjectHTML Encoding
Encode HTML
For those writing JavaScript in LabKey wiki pages and views, the most common risk is script injection. This occurs when your code accepts text input from a user, perhaps saves it to the database, and then later displays that input in a web page without HTML-encoding it. In general, you should always HTML-encode all text entered by a user before displaying it the page, as this prohibits a malicious user from entering JavaScript that could be executed when dynamically added to the page as HTML. HTML-encoding will convert all characters that would normally be interpreted as HTML markup into encoded versions so that they will be interpreted and displayed as plain text and not HTML.To HTML-encode text, use the following function in the Ext library, which is always available to you in a LabKey wiki page or view:var myValue = ...value from input control...
var myValueEncoded = Ext.util.Format.htmlEncode(myValue);
/ / … save myValueEncoded to the database, or redisplay it as follows:
Ext.get("myDisplayElement").update(myValueEncoded);
Cross-Site Request Forgery (CSRF) Protection
Background
Cross-Site Request Forgery (CSRF) is a type of vulnerability in web application, in which an attacker gets a user to visit a link in a browser that is already logged into an application. The user may not be aware of what the browser is sending to the server, but the server trusts the request because the user was authenticated.http://en.wikipedia.org/wiki/Cross-site_request_forgeryThese kinds of attacks can be defeated by including a token in the request which is known to the server, but not to the attacker.Implementation
LabKey Server implements CSRF protection by annotating Action subclasses with @CSRF. Forms that do an HTTP POST to those actions should include the <labkey:csrf /> tag, which renders an <input> into the form that includes the CSRF token:<input type=hidden name="X-LABKEY-CSRF" value="XXXX" />The actual value will be a GUID, associated with that user and the current HTTP session. Alternatively, the CSRF token value can be sent as an HTTP header named "X-LABKEY-CSRF".LabKey's client APIs, including our Java and JavaScript libraries, automatically set the CSRF HTTP header to ensure that their requests are trusted.Current Protection
LabKey Server current guards against CSRF for all key security, permission, and container operations. It is also automatically applied to all actions that require site admin or folder admin permissions.However, not all actions that cause application state changes are currently protected. We will continue to increase the number and percentage of all actions that are protected, being mindful of potential backward compatibility concerns with applications that may be hitting URLs directly without using the standard client API libraries. Actions that require administrator access (site or folder level) are generally of the highest priority.NOTE, it is important that session or database state is not affected by GET requests. CSRF is only used to protect POST methods.What you need to do
- In a JSP use <labkey:form> instead of <form>, or include <labkey:csrf /> inside of your <form>.
- Ext.Ajax, this is handled already. see ext-patches.js
- Ext.form.Panel add this to your items array: {xtype: 'hidden', name: 'X-LABKEY-CSRF', value: LABKEY.CSRF}
- GWT service endpoint, this is already handle for you. see ServiceUtil.configureEndpoint()
MiniProfiler
 Duplicate queries will be highlighted.
Duplicate queries will be highlighted. Clicking on the link in the sql column will bring up the queries page showing each query that was executed, it's duration, and a stacktrace showing where the query originated from.
Clicking on the link in the sql column will bring up the queries page showing each query that was executed, it's duration, and a stacktrace showing where the query originated from.
LabKey Open Source Project
- Source Code
- Release Schedule
- Issue Tracker
- LabKey Scrum FAQ
- Developer Email List
- Branch Policy
- Test Procedures
- Hotfix Policy
- Submit Contributions
- Confidential Data
- UI Design Patterns
- CSS Design Guidelines
- Naming Conventions for JavaScript APIs
- Check in to the Source Project
- Set up a Development Machine
Source Code
LabKey is an open-source Java application, distributed under the Apache 2.0 license. The complete source code is freely available via Subversion or as a downloadable archive. For information on building the LabKey source code, see our development documentation. See the LabKey Server version control documentation for more information on obtaining source code via our Subversion repository.
The current release of LabKey Server is version 17.1-49816.20, released March 16, 2017.
| LabKey Server Downloads |
||
| Source code | Sync to the SVN repository for branch 17.1. See Enlisting in the Version Control Project. | |
| Related Projects, Toolkits, and Files | ||
| Java Client API Source (.zip) | LabKey17.1-49816.20-ClientAPI-Java-src.zip | [info] |
Installation Files
LabKey supplies executable install files, plus binaries for manual installs and various other helper files such as demos. To register to download these files, click here.
Previous Releases
You can download older releases of the source from our download archive.
Release Schedule
LabKey produces new releases every four months, currently targeting mid March, July, and November.
Estimated ship dates of upcoming releases:
LabKey Server 17.2 - July 13, 2017
This schedule is subject to change at any time.
Ship dates for recent releases:
LabKey Server 17.1 - Released on March 16, 2017
LabKey Server 16.3 - Released on November 14, 2016
LabKey Server 16.2 - Released on July 15, 2016
LabKey Server 16.1 - Released on March 14, 2016
LabKey Server 15.3 - Released on November 16, 2015
LabKey Server 15.2 - Released on July 15, 2015
LabKey Server 15.1 - Released on March 17, 2015
LabKey Server 14.3 - Released on November 17, 2014
LabKey Server 14.2 - Released on July 15, 2014
LabKey Server 14.1 - Released on March 14, 2014
LabKey Server 13.3 - Released on November 18, 2013
LabKey Server 13.2 - Released on July 22, 2013
LabKey Server 13.1 - Released on April 22, 2013
Issue Tracker
Finding the LabKey issue tracker
All LabKey Server development issues are tracked in our issue tracker.Benefits
Using the issue tracker provides a number of benefits.- Clear ownership of bugs and features.
- Clear assignment of features to releases.
- Developers ramp down uniformly, thanks to bug goals.
- Testing of all new features and fixes is guaranteed.
Guidelines for Entering Feature Requests
- Feature requests should reflect standalone pieces of functionality that can be individually tested. They should reflect no more than 1-2 days of work.
- Feature requests should contain a sufficient specification (or description of its SVN location) to allow an unfamiliar tester to verify that the work is completed.
Guidelines for Entering Defects
- Include only one defect per opened issue
- Include clear steps to reproduce the problem, including all necessary input data
- Indicate both the expected behavior and the actual behavior
- If a crash is described, include the full crash stack
Issue Life Cycle
The basic life cycle of an issue looks like this:
- An issue is entered into the issue tracking system. Issues may be features (type "todo"), bugs (type "defect"), spec issues, documentation requirements, etc.
- The owner of the new issue evaluates it to determine whether it's valid and correctly assigned. Issues may be reassigned if the initial ownership was incorrect. Issues may be resolved as "Not reproducible", "Won't Fix", or "Duplicate" in some cases.
- The owner of the issue completes the work that's required and commits the change to source control (or makes configuration changes to the system in question, etc), and resolves the issue. If the owner opens the issue to themselves (as is common for features), the owner should assign the resolved bug to someone else. No one should ever close a bug that they have resolved.
- The owner of the resolved issue verifies that the work is completed satisfactorily, or that they agree with any "not reproducible" or "won't fix" explanation. If not, the issue can be re-opened to the resolver. If the work is complete, the issue should be closed. Issues should only be reopened if the bug is truly not fixed, or if the feature is truly incomplete. New or related problems/requests should be opened as new issues.
Related Topics
LabKey Scrum FAQ
Frequently asked questions about our internal Scrum process:
| 1. | Q | When is a buddy testing task considered complete? |
| A | Buddy testing tasks are not complete until any bugs found have been confirmed closed. If you have completed a round of buddy testing and found bugs, you should move your buddy testing task to the "Blocked" column, and adjust the hours remaining to reflect the time you think it will take to complete additional passes, and to close out the bugs you've filed. | |
| 2. | Q | When is a feature/story considered complete? |
| A | A story is not complete until any bugs that would prevent release have been closed out. | |
| 3. | Q | Where do I add additional stories for future sprints? |
| A | New items should be added to the Product Backlog, and ordered appropriately in relation to other stories for the same contract. The Product Backlog is for internal LabKey use only; please contact us with any questions about upcoming features. |
|
| 4. | Q | How can I find a list of stories completed in previous sprints? |
| A | A list of completed items can be found in the "Completed Items" worksheet of the Product Backlog. The Product Backlog is for internal LabKey use only; please contact us with any questions about completed features. |
|
| 5. | Q | When should the "Sprint" field be used? |
| A | Normal sprints: During a sprint, any bugs found in the course of testing one of that sprint's commitments that would block release should be marked with the number of that sprint. Stabilization sprint: Currently, the last sprint in a release cycle is primarily used for stabilization. Bugs should be flagged with the number of the stabilization sprint when a developer has committed to fixing the issue before the release is completed. |
|
| 6. | Q | How are Deliver / Accept & Reject / Deploy used? |
| A | Here is the progression:
|
Developer Email List
The developer email list is for anyone interested in monitoring or participating in the LabKey Server development process. Our subversion source code control system sends email to this list after every commit. Build break messages are sent to this list. We also use this list for periodic announcements about upcoming releases, changes to the build process, new Java classes or techniques that might be useful to other developers, etc. Message traffic is high, averaging around 20 messages per day.
The list is hosted by Fred Hutchinson Cancer Research Center (FHCRC) behind their firewall, so at the moment, anyone outside the FHCRC network can't view the archives or use the web UI to subscribe or change personal options. However, most of the interesting functionality can be accessed by sending email requests to various aliases. It's a bit clunky, but it works.
- Subscribe by sending a blank email to:
cpas-developers-subscribe@lists.fhcrc.org
You will receive a confirmation email and must reply to it.
- Unsubscribe by sending a blank email to:
cpas-developers-leave@lists.fhcrc.orgYou will receive a confirmation email and must reply to it.
- Make adjustments by sending a message to
cpas-developers-request@lists.fhcrc.org with help in the subject or body
You will receive a message with further instructions.
- Send a message to the group by emailing:
cpas-developers@lists.fhcrc.org
Note: some of the emails you receive from the system will include links to http://lists.fhcrc.org -- as mentioned above, these will be unreachable outside the FHCRC network. Use the email options instead.
Branch Policy
Release Branches
We create SVN branches for all of our official releases. This is the code used to build the installers that we post for all users. As such, we have a strict set of rules for what changes are allowed. The branches follow the general naming convention of "https://hedgehog.fhcrc.org/tor/stedi/branches/release13.2". They are created at the end of the final sprint of a given release. All check ins made to the release branch require:- An entry in the issue tracker.
- Approval from a member of the Triage committee.
- A code review from another developer.
- In the checkin description, reference the issue and say who did the code review.
Module Branches
Many of our customers want us to deliver new functionality more often than we do a general release. However, they still require that the core server remain stable. As such, we create a separate "modules" branch for each release. Checkins for a customer-specific module are allowed without a code review or triage approval. Note that no changes to the core server code are permitted, however. These branches use the naming convention of "https://hedgehog.fhcrc.org/tor/stedi/branches/modules13.2".Sprint Branches
We also create separate branches for each sprint (currently aligned with calendar months). Like release branches, changes to the sprint branch require an entry in the issue tracker, triage approval, and a code review. We typically make a very small number of changes in the sprint branch.Merges
We periodically do bulk merges from the release branch into the modules branch, and from the modules branch to the trunk. We also merge sprint branch changes into the trunk. Individual developers should NOT merge their checkins. This is currently a rotating responsibility, assigned to a developer for a period of time.If you make a branch checkin that you expect to be difficult to merge (for example, you know that the trunk code has already changed, or you make a better but riskier fix in the trunk), please alert the developer handling the merge duties and give guidance.Test Procedures
This document summarizes the test process that LabKey uses to ensure reliable, performant releases of LabKey Server:
- A client proposes a new feature or enhancement and provides a set of requirements and scenarios.
- LabKey writes a specification that details changes to be made to the system. The specification often points out areas and scenarios that require special attention during testing.
- Specifications are reviewed by developers, testers, and clients.
- Developers implement the functionality based on the specification.
- If deviations from the specification are needed (e.g., unanticipated complications in the code or implications that weren’t considered in the original specification), these are discussed with other team members and the client, and the specification is revised.
- If the change modifies existing functionality, the developer ensures relevant existing unit, API, and browser-based automated tests continue to pass. Any test failures are addressed before initial commit.
- If the change adds new functionality, then new unit, API, and/or browser-based automated tests (as appropriate, based on the particular functionality) are written and added to our test suites before the feature is delivered.
- Developers perform ad hoc testing on the areas they change before they commit.
- Developers also run the Developer Regression Test (DRT) locally before every commit. This quick, broad automated test suite ensures no major functionality has been affected.
- TeamCity, our continuous integration server farm, builds the system after every commit and immediately runs a large suite of tests, the Build Verification Test (BVT).
- TeamCity runs much larger suites of tests on a nightly basis. In this way, all automated tests are run on the system every day, on a variety of platforms (operating systems, databases, etc).
- TeamCity runs the full suite again on a weekly basis, using the oldest supported versions of external dependencies (databases, Java, Tomcat, etc), and in production mode. This ensures compatibility with the range of production servers that we support.
- Test failures are reviewed every morning. Test failures are assigned to an appropriate developer or tester for investigation and fixing.
- A buddy tester (a different engineer who is familiar with the area and the proposed changes) performs ad hoc testing on the new functionality. This is typically 3 – 5 hours of extensive testing of the new area.
- Clients obtain test builds by syncing and building anytime they want, downloading a nightly build from LabKey, retrieving a monthly sprint build, etc. Clients test the functionality they've sponsored, reporting issues to the development team.
- As an open-source project, the public syncs, builds, and tests the system and reports issues via our support boards.
- Production instances of LabKey Server send information about unhandled exception reports to a LabKey-managed exception reporting server. Exception reports are reviewed, assigned, investigated, and fixed. In this way, every unhandled exception from the field is addressed. (Note that administrators can control the amount of exception information their servers send, even suppressing the reports entirely if desired.)
- Developers and testers are required to clear their issues frequently. Open issues are prioritized (1 – 4). Pri 1 bugs must be addressed immediately, Pri 2 bugs must be addressed by the end of the month, and Pri 3 bugs by the end of the four-month release cycle. Resolved issues and exception reports must be cleared monthly.
- At the end of each monthly sprint, a "sprint branch" is made and a sprint build is created. This build is then:
- Tested by the team on the official LabKey staging server.
- Deployed to labkey.org for public, production testing.
- Pushed to key clients for testing on their test and staging server.
- The fourth month of every release cycle is treated as a "stabilization month," where the product is prepared for production-ready release.
- All team members are required to progressively reduce their issue counts to zero by the end of the month.
- Real-world performance data is gathered from customer production servers (only for customers who have agreed to share this information). Issues are opened for problem areas.
- Performance testing is performed and issues are addressed.
- The final release process occurs in the two weeks after the stabilization month:
- The sprint build at the end of the stabilization month is considered the first release candidate.
- This build is tested on staging and deployed to all LabKey-managed production servers, include labkey.org, our hosted server, and various client servers that we manage.
- The build is pushed to all key clients for extensive testing beta testing.
- Clients provide feedback, which results in issue reports and fixes.
- Once clients verify the stability of the release, clients deploy updated builds to their production servers.
- After all issues are closed (all test suites pass, all client concerns are addressed, etc.) an official, production-ready release is made.
- Bugs discovered by LabKey or clients after official release are considered for hotfix treatment if they meet the criteria documented here.
Running Automated Tests
Overview
The LabKey Server code base includes extensive automated tests. These, combined with hands-on testing, ensure that the software continues to work reliably. There are three major categories of automated tests.Unit Tests
Unit tests exercise a single unit of code, typically contained within a single Java class. They do not assume that they run inside of any particular execution context. They are written using the JUnit test framework. Unit tests can be run directly through IntelliJ by right clicking on the test class or a single test method (identified with an @Test annotation) and selecting Run or Debug. They can also be run through the web application, as described below for integration tests. Unit tests are registered at runtime via the Module.getUnitTests() method.Integration Tests
Integration tests exercise functionality that combines multiple units of code. They do not exercise the end-user interface. Integration tests are implemented using the JUnit test framework, like unit tests. They generally assume that they are running in a full web server execution context, where they have access to database connections and other resources. They can be invoked through the web application by going to http://localhost/labkey/junit/begin.view or its equivalent URL (based on the server, port, and context path). Integration tests are registered at runtime via the Module.getIntegrationTests() method.Functional Tests
Functional tests exercise the full application functionality, typically from the perspective of an end-user or simulated client application. Most functional tests use the Selenium test framework to drive a web browser in the same way that an end user would interact with LabKey Server. Unlike unit and integration tests, functional tests treat the server as a black-box, and their source code is completely separate from the main server code (though it lives in the same source code repository).Functional tests are separated into separate test suites, including the Developer Run Tests (DRT), Build Verification Tests (BVT), and Daily suites. The automated build and test system runs these suites at varying frequencies in response to code changes.Depending on the specific test, Selenium will use different web browsers. Most typically, tests use recent versions of Firefox or Chrome.To run a functional test on a development machine where LabKey Server is running locally, there are a number of relevant Ant targets in the server/test directory:- ant usage - Describes the different targets available, and their command-line parameters
- ant drt - Runs the DRTs
- ant bvt - Runs the BVTs
- ant drt -Dselenium.browser=firefox - Run the DRTs on Firefox
- ant test - Displays a UI to choose specific tests to run and set options
- ant test -Dtest=basic - Runs BasicTest
Hotfix Policy
Background
LabKey performs the vast majority of product testing during the development cycle of a new release. The development of every new feature includes buddy testing, creation of automated unit tests, and creation of browser-based integration tests. Our automated servers run large suites of tests against every commit and even larger suites on a nightly and weekly basis to identify new bugs and regressions. We distribute monthly sprint builds to many clients, encouraging them to exercise these builds on their test servers and promptly report problems they find in new and existing functionality. After our final (stabilization) sprint, we push bi-weekly release candidates to our clients and ask them to validate these on their servers using their data. This culminates in LabKey making an official release of a build that has been tested thoroughly by us and many of our clients, typically occurring a couple weeks after the end of the stabilization sprint.
Our clients often find bugs in released builds. In most cases, we fix these problems as part of the next release cycle. We don’t typically fix bugs in released products for several reasons:
- Risk. Hotfixes completely bypass the standard testing that takes place during the development cycle. These fixes are often deployed to production servers shortly after being committed, with limited opportunity to verify the fix. The bigger problem, though, is the risk of "unintended consequences." Like all other code changes, a hotfix can cause additional (often more severe) issues in other parts of the system. A hotfix provides no opportunity to detect these follow-on issues before production deployment.
- Focus. At the point when a potential hotfix is identified, developers are deeply engaged in implementing features for the next release. Asking several developers to stop feature work and focus instead on a hotfix often prevents them from finishing one or more scrum board features.
- Cost. Producing a hotfix is typically 3 – 5 times as costly as fixing the exact same issue during the development cycle. To mitigate the risks mentioned above, we must be extremely conservative with hotfixes. We start with an evaluation process that involves senior management and the client. We then design, discuss, implement, and test several potential solutions, trying to find the fix that best addresses the issue while minimizing impact on other functionality. All hotfixes are risk assessed by senior management and code reviewed by one or more developers familiar with the area. Testers must attempt to verify the change immediately. Often times, the isolated hotfix solution is not an appropriate long-term solution; in these cases, the hotfix changes are rolled back and replaced with a more comprehensive fix in the next release. All of this additional overhead makes hotfixes very time consuming and expensive.
Policy
We evaluate every hotfix candidate using the following factors and questions:
- Severity. How bad is the problem? Does the problem involve a security exposure or data loss? Is functionality blocked? If so, how important is that functionality?
- Scope. How many people will be affected by this issue? To what extent will it impair their work? Are other clients affected?
- Workarounds. Are there reasonable steps that avoid the problem? Can those affected be shown these steps?
- Regression status. Is the bug:
- A new problem with previously working functionality?
- A problem with new functionality?
- An old problem that’s been in the product for one or more previous releases?
- Cost of fixing. How long will it take to implement and test a fix?
- Risk of fixing. How invasive are the changes? What’s the likelihood that these changes will produce unintended consequences?
- Time. How long has the release been available? How long before a new release is made?
Evaluating a hotfix candidate is a subjective risk vs. reward trade-off. In most cases, our clients and we find the reward is simply not worth the risk and cost. But, as hinted in #7 above, the length of time since the last release does affect the evaluation. A critical issue discovered shortly after release needs to be evaluated seriously, but an issue that isn’t reported until three months into a release is almost certainly not a high priority (we release new versions every four months). Combining this temporal element with the other factors leads to some general guidelines that we use to quickly assess whether an issue is a hotfix candidate.
| Hotfix candidate | |
| Not a hotfix candidate |
|
|
One month after release | Two months after release | Always (until next release) |
|---|---|---|---|
| Security issue | |||
| Significant data loss issue | |||
| Blocking issue in old functionality (regression) | |||
| Blocking issue in new functionality | |||
| Performance issue | |||
| Issue present in previous release | These are not hotfix candidates | ||
| New feature or improvement request | |||
| Issue with reasonable workaround | |||
| Issue with limited impact | |||
The above guidelines are not hard and fast rules. The risks or costs of a fix may preclude an otherwise worthy hotfix. On the other hand, we'll occasionally take a simple, low risk fix that doesn’t meet these criteria.
We encourage all clients to test new functionality promptly (as the sprint builds are made available) and perform regular regression testing of important existing functionality. Reporting all issues before public release is the best way to avoid hotfixes entirely.
Previous Releases
Looking for the latest release of LabKey Server? Find it here.
Previous Releases of LabKey Server
Use the links below to download previous versions of LabKey Server. For documentation of previous releases, see Docs Archive.
Generally there are three releases of LabKey Server a year. We strongly recommend installing the latest release and only using the releases found here for testing or when absolutely required.
Related Topics
• Previous Releases - Documentation ArchivePrevious Releases -- Details
Looking for the latest release of LabKey Server? Find it here.
Binaries and Installers
NOTE: If Binaries or Installers are not available above, you will need to build from source, using the either the source archives or Subversion URLs below.
Toolkits, APIs and Source
Submit Contributions
- Make sure that you are not submitting Confidential Data.
- Make sure that your contribution follows LabKey design and naming guidelines:
- Post your request to contribute to the developer community forum. If your request is accepted, we will assign a committer to work with you to deliver your contribution.
- Update your SVN enlistment to the most recent revision. Related documentation: Set up a Development Machine.
- Test your contribution thoroughly, and make sure you pass the Developer Regression Test (DRT). See Check in to the Source Project for more details about running and passing the DRT.
- Create a patch file for your contribution and review the file to make sure the patch is complete and accurate.
- Using TortoiseSVN, left click a folder and select Create Patch...
- Using command line SVN, execute a command such as: svn diff > patch.txt
- Send the patch file to the committer. The committer will review the patch, apply the patch to a local enlistment, run the DRT, and (assuming all goes well) commit your changes to the Subversion repository.
Confidential Data
CSS Design Guidelines
For documentation on specific classes, see stylesheet.css.
General Guidelines
All class names should be lower case, start with "labkey-" and use dashes as separators (except for GWT, yui, and ext). They should all be included in stylesheet.css.
In general, check the stylesheet for classes that already exist for the purpose you need. There is an index in the stylesheet that can help you search for classes you might want to use. For example, if you need a button bar, use "labkey-button-bar" so that someone can change the look and feel of button bars on a site-wide basis.
All colors should be contained in the stylesheet.
Default cellspacing is 2px and default cellpadding is 1px. This should be fine for most cases. If you would like to set the cellspacing to something else, the CSS equivalent is "border-spacing." However, IE doesn't support it, so use this for 0 border-spacing:
border-spacing: 0px; *border-collapse: collapse;*border-spacing: expression(cellSpacing=0);
And this for n border-spacing:
border-collapse: separate; border-spacing: n px; *border-spacing: expression(cellSpacing = n );
Only use inline styles if the case of interest is a particular exception to the defaults or the classes that already exist. If the item is different from current classes, make sure that there is a reason for this difference. If the item is indeed different and the reason is specific to this particular occurence, use inline styles. If the item is fundamentally different and/or it is used multiple times, consider creating a class.
Data Region Basics
- Use "labkey-data-region".
- For a header line, use <th>'s for the top row
- Use "labkey-col-header-filter" for filter headers
- There are classes for row and column headers and totals (such as "labkey-row-header")
- Borders
- Use "labkey-show-borders" (in the table class tag)
- This will produce a strong border on all <th>'s, headers, and totals while producing a soft border on the table body cells
- "<col>"'s give left and right borders, "<tr>"'s give top and bottom borders (for the table body cells)
- If there are borders and you are using totals on the bottom or right, you need to add the class "labkey-has-col-totals" and/or "labkey-has-row-totals", respectively, to the <table> class for correct borders in all 3 browsers.
- Use "labkey-show-borders" (in the table class tag)
- Alternating rows
- Assign the normal rows as <tr class="labkey-row"> and the alternate rows as <tr class="labkey-alternate-row">
- Assign the normal rows as <tr class="labkey-row"> and the alternate rows as <tr class="labkey-alternate-row">
UI Design Patterns
- Introduction
- Button or Link?
- Button Labeling
- Button Positioning
- Using the Webpart Nav Menu
- Notifications
- Useful External Resources
Introduction
Below are the start of UI guidelines... this document is a work in progress! Also it may be helpful to note that "guidelines" are just that - not rules. There may be exceptions. So take seriously, but not rigidly. Comments and suggestions are welcome.
Button or Link?
That is the question - and a good one. Sometimes the answer can be ambiguous.
So, when trying to decide what to use, ask yourself:
"Am I going somewhere? Or, am I doing something?"
If you're going somewhere, you're navigating. So use a link. This includes drilling down to another level of content, or going to another page to perform a related action. Nothing about the data changes or is saved (yet), you're simply getting somewhere else or to the next step.
If you're doing something, use a button. This includes committing changes to the database, sending a message, adding or removing fields in a form - something is functionally happening or changing, you're not just moving to another screen.
What about popup modal windows? Do you open these with a button or link? You're proceeding to a next step, but not really going to another page (in fact you'll return to the same page, most likely with a changed state). So, it might be helpful to think of modal windows as "enhanced" doing, or an action that might be considered changing the form in some way, so launching with a button would be appropriate.
What about hover content (panels, tooltips, etc)? These can be activated with buttons or links. Sometimes you just need a little more information about what the button or link does, or what a piece of content or functionality means, so hover content shouldn't be based on the mechanism for revealing it, but on user needs. (note - this section may be adjusted to consider "additional info" or "help" panels activated with a "?" button or link)
Button Labeling
Oh, what to call these things! So many actions to take, so many different types of buttons to label. But, we'd like some consistency, so here's a place to start:
1. Be brief. Use one word - and make it a verb - whenever possible (see the core button list below). If you're tempted to add more words, ask: do the words *really* add meaning, clarity, or differentiation from other buttons on the page? If you find yourself inventing a new button label altogether, is it really a distinct action? If so, perhaps it can be added to the "core" list.
2. Stick with the following "core" buttons as-is, whenever possible:
| Button Label | Action | Shortcut Key |
|---|---|---|
| Save | Commit something new or updated to the database, and remain on the page. | (key) |
| Save & Close | Commit something new or updated to the database, and go to the next logical page, a summary view of the data entered, or if neither of these exist, to wherever the user came from before. | (key) |
| Delete | Remove something from the database. | |
| Revert | Revert to a previous state. | |
| Cancel | Stop an action, discard all changes without prompting and return user to where they were before. | |
| Reset | Before saving, clear all entries or reset to defaults. | |
| Add | Add an element to the page or form | |
| Upload | Upload files and data | |
| Import | Pull data into a LabKey format | |
| Export | Push data out in another format | |
| Infer | Reconciling data (?) | |
| Activate | Toggle something on | |
| Deactivate | Toggle something off | |
| Browse | Open a file browser window | |
| Search | Initiate a search query | |
| Reload | Reload the page to refresh the view | |
| Send | Send something somewhere or to someone | |
| Run | Execute a script or process | |
Button Positioning
For guidance when placing buttons, use the following decision tree:
1. first choice: directly below the related fields or form, especially if there is more than one form element (i.e. several text fields, radio buttons, etc that are processed together – button should appear directly below)
2. second choice: to the right of the field or form, especially when there is only one form element (i.e., webpart dropdown, single search field) or it makes sense to directly relate the button to the form element (i.e. a Browse button by text field)
3. third choice: if there is a long table or form that requires scrolling, buttons may appear at the top and the bottom so the user has quick access in either direction.
In addition...
When placing buttons side-by-side: Leave xx pixels of space between each button to minimize the chance of clicking the wrong choice.
When placing the "Cancel" button: Always place to the right of other buttons, so "Cancel" is always the last (rightmost) button in a group.
Using the Webpart Nav Menu
Use this component to reduce the number of text links within webparts, cleaning up the visual display.
What goes in a webpart nav menu... or, what remains a link? Where webpart menus are concerned, it might be easier to think about what *doesn't* go in a menu. When placing a text link, ask:
- Will this link be used by everyone?
- Is the link specific to a function within the webpart, where proximity is crucial?
- Is the link going to be used alot? Is it right in the path of action?
If a link can pass these tests, it might be appropriate to leave as a link, always visible, outside the menu. Otherwise, consider moving as many text links as possible into a logical menu system.
How to word the menu items: Like buttons, use words as sparingly as possible. If you're tempted to add words, ask: do they *really* provide clarity, or differentiation between similar menu items? If not, resist!
If you do write multi-word menu items, follow standard headline/subhead style, i.e. capitalize all major words while leaving prepositions and conjunctions lower case ("at", "the", "and", "but", "to", etc.)
Notifications
Its definitely a good thing to let users know what's happening. Here are some general guidelines:
Navigating away from a dirty page: If the user tries to leave a page with unsaved changes, the UI should prompt the user with an alert box saying:
"Are you sure you want to leave this page?
There are unsaved changes. Leaving now will abandon those changes.
Press OK to continue, or Cancel to stay on the current page."
Required Fields: When a form field is required, place a "*" next to the field names and note at the bottom of the form: *=required.
Error messages: Error messages should appear within the visible region of the window, and must be comprehensible to non-developers. Do not use code-specific terminology.
Also, whenever possible/appropriate, in addition to the error message provide suggestions on how the user might correct the error. Terminology should be accessible to users familiar with our UI.
Useful Resources
- How to Design a Great User Experience (MSDN)
- Design Pattern Library (Yahoo!)
Design Guidelines Supplemental
Here is a heading with h1
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Morbi commodo, ipsum sed pharetra gravida, orci magna rhoncus neque, id pulvinar odio lorem non turpis. Nullam sit amet enim. Suspendisse id velit vitae ligula volutpat condimentum. Aliquam erat volutpat. Sed quis velit. Nulla facilisi. Nulla libero. Vivamus pharetra posuere sapien.
Here is a subhead with h2
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Morbi commodo, ipsum sed pharetra gravida, orci magna rhoncus neque, id pulvinar odio lorem non turpis. Nullam sit amet enim. Suspendisse id velit vitae ligula volutpat condimentum. Aliquam erat volutpat. Sed quis velit. Nulla facilisi. Nulla libero. Vivamus pharetra posuere sapien.
Here is another h2 subhead
Here is an h3 subhead
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Morbi commodo, ipsum sed pharetra gravida, orci magna rhoncus neque, id pulvinar odio lorem non turpis. Nullam sit amet enim. Suspendisse id velit vitae ligula volutpat condimentum. Aliquam erat volutpat. Sed quis velit. Nulla facilisi. Nulla libero. Vivamus pharetra posuere sapien.
Here is another h3
Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Morbi commodo, ipsum sed pharetra gravida, orci magna rhoncus neque, id pulvinar odio lorem non turpis. Nullam sit amet enim. Suspendisse id velit vitae ligula volutpat condimentum. Aliquam erat volutpat. Sed quis velit. Nulla facilisi. Nulla libero. Vivamus pharetra posuere sapien.
Documentation Style Guide
See Also
References to UI Elements
Do- Use bold for UI elements, such as button names, page titles and links.
- When the use of bold would be confusing or overwhelming.
- For example, if you have subheadings that use bold and very little text beside UI element names, too much text would be bold. In such a case you might use quotations around UI element names, as an exception.
- Use quotes to highlight UI elements.
- Describe series of clicks by order of execution.
- Good: "Select Export -> Script"
- Bad: "Select Script from the Export menu."
Admin Menus
Do- Give directions based on the top right Admin drop-down
- Give directions based on options in the left nav bar. Never assume that the left nav bar is visible to anyone.
-ing Words in Headings
Do- Use active voice. Let's do something in this topic!
- -ing. It makes titles longer (the TOC is space constrained on width), it's passive and it's boring.
- Yes, you may have to mix noun phrases (Field Properties) and imperatives (Create a Dataset) in a TOC section. Still, it's usually possible to keep subsections internally consistent.
Parallelism
DoUse the same verb form (e.g., participles, imperatives or infinitives) consistently in bullets and titles.Consistently use either verb or nouns statements in bullets and section titles.Generally, prefer active verb phrases ("Create XYZ") over noun statements or participles.AvoidVary the use of verbs and nouns in sections. For example, a section should not have all three of the following forms used - better is to keep all bullets parallel and use the active form that appears in the first bullet for the others.- Create a wiki page
- How to create a wiki page
- Creating a wiki page
If You Move a Page...
- Update all related on-page TOCs, both in the section where the page came from and in the section where the page went to.
- If you do not do this, it is nearly impossible to track down that something is missing from an on-page TOC without going through every TOC item one-by-one.
- Ensure that the page title uses wording parallel to the other titles in its new node.
- For example, if a verb ("Do this") title moves into a section where all the pages are noun titles, you need to fix things so that the pages titles are all nouns or all verbs.
- There can be exceptions, but in general, titles should be parallel at the level of a node.
Resources
- MSTP v3. http://paws.wcu.edu/kprice/MSTP-V3.pdf
- Commas. http://owl.english.purdue.edu/owl/resource/607/02/
- Capitalization in titles. http://www.writersblock.ca/tips/monthtip/tipmar98.htm
- Note: Do capitalize prepositions of five characters or more ("after", "among", "between").)
- Hyphens for compound modifiers.
Check in to the Source Project
Update and Perform a Clean Build
Before you run any tests, follow these steps to ensure that you are able to build with the latest sources:- Stop your development instance of Tomcat if it is running.
- From a command prompt, navigate to <labkey-home>/server
- Run the ant clean build target to delete existing build information.
- From your <labkey-home> directory (the root directory of your LabKey Server enlistment), use the svn update command to update your enlistment with the latest changes made by other developers.
- Verify that any merged files have merged correctly.
- Resolve any conflicts within files that have been modified both by you and by another developer.
- Run the ant build target to build the latest sources from scratch.
Run the Test Suite(s)
LabKey maintains automated tests that verify most areas of the product. These tests use the Selenium Remote Control test harness to exercise and verify server functionality by automating the browser. LabKey develops and runs all tests using the most recent versions of Chrome and Firefox supported by Selenium. Other versions of Firefox have not been tested and are not recommended. You can have multiple versions of Firefox installed, as long as you specify the path to Firefox when you run the DRT. For example:ant drt -Dselenium.browser.path="c:\Program Files\Mozilla Firefox\firefox.exe"- Developer Regression Test (DRT): a quick (< 10 minutes) suite that developers run before every commit
- Build Verification Test (BVT): a longer (up to an hour) suite that our TeamCity-based server farm runs automatically after every commit
- Daily Test: an additional suite of tests that TeamCity runs once a night
- Start your development instance of Tomcat.
- From a command prompt, navigate to <labkey-home>/server/test
- Run the ant drt target. (Add -DhaltOnError=false to continue running if a test fails.)
- When prompted, enter the user name and password for an administrator account on your local development installation of LabKey Server.
- drt: Compile and run the DRT suite
- bvt: Compile and run the BVT suite
- daily: Compile and run the daily suite
- setPassword: Change your saved password. This target sets your login information in .cpasDRTPassword in your home directory.
- usage: Display instructions and additional options
Test Failures
If a test fails, you'll see error information output to the command prompt, including the nature of the error, the point in the test where it occurred, and the name of an HTML file and a PNG file, written to the <labkey-home>/server/test/build/logs directory, which can be viewed to see the state of the browser at the time the test failed.A helpful resource: Java Testing TipsModifying the Test Suites
You can add to or modify existing tests and create new tests. To build your changes, use the ant compile target. You can also set up a run/debug configuration in IntelliJ to build and debug changes to the DRT.To edit an existing test, locate the test class beneath the <labkey-home>/server/test/src directory.To create a new test, extend the BaseSeleniumWebTest class, and add the name of your new class to the TestSet enum in TestSet.java.Make sure that you carefully test any changes you make to the tests before checking them in.Checking In Code Changes
Once you pass the DRT successfully, you can check in your code. Make sure that you have updated your enlistment to include any recent changes checked in by other developers. To determine which files to check in, use the svn commit command. This command displays a list of the files that you have modified, which you can compare to the repository version. Be sure to provide a log message with your check-in so that other developers can easily ascertain what you have changed. An automated email describing your check-in is immediately sent to all who have access to the LabKey Server source project.After you check in, TeamCity will build the complete sources and run the full BVT on all of the supported databases as an independent verification. You'll receive another email from the automated system letting you know whether the independent verification passed or failed. We request that you remain available by email from the time you check in until you receive the email confirming that the automated build and test suite has passed successfully, so that if there is a problem with your check-in, you can revert your change or check in a fix and minimize the amount of time that others are blocked.If the automated test suite fails, all developers must halt check-ins until the problem is remedied and the test suite runs successfully. At that time the tree is once again open for check-ins.Renaming files in Subversion
Renaming files in svn
Occasionally a developer decides a file (and possibly associated classes) should be renamed for clarity or readability.
Subversion handles most file renames transparently. Rename the file locally through Intellij, verify your build and any tests, and commit. svn (unlike certain other vcs's such as cvs) is smart enough to preserve the version history.
The big exception to this is doing a case-only rename. (e.g., "myfile.java" -> "MyFile.java"). Because Windows file systems are case-insensitive, this causes major headaches. Don't do it as described above.
But what if I really need to do a case-only rename?
There are two solutions to this problem:
- Do the rename in two steps. Rename to an intermediate file name first, commit, then rename to the target, and commit again (myfile.java -> myfileA.java, commit, myfileA.java -> MyFile.java, commit)
- Perform the rename directly in the svn repository via command line, or (easier) the Repo Browser in TortoiseSVN, as explained here. (In brief, go to the TortoiseSVN Repo Browser, drill to the file, right click, and rename. Update, and you should pick up the change locally.)
Important notes with either procedure.
- Only do this in trunk. Doing this on a branch will make the developer on merge duty dislike you.
- Verify the build after each step. Depending upon what kind of file you are renaming, you may also have to rename classes.
- Because of the above, you may leave trunk in an unbuildable state during the intermediate steps. It is therefore better to do this after hours, after the dailies have started on Team City, or early in the day so you have time to fix your mess before disrupting anyone else.
Developer Reference
Reference resources for LabKey Server developers:
Java
JavaScript
R
Rserve
Perl
Python
SAS
XML
LabKey SQL
Additional Documentation
- Programmatic Quality Control & Transformations
- Using Java for Programmatic QC Scripts
- Substitution Syntax for URL Encoding.
LabKey Server is an open-source project licensed under the Apache Software License. We encourage Java developers to enlist in our Subversion project, explore our source code, and submit enhancements or bug fixes.
Administration
- Tutorial: Security - Learn the fundamentals for securing your data.
- Projects and Folders - Organize your data.
- Security - Set up user groups, assign different levels of access.
- Admin Console - Common administrative tasks.
- Install LabKey - Advanced installation topics.
- Upgrade LabKey - Upgrade an existing installation to the latest version of LabKey Server.
- Backup and Maintenance - Backup the database.
- Staging, Test and Production Servers - Testing your applications before going live.
Tutorial: Security
- Different groups and individuals require different levels of access to the data. Some groups should be able to see the data, but not change it. Others should be able to see only the data they have submitted themselves but not the entire pool of available data. Administrators should be able to see and change all of the data. Other cases require more refined permission settings.
- PHI data (Protected Health Information data) should have special handling, such as mechanisms for anonymizing and obscuring participant ids and exam dates.
- Administrators should have a way to audit and review all of the activity pertaining to the secured data, so that they can answer questions such as: 'Who has accessed this data, and when?'.
- Assign different permissions and data access to different groups.
- Test your configuration before adding real users.
- Audit the activity around your data.
- Provide randomized data.
Tutorial Steps:
- Step 1: Configure Permissions
- Step 2: Test Security with Impersonation
- Step 3: Audit User Activity
- Step 4: Handle Protected Health Information (PHI)
First Step
Step 1: Configure Permissions
Security Scenario
Suppose you are collecting data from multiple labs for a longitudinal study. You want the different teams involved to gather their data and perform quality control steps before the data is integrated into the study. You also want to ensure that the different teams cannot see each other's data until it has been added to the study. This step shows you how to realize these security requirements. You will install a sample workspace that provides a framework of folders and data to experiment with different security configurations.You configure security by assigning different levels of access to users and groups of users (for a given folder). Different access levels, such as Reader, Author, Editor, etc., allow users to do different things with the data in a given folder. For example, if you assign an individual user Reader level access to a folder, then that user will be able to see, but not change, the data in that folder. These different access/permission levels are called roles.Set Up Security Workspace
The tutorial workspace exists as a folder archive file (a .folder.zip file). It has been preconfigured with subfolders and team resources that you will work with in this tutorial. Below, you will install this preconfigured workspace by creating an empty folder and then importing the folder archive file into that empty folder.- If you haven't already installed LabKey Server, follow the steps in the topic Install LabKey Server (Quick Install).
- Open a web browser and go to: http://localhost:8080/labkey/project/home/begin.view
- Sign in. You need Project Administrator access to complete these steps. (Which you will have if you installed your own local server. If you are working on a pre-existing server instance, ask the Site Administrator for access.)
- Download the tutorial workspace: SecurityTutorial.folder.zip. Do not unzip.
- Create an empty default folder inside the Home project:
- Navigate to the Home project.
- To create a folder in the Home project: Go to Admin > Folder > Management and click Create Subfolder. Name the subfolder "Security Tutorial". Complete the wizard using the default values. In the next step you will import a folder archive into this empty folder, which will determine its properties.
- Import the folder archive file (SecurityTutorial.folder.zip) into the new folder:
- Go to Admin > Folder > Management > click the Import tab.
- Confirm Local zip archive is selected and click Choose File (or Browse) and select the SecurityTutorial.folder.zip you downloaded.
- Click Import Folder.
- When the folder is finished importing, click Start Page to go to the folder's default tab.
Structure of the Security Workspace
The security workspace contains four folders:- Security Tutorial -- The main parent folder.
- Lab A - Child folder intended as the private folder for the lab A team, containing data and resources visible only to team A.
- Lab B - Child folder intended as the private folder for the lab B team, containing data and resources visible only to team B.
- Study - Child folder intended as the shared folder visible to all teams.
- Hover over the Home link to see the menu of folders inside the Home project.
- Open the folder node Security Tutorial (which you just imported).
- You will see three subfolders inside: Lab A, Lab B, and Study.
- Click a subfolder name to navigate to it.

Configure Permissions for Lab Folders
How do you restrict access to the Lab A folder so that only members of team A can see and change it? The procedure for restricting access has two overarching steps:- Create a user group corresponding to team A.
- Assign the appropriate roles to this group.
- Navigate to the folder Lab A.
- Go to Admin > Folder > Permissions.
- Notice that the security configuration page is greyed-out. This is because the default security setting, Inherit permissions from parent, is checked. That is, security for Lab A starts out using the settings of its parent folder, Security Tutorial.
- Uncheck Inherit permissions from parent. Notice that the configuration page is activated.
- Click the tab Project Groups. Create the following groups:
- Lab A Group
- Lab B Group
- Study Group
- You don't need to add any users to the groups, just click Done in the popup window.
- Note that these groups are created at the project level, so they will be available in all project subfolders after this point.
- Click the Permissions tab.
- If necessary, select the Lab A folder in the left-side pane.
- Locate the Editor role. This role allows users to see and change items (data, resources, and user interfaces) in the current folder.
- Open the dropdown for the Editor role, select the group Lab A Group to add it.
- Locate the Reader role and remove the All Site Users and Guests groups, if present. If you see a warning when you remove these groups, simply dismiss it.

- Click Save.
- Select the Lab B folder, and repeat the steps on the permissions tab (substituting Lab B for Lab A throughout). Remember to remove all groups from the Reader role.
- Click Save and Finish.
(Optional) Configure Permissions for Study Folder
In this step we will configure the study folder with the following permissions:- Lab A and Lab B groups will have Reader access (so those teams can see the integrated data).
- The "Study Group" will have Editor access (intended for those users working directly with the study data).
- Navigate to the folder Study.
- Go to Admin > Folder > Permissions.
- Uncheck Inherit permissions from parent, to activate the configuration panel.
- Locate the Editor role and assign the group Study Group.
- Locate the Reader role and remove All Site Users and Guests, if any are present.
- Locate the Reader role and assign the groups Lab A Group and Lab B Group.
- Click Save and Finish.
Start Over | Next Step
Step 2: Test Security with Impersonation
Impersonate Groups
To test the applications behavior, impersonate the groups in question, confirming that each group has access to the appropriate folders.- Navigate to the Lab A folder.
- In the upper right, click your login badge -- this is your user name.
- Select Impersonate > Group, then select Lab A Group and click Impersonate in the popup.
- Hover over the folder menu.
- Notice that the Lab B folder is no longer visible -- while you impersonate, adopting the group A perspective, you don't have the role assignments necessary to see folder B at all.
- Using the login badge again, stop impersonating and switch to impersonation of group B. Notice that the server will return with the message "User does not have permission to perform this operation", because you are trying to see the Lab A folder while impersonating the Lab B group.
- Stop impersonating by clicking Stop Impersonating.

Previous Step | Next Step
Step 3: Audit User Activity
View the Audit Log
- Go to Admin > Site > Admin Console.
- If you have less than Project Admin permissions, you will see the message "User does not have permission to perform this operation". (You could either ask your Site Admin for improved permissions, or move to the next step in the tutorial.)
- If you have Project Admin permissions, you will see a list of user activities.
- In the Management section, click Audit Log.
- Click the dropdown and select Project and Folder Events. You will see a list like the following:

- Click the dropdown again to view other kinds of activity, for example:
- User Events (which shows who has logged in and when)
- Group Events (which shows which groups have been assigned which security roles).
Previous Step | Next Step
Step 4: Handle Protected Health Information (PHI)
- Randomizing participant ids so that the original participant ids are obscured.
- Shifting date values, such as clinic visits and specimen draw dates. (Note that dates are shifted per participant, leaving their relative relationships as a series intact, thereby retaining much of the scientific value of the data.)
- Holding back data that has been marked as 'protected'.
Examine Study Data
First look at the data to be exported.- Navigate to the Study folder (in Security Tutorial).
- Click the Clinical and Assay Data tab. This tab shows the individual datasets in the study. There are currently two datasets: "Participants" and "Physical Exam".
- Click Physical Exam. Notice that the participant ids are 6 digit numbers, starting with "110349". When we export this table, we will randomize these ids, to make it more difficult to identify the subjects of the study.
- Return to the Clinical and Assay Data tab.
- Click Participants in the dataset list. Notice the dates in the table are almost all from the last two weeks of April 2008. When we export this table, we will randomly shift these dates, to make it more difficult to identify when subject data was collected.
- Notice the columns for Country and Gender. We will mark these as "protected" columns, so they are not exported. (As an example, given that there is exactly one male patient from Germany in our sample, he would be easy to identify with only this information.)
Mark Protected Columns
To prepare the data for export, we will mark two columns, "Gender" and "Country" as protected columns making them non-exportable.- Click the Manage tab. Click Manage Datasets.
- Click Participants (the dataset, not the tab) and then Edit Definition.
- Under Dataset Fields select Gender.
- Click the Advanced tab and place a checkmark next to Protected.
- Repeat for the Country field.

- Click Save.
Set up Alternate Participant IDs
Next we will configure how participant ids are handled on export. We will specify that the ids are randomized using a given text and number pattern.- Click the Manage tab.
- Click Manage Alternate Participant IDs and Aliases.
- For Prefix, enter "ABC".
- Click Change Alternate IDs. Click to confirm.
- Scroll down and click Done.
Export/Publish Anonymized Data
Now we are ready to export this data, using the extra data protections in place.This procedure will "Publish" the study. That is, a new child folder will automatically be created and selected data from the study will be randomized and copied to the child folder. Once the child folder appears with the exported data, you can configure its security as fits your requirements.- If necessary click the Manage tab.
- Scroll down and click Publish Study.
- Complete the wizard, selecting all participants, datasets, and timepoints in the study. For fields not mentioned here, enter anything you like.
- Under Publish Options, check the following options:
- Use Alternate Participant IDs
- Shift Participant Dates
- Remove Protected Columns
- You could also check Mask Clinic Names which would protect any actual clinic names in the study by replacing them with a generic label "Clinic."
- Click Finish.
- Wait for the publishing process to finish.
- Navigate to the new folder (a child folder under Study).
- Look at the published datasets Physical Exam and Participants. Notice how the participant ids and dates have been randomized. Notice that the Gender and Country fields have been held back (not been published).
Security for the New Folder
How should you configure the security on this new folder?The answer depends on your requirements.- If you want the general public to see this data, you would add Guests to the Reader role. This allows non-logged-in users to see the folder.
- If want only members of the study team to have access, you would add Study Group to the Reader role, or a higher role.
Previous Step
What Next?
Projects and Folders
 As containers they divide up the server into different parcels of "real estate" forming the workspaces for arranging resources and collaboration areas. For example, a laboratory installation might create a different project for each grant or investigation the team is working on. Each project might have some users from within the lab and other users from other teams collaborating on the research. For details on how to arrange your projects and folders, see Site Structure: Best Practices.
As containers they divide up the server into different parcels of "real estate" forming the workspaces for arranging resources and collaboration areas. For example, a laboratory installation might create a different project for each grant or investigation the team is working on. Each project might have some users from within the lab and other users from other teams collaborating on the research. For details on how to arrange your projects and folders, see Site Structure: Best Practices.
Topics
- Navigate Site - How to navigate the projects and folders within a site.
- Site Structure: Best Practices - Considerations for project and folder structure.
- Manage Projects and Folders - Settings and configuration for projects/folders.
- Create a Project or Folder - Creating new projects and folders. Creating folders from templates.
- Move, Delete, Rename Projects and Folders - Rearranging the folder tree.
- Export / Import a Folder - Exporting and importing folders. Useful for templating resources and relocating them to a different context.
- Manage Email Notifications - Set default notification behavior when changes are made to a folder.
- Define Hidden Folders - Hidden folders can hold back-end resources and resources still in development.
- Folder Types - Different folder types support different research needs.
- Workbooks - Lightweight workbooks form an alternative to folders.
- Establish Terms of Use - Require users agree to "terms of use" before viewing a folder.
Related Topics
- Manage Project Users - Teams and user groups for a given project.
- Add Web Parts - Add web parts to pages.
- Look and Feel Settings. Apply style sheets and settings at the project and/or site level.
Navigate Site
- Project menu - select a project to open and work on.
- Folder menu - navigate the folder tree for the current project.
 Administrative menus are located along the right side of the menu bar and offer pulldown menus of options including:
Administrative menus are located along the right side of the menu bar and offer pulldown menus of options including:
- Admin - administrative options available to users granted this access.
- Help - context-sensitive help available throughout the site.
- Username - login and security options. Before you log in, this menu will read "Sign In"; once logged in, your username will be displayed here.
Project Menu
Hover over the project menu to see the available projects. Click a project to navigate there and set the current project.
Click a project to navigate there and set the current project.
Create a New Project
To create a new project, click the New Project icon in the lower left of the project menu.
Delete a Project
To delete a project, remember that projects are in many ways top level folders. Select Admin > Folder > Management, highlight the intended project and click Delete. You will be shown a list of the project contents and asked to confirm the deletion.Folder Menu
The folders inside a project are shown on the folder menu. Click the + symbol to expand a folder tree. Click the name of any folder to navigate there. Notice that the current project name appears at the top of the folder menu and the top row within it shows the current folder location: Project C > Folder 3 > Folder a in this example.
Notice that the current project name appears at the top of the folder menu and the top row within it shows the current folder location: Project C > Folder 3 > Folder a in this example.
Create a New Folder
Click the New Folder icon in the folder menu to create a new folder.
Delete a Folder
To delete a folder, select Admin > Folder > Management, highlight the intended folder and click Delete. You will be shown a list of the contents and asked to confirm the deletion.Permalink URL
Note that permalink URLs are available for each folder: click the paperclip icon next to the New Folder icon on the folders menu for a permalink to the current folder. Clicking this link from a project home page gives you a permalink to the project itself.Context Sensitive Help
Pull down the Help menu in the upper right to obtain a link directly to either the support forums or to the relevant portion of the documentation, when available.
Project and Folder Basics
 Projects are top-level folders with some extra functionality and importance. Because projects are, for the most part, important and central folders, oftentimes projects and folders are referred to together simply as "folders". (For example, projects are managed via the folder management page at Admin > Folder > Management.) Projects are the centers of configuration in LabKey Server: settings and objects in a project are generally available in its subfolders through inheritance. Think of separate projects as potentially separate web sites or applications. Many of the things that could distinguish web sites (e.g., user groups and look-and-feel) are configured at the project level, and can be inherited at the folder level. A new installation of LabKey Server comes with two pre-configured projects: the Home project and the Shared project. The Home project begins as a relatively empty project with a standard configuration. The Shared project has a special status: resources in the Shared project are available in the Home project and any other projects and folders you create.Folders can be thought of partly as pages on a website, and partly as functional data containers within a project. Folders are containers that partition the accessibility of data records within a project. For example, users might have read & write permissions on data within their own personal folders, no permissions on others' personal folders, and read-only permissions on data in the project-level folder. These permissions will normally apply to all records within a given folder. There are a variety of folder types (types which apply equally to projects) each preconfigured to support specific functionality, from collaboration and file sharing to complex assay analysis and data integration applications. For example, the study folder type is preconfigured for teams working with longitudinal and cohort studies. The assay folder type is preconfigured for teams working with instrument-derived data. For an inventory of the different folder types, see Folder Types. The specific functionality of a folder is determined by the modules it enables. Modules are units of add-on functionality containing a characteristic set of data tables and user interface elements. You can extend the functionality of any base folder type by enabling additional modules. Modules are controlled via the Folder Types tab at Admin > Folder > Management.A screen shot showing the the folder navigation menu:
Projects are top-level folders with some extra functionality and importance. Because projects are, for the most part, important and central folders, oftentimes projects and folders are referred to together simply as "folders". (For example, projects are managed via the folder management page at Admin > Folder > Management.) Projects are the centers of configuration in LabKey Server: settings and objects in a project are generally available in its subfolders through inheritance. Think of separate projects as potentially separate web sites or applications. Many of the things that could distinguish web sites (e.g., user groups and look-and-feel) are configured at the project level, and can be inherited at the folder level. A new installation of LabKey Server comes with two pre-configured projects: the Home project and the Shared project. The Home project begins as a relatively empty project with a standard configuration. The Shared project has a special status: resources in the Shared project are available in the Home project and any other projects and folders you create.Folders can be thought of partly as pages on a website, and partly as functional data containers within a project. Folders are containers that partition the accessibility of data records within a project. For example, users might have read & write permissions on data within their own personal folders, no permissions on others' personal folders, and read-only permissions on data in the project-level folder. These permissions will normally apply to all records within a given folder. There are a variety of folder types (types which apply equally to projects) each preconfigured to support specific functionality, from collaboration and file sharing to complex assay analysis and data integration applications. For example, the study folder type is preconfigured for teams working with longitudinal and cohort studies. The assay folder type is preconfigured for teams working with instrument-derived data. For an inventory of the different folder types, see Folder Types. The specific functionality of a folder is determined by the modules it enables. Modules are units of add-on functionality containing a characteristic set of data tables and user interface elements. You can extend the functionality of any base folder type by enabling additional modules. Modules are controlled via the Folder Types tab at Admin > Folder > Management.A screen shot showing the the folder navigation menu: Tabs are further subdivisions available in projects or folders. Tabs are used to group together different panels, tools, and functionality. Tabs are sometimes referred to as "dashboards", especially when they contain a collection of tools focused on an individual research task, problem, or set of data.Web Parts are user interface panels that can be placed on tabs. Each web part provides a different data tool, or way to interact with data in LabKey Server. Examples of web parts are: data grids, assay management panels, data pipeline panels, file repositories for browsing and uploading/downloading files, and many more. For an inventory of the different web parts, see Web Part Inventory.Applications are created by assembling the building blocks listed above. For example, you can assemble a data dashboard application by adding web parts to a tab providing tools and windows on underlying data. For details see Build User Interface.A screen shot showing an application built from tabs and web parts:
Tabs are further subdivisions available in projects or folders. Tabs are used to group together different panels, tools, and functionality. Tabs are sometimes referred to as "dashboards", especially when they contain a collection of tools focused on an individual research task, problem, or set of data.Web Parts are user interface panels that can be placed on tabs. Each web part provides a different data tool, or way to interact with data in LabKey Server. Examples of web parts are: data grids, assay management panels, data pipeline panels, file repositories for browsing and uploading/downloading files, and many more. For an inventory of the different web parts, see Web Part Inventory.Applications are created by assembling the building blocks listed above. For example, you can assemble a data dashboard application by adding web parts to a tab providing tools and windows on underlying data. For details see Build User Interface.A screen shot showing an application built from tabs and web parts:
Site Structure: Best Practices
Things to Consider When Setting Up a Project
Consider the following factors when deciding how to provision your work into projects and folders.Projects and FoldersShould I structure my work inside of one project, or many?- Single Project Strategy. In most cases, one project, with one layer of subfolders underneath is sufficient. Using this pattern, you configure permissions on the subfolders, granting focused access to the outside audience/group using them, while granting broader access to the project as a whole for admins and your team. If you plan to build views that look across data stored in different folders, it is generally best to keep this data in folders under the same project. The "folder filter" option for grid views (see Query Scope: Filter by Folder) lets you show data from child folders as long as they are stored in the same project.
- Multiple Project Strategy. Alternatively, you can set up separate projects for each outside group (for example, a lab, an institution, or a specific consortia). This keeps resources more cleanly partitioned between groups, but you will not be able to query data across all of the projects as easily, since it is generally more convenient to query data when it is all in the same project. That said, you can create queries that span multiple projects using custom SQL queries that pull data from each of the projects you want to include (for details see Cross-Folder Queries). Or you can use linked schemas to query data in another project (see Linked Schemas and Tables).
- If you wish different areas of your site to have distinct looks (colors, logos, etc.), make these areas separate projects. Folders do not have independent settings for look-and-feel.
- Avoid using separate folders just for navigation or presenting multiple user pages. Use tabs or wiki pages within one folder if you don't need the folder's security features.
- Many resources (such as assay designs and database schema) located at the project level are available by inheritance in that project's subfolders, reducing duplication and promoting data standardization.
- Use the "Shared" project, a project created by default on all sites, for global, site-wide resources.
- Site structure is not written in stone. You can relocate any folder, moving it to a new location in the folder hierarchy, either to another folder or another project. Note that you cannot convert a project in a folder or a folder into a project using the drag-and-drop functionality; but you can use export and re-import to promote a folder into a project or demote a project into a folder.
- Use caution when moving folders to a different project, as the some important aspects of the folder are generally not carried across projects. For example, security configuration and assay data dependent on project-level assay designs are not carried over when moving across projects.
- LabKey Server lets you create subfolders of arbitrary depth and complexity. But deep folder hierarchies tend to be harder to understand and maintain than shallow ones. One or two levels of folders below the project is sufficient for most applications.
- As a general rule, you should structure permissions around groups, not individual users. This helps ensure that you have consistent and clear security policies. Granting roles (= access levels) to individual users one at a time, makes it difficult to get a general picture of which sorts of users have which sorts of access, and makes it difficult to implement larger scale changes to your security policies. Before going live, design and test security configurations by impersonating groups, instead of individual users. Impersonation lets you see LabKey Server through the eyes of different groups, giving you a preview of your security configurations. See the security tutorial for details on impersonation.
- You should decide which groups have which levels of access before you populate those groups with individual users. Working with unpopulated groups gives you a safe way to test your permissions before you go live with your data.
- Make as few groups as possible to achieve your security goals. The more groups you have, the more complex your policies will be, which often results in confusing and counter-intuitive results.
- By default, folders are configured to inherit the security settings of their parent project. You can override this inheritance to control access to particular content using finer-grained permissions settings for folders within the project. For example, you may set up relatively restrictive security settings on a project as a whole, but selected folders within it may be configured to have less restrictive settings, or vice versa, the project may have relatively open access, but folders within it may be relatively closed and restricted.
- Configure LDAP authentication to link with your institutional directory server. Contact LabKey If if you need help configuring LDAP or importing users from an existing LDAP system.
- Take advantage of nested groups. Individual users can populate groups, and so can other groups. Use the overarching group to provide shallow, general access; use the child groups to provide deeper, specific access.
Related Topics
- Project and Folder Basics
- Tutorial: Security - Security basics.
- Look and Feel Settings - Select look and feel options for your site and projects.
- Linked Schemas and Tables - Provide access to selected data (schemas), without providing access to the entire folder.
- LabKey URLs - URLs in LabKey Server reflect paths/locations in the container hierarchy.
Manage Projects and Folders
- Create and arrange folders and control their types and which modules are available in them.
- Determine inheritance of settings from higher level folders and projects.
- Determine whether folder contents should be included in a search.
- Set the default email notification behavior for events that occur within the folder or project.
- Export and import into a folder archive.
- Manage file locations.
- Configure default date and number display formats at the folder level.
View Folder and Project Settings
- Navigate to the folder you want to view or manage.
- Select Admin > Folder > Management to view the Folder Management page.
- Click any tab:

Folder Tree
The folder tree view shows the layout of your site in projects and folders. You can Create a Project or Folder as well as Move, Delete, Rename Projects and Folders, including folders other than the one you are currently in.Folder Type
The available Folder Types are listed in the left hand panel. Selecting one will determine the availability of Modules, listed in the right hand panel, and thus the availability of web parts. You can only change the type of the folder you are currently in.If you choose one of the pre-defined LabKey Folder Types (Collaboration, Assay, Flow, etc.), a suite of Modules is selected for you. Only the web parts associated with checked modules are listed in the drop down Add Web Part on your pages. You can add more modules and web parts to your folder using the module checkboxes.If you choose the Custom Folder Type all modules are automatically included and all web parts will be available in your folder. Checkboxes in this case allow you to select which modules appear on tabs in the UI.Missing Value Indicators
Data columns can be configured to show special values indicating that the original data is missing or suspect. You can define indicators using the Admin Console. Within a folder you can configure which missing value indicators are available.Search
The full-text search feature will search content in all folders where the user has read permissions. Unchecking this box will exclude this folder's content unless the search originates from within the folder. For example, you might exclude archived content or work in progress. For more, see Search Administration.Notifications
The administrator can set default Email Notification Settings for events that occur within the folder. These will determine how users will receive email if they do not specify their own email preferences. For more information, see: Manage Email Notifications.Export/Import
A folder archive is a .folder.zip file or a collection of individual files that conforms to the LabKey folder export conventions and formats. Using export and import, a folder can be moved from one server to another or a new folder can be created using a standard template. For more information see, Export / Import a Folder.Files
LabKey Server allows you to upload and process your data files, including flow, proteomics and study-related files. By default, LabKey stores your files in a standard directory structure. A site administrators can override this location for each folder if desired.Formats
You can define default display formats for dates and floating point numbers to apply to entire folders, projects, and even sites. Format options are outlined in Date and Number Formats Reference. Formats set here will apply throughout the folder, but can be overridden on a per column basis if desired using the field editor on a dataset, list, or other query. If no column- or folder-level formats are defined, the parent-folder hierarchy is checked all the way up to the project and lastly site level.You can also set format defaults at the field-level, the project-level, and the site-level. For details see Date & Number Display Formats..
Formats set here will apply throughout the folder, but can be overridden on a per column basis if desired using the field editor on a dataset, list, or other query. If no column- or folder-level formats are defined, the parent-folder hierarchy is checked all the way up to the project and lastly site level.You can also set format defaults at the field-level, the project-level, and the site-level. For details see Date & Number Display Formats..
Information
The information tab contains information about the folder itself.Reorder the Projects Menu
By default, projects are listed on the popover menu in alphabetical order. To use a custom order instead:- Select Admin > Site > Admin Console.
- Click Project Display Order.
- Click the radio button for Use custom project order.

- Select any project and click Move Up or Move Down.
- Click Save when finished.
Projects Web Part
On the home page of your server, there is a Projects web part by default, listing all the projects on the server. You can add this web part to other pages as needed by selecting Projects from the <Select Web Part> menu in the lower left and clicking Add. The default web part shows all the projects on the server, but you can change what it displays by selecting Customize from the triangle menu. Options include:
The default web part shows all the projects on the server, but you can change what it displays by selecting Customize from the triangle menu. Options include:
- Specify a different Title or label for the web part.
- Change the display Icon Style.
- Folders to Display can be either:
- All Projects
- Specific Folder. When you choose a specific folder, you have two more options:
- Include Direct Children Only: unless you check this box, all subfolders of the given folder will be shown.
- Include Workbooks: workbooks are lightweight folders.
- Hide Create Button can be checked to suppress the create button shown in the web part by default.
Related Topics
Create a Project or Folder
Create a New Project
- To create a new project, either:
- Select Admin > Site > Create Project, or
- Click the Create Project icon at the bottom of the project menu.

- Enter a Name for your project. By default, the name will also be the project title.
- If you would like to specify an alternate title, uncheck the Use name as title box and a new box for entering the title will appear.
- Select a Folder Type, and click Next.
- Choose permissions for the project: My User Only, Copy from Existing Project or Configure Later. Click Next.
- Select Project Settings as desired (see list below), and click Finish.
- You will now be on the home page of your new project.
Project Settings:
- Properties
- Declare inheritance of permissions.
- Customize the look and feel of the project, including headings, colors, logos, and how to connect with project support.
- Customize settings used in system emails.
- Customize default formats for dates and numbers.
- Resources
- Customize the logo, icon, and stylesheets used in the project.
- Menu Bar
- Add or remove tools from the menu bar next to the project and folder menus.
- Folder Settings/Files tab
- Configure the file root for the project.
- Configure the data processing pipeline.
- Permissions
- Adjust permission settings.
- Define project groups and site groups.
Create a New Folder / Subfolder
- To add a folder to a project, navigate to where you want the subfolder. There are two options:
- Select Admin > Folder > Management and click Create Subfolder to create a new (child) folder.

- Or use the Create Folder icon at the bottom of the folder menu.

- Provide a Name. By default, the name will also be the folder title.
- If you would like to specify an alternate title, uncheck the Use name as title box and a new box for entering the title will appear.
- Select a Folder Type.
- Select how to determine Users/Permissions in the new folder.
- Click Finish.
Create a Folder from a Template
You can create a new folder based on an already existing template folder, selecting which objects to copy to the new folder.- To add a folder to a project, select Admin > Folder > Management.
- Select the parent folder.
- Click Create Subfolder to create a new (child) folder.
- Provide a Name, and optional alternate title.
- Select the "Folder Type" radio button Create from Template Folder which will open new input options:
- From the dropdown menu, select an existing folder to use as a template.

- Select the objects you wish to copy from the template and whether to include subfolders. Note that when using a study folder as a template, the dataset data and specimens are not copied to the new folder.
- Click Next.
- Select how to determine Users/Permissions in the new folder.
- Click Finish to accept the defaults (you can change them later) and go directly to your new folder.
- Select Finish and Configure Permissions to open the folder permissions page. When you save and finish, you will be in your new folder.
Move, Delete, Rename Projects and Folders
Move a Project
Since a project is essentially a top-level folder, you can not move it into another project or folder. An administrator can, however, adjust the order in which projects appear on the project menu.- Select Admin > Folder > Management.
- Click Change Display Order.
- Select Use custom project order and then select a project you want to move and click Move Up or Move Down to arrange as desired.
- Click Save.
Move a Folder
A folder can be moved within a project.- Select Admin > Folder > Management.
- To move a folder, drag and drop it into another folder.

- Click Confirm Move.
- If your folder inherits configuration or permissions settings from the parent project, be sure to confirm that inherited settings are as intended after the move to the new parent. An alternative is to export and re-import the folder which gives you the option to retain project groups and role assignments. For details, see Export and Import Permission Settings.
- If the folder is using assay designs or sample sets defined at the project level, they will no longer have access to them.
Delete a Folder / Project
- Select Admin > Folder > Management.
- Select a folder or project.
- Click Delete.
- You will see a list of the folder and subfolder contents to review.
- Confirm the deletion.
Change Folder Names and Titles
You can change the folder name or the folder title. The folder name determines the URL path to resources in the folder, so changing the name can break resources that depend on the URL path, such as reports and hyperlinks. If you need to change the folder name, we recommend leaving Alias current name checked to avoid breaking links into the folder.As an alternative to changing the folder name, you can change the title displayed by the folder in page headings. Only page headings are affected by a title change. Navigation menus show the folder name and are unaffected by a folder title change.- Select Admin > Folder > Management.
- Select a folder or project.
- Click Rename.

- To change the folder name, enter a new value under Folder Name, and click Save.
- To change the folder title, uncheck Same as Name, enter a new value under Folder Title, and click Save.
Changing Folder Name Case
Suppose you want to rename the "Demo" folder to the "demo" folder. To change capitalization, rename the folder in two steps to avoid a naming collision, for example, "Demo" to "foobar", then "foobar" to "demo".Hidden Folders
In some cases, you might want to hide a folder from users without administrative access. See Define Hidden Folders for more information and naming conventions.Enable a Module in a Folder
- Navigate to the LabKey folder where you wish to enable the module.
- Select Admin > Folder > Management > Folder Type tab.
- In the Modules list, add a checkmark next to your module to activate it in the current folder.
- Click Update Folder.

Export / Import a Folder
- Create a folder template for standardizing structure.
- Transfer a folder from a staging / testing environment to a production platform.
- Export a selected subset of a folder, such as masking all identifying information to enable sharing of results without compromising PHI.
Export
- To export a folder, go to Admin > Folder > Management and click the Export tab.
- Select the objects to export.
- Choose any options required (not all options are available in all folders).
- Select where to export the archive file.
- Click Export.

Select Export Options
Whether to Include Subfolders in your archive is optional.You can also select several options for protecting private information in a study.- Remove All Columns Tagged as Protected: Selecting this option will exclude all dataset, list, and participant columns that have been tagged as protected columns.
- Shift Participant Dates: Selecting this option will shift selected date values associated with a participant by a random participant-specific offset from 1 to 365.
- Export Alternate Participant IDs: Selecting this option will replace each participant ID with an alternate randomly generated ID.
- Mask Clinic Names: Selecting this option will change the labels for the clinics in the exported list of locations to a generic label (i.e. Clinic).
Select an Export Destination
- If you choose to export to the pipeline root, the exported archive will be placed in the export directory.
- You can place more than one folder archive in a directory if you give them different names.
Import
When you import a folder archive, a new subfolder is not created. Instead the configuration and contents are imported into the current folder, so be sure not to import into the parent folder of your intended location. To create the imported folder as a subfolder, first create a new empty folder, navigate to it, then import the archive there.- To import a folder archive, go to Admin > Folder > Management and click the Import tab.
- You can import from your local machine or from a server accessible location.

Import Folder From Local Source
- Local zip archive: check this option, then Browse or Choose an exported folder archive to import.
- Existing folder: select this option to bypass the step of exporting to an archive and directly import selected objects from an existing folder on the server. Note that this option does not support the import of specimen or dataset data from a study folder.
- Validate All Queries After Import: When selected, queries will be validated upon import and any failure to validate will cause the import job to raise an error. If you are using the check-for-reload action in the custom API, there is a suppress query validation parameter that can be used to achieve the same effect as unchecking this box in the check for reload action. During import, any error messages generated are noted in the import log file for easy analysis of potential issues.
- Show Advanced Import Options: When this option is checked, after clicking Import Folder, you will have the further opportunity to:
- Select specific objects to import
- Apply the import to multiple folders
- Fail import for undefined visits: when you import a study archive, you can elect to cancel the import if any imported dataset or specimen data belongs to a visit not already defined in the destination study or the visit map included in the imported archive. Otherwise, new visits would be automatically created.

Select Specific Objects to Import
By default, all objects and settings from an import archive will be included. For import from a template folder, all except dataset data and specimen data will be included. If you would like to import a subset instead, check the box to Select specific objects to import. You will see the full list of folder archive objects (similar to those you saw in the export options above) and use checkboxes to elect which objects to import. Objects not available in the archive or template folder will be disabled and shown in gray for clarity.This option is particularly helpful if you want to use an existing archive or folder as a structural or procedural template when you create a new empty container for new research.Apply to Multiple Folders
[ Video Overview: Applying Study Templates Across Multiple Folders ]By default, the imported archive is applied only to the current folder. If you would like to apply this imported archive to multiple folders, check Apply to multiple folders and you will see the list of all folders in the project. Use checkboxes to select all the folders to which you want the imported archive applied.Note that if your archive includes subfolders, they will not be applied when multiple folders are selected for the import.This option is useful when you want to generate a large number of folders with the same objects, and in conjunction with the selection of a subset of folder options above, you can control which objects are applied. For instance, if a change in one study needs to be propagated to a large number of other active studies, this mechanism can allow you to propagate that change. The option "Selecting parent folders selects all children" can make it easier to use a template archive for a large number of child folders. When you import into multiple folders, a separate pipeline job is started for each selected container.
When you import into multiple folders, a separate pipeline job is started for each selected container.
Import Folder from Server-Accessible Archive
Click Use Pipeline to select the server-accessible archive to import.Related Topics
Export and Import Permission Settings
- Project groups and their members, both user members and subgroup members (for project exports only)
- Role assignments to individual users and groups (for folder and project exports)
Importing Groups and Members
When groups and their members are imported, they are created or updated according to the following rules:- Groups and their members are created and updated only when importing into a project (not a folder).
- If a group exists with the same name in the target project its membership is completely replaced by the members listed in the archive.
- Members are added to groups only if they exist in the target system. Users listed as group members must already exist as users in the target server (matching by email address). Member subgroups must be included in the archive or already exist on the target (matching by group name).
Importing Role Assignments
When role assignments are imported, they are created according to the following rules:- Role assignments are created when importing to projects and folders.
- Role assignments are created only if the role and the assignee (user or group) both exist on the target system. A role might not be available in the target if the module that defines it isn't installed or isn't enabled in the target folder.
Export Folder Permissions
To export the configuration for a given folder:- Navigate to the folder you wish to export.
- Select Admin > Folder > Management.
- Click the Export tab.
- Place a checkmark next to Role assignments for users and groups.
- Review the other exportable options for your folder -- for details on the options see Export / Import a Folder.
- Click Export.
Export Project Permissions
To export the configuration for a given project:- Navigate to the folder you wish to export.
- Select Admin > Folder > Management.
- Click the Export tab.
- Select one or both of the options below:
- Project-level groups and members (This will export your project-level groups, the user memberships in those groups, and the group to group membership relationships).
- Role assignments for users and groups
- Review the other exportable options for your folder -- for details on the options see Export / Import a Folder.
- Click Export.
Related Topics
Manage Email Notifications
- File events (creation, deletion, and metadata changes)
- Message board events
- Report events, such as changes to report content or metadata. For details see Manage Reports and Charts
- Navigate to the folder you wish to manage.
- Select Admin > Folder > Management.
- Click the Notifications tab.

Default Settings
You can change the default settings for email notifications using the pulldown menus and clicking Update.Daily digest notifications are triggered at 12:05AM.Options for Files notifications include:- No Email: emails are never sent for file events.
- 15 minute digest: an email digest of file events is sent every 15 minutes.
- Daily digest: an email digest of file events is sent every 24 hours -- more precisely, an email will be send out daily at 12:05am.
- No Email: notifications are never sent when messages are posted.
- All conversations: email is sent for each message posted to the message board.
- My conversations: email is sent only if the user has posted a message to the conversation.
- Daily digest of all conversations: an email digest is sent for all conversations.
- Daily digest of my conversations: an email digest is sent only for conversations to which the user has posted messages.
User Settings
This section includes a table of all users with at least read access to this folder who are able to receive notifications by email for message boards and file content events. The current file and message settings for each user are displayed in this table. To edit user notification settings:- Select one or more users using the checkboxes.
- Click Update User Settings.
- Select either For Files or For Messages.

- In the popup, choose the desired setting from the pulldown, which includes an option to reset users to the folder default setting.

- Click Update Settings for X Users. (X is the number of users you selected).
Related Topics
- Manage Notifications - Subscribe to a digest of notifications when reports or datasets change within a LabKey Study.
- Administer Message Boards
Define Hidden Folders
Create a Hidden Folder
Folders whose names begin with "." or "_" are automatically hidden from non-admins in the navigation tree.Note that the folder will still be visible in the navigation tree if it has non-hidden subfolders (i.e., folders where the user has read permissions). If an admin wishes to hide subfolders of a hidden folder, he/she can prefix the names of these subfolders with a dot or underscore as well.Hiding a folder only affects its visibility in the navigation tree, not permissions to the folder. So if a user is linked to the folder or enters the URL directly, the user will be able to see and use the folder.View Hidden Folders
You can use the "Show Admin" / "Hide Admin" toggle to show the effect of hiding folders from the perspective of a non-admin.Folder Types
- Select Admin > Folder > Management.
- Choose the Folder Type tab.
- Folder types appear on the left.
- Each folder type comes with a characteristic set of activated modules. Modules appear on the right - activated modules have checkmarks.
| Folder Type | Description |
|---|---|
| Collaboration | A Collaboration folder is analogous to a web site for publishing and exchanging information. Available tools include Message Boards, Issue Trackers and Wikis. Depending on how your project is secured, you can share information within your own group, across groups, or with the public. |
| Assay | An Assay folder is used to design and manage instrument data and includes tools to analyze, visualize and share results. |
| Dataspace | This folder type is part of the Collorative Dataspace project, providing browsing and querying across multiple studies. For details see the CAVD Dataspace Case Study. |
| Flow | A Flow folder manages compensated, gated flow cytometry data and generates dot plots of cell scatters. Perform statistical analysis and create graphs for high-volume, highly standardized flow experiments. Organize, archive and track statistics and keywords for FlowJo experiments. |
| MS1 | A folder of type MS1 allows you to combine MS1 quantitation results with MS2 data. |
| MS2 | A folder of type MS2 is provided to manage tandem mass spectrometry analyses using a variety of popular search engines, including Mascot, Sequest, and X!Tandem. Use existing analytic tools like PeptideProphet and ProteinProphet. |
| Microarray | A Microarray folder allows you to import and analyze microarray data. |
| Panorama | Panorama folders are used for all workflows supported by Skyline (SRM-MS, MS1 filtering or MS2 based projects). Three configurations are available for managing targeted mass spectrometry data, management of Skyline documents, and quality control of instruments and reagents. |
| Study | A Study folder manages human and animal studies involving long-term observations at distributed sites, including multiple visits, standardized assays, and participant data collection. You can use a specimen repository for samples. Modules are provided to analyze, visualize and share results. |
| Custom | Create a tab for each LabKey module you select. A legacy feature used in older LabKey installations, provided for backward compatibility. Note that any LabKey module can also be enabled in any folder type via Folder Management. Note that in this legacy folder type, you cannot customize the tabs shown - they will always correspond with the enabled modules. |
| Create From Template Folder | Create a new project or folder using an existing folder as a template. You can choose which parts of the template folder are copied and whether to include subfolders. |
Community Modules
Announcements
Provides a ready-to-use message board where users can post announcements and files, and participate in threaded discussions. See Messages.Audit
Records user activity on the server. See Audit Site Activity.Core
The Core module provides central services such administration, folder management, user management, module upgrade, file attachments, analytics, and portal page management.DataIntegration
Implements the Extract-Transform-Load (ETL) functionality.Demo
The Demo module helps you get started building your own LabKey Server module. It demonstrates all the basic concepts you need to understand to extend LabKey Server with your own module.Elisa
Implements the ELISA assay.ELISpotAssay
Implements the ELISpot assay.Experiment
The Experiment module provides annotation of experiments based on FuGE-OM standards. This module defines the XAR (eXperimental ARchive) file format for importing and exporting experiment data and annotations, and allows user-defined custom annotations for specialized protocols and data.Web Parts included:- Experiment Runs
- Experiments
- Lists
- Sample Sets
- Single List
- Experiments -> Narrow
- Protocols -> Narrow
- Sample Sets -> Narrow
FCSExpress
Supports importation and analysis of flow cytometry data from FCS Express.FileContent
The FileContent module lets you share files on your LabKey Server via the web.Web parts included:- Files
Flow
The Flow module supplies flow-specific services to the flow application.- Flow Analysis (Flow Analysis Folders)
- Flow Analysis Scripts
- Flow Overview (Experiment Management)
Issues
The Issues module provides a ready-to-use workflow system for tracking tasks and problems across a group.List
Lists are light-weight data tables, often used to hold utility data that supports an application or project, such as a list of instrument configurations.Luminex
Supports Luminex data import and analysis.Microarray
Implements the Microarray assay type.MS1
The MS1 module supplies MS1-specific services to the MS1 application.MS2
The MS2 module supplies MS2-specific services to the MS2/CPAS application.- MS2 Runs
- MS2 Runs, Enhanced
- MS2 Sample Preparation Runs
- Protein Search
- MS2 Statistics -> Narrow
- Protein Search -> Narrow
NAb
The NAb module provides tools for planning, analyzing and organizing experiments that address Neutralizing Antibodies. No web parts are provided. Access NAb services via a custom tab in a custom folder.Pipeline
The Data Pipeline module uploads experiment data files to LabKey Server. You can track the progress of uploads and view log and output files. These provide further details on the progress of data files through the pipeline, from file conversion to the final location of the analyzed runs.Query
The Query module allows you to create customized views by filtering and sorting data.Search
The Search module offers full-text search of server contents, implemented by Lucene.Study
The Study module provides a variety of tools for integration of heterogeneous data types, such as demographic, clinical, and experimental data. Cohorts and participant groups are also supported by this module.Survey
The Survey module supports custom user surveys for collecting user information, feedback, or participant data.TargetedMS
Supports targeted mass spectrometry proteomics experiments.Visualization
Implements the core data visualization features, including box plots, scatter plots, time charts, etc.Wiki
The Wiki module provides a simple publishing tool for creating and editing web pages on the LabKey site. It includes the Wiki, Narrow Wiki, and Wiki TOC web parts.Workbooks
- Searchable with full-text search.
- A light-weight folder alternative, workbooks do not appear in the folder tree, instead they are displayed in the Workbooks web part.
- Some per-folder administrative options are not available, such as setting modules, missing value indicators or security. All of these settings are inherited from the parent folder.
- Lists and assay designs stored in the parent folder/project are visible in workbooks. A list may also be scoped to a single workbook.
Create a Workbook
Workbooks are an alternative to folders, added through the Workbooks web part. In addition to the name you give a workbook, it will be assigned an ID number.- Select Workbooks from the <Select Web Part> drop-down menu, and click Add.
- To create a new workbook, click Insert New.

- Specify a workbook Title and Description.
- Click Create Workbook.
Default Workbook
The default workbook includes the Experiment Runs and Files web parts for managing files and data. The workbook is assigned a number for easy reference, and you can edit both title and description by clicking the pencil icons.
Navigating Experiments and Workbooks
Since workbooks are not folders, you don't use the folder menu to navigate among them. From the Workbooks web part on the main folder page, you can click the Title of any workbook or experiment to open it. From within a workbook, click it's name in the navigation trail to return to the main workbook page.Display Workbooks from Subfolders
By default, only the workbooks in the current folder are shown in the Workbooks web part. If you want to roll up a summary including the workbooks that exist in subfolders, select Views > Folder Filter > Current folder and subfolders.
List Visibility in Workbooks
Lists defined within a workbook are scoped to the single workbook container and not visible in the parent folder or other workbooks. However, lists defined in the parent folder of a workbook are also available within the workbook, making it possible to have a set of workbooks share a common list if they share a common parent folder. Note that workbooks in subfolders of that parent will not be able to share the list, though they may be displayed in the parent's workbooks web part.In a workbook, rows can be added to a list defined in the parent folder. From within the workbook, you can only see rows belonging to that workbook. From the parent folder, all rows in the list are visible in the list, including those from all workbook children. Rows are associated with their container, so by customizing a grid view to display the Folder fields at the parent level, it is possible to determine the workbook or folder to which the row belongs.The URL for a list item in the parent folder will point to the row in the parent folder even for workbook rows.Establish Terms of Use

Project Specific Terms of Use
To add a terms of use page scoped to a particular project, create a wiki page at the project-level with the name _termsOfUse (note the underscore). To remove the terms of use restriction, you must delete the _termsOfUse wiki page from the project. If necessary, you can link to larger documents, such as other wiki pages or attached files, from this page.To add a project-scoped terms of use page:- In the Wiki web part, click the the dropdown triange and select New.
- Name the new page _termsOfUse
- Text provided in the Title field will show up in the table of contents for the wiki.
- Text added in the Body field will be rendered as HTML in the body of the page.
Site-Wide Terms of Use
A "site-wide" terms of use requires users to agree to terms whenever they attempt to login to any project on the server. Users will be required to accept the terms of use for the site for each new session, which includes each new log in. If the text of the terms of use changes after a user has already logged in and accepted the terms, this will not require that the terms be accepted again. When both site-scoped and project-scoped terms of use are present, then the project-scoped terms will override the site-scoped terms, i.e., only the project-scoped terms will be presented to the user, while the site-scoped terms will be skipped.To add a site-wide terms of use page:- Select Admin > Site > Admin Console.
- In the Mangagement section, click Site-wide Terms of Use.
- You will be taken to the New Page wizard:
- Notice the Name of the page is prepopulated with the value "_termsOfUse" -- do not change this value.
- Add a value for the Title.
- Add HTML content to the page, using either the Visual or Source tabs. (You can convert this page to a wiki-based page if you wish.) Explain to users what is required of them to utilize this site.
- Click Save and Close.
- The terms of use page will go into effect after saving the page.
- Select Admin > Site > Admin Console.
- In the Mangagement section, click Site-wide Terms of Use.
- Click Delete Page.
- Confirm the deletion by clicking Delete.
- The terms of use page will no longer be shown to users upon entering the site.
Security
Topics
- Tutorial: Security: Security basics.
- The Site Administrator: The site admin has global privileges on the LabKey site.
- Configure Permissions: Setting permissions for a group on a project or folder.
- Security Groups: Assigning users to security groups.
- Security Roles Reference: The permission levels available to be granted to users.
- User Accounts: Adding users to your LabKey site and managing their accounts.
- Authentication - Configure authentication providers.
- Test Security Settings: Testing security settings for users in various groups.
Related Topics
- Manage Study Security (Dataset-Level Security) - Covers security management specific to studies.
- Securing Portions of a Dataset (Row and Column Level Security) - How to expose specific portions of a dateset, without granting access to the dataset as a whole.
- Export and Import Permission Settings - Export and Re-import security settings to another environment.
- HTML Encoding - Describes the most important web application security vulnerabilities and how to protect against script injection.
- Remote Login API - The remote login/permissions service allows cooperating websites to use LabKey Server for authentication and attach permissions to their own resources based on permissions in LabKey Server.
Configure Permissions
Roles
A role is a named set of permissions that defines what members of a group can do. You secure a project or folder by specifying a role for each group defined for that resource. The privileges associated with the role are conferred on each member of the group. For more information, see Security Roles ReferenceSetting Project-level and Folder-level Permissions
To assign a role (a set of permissions) to a group or individual, navigate to the "Permissions" page at Admin > Folder > Permissions.Set the scope of the role assignment by selecting the project/folder in the left-hand pane. In the image below the demo subfolder is selected. (Note that the demo subfolder has a asterisk next to it. This means that the subfolder inherits the role assignments from its parent folder, Study.) To grant a role to a group, locate the role from the Roles column and then select the group from the downdown Add user to group. In the image below, the Editor role is being granted to the Issues Editors group.
To grant a role to a group, locate the role from the Roles column and then select the group from the downdown Add user to group. In the image below, the Editor role is being granted to the Issues Editors group. Permissions can be revoked from a group by clicking the x next to that group. In the image below, the Author role would be revoked from the Editors group by clicking the x.
Permissions can be revoked from a group by clicking the x next to that group. In the image below, the Author role would be revoked from the Editors group by clicking the x. You can also drag and drop users and groups from one role to another. Notice that dragging and dropping between roles removes the group from the source role and then adds it to the target role. If you want to end up with both roles assigned, you would need to add to the second group instead.
You can also drag and drop users and groups from one role to another. Notice that dragging and dropping between roles removes the group from the source role and then adds it to the target role. If you want to end up with both roles assigned, you would need to add to the second group instead. You can set a folder to inherit permissions from its immediate parent by checking the checkbox Inherit permissions from parent, as shown below.
You can set a folder to inherit permissions from its immediate parent by checking the checkbox Inherit permissions from parent, as shown below. Click Save and Finish or Save when you are finished configuring permissions. If you cancel or leave the page, your changes will not be saved.
Click Save and Finish or Save when you are finished configuring permissions. If you cancel or leave the page, your changes will not be saved.
Site-Level Permissions
A few specific permissions options are available at the site level, allowing access to certain features by non-admin users:- Troubleshooter: Allows access to an abbreviated admin menu; troubleshooters can to view but not change administration settings and diagnostics.
- See Email Addresses: Only admins or users granted this permission can see email addresses.
- See Audit Log Events: Only admins or users granted this permission may view audit log events.
- Email Non-Users: Allows emails to be sent to addresses that are not associated with LabKey Server accounts.
- Select Admin > Site > Site Permissions.

Permission Rules
The key things to remember about configuring permissions are:Permissions are additive. This means that if a user belongs to any group that has particular permissions for a project or folder, they will have the same permissions to that project or folder, even if they belong to another group that has no permissions for the same resource. If a user belongs to two groups with different levels of permissions, the user will always have the greater of the two sets of permissions on the resource. For example, if one group has admin privileges and the other has read privileges, the user who belongs to both groups will have admin privileges for that project or folder.Additive permissions can get tricky. If you are restricting access for one group, you need to make sure that other groups also have the correct permissions. For example, if you set permissions on a project for the Logged in users (Site Users) group to No Permissions, but the Guests (Anonymous) group has read permissions, then all site users will also have read permissions on the project.Folders can inherit permissions. In general, only admins automatically receive permissions to access newly-created folders. However, default permissions settings have one exception. In the case where the folder admin is not a project or site admin, permissions are inherited from the parent project/folder. This avoids locking the folder creator out of his/her own new folder. If you create such a folder, you will need to consider whether it should have different permissions than its parent.Permission Levels for Roles
Please see Security Roles Reference for a list of the available LabKey roles and the level of permissions available to each one. As described above, assigning a role to a groups sets the group's level of permissions.Permission for Reports and Views
Please see Matrix of Report, Chart, and Grid Permissions for additional information about how roles define report and view permissions.Security Groups
- global groups: built-in groups which have configurable permissions for every project.
- project groups: defined only for a particular project and the folders beneath it.
- site groups: defined by an admin on a site-wide basis which have configurable permissions for every project.
Related Video
Global Groups
The Site Administrators Group
The Site Administrators group includes all users who have been added as global administrators. Site administrators have access to every resource on the LabKey site, with a few limited special use exceptions. Only users who require these global administrative privileges should be added to the Site Administrators group. A project administrator requires a similarly high level of administrative access, but only to a particular project, and should be part of the Site Users group, described below and then added to the administrators group at the project level only.All LabKey security begins with the first site administrator, the person who installs and configures LabKey Server, and can add others to the Site Administrators group. Any site admin can also add new users to the LabKey site and add those users to groups. Only a site admin can create a new project on LabKey or designate administrative privileges for a new project. The site admin has other unique privileges as well; see Site Administrator for more information on the role of the site admin.The Site Administrators group is implicit in all security settings. There's no option to grant or revoke folder permissions to this group under Admin > Folder > Permissions.Developers Group
The Developers group is a site-level security group that allows the creation of server-side scripts and code. Developers can add the following:- <script> tags to HTML pages
- R reports to data grids (using the menu Reports > Create R Report on a data grid)
- JS reports to data grids (using the menu Reports > Create JavaScript Report on a data grid)
 Note that you cannot impersonate the Developers group directly. As a workaroud, impersonate an individual user who has been added to the Developers group.
Note that you cannot impersonate the Developers group directly. As a workaroud, impersonate an individual user who has been added to the Developers group.
The Site Users Group
The site-level group consists of all users who are logged onto the LabKey system, but not site admins. You don't need to do anything special to add users to the Site Users group; any users with accounts on your LabKey Server will be part of the Site Users group.The Site Users group is global, meaning that this group automatically has configurable permissions on every resource on the LabKey site.The purpose of the Site Users group is to provide a way to grant broad access to a specific resource within a project without having to open permissions for an entire project. Most LabKey users will work in one or a few projects on the site, but not in every project.For instance, you might want to grant Reader permissions to the Site Users group for a specific subfolder containing public documents (procedures, office hours, emergency contacts) in a project otherwise only visible to a select team. The select team members are all still members of the site users group, meaning the resource will be visible to all users regardless of other permissions or roles.The Guests/Anonymous Group
Anonymous users, or guests, are any users who access your LabKey site without logging in. The Guests group is a global group whose permissions can be configured for every project and folder. It may be that you want anonymous users to be able to view wiki pages and post questions to a message board, but not to be able to view MS2 data. Or you may want anonymous users to have no permissions whatsoever on your LabKey site. An important part of securing your LabKey site or project is to consider what privileges, if any, anonymous users should have.Permissions for anonymous users can range from no permissions at all, to read permissions for viewing data, to write permissions for both viewing and contributing data. Anonymous users can never have administrative privileges on a project.Site Groups
Create a Site Group and Manage Membership
View current site groups by selecting Admin > Site > Site Groups: Create a new group. Enter the name of the new group, then click the Create new group button. You may add users or groups and define permissions, then click Done.Manage a group. Users can also be added and deleted from a group by clicking on the group name to view a pop-up dialog box.
Create a new group. Enter the name of the new group, then click the Create new group button. You may add users or groups and define permissions, then click Done.Manage a group. Users can also be added and deleted from a group by clicking on the group name to view a pop-up dialog box.
- Add a single user or group using the pulldown at the top right.
- Remove a user from the group by clicking the [remove] button.
- View an individual's permissions via the [permissions] link next to his/her email address.
- Manage permissions for the group as a whole by clicking the Permissions > link at the top of the pop-up dialog box.
- The Manage Groups > link allows you to add or remove users in bulk as well as send a customized notification message to newly added users.
Grant Project-Level Permissions to a Site Group
To set project-level permissions to Site Groups (including the built-in groups Guests and All site users), select Admin > Folder > Permissions from the project or folder. See Configure Permissions for more information.Project Groups
Create a Project Group and Manage Membership
View current project groups by selecting Admin > Folder > Permissions and clicking the Project Groups tab. To create a new group, type the name into the box and click Create New Group. In the popup window, you can use the pulldown to add project or site users to your new group right away, or you can simply click Done to create the empty group. Your new group will be available for granting roles and can be impersonated even before adding actual users.Later, return to the project group list, click the group name, then Manage Group to add users.
In the popup window, you can use the pulldown to add project or site users to your new group right away, or you can simply click Done to create the empty group. Your new group will be available for granting roles and can be impersonated even before adding actual users.Later, return to the project group list, click the group name, then Manage Group to add users.
Default Project Groups
When you create a new project, you can elect whether to start the security configuration from scratch ("My User Only") or clone the configuration from an existing project. Every new project started from scratch includes a default "Users" group. It is empty when a project is first created, and not granted any permissions by default.It is common to create an "Administrators" group, either at the site or project level. It's helpful to understand that there is no special status confirmed by creating a group of that name. All permissions must be explicitly assigned to named groups. A site administrator can configure a project so that no other user has administrative privileges there. What is important is not whether a user is a member of a project's "Administrators" group, but whether any group that they belong to has the administrator role for a particular resource.Permissions are configured individually for every individual project and folder. Granting a user administrative privileges on one project does not grant them on any other project. Folders may or may not inherit permissions from their parent folder or project.Guests / Anonymous Users
Granting Access to Guest Users
You can choose to grant or deny access to guest users for any given project or folder.To change permissions for guest users, follow these steps:- Go to Admin > Folder > Permissions and confirm the desired project/folder is selected.
- Using the drop-down menus, add the guest group to the desired roles. For example, if you want to allow guests to submit but not read or edit, then add the Guests group in the Submitter section. For more information on the available permissions settings, see Configure Permissions.
- Click Save and Finish.
Default Settings
Guest Access to the Home Project
By default guests have read access to your Home project page, as well as to any new folders added beneath it. You can easily change this by editing folder permissions to uncheck the "inherit permissions from parent" box and removing the guests group from the reader role. To ensure that guest users cannot view your LabKey Server site at all, simply removing the group from the reader role at the home project level.Guest Access to New Projects
New projects by default are not visible to guest users, nor are folders created within them. You must explicitly change permissions for the Guests group if you wish them to be able to view any or all of a new project.Security Roles Reference
Security Roles
A role is a named set of permissions that defines what a user (or group of users) can do.Site Administrator: The site administrator role is the most powerful role in LabKey Server. Site admins can see and do everything that LabKey Server is designed to do in any project or folder on the server. They control the user accounts, configure security settings for any resource, assign roles to users and groups, create and delete folders, etc. See Site Administrator.Users and groups can be assigned the following roles at the project or folder level:Project and Folder Admin: Project and folder admins are like site admins, except their powers are granted only within a given project or folder. Within that scope, like site admins, project/folder admins can configure security settings, assign users to project groups, add new users to the server by adding them to a project group, create and delete subfolders, add web parts, and manage other project and study resources.Editor: The editor role lets the user add new information and in most cases modify existing information. For example, an editor can add and modify wiki pages, post new messages to a message board and edit existing messages, post new issues to an issue tracker and update existing issues, create and manage sample sets, view and manage MS2 runs, and so on.Author: The author role lets you create new data and in some cases edit or delete your own data, but an author may only read and not modify the work of others. For example, a user assigned the author role can edit or delete their own message board posts, but not anyone else's posts. With assay or study data, an author has an expanded role and can modify & delete the data they have added themselves.Reader: The reader role lets you read text and data, but generally you can't modify it.Message Board Contributor: This role lets you participate in message board converstations and Object-Level Discussions. You cannot start new discussions, but can post comments on existing discussions. You can also edit or delete your own comments on message boards.Submitter: The submitter role lets you insert new records, but not view or change other records.Assay Designer: Assay designers may perform several actions related to designing assays.Specimen Coordinator: Specimen Coordinators may perform a number of management tasks related to specimens. A Specimen Coordinator must also be given Reader permission. This role is available only in a project or folder containing a study or with a study in a descendant folder.Specimen Requester: Specimen Requesters may request specimen vials. This role is available only in a project or folder containing a study or with a study in a descendant folder. Developer: Developers can create executable code on the server, for example, adding <script> tags to wiki pages. The developer role is granted by adding a user to the site-level group "Developers". For details see Global Groups.Site Level Permissions
In addition to the above, there are specific permissions that may be assigned at the site level to grant specific subsets of admin permission to individual users or groups.To assign these roles, select Admin > Site > Site Permissions.Troubleshooter: Troubleshooter may view administration settings but may not change them. Troubleshooters see an abbreviated admin menu that allows them to access the Admin Console. Most of the diagnostic links on the Admin Console are available to Troubleshooters.See Email Addresses: Allows selected non-administrators to see email addresses.See Audit Log Events: Only admins and selected non-administrators granted this permission may view audit log events and queries.Email Non-Users: Allows sending email to addresses that are not associated with a LabKey Server user account.Site Administrator
Add Other Site Admins
Keep in mind that any users that you add to the Site Administrators group will have full access to your LabKey site. Most users do not require administrative access to LabKey, and should be added as site users rather than as administrators. Users who require admin permission to a particular project can be granted administrative access at the project level only.- Go to Admin > Site > Site Admins.
- In the Add New Members text box, enter the email addresses for other users who you want to add as global admins.
- Click Done.
Matrix of Report, Chart, and Grid Permissions
General Guidelines
- Guests: Can experiment with LabKey features (time charts, participant reports, etc) but cannot save any reports/report settings.
- Readers: Can save reports but not share them.
- Authors: Can save and share reports (not requiring code).
- Developers: Extends permission of role to reports requiring code.
- Admin: Same as editor permissions.
| Create | Save | Update (owned by me) | Delete (owned by me) | Share with others (mine) | Share with others in child folders | Update (shared by others) | Update properties (shared by others) | Delete (shared by others) | Change sharing (shared by others) | |
|---|---|---|---|---|---|---|---|---|---|---|
| Attachment | Author | Author | Author | Author | Author | Editor | Editor | Editor | Editor | |
| Server file attachment | Site Admin | Site Admin | Site Admin | Site Admin | Site Admin | Site Admin | Site Admin | Site Admin | Site Admin | Site Admin |
| Crosstab | Reader | Reader (non-guest) | Reader (non-guest) | Reader (non-guest) | Author | Project Admin | Editor | Editor | Editor | Editor |
| Custom Report | Reader | Reader (non-guest) | Reader (non-guest) | Reader (non-guest) | Author | Project Admin | Editor | Editor | Editor | Editor |
| Participant Report | Reader | Reader (non-guest) | Reader (non-guest) | Reader (non-guest) | Author | Project Admin | Editor | Editor | Editor | Editor |
| Time Chart | Reader | Reader (non-guest) | Reader (non-guest) | Reader (non-guest) | Author | Project Admin | Editor | Editor | Editor | Editor |
| Query Snapshot | Admin | Admin | Admin | Admin | Admin | Admin | Admin | Admin | ||
| Script-based: | ||||||||||
| Javascript | Developer + Author | Developer + Author | Developer + Author | Developer + Author | Developer + Author | Developer + Project Admin | Developer + Editor | Editor | Editor | Editor |
| R | Developer + Author | Developer + Author | Developer + Author | Developer + Author | Developer + Author | Developer + Project Admin | Developer + Editor | Editor | Editor | Editor |
Related Topics
Role / Permissions Table
Roles / Permissions Table
The table below shows the individual permissions that make up each
role. Roles are listed as columns, individual permissions are listed as
rows. A dot indicates that the individual permission is included in the
given role.
When you set "Update" as the required permission, you are making the
web part visible only to Site Admins, Project Admins, and Editors.
Use this table when deciding the permissions required to view a web part.
| Roles | ||||||||||||||||
| Permissions | Site Admin | Project/Folder Admin | Editor | Author | Reader | Message Board Contributor | Submitter | Assay Designer | Specimen Coordinator | Specimen Requester | Troubleshooter | See Email Addresses | See Audit Log Events | MPower Secure Submitter | Adjudicator | Adjudication Lab Personnel |
| Read | ● | ● | ● | ● | ● | ● | ||||||||||
| Insert | ● | ● | ● | ● | ● | |||||||||||
| Update | ● | ● | ● | |||||||||||||
| Delete | ● | ● | ● | |||||||||||||
| Read Some (= read resources that you own) | ● | ● | ● | ● | ● | ● | ||||||||||
| Administrate | ● | ● | ||||||||||||||
| Design Assays | ● | ● | ● | |||||||||||||
| Design Lists | ● | ● | ● | |||||||||||||
| Edit Shared Query Views | ● | ● | ● | |||||||||||||
| Edit Shared Report | ● | ● | ● | ● | ||||||||||||
| Edit Specimen Data | ● | ● | ● | ● | ||||||||||||
| Export Folder | ● | ● | ||||||||||||||
| Lock Specimens | ● | ● | ● | |||||||||||||
| Manage New Request Form | ● | ● | ● | |||||||||||||
| Manage Notifications | ● | ● | ● | |||||||||||||
| Manage Request Statuses | ● | ● | ● | |||||||||||||
| Manage Specimen Actors | ● | ● | ● | |||||||||||||
| Manage Specimen Display Settings | ● | ● | ● | |||||||||||||
| Manage Specimen Request and Tracking Settings | ● | ● | ● | |||||||||||||
| Manage Specimen Request Default Requirements | ● | ● | ● | |||||||||||||
| Manage Specimen Requests | ● | ● | ● | |||||||||||||
| Manage Study | ● | ● | ● | |||||||||||||
| Read-Only Administrator | ● | ● | ● | |||||||||||||
| Request Specimens | ● | ● | ● | ● | ||||||||||||
| Participate in Message Board Discussions | ● | ● | ● | ● | ● | |||||||||||
| Start New Discussions | ● | ● | ● | ● | ||||||||||||
| Read Secure Message Board | ● | ● | ● | |||||||||||||
| Respond on Secure Message Board | ● | ● | ● | |||||||||||||
| See E-Mail Address | ● | ● | ● | |||||||||||||
| Set Specimen Comments | ● | ● | ● | |||||||||||||
| Share Participant Groups | ● | ● | ● | |||||||||||||
| Share Report | ● | ● | ● | |||||||||||||
| View audit log | ● | ● | ● | ● | ||||||||||||
| Email Non-Users | ● | ● | ||||||||||||||
| Write to secure MPower Controller | ● | |||||||||||||||
| Adjudication | ● | |||||||||||||||
| Adjudication Lab Personnel | ● | |||||||||||||||
Related Topics
User Accounts
Add Users
Users Authenticated by LDAP and Single Sign On
If your LabKey Server installation has been configured to authenticate users with an LDAP server or CAS single sign on, you don't need to explicitly add user accounts to LabKey Server.Every user recognized by the LDAP or single sign on servers can log into LabKey as a member of the global Site Users group using their user name and password. And any user who logs in will automatically be added to the Site Users group, which includes all users who have accounts on the LabKey site.Users Authenticated by LabKey
If you are not using LDAP or single sign on authentication, then you must explicitly add each new user to the site.If you are a site administrator, you can add new users to the LabKey site by entering their email addresses on the Site Users page:- Select Admin > Site > Site Users.
- Click Add Users.
- Enter one or more email addresses.
- Clone permissions from an existing user if appropriate, otherwise individually assign permissions next.
- Click Done.
- Select Admin > Folder > Permissions.
- Click the Project Groups tab.
- Create a new project group or add the user's email address to an existing group.
- Return to the Permissions tab to define the security roles for that group if needed.
- Click Save and Finish when finished.
Manage Users
Site Users
The site administrator can manage all registered users on the site on the Site Users page. Edit user contact information and view group assignments and folder access for each user in the list.- Select Admin > Site > Site Users.

Edit User Contact Info
To edit user contact information, click the Details link next to a user on the Site Users page. Users can also manage their own contact information when they are logged in, by selecting the My Account link from the username pulldown menu that appears in the upper right corner of the screen. The administrator may also force the user to change their password by clicking Reset Password. This will clear the current password and send an email to the user with a link to set a new one before accessing the site.
The administrator may also force the user to change their password by clicking Reset Password. This will clear the current password and send an email to the user with a link to set a new one before accessing the site.
Customize User Properties
You can add fields to the site users table, change display labels or order of existing fields and also define which fields are required during the user registration process.- Select Admin > Site > Site Users.
- Click Change User Properties.
- To add a new field, such as MiddleName shown below:
- Click Add Field and enter the name, label, and type.
- To mark a field as required:
- Select the desired field to open the property editor panel.
- Click the Validators tab.
- Place a checkmark next to Required.
- Click Save when finished.

Manage Permissions
To view the groups that a given users belongs to and the permissions they currently have for each project and folder on the site, click the [permissions] link next to the user's name on the Site Users page.Activate/Deactivate Users
The ability to inactivate a user allows you to preserve a user identity within your LabKey Server even after site access has been withdrawn from the user.When a user is deactivated, they can no longer log in and they no longer appear in drop-down lists that contain users. However, records associated with inactive users still display the users' names. If you instead deleted the user completely, the display name would be replaced with a user ID number.The Site Users and Project Users pages show only active users by default. Inactive users can be shown as well by clicking Include Inactive Users. Site admins can Deactivate and Re-activate users using the links above the grid.
Site admins can Deactivate and Re-activate users using the links above the grid.
View History
The History button leads you to a log of user actions. These include the addition of new users, admin impersonations of users, user deletion, user deactivation, and user reactivation.My Account

Change Password
To change your password click the Change Password button. An administrator may also change the users password, and also has an option to force a reset which will immediately cancel the user's current password and send an email to the user containing a link to the reset password page. The user will remain logged in for their current session, but once that session expires, the user must reset their password before they log in again.Change Email
[ Video Overview: Self-service Email Changes ]To change your email address, click Change Email. You cannot use an email address already in use by another account on the server. Once you have changed your email address, verification from the new address is required within 24 hours or the request will time out. When you verify your new email address you will also be required to enter the old email address and password to prevent hijacking of an unattended account.When all changes are complete, click Done.Edit Account Information
To change your information, click the Edit button. The display name defaults to your email address. It can be set manually to a name that identifies the user but is not a valid email address to avoid security and spam issues. You cannot change your user name to a name already in use by the server. When all changes are complete, click Done.Add an Avatar
You can add an avatar image to your account information by clicking Edit, then clicking Browse or Choose File for the Avatar field.
Manage Project Users
Project Users Management for Project Administrators
The Project Users page allows project administrators without site-level permissions to manage users at the project level.Site admins can manage users across the site via the Site Users page. For this option, see: Manage UsersProject User List
On the Admin -> Folder -> Project Users page, project admins can view and export a list of all project users, plus view their full user event history. The project users page looks and works like Admin -> Site -> Site Users, which is described on the Manage Users page.A project user is defined as any user who is a member of any group within the project. Note that there may be users who have permissions to a project but are not project users (e.g., site admins or users who have permissions because of a site group). Likewise, a project user may not actually have any permissions within a project (e.g., the group they belong to has not been granted any permissions).View/Edit Project User Details
On the Admin -> Folder -> Project Users page, project admins can view (but not modify) each project user's details: profile, user event history, permissions tree within the project, and group events within the project.Impersonate Project Users
Project admins can impersonate project users within the project, allowing the admin to view the project just as the member sees it. While impersonating, the admin can not navigate to any other project (including the Home project). Impersonation is available at Admin -> Folder -> Permissions.Authentication
- Configure Database Authentication - Use LabKey Server's built-in authentication service.
- Configure LDAP - Connect to an LDAP (Lightweight Directory Access Protocol) server to authenticate users against an organization's directory server.
- Configure CAS Single Sign On Authentication - Authenticate users against an Apereo CAS server.
- Configure Duo Two-Factor Authentication - Requires users to provide an additional piece of information to be authenticated.
User Account Creation Options
To open the authentication page:- Select Admin > Site > Admin Console.
- Click Authentication in the configuration section.
Self Sign-up
Self sign-up allows users to register for new accounts themselves when using database authentication. Use caution when enabling this if you have enabled sending email to non-users.When enabled via the authentication page, users will see a "Register for a new account" link on the login page. Clicking it allows them to enter their email address, verify it, and create a new account.
Auto-create Authenticated Users
If one or more of the authentication providers is enabled, auto-creation of new accounts for users who are authenticated is enabled by default. You can disable it, but if you do so, be sure to communicate to your users the process they should follow for creating a LabKey account. For instance, you might require an email request to a central administrator to create accounts.
Additional Topics
- Create a .netrc or _netrc file. Useful for setting up autologin for RlabKey and SAS library access.
- HTTP Basic Authentication. Useful for command-line tools and testing in a trusted environment.
Configure LDAP
Configure LDAP Authentication
To configure LDAP, follow these steps:- Select Admin > Site > Admin Console.
- On the Site Administration page, click Authentication.
- On the Authentication page, next to LDAP, click Configure.
 LDAP Servers: Specifies the addresses of your organization's LDAP server or servers. You can provide a list of multiple servers separated by semicolons. The general form for the LDAP server address is ldap://servername.domain.org:389, where 389 is the standard port for non-secured LDAP connections. The standard port for secure LDAP (LDAP over SSL) is 636. Please note that if you are using secure SSL connections, Java needs to be configured to trust the SSL certificate, which may require adding certificates to the cacerts file.LDAP Domain: A domain name (e.g., "labkey.org") that determines if LabKey attempts LDAP authentication. When a user enters an email address that ends in this domain, LabKey Server attempts LDAP authentication; for all other email addresses, LabKey Server skips LDAP authentication. Use '*' to attempt LDAP authentication on all email addresses entered, regardless of domain.LDAP Principal Template: Enter an LDAP principal template that matches the requirements of the configured LDAP server(s). The template supports substitution syntax: include ${email} to substitute the user's full email address and ${uid} to substitute the left part of the user's email address. The default value is ${email}, which is the format required by Microsoft Active Directory. Other LDAP servers require different authentication templates. For example, Sun Directory Server requires a more detailed DN (distinguished name) such as: uid=myuserid,ou=people,dc=mydomain,dc=org. Check with your network administrator to learn more about your LDAP server.Use SASL authentication: Check the box to use SASL authentication.You can use the Test LDAP Settings link on this page to test your LDAP authentication settings. See below.
LDAP Servers: Specifies the addresses of your organization's LDAP server or servers. You can provide a list of multiple servers separated by semicolons. The general form for the LDAP server address is ldap://servername.domain.org:389, where 389 is the standard port for non-secured LDAP connections. The standard port for secure LDAP (LDAP over SSL) is 636. Please note that if you are using secure SSL connections, Java needs to be configured to trust the SSL certificate, which may require adding certificates to the cacerts file.LDAP Domain: A domain name (e.g., "labkey.org") that determines if LabKey attempts LDAP authentication. When a user enters an email address that ends in this domain, LabKey Server attempts LDAP authentication; for all other email addresses, LabKey Server skips LDAP authentication. Use '*' to attempt LDAP authentication on all email addresses entered, regardless of domain.LDAP Principal Template: Enter an LDAP principal template that matches the requirements of the configured LDAP server(s). The template supports substitution syntax: include ${email} to substitute the user's full email address and ${uid} to substitute the left part of the user's email address. The default value is ${email}, which is the format required by Microsoft Active Directory. Other LDAP servers require different authentication templates. For example, Sun Directory Server requires a more detailed DN (distinguished name) such as: uid=myuserid,ou=people,dc=mydomain,dc=org. Check with your network administrator to learn more about your LDAP server.Use SASL authentication: Check the box to use SASL authentication.You can use the Test LDAP Settings link on this page to test your LDAP authentication settings. See below.
Enable LDAP Authentication
Once you have configured an LDAP server for LabKey Server to use, you can enable it:- To configure LDAP authentication, select Admin > Site > Admin Console.
- On the Site Administration page, click Authentication.
- On the Authentication page, next to LDAP, click Enable.
Authentication Process
When a user logs into LabKey with an email address ending in the LDAP domain, LabKey attempts an LDAP connect to the server(s) using the security principal and password the user just entered. If the LDAP connect succeeds, the user is authenticated; if the LDAP connect fails, LabKey attempts authenticating the credentials using database authentication. See Authentication for more details about the authentication process.LDAP Security Principal Template
The LDAP security principal template must be set based on the LDAP server's requirements. You can specify two properties in the string that LabKey will substitute before sending to the server:| Property | Substitution Value |
|---|---|
| ${email} | Full email address entered on the login page, for example, "myname@somewhere.org" |
| ${uid} | Left part (before the @ symbol) of email address entered on the login page, for example, "myname" |
| Server | Sample Security Principal Template |
|---|---|
| Sun Directory Server | uid=${uid},ou=people,dc=cpas,dc=org |
| Microsoft Active Directory Server | ${email} |
Testing the LDAP Configuration
- From the LDAP Configuration page, click Test LDAP Settings.
- Enter your LDAP Server URL, the exact security principal to pass to the server (no substitution takes place), and the password.
- Check the box if you want to use SASL Authentication.
- Click Test and an LDAP connect will be attempted.
LDAP Search Option
If your LDAP system uses an additional mapping layer between email usernames and security principal account names, it is possible to configure LabKey Server to search for these account names prior to authentication. For example, a username that the LDAP server accepts for authentication might look like 'JEckels', while a user's email address is 'josh.eckels@labkey.com'. Once this alternate mode is activated, instead of an LDAP template, you would provide credentials and a source database in which to look up the security principal account names. To enable:- Add LDAP configuration settings to the labkey.xml configuration file, inside the <context> element. For example:
<Environment name="ldapSearch_username" value="ldapAdmin@email.org" type="java.lang.String" override="false"/>
<Environment name="ldapSearch_password" value="***" type="java.lang.String" override="false"/>
<Environment name="ldapSearch_searchBase" value="dc=email,dc=org" type="java.lang.String" override="false"/>
<Environment name="ldapSearch_lookupField" value="userPrincipalName" type="java.lang.String" override="false"/>
<Environment name="ldapSearch_searchTemplate" value="(&(objectClass=user)(userPrincipalName=${email}))" type="java.lang.String" override="false"/>
- "ldapSearch_username" is the email address of the LDAP user who has permission to "search" your LDAP directory.
- "ldapSearch_password" is the password for the LDAP user specified with "ldapSearch_username"
- "ldapSearch_searchBase" is the searchBase to be used. This could be the root of your directory or the base which contains all of your user accounts.
- "ldapSearch_lookupField" is the optional field to use as a login following the LDAP search. (Default: "sAMAccountName")
- "ldapSearch_searchTemplate" is the optional filter to apply during the LDAP search. Valid substitution patterns are ${email} and ${uid}. (Default: "(&(objectClass=user)(mail=${email}))")
- Restart your Tomcat server.
Configure Database Authentication
- To manage database authentication, select Admin > Site > Admin Console.
- On the Site Administration page, click Authentication.
- On the Authentication page, next to database, click Configure.
Passwords
For details on password configuration see:Passwords
Password Best Practices for LDAP and SSO Users
For installations that run on LDAP or SSO authentication servers, it is recommended that at least one Site Administrator account be associated with LabKey's internal database authenticator as a failsafe. This will help prevent a situation where all users and administrators become locked out of the server should the external LDAP or SSO system fail or change unexpectedly. If there is a failure of the external authentication system, a Site Administrator can sign in using the failsafe database account and create new database authenticated passwords for the remaining administrators and users, until the external system is restored.To create a failsafe database-based password:- Click your login badge (= your user name displayed as a link) in the far upper right.
- Click Create Password. (This will create a failsafe password in the database.)
- Enter your password and click Set Password.
Password Rules
User passwords can be set to either "weak" or "strong" rules.Weak rules require only that the password- Must be more than 6 characters long.
- Must not match the user's email address.
- Must be eight or more characters long.
- Must contain characters from at least three of the following character types:
- lowercase letter (a-z)
- uppercase letter (A-Z)
- digit (0-9)
- symbol (! @ # $ % & / < > = ?)
- Must not contain a sequence matching three or more characters from the user's email, address, display name, first name or last name.
- Must not match any of the user's 10 previous passwords.
Password Expiration
Administrators can also set the password expiration interval. Available expiration intervals are:- Never
- Three months
- Six months
- Twelve months
Password Reset & Security
Password Reset
You can reset your password from the logon screen. Use the "Forgot your password?" link circled in red in the screencapture below: Once you have clicked on this link, you will be prompted for the email address you use on your LabKey Server installation.You will be mailed a secure link. When you follow this link, you will have the opportunity to reset your password.
Once you have clicked on this link, you will be prompted for the email address you use on your LabKey Server installation.You will be mailed a secure link. When you follow this link, you will have the opportunity to reset your password.
Password Security
You are mailed a secure link to maintain security of your account. Only an email address associated with an existing account on your LabKey Server will be recognized and receive a link for a password reset. This is done to ensure that only you, the true owner of your email account, can reset your password, not just anyone who knows your email address.LabKey Server Account Names and Passwords
The name and password you use to log on to your LabKey Server are not typically the same as the name and password you use to log on to your computer itself. These credentials also do not typically correspond to the name and password that you use to log on to other network resources in your organization.You can ask your Admin whether your organization enabled LDAP and made it possible for you to use the same logon credentials on multiple systems.Configure SAML Authentication
 Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
How SAML Authentication Works
From a LabKey sign in page, or next to the Sign In link in the upper right, a user clicks the “SAML” link. As with other authentication providers, this link can be configured with a logo. LabKey generates a SAML request, and redirects the user’s browser to the identity provider's SSO URL with the request attached.The identity provider (IdP) presents the user with its authentication challenge. This is typically in the form of a login screen, but more sophisticated systems might use biometrics, authentication dongles, or other two-factor authentication mechanisms. If the IdP verifies the user against its user store, a signed SAML response is generated, and redirects the user’s browser back to LabKey Server with the response attached.LabKey Server then verifies the signature of the response, decrypts the assertion if it was optionally encrypted, and verifies the email address from the nameId attribute. At this point, the user is considered authenticated with LabKey Server and directed to the server home page (or to whatever page the user was originally attempting to reach). LabKey Server will auto-create the user if they don’t exist (provide the server is configured for auto-creation.)Configure SAML Authentication
- Go to Admin > Site > Admin Console. In the Configuration section, click Authentication.
- You can add logo images that will appear on the standard LabKey sign in page or on the page header "Sign In" link in the upper right. To add logo images, click Pick Logos, and click Choose File for the page header and/or login page links. See the Configure CAS Single Sign On Authentication topic for screenshots of the logo locations.
- Next to SAML, click Configure.
- Note that the configuration settings make use of the encrypted property store, so in order to configure/use SAML, the MasterEncryptionKey must be set in the labkey.xml file. (If it’s not set, attempting to go to the SAML configuration screen displays an error message, directing the administrator to configure the labkey.xml file.)

- Upload Type: For each certificate and key field, select Copy/Paste to paste the content of an X.509 certificate or key pem file. Select File to upload a pem file.
- IdP Signing Certificate: Required field. Either paste an X.509 certificate/pem file directly into the text area or upload a pem file.
- Encryption Certificate and SP Private Key: Optional fields. The encryption certificate and private key for the service provider (SP) Use these fields if you want the assertion in the SAML response to be encrypted. These field work together: they either must both be set, or neither should be set.
- IdP SSO URL: Required field. The target IdP (identity provider) URL for SSO authentication, where the SAML identity provider is found.
- Issuer URL: Optional field. The issuer of the service provider SAML metadata. Some IdP configurations require this, some do not. If required, it’s probably the base URL for the LabKey Server instance.
- NameIdformat: Optional field. This is the NameIdformat specified in the SAML request. Default is emailAddress. Options are emailAddress, transient, and unspecified. If IdP does not support “emailAddress”, one of the other formats may work.
- Force Authorization: Optional field. If checked, sets the “ForceAuthn” attribute in the SAML request, instructing the IdP to ignore any session the user may already have with the IdP and require the user to authenticate again.
- Click Save.
- On the main Authentication configuration page, next to SAML, click Enable and then Done.


SAML Terminology
- IdP: Identity Provider. The authenticating SAML server. This may be software (Shibboleth and OpenAM are two open source software IdPs), or hardware (e.g., an F5 BigIp appliance with the APM module). This will be connected to a user store, frequently an LDAP server.
- SP: Service Provider. The application or server requesting authentication.
- SAML Request: The request sent to the IdP to attempt to authenticate the user. Note that the Base Server URL is included in the SAML request as the EntityId. To control the Base Server URL, go to Admin > Site > Admin Console and click Site Settings. On the Customize Site page, change the Base Server URL as necessary. Note that changing this setting will effect links in emails sent by the server, as well as any short URLs you generate. For details see Site Settings.
- SAML Response: The response back from the IdP that the user was authenticated. A request contains an assertion about the user. The assertion contains one or more attributes about the user. At very least the nameId attribute is included, which is what identifies the user.
SAML Functionality Not Currently Supported
- Metadata generation - LabKey Server supports only static service provider metadata xml.
- Metadata discovery - LabKey Server does not query an IdP for its metadata, nor does the server respond to requests for its service provider metadata.
- Federation participation is not supported.
- More complex scenarios for combinations of encrypted or signed requests, responses, assertions, and attributes are not supported. For example, signed assertions with individually encrypted attributes.
- Processing other attributes about the user. For example, sometimes a role or permissions are given in the assertion; LabKey Server ignores these if present.
- Interaction with an independent service provider is not supported.
- Single logout (SLO)
Configure CAS Single Sign On Authentication
 Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
Enable CAS Single Sign On
To enable CAS single sign on:- Select Admin > Site > Admin Console.
- On the Site Administration page, click Authentication.
- On the Authentication page, next to CAS, click Enable.
Specify a CAS Server
To specify a CAS single sign on server:- If you are not still on the authentication page, select Admin > Site > Admin Console and click Authentication.
- On the Authentication page, next to CAS, click Configure.
- Next to Apereo CAS Server URL, enter a pre-existing CAS server. The URL should end with "/cas"
- Click Save.
Single Sign On Logo
The logos, which can be displayed on either the header area or on the login page, signals to users that single sign on is available. When the logo is clicked, LabKey Server will attempt to authenticate the user against the CAS server.
 To upload logos:
To upload logos:- If you are not still on the authentication page, select Admin > Site > Admin Console and click Authentication.
- On the Authentication page, next to CAS, click Pick Logos.
- Click Choose File to upload header and login page logos.
- Click Save.
Configure Duo Two-Factor Authentication
 Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey

Duo Security Set Up
To set up two-factor authentication, administrator permissions are required. You first sign up for a Duo Administrator account at the following location:Next, you specify how Duo will enroll users, and acquire the necessary information to configure LabKey Server:- Login to Duo at: https://admin.duosecurity.com/login
- On the Duo website, select Applications > New Application.
- On the Application Type dropdown select "Web SDK" and provide an Application Name of your choice.
- Click Create Application.

- Once the Duo Application has been created, you will be provided with an Integration Key, Secret Key, and an API Hostname, which you will use to configure LabKey Server.

- Under Policy, specify the options for how users will be enrolled in Duo.
Configure Two-Factor Authentication on LabKey Server
- Select Admin > Site > Admin Console.
- On the Site Administration page, click Authentication.
- On the Authentication page, next to "Duo 2 Factor", click Configure.
- Enter the following values which you acquired in the previous step:
- Integration Key
- Secret Key
- API Hostname
- User Identifier: Select how to match user accounts on LabKey Server to the correct Duo user account. The default is by User ID, but you can also match based on username or full email address. To match by username, the Duo user name must exactly match the LabKey Server display name.

- Click Test to verify these values.
- Click Save after the verification test is successful.
Enable Two-Factor Authentication
Finally, enable two-factor authentication on LabKey Server:- Select Admin > Site > Admin Console.
- On the Site Administration page, click Authentication.
- On the Authentication page, next to "Duo 2 Factor", click Enable.
Disable Two-Factor Authentication
The preferred way to disable two-factor authentication is through the web interface:- Select Admin > Site > Admin Console.
- On the Site Administration page, click Authentication.
- On the Authentication page, next to Duo 2 Factor, click Disable.
Create a .netrc or _netrc file
Overview
A netrc file is used to hold credentials necessary to login to your labkey server and authorize access to data stored there. The netrc file contains configuration and autologin information for the File Transfer Protocol client (FTP) and other programs. It may be used when working with SAS Macros, Transformation Scripts in Java or using the Rlabkey package.If you receive "unauthorized" error messages when trying to retrieve data from a remote server you should check that your netrc file is configured correctly, you have an entry for that remote machine, and the login credentials are correct. Additional troubleshooting assistance is provided below.Set Up a netrc File
On a Mac, UNIX, or Linux system the netrc file should be named .netrc (dot netrc) and on Windows it should be named _netrc (underscore netrc). The file should be located in your home directory and the permissions on the file must be set so that you are the only user who can read it, i.e. it is unreadable to everyone else. It should be set to at least Read (400), or Read/Write (600)To create the netrc on a Windows machine, first create an environment variable called ’HOME’ that is set to your home directory (c:/Users/<User-Name> on Vista or Windows 7) or any directory you want to use.In that directory, create a text file with the prefix appropriate to your system, either an underscore or dot.The following three lines must be included in the file. The lines must be separated by either white space (spaces, tabs, or newlines) or commas:machine <remote-instance-of-labkey-server>
login <user-email>
password <user-password>
machine mymachine.labkey.org
login user@labkey.org
password mypassword
machine mymachine.labkey.org login user@labkey.org password mypassword
Troubleshooting
Port Independence
Note that the netrc file only deals with connections at the machine level and should not include a port or protocol designation, meaning both "mymachine.labkey.org:8888" and "https://mymachine.labkey.org" are incorrect.If you see an error message similar to "Failed connect to mymachine.labkey.org:443; Connection refused", remove the port number from your netrc machine definition.File Location
An error message similar to "HTTP request was unsuccessful. Status code = 401, Error message = Moved Temporarily" could indicate an incorrect location for your netrc file. In a typical installation, R will look for libraries in a location like \home\R\win-library. If instead your installation locates libraries in \home\Documents\R\win-library, for example, then the netrc file would need to be placed in \home\Documents instead of the \home directory.HTTP Basic Authentication
Basic Authentication
LabKey Server uses form-based authentication by default for all user-agents (browsers). However, it will correctly accept http basic authentication headers if presented. This can be useful for command line tools that you might use to automate certain tasks.For instance, to use wget to retrieve a page readable by 'user1' with password 'secret' you could write:wget <<protectedurl>> --user user1 --password secret
Other Resources
Test Security Settings by Impersonation
- Impersonate a User
- Impersonate a Group
- Impersonate a Role
- Stop Impersonating
- Project-Level Impersonation
- Logging of Impersonations
Impersonate a User:
Impersonating a user is useful for testing a specific user's permissions or assisting a user having trouble on the site.- Select [user account link] > Impersonate > User

- Select a user from the dropdown and click Impersonate
Impersonate a Group:
Impersonating a security group is useful for testing the permissions granted to that group.- Select [user account link] > Impersonate > Group
- Select a group from the dropdown and click Impersonate
Is it Possible to Impersonate the "Guests" Group?
Note that the "Guests" group (those users who are not logged into the server) does not appear in the dropdown for impersonating a group. This means you cannot directly impersonate a non-logged in user. But you can see the server through a Guests eyes by logging out of the server yourself. When you log out of the server, you are seeing what the Guests will see. When comparing the experience of logged-in (Users) versus non-logged-in (Guests) users, it is often convenient to use two different browser types, such as Chrome and Firefox: login using one browser, but remain logged out use the other browser.Impersonate Roles:
Impersonating security roles is useful for testing how the system responds to those roles. This is typically used when developing or testing new features, or by administrators who are curious about how features behave.- Select [user account link] > Impersonate > Roles
- Select one or more roles in the list box and click Impersonate
Stop Impersonating
To return to your own account, click [user account link] > Stop Impersonating.
Project-Level Impersonation
When any admin impersonates a user from the project users page, the administrator sees the perspective of the impersonated user within the current project. All projects that the impersonated user may have access to outside the current project are invisible while in impersonation mode. For example, when impersonating a project-scoped group, a project administrator who navigates outside the project will have limited permissions (having only the permissions that Guests and All Site Users have). Site admins who want to impersonate a user across the entire site can do so from the site users page or the admin console.A project impersonator sees all permissions granted to the user's site and project groups. However, a project impersonator never receives authorization from the user's global roles (currently site admin and developer) -- they are always disabled.Logging of Impersonations
The audit log includes an "Impersonated By" column. This column is typically blank, but when an administrator performs an auditable action while impersonating a user, the administrator's display name appears in that column.Compliance
 Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
Topics
- Compliance: Protected Health Information - Mark columns as either non-PHI, PHI, or Limited. Use this column metadata to control user access in your application. Administrators may control the metadata assignments without viewing the actual PHI data.
- Compliance Settings - Control when unused user accounts expire, how administrators are notified in case of audit logging failures, and set the maximum number of login attempts.
- Compliance Terms of Use - Configure the terms of use presented to the user.
- Compliance Module Logging - Intensive logging for auditing purposes.
Related Topics
- Compliant Access via Session Key - Configure the server to obtain a session key when users log in to avoid storing user credentials on the client machine.
Compliance: Protected Health Information
- Use the LabKey user interface
- Use XML metadata
Using the LabKey User Interface
Note: this functionality will be available in version 17.2.Using XML Metadata
You can mark columns as PHI in the schema definition XML file.In the example below, the column DeathOrLastContactDate has been marked as "Limited":<column columnName="DeathOrLastContactDate">
<formatString>Date</formatString>
<phi>Limited</phi>
</column>
- NotPHI
- Limited
- PHI
- Restricted
Compliance Settings
- Manage Account Expiration
- Manage Inactive Accounts
- Audit Process Failures
- Limit Login Attempts
- Limit Third-Party Identity Service Providers
Manage Account Expiration
You can configure user accounts to expire after a set date. Expiration dates can be set for individual accounts. To set up expiration dates, follow these instructions:- Go to Admin > Site > Admin Console and click Compliance Settings.
- On the Accounts tab, under Manage Account Expiration select Allow accounts to expire after a set date.
- Click Save.
- You can now set expiration dates for user accounts.

- Click the link to the Site Users table. (Or go to Admin > Site > Site Users.)

- Note the Show temporary accounts link. This filters the table to those accounts which are set to expire at some date.
- Click Details for the desired user account.
- On the account details page click Edit.
- Enter an Expiration Date, using the date format Year-Month-Day. For example, to indicate March 3rd 2017, enter "2107-03-01".
- Click Submit.

Manage Inactive Accounts
Inactive accounts can be automatically disabled (i.e., login is blocked) after a set number of days. To set the number of days after which accounts are disabled, follow the instructions below:- Go to Admin > Site > Admin Console and click Compliance Settings.
- On the Accounts tab, under Manage Inactive Accounts, select Disable inactive accounts after X days.
- Use the dropdown to select when the accounts are disabled. Options include: 1 day, 30 days, 60 days, or 90 days.
Audit Process Failures
These settings allow you to send a notification email to administrators if any audit processing fails (for example, if there are any software errors, audit capturing bugs, or if audit storage capacity has been reached). If any of the events that should be stored in LabKey’s Audit Log aren’t processed properly, administrators are informed of the error in order to escalate, fix, or otherwise take action on the issue.You can also control which administrators are informed: either the primary administrator or all site administrators.- Go to Admin > Site > Admin Console and click Compliance Settings.
- Click the Audit tab.
- Under Audit Process Failures, select Response to audit processing failures.
- Select the audience as: Primary Site Admin or All Site Admins.
- Click Save.
- To control the content of the email, click the link email customization, and edit the notification template named "Audit Processing Failure". For details see Email Template Customization.

Unsuccessful Login Attempts
You can decrease the likelihood of an automated, malicious login by limiting the allowable number of login attempts. These settings let you disable logins for a user account after a specified number of attempts have been made. (Site administrators are exempt from this limitation on login attempts.)To see those users with disabled logins, go to the Audit log, and select User events from the dropdown.- Go to Admin > Site > Admin Console and click Compliance Settings.
- Click the Login tab.
- In the section Unsuccessful Logins Attempts, place a checkmark next to Enable login attempts controls.
- Also specify:
- the number attempts that are allowed
- the time period in which the attempts can be made
- the amount of time (in minutes) login will be disabled
Third-Party Identity Service Providers
To restrict the identity service providers to only FICAM-approved providers, follow the instruction below. When the restriction is turn on, non-FICAM authentication providers will be greyed out in the Authentication panel.- Go to Admin > Site > Admin Console and click Compliance Settings.
- Click the Audit tab.
- In the section Third-Party Identity Service Providers, place a checkmark next to Accept only FICAM-approved third-party identity service providers.
Related Topics
Compliance Terms of Use
Configure Terms of Use
- To enter terms of use, go to Admin > Go To Module > Compliance.
- On the Compliance Module Configuration page, click Terms of Use.

- On the Terms of Use grid, select Insert > New Row (to enter a single terms of use) or Insert > Import Bulk Data (to enter multiple terms using an Excel spreadsheet or similar tabular file).

- Field descriptions:
- Activity: Activity roles associated with the terms of use.
- IRB: The Internal Review Board number under which the user is entering the data environment.
- PHI: The PHI level associated with the terms of use.
- Term: Text of the terms of use.
- Sort Order: Determines how the terms are displayed to the user.

Related Topics
Compliance Module Logging
- Which users have seen a given patient's data? What data was viewed by each user?
- Which patients have been seen by a particular user? What data was viewed for each patient?
- Which roles and PHI levels were declared by each user? Were those declarations appropriate to their job roles & assigned responsibilities?
- Was all data the user accessed consistent with the user's declarations?
What Gets Logged
Logging behavior is customized for each client's regulatory requirements. Each application determines how the logging is configured. Possible logging events include:- the security role, IRB, PHI level, and terms of use declared on login.
- the ParticipantIds and columns accessed, including the PHI columns.
- the SQL query used to access data
Related Topics
Admin Console
- View detailed information about the system configuration and installed modules.
- Audit user activity including who is logged in and when.
- Customize the LabKey site, including configuration and testing of LDAP settings.
- View information about the JAR files and executable files shipped with LabKey.
- View information about memory usage and errors.
Navigate to the Admin Console
The Admin Console can be accessed by Site Administrators:- At the top right of your screen, select Admin > Site > Admin Console
Use the Admin Console
A variety of tools and information resources are provided on the Admin Console.Configuration
- Analytics Settings. Add JavaScript to your HTML pages to enable Google Analytics or add other custom script to the head of every page.
- Authentication. View, enable, disable and configure authentication providers (e.g. LDAP, CAS, Duo).
- Change User Properties. Edit fields in the Users table.
- Email Customization. Customize auto-generated emails sent to users.
- Experimental Features. Offers the option to enable experimental features. Proceed with caution as no guarantees are made about the features listed here.
- Files. Configure file system access by setting site file root and configuring file and pipeline directories.
- Flow Cytometry. Settings for the flow module.
- Folder Types. Select which folder types will be available for new project and folder creation. Disabling a folder type here will not change the type of any current folders already using it.
- Look and Feel Settings. Customize colors, fonts, formats, and graphics.
- Mascot Server. Set up integration with a Mascot server.
- Missing Value Indicators. Manage indicators for datasets.
- Profiler. Tracks the duration of requests and any queries executed during the request. Available on servers running in dev mode or for developers in production mode.
- Project Display Order. Choose whether to list projects alphabetically or specify a custom order.
- Short URLs. Define short URL aliases for more convenient sharing and reference.
- Site Settings. Configure a variety of basic system settings, including the name of the default domain and the frequency of system maintenance and update checking.
- System Maintenance. These tasks are typically run every night to clear unused data, update database statistics, perform nightly data refreshes, and keep these server running smoothly and quickly. We recommend leaving all system maintenance tasks enabled, but some of the tasks can be disabled if absolutely necessary. By default these tasks run on a daily schedule. You can change the time of day which they run if desired. You can also run a task on demand by clicking these links:
- Database Maintenance.
- Report Service Maintenance.
- MS1 Data File Purge Task.
- Search Service Maintenance.
- Purge Unused Participants.
- Refresh Study Snapshot Specimen Data. Refreshes the specimen data inside of published studies.
- Views and Scripting. Allows you to configure different types of scripting engines.
- Configure Scripting Engines. Configure scripting engines for quality control or transformation of assay data.
- Install and Set Up R. Configure R scripting engine.
Management
- Audit Log. View the audit log. This includes Copy-To-Study History.
- ETL-All Job History. View a history of all ETLs that have run on the site.
- ETL-Run Site Scope ETLs. ETLs that are "site scoped" (not scoped to a particular folder/container) can be run from here.
- Full-Text Search. Configure and view both primary and external search indexing.
- MS1 and MS2. Administrative information for these modules.
- Ontology. Admin console for defining types, such as SampleSets or Forms.
- Pipeline. Administrative information for the pipeline module.
- Pipeline Email Notification. Enable pipeline notification emails.
- Protein Databases. Protein Database Administration interface.
- Site-Wide Terms of Use. Require users to agree to a terms of use whenever they attempt to login to any project on the server.
Diagnostics
Various links to diagnostic pages and tests that provide usage and troubleshooting information.- Actions. View information about the time spent processing various HTTP requests.
- Caches. View information about caches within the server.
- Check Database. Check database table consistency, validate that domains match tables, and generate a database schema in XML format.
- Credits. Jar and Executable files distributed with LabKey Server modules.
- Data Sources. A list of all the data sources defined in labkey.xml that were available at server startup and the external schemas defined in each.
- Dump Heap. Write the current contents of the server's memory to a file for later analysis.
- Environment Variables. A list of all the current environment variables and their values, for example, CATALINA_HOME = C:apacheapache-tomcat-7.0.52
- Loggers. Log4j loggers. Set the level (info, warn, error, etc.). Use the text box to enter filters.
- Memory Usage. View current memory usage within the server.
- Queries. View the SQL queries run against the database, how many times they have been run, and other performance metrics.
- Reset Site Errors. Reset the start point in the labkey-errors.log file. See View All Site Errors Since Reset below.
- Running Threads. View the current state of all threads running within the server.
- Site Validation. Runs any validators that have been registered. (Validators are registered with the class SiteValidationProvider.)
- SQL Scripts. Provides a list of the SQL scripts that have run, and have not been run, on the server. Includes a list of scripts with errors, and "orphaned" scripts, i.e., scripts that will never run because another script has the same "from" version but a later "to" version.
- System Properties. A list of current system properties and their values, for example, devmode = true.
- Test Email Configuration. View and test current SMTP settings. See labkey.xml Configuration File for information about setting them.
- View All Site Errors. View the current contents of the labkey-errors.log file from the TOMCAT_HOME/logs directory, which contains critical error messages from the main labkey.log file.
- View All Site Errors Since Reset. View the contents of labkey-errors.log that have been written since the last time its offset was reset through the Reset Site Errors link.
- View Primary Site Log File. View the current contents of the labkey.log file from the TOMCAT_HOME/logs directory, which contains all log output from LabKey Server.
Core Database Configuration and Runtime Information
View detailed information about the system configuration.Module Information
View detailed version information for installed modules.Active Users in the Last Hour
Lists who has used the site recently and how long ago.Site Settings
Set site administrators
- Primary site administrator. Use this dropdown to select the primary site administrator. This user must have the Site Administrator role. This dropdown defaults to the first user assigned Site Administrator on the site. LabKey staff may contact this administrator to assist if the server is submitting exception reports or other information that indicates that there is a problem.
Set default domain for user sign-in and base server URL
- System Default Domain: Specifies the default email domain for user ids. When a user tries to sign in with an email address having no domain, the specified value will be automatically appended. You can set this property as a convenient shortcut for your users. Leave this setting blank to always require a fully qualified email address.
- Base Server URL: Used to create links in emails sent by the system and also the root of Short URLs. The base URL should contain the protocol (http or https), hostname, and port if required. The webapp context path should never be added. Examples: "https://www.example.com/" or "https://www.labkey.org:9000" (but not "https://www.example.com/labkey").
- Use "path first" urls (/home/project-begin.view): See LabKey URLs
Automatically check for updates to LabKey Server and report basic usage statistics to the LabKey team
Checking for updates helps ensure that you are running the most recent version of LabKey Server. Reporting anonymous usage statistics helps the LabKey team improve product quality. All data is transmitted securely over SSL.There are two usage reporting levels. For a complete list of usage statistics that are reported, see Usage/Exception Reporting - Details.- Low level: System information including the build number, server operating system, database name and version, JDBC driver and version, number of projects, etc.
- Medium level: All information included at the low level, plus more details including site description, site administrator's email address, the list of modules, etc.
Automatically report exceptions
Reporting exceptions helps the LabKey team improve product quality. All data is transmitted securely over SSL.There are three levels of exception reporting available. For a complete list of information reported at each level, see Usage/Exception Reporting - Details.- Low level: Include anonymous system and exception information, including the stack trace, build number, server operating system, database name and version, JDBC driver and version, etc.
- Medium level: All of the above, plus the exception message and URL that triggered it.
- High level: All of the above, plus the user's email address. The user will be contacted only to ask for help in reproducing the bug, if necessary.
Customize LabKey system properties
Log memory usage frequency: If you are experiencing OutOfMemoryErrors with your installation, you can enable logging that will help the LabKey development team track down the problem. This will log the memory usage to TOMCAT_HOME/logs/labkeyMemory.log. This setting is used for debugging, so it is typically disabled and set to 0.Maximum file size, in bytes, to allow in database BLOBs: LabKey Server stores some file uploads as BLOBs in the database. These include attachments to wikis, issues, and messages. This setting establishes a maximum file size to be stored as a BLOB. Users are directed to upload larger files using other means, which are persisted in the file system itself.Require ExtJS v3.4.1 to be loaded on each page: Optional.Require ExtJS v3.x based Client API be loaded on each page: Optional.Configure Security
Require SSL connections: Specifies that users may connect to your LabKey site only via SSL (that is, via the https protocol).SSL port: Specifies the port over which users can access your LabKey site over SSL. The standard default port for SSL is 443. Note that this differs from the Tomcat default port, which is 8443. Set this value to correspond to the SSL port number you have specified in the <tomcat-home>/conf/server.xml file. See Configure the LabKey Web Application for more information about configuring SSL.API session keys: Enable to make session keys available to logged in users for use in client APIs. See Compliant Access via Session Key for more details.Configure Pipeline settings
Pipeline tools. A semicolon separated list of directories on the web server which contain the executables that are run for pipeline jobs. It should include the directories where your TPP and XTandem files reside. The appropriate directory will entered automatically in this field the first time you run a schema upgrade and the web server finds it blank.Map network drive (Windows only)
LabKey Server runs on a Windows server as an operating system service, which Windows treats as a separate user account. The user account that represents the service may not automatically have permissions to access a network share that the logged-in user does have access to. If you are running on Windows and using LabKey Server to access files on a remote server, for example via the LabKey Server pipeline, you'll need to configure the server to map the network drive for the service's user account.Configuring the network drive settings is optional; you only need to do it if you are running Windows and using a shared network drive to store files that LabKey Server will access.Drive letter: The drive letter to which you want to assign the network drive.Path: The path to the remote server to be mapped using a UNC path -- for example, a value like "\\remoteserver\labkeyshare".User: Provide a valid user name for logging onto the share; you can specify the value "none" if no user name or password is required.Password: Provide the password for the user name; you can specify the value "none" if no user name or password is required.Ribbon Bar Message
Display Message: whether to display the message defined in Message HTML in a bar at the top of each page.Put web site in administrative mode
Admin only mode: If checked, only site admins can log into this LabKey Server installation.Message to users when site is in admin-only mode: Specifies the message that is displayed to users when this site is in admin-only mode. Wiki formatting is allowed in this message.HTTP security settings
CSRF checking (Cross Site Request Forgery)
Controls how the server enforces CSRF for POSTs.- Admin requests: Only administrator related POSTs are enforced. Admin requests are any request that includes "admin-" as the module value in the URL, for example "https://www.labkey.org/admin-customizeSite.view?"
- All POST requests: CSRF enforcement is applied to all POSTs, both admin related and non-admin.
X-Frame-Options
Controls whether or not a browser may render a server page in a <frame> , <iframe> or <object>.- Same Origin - Pages may only be rendered in a frame, only when the frame is in the same domain.
- Allow - Pages may be rendered in a frame in all circumstances.
Usage/Exception Reporting - Details
Basic Usage Reporting
When usage reporting is turned on, the following details are reported back to LabKey:- Low Level Reporting
- Build number
- VCS (svn) URL, if known
- OS name
- Java version
- The max heap size for the JVM
- Tomcat version
- Database platform (SQL Server or Postgres)
- DB version
- JDBC driver
- JDBC driver version
- Unique ids for server & server session
- Enterprise pipeline enabled?
- Was a graphical installer used?
- Total users
- Total users logged in in last 30 days
- Total project count
- Total folder count
- Distribution name
- Configured usage reporting level
- Configured exception reporting level
- Total logins in last 30 days
- Total logouts in last 30 days
- Average user session length in last 30 days
- Number of days in the last 30 in which user logged in
- Medium Level Reporting: Includes all of the information from "Low" level usage reporting, plus:
- Web site description
- Site admin email
- Organization name
- Site short name
- Logo link
- List of installed modules
- Number of hits for pages in each module
- Number of TargetedMS runs
- Number of folders of each folder type
Exception Reporting
When exception reporting is turned on, the following details are reported back to LabKey:- Low Level Reporting
- Build number
- VCS (svn) URL, if known
- OS name
- Java version
- The max heap size for the JVM
- Tomcat version
- Database platform (SQL Server or Postgres)
- DB version
- JDBC driver
- JDBC driver version
- Unique ids for server & server session
- Enterprise pipeline enabled?
- Was a graphical installer used?
- Distribution name
- Configured usage reporting level
- Configured exception reporting level
- Stack trace
- SQL state (when there is a SQL exception)
- Web browser
- Controller
- Action
- Medium Level Reporting: Includes all of the information from "Low" level exception reporting, plus:
- Exception message
- Request URL
- Referrer URL
- High Level Reporting: Includes all of the information from "Medium" level exception reporting, plus:
- User email
Resources
- Usage-Exception Reporting Data Collected.xlsx - A spreadsheet version of the above information
Related Topics
Look and Feel Settings
Site-Level Settings
To customize the Look and Feel at the site level:- Go to Admin > Site > Admin Console.
- Click Look and Feel Settings.

Properties Tab
Customize the Look and Feel of Your LabKey Server Installation
- System description: A brief description of your server that is used in emails to users.
- Header short name: Specifies the name of your server as it appears in the page header and in system-generated emails. By default, this property is set to LabKey.
- Web theme: Specifies the color scheme for your server. Custom themes may be defined at the site level and subsequently selected at either the site or project level.
- Font size: Specify Smallest, Small, Medium, or Large; examples are shown.
- Show Navigation: Select the conditions under which the project and folder menus are visible. Options: always, or only shown to administrators.
- Show LabKey Help menu item: Specifies whether to show the built in "Help" menu.
- Enable Object-Level Discussions: Specifies whether to show "Discussion >" links on wiki pages and reports. If object-level discussions are enabled, users must have "Message Board Contributor" permission to participate.
- Logo link: Specifies the page that the logo in the page header section of the web application links to. By default: /labkey/project/home/home.view The logo image is provided on the resources tab.
- Support link: Specifies page where users can request support.
- Support email: Email address to show to users to request support with issues like permissions and logins.
Customize Settings Used in System Emails
- System email address: Specifies the address which appears in the From field in administrative emails sent by the system.
- Organization name: Specifies the name of your organization, which appears in notification emails sent by the system.
Customize Date and Number Formats
- Date Parsing Mode: Select how user-entered and uploaded dates will be parsed: Month-Day-Year (as typical in the U.S.) or Day-Month-Year (as typical outside the U.S.). This setting applies to the entire site. Year-first dates are always interpreted as YYYY-MM-DD.
- Default display format for dates: Define the default date display format. This format determines the way a date is displayed, not the way a user-entered date is parsed. It may be overridden at the project or folder level.
- Default display format for date-times: Define the default date-time display format. This format determines the way a date-time is displayed, not the way a user-entered date is parsed. It may be overridden at the project or folder level.
- Default display format for numbers: Define the default number display format. This format may be overridden at the project or folder level.
Customize Column Restrictions
- Restrict charting columns by measure and dimension flags: See Measure and Dimension Columns
Provide a Custom Login Page
- To provide a customized login page to users, point to your own HTML login page deployed in a module. Specify the page as a string composed of the module name and an page name in the format: <module>-<page>. For example, to use a login HTML page located at myModule/views/customLogin.html, enter the string 'myModule-customLogin'. By default, LabKey Server uses the login page at modules/core/resources/views/login.html which you can use as a template for your own login page. Copy the template HTML file into your module (at MODULE_NAME/views/LOGIN_PAGE.html) and modify it according to your requirements. Note that the template works in conjunction with a .view.xml file and a JSP file called login.jsp, which provides access to the Java actions that handle user authentication. Your login page should retain the use of these actions.
Save and Reset
- Save: Save changes to all properties on this page.
- Reset: Reset all properties on this page to default values.
Resources Tab
- Header logo (optional): Specifies the custom image that appears in every page header in the upper left. 147 x 56 pixels.
- Favorite icon (optional): Specifies an icon file (*.ico) to show in the favorites menu or bookmarks. Note that you may have to clear your browser's cache in order to display the new icon.
- Custom stylesheet: Custom style sheets are optional but can be provided at the site and/or project levels. A project style sheet takes precedence over the site style sheet. Resources for designing style sheets:
- CSS Design Guidelines
- Documentation on specific classes: stylesheet.css
Project-Level Settings
To customize the Look and Feel at the project level:- Navigate to the project home page.
- Go to Admin > Folder > Project Settings.

- Security defaults: When this box is checked, new folders created within this project inherit project-level permission settings by default.
Menu Bar
You can add a custom menu at the project level. See Add Custom Menus for a walkthrough of this feature.Files
This tab allows you to optionally configure a project-level file root, data processing pipeline, and/or shared file web part. See Set File Roots.Branding
 Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
Premium Feature — Available in the Professional, Professional Plus, and Enterprise Editions. Learn more or contact LabKey
Default Footer
By default, every page on LabKey Server displays a footer "Powered By LabKey". To remove the footer, see the instructions below. To replace it with a custom footer see Modules: Custom Footer.Turn off the Default LabKey Server Footer
By default, LabKey Server provides a built-in footer at the bottom of every page. To turn off this footer, go to Admin > Site > Admin Console and click Configure Footer. Under Configure Footer, uncheck Show standard footer, and click Save.
Under Configure Footer, uncheck Show standard footer, and click Save.
Related Topics
Web Site Theme
Select a Web Theme
To select a web theme from a list of available web themes:- Go to Admin > Site > Admin Console > Look and Feel Settings.
- Select a web theme from the dropdown labeled Web theme (color scheme).
- Click Save Properties.
 Harvest
Harvest
Web Theme Customizer
To create a new theme for your site:- Go to Admin > Site > Admin Console > Look and Feel Settings > Define Web Themes.
- Fill out the form, specifying a Theme Name, Text Color, etc.
- Click Save.
- To activate your new theme, on the Look and Feel Settings page, click Save again.
 The table below describes the existing web themes that you can choose from.
The table below describes the existing web themes that you can choose from.| Web Themes | ||||||
|---|---|---|---|---|---|---|
| Web Theme Name | Blue | Brown | Harvest | Madison | Sage | Seattle |
| Text Color | 212121 | 212121 | 212121 | 212121 | 212121 | 000000 |
| Link Color | 21309A | 682B16 | 892405 | 990000 | 0F4F0B | 126495 |
| Grid (Header) Color | E4E6EA | EBE2DB | F5E2BB | FFECB0 | D4E4D3 | E7EFF4 |
| Primary Background Color | F4F4F4 | F4F4F4 | F4F4F4 | FFFCF8 | F4F4F4 | F8F8F8 |
| Secondary Background Color | FFFFFF | FFFFFF | FFFFFF | FFFFFF | FFFFFF | FFFFFF |
| Border and Title Color | 3441A1 | 682B16 | 892405 | CCCCCC | 386135 | 676767 |
| WebPart Color | D0DBEE | DFDDD9 | DBD8D2 | EEEBE0 | E1E5E1 | E0E6EA |
Email Template Customization
- Select Admin > Site > Admin Console.
- Click Email Customization.
- Select an Email Type from the pulldown to customize the templates. Available template types:
- Audit Processing Failure (see Compliance Settings)
- Change email address
- Request email address
- Register new user (with or without a bcc to Admin)
- Reset password (with or without a bcc to Admin)
- Issue update
- Pipeline jobs succeeded (digest form optional)
- Pipeline jobs failed (digest form optional)
- Message board notification (digest form optional)
- Report/dataset change (digest)
- Specimen request notification
Substitution Strings
Subject, as well as From and the Message can contain a mix of static text and substitution parameters. The From field sets the sender's description, while the actual sender email address will be the one configured via site or project settings. A substitution parameter is inserted into the text when the email is generated. The syntax is: ^<param name>^ where <param name> is the name of the substitution parameter.Each message type includes a full list of available substitution parameters with type, description, and current value if known, at the bottom of the email customization page. For example, some strings used in emails for user management:- ^currentDateTime^ -- Current date and time in the format: 2017-02-15 12:30
- ^emailAddress^ -- The email address of the person performing the operation -- see Look and Feel Settings.
- ^errorMessage^ -- The error message associated with the failed audit processing -- see Compliance.
- ^homePageURL^ -- The home page of this installation -- see Site Settings.
- ^organizationName^ -- Organization name -- see Look and Feel Settings.
- ^recipient^ -- The email address on the 'to:' line.
- ^siteShortName^ -- Header short name -- see Look and Feel Settings.
- ^supportLink^ -- Page where users can request support.
- ^systemEmail^ -- The 'from:' address for system notification emails.
- ^verificationURL^ -- The unique verification URL that a new user must visit in order to confirm and finalize registration. This is auto-generated during the registration process.
Message Board Notifications
For Message board notification emails, there is a default message reading "Please do not reply to this email notification. Replies to this email are routed to an unmonitored mailbox." If that is not true for your message board you may change the template at the site or folder level. You may also choose whether to include the portion of the email footer that explains why the user received the given email and gives the option to unsubscribe. Include the parameter ^reasonFooter^ to include that portion; the text itself cannot be customized.Format Strings
You may also supply an optional format string. If the value of the parameter is not blank, it will be used to format the value in the outgoing email. The syntax is: ^<param name>|<format string>^For example:^currentDateTime|The current date is: %1$tb %1$te, %1$tY^
^siteShortName|The site short name is not blank and its value is: %s^
Folder Level Email Customizations
Email template customizations are generally done at the site level. Some like issue and message board notifications can also be customized at the project or folder level if required.- Replace the controller "project" with "admin"
- Replace "begin.view?" with "customizeEmail.view?"
- For example, "localhost:8080/labkey/admin/home/customizeEmail.view?" is where you would email template changes that only apply to the 'home' project on a default locally installed server.
- Only the subset of templates available at that level will be included on the dropdown. Otherwise the interface available and parameters used are the same.
Experimental Features
- Select Admin > Site > Admin Console.
- Click Experimental Features.
- Carefully read the warnings and descriptions below before enabling any features.
Javascript Documentation
Display LabKey JavaScript APIs from the Developer Links menu.Combined Navigation Drop-down
This feature combines the navigation of Projects and Folders into one drop-down. Instead of viewing projects from the projects menu and folders from a separate drop down folder menu, the combined navigation bar offers both levels of container in one combined navigation menu. The left hand column shows projects, the right shows a combined listing of projects and subfolders. Clicking on a project or folder navigates directly to that container.
Notifications Menu
Display a notifications 'inbox' icon in the header bar with a display of the number of notifications; click to show the notifications panel of unread notifications.
Generic [details] link in grids/queries
This feature will turn on generating a generic [details] URL link in most grids.Data Region & Query Web Part Migration
Use the ExtJS independent Data Region and Query Web Part components for all grids.Visualization Column Analytics Providers
This feature allows columns marked as measures and dimensions to display visualizations of their data in the data region message area.Client-side Exception Logging to Mothership
Report unhandled JavaScript exceptions to mothership.Client-side Exception Logging to Server
Report unhandled JavaScript exceptions to the server log.Rserve Reports
Use an R Server for R script evaluation instead of running R from a command shell.To set up:- Go to Admin > Site > Admin Console and click Experimental Features. Enable the RServe experimental feature.
- Go to Admin > Site > Admin Console and click Views and Scripting. Add/edit the R engine configuration to include the hostname, port, remote report temp directory, remote pipeline directory, and the remote user and password if needed. Guidelines for using an RServe user and password are described here:
User Folders
Enable personal folders for users.Create Specimen Study
Adds a button to the specimen request details page that creates a new child study containing the selected specimens, associated participants, and selected datasets.Manage Missing Value Indicators / Out of Range Values
Customizable "Missing Value" indicators
Field-level "Missing Value" (MV) indicators allow individual data fields to be flagged.Administrators can customize which MV values are available. A site administrator can customize the MV values at the site level and project administrators can customize the MV values at the folder level. If no custom MV values are set for a folder, they will be inherited from their parent folder. If no custom values are set in any parent folders, then the MV values will be read from the server configuration. MV value customization consists of creating or deleting MV values, plus editing their descriptions.Two customizable MV values are provided by default:- Q: Data currently under quality control review.
- N: Required field marked by site as 'data not available'.
Customization at the Site level
- Select Admin > Site > Admin Console and click Missing Value Indicators.

Customization at the Folder level
- Select Admin > Folder > Management. Select the "Missing Values" tab.

How Missing Value Indicators Work
Two columns stand behind any missing-value-enabled field. This allows LabKey Server to display the raw value, the missing value indicator or a composite of the two (the default).One column of the columns behind the MV-enabled field contains the raw value for the field (or a blank if no value has been provided). The other contains the missing value indicator (such as UNK) if an indicator has been assigned; otherwise it is blank. For example, an integer field that is missing-value-enabled may contain the number "1" in its raw column and "UNK" in its missing value indicator column.A composite of these two columns is displayed for the field. If a missing value indicator has been assigned, it is displayed in place of the raw value. If no missing value indicator has been assigned, the raw value is displayed.Normally the composite view is displayed, but you can also use custom views to specifically select the display of the raw column or the indicator column.MV indicators render with three column choices:- ColumnName: shows just the value if there's no MV indicator, or just the MV plus a little flag if there is. The tooltip shows the original value.
- ColumnNameMVIndicator (a hidden column): shows just the MV indicator, or null if there isn't one.
- ColumnNameRawValue: shows just the value itself, or null if there isn't one.
Out of Range (OOR) Values
Enable OOR notification by adding a secondary string column that has the name of another column, plus the suffix "OORIndicator". You can have whatever values you like in the OORIndicator column, such as "<", ">", "<=", or "My OOR Indicator Value". In terms of insert and update, they're treated as two separate columns. But when the dataset is rendered, LabKey Server recognizes the columns as linked and offers four ways to display them (via the View Customizer):- ColumnName: shows the two values concatenated together ("< 10") but sorts/filters on just the number.
- ColumnNameOORIndicator: shows just the OOR indicator.
- ColumnNameNumber: shows just the number value.
- ColumnNameInRange: shows just the number, but only if there's no OOR indicator for that row, otherwise its value is null.
Short URLs
Define Short URLs
Short URLs are relative to the server and port number on which they are defined. The current server location is shown in the UI as circled in the screenshot below. If this is incorrect, you can correct the Base Server URL in Site Settings. Typically a short URL is a single word without special characters. TheTo define a short URL:- Select Admin > Site > Admin Console.
- Click Short URLs. Any currently defined short URLs will be listed in the Existing Short URLs web part.

- Type the desired short URL word into the entry window (the .url extension is added automatically).
- Paste or type the full destination URL minus the server or port into the Target URL window. To use the above example, the destination URL begins "/study/home/..."
- Click Submit.
Security
The short URL can be entered by anyone, but access to the actual target URL and content will be subject to the same permission requirements as if the short URL had not been used.Configure System Maintenance
- 1:15AM may occur twice - duplicate firings are possible
- 2:15AM may never occur - missed firings are possible
Configure Scripting Engines
- R, Java or Perl scripts can perform data validation or transformation during assay data upload (see: Transformation Scripts).
- R scripts can provide advanced data analysis and visualizations for any type of data grid displayed on LabKey Server. For information on using R, see: R Reports. For information on configuring R beyond the instructions below, see: Install and Set Up R.
Add a New Script Engine
- Sign in to your LabKey Server.
- Select Admin > Site > Admin Console.
- Under Configuration, click Views and Scripting.
 Name: Choose a name for this engine.Language: Choose the language of the engine. Example: "R".File extensions: These extensions will be associate with this scripting engine. Example: For R, choose "R,r" to associate the R engine with both uppercase (.R) and lowercase (.r) extensions.Program Path: Specify the absolute path of the scripting engine instance on your LabKey Server, including the program itself. Example: The instance of the R program will be named "R.exe" on Windows, but "R" on Unix and Mac machines. Thus, the "Program Path" for the instance of R shown in the screenshot above is "/usr/local/bin/R".Program Command: This is the command used when the program is invoked.Example: For R, you would typically will use the default command: "CMD BATCH --slave". The R command is the command used by the LabKey server to execute scripts created in an R view. The default command is sufficient for most cases and usually would not need to be modified.Output File Name: If the console output is written to a file, the name should be specified here.Use pandoc and rmarkdown: Enable if you have rmarkdown and pandoc installed. If enabled, Markdown v2 will be used to render knitr R reports; if not enabled, Markdown v1 will be used. See R Reports with knitrEnabled: Please click this checkbox to enable the engine.Click "Submit" to save your changes and add the new engine.
Name: Choose a name for this engine.Language: Choose the language of the engine. Example: "R".File extensions: These extensions will be associate with this scripting engine. Example: For R, choose "R,r" to associate the R engine with both uppercase (.R) and lowercase (.r) extensions.Program Path: Specify the absolute path of the scripting engine instance on your LabKey Server, including the program itself. Example: The instance of the R program will be named "R.exe" on Windows, but "R" on Unix and Mac machines. Thus, the "Program Path" for the instance of R shown in the screenshot above is "/usr/local/bin/R".Program Command: This is the command used when the program is invoked.Example: For R, you would typically will use the default command: "CMD BATCH --slave". The R command is the command used by the LabKey server to execute scripts created in an R view. The default command is sufficient for most cases and usually would not need to be modified.Output File Name: If the console output is written to a file, the name should be specified here.Use pandoc and rmarkdown: Enable if you have rmarkdown and pandoc installed. If enabled, Markdown v2 will be used to render knitr R reports; if not enabled, Markdown v1 will be used. See R Reports with knitrEnabled: Please click this checkbox to enable the engine.Click "Submit" to save your changes and add the new engine.
Audit Site Activity
Master Audit Log
The master Audit Log is available to site administrators from the Admin Console:- Select Admin > Site > Admin Console.
- Click Audit Log.
- Use the dropdown to select the kind of activity to view. See below for detailed descriptions of each dropdown value.

- Assay/Experiment events: Assay run import and deletion, assay publishing and recall.
- Attachment events: Adding, deleting, and downloading attachments on wiki pages and issues.
- Authentication Provider Configuration events: Enabling and disabling authentication providers, such as LDAP.
- Client API Actions: Errors raised by client API calls.
- Copy-to-Study Assay events: Events related to copying assay data into a study.
- Dataset events: Inserting, updating, and deleting datasets records. QC state changes.
- Domain events: Changes to column properties. Creating and deleting domains.
- File events: Changes to a file repository.
- Group events: The following group-related events are logged:
- Administrator created a group.
- Administrator deleted a group.
- Administrator added a user or group to a group.
- Administrator removed a user or group from a group.
- Administrator assigned a role to a user or group.
- Administrator unassigned a role from a user or group.
- Administrator renamed a group.
- Administrator configured a container to inherit permissions from its parent.
- Administrator configured a container to no longer inherit permissions from its parent.
- List events: Creating and deleting lists. Inserting, updating, and deleting records in lists.
- Logged sql queries: SQL queries sent to the database, including the date, the container, the user, and any impersonation information. Applies to SQL queries sent to the native database only; does not apply to external data sources. To log SQL queries from external data sources, see SQL Query Logging.
- Message events: Message board activity, such as email messages sent.
- Project and Folder events: Creation, deletion, renaming, and moving of projects and folders.
- Query export events: Query exports to different formats, such as Excel, TSV, and script formats.
- Query update events: Changes to SQL queries, such as inserting and updating records in the query.
- Sample Set events: Records inserted and updated in sample sets.
- Search: Text searches requested by users.
- Site Settings events: Changes to the site settings made on the "Customize Site" and "Look and Feel Settings" pages.
- Specimen Comments and QC: Comments and QC changes in specimen repositories.
- User events: All user events are subject to the 10 minute timer. For example, the server will skip adding user events to the log if the same user signs in from the same location within 10 minutes of their initial login. If the user waits 10 minutes to login again then the server will log it.
- User added to the system (via an administrator, self sign-up, LDAP, or SSO authentication).
- User verified and chose a password.
- User logged in successfully (including the authentication provider used, whether it is database, LDAP, etc).
- User logged out.
- User login failed (including the reason for the failure, such as the user does not exist, incorrect password, etc).
- User changed password.
- User reset password.
- User login disabled because too many login attempts were made.
- Administrator impersonated a user.
- Administrator stopped impersonating a user.
- Administrator changed a user's email address.
- Administrator reset a user's password.
- Administrator disabled a user's account.
- Administrator re-enabled a user's account.
- Administrator deleted a user's account.
Allowing Non-Admins to See the Audit Log
By default, only administrators can view audit log events and queries. If an administrator would like to grant access to read audit log information to a non-admin user or group, they can do so assigning the role "See Audit Log Events". For details see Security Roles Reference.Other Logs
Other event-specific logs are available in the following locations:| Logged Event | Location of Log |
|---|---|
| Assays Copied to a Study | See Copy-To-Study History. |
| Datasets | Go to the dataset's properties page, click Show Import History. See Edit Dataset Properties. |
| ETL Jobs | See ETL: All Jobs History. |
| Files Web Part | See File Repository Administration. |
| Lists | See Manage Lists. |
| Project Users | Go to Admin > Folder > Project Users, then click History. |
| Queries (for external data sources) | See SQL Query Logging. |
| Site Users | Go to Admin > Site > Site Users, then click History. |
| All Site Errors | Go to Admin > Site > Admin Console and click View All Site Errors. Shows the current contents of the labkey-errors.log file from the TOMCAT_HOME/logs directory, which contains critical error messages from the main labkey.log file. |
| All Site Errors Since Reset | Go to Admin > Site > Admin Console and click View All Site Errors Since Reset. View the contents of labkey-errors.log that have been written since the last time its offset was reset through the Reset Site Errors link. |
| Primary Site Log File | Go to Admin > Site > Admin Console and click View Primary Site Log File. View the current contents of the labkey.log file from the TOMCAT_HOME/logs directory, which contains all log output from LabKey Server. |
Setting Audit Detail Level
You can set the level of auditing detail on a table-by-table basis, determining the level of auditing for insert, update, and delete operations. Option include:- NONE - No audit record.
- SUMMARY - Audit log reflects that a change was made, but does not mention the nature of the change.
- DETAILED - Provides full details on what change was made, including values before and after the change.

Related Topics
SQL Query Logging
 Premium Feature — Available in the Professional Plus and Enterprise Editions. Learn more or contact LabKey
Premium Feature — Available in the Professional Plus and Enterprise Editions. Learn more or contact LabKey
Set Up
To configure a data source to log queries, add a Parameter element to the labkey.xml file. For example, if you have a data source named “mySqlDataSource”, <Resource name="jdbc/mySqlDataSource" auth="Container" type="javax.sql.DataSource" username="myname" password="mypassword" driverClassName="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/?autoReconnect=true& useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull" maxActive="15" maxIdle="7" useInformationSchema="true" accessToUnderlyingConnectionAllowed="true" validationQuery="/* ping */"/>then add the following Parameter element. Note that ":LogQueries" has been appended to the name. <Parameter name="mySqlDataSource:LogQueries" value="true"/> The labkey data source itself cannot be configured to log queries in this way. Doing so will cause a warning in the server log at startup -- then startup will proceed as normal.Viewing Logged SQL Queries
Logged SQL queries can be viewed in the Audit Log. Go to Admin > Site > Admin Console, click Audit Log in the management section, and select Logged sql queries from the dropdown menu.
Related Topics
Actions Diagnostics
Overview
The Actions option within the Admin Console allows administrators to view information about the performance of web-based requests of the server. Within the server, an action corresponds to a particular kind of page, such as the Wiki editor, a peptide's detail page, or a file export. It is straightfoward to translate a LabKey Server URL to its implementing controller and action. This information can be useful for identifying performance problems within the server.Summary View
The summary tab shows the information, with the actions grouped within their controller. A module typically provides one or more controllers that encompass its actions and comprise its user interface. This summary view shows how many actions are available within each controller, how many of them have been run since the server started, and the percent of actions within that controller that have been run.Details View
The details tab breaks out the full action-level information for each controller. It shows how many times each action has been invoked since the server started, the cumulative time the server has spent servicing each action, the average time to service a request, and the maximum time to service a request.Cache Statistics
Overview
The Caches option within the Admin Console allows administrators to view information about the current and previous states of various caches within the server. Caches provide quick access to frequently used data, and reduce the number of database queries and other requests that the server needs to make. Caches are used to improve overall performance by reusing the same data multiple times, at the expense of using more memory. Limits on the number of objects that can be cached ensure a reasonable tradeoff.Cache Information
The page enumerates the caches that are in use within the server. Each holds a different kind of information, and may have its own limit on the number of objects it can hold and how long they might be stored in the cache. The Get column shows how many times that code has tried to get an object from the cache. The Put column shows how many times an item has been put in the cache. The Max and Current Size columns show the maximum number of objects held in the cache since the server started, and the current number of objects in the cache, respectively.Caches that have reached their size limit are indicated separately, and may be good candidates for a larger cache size.The full information on this page can be analyzed to help tune server performance, typically by LabKey staff.Dump Heap
Memory Usage
Memory Graphs
The top section of the page shows graphs of the various memory spaces within the Java Virtual Machine, including their current utilization and their maximum size. The Heap, Metaspace (Java 8), and PS Perm Gen (Java 7) sections are typically the most likely to hit their maximum size.Object Tracking
When the server is running with Java asserts enabled (via the -ea parameter on the command-line), the bottom of the page will show key objects that are tracked to ensure that they are not causing memory leaks. This is not a recommended configuration for production servers.Links
The links at the top of the page allow an administrator to clear the caches and request that the Java Virtual Machine perform a garbage collection to free memory claimed by unused objects. This can be useful to see how much memory is truly in use at a given point in time.Running Threads
Query Performance
- Select Admin > Site > Admin Console.
- Click Queries in the Diagnostics section.
| Column name | Description |
|---|---|
| Count | The number of times that the server has executed the query since it started, or statistics were reset. |
| Total | The aggregate time of all of the invocations of the query, in milliseconds. |
| Avg | The average execution time, in milliseconds. |
| Max | The longest execution time for the query, in milliseconds. |
| Last | The last time that the query was executed. |
| Traces | The number of different call stacks from the application code that have invoked the query. Clicking the link shows the stack traces, which can be useful for developers to track down the source of the query. |
| SQL | The query itself. Note that this is the actual text of the query that was passed to the database via the JDBC driver. It may contain substitution syntax. |
Site/Container Validation
- required schema objects, such as tables and columns
- the existence of required data in tables
Implementation Steps:
- Implement SiteValidationProvider
- Implement runValidation():
- Instantiate a SiteValidationResultList
- For each of your validation steps, call SiteValidationResultList.addInfo(), addWarn() or addError()
- In your module's doStartup(), call SiteValidationService.registerProvider() to register your validator
Sample Code
An example validator that checks whether any Guest users have read or edit permissions: PermissionsValidator.java.Install LabKey
Getting Started
- Installation Basics - What should I expect? What hardware is required?
Installation Options
- Install LabKey Server (Windows Graphical Installer) - Optimized installation of a single-machine, PostgreSQL-based LabKey Server on Windows, primarily for evaluation purposes. Tested on English-language versions of Windows.
- Install LabKey Server
- Windows: install required components independently. Suitable for evaluation or for more complex, enterprise-scale installations.
- Linux, Unix, or Mac: install required components independently.
- Install a Remote Pipeline Server via the Windows Installer - Install a server for running queued, background jobs.
- Enterprise Pipeline - Install the enterprise pipeline.
Troubleshooting
Other Install Topics
Installation Basics
What Happens When I Install LabKey? (Windows Graphical Installer Only)
When you install LabKey, the following components are installed on your computer:- The Apache Tomcat web server, version 7
- The Java Runtime Environment (JRE), version 1.8
- The PostgreSQL database server, version 9.5 If you install manually, you may choose to run LabKey against Microsoft SQL Server instead.
- The LabKey web application components
- Additional third-party components. These are installed to the /bin directory of your LabKey installation.
What Happens to Existing Components When I Upgrade LabKey? (Windows Installer Only)
All included components are automatically upgraded. The installer will notify you of any Postgres, Tomcat, or Java upgrades that must be performed.- The Apache Tomcat web server
- Upgrading an existing LabKey Server will upgrade the Tomcat version automatically.
- Tomcat configuration files and service settings may not be automatically transferred. If you have done some manual configuration of the Tomcat installation included with LabKey server, those changes may need to be transferred manually (see http://tomcat.apache.org/migration.html)
- The Java Runtime Environment (JRE)
- Upgrading an existing LabKey Server will upgrade the JRE installed by the previous LabKey installer to JRE 1.8.
- The LabKey Server installer will ignore any externally installed JRE.
- The PostgreSQL database server
- Upgrading an existing LabKey Server will upgrade the PostgeSQL version automatically.
- To support the 8.* versions of the Postgres installer, old versions of the LabKey installer required manual configuration of the Postgres service user. The creation of this user is now automatic and any old service user will be deleted during the upgrade.
- The LabKey web application components
- These are upgraded automatically.
- Additional third-party components.
- These are upgraded automatically. They are installed to the /bin directory of your LabKey installation.
- Any manually added components must be re-added after upgrading.
What System Resources are Required for Running LabKey?
LabKey is a web application that runs on Tomcat and accesses a PostgreSQL or Microsoft SQL Server database server. The resource requirements for the web application itself are minimal, but the computer on which you install LabKey must have sufficient resources to run Tomcat and the database server (unless you are connecting to a remote database server, which is also an option). The performance of your LabKey system will depend on the load placed on the system, but in general a modern server-level system running Windows or a Unix-based operating system should be sufficient.We recommend the following resources as the minimum for running LabKey Server:- Processor: a high-performing CPU such as an Intel i7 quad core or similar
- Physical memory: 4 gigabyte RAM or more
- Disk space: 10 gigabyte hard drive space free
What Else Should I Install?
R.For most users, we recommend installing R after you have finished installing LabKey Server. R is not included as part of the LabKey Server installers, but it is a prerequisite for using LabKey Server's R features, including the built-in scripting interface.More Troubleshooting Help
Install LabKey Server (Windows Graphical Installer)
Steps to Install LabKey Server
- Register with LabKey, then download and run the Windows installer: {https://www.labkey.com/forms/register-to-download-labkey-server}
- On the Installation Type page, select LabKey Server (Standard Installation).
- Indicate that you understand that when you install LabKey, your computer becomes a web server and a database server.
- Accept the license agreement.
- Decide whether to install MSFileReader libraries. These libraries are used for mass spectrometry applications, specifically to convert MS/MS files to the mzXML format. For details see RAW to mzXML Converters.
- Provide connection information for an outgoing SMTP mail server. (You can change these settings after installation is complete.)
- Provide a user name and password for the database superuser for PostgreSQL, the database server which is installed by the installer. In PostgreSQL, a superuser is a user who is allowed all rights, in all databases, including the right to create users. You can provide the account information for an existing superuser, or create a new one. You may want to write down the user name and password you provide.
- Specify the directory location for the LabKey Server installation.
Setting Up Your Account
At the end of the installation process, the LabKey installer will automatically launch your default web browser and launch LabKey if you have left checked the default option Open browser to LabKey Server. Otherwise, open your web browser and navigate to http://localhost:8080/labkey.Once you launch LabKey, you'll be prompted to set up an account by entering your email address and a password. You are now the first site administrator for this LabKey installation.Modules
LabKey will install all modules and then give you the choice of customizing the installation by setting properties for the LabKey application.Installer Troubleshooting
Note that the LabKey installer installs PostgreSQL on your computer. You can only have one PostgreSQL installation on your computer at a time, so if you have an existing installation, the LabKey installer will fail. Try uninstalling PostgreSQL, or if you want to use your existing PostgreSQL installation, perform a manual installation of LabKey instead.Additional help can be found in Troubleshoot Installation.After Installation
After installation, you may also find it helpful to tune PostgreSQL for performance and further customize your installation.Securing the LabKey Configuration File
Important: The LabKey configuration file contains user name and password information for your database server, mail server, and network share. For this reason you should secure this file within the file system, so that only designated network administrators can view or change this file. For more information on this file, see labkey.xml Configuration File.Install LabKey Manually
- There is an existing PostgreSQL installation on your Windows computer. Only one instance of PostgreSQL can be installed per computer. LabKey server can be manually configured to use an existing PostgreSQL installation, but the Windows Graphical Installer will fail.
- There is an existing Tomcat installation on your Windows computer and you want LabKey Server to use it, rather than installing a new instance. Note that Tomcat can be installed multiple times on the same machine.
- You are installing on Linux, Unix, or Macintosh.
- You are running a non-English version of Windows.
- The graphical installer was unsuccessful.
- You want fine-grained control over file locations for LabKey Server in a production environment.
Step-by-Step Manual Install
If you are manually installing LabKey Server, you need to download, install, and configure all of its components yourself. The following topics explain how to do this in a step-by-step fashion:- Step 1: Install Required Components
- Step 2: Configure the LabKey Web Application
- Step 3: labkey.xml Configuration File
- Step 4: Third-Party Components and Licenses
Related Topics
Install Required Components
Install the Java Runtime Environment
- Download the Server Java Runtime Environment (Server JRE) Version 8 from http://www.oracle.com/technetwork/java/javase/downloads/index.html. ( The Server JRE is identical to the JRE, except all client side code (such as applets) has been removed making it far more secure and less memory intensive. )
- Install the Server JRE to the chosen directory.
- On Windows the default installation directory is C:\Program Files\Java\jre8
- On Linux a common place to install the Server JRE is /usr/local/jre<version>. We suggest creating a symbolic link from /usr/local/java to /usr/local/jre<version>. This will make upgrading the Server JRE easier in the future.
- If you are planning on building the LabKey Server source code, you must install the JDK 1.8 and configure JAVA_HOME to point to the JDK. For more information, see Set up a Development Machine.
- OpenJava is not supported.
Install the Apache Tomcat Web Server
We recommend running LabKey Server with the latest version of Tomcat. For details, see Supported Tomcat Versions.- Install Tomcat. On Linux, install to /usr/local/apache-tomcat<version>, then create a symbolic link from /usr/local/tomcat to /usr/local/apache-tomcat<version>. We will call this directory <tomcat-home>. Note that if you were to install Tomcat using their package manager, files and directories such as lib may be placed in different locations. For Unix systems, the following provides a good installation overview: Installing Tomcat 8 on OS X 10.11 El Capitan.
- Configure Tomcat to use the Server JRE installed above. You can do this either by creating a JAVA_HOME environment variable under the user account that will be starting tomcat, or by adding that variable to the tomcat startup scripts, <tomcat-home>/bin/startup.sh on Linux or startup.bat on Windows. For example, on Linux add this line to the beginning of the tomcat's startup.sh file: Export JAVA_HOME=/usr/local/java.
- Start Tomcat. On Linux run <tomcat-home>/bin/startup.sh. If you want Tomcat to start up automatically when you restart your computer see the Tomcat documentation.
- Test your Tomcat installation by entering http://<machine_name or localhost or IP_address>:8080 in a web browser. If your Java and Tomcat installations are successful you will see the Tomcat success page.
Install the Database Server
Install one of the following database servers:- PostgreSQL (for version details see: Supported Technologies)
- Microsoft SQL Server (for version details see: Supported Technologies)
- Install PostgreSQL (Windows)
- Install PostgreSQL (Linux, Unix or Macintosh)
- Install Microsoft SQL Server
Install the LabKey Server System Components
1. Download- the current binary zip distribution (LabKeyXXXX-XXXXX-bin.zip) if you are installing on a Windows system
- or
- the current binary tar.gz distribution (LabKeyXXXX-XXXXX-bin.tar.gz) if you are installing on a Unix-based system
- bin: Binary files required by LabKey Server (only in Windows distributions).
- labkeywebapp: The LabKey Server web application.
- modules: LabKey Server modules.
- pipeline-lib: Jars for the data processing pipeline.
- tomcat-lib: Required server library jars. (The tomcat-lib directory was introduced in LabKey Server version 13.3. It consolidates the server-lib and common-lib directories used in previous distributions. )
- labkey.xml: LabKey Server configuration file.
- manual-upgrade.sh: Manual upgrade script for MacOSX, Solaris, and non-supported Linux installations.
- README.txt: A file pointing you to this documentation.
- VERSION: A file containing the release number and build number.
Next Step in Manual Installation
After you've downloaded and installed all components, you'll configure the LabKey Server web application to run on Tomcat. See Configure the LabKey Web Application.Configure the LabKey Web Application
Configure Tomcat to Run the LabKey Server Web Application
Follow these steps to run LabKey Server on Tomcat:- Move the LabKey Server Libraries
- Configure your LabKey Server home directory
- Move the LabKey Server Binary Files and Add a Path Reference
- Move the LabKey Server Configuration File
- Replace Values in the LabKey Server Configuration File
- Configure Webapp Memory
- Configure LabKey Server to Run Under SSL (Recommended)
- Configure Tomcat Session Timeout (Optional)
- Configure Tomcat to Support Extended Characters in URLs (Optional)
- Configure Tomcat to Use Gzip (Optional)
- Start the Server
1. Move the LabKey Server Libraries
If you did not download and unzip the LabKey Server binaries in the previous step, do so here.Copy the following JAR files to the <tomcat-home>/lib directory:tomcat-lib/ant.jar
tomcat-lib/jtds.jar
tomcat-lib/mail.jar
tomcat-lib/mysql.jar
tomcat-lib/postgresql.jar
tomcat-lib/labkeyBootstrap.jar
2. Configure your LabKey Server home directory
Create a location for your LabKey Server program files. We will refer to this as <labkey_home>:- On Windows the default is C:/Program Files (x86)/LabKey Server
- On Unix the default is /usr/local/labkey
sudo chown steveh /usr/local/labkey
/bin
/labkeywebapp
/modules
/pipeline-lib
Notes:
- Make sure that you do not move the /labkeywebapp directory to the <tomcat-home>/webapps folder.
- The user who is executing the Tomcat process must have write permissions for the /labkeywebapp and /modules directories.
3. Move the LabKey Server Binary Files and Add a Path Reference
The Windows LabKey Server binary distribution includes a /bin directory that contains a number of pre-built Windows executable files required by LabKey Server. On Windows, you have already moved this directory to <labkey_home> in the previous step. On Unix you must download and either install or build these components for your system, and install them to <labkey_home>/bin. For more information see Third-Party Components and Licenses.Once the components are in place, add a reference to this directory to the system path of the user account that will start Tomcat.4. Move the LabKey Server Configuration File
The LabKey Server configuration file, named labkey.xml by default, contains a number of settings required by LabKey Server to run. This file must be moved into the <tomcat-home>/conf/Catalina/localhost directory.5. Replace Values in the LabKey Server Configuration File
The LabKey Server configuration file contains basic settings for your LabKey Server application. When you install manually, you need to edit this file to provide these settings. The parameters you need to change are surrounded by "@@", for example, @@appDocBase@@, @@jdbcUser@@, @@jdbcPassword@@, etc.- Replace @@appDocBase@@ with <labkey_home>/labkeywebapp
- Replace @@jdbcUser@@ & @@jdbcPassword@@ with administrator credentials for your chosen database (PostgreSQL or SQL Server).
6. Configure Webapp Memory
Follow the instructions in the following topic: Configure Webapp Memory.7. Configure LabKey Server to Run Under SSL (Recommended)
You can configure LabKey Server to run under SSL (Secure Sockets Layer). We recommend that you take this step if you are setting up a production server to run over a network or over the Internet, so that your passwords and data are not passed over the network in clear text.To configure Tomcat to run LabKey Server under SSL:- Follow the instructions in the Tomcat documentation: SSL Configuration How-To.
- Note that Tomcat's default SSL port is 8443, while the standard port for SSL connections recognized by web browsers is 443. To use the standard port, change this port number in the server.xml file.
- In the LabKey Server Admin Console (Admin > Site > Admin Console), click the Site Settings link.
- Check Require SSL connections.
- Enter the SSL port number that you configured in the previous step in the SSL Port field.
8. Configure Tomcat Session Timeout (Optional)
Tomcat's session timeout specifies how long a user remains logged in after their last session activity, 30 minutes by default. To increase session timeout, edit <tomcat-home>/conf/web.xml . Locate the <session-timeout> tag and set the value to the desired number of minutes.9. Configure Tomcat to Support Extended Characters in URLs (Optional)
If you originally installed LabKey using the graphical installer, Tomcat is automatically configured to support extended characters.If you installed Tomcat manually, it does not by default handle extended characters in URLs. To configure Tomcat to handle extended characters:- Edit the <tomcat-home>/conf/server.xml file.
- Add the following two attributes to the Tomcat connector via which users are connecting to LabKey Server:
useBodyEncodingForURI="true"
URIEncoding="UTF-8"
<!-- Define a non-SSL HTTP/1.1 Connector on port 8080 -->
<Connector port="8080" maxHttpHeaderSize="8192"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true"
useBodyEncodingForURI="true" URIEncoding="UTF-8"/>
10. Configure Tomcat to Use Gzip (Optional)
You may be able to improve responsiveness of your sever by configuring Tomcat to use gzip compression when it streams data back to the browser.You can enable gzip in <tomcat_home>/conf/server.xml by adding a few extra attributes to the active non-SSL <Connector> elements:compression="on" compressionMinSize="2048"
noCompressionUserAgents="gozilla, traviata"
compressableMimeType="text/html, text/xml, text/javascript, text/plain, text/css, application/json"
11. Start the Server
Start Tomcat as a Service
If you are using LabKey Server only on your local computer, you can start and stop Tomcat manually using the scripts in <tomcat-home>/bin. In most cases, however, you'll probably want to run Tomcat automatically, so that the operating system manages the server's availability. Running Tomcat as a service is recommended on Windows, and the LabKey Server installer configures Tomcat to start as a service automatically when Windows starts. You can call the service.bat script in the <tomcat-home>/bin directory to install or uninstall Tomcat as a service running on Windows. After Tomcat has been installed as a service, you can use the Windows Services management utility (Control Panel > Administrative Tools > Services) to start, stop, and restart the LabKey Server Apache Tomcat service.If you are installing on a different operating system, you will probably also want to configure Tomcat to start on system startup.Start Tomcat with Startup Scripts
You can also start the Tomcat server using the startup scripts in the <tomcat-home>/bin directory.View the LabKey Server Home Page
After you start the server, point your web browser at http://localhost:8080/labkey/ if you have installed LabKey Server on your local computer, or at http://<server-name>:8080/labkey/ if you have installed LabKey Server on a remote server.Configure the Tomcat Default Port
Note that in the addresses list above, the port number 8080 is included in the URL. Tomcat uses port 8080 by default, and to load any page served by Tomcat, you must either specify the port number as shown above, or you must configure the Tomcat installation to use a different port number. To configure the Tomcat HTTP connector port, edit the server.xml file in the <tomcat-home>/conf directory. Find the entry that begins with <Connector port="8080" .../> and change the value of the port attribute to the desired port number. In most cases you'll want to change this value to "80", which is the default port number used by web browsers. If you change this value to "80", users will not need to include the port number in the URL to access LabKey Server.Existing Installations of Tomcat
For detailed version information, see Supported Tomcat Versions.You can run two web servers on the same machine only if they use different port numbers, so if you have a web server running you may need to reconfigure one to avoid conflicts.If you have an existing installation of Tomcat, you can configure LabKey Server to run on that installation. Alternately, you can install a separate instance of Tomcat for LabKey Server; in that case you will need to configure each instance of Tomcat to use a different port. If you have another web server running on your computer that uses Tomcat's default port of 8080, you will also need to configure Tomcat to use a different port.If you receive a JVM_BIND error when you attempt to start Tomcat, it means that the port Tomcat is trying to use is in use by another application. The other application could be another instance of Tomcat, another web server, or some other application. You'll need to configure one of the conflicting applications to use a different port. Note that you may need to reconfigure more than one port setting. For example, in addition to the default HTTP port defined on port 8080, Tomcat also defines a shutdown port at 8005. If you are running more than one instance of Tomcat, you'll need to change the value of the shutdown port for one of them as well.Next Step in Manual Installation
- labkey.xml Configuration File: Change settings in the labkey.xml file.
labkey.xml Configuration File
- Configuration File Name
- Securing the LabKey Configuration File
- Modifying Configuration File Settings
- The path Attribute
- The appDocBase Attribute
- Database Settings
- GUID Settings
- SMTP Settings (Optional, Recommended)
- Master Encryption Key
Configuration File Name
The default URL for your LabKey Server installation is http://<servername>/labkey. You can change the name to something else if you wish by renaming labkey.xml. It's best to do this when you first install LabKey Server, as changing the name will cause any external links to your application to break. Note that Tomcat treats URLs as case-sensitive.Note that if you rename the configuration file, you will also need to edit the context path setting within it, as described below.If you wish for your LabKey Server application to run at the server root, you can rename labkey.xml to ROOT.xml. In this case, you should set the context path to be "/". You would then access your LabKey Server application with an address like http://<servername>/.Securing the LabKey Configuration File
Important: The LabKey configuration file contains user name and password information for your database server, mail server, and network share. For this reason you should secure this file within the file system, so that only designated network administrators can view or change this file.Modifying Configuration File Settings
You can edit the configuration file with your favorite text or XML editor. You will need to modify the LabKey Server configuration file if you are manually installing or upgrading LabKey Server, or if you want to change any of the following settings.- The appdocbase attribute, which indicates the location of the web application in the file system
- Database settings, including server type, server location, username, and password for the database superuser.
- SMTP settings, for specifying the mail server LabKey Server should use to send email to users.
- Encryption Key - Configure an encryption key for the encrypted property set.
The path Attribute
The path attribute of the Context tag specifies the context path for the application URL. The context path identifies this application as a unique application running on Tomcat. The context path is the portion of the URL that follows the server name and port number. By default, the context path is set to "labkey".Note that the name of the configuration file must match the name of the context path, including case, so if you change the context path, you must also change the name of the file.The appDocBase Attribute
The appDocBase attribute of the Context tag must be set to point to the directory where you have extracted or copied the labkeywebapp directory. For example, if the directory where you've copied labkeywebapp is C:\Program Files\LabKey Server on a Windows machine, you would change the initial value to "C:\Program Files\LabKey Server\labkeywebapp".Database Settings
The username and password attributes must be set to a user name and password with admin rights on your database server. The user name and password that you provide here can be the ones that you specified during the PostgreSQL installation process for the database superuser. Both the name and password attribute are found in the Resource tag named "jdbc/labkeyDataSource". If you are running a local version of PostgreSQL as your database server, you don't need to make any other changes to the database settings in labkey.xml, since PostgreSQL is the default database choice.If you are running LabKey Server against Microsoft SQL Server, you should comment out the Resource tag that specifies the PostgreSQL configuration, and add a Resource tag for the Microsoft SQL Server configuration. A template Resource tag for MS SQL Server is available at: Install Microsoft SQL Server.Note: LabKey Server does not use Windows authentication to connect to Microsoft SQL Server; you must configure Microsoft SQL Server to accept SQL Server authentication.If you are running LabKey Server against a remote installation of a database server, you will also need to change the url attribute to point to the remote server; by default it refers to localhost.GUID Settings
By default, LabKey Servers periodically communicate back to LabKey developers whenever the server has experienced an exception. LabKey rolls up this data and groups it by the GUID of each server. You can override the Server GUID stored in the database with the one specified in labkey.xml. This ensures that the exception reports sent to LabKey Server developers are accurately attributed to the server (staging vs. production) that produced the errors, allowing swift delivery of fixes. For details, see Tips for Configuring a Staging Server.SMTP Settings (Optional, Recommended)
LabKey Server uses an SMTP mail server to send messages from the system, including email to new users when they are given accounts on LabKey. Configuring LabKey Server to connect to the SMTP server is optional; if you don't provide a valid SMTP server, LabKey Server will function normally, except it will not be able to send mail to users.At installation, you will be prompted to specify an SMTP host, port number, user name, and password, and an address from which automated emails are sent. Note that if you are running Windows and you don't have an SMTP server available, you can set one up on your local computer.The SMTP settings are found in the Resource tag named "mail/Session".- mail.smtp.host Set to the name of your organization's SMTP mail server.
- mail.smtp.user Specifies the user account to use to log onto the SMTP server.
- mail.smtp.port Set to the SMTP port reserved by your mail server; the standard mail port is 25. SMTP servers accepting a secure connection may use port 465 instead.
- mail.smtp.from This is the full email-address that you are would like to send the mail from. It can be the same as mail.smtp.user, but it doesn't need to be.
- mail.smtp.password This is the password.
- mail.smtp.starttls.enable When set to "true", configures the connection to use Transport Level Security (TLS).
- mail.smtp.socketFactory.class When set to "javax.net.ssl.SSLSocketFactory", configures the connection to use an implementation that supports SSL.
- mail.smtp.auth= When set to "true", forces the connection to attempt to authenticate using the user/password credentials.
- If you do not configure an SMTP server for LabKey Server to use to send system emails, you can still add users to the site, but they won't receive an email from the system. You'll see an error indicating that the email could not be sent that includes a link to an HTML version of the email that the system attempted to send. You can copy and send this text to the user directly if you would like them to be able to log into the system.
- If you are running on Windows XP or a later version of Windows and you don't have a mail server available, you can configure the SMTP service. This service is included with Internet Information Server to act as your local SMTP server. Follow these steps:
- From the Start menu, navigate to Control Panel | Add or Remove Programs, and click the Add/Remove Windows Components button on the left toolbar.
- Install Internet Information Services (IIS).
- From Start | Programs | Administrative Tools, open the Windows Services utility, select World Wide Web Publishing (the name for the IIS service), display the properties for the service, stop the service if it is running, and set it to start manually.
- From Start | Programs | Administrative Tools, open the Internet Information Services utility.
- Navigate to the Default SMTP Virtual Server on the local computer and display its properties.
- Navigate to the Access tab, click Relay, and add the address for the local machine (127.0.0.1) to the list of computers which may relay through the virtual server.
Master Encryption Key
LabKey Server deployments can be configured to authenticate and connect to external systems to retrieve data or initiate analyses. In these cases, LabKey must store credentials (user names and passwords) in the primary LabKey database. While your database should be accessible only to authorized users, as an additional precaution, LabKey encrypts these credentials before storing them and decrypts them just before use. This encryption/decryption process uses a "master encryption key" that administrations set in labkey.xml; LabKey will refuse to save credentials if an encryption key is not configured.Specify a master encryption key as follows:<Parameter name="MasterEncryptionKey" value="@@masterEncryptionKey@@" />
Related Topics
Next Step in Manual Installation
- Third-Party Components and Licenses: Install common tools, such as R.
Third-Party Components and Licenses
R
- Website: http://www.r-project.org/
- LabKey Development Owner: jeckels#at#labkey.com
- Install Instructions: Install and Set Up R.
- License: GNU GPL 2.0
Graphviz (All)
- Component Name: Graphviz
- LabKey Development Owner: jeckels#at#labkey.com
- Install Instructions: http://www.graphviz.org/Download.php.
- Build instructions:
- For current version, use the INSTALL link here: http://www.graphviz.org/doc/build.html
- Ensure that the location of dot.exe is on your server path (i.e., the path of the user running the Tomcat server process).
- Alternative:
- Sun also ships an old version with Solaris (http://www.sun.com/software/solaris/freeware/), although we have not tested LabKey Server with that version.
- License: Common Public License
Trans Proteomic Pipeline (MS2)
- LabKey Development Owner: jeckels#at#labkey.com
- Information on TPP: http://tools.proteomecenter.org/wiki/index.php?title=Software:TPP
- Install Instructions:
- Download the source distribution of v4.6.3 of the tools and unzip or obtain directly from Subversion at https://sashimi.svn.sourceforge.net/svnroot/sashimi/tags/release_4-6-3.
- Build the tools
- Edit trans_proteomic_pipeline/src/Makefile.incl
- Add a line with XML_ONLY=1
- Modify TPP_ROOT to point to the location you intend to install the binaries. NOTE: This location must be on your server path (ie the path of the user running the Tomcat server process).
- Run 'make configure all install' from trans_proteomic_pipeline/src
- Copy the binaries to the directory you specified in TPP_ROOT above.
- License: LGPL
- Notes:
- For Mac OSX, this software is only supported for Macs running on Intel CPUs.
- If you wish to use TPP version 4.3.1 to produce comparable results to previous datasets, follow these instructions for getting the source instead:
- Download Location: http://sourceforge.net/project/showfiles.php?group_id=69281&package_id=126912
- Download v4.3.1 of the tools and unzip or obtain directly from Subversion at https://sashimi.svn.sourceforge.net/svnroot/sashimi/tags/release_4-3-1.
- Apply the attached patch file.
- If you experience a problem applying the patch using your subversion client, then use the attached zip file. The file structure of the zip file matches the directory structure of the source files.
X!Tandem (MS2)
- Component Name: X!Tandem
- LabKey Development Owner: jeckels#at#labkey.com
- Information: As of version 9.3, LabKey Server uses a version of X!Tandem that is included with the TPP.
Proteowizard (MS1, MS2)
- LabKey Development Owner: jeckels#at#labkey.com
- Information on ProteoWizard: http://proteowizard.sourceforge.net/
- Windows binary is included with LabKey Server installer.
- Install Instructions:
- Download Location: http://proteowizard.sourceforge.net/downloads.shtml
- Download source or binaries as appropriate for your platform.
- If downloading source, build as appropriate for your platform.
- Copy to your pipeline tools directory.
peakaboo (MS1)
- LabKey Development Owner: jeckels#at#labkey.com
- Information on ProteoWizard: http://proteowizard.sourceforge.net/
- Windows binary is included with LabKey Server installer.
- Install Instructions:
- Download Location: http://proteowizard.sourceforge.net/download.html
- Download source or binaries as appropriate for your platform.
- If downloading source, build as appropriate for your platform.
- Copy to your pipeline tools directory.
pepmatch (MS1, MS2)
- LabKey Development Owner: jeckels#at#labkey.com
- Windows binary is included with LabKey Server installer.
- Install Instructions:
- Download source code: pepmatch.tar.gz (zipfile) or
- Check out source code using Subversion. https://hedgehog.fhcrc.org/tor/stedi/trunk/tools/pepmatch
- username = cpas
- password = cpas
- Run "make" to build.
- Copy pepmatch binary to your pipeline tools directory.
Credits
See full credits.Install a Remote Pipeline Server via the Windows Installer
Steps to Install: Remote Pipeline Server
- Download and run the Windows installer: free download after registration.
- On the Installation Type page, select Remote Pipeline Server.
- Accept the license agreement.
- To use the wizard-based installation, select Config Wizard.
- Specify the JMS Server to communicate with the Remote Pipeline Server:
- host
- port.
- Specify the pipeline file locations.
- LabKey Server webserver path to data files
- Pipeline Remote Server path to data files
- Specify how to mount the network file share, either automatically or externally.
- If you choose automatically, you'll also be prompted to specify information for mapping a network drive where LabKey Server can access files on a remote server:
- Drive Letter
- Network Drive Path (the UNC path to the remote server)
- DOMAIN\username and password for accessing that share. User name and password can be left blank if they are not required by the file share.
- Accept the MSFileReader agreement. MSFileReader is a 3rd party tool that converts binary mass spectrometry files to the mzXML format.
- Specify the directory location for the Remote Pipeline Server installation.
PremiumStats Install
- If the automatic installation has failed, site administrators will see a banner message on the running server reading "The premeium aggregate functions are not installed. These functions are required for premium feature summary statistics." with two links.
- Click Download installation script to download the required script: "premiumAggregatesInstall.sql"
- Click View installation instructions to open to this topic.
- Connect to the Microsoft SQL Server using an account with membership in the sysadmin role.
- Execute the downloaded SQL script in the database.
- Confirm that PremiumStats is installed in the core schema.
- Restart Tomcat. The changes to the database will be recognized by the server only after a restart.
Related Topics
Supported Technologies
Supported Technologies Roadmap
This chart summarizes server-side dependency recommendations for past & current releases, and predictions for upcoming (*) releases.
| Recommended: fully supported and thoroughly tested with this version of LabKey | |
| Use with caution: either deprecated or not fully supported/tested yet on this version of LabKey | |
| Do not use: incompatible with this version of LabKey and/or past end of life (no longer supported by the organization that develops the component) |
| Component | Version | LabKey 16.2 (July 2016) | LabKey 16.3 (Nov 2016) | LabKey 17.1 (Mar 2017) | LabKey 17.2* (July 2017) | LabKey 17.3* (Nov 2017) |
|---|---|---|---|---|---|---|
| Java | 8.x | |||||
| Tomcat | 8.5.x | |||||
| 8.0.x | ||||||
| 7.0.x | ||||||
| PostgreSQL | 9.6 | |||||
| 9.5 | ||||||
| 9.4 | ||||||
| 9.3 | ||||||
| 9.2 | ||||||
| Microsoft SQL Server | 2016 | |||||
| 2014 | ||||||
| 2012 |
Browsers
LabKey Server requires a modern browser for many advanced features, such as locking data table column headers in place when scrolling, creating charts, or visualizing security group relationships. To take advantage of all features, we recommend upgrading your browser(s) to the latest release. We understand that this is not always possible, so the LabKey team attempts to maintain basic compatibility and fix major issues with the following browsers:
- Chrome 56+
- Firefox 51+
- Firefox ESR 45+
- Safari 10+
- Internet Explorer 11+
- Edge 38+
As a general rule, LabKey Server supports the latest version of the browsers listed above. For the latest versions of these browsers, click the links provided.
If you experience a problem with a supported browser feel free to post the details to the support forum so we're made aware of the issue.
Java
LabKey Server requires Java 8. We strongly recommend using the latest Java 8 runtime from Oracle, currently Java SE 8u121.
LabKey Server no longer supports Java 7 due to Oracle ending public updates of Java 7 (see Oracle Java SE Support Roadmap). LabKey Server has not been tested with non-Oracle Java implementations (e.g., OpenJava, OpenJDK, IBM J9, etc.).
Apache Tomcat
We recommend using the latest release of Apache Tomcat 8.5.x (currently 8.5.12). Due to a recently fixed Tomcat issue, do not use 8.5.8 or earlier.
LabKey continues to support Tomcat 8.0.x and 7.0.x, though here also we strongly recommend installing the latest point release (currently 8.0.42 or 7.0.76).
We recommend installing Tomcat using the binary distributions; if a package manager is used, the lib directory may be installed in a different location. Also, the packages sometimes include alternative versions of some components (like JDBC connection pools) that can cause incompatibilities.
We recommend not using the Apache Tomcat Native library; this library can interfere with SSL and prevent server access via LabKey's client libraries.
PostgreSQL
For installations using PostgreSQL as the primary database, we recommend using the latest release of PostgreSQL 9.6.x (currently 9.6.2).
For those who can't transition to 9.6 yet, LabKey continues to support PostgreSQL 9.5, 9.4, 9.3, and 9.2, though here also we strongly recommend installing the latest point release (currently 9.5.6, 9.4.11, 9.3.16, and 9.2.20) to ensure you have all the latest security, reliability, and performance fixes.
PostgreSQL provides instructions for how to upgrade your installation, including moving your existing data database.
Microsoft SQL Server
For installations using Microsoft SQL Server as the primary database, we recommend using Microsoft SQL Server 2016. LabKey continues to support and test on SQL Server 2014 and 2012. LabKey does not support SQL Server 2008 R2 or earlier releases.
Troubleshoot Installation
Step-by-Step Installation Documentation
In case of errors or other problems when installing and starting LabKey Server, first review installation basics and options linked on the Install LabKey page.Step-by-step instructions for each mode of installation are available on these pages:Developer Mode
Running a server in "devmode" provides enhanced logging, enables the MiniProfiler, and provides resource reloading without the need to restart or rebuild the server. To run the server in devmode:- Open a command prompt.
- Go to the CATALINA_HOMEbin directory, for example:
C:\Program Files (x86)\LabKey Server\apache-tomcat-7.0.xx\bin
- Execute the tomcat7w.exe program:
tomcat7w.exe //ES//LabKeyTomcat7
- The command will open a program window. Click the Java tab.
- In the Java Option box, scroll to the bottom of the properties. Add the following property at the bottom of the list:
-Ddevmode=true- Close the program window and restart the server.
- To confirm that the server is running in devmode, go to Admin > Site > Admin Console. Click System Properties. Locate the devmode property, and confirm that its value is 'true'.
Which version of LabKey Server Is Running?
- Find your version number at Admin -> Site -> Admin Console.
- Under Module Information, locate the Core module. The version shown here, is the version number for your installation of LabKey Server.
Common Issues
Conflicting Applications
Before installing LabKey Server, you should shut down all other running applications. If you have problems during the installation, try additionally shutting down any virus scanning application, internet security applications, or other applications that run in the background.Compatible Component Versions
Confirm that you are using the supported versions of the required components, as detailed in the Supported Technologies Roadmap. It is possible to have multiple versions of some software, like Java, installed at the same time. Check that other applications, such as Tomcat, are configured to use the correct versions.Postgres Installation
You can only install one instance of PostgreSQL on your computer at a time.- If you already have PostgreSQL installed for another purpose, LabKey can use your installed instance; however, you will need to install LabKey manually.
- The Windows Graphical Installer will attempt to install a new instance of PostgreSQL for you.
- If you have previously installed Postgres (whether as part of prior LabKey server installation or not), first manually uninstall the program. You may also need to manually delete the PostgreSQL data directory.
- You may also need to remove references to Cygwin from your Windows system path before installing LabKey, due to conflicts with the PostgreSQL installer. The PostgreSQL installer also conflicts with some antivirus or firewall software programs. (see http://wiki.postgresql.org/wiki/Running_%26_Installing_PostgreSQL_On_Native_Windows for more information).
- If you are upgrading an existing LabKey server installation using the Windows Graphical Installer, have tried the above and still have problems installing postgres, you may need to manually stop a running LabKey_pgsql-## service.
Non-English Versions of Windows
If you are running a non-English version of Windows, please use the manual install process, not the Windows Graphical Installer.Tomcat Failure to Start
If installation fails to start tomcat (such as with an error like "The specified service already exists."), you may need to manually stop or delete a failing Tomcat service.To stop the service on Windows, open Control Panel > Administrative Tools > Services; click LabKey Server Apache Tomcat 7.0; click Stop.To delete, from the command line (may need to run as administrator):sc delete LabKeyTomcat7
Java 8 Upgrade Note
When you upgrade to Java 8, be sure to remove the setting of MaxPermSize. If your CATALINA_OPTS or other configuration files include something like "-XX:MaxPermSize=256M" you may have errors when starting your server.Restart Installation from Scratch
If you have encountered prior failed installations, don't have any stored data you need to keep, and want to clean up and start completely from scratch, the following process may be useful:- Delete the Tomcat service (if it seems to be causing the failure):
- From the command line (may need to run as administrator):
sc delete LabKeyTomcat7
- Uninstall Postgres using their installer.
- Control Panel > Programs and Features
- Select Postgres program (PostgreSQL9.2 or similar).
- Click Uninstall.
- Delete the entire LabKey installation directory:
C:\Program Files\LabKey Server
- Run the LabKey Installer again.
Error Messages
Please see Installation Error Messages.Community Forums
You can search for problems resolved through community support in the LabKey Community Support Forums.If you don't see your issue listed there, you can post a new question. If the install seems successful, it is often helpful to submit debugging logs for diagnosis.If the install failed to complete, please include the install.log and install-debug.log from your selected LabKey install directory (Note: you may wish to sanitize the logs of any database login information you provided to the installer). PostgreSQL logs its installation process separately. If the installer indicates that PostgreSQL installation/upgrage failed, please locate and include the postgres install logs as well.- Instructions for locating postgres install logs can be found here - http://wiki.postgresql.org/wiki/Troubleshooting_Installation
Installation Error Messages
If you have encountered errors or other problems when installing and starting LabKey Server, first review the Installation Troubleshooting Guide. If you're still encountering problems, please review the list below for common errors messages and problems.
You can also search the LabKey Community Support Forums for guidance. If you don't already see your issue listed there, please post a new question.
1.
| Error |
The LabKey Windows Graphical Installer hangs or fails while attempting to install PostgreSQL. You may see various postgres related errors such as:
|
| Problem |
You can only install one instance of PostgreSQL on your computer at a time. The PostgreSQL installer also has some conflicts with some antivirus or firewall software programs. |
| Solution |
|
2.
| Error | Error on startup, "Connection refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections." |
| Problem | Tomcat cannot connect to the database. |
| Likely causes |
|
| Solution | Make sure that database is started and fully operational before starting Tomcat. Check the database connection URL, user name, and password in the <tomcat>/conf/Catalina/localhost/labkey.xml file. |
3.
| Error | Error when starting new LabKey Server installation, "PL/PgSQL not installed". |
| Problem | This is a blocking error that will appear the first time you try to start LabKey Server on a fresh installation against PostgreSQL. It means that the database is working and that LabKey Server can connect to it, but that the Postgres command language, which is required for LabKey Server installation scripts, is not installed in PostgreSQL. |
| Solution | Enter the command <postfix>/bin/createlang plpgsql cpas, then shutdown and restart Tomcat. |
4.
| Problem | Error when connecting to LabKey server on Linux: Can't connect to X11 window server or Could not initialize class ButtonServlet. |
| Solution | Run tomcat headless. Edit tomcat's catalina.sh file, and add the following line near the top of the file:
CATALINA_OPTS="-Djava.awt.headless=true"Then restart tomcat. |
5.
| Error |
You receive a message "The requested resource () is not available." OR "500: Unexpected server error" and see something like one of the following in the log file: |
| Problem |
SEVERE: Error deploying configuration descriptor labkey.xml 2. A failure occurred during LabKey Server startup. 3. A failure occurred during LabKey Server startup. |
| Solution |
You may need to be using a newer version of the JDK. See Install Required Components. Confirm that Tomcat is configured to use the correct version of Java, as it is possible to have multiple versions installed simultaneously. |
6.
| Problem |
After upgrading to building with Java 8, your server may still include some trunk code that was built with Java 7. |
| Error |
java.lang.NullPointerException |
| Solution |
Use "ant rebuild" to build from scratch. |
Dump Memory and Thread Usage Debugging Information
Introduction
To assist in debugging the LabKey Server process, an administrator can force the LabKey Server process to the dump the list of threads and memory to disk. This information can then be sent to LabKey for review.A memory/heap dump is useful for diagnosing issues where LabKey Server is running out of memory, or in some cases where the process is sluggish and consuming a lot of CPU.A thread dump is useful for diagnosing issues where LabKey Server is hung or some requests spin forever in the web browser.This can be done either through the LabKey Server web user interface or manually by touching a file on the web server.Definitions:
- LABKEY_HOME: Installation location of the LabKey Server
- If you performed a Manual Installation and followed these instructions, then this is most likely
- /usr/local/labkey
- If you used our Windows installer, then this is most likely one of the following:
- C:\Program Files (x86)\LabKey Server\
- C:\Program Files\LabKey Server\
- CATALINA_HOME: Installation location of the Apache Tomcat Web Server
- If you performed a Manual Installation and followed these instructions, then this is most likely
- /usr/local/tomcat
- If you used our Windows installer, then this is most likely one of the following:
- C:\Program Files (x86)\LabKey Server\apache-tomcat-*.*.*
- C:\Program Files\LabKey Server\apache-tomcat-*.*.*
Request LabKey Server dump its memory
This can be done using either the web UI or the command line.Using the web UI
- Goto to the Admin Console for your server
- Click on the link dump heap
Manually via the command line
Unix. On a Unix server (Linux, MacOSX, Solaris), use the command line execute the following commands:- Change to the `LABKEY_HOME` directory. For example, if your directory is located at /usr/local/labkey, then the command will be
cd /usr/local/labkey
- Force the server to dump its memory
touch heapDumpRequest
- Open a Command Prompt
- Start --> Programs --> Accessories --> Command Prompt
- Change to the `LABKEY_HOME\bin` directory. For example, if your 'LABKEY_HOME' directory is located at `C:\Program Files\LabKey Server\`, then the command will be
cd "C:\Program Files\LabKey Server"- Force the server to dump its memory. The command will open the heapDumpRequest file in the notepad program.
notepad heapDumpRequest
- Place the cursor at the top of the file and hit the Enter key twice.
- Save the file
- Close notepad
Request LabKey Server dump the list of running threads
This can be done using either the web UI or the command line.Using the web UI
- Goto to the Admin Console for your server
- Click on the link running threads
- This will show the state of all active threads in the browser, as well as writing the thread dump to the server log file
Manually via the command line
Unix. On a Unix server (Linux, MacOSX, Solaris), use the command line execute the following commands:- Change to the `LABKEY_HOME` directory. For example, if your 'LABKEY_HOME' directory is located at `/usr/local/labkey`, then the command will be
cd /usr/local/labkey
- Force the server to dump its memory
touch threadDumpRequest
- Open a Command Prompt
- Start --> Programs --> Accessories --> Command Prompt
- Change to the `LABKEY_HOME\bin` directory. For example, if your 'LABKEY_HOME' directory is located at `C:\Program Files\LabKey Server\`, then the command will be
cd "C:\Program Files\LabKey Server"- Force the server to dump its memory. The command will open the heapDumpRequest file in the notepad program.
notepad threadDumpRequest
- Place the cursor at the top of the file and hit the "Enter" key twice
- Save the file
- Close notepad
Gather debugging information about Postgres errors
LabKey server is unable to log errors thrown by Postgres, so in the case of diagnosing some installation and startup errors, it may be helpful to to view the event log.- Launch eventvwr.msc
- Navigate to Windows Logs > Application.
- Search for errors there corresponding to the installation failures, which may assist LabKey support in diagnosing the problem.
- If you can't find relevant messages, you may be able to trigger the error to occur again by running net start LabKey_pgsql-9.2 from the command line.
Collect SQL Server information about running queries and locks
To get a full pictures of some problems, it's useful to have both a thread dump (described above) and information about the state of database connections. The latter needs to be obtained directly from SQL Server.- Launch SQL Server Management Console or a similar tool
- Open a connection to the LabKey Server database, often named 'labkey'.
- Run and capture the output from the following queries/stored procedures:
- sp_lock
- sp_who2
- SELECT t1.resource_type, t1.resource_database_id, t1.resource_associated_entity_id, t1.request_mode, t1.request_session_id, t2.blocking_session_id FROM sys.dm_tran_locks as t1 INNER JOIN sys.dm_os_waiting_tasks as t2 ON t1.lock_owner_address = t2.resource_address;
Common Install Tasks
- Install Microsoft SQL Server
- Install PostgreSQL (Windows)
- Install PostgreSQL (Linux, Unix or Macintosh)
- Install LabKey Server on Solaris
- Notes on Installing PostgreSQL on All Platforms
- Install and Set Up R
- Install SAS/SHARE for Integration with LabKey Server
- Configure Webapp Memory
- Set Up Robots.txt and Sitemaps
Install Microsoft SQL Server
Install and Configure Microsoft SQL Server 2012 or 2014
As part of installing required components, you need to install a database server. You can use either PostgreSQL or Microsoft SQL Server. Follow these steps if you wish to use Microsoft SQL Server.For current supported versions of Microsoft SQL Server, see Supported Technologies.To install Microsoft SQL Server 2012 or 2014:1. If you don't have a licensed version of Microsoft SQL Server, you can download the free Express Edition of either from http://www.microsoft.com/express/sql/download/. Note that the Express Edition has database size limitations that generally make it inappropriate for production deployments. Download SQL Server Management Studio graphical database management tool from http://www.microsoft.com/en-us/download/details.aspx?id=42299 --> Click Download --> Select appropriate SQLManagementStudio .exe to download. Use Windows Update to install the latest service packs.2. During installation, configure Microsoft SQL Server to accept both Windows Authentication and SQL Server Authentication, and specify a user name and password for the administrative account. Keep track of this user name and password; LabKey Server uses it to authenticate to SQL Server. It must be provided in plaintext in labkey.xml. If you've already installed SQL Server without enabling SQL Server Authentication then see How to: Change Server Authentication Mode in the Microsoft SQL Server documentation.3. After you've installed SQL Server, you'll need to configure it to use TCP/IP. Follow these steps:- Launch the SQL Server Configuration Manager in the Microsoft SQL Server program group on the Windows start menu. (on win8+, there won't be a program group- it's an MMC snap-in. To launch, type SqlServerManager12.msc (for server2014) and press Enter. For details: https://technet.microsoft.com/en-us/library/ms174212.aspx)
- Under the SQL Server Network Configuration node, select Protocols for <servername>.
- In the right pane, right-click on TCP/IP and choose Enable.
- Right-click on TCP/IP and choose Properties.
- Switch to the IP Addresses tab.
- Under the IPAll section, clear the value next to TCP Dynamic Ports and set the value for TCP Port to 1433 and click OK. By default, SQL Server will choose a random port number each time it starts, but the JDBC driver expects SQL Server to be listening on port 1433.
- Restart the service by selecting the SQL Server Services node in the left pane, selecting SQL Server <edition name> in the right pane, and choosing Restart from the Action menu (or use the Restart button on the toolbar).
- Run SQL Server Management Studio. Connect to the database. Under Security -> Logins, add a new login, and type the user name and password.
- Use this password to configure the data source below.
Comment out PostgreSQL Resource Tag
<!--
<Resource name="jdbc/labkeyDataSource" auth="Container"
type="javax.sql.DataSource"
username="postgres"
password="sa"
driverClassName="org.postgresql.Driver"
url="jdbc:postgresql://localhost:5433/labkey162"
maxTotal="20"
maxIdle="10"
accessToUnderlyingConnectionAllowed="true"
validationQuery="SELECT 1"
/>
-->
Add MS SQL Server Resource Tag
Use the following template for configuring a MS SQL Server data source. Replace USERNAME, PASSWORD, and DATABASE_NAME to fit the particulars of your target data source. The following template applies to Tomcat 8. See an earlier version of this topic for a Tomcat 7 template.<Resource name="jdbc/labkeyDataSource" auth="Container"
type="javax.sql.DataSource"
username="USERNAME"
password="PASSWORD"
driverClassName="net.sourceforge.jtds.jdbc.Driver"
url="jdbc:jtds:sqlserver://localhost:1433/DATABASE_NAME"
maxTotal="20"
maxIdle="10"
accessToUnderlyingConnectionAllowed="true"
validationQuery="SELECT 1"/>
Install PostgreSQL (Windows)
Install PostgreSQL on Windows
To install PostgreSQL on Windows:- Download and run the Windows PostgreSQL one click installer.
- Install PostgreSQL as a Windows Service.
- Keep track of the PostgreSQL Windows Service account name and password. LabKey Server doesn't really care what this password is set to, but we need to ask for it so that we can pass it along to the PostgreSQL installer.
- Keep track of the database superuser name and password. You'll need these to configure LabKey Server. LabKey Server uses this password to authenticate itself to PostgreSQL.
- Select the PL/pgsql procedural language for installation when prompted by the installer.
- We recommend that you install the graphical tool pgAdminIII for easy database administration. Leave the default settings as they are on the "Installation Options" page to include pgAdminIII.
- If you have chosen to install pgAdminIII, enable the Adminpack contrib module when prompted by the installer.
- Please read the notes below to forestall any difficulties with the PostgreSQL installation.
- You can only install one instance of PostgreSQL on your computer. If you already have PostgreSQL installed, LabKey Server can use that installed instance, provided the version is supported.
- You may need to disable your antivirus or firewall software before installing PostgreSQL, as the PostgreSQL installer conflicts with some antivirus or firewall software programs. (see http://wiki.postgresql.org/wiki/Running_%26_Installing_PostgreSQL_On_Native_Windows for more information).
- On Windows you may need to remove references to Cygwin from your Windows system path before installing PostgreSQL (see http://wiki.postgresql.org/wiki/Running_%26_Installing_PostgreSQL_On_Native_Windows for more information).
- If you uninstall and reinstall PostgreSQL, you may need to manually delete the data directory in order to reinstall. By default the data directory on a Windows computer is C:\Program Files\PostgreSQL\8.x\data.
- On Vista, you may need to run 'cmd.exe' as administrator and run the installer .msi from the command line.
- See also: Notes on Installing PostgreSQL on All Platforms
- After installation, you may find it helpful to tune PostgreSQL for performance.
Install PostgreSQL (Linux, Unix or Macintosh)
Install PostgreSQL on Linux, Unix or Macintosh
As part of installing required components, you need to install a database. To install PostgreSQL on Linux, Unix or a Mac:- See Supported Technologies page for list of supported versions of PostgreSQL
- From http://www.postgresql.org/download/ download the PostgreSQL binary packages or source code. Follow the instructions in the downloaded package to install PostgreSQL.
- Please read the notes below to forestall any difficulties with the PostgreSQL installation.
- If you uninstall and reinstall PostgreSQL, you may need to manually delete the data directory in order to reinstall.
- Don't forget to set the password for your database user, typically 'postgres'. (You can do this by opening Psql with something like ALTER USER "postgres" WITH PASSWORD 'new_password';) It should match whatever is in your config.properties file in the LabKey server directory.
- See: Notes on Installing PostgreSQL on All Platforms
- After installation, you may find it helpful to tune PostgreSQL for performance.
Install LabKey Server on Solaris
Install LabKey in a non-Global Zone
We recommend using a Whole Root Zone to run LabKey Server. The reasons for this are:- You are able to install binary version of PostgreSQL (that can be downloaded directly from postgresql.org)
- You are able to install JAVA in default location
- To install JSVC (Apache Commons Daemon), you will need to compile it from source. This means you will need to install modern versions of GCC, autoconf and m4. This is easiest to do via the Package Manager software.
How to Configure Tomcat to run as a non-root user.
Building Apache Commons Daemon on Solaris (ie JSVC)
The Apache Commons Daemon allows you to run Tomcat on port 80/443 as a user other than root. This is our recommended configuration. The Apache Commons Daemon is shipped as part of the Tomcat distribution file and must be compiled from source. To compile the Daemon, you will need to install- GCC
- Autoconf
- m4
- libsigsegv
cd $CATALINA_HOME/bin
tar xzf commons-daemon-1.0.5-native-src.tar.gz
cd commons-daemon-1.0.5-native-src/unix
support/buildconf.sh
./configure
make
Create a Tomcat Start script using the Apache Commons Daemon
A sample script is locate with the Apache Commons Daemon distribution, in the samples directory. If you are using Tomcat 5.5 or Tomcat 6.x, you should use the script named`tomcat.sh`. Edit this script to fit your installation. The following variables will need to be changed- `JAVA_HOME`:
- `CATALINA_HOME`
- `DAEMON_HOME`: This is usually `$CATALINA_HOME/bin/commons-daemon-1.0.5-native-src`
- `TOMCAT_USER`: The user that you want run the Tomcat server as
Configuring the Tomcat Server to run as a service.
Now that you have created the Tomcat start/stop script, you will need to configure Tomcat to run as a service (i.e., Tomcat will start at boot-time and can be managed via Service Admin (svcs))Create the Service Manifest A sample service manifest is below. The example assumes the start/stop script is located at `/usr/local/bin/tomcat.sh`<?xml version="1.0"?>
<!DOCTYPE service_bundle SYSTEM "/usr/share/lib/xml/dtd/service_bundle.dtd.1">
<!--
tomcat.xml : Sample Tomcat service manifest
-->
<service_bundle type='manifest' name='Tomcat'>
<service name='application/web/tomcat' type='service' version='1'>
<single_instance />
<exec_method
type='method'
name='start'
exec='/usr/local/bin/tomcat.sh'
timeout_seconds='30' />
<exec_method
type='method'
name='stop'
exec='/usr/local/bin/tomcat.sh'
timeout_seconds='30' />
<instance name='default' enabled='false' />
<stability value='Unstable' />
<template>
<common_name>
<loctext xml:lang='C'>Apache Tomcat</loctext>
</common_name>
<documentation>
<manpage title='tomcat' section='1' manpath='/usr/man' />
</documentation>
</template>
</service>
</service_bundle>
svccfg import /var/svc/manifest/application/web/tomcat.xml
svcadm enable tomcat
svcadm disable tomcat
svcs -lp tomcat
Notes on Installing PostgreSQL on All Platforms
Notes on Installing PostgreSQL on All Platforms
If you are using PostgreSQL, you will need to increase the join collapse limit. Edit postgresql.conf and change the following line:# join_collapse_limit = 8
join_collapse_limit = 10
Install and Set Up R
- Install R
- Configure LabKey Server to Work with R
- Configure Authentication and Permissions
- Install & Load Additional R Packages
- Install the X Virtual Frame Buffer (Headless Unix servers only)
- Fix Hostname Resolution Problems (MacOSX only)
Install R
- On the R site, choose a CRAN mirror near you.
- Click Download for the OS you are using (Linux, MacOSX, or Windows).
- Click the subcategory base.
- Download the installer using the link provided, for example Download R 3.1.3 for Windows.
- Install using the downloaded file.
- You don’t need to download the “contrib” folder on the Install site. It’s easy to obtain additional R packages individually from within R.
- Details of R installation/admin can be found here.
- Linux. An example of installing R on Linux is included on the Configure R on Linux page.
- Windows. On Windows, install R in a directory whose path does not include a space character. The R FAQ warns to avoid spaces if you are building packages from sources.
Configure LabKey Server to Work with R
- Follow the instructions in the topic: Configure Scripting Engines.
Configure Authentication and Permissions
Authentication. If you wish to modify a password-protected LabKey Server database through the Rlabkey macros, you will need to set up authentication. See: Create a .netrc or _netrc file.Permissions. Refer to Configure Permissions for information on how to adjust the permissions necessary to create and edit R Views. Note that only users who are part of the "Developers" site group or have Site Admin permissions can edit R Views.Batch Mode. Scripts are executed in batch mode, so a new instance of R is started up each time a script is executed. The instance of R is run using the same privileges as the LabKey Server, so care must be taken to ensure that security settings (see above) are set accordingly. Packages must be re-loaded at the start of every script because each script is run in a new instance of R.Install & Load Additional R Packages
You will likely need additional packages to flesh out functionality that basic install does not include. Additional details on CRAN packages are available here. Packages only need to be installed once on your LabKey Server. However, they will need to be loaded at the start of every script when running in batch mode.How to Install R PackagesUse the R command line or a script (including a LabKey R script) to install packages. For example, use the following to install two useful packages, "GDD" and "Cairo":install.packages(c("GDD", "Cairo"), repos="http://cran.r-project.org" )
install.packages('knitr', dependencies=TRUE)library(Cairo)
Headless Unix Servers Only: Install the X Virtual Frame Buffer
On Unix servers, the png() and jpg() functions use the device drivers provided by the X-windows display system to do rendering. This is a problem on a headless server where there is generally no display running at all.As a workaround, you can install the X Virtual Frame Buffer. This allows applications to connect to an X Windows server that renders to memory rather than a display.For instructions on how to install and configure the X Virtual Frame Buffer on Linux, see Configure the Virtual Frame Buffer on Linux.If you do not install the X Virtual Frame Buffer, your users may need to use graphics packages such as GDD or Cairo to replace the png() and jpeg() functions. See Determine Available Graphing Functions for further details.MacOSX Only: Fix Hostname Resolution Problems
When a LabKey Server runs on MacOSX, R views can only resolve hostnames that are stored in the server's host file.It appears that MacOSX security policy blocks spawned processes from accessing the name service daemon for the operating system.You can use one of two work-arounds for this problem:- Add the hostname (e.g., www.labkey.org) to the hosts file (/etc/hosts). Testing has shown that the spawned process is able to resolve hostnames that are in the host file.
- Use the name "localhost" instead of DNS name in the your R script.
Related Topics
Determine Available Graphing Functions
Determine Available Graphing Functions
Test Machine Capabilities. Before reading this section further, figure out whether you need to worry about its contents. Execute the following script in the R script builder:if(!capabilities(what = "jpeg") || !capabilities(what="X11"))
warning("You cannot use the jpeg() function on your LabKey Server");
if(!capabilities(what = "png") || !capabilities(what="X11"))
warning("You cannot use the png() function on your LabKey Server");
- Ask your admin to install a display buffer on the server such that it can access the appropriate device drivers.
- Avoid jpeg() and png(). There are currently three choices for doing so: Cairo(), GDD() and bitmap().
Strategy #1: Use the Cairo and/or GDD Packages
You can use graphics functions from the GDD or Cairo packages instead of the typical jpeg() and png() functions.There are trade-offs between GDD and Cairo. Cairo is being maintained, while GDD is not. GDD enables creation of .gif files, a feature unavailable in Cairo. You will want to check which image formats are supported under your installation of Cairo (this writer's Windows machine can not create .jpeg images in Cairo). Execute the following function call in the script-builder window to determine formats supported by Cairo on your machine:Cairo.capabilities();
# Load the Cairo package, assuming your Admin has installed it:
library(Cairo);
# Identify which "types" of images Cairo can output on your machine:
Cairo.capabilities();
# Open a Cairo device to take your plotting output:
Cairo(file="${imgout:labkeyl_cairo.png}", type="png");
# Plot a LabKey L:
plot(c(rep(25,100), 26:75), c(1:100, rep(1, 50)), ylab= "L", xlab="LabKey",
xlim= c(0, 100), ylim=c(0, 100), main="LabKey in R");
dev.off();

# Load the GDD package, assuming your Admin has installed it:
library(GDD);
# Open a GDD device to take your plotting output:
GDD(file="${imgout:labkeyl_gdd.jpg}", type="jpeg");
# Plot a LabKey L:
plot(c(rep(25,100), 26:75), c(1:100, rep(1, 50)), ylab= "L", xlab="LabKey",
xlim= c(0, 100), ylim=c(0, 100), main="LabKey in R");
dev.off();

Strategy #2: Use bitmap()
It is possible to avoid using either GDD or Cairo for graphics by using bitmap(). Unfortunately, this strategy relies on Ghostscript, reportedly making it slower and lower fidelity than other options. Instructions for installing Ghostscript are available here.NB: This method of creating jpegs has not been thoroughly tested.Calls to bitmap will specify the type of graphics format to use:bitmap(file="${imgout:p2.jpeg}", type = "jpeg");
Install SAS/SHARE for Integration with LabKey Server
Overview
Publishing SAS datasets to your LabKey Server provides secure, dynamic access to datasets residing in a SAS repository. Published SAS data sets appear on the LabKey Server as directly accessible datasets. They are dynamic, meaning that LabKey treats the SAS repository as a live database; any modifications to the underlying data set in SAS are immediately viewable on LabKey. The data sets are visible only to those who are authorized to see them.Authorized users view published data sets using the familiar, easy-to-use grid user interface used throughout LabKey. They can customize their views with filters, sorts, and column lists. They can use the data sets in custom queries and reports. They can export the data in Excel, web query, or TSV formats. They can access the data sets from JavaScript, SAS, R, and Java client libraries.Several layers keep the data secure. SAS administrators expose selected SAS libraries to LabKey. LabKey administrators then selectively expose SAS libraries as schemas available within a specific folder. The folder is protected using standard LabKey security; only users who have been granted permission to that folder can view the published data sets.SAS Setup
Before SAS datasets can be published to LabKey, an administrator needs to do three things:- Set up the SAS/SHARE service on the SAS installation
- Set up the SAS/SHARE JDBC driver on the LabKey web server
- Define SAS libraries as external schemas within LabKey
Usage
Once defined via the Schema Administration page, a SAS library can be treated like any other database schema (with a couple important exceptions listed below). The query schema browser lists all its data sets as “built-in tables.” A query web part can be added to the folder’s home page to display links to a library’s data sets. Links to key data sets can be added to wiki pages, posted on message boards, or published via email. Clicking any of these links displays the data set in the standard LabKey grid with filtering, sorting, exporting, paging, customizing views, etc. all enabled. Queries that operate on these datasets can be written. The data sets can be retrieved using client APIs (Java, JavaScript, R, and SAS).Limitations
The two major limitations with SAS data sets are currently:- SAS data sets can be joined to each other but not joined to data in the LabKey database. Any attempt to join between different databases (e.g., a table in PostgreSQL with a data set in SAS) results in an error message.
- The SAS/SHARE JDBC driver provides read-only access to SAS data sets. You cannot insert, update, or delete data in SAS data sets from LabKey.
Related Topics
Configure Webapp Memory
Overview
LabKey recommends that the Tomcat web application be configured to have a maximum JVM Heap size of 1024MB for a workstation or small test server, and 2048MB for a dedicated server machine. This page includes instructions for changing the Tomcat memory configuration on both Windows and Unix (Linux, MacOSX and Solaris) operating systems.
What do these settings do? As you probably know, LabKey Server is Java web application that runs on Tomcat. The Tomcat server is run within a Java Virtual Machine. It is this Java Virtual Machine (JVM) that controls the amount of memory available to LabKey Server. (See Wikipedia for more information the JVM Heap.)
Definitions
- CATALINA_HOME: Installation location of the Apache Tomcat Web Server
- If you performed a Manual Installation and followed these steps, then this is most likely
/usr/local/tomcat
- If you used the LabKey Windows installer, then this is most likely
C:\Program Files (x86)\LabKey Server\apache-tomcat-7.0.xxorC:\Program Files\LabKey Server\apache-tomcat-7.0.xx
- If you performed a Manual Installation and followed these steps, then this is most likely
Instructions for changing the JVM memory configuration on Windows Computers
Tomcat is usually started as a service on Windows, and it includes a dialog for configuring the JVM. The maximum total memory allocation is configured in its own text box, but other settings are configured in the general JVM options box using the Java command line parameter syntax.
Method 1:
- Open Windows Explorer
- Go to the CATALINA_HOME directory
- Double-click on the bin directory
- Double-click on tomcat7w.exe or the tomcat7w program (On some operating systems, you may have to sign on as an administrator to open this program successfully.)
- The command will open a program window.
- If this produces an error that says The specified service does not exist on the server, then please go to Method 2.
- Go to the Java tab in the new window.
- In the Java Options box, scroll to the bottom of the properties, and set the following property:
-XX:-HeapDumpOnOutOfMemoryError
- Change the Initial memory pool to be 128
- Change the Maximum memory pool to be 1024 for non-servers, 2048 for servers.
- Click the OK button
- Restart LabKey Server
Method 2:
You will need to use this method if you have used the LabKey Installer or if you customized the name of the LabKey Windows Service.
- Open a Command Prompt
- Start —> Programs —> Accessories —> Command Prompt
- Change to the
CATALINA_HOME\bindirectory. For example, if your CATALINA_HOME directory is located atC:\Program Files (x86)\LabKey Server\apache-tomcat-7.0.xx, then the command will be:cd "C:\Program Files (x86)\LabKey Server\apache-tomcat-7.0.xx\bin"
-
Execute the tomcat7w.exe program
tomcat7w.exe //ES//LabKeyTomcat7
- The command will open a program window.
- If this produces an error that says The specified service does not exist on the server, then see the note below.
- Go to the Java tab in the new window.
- In the Java Options box, scroll to the bottom of the properties, and set the following property:
-XX:-HeapDumpOnOutOfMemoryError
- Change the Initial memory pool: to be 128
- Change the Maximum memory pool: to be 1024 for non-servers, 2048 for servers.
- Click the OK button
- Restart LabKey Server
NOTE: The text after the //ES// must exactly match the name of the Windows Service that is being used to start/stop your LabKey Server. You can determine the name of your Windows Service by taking the following actions:
- Double-click on the Administrative Tools icon in the Control Panel
- Double-click on the Services icon
- Find the Service which is being used to start to start LabKey Server. It might be called something like Apache Tomcat or LabKey
- Double-click on the service
- In the command above, replace the text LabKeyTomcat6 with the text in shown next to ServiceName in the Properties dialog.
Instructions for changing the JVM Heap Size on Unix Computers (Linux, MacOSX and Solaris)
Method 1: If you use JSVC to start/stop LabKey Server
- Find the JSVC service script.
- On Linux or Solaris servers, this is usually in the
/etc/init.ddirectory and named eithertomcatortomcat7 - On MacOSX servers this might be in
/usr/local/jsvc/Tomcat7.sh
- On Linux or Solaris servers, this is usually in the
- Open the JSVC service script using your favorite editor
- Find the line for setting CATALINA_OPTS and add the following settings inside the double quotes.
For a server machine, use:
For a workstation or small test server, use:-Xms128m -Xmx2048m -XX:-HeapDumpOnOutOfMemoryError-Xms128m -Xmx1024m -XX:-HeapDumpOnOutOfMemoryError - Save the file
- Restart LabKey Server
Method 2: If use startup.sh and shutdown.sh to start/stop LabKey Server
- Change directory to CATALINA_HOME
- If you have followed our Manual Installation instructions, then this is usually
/usr/local/tomcat
- If you have followed our Manual Installation instructions, then this is usually
- The start script is located at
bin/catalina.sh - Open the Start script using your favorite editor
- Review the file
- Above the line with "
# OS specific support. $var _must_ be set to either true or false." add the following line.
For a server machine, use:JAVA_OPTS="$JAVA_OPTS -Xms128m -Xmx2048m -XX:-HeapDumpOnOutOfMemoryError"
For a workstation or small test server, use:JAVA_OPTS="$JAVA_OPTS -Xms128m -Xmx1024m -XX:-HeapDumpOnOutOfMemoryError"
- Save the file
- Restart LabKey Server
Set Up Robots.txt and Sitemaps
GROUP_CONCAT Install
- If the automatic installation has failed, site administrators will see a banner message on the running server reading "The GROUP_CONCAT aggregate function is not installed. This function is required for optimal operation of this server." with two links:
- Click Download installation script to download the required script: "groupConcatInstall.sql"
- Click View installation instructions to open to this topic.
- Connect to the Microsoft SQL Server using an account with membership in the sysadmin role.
- Execute the downloaded SQL script in the database.
- Confirm that group_concat is installed in the core schema.
- Restart Tomcat. The changes to the database will be recognized by the server only after a restart.
Related Topics
Example Setups and Configurations
- Example Hardware/Software Configuration
- Set up a JMS-Controlled Remote Pipeline Server
- Example Installation of Flow Cytometry on Mac OSX
- Set up R on a LabKey Server
- Linux Example: Configure R on Linux
- General Documentation: Install and Set Up R
- Set up R graphics on a server that lacks the X Windows display system (a.k.a. a headless server)
- Linux Example: Configure the Virtual Frame Buffer on Linux
- General Documentation: See the last section on the Install and Set Up R page.
- Install Proteomics.
- Linux Example: Example Linux Installation
Example Hardware/Software Configuration
This topic shows an example hardware/software configuration to support a LabKey installation. Your own configuration should be adjusted to suit your needs. Installation instructions and supported technologies can be found at the links below:
- https://www.labkey.org/home/Documentation/wiki-page.view?name=manualInstall
- https://www.labkey.org/home/Documentation/wiki-page.view?name=supported
Assumptions
The configuration shown here is based on the following assumptions:
- For each environment (i.e., Production, test, development), Tomcat and PostgreSQL will be running on the same machine, or a virtual machine (M/VM)
- For Production environment the M/VM will have 2 CPU(core) and 4GB of memory
-
- As your Production environment sees more usage, we recommend increasing the amount of memory to 8GB at a minimum (and then increasing the memory used by Tomcat and PostgreSQL accordingly).
- Test Environment will use M/VM with same configuration as Production.
- PostgreSQL instead of MsSQL (Both work just fine.)
Oracle JAVA
- Java Version: 8u111 or 8u112
- Use the ServerJRE distribution which is available at http://www.oracle.com/technetwork/java/javase/downloads/server-jre8-downloads-2133154.html
Apache Tomcat
- Tomcat Version: 8.5.9
- Use Binary distribution which is available at https://tomcat.apache.org/download-70.cgi
- Configuration Settings:
-
- Start-up Parameters (usually configured via the service startup script):
-
- MaxHeapSize: 2GB
-
- When using setting -Xmx2048M
- StartHeapSize: 256MB
-
- When using setting -Xmx256M
- Documentation: https://www.labkey.org/wiki/home/Documentation/page.view?name=configWebappMemory
- Server configuration
-
- We recommend using our sample configuration file. This configuration file contains our recommended settings described in our documentation.
- Download of sample configuration file from
-
- If using HTTP-only: https://github.com/LabKey/samples/blob/master/ops/config-examples/server.xml
-
- Simply download this file and copy it to TOMCAT_INSTALL_DIR/conf/ directory, replacing the file shipped with the distribution.
- If using HTTP and SSL: https://github.com/LabKey/samples/blob/master/ops/config-examples/server-SSL.xml
-
- Configuration of this file is a little more involved as you have to change the HTTPS connector configuration to use your SSL certificate.
- Change the Tomcat session timeout
-
- This setting controls how long before an idle login session is timed-out (i.e., the user is forced to log in again). By default the timeout is set to 30 minutes.
- Instructions: https://www.labkey.org/home/Documentation/wiki-page.view?name=configTomcat#8
- For servers which do not contain PHI or confidential information, most users change this value to 1 day (1440 minutes).
PostgreSQL Configuration
- Version: 9.6.1
- Configuration Settings:
-
- Server configuration(postgresql.conf file located in PGDATA directory). Recommended settings:
-
- Shared Buffers: 1024MB
- Work mem: 10MB
- Maintenance work mem: 1024MB
- Checkpoint segments: 10
- Checkpoint timeout: 15min
- Random page count: 1.4
- Effective cache size: 3072MB
- join_collapse_limit: 10
Set up a JMS-Controlled Remote Pipeline Server
The topic provides step by step instructions for setting up the following configuration:
- a stand-alone LabKey Server installation
- a Remote Pipeline Server (running on a different machine)
- a JMS service for communication between these servers

Steps:
- Set Up a Shared File System
- Set Up a JMS Queue
- Install LabKey Server
- Install Remote Pipeline Service
#1. Set up a Shared File System
- Decide on the location where the source data files will reside.
- Share out this directory as a network share so that the Remote Pipeline Server machine can mount it.
- Mount the directory, mapping it to a drive.
- Record the network share and the mapped drive for use later in the Remote Pipeline Server installation wizard. In the wizard, these paths are referred to as:
- LabKey Server webserver path to data files
- Pipeline Remote Server path data files
#2. Set up a JMS Queue
As you install the JMS queue, record these values for use later in the Remote Pipeline Server installation wizard:
- Host
- Port
JMS: Installation Steps
- Choose a server on which to run the JMS Queue
- Install the Java Runtime Environment
- Install and Configure ActiveMQ
- Test the ActiveMQ Installation
Choose a server to run the JMS Queue
ActiveMQ supports all major operating systems (including Windows, Linux, Solaris and Mac OSX). (For example, the Fred Hutchinson Cancer Research Institute runs ActiveMQ on the same linux server as the GRAM Server.) For this documentation we will assume you are installing on a Linux based server.Install the Java Runtime Environment
- Download the Java Runtime Environment (JRE) from http://java.sun.com/javase/downloads/index.jsp
- Install the JRE to the chosen directory.
- Create the JAVA_HOME environmental variable to point at your installation directory.
Install and Configure ActiveMQ
Download and Unpack the distribution
- Download ActiveMQ from ActiveMQ's download site
- Unpack the binary distribution from into /usr/local
- This will create /usr/local/apache-activemq-5.1.0
- Create the environmental variable <ACTIVEMQ_HOME> and have it point at /usr/local/apache-activemq-5.1.0
Configure logging for the ActiveMQ server
To log all messages sent through the JMSQueue, add the following to the <broker> node in the config file located at <ACTIVEMQ-HOME>/conf/activemq.xml<plugins>
<!-- lets enable detailed logging in the broker -->
<loggingBrokerPlugin/>
</plugins>
#log4j.rootLogger=DEBUG, stdout, out
log4j.rootLogger=INFO, stdout, out
Authentication, Management and Configuration
- Configure JMX to allow us to use Jconsole and the JMS administration tools monitor the JMS Queue
- We recommend configuring Authentication for your ActiveMQ server. There are number of ways to implement authentication. See http://activemq.apache.org/security.html
- We recommend configuring ActiveMQ to create the required Queues at startup. This can be done by adding the following to the configuration file <ACTIVEMQ-HOME>/conf/activemq.xml
<destinations>
<queue physicalName="job.queue" />
<queue physicalName="status.queue" />
</destinations>
Start the server
To start the ActiveMQ server, you can execute the command below. This command will start the ActiveMQ server with the following settings- Logs will be written to <ACTIVEMQ_HOME>/data/activemq.log
- StdOut will be written to /usr/local/apache-activemq-5.1.0/smlog
- JMS Queue messages, status information, etc will be stored in <ACTIVEMQ_HOME>/data
- job.queue Queue and status.queue will be durable and persistant. (I.e., messages on the queue will be saved through a restart of the process.)
- We are using AMQ Message Store to store Queue messages and status information
<ACTIVEMQ_HOME>/bin/activemq-admin start xbean:<ACTIVEMQ_HOME>/conf/activemq.xml > <ACTIVEMQ_HOME>/smlog 2>&1 &
Monitoring JMS Server, Viewing JMS Queue configuration and Viewing messages on a JMS Queue.
Using the ActiveMQ management tools
Browse the messages on queue by running<ACTIVEMQ_HOME>/bin/activemq-admin browse --amqurl tcp://localhost:61616 job.queue
<ACTIVEMQ_HOME>/bin/activemq-admin query
Using Jconsole
Here is a good quick description of using Jconsole to test your ActiveMQ installation. Jconsole is an application that is shipped with the Java Runtime. The management context to connect to isservice:jmx:rmi:///jndi/rmi://localhost:1099/jmxrmi
#3. Install LabKey Server (on Linux)
This Wiki web part is not configured to display content.
#4. Install Remote Pipeline Server (on Windows)
Steps to Install: Remote Pipeline Server
- Download and run the Windows installer: free download after registration.
- On the Installation Type page, select Remote Pipeline Server.
- Accept the license agreement.
- To use the wizard-based installation, select Config Wizard.
- Specify the JMS Server to communicate with the Remote Pipeline Server:
- host
- port.
- Specify the pipeline file locations.
- LabKey Server webserver path to data files
- Pipeline Remote Server path to data files
- Specify how to mount the network file share, either automatically or externally.
- If you choose automatically, you'll also be prompted to specify information for mapping a network drive where LabKey Server can access files on a remote server:
- Drive Letter
- Network Drive Path (the UNC path to the remote server)
- DOMAIN\username and password for accessing that share. User name and password can be left blank if they are not required by the file share.
- Accept the MSFileReader agreement. MSFileReader is a 3rd party tool that converts binary mass spectrometry files to the mzXML format.
- Specify the directory location for the Remote Pipeline Server installation.
Example Installation of Flow Cytometry on Mac OSX
- Sun Java
- Xcode
- Apache Tomcat
- Postgres
- LabKey Server
- Proteomics Tools (such as X!Tandem, TPP, etc)
- Xvfb (see Configure the Virtual Frame Buffer on Linux)
- ftpserver (see Upload Files: WebDAV)
- Mac OSX 10.5.3 (Leopard)
- These instructions assume that you will run the LabKey Flow Cytometry server as a user named "labkey".
- All downloaded files will be placed in a sub-directory of my home directory /Users/bconn/Download
Install Sun Java
The Sun Java JDK is installed by default on Mac OSX 10.5.x.Note: <YourServerName> represents the name of the server where you plan to install LabKey Server<YourServerName>:~ bconn$ java -version
java version "1.5.0_13"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.5.0_13-b05-237)
Java HotSpot(TM) Client VM (build 1.5.0_13-119, mixed mode, sharing)
Install XCode
XCode is the MacOSX development tools. It is a free download from Apple. This is required to compile Postgres and provides you with other development and open source tools.- Download XCode 3.0 from http://developer.apple.com/tools/download/
- Simply follow the instructions to install.
- Select all the defaults during the install
Install Apache
We will be- Using Tomcat v5.5.26
- Installing Tomcat in the directory /usr/local/apache-tomcat-5.5.26
- Tomcat will be configured to use port 8080 (see the Configure the Tomcat Default Port section on Configure the LabKey Web Application to change the Default Port )
- Tomcat will not be configured to use SSL (see the Configure LabKey Server to Run Under SSL (Optional, Recommended) section on Configure the LabKey Web Application to configure your server to use SSL )
Download and unpack Tomcat v5.5.26
<YourServerName>:~ bconn$ cd ~/Download
<YourServerName>:Download bconn$ curl
http://apache.oc1.mirrors.redwire.net/tomcat/tomcat-5/v5.5.26/bin/apache-tomcat-5.5.26.tar.gz -o
apache-tomcat-5.5.26.tar.gz
<YourServerName>:Download bconn$ sudo -s
bash3.2# cd /usr/local
bash3.2# tar xzf ~/Download/apache-tomcat-5.5.26.tar.gz
bash3.2# cd apache-tomcat-5.5.26/
bash3.2# ls
bin common conf LICENSE logs NOTICE RELEASE-NOTES RUNNING.txt server shared temp webapps work
Create the labkey user
- This user will be the user that runs the tomcat server.
- This user will have the following properties
- UID=900
- GID=900
- Home Directory= /Users/labkey
- Password: No password has been set. This means that you will not be able to login as the user labkey. If you want to run as the user labkey you will need to run sudo su - labkey from the command line.
bash-3.2# dseditgroup -u USERNAME -P PASSWORD -o create -n . -r "labkey" -i 900 labkey
bash-3.2# mkdir /Users/labkey
bash-3.2# dscl . -create /Users/labkey
bash-3.2# dscl . -create /Users/labkey UserShell /bin/bash
bash-3.2# dscl . -create /Users/labkey RealName "LabKey User"
bash-3.2# dscl . -create /Users/labkey UniqueID 900
bash-3.2# dscl . -create /Users/labkey PrimaryGroupID 900
bash-3.2# dscl . -create /Users/labkey NFSHomeDirectory /Users/labkey
bash-3.2# dscl . -read /Users/labkey
AppleMetaNodeLocation: /Local/Default
GeneratedUID: A695AE43-9F54-4F76-BCE0-A90E239A9A58
NFSHomeDirectory: /Users/labkey
PrimaryGroupID: 900
RealName:
LabKey User
RecordName: labkey
RecordType: dsRecTypeStandard:Users
UniqueID: 900
UserShell: /bin/bash
bash-3.2# vi ~labkey/.bash_profile
#Created to be used for starting up the LabKey Server
JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/CurrentJDK/Home
CATALINA_HOME=/usr/local/apache-tomcat-5.5.26
CATALINA_OPTS=-Djava.awt.headless=true
export CATALINA_OPTS
export JAVA_HOME
export CATALINA_HOME
# Append Path
PATH=$PATH:/usr/local/pgsql/bin:/usr/local/bin:/usr/local/labkey/bin
bash-3.2# chown -R labkey.labkey /Users/labkey
bash-3.2# chown -R labkey.labkey /usr/local/apache-tomcat-5.5.26
Configure the Tomcat server
Enable Access Logging on the server(This allows you to see which URLs are accessed):bash-3.2# vi /usr/local/apache-tomcat-5.5.26/conf/server.xml
<!--
<Valve className="org.apache.catalina.valves.FastCommonAccessLogValve"
directory="logs" prefix="localhost_access_log." suffix=".txt"
pattern="common" resolveHosts="false"/>
-->
<Valve className="org.apache.catalina.valves.FastCommonAccessLogValve"
directory="logs" prefix="localhost_access_log." suffix=".txt"
pattern="combined" resolveHosts="false"/>
Create "init" script that will be used to start and stop the tomcat server
Here we use the JSVC tool to create an init script. The JSVC is an Apache project and is shipped with the Tomcat distribution. There are many ways you can create an init script, but for this example, this is the tool we used. Build JSVC DaemonNote: You need to build this package. In order to do so, you will need GCC, Autoconf. These are installed with with the XCode package Note2: In addition, you need to make sure the JAVA_HOME environment variable is set for the user building this softwarebash-3.2# cd /usr/local/
bash-3.2# tar xzf /usr/local/apache-tomcat-5.5.26/bin/jsvc.tar.gz
bash-3.2# export JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/CurrentJDK/Home
bash-3.2# cd /usr/local/jsvc-src/
bash-3.2# vi native/jsvc.h
/* Definitions for booleans */
typedef enum {
false,
true
} bool;
#include <stdbool.h>
bash-3.2# vi support/apsupport.m4
CFLAGS="$CFLAGS -DOS_DARWIN -DDSO_DYLD"CFLAGS="$CFLAGS -DOS_DARWIN -DDSO_DLFCN"bash-3.2# sh support/buildconf.sh
bash-3.2# sh ./configure
...
bash-3.2# make
...
bash-3.2# mkdir /usr/local/jsvc
bash-3.2# cp /usr/local/jsvc-src/jsvc /usr/local/jsvc
Configure the server to Start Tomcat using the JSVC daemon at boot-time
On Mac OSX this is a little more complicated to setup than on other unix platforms. There are 2 steps to this process- Create "start-up" script
- Create plist file (file that launchd reads to start the Tomcat process )
bash-3.2# vi /usr/local/jsvc/Tomcat5.sh
#!/bin/sh
##############################################################################
#
# Copyright 2004 The Apache Software Foundation.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##############################################################################
#
# Small shell script to show how to start/stop Tomcat using jsvc
# If you want to have Tomcat running on port 80 please modify the server.xml
# file:
#
# <!-- Define a non-SSL HTTP/1.1 Connector on port 80 -->
# <Connector className="org.apache.catalina.connector.http.HttpConnector"
# port="80" minProcessors="5" maxProcessors="75"
# enableLookups="true" redirectPort="8443"
# acceptCount="10" debug="0" connectionTimeout="60000"/>
#
# That is for Tomcat-5.0.x (Apache Tomcat/5.0)
#
# chkconfig: 3 98 90
# description: Start and Stop the Tomcat Server
#
#Added to support labkey
PATH=$PATH:/usr/local/labkey/bin
export PATH
#
# Adapt the following lines to your configuration
JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/CurrentJDK/Home
CATALINA_HOME=/usr/local/apache-tomcat-5.5.26
DAEMON_HOME=/usr/local/jsvc
TOMCAT_USER=labkey
# for multi instances adapt those lines.
TMP_DIR=/var/tmp
PID_FILE=/var/run/jsvc.pid
CATALINA_BASE=/usr/local/apache-tomcat-5.5.26
CATALINA_OPTS=""
CLASSPATH= $JAVA_HOME/lib/tools.jar: $CATALINA_HOME/bin/commons-daemon.jar: $CATALINA_HOME/bin/bootstrap.jar
case "$1" in
start)
#
# Start Tomcat
#
$DAEMON_HOME/jsvc -user $TOMCAT_USER -home $JAVA_HOME -Dcatalina.home=$CATALINA_HOME -Dcatalina.base=$CATALINA_BASE -Djava.io.tmpdir=$TMP_DIR -wait 10 -pidfile $PID_FILE -outfile $CATALINA_HOME/logs/catalina.out -errfile '&1' $CATALINA_OPTS -cp $CLASSPATH org.apache.catalina.startup.Bootstrap
#
# To get a verbose JVM
#-verbose # To get a debug of jsvc.
#-debug exit $?
;;
stop)
#
# Stop Tomcat
#
$DAEMON_HOME/jsvc -stop -pidfile $PID_FILE org.apache.catalina.startup.Bootstrap
exit $?
;;
*)
echo "Usage Tomcat5.sh start/stop"
exit 1;;
esac
bash-3.2$ vi /Library/LaunchDaemons/org.apache.commons.jsvc.plist
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Disabled</key>
<false/>
<key>Label</key>
<string>org.apache.commons.jsvc</string>
<key>ProgramArguments</key>
<array>
<string>/usr/local/jsvc/Tomcat5.sh</string>
<string>start</string>
</array>
<key>RunAtLoad</key>
<true/>
<key>WorkingDirectory</key>
<string>/usr/local/apache-tomcat-5.5.26</string>
</dict>
</plist>
Test Tomcat Installation
First, lets test if Apache is installed properly.bash-3.2# export JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/CurrentJDK/Home
bash-3.2# export CATALINA_HOME=/usr/local/apache-tomcat-5.5.26
bash-3.2# export CATALINA_OPTS=-Djava.awt.headless=true
bash-3.2# /usr/local/apache-tomcat-5.5.26/bin/startup.sh
bash-3.2# /usr/local/apache-tomcat-5.5.26/bin/shutdown.sh
bash-3.2# /usr/local/jsvc/Tomcat5.sh start
bash-3.2# /usr/local/jsvc/Tomcat5.sh stop
bash-3.2# launchctl load /Library/LaunchDaemons/org.apache.commons.jsvc.plist
bash-3.2# /usr/local/jsvc/Tomcat5.sh stop
bash-3.2# exit
Postgres Installation and Configuration
We will download and build Postgres from source. There are some binary versions of Postgres for Mac, but the official documentation recommends building from source.We will be- Using Postgresql v8.2.6
- Installing Postgresql in the directory /usr/local/pgsql
- The postgres server will be run as the user postgres which will be created.
- New super-user role named labkey will be created and used by the Tomcat server to talk to postgres
Download and expand the source
<YourServerName>:Download bconn$ curl
http://ftp7.us.postgresql.org/pub/postgresql//source/v8.2.9/postgresql-8.2.9.tar.gz
-o postgresql-8.2.9.tar.gz
<YourServerName>:Download bconn$ sudo su -
bash-3.2# cd /usr/local
bash-3.2#tar -xzf ~bconn/Download/postgresql-8.2.9.tar.gz
Build Postgres
bash-3.2# ./configure
bash-3.2# make
...
bash-3.2# make check
...
bash-3.2# make install
...
Create the labkey user
- This user will be the user that runs the postgres server.
- This will create a user named postgres
- This user will have the following properties
- UID=901
- GID=901
- Home Directory=/usr/local/pgsql
- Password: No password has been set. This means that you will not be able to login as the user postgres. If you want to run as the user postgres you will need to run sudo su - postgres from the command line.
dseditgroup -o create -n . -r "postgres" -i 901 postgresbash-3.2# dscl . -create /Users/postgres
bash-3.2# dscl . -create /Users/postgres UserShell /bin/bash
bash-3.2# dscl . -create /Users/postgres RealName "Postgres User"
bash-3.2# dscl . -create /Users/postgres UniqueID 901
bash-3.2# dscl . -create /Users/postgres PrimaryGroupID 901
bash-3.2# dscl . -create /Users/postgres NFSHomeDirectory /usr/local/pgsql
bash-3.2# dscl . -read /Users/postgres
AppleMetaNodeLocation: /Local/Default
GeneratedUID: A695AE43-9F54-4F76-BCE0-A90E239A9A58
NFSHomeDirectory: /usr/local/pgsql
PrimaryGroupID: 901
RealName:
Postgres User
RecordName: postgres
RecordType: dsRecTypeStandard:Users
UniqueID: 901
UserShell: /bin/bash
Initialize the Postgres database
Create the directory which will hold the databasesbash-3.2# mkdir /usr/local/pgsql/data
bash-3.2# mkdir /usr/local/pgsql/data/logs
bash-3.2# chown -R postgres.postgres /usr/local/pgsql/data
bash-3.2# su - postgres
<YourServerName>:pgsql postgres$ /usr/local/pgsql/bin/initdb -D /usr/local/pgsql/data
<YourServerName>:pgsql postgres$ /usr/local/pgsql/bin/pg_ctl -D /usr/local/pgsql/data -l
/usr/local/pgsql/data/postgres.log start
Create a new database super-user role named "labkey":
<YourServerName>:pgsql postgres$ /usr/local/pgsql/bin/createuser -P -s -e labkey
Enter password for new role:
Enter it again:
CREATE ROLE "labkey" PASSWORD 'LabKey678' SUPERUSER CREATEDB CREATEROLE INHERIT LOGIN;
CREATE ROLE
Add the PL/pgsql language support to the postgres configuration
<YourServerName>:pgsql postgres$ createlang -d template1 PLpgsql
Change authorization so that the labkey user can login.
By default, postgres uses the ident method to authenticate users. However, the ident daemon is not available on many servers. Thus we have decided to use the "password" authentication method for all local connections. See http://www.postgresql.org/docs/8.2/static/auth-methods.html for more information on authentication methods.Stop the server<YourServerName>:pgsql postgres$ /usr/local/pgsql/bin/pg_ctl -D /usr/local/pgsql/data -l
/usr/local/pgsql/logs/logfile stop
<YourServerName>:pgsql postgres$ exit
bash-3.2# vi /usr/local/pgsql/data/pg_hba.cfg
# TYPE DATABASE USER CIDR-ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all ident sameuser
# IPv4 local connections:
host all all 127.0.0.1/32 ident sameuser
# IPv6 local connections:
host all all ::1/128 ident sameuser
# TYPE DATABASE USER CIDR-ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all ident sameuser
# IPv4 local connections:
host all all 127.0.0.1/32 password
# IPv6 local connections:
host all all ::1/128 ident sameuser
Increase the join collapse limit.
This allows the LabKey server to perform complex queries against the database.bash-3.2# vi /var/lib/pgsql/data/postgresql.conf Change:# join_collapse_limit = 8
join_collapse_limit = 10
Start the postgres database
<YourServerName>:pgsql postgres$ /usr/local/pgsql/bin/pg_ctl -D /usr/local/pgsql/data -l
/usr/local/pgsql/data/logs/logfile start
Create the "init" script that will start Postgres at boot-time
Luckily, with Postgres, there are scripts that ship with the source that can be used to start the Postgres server at boot-time. Postgres will use a different mechanism for getting started than Tomcat.Create the required directories and copy of the Startup files from the source directorybash-3.2# mkdir /Library/StartupItems/PostgreSQL/
bash-3.2# cp /usr/local/postgresql-8.2.9/contrib/start-scripts/PostgreSQL.darwin
/Library/StartupItems/PostgreSQL/PostgreSQL
bash-3.2# cp /usr/local/postgresql-8.2.9/contrib/start-scripts/StartupParameters.plist.darwin
/Library/StartupItems/PostgreSQL/StartupParameters.plist
bash-3.2# vi /Library/StartupItems/PostgreSQL/PostgreSQL
# do you want to rotate the log files, 1=true 0=false
ROTATELOGS=1
# do you want to rotate the log files, 1=true 0=false
ROTATELOGS=0
Install Graphviz
Download and expand Graphviz
<YourServerName>:Download bconn$ curl
http://www.graphviz.org/pub/graphviz/ARCHIVE/graphviz-2.16.1.tar.gz
-o graphviz-2.16.1.tar.gz
<YourServerName>:Download bconn$ sudo su -
bash-3.2# cd /usr/local
bash-3.2#tar -xzf ~bconn/Download/graphviz-2.16.1.tar.gz
Build and install Graphviz binaries into /usr/local/bin
bash-3.2# tar xzf ~/Downloads/graphviz-2.16.1.tar.gz
bash-3.2# /usr/local/graphviz-2.16.1
bash-3.2# ./configure
...
bash-3.2# make
...
bash-3.2# make install
...
Install LabKey Server
Download and expand LabKey server
Download LabKey Server from http://www.labkey.com and place the tar.gz file into your Download directorybash-3.2# cd /usr/local
bash-3.2# tar xzf ~bconn/Download/LabKey8.2-XXXX-bin.tar.gz
bash-3.2# cd LabKey8.2-XXXX-bin
bash-3.2# ls
common-lib labkeywebapp labkey.xml modules README.txt server-lib manual-upgrade.sh
bash-3.2# cd common-lib/
bash-3.2# ls
activation.jar jtds.jar mail.jar postgresql.jar
bash-3.2# cp *.jar /usr/local/apache-tomcat-5.5.26/common/lib/
bash-3.2# cd ../server-lib/
bash-3.2# ls
labkeyBootstrap.jar
bash-3.2# cp *.jar /usr/local/apache-tomcat-5.5.26/server/lib/
bash-3.2# mkdir /usr/local/labkey
bash-3.2# cd ..
bash-3.2# ls
common-lib labkeywebapp labkey.xml modules README.txt server-lib manual-upgrade.sh
bash-3.2# mkdir /usr/local/labkey/labkeywebapp
bash-3.2# mkdir /usr/local/labkey/modules
bash-3.2# cp -R labkeywebapp/* /usr/local/labkey/labkeywebapp/
bash-3.2# cp -R modules/* /usr/local/labkey/modules/
bash-3.2# cp labkey.xml /usr/local/apache-tomcat-5.5.26/conf/Catalina/localhost/
bash-3.2# vi /usr/local/apache-tomcat-5.5.26/conf/Catalina/localhost/labkey.xml
<Context path="/labkey" docBase="/usr/local/labkey/labkeywebapp" debug="0"
reloadable="true" crossContext="true">
<Environment name="dbschema/--default--" value="jdbc/labkeyDataSource"
type="java.lang.String"/>
<Resource name="jdbc/labkeyDataSource" auth="Container"
type="javax.sql.DataSource"
username="labkey"
password="LabKey678"
driverClassName="org.postgresql.Driver"
url="jdbc:postgresql://localhost/labkey"
maxActive="20"
maxIdle="10" accessToUnderlyingConnectionAllowed="true"/>
<Resource name="jms/ConnectionFactory" auth="Container"
type="org.apache.activemq.ActiveMQConnectionFactory"
factory="org.apache.activemq.jndi.JNDIReferenceFactory"
description="JMS Connection Factory"
brokerURL="vm://localhost?broker.persistent=false&broker.useJmx=false"
brokerName="LocalActiveMQBroker"/>
<Resource name="mail/Session" auth="Container"
type="javax.mail.Session"
mail.smtp.host="localhost"
mail.smtp.user="labkey"
mail.smtp.port="25"/>
<Loader loaderClass="org.labkey.bootstrap.LabkeyServerBootstrapClassLoader"
useSystemClassLoaderAsParent="false" />
<!-- <Parameter name="org.mule.webapp.classpath" value="C:mule-config"/> -->
</Context>
["error">root@<YourServerName> LabKey2.3-7771-bin?]# chown -R labkey.labkey /usr/local/labkey
["error">root@<YourServerName> LabKey2.3-7771-bin?]# chown -R labkey.labkey /usr/local/apache-tomcat-5.5.26
bash-3.2# /usr/local/jsvc/Tomcat5.sh start
http://<YourServerName>:8080/labkey
Configure R on Linux
Steps
The following example shows how to install and configure R on a Linux machine.If <YourServerName> represents the name of your server, these are the steps for building:["error">root@<YourServerName> Download?]# wget http://cran.r-project.org/src/base/R-2/R-2.6.2.tar.gz
["error">root@<YourServerName> Download?]# tar xzf R-2.6.2.tar.gz
["error">root@<YourServerName> Download?]# cd R-2.6.2
["error">root@<YourServerName> R-2.6.2?]# ./configure
...
["error">root@<YourServerName> R-2.6.2?]# make
...
["error">root@<YourServerName> R-2.6.2?]# make install
...
Additional Notes
- These instructions install R under /usr/local (with the executable installed at /usr/local/bin/R
- Support for the X11 device (including png() and jpeg()) is compiled in R by default.
- In order to use the X11, png and jpeg devices, an Xdisplay must be available. Thus you may still need to Configure the Virtual Frame Buffer on Linux.
Related Topics
Configure the Virtual Frame Buffer on Linux
Example Configuration
- Linux Distro: Fedora 7
- Kernel: 2.6.20-2936.fc7xen
- Processor Type: x86_64
Install R
Make sure you have completed the steps to install and configure R. See Install and Set Up R for general setup steps. For Linux-specific instructions, see Configure R on Linux.Install Xvfb
If the name of your machine is <YourServerName>, use the following:[root@<YourServerName> R-2.6.1]# yum update xorg-x11-server-Xorg
[root@<YourServerName> R-2.6.1]# yum install xorg-x11-server-Xvfb.x86_64
Start and Test Xvfb
To start Xvfb, use the following command:[root@<YourServerName> R-2.6.1]# /usr/bin/Xvfb :2 -nolisten tcp -shmem
[root@<YourServerName> R-2.6.1]# export DISPLAY=:2.0
[root@<YourServerName> R-2.6.1]# bin/R
> capabilities()
jpeg png tcltk X11 http/ftp sockets libxml fifo
TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
cledit iconv NLS profmem
TRUE TRUE TRUE FALSE
Make configuration changes to ensure that Xvfb is started at boot-time
You need to make sure that Xvfb runs at all times on the machine or R will not function as needed. There are many ways to do this. This example uses a simple start/stop script and treats it as a service.The script:[root@<YourServerName> R-2.6.1]# cd /etc/init.d
[root@<YourServerName> init.d]# vi xvfb
#!/bin/bash
#
# /etc/rc.d/init.d/xvfb
#
# Author: Brian Connolly (LabKey.org)
#
# chkconfig: 345 98 90
# description: Starts Virtual Framebuffer process to enable the
# LabKey server to use R.
#
#
XVFB_OUTPUT=/usr/local/labkey/Xvfb.out
XVFB=/usr/bin/Xvfb
XVFB_OPTIONS=":2 -nolisten tcp -shmem"
# Source function library.
. /etc/init.d/functions
start() {
echo -n "Starting : X Virtual Frame Buffer "
$XVFB $XVFB_OPTIONS >>$XVFB_OUTPUT 2>&1&
RETVAL=$?
echo
return $RETVAL
}
stop() {
echo -n "Shutting down : X Virtual Frame Buffer"
echo
killproc Xvfb
echo
return 0
}
case "$1" in
start)
start
;;
stop)
stop
;;
*)
echo "Usage: xvfb {start|stop}"
exit 1
;;
esac
exit $?
[root@<YourServerName> etc]# /etc/init.d/xvfb start
[root@<YourServerName> etc]# /etc/init.d/xvfb stop
[root@<YourServerName> etc]# /etc/init.d/xvfb
$XVFB_OUTPUT.
[root@<YourServerName> init.d]# chkconfig --add xvfb
[root@<YourServerName> init.d]# chkconfig --list xvfb
xvfb 0:off 1:off 2:off 3:on 4:on 5:on 6:off
[root@<YourServerName> init.d]# ls -la /etc/rc5.d/ | grep xvfb
lrwxrwxrwx 1 root root 14 2008-01-22 18:05 S98xvfb -> ../init.d/xvfb
Start the Xvfb Process and Setup the DISPLAY Env Variable
Start the process using:[root@<YourServerName> init.d]# /etc/init.d/xvfb start
[root@<YourServerName> ~]# vi ~tomcat/.bash_profile
[added]
# Set DISPLAY variable for using LabKey and R.
DISPLAY=:2.0
export DISPLAY
Restart the LabKey Server or it will not have the DISPLAY variable set
On this server, we have created a start/stop script for TOMCAT within /etc/init.d. So I will use that to start and stop the server[root@<YourServerName> ~]# /etc/init.d/tomcat restart
Test the configuration
The last step is to test that when R is run inside of the LabKey server, the X11,JPEG and PNG devices are availableExample:The following steps enable R in a folder configured to track Issue/Bug Tracking:- Log into the Labkey Server with an account with Administrator privs
- In any Project, create a new SubFolder
- Choose a "Custom"-type folder
- Uncheck all boxes on the right side of the screen except "Issues."
- Hit Next
- Click on the button "Views" and a drop-down will appear
- Select "Create R View"
- In the text box, enter "capabilities()" and hit the "Execute Script" button.
jpeg png tcltk X11 http/ftp sockets libxml fifo
TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
cledit iconv NLS profmem
FALSE TRUE TRUE FALSE
> proc.time()
user system elapsed
0.600 0.040 0.631
Example Linux Installation
This page provides an example of how to perform a complete installation of LabKey's CPAS Application on Linux.Items installed via these instructions:
- Sun Java
- Apache Tomcat
- postgres
- X!tandem
- TPP Tools
- Graphviz
- CPAS
- R (see Configure R on Linux)
- Xvfb (see Configure the Virtual Frame Buffer on Linux)
- ftpserver (see Upload Files: WebDAV)
- Linux Distro: Fedora 7
- Kernel: 2.6.20-2936.fc7xen
- Processor Type: x86_64
Install Sun Java
By default Fedora, RHEL and SUSE distributions have the GCJ, the GCC compiler for JAVA, installed. These distributions also use the Alternatives system (see http://linux.die.net/man/8/alternatives ) and in order for GCJ to be compatible they are using the JPackage (Jpackage.org). For further details on this, see http://docs.fedoraproject.org/release-notes/f8/en_US/sn-Java.html).CPAS requires the use of Sun Java and GCJ is not supported.To install Sun Java, you will need to install two packages:- JDK 6 Update 3 from Sun. This is a Linux RPM self-extracting file.
- JPackage Compatibility RPM (this RPM creates the proper links such that Sun Java is compatible with JPackage and the alternatives system)
root@<YourServerName> Download# chmod +x jdk-6u3-linux-i586-rpm.bin
root@<YourServerName> Download# ./jdk-6u3-linux-i586-rpm.bin
...
root@<YourServerName. Download# rpm --erase sun-javadb-client sun-javadb-common
sun-javadb-core sun-javadb-demo sun-javadb-docs sun-javadb-javadoc
root@<YourServerName. Download# wget
http://mirrors.dotsrc.org/jpackage/5.0/generic/non-free/RPMS/java-1.6.0-sun-compat-1.6.0.03-1jpp.i586.rpm
root@<YourServerName> Download# rpm --install java-1.6.0-sun-compat-1.6.0.03-1jpp.i586.rpm
root@<YourServerName> Download# alternatives --config java
Selection Command
-----------------------------------------------
1 /usr/lib/jvm/jre-1.5.0-gcj/bin/java
*+ 2 /usr/lib/jvm/jre-1.6.0-sun/bin/java
root@<YourServerName> Download# java -version
java version "1.6.0_03"
Java(TM) SE Runtime Environment (build 1.6.0_03-b05)
Java HotSpot(TM) Server VM (build 1.6.0_03-b05, mixed mode)
root@<YourServerName> Download#
root@<YourServerName> LabKey2.3-7771-bin# vi ~/.bash_profile
[added]
JAVA_HOME=/usr/lib/jvm/java-1.6.0-sun
CATALINA_HOME=/usr/local/apache-tomcat-5.5.25
CATALINA_OPTS=-Djava.awt.headless=true
export CATALINA_OPTS
export JAVA_HOME
export CATALINA_HOME
Install the Tomcat Server
Download and unpack Tomcat v5.5.25
root@<YourServerName> Download# wget
http://apache.mirrors.redwire.net/tomcat/tomcat-5/v5.5.25/bin/apache-tomcat-5.5.25.tar.gz
root@<YourServerName> Download# cd /usr/local
root@<YourServerName> local# tar xzf ~/Download/apache-tomcat-5.5.25.tar.gz
root@<YourServerName> local# cd apache-tomcat-5.5.25/
root@<YourServerName> apache-tomcat-5.5.25# ls
bin common conf LICENSE logs NOTICE RELEASE-NOTES RUNNING.txt server shared temp webapps work
Create the tomcat user
This user will be the user that runs the tomcat server.root@<YourServerName> ~# adduser -s /sbin/nologin tomcat
root@<YourServerName> ~# su - tomcat
tomcat@<YourServerName> ~$ vi .bashrc
JAVA_HOME=/usr/lib/jvm/java-1.6.0-sun
CATALINA_HOME=/usr/local/apache-tomcat-5.5.25
CATALINA_OPTS=-Djava.awt.headless=true
export CATALINA_OPTS
export JAVA_HOME
export CATALINA_HOME
tomcat@<YourServerName> ~$ exit
logout
Configure the apache server
This is an optional configuration change. It enables access logging on the server. This allows you to see which URLs are accessed.Enabled Access Logging on the server:root@<YourServerName> ~# vi /usr/local/apache-tomcat-5.5.25/conf/server.xml
<!--
<Valve className="org.apache.catalina.valves.FastCommonAccessLogValve"
directory="logs" prefix="localhost_access_log." suffix=".txt"
pattern="common" resolveHosts="false"/>
-->
<Valve className="org.apache.catalina.valves.FastCommonAccessLogValve"
directory="logs" prefix="localhost_access_log." suffix=".txt"
pattern="combined" resolveHosts="false"/>
Create "init" script that will be used to start and stop the tomcat server
Here we use the JSVC tool to create an init script. The JSVC is an Apache project and is shipped with the Tomcat distribution. There are many ways you can create an init script, but for this example, this is the tool we used.building jsvc
root@<YourServerName> ~# cd /usr/local/
root@<YourServerName> /usr/local# sudo tar xzf /usr/local/apache-tomcat-5.5.25/bin/jsvc.tar.gz
root@<YourServerName> /usr/local# cd /usr/local/jsvc-src
root@<YourServerName> /usr/local# sh support/buildconf.sh
root@<YourServerName> /usr/local# chmod +x configure
root@<YourServerName> /usr/local# ./configure
...
root@<YourServerName> /usr/local# make
...
Create the "init" script that will use JSVC
Now we use the example startup script at /usr/local/jsvc-src/native/Tomcat5.sh to create the startup script. We place it in /etc/init.d directory:root@<YourServerName> /usr/local# cat vi /etc/init.d/tomcat5.sh
#!/bin/sh
##############################################################################
#
# Copyright 2004 The Apache Software Foundation.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
##############################################################################
#
# Small shell script to show how to start/stop Tomcat using jsvc
# If you want to have Tomcat running on port 80 please modify the server.xml
# file:
#
# <!-- Define a non-SSL HTTP/1.1 Connector on port 80 -->
# <Connector className="org.apache.catalina.connector.http.HttpConnector"
# port="80" minProcessors="5" maxProcessors="75"
# enableLookups="true" redirectPort="8443"
# acceptCount="10" debug="0" connectionTimeout="60000"/>
#
# That is for Tomcat-5.0.x (Apache Tomcat/5.0)
#
# chkconfig: 3 98 90
# description: Start and Stop the Tomcat Server
#
#Added to support labkey
PATH=$PATH:/usr/local/labkey/bin
export PATH
#
# Adapt the following lines to your configuration
JAVA_HOME=/usr/lib/jvm/java-1.6.0-sun
CATALINA_HOME=/usr/local/apache-tomcat-5.5.25
DAEMON_HOME=/usr/local/jsvc-src
TOMCAT_USER=tomcat
# for multi instances adapt those lines.
TMP_DIR=/var/tmp
PID_FILE=/var/run/jsvc.pid
CATALINA_BASE=/usr/local/apache-tomcat-5.5.25
CATALINA_OPTS="-Djava.library.path=/home/jfclere/jakarta-tomcat-connectors/jni/native/.libs"
CLASSPATH= $JAVA_HOME/lib/tools.jar: $CATALINA_HOME/bin/commons-daemon.jar: $CATALINA_HOME/bin/bootstrap.jar
case "$1" in
start)
#
# Start Tomcat
#
$DAEMON_HOME/jsvc -user $TOMCAT_USER -home $JAVA_HOME -Dcatalina.home=$CATALINA_HOME -Dcatalina.base=$CATALINA_BASE -Djava.io.tmpdir=$TMP_DIR -wait 10 -pidfile $PID_FILE -outfile $CATALINA_HOME/logs/catalina.out -errfile '&1' $CATALINA_OPTS -cp $CLASSPATH org.apache.catalina.startup.Bootstrap
#
# To get a verbose JVM
#-verbose # To get a debug of jsvc.
#-debug exit $?
;;
stop)
#
# Stop Tomcat
#
$DAEMON_HOME/src/native/unix/jsvc -stop -pidfile $PID_FILE org.apache.catalina.startup.Bootstrap
exit $?
;;
*)
echo "Usage Tomcat5.sh start/stop"
exit 1;;
esac
Use the chkconfig tool to configure the start/stop script
- Notice the line "# chkconfig: 3 98 90" in the script. This tells the chkconfig tool how to create the links needed to start/stop the Tomcat process at each runlevel. This says that the Tomcat server should:
- Only be started if using runlevel 3. It should not be started if using any other runlevel.
- Start with a priority of 98
- Stop with a priority of 90.
- Now run the chkconfig tool:
<YourServerName> /usr/local# chkconfig --add tomcat5
Postgres Installation and Configuration
Postgres is already installed on the serverroot@<YourServerName> Download# rpm -q -a | grep postgres
postgresql-8.2.5-1.fc7
postgresql-libs-8.2.5-1.fc7
postgresql-server-8.2.5-1.fc7
postgresql-python-8.2.5-1.fc7
root@<YourServerName> Download# su - postgres
postgres@<YourServerName> ~# /usr/bin/createuser -P -s -e tomcat
Enter password for new role:
Enter it again:
CREATE ROLE "tomcat" PASSWORD 'LabKey678' SUPERUSER CREATEDB CREATEROLE INHERIT LOGIN;
CREATE ROLE
Add the PL/pgsql language support to the postgres configuration
postgres@<YourServerName> ~# createlang -d template1 PLpgsql
Change authorization so that the Tomcat user can login.
By default, postgres uses the ident method to authenticate the user (in other words, postgres will use the ident protocol for this user's authentication). However, the ident method cannot be used on many linux servers as ident is not installed.In order to get around the lack of ident, we make "password" the authentication method for all local connections (i.e., connections coming from the localhost). See http://www.postgresql.org/docs/8.2/static/auth-methods.html for more information on authentication methods.root@<YourServerName> ~# vi /var/lib/pgsql/data/pg_hba.cfg# TYPE DATABASE USER CIDR-ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all ident sameuser
# IPv4 local connections:
host all all 127.0.0.1/32 ident sameuser
# IPv6 local connections:
host all all ::1/128 ident sameuser
# TYPE DATABASE USER CIDR-ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all ident sameuser
# IPv4 local connections:
host all all 127.0.0.1/32 password
# IPv6 local connections:
host all all ::1/128 ident sameuser
Increase the join collapse limit.
Edit postgresql.conf and change the following line:# join_collapse_limit = 8
join_collapse_limit = 10
Now start the postgres database
root@<YourServerName> ~# /etc/init.d/postgresql start
Install X!Tandem
The supported version of X!Tandem is available from the LabKey subversion repository. See https://www.labkey.org/wiki/home/Documentation/page.view?name=thirdPartyCode for further information.Download the X!Tandem files using subversion:root@<YourServerName> ~# cd Download
root@<YourServerName> Download# mkdir svn
root@<YourServerName> Download# cd svn
root@<YourServerName> svn# svn checkout --username cpas --password cpas
https://hedgehog.fhcrc.org/tor/stedi/tags/tandem_2007-07-01/
Error validating server certificate for 'https://hedgehog.fhcrc.org:443':
- The certificate is not issued by a trusted authority. Use the
fingerprint to validate the certificate manually!
Certificate information:
- Hostname: hedgehog.fhcrc.org
- Valid: from Jun 22 14:01:09 2004 GMT until Sep 8 14:01:09 2012 GMT
- Issuer: PHS, FHCRC, Seattle, Washington, US
- Fingerprint: d8:a6:7a:5a:e8:81:c0:a0:51:87:34:6d:d1:0d:66:ca:22:09:9e:1f
(R)eject, accept (t)emporarily or accept (p)ermanently? p
....
root@<YourServerName> svn# g++ --version
g++ (GCC) 4.1.2 20070925 (Red Hat 4.1.2-27)
Copyright (C) 2006 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
root@<YourServerName> svn# cd tandem_2007-07-01/src
root@<YourServerName> src# vi Makefile
[change]
CXXFLAGS = -O2 -DGCC -D_LARGEFILE_SOURCE -D_FILE_OFFSET_BITS=64 -DPLUGGABLE_SCORING
#CXXFLAGS = -O2 -DGCC4 -D_LARGEFILE_SOURCE -D_FILE_OFFSET_BITS=64 -DPLUGGABLE_SCORING
[to]
#CXXFLAGS = -O2 -DGCC -D_LARGEFILE_SOURCE -D_FILE_OFFSET_BITS=64 -DPLUGGABLE_SCORING
CXXFLAGS = -O2 -DGCC4 -D_LARGEFILE_SOURCE -D_FILE_OFFSET_BITS=64 -DPLUGGABLE_SCORING
root@<YourServerName> src# make
....
Copy the tandem binary to the server path
root@<YourServerName> src# cp ../bin/tandem.exe /usr/local/labkey/bin
TPP Installation.
Labkey Server v2.3 supports TPP v3.4.2.First, download the software:root@<YourServerName> Download# wget
http://downloads.sourceforge.net/sashimi/TPP_v3.4.2_SQUALL.zip?modtime=1207909790&big_mirror=0root@<YourServerName> Download# unzip TPP_v3.4.2_SQUALL.zip
root@<YourServerName> Download# cd trans_proteomic_pipeline/src
root@<YourServerName> src# vi Makefile.inc
TPP_ROOT=/tpp/bin/tpp/
TPP_ROOT=/usr/local/labkey/bin/tpp/
XML_ONLY=1
root@<YourServerName> src# yum list available boost*
Available Packages
boost-devel-static.x86_64 1.33.1-13.fc7 fedora
boost-doc.x86_64 1.33.1-13.fc7 fedora
root@<YourServerName> src# yum install boost-devel-static.x86_64
Setting up Install Process
Parsing package install arguments
Resolving Dependencies
--> Running transaction check
---> Package boost-devel-static.x86_64 0:1.33.1-13.fc7 set to be updated
--> Finished Dependency Resolution
Dependencies Resolved
=============================================================================
Package Arch Version Repository Size
=============================================================================
Installing:
boost-devel-static x86_64 1.33.1-13.fc7 fedora 1.7 M
Transaction Summary
=============================================================================
Install 1 Package(s)
Update 0 Package(s)
Remove 0 Package(s)
Total download size: 1.7 M
Is this ok [y/N]: y
Downloading Packages:
(1/1): boost-devel-static 100% |=========================| 1.7 MB 00:01
Running rpm_check_debug
Running Transaction Test
Finished Transaction Test
Transaction Test Succeeded
Running Transaction
Installing: boost-devel-static ######################### [1/1]
Installed: boost-devel-static.x86_64 0:1.33.1-13.fc7
Complete!
root@<YourServerName> src# vi Makefile
#
# cygwin or linux?
#
ifeq (${OS},Windows_NT)
OSFLAGS= -D__CYGWIN__
GD_LIB= /lib/libgd.a
BOOST_REGEX_LIB= /lib/libboost_regex-gcc-mt.a
else
OSFLAGS= -D__LINUX__
GD_LIB= -lgd
BOOST_REGEX_LIB= /usr/libboost_regex/libboost_regex.a -lpthread
endif
#
# cygwin or linux?
#
ifeq (${OS},Windows_NT)
OSFLAGS= -D__CYGWIN__
GD_LIB= /lib/libgd.a
BOOST_REGEX_LIB= /lib/libboost_regex-gcc-mt.a
else
OSFLAGS= -D__LINUX__
GD_LIB= -lgd
BOOST_REGEX_LIB= /usr/lib64/libboost_regex.a -lpthread
endif
[root@<YourServerName> src]# make
.....
root@<YourServerName> src# make install
# Create Directories
mkdir -p /usr/local/labkey/bin/tpp/
mkdir -p /usr/local/labkey/bin/tpp/bin/
mkdir -p /usr/local/labkey/bin/tpp/schema/
# Copy all source executables and configuration files to their location
cp -f ASAPRatioPeptideParser /usr/local/labkey/bin/tpp/bin/
cp -f ASAPRatioProteinRatioParser /usr/local/labkey/bin/tpp/bin/
cp -f ASAPRatioPvalueParser /usr/local/labkey/bin/tpp/bin/
cp -f Comet2XML /usr/local/labkey/bin/tpp/bin/
cp -f CompactParser /usr/local/labkey/bin/tpp/bin/
cp -f DatabaseParser /usr/local/labkey/bin/tpp/bin/
cp -f EnzymeDigestionParser /usr/local/labkey/bin/tpp/bin/
cp -f InteractParser /usr/local/labkey/bin/tpp/bin/
cp -f LibraPeptideParser /usr/local/labkey/bin/tpp/bin/
cp -f LibraProteinRatioParser /usr/local/labkey/bin/tpp/bin/
cp -f Mascot2XML /usr/local/labkey/bin/tpp/bin/
cp -f PeptideProphetParser /usr/local/labkey/bin/tpp/bin/
cp -f ProteinProphet /usr/local/labkey/bin/tpp/bin/
cp -f ../perl/ProteinProphet.pl /usr/local/labkey/bin/tpp/bin/
cp -f ../perl/TPPVersionInfo.pl /usr/local/labkey/bin/tpp/bin/
cp -f ../perl/SSRCalc3.pl /usr/local/labkey/bin/tpp/bin/
cp -f ../perl/SSRCalc3.par /usr/local/labkey/bin/tpp/bin/
cp -f RefreshParser /usr/local/labkey/bin/tpp/bin/
cp -f MzXML2Search /usr/local/labkey/bin/tpp/bin/
cp -f runperl /usr/local/labkey/bin/tpp/bin/
cp -f Sequest2XML /usr/local/labkey/bin/tpp/bin/
cp -f Out2XML /usr/local/labkey/bin/tpp/bin/
cp -f Sqt2XML /usr/local/labkey/bin/tpp/bin/
cp -f CombineOut /usr/local/labkey/bin/tpp/bin/
cp -f Tandem2XML /usr/local/labkey/bin/tpp/bin/
cp -f xinteract /usr/local/labkey/bin/tpp/bin/
cp -f XPressPeptideParser /usr/local/labkey/bin/tpp/bin/
cp -f XPressProteinRatioParser /usr/local/labkey/bin/tpp/bin/
cp -f Q3ProteinRatioParser /usr/local/labkey/bin/tpp/bin/
cp -f spectrast /usr/local/labkey/bin/tpp/bin/
cp -f plotspectrast /usr/local/labkey/bin/tpp/bin/
cp -f runsearch /usr/local/labkey/bin/tpp/bin/
cp -f dtafilter /usr/local/labkey/bin/tpp/bin/
cp -f readmzXML.exe /usr/local/labkey/bin/tpp/bin/ # consider removing .exe for linux builds
cp -f dta2mzxml /usr/local/labkey/bin/tpp/bin/
cp -f out2summary /usr/local/labkey/bin/tpp/bin/ # to be retired in favor of out2xml
cp -f ../schema/msms_analysis3.dtd /usr/local/labkey/bin/tpp/schema/
cp -f ../schema/pepXML_std.xsl /usr/local/labkey/bin/tpp/schema/
cp -f ../schema/pepXML_v18.xsd /usr/local/labkey/bin/tpp/schema/
cp -f ../schema/pepXML_v9.xsd /usr/local/labkey/bin/tpp/schema/
cp -f ../schema/protXML_v1.xsd /usr/local/labkey/bin/tpp/schema/
cp -f ../schema/protXML_v3.xsd /usr/local/labkey/bin/tpp/schema/
cp -f ../schema/protXML_v4.xsd /usr/local/labkey/bin/tpp/schema/
chmod g+x /usr/local/labkey/bin/tpp/bin/*
chmod a+r /usr/local/labkey/bin/tpp/schema/*
root@<YourServerName> src# cd ..
root@<YourServerName> trans_proteomic_pipeline# ls
CGI COVERAGE extern HELP_DIR HTML images perl README schema src TESTING XML_sample_files.tgz
root@<YourServerName> trans_proteomic_pipeline# cd COVERAGE/
root@<YourServerName> COVERAGE# ls
batchcoverage batchcoverage.dsp batchcoverage.vcproj Coverage.h main.o Protein.h
batchcoverage2003.sln batchcoverage.dsw constants.h Coverage.o Makefile sysdepend.h
batchcoverage2003.vcproj batchcoverage.sln Coverage.cxx main.cxx Protein.cxx
root@<YourServerName> COVERAGE# cp batchcoverage /usr/local/labkey/bin/tpp/bin/
root@<YourServerName> COVERAGE# vi ~tomcat/.bashrc
PATH=$PATH:$HOME/bin
PATH=$PATH:$HOME/bin:/usr/local/labkey/bin/tpp/bin
Install the Graphviz tool
add notes hereInstall the LabKey CPAS server
root@<YourServerName>Download# wget
https://www.labkey.org/download/2.3/LabKey2.3-7771-bin.tar.gz
root@<YourServerName> Download# tar xzf LabKey2.3-7771-bin.tar.gz
root@<YourServerName> Download# cd LabKey2.3-7771-bin
root@<YourServerName> LabKey2.3-7771-bin# ls
common-lib labkeywebapp labkey.xml modules README.txt server-lib manual-upgrade.sh
root@<YourServerName> LabKey2.3-7771-bin# cd common-lib/
root@<YourServerName> common-lib# ls
activation.jar jtds.jar mail.jar postgresql.jar
root@<YourServerName> common-lib# cp *.jar /usr/local/apache-tomcat-5.5.25/common/lib/
root@<YourServerName> common-lib# cd ../server-lib/
root@<YourServerName> server-lib# ls
labkeyBootstrap.jar
root@<YourServerName> server-lib# cp
labkeyBootstrap.jar /usr/local/apache-tomcat-5.5.25/server/lib/
root@<YourServerName> server-lib# mkdir /usr/local/labkey
root@<YourServerName> server-lib# cd ..
root@<YourServerName> LabKey2.3-7771-bin# ls
common-lib labkeywebapp labkey.xml modules README.txt server-lib manual-upgrade.sh
root@<YourServerName> LabKey2.3-7771-bin# mkdir /usr/local/labkey/labkeywebapp
root@<YourServerName> LabKey2.3-7771-bin# mkdir /usr/local/labkey/modules
root@<YourServerName> LabKey2.3-7771-bin# cp -R labkeywebapp/* /usr/local/labkey/labkeywebapp/
root@<YourServerName> LabKey2.3-7771-bin# cp
-R modules/* /usr/local/labkey/modules/
root@<YourServerName> LabKey2.3-7771-bin# cp labkey.xml
/usr/local/apache-tomcat-5.5.25/conf/Catalina/localhost/
root@<YourServerName> LabKey2.3-7771-bin# vi
/usr/local/apache-tomcat-5.5.25/conf/Catalina/localhost/labkey.xml
<Context path="/labkey" docBase="/usr/local/labkey/labkeywebapp" debug="0"
reloadable="true" crossContext="true">
<Environment name="dbschema/--default--" value="jdbc/labkeyDataSource"
type="java.lang.String"/>
<Resource name="jdbc/labkeyDataSource" auth="Container"
type="javax.sql.DataSource"
username="tomcat"
password="LabKey678"
driverClassName="org.postgresql.Driver"
url="jdbc:postgresql://localhost/labkey"
maxActive="20"
maxIdle="10" accessToUnderlyingConnectionAllowed="true"/>
<Resource name="jms/ConnectionFactory" auth="Container"
type="org.apache.activemq.ActiveMQConnectionFactory"
factory="org.apache.activemq.jndi.JNDIReferenceFactory"
description="JMS Connection Factory"
brokerURL="vm://localhost?broker.persistent=false&broker.useJmx=false"
brokerName="LocalActiveMQBroker"/>
<Resource name="mail/Session" auth="Container"
type="javax.mail.Session"
mail.smtp.host="localhost"
mail.smtp.user="tomcat"
mail.smtp.port="25"/>
<Loader loaderClass="org.labkey.bootstrap.LabkeyServerBootstrapClassLoader"
useSystemClassLoaderAsParent="false" />
<!-- <Parameter name="org.mule.webapp.classpath" value="C:mule-config"/> -->
</Context>
root@<YourServerName> LabKey2.3-7771-bin# chown -R tomcat.tomcat /usr/local/labkey
root@<YourServerName> LabKey2.3-7771-bin# chown -R tomcat.tomcat /usr/local/apache-tomcat-5.5.25
root@<YourServerName> ~# /etc/init.d/tomcat5 start
http://<YourServerName>:8080/labkey
Upgrade LabKey
Preparation Steps
Before you upgrade, you should backup your database and notify your users that the system will be down for a period of time.If you are upgrading to a new version of Apache Tomcat, see Supported Tomcat Versions for important information about using different versions of Tomcat with LabKey Server.Upgrade Options
Windows
- If you are upgrading an instance of LabKey Server that was originally installed using the Windows Graphical Installer wizard, then you can use the same wizard to perform the upgrade.
- Otherwise, you need to upgrade LabKey Server manually. You can use the upgrade batch script described here.
- After upgrade, you may need to reset your browser cache. See Troubleshooting Upgrade.
Linux, Solaris or Mac OSX
You can use the manual-upgrade.sh script to streamline the upgrade process. See Manual Upgrade Script for Linux, MacOSX, and Solaris for more information.Supported Versions for Upgrade
Please see LabKey's Upgrade Support Policy.Manual Upgrade Checklist
- Download the appropriate LabKey Server archive file for your operating system from the download page. On Windows, use LabKeyxx.x-xxxx-bin.zip; on Unix-based systems, used LabKeyxx.x-xxxx-bin.tar.gz.
- Unzip or untar the archive file to a temporary directory on your computer. On Unix-based systems, the command tar xfz LabKeyxx.x-xxxx-bin.tar.gz will unzip and untar the archive. For a description of the files included in the distribution, see the section Install the LabKey Server System Components in the topic Install Required Components.
Locate Your Existing LabKey Server Installation
- Locate your LabKey Server home (<labkey-home>) directory, the directory to which you previously installed LabKey Server. For example, if you used the LabKey Server binary installer to install LabKey Server on Windows, your default <labkey-home> directory is C:\Program Files\LabKey Server.
- Find your Tomcat home directory (<tomcat-home>). If you used the LabKey Server binary installer to install an earlier version of LabKey Server on Windows, your default Tomcat directory is <labkey-home>/jakarta-tomcat-n.n.n.
- Find the existing LabKey Server files on your system for each of the following components, in preparation for replacing them with the corresponding LabKey Server files:
- lib: The existing LabKey Server libraries should be located in <tomcat-home>/lib.
- labkeywebapp: The directory containing the LabKey Server web application (<labkeywebapp>) may be named labkeywebapp or simply webapp. It may be in the <labkey-home> directory or may be a peer directory of the <tomcat-home> directory.
- modules: The directory containing the LabKey Server modules. This directory is found in the <labkey-home> directory.
- externalModules: The directory containing additional, user-developed LabKey Server modules. This directory is found in the <labkey-home> directory. (Not all installations contain an externalModules directory. If you don't see an externalModules directory, you can skip this step.)
- labkey.xml: The LabKey Server configuration file should be located in <tomcat-home>/conf/Catalina/localhost/. This file may be named labkey.xml, LABKEY.xml, or ROOT.xml.
Prepare to Copy the New Files
- Shut down the Tomcat web server. If you are running LabKey Server on Windows, it may be running as a Windows service, and you should shut down the service. (You can do this via the Services panel on Windows.) If you are running on a Unix-based system, you can use the shutdown script in the <tomcat-home>/bin directory. Note that you do not need to shut down the database that LabKey Server connects to.
- Create a new directory to store the a backup of your current configuration. Create the directory <labkey-home>/backup1
- NOTE: if the directory <labkey-home>/backup1 already exists, increment that directory name by 1. For example, if you already have backup directories named backup1 and backup2, then new backup directory should be named <labkey-home>/backup3
- Back up your existing labkeywebapp directory:
- Move the <labkeywebapp> directory to the backup directory
- Back up your existing modules directory:
- Move the <labkey-home>/modules directory to the backup directory
- Back up your existing externalModules directory, if it exists:
- Move the <labkey-home>/externalModules directory to the backup directory
- Back up your <tomcat-home>/lib directory:
- Copy the <tomcat-home>/lib directory to the backup directory
- Back up your <tomcat-home>/conf directory:
- Copy the <tomcat-home>/conf directory to the backup directory
- Create the following new directories
- <labkey-home>/labkeywebapp
- <labkey-home>/modules
- <labkey-home>/externalModules (If your installation includes an externalModules directory.)
- For installations that use the LabKey Server Enterprise Pipeline, on the remote server:
- Perform the same steps for the labkeywebapp and modules directories as described above
- Copy the <labkey-home>/pipeline-lib directory on the remote server to the backup directory
- Create a new directory <labkey-home>/pipeline-lib on the remote server
Copy Files from the New LabKey Server Distribution
- Copy the contents of the LabKeyxx.x-xxxx-bin/labkeywebapp directory to the new <labkey-home>/labkeywebapp directory.
- Copy the contents of the LabKeyxx.x-xxxx-bin/modules directory to the new <labkey-home>/modules directory.
- Copy the contents of the LabKeyxx.x-xxxx-bin/externalModules directory to the new <labkey-home>/externalModules directory.
- If you are running Windows, copy the executable files and Windows libraries in the LabKeyxx.x-xxxx-bin/bin directory to the <labkey-home>/bin directory. If you are running on Unix, you will need to download these components separately. See Third-Party Components and Licenses for more information.
- Copy the LabKey Server libraries from the /LabKeyxx.x-xxxx-bin/tomcat-lib directory into <tomcat-home>/lib. Choose to overwrite any jars that are already present. Do not delete or move the other files in this folder (<tomcat-home>/lib), as they are required for Tomcat to run.
- If you have customized the stylesheet for your existing LabKey Server installation, copy your modified stylesheet from the backup directory into the new <labkey-home>/labkeywebapp directory.
- For installations that use the LabKey Server Enterprise Pipeline, on the remote server::
- Copy the labkeywebapp directory to <labkey-home> on the remote server
- Copy the modules directory to <labkey-home> on the remote server
- Copy the pipeline-lib directory to <labkey-home> on the remote server
- Copy the bin directory to <labkey-home> on the remote server (if on Windows)
- Copy the file tomcat-lib/labkeyBootstrap.jar to <labkey-home> on the remote server
Install Third Party Components
- If you are running Windows:
- Back up your existing bin directory: Move the <labkey-home>/bin directory to the backup directory. Note that this will lose any third-party binaries that you might have installed manually. Be sure to reapply them again if needed.
- Create the directory <labkey-home>/bin
- Copy the executable files and Windows libraries in the LabKeyxx.x-xxxx-bin/bin directory to the <labkey-home>/bin directory.
- If you are running on Unix:
- You will need to download and upgrade these components. See Third-Party Components and Licenses for the list of required components, required versions and installation instructions.
- Ensure that the <labkey-home>/bin directory is on your system path, or on the path of the user account that will be starting Tomcat.
Copy the LabKey Server Configuration File
- Back up the existing LabKey Server configuration file (the file named labkey.xml, LABKEY.xml, or ROOT.xml)
- The file is located in <tomcat-home>/conf/Catalina/localhost/
- Copy the file to the backup directory
- Copy the new labkey.xml configuration file from the /LabKeyxx.x-xxxx-bin directory to <tomcat-home>/conf/Catalina/localhost/labkey.xml.
- Alternately, if your existing LabKey Server installation has been running as the root web application on Tomcat and you want to ensure that your application URLs remain identical after the upgrade, copy labkey.xml to <tomcat-home>/conf/Catalina/localhost/ROOT.xml.
- Merge any other settings you have changed in your old configuration file into the new one. Open both files in a text editor, and replace all parameters (designated as @@param@@) in the new file with the corresponding values from the old file.
- Important: The name of the LabKey Server configuration file determines the URL address of your LabKey Server application. If you change this configuration file, any external links to your LabKey Server application will break. Also, since Tomcat treats URLs as case-sensitive, external links will also break if you change the case of the configuration file. For that reason, you may want to name the new configuration file to match the original one. For more information, see labkey.xml Configuration File.
Restart Tomcat and Test
- Restart the Tomcat web server. If you have any problems starting Tomcat, check the Tomcat logs in the <tomcat-home>/logs directory.
- Navigate to your LabKey Server application with a web browser using the appropriate URL address, and upgrade the LabKey Server application modules when you are prompted to do so.
- It is good practice to review the Properties on the Admin Console immediately after the upgrade to ensure they are correct.
TroubleshootingIf menus, tabs, or other UI features appear to display incorrectly after upgrade, particularly if different browsers show different layouts, you may need to clear your browser cache to clear old stylesheets. For example, the left screenshot below shows an incorrect display after upgrade from version 11.2 to 13.3 on windows8; the right image is after a hard reset (ctrl-F5 in Chrome) and shows the correct default home page layout.

Manual Upgrade Script for Linux, MacOSX, and Solaris
Overview
LabKey Server ships with a script for upgrading a LabKey Server running on Linux, MacOSX, Solaris, or other UNIX-style operating systems. This script, named manual-upgrade.sh, can be used to upgrade your LabKey Server to the latest version.How to use this script
Type "manual-upgrade.sh" with no parameters in a console window for help on the script's parameters.The script provides a number of command line options:Usage:
manual-upgrade.sh -l dir [-d dir] [-c dir] [-u tomcatuser] [--service] [--catalina]
-l dir: LABKEY_HOME directory to be upgraded. This directory contains the
the labkeywebapp, modules, pipeline-lib, etc directories for the running
LabKey Server instance. (Required)
-d dir: Upgrade distribution directory: contains labkeywebapp, lib, and manual-upgrade.sh.
Defaults to current working directory. (Required)
-c dir: TOMCAT_HOME; root of LabKey Apache Tomcat installation.
Defaults to value of CATALINA_HOME environment variable. (Required)
-u owner: the tomcat user account (default current user)
--service: use /etc/init.d/tomcat to start/stop web server (default)
--catalina: use CATALINA_HOME/bin/shutdown.sh and CATALINA_HOME/bin/startup.sh to start/stop web server
Example
For this example, we will assume that- LABKEY_HOME directory: /usr/local/labkey
- Upgrade distribution directory: /usr/local/src/labkey/LabKey11.1-r16000-enterprise-bin
- TOMCAT_HOME directory: /usr/local/tomcat
- TOMCAT version: 6.0
- Owner: tomcat
cd /usr/local/src/labkey/LabKey11.1-r16000-enterprise-bin
manual-upgrade.sh -l /usr/local/labkey -d /usr/local/src/labkey/LabKey11.1-r16000-enterprise-bin -c /usr/local/tomcat -u tomcat --service
Additional Notes
Roll back to previous version:- This script does not keep a backup copy of the LabKey Server java files after the upgrade. In order to install a previous version, you will need to have the LabKey Server distribution files available on your file system.
- You can then simply execute the script again specifying the previous version's directory containing the uncompressed LabKey Server distribution files
- This script does not perform a backup of your LabKey Server database.
- LabKey recommends that you perform a backup of your LabKey Server database before upgrading your LabKey Server using this script.
- See Backup and Maintenance and Sample Scripts for Backup Scenarios for more information on backing up your database.
Upgrade Support Policy
- We support upgrading from production releases for two years after their initial release. For example, any installation running v14.3 (Nov, 2014 release) or later official releases should be able to upgrade to v17.1; earlier releases (v14.2 and before) will not be able to upgrade directly to v17.1.
- We especially discourage running "interim development builds" (builds from the development process that are not production releases) in any production environment. Interim builds are not fully tested and are sure to contain bugs and incomplete features; they should be upgraded to a production release ASAP. We try to support upgrading from interim development builds for two production releases. For example, v17.1 should be able to upgrade from any interim build created after the v16.2 production release.
| LabKey Release | Can Upgrade From These Official Releases | Can Upgrade From These Interim Releases |
|---|---|---|
| 17.3* | 15.2 and later | 17.1 and later |
| 17.2* | 15.1 and later | 16.3 and later |
| 17.1 | 14.3 and later | 16.2 and later |
| 16.3 | 14.2 and later | 16.1 and later |
| 16.2 | 14.1 and later | 15.3 and later |
| 16.1 | 13.3 and later | 15.2 and later |
| 15.3 | 13.2 and later | 15.1 and later |
| 15.2 | 13.1 and later | 14.3 and later |
| 15.1 | 12.3 and later | 14.2 and later |
| 14.3 | 12.2 and later | 14.1 and later |
| 14.2 | 12.1 and later | 13.3 and later |
| 14.1 | 11.3 and later | 13.2 and later |
| 13.3 | 11.2 and later | 13.1 and later |
| 13.2 | 11.1 and later | 12.3 and later |
| 13.1 | 10.3 and later | 12.2 and later |
| 12.3 | 10.2 and later | 12.1 and later |
| 12.2 | 10.1 and later | 11.3 and later |
| 12.1 | 9.3 and later | 11.2 and later |
| 11.3 | 9.2 and later | 11.1 and later |
| 11.2 | 9.1 and later | 10.3 and later |
| 11.1 | 8.3 and later | 10.2 and later |
| 10.3 | 8.2 and later | 10.1 and later |
Backup and Maintenance
- Backup Checklist. A checklist of data to backup.
- A Sample Backup Plan. A sample plan for backing up an enterprise-class LabKey installation.
- Sample Scripts for Backup Scenarios. Sample scripts for backing up Postgres databases.
- PostgreSQL Maintenance. How to maintain your database.
- Administer the Site Down Servlet. Useful if you need to make your site temporarily unavailable during maintenance.
Backup Checklist
- Database
- Data Files
- Configuration and Log Files
1. Database
LabKey Server stores your data in a relational database. By default LabKey is installed with the open-source relational database PostgreSQL. You may also use LabKey with Microsoft SQL Server. The links below provide backup information specific to these databases.PostgreSQL. PostgreSQL provides commands for three different levels of database backup: SQL dump, file system level backup, and on-line backup. The PostgreSQL documentation for backing up your database can be found here: Microsoft SQL Server. For further information on administering Microsoft SQL Server, see the documentation that came with your Microsoft SQL Server installation.2. Data Files
Site-level File Root. You should backup the contents (files and sub-directories) of the site-level file root. The location of the site-level file root is set at: Admin -> Site -> Admin Console -> Files.Pipeline Files. You should also back up any directories or file shares that you specify as root directories for the LabKey pipeline. In addition to the raw data that you place in the pipeline directory, LabKey will generate files that are stored in this directory. The location of the pipeline root is available at:Other File Locations. To see a summary list of file locations: go to Admin -> Site -> Admin Console -> Files, and then click Expand All. Note the Default column: if a file location has the value false, then you should backup the contents of that location manually.3. Configuration and Log Files
Log Files. Log files are located in <CATALINA_HOME>/logs.Configuration Files. Cofiguration files are located in <LABKEY_HOME>.A Sample Backup Plan
- You should backup the following data in your LabKey Server:
- Database
- Site-level file root
- Pipeline root and FileContent module files
- LabKey Server configuration and log files
- For some LabKey Server modules, the files (Pipeline Root or File Content Module) and the data in the database are very closely linked. Thus, it is important to time the database backup and the file system backup as closely as possible.
- Backup Frequency: For robust enterprise backup, this plan suggests performing incremental and transaction log backups hourly. In the event of a catastrophic failure, researchers will lose no more than 1 hour of work. You will tailor the frequency of all types of backups to your organization's needs.
- Backup Retention: For robust enterprise backup, this plan suggests a retention period of 7 years. This will allow researchers to be able to restore the server to any point in time within the last 7 years. You will tailor the retention period to your organization's needs.
- Full Backup of Database: Monthly
- This should occur on a weekend or during period of low usage on the server
- Differential/Incremental Backup of Database: Nightly
- For Servers with large databases, use an Incremental Backup Design
- Such databases may be >10GB in size or may be fast-growing. An example would be a LabKey database that supports high-throughput Proteomics
- "Incremental" means that you backup all changes since the last Full or Incremental backup
- For Servers with smaller databases, use a Differential Backup Design
- "Differential" means that you backup all changes since the last Full backup
- Transaction Log Backups: Hourly
- Full Backup of Files: Monthly
- This should occur on a weekend or during period of low usage on the server
- To determine the site-level file root go to: Admin -> Site -> Admin Console -> Files. Backup the contents of this file root.
- Make sure to check for any file locations that have overriden the site-level file root. For a summary of file locations, go to Admin -> Site -> Admin Console -> Files -> Expand All.
- Full Backup of Files: Monthly
- This should occur on a weekend or during period of low usage on the server
- Incremental Backup of Database: Hourly
- These files are stored in the following locations
- Log Files are located in <CATALINA_HOME>logs
- Configuration files are located in <LABKEY_HOME>
- Full Backup of Files: Monthly
- This should occur on a weekend or during period of low usage on the server
- Incremental Backup of Database: Nightly
Sample Scripts for Backup Scenarios
- backupFile is the file in which the backup is stored.
- dbName is the name of the database for the LabKey Server. This is normally labkey
pg_dump --compress=5 --format=c -f backupFile dbName
su - postgres -c '/usr/bin/pg_dump --compress=5 --format=c -f /labkey/backups/labkey_database_backup.bak labkey'
- $labkeyHome: this is the directory where have installed the LabKey binaries. Normally /usr/local/labkey
- $labkeyFiles: this is the site-level file root. By default this located in the files subdirectory of $labkeyHome
- $labkeyBackupDir: the directory where the backup files will be stored
- $labkeyDbName: the name of the LabKey database. By default this is named labkey.
- You have perl installed on your server
- You are using the PostgreSQL database and it is installed on the same computer as the LabKey server.
- PostgreSQL binaries are installed are on the path.
- See the script for more information
Related Topics
PostgreSQL Maintenance
Administer the Site Down Servlet
- In the <labkey-home>/labkeywebapp/WEB-INF directory, locate and edit the web.xml file.
- Locate the <servlet-mapping> entry for the site down servlet, as shown below. To find it, search for the file for the string "SiteDownServlet".
- Remove the comments around the <servlet-mapping> entry to activate the site down servlet.
- Modify the message displayed to users if you wish.
- Restart Tomcat.
<servlet>
<servlet-name>SiteDownServlet</servlet-name>
<servlet-class>org.fhcrc.cpas.view.SiteDownServlet</servlet-class>
<init-param>
<param-name>message</param-name>
<param-value>
LabKey is currently down while we work on the server.
We will send email once the server is back up and available.
</param-value>
</init-param>
</servlet>
<!-- To display a nice error message in the case of a database error,
remove the comments around this servlet-mapping
and edit the message in in the init-param above.
<servlet-mapping>
<servlet-name>SiteDownServlet</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
-->
Staging, Test and Production Servers
Topics
- Example of a Large-Scale Installation. Describes an installation of LabKey Server that uses production, staging and test servers.
- Tips for Configuring a Staging Server. Configure error reporting and look-and-feel settings for a staging server.
Example of a Large-Scale Installation
Overview
The Atlas installation of LabKey Server at the Fred Hutch Cancer Research Center provides a good example of how staging, test and production servers can provide a stable experience for end-users while facilitating the rapid, secure development and deployment of new features. Atlas serves a large number of collaborating research organizations and is administered by SCHARP, the Statistical Center for HIV/AIDS Research and Prevention at the Fred Hutch. The staging server and test server for Atlas are located behind the SCHARP firewall, limiting any inadvertent data exposure to SCHARP itself and providing a safer environment for application development and testing.Reference: LabKey Server: An open source platform for scientific data integration, analysis and collaboration. BMC Bioinformatics 2011, 12:71.Staging, Production and Test Servers
The SCHARP team runs three nearly-identical Atlas servers to provide separate areas for usage, application development and testing:- Production. Atlas users interact with this server. It runs the most recent, official, stable release of LabKey Server and is updated to the latest version of LabKey every 3-4 months.
- Staging. SCHARP developers use this server to develop custom applications and content that can be moved atomically to the production server. Staging typically runs the same version of LabKey Server as production and contains most of the same content and data. This mimics production as closely as possible. This server is upgraded to the latest version of LabKey just before the production server is upgraded, allowing a full test of the upgrade and new functionality in a similar environment. This server is located behind the SCHARP firewall, providing a safer environment for application development by limiting any inadvertent data exposure to SCHARP itself.
- Test. SCHARP developers use this server for testing new LabKey Server features while these features are still under development and developing applications on new APIs. This server is updated on an as-needed basis to the latest build of LabKey Server. Just like the staging server, the test server is located behind the SCHARP firewall, enhancing security during testing.
Hardware Specifics
Atlas’s hardware specifications provide an example of the hardware needs of a large LabKey Server installation. The Atlas production web server and the Atlas PostgreSQL database both run on a single Dell R710 machine with dual X5570 Intel Xeon processors. These processors have 8 MB caches and run at 2.93 GHz with a 1333 Mhz bus speed. The machine has eight cores with hyper-threading, for a total of 16 cores. It has 72 GB of memory running at 800 MHz and eight 300 GB 10K hard drives attached to a Dell PERC 6/I (PowerEdge RAID Controller) in a RAID (redundant array of independent disks) 10 array. Backend storage is provided by a clustered Netapp FAS3020 containing 56 fiber channel drives.The machine runs a Xen Hypervisor with each server application running in a Linux SLES11 virtual machine. The web server's virtual machine includes eight processor cores and 10GB of assigned RAM, with about 4GB currently used. The PostgreSQL database server’s virtual machine includes eight processor cores and 52 GB of RAM, with an average usage of 10-20GB.Tips for Configuring a Staging Server
A number of the larger labs and institutions which run a LabKey Server, utilize a staging or test server. Test servers are used for many different reasons, such as, ensuring that a upgrade of the LabKey Server does not break any customization or to test new modules, views or queries being developed by their developers.
We have found that when using a Staging or Test server, changing the color scheme(Web Theme), server name and other look and feel settings makes it much easier for users and/or administrators to know that they are working on the test server and not the Production server. This lowers the chances that a mistake will be made which might result in data loss on the Production server (i.e., the server that is used on a day to day basis for their research).
Changes to the Test server’s settings can easily be made through the LabKey Server’s Admin Console. In addition, they can be made programmatically via the LabKey Server’s database.
Below, is our recommended list of server settings that should be changed to when using test/staging server.
Caveats
Of course there are a few caveats:
- The SQL statements found below are only for PostgreSQL databases. The MSSQL statements are similar, but not identical. The MSSQL statements will be added a later date.
- If you use the SQL statements to make these changes. Make the changes after you restore the Production database on the Test server and before you have started the LabKey Server.
- This does not cover all possible changes, but just a subset of the most useful. I leave it up to the reader to create their own list of settings that should be changed on the test server.
Change the Server GUID
Summary. You can override the Server GUID stored in the database with the one specified in the LabKey XML configuration file (labkey.xml). This ensures that the exception reports received by LabKey developers are accurately attributed to the server (staging vs. production) that produced the errors, allowing swift delivery of fixes.
Background. By default, LabKey Servers periodically communicate back to LabKey developers whenever the server has experienced an exception. LabKey rolls up this data and groups it by GUID of each server. When using Test or Staging servers like you are now, the Test/Staging server will have the same GUID as the Production server (because you are restoring the Production servers database periodically to your Test/Staging servers). This can cause some confusion for LabKey developers when they are researching exception reports and trying to determine fixes for these problems. Changing the Server GUID for the staging server helps LabKey quickly track down exceptions and fix bugs detected on your staging server.
How-to. This change is made in the LabKey Server configuration file for your test server. This file is located in the configuration directory of your Tomcat installation.
- On Windows, the directory where this file is located is
%CATALINA_HOME%\conf\Catalina\localhost - On Solaris or MacOSX, the directory where this file is located is
$CATALINA_HOME/conf/Catalina/localhost
The configuration file will be named either labkey.xml or ROOT.xml
To make the change
- Open the configuration file
-
Find this line in the file
<Loader loaderClass="org.labkey.bootstrap.LabkeyServerBootstrapClassLoader"
useSystemClassLoaderAsParent="false" /> -
Add the following text below line found in step 2
<!-- Set new serverGUID --> <Parameter name="org.labkey.mothership.serverGUID" value="HOSTNAME"/>- Replace
HOSTNAMEwith the name of your test server
- Replace
- Save the file
- Restart the LabKey Server.
Change the Site Settings
Change the Site Settings manually
- Logon to your test server as a Site Admin
- In the upper right hand corner of the page, select Admin -> Site -> Admin Console.
- On the Admin Console page, click Site Settings.
- On the Site Settings page, change the following settings
- [Recommended]: Base server url: change this to URL for your test server.
- Optional Settings to change
- Pipeline tools directory:
- If your test server is installed in a directory location than your Production server, change this to proper location.
- Require SSL connections:
- If you want to allow non-SSL connections to your test server, uncheck this box
- SSL port number:
- If your SSL port number has changed. By default Tomcat will run SSL connection on 8443 instead of 443. Change this value if you test server is using a different port.
- Pipeline tools directory:
Change the Site Settings via SQL statements These commands can be run via psql or pg_admin
To change the Base Server URL run
UPDATE prop.Properties p SET Value = 'http://testserver.test.com'
WHERE (SELECT s.Category FROM prop.PropertySets s WHERE s.Set = p.Set) = 'SiteConfig'
AND p.Name = 'baseServerURL';
-- Replace `http://testserver.test.com` with the URL or your test server
To change the Pipeline Tools directory run
UPDATE prop.Properties p SET Value = '/path/to/labkey/bin'
WHERE p.Name = 'pipelineToolsDirectory';
-- Replace the `/path/to/labkey/bin` with the new path to the Pipeline tools directory
To change the SSL Port number:
UPDATE prop.Properties p SET Value = '8443'
WHERE (SELECT s.Category FROM prop.PropertySets s WHERE s.Set = p.Set) = 'SiteConfig'
AND p.Name = 'sslPort';
-- Replace the `8443` with the SSL port configured for your Test Server
To disable the SSL Required setting
UPDATE prop.Properties p SET Value = FALSE
WHERE (SELECT s.Category FROM prop.PropertySets s WHERE s.Set = p.Set) = 'SiteConfig'
AND p.Name = 'sslRequired';
Change the Look and Feel
Change the Look and Feel Manually
- Logon to your Test server as a Site Admin
- In the upper right hand corner of the page, select Admin -> Site -> Admin Console.
- On the Admin Console page, click Look and Feel Settings.
- On the Look and Feel Settings page, change the following settings
- System description: Recommend pre-pending the word
[TEST]or something similar the text in this field - Header short name: This is the name shown in the header of every page. I recommending appending
[TEST]to the existing name or changing the name entirely to indicate it is the Test server - Web Theme: Using the drop-down change this to a different theme name
- System description: Recommend pre-pending the word
NOTE: Following these instructions will change the Site Look and Feel settings. If you have customized the Look and Feel on an individual project(s), you will need to go to the Look and Feel settings for each Project and make a similar change,
Change the Site Settings via SQL statements These commands can be run via psql or pg_admin
To change the Header short name for the Site and for all Projects:
UPDATE prop.Properties p SET Value = 'LabKey Test Server'
WHERE (SELECT s.Category FROM prop.PropertySets s WHERE s.Set = p.Set) = 'LookAndFeel'
AND p.Name = 'systemShortName';
-- Replace "LabKey Test Server" with the short name for your Test server.
To change the System description for the Site and for all Projects
UPDATE prop.Properties p SET Value = 'Test LabKey Server'
WHERE (SELECT s.Category FROM prop.PropertySets s WHERE s.Set = p.Set) = 'LookAndFeel'
AND p.Name = 'systemDescription';
-- Replace "Test LabKey Server" with the system description for your Test server
To change the Web Theme for the Site and for all Projects:
UPDATE prop.Properties p SET Value = 'Harvest'
WHERE (SELECT s.Category FROM prop.PropertySets s WHERE s.Set = p.Set) = 'LookAndFeel'
AND p.Name = 'themeName';
-- Replace "Harvest" with the name of the Web Theme you would like to use on your Test Server.
Other settings [For Advanced Users]
Below are some additional configuration settings that we have found useful in working with our larger customers. Below is only the SQL statements for making these changes, so of these changes can only be reasonably be done via these SQL statements.
Deactivate all non-Site Admin users
This is important to do as it will not allow one of your researchers to accidentally log into the Test Server.
update core.Principals SET Active = FALSE WHERE type = 'u' AND UserId NOT IN
(select p.UserId from core.Principals p inner join core.Members m
on (p.UserId = m.UserId and m.GroupId=-1));
Mark all non-complete Pipeline Jobs to COMPLETE
This will ensure that any Pipeline Jobs that were scheduled to be run at the time of the Production server backup do not now run on the Test server. If you are using MS2, MS1, GenMicroarray or Flow I highly recommend this.
UPDATE pipeline.statusfiles SET status = 'ERROR' WHERE status != 'COMPLETE' AND status != 'ERROR';
Change the Site Wide File Root
Only use this if the Site File Root is different on your Test server from your Production server
UPDATE prop.Properties p SET Value = '/labkey/labkey/files'
WHERE (SELECT s.Category FROM prop.PropertySets s WHERE s.Set = p.Set) = 'SiteConfig'
AND p.Name = 'webRoot';
Have the Test server startup in Admin Only mode
UPDATE prop.Properties p SET Value = TRUE
WHERE (SELECT s.Category FROM prop.PropertySets s WHERE s.Set = p.Set) = 'SiteConfig'
AND p.Name = 'adminOnlyMode';
Products and Services
Overview
Researchers and clinicians dedicated to the common good deserve quality tools to help them focus on discovery and care rather than battling information bottlenecks. LabKey's offerings reflect our team’s deep commitment to providing life science and healthcare groups with open, professional-grade, cost-effective solutions. We offer a balance of free and premium products to help us ensure a strong, open, sustainable platform for all.Products and Services
LabKey Server- LabKey Server Editions include a freely available Community Edition and several Premium Editions to meet different levels of need for support and functionality.
- When your needs go beyond the existing platform, we invite you to engage our custom development services. For further details, please see LabKey Professional Development Services or contact LabKey.
LabKey Server Editions
LabKey Server Editions
LabKey offers multiple Editions of LabKey Server and a suite of Add-Ons to best meet different levels of need for support and functionality. See LabKey Server Editions for details or contact LabKey to discuss.
Click the tabs below to see the functionality included in the LabKey Server Premium Editions.
|
Functionality
|
Services
|
| Community | Professional | Professional Plus | Enterprise | ||
| General |
Source Code & Installers
Access to associated source code and
installers. Learn More
|
||||
|
Branding
Extended look-and-feel customization. Learn More
|
|||||
| Security |
Two-Factor Authentication
Provide an additional security layer which
requires users to perform a second
authentication step. Learn
More
|
||||
|
Single Sign On
Allow users to sign on to multiple applications
while providing their credentials only
once.
Learn
More
|
|||||
|
SAML Authentication
Authenticate users against a SAML identity provider.
Learn
More
|
|||||
|
Compliance
Featured designed to help you meet compliance requirements for HIPAA, FISMA, and other standards.
Learn
More
|
|||||
|
SQL Query Logging
Log each query request against an external data source including the user,
the date and time, and the SQL statement used to query the data source.
Learn
More
|
|||||
| System Integration |
RStudio
Design RStudio reports for data stored in LabKey Server.
Learn More
|
||||
|
REDCap
Import data from your REDCap projects into
LabKey Server. Learn More
|
|||||
|
FreezerPro
Integrate with existing FreezerPro data.
Learn
More
|
|||||
|
SQL Server Synonyms
SQL Server Synonyms function like shortcuts or
symlinks, allowing you to mount tables and
views which exist in another schema or
database. Learn More
|
|||||
| Community | Professional | Professional Plus | Enterprise | ||
| Consulting |
Project Roadmap
Development of project roadmap including
initial design planning.
|
||||
|
System Architecture
Ongoing system architecture and design advice
from technical leads.
|
|||||
| Training |
Documentation
Online documentation, tutorials, videos and
community forums.
Documentation Home Page
|
||||
|
Administrator Training
Custom-tailored user and administrator
training. Learn More
|
1 session/year |
2 sessions/year |
|||
|
Developer Training
Custom-tailored developer training. Learn More
|
1 session/year |
||||
|
Feature Previews
Early preview of new features and ability to
provide input on product roadmap.
|
|||||
| Support |
Community Support
Community support boards provides answers to
your questions from both our staff support team
and user community members. Community Forums
|
||||
Administrator and User Support
|
|||||
Operations Support
|
|||||
Developer Support
|
|||||
- Community Edition: Free to download and use forever. Best suited for technical enthusiasts and evaluators in non-mission-critical environments. LabKey provides community forums and documentation to help users support each other.
- Premium Editions: Paid subscriptions that provide additional functionality to help teams optimize workflows, manage complex projects, and explore multi-dimensional data. Premium Editions also include professional support services for the long-term success of your informatics solutions. Subscription prices start at $39K/year plus sales tax.
- Add-Ons: Add-Ons are functionality and services available for subscription purchase when your team subscribes to a premium Edition of LabKey Server.
Other Products and Modules
Training
Administrator Training
LabKey's administrator training course, LabKey Fundamentals, is included in the Professional and Professional Plus Editions. It provides an introduction to the following topics:- LabKey Server Basics: Explains the basic anatomy/architecture of the server and its moving parts. It outlines the basic structures of folders and data containers, and the modules that process requests and craft responses. Best practices for configuring folders is included. The role of Administrators is also described.
- Security: Describes LabKey Server's role-based security model--and how to use it to protect your data resources. General folder-level security is described, as well as special security topics, such as dataset-level security and Protected Health Information (PHI) features. Practical security information is provided, such as how to set up user accounts, assigning groups and roles, best practices, and testing security configurations using impersonation.
- Collaboration: Explains how to use the Wiki, Issues, and Messages modules. Branding and controlling the look-and-feel of your server are also covered.
- Files and the Database: Explains the two basic ways that LabKey Server can hold data: (1) as files and (2) as records in a database. Topics include: full-text search, converting tabular data files into database tables, special features of the LabKey database (such as 'lookups'), the role of SQL queries, adding other databases as external data sources.
- Instrument Data: Explains how LabKey Server models and captures instrument-derived data, including how to create a new assay "design" from scratch, or how to use a prepared assay design. Special assay topics are covered, such as transform scripts, creating new assay design templates ("types") from simple configuration files, and how to replace the default assay user interface.
- Clinical/Research Study Data Management: Explains how to integrate heterogeneous data, such as instrument, clinical, and demographic data, especially in the context of longitudinal/cohort studies.
- Reports: Explains the various ways to craft reports on your data, including R reports, JavaScript reports, and built-in visualizations, such as Time Charts, Box Plots, and Scatter Plots.
- Specimens: Explains the ways that LabKey Server can model and manage specimen/sample data.
- Development: A high-level overview of how to extend LabKey Server. The Professional Edition includes support for users writing custom SQL and R scripts. The Professional Plus Edition provides support for users extending LabKey Server with JavaScript/HTML client applications, user-created file modules, and more (see Developer Training below).
- Operations: Describes best practices from an IT point-of-view, including installing a server, hardware requirements, logging, and how to debug and track down problems with the server.
Developer Training
LabKey's developer training is included in the Professional Plus Edition. It is tailored to your project's specific needs and can cover:- Server-to-server integrations
- Client APIs
- ETLs
- Assay transform scripts
- Remote pipeline processing servers and clusters
- Custom LabKey-based pipelines
- Module development assistance
Custom Community Modules
Custom Community Modules
Certain LabKey Server modules are open source, but not included in the LabKey Server Community Edition or other Products. This is because they typically require significant customization and assistance.Developers can still build these modules from source code in the LabKey repository.| Module | Description | Documentation | Open source |
|---|---|---|---|
| Genotyping | Data management and workflow automation for DNA sequencing and genotyping experiments | docs | SVN Source |
| Reagent Inventory | Organize and track lab reagents. | docs | SVN Source |
| GitHub Projects | Many modules are available as GitHub projects, including Signal Data and Workflow. | For documentation, see the README.md file in each project. | GitHub Source |
LabKey Argos
Introduction
LabKey Argos is available for subscription purchase from LabKey. For further information, please contact LabKey.Argos is a data-driven web application that provides self-service tools for scientists and clinicians to quickly find, filter and visualize rich data resources in a secure environment that protects patient confidentiality. Argos enables researchers to efficiently search for patterns and compare patient data, helping them generate hypotheses, discover suitable cohorts, investigate study feasibility and evaluate courses of treatment.The application was originally developed in partnership with the Fred Hutchinson Cancer Research Center to provide a data exploration and visualization portal for the Hutch Integrated Data Repository & Archive (HIDRA), a collaborative effort of the Fred Hutch/University of Washington Cancer Consortium. As of early 2015, HIDRA already includes data for 335,000 patients.As a LabKey Server-based application, Argos is designed for adaptation to the needs of other research organizations. The first version of Argos relies upon the Caisis data model. To explore Argos further, see:- Argos Tour
- 6-minute video
- 1-page overview (PDF)
- Case study
- Fred Hutch Argos overview on the HIDRA web site
- Fred Hutch Argos training slide deck
- Live demonstration site (access available upon request)

Argos Tour
Scenario overview
LabKey Argos currently facilitates five scenarios:- Browse and visualize available data across multiple dimensions, such as patient characteristics and specimen and study metadata
- Identify a population that matches a particular set of characteristics, such as those of a patient who has presented for treatment, and save for further investigation
- Review trends for this population
- Dig deeper into more detailed data for the selected population
- Comply with data confidentiality and security regulations that guard protected health information (PHI), such as HIPAA and FISMA
- Survival curves for comparing outcomes for different patient populations
- Timeline views for visualizing treatment events for individuals in selected population
- Accrual reports for forecasting how long it will take for patients with the set of characteristics needed for a future study to walk in the door
Screenshot Tour
Disease Portals
Argos provides customizable, group-specific portals to help researchers focus on the subset of data most relevant to them within an environment tailored to their particular kind of research. Each portal displays dashboards tailored to a specialized area of research and can supply access to either a subset or all available data. Administrators configure access permissions, available data, and summary dashboards for each portal.An investigator begins exploring available data by choosing a disease portal to browse. In this demonstration, we will explore the Brain Cancer Portal.
Login
After choosing a disease portal, the user must log in and select their intended activity (why they need access to patient data), PHI access level (what level of patient identification is required), and IRB number (what permissions they have for data access/use). To protect patient confidentiality, researchers who do not need to see PHI can opt not to see it.
Terms of Use
Argos also helps researchers comply with HIPAA and FISMA requirements by requiring users to log in under Terms of Use that are tailored to the user's intended activity, PHI level and IRB number. Once users have signed the Terms of Use, their activity is logged, including records of all PHI columns and participant IDs viewed, providing auditors with a clear picture of who has viewed which patient records and the terms of data access.
Dashboard
After login, a user sees the home Dashboard for the chosen disease portal. The Dashboard provides a high-level overview of the available data within the portal and a quick breakdown of patients in the disease group. Data summaries are customizable by administrators. The Dashboard also provides easy access to previously Saved Filters (groups of patients) and Saved Grids (detailed data for particular patient groups) in the lower left corner.From the Dashboard, users can browse available data by different dimensions, such as Patients, Specimens and Studies (a.k.a. protocols), as shown in the upper right. We will start exploring by selecting "Patients" in the upper right.
Population Filters
After selecting the Patient dimension, the user sees options for filtering the available patient population based on categories of characteristics, such as gender or radiation type.Here we select Medical Therapy Agent, aiming to compare trends for patients treated with a specific medical therapy with the overall population of brain cancer patients whose data is contained in the portal. After we select this category, histograms show the number of patients with each characteristic.
After we select this category, histograms show the number of patients with each characteristic. Among Medical Therapy Agents, we select Temozolomide. This filters the patient population down to those treated with this agent. The number of patients in this group is shown in orange on the right information pane, next to the total population available within the portal repository. The applied filter is listed in the lower right corner, along with any previously applied filters.
Among Medical Therapy Agents, we select Temozolomide. This filters the patient population down to those treated with this agent. The number of patients in this group is shown in orange on the right information pane, next to the total population available within the portal repository. The applied filter is listed in the lower right corner, along with any previously applied filters. If we wish, we could further filter the available population by a sub-characteristic, such as the timing of delivery of the medical agent (e.g., delivery at first progression).
If we wish, we could further filter the available population by a sub-characteristic, such as the timing of delivery of the medical agent (e.g., delivery at first progression).
Survival
After filtering the available population down to a group of interest, we can explore trends for this group using a variety of visualizations.The Survival view allows us to compare survival trends for the selected group (= those treated with Temozolomide) with all patients whose data is available within the portal.
Accrual
The Accrual report shows how quickly patients with a particular set of characteristics are being added to the population. This report can help researchers forecast how quickly study participants will walk in the door who might could be eligible for a study that requires participants with particular histories and demographics. Note: For those with access to the Argos demo area, the accrual report will not show results unless you modify the URL to adjust the current date to match the demo data. For example: https://argos.labkey.com/argos/home/Brain%20Portal/app.view?_testEndDate=2012-03-15#Patients/patients/accrual
Note: For those with access to the Argos demo area, the accrual report will not show results unless you modify the URL to adjust the current date to match the demo data. For example: https://argos.labkey.com/argos/home/Brain%20Portal/app.view?_testEndDate=2012-03-15#Patients/patients/accrual
Timeline
The patient event Timeline helps users visualize and align patient events, such as diagnosis, treatment phases, and outcomes, alongside additional characteristics, such as grade or age at diagnosis.Here we have aligned patient diagnosis events, ordered patients by survival, and highlighted the surviving group by click/drag (the red box on the right). If we create a filter using the selected group, the selected population is filtered down to those treated with Temozolomide who remains alive. Hovering over a data point displays the type and date of the event it represents.
If we create a filter using the selected group, the selected population is filtered down to those treated with Temozolomide who remains alive. Hovering over a data point displays the type and date of the event it represents.
Saved filters
After identifying a population of interest, you may wish to revisit it later. The "Save Filter" option in the lower right of the Argos interface enables this. A saved filter can either retrieve the exact patient set available when the filter was created, or a patient set that is updated as new patients arrive that match the filter criteria.
Data grids
The View option helps you dig into more detailed data for a selected patient population by accessing the Column Chooser. The Column Chooser allows you to select specific columns from the Caisis tables that hold the data displayed in Argos. Tables are on the left and accompanied by the number of rows available in each; columns are on the right. After displaying selected columns, you can sort and filter them. You can also save the grid you have created and return to it later via the Dashboard. The grid will update with new information as it becomes available.
After displaying selected columns, you can sort and filter them. You can also save the grid you have created and return to it later via the Dashboard. The grid will update with new information as it becomes available.
Logging and Auditing
Details of user activities are logged to support auditing and regulatory compliance needs. Data access logs include information on the researcher, the date and time of data access, the PHI columns accessed, the terms of use accepted to access the data, identifiers of the patients viewed, and the query used to access the data, among other things.Administrators can extract any information needed from these logs using the rich reporting and querying tools built into LabKey Server. For example, administrators can easily determine which researchers viewed a particular patient’s data (in the case of an information request), or which patients were viewed by a particular researcher (in case of concern about data use by an individual).

LabKey Natural Language Pipeline (NLP)
Overview
Large amounts of clinical data is locked up in free-hand notes, and other document formats that were not originally designed for entry into computer systems. How can this data be extracted for the purposes of standardization, consolidation, and, ultimately, for clinical research? LabKey Server's Natural Language Processing Pipeline (NLP) and document abstraction workflow tools help to unlock this data and transform it into a format that can better yield clinical insight.LabKey Server's solution focuses on the overall workflow required to efficiently transform large of amounts of data into formats usable by researchers. Whether your group is already using an NLP engine, developing algorithms to support one, or doing all document abstraction manually, the process requires the following:- A human and/or machine process that prepares the documents for submission to the process.
- Fault-tolerant integration of multiple independent systems, so that your workflow can recover from interruptions in service.
- A system of human and/or machine abstraction that applies algorithms and knowledge to abstract the data from the documents.
- Scoring and review of results at multiple points within the workflow.
- Feedback on algorithms or human abstractors to improve reliability.
- Flexible scalability as new scenarios and data sources are added to the overall workflow.
Documentation
- Configure LabKey NLP - Install and configure required software.
- Process Files Using Natural Language Pipeline (NLP) - Run the NLP pipeline directly against source files.
- Document Abstraction Workflow - Track documents through the various steps of the process.
- Automatic Assignment for Abstraction - Automatic assignment for document abstraction and review.
- Manual Assignment for Abstraction - Manual assignment for document abstraction and review.
- Document Abstraction - Abstract information from a document through the UI.
- Review Document Abstraction - Review of abstracted information.
Resources
Configure LabKey NLP
Install Required Components
Install python (2.7.9)
The NLP engine will not run under python 3. If possible, there should be only one version of python installed. If you require multiple versions, it is possible to configure the LabKey NLP pipeline accordingly, but that is not covered in this topic.- Download python 2.7.9 from https://www.python.org/download/
- Double click the .msi file to begin the install. Accept the wizard defaults, confirm that pip will be installed as show below. Choose to automatically add python.exe to the system path on this screen by selecting the install option from the circled pulldown menu.

- When the installation is complete, click Finish.
- By default, python is installed on windows in C:/Python27/
- Confirm that python was correctly added to your path by opening a command shell and typing "python -V" using a capital V. The version will be displayed.
Install the NumPy package (1.8.x)
NumPy is a package for scientific computation with Python. Learn more here: http://www.numpy.org/- For windows, download a pre-complied whl file for NumPy from: http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy
- The whl you select must match the python version you downloaded (for 2.7.9 select "cp27") as well as the bit-width (32 vs 64) of your system.
- To confirm your bit-width, open the Windows Control Panel, select System and Security, then select System. The system type is shown about mid page.
- For instance, if running 64-bit windows, you would download: numpy‑1.9.2+mkl‑cp27‑none‑win_amd64.whl
- Move the downloaded package to the scripts directory under where python was installed. By default, C:/Python27/Scripts/
- A bug in pip requires that you rename the downloaded package, replacing "win_amd64" with "any".
- In a command shell, navigate to that same Scripts directory and run:
pip install numpy‑1.9.2+mkl‑cp27‑none‑any.whl
Install the LabKey distribution
Install the LabKey distribution. Complete instructions can be found here. The location where you install your LabKey distribution is referred to in this topic as ${LABKEY_INSTALLDIR}.Configure the NLP pipeline
The LabKey distribution already contains an NLP engine, located in:${LABKEY_INSTALLDIR}\bin\nlpC:\alternateLocation\nlp
- Select Admin > Site > Admin Console.
- Click Site Settings.
- The Pipeline tools field contains a semicolon separated list of paths the server will use to locate tools including the NLP engine. By default the path is "${LABKEY_INSTALLDIR}\bin" (in this screenshot, "C:\labkey\labkey\bin")
- Add the location of the alternate NLP directory to the front of the Pipeline tools list of paths.
- For example, to use an engine in "C:\alternateLocation\nlp", add "C:\alternateLocation;" as shown here:

- Click Save.
- No server restart is required when adding a single alternate NLP engine location.
Configure to use Multiple Engine Versions
You may also make multiple versions of the NLP engine available on your LabKey Server simultaneously. Each user would then configure their workspace folder to use a different version of the engine. The process for doing so involves additional steps, including a server restart to enable the use of multiple engines. Once configured, no restarting will be needed to update or add additional engines.- Download the nlpConfig.xml file.
- Select or create a location for config files. For example, "C:\labkey\configs, and place nlpConfig.xml in it.
- The LabKey Server configuration file, named labkey.xml by default, or ROOT.xml in production servers, is typically located in a directory like [TOMCAT_HOME]\conf\Catalina\localhost. This file must be edited to point to the alternate config location.
- Open it for editing, and locate the pipeline configuration line, which will look something like this:
<!-- Pipeline configuration -->
<!--@@pipeline@@ <Parameter name="org.labkey.api.pipeline.config" value="@@pipelineConfigPath@@"/> @@pipeline@@-->
- Uncomment and edit to point to the location of nlpConfig.xml, in our example, "C:\labkey\configs". The edited line will look something like this:
<!-- Pipeline configuration -->
<Parameter name="org.labkey.api.pipeline.config" value="C:\labkey\configs"/>
- Save.
- Restart your LabKey Server.
C:\alternateLocation\nlp\engineVersion1
C:\alternateLocation\nlp\engineVersion2
Related Topics
Process Files Using Natural Language Pipeline (NLP)
Set Up a Workspace
Each user should work in their own folder, particularly if they intend to use different NLP engines.- Log in to the server.
- Create a new folder to work in (you must be a folder administrator to create a new folder).
- Select Admin > Folder > Management.
- Click Create Subfolder.
- Enter a (unique) name for your folder and click the button for type NLP.
- Click Next and then Finish.
- This walkthrough and associated screencaps use the folder name "NLP Test Space".
Setup the Data Pipeline
- In the Data Pipeline web part, click Setup.
- Select Set a pipeline override.
- Enter the primary directory where the files you want to process are located.
- Set searchability and permissions appropriately.
- Click Save.
- Click NLP Dashboard.
Define Pipeline Protocol(s)
When you import a TSV file, you will select a Protocol which may include one or more overrides of default parameters to the NLP engine. If there are multiple NLP engines available, you can include the NLP version to use as a parameter. With version-specific protocols defined, you then simply select the desired protocol during file import. You may define a new protocol on the fly during any tsv file import, or you may find it simpler to predefine one or more. To quickly do so, you can import a small stub file, such as the one attached to this page.- Download this file: stub.nlp.tsv and place in the location of your choice.
- Click Process and Import Data on the NLP Dashboard.
- Drag and drop the stub.nlp.tsv file into the upload window.
- Click Process and Import Data on the NLP Dashboard.
- Select the stub.nlp.tsv file and click Import Data.
- Select "NLP engine invocation and results" and click Import.

- From the Analysis Protocol dropdown, select "<New Protocol>". If there are no other protocols defined, this will be the only option.
- Enter a name (required) and description for this protocol. Using the version number in the name will help you easily differentiate them later.
- Add a new line to the Parameters section giving the subdirectory that contains the intended version. In the example in our setup documentation, the subdirectories are named "engineVersion1" and "engineVersion2" but your naming may differ.
<note label="version" type="input">engineVersion1</note>
- Confirm "Save protocol for future use" is checked.

- Click Analyze.
- Return to the files panel by clicking NLP Dashboard, then Process and Import Data.
- Select the "stub.nlp.tsv" file again and repeat the import. This time you will see the first protocol you defined as an option.
- Select "<New Protocol>" and enter the name of the next engine subdirectory as the version parameter.
- Repeat as needed.
Run Data Through the NLP Pipeline
First upload your TSV files to the pipeline.- In the Data Pipeline web part, click Process and Import Data.
- Drag and drop files or directories you want to process into the window to upload them.

- Click NLP Dashboard and then Process and Import Data.
- Navigate uploaded directories if necessary to find the files of interest.
- Check the box for a tsv file of interest and click Import Data.
- Select "NLP engine invocation and results" and click Import.

- Choose an existing Analysis Protocol or define a new one.
- Click Analyze.
- While the engine is running, the pipeline web part will show a job in progress. When it completes, the pipeline job will disappear from the web part.
- Refresh your browser window to show the new results in the NLP Job Runs web part.
View and Download Results
Once the NLP pipeline import is successful, the input and intermediate output files are both deleted from the filesystem.The NLP Job Runs lists the completed run, click Details on the right to see both input and how it was interpreted into tabular data.
Download Results
To download the results, select Export above the grid and choose the desired format.Rerun
To rerun the same file with a different version of the engine, simply repeat the original import process, but this time choose a different protocol (or define a new one) to point to a different engine version.Error Reporting
During processing of files through the NLP pipeline, some errors which occur require human reconcilation before processing can proceed. The pipeline log is available with a report of any errors that were detected during processing, including:- Mismatches between field metadata and the field list. To ignore these mismatches during upload, set "validateResultFields" to false and rerun.
- Errors or excessive delays while the transform phase is checking to see if work is available. These errors can indicate problems in the job queue that should be addressed.
Related Topics
Document Abstraction Workflow
- Document Upload: with or without initial automatic abstraction using an NLP Engine to obtain some metadata and text fields.
- Assignment to a Manual Abstractor and/or Reviewer - may be done automatically or manually.
- Abstraction of Information
- Review of Abstracted Information
- Potential Reprocessing or Additional Abstraction Rounds
- Approval
Roles and Tasks
- NLP/Abstraction Administrator:
- Review list of documents ready for abstraction
- Make assignments of roles and tasks to others
- Manage project groups corresponding to the expected disease groups and document types
- Create document processing configurations
- Abstractor:
- Choose a document to abstract from assigned list
- Abstract document
- Submit abstraction for review - or approval if no reviewer is assigned
- Reviewer:
- Review list of documents ready for review
- Review abstraction results
- Mark document as ready to progress to the next stage - either approve or reject
- Review and potentially edit previously approved abstraction results
Abstraction Workflow
 The document itself passes through a series of states within the process:
The document itself passes through a series of states within the process:
- Ready for assignment: when automatic abstraction is complete, automatic assignment was not completed, or reviewer requests re-abstraction
- Ready for manual abstraction: once an abstractor is assigned
- Ready for review: when abstraction is complete, if a reviewer is assigned
- (optional) Ready for reprocessing: if requested by the reviewer
- Approved
Abstraction Task List
The Abstraction Task List web part on the Portal tab will be unique for each user, showing a tailored view of the particular tasks they are to complete. Typically a user will have only one type of task to perform, but if they play different roles, such as for different document types, they will see multiple lists. Below the personalized task list(s), the All Cases list gives an overview of the latest status of all cases visible to the user in this container - both those in progress and those whose results have been approved. In this screenshot, an admin user has assignment tasks, and is also assigned one document to abstract and another to review. All task list grids can be sorted to provide the most useful ordering to the individual user. Save the desired sorted grid as the "default" view to use it for automatically ordering your tasks. When an abstraction or review task is completed, the user will advance to the next task on their default view of the appropriate task list.
All task list grids can be sorted to provide the most useful ordering to the individual user. Save the desired sorted grid as the "default" view to use it for automatically ordering your tasks. When an abstraction or review task is completed, the user will advance to the next task on their default view of the appropriate task list.
Assignment
Following the initial step of automatic abstraction using the NLP engine, many documents will also be assigned for manual abstraction. The manual abstractor begins with the information garnered by the NLP engine and validates, corrects, and adds additional information to the abstracted results.The assignment of documents to individual abstractors may be done automatically or manually by an administrator. An administrator can also choose to bypass the abstraction step by unassigning the manual abstractor, immediately forwarding the document to the review phase.Abstraction
The assigned user completes a manual document abstraction following the steps outlined here:Review
Once abstraction is complete, the document is "ready for review" (if a reviewer is assigned) and the task moves to the assigned reviewer. If the administrator chooses to bypass the review step, they can leave the reviewer task unassigned for that document. Reviewers select their tasks from their personalized task list, but can also see other cases on the All Tasks list. In addition to reviewing new abstractions, they can review and potentially reject previously approved abstraction results. Abstraction administrators may also perform this second level review. A rejected document is returned for additional steps as described in the table here.Developer Note: Retrieving Approved Data via API
The client API can be used to retrieve information about imported documents and results. However, the task status is not stored directly, rather it is calculated at render time when displaying task status. When querying to select the "status" of a document, such as "Ready For Review" or "Approved," the reportID must be provided in addition to the taskKey. For example, a query like the following will return the expected calculated status value:SELECT reportId, taskKey FROM Report WHERE ReportId = [remainder of the query]
Automatic Assignment for Abstraction
Automatic Task Assignment
When setting up automatic task assignment, the abstraction administrator defines named configurations for the different types of documents to be abstracted and different disease groups those documents cover. The administrator can also create specific project groups of area experts for these documents so that automatic assignment can draw from the appropriate pool of people.Project Group Curation
The abstraction administrator uses project groups to identify the people who should be assigned to abstract the particular documents expected. It might be sufficient to simply create a general "Abstractors" group, or perhaps more specific groups might be appropriate, each with a unique set of members:- Lung Abstractors
- Multiple Myeloma Abstractors
- Brain Abstractors
- Thoracic Abstractors
- Create the groups you expect to need via Admin > Folder > Permissions > Project Groups.
- On the Permissions tab, add the groups to the relevant abstraction permission role:
- Abstractor groups: add to Document Abstractor.
- Reviewer groups: add to Abstraction Reviewer.
- Neither of these abstraction-specific roles carries any other permission to read or edit information in the folder. All abstractors and reviewers will also require the Editor role in the project in order to record information. Unless you have already granted such access to your pool of users, also add each abstractor and reviewer group to the the Editor role.
- Next add the appropriate users to each of the groups.
NLP Document Processing Configurations
Named task assignment configurations are created by an administrator using an NLP Document Processing Configurations web part. Configurations include the following fields:- Name
- DocumentType
- Pathology Reports
- Cytogenetics Reports
- All Documents (including the above)
- Disease Groups - check one or more of the disease groups listed. Available disease groups are configured via a metadata file. The disease group control for a document is generated during the initial processing through the NLP engine. Select "All" to define a configuration that will apply to any disease group not covered by a more specific configuration.
- Status - can be "active" or "inactive"
- ManualAbstractPct - the percentage of documents to assign for manual abstraction (default is 5%).
- ManualAbstractReviewPct - the percentage of manually abstracted documents to assign for review (default is 5%).
- EngineAbstractReviewPct - the percentage of automatically abstracted documents to assign for review (default is 100%).
- MinConfidenceLevelPct - the minimum confidence level required from the NLP engine to skip review of those engine results (default is 75%).
- Assignee - use checkboxes to choose the group(s) from which abstractors should be chosen for this document and disease type.
- DocumentsProcessed
- LastAbstractor
- LastReviewer
 You can also define multiple configurations for a given document type. For example, you could have a configuration requiring higher levels of review and only activate it during a training period for a new abstractor. By selecting which configuration is active at any given time for each document type, different types of documents can get different patterns of assignment for abstraction. If no configuration is active, all assignments must be done manually.
You can also define multiple configurations for a given document type. For example, you could have a configuration requiring higher levels of review and only activate it during a training period for a new abstractor. By selecting which configuration is active at any given time for each document type, different types of documents can get different patterns of assignment for abstraction. If no configuration is active, all assignments must be done manually.
Outcomes of Automatic Document Assignment
The following table lists what the resulting status for a document will be for all the possible combinations of whether engine abstraction is performed and whether abstractors or reviewers are assigned.| Engine Abstraction? | Abstractor Auto-Assigned? | Reviewer Auto-Assigned? | Document Status Outcome |
|---|---|---|---|
| Y | Y | Y | Ready for initial abstraction; to reviewer when complete |
| Y | Y | N | Ready for initial abstraction; straight to approved when complete |
| Y | N | Y | Ready for review (a common case when testing engine algorithms) |
| Y | N | N | Ready for manual assignment |
| N | Y | Y | Ready for initial abstraction; to reviewer when complete |
| N | Y | N | Ready for initial abstraction; straight to approved when complete |
| N | N | Y | Not valid; there would be nothing to review |
| N | N | N | Ready for manual assignment |
Manual Assignment for Abstraction
Manual Assignment
When documents need to be manually assigned to an abstractor, they appear as tasks for an abstraction administrator.Task List View
The task list view allows manual assignment of abstractors and reviewers for a given document. To be able to make manual assignments, the user must have "Abstraction Administrator" permission; folder and project administrators also have this permission.Users with the correct roles are eligible to be assignees:- Abstractors: must have both "Document Abstractor" and "Editor" roles.
- Reviewers: must have both "Abstraction Reviewer" and "Editor" roles.
 Click Assign on the task list.
Click Assign on the task list. In the popup, the pulldowns will offer the list of users granted the permission necessary to be either abstrators or reviewers. Select to assign one or both tasks. Leaving either pulldown without a selection means that step will be skipped.
Click Save and the document will disappear from your "to assign" list and move to the pending task list of the next user you assigned.
In the popup, the pulldowns will offer the list of users granted the permission necessary to be either abstrators or reviewers. Select to assign one or both tasks. Leaving either pulldown without a selection means that step will be skipped.
Click Save and the document will disappear from your "to assign" list and move to the pending task list of the next user you assigned.
Reassignment and Unassignment
After assigment, the task is listed in the All Cases grid. Here the Assign link allows an administrator to change an abstraction or review assignment to another person.If abstraction has not yet begun (i.e. the document is still in the "Ready for initial abstraction" state), the administrator can also unassign abstraction by selecting the null row on the assignment pulldown. Doing so will immediately send the document to the review step, or if no reviewer is assigned, the document will be approved and sent on.Once abstraction has begun, the unassign option is no longer available.Document Abstraction
Abstraction Task List
The assigned user must have "Abstractor" permissions and will initiate a manual abstraction by clicking Abstract on the task list. The task list grid can be sorted and filtered as desired, and grid views saved for future use. After completion of a manual abstraction, the user will advance to the next document in the user's default view of the task list.
The task list grid can be sorted and filtered as desired, and grid views saved for future use. After completion of a manual abstraction, the user will advance to the next document in the user's default view of the task list.
Abstraction UI
The document abstraction UI is shown in two panels. The imported text on the right can be scrolled, highlighted, and reviewed for key information. The left hand panel shows a list of field results into which information found in the text will be abstracted. The fields are organized in categories that can vary based on the document type. For example, Pathology Report field categories include:- Pathology
- Pathology/Stage/Grade
- Engine Report Info
- Pathology Finding
- Node Path Finding
- Path Test
 If an automated abstraction pass is done prior to manual abstraction, pulldowns may be prepopulated with information gathered by the abstraction (NLP) engine. In particular, if the disease group can be identified, this can narrow the set of values for each field offered to a manual abstractor. The type of document also drives some decisions about how to interpret parts of the text. By default, the first table and specimen are expanded when the abstractor first opens the UI.The abstractor scans for relevant details in the text, selects or enters information in the field in the results section, and can highlight one or more relevant pieces of text on the right. Some fields allow free text entry, other fields use pulldowns offering a set of possible values.Expand and contract field category sections by clicking the title bars. Select a field by clicking the label; the selected row will show in yellow, as will any associated text highlights previously added for that field. Choose a value from the menu, start typing to narrow the options, or keep typing to enter free text as appropriate. There are two types of fields with pulldown menus. Open-class fields allow you to either select a listed value or enter a new one of your own; closed-class fields require a selection of one of the listed values. You can still type to enter the value, but only matching values will be accepted.At any point you can highlight a string of text in the right hand panel to associate with the currently selected field. If you do so before entering a value for the field, the selected text will be entered as the value if possible. For a free text field, the entry is automatic. For a field with a pulldown menu, if you highlight a string in the text that matches a value on the given menu, it will be selected. If you had previously entered a different value, however, that earlier selection takes precedence and is not superceded by later text highlighting. You may multi-select several regions of text for any given field result as needed.In the following screenshot, several types of text highlighting are shown. When you click to select a field, the field and any associated highlights are colored yellow. If you double-click the field label, the text panel will be scrolled to place the first highlighted region within the visible window, typically three rows from the top. Shown selected here, the text "Positive for malignancy" was just linked to the active field Behavior with the value "Malignant". Also shown here, when you hover over the label or value for a field which is not active, in this case "PathHistology" the associated highlighted region(s) of text will be shown in green.
If an automated abstraction pass is done prior to manual abstraction, pulldowns may be prepopulated with information gathered by the abstraction (NLP) engine. In particular, if the disease group can be identified, this can narrow the set of values for each field offered to a manual abstractor. The type of document also drives some decisions about how to interpret parts of the text. By default, the first table and specimen are expanded when the abstractor first opens the UI.The abstractor scans for relevant details in the text, selects or enters information in the field in the results section, and can highlight one or more relevant pieces of text on the right. Some fields allow free text entry, other fields use pulldowns offering a set of possible values.Expand and contract field category sections by clicking the title bars. Select a field by clicking the label; the selected row will show in yellow, as will any associated text highlights previously added for that field. Choose a value from the menu, start typing to narrow the options, or keep typing to enter free text as appropriate. There are two types of fields with pulldown menus. Open-class fields allow you to either select a listed value or enter a new one of your own; closed-class fields require a selection of one of the listed values. You can still type to enter the value, but only matching values will be accepted.At any point you can highlight a string of text in the right hand panel to associate with the currently selected field. If you do so before entering a value for the field, the selected text will be entered as the value if possible. For a free text field, the entry is automatic. For a field with a pulldown menu, if you highlight a string in the text that matches a value on the given menu, it will be selected. If you had previously entered a different value, however, that earlier selection takes precedence and is not superceded by later text highlighting. You may multi-select several regions of text for any given field result as needed.In the following screenshot, several types of text highlighting are shown. When you click to select a field, the field and any associated highlights are colored yellow. If you double-click the field label, the text panel will be scrolled to place the first highlighted region within the visible window, typically three rows from the top. Shown selected here, the text "Positive for malignancy" was just linked to the active field Behavior with the value "Malignant". Also shown here, when you hover over the label or value for a field which is not active, in this case "PathHistology" the associated highlighted region(s) of text will be shown in green. Text that has been highlighted for a field that is neither active (yellow) nor hovered-over (green) is shown in light blue. Click on any highlighting to activate the associated field and show both in yellow.A given region of text can also be associated with multiple field results. The count of related fields is shown with the highlight region ("1 of 2" for instance).Unsaved changes are indicated by red corners on the entered fields. If you make a mistake or wish to remove highlighting on the right, click the 'x' attached to the highlight region.Save work in progress any time by clicking Save Draft. If you leave the abstraction UI, you will still see the document as a task waiting to be completed, and see the message "Initial abstraction in progress". When you return to an abstraction in progress, you will see previous highlighting, selections, and can continue to review and abstract more of the document.Once you have completed the abstraction of the entire document, you will click Submit to close your task and pass the document on for review, or if no review is selected, the document will be considered completed and approved.When you submit the document, you will automatically advance to the next document assigned for you to abstract, according to the sort order established on your default view of your task list. There is no need to return to your task list explicitly to advance to the next task.
Text that has been highlighted for a field that is neither active (yellow) nor hovered-over (green) is shown in light blue. Click on any highlighting to activate the associated field and show both in yellow.A given region of text can also be associated with multiple field results. The count of related fields is shown with the highlight region ("1 of 2" for instance).Unsaved changes are indicated by red corners on the entered fields. If you make a mistake or wish to remove highlighting on the right, click the 'x' attached to the highlight region.Save work in progress any time by clicking Save Draft. If you leave the abstraction UI, you will still see the document as a task waiting to be completed, and see the message "Initial abstraction in progress". When you return to an abstraction in progress, you will see previous highlighting, selections, and can continue to review and abstract more of the document.Once you have completed the abstraction of the entire document, you will click Submit to close your task and pass the document on for review, or if no review is selected, the document will be considered completed and approved.When you submit the document, you will automatically advance to the next document assigned for you to abstract, according to the sort order established on your default view of your task list. There is no need to return to your task list explicitly to advance to the next task.
Multiple Specimens per Document
There may be information about multiple specimens in a single document. Each field results category can have multiple panels of fields, one for each specimen. To add information for an additional specimen, open the relevant category in the field results panel, then click Add another specimen and select New Specimen from the menu. Once you have defined multiple specimens for the document, you can use the same menu to select among them.Specimen names can be changed and specimens deleted from the abstraction using the cog icon for each specimen panel.
Once you have defined multiple specimens for the document, you can use the same menu to select among them.Specimen names can be changed and specimens deleted from the abstraction using the cog icon for each specimen panel.
Reopen an Abstraction Task
If you mistakenly approve a document too quickly, you can use the back button in your browser to return to it. Click Reopen to return it to an unapproved status.Review Document Abstraction
 The review page shows the abstracted information and source text side by side. Only populated field results are displayed by default. Hover over any field to highlight the linked text in green. Click to scroll the document to show the highlighted element within the visible window, typically three rows from the top. A tooltip shows the position of the information in the document. To see all available fields, and enable editing of any entries or adding any additional abstraction information, the reviewer can click the pencil icon.
The review page shows the abstracted information and source text side by side. Only populated field results are displayed by default. Hover over any field to highlight the linked text in green. Click to scroll the document to show the highlighted element within the visible window, typically three rows from the top. A tooltip shows the position of the information in the document. To see all available fields, and enable editing of any entries or adding any additional abstraction information, the reviewer can click the pencil icon. Once the pencil icon has opened the abstraction results for potential editing, the reviewer has the intermediate option to Save Draft in order to preserve work in progress and return later to complete their review.
Once the pencil icon has opened the abstraction results for potential editing, the reviewer has the intermediate option to Save Draft in order to preserve work in progress and return later to complete their review. The reviewer finishes with one of the following clicks:
The reviewer finishes with one of the following clicks:
- Approve to accept the abstraction and submit the results as complete. If you mistakenly click approve, use your browser back button to return to the open document; there will be a Reopen button allowing you to undo the mistaken approval.
- Reprocess which rejects the abstraction results and returns the document for another round of abstraction. Either the engine will reprocess the document, or an administrator will assign a new manual abstractor and reviewer.
Reprocessing
When a reviewer clicks Reprocess, the document will be given a new status and returned for reprocessing according to the following table:| Engine Abstracted? | Manually Abstracted? | Reviewed? | Action | Result |
|---|---|---|---|---|
| Yes | No | No | Reopen | Ready for assignment |
| Yes | No | Yes | Reopen | Ready for review; assign to same reviewer |
| Yes | No | Yes | Reprocess | Engine reprocess; ready for assignment |
| Yes | Yes | No | Reopen | Ready for assignment |
| Yes | Yes | Yes | Reopen | Ready for review; assign to same reviewer |
| Yes | Yes | Yes | Reprocess | Engine reprocess, then ready for assignment |
| No | Yes | No | Reopen | Ready for assignment |
| No | Yes | Yes | Reopen | Ready for review; assign to same reviewer |
| No | Yes | Yes | Reprocess | Ready for assignment |
LabKey Biologics
Overview
LabKey Biologics will be available for subscription purchase from LabKey Software in 2017. Please contact LabKey if you'd like to influence product development or learn more.Press Release
LabKey and Just Biotherapeutics, Inc. have signed a multi-year agreement to develop a new software product that helps biotechnology R&D teams produce more effective and affordable biotherapeutics by optimizing development processes.The new solution will enable preclinical research groups to accelerate lab workflows, automate project tracking, and gain immediate insight into molecules, processes and resources. With data intelligence on hand, teams can focus on developing high-quality therapeutics instead of battling bottlenecks in data entry, integration and analysis.“LabKey builds software solutions that help research scientists integrate, analyze and share biomedical data, speeding their efforts to treat and cure diseases. We’re thrilled to be working with a team focused on innovation in biotherapeutics,” says Michael Gersch, CEO of LabKey. “We are very impressed with the Just team and their inspiring vision of bringing biologic medicines to global markets. We’re delighted to partner with them on this new product.”The two companies will design, develop and implement a LabKey Software product for biotherapeutics R&D development based on Just’s specifications and requirements. The product will also be available for other companies to use.“Today's software solutions aren't geared toward the problems that Just and other companies are working to solve with large molecule development,” says Jim Thomas, CEO of Just. “This partnership and resulting innovative product will make it easier for companies to accelerate the development of biotherapeutics.”LabKey Biologics: Preview
Feature Highlights
Developers are currently building LabKey Biologics, to help researchers navigate the complex processes of molecule development. LabKey Biologics helps researchers ensure efficiency and reproducibility in all stages of molecule development, from candidate discovery, evaluation, and production. Feature highlights include:
- Biologic Entity Registration. Molecule and sequence uniqueness is determined by running checks through an identity service.
- Lineage Tracking. Complex production processes and parentage relationships are tracked to ensure reproducibility and reliable manufacturability.
- Molecular Species. LabKey Biologics captures information about alternate molecular species that are observed experimentally. These species are associated back with the original protein of interest.
- Assay Data Integration. By linking a candidate molecule with assay runs, a portrait of characteristics is developed, which can be used to evaluate its therapeutic properties.
User Interface Highlights
The following screen shots a provided as a preview of the application in development. The details may change before the official release, but the following images give you a sense of the user experience.
Application Portals
The LabKey Biologics main page provides a search box and five different portals into different aspects of the data:
- Registry - Browse all of the entities in the registry.
- Assays - Assay results for candidate molecules.
- Samples - A dashboard for tracking samples.
- Inventory - Manage supplies and freezer locations.
- Workflow - Track processes and progress.
Search
Search results for "ES-2". The results shown below are broadly filtered to include all items related to "ES-2" (expression system #2), including Vectors, Constructs, and Samples. Results can be more narrowly filtered for more specific results.
Sequence and Molecule Registry
The Registry dashboard shows all of the unique entities that have been added, such as Expression Systems, Cell Lines, etc.
Details page for the expression system "ES-2". Note the separate panels that provide a graphical representation of the lineage/parentage, the associated samples, and detailed properties. Also buttons are available to kick off related actions, such as running an assay.
Assays
Assay data broken down by type and date.
Samples
The Samples dashboard shows:
- a catalog of the different samples
- detailed views on each sample, including its lineage.
Contact Us
For more information, contact us.
For news on the latest features and developments, subscribe to our newsletter.
Panorama Partners Program
Overview
The Panorama Partners Program (P3) is a premium offering for users of Panorama, the LabKey-based repository for targeted proteomics.The Panorama Partners Program (currently including Roche, Genentech, and Merck & Co., Inc.) is designed to help members make the most of Panorama and provides a unique opportunity to guide its development. Members engage directly with developers at regularly scheduled conference calls. Developers will present recent changes and improvements related to Panorama, and provide input on how to best use Panorama based on the organization's needs. Members are invited to provide input on how Panorama might be improved and suggest changes for future development.Membership also includes a LabKey Server Professional Edition subscription, including full support and training for installation, maintenance, configuration, and general usage of LabKey Server, plus access to premium features.To inquire about membership as a Panorama Partner, please contact LabKey.Screenshot: Part of the quality control workflow from the Panorama module.
LabKey User Conference Resources
LabKey User Conference 2016
LabKey User Conference
Integrating Clinical and Laboratory Data from National Health Service Hospitals for Viral Hepatitis Research=== David Smith, University of Oxford
- View Slides
- Watch Presentation
- National Institute for Health Research Health Informatics Collaborative (NIHR HIC)
- STOP-HCV Consortium
Optide-Hunter: Informatics Solutions for Optimized Peptide Drug Development Through the Integration of Heterogeneous Data and Protein Engineering Hierarchy
=== Mi-Youn Brusniak, Fred Hutch
Skyline and Panorama: Key Tools for Establishing a Targeted LC/MS Workflow
=== Kristin Wildsmith, Genentech, Inc. (a member of the Roche Group)
- View Slides
- Watch Presentation
- Skyline: open-source software available from MacCoss lab at University of Washington
- PanoramaWeb
- Chromatogram Libraries, Experimental Data, and Panorama QC Folders
Real-Time Open Data Sharing of Zika Virus Research using LabKey
=== Michael Graham, University of Wisconsin-Madison
- View Slides
- Watch Presentation
- Zika Open-Research Portal
- Highlighted mentions: Nature, The New York Times, NPR, NIH, The Indian Express
Therapeutic Antibody Designs for Efficacy and Manufacturability
=== Randy Ketchem, Just Biotherapeutics
LabKey User Workshop
Workflow Tech Workshop=== Susan Hert, LabKey
- View Slides
- Download Sample Code
- Referenced documentation:
QC Tech Workshop
=== Josh Eckels, LabKey
- View Slides
- Referenced documentation:
Visualization Tech Workshop
=== Cory Nathe, LabKey
- View Slides
- Referenced documentation:
- Reports and Visualizations
- Data Views Browser
- LabKey Client APIs
- Column Visualizations
- Column Summary Statistics
- Data Grids: Basics
- R Reports with knitr
- Built in assay visualizations:
- Additional examples shown:
Best Practices for Server Administration
=== Brian Connolly, LabKey
LabKey User Conference 2015
LabKey User Conference
Evolving Lab Workflows to Meet New Demands in the U.S. Military HIV Research Program (MHRP)=== Stephen Goodwin, Henry M Jackson Foundation
Providing Access to Aggregated Data without Compromising PHI
=== Nola Klemfuss, Institute for Prostate Cancer Research (IPCR)
Using Data Transparency to Improve Cancer Care
=== Karma Kreizenbeck, Fred Hutch (HICOR)
Data Management at ESBATech
=== Stefan Moese, ESBATech
The UK 100,000 Genomes Project
=== Jim Davies, Genomics England
Maximizing the Research Value of Completed Studies
=== Steven Fiske, University of South Florida
Unlocking Medical Records with Natural Language Processing
=== Sarah Ramsay and Emily Silgard, Fred Hutch
LabKey User Workshop
Developing a Mobile UI for Electronic Health Records=== - Jon Richardson, University of Wisconsin
When to Customize: Design of Unique Visual Tools in CDS
=== Dave McColgin, Artefact
Panorama Public: Publishing Supplementary Targeted Proteomics Data Process with Skyline
=== Vagisha Sharma, MacCoss Lab, UW
Creating Interactive and Reproducible R Reports Using LabKey, Rserve, and knitr
=== Leo Dashevskiy, Gottardo Lab, Fred Hutch
Realtime, Synchronous Data Integration across LabKey Application Server Data using High-throughput Distributed Messaging Systems
=== Lewis McGibbney, JPL
Data Visualization Studio: Scientific Principles, Design Choices, and Implementation in LabKey
=== Catherine Richards, Fred Hutch, and Cory Nathe, LabKey
Schema Studio: Extending LabKey Using a Custom Database Schema
=== Matt Bellew, LabKey
LabKey User Conference 2014
LabKey User Conference
Using Existing LabKey Modules to Build a Platform for Immunotherapy Trials=== Hannah Smithers, Ben Towne Center for Childhood Cancer Research
Management and Integration of Diverse Data Types in Type 1 Diabetes Research
=== John Rue, Novo Nordisk
The Collaborative Dataspace Program: An Integrated Approach to HIV Vaccine Data Exploration
=== Drienna Holman, SCHARP
Using Web Technologies to Improve Data Quality
=== Amy Tsay, Rho
Enabling Integrative Modeling of Human Immunological Data with Immunespace
=== Raphael Gottardo, Fred Hutch
Progress Report on the Hutch Integrated Data Repository and Archive
=== Eric Holland and Paul Fearn, Fred Hutch
LabKey User Workshop
The Adventures of Biocat and Knockout Mouse: ITN TrialShare's Automated Specimen and Dataset Loading Application for LabKey=== Dennis Wightman, ITN
Complex Animal Studies
=== Tom Hudson, WNPRC
Integrating FCS Express and LabKey Server for Flow and Image Cytometry Data Management
=== Kaya Ghosh, De Novo Software
End-User Feedback and Testing
=== Daniel Nicolalde, WNPRC
LabKey User Conference 2013
LabKey User Conference
HIDRA: Hutch Integrated Data Repository and Archive=== Paul Fearn, Fred Hutch
ITN TrialShare: Advancing Clinical Trial Transparency Through Data Sharing
=== Tanya Antonille, ITN
The Use of LabKey Server in a Globally Distributed Research Program
=== Laura Chery and Jennifer Maki, ICEMR
- Watch Presentation
- View Slides
- Malaria Evolution in South Asia - International Centers of Excellence for Malaria Research (ICEMR)
Enabling Integrative Modeling of Human Immunological Data in a Reproducible Manner with ImmuneSpace
=== Raphael Gottardo, HIPC
DataShare: Accelerating Type 1 Diabetes Basic Science Research
=== John Kaddis and Les Jebson, NPOD
Integrated Research Data Management at U of Rochester/BLIS
=== Jeanne Holden-Wiltse, URMC
LabKey User Workshop
Building Rich Electronic Case Report Forms in LabKey=== Anthony Corbett, University of Rochester
Lung Cancer Research Initiative
=== Bront Davis, University of Kentucky
TrialShare - Extending the LabKey Framework
=== Dennis Wightman, ITN
A Framework for Java Assay Module Development
=== Andy Straw, University of Rochester
LabKey User Conference 2012
LabKey User Conference
If The Shoe Fits: Adapting LabKey for Novel Applications=== Quinton Dowling, IDRI
ATLAS: Data Sharing in HIV Research
=== SPEAKER, ORGANIZATION
User-centric Design for Research Tools: The CDS as a Case Study
=== Dave McColgin, Artefact
ITN Trialshare: From Concept to Deployment
=== Adam Asare, ITN
LabKey User Conference 2011
LabKey User Conference
Adapting LabKey to Pathogen Research=== Victor Pollara, Noblis, Inc.
Adjuvant Formulations: Applied LabKey Server in Process Development
=== Quinton Dowling, IDRI
Katze Lab and LabKey
=== Richard Green, Katze Lab
Generating Solutions for Translational Research
=== Trent Schafer, Charles Darwin University
WNPRC Electronic Health Record
=== Ben Bimber, WNPRC